1. Introduction
Developing an effective theory of collective intelligence is a considerable challenge for both artificial intelligence (AI) and social psychology; see, for example, Wolpert et al. [
1], Suran et al. [
2], or Kameda et al. [
3]. One aspect of this challenge comes from the tension between the individual competency of an agent and the co-ordination of group behaviour that allows for the collective output to be of higher quality than any individual agent. Some important contributing factors are already understood from social psychology, for example, the topology of a social network is important, as shown by Momennejad [
4], as is the fractal-like scaling of social group sizes, as shown by Harré and Prokopenko [
5]. Work by Woolley et al. [
6] demonstrated this tension between the individual and the collective: individual skill and effort contribute most to a group’s outcome, but performance is also improved by individual members possessing a capacity for Theory of Mind (ToM), the ability to infer the internal cognitive states of other agents, as shown in the work of Frith [
7]. This leads to questions regarding the incentive structure, such as which rewards optimise group performance, a question that was studied by Mann and Helbing [
8] using game theoretical mechanisms.
The relationship between game theory and ToM has been developed extensively beginning with Yoshida et al. [
9] establishing foundational results. More recent work by researchers in the Meta Team et al. [
10] developed the AI Cicero that uses a representation of other agents’ strategies in order to play the game of Diplomacy at a strong human level. The type of opponent decision making used in their KL-divergence module
piKL is closely related to the entropic methods of games against nature described by Grünwald et al. [
11] and the MaxEnt methods of game theory developed in Wolpert et al. [
12]; see, for example, the recent review of inverse reinforcement learning algorithms for an AI-ToM in Ruiz-Serra and Harré [
13]. This ‘game theory of mind’ perspective has proliferated in recent years. In Lee [
14] and Lee and Seo [
15], game theory is used in behavioural studies of macaque monkeys to test for a ToM in animals; in AI research, Bard et al. [
16] suggest that ToM is a necessary element for success in complex games such as Hanabi; in social psychology, Ho et al. [
17] posit that ToM is a part of planning via the need to change others’ thoughts and actions; and some of the psychological aspects are reported in Harré [
18].
With that in mind, we also note that there are multiple scales at which an AI can be formulated with ‘neural’ reality being balanced against ‘psychological’ reality [
19,
20,
21], in particular, the ‘dynamical minimalism’ suggested by Nowak [
22]. That psychological phenomena are an emergent property of biological neural networks embedded in an environment is not controversial, but it has only been relatively recently that studies have shown how this may come about. For example, ADHD-related changes in brain function have been shown to have an impact on global, low-dimensional manifold dynamics [
23]. These attractor dynamics have also been used to explain memory [
24] and decision making [
25,
26,
27] in biological neural networks, as well as extracting psychological phenomena from artificial neural networks [
28].
In this spirit, the control parameters of the AI models used in the current study are akin to the ‘…slow dynamical variables that dominate the fast microscopic dynamics of individual neurons and synapses’ [
29]. As such, it is not always necessary to model microscopic elements explicitly in an AI in order to test psychological models in and of themselves. Thus, here we model decision making at a high level, where learning is by gradient descent on macroscopic parameters. These parameters are not arbitrary though; instead, they are representations of known psychological properties and have explicit interpretations: as constraints, preferences, beliefs, desires, etc. This is because it can be informative to study the learning and decision-making process from a point of view that allows us to explicitly encode psychological factors that do not have an immediate or obvious mapping to the microscopic neurobiology of the emergent phenomenology.
With the previous discussion in mind, neural level models can make it difficult to explain the structural elements of decision making that mathematical models can make explicit. An example is the modelling of non-strategic decisions in the work of Peterson et al. [
30] where they gathered data on 9831 distinct ‘problems’ in order to evaluate formal models of decision making: 12 expected utility (EU) models and a further 8 prospect theory (PT) models that extend the EU models. Peterson et al. [
30] also included an unconstrained artificial neural network (ANN) that, as would be expected, performed better than any of the structural models in their analysis and could act as a performance benchmark for comparative analysis, an approach we duplicate in this work. They showed that with sufficient data, new theories can be discovered that shed light on centuries of earlier theoretical work.
In this work, we adapt the formal decision theory models of Peterson et al. [
30] to the task of using an AI-ToM to model the first player’s decisions in the extensive form game data of human subjects from Ert et al. [
31] (see the website of Ert:
https://economics.agri.huji.ac.il/eyalert/choice (accessed on 15 October 2023). The goal is to evaluate which AI-ToM decision models most effectively predict first mover choice in extensive form games, tested against several artificial neural network models that do not have an explicit ToM aspect, but that do have complete knowledge of the players’ choices and the games’ payoffs. In contrast, AI-ToM models are highly structured decision models that explicitly include the constraints of the second player’s decision making. This evaluates constrained AI-ToM models against the theoretical best ANN models available, but the unconstrained neural network has no explanatory power, whereas the structural models have well-studied and often psychologically grounded explanations. The main limitation of this study is in the nature of the experimental games: ‘game theory of mind’ is a very specific form of ToM and a more complete test of an AI-ToM would be based in a naturalistic setting.
2. Materials and Methods
In this section, we introduce the games that the human subjects played in the original article by Ert et al. [
31], describing the incentives for each decision and how the incentive structures can categorise the games. We then introduce the payoff model, Equation (
1), in which the parameters of the players’ payoff function are introduced, again following [
31]. The expected utility decision models and then their prospect theory modifications are introduced in the last two subsections.
2.1. Game Structure
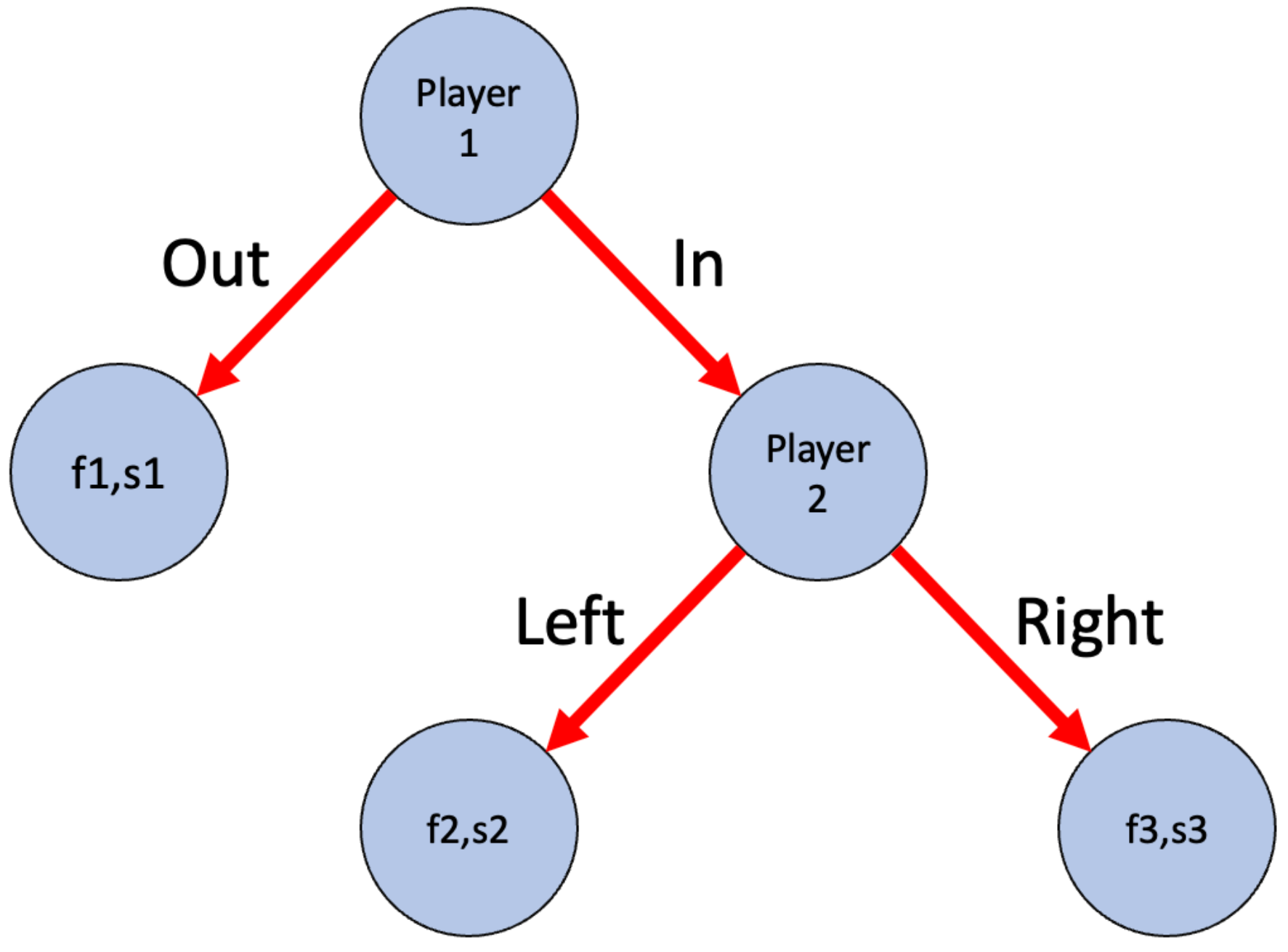
The structure of the interaction between two agents and the labelling convention is shown in
Figure 1.
The games that were played can be categorised according to the relative relationships between the payoffs for the various joint strategies
for
. Game categories are not uniquely identified, and some game configurations can belong to multiple categories, see Ert et al. [
31] for further details:
All: all choices are combined without differentiating between games in which they were made.
Common Interest: there is one option that is best for both players, e.g., and .
Safe Shot: “In” is the optimal choice for player 1, e.g., and .
Strategic Dummy: player 2 cannot affect the payoffs, e.g., and .
Near Dictator: the best payoff for player 1 is independent of player 2’s choice, e.g., and .
Free Punish: player 2 can punish player 1’s “In” choice with no cost, e.g., and .
Rational Punish: punishing player 1’s “In” choice maximises player 2’s payoff, e.g., and .
Costly Punish: punishing player 1’s “In” choice is costly, e.g., and .
Free Help: improving the other’s payoff is not costly, e.g., and .
Costly Help: improving the other’s payoff is costly for the helper, e.g., and .
Trust Game: choosing “In” improves 2’s payoff but reciprocation is irrational for player 2, e.g., and (Trust is a subset of Costly Help).
Conflicting Interest: player 1’s reward is maximised only if player 2 chooses suboptimally after player 1 plays “In”, i.e., but , while “Out” is neither minimal nor maximal for player 1, e.g., and .
2.2. Experimental Data and Decision Model
The data used are from the Ert et al. [
31] study where the experimental setup is as follows. A total of 116 students were recruited to play extensive form games from a selection of 240 total games, and four independent sessions were run; presented in Table 2 are the games of Ert et al. [
31], and the original article also has the complete study protocols. All parametric learning is carried out using gradient descent.
We use the same function as Ert et al. [
31] in which their core assumption is an inequity aversion model developed in Fehr and Schmidt [
32] where individuals incur a loss of utility based on differences between their outcomes and the outcomes of others. In this sense, the specific value player 1 associates with a joint choice
is given by:
where
and
and arguments are reversed for player 2. The
term provides weights for disadvantageous inequality and the
term provides weights for advantageous inequality. These parameters are discovered via gradient descent in the training phase. Note that, in the case where
, this simplifies to the first argument:
. In
Section 2.3 and
Section 2.4, the utilities
and prospect theory models
are defined, but first we define the probability of player 2 choosing “left” (L) or “right” (R), from which we can derive player 1’s probability of choosing “in” (I) or “out” (O):
Note that player 1’s decision model includes their (subjective) model of player 2’s (subjective) preferences and constraints [
33]. The
terms parameterise uncertainty in choices.
2.3. Expected Utility Models
EU models can incorporate arbitrary transformations
of outcome
x, such that their utility is regarded subjectively, and
. In general, different forms of
are typically non-linear, monotonic, parametric functions, and we evaluated 11 parametric forms of
. Next are descriptions of the 5 neural networks and the 8 mathematical functions of the AI models in Peterson et al. [
30] that are further modulated by different prospect theory models.
UNN: unconstrained neural network. The UNN model is a multi-layer perceptron with 5 layers: a 6 neuron input layer (one for each for the 2 players’ payoffs), 1 neuron output, and 3 hidden layers with 5, 10, and 10 neurons each. Model weights are randomly initialised in the range [0,1]. Training is conducted on a 50% subset of the data with the remainder reserved for model testing. activation functions are used in the classifier network. The RMSE is then the observed root mean square error in the predicted choice of player 1 against observation (the RMSE is used throughout for gradient descent).
UNN Feature Engineering: an unconstrained neural network with feature engineering on the payoffs. Rather than consider the individual payoffs for each game directly (as in the unconstrained network), this model takes comparisons between a subset of the payoffs; namely (), (), (), (), (), and (). This network is defined as a multi-layer perceptron comprising 5 layers: a 6 node input layer (the defining payoffs of each game), a single node output layer, and 25 hidden nodes across the remaining hidden layers (5,10,10).
EU NN: an expected utility neural network without a PT model. The aim of this method is to estimate a suitable non-linear form of the utility function from game data. Following the convention of the non-neural models, a softmax function is used to select between the two outcomes based on the expected utilities of the two choices each player faces. The model’s parameters (advantageous inequity and disadvantageous inequity), and the softmax sensitivity parameter are all estimated using gradient descent along with the neural network weights. This is achieved with a 4 layer neural net including 1 neuron input, 1 neuron output, and 2 hidden layers with 5 and 10 neurons in the hidden layers. ReLU activation functions are employed in the network. The results are not significantly sensitive to these parameter choices.
MoT NN: mixture of theories neural network. This builds on the MoT model presented in Peterson et al. [
30]—namely, it employs a ‘mixture of experts’ neural network architecture, where the neural network considers a subset of models, and selects between them based on the payoffs
. In this specification, the MoT model was designed to select between a generalised linear EU model, a Kahneman–Tversky PT model, an expected value model, and a Kahneman–Tversky PT model fixed at unit values. The latter two were employed because they are the simplest among the EU and PT models (i.e., no free parameters) and reduce the complexity of the model. The former two models were chosen because they are among the most stable models for the simple specifications examined. The MoT model is defined as a multi-layer perceptron comprising 5 layers: a 6 node input layer (the defining payoffs of each game), 1 node output layer, and 3 hidden layers with 5, 10, and 10 neurons each. ReLU activation functions are employed in the classifier network.
EU NN + PT NN: the EU NN with an additional neural network for learning a PT model. The EU NN uses unmodified probability weightings in the calculation of expected utilities, and the ‘Prospect Theory Neural Network’ also includes a prospect theory function around the input probabilities. Similar to the EU NN model, the prospect theory function is defined as a multi-layer perceptron comprising 4 layers: a single node input layer (the probability outcome), a single node output layer, and 2 hidden layers with 5 and 10 neurons each. ReLU activation functions are employed in the network and hyperparameter tuning is conducted through a Gaussian processes Bayesian optimiser. In this model, the network weights for both functions are optimised simultaneously using gradient descent.
The following mathematical models are highly structured and each has their own extensive history as noted by Peterson et al. [
30]. The advantage of these is that their structure is motivated by specific conceptualisations regarding how decisions are made and what information is taken in and then manipulated in the decision-making process, a view that is not easily taken using conventional ANNs.
Akin to the previously described neural network models, the listed functions that follow are obtained from Peterson et al. [
30]:
Linear Loss Aversion Behaviour:
General Linear Loss Aversion Behaviour:
Normalised Exponential Loss Aversion Behaviour,
Power Law Loss Aversion Behaviour:
General Power Loss Aversion Behaviour:
Exponential Power Loss Aversion Behaviour:
Quadratic Loss Aversion Behaviour:
2.4. Prospect Theory Models
Following Peterson et al. [
30], the below PT models are employed to transform the modelled probability judgements:
None:
Kahneman–Tversky:
Log-Odds Linear:
Power law:
NeoAdditive:
Hyperbolic Log:
Exponential Power:
Compound Invariance:
Constant Relative Sensitivity:
4. Discussion
Formal models of decision making have been around for over a century, and for individual’s to benefit from their joint use, e.g., in collective intelligence, they must be mutually understood between agents. However, several issues arise that complicate the issue discussed here. We also recall that the AIs are trained on human responses and tested on out-of-sample human responses, and so they do not represent optimal behaviour but rather the natural responses of real people in strategic situations.
With that in mind, it is interesting to note the robustness of the linear models as a class in the out-of-sample testing and also as a ratio of in-sample to out-of-sample RMSE values. In
Figure 2, we can clearly see that linear models perform poorly across all PT models during training, but in
Figure 3, we see that during post-training testing, the linear EU models have exceptionally low variance across all of the PT models compared to all other other EU models, and some individual linear EU-PT models outperform UNN, PT NN, and EU NN in out-of-sample testing but, curiously, not the UNN with feature engineering. As a matter of practicality it might be the case that having a simple approach to the many different types of games is just an efficient way of addressing the complexity and uncertainty of the environment. However, while we are not able to explore this point any further with the data we have, there are other results that shed light on the matter.
One of these results is the performance of the UNN with feature engineering where it is the relative, rather than absolute, payoffs that the neural network is trained on. We note that, in general, the psychophysics of
relative perception has been very successful in explaining biases in perception and decision making. As Weber [
34] notes, this is also true in economics, and this is confirmed here in the strong performance of UNN with feature engineering in out-of-sample, performing better than all models including both the UNN and linear models, and while the ratio of in-sample to out-of-sample errors is better than the UNN, it is not as good as the linear models.
The final model we draw attention to is the mixture of theories model. This performed very well in testing, second only to UNN with feature engineering, and the ratio of training to testing performance was very good. This raises an interesting question that we are not able to answer with the data we have, but it is important in terms of the psychocognitive mechanisms in use when there is uncertainty in both the other player’s ‘rationality’ and the type of interaction an agent will be confronted with. The MoT model suggests that being able to switch between different models of the other player depending on the strategic context is useful, in contrast to having a single model of the other player for all of the different strategic interactions. In the natural world, agents are confronted with a variety of different agents where the interactions are of varying degrees of social and strategic complexity, so having a neural network that controls which of these models is used contingent on the context could be both efficient and highly adaptive in real situations. This suggests it would be useful to study when and how agents manipulate different models of the ‘other’, i.e., ToM model selection, as well as models of the ‘self’, i.e., introspectively adjusting the agent’s own decision model [
18].
We believe the main limitation of this study lies in the nature of the experimental games, where ‘game theory of mind’ is a very specific form of ToM and a more complete test of an AI-ToM would be based in a naturalistic setting. In addition, a larger dataset would likely have enabled better generalisation of performance in the out-of-sample test set, unlocking the performance of the neural network models. However, this does highlight that the best performing models (the MoT and UNN with feature engineering) are able to learn efficiently, including from datasets that can be readily processed with commodity laptop hardware as developed in this study.
Similarly to the work of Peterson et al. [
30], here we have been able to show, through the use of large numbers of individual human decisions and a variety of strategic contexts, that we can evaluate a large suite of decision models. This has provided both new insights and provided quantitative confirmation of long standing models, while testing the limits of recent developments in artificial neural networks.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




