3.1. Representation Spaces
Before we proceed with the formal definition of a problem representation and of a representation space, let us outline two properties representations should have:
Representations should be inductively defined: We want our problem representations to be inductively defined, i.e., the representation of large decision problems should be built from the representation of some of its sub-problems. For instance, a large list might be formed by concatenating two smaller lists, or a decision tree should be built from smaller decision trees. This is an important feature, as it ensures that represented problems are constructed in a modular way.
Representations should be parametric on the set of alternatives X: Similar to the definition of a decision problem which is valid for different kinds of alternatives we also want to define representations without being tied up to a particular set of alternatives X. For instance, we should be able to define the “list representation” of X, without referring to anything specific about X, so that we can then deal with “lists of cars” or “lists of wines” in a uniform way. This is also an important feature, as it ensures that representations are constructed in a uniform way.
Recall, in the introduction we used the example of shopping online. Products
X are displayed as a paginated list of results, with 10 results on each page. This representation is
inductively constructed from the set
X via a limited number of operations: creating a single item, organizing 10 items in a page, and finally combining all pages into a list. Moreover, the representation structure is also
uniform in
X, we can use the same structure for different sets of alternative
X. Like mathematical expressions built from numbers via mathematical operations, or like sentences built from words which are themselves built from letters, search results are built from primitive objects and operations defined on them. (In mathematics, such structured sets are
algebras. They have led to the development of
algebraic types in computer science on which we base our approach. See Chapters on Finite Data Types (Product Types and Sum Types) in [
27]).
In other words, we can think of our search results as a formal language that uses the values of X in some fixed way to build lists of pages of items. Formally, this boils down to thinking of represented decision problems as words in a grammar. For instance, the grammar that describes a search result in our online retailer would be:
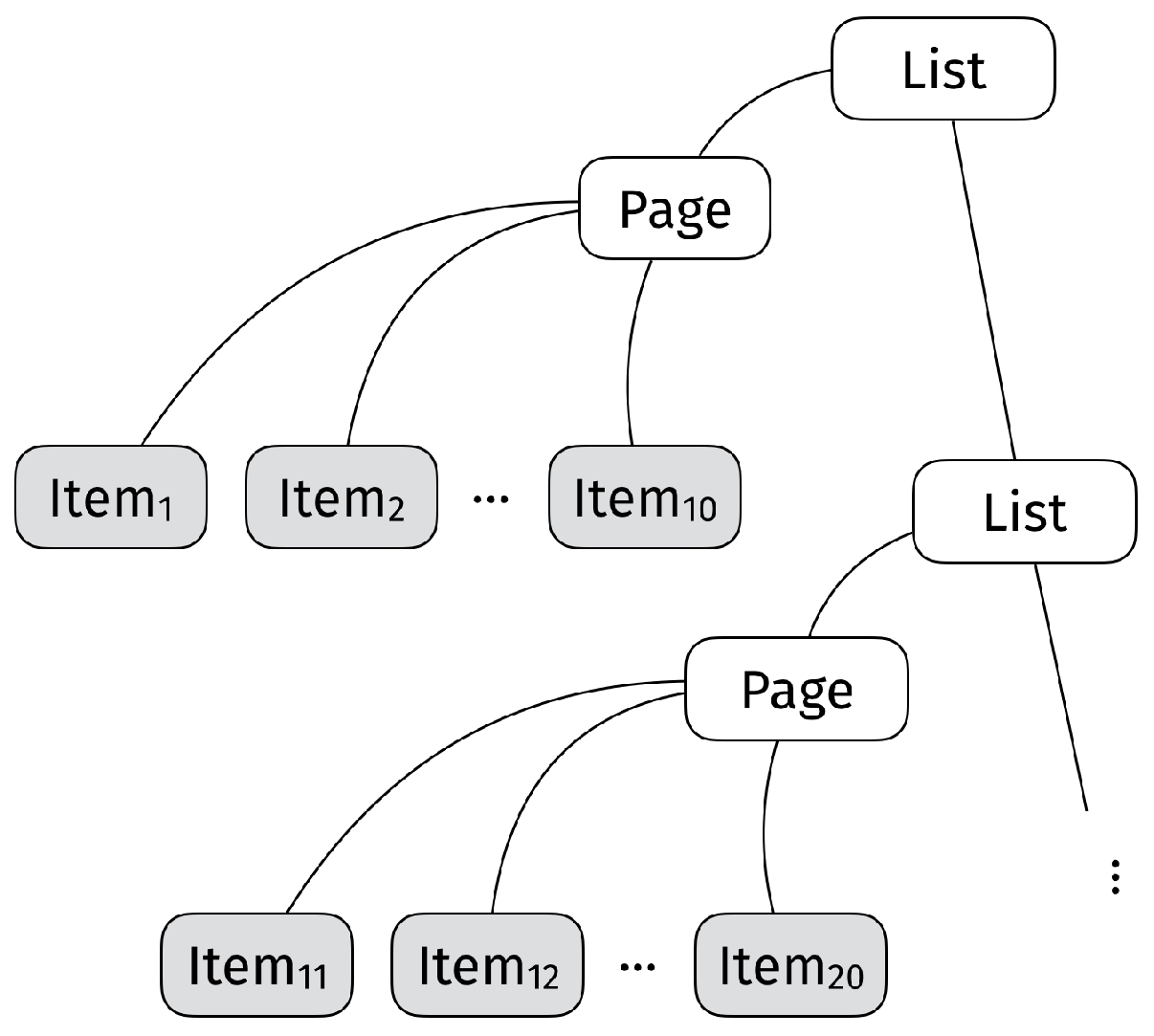
Item ⇒ x, for each
Page ⇒ [Item, …, Item]
List ⇒ Page or Page, List
The first line says that any is considered a “Search Item”. The second line says that a list of 10 items forms a “Page”. Furthermore, the last line says that a “List of Results” is inductively defined as either a single page, or an initial page followed by more pages. It is this last recursive definition (we are defining List in terms of List) that allows us to describe lists of arbitrary (and possibly infinite) length in a finite way.
The above representation of a search result fulfills our two desiderata—it is both
inductively defined and
parametric on the set of alternatives X. Moreover, notice that any concrete search result can be presented diagrammatically as shown in
Figure 1, where the various items are placed at the terminal nodes, and the internal nodes are used to describe the various labels such as “Page” or “List”. A user choosing one of the items in a search result needs to navigate this structure in order to reach each of the items available.
Let us move on to a formal definition:
Definition 1 (T-representation for ). Given a set of triples , where each is a name and are natural numbers, with for , let denote the set obtained by repeated application of the following rule
If and then , for each .
We call the T-representation space of , and each a T-represented decision problem. We also refer to each name as a constructor, as these are the only possible ways of creating represented problems in .
When constructing new elements of , we can use both, elements of X (the ) or previously constructed elements of (the ). So and specify the arity of the constructor on each of these.
Definition 2. We must have at least one with and , to ensure that is not an empty set. We will assume this is the case from now on.
Note, the diagram above might suggest that we are restricted to representations of decision problems as trees. However, the notion of a T-representation is more general and includes other representations of alternatives such as lists, queues, stacks, etc. (One can think of a T-representation as sentences in a language. In any language which is described by a grammar (which includes both computer programs but also natural language) one can “parse” the sentences of that language into a syntax tree. However, that syntax tree representation of sentences is in no way restricting the expressive power of languages themselves. Once we fix a T-representation we are in some sense fixing the grammar of the language, and the diagrammatic representation of the elements in this language is nothing more than the syntax tree of that element of the language).
Let us illustrate the definition (In functional programming these
T-representations are known as
algebraic data types (Chapter 8, [
28]). For instance,
corresponds to the data type of non-empty lists). above using our search result example. In this case, we are actually using three nested representations. First, single items need to be represented, which we do with
. Here we are using the name
to label an item,
(we use one element of
X) but
(we do not use previously created items). That only allows us to represent singleton sets. For instance, if
, then
only has three elements
We think of as representing the set as an “item” of a search result. So, the representation space allows us to represent the three singleton sets and .
However, we can then group items into a page—we think of a page as a list of 10 represented items. Formally, we would take
. Here we use the name
to label a page,
(we use 10 elements to create a page) but
(we do not use previously created pages to create a new page). Hence,
is the set of “pages” each containing 10 elements from the set
Y. If we take the set
, i.e., items from
X, we are then nesting representations: a page represents a list of 10 represented items. For example, given
, one possible element of
is
which we view as a representation of the set
. We are not ruling out repetitions in the represented problem. So we could have that all
are equal to some
x, which means that this page with apparently 10 items actually represents the singleton set
. Furthermore, note that the order in which the elements appear in the representation matters. The representation where the elements are listed in inverse order
is a different representation of the same set
.
Finally, the representation of the ultimate search result as a list of pages involves a choice: a list is either a single page, or a page followed by other pages. This is formally achieved by defining a representation space with two constructors for singleton lists and compound lists. Our search result over a set of alternatives X is then represented as an element of , i.e., a list of pages that each contain 10 items.
In general, a representation models how an agent can access information regarding alternatives in a fine-grained manner. Which representation makes sense, depends on the situation.
Obviously, it would be a rather futile exercise to fix a specific “grammar” such as the example above and characterize when a procedure operating on it can be rationalized. Instead, we consider grammars in the abstract. The properties we will later introduce in order to characterize a decision procedure, hold for grammars in general and not just specific cases.
Our framework is sufficiently expressive so that we could study procedures which do not pick elements of X but instead represented problems such as a list of alternatives, while this is certainly interesting, for the beginning we believe it is more relevant to understand when a procedure results in a concrete element.
Lastly, note, as is standard in the literature, we assume throughout that the set of alternatives X is known. (As a consequence, the agents face no uncertainty regarding the alternatives they choose. We keep this assumption intact in order to make our results comparable to the standard in the revealed preference literature. However, in principle, the case where the agent faces uncertainty is of course interesting and could be modelled within our framework).
3.2. The Extension and Representation Maps
What is the relationship between represented decision problems and classical decision problems?
As representation spaces are inductively defined from a finite set of constructors , we can also “deconstruct” a represented problem in an inductive way. For instance, given a represented problem we can distinguish between the elements of X which are “immediately accessible” and those which are part of some “sub-problem”:
Definition 3 (Immediate values and sub-problems). Given a representation and a set X, define two functions (immediate values) and (sub-problems), inductively as:
The function extracts the immediate values contained in that represented problem (and ignores nested elements deeper down the representation), whereas performs the dual functionality, it gives us the set of sub-problems in a given representation, ignoring the immediate values. Using these we can define the extension of a represented problem as the subset whose elements are represented in a:
Definition 4 (Extension map)
. Given a representation , define (uniformly in X) the extension map inductively as follows: This is well-defined on well-founded (i.e., finite) represented problems
. So the mapping
translates represented decision problems into their set extension. For instance, if
X is the set of numbers then
is the space of representations of lists of numbers. Using this representation, the list
corresponds to the element
which has set extension
Hence, the extension map “extracts” the classical decision problem from a represented decision problem.
Another, hands on way to interpret the extension map is to view it from the perspective of an agent who wants to inspect all alternatives available in an online shop. In a such a shop, the agent might need to navigate through all the pages manually and inspect all the items by hand. The extension map instead would extract out all alternatives at once. (Comparable functionality exists for many web shops which allow users to show all results in one page. Of course, even there, depending on the number of alternatives, agents will need to scroll down the page manually and will not perceive all elements at once).
Definition 5 (Equivalent represented decision problems). We say that two represented decision problems are extensionally equivalent, written , if they represent the same set, i.e., .
Although and are different represented problems, they are extensionally equivalent as they both represent the set .
Conversely, we can also consider functions that take a classical decision problem and represent it as an element of the representation space . Hence, a represented decision problem can be thought of as an “enriched” classical decision problem.
Definition 6 (T-representation map). Let denote the set of non-empty finite subsets of X. A map will be called a T-representation map if , for any .
A T-representation map provides a specific way of representing a classical problem as an element of the representation space . We assume in this paper that the representations admit a T-representation map. This is necessary so that any decision problem can be represented by an element , i.e., . All of the standard representations such as lists and trees admit a representation map.
The T-representation map can also be practically interpreted from the perspective of a web shop. In essence, it describes how alternatives should be represented. Should they be listed? If so, how many items can a customer view at once? How will a customer proceed to the next results? Or, should alternatives be organized in a tree, for instance by a configuration assistant?
3.3. Intensional Aspects of the Representation
Let us conclude this section discussing purely
intensional aspects of the representation, i.e., properties of the representation that are independent of the values being represented. For instance, given a represented problem
, we can navigate the representation in a depth-first search and inductively replace the values in
X by natural numbers (see
Figure 2 where this is done for elements of
with
).
Definition 7 (Index representation). Given a representation and a set X, let denote the function which, given a represented problem , will inductively (in a depth-first search) replace the values in X by indices in , returning an element . We call the index representation of the represented problem .
We can associate with each occurrence of some
in
its corresponding index, and also the value
of a given index
in
. For example, given the list of names
its index representation is
so we can say the last occurrence of “Mary” has index 3, and the value at index 2 is “John”. We will write
for the value at index
i in the decision problem
a, so, for instance, in the example above we have
John and
Mary.
Looking at the index representation is a powerful way of separating the structure of the representation from the concrete set being represented.
Definition 8 (Equivalent underlying representation)
. Given , letbe the equivalence relation on which identifies two represented problems that have the same underlying index representation. For instance, in
Figure 2 the two lists on the left have the same underlying representation, which is captured by the index representation on the right.
Definition 9 (Representation space quotient). We will denote by the quotient space of consisting of the equivalence classes of ≃. We use for the elements of . It is also easy to see that the mapping can be lifted to an injection .
Indeed, by the definition of and the relation equivalence class , for each all the represented problems in will map to the same index representation , so we have .


{kind=link}
{kind=link}

