1. Introduction
Fiscal policies are one of the main tools for governments to intervene in their economies, and lasting democracy with rationalized taxation is necessary for economic growth [
1]. Optimal tax theory has received plenty of attention by both economists and policymakers [
2]. Early works can be traced back to Ramsey [
3], with a much higher interest in the subject during the last 40 years thanks to the works of Mirrlees [
4], which became the dominant approach for theorists. Mankiw et al. [
2] present lessons from comparing optimal tax theory to a few decades of OECD tax policy [
5]. For example:
Lesson 2: “The optimal marginal tax schedule could decline at high incomes.”
Lesson 3: “A flat tax, with a universal lump-sum transfer, could be close to optimal.”
Lesson 5: “Optimal taxes should depend on personal characteristics and income.”
Lesson 7: “Capital income ought to be untaxed, at least in expectation.”
The selected lessons can identify possible implications of democracy on the optimal tax theory. For example, the Lame-Duck effect [
6], the probabilistic voting mode [
7], as well as the changes in fiscal rules and public spending before the election [
8] are among the studies on democracy and economy interplay.
While a supermajority determination of taxation policy may usually ensure efficiency [
9,
10,
11,
12] and tax mimic across regions [
13,
14], the widely observed political business cycle may introduce unwanted fiscal effects on efficiency and equality [
15,
16,
17]. Yardstick competition is one of the mechanisms first introduced by Shleifer [
18] in describing firm competitions, followed by Besley and Case [
19], who developed this idea into a political competition theory to explain how voters make decisions based upon incumbent’s and neighboring jurisdiction’s tax policies. They present a political economy tax-setting model where the voters make comparisons between jurisdictions resulting in a yardstick vote. In a cross-mandate case, the incumbent’s current tax policy will be viewed as a “yardstick” for the myopic voters and determines their reference point for the next election. The yardstick vote may also account for the social welfare services provided by the government and evaluate if the tax revenue has been efficiently spent. A vast amount of literature has found that voters punish incumbents for higher tax rates, depending on government traits and potential policy competitors [
20,
21].
The yardstick vote introduces strategic policy-making for any neutral government that only cares about the election results. If the incumbent government wants to be re-elected, it may not be enough for them to maintain the current regime that derives the same well-being of the voters. Instead, they need to consider the competing taxation regimes with which any potential political competitors may show up and strategically interact. Therefore, the yardstick competition implies that any government that wants to stay incumbent must keep beating itself rather than keeping the status quo, which leads to sequential policy-making. However, how the yardstick voting affects political turnovers and the corresponding optimal taxation remains unknown.
The motivation of the present paper is to provide a simple yet representative model able to reproduce the fiscal and economic evolution of a society under the constraint of a simple majority democracy and yardstick vote to demonstrate the relation between wealth distribution, policymaking, and voting intention.
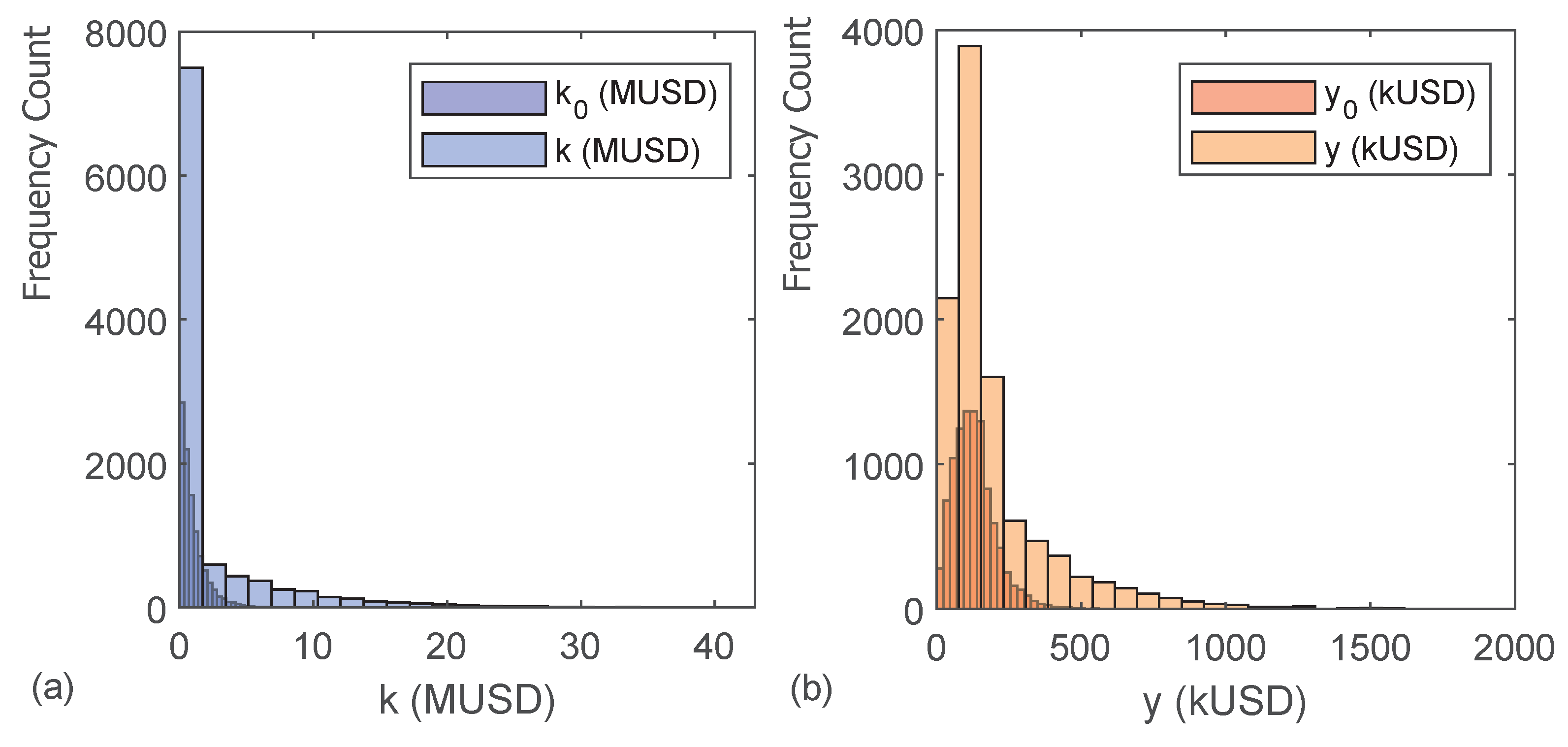
We develop a simple model and numerically simulate the taxation regime evolution to answer this question. A virtual population with an incentive and ability-based wage, capital yield from savings, social welfare system, and total income subject to taxation and political turnovers are considered under the parameters calibrating economic growth in the past several decades and the distribution of household wealth in the U.S. (
Figure 1). In each mandate, the government determines its optimal income tax regime characterized by a truncated linear function of the marginal tax rate. It then distributes the revenue back to the population equally in public goods. Their relative social ranking determines voters’ preferences and political attitudes, and the government’s problem is to maximize the voting to be re-elected.
Meta-heuristics method, particle swarm optimization (PSO) in particular, is used to find optimal taxation given the constraints of a simple majority democracy with a yardstick vote. Results show that the policymaker tends to a taxation regime that is highly punitive for a moving minority in order to win the election by benefiting others. Such decision-making leads to a cyclic taxation policy with punitive taxation targeting sequential portions of the population.
The paper is organized as follows.
Section 2 details the numerical model, its assumptions, and the numerical values resulting from calibration.
Section 3 presents experimental results from the proposed model.
Section 4 introduces the meta-heuristics to optimize the problem defined by the model and a yardstick reference.
Section 5 performs an experimental study with successive mandates.
Section 6 discusses the results, and
Section 7 concludes.
2. Model
An in-house numerical model with a fixed population is used to simulate the economic evolution of a virtual society, assuming that the individuals of this society can obtain a capital yield from their savings and wage income and are liable to taxation according to their total income. This assumption is chosen as a compromise between Lesson 7 in the literature review [
23] and the OECD countries not yet applying a zero capital tax [
24]. This taxation mechanism is consistent with most countries not applying tags or discriminating taxation other than by income. For the sake of simplicity, migrations are not allowed in the virtual society and the total population remains constant. Wage income depends on ability and incentive, and the ability is taken constantly along the simulation with a given initial distribution. While macroeconomic aspects are not the final purpose of the model, our main objective is to model wealth distribution with the representative variables of capital yield, tax rates and tranches. The initial capital (
) of each individual
i in the total population
n is assumed to follow the additive uniform exponential distribution (AUED) [
25]:
being a uniform probability distribution between
a and
b,
an exponential probability distribution with mean
d,
,
coefficients and
the mean of the exponential probability distribution defined in
Table 1. Similarly, the initial income (
) of each individual is assumed to follow the AUED distribution:
with
,
being coefficients and
the mean of the exponential probability distribution defined in
Table 1. Mixed distributions are useful to describe variables with components of different nature; in the present case, total income is composed of ability-based income and capital yield. An example of application of the AUED distribution can be found in the modeling of manpower total length of service [
26].
Capital (
k) and income (
y) coefficients are calibrated to approximately match the distribution of household income in the U.S. in 2019, published by the U.S. Census Bureau (
Table 1):
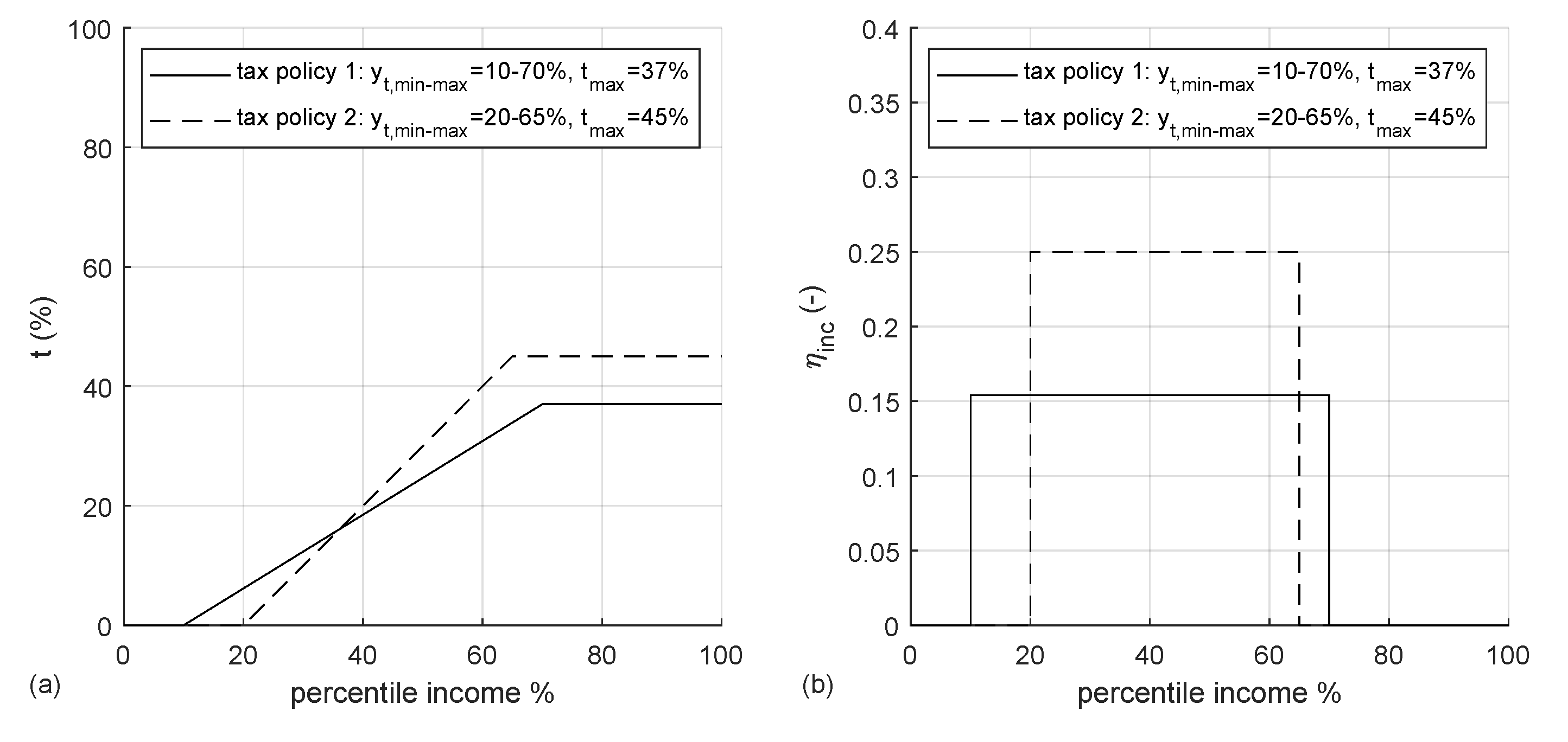
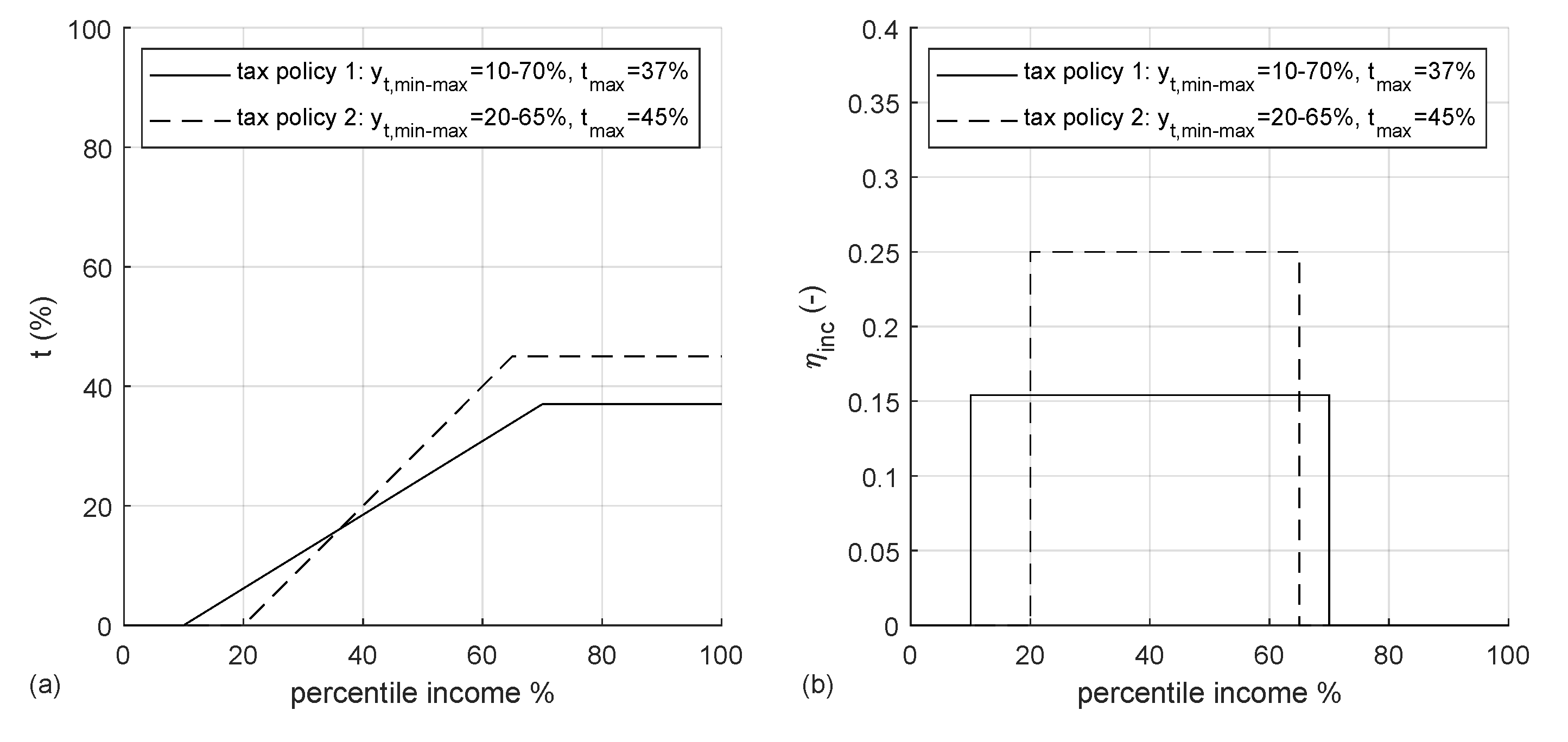
The model assumes that individuals are subject to income taxation by the government: the tax rate is a non-decreasing function of their income
y, and the total amount of tax is a non-increasing function of
y. The top marginal tax rate is set to zero after a maximum income
consistent with Lesson 2 in the literature review [
4]. The lowest income is set to zero to match redistribution policies seen in most OECD countries, this also makes the lowest incomes have a zero marginal tax rate, which is suboptimal according to the theory. Tax rate
t is defined in (Equation (
3)):
where
is the taxation function of a variable
z,
and
are the minimum and maximum tax rates, with
,
and
being the income values defining the limits of the progressive taxation tranche. It is assumed that the government adjusts
and
values every year in order to match a given percentile regardless of income level. Reference minimum and maximum percentiles have been taken as
and
, so that the values
and
closely match U.S. taxation in 2019. The income
y in each year is the result of applying an incentive factor function of the tax rates (Equation (
4)) to the ability based initial income distribution (Equation (
2)):
where the tax disincentive
is a coefficient with a real positive value,
meaning no tax rate disincentive. The resulting incentive factor is defined in each tax tranche in (Equation (
5)):
where
is the incentive function of a variable
z. A numerical example in
Figure 2 illustrates previous equations (Equations (
3) and (
5)).
The total amount of collected tax
T in one exercise (1 year) is defined as (Equation (
6)):
and is spent in social welfare in the next exercise, the social welfare expenses are considered to be equally shared among all individuals. An efficiency coefficient
with a real positive value,
meaning perfect efficiency, is applied to the social welfare benefits to account for the eventual misuse of resources. An individual expenditure function is used with a constant value of expenses for all the population subject to capital
k availability, it is considered that social welfare benefits alleviate the need for individual expenditures. If an individual has a capital less than the annual expenses minus the social welfare assignation, the expenses are not applied in the present year (Equation (
7)):
where
is the expenses function of a variable
z,
are the individual expenses with a value
USD for all individuals, an improvement of the model could consist in the introduction of expenses function of income, for sake of clarity this has not been done in the present research.
Finally, individuals can obtain an extra income from capital yield
r, a value of
is adopted which is the average of U.S. economy in the period 1947–2020. The model for one individual in one fiscal exercise becomes:
where
is either the individual’s initial capital or the capital resulting from the previous exercise,
takes the value of
in the initial condition,
k is the capital after adding the previous net income according to Equation (
3) and subtracting the expenses
according to Equation (
7). The income
y is then computed by applying the incentive factor and adding capital yield to the wage based income:
and finally both capital
and income
are updated for the next exercise:
note that capital (
) is accumulated by individuals during the history of the model, while wage based income (
) is constant throughout the history as ability is assumed to have a fixed distribution. Equations (
8)–(
11) are run in nested loops for all the individuals and the successive exercises.
4. Meta-Heuristics Based Policymaking: Optimization
The previous section explores the effects of taxation on wealth distribution in the full spectrum of society. Given the constraint of democracy with a plurality vote, the incumbent government’s optimization problem is to minimize the population unhappy with the newly proposed economic policy. Therefore, an income-based yardstick vote [
19,
20,
21], is used as a criterion to measure voters’ intentions. Contrary to strategic voting [
27,
28], in the present model, voting is assumed to be sincere: the vote is for the policy that maximizes its interest, and voters do not have information about other voter’s intentions. With this logic, voters evaluate the incumbent’s policy at the end of a mandate. The other candidates never come into play because it is assumed that the incumbent always adopts the optimal policymaking regarding re-election. The model does not account for population fluxes; while migrations can have a major impact on demographics and aggregate productivity at long term, in the present work it is considered that short term policymaking perceives potential migrations as lost or gained votes.
Due to the non-linearity, non-derivability, and presence of multiple local minima of the problem, classical and gradient-based optimization methods cannot be used. Particle swarm optimization (PSO), first developed by Kennedy and Eberhart [
29] and Eberhart and Kennedy [
30], is adopted as a derivative-free meta-heuristics optimizer. The reasons for PSO popularity can be numerous; its simplicity and adaptability to a multitude of real-world problems are among the most appealing features. In the present case, and because of the unknown nature of the problem resulting from a yardstick process, the ability to tune the exploration–exploitation bias of the algorithm has been determining. Using a meta-heuristic with poor exploration capability could lead to local optima trapping. PSO allows us to initially tune the algorithm to ensure a thorough search space exploration, once more information about the global optimum position is obtained exploitation can be increased back to gain performance. In this work, the later improvement inertia-PSO or
PSO [
31] is adopted. This version of the algorithm gives inertia weight to the particles, which improves the exploitation phase during the search.
The optimization variables being
,
and
, they are grouped in this order in the vector
x. Results of the model in the previous section after a 73 year run with
are used as initial conditions. One simulation is run for a given period with the same values of
x as in the 73 year pre-initial condition period, serving as a yardstick reference. The optimization is performed in an incumbent run with the same initial conditions as the yardstick reference and with the same time length. At the end of the incumbent run, each
i of the population
n is compared against its yardstick reference homologous, and the income level
y is used as a criterion to determine vote intention; if the income
y is lower compared to the yardstick reference, yardstick vote punishes the incumbent. The length of the incumbent run is taken equal to four years, coinciding with a usual electoral mandate. The optimization problem to be solved reads:
subject to:
where
is the number of individuals unhappy with the economic policy according to the yardstick vote. Note that the ranges of the optimization variables are all
, while
is never larger than
. To avoid search in the infeasible space, a penalization method is adopted [
32]. Previous minimization (Equation (
12)) becomes:
where
is the penalty term with
the penalty coefficient defined by the function
q:
where a value of
is selected as the minimum distance between
and
to avoid infinite tax gradients. The parameters used in the PSO algorithm are intended to maximize exploration, thus a relatively high swam size is used, inertia range is clipped at
to avoid premature convergence and the self adjustment weight (cognitive component) is set to twice the population adjustment weight (social component).
Table 2 presents the set of PSO parameters prior to swarm size determination:
A parametric study on the swarm size is performed, and the swarm sizes are chosen to be multiples of 8 to maximize the performance of the 8 thread parallelization. Only one optimization result is shown for each swarm size (
Table 3). The two simulations with swarm sizes below 32 do not present a good convergence on
. Starting at swarm size 32 and up, the best
are convergent and the value of the optimized
x tends to a global optimum close to
x =
, which is the value with the lowest
(simulation 4).
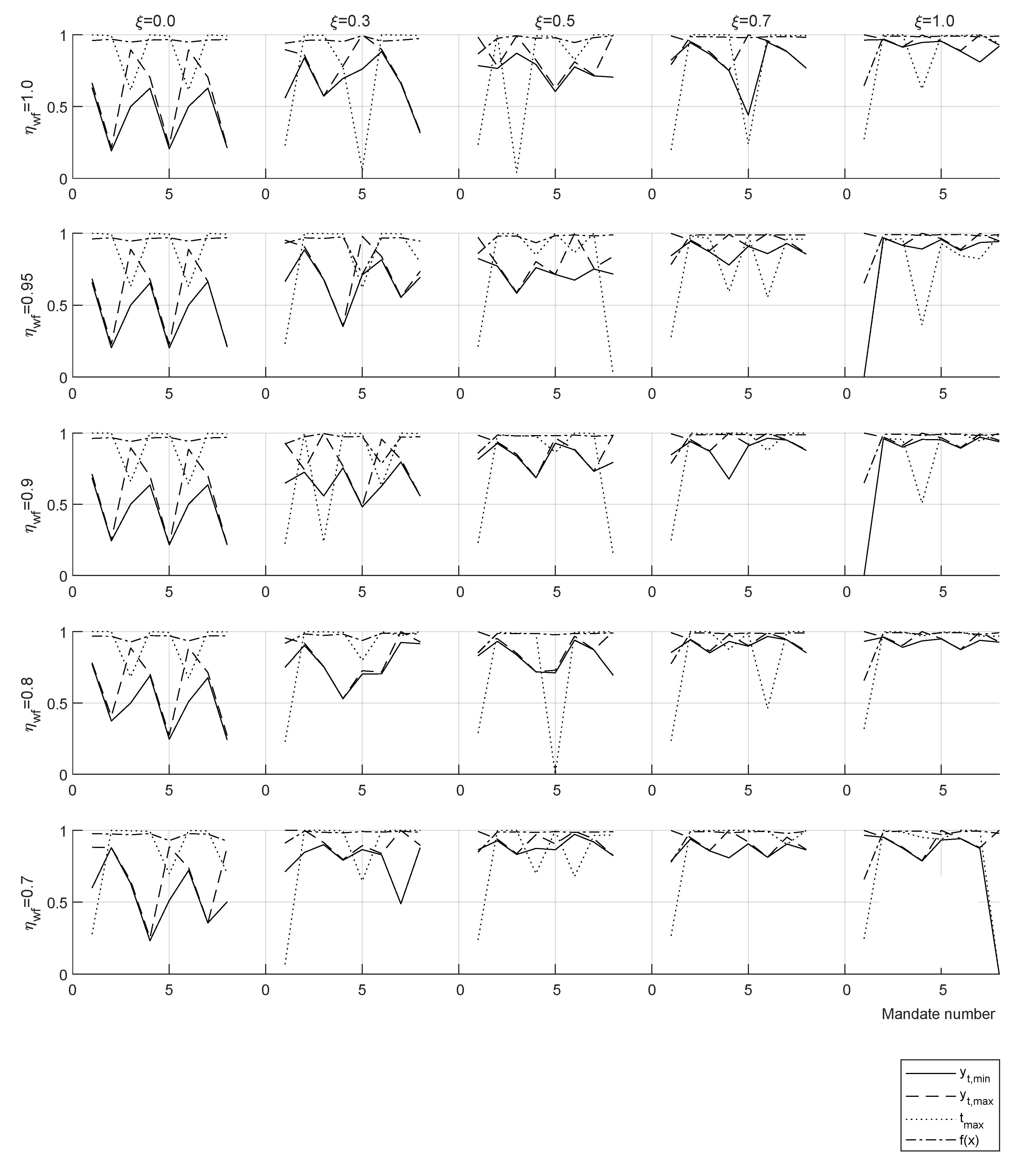
Given previous experimental outcomes and the available computational resources, a swarm size 120 is selected. A series of simulations are used to test the convergence to a unique solution and validate the PSO parameters. A total of 30 optimizations give a mean best target function
with standard deviation
. The small standard deviation for the mean provides reasonable confidence about the results using a swarm size of 120. A parametric study on welfare efficiency and work incentive with values in the ranges
and
is performed for one mandate (4 years) and a selection of the results is presented in
Table 4.
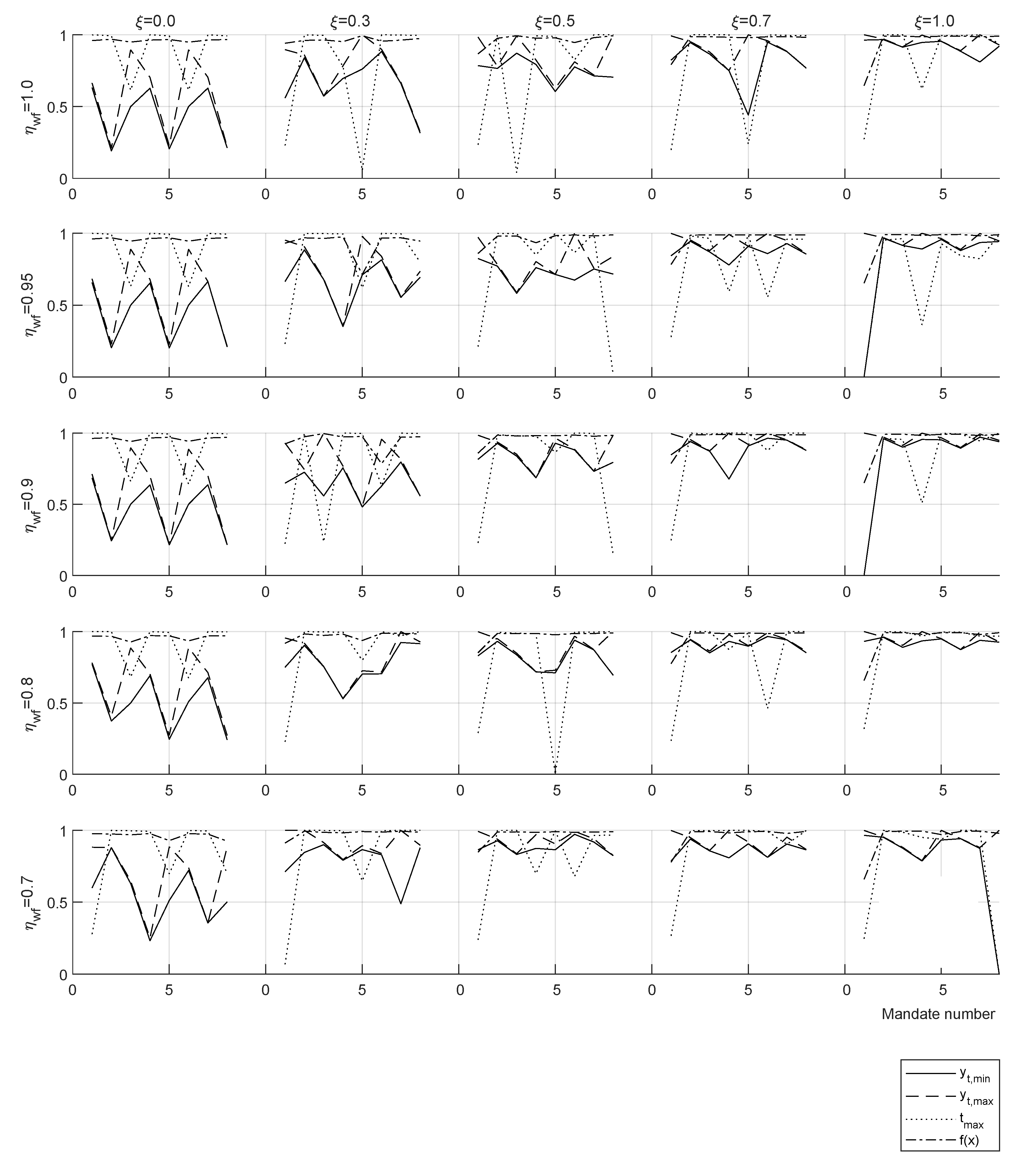
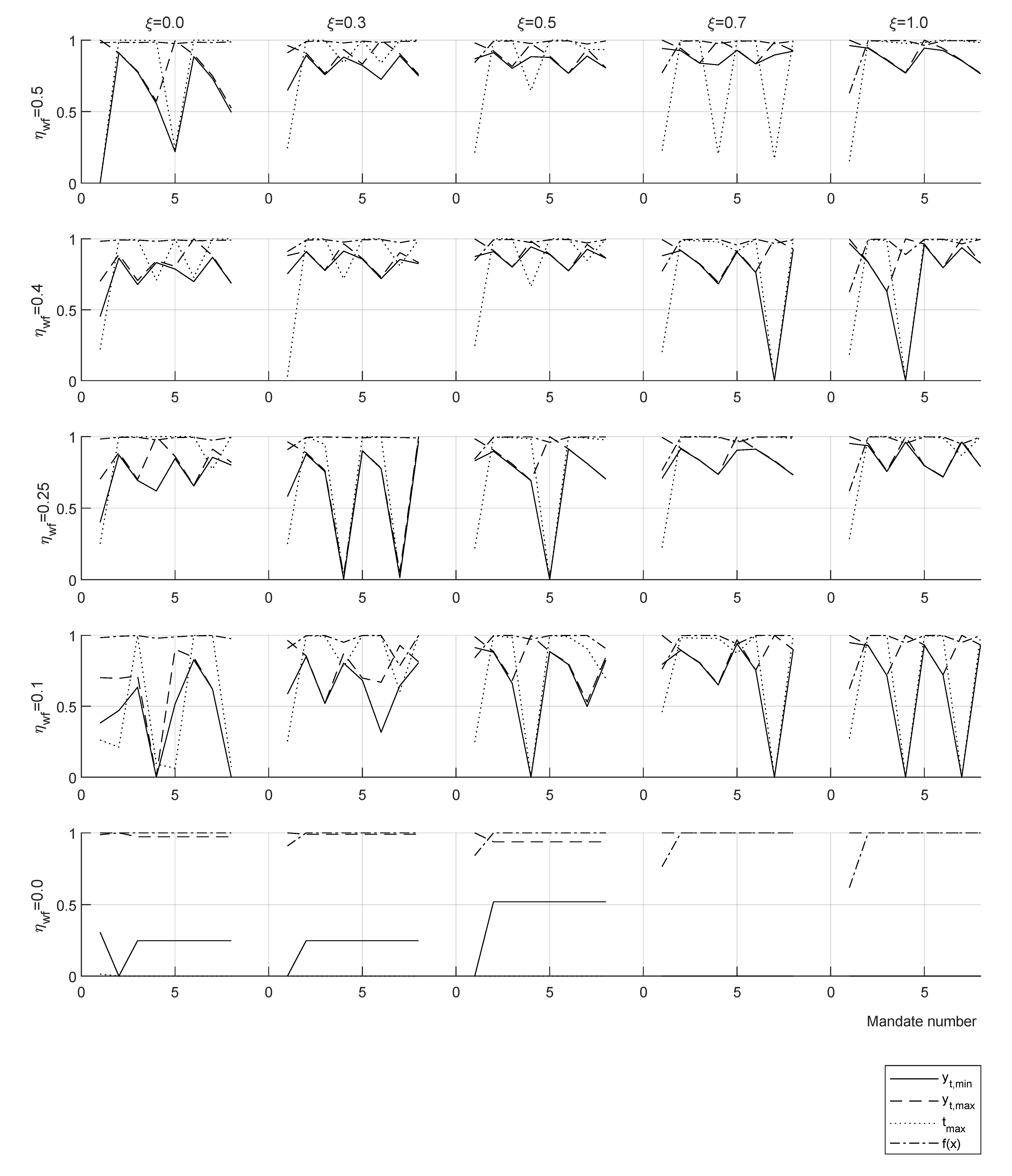
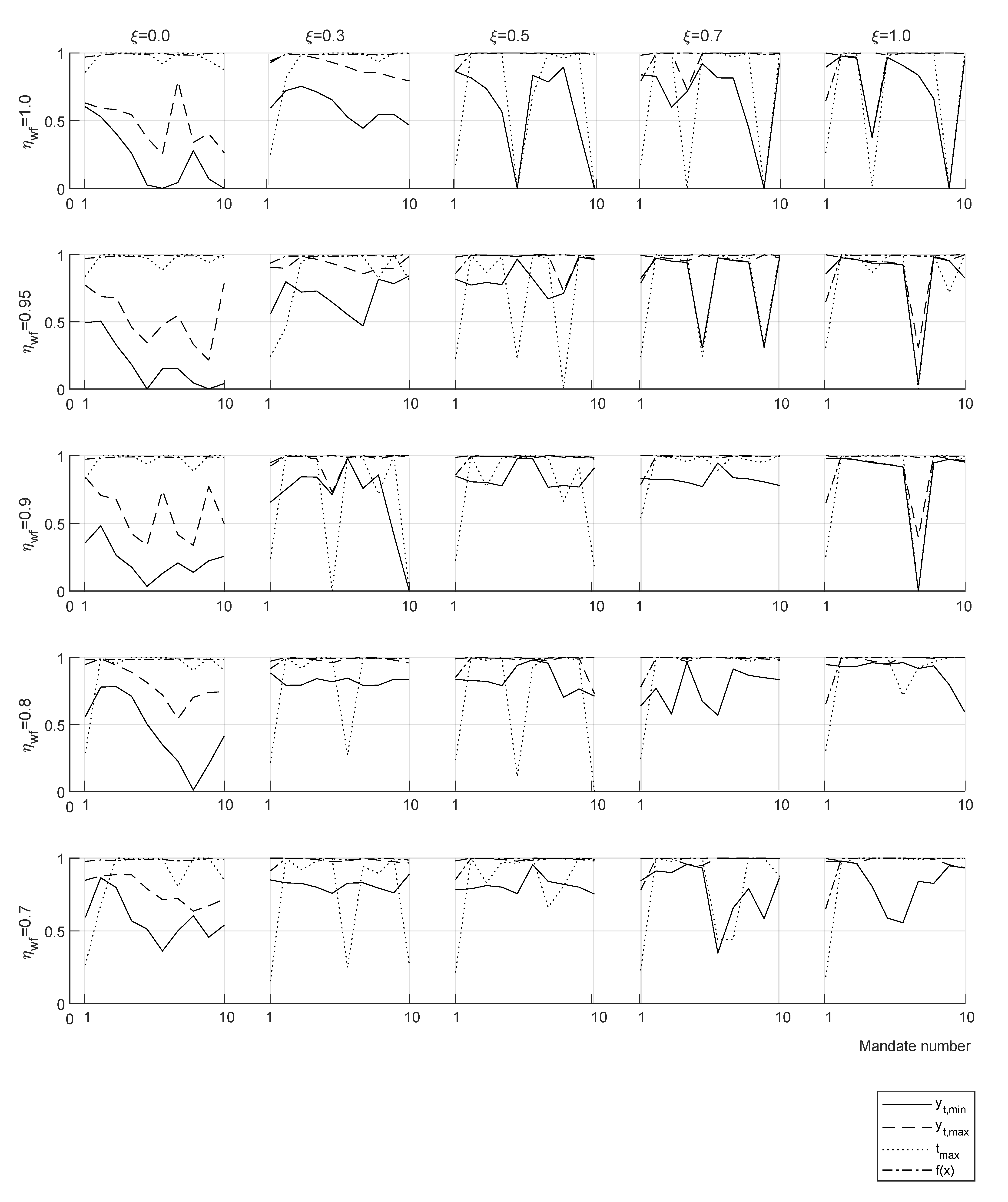
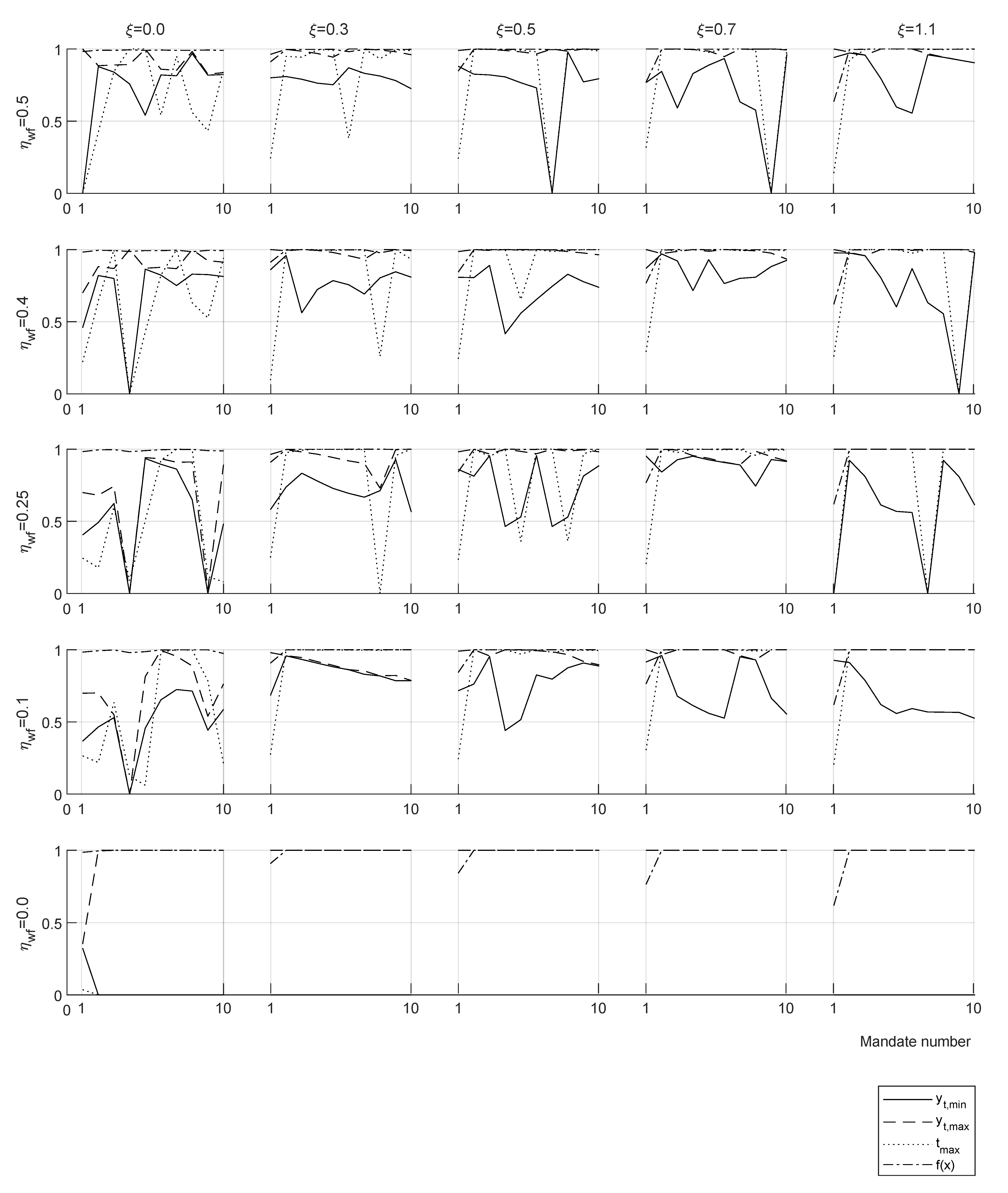
Welfare efficiency
gives a non-zero top-marginal rate up to tax disincentive
, suggesting that in real economy, at least one of the conditions
or
is found. Results with
show a progressive decrease of optimal taxation overall income
y range for an increasing value of
starting at
. The same selected results of the parametric study are presented in
Table 5 for two consecutive mandates (8 years). A full parametric study including 30 results for each case of one and two mandates can be found in the repository:
https://doi.org/10.6084/m9.figshare.16442916.v3 26 August 2021—First online date, Posted date, Accessed date).
For a welfare efficiency
taxation decrease is observed for all values of
, with
increasing up to approx.
in all the range. For suboptimal welfare efficiencies
taxation reductions are larger and present non-zero top-marginal rate
and tend to zero taxation for
(
Table 5).
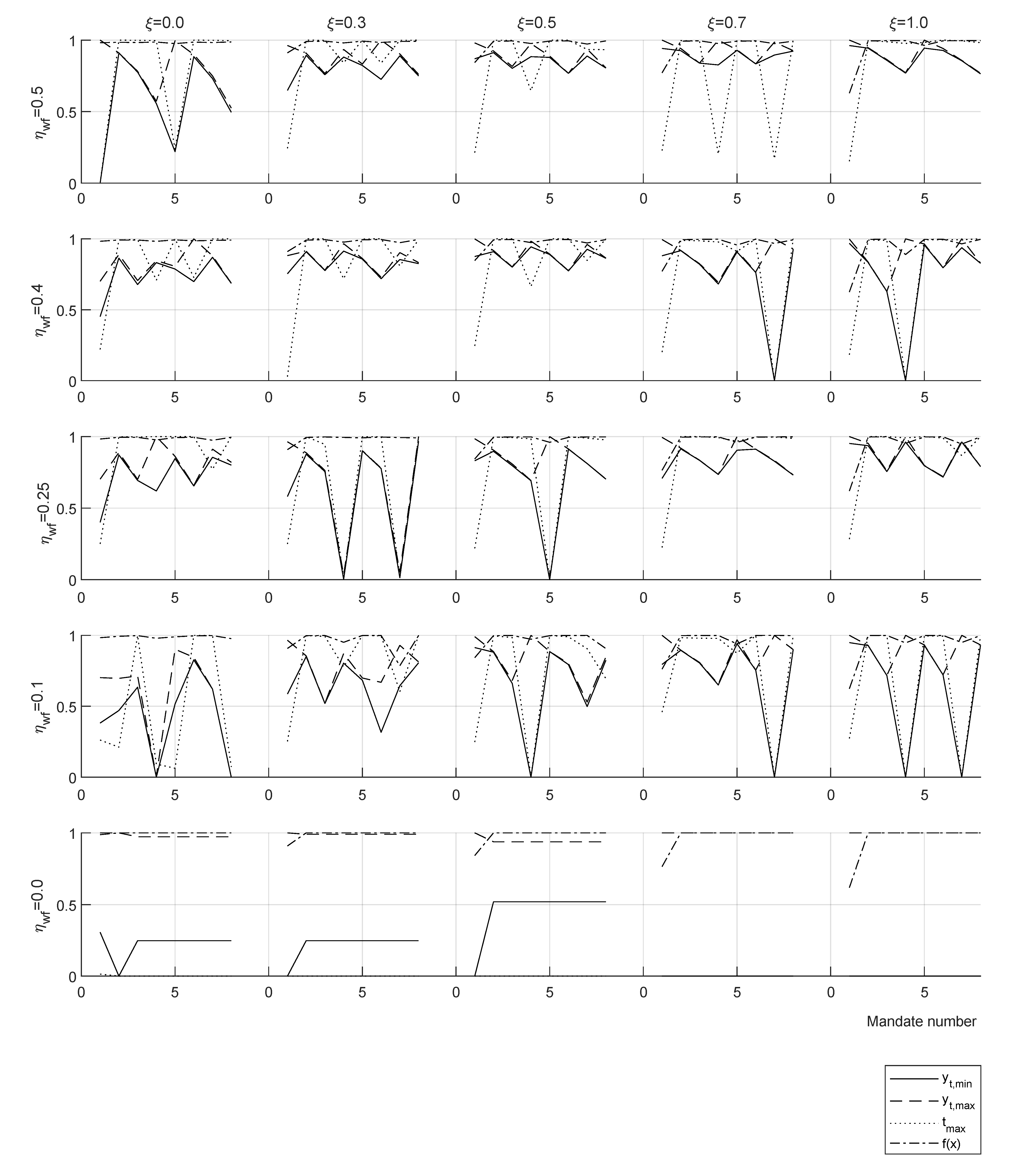
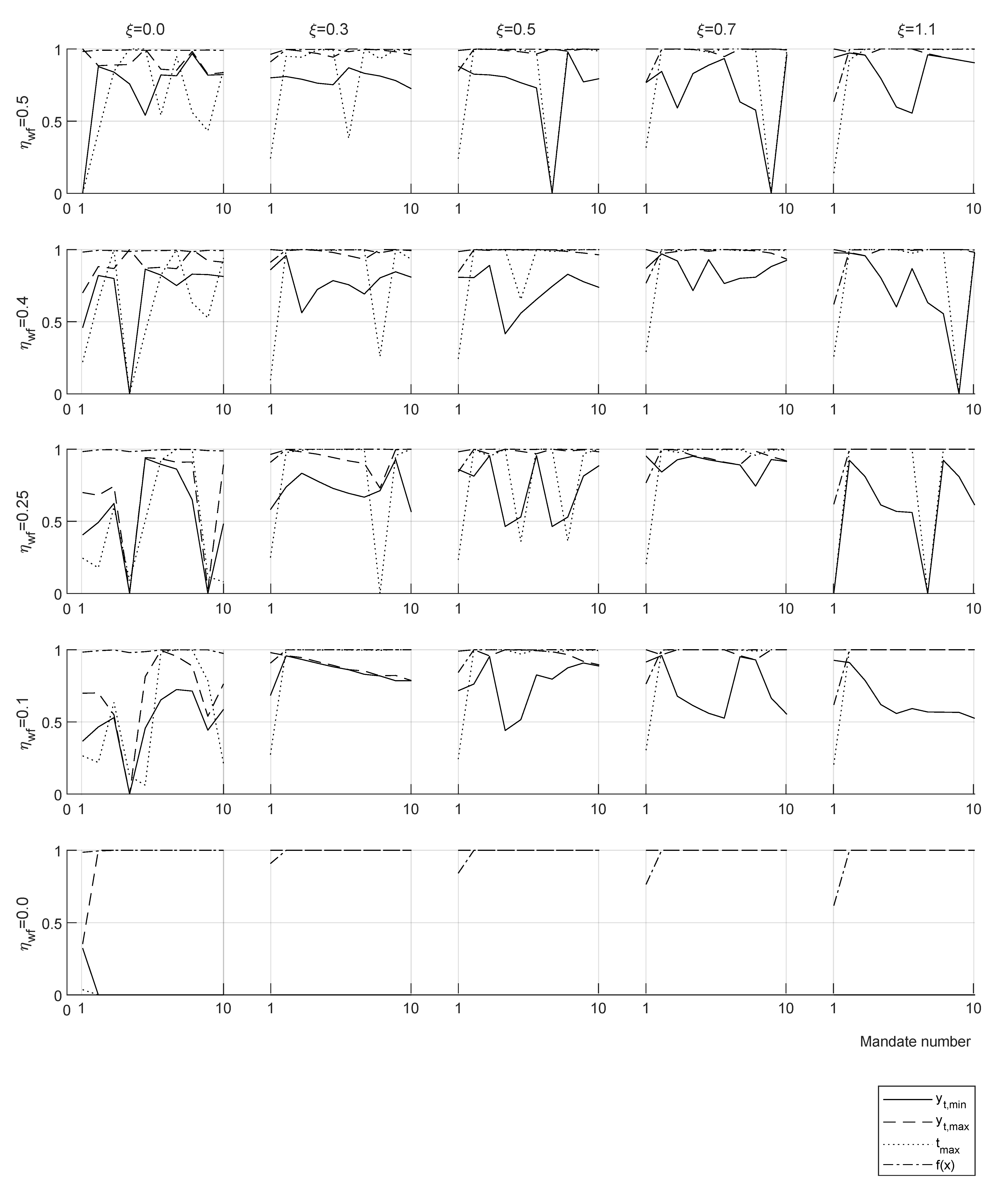
Two optimization cases are shown for the case
and
for one mandate (
Figure 7, top row) and two mandates (
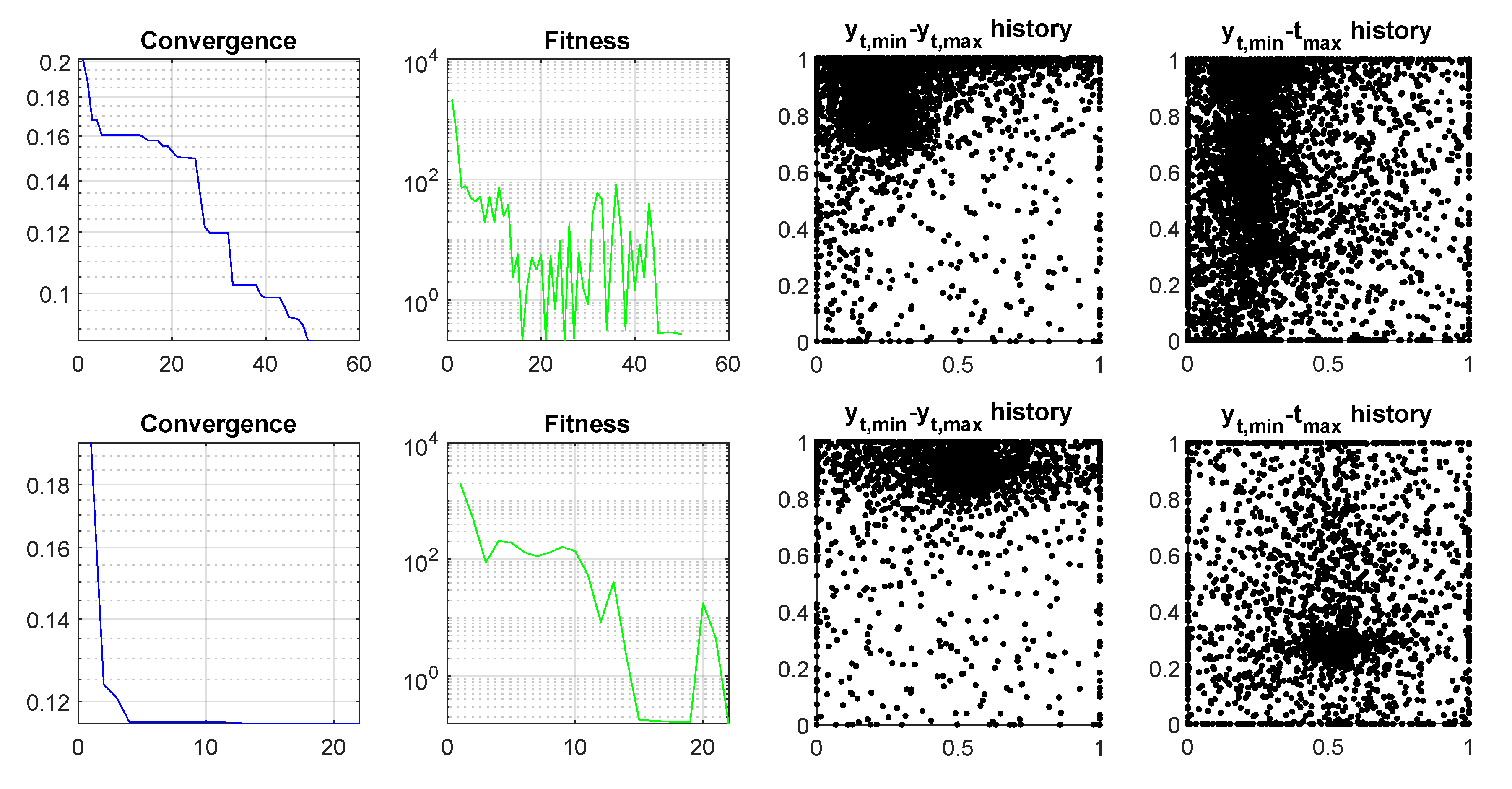
Figure 7, bottom row), this case appears to be close to real economies. Convergence presents the decrease of the best evaluation of the target function (Equation (
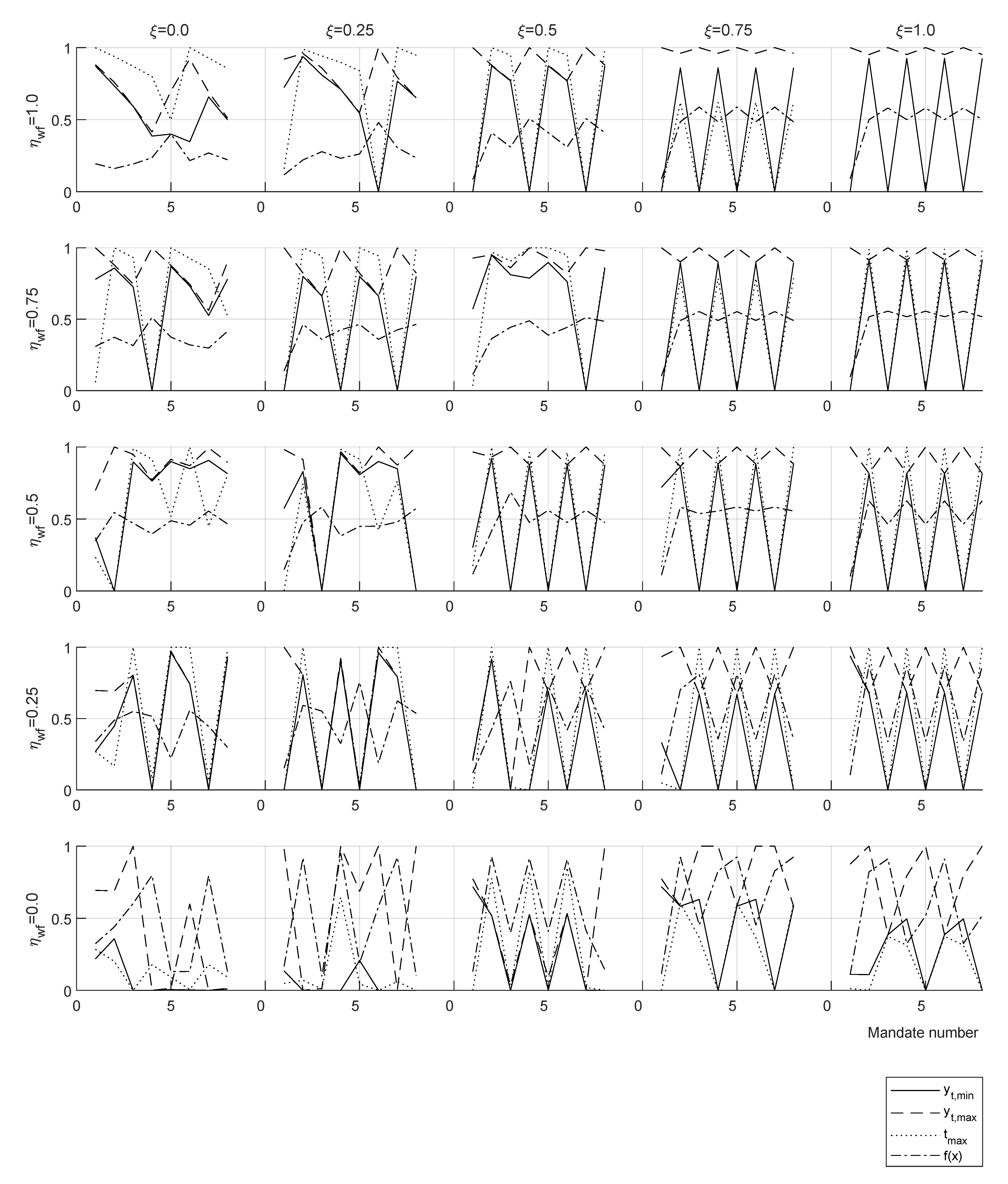
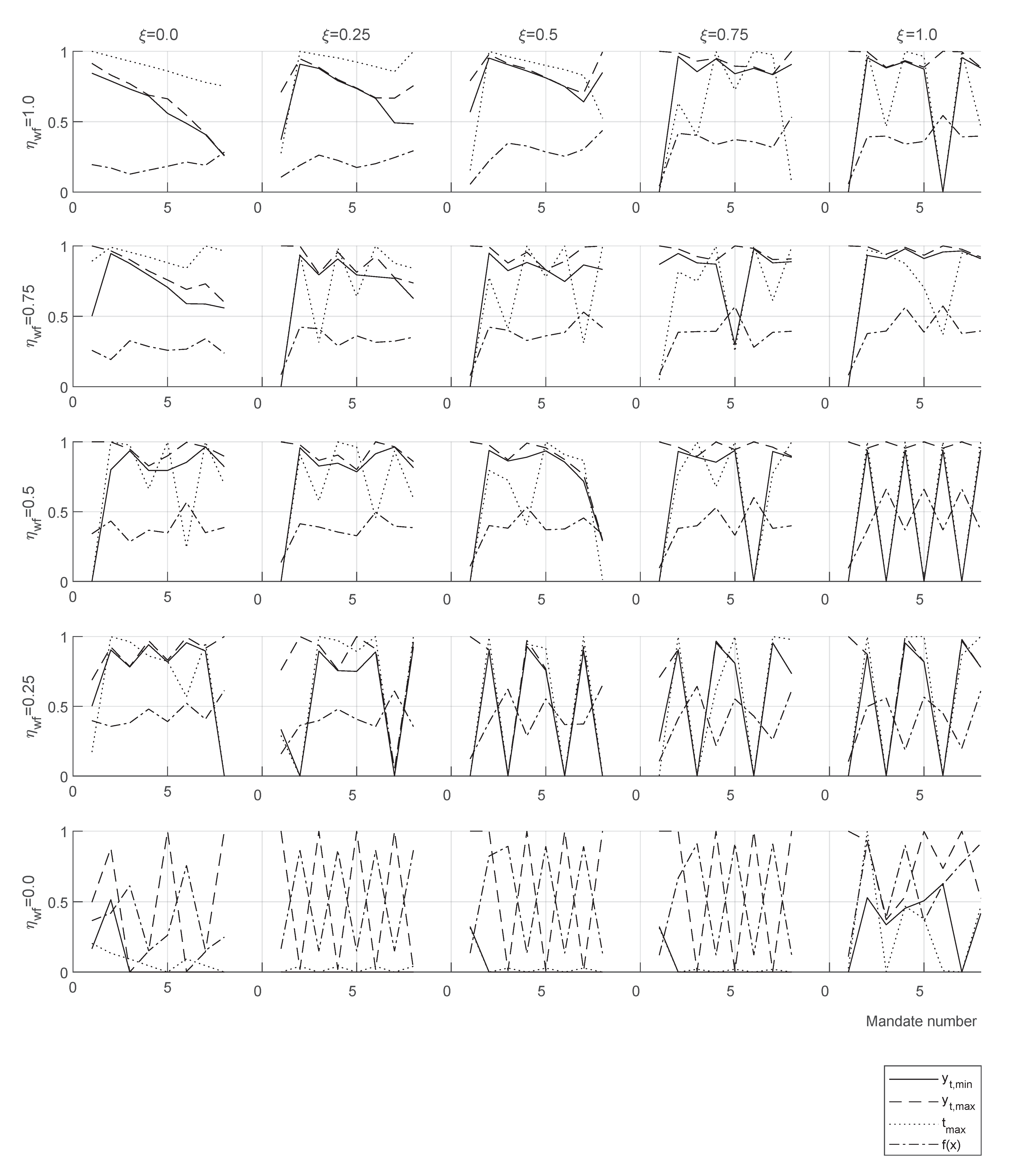
12)), fitness is the evolution of the average value of target function evaluations in the swarm, and the scatter plots present the history of particle positions in two planes of the optimization space
x.
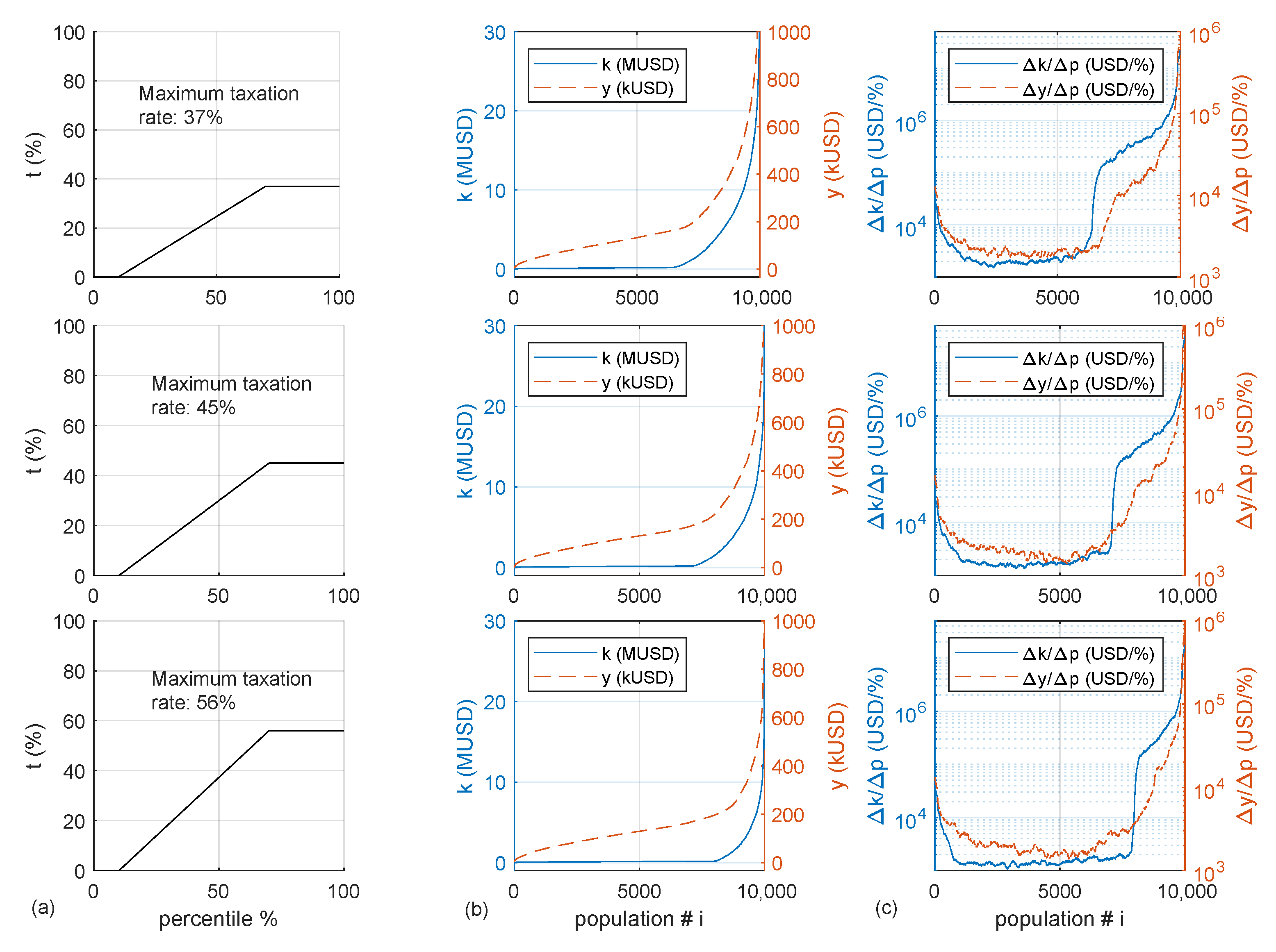
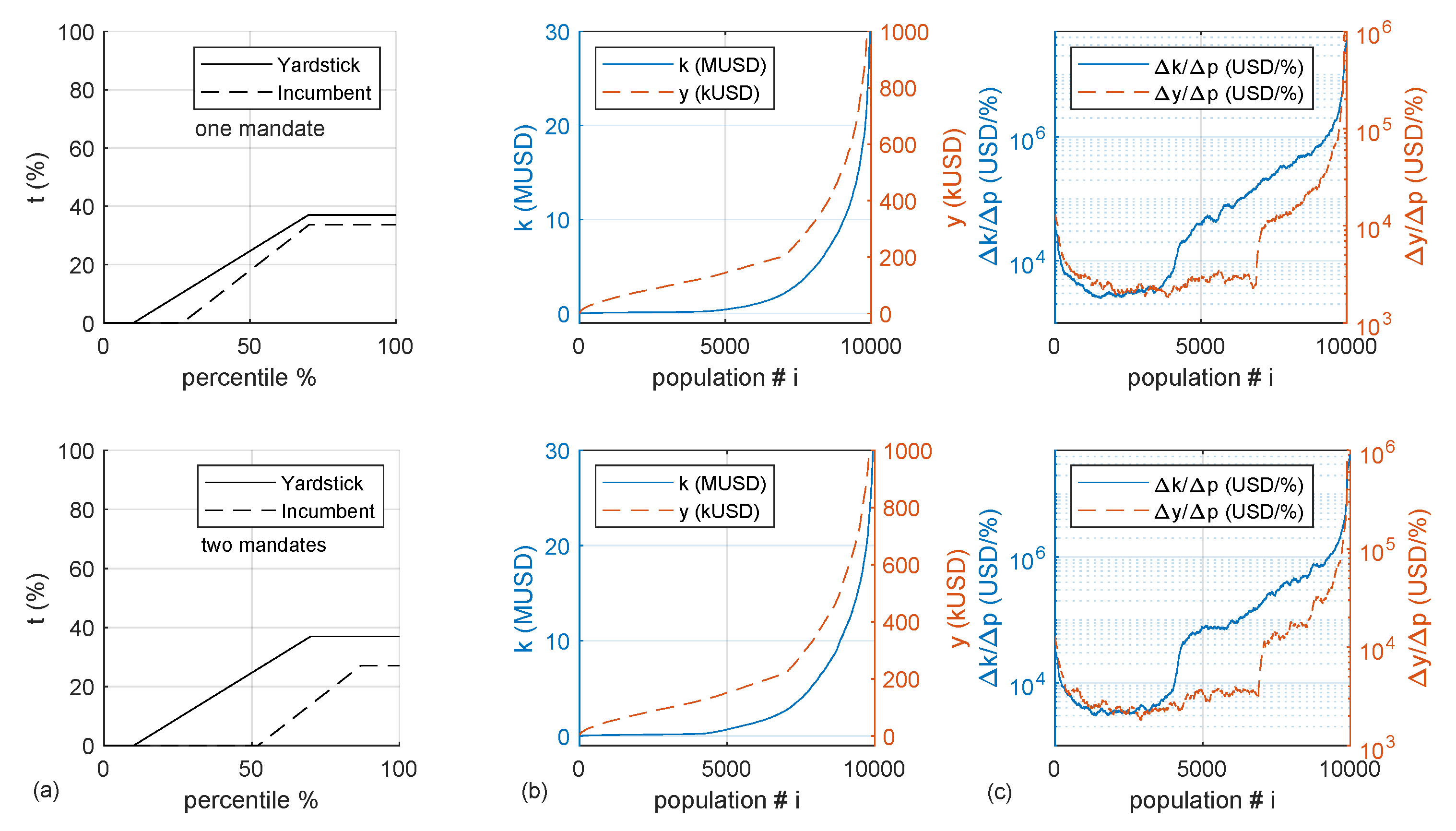
The same two cases are presented in terms of tax policy and wealth distribution for one mandate (
Figure 8, top row) and two mandates (
Figure 8, bottom row).
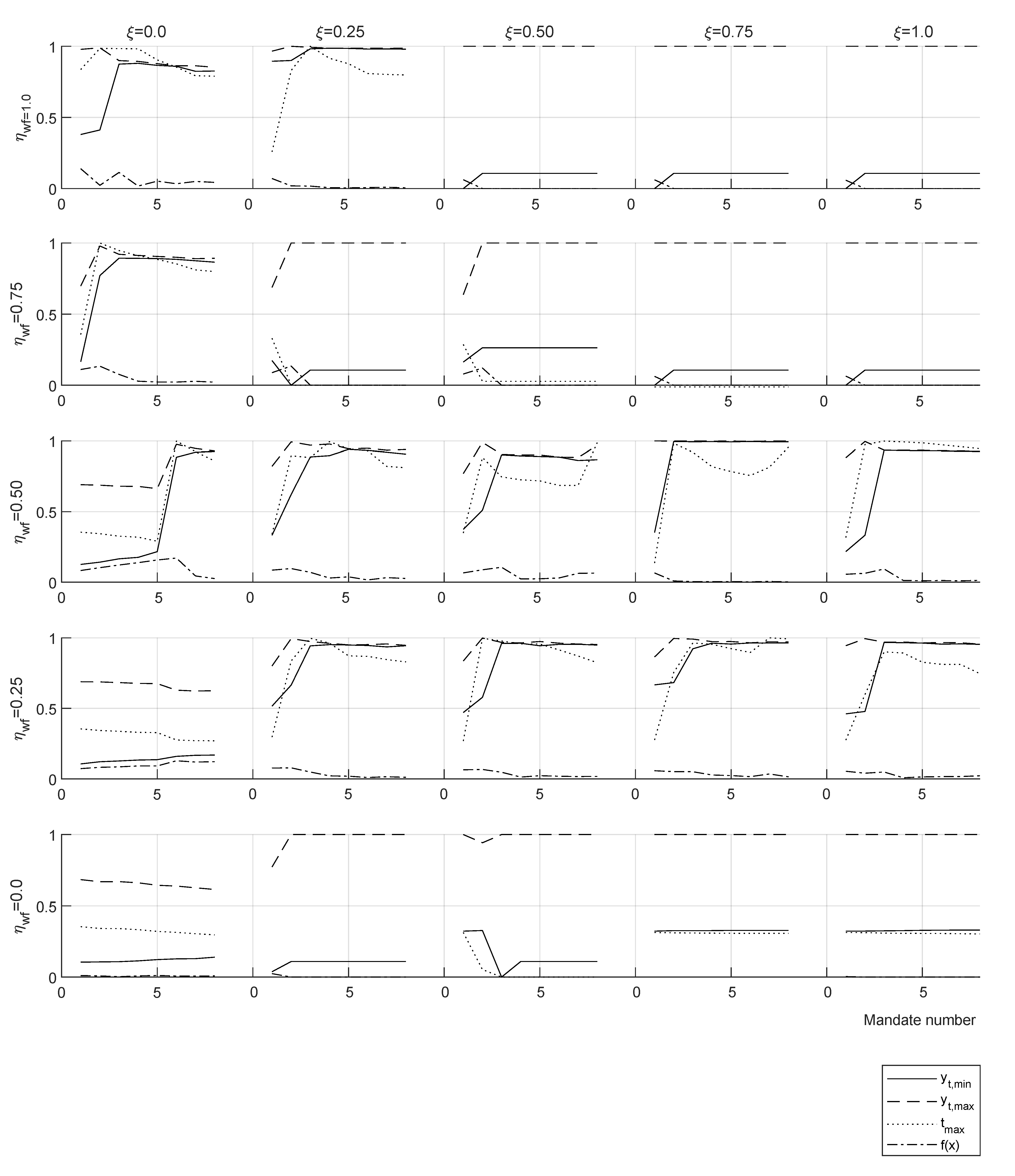
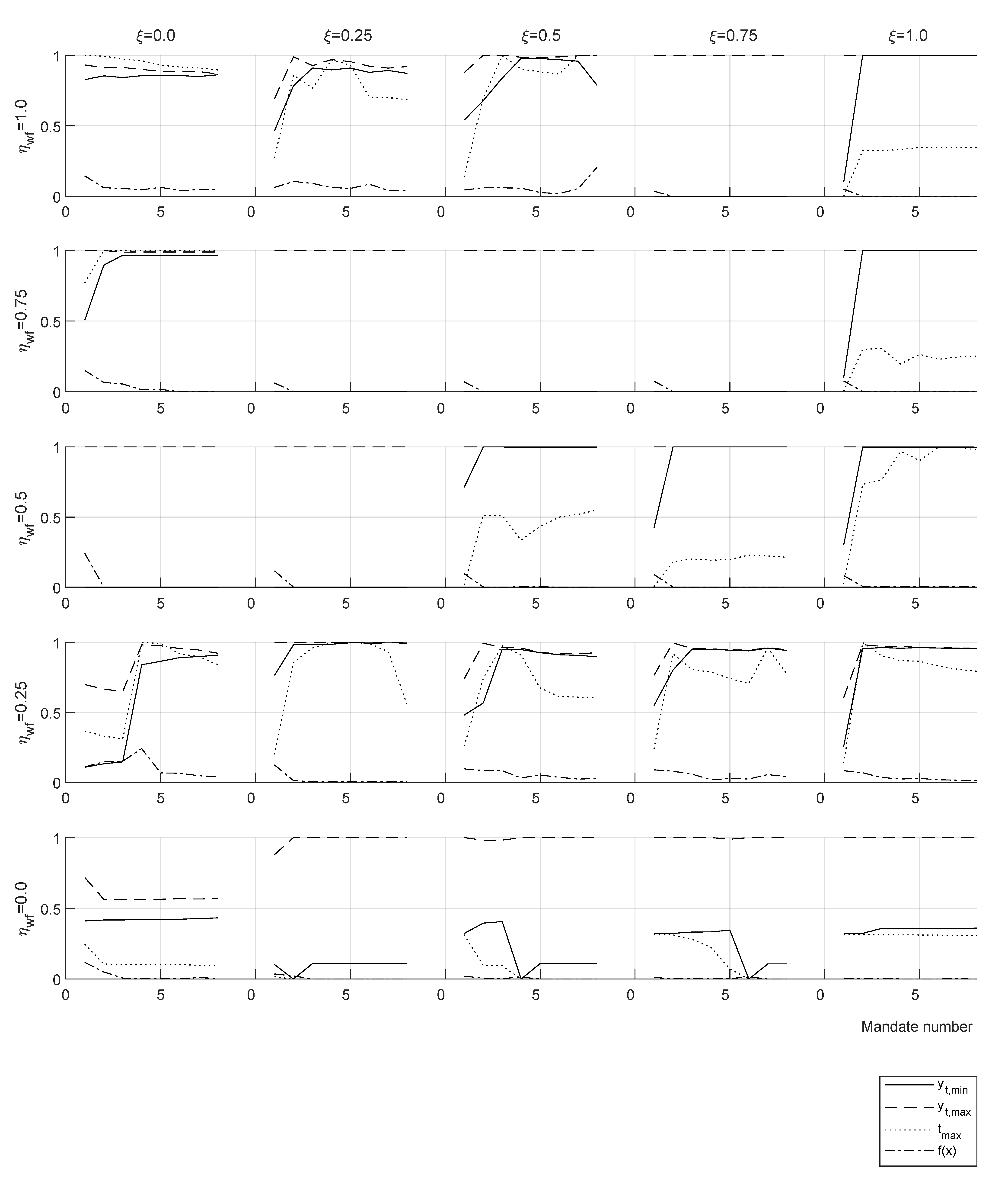
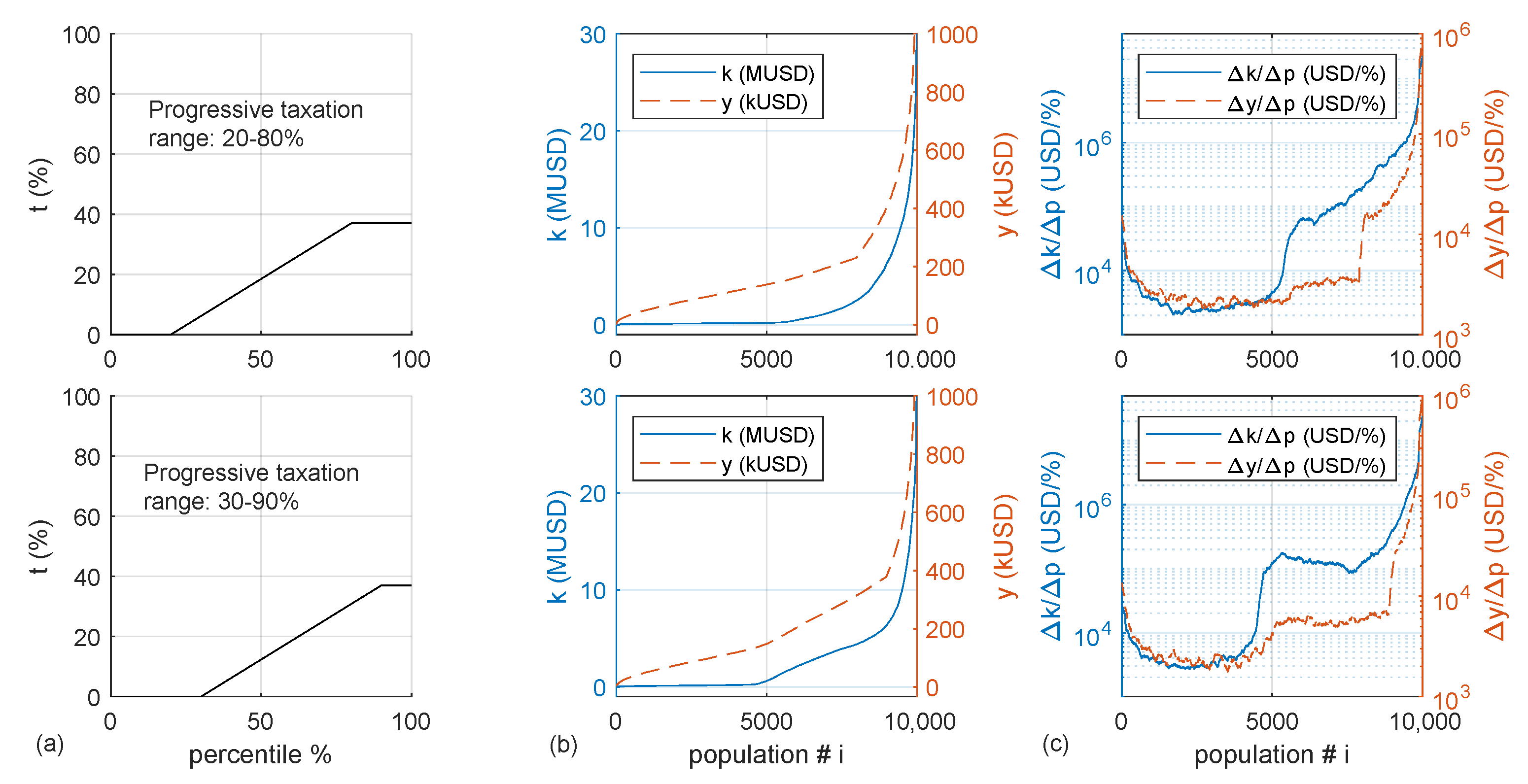
Tax tranches show the lower optimal taxation for longer mandates for the yardstick reference. The consequence of this policy is a slight displacement towards the low rents of the high values of around the percentile . This is due to an increase in the population that accumulates capital and votes for the incumbent, while losing votes from the lowest end due to a shrinking welfare system.
6. Discussion
The main focus of the work is to study the yardstick vote, wealth distribution, and policymaking. Notably, the model is not based on a general equilibrium concept but on a household-based population, with the economic growth as a calibrated parameter instead of a variable.
The validation using initial and final wealth and income histograms taken from real economies confirms the ability of the model to predict wealth distribution in a period of 73 years. This setup allows the model to experimentally study the relation between policymaking, voting, and wealth distribution for a short number of mandates.
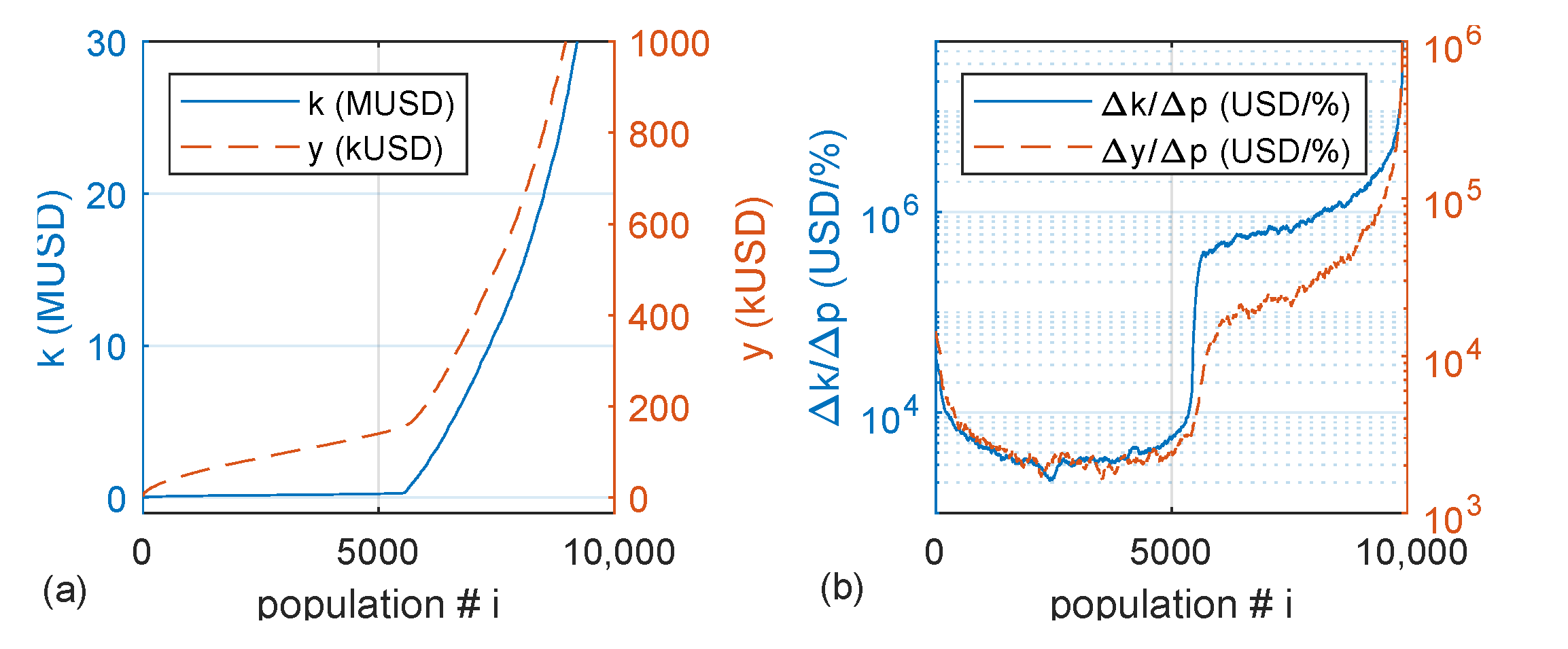
Results show that a progressive increase of taxation for the income percentile can flatten the income curve and increase the extent of the population not being able to accumulate capital. Regardless of the maximum taxation level in the progressive tranche, once the capital yield can outpace the maximum taxation income , the wealth distribution in this region becomes the same as in a zero tax case. This finding highlights that the flat marginal rate for the higher rents recommended by the optimal tax theory increases the population’s economic disparity.
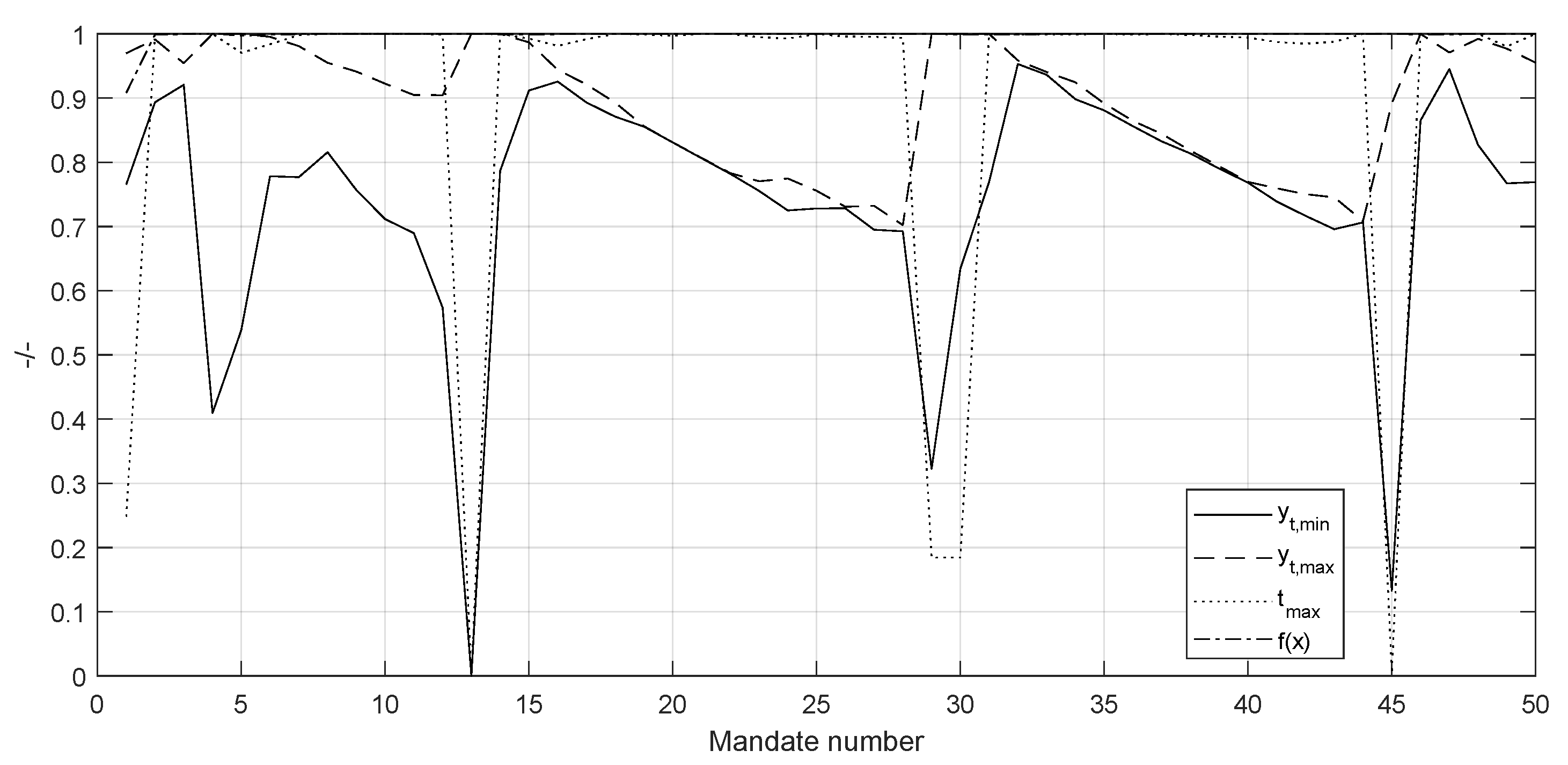
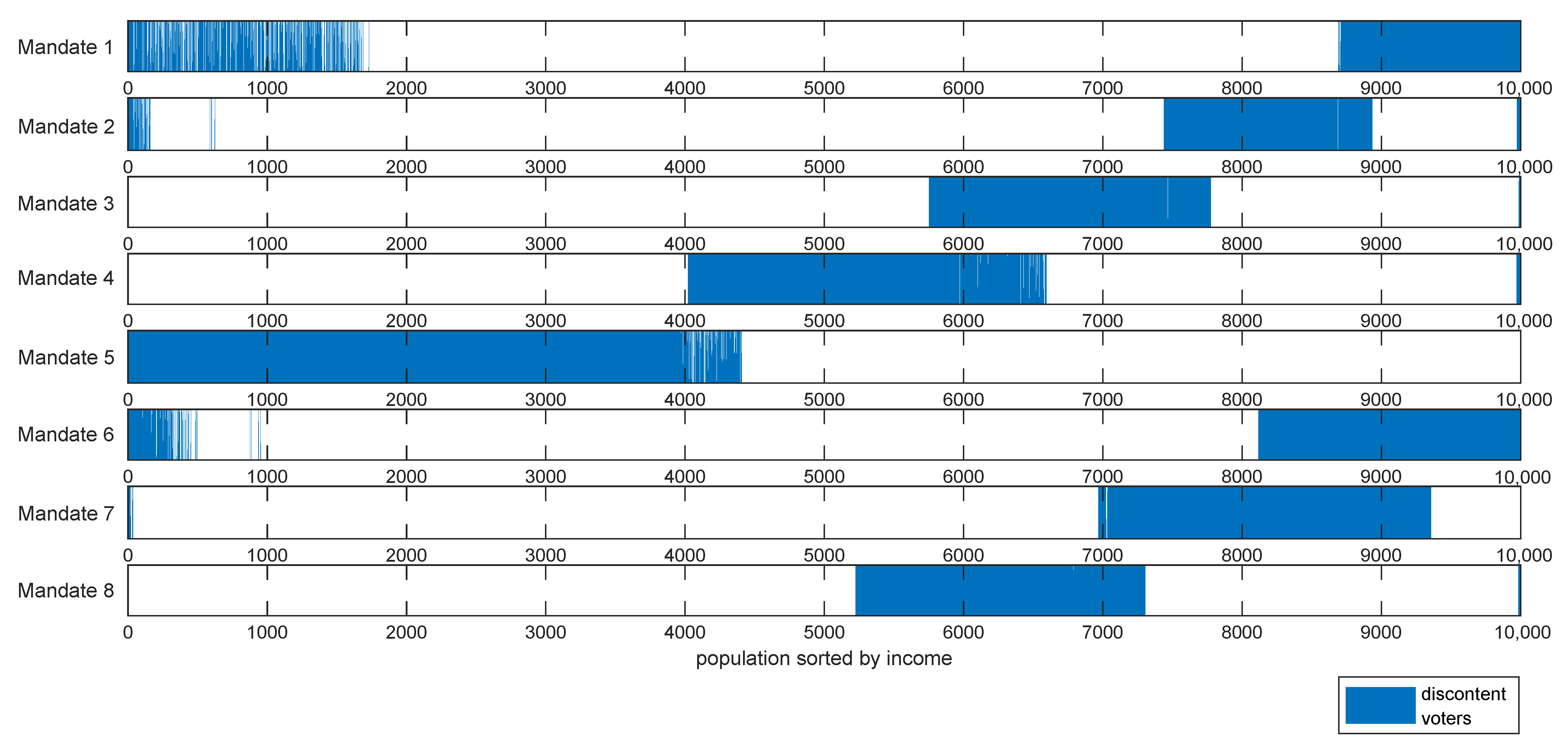
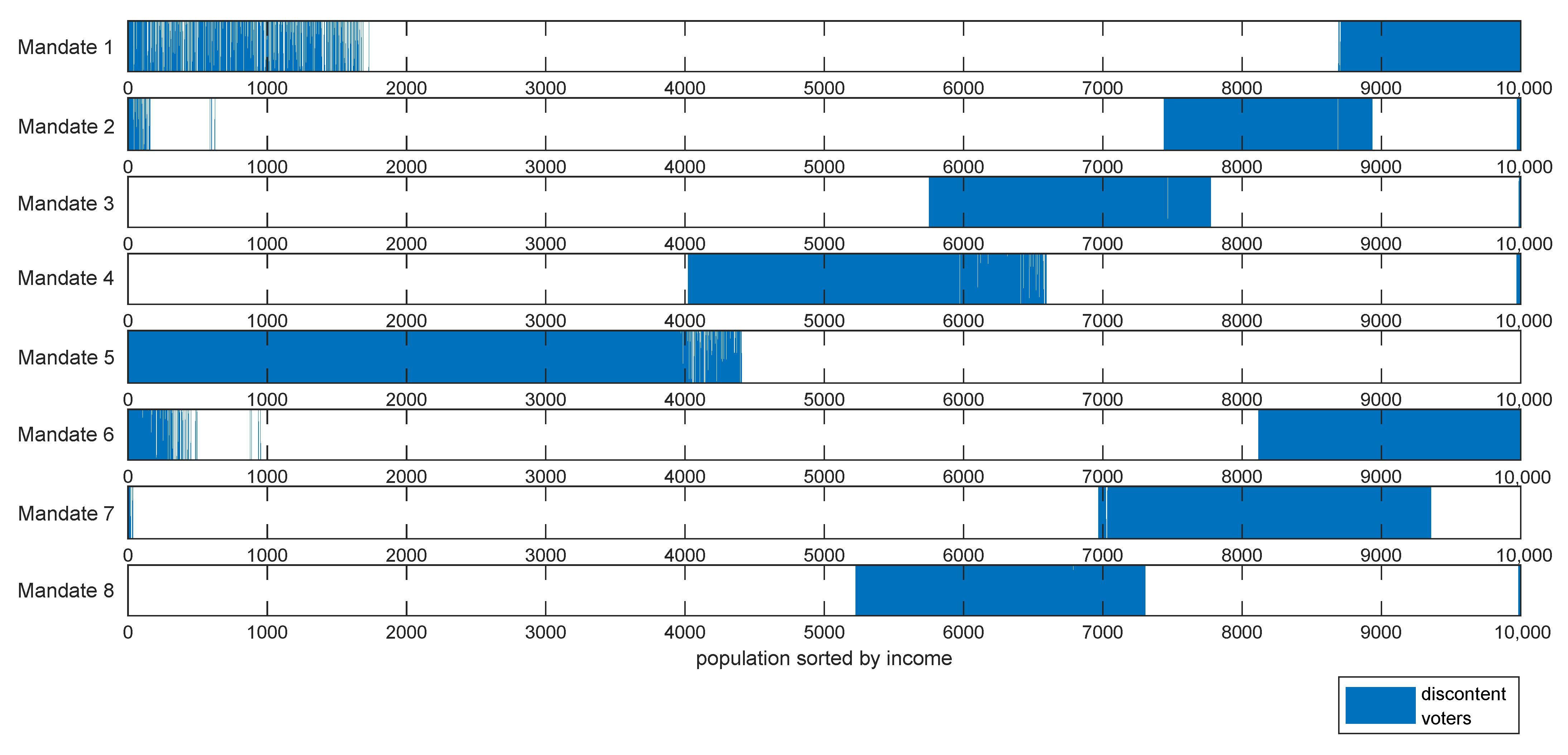
Meta-heuristics optimized tax policy for one single mandate gives a progressive tax tranche with flat marginal rates in both income extremes for any case with welfare efficiency and work disincentive . This is in agreement with the results of the optimal tax theory for the high rents and shows that in the ideal case with and the progressive tax tranche would span most of the population spectrum. Optimization of recursive mandates using a yardstick vote criterion implies that the policymaker must constantly change the tax policy to obtain a majority in the vote. This result holds in a variety of assumptions, i.e., policymaking targeted at the median income or per citizen, income advantage required by voters or , mandate length 4 or 8 years, even in the case of an explicitly formulated rejection of such strategy by the voters.
The obtained tax policy strategy does not fit the recommendations of the optimal tax theory nor the common sense of social equity. It is yet to be determined the effects of such a strategy on economic growth. Combining the present results with a global equilibrium model can help answer this question. Another question is the system’s fairness in the long run; after the tax policy has cycled through the income spectrum several times, does it result in an equally tax-punished society? Further research should also study the effect of inter-mandate memory, strategic vote, and other voting rules such as supermajority.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}