1. Introduction
The relationship between decision-making algorithms and game theory is characterized by their shared focus on the process of selecting optimal decisions within contextual parameters. Decision-making algorithms, which are frequently employed in the fields of computer science and artificial intelligence, frequently incorporate principles derived from game theory. The proposed algorithms in this paper have been specifically developed to facilitate decision-making processes or problem-solving tasks, considering many elements and potential outcomes, akin to the principles observed in game theory. Individuals engage in the process of evaluating various scenarios by making predictions regarding the conduct of others and ultimately selecting the optimal course of action.
Here, we consider a group of cooperating agents who are trying to reach the same decision point [
1,
2,
3,
4,
5,
6,
7,
8]. In Multi-Agent Systems (MAS), deciding between several potential courses of action can be computationally expensive and difficult. Fortunately, in many contexts, an agent must coordinate its actions with a small number of agents, and the other agents can behave autonomously with respect to one another. The problem can be made more manageable by factorizing the action space into that of a team of agents who coordinate their judgments. In Cooperative Multi-Agent Systems (CMAS) with a common goal, coordination is essential for making good decisions. Each agent acts independently to achieve a locally optimal goal while also helping the team achieve a global one.
Coordinating the independent decision-making processes of each agent is an essential component of putting a policy for CMAS into action. This challenge of coordination might be handled by establishing a centralized coordinator for the entire system. This coordinator could decide what action each agent should perform and then convey this decision to the agents. This technique is not reliable since there is a possibility that the centralized coordinator may fail to work properly or that agents would struggle to communicate with one another. As a result, we will investigate the possibility of employing a hybrid approach that integrates both centralized and decentralized (or distributed) coordination. In the absence of a central unit (also known as a coordinator), the agents need to find a way to coordinate their actions toward the achievement of the common objective by employing a distributed algorithm that considers the costs of those actions. This type of algorithm is being proposed for the first time in this work.
Here, we would like to provide an anytime algorithm that can return a result at any time, improving with time until the best result is obtained. The joint action with the highest payout should be reported if the algorithm ends due to budgetary restrictions (time, cost of activities, etc.).
The single Markov Decision Process (MDP) modeling that is the foundation of MAS is generalized into a Multi-agent Markov Decision Process (MMDP), which adds the concept of numerous cooperating agents who have their own action sets each (as specified in Definition 1, page 962 [
9]). It is possible for an MMDP to either centralize or decentralize the decision-making process. In algorithms with centralized decision makers, a single decision maker decides what actions should be taken by all the agents, but in algorithms with decentralized decision makers, each agent acts as its own decision maker. Our contribution is part of the Constraint Multi-agent Markov Decision Process (CMMDP) field and focuses on online planning [
9]. The CMMDP presents a greater challenge in terms of obtaining a solution compared to the MMDP due to the limitations placed on the available resources. These limitations on resources influence the decisions that are made by the CMAS.
In general, the framework of the Coordination Graphs (CG) and the Variable Elimination (VE) algorithms that can be employed in this respect are what are used to solve an MMDP [
1,
2,
3,
4,
5,
6,
7,
9,
10]. These methods can be used to solve MMDPs. This VE technique works by removing agents one at a time using a local maximization step. Its complexity increases exponentially with the size of the induced tree width, which is determined by the size of the largest clique that is produced during the process of eliminating nodes. Unfortunately, the VE method is not an anytime algorithm, and the Max-Plus algorithm, which is offered in both a centralized and a decentralized version in [
3,
4,
5], is a solution for the anytime MMDP. The Max-Plus algorithm is a payout propagation algorithm. Using this algorithm, agents will exchange suitable payoff messages over the CG. Then, the agents will be able to compute their individual actions based on the convergence of this approach. There is only a limited amount of information available regarding the hybrid version of the Max-Plus method with constraints, which is the primary topic of this work.
The goal of our work is to come up with a hybrid solution for a constrained scalable decision-making method (centralized and distributed coordination) in MAS. The online methods for making decisions offer an alternative approach in which the agents must plan and carry out their actions at different times.
Online planning frequently uses the anytime method known as Monte Carlo Tree Search (MCTS). In the context of MCTS, dealing with a sizable decision space is an open problem that is constantly attracting attention. The scalability and huge branching factor of the MCTS method are its drawbacks, which prevent it from scaling well beyond a certain point. For the scaled coordinated coordination of agents, there are currently two prominent methods, [
1,
2], which include three components: (a) online planning using MCTS, (b) factored representation with CG, and (c) centralized Max-Plus method for joint action selection. Ref. [
1] does not present the distributed Max-Plus method and ignores the cost of action. Ref. [
2] lacks the cost of actions and anytime aspects. To solve the centralized multi-agent POMDP model, the authors use MCTS. A cutting-edge algorithm is used as the answer to the multi-agent POMDP problem. But as the agent’s degree of connection rises, it becomes unsolvable. Factored Value MCTS with Max Plus (FV-MCTS-Max-Plus) and FV-POMDP, respectively, are the names of the suggested methods in [
1,
2].
This is, as far as we are aware, the first paper to deal with hybrid value factored representation using MCTS for planning. This is a novel approach, and the justifications for this two-step decision-making procedure are as follows:
- (1)
Contingent upon the circumstance (state), different actions have different levels of relevance. Based on the current scenario, local-level decision-making determines the order of activities, from high likelihood to low probability in terms of effectiveness. Thus, increasing the likelihood that the best solution would be discovered early is a highly helpful step for the anytime method.
- (2)
In a dynamic context, network segmentation is unavoidable since network connectivity is necessary for global-level optimization in multi-agent environments. In some circumstances (such as those involving cyberattacks or network problems), this communication may not always be assured. The local optimal solution in the first step may be the best option in such scenarios because the algorithm may not be able to reach the global optimal solution in such hostile situations.
We favor fully hybrid coordinating for multi-agent decision making for the following reasons:
- (a)
In centralized arrangements, the central controller observes all agents jointly and makes joint choices for all agents. Each agent acts in response to the central controller’s decision. Failure or malfunction of the central controller is equal to the entire MAS failing.
- (b)
To exchange information, the central controller must communicate with each agent, increasing the communication overhead at the single controller. This may reduce the scalability and robustness of MAS.
- (c)
In a centralized setup (centralized controller), agents are not permitted to exchange information about state transitions or rewards with one another. A hybrid MAS coordination strategy could allow each agent to interact to make local and correlated decisions.
Our contribution has three components:
We consider a budget constraint approach in which each action is assigned a cost. Different actions consume varying quantities of resources, which may be correlated to the team’s global payoff [
11]. In such a scenario, the goal of the local decision maker is to optimize his decision under cost and budget constraints at any given time. Consequently, the global team reward at each time step is calculated by subtracting the total cost incurred in analyzing the cost of the local actions. In this manner, we extend previous works [
1,
2,
3] on centralized coordination where the only budgetary constraint was time.
We devise the Hybrid (i.e., centralized and distributed) coordination of the Max-Plus algorithm [
3,
4] where each agent computes and sends updated messages after receiving new and distinct messages from a neighbor. Messages are sent in parallel, which provides some computational advantages over the sequential execution of previous centralized coordination algorithms [
1,
2].
We developed a new FV-MCTS-Hybrid Cost-Max-Plus decision-making method with two stages. Our contribution is the development of a theoretical framework for integrating Monte Carlo Tree Search (MCTS) with the Cost Hybrid Max-Plus algorithm for decision making and execution. The proposed method is a suboptimal Dec-POMDP solution. Even for two agents, it is known that the exact solution to a Dec-POMDP is intractable and complete non-deterministic exponential (NEXP) [
12].
Here is a summary of the paper’s structure. Our presentation of the relevant literature is in
Section 2. In
Section 3, the mathematical foundation is laid. In
Section 4, we examine and improve upon both cost-free variations of the Max-Plus algorithm, and in
Section 5, we introduce the novel cost-based distributed Max-Plus algorithms. In
Section 6, we looked at the Max Plus Hybrid Algorithm from a cost perspective. In
Section 7, there is information about the FV-MCTS-Hybrid Cost-Max-Plus approach that was suggested.
Section 8 contains our findings and suggestions for the future.
3. Mathematical Background
We explore a cooperative multi-agent planning problem with a system that has N agents, a finite horizon called T, and an approach that takes place in discrete time. At every time step
, every agent
takes an individual action
from its set of actions
. The team has decided on the joint action represented by the vector of team actions denoted by
,
, …,
, …,
) and the reward function associated with the team is denoted by
. This function does not consider the cost of joint action. The goal of the classic coordination issue [
6] is to determine the global optimal joint action
,
that maximizes the global payoff function
, i.e.,
If one were to take a naive approach, they would list all the various joint actions that might be taken by all the agents and then choose the one that maximizes the global payoff function
. This is obviously unrealistic because the global team action space
is an
fold cartesian product that grows exponentially as the number of agents
rises. Since the cost of actions is not negligible in some application domains, it is challenging to apply this model to some real-world situations because the payoff function Q(a) utilized in Equation (1) does not take this into account [
11].
We then investigate the discrete variable
, the local state of agent
. The global state of the system is denoted by
which is factored across the agents
. At time
, the MAS is in a global state
, and in the next time step
, the system will transition to a new global state
. The probability of transitioning to the next state
is
. We look at the most basic circumstances for factorizing the action space (FAS), where the system’s state is entirely observed and available for determining an action for each component in the action space factorization. An MMDP can be used to model the aforementioned FAS [
23].
The cost function of doing an individual action from its set of actions maps an action to a real number. The cost of the global joint optimal action of the team is also a real-valued function. When two agents and interact with each other, the cost incurred due to their interaction is denoted by , which maps a pair of actions to a real number. In the version that is distributed, we assume that only connected agents on an edge coordinate their local activities at a specific time .
Following the approach from [
1] the overall cost,
in CMAS is linear in the number of agents
, and in
, the number of pair interactions
:
We define the global payoff (a.k.a. Global Reward) of the team as , where is the benefit to mission accomplished by the team of agents, and is the cost of the global joint action.
The new coordination problem is to find the cost-optimal joint action
that maximizes the Global Reward of the team with cost, i.e.,
The reward (payoff) function with the cost of an action of agent
is defined as
[
3] and, for two agents that are connected on the edge
, the reward function is defined as
, where the joint payoff values are given by
and the associated joint cost values are
.
In general, in the Max-Plus algorithm, each agent calculates the edge reward by dispatching messages to its neighbors [
6]. Including the cost
for action
(assuming the cost of the action is not dependent on the local state) and the cost of joint action
, then a general message is sent from agent
to agent
(which is action
) is a scalar-valued function of the action space of the receiving agent
as given below:
The only variable in the right part of (4) is the action
. For convergence, the local agent
will select its local action
(from its set of local actions
) to send the maximum payoff value
given by (4) to its neighbor
, producing the following message:
The message
can be regarded as a local payoff function of the agent
. Due to the cost, the scalar value given by (5) could become negative. In this case, the contribution to the edge payoff due to the other agents is defined as
Finally, each agent computes its optimum action individually:
If the edge payoff is 0, then the agent does not need to take any new action and keep the old action.
4. Both Variants of No Cost Max-Plus Algorithms
Max-Plus is a well-known algorithm for computing the maximal posterior configuration in an (unnormalized) undirected graph model. This algorithm is like the belief propagation (BP) algorithm or the sum-product algorithm in Bayesian Networks [
5,
7]. In this algorithm, two agents
and
send information regarding their locally optimized payoff values in an iterative manner. The earlier versions of this algorithm [
1,
2] did not incorporate the cost of actions and the mission benefit for a particular agent.
The iterative sequential operation of iterations is utilized by the centralized Max-Plus algorithm. The central coordinator picks an agent i and starts the process. In every iteration, each agent i computes and sends a message to the neighbor j (connected on an edge) in a predefined order. This process continues until all messages are convergent to a fixed point, or until a “deadline” signal is received (either from an external source or from an internal timing signal). Then, the most recent joint action is reported. For anytime extension, we update the joint action when it improves upon the best value found so far.
A coordination graph (CG) is a graph
where each node
represents an agent and each edge
defines the dependency between two agents:
and
. The Max-Plus algorithm is scalable in terms of the number of agents
and their number of local connections
in the CG representation [
3]. In general, for any CG, we can
factor the global payoff function
value as follows:
where
denotes a local payoff for agent
and it is only based on its individual action when contributing to the system individually.
Considering an edge
for agents
and
, a local joint payoff function
takes an input, a pair of actions
and provides a real number. In the Max-Plus algorithm with no cost, in each time step
each agent
that is in its local state
takes action
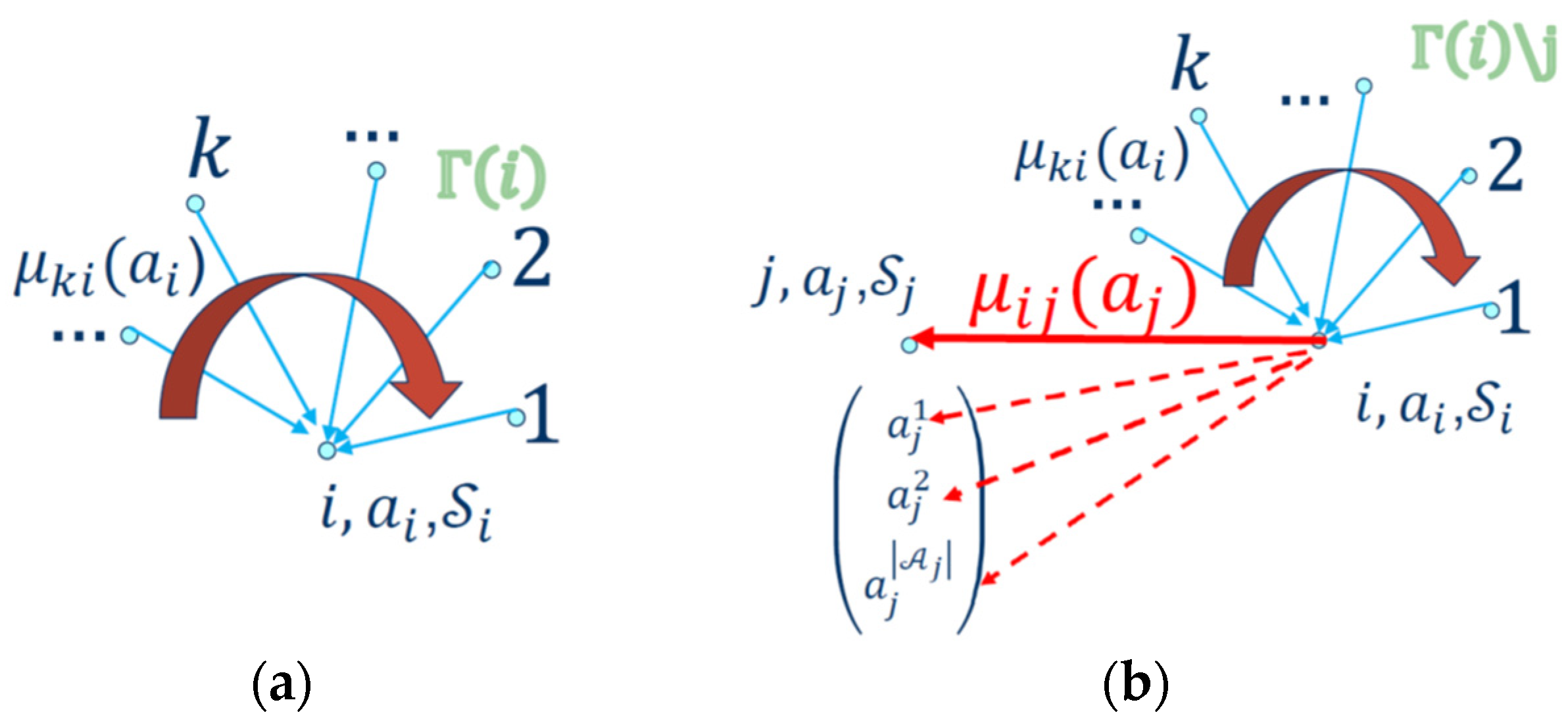
by collecting the payoffs from its neighbors as in
Figure 2a. This agent sends a local message
that maps an action
of an agent
to a real number as shown in
Figure 2b.
In
Figure 2b, the transmitted message
from agent
to agent
in response to the action
taken by agent
contains information about the payoff of agent
that is the local payoff
), joint payoff
and the cumulated payoff from all its neighbors
of node
except node
is as given below:
The first term in relation (8) is the local payoff of the agent
when taking the local action
that is independent of the action
of its neighbor
. The second term of (8) shows that agent
is collecting all the payoffs from its neighbors
(except neighbor
) when all its neighbors are observing the action
The agent
is sending its collected payoff only to its neighbor
. The joint payoff
is shared for both agents. Each one contributes half of it as follows:
The agent
can send payoff messages for any action of agent
as in
Figure 2b (dotted arrows). The agents keep exchanging messages at each iteration until they converge. It is proved that for tree-structured graphs (no loops), the message updates converge to a
fixed point after a finite number of iterations [
6].
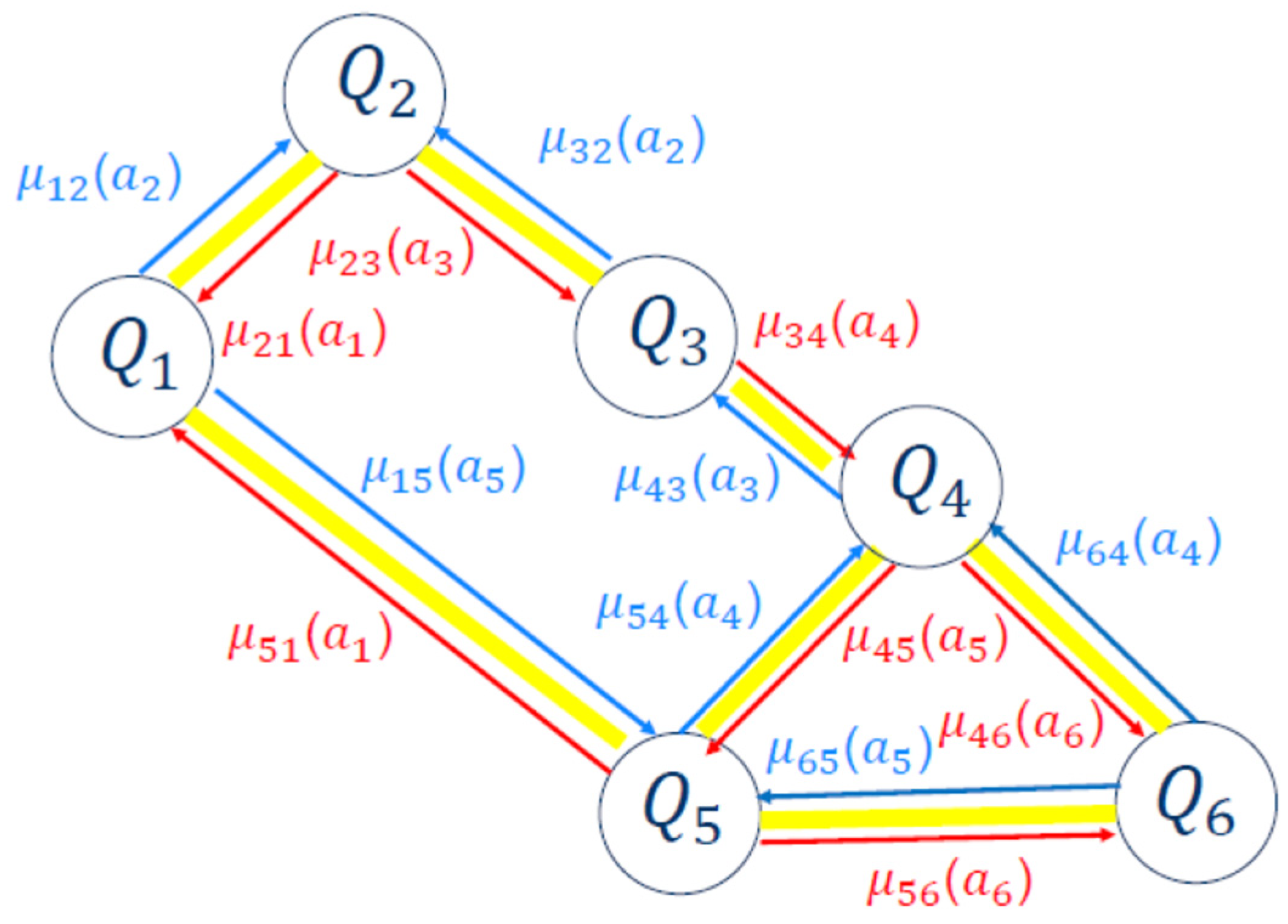
As an example, a coordination graph with six agents is shown in
Figure 3. From Agent 2’s perspective, Agents 1, 3, 4, 5, and 6 are leaves (children), while Agents 1, 2, 3, and 4 are roots (parents). The messages transmitted “up” to roots (parents) are different from messages sent “down” to their children (leaves). Calculating relation (7) is different for different types of agents. If an agent is a leaf, it can respond immediately. However, if an agent is a parent, it waits for its children to send it their payoffs.
As mentioned before, the Max-Plus centralized coordination problem with no cost is to find the optimal joint action
that maximizes
defined in (9) as follows:
It should be noted that for the cumulated payoff of the agent from , all its neighbors in (8) are already included in the local payoff of agent j in (7). The exact solution of Equation (9) is the Variable Elimination (VE) algorithm, which unfortunately is not an anytime algorithm.
- B.
Distributed Iterative Max-Plus Algorithm with no Cost
The distributed version of the Max-Plus algorithm with no cost is much more complex in terms of implementation and increased number of iterations since the agents have no access to the factored global payoff function given by (7). The Global Reward should be evaluated within the MAS and communicated to all agents. Therefore, the agents participating in the distributed algorithm will have enhanced capabilities to compare those participating in the centralized algorithm. We need to distinguish between the evaluated Global Reward in distributed MAS, the instantaneous Global reward at iteration as and the initial desired Global Reward as that is presented to all agents at the initial time step of the horizon . We assume a distributed synchronous coordination.
The global payoff function after calculating using (7) of every synchronous time step must be calculated and stored. A trivial approach would be to centralize the value to a single agent in every time step. This agent would then inform the other agents each time a solution that improves the results on all previous solutions is obtained. However, this method has drawbacks both in terms of the increase in the number of messages and the violation of the agent’s privacy caused by the need to inform a single agent (not necessarily a neighbor) about the joint payoff function which represents the payoff of the coordinated action of the other two agents and .
An elegant solution to overcome the above issue is to use a Spanning Tree (ST)
where at each time step
the number of agents is fixed as
, while the number of connections (
) depends on the MAS configuration at that time. We still consider the case where all agents are connected (the domain is connected). An example of ST associated with the CG given in
Figure 3 is represented in
Figure 4. In general, an ST associated with a CG is not unique and should be known by all the agents at every time step
. If the ST is fixed (as we assume for simplicity in this paper) then it will be initialized at the beginning of the distributed Max-Plus algorithm.
In an ST, every agent receives information from his children, calculates the resulting payoff including their own contribution, and passes it to their parents. For example, in
Figure 4, Agent 2 is the
root that makes the final calculation based on the payoff received from its children, Agents 1 and 3, respectively. Agent 3 is also a parent (
rooted) and, in its calculations, it considers the payoff from its child, Agent 4. Agents 1, 5, and 6 are leaves which report to their parents.
After calculating the global payoff value in this ST, Agent 2 communicates this value to other agents, i.e., 1, 3, 4, 5, and 6, by propagating down in the ST. Using this mechanism, all the agents in the distributed MAS are aware of the global payoff value at every time step .
Other important issues are (1) the status of every agent in MAS and (2) the time when the agents start their local algorithm. Every agent is in waiting mode and any agent will initiate the process of calculating the Global Reward in MAS when it believes it will make a significant contribution to it. This happens when an agent has an increased change in its local payoff or/and edge payoff with its neighbor .
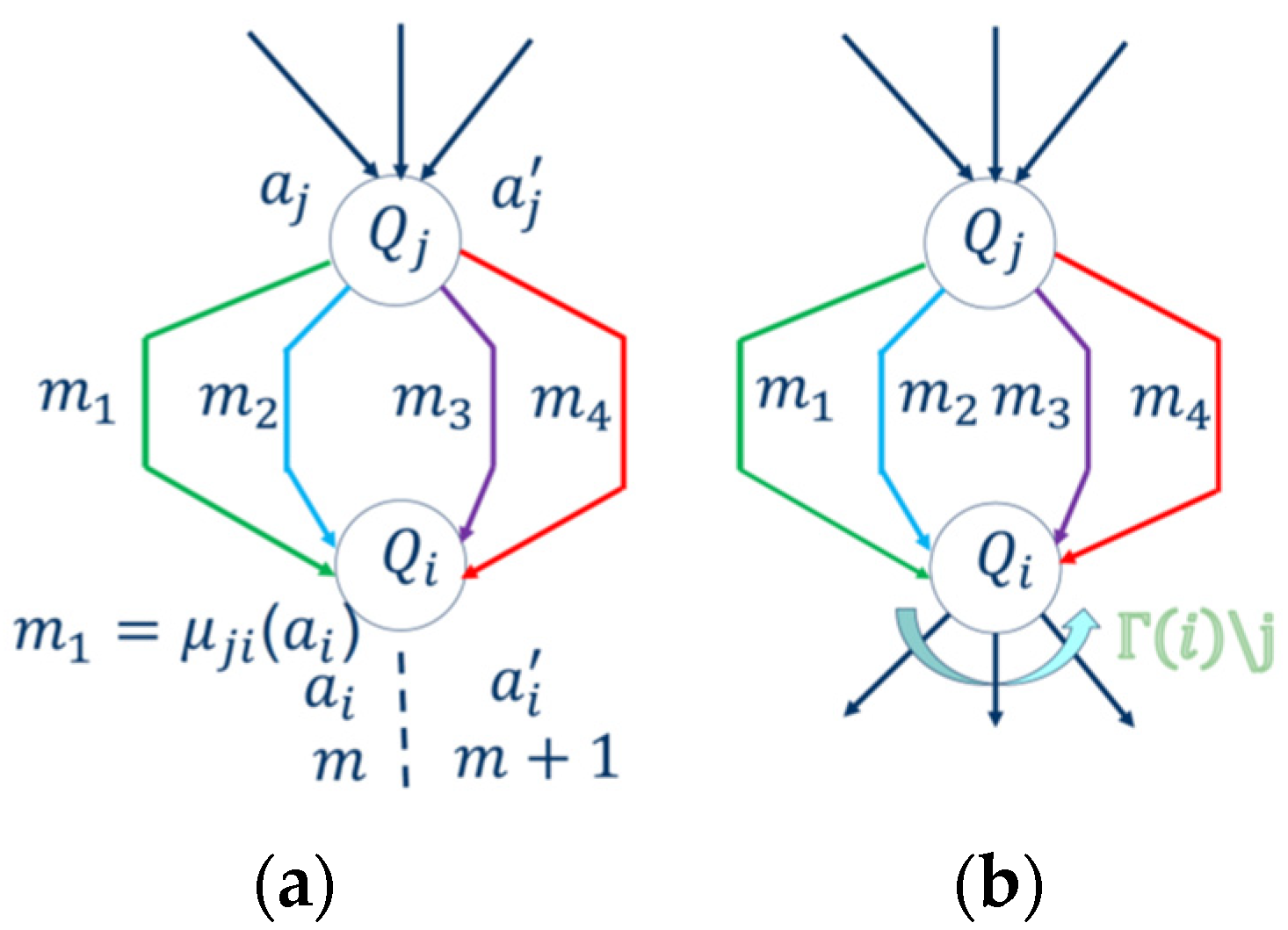
In the distributed Max-Plus algorithm with no cost, the agent
at any iteration
may receive four types of messages
,
sent by agent
and therefore its response to agent
should match the incoming messages. As mentioned before, any agent can initiate exchange messages at any time. In addition, we need to distinguish if the agent
is a leaf or root, as shown in
Figure 5a,b.
The main difference between the leaf (terminal node) and the root (parent node) is the computational time. If the agent
is a leaf, then it can respond immediately in the next iteration
with its optimal action
as shown in
Figure 5a. Otherwise, the agent
must wait for payoff calculation from its children denoted by
as shown in
Figure 5b. Please note the difference between the actions and the reported payoff as explained below.
The incoming messages received from agent are explained next.
(1) Message
(green line in
Figure 5a) is a Max-Plus typical message received from agent
when agent
is taking action
. Agent
will respond with the message
and will start exchanging messages until the local convergency is achieved:
(no improvement of the local reward or no significant difference in the messages exchanged). The final action of agent
is the action
as in (9). Agent
initiates the process since it observes a significant change in the reported payoff from agent
,
. The same process can also be started by agent
which observes a significant change in the reported payoff of agent
. When local convergency is reached, the action presented by agent
to its neighbors is
(which is not necessarily the optimal one
). Since the local information of agent
is modified and possibly improved at convergency, agent
also believes that the team Global Reward has been improved. In this case, after local convergency, agent
will ask for a payoff evaluation in the distributed MAS system and agent
will respond in this regard by sending the message
. Before asking for this payoff evaluation, the action of agent
is
and its reward is
since agent
must share the edge reward with agent
which also contributes to
reward via its action
. In (7), the payoff function
contains the cumulated factor ½ from each agent on the edge.
The distributed Max-Plus Algorithm runs more iterations than those of the Centralized Max-Plus Algorithm. The centralized version runs at most
iterations which are necessary for the convergency to reach the fixed point. Usually, this number is small
and depends on the applications. If the convergency cannot be reached within
iterations, the Centralized Max-Plus algorithm will stop. For the distributed Max-Plus version, there are additional hops
as illustrated in
Figure 4. To send the evaluated Global Reward in the particular case illustrated in
Figure 4, where there are three hops, there are necessary
additional steps (
upward and
downward) to propagate the evaluated Global Reward upward to Agent 2 from Agents 1, 3, 4, 5, and 6. There are three other hops to send the evaluated Global Reward from Agent 2 to Agents 1, 3, 4, 5, and 6. For
agents, the worst scenario is the
step, so the distributed Max-Plus algorithm runs at most
iterations.
Let us assume that anytime Global Reward value in the distributed coordination Max Plus algorithm at iteration is Since we assume a distributed synchronous coordination, each agent is synchronized at iteration . Each agent will be able to go to iteration without a coordinator (controller). There is no possibility that any other agent will start iteration . The rest of the messages (, ) described below are necessary to calculate the time Global Reward and the evaluated Global Reward in the MAS system denoted by . These two payoff values and are compared against the desired Global Reward denoted by presented to all agents at the initial time step of the horizon time step .
The Evaluated Global Reward (anytime or at the end of the horizon time ) will be calculated in three successive phases: (a) request message for payoff calculation sent to agent , (b) request message for payoff accumulation in the system, and (c) request message to calculate the Global Reward of the team which is shared by all neighbors.
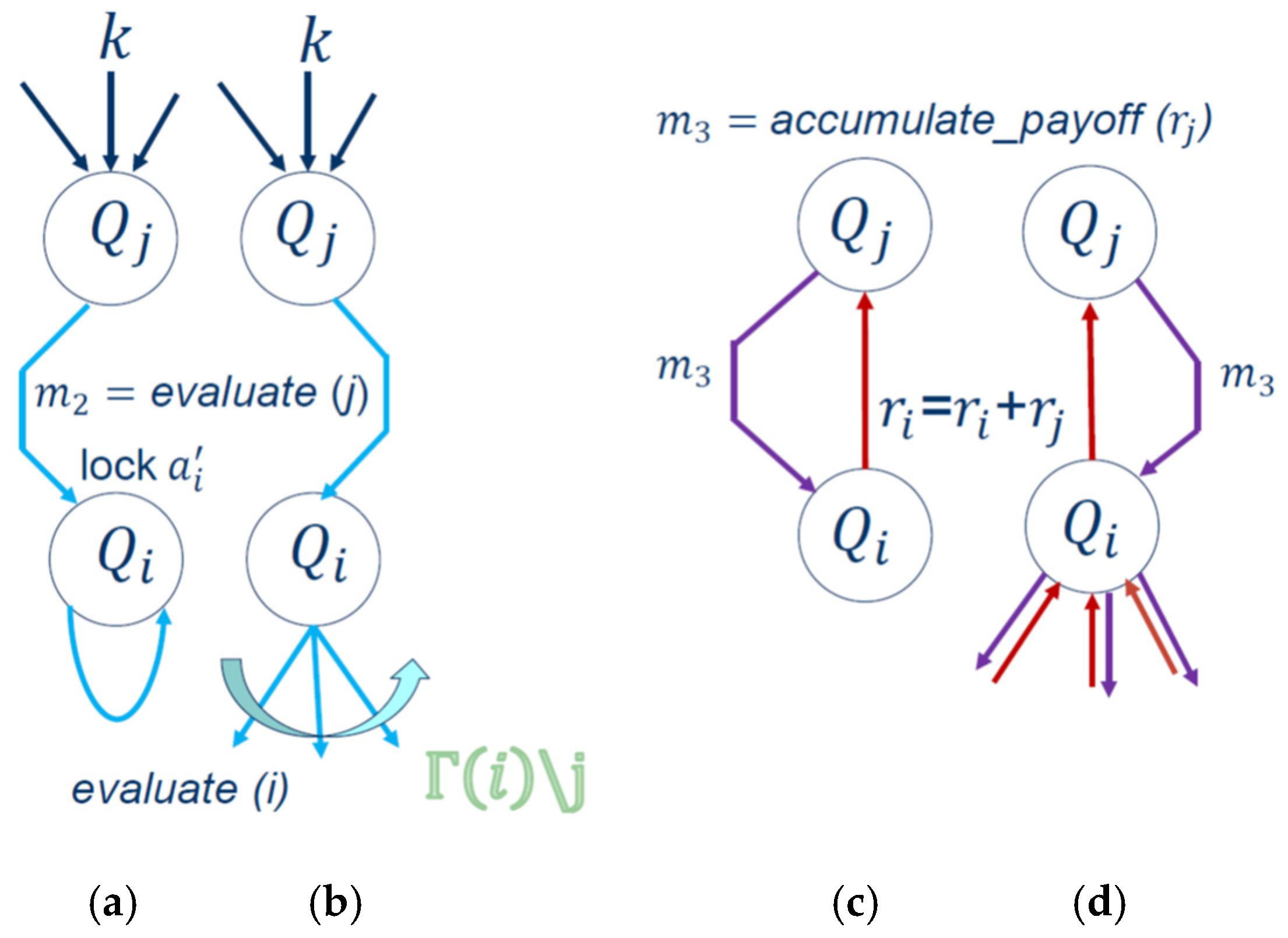
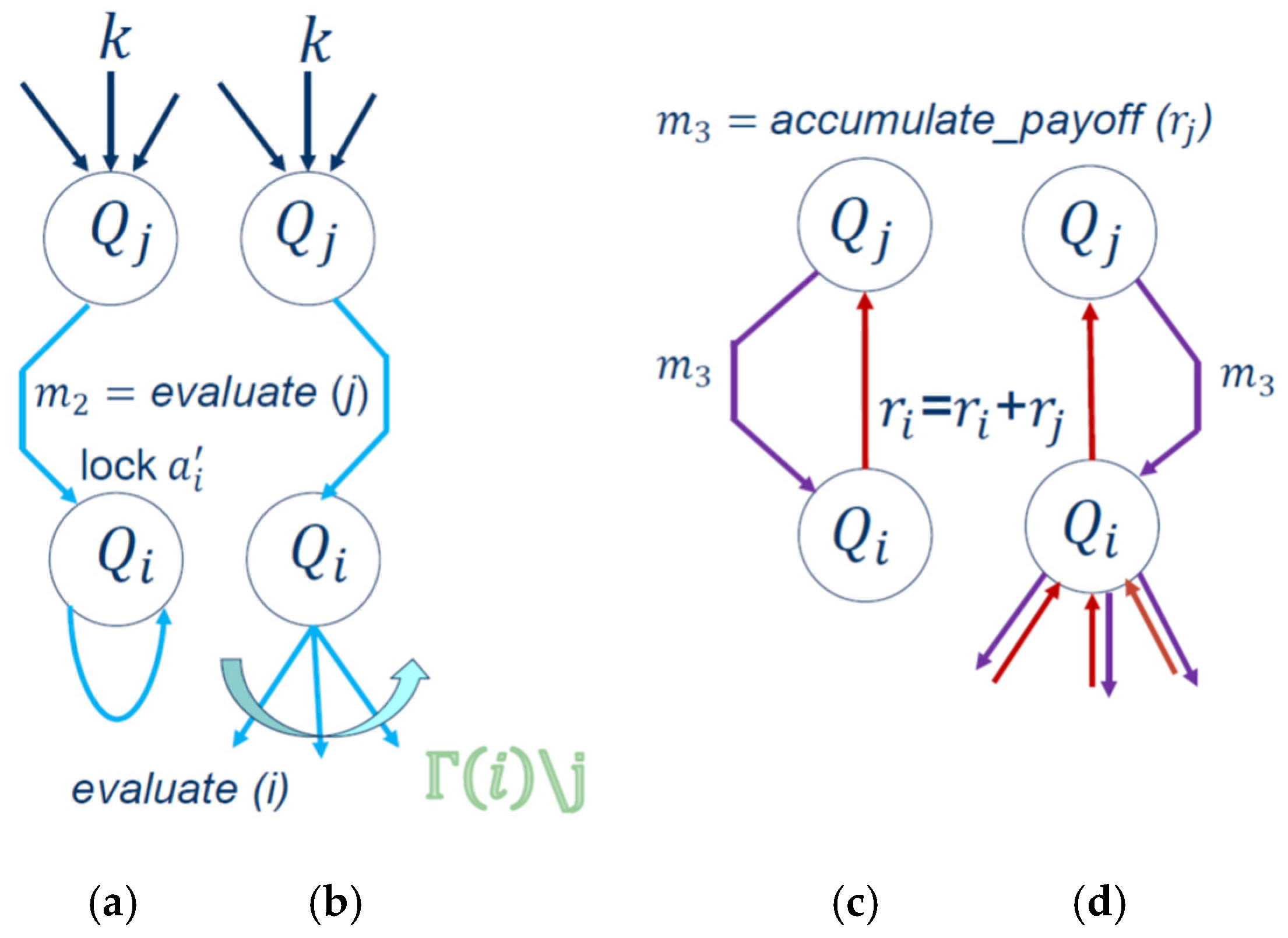
(2) Message
(blue line in
Figure 5a) is a request for payoff evaluation sent to agent
from agent
. Agent
will respond with the message
. This process is illustrated in
Figure 6a,b depending on whether agent
is a leaf or root. When agent
receives this request and it is a leaf (
Figure 6a), it will lock the best action
found so far and respond to it. In its response to agent
agent
will communicate its best action found so far:
which equals the contribution of the individual function of agent
and different subtrees with the neighbors of agent
as root and its local payoff
No further action is required from agent .
If agent
is a root (
Figure 6b), it will not lock its action
. It will send the message
to all its children. As a root, agent
is asking all its children to report their payoffs to it and it will initiate the calculation of the payoff accumulation, which is explained next. Agent
will fix its individual action after the evaluation.
(3) Message
(purple line in
Figure 6c,d) is a request from agent
to calculate the accumulated payoff in the MAS system. Agent
will send its local reward
accumulated so far to agent
as illustrated in
Figure 6c (leaf) and
Figure 6d (root), respectively. If agent
is a leaf, then it will modify its accumulated local reward to
and it will stay in this state until it receives the last message for calculating the Global Reward for the team as shown in
Figure 7. If the agent is a root (parent), it will send a request message to calculate the global payoff to all its children (purple arrows) by sending its value
as shown in
Figure 6d. As a parent, it will receive the payoff for all its children (red line) and send it to its parent, agent
(red line), as shown in
Figure 6d. In other words, after receiving this message of
calculating the accumulated payoff, agent
will send the information regarding its local payoff either back to the neighbor
or to all its children.
Note that when agent is receiving the accumulated rewards from all its children, it might choose a different value for its action found so far in MAS. Since this action is fixed in iteration the agent must unlock this action for calculating the global payoff of the MAS for the next iteration of the distributed Max-Plus algorithm.
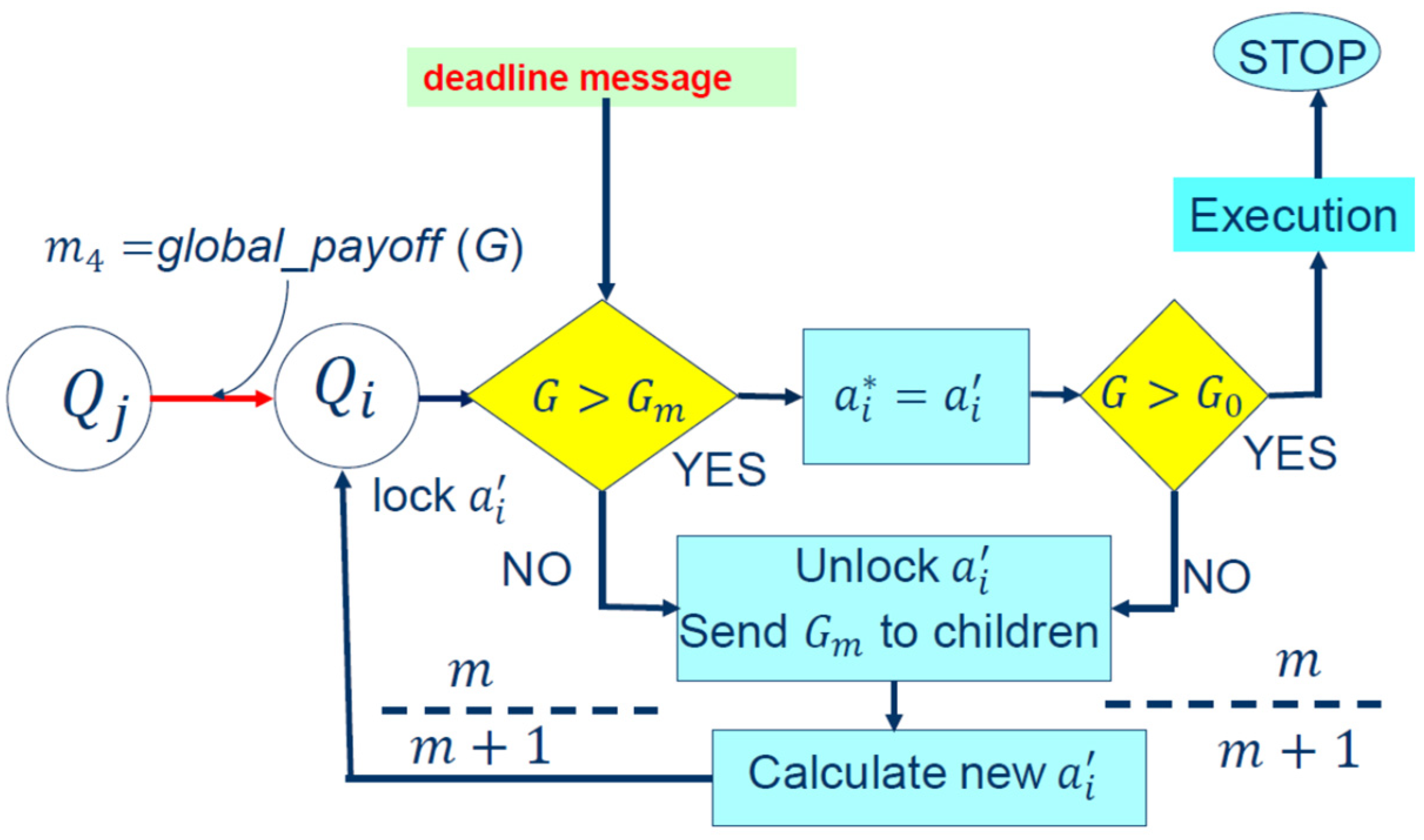
The last message
(red line in
Figure 5a and
Figure 7) is the message sent by agent
to agent
, and it contains the information about the evaluated Global Reward
of the team calculated so far. Agent
is not aware of this value when it notices an increase in its local payoff, and it believes that it can make a significant contribution to the MAS evaluated Global Reward. Agent
will check if it must continue its local process of finding new optimal actions or not. To do so, it must compare the evaluated Global Reward
against the instantaneous Global Reward
and finally compare it against the imposed Global Reward
. This mechanism is illustrated in
Figure 7 and it is called “
anytime”.
(4) After receiving the message
, agent
will lock the action and calculate its contribution to the team by calculating the instantaneous Global Reward
. If its contribution to team (instantaneous Global Reward)
is not increasing and it is less than the evaluated Global Reward so far (NO in
Figure 7), i.e., the best action found so far
is not increasing the team’s Global Reward
, then it will ask for help from its children. Agent
will unlock
and repeat its optimization process. If its contribution is increasing the team’s Global Reward
(YES) at iteration,
then its optimal action
will be reported as an optional one
and the evaluated Global Reward
will become
. This instantaneous value will be communicated to its neighbors (team). In this way, its belief that it can contribute to the instantaneous Global Reward
is certain. Now, agent
needs to know if the team must move forward or stop. The anytime algorithm will STOP if the resources of agent
or a deadline message arrives, or if the desired Global Reward is met. This is a very important task. As mentioned before, it will allow the algorithm to escape from local maxima and the team will move forward to achieve the desired Global Reward assignment
presented to all agents at the initial time step of the horizon
.
If the instantaneous Global Reward
(
Figure 7) and the evaluated Global Reward
are both greater than the desired Global Reward
(YES), then the root Agent 2 (see
Figure 4) will stop working and communicate its decision to the rest of the team. The actions can be executed if it is required. If not (NO) then the agent will continue its optimization process. Therefore, the team will work together in a distributed coordination until the time
. This is a major difference in contrast with the Max-Plus centralized coordination version. In the distributed implementation, in addition to the anytime aspect, each member of the team must check if the desired Global Reward
is achieved. Therefore, in the distributed version, the capabilities of the agent are enhanced in contrast with the centralized version.
6. Hybrid Max-Plus Algorithm with Cost
In the Cost Hybrid Max-Plus algorithm, every agent
may receive a vector segmentation status message
. Message
is a segmentation message (represented with a
dotted red arrow in
Figure 8) indicating the communication status to the centralized coordinator for all agents in the system. Initially, at moment
all the agents are working together in a centralized scenario on a CG under the supervision of the centralized controller. Later, at
, the agents will regroup together keeping the same complexity of the message under the same centralized controller. If
for all agents at time step
, then no segmentation occurs in the system for all
agents. All agents will continue in their centralized setting by using CG until a segmentation message occurs. However, if
for some
agents at time step
, then a segmentation process occurs. The group of
agents will split into two groups,
. The
agents will continue under the supervision of centralized coordinators (left side) on a CG, and
agents (right side) will execute the distributed Max-Plus algorithm on a spanning tree (ST). Later, the two aforementioned groups may reorganize under centralized supervision.
For
agents, from our example in
Figure 3, the system will split into two groups by cutting the link between the agents
,
and
,
respectively, as soon as the segmentation message
is received. The grouping
is composed of the agents
chosen to take part in a Spanning Tree formation (decentralized) [
4]. The group
consists of agents
chosen to participate in the centralized CG setting [
3]. For the sake of illustration and numerical experimentation, we have divided them into equal groups. The group
that can still connect with the centralized coordinator will remain in their centralized setting (CG) (left green arrow in
Figure 8). The secondary group
that is unable to maintain communication with the coordinator will continue in a distributed Max-Plus algorithm (right red arrow in
Figure 8) in a Spanning Tree (ST) setting [
4]. After a while, at time step
if
, every agent will reassemble into a group.
Another message received only by agents in the group that loses connection with the central coordinator is . Message is used by the distributed Max-Plus algorithm and it typically tells each agent what part of distributed Max-Plus algorithm should be executed. For example, it can be , which is a typical Max-Plus message (line 23 in the algorithm below). When the message is a request to calculate the accumulated payoff from agent (line 30 in algorithm below), then the agent will calculate the accumulated payoff in the MAS. The last form of incoming message (line 39) is the message sent by agent to agent and it contains information about the evaluated Global Reward of the team calculated so far.
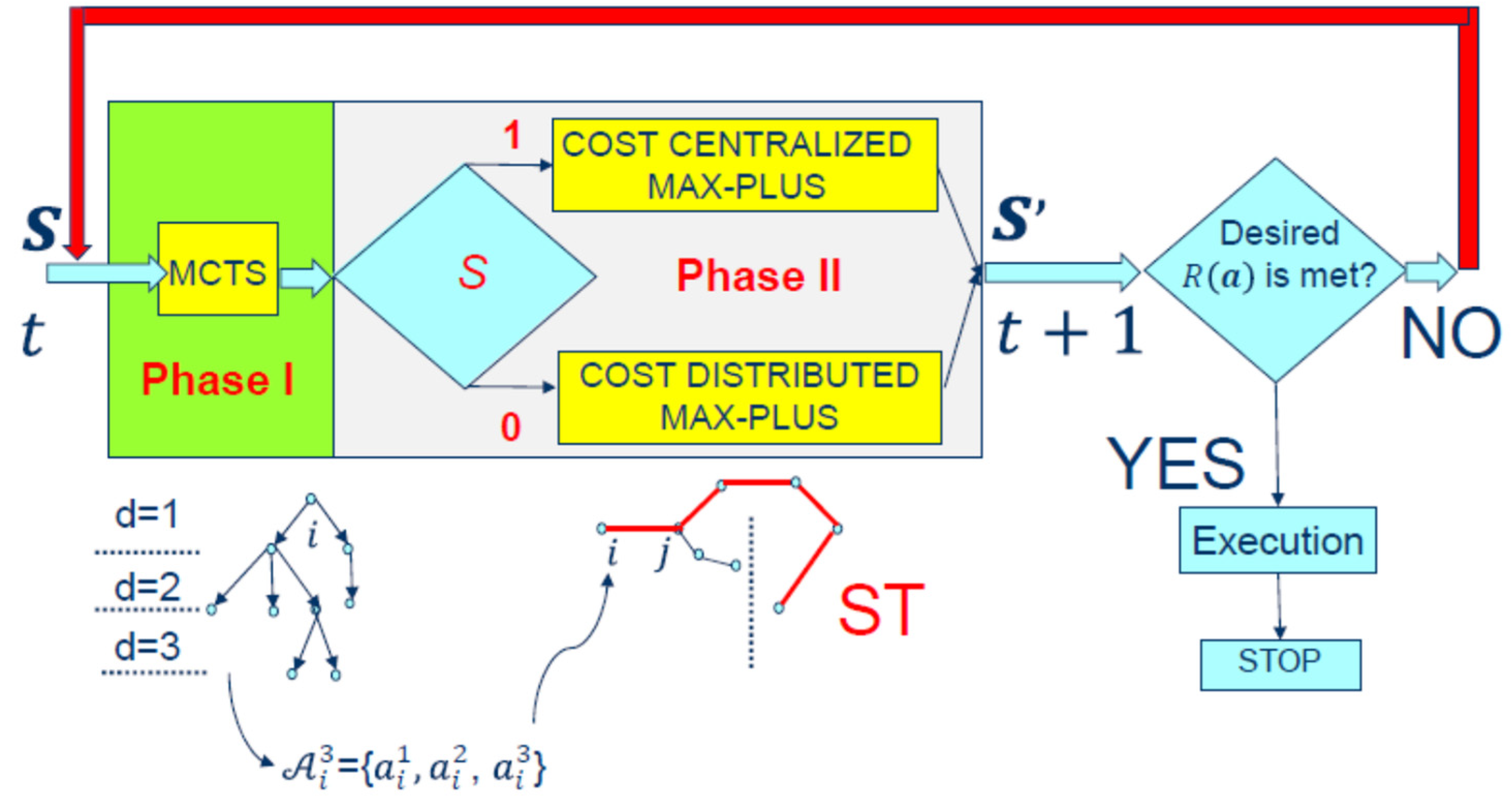
We present the pseudocode of the proposed cost hybrid algorithm as Algorithm 1 below. We provided at the input of our proposed algorithm the number of agents , CG configuration, and the following information about every agent :
Actions for any agent
Initialization by the centralized coordinator for any agent , for any , , , and for any agent , and .
The costs of actions for any agent and the costs for any pair of actions .
| Algorithm 1 Wait for segmentation message as shown in Figure 8 |
| 1. IF an agent receives the segmentation message Go to the Cost Centralized Max Plus algorithm given below://All agents that receive s = 1 |
| 2. WHILE the fixed point is not reached, time and cost budget are not reached//the centralized coordinator is evaluating this condition |
| 3. DO for any iteration |
| 4. FOR any agent |
| 5. FOR all neighbors |
| 6. a. compute |
| 7. b. normalize the message |
| 8. c. send the message to the agent |
| 9. d. check if is closed to the previous message (equivalent to reaching the convergence) |
| 10. END FOR all neighbors |
| 11. Calculate by centralized coordinator |
| |
| 12. Determine , the optimal global action so far including all previous |
| 13. //Use anytime: |
| 14. IF THEN ; ) |
| 15. ELSE |
| 16. END IF |
| 17. END FOR every agent |
| 18. END DO for any iteration |
| 19. END WHILE |
| 20. Return the global reward |
| 21. ELSE IF//All agents that receive s = 0 |
| 22. Provide the Spanning Tree with algorithm in [15] and Go To the decentralized Max-Plus |
| WHILE the fixed point is not reached, horizon time , and cost budget are not reached |
| //Root agent is evaluating this condition |
| 23. IF = (regular Max Plus typical message given by (4)) |
| 24. FOR any iteration |
| 25. FOR all neighbors |
| a. compute |
|
|
| b. normalize the message for convergence |
| c. send the message to the agent if different from previous |
| d. check if is closed the previous message value |
| 26. END FOR//for all neighbors. |
| 27. Calculate with (6) the optimal individual |
| action |
| 28.
|
| 29. END FOR//all iterations |
| 30. (a request for payoff evaluation) |
| 31. send the evaluation request to all children. |
| 32. is a leaf initiate the accumulation payoff |
| 33. END IF |
| 34. ELSE IF = (request to calculate the accumulated payoff denoted by for agent ) |
| 35.
|
| 36. is a root sends the global payoff to all children |
| 37. ELSE sends the global payoff to parent |
| 38. END IF |
| 39. (evaluate Global Reward) |
| 40. Calculate the evaluated global reward |
| 41. Use anytime: |
| 42. IF |
| 43. and ) |
| 44. ELSE |
| 45. |
| 46. END IF |
| 47. END IF) |
| 48. END WHILE |
| 49. Return the best joint actions accumulated so far |
| 50. END IF//(segmentation message 0) |
The anytime extension of the distributed Max-Plus method is more complex. Therefore, in this system, an agent only initiates the evaluation of distributed joint action when it is deemed worthwhile. The fact that messages are transmitted in parallel gives this method a computational edge over centralized Max-Plus algorithms that execute sequentially. A distributed Max-Plus method, on the other hand, requires more work than a centralized one because each agent has to decide whether to report the action individually or for the system to converge.
In a distributed Max-Plus algorithm, each agent computes its local contributions to the global payout by initiating the propagation of an evaluation message via a spanning tree and then forwards it to the parent node. A parent node then adds its own reward to the total of all the payoffs of its children and sends the result to all of its parent nodes before combining the payoffs for all nodes.
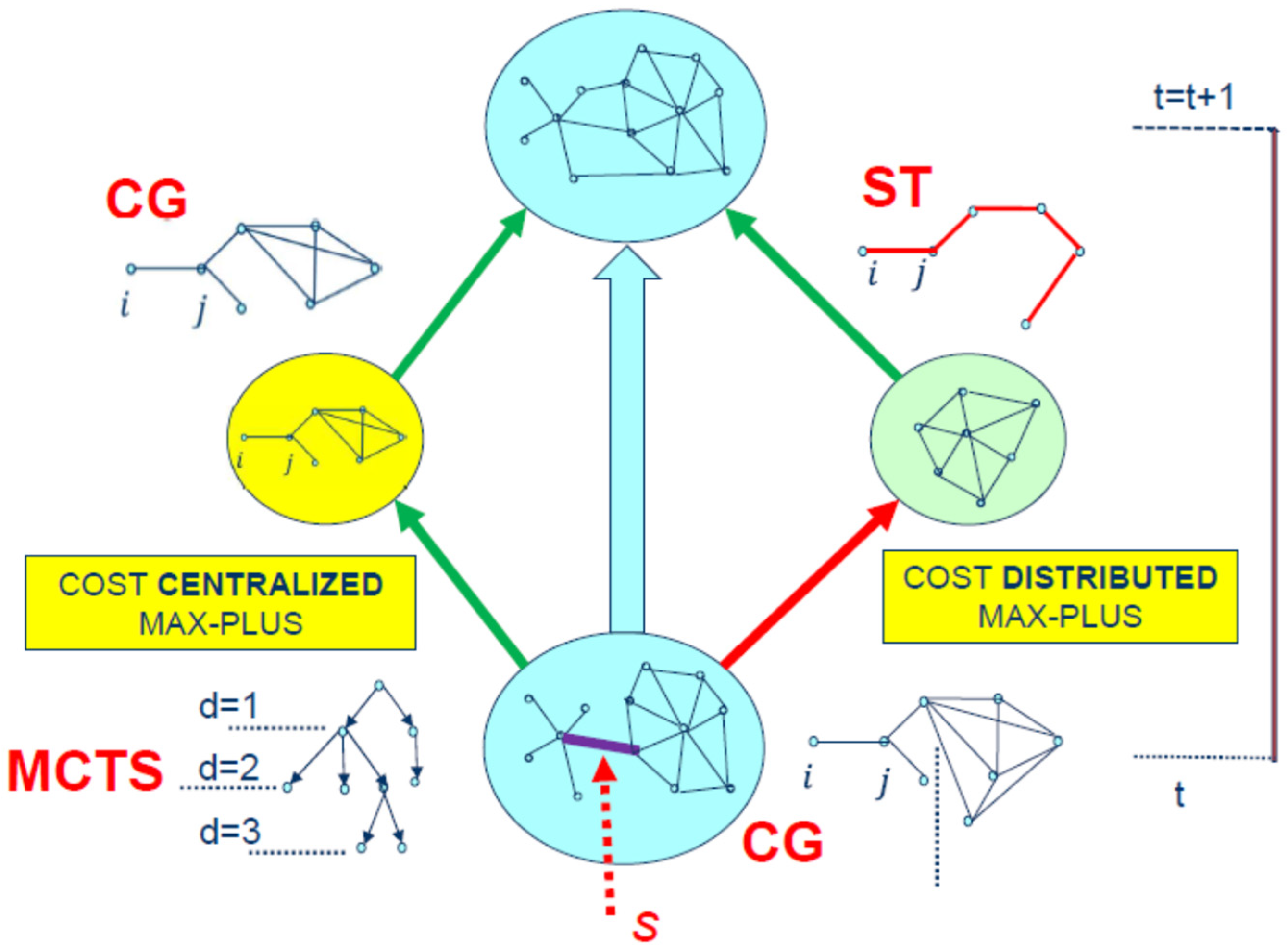
7. Factored-Value MCTS Hybrid Cost Max-Plus Method
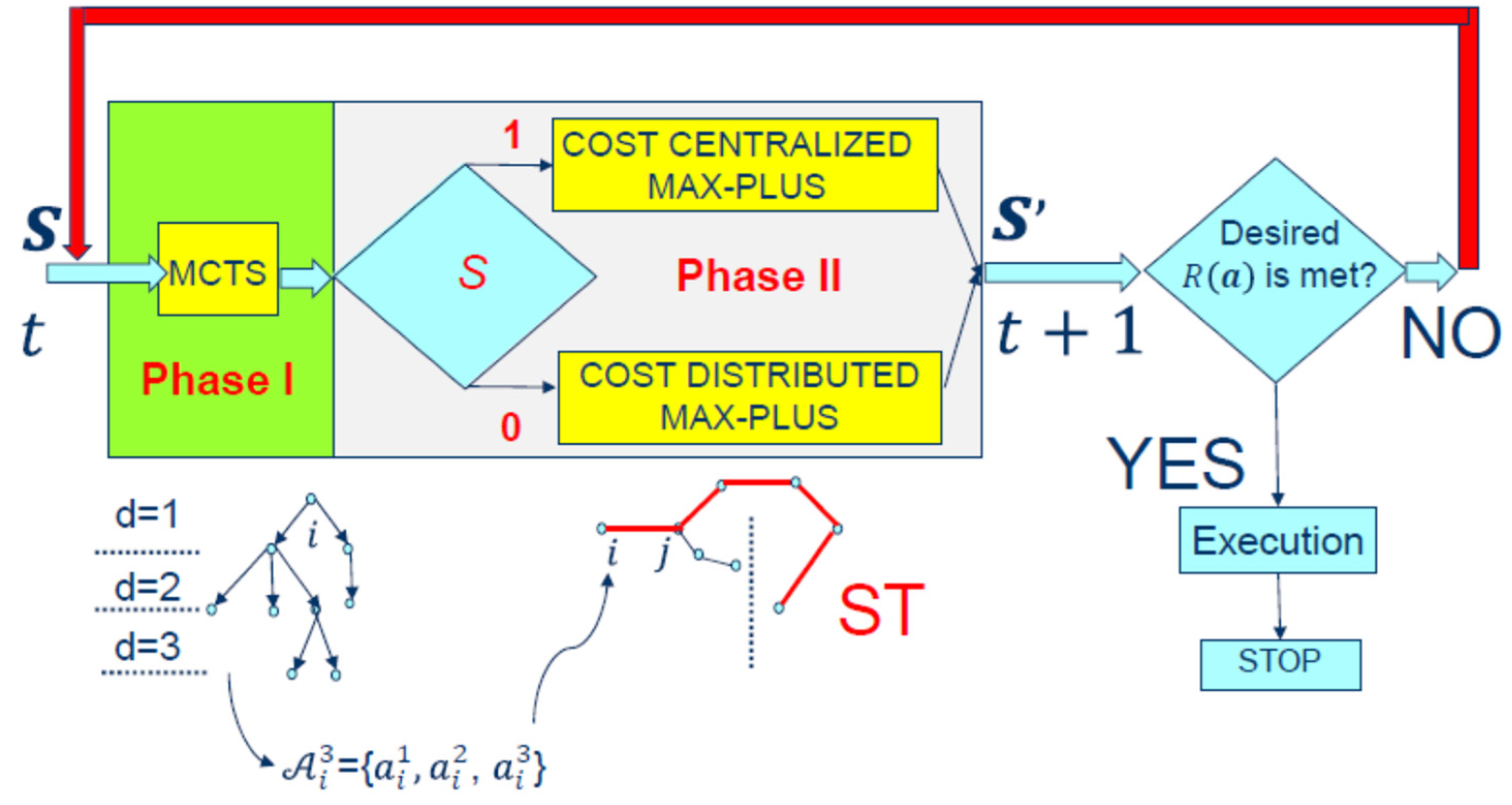
The primary innovation we offer is the Cost Hybrid Factored Value MCTS Max-Plus method (
Figure 9), a new approach to planning and acting. Decision making is performed using this two-phase method:
(I) For Phase I (
Figure 9, green), each agent individually runs the MCTS algorithm (MCTS depth steps are marked by
), resulting in a condensed, ordered list of its best possible actions (we will not discuss the MCTS findings [
11] here). We limit our attention to the Cost MP algorithm. For each and every state agent
, at time step
the initial set of actions
is now reduced to the new set
where
as in
Figure 9 where an example is illustrated for three actions:
. After Phase I is over, each agent will give the team this sorted, selected set. After Phase I, the segmentation message may occur, and Phase I can restart later at any time
when the agents are regrouped in the state
as shown in
Figure 8 and
Figure 9. In
Figure 9, this segmentation process is depicted by a red feedback connection.
Given by decreasing the branching factor
for every agent, the number of actions per state
will be significantly diminished, as the potential action space for each agent exhibits an exponential cardinality in relation to the time horizon. The proposed methodology for decreasing the branching factor
for each agent is superior to randomly contracting the sample space as described in reference [
8], or selecting actions based on a uniform probability distribution as mentioned in reference [
10]. This is due to the fact that our method gives the most likely activities for preparation and implementation the highest probability.
(II) During Phase II, as soon as the segmentation message
occurs, there will be two subgroups created from the original agent group. If
(Line 2 of Section V’s algorithm), the Cost Centralized Max-Plus algorithm will then be used by a small group of agents to carry out the decision-making process as shown in
Figure 2. The other subgroup, which loses contact with the centralized coordinator (
), will employ the Cost-Distributed MP algorithm, as outlined in lines 21 through 49 of the pseudocode, during that same time period. It should be noted that, based on our experiments, there may be a difference in the number of iterations required to run the cost MP algorithm in a decentralized and centralized setting. The results will be gathered at time step
in any case.
During this time step
the MAS is in the global state
and in the following time step
the system will undergo a global transition.
. The possibility of transitioning to the following state
is
(is certain) if the intended Global Reward
is not achieved by the team as in
Figure 9 (NO option). If
, the MAS is going to maintain its current state.
or
with
if the intended Global Reward is met (YES option). In the latter scenario, MAS agents execute the best joint action
,
discovered thus far if it is needed by the team, and the algorithm will terminate.
Our approach is capable of surmounting the centralized MCTS solution that was suggested in reference [
1]. The final coordinated actions of the team are determined within that system via simulation of the global state
n. Nevertheless, progress towards the subsequent global state cannot be assured. Our proposed approach is capable of surmounting this challenge.
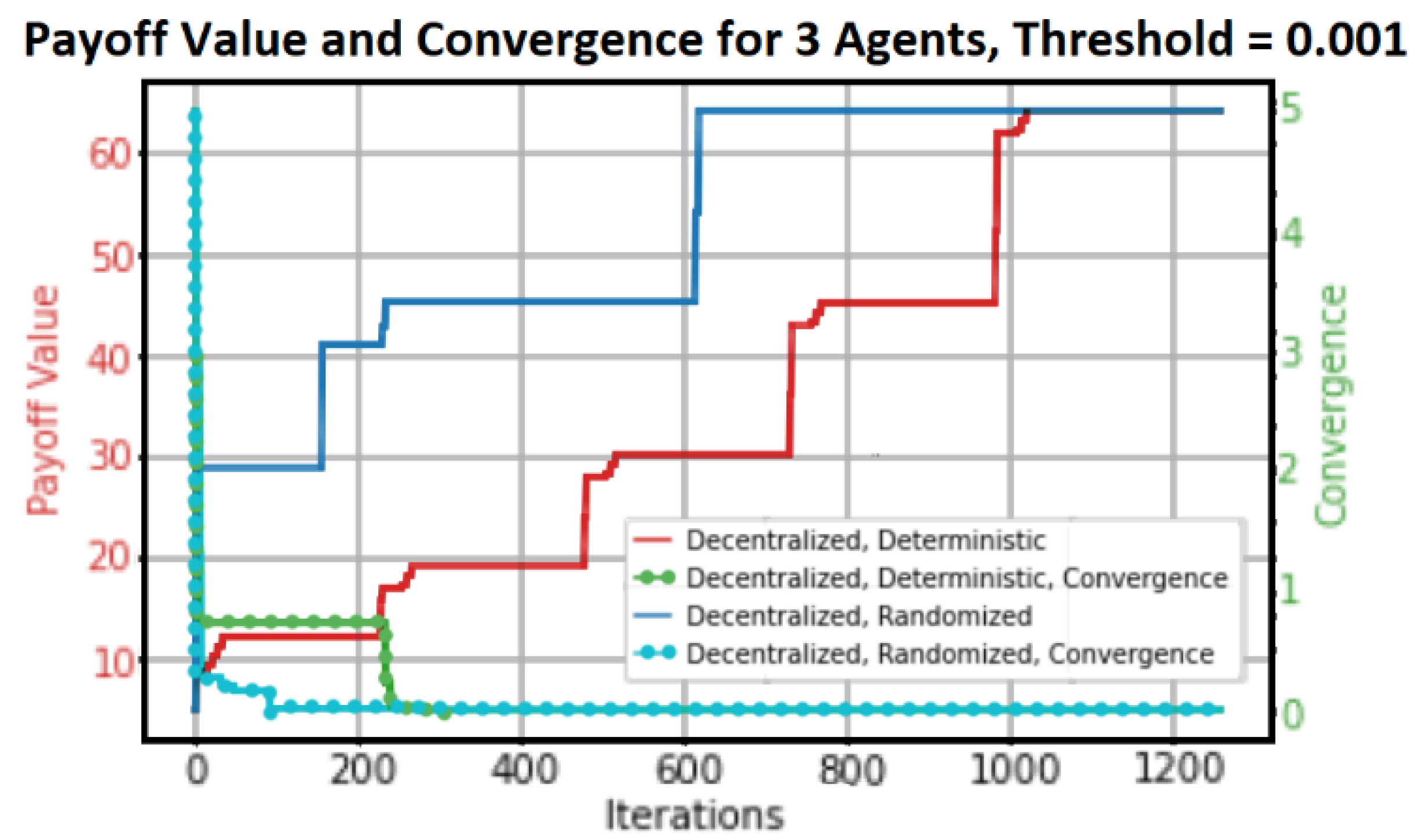
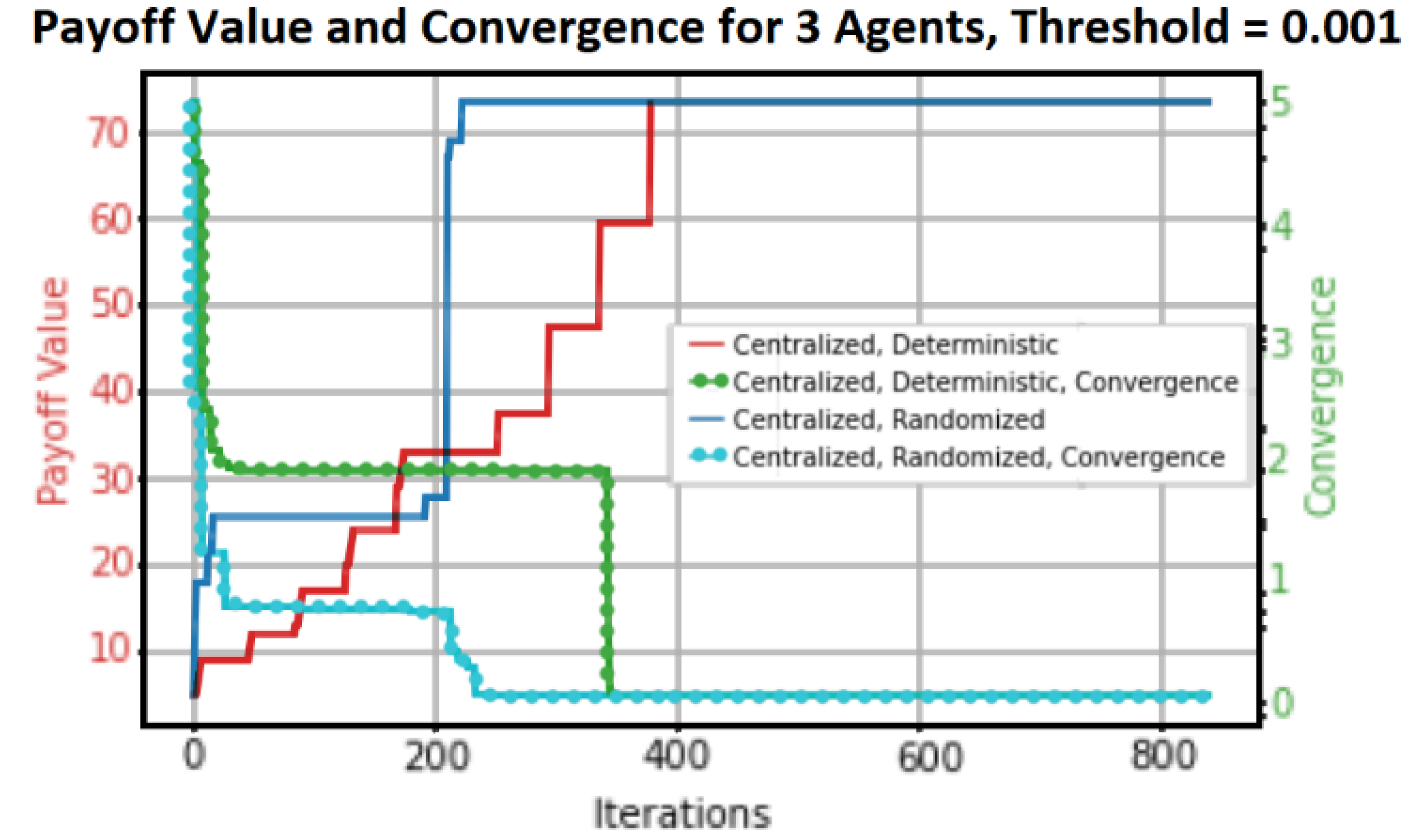
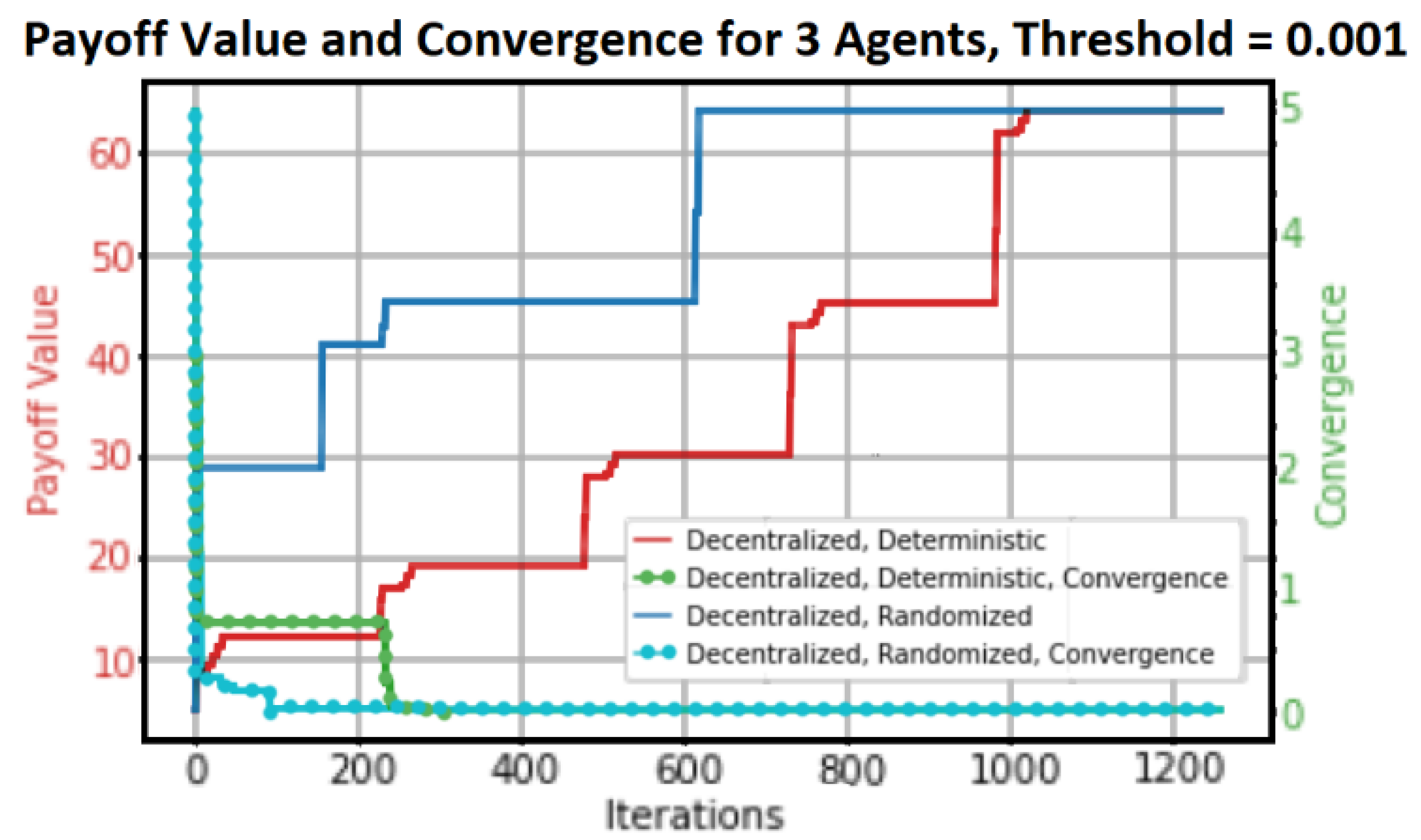
In order to comprehend the hybrid algorithm’s performance characteristics, we only provide the numerical results of the Payoff Value and Convergence of reaching the fixed point in this paper. Any online strategy must consider convergence as a primary concern, and the suggested algorithm’s efficiency in achieving the set payoff value is a determining factor. The Cost-Distributed Max-Plus algorithm (
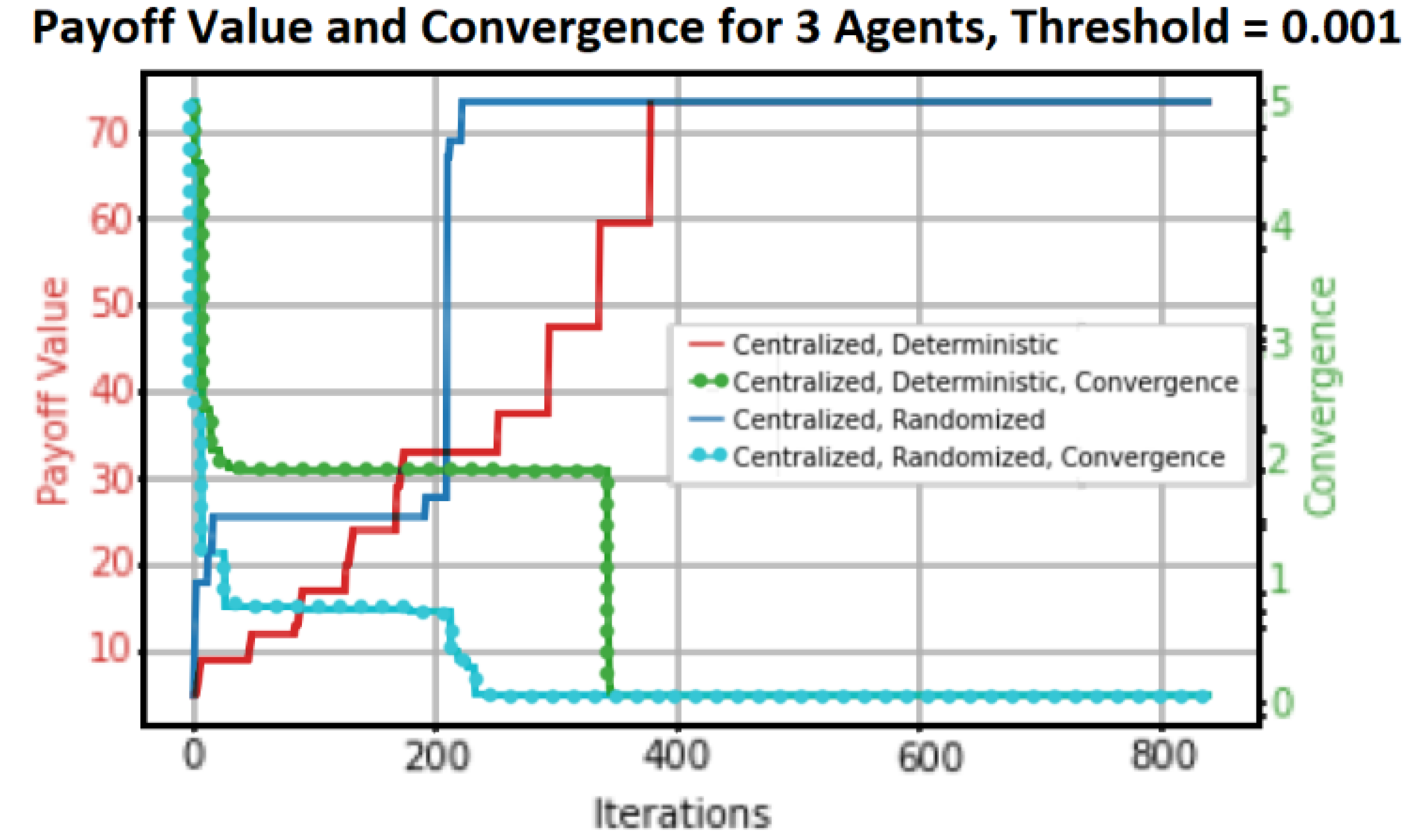
Figure 10) and the Cost Centralized MP algorithm (
Figure 11) are graphical plots that represent our results. The four primary scenarios of decentralized deterministic, decentralized randomized, centralized deterministic, and centralized randomized are generated by the combination of the reached Payoff value and the convergence of the algorithms.
The blue plots show random actions, and the red plots show deterministic payoff, or performing actions in a deterministic order. In order to compare with sequential decision-making systems, randomized action (uniform distribution) is taken into consideration. For every plot, the red scale on the left represents the payoff value range, and the green scale on the right represents the convergence scale. The splitting segmentation process in a three-node MAS configured in both distributed and centralized algorithms depends on the actual case at time t. This is explained in the above section.
We examine the CG scenario with six agents, akin to
Figure 3. We will split into two groups if a segmentation message
s is received by either of them (red arrow). In this scenario, there will be no communication between the two groups of six agents. The results are plotted in
Figure 10 for the first tree agents,
Q − 1.,
Q − 2.,
Q − 3., which will be configured in a Spanning Tree configuration (distributed or decentralized). The payoff value and the convergency performance for the second group (centralized in CG settings) of agents,
Q − 4.,
Q − 5., and
Q − 6., will be plotted, respectively, as shown in
Figure 11. We maintained the same action costs.
Every plot has a convergence threshold and four graphical structures. The maximum payout for the centralized algorithm is reached after approximately 374 iterations for a convergence threshold of 0.001, whereas the maximum payout for the decentralized algorithm is reached after approximately 1023 iterations. But the centralized algorithm reaches convergence after roughly 344 iterations, and the distributed algorithm does so after about 215 iterations. Take note of the various maximum payoff amounts as well. In the decentralized case, the maximum payoff value is approximately 67, whereas in the centralized scenario, it is approximately 74.
The payoff value is greater in the centralized scenario because the centralized controller has “global view” information of all the agents in the MAS and can therefore control the Global Reward (GR) or payoff. Local agents in the scenario involving distributed control have a “partial view” of the environment in which they function. It has been observed that the distributed algorithm converges more quickly than the centralized algorithm for the same number of agents; nevertheless, it requires a longer duration to reach GR.
Within a centralized environment managed by a central coordinator, the agents are prohibited from sharing any information. A completely decentralized coordination strategy for MAS might enable correlated and localized decisions for every agent capable of communication. When local rewards are considered, the decentralized approach is unable to attain the maximum network-wide reward that the centralized case is capable of accomplishing.
As a result, we can conclude that (a) the centralized algorithm reaches a maximum payoff before the distributed algorithm, (b) the distributed algorithm converges more quickly than the centralized algorithm, (c) the centralized algorithm reaches a maximum payoff earlier than the distributed algorithm, and (d) the centralized algorithm reaches a higher maximum payoff than the distributed algorithm during the convergence process.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}