Abstract
This paper deals with the problem of calculating the Shapley–Shubik power index in weighted majority games. We propose an efficient Monte Carlo algorithm based on an implicit hierarchical structure of permutations of players. Our algorithm outputs a vector of power indices preserving the monotonicity, with respect to the voting weights. We show that our algorithm reduces the required number of samples, compared with the naive algorithm.
1. Introduction
The analysis of power is a central issue in political science. In general, it is difficult to define the idea of power, even in restricted classes of the voting rules commonly considered by political scientists. The use of game theory to study the power distribution in voting systems can be traced back to the invention of “simple games” by von Neumann and Morgenstern [1]. A simple game is an abstraction of the constitutional political machinery for voting.
In 1954, Shapley and Shubik [2] proposed the specialization of the Shapley value [3] to assess the a priori measure of the power of each player in a simple game. Since then, the Shapley–Shubik power index (S–S index) has become widely known as a mathematical tool for measuring the relative power of the players in a simple game.
In this paper, we consider a special class of simple games, called weighted majority games, which constitute a familiar example of voting systems. Let N be a set of players. Each player has a positive integer voting weight as the number of votes or weight of the players. A positive integer q is the quota needed for a coalition to win. A coalition is a winning coalition if holds; otherwise, it is a losing coalition. Many works analyze weighted majority games in a variety of settings, including the Council of the European Union [4,5,6], the U.S. Electoral College [7,8], and the International Monetary Fund [9,10]. Weighted majority games and power indices are applicable beyond classical voting situations in politics. Applications of power indices include cost allocation [11], analyses of genetic networks [12], analyses of social networks [13,14], and reliability problems in the maintenance of computer networks [15].
The difficulty involved in calculating the S–S index in weighted majority games is described in [16] without a proof (see p. 280, problem [MS8]). Deng and Papadimitriou [17] showed the problem of computing the S–S index in weighted majority games to be #P-complete. Prasad and Kelly [18] proved the NP-completeness of the problem of verifying the positivity of a given player’s S–S index in weighted majority games. The problem of verifying the asymmetry of a given pair of players was also shown to be NP-complete [19]. It is known that even approximating the S–S index within a constant factor is intractable, unless [20].
There are variations of methods for calculating the S–S index. These include algorithms based on the Monte Carlo method [21,22,23,24,25,26], multilinear extensions [27,28], dynamic programming [22,29,30,31,32], generating functions [33], binary decision diagrams [34], the Karnaugh map [35], relation algebra [36], or the enumeration technique [37]. A survey of algorithms for calculating power indices in weighted voting games is presented in [22].
In the classical theory of cooperative games, it is assumed that all players can communicate freely. Alonso-Meijide et al. [38] consider situations where some players are incompatible, i.e., some players cannot cooperate among themselves for ideological or economic reasons. They proposed a method for calculating the S–S and Banzhaf–Coleman power indices when some players are incompatible, using generating functions. Courtin et al. [39] discussed multi-type games in which there are several non-ordered types in the input, while the output consists of a single real value. When the output is dichotomous, they extend and fully characterize the S–S index.
This paper addresses Monte Carlo algorithms for calculating the S–S index in weighted majority games. In the following section, we describe the notations and definitions used in this paper. In Section 3, we analyze a naive Monte Carlo algorithm (Algorithm 1) and extend some results obtained in the study reported in [25]. In Section 4, we propose an efficient Monte Carlo algorithm (Algorithm 2) and show that our algorithm reduces the required number of samples compared to the naive algorithm. Table 1 summarizes the results of this study, where denotes the S–S index and denotes the estimator obtained by Algorithm 1 or 2.

Table 1.
Required Number of Samples.
2. Notations and Definitions
In this paper, we consider a special class of cooperative games called weighted majority games. Let be a set of players. A subset of players is called a coalition. A weighted majority game G is defined by a sequence of positive integers , where we may think of as the number of votes or the weight of player i, and q as the quota needed for a coalition to win. In this paper, we assume that .
A coalition is called a winning coalition when the inequality holds. The inequality implies that N is a winning coalition. A coalition S is called a losing coalition if S is not winning. We define an empty set as a losing coalition.
Let be a permutation defined on the set of players N, which provides a sequence of players . We denote the set of all the permutations by . We say that the player is the pivot of the permutation , if is a losing coalition and is a winning coalition. For any permutation , denotes the pivot of . For each player , we define . Obviously, becomes a partition of . The S–S index of player i, denoted by , is defined by . We know that and .
Assumption A1.
The set of players is arranged to satisfy .
Clearly, this assumption implies that .
3. Naive Algorithm and Its Analysis
In this section, we describe a naive Monte Carlo algorithm and analyze its theoretical performance. In the following, M denotes the number of samples generated in our algorithm.
| Algorithm 1 Naive Algorithm. |
| Step 0: Set , . Step 1: Choose uniformly at random. Put (the random variable) . Update . Step 2: If , then output and stop. Else, update and go to Step 1. |
For each permutation , we can find the pivot in time. Thus, the time complexity of Algorithm 1 is bounded by , where denotes the computational effort required for the random generation of a permutation.
We denote the vector (of random variables) obtained by executing Algorithm 1 by . The following theorem is obvious.
Theorem 1.
For each player , .
The following theorem provides the number of samples required in Algorithm 1.
Theorem 2.
For any and , we have the following.
(1) Ref. [25] If we set , then each player satisfies that
(2) If we set , then
(3) If we set , then
The distance measure appearing in (3) is called the total variation distance.
Proof.
Let us introduce random variables in Step 1 of Algorithm 1, defined by
It is obvious that, for each player , is a Bernoulli process satisfying , . Hoeffding’s inequality [40] implies that each player satisfies
(1) If we set , then
(2) If we set , then we have that
(3) The vector of random variables
is multinomially distributed with parameters M and . Then, the Bretagnolle–Huber–Carol inequality [41] (Theorem A1 in Appendix A) implies that
and thus, we have the desired result. □
4. Our Algorithm
In this section, we propose a new algorithm based on the hierarchical structure of the partition . First, we introduce a map for each . For any , denotes a permutation obtained by swapping the positions of players i and in the permutation . Because (Assumption 1), it is easy to show that the pivot of becomes the player . The definition of directly implies that ; if , then . Thus, we have the following.
Lemma 1.
For any , the map is injective.
Figure 1 shows injective maps induced by .
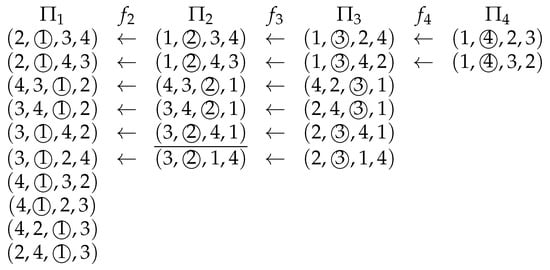
Figure 1.
Injective maps induced by . The circled number (player) denotes the pivot player.
When an ordered pair of permutations satisfies that either (1) or (2) , , , and , we say that is an ancestor of . Here, we note that is always an ancestor of itself. Lemma 1 implies that every permutation has a unique ancestor, called the originator, satisfying either that or that its inverse image . For each permutation , denotes the pivot of the originator of ; i.e., includes the originator of .
Now, we describe our algorithm.
| Algorithm 2 Our Algorithm. |
| Step 0: Set , . Step 1: Choose uniformly at random. Put the random variable . Update Step 2: If , then output and stop. Else, update and go to Step 1. |
In the example shown in Figure 1, if we choose at Step 1 of Algorithm 2, then , and Algorithm 2 updates
For each permutation , we can find the originator in time. Thus, the time complexity of Algorithm 2 is also bounded by , where denotes the computational effort required for the random generation of a permutation.
We denote the vector (of random variables) obtained by executing Algorithm 2 by . We have the following properties.
Theorem 3.
(1) For each player , .
(2) For each pair of players , if , then
(3) For each pair of players , if , then
Proof.
(1) For each we define that It is obvious that If we choose uniformly at random, then holds. From the above, it is easy to see that, for each , a random variable defined by
satisfies that
When denotes a sequence of permutations generated in Algorithm 2, we have that
(2) Assumption 1 implies that, if , then , and thus, . The update formula of in Algorithm 2 directly implies that inequalities hold throughout the iterations of Algorithm 2, which leads to inequalities . From the above, we obtain that
(3) In the following, we assume that and . Assumption 1 implies that , and thus, From Lemma 1, are bijections; thus, Then, the update formula of in Algorithm 2 implies that equalities hold throughout the iterations of Algorithm 2, which leads to the desired result: . □
The following theorem provides the number of samples required in Algorithm 2.
Theorem 4.
For any and , we have the following.
(1) For each player , if we set , then
(2) If we set , then
(3) If we set , then
where , i.e., is equal to the size of the maximal player subset, the S–S indices of which are mutually different.
Proof.
Let us introduce random variables in Step 2 of Algorithm 2, defined by
It is obvious that, for each player , is a collection of independent and identically distributed random variables satisfying
for all Hoeffding’s inequality [40] implies that each player satisfies
(1) If we set , then
(2) If we set , then we have that
(3) We introduce random variables in Step 2 of Algorithm 2, defined by
Because , the above definition directly implies that
For each player and , we define . It is easy to show that for each . The above definitions imply that
For each player , we have the equalities , which yields that is a bijection; thus, does not include any originator. From the above, it is obvious that, if , then . For each , is a Bernoulli process satisfying . Thus, implies that for any . To summarize the above, we have shown that
Now, we have an upper bound of the total variation distance
The vector of random variables is multinomially distributed and satisfies that the total sum is equal to M. Then, the Bretagnolle–Huber–Carol inequality [41] (Theorem A1 in Appendix A) implies that
and thus, we have the desired result. □
The following corollary provides an approximate version of Theorem 4 (2). Surprisingly, it says that the required number of samples is irrelevant to n (number of players).
Corollary 1.
For any and , we have the following.
If we set , then
Proof.
If we put , then Theorem 2 (2) implies that
□
Here, we note that and .
In a practical setting, it is difficult to estimate the size of defined in Theorem 4 (3) since the problem of verifying the asymmetricity of a given pair of players is NP-complete [19]. The following corollary is useful in some practical situations.
Corollary 2.
For any and , we have the following.
If we set , then
where , i.e., is equal to the size of a maximal player subset with mutually different weights.
Proof.
Since implies , it is obvious that , and we have the desired result. □
A game of the power of the countries in the EU Council is defined by (255; 29, 29, 29, 29, 27, 27, 14, 13, 12, 12, 12, 12, 12, 10, 10, 10, 7, 7, 7, 7, 7, 4, 4, 4, 4, 4, 3) [42,43]. In this case, and . A weighted majority game defined by [44] (Section 12.4) for a voting process in the United States has a vector of weights
5. Computational Experiments
This section reports the results of our preliminary numerical experiments. All the experiments were conducted on a Windows machine, i7-7700 CPU@3.6GHz Memory (RAM) 16 GB. Algorithms 1 and 2 were implemented using Python 3.6.5.
We tested the EU Council instance and the United States instance described in the previous section. In each instance, we set M in Algorithms 1 and 2 (the number of generated permutations) to . For each value of M, we executed Algorithms 1 and 2 100 times. Figure 2 and Figure 3 show the results of some players. For each value of M, we calculated the mean number of , denoted by , in an average of 100 trials. The horizontal axes of Figure 2 and Figure 3 show the value . Under the assumption that , we estimated by the least squares method. Table 2 shows the results and ratios of of the two algorithms.
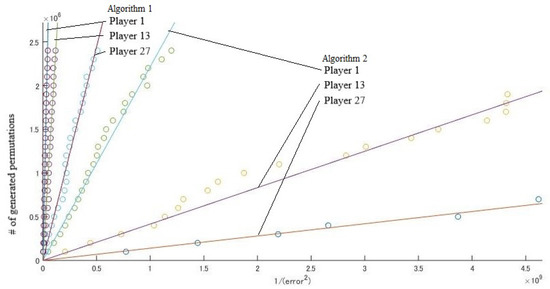
Figure 2.
EU Council.
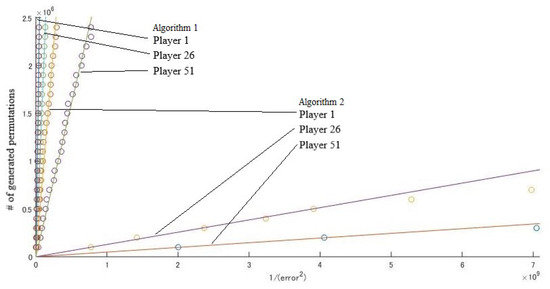
Figure 3.
United States.
Table 2.
Comparison of Algorithms 1 and 2.
For each (generated) permutation, the computational effort of both Algorithms 1 and 2 are bounded by . Here, we discuss the constant factors of computations. We tested the cases where weights are generated uniformly at random from the intervals or , and the quota is equal to . For each , we executed Algorithms 1 and 2 by setting M = 10,000. Under the assumption that computational time is equal to , we estimated a and b by the least squares method. Figure 4 shows that for each permutation, the computational effort of Algorithm 2 increases about five-fold compared to Algorithm 1.
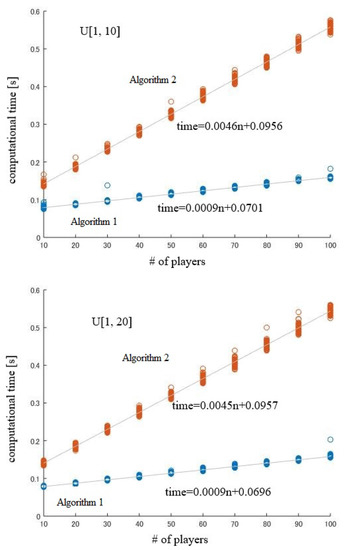
Figure 4.
Computational time.
6. Conclusions
In this paper, we analyzed a naive Monte Carlo algorithm (Algorithm 1) for calculating the S–S index denoted by in weighted majority games. By employing the Bretagnolle–Huber–Carol inequality [41] (Theorem A1 in Appendix A), we estimated the required number of samples that gives an upper bound of the total variation distance.
We also proposed an efficient Monte Carlo algorithm (Algorithm 2). The time complexity of each iteration of our algorithm is equal to that of the naive algorithm (Algorithm 1). Our algorithm has the property that the obtained estimator satisfies
We proved that, even if we consider the property
the required number of samples is irrelevant to n (the number of players).
Author Contributions
Y.U.: validation, original draft preparation; M.T.: visualization, coding simulations; T.M.: manuscript writing, project supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by JSPS KAKENHI, Grant Numbers JP26285045, JP26242027, and JP20K04973.
Conflicts of Interest
The authors declare that they have no conflict of interest.
Appendix A. (Bretagnolle–Huber–Carol Inequality)
Theorem A1
([41]). If the random vector is multinomially distributed with parameters and satisfies , then
Proof.
It is easy to see that
For any subset , there exists a Bernoulli process satisfying and . Hoeffding’s inequality [40] implies that
□
References
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Shapley, L.S.; Shubik, M. A method for evaluating the distribution of power in a committee system. Am. Political Sci. Rev. 1954, 48, 787–792. [Google Scholar] [CrossRef]
- Shapley, L.S. A value for n-person games. In Contributions to the Theory of Games II; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; pp. 307–317. [Google Scholar]
- Laruelle, A.; Widgrén, M. Is the allocation of voting power among EU states fair? Public Choice 1998, 94, 317–339. [Google Scholar] [CrossRef]
- Leech, D. Designing the voting system for the Council of the European Union. Public Choice 2002, 113, 437–464. [Google Scholar] [CrossRef]
- Życzkowski, K.; Słomczyński, W. Square Root Voting System, Optimal Threshold and π. In Power, Voting, and Voting Power: 30 Years After; Springer: Berlin/Heidelberg, Germany, 2013; pp. 573–592. [Google Scholar]
- Owen, G. Evaluation of a presidential election game. Am. Political Sci. Rev. 1975, 69, 947–953. [Google Scholar] [CrossRef]
- Miller, N.R. A priori voting power and the US Electoral College. In Power, Voting, and Voting Power: 30 Years After; Springer: Berlin/Heidelberg, Germany, 2013; pp. 411–442. [Google Scholar]
- Leech, D. Voting power in the governance of the International Monetary Fund. Ann. Oper. Res. 2002, 109, 375–397. [Google Scholar] [CrossRef]
- Leech, D.; Leech, R. A new analysis of a priori voting power in the IMF: Recent quota reforms give little cause for celebration. In Power, Voting, and Voting Power: 30 Years After; Springer: Berlin/Heidelberg, Germany, 2013; pp. 389–410. [Google Scholar]
- Young, H.P. Cost allocation. Handb. Game Theory Econ. Appl. 1994, 2, 1193–1235. [Google Scholar]
- Lucchetti, R.; Radrizzani, P. Microarray data analysis via weighted indices and weighted majority games. In International Meeting on Computational Intelligence Methods for Bioinformatics and Biostatistics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 179–190. [Google Scholar]
- Holler, M.J.; Rupp, F. Power in networks: A PGI analysis of Krackhardt’s Kite Network. In Transactions on Computational Collective Intelligence XXXIV; Springer: Berlin/Heidelberg, Germany, 2019; pp. 21–34. [Google Scholar]
- Holler, M.J.; Rupp, F. Power in Networks: The Medici. Homo Oeconomicus 2021, 38, 59–75. [Google Scholar] [CrossRef]
- Bachrach, Y.; Rosenschein, J.S.; Porat, E. Power and stability in connectivity games. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems, Estoril, Portugal, 12–16 May 2008; Volume 2, pp. 999–1006. [Google Scholar]
- Garey, M.R.; Johnson, D.S. Computers and Intractability; Freeman: San Francisco, CA, USA, 1979; Volume 174. [Google Scholar]
- Deng, X.; Papadimitriou, C.H. On the complexity of cooperative solution concepts. Math. Oper. Res. 1994, 19, 257–266. [Google Scholar] [CrossRef]
- Prasad, K.; Kelly, J.S. NP-completeness of some problems concerning voting games. Int. J. Game Theory 1990, 19, 1–9. [Google Scholar] [CrossRef]
- Matsui, Y.; Matsui, T. NP-completeness for calculating power indices of weighted majority games. Theor. Comput. Sci. 2001, 263, 305–310. [Google Scholar] [CrossRef]
- Elkind, E.; Goldberg, L.A.; Goldberg, P.W.; Wooldridge, M. Computational complexity of weighted threshold games. In AAAI; Association for the Advancement of Artificial Intelligence: Menlo Park, CA, USA, 2007; pp. 718–723. [Google Scholar]
- Mann, I.; Shapley, L.S. Values of Large Games, IV: Evaluating the Electoral College by Montecarlo Techniques; Technical Report RM-2651; The RAND Corporation: Santa Monica, CA, USA, 1960. [Google Scholar]
- Matsui, T.; Matsui, Y. A survey of algorithms for calculating power indices of weighted majority games. J. Oper. Res. Soc. Jpn. 2000, 43, 71–86. [Google Scholar] [CrossRef][Green Version]
- Fatima, S.S.; Wooldridge, M.; Jennings, N.R. A linear approximation method for the Shapley value. Artif. Intell. 2008, 172, 1673–1699. [Google Scholar] [CrossRef]
- Castro, J.; Gómez, D.; Tejada, J. Polynomial calculation of the Shapley value based on sampling. Comput. Oper. Res. 2009, 36, 1726–1730. [Google Scholar] [CrossRef]
- Bachrach, Y.; Markakis, E.; Resnick, E.; Procaccia, A.D.; Rosenschein, J.S.; Saberi, A. Approximating power indices: Theoretical and empirical analysis. Auton. Agents-Multi-Agent Syst. 2010, 20, 105–122. [Google Scholar] [CrossRef]
- Castro, J.; Gómez, D.; Molina, E.; Tejada, J. Improving polynomial estimation of the Shapley value by stratified random sampling with optimum allocation. Comput. Oper. Res. 2017, 82, 180–188. [Google Scholar] [CrossRef]
- Owen, G. Multilinear extensions of games. Manag. Sci. 1972, 18, 64–79. [Google Scholar] [CrossRef]
- Leech, D. Computing power indices for large voting games. Manag. Sci. 2003, 49, 831–837. [Google Scholar] [CrossRef]
- Brams, S.J.; Affuso, P.J. Power and size: A new paradox. Theory Decis. 1976, 7, 29–56. [Google Scholar] [CrossRef]
- Lucas, W.F. Measuring power in weighted voting systems. In Political and Related Models; Springer: Berlin/Heidelberg, Germany, 1983; pp. 183–238. [Google Scholar]
- Mann, I.; Shapley, L.S. Values of Large Games, VI: Evaluating the Electoral College Exactly; Technical Report RM-3158-PR; The RAND Corporation: Santa Monica, CA, USA, 1962. [Google Scholar]
- Uno, T. Efficient computation of power indices for weighted majority games. In International Symposium on Algorithms and Computation; Springer: Berlin/Heidelberg, Germany, 2012; pp. 679–689. [Google Scholar]
- Bilbao, J.M.; Fernandez, J.R.; Jiménez-Losada, A.; Lopez, J.J. Generating functions for computing power indices efficiently. Top 2000, 8, 191–213. [Google Scholar] [CrossRef]
- Bolus, S. Power indices of simple games and vector-weighted majority games by means of binary decision diagrams. Eur. J. Oper. Res. 2011, 210, 258–272. [Google Scholar] [CrossRef]
- Rushdi, A.M.A.; Ba-Rukab, O.M. Map calculation of the Shapley-Shubik voting powers: An example of the European Economic Community. Int. J. Math. Eng. Manag. Sci. 2017, 2, 17–29. [Google Scholar] [CrossRef]
- Berghammer, R.; Bolus, S.; Rusinowska, A.; De Swart, H. A relation-algebraic approach to simple games. Eur. J. Oper. Res. 2011, 210, 68–80. [Google Scholar] [CrossRef]
- Klinz, B.; Woeginger, G.J. Faster algorithms for computing power indices in weighted voting games. Math. Soc. Sci. 2005, 49, 111–116. [Google Scholar] [CrossRef]
- Alonso-Meijide, J.M.; Casas-Méndez, B.; Fiestras-Janeiro, M.G. Computing Banzhaf–Coleman and Shapley–Shubik power indices with incompatible players. Appl. Math. Comput. 2015, 252, 377–387. [Google Scholar] [CrossRef]
- Courtin, S.; Nganmeni, Z.; Tchantcho, B. The Shapley–Shubik power index for dichotomous multi-type games. Theory Decis. 2016, 81, 413–426. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. J. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]
- van der Vaart, A.W.; Wellner, J.A. Weak Convergence and Empirical Processes: With Applications to Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Felsenthal, D.S.; Machover, M. The Treaty of Nice and qualified majority voting. Soc. Choice Welf. 2001, 18, 431–464. [Google Scholar] [CrossRef]
- Bilbao, J.M.; Fernandez, J.R.; Jiménez, N.; Lopez, J.J. Voting power in the European Union enlargement. Eur. J. Oper. Res. 2002, 143, 181–196. [Google Scholar] [CrossRef][Green Version]
- Owen, G. Game Theory; Academic Press: Cambridge, MA, USA, 1995. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).