
BangA: An Efficient and Flexible Generalization-Based Algorithm for Privacy Preserving Data Publication


Abstract
:1. Introduction
1.1. Motivation
1.2. Basic Requirements
1.3. Typical Use Case
- Indistinguishability principle—to achieve generalization;
- Mutually disjoint equivalence classes—to preserve quality of the anonymous public release;
- Multidimensional point partitioning—to support point and range queries on the anonymous public release;
- Hyper-rectangular coding of equivalence classes—to allow decomposition of orthogonal range queries.
1.4. Related Work
1.5. Synopsis
- k-anonymity is conceptually simple;
- k-anonymity does not enforce any constraint on the distribution of sensitive information in a public release [25]. This is one of the main reasons it can be extended to achieve more stronger notions of privacy e.g., differential privacy ().
2. General Overview
2.1. Preliminaries
- The strategy has conceptual simplicity.
- It is usually tractable to obtain an optimal solution [3].
- Finally, the inferences among the remaining attributes stay uniform with the original data set.
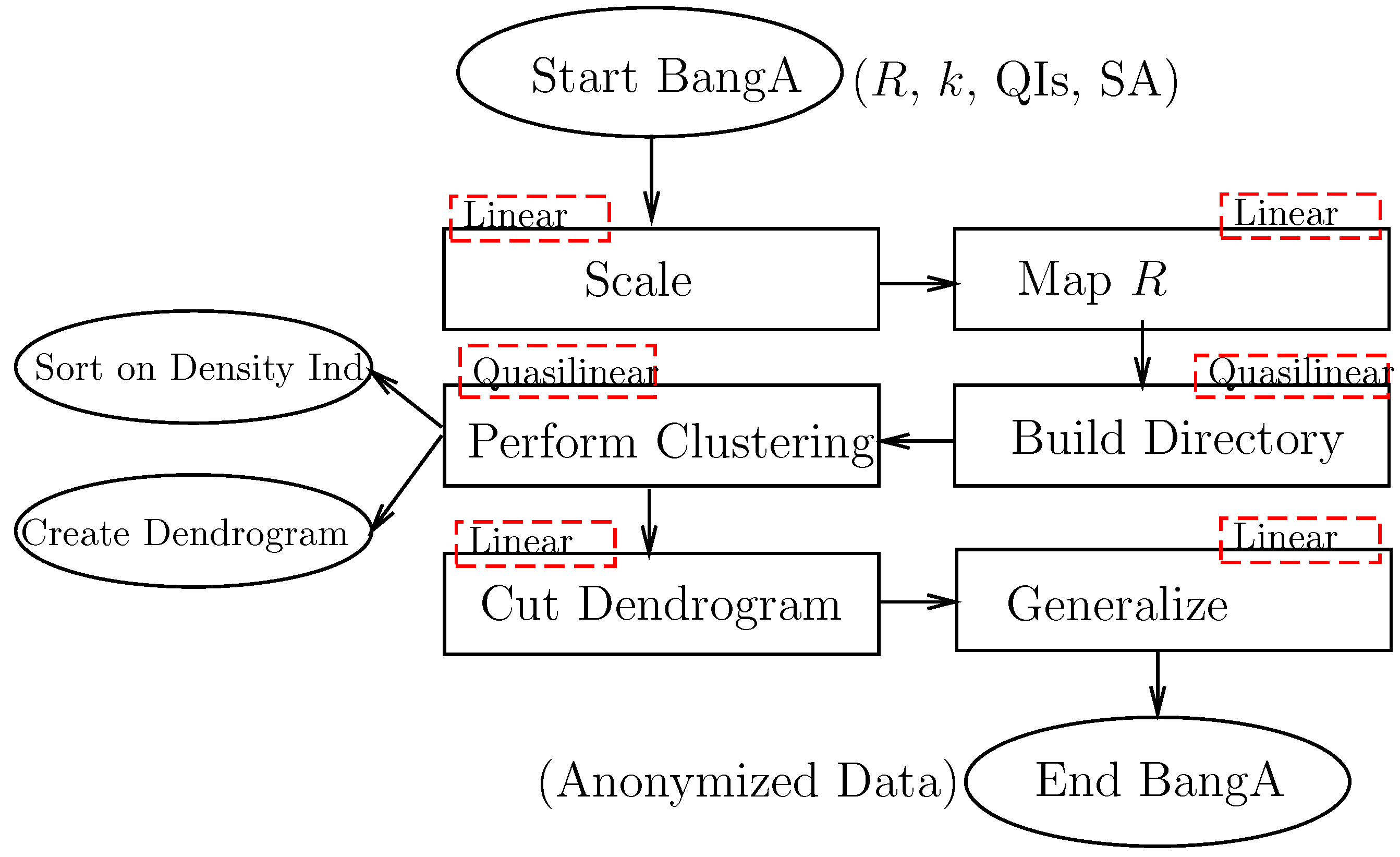
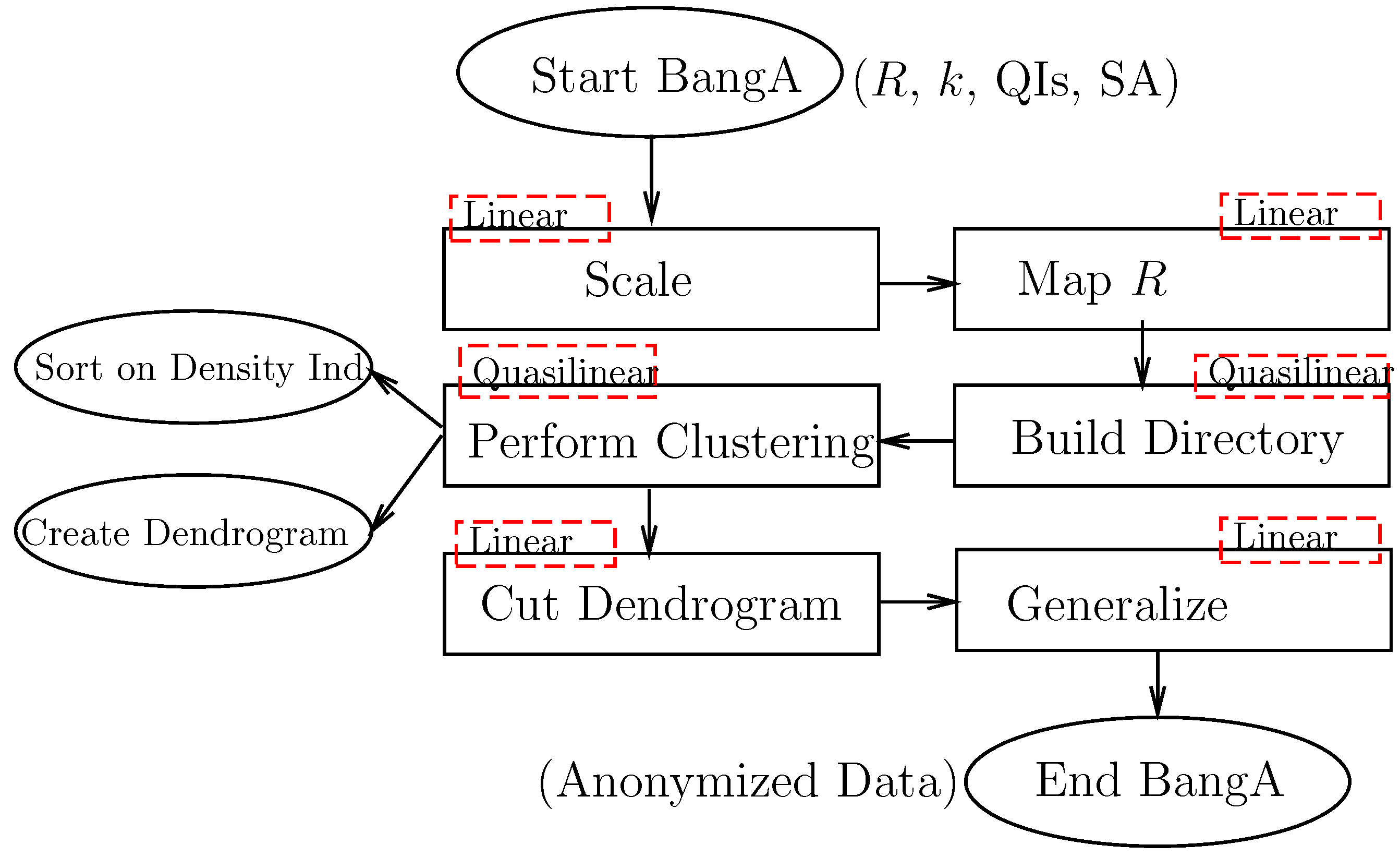
2.2. Overview of BangA
- Spatial indexing technique—to leverage 30 years of research and experience in effective and efficient external multidimensional partitioning data structures built from very large data sets;
- BANG file revisited—to accommodate a well-studied logical structure to the generalization problem;
- Axis–parallel coding of equivalence classes—to ease orthogonal range queries for the end-user;
- Nested hyper-rectangles—to improve quality of the anonymous public release keeping the axis-parallel coding feature up;
- Grid-based partitioning—to make the computation faster and to control the privacy requirement by means of knowledge about the data;
- Density-based clustering of blocks—to enforce quality of the anonymous public release in the process of block merging;
- Multi-granular anonymization—to allow different settings for the k value with a single run of the algorithm.
- Methodology for point and orthogonal range queries on non hyper-rectangular tabular data—to support exact match and basic range searching against anonymous public releases into spreadsheets.
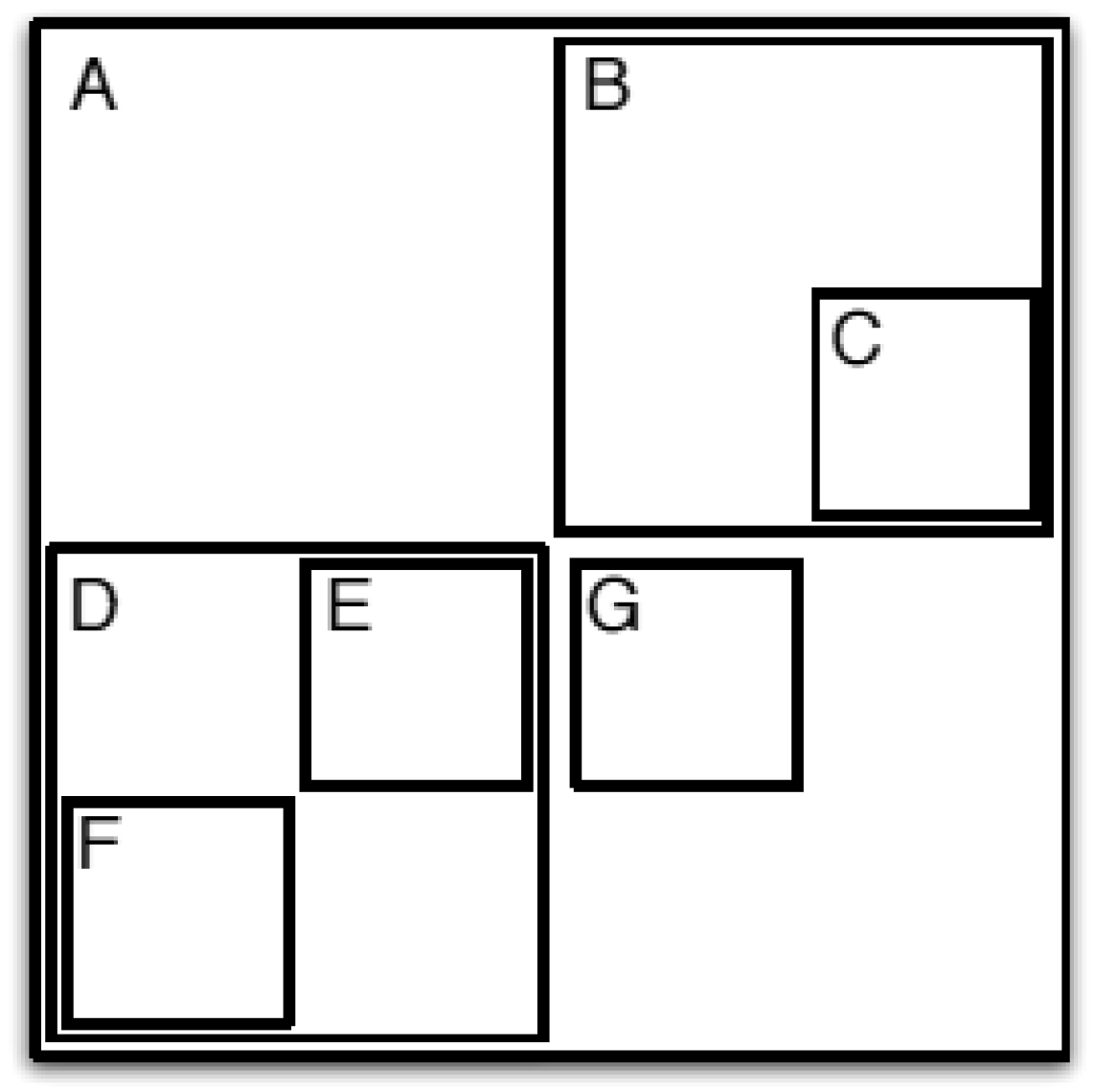
3. From Raw Data to the BANG Directory
3.1. Data Space Partitioning
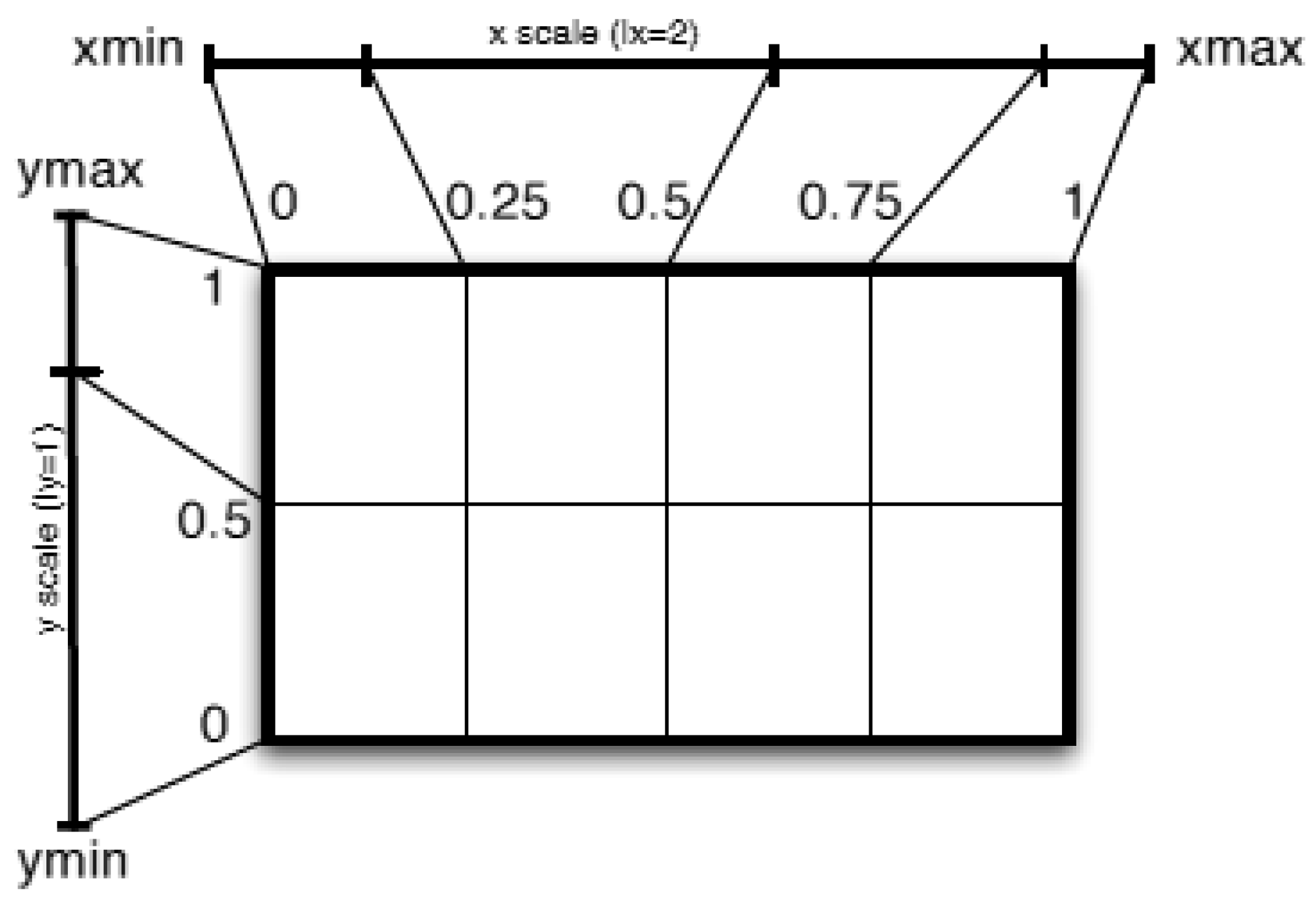
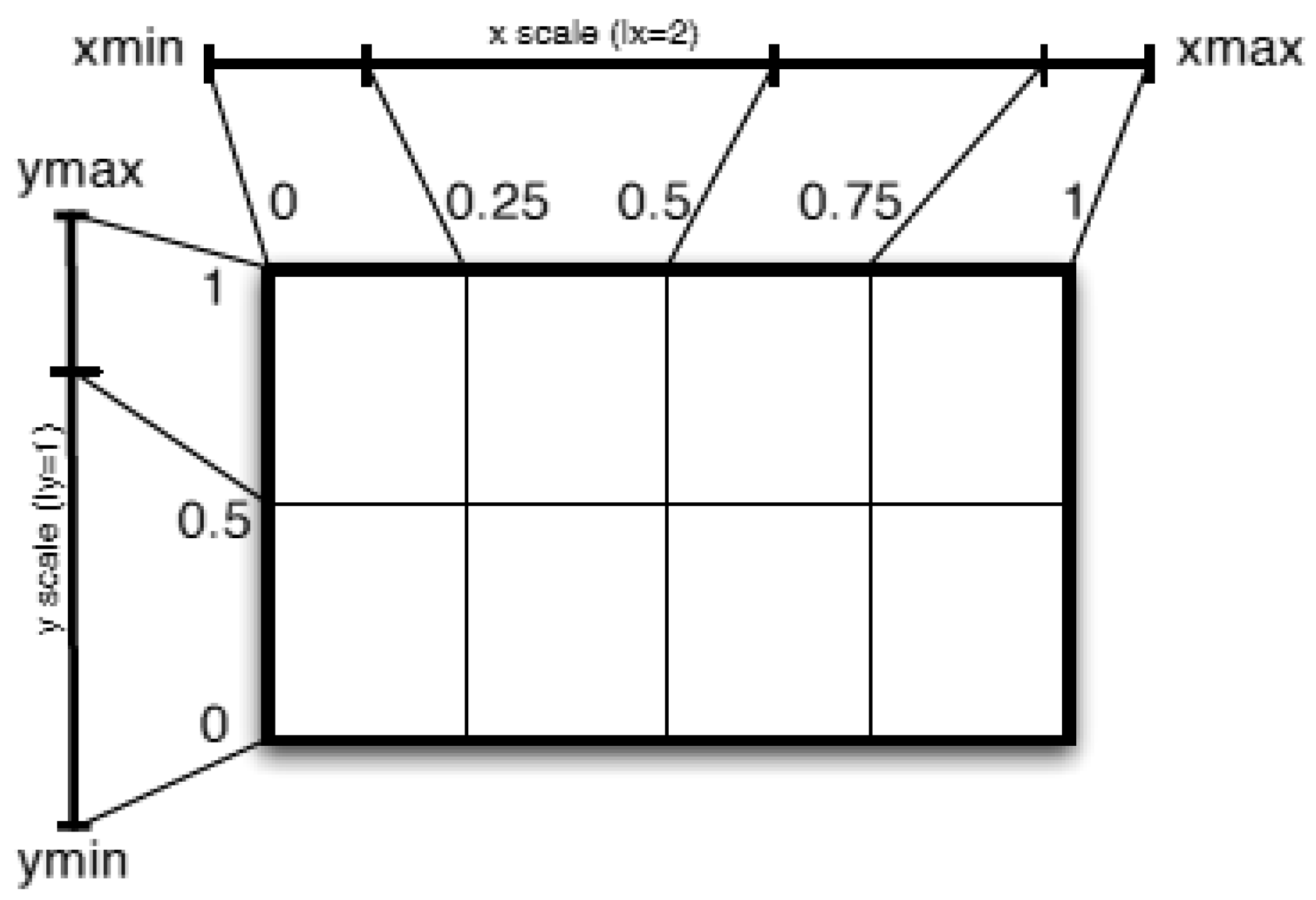
3.1.1. Mapping n-Tuples to the Unit Hypercube
3.1.2. Grid Partitioning and Resolution
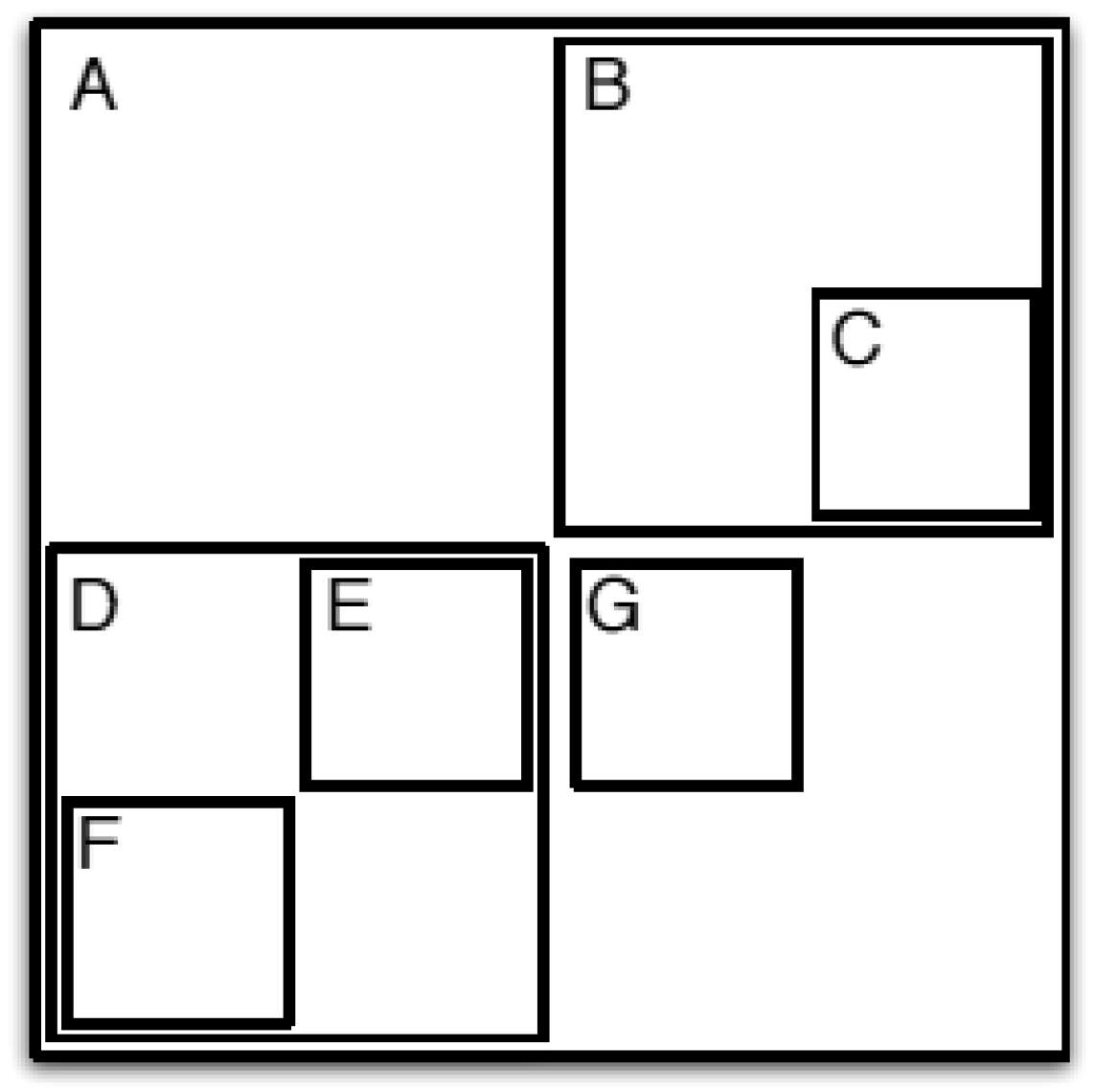
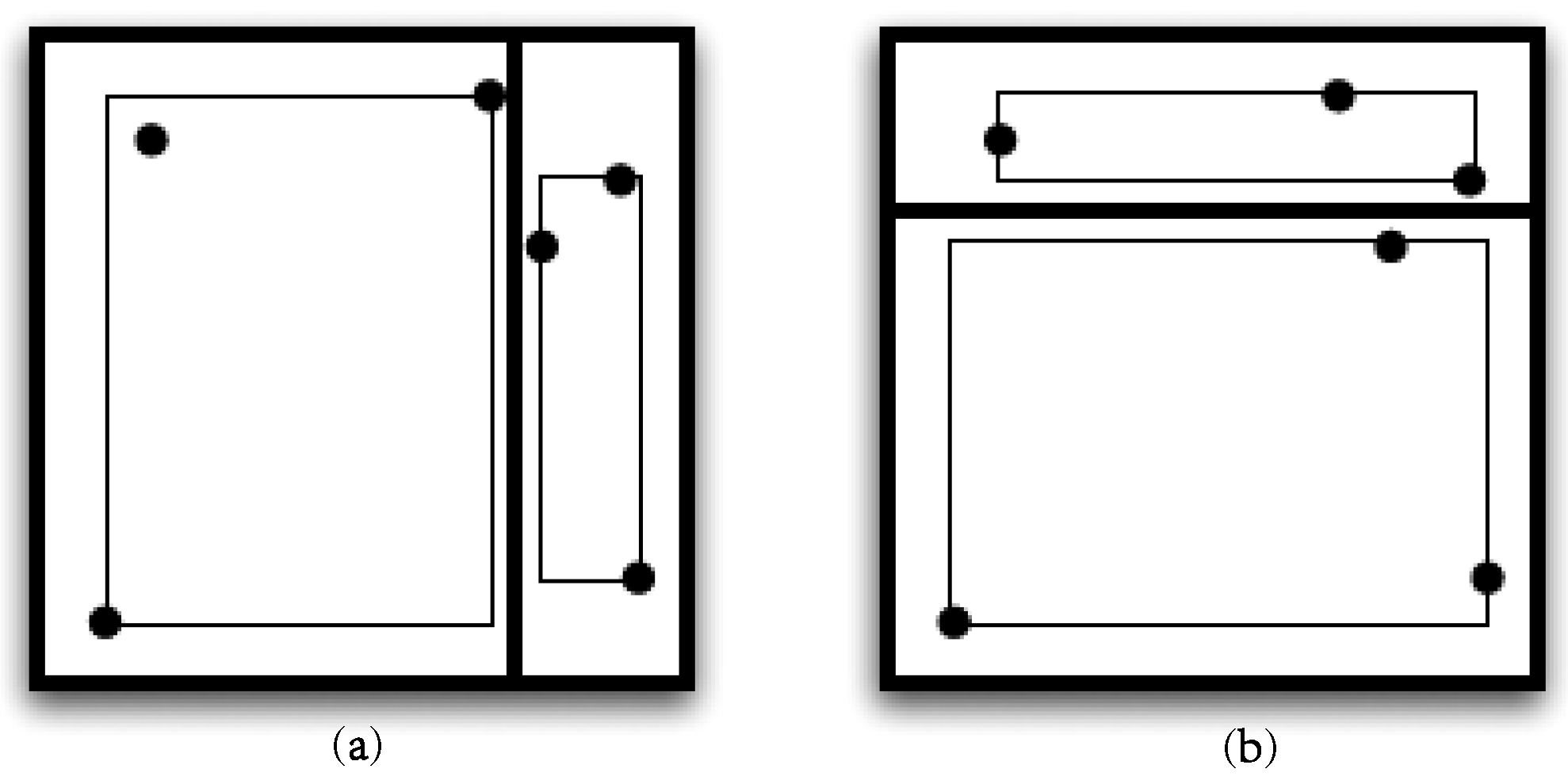
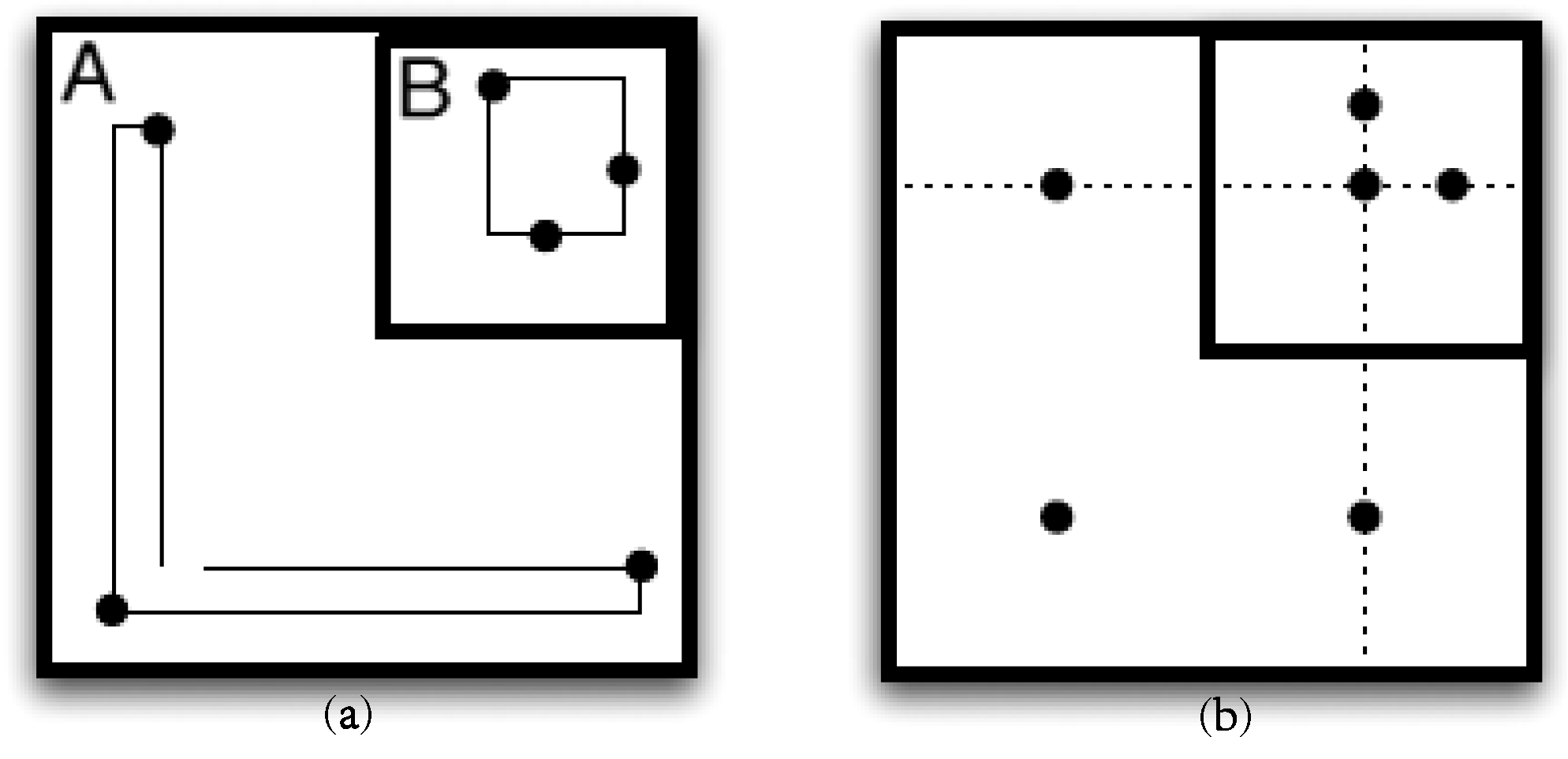
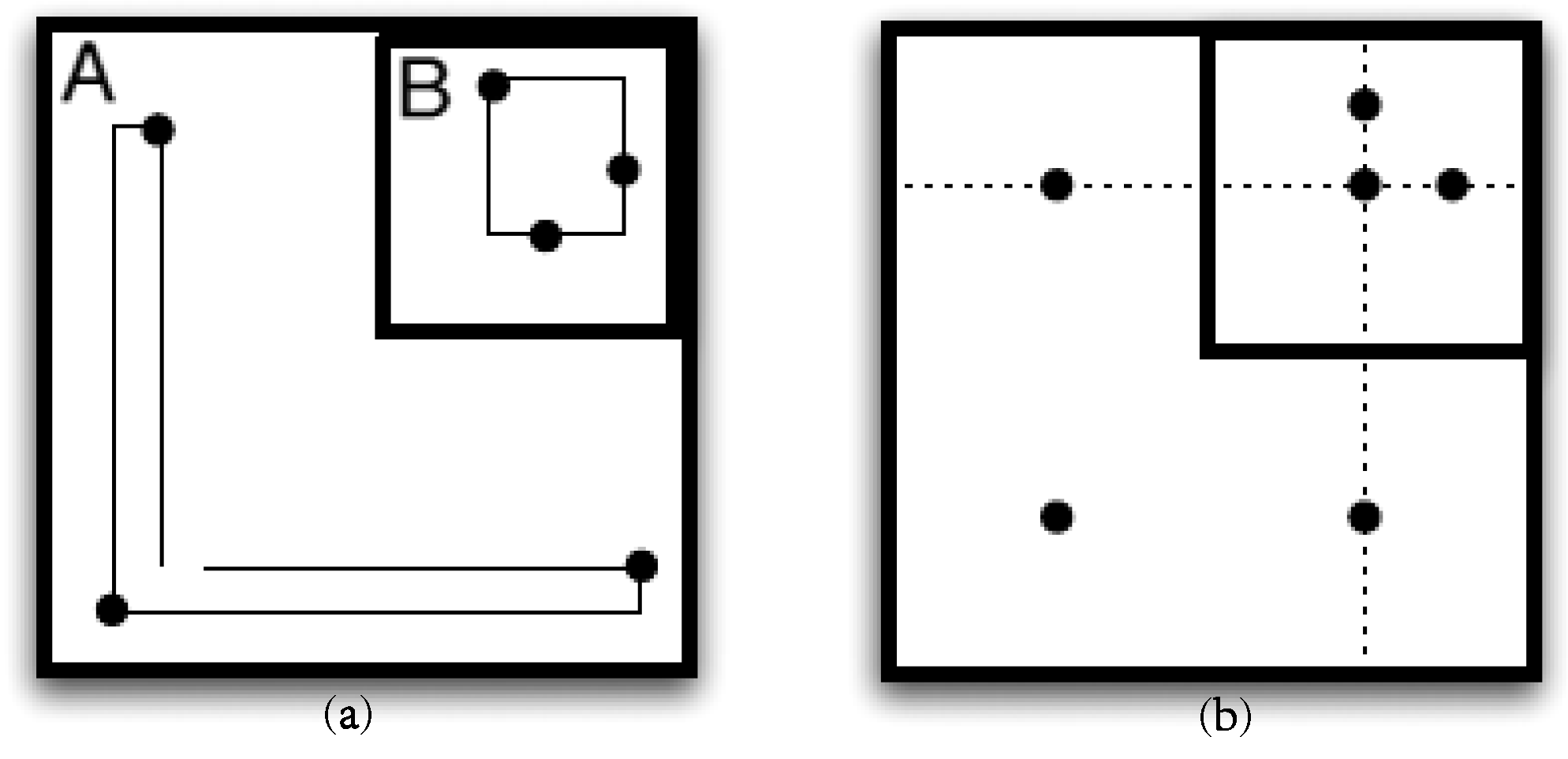
3.1.3. About Shape
- The union of all sub-spaces into which the data space has been partitioned must span the data space.
- If two sub-spaces into which the data space has been partitioned intersect, then one of these sub-spaces completely encloses the other.
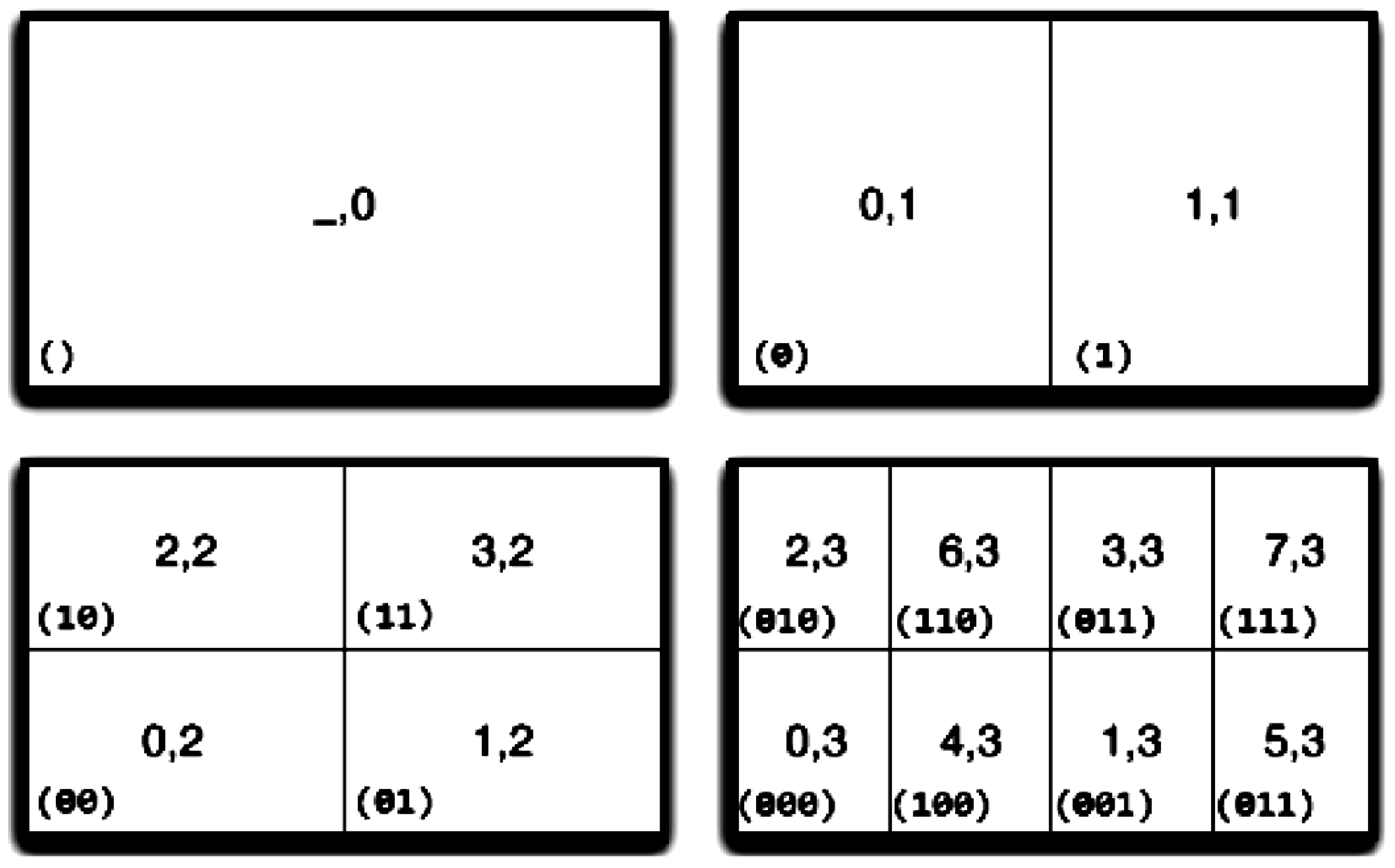
3.2. Mapping Scheme
- Level is created by splitting each region in a specific dimension.
- The total number of regions for the level 1 is .
- The region can be split into and .
- Region numbers r and are two possible extensions of the binary representation of r by one bit (the most significant).
- The value space of a scale is doubled, if the splitting level in dimension i increases from to . This indicates an extension by one bit.
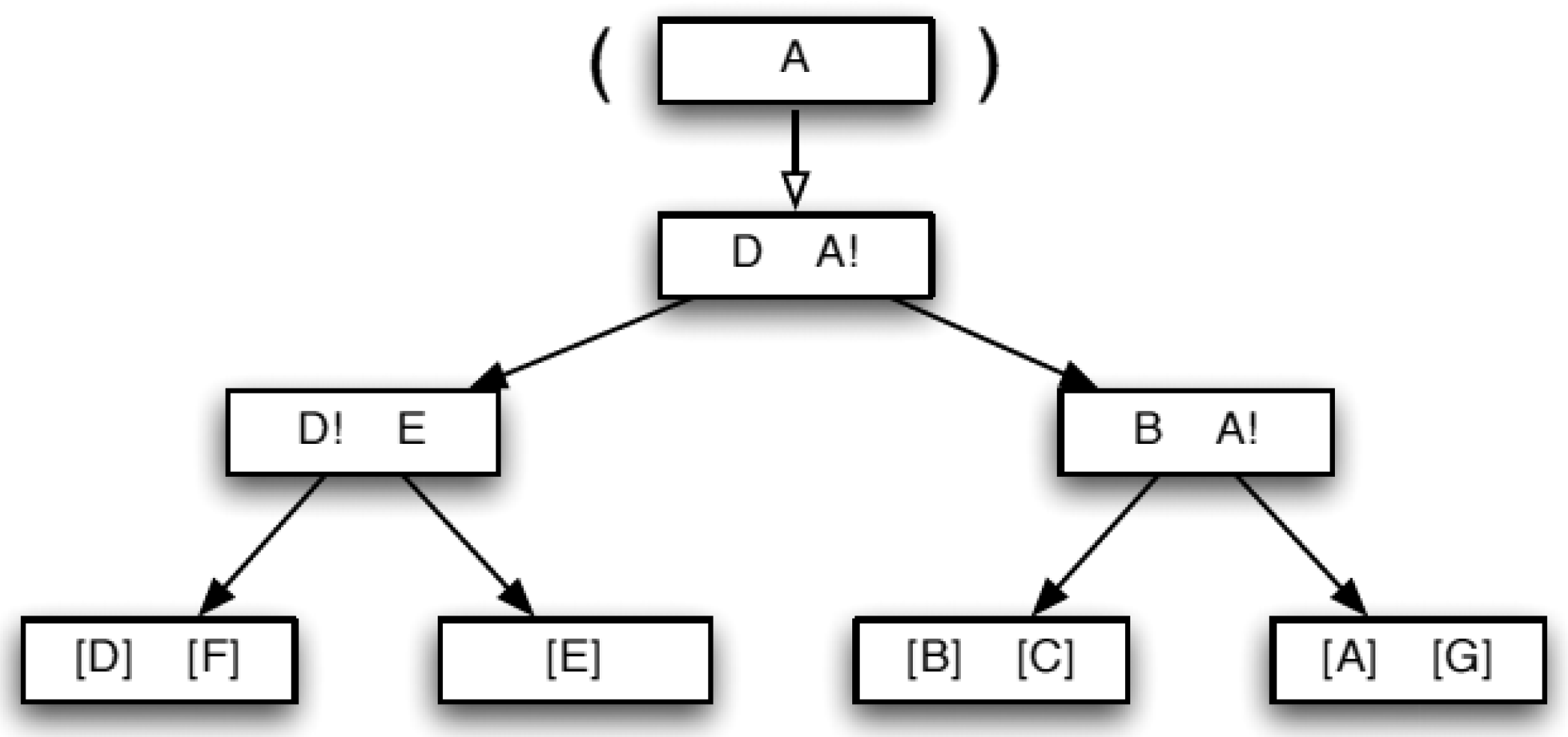
| Algorithm 1: Mapping Scheme [33] |
 |
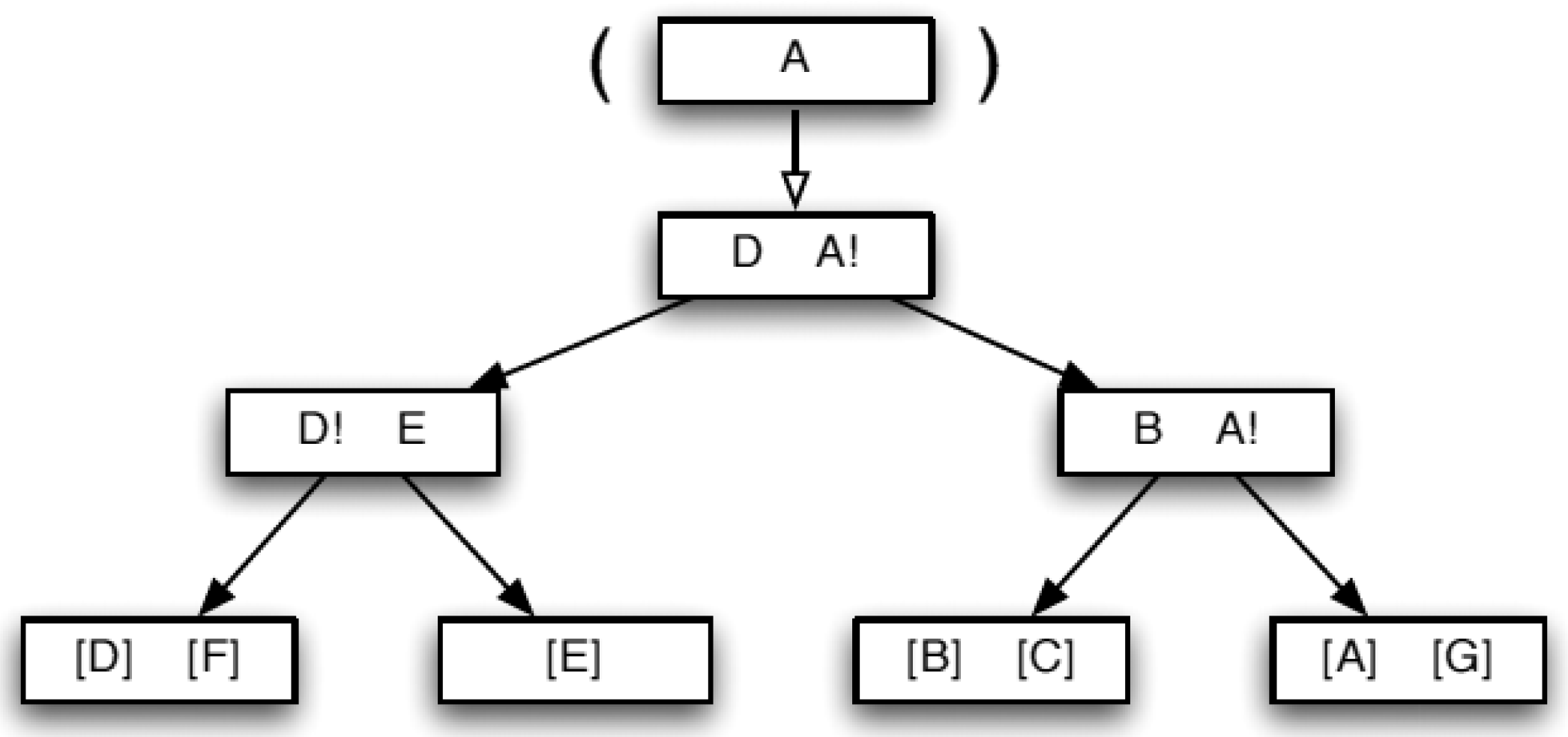
3.3. BANG Directory
4. From BANG Directory to Anonymous Public Release
4.1. Density-Based Clustering
4.2. Multi-Granular Anonymity
4.3. BangA and Other Syntactic Generalization Models
4.4. Compaction Procedure
5. Experimental Validation
5.1. Preparation and Settings
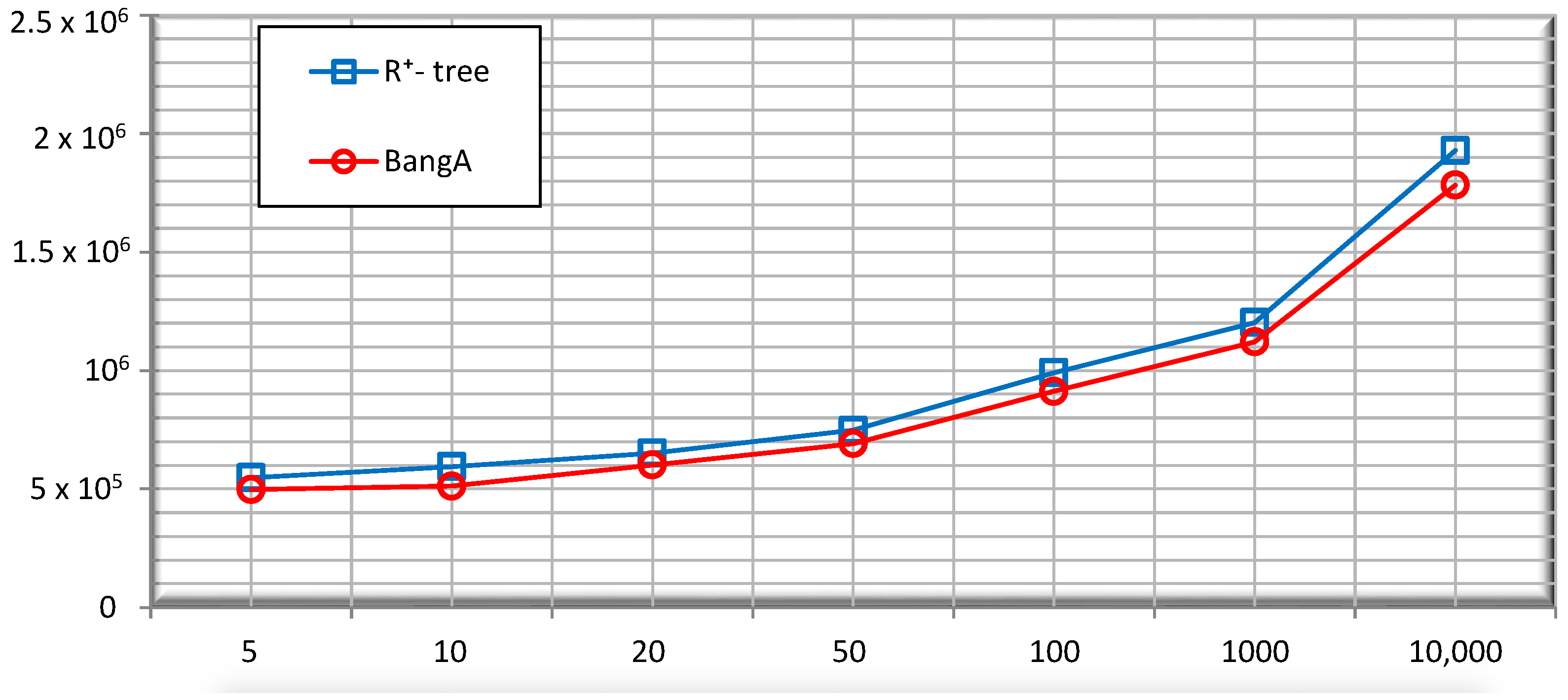
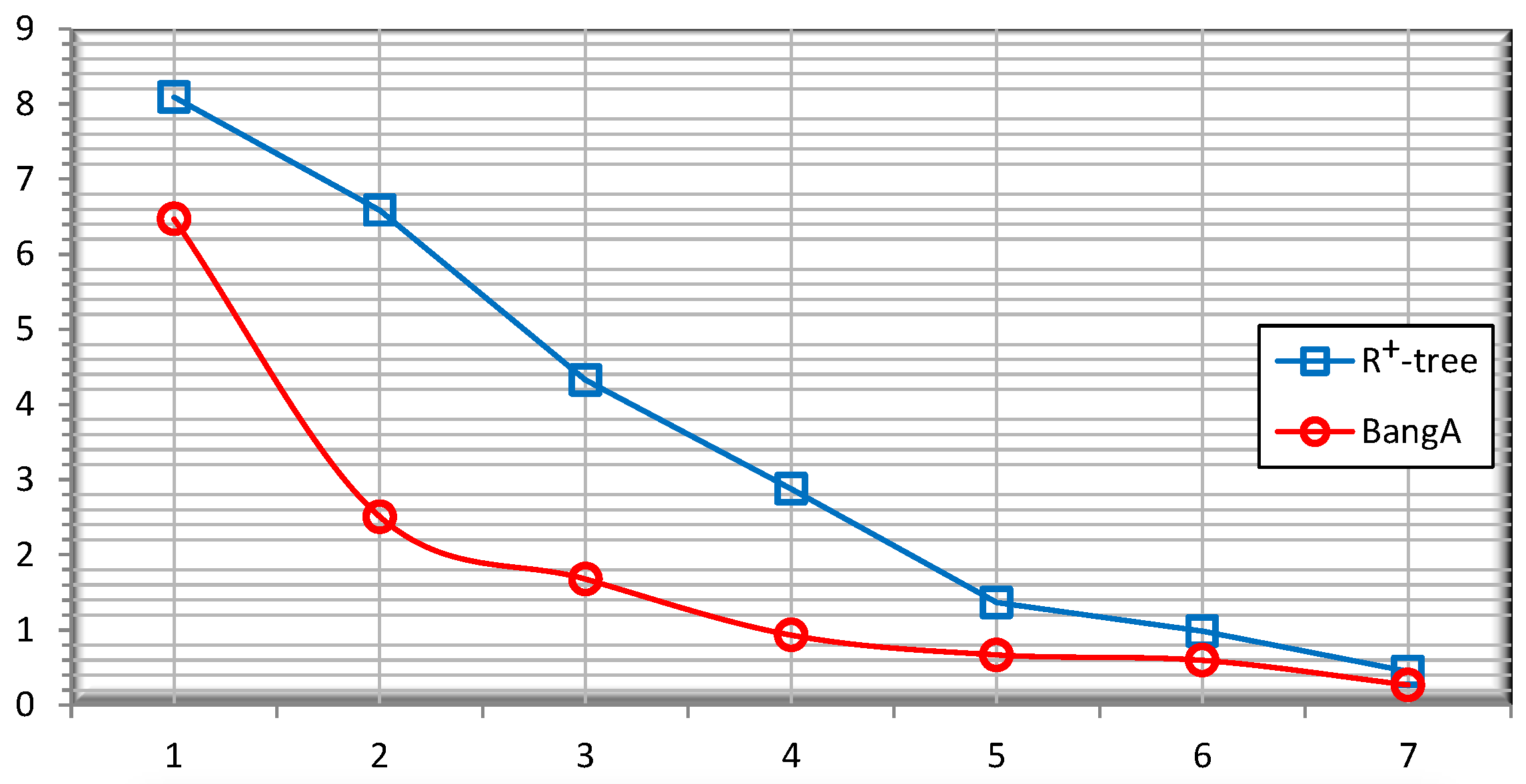
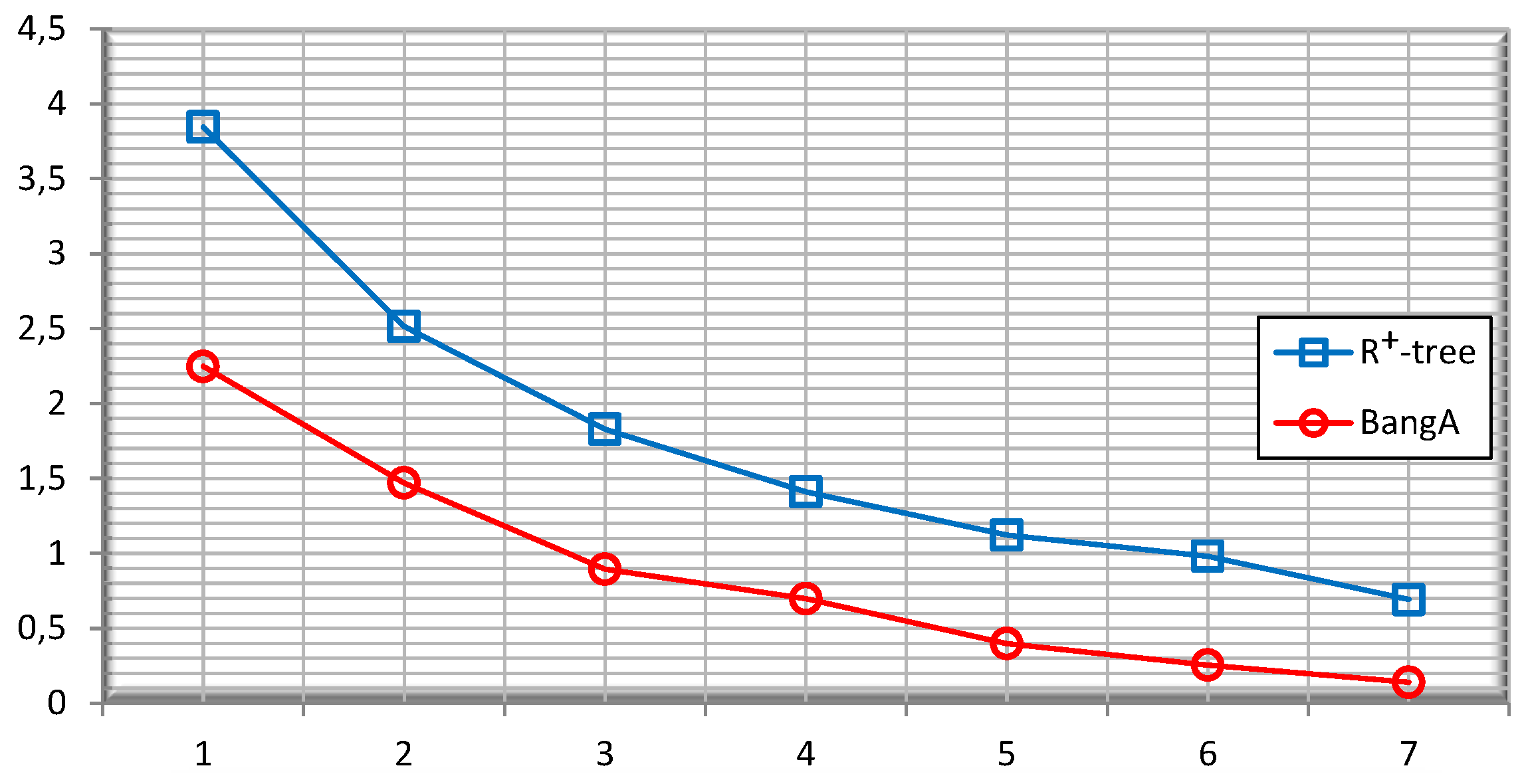
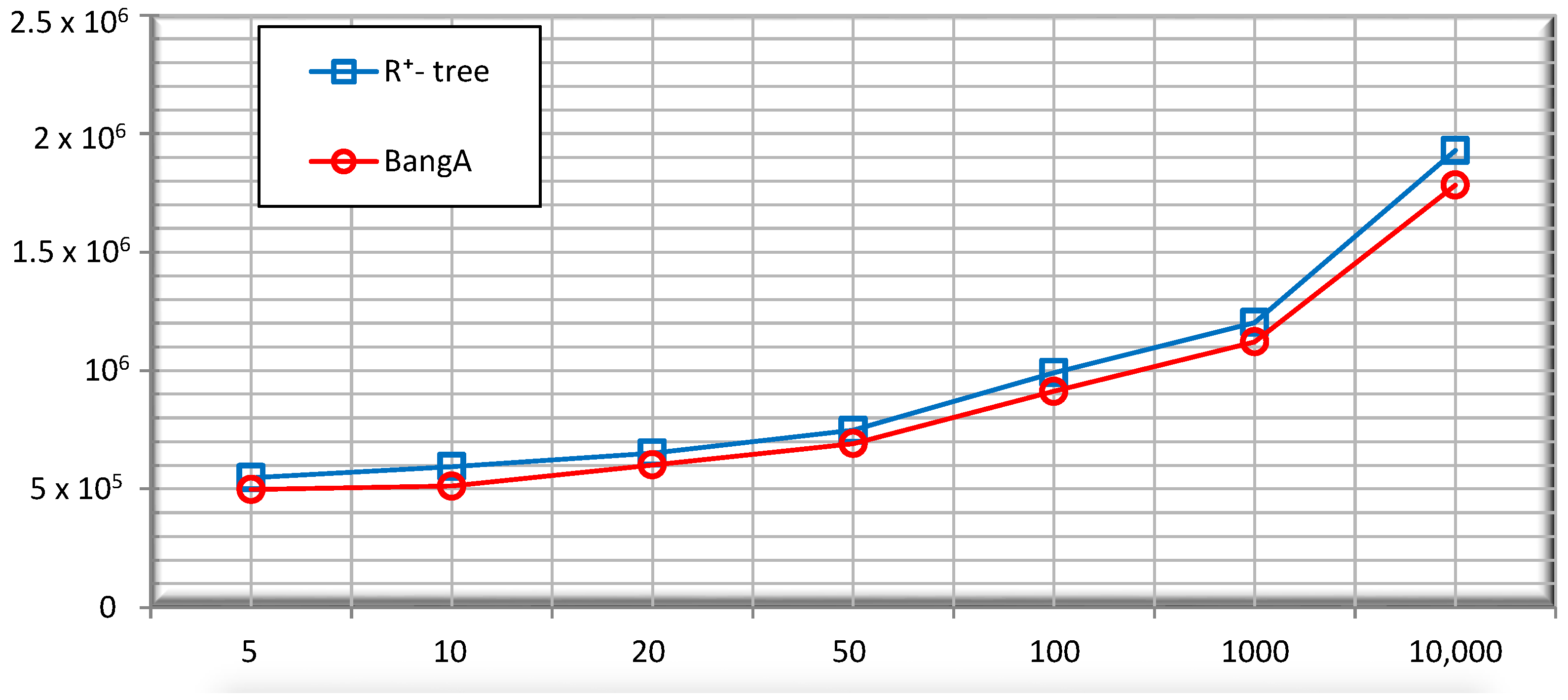
5.2. Performance
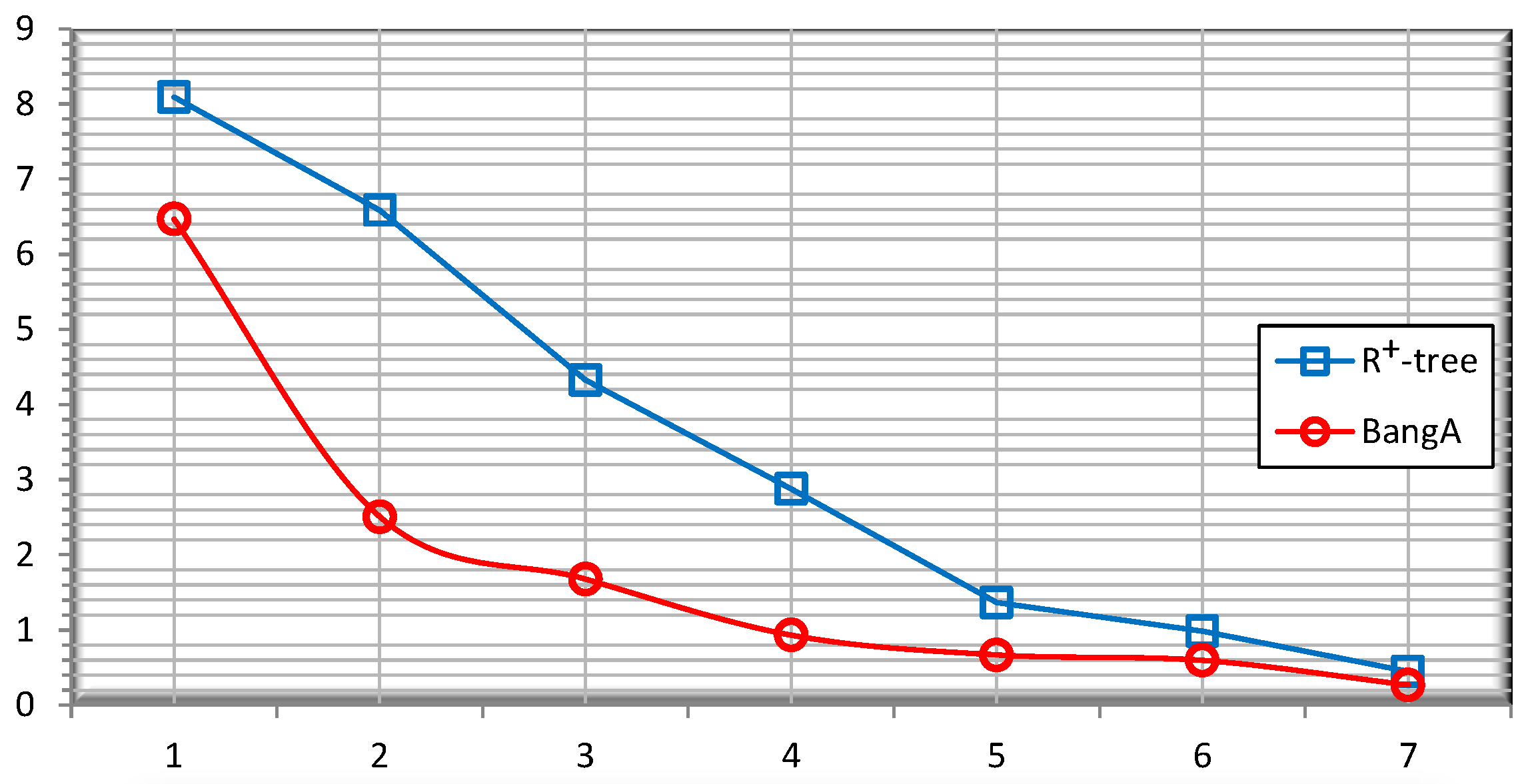
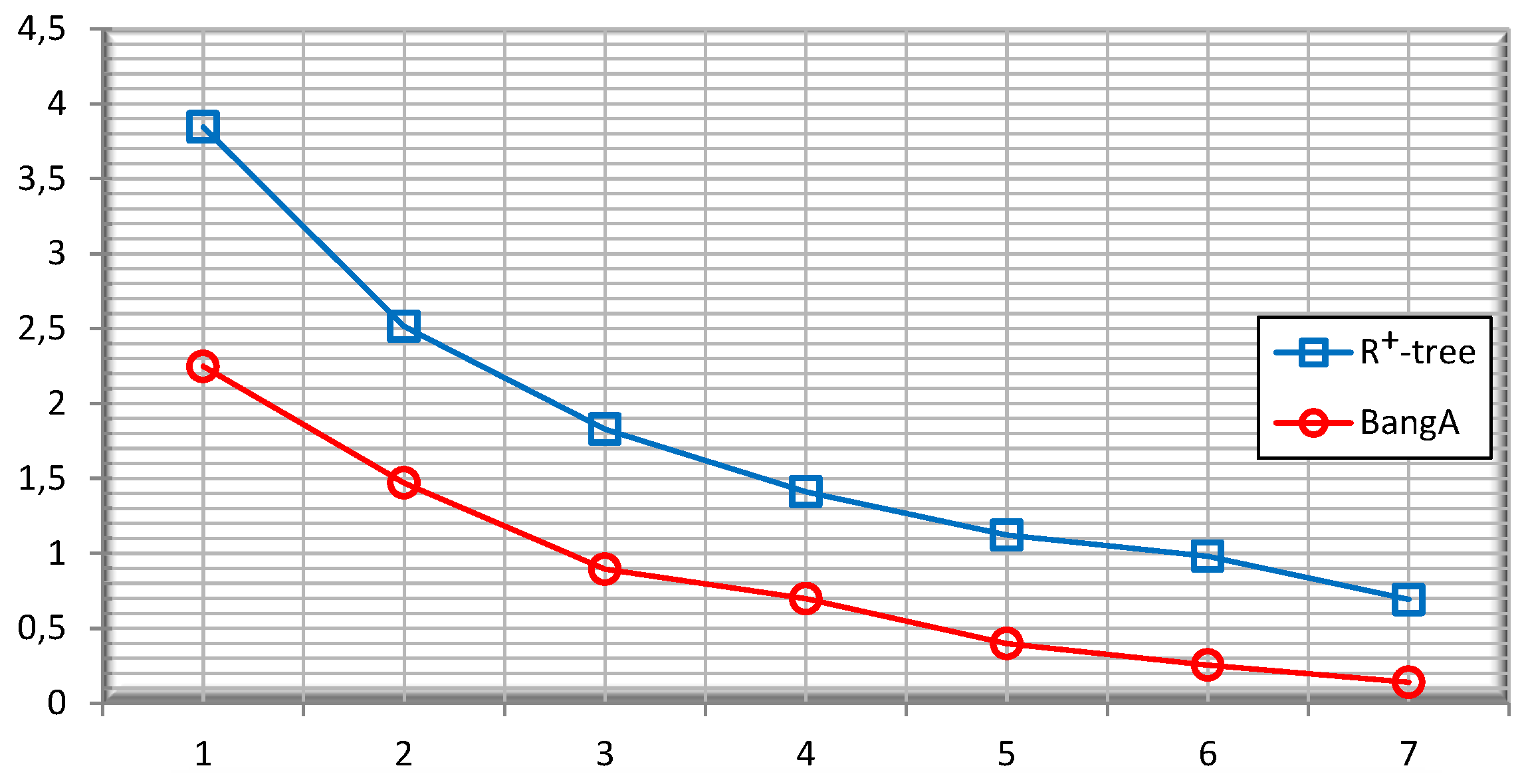
5.3. Quality of the Public Release
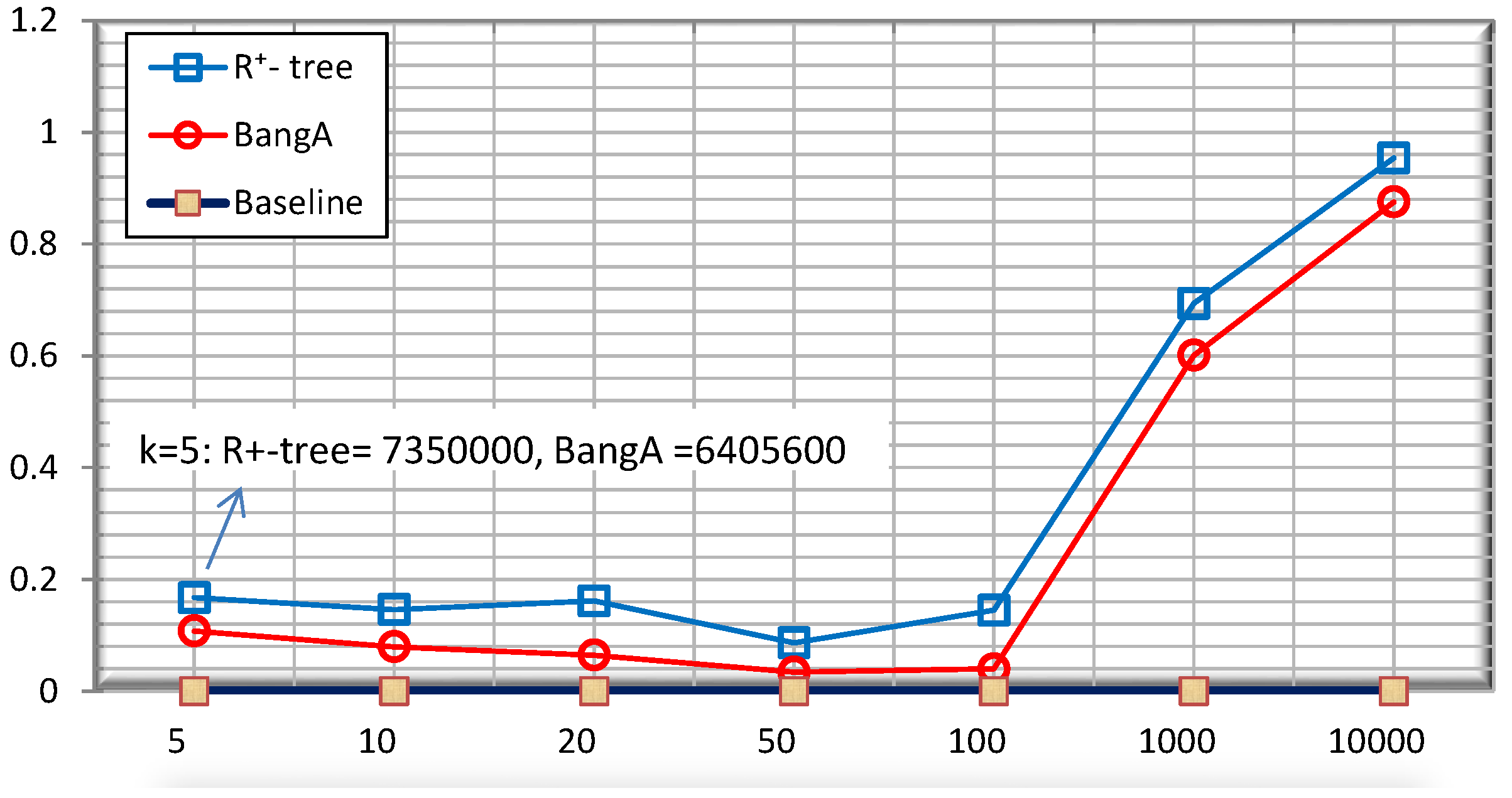
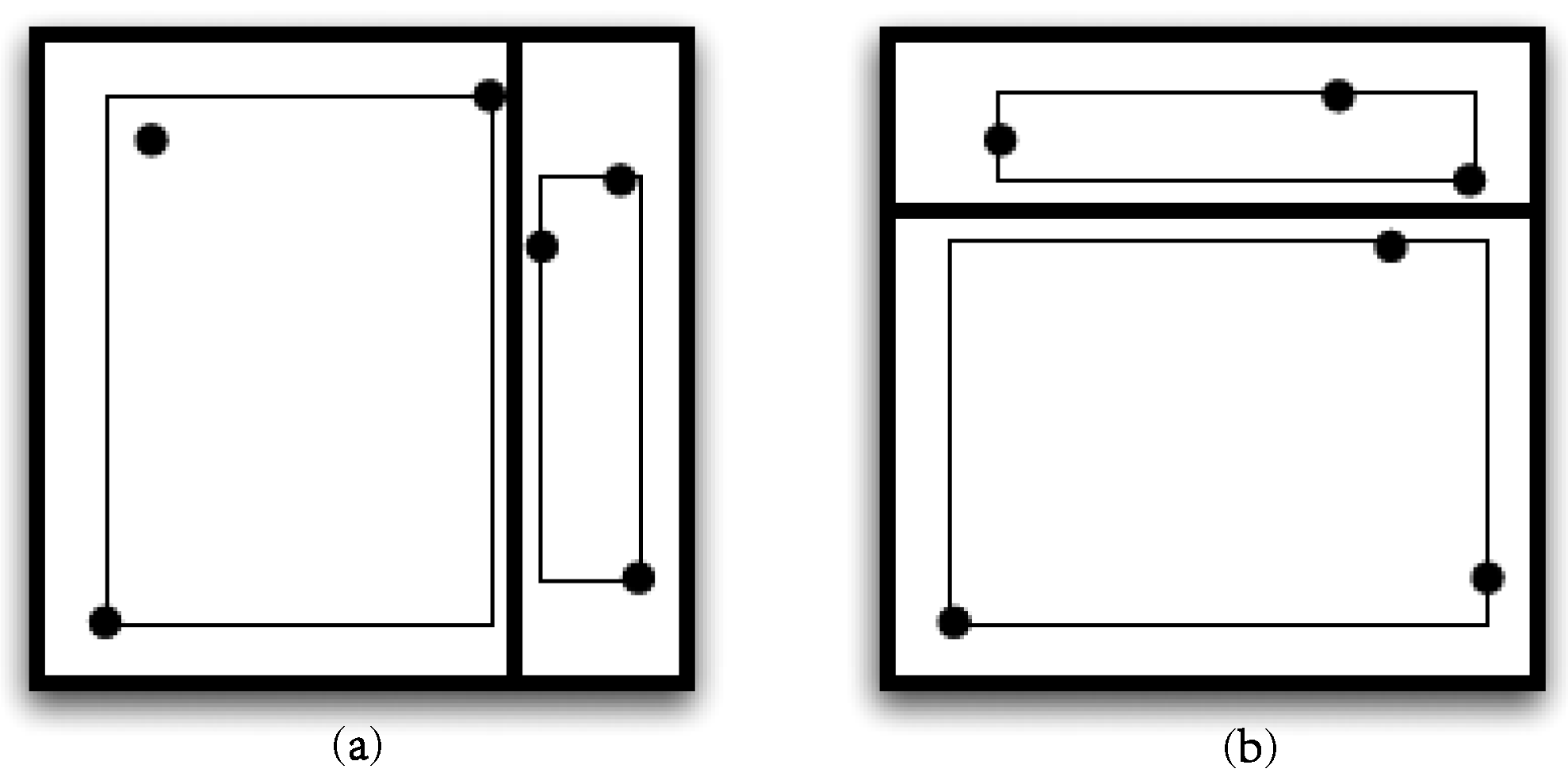
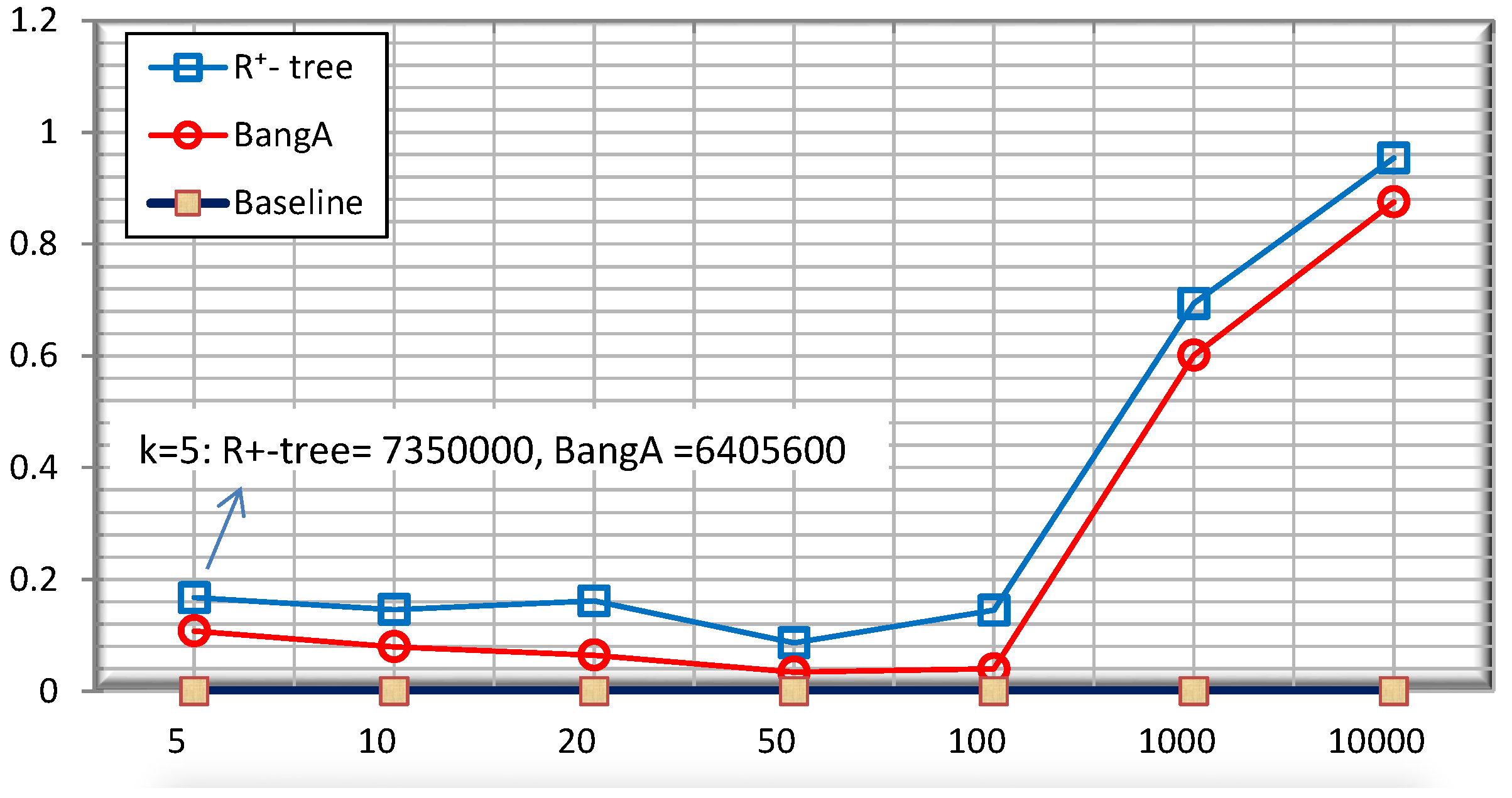
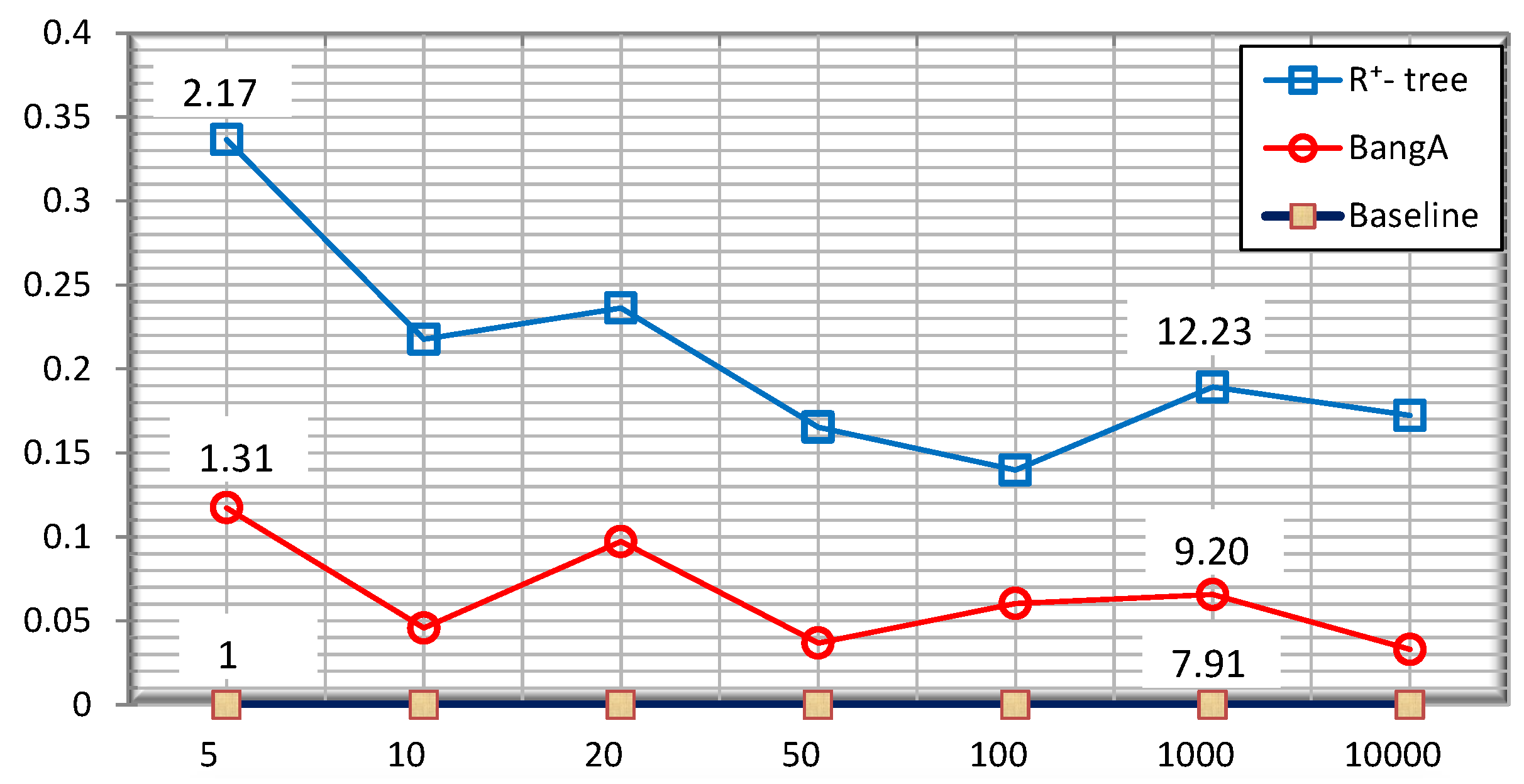
5.4. Query Accuracy
- SELECT COUNT(*) from R
- WHERE qi1 ∈ D(QI1)
- AND … AND qiq ∈ D(QIq)
- SELECT COUNT(*) from R
- WHERE R.QI1 ≥ qi1 AND R.QI1 ≤ qi2
- AND
- …
- AND
- R.QI7 ≥ qi7 AND R.QI7 ≤ qi7
6. Conclusions
- random sampling,
- regular generalization mechanism with multidimensional partitioning,
- Laplace mechanism for blocks with small counts.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Agarwal, P. Range Searching. In Handbook of Discrete and Computational Geometry; CRC Press, Inc.: Boca Raton, FL, USA, 1997; Volume 2, pp. 809–838. [Google Scholar]
- Bayardo, R.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the 21st International Conference on Data Engineering (ICDE 2005), Tokyo, Japan, 5–8 April 2005; pp. 217–228.
- Kifer, D.; Gehrke, J. Injecting utility into anonymized datasets. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; ACM: New York, NY, USA, 2006; p. 228. [Google Scholar]
- Xu, J.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A. Utility-based anonymization using local recoding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006; p. 790. [Google Scholar]
- Meyerson, A.; Williams, R. On the complexity of optimal k-anonymity. In Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Paris, France, 14–16 June 2004; ACM: New York, NY, USA, 2004; pp. 223–228. [Google Scholar]
- Fung, B.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. (CSUR) 2010, 42, 14. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering ICDE’06, Atlanta, GA, USA, 3–7 April 2006; p. 25.
- Iwuchukwu, T.; Naughton, J. K-anonymization as spatial indexing: Toward scalable and incremental anonymization. In Proceedings of the 33rd International Conference on Very Large Data Bases, VLDB Endowment, Vienna, Austria, 23–27 September 2007; pp. 746–757.
- Ghinita, G.; Kalnis, P.; Khoshgozaran, A.; Shahabi, C.; Tan, K. Private queries in location based services: Anonymizers are not necessary. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; ACM: New York, NY, USA, 2008; pp. 121–132. [Google Scholar]
- Gruteser, M.; Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services, San Francisco, CA, USA, 5–8 May 2003; pp. 31–42.
- Damiani, M.; Bertino, E.; Silvestri, C. The probe framework for the personalized cloaking of private locations. Trans. Data Priv. 2010, 3, 123–148. [Google Scholar]
- Mokbel, M.; Chow, C.; Aref, W. The new casper: Query processing for location services without compromising privacy. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006; pp. 763–774.
- Chor, B.; Goldreich, O.; Kushilevitz, E.; Sudan, M. Private information retrieval. In Proceedings of the 36th Annual Symposium on Foundations of Computer Science, Milwaukee, WI, USA, 23–25 October 1995; pp. 41–50.
- Krishnamachari, B.; Ghinita, G.; Kalnis, P. Privacy-Preserving Publication of User Locations in the Proximity of Sensitive Sites. In Scientific and Statistical Database Management; Springer: New York, NY, USA, 2008; pp. 95–113. [Google Scholar]
- Navarro-Arribas, G.; Torra, V.; Erola, A.; Castellà-Roca, J. User k-anonymity for privacy preserving data mining of query logs. Inf. Process. Manag. 2012, 48, 476–487. [Google Scholar] [CrossRef]
- Erola, A.; Castellà-Roca, J.; Navarro-Arribas, G.; Torra, V. Semantic Microaggregation for the Anonymization of Query Logs. In Privacy in Statistical Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 127–137. [Google Scholar]
- Aggarwal, G.; Feder, T.; Kenthapadi, K.; Khuller, S.; Panigrahy, R.; Thomas, D.; Zhu, A. Achieving anonymity via clustering. In Proceedings of the Twenty-Fifth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Chicago, IL, USA, 26–28 June 2006; ACM: New York, NY, USA, 2006; pp. 153–162. [Google Scholar]
- Byun, J.; Kamra, A.; Bertino, E.; Li, N. Efficient k-anonymization using clustering techniques. In Proceedings of the Advances in Databases: Concepts, Systems and Applications, Bangkok, Thailand, 9–12 April 2007; pp. 188–200.
- Chiu, C.; Tsai, C. A k-anonymity clustering method for effective data privacy preservation. In Proceedings of the Advanced Data Mining and Applications, Harbin, China, 6–8 August 2007; pp. 89–99.
- Pilevar, A.; Sukumar, M. Gchl: A grid-clustering algorithm for high-dimensional very large spatial data bases. Pattern Recognit. Lett. 2005, 26, 999–1010. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. In Proceedings of the International Conference on Very Large Data Bases, Athens, Greece, 26–29 August 1997; pp. 186–195.
- Samarati, P.; Sweeney, L. Generalizing data to provide anonymity when disclosing information. In Proceedings of the ACM SIGACT SIGMOD SIGART Symposium on Principles of Database Systems, Seattle, WA, USA, 1–3 June 1998; Volume 17, p. 188.
- Aggarwal, C. On k-anonymity and the curse of dimensionality. In Proceedings of the 31st international conference on Very Large Data Bases, VLDB Endowment, Trondheim, Norway, 30 August–2 September 2005; pp. 901–909.
- Li, N.; Qardaji, W.; Su, D. Provably Private Data Anonymization: Or, k-Anonymity Meets Differential Privacy. Available online: https://www.cerias.purdue.edu/assets/pdf/bibtex_archive/2010-24.pdf (accessed on 29 December 2016).
- Gehrke, J.; Hay, M.; Lui, E.; Pass, R. Crowd-Blending Privacy. In Advances in Cryptology–CRYPTO 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 479–496. [Google Scholar]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Martínez, S. Enhancing data utility in differential privacy via microaggregation-based k-anonymity. VLDB J. 2014, 23, 771–794. [Google Scholar] [CrossRef]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 3. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Incognito: Efficient full-domain k-anonymity. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; ACM: New York, NY, USA, 2005; p. 60. [Google Scholar]
- Freeston, M. The BANG file: A new kind of grid file. ACM SIGMOD Rec. 1987, 16, 260–269. [Google Scholar] [CrossRef]
- Samet, H. Foundations of Multidimensional and Metric Data Structures; Morgan Kaufmann: Burlington, MA, USA, 2006. [Google Scholar]
- Schikuta, E.; Erhart, M. The BANG-Clustering System: Grid-Based Data Analysis. In Advances in Intelligent Data Analysis Reasoning about Data; Springer: Berlin/Heidelberg, Germany, 1997; pp. 513–524. [Google Scholar]
- Schikuta, E. Grid-clustering: An efficient hierarchical clustering method for very large data sets. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996; Volume 2, pp. 101–105.
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the IEEE 23rd International Conference on Data Engineering, ICDE 2007, Istanbul, Turkey, 16–20 April 2007; pp. 106–115.
- Datanamic Data Generator. Available online: http://www.datanamic.com/datagenerator/index.html (accessed on 31 December 2016).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Age | Zip Code | Gender | Disease |
|---|---|---|---|---|
| 1 | (48–62) (62) | 441XX (44120) | *(F) | Flu |
| 2 | (48–62) (51) | 441XX (44190) | *(M) | Flu |
| 3 | (48–62) (48) | 441XX (44100) | *(M) | HIV |
| 4 | (59–77) (59) | 444XX (44470) | *(F) | Flu |
| 5 | (59–77) (77) | 444XX (44420) | *(M) | Gastritis |
| 6 | (59–77) (66) | 444XX (44420) | *(M) | HIV |
| Data Set | Size | Quasi-Identifiers | -Tree | BangA |
|---|---|---|---|---|
| Voter list | 54,803 | 3 | 6 s | 3 s |
| Adults | 1 million | 3 | 91 s | 55 s |
| Customer | 1 million | 15 | Out of memory | 240 s |
| Customer | 1 million | 7 | 1214 s | 112 s |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anjum, A.; Raschia, G. BangA: An Efficient and Flexible Generalization-Based Algorithm for Privacy Preserving Data Publication. Computers 2017, 6, 1. https://doi.org/10.3390/computers6010001
Anjum A, Raschia G. BangA: An Efficient and Flexible Generalization-Based Algorithm for Privacy Preserving Data Publication. Computers. 2017; 6(1):1. https://doi.org/10.3390/computers6010001
Chicago/Turabian StyleAnjum, Adeel, and Guillaume Raschia. 2017. "BangA: An Efficient and Flexible Generalization-Based Algorithm for Privacy Preserving Data Publication" Computers 6, no. 1: 1. https://doi.org/10.3390/computers6010001
APA StyleAnjum, A., & Raschia, G. (2017). BangA: An Efficient and Flexible Generalization-Based Algorithm for Privacy Preserving Data Publication. Computers, 6(1), 1. https://doi.org/10.3390/computers6010001