Evaluation of a Cyber-Physical Computing System with Migration of Virtual Machines during Continuous Computing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Cyber-physical systems can improve production processes by providing real-time information exchange between agents in the production chain.
- Cyber-physical systems can monitor indicators of the human body.
- In “smart” cities, houses, and devices, cyber-physical systems can optimize the use of resources for the most efficient existence of this environment.
- In the transport infrastructure, such systems can optimize traffic by processing traffic information, repairs, and other information.
- In the information space of the Internet, cyber-physical systems can improve the interaction of applications with users.
- Embedded computers are directly connected and located in the construct of the physical system; as a rule, they implement real-time monitoring and control functions. Classic embedded systems are implemented on the basis of controllers that perform control functions. With the limited computing capabilities of the controllers, they implement the lower level of control, often based on a simplified view of the physical object and the environment. Modern cyber-physical systems can exist and make decisions in the real modern world; accordingly, the security and accuracy of the decisions of such systems have increased.
- Cluster computer systems: A cluster is a related summation of several computing systems, working together to perform a common task. In the event of failure of cluster nodes, their functions are redistributed among other devices. The cluster implements the functions of the upper level control of the cyber-physical system.
- Distributed computer systems: A distributed system is a system in which the processing of information is concentrated not on one computer, but distributed among several computers.
- Networks: They are designed to interconnect computer systems.
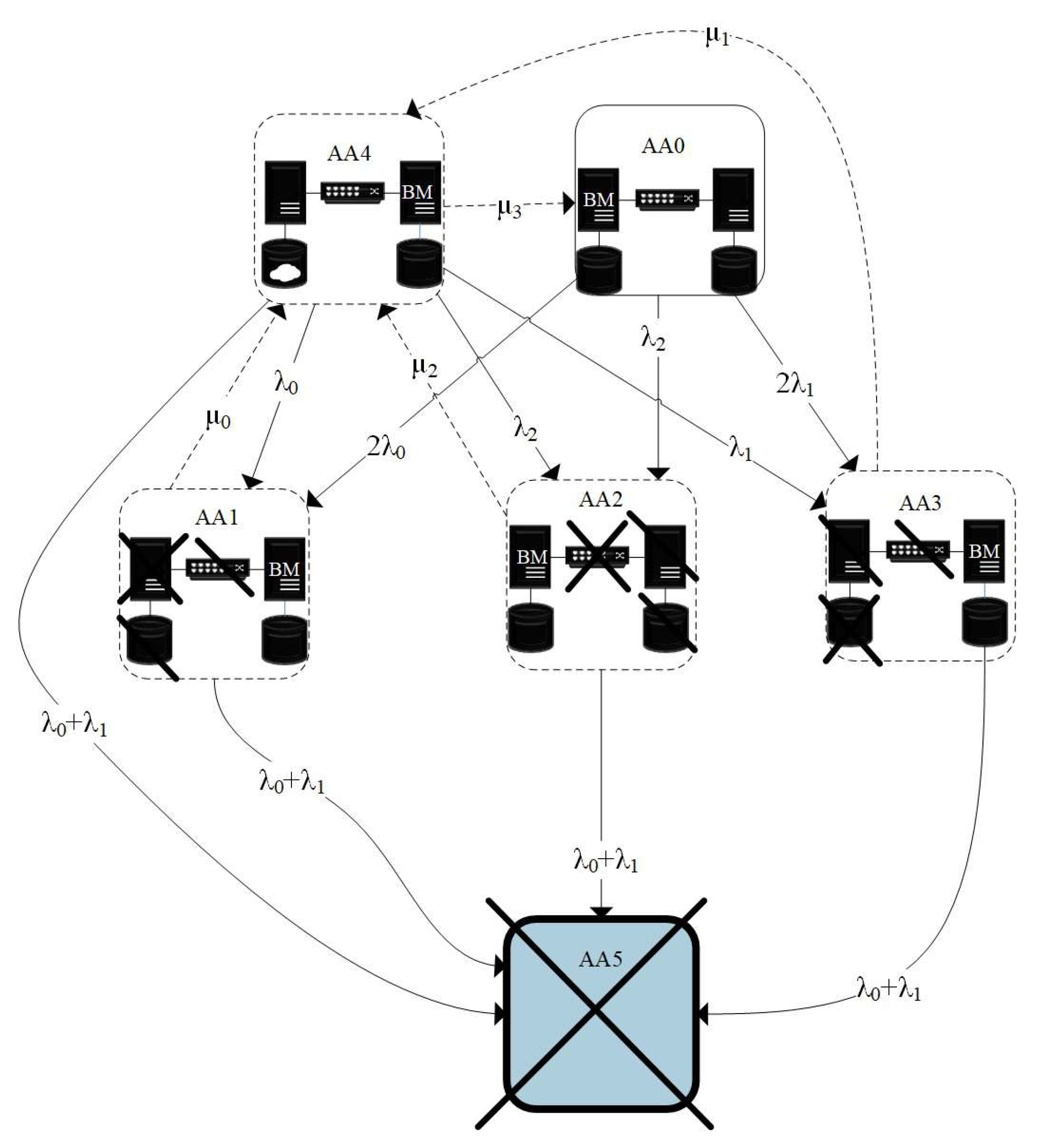
- A Markov model reflecting the restrictions on the maximum permissible interruption of the computing process and the danger of violations of these restrictions during the implementation of calculations in the recovery period of failed computing resources is constructed (Markov model of a system with the migration of virtual machines while ensuring the continuity of the computing process).
- The model is modified with the modes of functioning of the cluster without restoring the system in the case of failure of part of the system resources that do not lead to loss of continuity of the computing process (Markov model of a system with the migration of virtual machines while ensuring the continuity of the computing process).
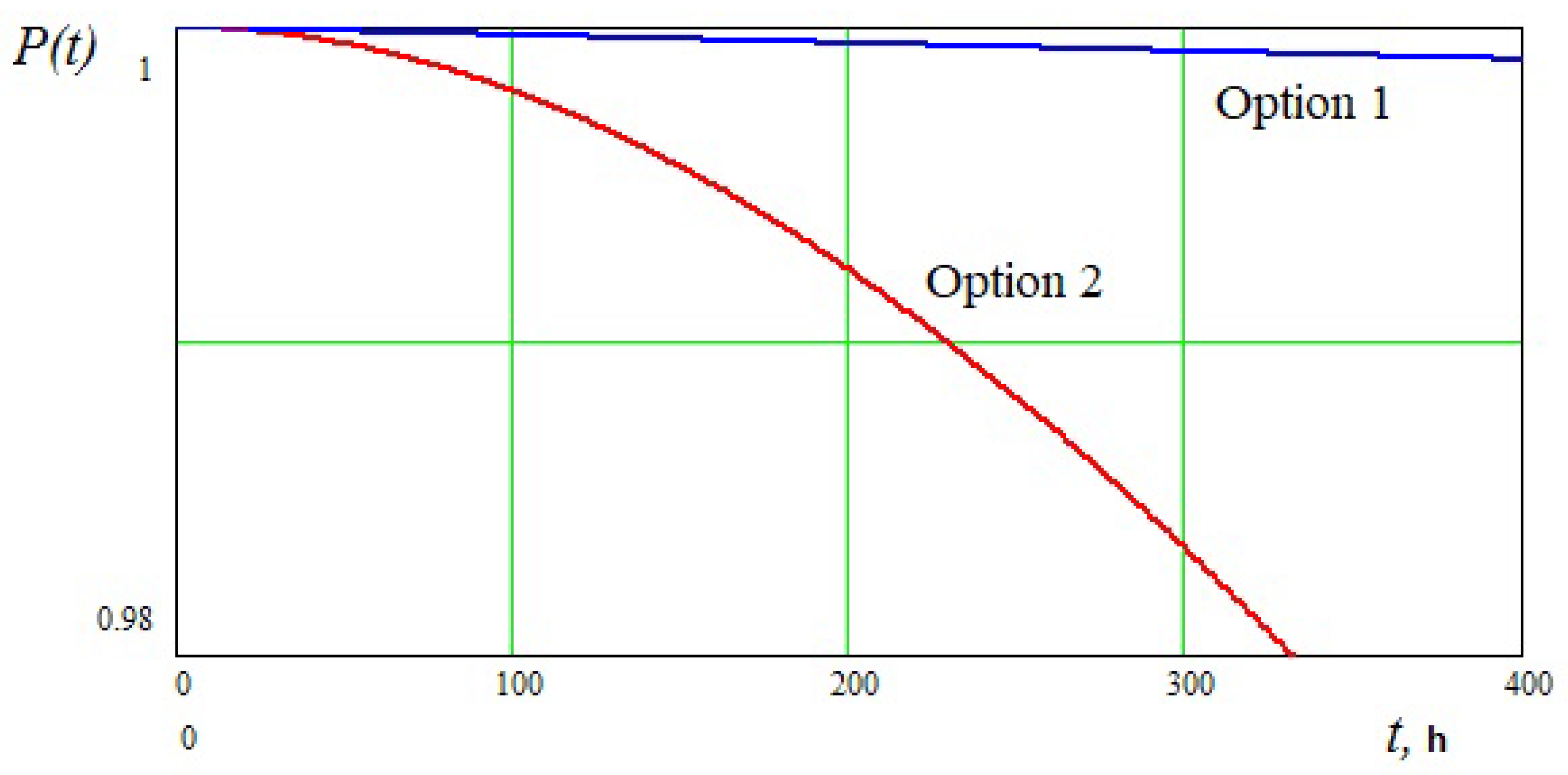
- The probability of system operability while ensuring continuity of calculations is assessed (calculation of the probability of operability of duplicated systems)
- The time to failure, leading to the interruption of the computational (control) process in excess of the maximum permissible time, is estimated (calculation of the probability of operability of duplicated systems)
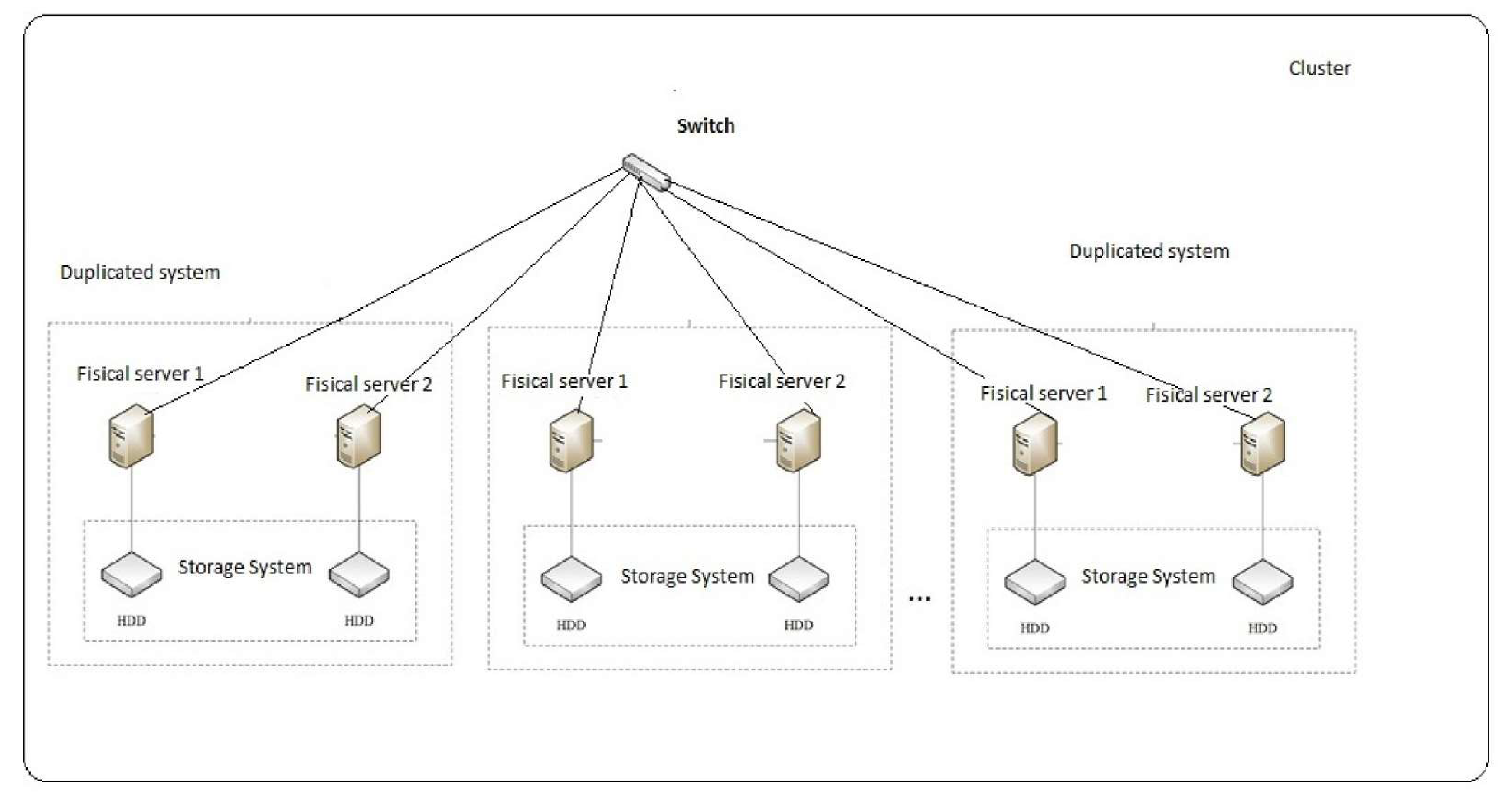
2. Cluster Organization and Options for Its Recovery
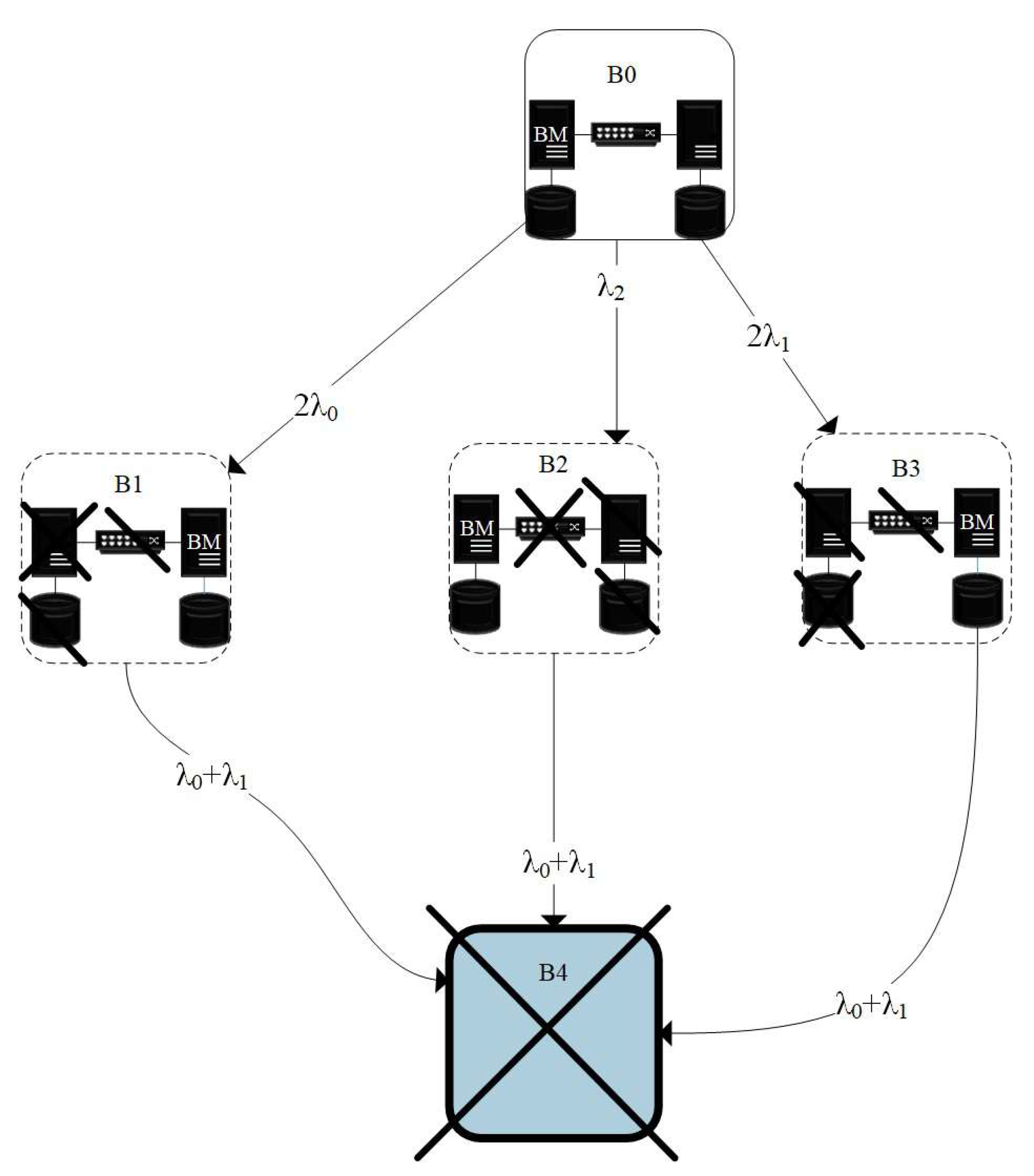
- Option A provides for system recovery, provided there is no disruption to the continuity of the computing process.
- Option B does not involve system recovery.
3. Markov Model of a System with the Migration of Virtual Machines While Ensuring the Continuity of the Computing Process
4. Calculation of the Probability of Operability of Duplicated Systems, Provided that the Computational Process Is Continuous
5. Calculation of the Probability of Operability of Duplicated Systems
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kopetz, H. Real-Time Systems: Design Principles for Distributed Embedded Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Sorin, D. Fault Tolerant Computer Architecture; Morgan & Claypool: Madison, WI, USA, 2009; p. 103. [Google Scholar]
- Dudin, A.N.; Sun, B. A multiserver MAP/PH/N system with controlled broadcasting by unreliable servers. Autom. Control Comput. Sci. 2009, 5, 32–44. [Google Scholar] [CrossRef]
- Zakoldaev, D.A.; Korobeynikov, A.G.; Shukalov, A.V.; Zharinov, I.O. Cyber and physical systems technology classification for production activity of the Industry 4.0 smart factory. IOP Conf. Ser. Mater. Sci. Eng. 2019, 1, 012007. [Google Scholar] [CrossRef]
- Astakhova, T.; Verzun, N.; Kolbanev, M.; Shamin, A. A model for estimatingenergy consumption seen when nodes of ubiquitous sensor networks communicate information to each other. In Proceedings of the 10th Majorov International Conference on Software Engineering and Computer Systems, Saint Petersburg, Russia, 20–21 December 2018. [Google Scholar]
- Poymanova, E.D.; Tatarnikova, T.M. Models and Methods for Studying Network Traffic. In Proceedings of the Wave Electronics and its Application in Information and Telecommunication Systems (WECONF), St. Petersburg, Russia, 1–5 June 2018. [Google Scholar] [CrossRef]
- Jin, H.; Li, D.; Wu, S.; Shi, X.; Pan, X. Live virtual machine migration with adaptive memory compression. In Proceedings of the IEEE International Conference on Cluster Computing (CLUSTER ’09), New Orleans, LA, USA, 29 August–4 September 2009. [Google Scholar] [CrossRef]
- Sahni, S.; Varma, V. A hybrid approach to live migration of virtual machines. In Proceedings of the IEEE International Conference on Cloud Computing for Emerging Markets (CCEM 2012), Bangalore, India, 23–24 November 2012. [Google Scholar] [CrossRef]
- Machida, F.; Kawato, M.; Maeno, Y. Redundant virtual machine placement for fault-tolerant consolidated server clusters. In Proceedings of the IEEE Network Operations and Management Symposium–NOMS 2010, Osaka, Japan, 19–23 April 2010; pp. 32–39. [Google Scholar] [CrossRef]
- Kim, S.; Choi, Y. Constraint-aware VM placement in heterogeneous computing clusters. Clust. Comput. 2020, 23, 71–85. [Google Scholar] [CrossRef]
- Yang, C.T.; Liu, J.C.; Hsu, C.H.; Chou, W.L. On improvement of cloud virtual machine availability with virtualization fault tolerance mechanism. J. Supercomput. 2014, 69, 1103–1122. [Google Scholar] [CrossRef]
- Jo, C.; Cho, Y.; Egger, B. A machine learning approach to live migration modeling. In Proceedings of the 2017 Symposium on Cloud Computing, Santa Clara, CA, USA, 24–27 September 2017; Volume 17, pp. 351–364. [Google Scholar]
- Keller, G.; Lutfiyya, H. Dynamic management of applicationswith constraints in virtualized data centres. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015. [Google Scholar]
- Wang, Y.B.; Hong, Z.G.; Shi, M.Y. Markov Process-Based Availability Analysis of Rendering Cluster Systems. In Advanced Materials Research; Trans Tech Publications, Ltd.: Stafa-Zurich, Switzerland, 2011; Volume 225–226, pp. 1024–1027. [Google Scholar] [CrossRef]
- Li, X.Q.; Li, R.L.; Xie, Y.J. Reliability Analysis Based on Markov Process for Repairable Systems. In Applied Mechanics and Materials; Trans Tech Publications, Ltd.: Stafa-Zurich, Switzerland, 2014; Volume 571–572. [Google Scholar] [CrossRef]
- Wang, C.C.; Liu, X.J.; Wang, C.X. Research on Reliability Analysis Method of Industrial Control System Based on Markov Process. In Applied Mechanics and Materials; Trans Tech Publications, Ltd.: Stafa-Zurich, Switzerland, 2014; Volume 541–542. [Google Scholar] [CrossRef]
- Wang, Y.B.; Hong, Z.G.; Shi, M.Y. Markov Process-Based Availability Analysis of Rendering Cluster Systems. In Applied Mechanics and Materials; Trans Tech Publications, Ltd.: Stafa-Zurich, Switzerland, 2014; Volume 225–226. [Google Scholar] [CrossRef]
- Bogatyrev, V.A.; Aleksankov, S.M.; Derkach, A.N. Model of Cluster Reliability with Migration of Virtual Machines and Restoration on Certain Level of System Degradation. In Proceedings of the Wave Electronics and Its Application in Information and Telecommunication Systems (WECONF-2018), St. Petersburg, Russia, 26–30 November 2018; p. 8604317. [Google Scholar]
- Bogatyrev, V.A.; Bogatyrev, S.V.; Derkach, A.N. Timeliness of the Reserved Maintenance by Duplicated Computers of Heterogeneous Delay-Critical Stream. CEUR Workshop Proc. 2019, 2522, 26–36. [Google Scholar]
- Bogatyrev, V.A.; Bogatyrev, S.V.; Bogatyrev, A.V. Model and Interaction Efficiency of Computer Nodes Based on Transfer Reservation at Mul-tipath Routing. In Proceedings of the Wave Electronics and Its Application in Information and Telecommunication Systems (WECONF), St. Petersburg, Russia, 3–7 June 2019; pp. 1–4. [Google Scholar]
- Bogatyrev, V.A.; Vinokurova, M.S. Control and Safety of Operation of Duplicated Computer Systems. Commun. Comput. Inf. Sci. 2017, 700, 331–342. [Google Scholar]
- Victorova, V.S.; Stepanjanc, A.C.T. About reliability indicators of the average operating time type. Reliability 2014, 4, 27–36. [Google Scholar]
- Victorova, V.S.; Stepanjanc, A.C.L. Models and Methods for Calculating the Reliability of Technical Systems; URSS LLC Lenand: Moscow, Russia, 2016. [Google Scholar]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bogatyrev, V.; Derkach, A. Evaluation of a Cyber-Physical Computing System with Migration of Virtual Machines during Continuous Computing. Computers 2020, 9, 42. https://doi.org/10.3390/computers9020042
Bogatyrev V, Derkach A. Evaluation of a Cyber-Physical Computing System with Migration of Virtual Machines during Continuous Computing. Computers. 2020; 9(2):42. https://doi.org/10.3390/computers9020042
Chicago/Turabian StyleBogatyrev, Vladimir, and Aleksey Derkach. 2020. "Evaluation of a Cyber-Physical Computing System with Migration of Virtual Machines during Continuous Computing" Computers 9, no. 2: 42. https://doi.org/10.3390/computers9020042
APA StyleBogatyrev, V., & Derkach, A. (2020). Evaluation of a Cyber-Physical Computing System with Migration of Virtual Machines during Continuous Computing. Computers, 9(2), 42. https://doi.org/10.3390/computers9020042