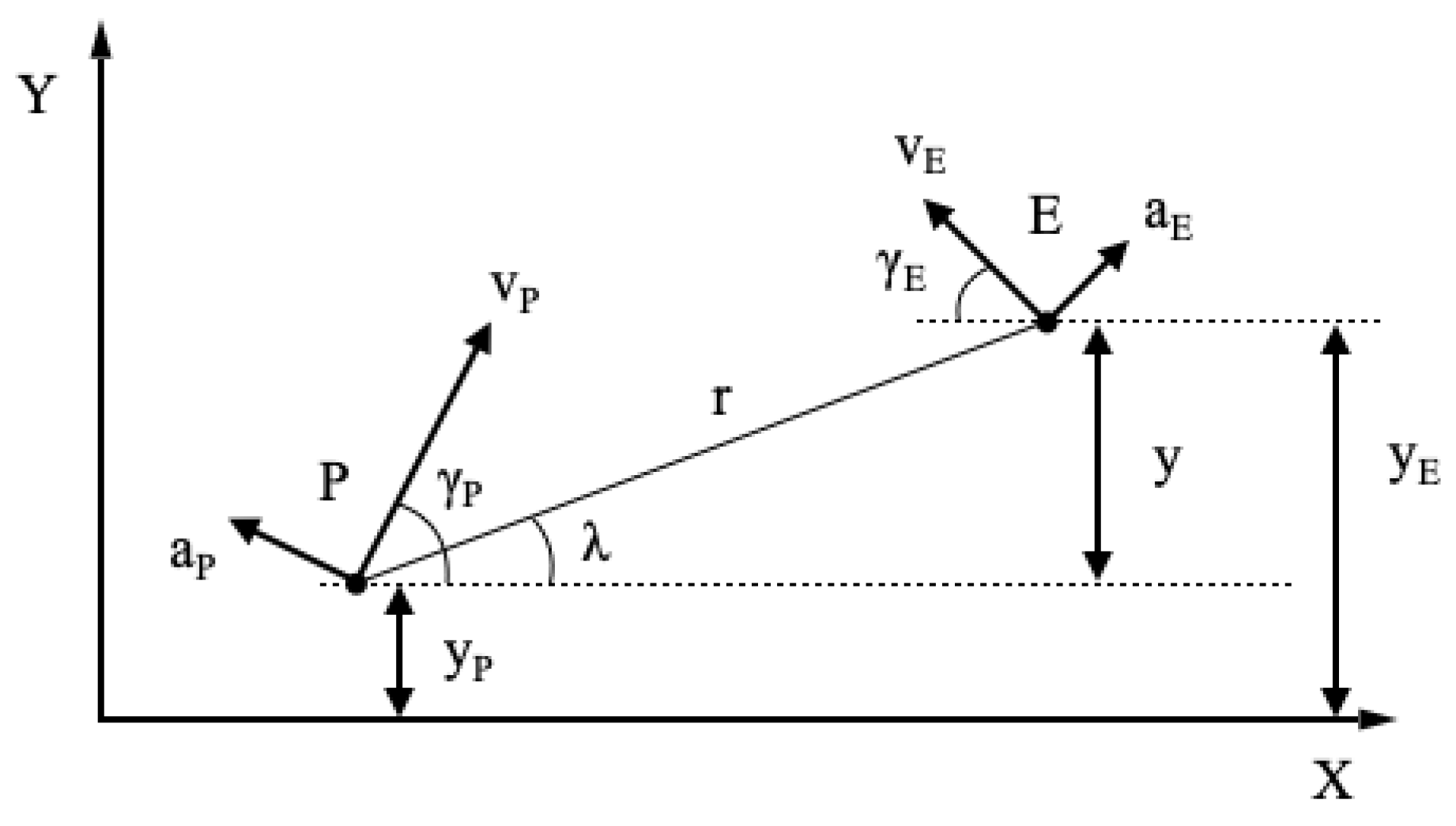
1. Introduction
Pursuit-evasion differential games have been applied to autonomous vehicles guidance problems in various contexts ranging from missile guidance [
1], to spacecraft orbital maneuvers [
2], and mobile robots [
3]. Since their introduction in [
4], other versions have been formulated, including stochastic [
5] and multi-agent [
6] games.
A common solution for simplifying the architectures and reducing the weights and costs of autonomous vehicles is to adopt a single instrument (bearing or range sensor) for target tracking or navigation [
7,
8]. This work focuses on a missile application, but the results can be easily extended to other scenarios and to different sets of measurements. In missile systems, passive sensors like electro-optical or optical seekers are often used to provide the target direction with respect to the vehicle. This bearings-only measurement system comes at the cost of not having information on the range to the target when an optimal guidance law is employed. To enhance the observability of the range and, therefore, to improve the performance of the engagement, it is necessary to deviate from the optimal guidance strategy. Different strategies for optimizing these maneuvers have been extensively studied in the literature. Reference [
9] looks at the maneuver that maximizes the determinant of the Fisher information matrix, while [
10] maximizes the eigenvalues of the normalized error covariance matrix; reference [
11] tries to maintain the line of sight rate larger than a certain threshold, while [
12] imposes different intercept angles between consecutive pursuers, and [
13] uses a performance measure of observability based on geometric conditions.
Two stochastic metrics that have found application in the study of maneuvers effects on target estimation with different sets of sensors are the Cramér–Rao lower bound (CRLB) [
14,
15] and the Fisher information [
16,
17]. The CRLB returns an indication of the performance of a maximum likelihood estimator in terms of error covariance. The Fisher information is related to the CRLB by an inverse relationship, as will be shown later in the paper. An issue related to the use of these metrics in missile applications is that, for an unobservable system, their numerical computation can be prone to errors because the Fisher information matrix would result in being nonsingular [
18].
Rather than a new sub-optimal guidance law to optimize maneuvers, this paper proposes a method for characterizing the game space of a pursuit-evasion game using another stochastic metric, the Mahalanobis distance, which can be calculated independently from the CRLB and the Fisher information and thus will suffer less from numerical issues. The proposed method allows for obtaining a map of the confidence in the estimation of the main variable of a pursuit-evasion guidance law, called the Zero Effort Miss (ZEM). This knowledge can be exploited as a cost to numerically minimize in guidance algorithms or as an information to feed reinforcement learning algorithms [
19]. An advantage of this solution is that it is not computationally heavy, as it only involves the calculation of the Mahalanobis distance from the covariance matrix of the Kalman filter.
The rest of this paper is organized as follows:
Section 2 reviews the pursuit-evasion games framework;
Section 3 defines a method to characterize the capture zone of the game from a stochastic point of view; a numerical example in presented in
Section 4; conclusions are given in
Section 5.
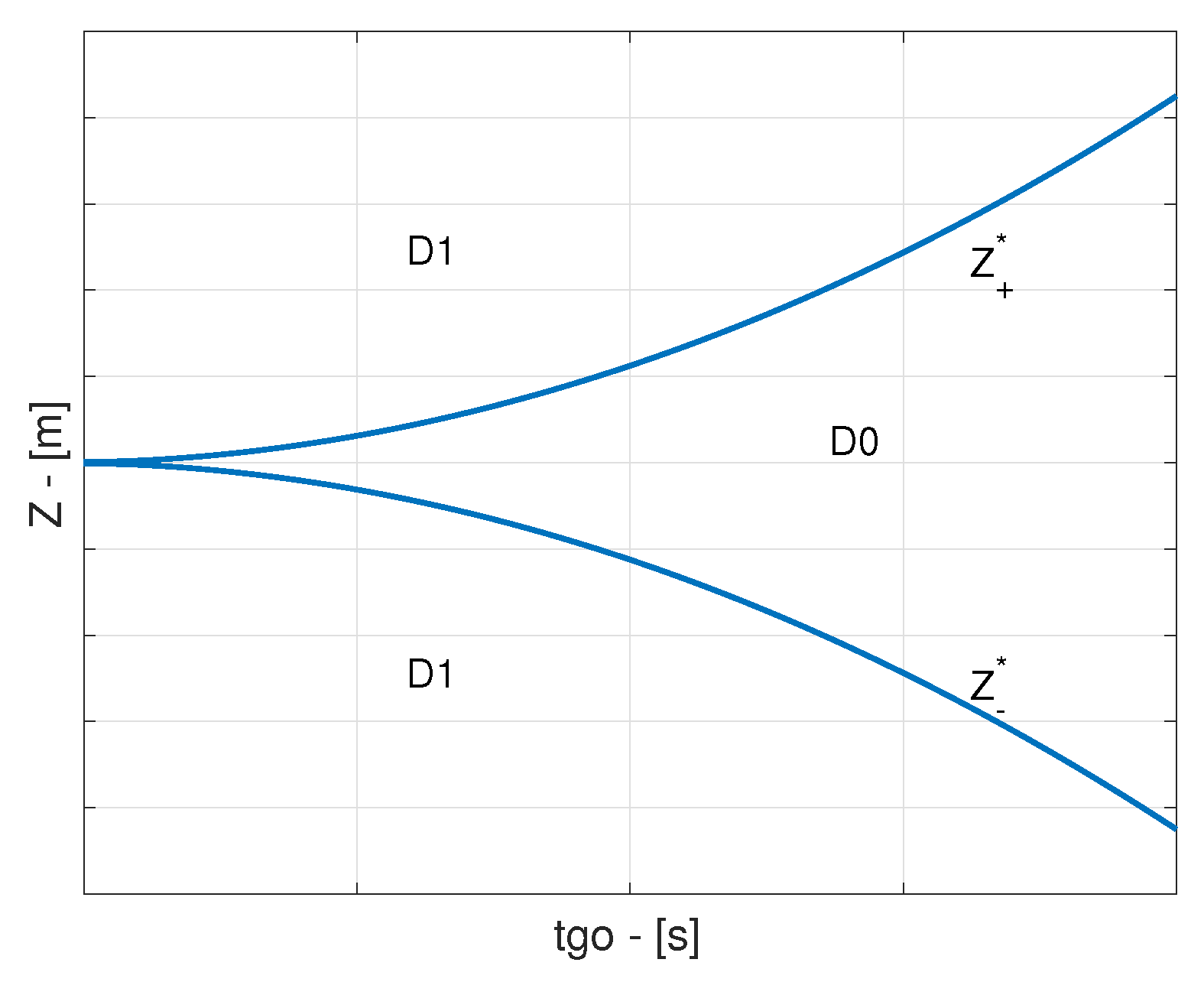
3. Characterization of the Game Structure
It is very important for the pursuer to have a good estimate of the so as to apply the best guidance command possible. In addition, if the adopted guidance strategy does not intend to maintain the around 0, it is crucial to know how good its estimate is. Although can be calculated exactly using a regressive value, its distance from the estimated is random, since is itself a random variable. It seems interesting, therefore, to characterize the D0 region in terms of a stochastic metric. To this purpose, the concept of Mahalanobis distance will be introduced in this section, along with the CRLB of the estimator considered in this study.
3.1. Mahalanobis Distance
The Mahalanobis distance
between a random variable
and a point
is defined as:
where
is the covariance matrix associated with the random variable
.
represents a region in the neighborhood of
where
should be. In other words,
is a measurement of the confidence in the estimation of the real parameter
: a null
means that
coincides with the mean of
; a larger
means that the estimation of
is less correct. The interest of this work lies in determining the confidence on the estimation of the
at each value of
. To this end, a Mahalanobis distance for
is defined as:
The covariance can be obtained at each time instant using the value of the error covariance of the Kalman filter. This can be easily done on the go, i.e., in real time with the estimator, returning a value of that depends on the features of the filtering algorithm (e.g., approximation of the nonlinear dynamics, tuning parameters, etc.). As a mean of comparison, another covariance can be used in the calculation, which is that obtained through the CRLB associated with the estimator. This can be interpreted as an ideal performance test, as it would return the minimum value for , independent from the filtering algorithm.
3.2. Cramér–Rao Bound
The CRLB is defined as the minimum estimation covariance bound of an unbiased estimator. In practice, it tells how good an estimator can theoretically be, given a noisy measurement. An estimator is called efficient if its variance is equal to the CRLB, meaning that its mean squared estimation error is the lowest possible among all unbiased estimators. Such an estimator is sometimes called not practical, as it would yield the best theorical performance. According to the Cramér–Rao theorem, the minimum variance of an unbiased estimator
of the parameter
is always larger than the inverse of the associated Fisher information matrix
F [
22]:
where
f is the likelihood function of the
n measurements sequence
z given
.
The CRLB of a function
of the parameter
is given by:
In this work, the function
g is the
of Equation (
10), while
is the vector
of Equation (
12). When the estimation is carried out using a Kalman filter, as in this work, the Fisher information matrix of Equation (
20) at the
k-th step can be written in a recursive form [
23]:
The initial condition on
F is defined considering a filter with infinite initial error covariance matrix, therefore:
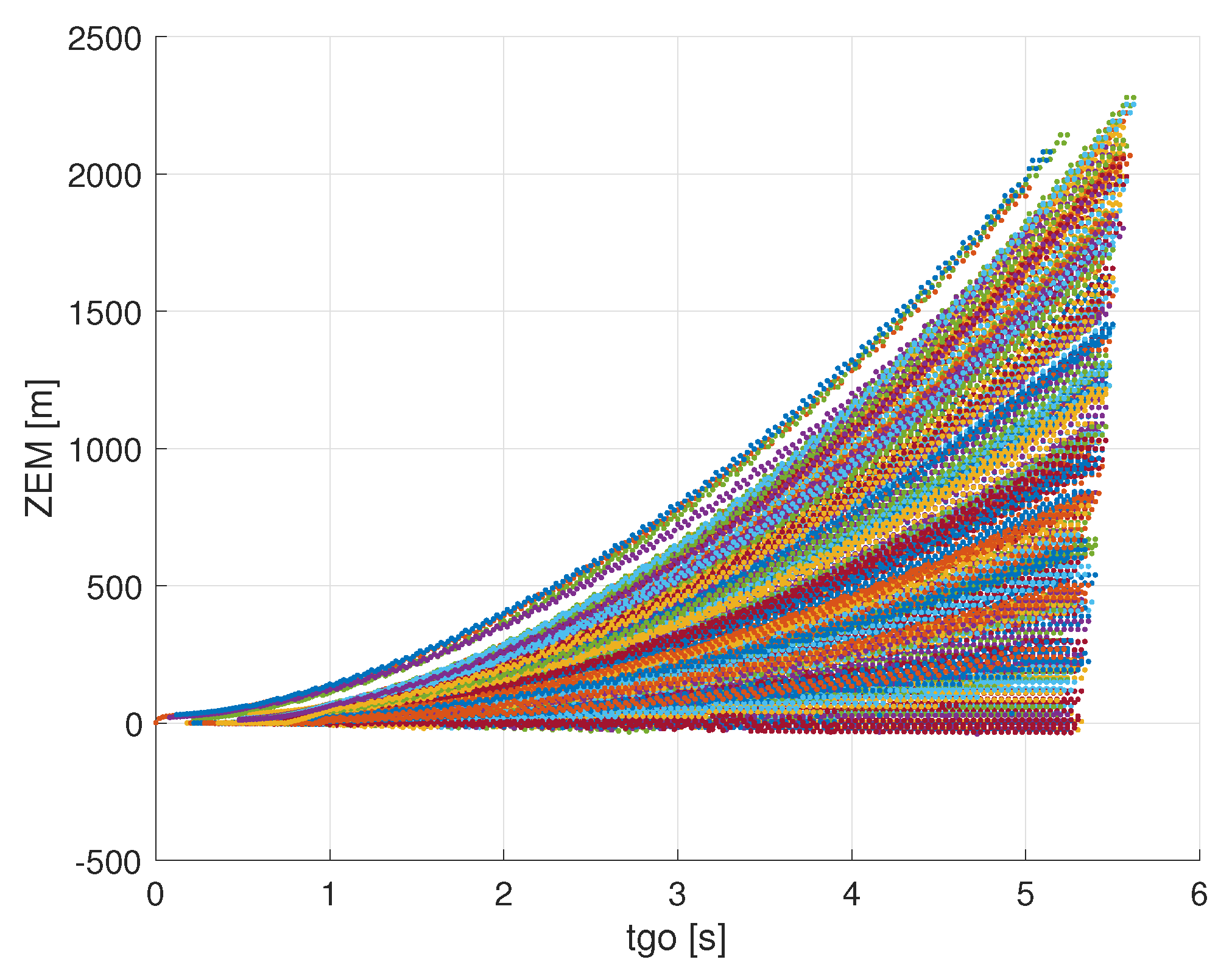
4. Numerical Example
Two numerical simulations, each one consisting of 200 Monte Carlo runs, were carried out to calculate the values of
across the D0 region. The first simulation uses both bearings and range measurements as in Equation (
14), while the second employs the bearings-only measurements of Equation (
13). Different paths are travelled in each run of the simulation in order to cover the entire D0 region, as shown in
Figure 3, where each colour represents a different run. The trajectories of both players for a single run are shown in
Figure 4. The Mahalanobis distance is calculated in correspondence of each dot of
Figure 3 in two ways: first using the values of the CRLB from Equation (
22) as the covariance
in Equation (
18), and then using the error covariance matrix calculated by the filter. The numerical initial values (
,
,
,
,
,
) and parameters used in the simulations are reported in
Table 1.
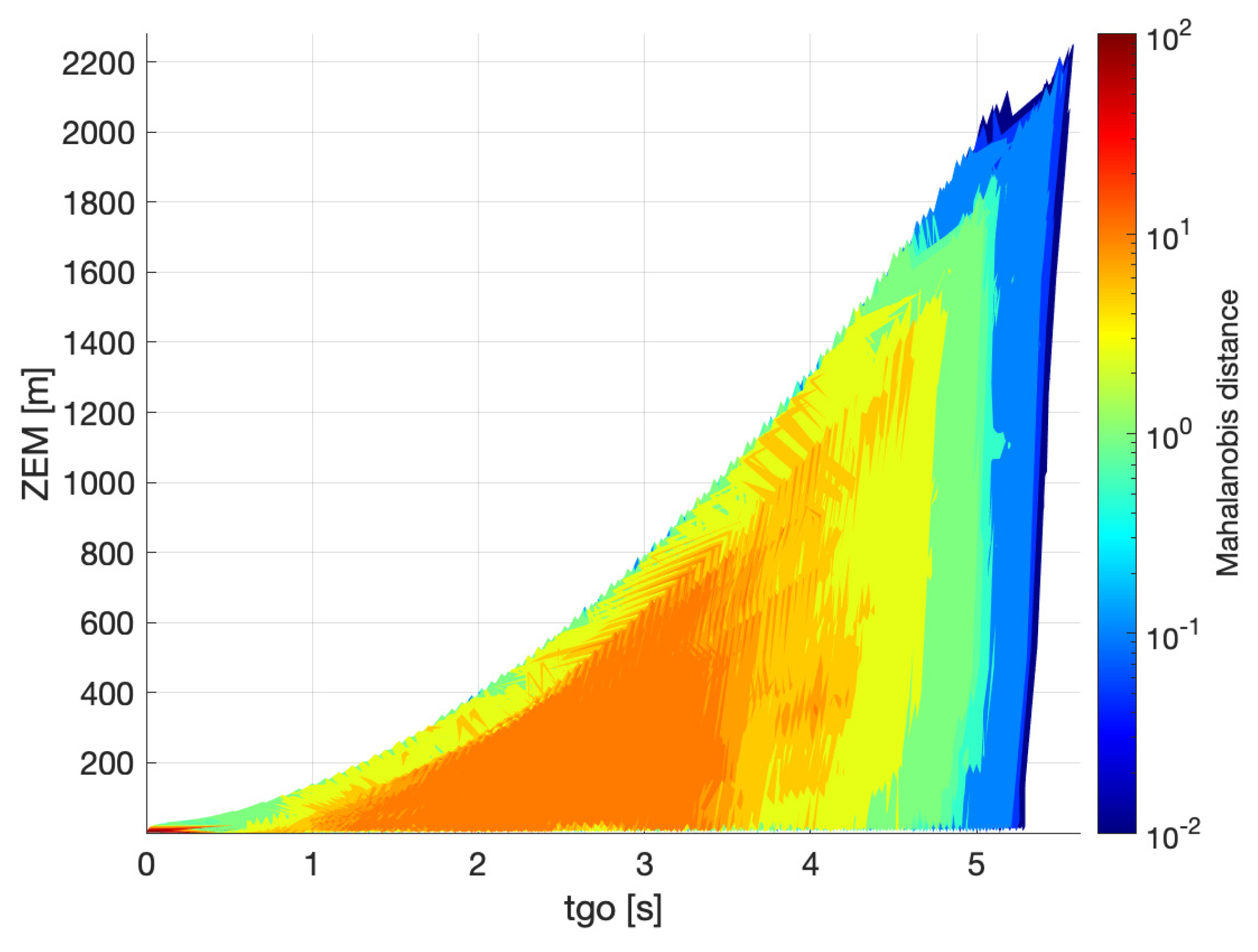
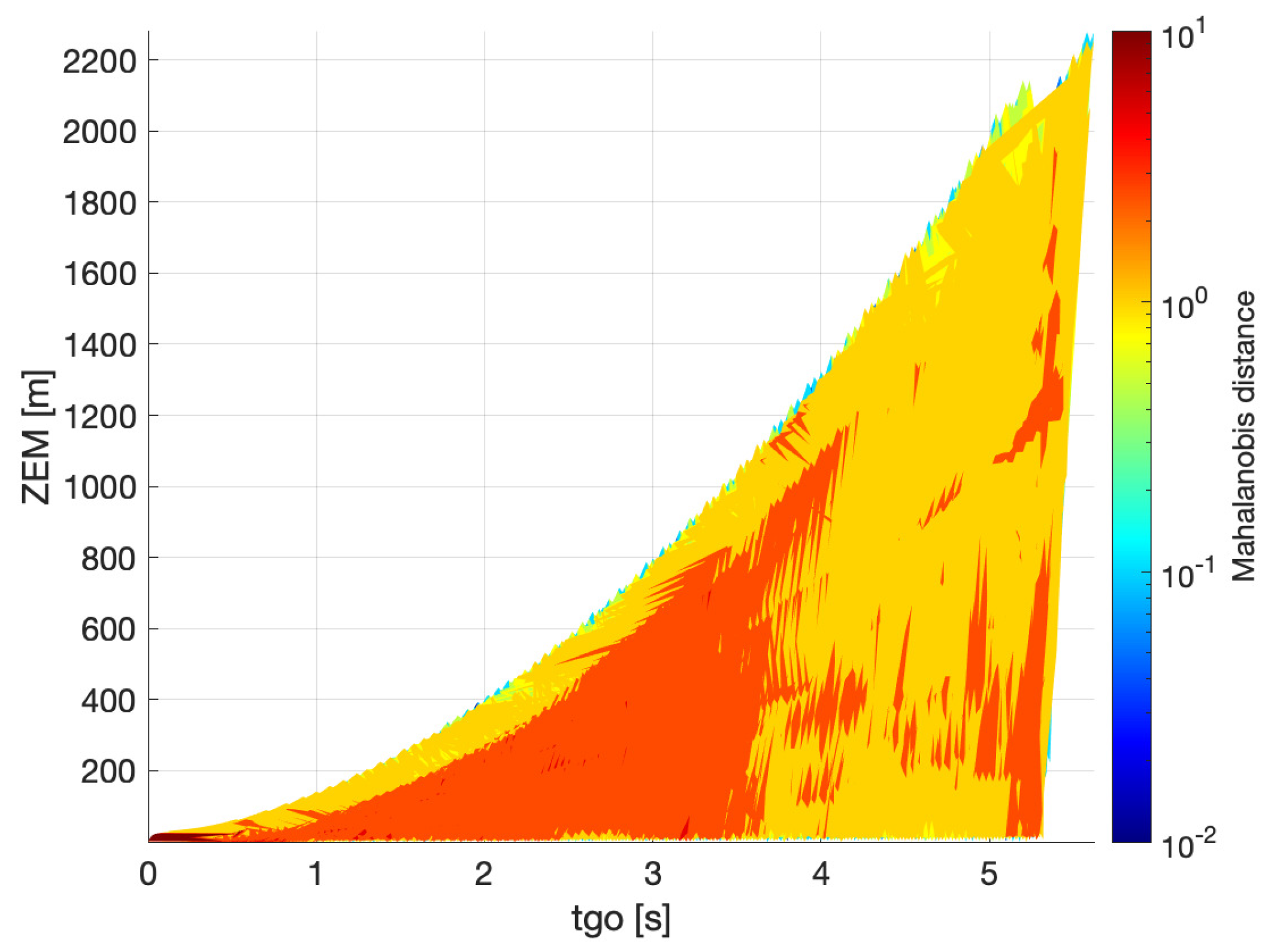
Figure 5 and
Figure 6 show the result of the simulation for the case of bearings and range measurements. The levels of the Mahalanobis distance are associated with different colors in the maps, as indicated in the sidebar. The red regions are those where the estimation of
is worse, and the blue regions where it is best. The maps are generated by merging the results of all the runs at each time instant. The value of the Mahalanobis distance in
Figure 5 is calculated using the CRLB, while that in
Figure 6 is obtained from the filter. At the beginning of the engagement (
s), the value of
in
Figure 5 is very low and increases as the engagement moves on. This is a consequence of the initialization of the Fisher information in this method (Equation (
24)). Since the CRLB is the inverse of the Fisher information, the initial
will be very large and, therefore,
will be very small at the beginning. Since in the case of
Figure 6 the initial covariance is finite, the value of
at the beginning is larger than in
Figure 5, which is more realistic, as the uncertainty over the estimation of a variable is finite in practice. Another difference is that the levels of Mahalanobis distance obtained with the CRLB are lower than those calculated through the filter. However, this was expected as the CRLB is an ideal bound for the estimator and the performance of a practical filter is always worse. A feature in common for the two cases is that
is smaller in the proximity of the upper bound
. This can be explained with the observability improvement obtained when maneuvering away from the collision triangle, even though the range measurements here already provide a certain level of observability. The high levels of
towards the end of the engagement suggest that then it is risky to maneuver away from the collision triangle because a last-minute maneuver from the evader might suddenly increase the
and cause the passage to the avoidance zone.
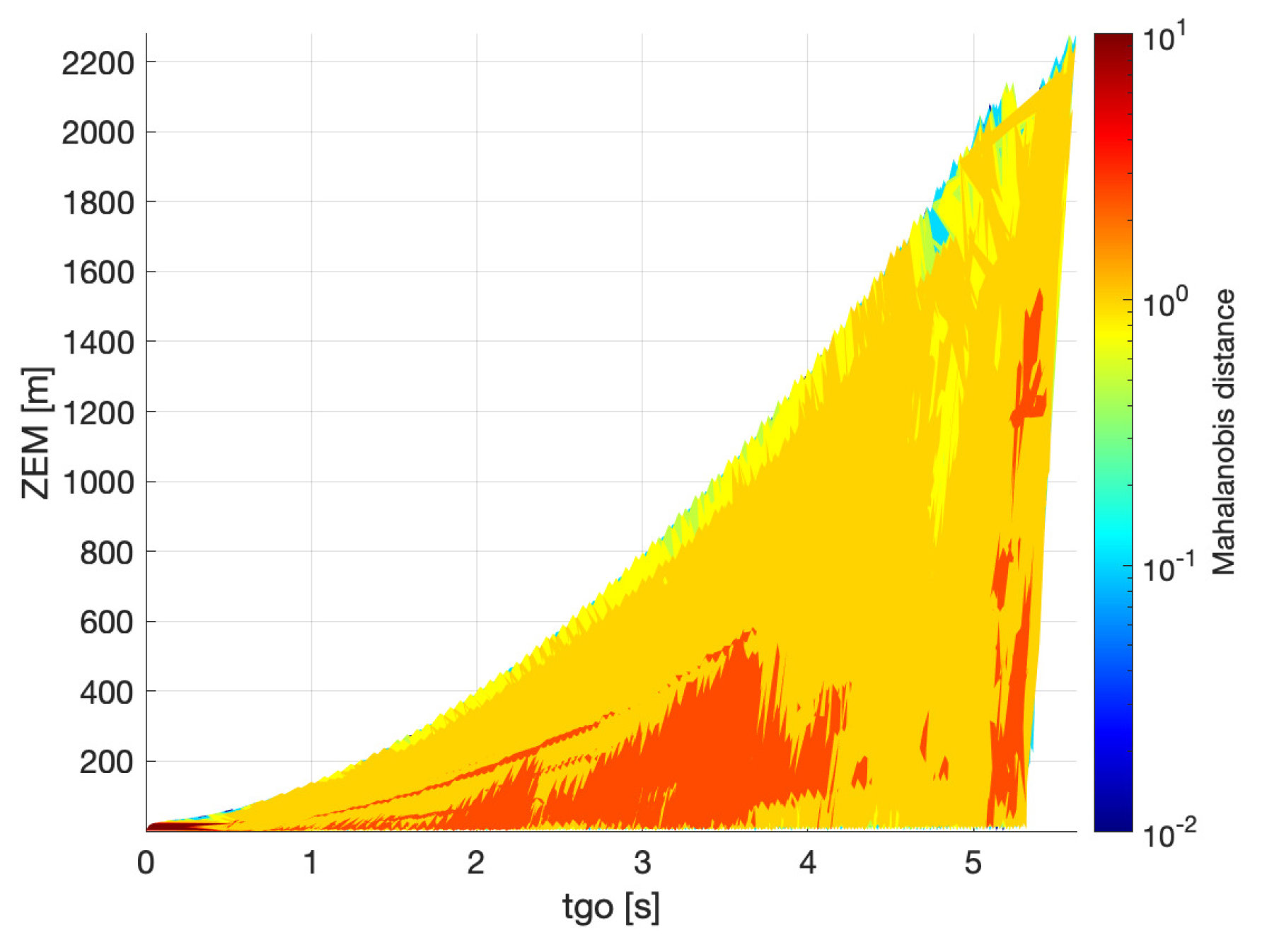
The case of bearings-only measurements is presented in
Figure 7 and
Figure 8. The results obtained with the CRLB are prone to numerical issues due to the fact that the system in this case is unobservable, and therefore a good portion of the data at the beginning of the engagement is missing in
Figure 7. The matrix computed through Equation (
23) is not invertible and therefore the CRLB cannot be initially calculated. The values of
obtained from the filter (
Figure 8) in the first instants of the engagement (
> 4 s) are similar to those of
Figure 6: this is no surprise as the filter is initialized in the same way in both cases. As the engagement moves on, the tendency of having smaller values of
(and hence a better estimation of the
) in the proximity of the bound is even more evident than in the previous case: the 0 level of the
is characterized by a red strip, while yellow and even blue layers can be found next to the bound. Since there are no range measurements here, the only way to enhance the observability is to maneuver away from the collision triangle, evidently. As in the case of bearings and range measurements, the values of
are larger when calculated through the filter (
Figure 8) than when computed through the CRLB (
Figure 7).
5. Conclusions
Pursuit-evasion games offer a compact solution to the problem of target interception or rendez-vous for autonomous vehicles, but need to rely on a good estimation of the variables needed in the guidance formulation. This is not always possible, as the number of on-board sensors is often limited by weights and cost constraints.
This paper has presented a method for characterizing the capture region of a pursuit-evasion game in terms of the confidence on the estimation of the . The method consists of calculating the Mahalanobis distance associated with the estimated by the on-board nonlinear filter. A comparison with the Mahalanobis distance obtained through the CRLB showed that the proposed method provides consistent results, which are less prone to numerical issues than the other.
These results can be used to design modern guidance laws that consider observability issues in their formulation, in addition to the classic considerations on miss distance and control effort minimization. This is especially valuable in scenarios where not all the necessary sensors are available, but there is a demand for high performance in terms of accuracy.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}