1. Introduction
Differential game theory, as a natural extension of optimal control theory, deals with the problem where each control agent (player) tries to maximize his own profit, which conflicts with others, and it has received considerable attention in economics and management sciences in recent decades. It covers a large area in macroeconomics, microeconomics, resource management and bioeconomics. Some of the applications of this theory have been considered in many textbooks. In [
1], an introduction to the theory of noncooperative differential games and its applications, such as marketing, natural resources and environmental economics are offered. Advertising competition and the Lanchester model are studied in [
2]. Both deterministic and stochastic cooperative differential games are covered in [
3], and some applications in resources and environmental economics are contained therein.
The Nash strategy is regarded as an equilibrium solution for simultaneous games, in which players cannot improve their payoffs by deviating unilaterally from it [
4]. There exist two main types of equilibrium solutions for differential games, namely, closed-loop (or feedback) and open-loop. The closed-loop equilibrium is where each player’s strategy is a function of time and state variables, whereas in open-loop equilibrium, the strategy of each player is a function of time and initial state. To identify the open-loop Nash equilibrium in a differential game, the system of two-point boundary value problems (TPBVPs) derived from Pontryagin’s maximum principle as the necessary conditions for the existence of an open-loop Nash equilibrium must be solved [
5]. Regarding this approach, the obtained system of TPBVPs is reduced to a system of algebraic equations that can be solved using well-known analytical and numerical techniques for systems of ordinary differential equations [
6]. Solving differential game problems numerically is the most logical way to treat them as their analytical solutions are not always available. The main research studies in this field contain obtaining open-loop Nash equilibrium in linear quadratic dynamic games [
7,
8,
9,
10,
11]. In [
12], solving a nonlinear differential game arising from a pollution control problem is considered. The quasi-equilibrium of a special case of nonlinear differential games is found by studying the state-dependent Riccati equations [
13]. In [
14], a dynamic programming approach is presented to obtain the saddle point of a kind of nonlinear zero-sum differential game.
One of the best methods in terms of accuracy and efficiency, for a numerical solution of different kinds of differential equations by means of truncated series of orthogonal polynomials, is the spectral method [
15,
16,
17,
18,
19]. There are three well-known spectral methods, namely, the Galerkin, Tau, and collocation methods, and the selection of the suitable spectral method depends on the type of differential equation and the boundary conditions governed by it [
20,
21]. The aim of this paper is to propose a numerical approach based on Pontryagin’s maximum principle and the Tau method to find the open-loop Nash equilibrium of noncooperative nonzero-sum differential games.
The remainder of the paper is organized as follows: In
Section 2, the definition of a noncooperative nonzero-sum two-player differential game, open-loop Nash equilibrium, and the analytical form of the necessary conditions for an open-loop Nash equilibrium are revised. In
Section 3, the Tau method for obtaining the open-loop Nash equilibrium of such games is introduced. In
Section 4, a differential game arising from bioeconomics is presented to illustrate the accuracy and efficiency of the proposed method. Finally, the paper is concluded with a conclusion.
2. Problem Statement
In this section, we deal with a noncooperative nonzero-sum two-player differential game that is described by the following definition:
Definition 1. A noncooperative nonzero-sum two-player differential game is defined as follows [
22]:
withand.
In performance index given in (1), and are the controls (strategies) of players and , respectively; function is player ’s instantaneous payoff, and function is terminal payoff. The goal of game for players is maximizing their performance indices by choosing suitable control actions .
A player’s open-loop strategy is the planned time path of his action. This type of equilibrium concept is time consistent, meaning that along the equilibrium path, no player is incentivized to deviate from his original plan [
23]. Thus, the definition of an open-loop solution concept (equilibrium) can be as follows:
Definition 2. The ordered pairof functionsis called an open-loop Nash equilibrium if, for each, an optimal control pathof the problem (1) exists and is given by the open-loop Nash strategy[
1].
An open-loop Nash equilibrium is characterized by introducing the Hamiltonian functions for formulating the first order necessary conditions of optimality for nonzero-sum differential games (1), and are introduced as the following [
24]:
where the variables
,
are called the costate variables or the adjoint variables associated with the state variable
.
To simplify the notation in the Hamiltonian functions, the time dependence has been neglected in the functions
.
1Assuming that all functions in (1) are continuously differentiable, first order necessary conditions for optimality are provided by Pontryagin’s maximum principle.
Based on Pontryagin’s maximum principle, the set of necessary conditions for the open-loop Nash equilibrium of a nonzero-sum differential game is obtained as follows:
with
and
.
Algebraic Equation (4) can be solved to obtain an expression for
,
in terms of
and
; that is,
Substituting this expression into Equations (2) and (3), a system of differential equations is obtained involving only
,
and
,
. This system of TPBVPs can be expressed as:
where
for
.
In general, this system of TPBVPs is nonlinear with split boundary values, hence obtaining an exact and analytical solution for the open-loop Nash equilibrium is difficult. Therefore, using a suitable numerical method is indispensable.
3. The Tau Method for Nonzero-Sum Differential Games
In this section, the implementation of the Tau method for solving the system of TPBVPs and finding the open-loop Nash equilibrium of a nonzero-sum differential game is presented.
The fundamental idea of this approach is the expansion of the function
into the form of a finite series of basis functions as
where
are Legendre polynomials and
are spectral coefficients [
25].
Definition 3. The Legendre polynomialsare the eigenfunctions of the singular Sturm–Liouville problem They are orthogonal on the interval
with respect to the weight function
and satisfy the following recurrence formula:
where
Theorem 1. Let(Sobolev space),be the best approximation ofin, then
where
is a positive constant, which depends on the selected norm, independent of
and
Regarding Theorem 1, it is concluded that approximation rate of Legendre polynomials is
The basic results of the presented approach and theoretical treatment of its convergence are based on the well-known Weierstrass approximation theorem.
Theorem 2. (Weierstrass approximation theorem)Letand. Then there exists a unique, the space of all polynomials of degree at most, such that
where
and
form an
orthogonal basis of
.
To use the Legendre polynomials on interval
, it is necessary to shift the defining domain by the following variable substitution:
It is assumed that the solutions
and
of the TPBVPs 5–8 are approximated by a linear combination of the shifted Legendre polynomials as follows:
where
and
are unknown coefficients and
is the shifted Legendre polynomial on interval
.
The first derivative of
and
can be approximated as follows:
Equations (9)–(14) can be restated as the following vector forms:
where
To implement the Tau method, Equations (15)–(20) are substituted at first into the understudied differential Equations (5) and 6 to form the residuals as follows:
Then, the residuals are multiplied by
, integrated over the domain
and finally set equal to zero. This procedure, along with the initial and boundary conditions 7 and 8, generate the following system of algebraic equations:
where unknown coefficients of the vectors
,
and
are determined by solving it.
4. Illustrative Example
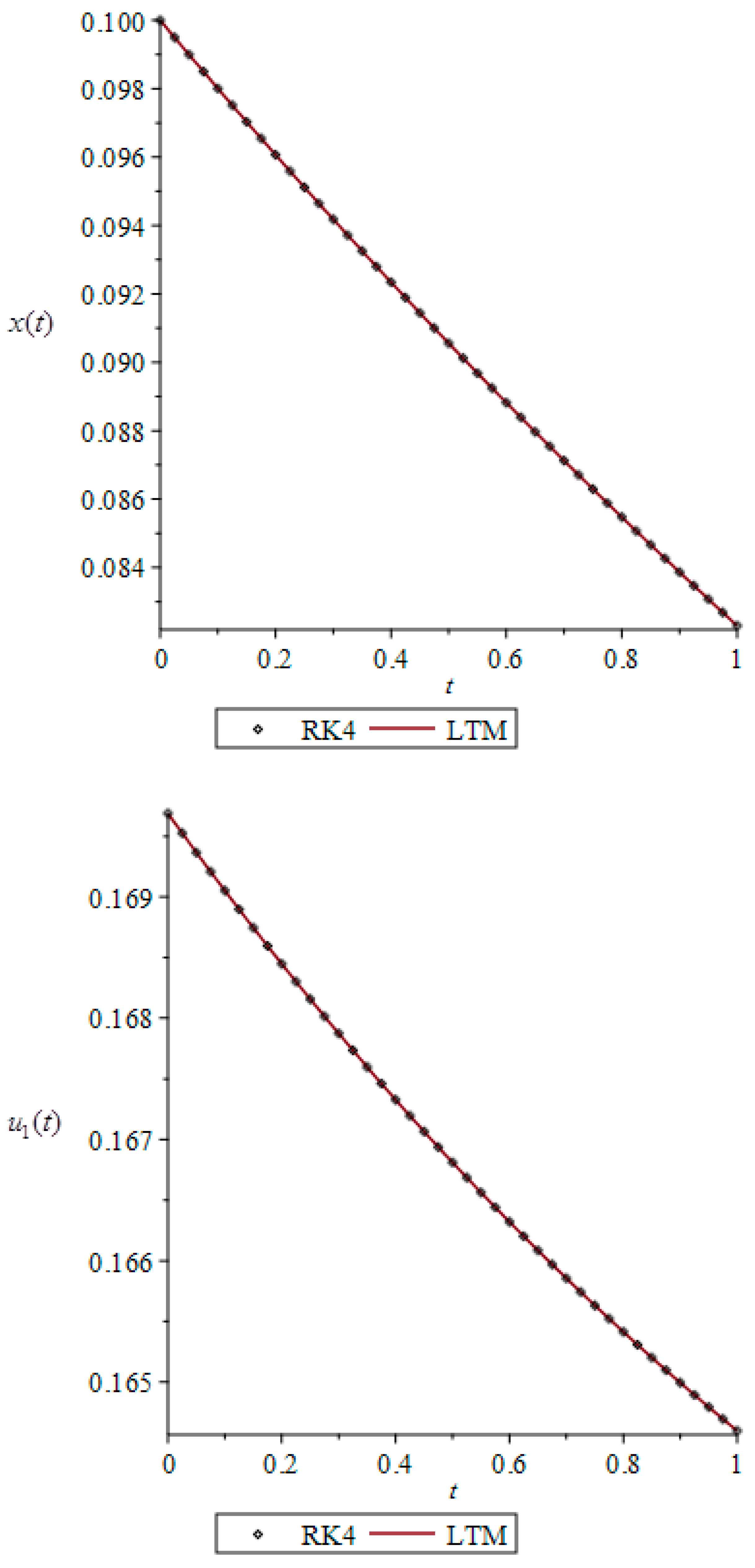
In this section, a differential game arising from a bioeconomic model is investigated to demonstrate the accuracy and efficiency of the Legendre Tau method (LTM). In this model, each firm harvests a common natural renewable resource (e.g., in a fishery).
The motivation for using this bioeconomic model is that its system of TPBVPs, in contrast to many other economic models such as the competitive advertising in Sorger [
28], is a strong nonlinear one, which can properly show the accuracy and efficiency of the presented numerical method. To check the accuracy of the presented method for this example, a comparison is made with the numerical solution obtained by using the discretization of time and the fourth order Runge–Kutta method (RK4) with time step
The rate of change of the natural renewable resource population over the time interval
is described by the following state equation and initial condition [
29]:
where the differentiable function
is the natural growth rate of the renewable resource, described by the logistic growth function as
, where
is an intrinsic growth rate and
is a carrying capacity. The quantity
is the population level of the renewable resource at time
, the quantities
and
are the harvesting efforts of the firms at time
and the constants
and
denote the catchability coefficients.
The payoff of each firm over the time interval
is given by
for firm 1, and by
for firm 2, where constants
and
represent the unit price of natural renewable resource for each firm. Furthermore,
and
show the harvesting costs at effort levels
and
, respectively [
29].
To derive the Nash equilibrium of this bioeconomic game, the Hamiltonian for each firm is defined as the following:
By minimizing
and
with respect to
and
, the open-loop Nash equilibriums for firm 1 and firm 2 are determined respectively by
The adjoint dynamic of player 1 is as follows:
Substituting Equation (22) into Equation (23) yields:
and the adjoint dynamic of player 2 is as follows:
where substituting Equation (22)into Equation (24) yields:
Therefore, the system of TPBVPs for this differential game can be expressed as follows:
Suppose that the unique solution of Equation (25) with the initial condition shown in Equation (28) is denoted by . Furthermore, let the unique solutions of Equations (26) and (27) with terminal conditions shown in Equation (29) be denoted by and , respectively.
By the following theorem, the unique open-loop Nash equilibrium of the introduced bioeconomic game is characterized.
Theorem 3. The unique open-loop Nash equilibrium for the introduced differential game is given by Proof of Theorem 3. For given controls
,
, the following optimal control problems are considered:
and
The dynamical system of these problems is linear with respect to the control variables
,
and the integrand of performance index
,
, is concave with respect to
,
, because
Therefore, these optimal control problems satisfy the existence and uniqueness conditions of the Filippov–Cesari existence theorem [
30]. From this analysis, it is clear that the only candidates which satisfy these conditions are determined by Equations (30) and (31), and hence, the unique open-loop Nash equilibrium for the mentioned differential game is determined. □
The system of TPBVPs shown in Equations (25)–(29) is a system of nonlinear differential equations with split boundary values, and has no analytical solution in general. To solve it numerically by the method presented in the previous section, the numerical values of the parameters in the standard case are chosen as the following:
Thus, the system of TPBVPs that should be solved numerically is as follows:
In order to solve the above system of TPBVPs, the following approximations for
,
and
are considered:
where
and
are unknown vectors and
is the vector of the shifted Legendre Polynomials.
These approximations are substituted into the equations of this system of TPBVPs to form the residuals as follows:
The numerical results for optimal payoff functionals
and
with different values of
are shown in
Table 1 and compared with RK4. The graphs of approximate solutions for open-loop Nash equilibrium for
are given in
Figure 1.






{kind=link}
{kind=link}