

Robust Data Sampling in Machine Learning: A Game-Theoretic Framework for Training and Validation Data Selection


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- training data selector (trainer): selects an optimal set of training data that minimizes the test error;
- validation data selector (validator): selects another set of vehicle trajectory records that maximizes test error.
2. Related Works
2.1. Car-Following Models
2.2. Reinforcement-Learning-Aided MCTS (RL-MCTS)
3. Methodology
3.1. Problem Statement
- Sampling: The dataset is divided into training, validation, and test sets, i.e., . The training set is used to update the model parameter by implementing back-propagation algorithms. The validation set is used to monitor the model’s out-of-sample performance during training, and the test set is for the final evaluation of model f after training. The sizes of the training, validation, and test datasets are , , and , respectively.
- Training: The training set is used to update the model parameter , and the validation set is used to avoid overfitting.
- Evaluation: The trained model f is evaluated using the test set .
3.2. Two-Player Game
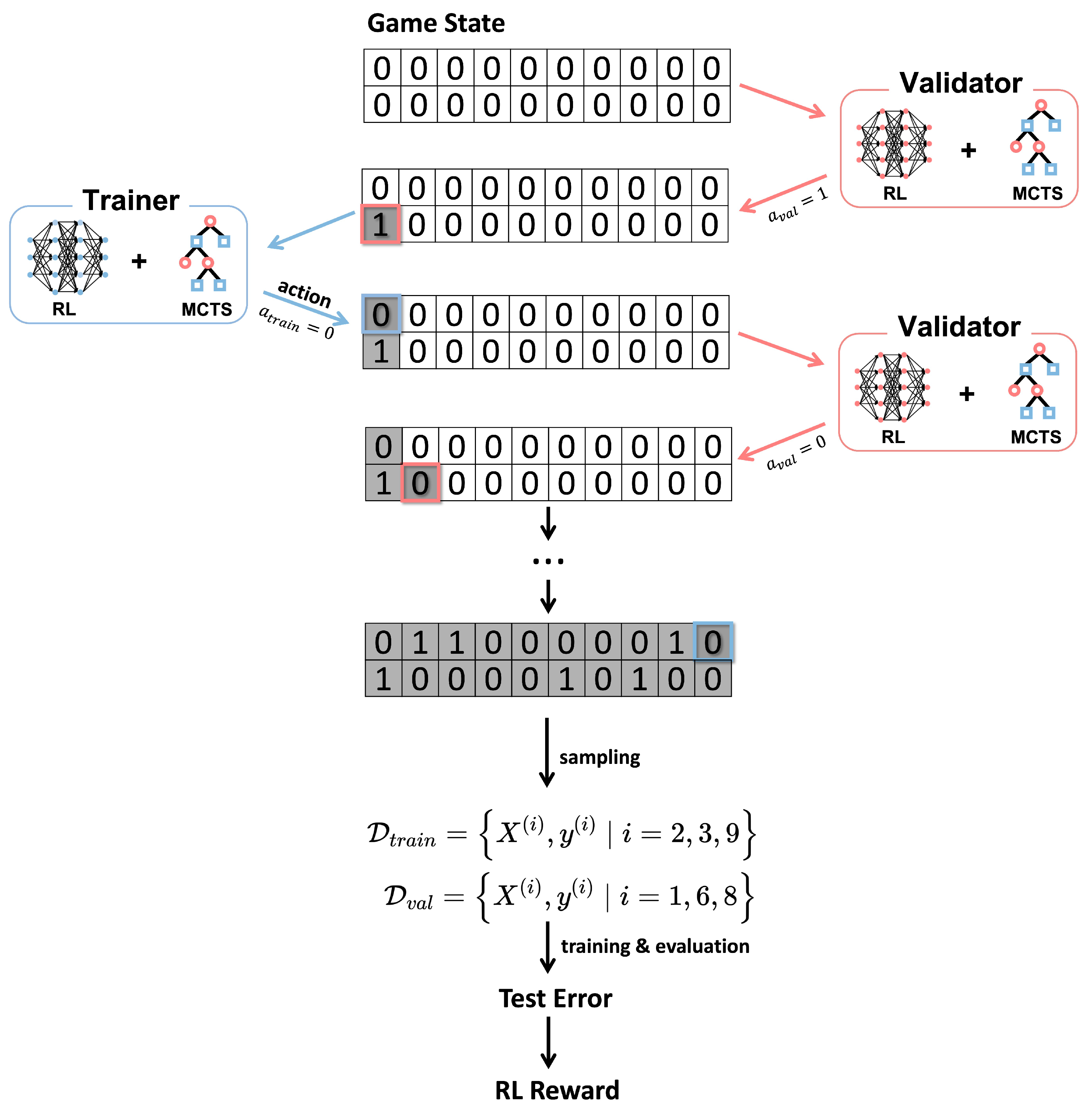
3.2.1. Game State
3.2.2. Game Action
3.2.3. Game Rule
3.2.4. Game Score
3.2.5. Game Reward
- If and , then and
- If and , then and
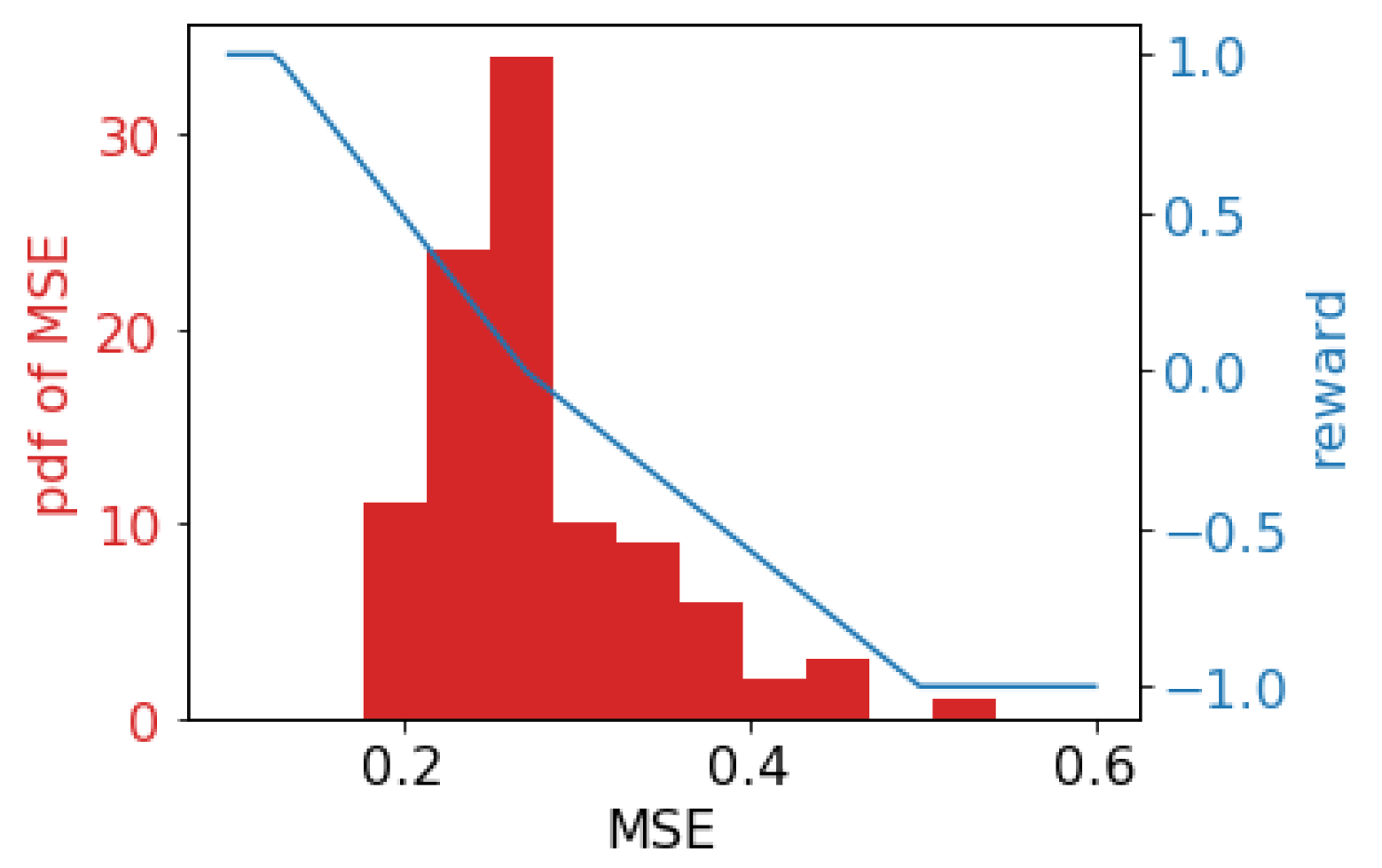
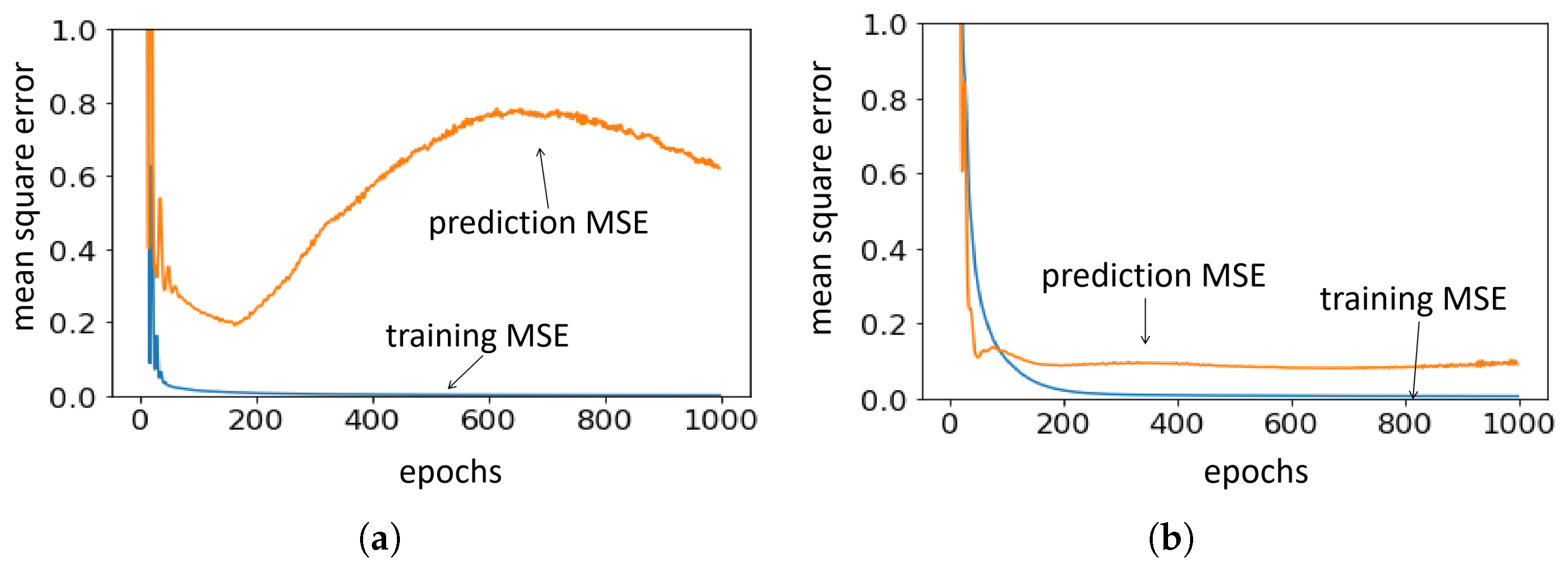
- Otherwise, a piece-wise linear function is adopted to map the score to the reward, which is shown in Figure 2. We randomly sample the training and validation data, then train and evaluate a CF model (the CF model will be introduced in Section 4), and Figure 2 shows the distribution of the test MSE (left y-axis). The blue line shows the piece-wise mapping function of the reward (right axis), and the validator’s score-to-reward mapping is the opposite of the trainer.
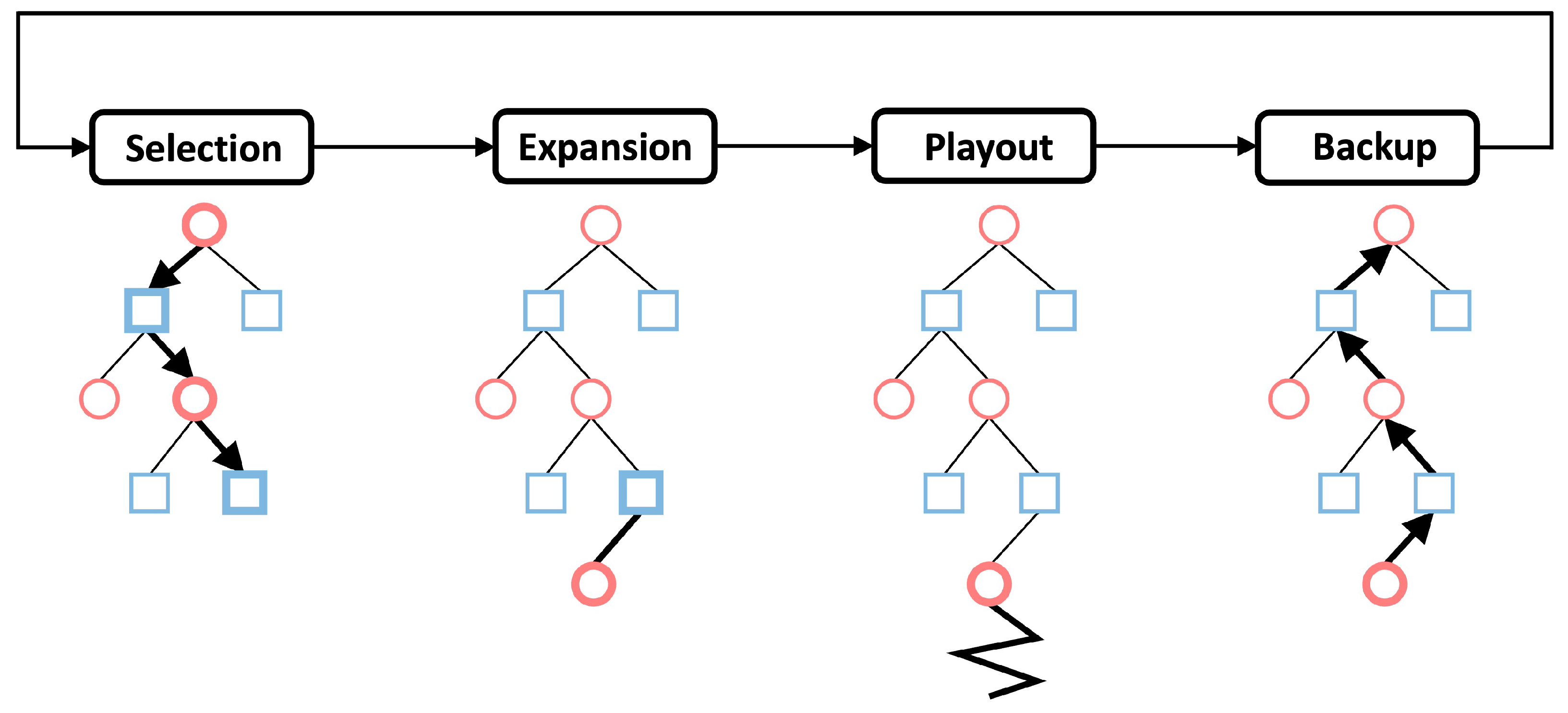
3.3. Monte Carlo Tree Search (MCTS)
- Selection. The first phase starts with the root node and sequentially selects the next node to visit until a leaf node is encountered. Each selection is based on:where is the average reward gathered over all tree-walks, is the number of visit of edge a, and is the number of visit of node s. is a constant determining the level of exploration.
- Expansion. When a leaf node is encountered, one of its children nodes is appended and the tree thus grows.
- Playout. After the expansion phase, a random playout is used to finish the remaining search. That is, each player will randomly move in the rest of the game the termination node is reached and computing the associated reward.
- Backup. The node and edge statistics are updated in the last phase of a searching iteration. First, the number of the visit of all traversed nodes and edges are incremented by one. Second, the current reward computed in the playout phase is back-propagated along the traversed path, and is used to update the average reward .
3.4. Reinforcement-Learning-Aided MCTS (RL-MCTS)
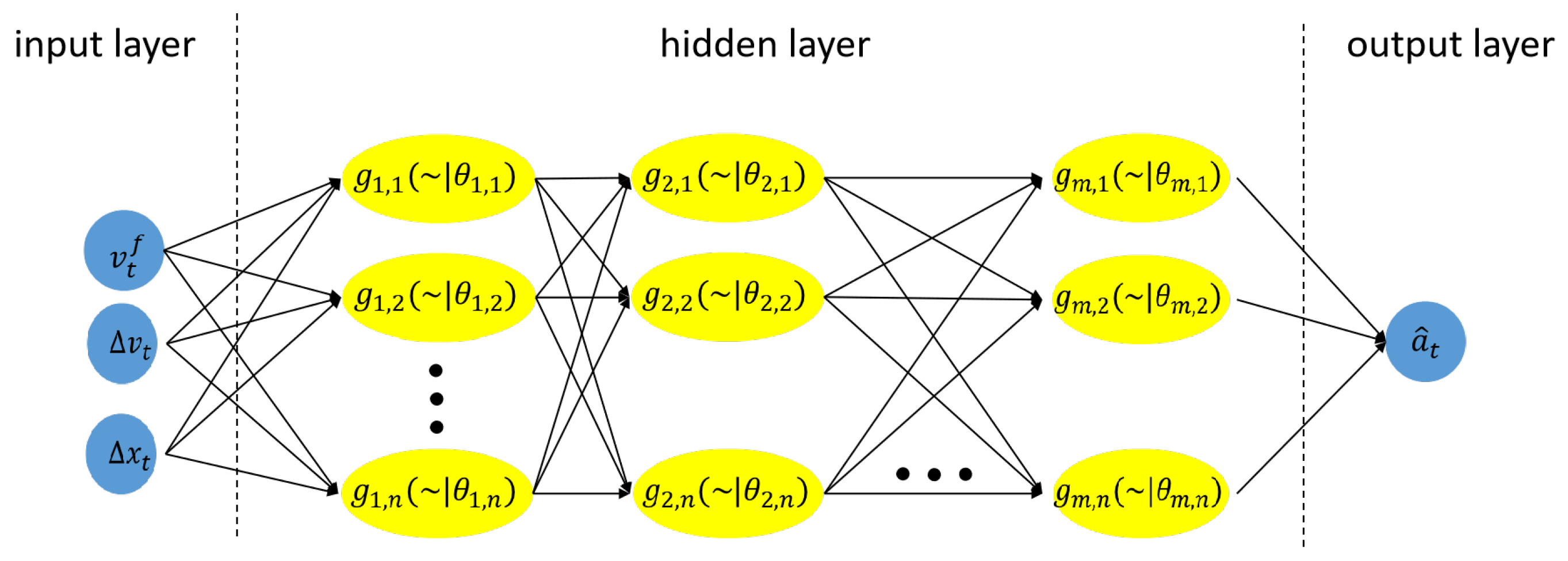
3.4.1. Value Network
3.4.2. MCTS with Value Networks
- Selection. Each selection is based on:Compared with Equation (3), the difference of RL-MCTS’s selection phase is that the average reward is replaced with the evaluation of the value function.
- Expansion. This phase is the same as the MCST.
- Playout. The reward attained from a random playout is replaced with the evaluation of the q value function.
- Backup. The backup is the same as the MCTS, except for that the q value rather than the average reward is the statistic to be updated.
3.5. Summary
| Algorithm 1: Two-player game |
| Input: The components of the two-player game defined in Section 3. Output: Two trained value networks for both players, which will manage to evaluate the current position according to the current player. Initialization: |
|
4. Case Study: Car-Following Modeling
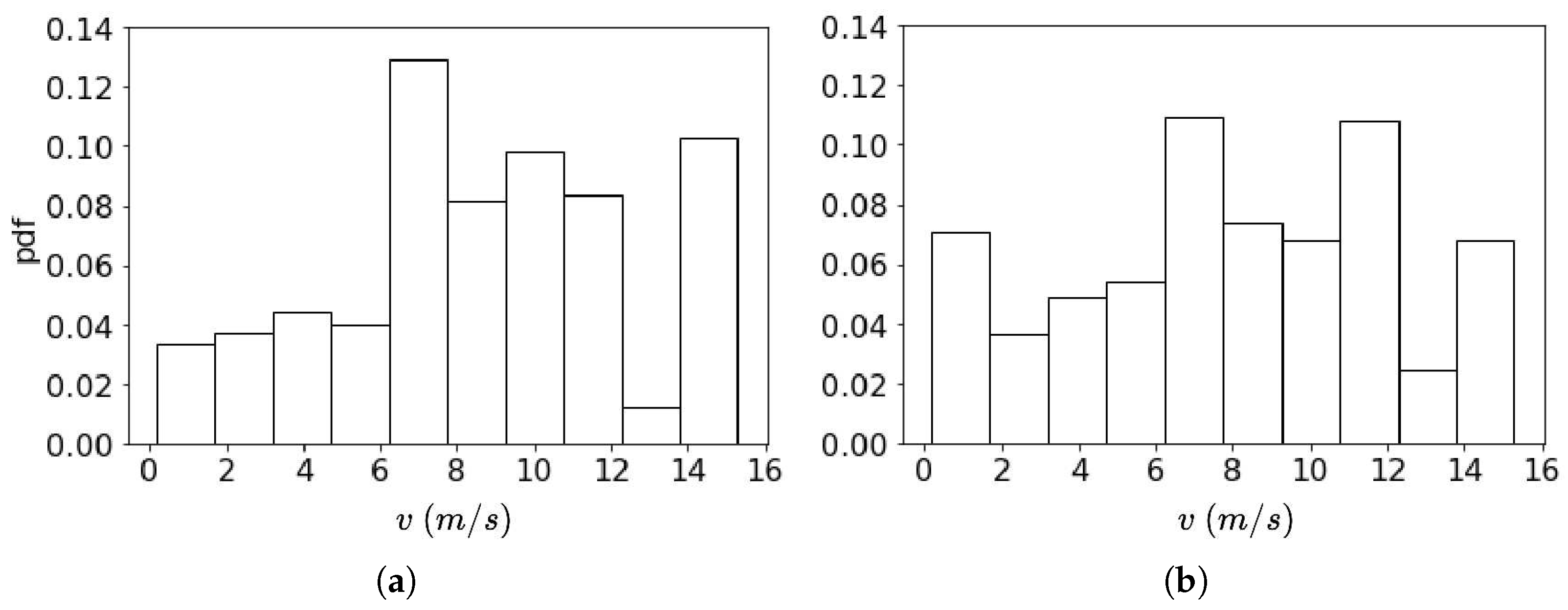
4.1. Data Description
4.2. Experiment Setting
4.3. Results
5. Conclusions
- We have only verified the algorithm in a small dataset. We can apply this algorithm to a bigger dataset with diverse characteristics.
- Transforming the original one-shot problem to a sequential one will lead to a sub-optimal solution. This problem can be addressed if we allow the player to retract a false move.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fu, Y.; Xiang, T.; Jiang, Y.G.; Xue, X.; Sigal, L.; Gong, S. Recent advances in zero-shot recognition: Toward data-efficient understanding of visual content. IEEE Signal Process. Mag. 2018, 35, 112–125. [Google Scholar] [CrossRef]
- Mo, Z.; Shi, R.; Di, X. A physics-informed deep learning paradigm for car-following models. Transp. Res. Part C Emerg. Technol. 2021, 130, 103240. [Google Scholar] [CrossRef]
- Mo, Z.; Fu, Y. TrafficFlowGAN: Physics-informed Flow based Generative Adversarial Network for Uncertainty Quantification. In Proceedings of the European Conference on Machine Learning and Data Mining (ECML PKDD), Bilbao, Spain, 13–17 September 2022. [Google Scholar]
- Shi, R.; Mo, Z.; Huang, K.; Di, X.; Du, Q. A physics-informed deep learning paradigm for traffic state and fundamental diagram estimation. IEEE Trans. Intell. Transp. Syst. 2021, 23, 11688–11698. [Google Scholar] [CrossRef]
- Shi, R.; Mo, Z.; Di, X. Physics-informed deep learning for traffic state estimation: A hybrid paradigm informed by second-order traffic models. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 540–547. [Google Scholar]
- Ossen, S.; Hoogendoorn, S.P. Validity of trajectory-based calibration approach of car-following models in presence of measurement errors. Transp. Res. Rec. 2008, 2088, 117–125. [Google Scholar] [CrossRef]
- Hoogendoorn, S.; Hoogendoorn, R. Calibration of microscopic traffic-flow models using multiple data sources. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2010, 368, 4497–4517. [Google Scholar] [CrossRef] [PubMed]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Tokdar, S.T.; Kass, R.E. Importance sampling: A review. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 54–60. [Google Scholar] [CrossRef]
- Kantarcıoğlu, M.; Xi, B.; Clifton, C. Classifier evaluation and attribute selection against active adversaries. Data Min. Knowl. Discov. 2011, 22, 291–335. [Google Scholar] [CrossRef]
- Liu, X.; Hsieh, C.J. From adversarial training to generative adversarial networks. arXiv 2018, arXiv:1807.10454. [Google Scholar]
- Liu, G.; Khalil, I.; Khreishah, A. GanDef: A GAN based Adversarial Training Defense for Neural Network Classifier. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Lisbon, Portugal, 25–27 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 19–32. [Google Scholar]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A survey of monte carlo tree search methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Zhou, M.; Qu, X.; Li, X. A recurrent neural network based microscopic car following model to predict traffic oscillation. Transp. Res. Part C Emerg. Technol. 2017, 84, 245–264. [Google Scholar] [CrossRef]
- Sharma, A.; Zheng, Z.; Bhaskar, A. Is more always better? The impact of vehicular trajectory completeness on car-following model calibration and validation. Transp. Res. Part B Methodol. 2019, 120, 49–75. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, R.; Li, L.; Lin, Y.; Zheng, X.; Wang, F.Y. Capturing car-following behaviors by deep learning. IEEE Trans. Intell. Transp. Syst. 2017, 19, 910–920. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Nageshrao, S.; Tseng, E.; Filev, D. Autonomous Highway Driving using Deep Reinforcement Learning. arXiv 2019, arXiv:1904.00035. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Sun, W.; Du, Q. A cooperative game for automated learning of elasto-plasticity knowledge graphs and models with AI-guided experimentation. Comput. Mech. 2019, 64, 467–499. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, Z.; Di, X.; Shi, R. Robust Data Sampling in Machine Learning: A Game-Theoretic Framework for Training and Validation Data Selection. Games 2023, 14, 13. https://doi.org/10.3390/g14010013
Mo Z, Di X, Shi R. Robust Data Sampling in Machine Learning: A Game-Theoretic Framework for Training and Validation Data Selection. Games. 2023; 14(1):13. https://doi.org/10.3390/g14010013
Chicago/Turabian StyleMo, Zhaobin, Xuan Di, and Rongye Shi. 2023. "Robust Data Sampling in Machine Learning: A Game-Theoretic Framework for Training and Validation Data Selection" Games 14, no. 1: 13. https://doi.org/10.3390/g14010013
APA StyleMo, Z., Di, X., & Shi, R. (2023). Robust Data Sampling in Machine Learning: A Game-Theoretic Framework for Training and Validation Data Selection. Games, 14(1), 13. https://doi.org/10.3390/g14010013