Abstract
In the era of Big data, there is still place for techniques which reduce the data size with maintenance of its internal knowledge. This problem is the main subject of research of a family of granulation techniques proposed by Polkowski. In our recent works, we have developed new, really effective and simple techniques for decision approximation, homogenous granulation and epsilon homogenous granulation. The real problem in this family of methods was the choice of an effective parameter of approximation for any datasets. It was resolved by homogenous techniques. There is no need to estimate the optimal parameters of approximation for these methods, because those are set in a dynamic way according to the data internal indiscernibility level. In this work, we have presented an extension of the work presented at ICIST 2018 conference. We present results for homogenous and epsilon homogenous granulation with the comparison of its effectiveness.
1. Introduction
Granular rough computing is one of the techniques used for decision system approximation. This method relies on knowledge granules which are formed from objects with selected, similar features. The main goal is to reduce the amount of data being used for classification or regression, maintaining internal knowledge of the decision system. In the era of processing large datasets these techniques can play a significant role. Basic granulation methods were proposed by Polkowski [1,2]. In the works of Artiemjew [3,4], Polkowski [1,2,5,6,7,8], and Polkowski and Artiemjew [9,10,11,12,13,14] we have presented standard granulation, concept dependent and layered granulation in the context of data reduction, missing values absorbtion and usage in the classification process.
Our motivation to perform this research was an idea to determine effective indiscernibility ratio of decision system approximation without its estimation. The ratio of approximation has influence on the original data size reduction. In our previous methods. we had to estimate this parameter reviewing the set of radii from 0 to 1. In the methods proposed in this work, we do not have to perform this operation. The ratio, for particular central object, is chosen in an automatic way, by extending it until the set of objects is homogenous in the sense of belonging to the decision class. Instead of performing granulation several times, depending on the number of attributes of the object, this process is performed only once, solving the problem of optimal radii search. Our results are showing reduction of training dataset size by up to 50 percent maintaining the internal knowledge at a satisfying level which was measured by efficiency of the classification process. The method is simple, has a square time complexity, main operations time the scalar . U is the set of objects of decision system, A the set of conditional attributes.
In this work, we have described the results of our previous research, presented in detail in [15,16]. The results are prepared for nominal (Homogenous granulation) data and numerical data (Epsilon homogenous granulation). It is worth to mention that our new methods were implemented in really effective new ensemble model; see [17].
The paper has the following content. In Section 2 there is a theoretical background. In Section 3 and Section 4 we present a description of a our granulation techniques. In Section 5 we present a description of a classifier used in the experimental part. In Section 6 there are the results of our experiments and the conclusion is presented in Section 7.
There are three basic steps of the granulation process. The granules are computed for each training object, then, the training dataset is covered using the selected strategy and in the last step, majority voting is being used to get granular reflection of the training system.
In the next section, we describe the first step of the mentioned procedure.
2. Granular Rough Inclusions
Some more theory about rough inclusions can be found in Polkowski [1,6,7,18,19], a detailed discussion may be found in Polkowski [8].
For given objects u and v from training decision system , where U is the universe of objects, A the set of conditional attributes, and d is the decision attribute. The standard rough inclusion is defined as
where
The parameter r is the granulation radius from the set .
2.1. –Modification of the Standard Rough Inclusion
Given a parameter valued in the unit interval , we define the set
and, we set
2.2. Covering of Universe of Training Objects
During the process of covering the objects of the training system are covered based on chosen strategy. Simple random choice was used in this experiment, because it is the most effective method among studied ones; see [14]).
The last step of the granulation process is shown in the next section.
2.3. Granular Reflections
In this step the granular reflections of the original training system are formed based on the granules from the found coverage. Each granule from the coverage is finally represented by a single object which attributes are chosen using the Majority Voting () strategy.
The granular reflection of the decision system is the decision system , the set of objects formed from granules.
for a given rough (weak) inclusion .
Detailed information about our new method of granulation is presented in the next section.
3. Homogenous Granulation
In this section we have a formal definition of the homogenous granulation process. In plain words, considering the set of samples from a decision system, we can try to lower the size of the system by searching for groups of objects similar in a fixed ratio. Having those sets (the granules), we can cover the original system searching for granules, which represent all the knowledge from original decision systems. In this particular method, we form the group of objects, which belong to the same decision class and have the lowest possible indiscernibility ratio. It means that the similarity of samples is as low as possible until they are in the same class. The granule according to this assumption can be defined as ; see the equation below.
The granules are formed as follows,
where
and
3.1. Simple Example of Homogenous Granulation
In the Table 1, we have exemplary training decision system, which we based on while computing homogenous granules defined in previous section. The decision system is the set of resolved problems, useful in modelling the automatic decision process. is the set of objects from until , B is the set of conditional attributes (description of samples) and contains values from until . d is a decision attribute, which contains the expert decision used for creating the model of the classification. In our case two possible classes exist: . Lets explain the process of granules formation. For given object , which belongs to class 1 we are looking for the objects from the same class starting from the identical objects (similar in degree 1) until the objects are indiscernible in smallest possible degree (are the least similar to ) and all of them are in class 1. In case we greatly lower the indiscernibility ratio, the objects r-indiscernible will not point on the decision class in an unambiguous way. In our example ratio for granule means that the set contain objects, which are identical with the central one () at least on 5 positions. For instance, object and have the following common descriptors: , , , , and . In the covering part we are looking for the set of granules, which represent each object from at least once.

Table 1.
Example of decision system .
Considering training decision system from Table 1.
Homogenous granules are formed as follows:
We cover the universe of objects by random choice:
Final granular system is in Table 2.
Table 2.
Granular decision system formed from Covering granules.
Exemplary visualization of granulation process is presented in Figure 1.
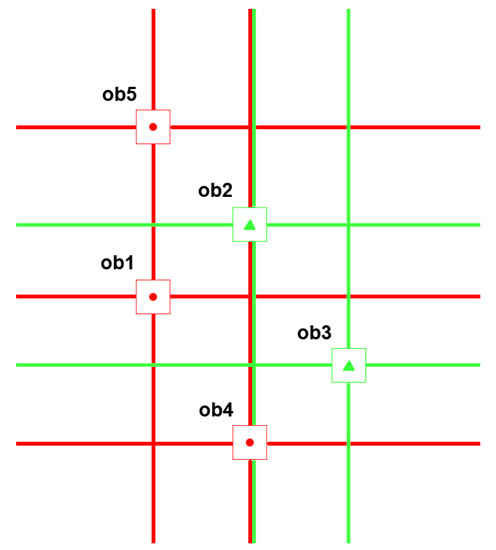
Figure 1.
Simple demonstration of granulation for objects represented by the pairs of attributes. In the picture we have objects of two classes, circles and triangles. Granulating the decision system in homogenous way we can obtain , , , , . The set of possible radii is .
4. Epsilon Variant of Homogenous Granulation
The only difference according to homogenous granulation described in Section 3.1 is the addition of the parameter , which allows us to use a floating point value in the process of granulation. The rest of the techniques are similar.
The method is defined in the following way,
where
and
where , are the maximal and minimal attribute values for in the original dataset.
The metrics for epsilon granulation and classification are defined in Equations (9) and (10) respectively. The Hamming metric for symbolic data is placed in Equation (9). -normalized Hamming metric as modification for numerical values, for given is in Equation (10).
Considering training decision system from Table 3 the hand example of homogenous granulation is as follows.
Table 3.
Training data system , (a sample from australian credit dataset), for .
The granules are computed below:
Granules covering training system by random choice:
- Covering granules:
Final approximation of training decision system is in Table 4:
Table 4.
Granular decision system formed from Covering granules.
In the Figure 2 there is a simple visualization of granulation process.
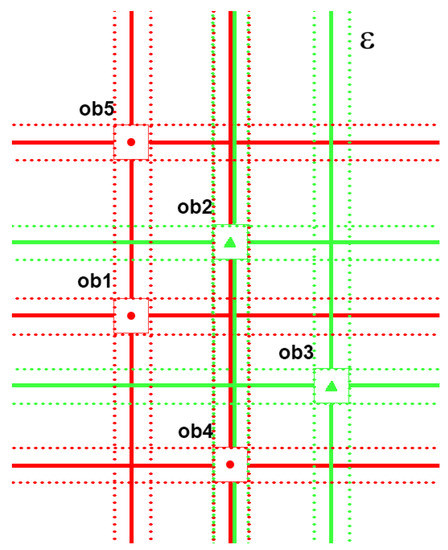
Figure 2.
Exemplary toy demonstration for objects represented as pairs of attributes. We have two decision concepts: circles and rectangles. Epsilon homogenous granules can be , , , , . The set of possible radii is . The descriptors can be shifted in the range determined by and still were treated as indiscernible.
5. Description of Classifier Used for Evaluation of the Granulation
A classifier has been used in the experiments to verify the effectiveness of approximation. The procedure is as follows.
- Step 1.
- The training granular decision system and the test decision system are given, where A is a set of conditional attributes, d is the decision attribute, and a granulation radius.
- Step 2.
- Classification of test objects, by means of granules of training objects, is performed as follows.
For all conditional attributes , training objects , and test objects , we compute weights based on the Hamming metric.
In the voting procedure of the classifier, we use optimal k estimated by CV5, details of the procedure are highlighted in the next section.
If the cardinality of the smallest training decision class is less than k, we apply the value for
The test object u is classified by means of weights computed for all training objects v. Weights are sorted in ascending order as,
where are all decision classes in the training set.
Based on computed and sorted weights, training decision classes vote by means of the following parameter, where c runs over decision classes in the training set,
Finally, the test object u is classified into the class c with a minimal value of .
After all test objects u are classified, the quality parameter of accuracy (acc) is computed, according to the formula
Parameter Estimation in Classifier
In our experiments, we use the classical version of classifier based on the Hamming metric. In the first step, we estimate the optimal k based on 5× CV5 cross-validation on the part of dataset. In the next step, we use the estimated value of k in order to find k nearest objects for each decision class and then voting is performed to select the decision. If the value of k is larger than the smallest training decision class cardinality then k value is equal to cardinality of this class.
In Table 5 we can see the estimated values of k for all tested datasets. These values were chosen as optimal based on the experiments with various values of k and results estimated by multiple operations.
Table 5.
Estimated parameters for based on cross–validation, data from UCI Repository [20].
6. The Results of Experiments
To show the effectiveness of the new method, we have carried out a series of experiments with real data from University of Irvine Repository (see [20]). The reference classifier is with Cross Validation 5 model. Data for experiments are listed in Table 6. The k parameter was evaluated in our previous works [14]. The list of optimal parameters of k is shown in Table 5. The single test consists of splitting the data into training and test set, where the training samples are granulated using our homogenous method. The results of the experiments are presented in Table 7. We have shown the comparable effectiveness of this new method in comparison with our best concept dependent granulation method; see Table 8. The new technique is significantly different from existing methods. Dynamic tuning of radius during granulation results with granules directed on decisions of their central objects. The radius is selected in automatic way during granulation process so there is no need to estimate optimal radius of granulation. The approximation level depends on objects indiscernibility ratio in the particular decision classes. Epsilon variant; see Table 9 is fully comparable to the homogenous method and works more precisely for numerical data.
Table 6.
Basic information about datasets-[20].
Table 7.
The result for dynamic granulation; method with classifier; , , , , .
Table 8.
Summary of results for Classifier, granular and non granular case, = accuracy of classification, = percentage reduction in object number, r = granulation radius, = variant of Naive Bayes classifier, = non granular case.
Table 9.
The result for homogenous granulation () and for epsilon homogenous granulation (); ; average accuracy for , average accuracy for , decision system size, decision system size, , reduction in object number in training set for , reduction in object number in training set for , spectrum of radii for , spectrum of radii for , = Australian-credit, = German-credit, = Heartdisease, = Hepatitis.
7. Conclusions
In this work, we have the results of experiments for our new granulation techniques; homogenous and epsilon homogenous granulation. The main advantage of this methods is that there is no need of parameter estimation during approximation. The parameters are tuned in an automatic way by lowering the indiscernibility ratio until the granule contains objects from the same decision class. The reduction of the size of the original decision systems is up to 50 percent. In future works, we plan to check the best classification methods for our new approximation algorithms. Additionally, we wonder if tolerating a fixed percentage of objects from other classes in the granule could improve the quality of classification.
Author Contributions
Conceptualization, P.A. and K.R.; Methodology, P.A. and K.R.; Software, P.A. and K.R.; Validation, P.A. and K.R.; Formal Analysis, P.A. and K.R.; Investigation, P.A. and K.R.; Resources, P.A. and K.R.; Writing—Original Draft Preparation, P.A. and K.R.; Writing—Review and Editing, P.A. and K.R.; Visualization, P.A. and K.R.; Project Administration, P.A. and K.R. Funding Acquisition, P.A. and K.R.
Funding
This work has been fully supported by the grant from Ministry of Science and Higher Education of the Republic of Poland under the project number 23.610.007-300.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Polkowski, L. Formal granular calculi based on rough inclusions. In Proceedings of the IEEE 2005 Conference on Granular Computing GrC05, Beijing, China, 25–27 July 2005; pp. 57–62. [Google Scholar]
- Polkowski, L. A model of granular computing with applications. In Proceedings of the IEEE 2006 Conference on Granular Computing GrC06, Atlanta, GA, USA, 10–12 May 2006; pp. 9–16. [Google Scholar]
- Artiemjew, P. Classifiers from Granulated Data Sets: Concept Dependent and Layered Granulation. In Proceedings of the RSKD’07. The Workshops at ECML/PKDD’07, Warsaw, Poland, 21 September 2007; pp. 1–9. [Google Scholar]
- Artiemjew, P. A Review of the Knowledge Granulation Methods: Discrete vs. Continuous Algorithms. In Rough Sets and Intelligent Systems. ISRL 43; Skowron, A., Suraj, Z., Eds.; Springer: Berlin, Germany, 2013; pp. 41–59. [Google Scholar]
- Polkowski, L. The paradigm of granular rough computing. In Proceedings of the ICCI’07, Lake Tahoe, NV, USA, 6–8 August 2007; pp. 145–163. [Google Scholar]
- Polkowski, L. Granulation of knowledge in decision systems: The approach based on rough inclusions. The method and its applications. In Proceedings of the RSEISP 07, Warsaw, Poland, 28–30 June 2007; Lecture Notes in Artificial Intelligence. Springer: Berlin, Germany, 2007; Volume 4585, pp. 271–279. [Google Scholar]
- Polkowski, L. A unified approach to granulation of knowledge and granular computing based on rough mereology: A survey. In Handbook of Granular Computing; Pedrycz, W., Skowron, A., Kreinovich, V., Eds.; John Wiley and Sons Ltd.: Chichester, UK, 2008; pp. 375–400. [Google Scholar]
- Polkowski, L. Approximate Reasoning by Parts. An Introduction to Rough Mereology; Springer: Berlin, Germany, 2011. [Google Scholar]
- Polkowski, L.; Artiemjew, P. Granular computing: Granular classifiers and missing values. In Proceedings of the ICCI’07, Lake Tahoe, NV, USA, 6–8 August 2007; pp. 186–194. [Google Scholar]
- Polkowski, L.; Artiemjew, P. On granular rough computing with missing values. In Proceedings of the RSEISP 07, Warsaw, Poland, 28–30 June 2007; Lecture Notes in Artificial Intelligence. Springer: Berlin, Germany, 2007; Volume 4585, pp. 271–279. [Google Scholar]
- Polkowski, L.; Artiemjew, P. Towards Granular Computing: Classifiers Induced from Granular Structures. In Proceedings of the RSKD’07. The Workshops at ECML/PKDD’07, Warsaw, Poland, 21 September 2007; pp. 43–53. [Google Scholar]
- Polkowski, L.; Artiemjew, P. On granular rough computing: Factoring classifiers through granulated decision systems. In Proceedings of the RSEISP 07, Warsaw, Poland, 28–30 June 2007; Lecture Notes in Artificial Intelligence. Springer: Berlin, Germany, 2007; Volume 4585, pp. 280–290. [Google Scholar]
- Polkowski, L.; Artiemjew, P. Classifiers based on granular structures from rough inclusions. In Proceedings of the 12th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems IPMU’08, Torremolinos (Malaga), Spain, 22–27 June 2008; pp. 1786–1794. [Google Scholar]
- Polkowski, L.; Artiemjew, P. Granular Computing in Decision Approximation—An Application of Rough Mereology. In Intelligent Systems Reference Library 77; Springer: Berlin, Germany, 2015; pp. 1–422. ISBN 978-3-319-12879-5. [Google Scholar]
- Ropiak, K.; Artiemjew, P. On Granular Rough Computing: epsilon homogenous granulation. In Proceedings of the International Joint Conference on Rough Sets, IJCRS’18, Quy Nhon, Vietnam, 20–24 August 2018; Lecture Notes in Computer Science (LNCS). Springer: Heidelberg, Germany, 2018. [Google Scholar]
- Ropiak, K.; Artiemjew, P. A Study in Granular Computing: homogenous granulation. In Information and Software Technologies. ICIST 2018. Communications in Computer and Information Science; Dregvaite, G., Damasevicius, R., Eds.; Springer: Berlin, Germany, 2018. [Google Scholar]
- Artiemjew, P.; Ropiak, K. A Novel Ensemble Model—The Random Granular Reflections. In Proceedings of the 27th International Workshop on Concurrency, Specification and Programming, Berlin, Germany, 24–26 September 2018. [Google Scholar]
- Polkowski, L. Rough Sets. Mathematical Foundations; Physica Verlag: Heidelberg, Germany, 2002. [Google Scholar]
- Polkowski, L. A rough set paradigm for unifying rough set theory and fuzzy set theory. In Proceedings of the RSFDGrC 2003: Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing, Chongqing, China, 26–29 May 2003. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 14 February 2019).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).