Abstract
This paper studies the problem of information design in a general security game setting in which multiple self-interested defenders attempt to provide protection simultaneously for the same set of important targets against an unknown attacker. A principal, who can be one of the defenders, has access to certain private information (i.e., attacker type), whereas other defenders do not. We investigate the question of how that principal, with additional private information, can influence the decisions of the defenders by partially and strategically revealing her information. In particular, we develop a polynomial time ellipsoid algorithm to compute an optimal private signaling scheme. Our key finding is that the separation oracle in the ellipsoid approach can be carefully reduced to bipartite matching. Furthermore, we introduce a compact representation of any ex ante persuasive signaling schemes by exploiting intrinsic security resource allocation structures, enabling us to compute an optimal scheme significantly faster. Our experiment results show that by strategically revealing private information, the principal can significantly enhance the protection effectiveness for the targets.
1. Introduction
In many real-world security domains, there are often multiple self-interested security teams who conduct patrols over the same set of important targets without coordinating with each other [1]. Among others, an important motivating domain of this paper is wildlife conservation: while patrol teams from various NGOs or provinces patrol within the same conservation area to protect wildlife from poaching, different NGOs or provinces typically have different types of targeted species and tend to operate separately (for instance, the Snow Leopard Foundation in Pakistan cares about leopards, whereas the Pakistan Bird Conservation Network primarily focuses on watching and protecting endangered birds [2]). Similarly, there are multiple different countries that simultaneously plan their own anti-crime actions against illegal fishing in international waters [3].
The study of multi-defender security games has attracted much recent attention. Unfortunately, most findings so far are relatively negative. Specifically, [4] showed that the lack of coordination among defenders may significantly lessen the overall protection effectiveness, leading to unbounded price of anarchy. In addition, [5] recently showed that finding a Nash Stackelberg equilibrium among the defenders, taking into account the strategic response of the attacker, is computationally NP-hard. Given these negative results, this paper asks the following question:
How can one obtain defense effectiveness and computation efficiency in multi-defender security games?
To answer the above question, we exploit the use of information as a “knob” to coordinate strategic agents’ decisions. Specifically, we study how a principal with privileged private information (e.g., more accurate information about how much profit an attacker has from poaching) can influence the decisions of all defenders by strategically revealing her information, a task also known as information design or persuasion [6]. Concretely, we study information design in a Bayesian security game setting with multiple self-interested defenders. These defenders attempt to protect important targets against an unknown attacker. The attacker type is unknown to the defenders. Nevertheless, all defenders share a common knowledge of a prior distribution over the attacker types. In this setting, there is a principal who has additional information about the attacker type and wants to communicate with both the defenders and the attacker through a persuasion signaling mechanism in order to influence all of their decisions towards the principal’s goal.1 In wildlife protection, for example, the principal may be the national park office, whereas different defenders correspond to different NGOs with their own focused species to protect. Since many poachers (or the attacker) are local villagers, park rangers can have access to private information through local informants about whom (i.e., which attacker type) is conducting poaching [9].
In summary, our results show that information design not only significantly improves protection effectiveness but also leads to efficient computation. Concretely, assuming the principal can communicate with defenders privately (also known as private signaling [10]), we develop an ellipsoid-based algorithm in which the separation oracle component can be decomposed into a polynomial number of sub-problems, and each sub-problem reduces to a bipartite matching problem. We remark that this by no means is an easy task, neither conceptually nor technically, since the outcomes of private signaling form the set of Bayes correlated equilibria [11], and computing an optimal correlated equilibrium is a fundamental and well-known intractable problem [12]. Our proof is technical and crucially explores the special structure of security games. In addition, we also investigate the ex ante private signaling scheme (a relaxation of private signaling in which the defenders and attacker decide whether to follow the principal’s signals or not before any signal is realized [13]). In this scenario, we develop a novel compact representation for the principal’s signaling schemes by compactly characterizing jointly feasible marginals. This finding enables us to significantly reduce the signaling scheme computation.
Finally, we present extensive experimental results evaluating our proposed algorithms in various game settings. We evaluate two different principal objectives: (i) maximizing the defenders’ social welfare; and (ii) maximizing her own utility. Our results show that through signaling schemes, the principal can significantly increase the social welfare of the defenders while substantially reducing the attacker’s utility.
Comparison with Previous Works
Defense and Attack Models for Security: There is extensive literature studying defense and attack models for security. Our discussion here cannot do justice to this large body of literature; we thus refer interested readers to an excellent survey paper [14], which classifies previously studied models according to three dimensions: system structure (eight types), defense measures (six types), and attack tactics and circumstances (seven types). Under their language, our work falls within the multiple elements system structure, protection defense measure, and attack against single element attack tactics. Prior to the writing of the survey article, not much previous work fell into this particular category. The most relevant publications for us are [15,16], which provide a systematic equilibrium analysis for the strategic game between a multi-resource defender and a single-element attacker. However, these works differ from ours in two key aspects: (1) their study is analytical, whereas our work is computational and tries to find the optimal defense strategy; (2) they consider simultaneous-move games, whereas our game is sequential and falls into the Stackelberg game framework. Specifically, we adopt the widely used class of games termed Stackelberg Security games, which capture strategic interactions between defenders and attackers in security domains [17]. This research advance comes slightly after the survey article [14], but has nevertheless led to a significant impact with deployed real-world applications, e.g., for airport security [18], ferry protection [19], and wildlife conservation [20].
Within the security game literature, most-relevant to our work is the recent study of multiple-defender security games. Several of them consider defenders to have identical interests [1,21] or to have their own disjointed sets of targets [4,22,23,24,25]. The game model in [5] is the most-related to ours. This previous work investigates the existence and computation of a Nash Stackelberg equilibrium among the defenders. To our knowledge, our work is the first to study information design in multi-defender security games. In contrast to previous negative results, our findings are much more encouraging. Our positive results even extend to more realistic game models with defender patrolling costs, which cannot be handled by the existing work.
Strategic Information Disclosure for Security: Information design, also known as signaling, has attracted much interest in various domains, such as public safety [7,8], wildlife conservation [26], traffic routing [13,27], and auctions [28,29]. Most-related to us is [30], which studies signaling in Bayesian Stackelberg games. All previous work assumes a single defender, whereas our paper tackles the complex multiple-defender setup. This requires us to work with exponentially large representations of signaling schemes and necessitates novel algorithmic techniques with compact representations.
Other Learning-based Solutions: Recent research in multi-agent reinforcement learning (MARL) has studied factors that influence agents’ behavior in a shared environment. For example, [31] studies how to convey private information through actions in cooperative environments. Ref. [32] uses monetary reward (which they call ’causal inference reward’) to influence opponents’ actions. Unlike the tools studied in previous multi-agent reinforcement learning literature, our model takes advantage of information asymmetry between the principal and various stakeholders (including both defending agencies and the attacker) to influence their actions. Therefore, both our setup and approach are different from these previous learning-based methods.
2. Preliminary
We consider a general security game setting in which there are multiple self-interested defenders who have to protect important targets from an attacker. Each defender can protect at most one target.2 The defenders do not know the attacker’s type, but they share common prior knowledge about the distribution over possible attacker types: with , where is the probability that the attacker has type . If a defender d decides to go to a target t, he has a patrolling cost of . If the attacker successfully attacks a target t, he receives a reward , while each defender d receives a penalty . Conversely, if any of the defenders catches the attacker at t, the attacker receives a penalty , while each defender d obtains a reward . Notably, one defender suffices to fully protect a target, whereas multiple defenders on the same target are not any more effective. This leads to interdependence among defenders and is the major source of inefficiency without coordination [4].
3. Optimal Private Signaling
We first study the design of private signaling schemes that help the principal to coordinate the defenders. The principal leverages her private information about the attacker type to influence the decisions of all players (including the attacker) by strategically revealing her information. We adopt the standard assumption of information design [33] and assume that the principal commits to a signaling scheme and that is publicly known to all players. At a high level, a private signaling scheme generates a random variable called signal profile , which is correlated with , where is the private signal sent to the defender d, and is the signal sent to the attacker. Each defender d, once receiving a certain private signal , updates his belief on the attacker type using Bayes rule as follows:
where is the probability the signal profile is generated given the attacker type is .
Any private signaling scheme induces a Bayesian game among players. According to [11], all the Bayes–Nash equilibria that can possibly arise for any private signaling scheme form the set of Bayes correlated equilibria (BCEs). Similar to the standard correlated equilibria, the signals of a private signaling scheme in a BCE can also be interpreted as obedient action recommendations. Therefore, a private signal profile can be represented as , where is the suggested protection target for defender , and is the “suggested” target3 for the attacker to attack. With slight abuse of notations, we use to represent the profile of signals sent to all the defenders, respectively, and is the profile of signals sent to other defenders except defender d.
Example 1.
To illustrate the idea, let us consider a simple example motivated realistically by wildlife conservation. Suppose there are three main regions with important species, and there are two defending/patrolling agencies . Defender (e.g., the Snow Leopard Foundation in Pakistan) only cares about species 1 (e.g., leopard), whereas defender only cares about species 2. Species 1 is distributed across only regions , with more in A—specifically, defender suffers cost 9 (which is the poacher’s gain) in region A but suffers cost 4 in region B for failing to protect them. species 2 is distributed mainly in targets but with more at C—specifically, defender suffers cost 4 at target B but cost 9 at target C. The defenders’ utility for successfully protecting any target is normalized to 0 for ease of analysis. There are three possible types of poachers: those interested in poaching species 1, those interested in 2, and those interested in both. The two defending agencies share a common prior that a random poacher has type or each with probability but has type with probability (i.e., fewer poachers are interested in both species).
We stand at the perspective of the national park office, which looks to optimize the protection of both species 1 and 2. We assume that the national park office can observe the exact type of the poacher,4 and would like to strategically reveal this information to the two defending agencies in order to optimize the overall protection of the two species. For simplicity, suppose the national park does not have patrolling resources (though the illustrated idea would apply in that instance as well).
A natural first thought one may have is that the national park should be transparent and fully reveal the poacher type to both defenders. Unfortunately, this turns out not to be a good policy. If the poacher is type , then it is easy to verify that it is a unique Nash equilibrium for defender to patrol A with probability and B otherwise, and to patrol C with probability and B otherwise. This leads to overall protection probability at target B and at . The rational poacher type will attack the more profitable target B, leading to cost to the national park. If the poacher has type (or ), then only defender (or ) will conduct patrolling at target . Simple calculation shows that the optimal strategy is to protect A with probability , leading to defender cost . This, in total, leads to expected defender cost .
It turns out that revealing different information privately to the two defenders leads to much higher utility. Specifically, consider the policy that reveals to defender whether the poacher is instead in species 2 (i.e., having type or ) or not (i.e., having type ). In the first situations, knows that the poacher is definitely interested in species 2 but is unsure whether he is interested in 1—simple posterior updates shows that there is probability that the poacher is interested in species 1 as well. So will nevertheless conduct patrolling just in case poacher is interested in species 1. Calculation shows that defender ’s equilibrium strategy will patrol target A with probability and B with . In the second situation, knows for sure that the poacher is interested in species 1, and his equilibrium strategy will now put probability on target A. Due to symmetry, defender has a symmetric strategy. Overall, it can be calculated that the defender will suffer cost whenever the poacher is interested in only one species and cost when the poacher is interested in both. This overall leads to total defender cost . This reduces the cost under the transparent policy almost by half. Intuitively, this is because the private signaling policy carefully obfuscates the poacher type so that is incentivized to protect target B even when the poacher is not interested in species 2. This allows to focus more on the protection of A.
3.1. An Exponential-Size LP Formulation
Like a typical formulation of optimal correlated equilibrium, optimal private signaling can also be formulated as an exponentially large linear program (LP). Specifically, the principal attempts to find an optimal signaling scheme to optimize her objective, which can be either her own utility (if she is a defender) or the social welfare of the defenders. We abstractly represent the principal’s objective function with respect to a signal as . The optimal private signaling can be formulated as the following LP:
where (2) and (3) are obedience constraints that guarantee the attacker of any type and all defenders will follow the principal’s recommendation. The utilities of each defender d and each attacker type are determined as follows:
Problems (1)–(4) have an exponential number of variables due to exponentially many possible defender allocations. This is also the common challenge in computing optimal correlated equilibria for succinctly represented games with many players (defenders in our case). Indeed, an optimal correlated equilibrium has been proven to be NP-hard in many succinct games [12]. Perhaps surprisingly, next, we show that LPs (1)–(4) can be solved in polynomial time in our case.
3.2. A Polynomial-Time Algorithm
We prove the following main positive result.
Theorem 1.
The optimal private signaling scheme can be computed in polynomial time.
The rest of this section is devoted to the proof of Theorem 1. We elaborate the proof for the principal objective of maximizing the defender social welfare, i.e., . The proof is similar when the principal is one of the defenders. Our proof is divided into three major steps and crucially exploits the structure of security games.
Step 1: Restricting to simplified pure strategy space. One challenge of designing the signaling scheme is when multiple defenders are recommended a same target, which significantly complicates computation of marginal target protection. Therefore, our first step is to simplify the pure strategy space to include only those in which all defenders cover different targets. To do so, we create dummy targets for which rewards, penalties, and costs are zero for both the defenders and the attacker.5 When the players choose one of these dummy targets, it means they choose to do nothing. As a result, we have targets in total, including these dummy targets. The creation of these dummy targets does not influence the actual outcome of any signaling scheme but introduces a nice characteristic of the optimal signaling scheme (Lemma 1). This characteristic of at most one defender at each target allows us to provide more efficient algorithms to find an optimal signaling scheme.
Lemma 1.
There is an optimal signaling scheme such that for any signal profile with a positive probability (i.e., ), then for all .
Proof.
Let us assume that in a signaling scheme there is a signal for which multiple defenders are sent to the same target t. We revise this signal by only suggesting the defender d with the lowest cost to t and other defenders are sent to dummy targets instead. First of all, the expected cost is reduced, while the coverage probability at each non-dummy target remains the same. As a result, the principal’s objective does not change. Second, the attacker’s obedience constraints do not change. Third, the LHS of the defender’s obedience constraints increases, while the RHS is the same. This means no obedience constraint is violated. □
Step 2: Working in the dual space. Since LP (1)–(4) has exponentially many variables, we first reduce it to the following dual linear program (1)–(4) via the standard linear duality theory [17], which turns out to be more tractable to work with:
where each constraint in (6) corresponds to the primal variable . The dual variables correspond to attacker obedience constraints (2). The dual variables correspond to defender obedience constraints (3). Finally, the variables correspond to constraints (4).
Problems (5)–(7) have an exponential number of constraints. We employ the ellipsoid method [35] by designing a polynomial–time separation oracle. In this oracle, given a value of , it either establishes that this value is feasible for the problem or, if not, it outputs a hyper-plane separating this value from the feasible region. In the following, we focus on a particular type of oracle: those generating violated constraints. The oracle solves the following optimization problems; each corresponds to a fixed and (to be some target ),
If the optimal objective of this problem is strictly less than for any , it means we found a violated constraint corresponding to , where is an optimal solution of (8). We iterate over every to find all violated constraints and add them to the current constraint set.
Step 3: Establishing an efficient separation oracle. We now solve (8) for any given . We further divide this problem into two sub-problems; each can be solved via bipartite matching (which is polynomial time). More specifically, we divide the signal set into two different subsets, as elaborated in the following.
Case 1 of Step 3: Attacked target is not covered. The first subset consists of all signals such that ; that is, none of the defenders are assigned to . In this case, the attacker will receive a reward for attacking , while every defender d receives a penalty . Thus, each of the following elements in (8) is straightforward to compute:
Given the above computation, we observe that the second and third components (in the second and third lines) of the objective (8), which only depends on the defender utilities, consists of multiple terms—each term depends only on the allocation of each individual defender . On the other hand, the first component (in the first line) of the objective, which depends on the attacker’s utility, has terms which depend on targets not in the defender allocation. Therefore, in order to create a corresponding bipartite matching problem, we introduce new dummy defenders and the following weights between defenders and targets:
Weights associated with these dummy defenders correspond to the terms in (8), which depends on targets not in the actual defender allocation. The weight is to ensure that no actual defender in will be assigned to .
We now present Lemma 2 (which can be proved via a couple of algebraic computation steps), showing that Problem (8) becomes a Minimum Bipartite Matching between defenders and targets.
Lemma 2.
Case 2 of Step 3: Attacked target is covered. On the other hand, the second subset consists of all signals such that is assigned to one of the defender. In this case, we further divide this sub-problem into multiple smaller problems by fixing the defender who covers , denoted by . Similar to Sub-problem P1, we introduce the following weights:
Lemma 3.
The problem (8) can now be reduced to the following bipartite matching problem using :
after removing the constant terms . In addition, is removed from our matching setting.
We now have the problem of a Minimum Bipartite Matching between defenders to targets, which can be solved in polynomial time.
4. Optimal Ex Ante Private Signaling
This section relaxes the private signaling requirement and assumes that players make decision on whether to follow signals or not before any signal is sent. Such ex ante private signaling has been studied recently in routing [13] and abstract games [36]. However, both works used the ellipsoid algorithm to compute the optimal scheme. While the ellipsoid algorithm is theoretically efficient, as we will show in our experiments, is it practically quite slow. In our case, we could have also just employed a similar technique. However, we take one step further and present a novel idea of using a compact representation of the signaling schemes such that the “reduced” signaling space becomes polynomial size for the number of targets. This important result helps to significantly scale up the problem computation.
4.1. An Exponential-Size LP Formulation
Overall, the problem of finding an optimal ex ante private signaling scheme can be formulated as the following LP, which has an exponential number of variables :
Similar to private signaling, we show that the optimal ex ante signaling scheme can be computed in polynomial time (Theorem 2) by developing an ellipsoid algorithm.
Theorem 2.
The optimal private ex ante signaling scheme can be computed in polynomial time.
4.2. Compact Signaling Representation
As we mentioned previously, while the ellipsoid algorithm is theoretically efficient, it runs slowly in practice. Therefore, we further show that in this scenario, we can provide a compact representation of signaling schemes such that the signaling space is polynomial for the number of targets. This immediately leads to a polynomial time algorithm for optimal ex ante private signaling by directly solving the polynomial-size linear program. Given any signaling scheme , we introduce the new variable , which is the marginal probability that the attacker is sent to target t and the defender d is sent to target given that the attacker type is . In addition, we introduce , which is the probability the attacker is sent to t. Reformulating (9)–(11) based on these new variables is straightforward. For example, the objective (9) is reformulated as the following:
The crux of this section is the following theorem. It fully characterize the conditions under which the compact representation corresponds to a feasible ex ante signaling scheme.
Theorem 3.
The following conditions are necessary and sufficient conditions to generate a feasible ex ante signaling scheme from a compact representation :
Proof.
It is obvious that these conditions are necessary. Let us consider and satisfying these conditions. We will show that these correspond to a feasible signaling scheme. First, we have:
which is the probability of assigning defender d to target given the attacker is of type and is assigned to target t. By fixing and , we use as an abbreviation of when the context is clear. We will prove that any satisfying the following conditions correspond to a feasible signaling scheme:
In order to do so, we introduce the following general lemma:
Lemma 4.
For any a coverage vector such that:
given , there is an assignment of defenders to targets, denoted by , such that:6
- for all
- Every maximally covered target t, i.e., , is assigned to a defender; that is, .
Proof.
Let be the support defender set of target t. Similarly, we also denote by the support target set of defender d. We divide the set of targets into two groups: (i) the group of all maximally covered targets ; and (ii) the group of other targets . Without loss of generality, we represent and , where is a permutation of targets .
Step 1: Inclusion of high-coverage target group . We first prove that there is a partial allocation from defenders to targets in , denoted by , such that for all , and they are pair-wise different, i.e., for all . We use induction with respect to t.
As a baseline, , the above statement holds true. Let us assume this statement is true for some . We will prove that it is also true for . Let us denote by the current sequence of defender-to-target assignments. At target , if there is such that for all , then we obtain a new satisfactory partial assignment .
Conversely, if , without loss of generality, we assume for some . We obtain:
Observation 1.
There exists a target and a defender such that .
Indeed, if there is no such , it means all targets can only be assigned to one of the defenders in . As a result, we will have:
Now, if that target , then we obtain a new partial assignment by assigning to target and reallocating to while keeping other assignments the same. On the other hand, if , it means for all . Without loss of generality, let us assume that target . We observe that there must exist a target and a defender such that . Indeed, if there is no such , it means all targets can be only assigned to one of the defenders in . As a result, we have:
Now, if that target and , then we can do the swap while keeping other assignments the same. If that target and , then we can do a different swap . Finally, if , without loss of generality, we assume . We repeat the above analysis process until at some point we either find a feasible assignment or reach the following situation:
- s.t
- s.t.
- …
- and such that where .
In this situation, we first swap . There are two cases. If , then we found a solution. If is equal to some for some , we then reassign . At this step, there are two cases again. That is, either , or is one of . The former case means we found a solution, while the latter case indicates we have to do the reassignment again for a target in . Observe that every time we have to do a reassignment, the index of the target for the reassignment is decreased. In the end, it will reach target , for which we can reassign and obtain a feasible solution.
Step 2: Extension to include target group . We are going to prove that there is an assignment from defenders to targets that includes all targets in . We apply induction with respect to the defender d. Note that we cannot apply induction with respect to the targets t since we include target group in this analysis, and as a result, the equality on the LHS of (19) no longer holds.
As a baseline, we start with the feasible assignment of the group . Then at each induction step, we perform a defender–target swapping process that is similar to the case of the high-coverage target group . The tricky part is that for any swapping, we do not get rid of any targets that have been assigned so far (besides changing the defender assigned to them). This means that in the final assignment of the induction process, denoted by , all targets in are still included. The details of this induction process are in the Appendix A. □
Based on the result of Lemma 4, we allocate the following non-zero probability to the assignment with :
5. Experiments
In our experiments, we aim to evaluate both the solution quality and runtime performance of our algorithms in various game settings. All the LPs in our algorithms are solved with the CPLEX solver (version 20.1). We run our algorithms on a machine with an Intel i7-8550U CPU and 15.5 GB memory. The rewards and penalties of players are generated uniformly at random between [0, 20] and [−20, 0], respectively. All data points are averaged over 40 random games, and the error bars represents the standard error.
We compare our private and ex ante signaling schemes with: (i) a baseline method in which each defender optimizes his utility separately by solving a Bayesian Stackelberg equilibrium between that defender and the attacker without considering the strategies of the other defenders; and (ii) the Nash Stackelberg equilibrium (NSE) among the defenders. We use the method provided in [5] to approximate an NSE. We evaluate our signaling schemes in two scenarios corresponding to two different objectives of the principal: (i) maximizing the social welfare of the defenders (Figure 1, Figure 2 and Figure 3); and (ii) maximizing her own defense utility (i.e., the principal is one of the self-interested defenders) (Figure 4). Next, we highlight our important results. Additional results can be found in the Appendix B.
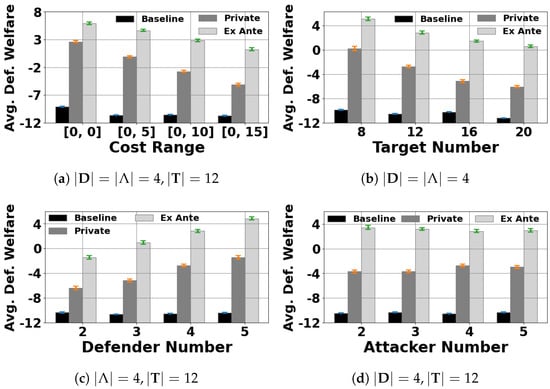
Figure 1.
Average defender social welfare: the defenders’ cost range is fixed to in sub-figures (b–d).
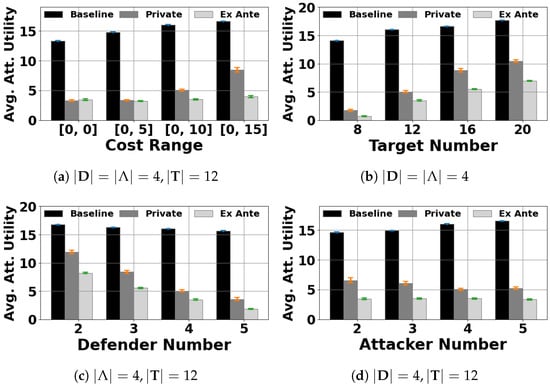
Figure 2.
Average attacker utility: the defenders’ cost range is fixed to in sub-figures (b–d).
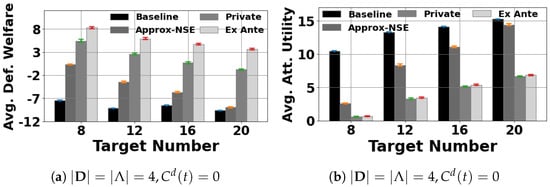
Figure 3.
All evaluated algorithms, no patrolling costs.
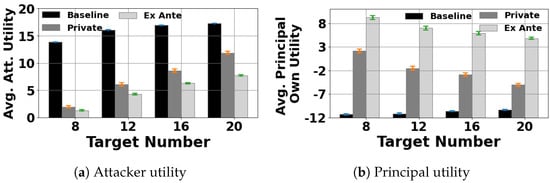
Figure 4.
The principal optimizes her own utility when and the defenders’ cost range .
In Figure 1 and Figure 2, the x-axis is either the defender’s cost range (the defense cost of each defender is randomly generated within this range), the number of targets, the number of defenders, or the number of attacker types. The y-axis is either the defender social welfare (Figure 1) or the average utility of the attacker (Figure 1). Note that in these figures, we do not consider the Nash Stackelberg equilibrium (NSE) among the defenders. This is because the method provided in [5] to approximate an NSE is only applicable for the no-patrolling-cost setting. Figure 1 shows that signaling schemes ( and ) help to significantly increase the defender social welfare compared to the case. In addition, the defender social welfare in is substantially higher than in the case. This result makes sense, since the persuasion constraints in are less restricted. In addition, the social welfare is roughly a decreasing linear function of the cost range and the number of targets, while it increases linearly for the number of defenders. This is because the social welfare is a decreasing function of the defenders’ coverage probability at each target, and the higher the number of defenders is, the more coverage there is at each target. Conversely, we see an opposite trend in the attacker graphs (Figure 2).
Furthermore, we include the NSE in our experiments with no defense cost. Figure 3 shows that despite resulting in higher social welfare for the defenders compared to , in which each defender ignores the presence of other defenders, the social welfare in is still significantly lower than that in and . The results in Figure 1, Figure 2 and Figure 3 clearly show that coordinating the defenders through the principal’s signaling schemes helps to significantly enhance the protection effectiveness on the targets.
In Figure 4, we examine the situation in which the principal attempts to maximize her own utility (given she is one of the self-interested defenders). We again observe that the attacker suffers a significant loss in utility compared to (Figure 4a, and versus ). Conversely, the principal can get a significant benefit by strategically revealing her private information through the signaling mechanisms (Figure 4b).
Figure 5 shows the logarithm runtime of our algorithms compared to and . We observe that our algorithms ( and ) are suitable for medium games. In Figure 5a, it takes and approximately 23 min and 40 s, respectively, to solve 20-target games. Furthermore, our compact representation method () helps solve the signaling scheme significantly faster. It only takes approximately 2.7 s to solve 20-target games.
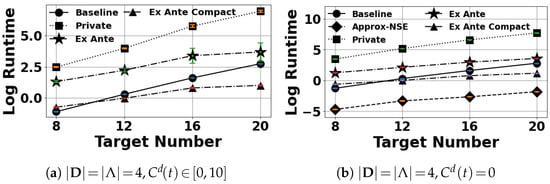
Figure 5.
Log run time in seconds.
Finally, we examine the performance in the ex ante case with a large number of targets or attacker types in Figure 6. Our algorithms can easily scale to about 160 targets, which is a large improvement compared to previous works [37,38]. We remark that it is typically impossible to test running time for such complicated security games for more than 200 targets on a single machine (most real-world applications such as conservation area protection or border protection have fewer than 200 targets as well). For a large number of attacker types, our experiments show that the running time dependence of our algorithm with respect to the number of attacker types is linear, which is extremely efficient.
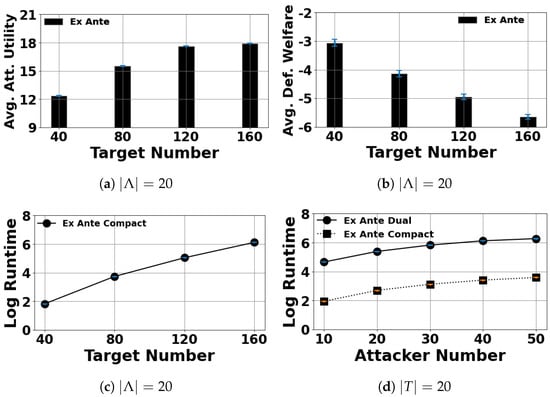
Figure 6.
Scalability of target number or attacker types in ex ante setting when and the defenders’ cost range .
6. Summary
In this paper, we study information design in a Bayesian security game setting with multiple interdependent defenders. Our results (both theoretically and empirically) show that information design not only significantly improves protection effectiveness but also leads to efficient computation. In particular, in computing an optimal private signaling scheme, we develop an ellipsoid-based algorithm in which the separation oracle component can be decomposed into a polynomial number of sub-problems, and each sub-problem reduces to a bipartite matching problem. This is a non-trivial task, since the outcomes of private signaling form the set of Bayes correlated equilibria, and computing an optimal correlated equilibrium is a fundamental and well-known intractable problem. Our proof is technical and crucially explores the special structure of security games. Furthermore, we investigate the ex ante private signaling scheme. In this scenario, we develop a novel compact representation for the signaling schemes by compactly characterizing jointly feasible marginals. This finding enables us to significantly reduce the signaling scheme computation compared to the ellipsoid approach (which is efficient in theory but slow in practice).
Author Contributions
Conceptualization, H.X. and T.H.N.; Formal analysis, C.Z.; Funding acquisition H.X. and T.H.N.; Investigation, C.Z.; Methodology C.Z., H.X., and T.H.N.; Resources, C.Z.; Software, C.Z. and A.S.; Supervision H.X. and T.H.N.; Validation, C.Z.; Visualization, C.Z.; Writing—original draft, C.Z.; Writing—review and editing, C.Z., H.X., and T.H.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
Haifeng Xu is supported by an NSF grant CCF-2132506; this work is done while Xu is at the University of Virginia. Thanh H. Nguyen is supported by ARO grant W911NF-20-1-0344 from the US Army Research Office.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BCE | Bayes correlated equilibrium |
| CPU | Central processing unit |
| LHS | Left-hand side |
| LP | Linear program |
| MARL | Multi-agent reinforcement learning |
| NSE | Nash Stackelberg equilibrium |
| RHS | Right-hand side |
Appendix A. Proof of Lemma 4
Extension to Include Target Group
We are going to prove that there is an assignment from defenders to targets that includes all targets in . We apply induction with respect to the defender d. Note that we cannot apply induction with respect to the targets t since we include target group in this analysis, and as a result, the equality on the LHS of (19) no longer holds.
As a baseline, without loss of generality, we have as the feasible assignment where as the result of the group . Let us assume it is true for some . We will prove that it is true for . If there is a such that , then we obtain the new assignment with additional .
Conversely, if . Let us assume for some . We observe that there must exist a defender and a target such that . Indeed, if there is no such , it means all defenders in have to be assigned to targets in . As a result,
which is contradictory.
Now if that defender , then we obtain a new partial assignment by updating . On the other hand, let us consider the case when has to be outside of . This means for all . Without loss of generality, we assume . We apply the same procedure until we find a solution or reach the following situation:
- s.t
- s.t.
- …
- and such that where .
We can do a similar swapping. Note that for any swapping, we do not get rid of any targets that have been assigned so far (besides changing the defender assigned to them). This means that in the final assignment, denoted by , all targets in are included.
Appendix B. Additional Experiments
This section shows additional results varying the number of defenders and attackers.

Figure A1.
Log runtime performance.


Figure A2.
All evaluated algorithms, no patrolling costs.


Figure A3.
The principal optimizes her own utility when and the defenders’ cost range .

Notes
| 1 | Notably, the defender can signal to the attacker as well, to either deter him from attacking or induce him to attack a specific target in order to catch him. Previous works have shown that this can benefit the defender [7,8] even though the attacker is fully aware of the strategic nature of the signal and will best respond to the revealed information. |
| 2 | This is without loss of generality, since any defender who can cover multiple targets can be “split” into multiple defenders with the same utilities. |
| 3 | The term “suggested” here should only be interpreted mathematically—i.e., given all the attacker’s available information, is identified as the most profitable target for the attacker to attack—and should not be interpreted as a real practice that the defender suggests the attacker to attack some target. Such a formulation, analogous to the revelation principle, is used for the convenience of formulating the optimization problem. |
| 4 | Such information can often by learned from informants such as local villagers [34]. |
| 5 | In reality, such a dummy target could be unimportant infrastructure (e.g., a nearby rest area at the border of a national park with no animals around, as in wildlife conservation), which does not matter to any defender nor the attacker. |
| 6 | Since we have targets in total while there are only defenders, some targets will not be assigned to any defenders. |
References
- Jiang, A.X.; Procaccia, A.D.; Qian, Y.; Shah, N.; Tambe, M. Defender (mis) coordination in security games. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Ministry of WWF-Pakistan. National Plan of Action for Combating Illegal Wildlife Trade in Pakistan; Ministry of WWF-Pakistan: Islamabad, Pakistan, 2015. [Google Scholar]
- Klein, N. Can International Litigation Solve the India-Sri Lanka Fishing Dispute? 2017. Available online: https://researchers.mq.edu.au/en/publications/can-international-litigation-solve-the-india-sri-lanka-fishing-di (accessed on 10 October 2022).
- Lou, J.; Smith, A.M.; Vorobeychik, Y. Multidefender security games. IEEE Intell. Syst. 2017, 32, 50–60. [Google Scholar] [CrossRef]
- Gan, J.; Elkind, E.; Wooldridge, M. Stackelberg Security Games with Multiple Uncoordinated Defenders. In Proceedings of the AAMAS ’18, Stockholm, Sweden, 10–15 July 2018; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2018; pp. 703–711. [Google Scholar]
- Dughmi, S. Algorithmic Information Structure Design: A Survey. ACM Sigecom Exch. 2017, 15, 2–24. [Google Scholar] [CrossRef]
- Xu, H.; Rabinovich, Z.; Dughmi, S.; Tambe, M. Exploring Information Asymmetry in Two-Stage Security Games. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Rabinovich, Z.; Jiang, A.X.; Jain, M.; Xu, H. Information Disclosure as a Means to Security. In Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, Istanbul, Turkey, 4–8 May 2015. [Google Scholar]
- Viollaz, J.; Gore, M. Piloting Community-Based Conservation Crime Prevention in the Annamite Mountains; Michigan State University: East Lansing, MI, USA, 2019. [Google Scholar]
- Dughmi, S.; Xu, H. Algorithmic persuasion with no externalities. In Proceedings of the 2017 ACM Conference on Economics and Computation, Cambridge, MA, USA, 26–30 June 2017; pp. 351–368. [Google Scholar]
- Bergemann, D.; Morris, S. Bayes correlated equilibrium and the comparison of information structures in games. Theor. Econ. 2016, 11, 487–522. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Roughgarden, T. Computing correlated equilibria in multi-player games. JACM 2008, 55, 1–29. [Google Scholar] [CrossRef]
- Castiglioni, M.; Celli, A.; Marchesi, A.; Gatti, N. Signaling in Bayesian Network Congestion Games: The Subtle Power of Symmetry. Proc. AAAI Conf. Artif. Intell. 2021, 35, 5252–5259. [Google Scholar] [CrossRef]
- LEVITIN, K.H.G. Review of systems defense and attack models. Int. J. Perform. Eng. 2012, 8, 355. [Google Scholar]
- Bier, V.; Oliveros, S.; Samuelson, L. Choosing what to protect: Strategic defensive allocation against an unknown attacker. J. Public Econ. Theory 2007, 9, 563–587. [Google Scholar] [CrossRef]
- Powell, R. Defending against terrorist attacks with limited resources. Am. Political Sci. Rev. 2007, 101, 527–541. [Google Scholar] [CrossRef]
- Tambe, M. Security and Game Theory: Algorithms, Deployed Systems, Lessons Learned; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Pita, J.; Jain, M.; Marecki, J.; Ordóñez, F.; Portway, C.; Tambe, M.; Western, C.; Paruchuri, P.; Kraus, S. Deployed armor protection: The application of a game theoretic model for security at the los angeles international airport. In Proceedings of the AAMAS: Industrial Track, Estoril, Portugal, 12–16 May 2008; pp. 125–132. [Google Scholar]
- Shieh, E.; An, B.; Yang, R.; Tambe, M.; Baldwin, C.; DiRenzo, J.; Maule, B.; Meyer, G. Protect: A deployed game theoretic system to protect the ports of the united states. In Proceedings of the AAMAS, Valencia, Spain, 4–8 June 2012; pp. 13–20. [Google Scholar]
- Fang, F.; Nguyen, T.H.; Pickles, R.; Lam, W.Y.; Clements, G.R.; An, B.; Singh, A.; Tambe, M.; Lemieux, A. Deploying PAWS: Field optimization of the protection assistant for wildlife security. In Proceedings of the Twenty-Eighth IAAI Conference, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Basilico, N.; Celli, A.; De Nittis, G.; Gatti, N. Computing the team–maxmin equilibrium in single–team single–adversary team games. Intell. Artif. 2017, 11, 67–79. [Google Scholar] [CrossRef]
- Laszka, A.; Lou, J.; Vorobeychik, Y. Multi-defender strategic filtering against spear-phishing attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Lou, J.; Vorobeychik, Y. Decentralization and security in dynamic traffic light control. In Proceedings of the Symposium and Bootcamp on the Science of Security, Pittsburgh, PA, USA, 19–21 April 2016; pp. 90–92. [Google Scholar]
- Lou, J.; Vorobeychik, Y. Equilibrium analysis of multi-defender security games. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Smith, A.; Vorobeychik, Y.; Letchford, J. Multidefender security games on networks. ACM Sigmetrics Perform. Eval. Rev. 2014, 41, 4–7. [Google Scholar] [CrossRef]
- Bondi, E.; Oh, H.; Xu, H.; Fang, F.; Dilkina, B.; Tambe, M. Broken signals in security games: Coordinating patrollers and sensors in the real world. In Proceedings of the AAMAS, Montreal, QC, Canada, 13–17 May 2019; pp. 1838–1840. [Google Scholar]
- Vasserman, S.; Feldman, M.; Hassidim, A. Implementing the wisdom of waze. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Li, Z.; Das, S. Revenue enhancement via asymmetric signaling in interdependent-value auctions. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2093–2100. [Google Scholar]
- Emek, Y.; Feldman, M.; Gamzu, I.; Paes Leme, R.; Tennenholtz, M. Signaling Schemes for Revenue Maximization. In Proceedings of the 13th ACM Conference on Electronic Commerce, EC ’12, Valencia, Spain, 4–8 June 2012; pp. 514–531. [Google Scholar]
- Xu, H.; Freeman, R.; Conitzer, V.; Dughmi, S.; Tambe, M. Signaling in Bayesian Stackelberg Games. In Proceedings of the AAMAS, Singapore, 9–13 May 2016; pp. 150–158. [Google Scholar]
- Tian, Z.; Zou, S.; Davies, I.; Warr, T.; Wu, L.; Ammar, H.B.; Wang, J. Learning to Communicate Implicitly by Actions. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7261–7268. [Google Scholar] [CrossRef]
- Jaques, N.; Lazaridou, A.; Hughes, E.; Gulcehre, C.; Ortega, P.; Strouse, D.; Leibo, J.Z.; De Freitas, N. Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3040–3049. [Google Scholar]
- Kamenica, E.; Gentzkow, M. Bayesian persuasion. Am. Econ. Rev. 2011, 101, 2590–2615. [Google Scholar] [CrossRef]
- Shen, W.; Chen, W.; Huang, T.; Singh, R.; Fang, F. When to follow the tip: Security games with strategic informants. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2020. [Google Scholar]
- Grötschel, M.; Lovász, L.; Schrijver, A. The ellipsoid method and its consequences in combinatorial optimization. Combinatorica 1981, 1, 169–197. [Google Scholar] [CrossRef]
- Xu, H. On the tractability of public persuasion with no externalities. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms; SIAM: Philadelphia, PA, USA, 2020; pp. 2708–2727. [Google Scholar]
- Yin, Z.; Tambe, M. A unified method for handling discrete and continuous uncertainty in bayesian stackelberg games. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 2, Auckland, New Zealand, 9–13 May 2012; pp. 855–862. [Google Scholar]
- Nguyen, T.H.; Jiang, A.X.; Tambe, M. Stop the compartmentalization: Unified robust algorithms for handling uncertainties in security games. In Proceedings of the AAMAS, Paris, France, 5–9 May 2014; pp. 317–324. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).