
Towards Trustworthy Collaborative Editing



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Replication: With replication, each participant has a copy of the shared document. In this configuration, each participant acts as both a client and a server replica because anyone could make changes to the shared document. Changes made would be propagated to all other participants. In essence, a collaborative editing application is a form of fault tolerance system with active replication [5] and every participant constitutes as a replica. On the other hand, a client–server application configuration by itself does not have built-in replication feature. If fault tolerance is necessary, the server must be explicitly replicated in client–server applications. The intrinsic replication design in collaborative editing systems makes it very attractive to employ replication-based fault tolerance solutions to increase the trustworthiness. Since the redundancy has already been built into the application, both the hardware cost (i.e., no need to purchase more computers) and runtime overhead are reduced (i.e., the application itself must have incorporated some replica coordination mechanisms).
- Concurrency: Real-time collaborative editing systems are designed to allow concurrent updates to a shared document [6]. Therefore, it is not acceptable to impose any sequential order on the updates to the shared document among all participants because this would be completely against the design purpose of the collaborative editing applications. For typical client–server applications, however, losing concurrency constitutes only a performance issue. For collaborative editing, we will adopt the optimistic replication strategy [7], which means that the states of the replicas could diverge temporarily and it is inevitable for us to use the eventual replica consistency model.
- Role: In collaborative editing applications, each participant acts both as a client and a server. As the client, it may introduce state changes to the shared document. As a server, it will receive and incorporate changes made by other participants. In typical client–server applications, a client only issues requests to the server and anticipates the corresponding replies from the server, and the server passively waits for requests issued by clients and processes the requests and generates replies. Basically, the server provides a function to serve its clients. The server state will not change unless it has processed a request. With the adoption of the optimistic replication strategy, the dual-role of each participant in collaborative editing is no longer an issue.
- Membership: In general, a real-time collaborative editing application only allows a finite set of participants to modify a shared document. For a user to participate, he/she would have to register with the application prior to being granted the privilege to change the shared document. However, client–server applications typically are designed to serve many clients concurrently. Hence, we normally do not need to worry about the scalability issues for collaborative editing applications.
2. Background
2.1. Collaborative Editing
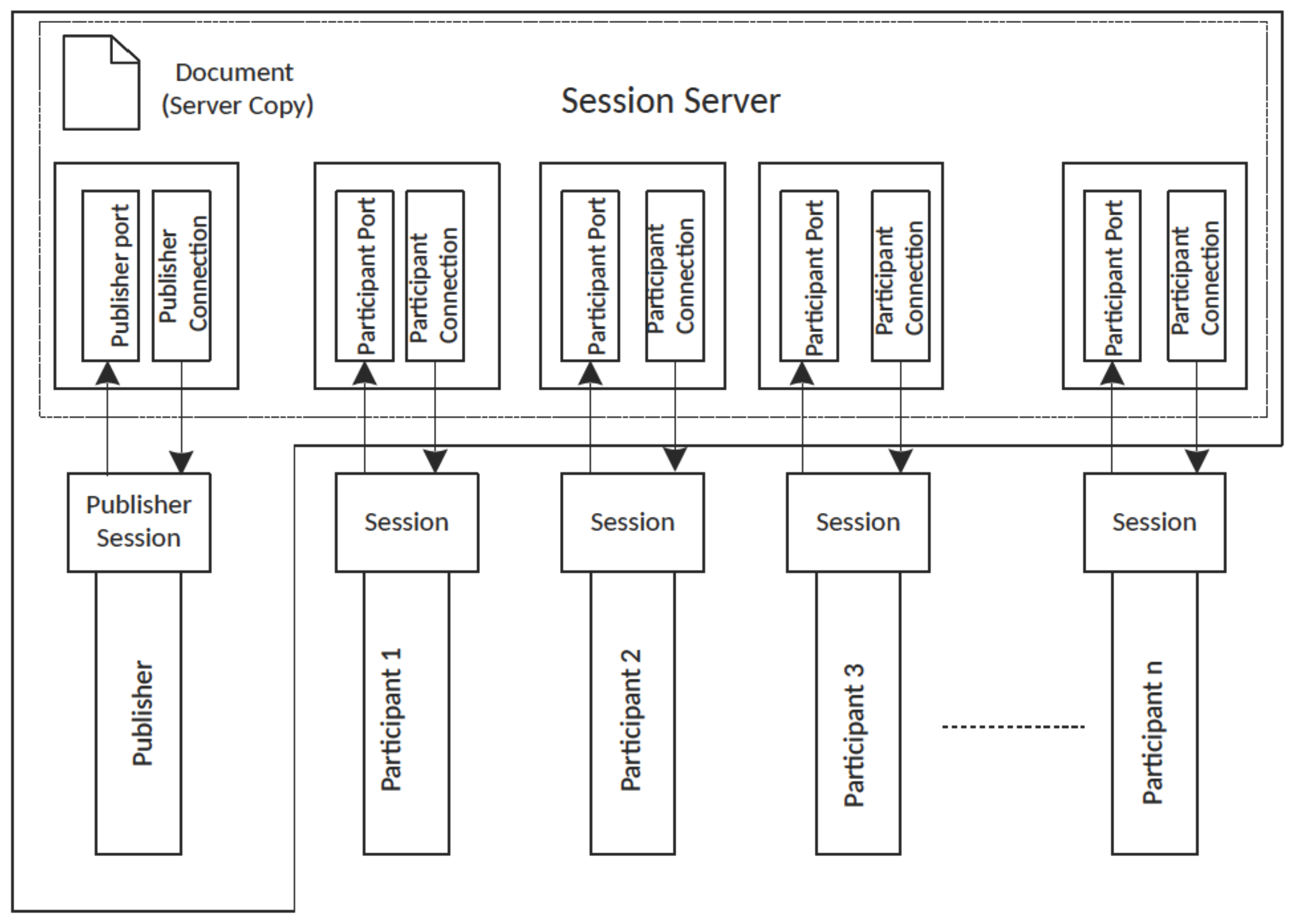
2.2. The ACE Collaborative Editor
2.3. Related Work
3. Methods
3.1. Threat Analysis
3.1.1. Threats from a Faulty Publisher
- Malicious updates: A faulty publisher might introduce malicious updates on the shared document.
- Partition attack: A faulty publisher may selectively pass on a membership change to a portion of participants with the intention of creating artificial partitions among the participants. The consequence of this attack is that participants in different partitions would have different versions of the shared document.
- Inconsistent updates: A faulty publisher may selectively relay an update submitted by a participant to a subset of the participants. Again, this attack would cause participants to have different versions of the shared document.
- Denial-of-service attack: A faulty publisher might launch a denial-of-service attack on any of the participants by refusing to accept a join request.
3.1.2. Threats from a Faulty Participant
- Malicious updates: A faulty participant can inject malicious updates to the shared document. For example, a faculty participant can introduce inappropriate texts or delete texts that should not be deleted from the shared document.
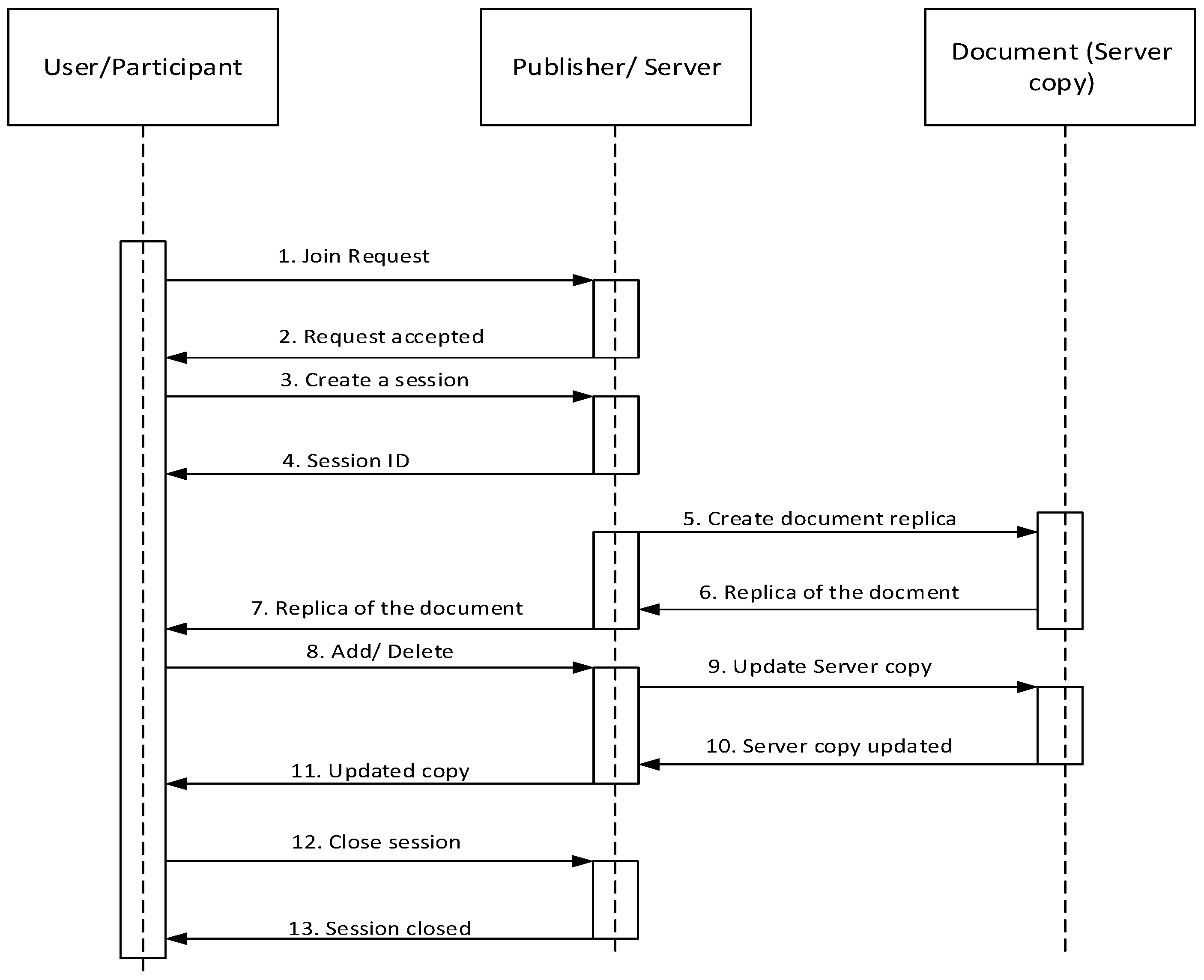
- Denial-of-service attack: A faulty participant can repeatedly join and leave an editing session with the intention to increase the load on the publisher (the session server to be specific). Handling the join request is an expensive operation for the publisher because the publisher would have to send the current shared document to the new participant on each join. This constitutes a form a denial-of-service attack on the publisher (and hence on the entire application).
3.2. The Lightweight BFT Mechanisms
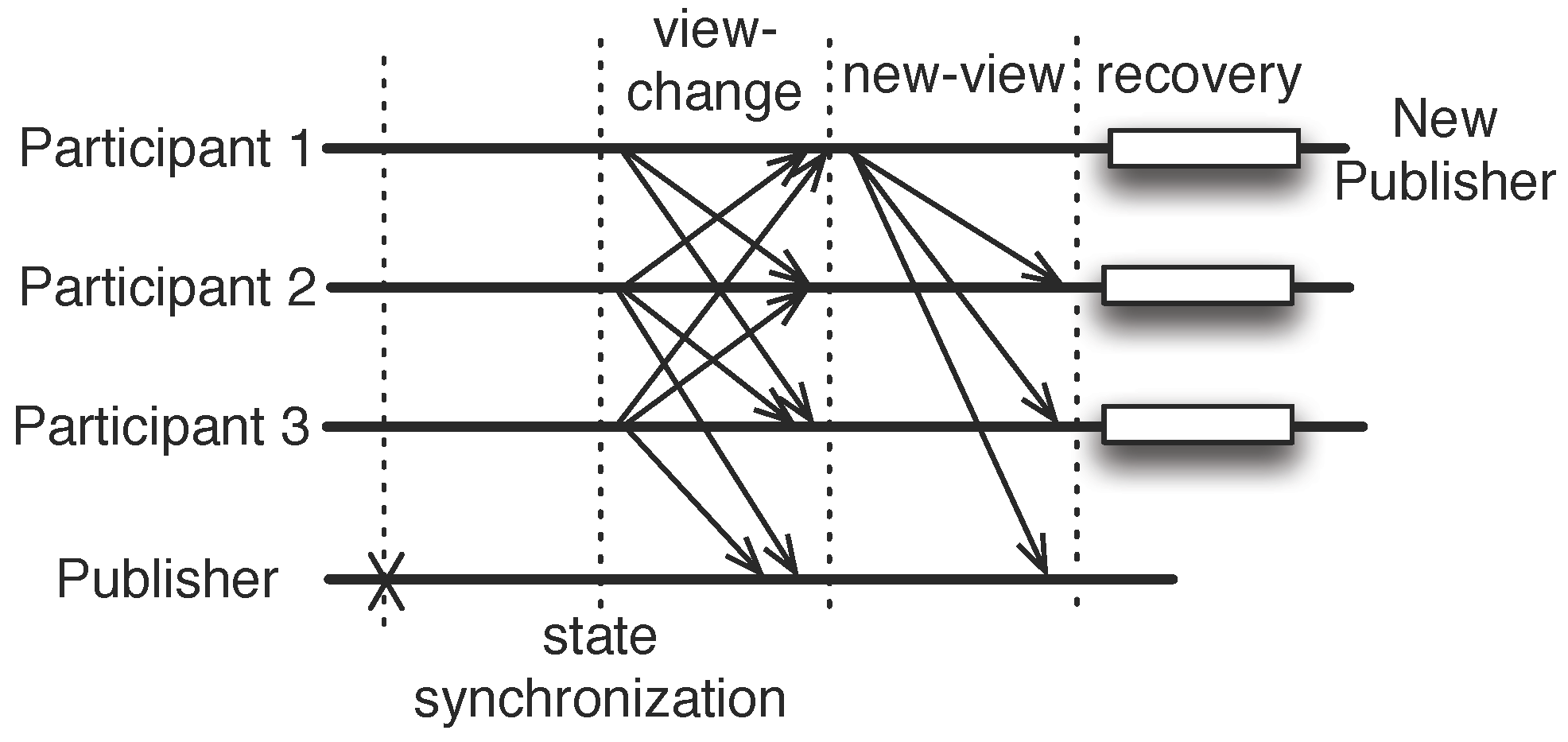
3.2.1. System Model
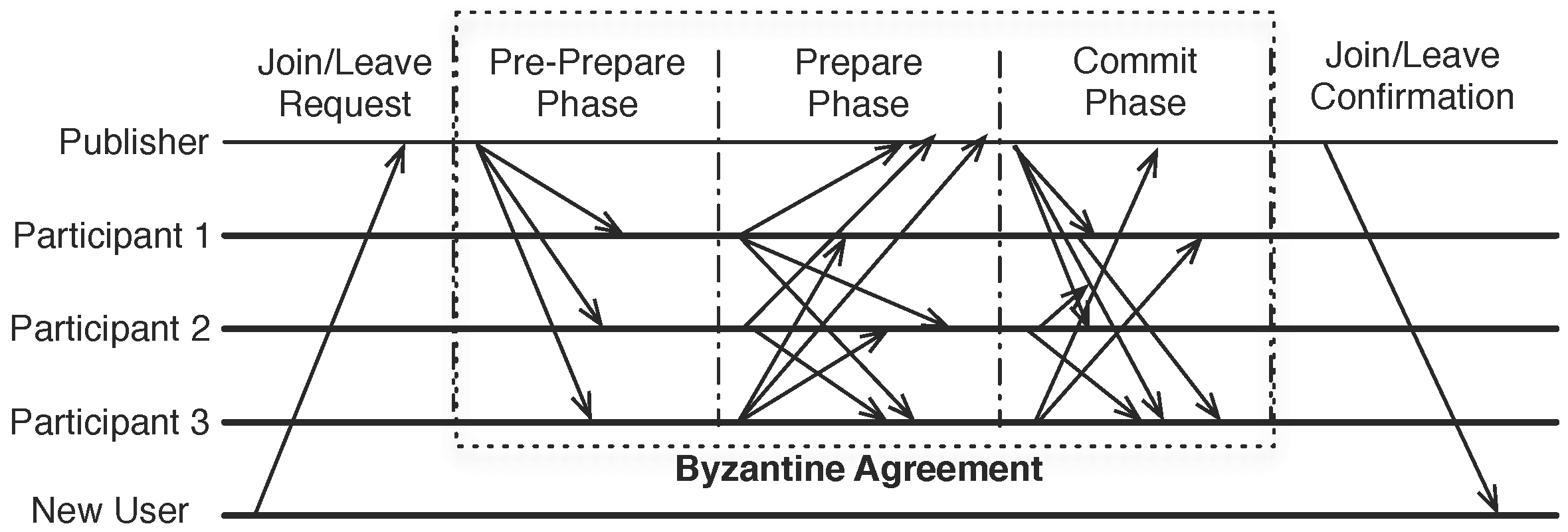
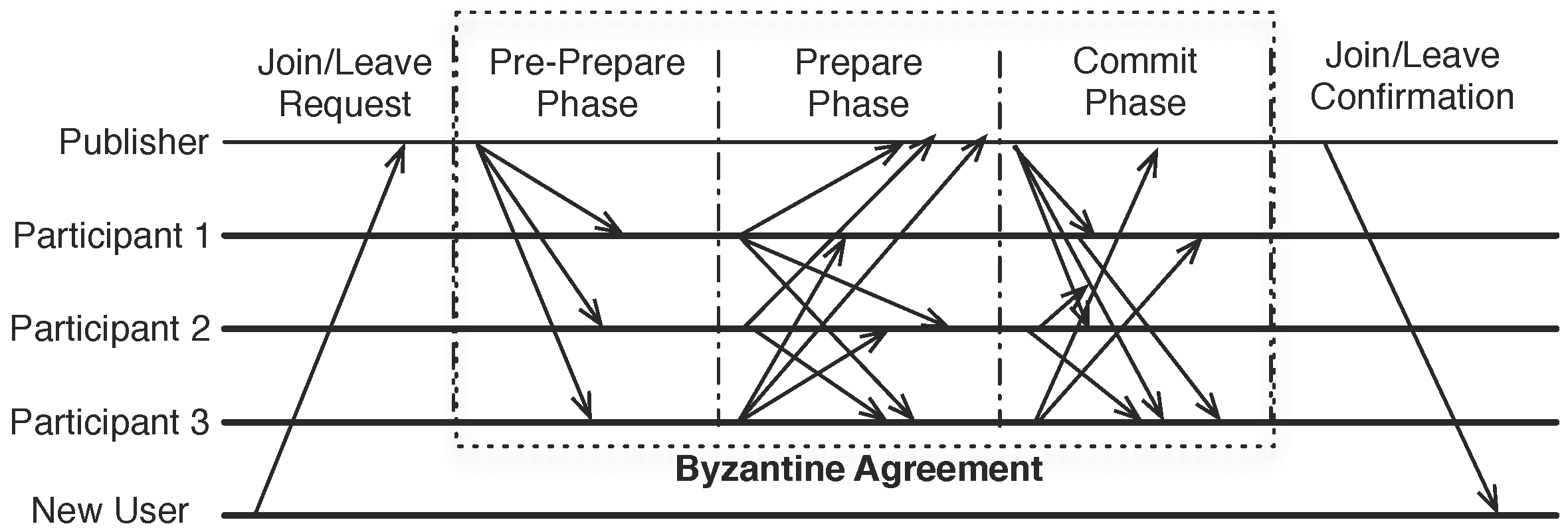
3.2.2. Consistent Membership
- The PBFT algorithm only ensures the agreement on one thing: the binding between a particular sequence number (representing the total order) and an incoming request. In our case, we want to reach an agreement on the new membership. Hence, the sequence number is replaced by a membership operation sequence number, and the message digest of the request is replaced by the full membership set.
- If the publisher could complete the Byzantine agreement step, it approves the membership and notifies the new user about the membership. In the notification message, the full membership information signed by all voting participants is included so that the new participant could participate future group-wise activities, such as new membership changes and state synchronizations. It is important that the membership is signed by every voting participant so that a faulty publisher cannot send a fake membership to the new participant.
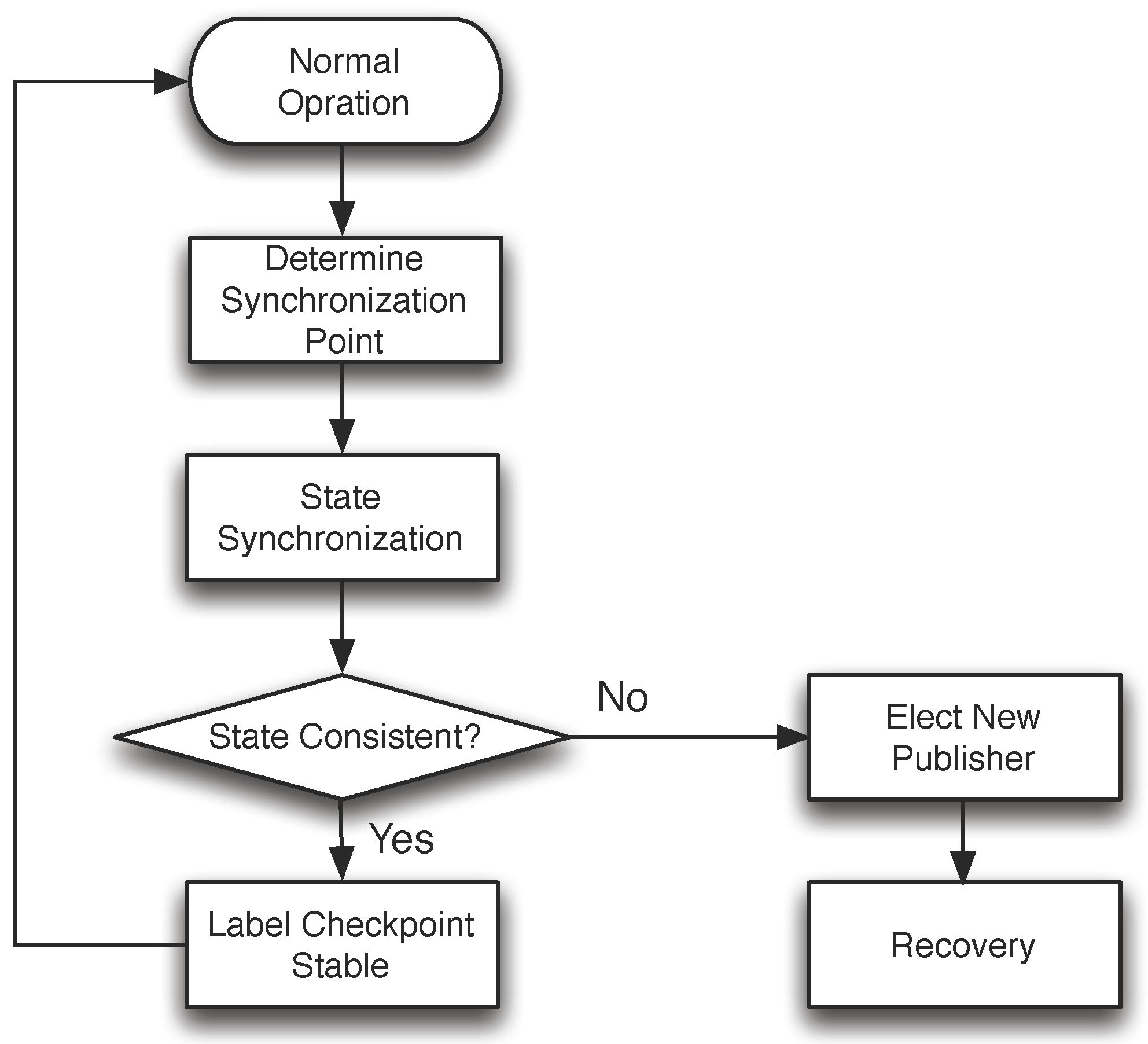
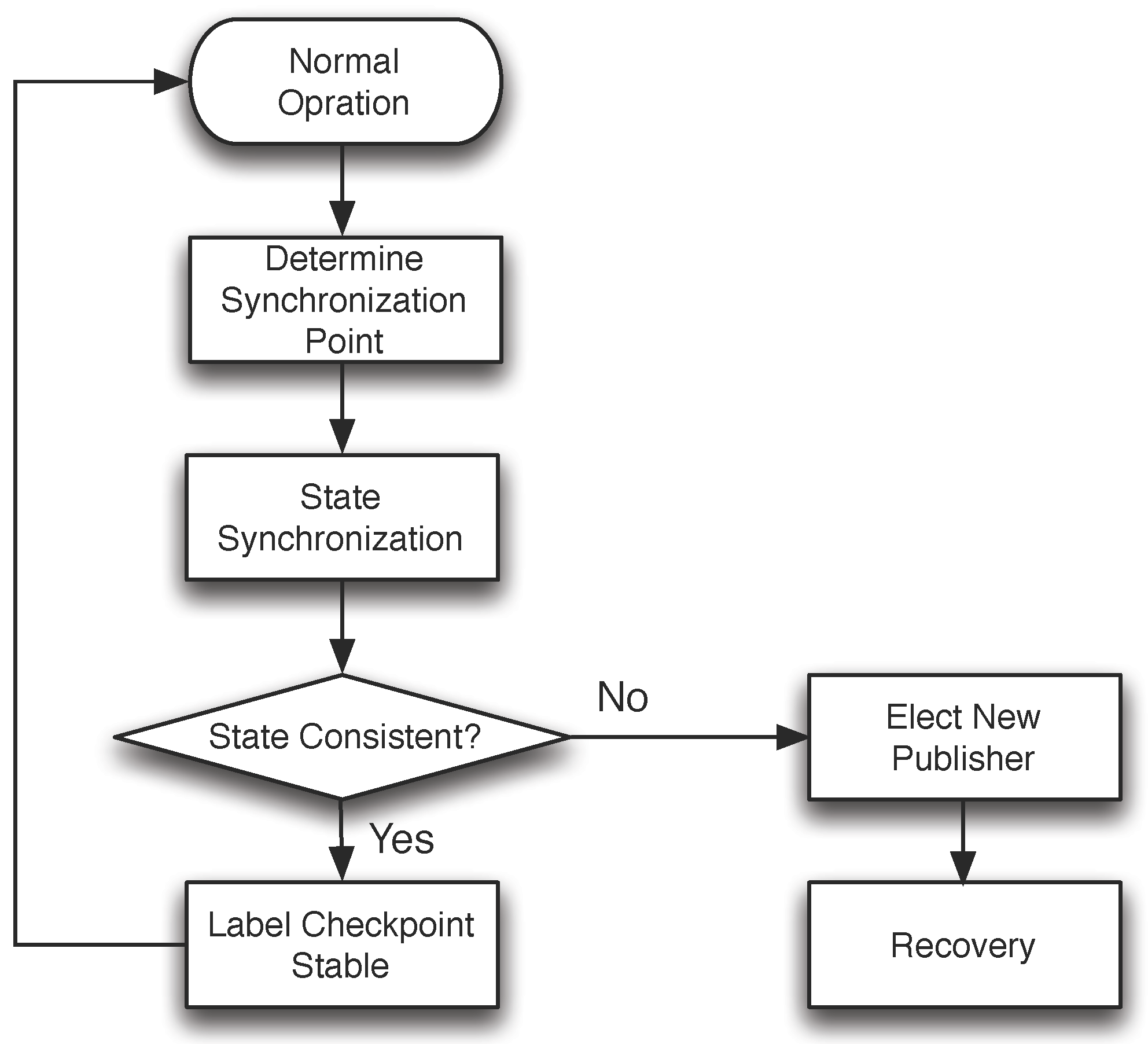
3.2.3. State Synchronization
- A faulty publisher could send different sync-init messages (for the same round of state synchronization) to different participants with the malicious intent of getting nonfaulty participants to commit to different states;
- A faulty participant sends a sync-prepare message with a different digest from that of the nonfaulty publisher.
3.2.4. Discussion
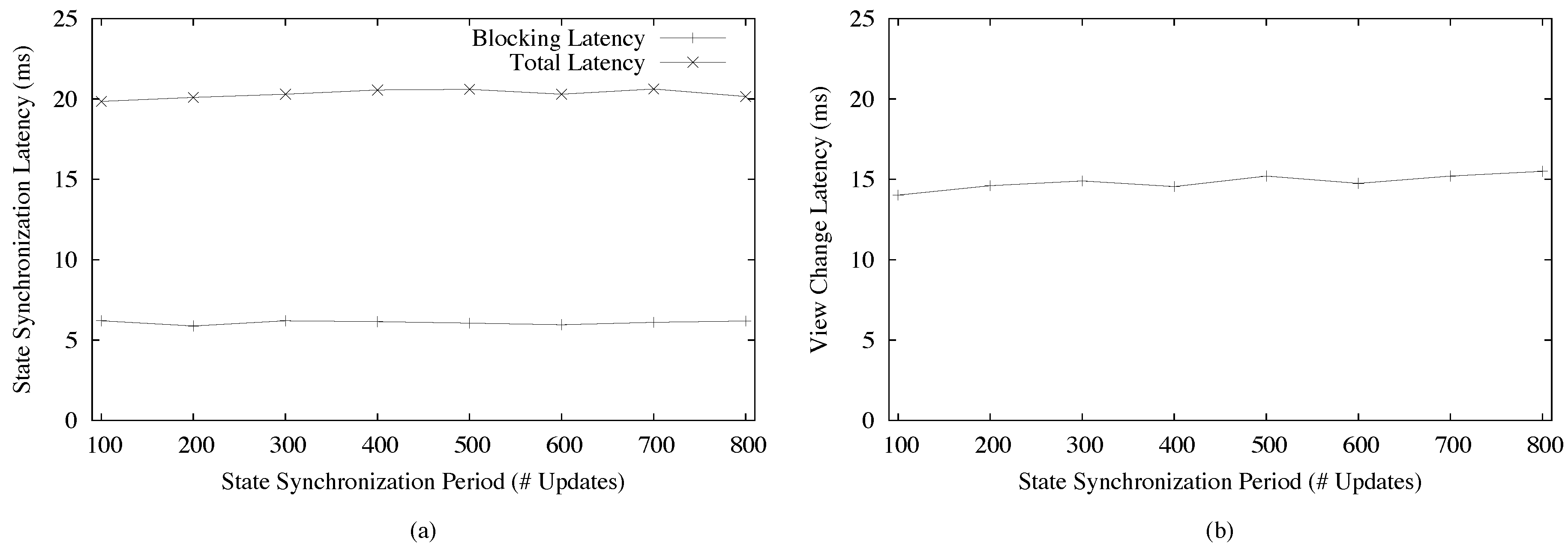
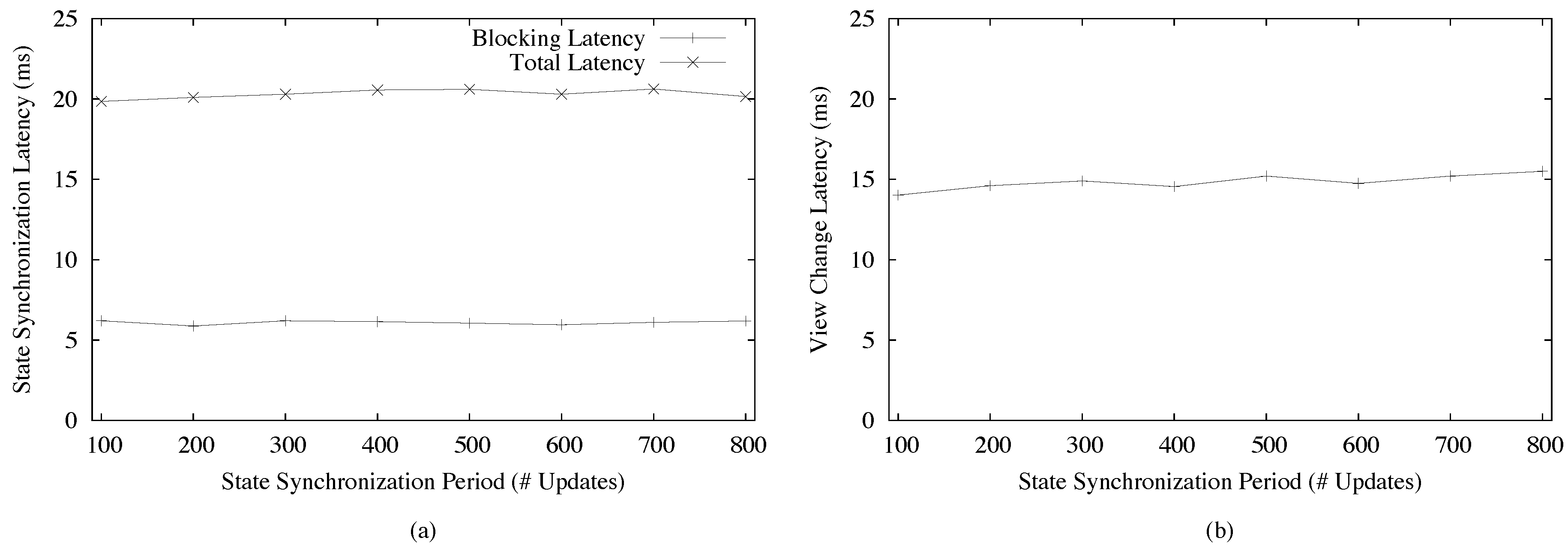
4. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| BFT | Byzantine fault tolerance |
| PBFT | Practical Byzantine Fault Tolerance |
| OT | Operational transformation |
| TCP | Transmission Control Protocol |
| DNS | Domain Name System |
Appendix A
References
- Ellis, C.A.; Gibbs, S.J. Concurrency control in groupware systems. In Proceedings of the 1989 ACM SIGMOD International Conference on Management of Data (SIGMOD ’89), Portland, OR, USA, 31 May–2 June 1989; ACM: New York, NY, USA, 1989; pp. 399–407. [Google Scholar]
- Li, D.; Li, R. An Admissibility-Based Operational Transformation Framework for Collaborative Editing Systems. Comput. Support. Coop. Work 2010, 19, 1–43. [Google Scholar] [CrossRef]
- Sun, C.; Jia, X.; Zhang, Y.; Yang, Y.; Chen, D. Achieving convergence, causality preservation, and intention preservation in real-time cooperative editing systems. ACM Trans. Comput. Hum. Interact. 1998, 5, 63–108. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical Byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst. 2002, 20, 398–461. [Google Scholar] [CrossRef]
- Zhao, W. Building Dependable Distributed Systems; Wiley-Scrivener: Beverly, MA, USA, 2014. [Google Scholar]
- Zhao, W. Concurrency Control in Real-Time E-Collaboration Systems. In Encyclopedia of E-Collaboration; Kock, N., Ed.; Idea Group Publishing: Hershey, PA, USA, 2008; pp. 95–101. [Google Scholar]
- Zhao, W. Optimistic Byzantine fault tolerance. Int. J. Parallel Emerg. Distrib. Syst. 2016, 31, 254–267. [Google Scholar] [CrossRef]
- Babi, M.; Zhao, W. Conflicts and Resolutions in Computer Supported Collaborative Work Applications. In Encyclopedia of Information Science and Technology, 3rd ed.; Khosrow-Pour, M., Ed.; IGI Global: Hershey, PA, USA, 2015; pp. 567–575. [Google Scholar]
- Babi, M.; Zhao, W. Increasing the Trustworthiness of Collaborative Applications. In Encyclopedia of Information Science and Technology, 3rd ed.; Khosrow-Pour, M., Ed.; IGI Global: Hershey, PA, USA, 2015; pp. 4317–4324. [Google Scholar]
- Sun, C.; Ellis, C. Operational transformation in real-time group editors: Issues, algorithms, and achievements. In Proceedings of the 1998 ACM Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 14–18 November 1998; pp. 59–68. [Google Scholar]
- Li, R.; Li, D. A new operational transformation framework for real-time group editors. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 307–319. [Google Scholar] [CrossRef]
- Nichols, D.A.; Curtis, P.; Dixon, M.; Lamping, J. High-latency, low-bandwidth windowing in the Jupiter collaboration system. In Proceedings of the 8th Annual ACM Symposium on User Interface and Software Technology (UIST ’95), Pittsburgh, PA, USA, 15–17 November 1995; ACM: New York, NY, USA, 1995; pp. 111–120. [Google Scholar]
- Sun, D.; Xia, S.; Sun, C.; Chen, D. Operational transformation for collaborative word processing. In Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work, Chicago, IL, USA, 6–10 November 2004; pp. 437–446. [Google Scholar]
- Zhao, W.; Babi, M. Byzantine fault tolerant collaborative editing. In Proceedings of the IET International Conference on Information and Communications Technologies, Beijing, China, 27–29 April 2013; pp. 233–240. [Google Scholar]
- Zhao, W.; Babi, M.; Yang, W.; Luo, X.; Zhu, Y.; Yang, J.; Luo, C.; Yang, M. Byzantine fault tolerance for collaborative editing with commutative operations. In Proceedings of the IEEE International Conference on Electro Information Technology, Grand Forks, ND, USA, 19–21 May 2016; pp. 246–251. [Google Scholar]
- Qin, X.; Sun, C. Efficient Recovery Algorithm in Real-Time and Fault-TolerantCollaborative Editing Systems. In Proceedings of the ACM Workshop on Collaborative Editing Systems, Philadelphia, PA, USA, 2–6 December 2000. [Google Scholar]
- Qin, X.; Sun, C. Recovery Support for Internet-Based Real-Time Collaborative Editing Systems. In Proceedings of the International Conference on Computer Networks and Mobile Computing (ICCNMC ’01), Beijing China, 16–19 October 2001; IEEE Computer Society: Washington, DC, USA, 2001; p. 181. [Google Scholar]
- Shim, H.S.; Prakash, A. Tolerating Client and Communication Failures in Distributed Groupware Systems. In Proceedings of the 17th IEEE Symposium on Reliable Distributed Systems, Madrid, Spain, 2–4 December 1998; IEEE Computer Society: Washington, DC, USA, 1998; p. 221. [Google Scholar]
- Amir, Y.; Danilov, C.; Kirsch, J.; Lane, J.; Dolev, D.; Nita-Rotaru, C.; Olsen, J.; Zage, D. Scaling Byzantine fault-tolerant replication to wide area networks. In Proceedings of the International Conference on Dependable Systems and Networks, Philadelphia, PA, USA, 25–28 June 2006; pp. 105–114. [Google Scholar]
- Chai, H.; Zhang, H.; Zhao, W.; Melliar-Smith, P.M.; Moser, L.E. Toward trustworthy coordination of Web services business activities. IEEE Trans. Serv. Comput. 2013, 6, 276–288. [Google Scholar] [CrossRef]
- Cowling, J.; Myers, D.; Liskov, B.; Rodrigues, R.; Shrira, L. HQ Replication: A Hybrid quorum protocol for Byzantine fault tolerance. In Proceedings of the Seventh Symposium on Operating Systems Design and Implementations, Seattle, WA, USA, 6–8 November 2006. [Google Scholar]
- Kotla, R.; Alvisi, L.; Dahlin, M.; Clement, A.; Wong, E. Zyzzyva: Speculative Byzantine fault tolerance. In Proceedings of the 21st ACM Symposium on Operating Systems Principles, Stevenson, WA, USA, 14–17 October 2007. [Google Scholar]
- Zhang, H.; Zhao, W.; Moser, L.E.; Melliar-Smith, P.M. Design and implementation of a Byzantine fault tolerance framework for non-deterministic applications. IET Softw. 2011, 5, 342–356. [Google Scholar] [CrossRef]
- Zhang, H.; Chai, H.; Zhao, W.; Melliar-Smith, P.M.; Moser, L.E. Trustworthy coordination for Web service atomic transactions. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1551–1565. [Google Scholar] [CrossRef]
- Zhao, W. Performance optimization for state machine replication based on application semantics: A review. J. Syst. Softw. 2016, 112, 96–109. [Google Scholar] [CrossRef]
- Veronese, G.S.; Correia, M.; Bessani, A.N.; Lung, L.C.; Verissimo, P. Efficient byzantine fault-tolerance. IEEE Trans. Comput. 2013, 62, 16–30. [Google Scholar] [CrossRef]
- Behl, J.; Distler, T.; Kapitza, R. Consensus-oriented parallelization: How to earn your first million. In Proceedings of the 16th Annual Middleware Conference, Vancouver, BC, Canada, 7–11 December 2015; pp. 173–184. [Google Scholar]
- Duan, S.; Peisert, S.; Levitt, K.N. hBFT: Speculative Byzantine fault tolerance with minimum cost. IEEE Trans. Dependable Secur. Comput. 2015, 12, 58–70. [Google Scholar] [CrossRef]
- Sousa, J.; Bessani, A. Separating the wheat from the chaff: An empirical design for geo-replicated state machines. Proceedigns of the IEEE 34th Symposium on Reliable Distributed Systems IEEE, Montreal, QC, Canada, 28 September–1 October 2015; pp. 146–155. [Google Scholar]
- Chai, H.; Zhao, W. Byzantine fault tolerant event stream processing for autonomic computing. In Proceedings of the IEEE 12th International Conference on Dependable, Autonomic and Secure Computing, Dalian, China, 24–27 August 2014; pp. 109–114. [Google Scholar]
- Luiz, A.F.; Lung, L.C.; Correia, M. Byzantine fault-tolerant transaction processing for replicated databases. In Proceedings of the 10th IEEE International Symposium on Network Computing and Applications, Cambridge, MA, USA, 25–27 August 2011; pp. 83–90. [Google Scholar]
- Zero Configuration Networking (Zeroconf). Available online: http://www.zeroconf.org/ (accessed on 23 March 2017).
- Krochmal, M. Rendezvous Is Changing to ... Available online: https://lists.apple.com/archives/rendezvous-dev/2005/Apr/msg00001.html (accessed on 23 March 2017).
- Reiter, M.K. A secure group membership protocol. IEEE Trans. Softw. Eng. 1996, 22, 31–42. [Google Scholar] [CrossRef]
- Correia, M.; Neves, N.F.; Lung, L.C.; Veríssimo, P. Worm-IT—A wormhole-based intrusion-tolerant group communication system. J. Syst. Softw. 2007, 80, 178–197. [Google Scholar] [CrossRef]
- Zhao, W. Design and implementation of a Byzantine fault tolerance framework for Web services. J. Syst. Softw. 2009, 82, 1004–1015. [Google Scholar] [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Babi, M.; Zhao, W. Towards Trustworthy Collaborative Editing. Computers 2017, 6, 13. https://doi.org/10.3390/computers6020013
Babi M, Zhao W. Towards Trustworthy Collaborative Editing. Computers. 2017; 6(2):13. https://doi.org/10.3390/computers6020013
Chicago/Turabian StyleBabi, Mamdouh, and Wenbing Zhao. 2017. "Towards Trustworthy Collaborative Editing" Computers 6, no. 2: 13. https://doi.org/10.3390/computers6020013
APA StyleBabi, M., & Zhao, W. (2017). Towards Trustworthy Collaborative Editing. Computers, 6(2), 13. https://doi.org/10.3390/computers6020013