
An Automated System for Garment Texture Design Class Identification

Abstract
:1. Introduction
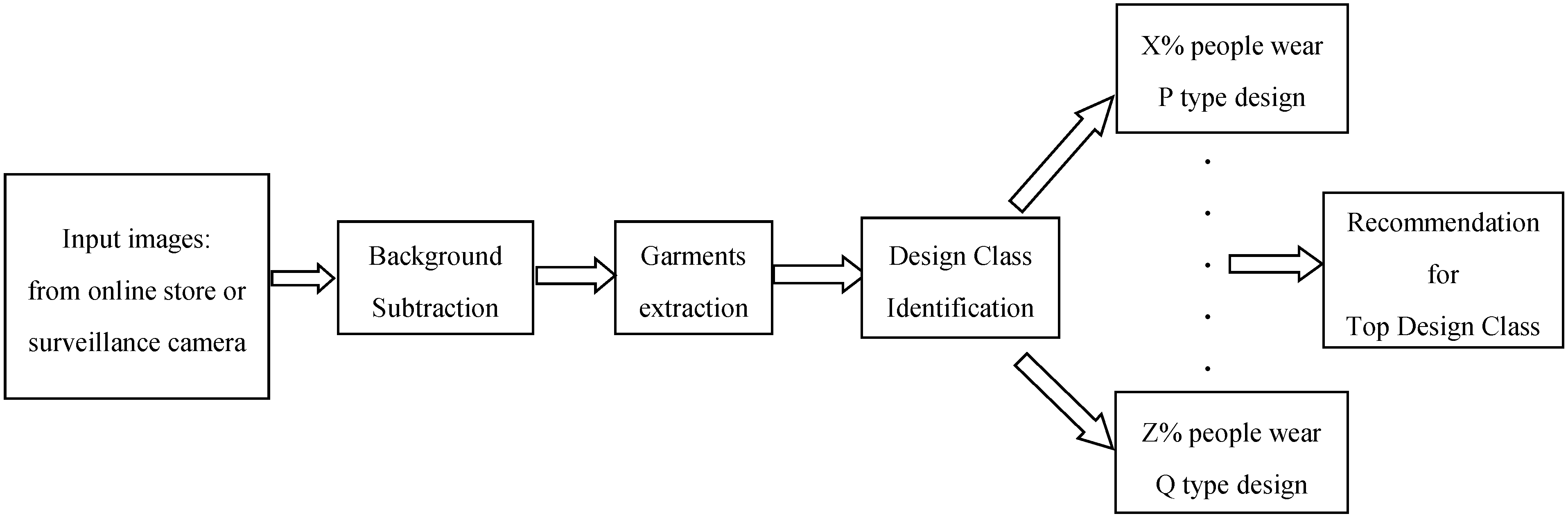
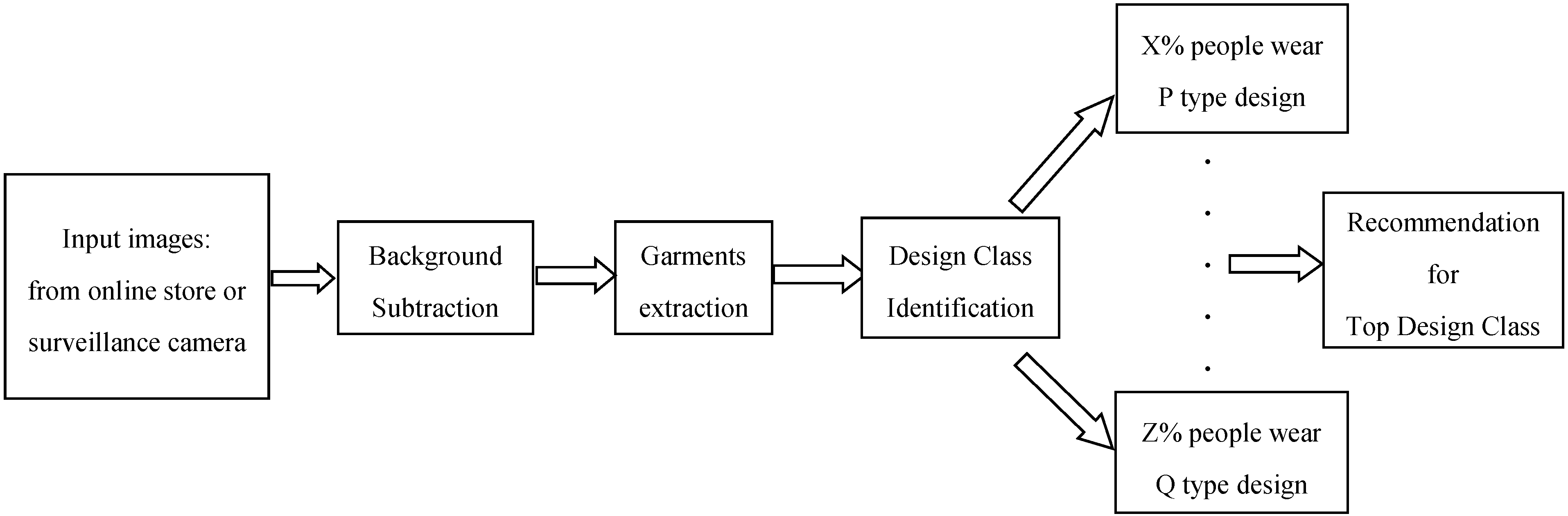
- We have introduced an automated system which can categorize garment products into some specific design classes,
- For capturing rotation invariant texture properties, we have proposed cCENTRIST and,
- Propose tCENTRIST, where there are no rotation invariant textures
2. Background Studies
2.1. Garment Product Segmentation and Type Identification
2.2. Texture Based Classification
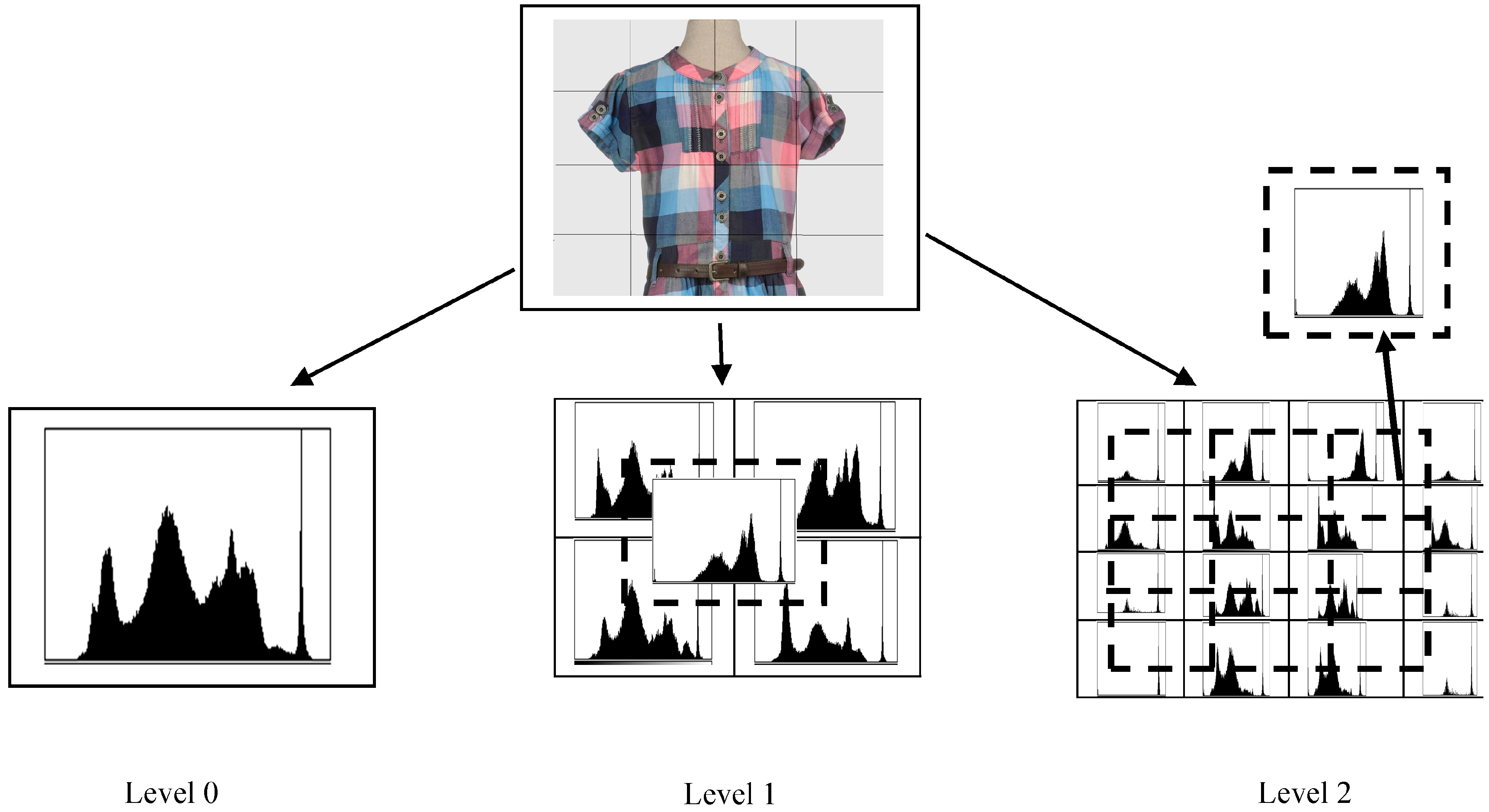
2.3. A Brief Description of Texture Descriptors
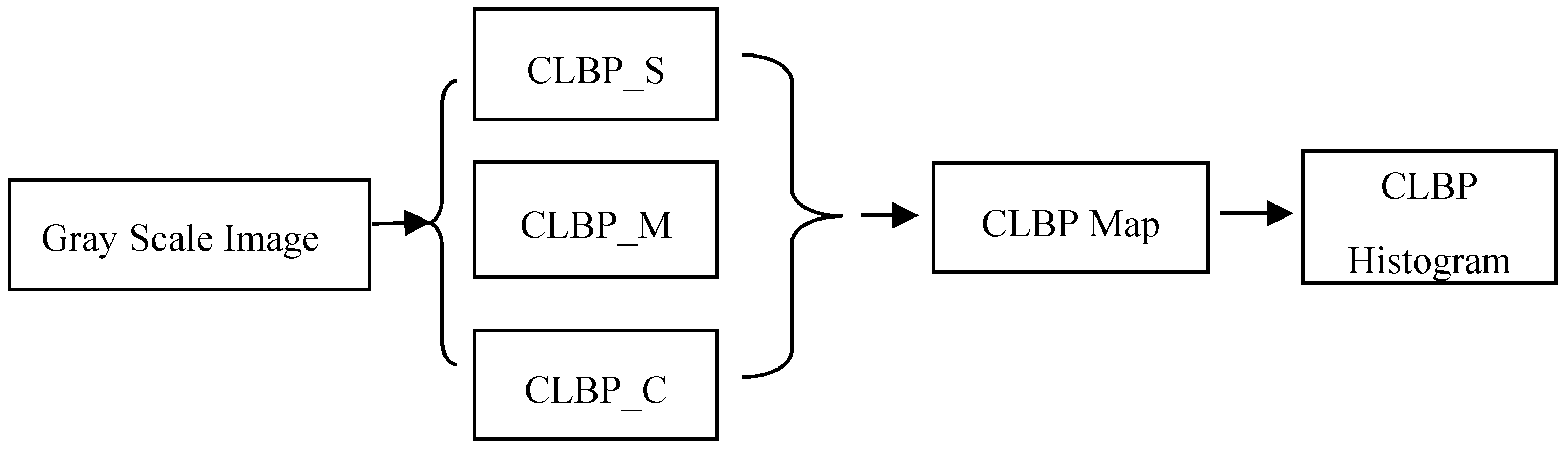
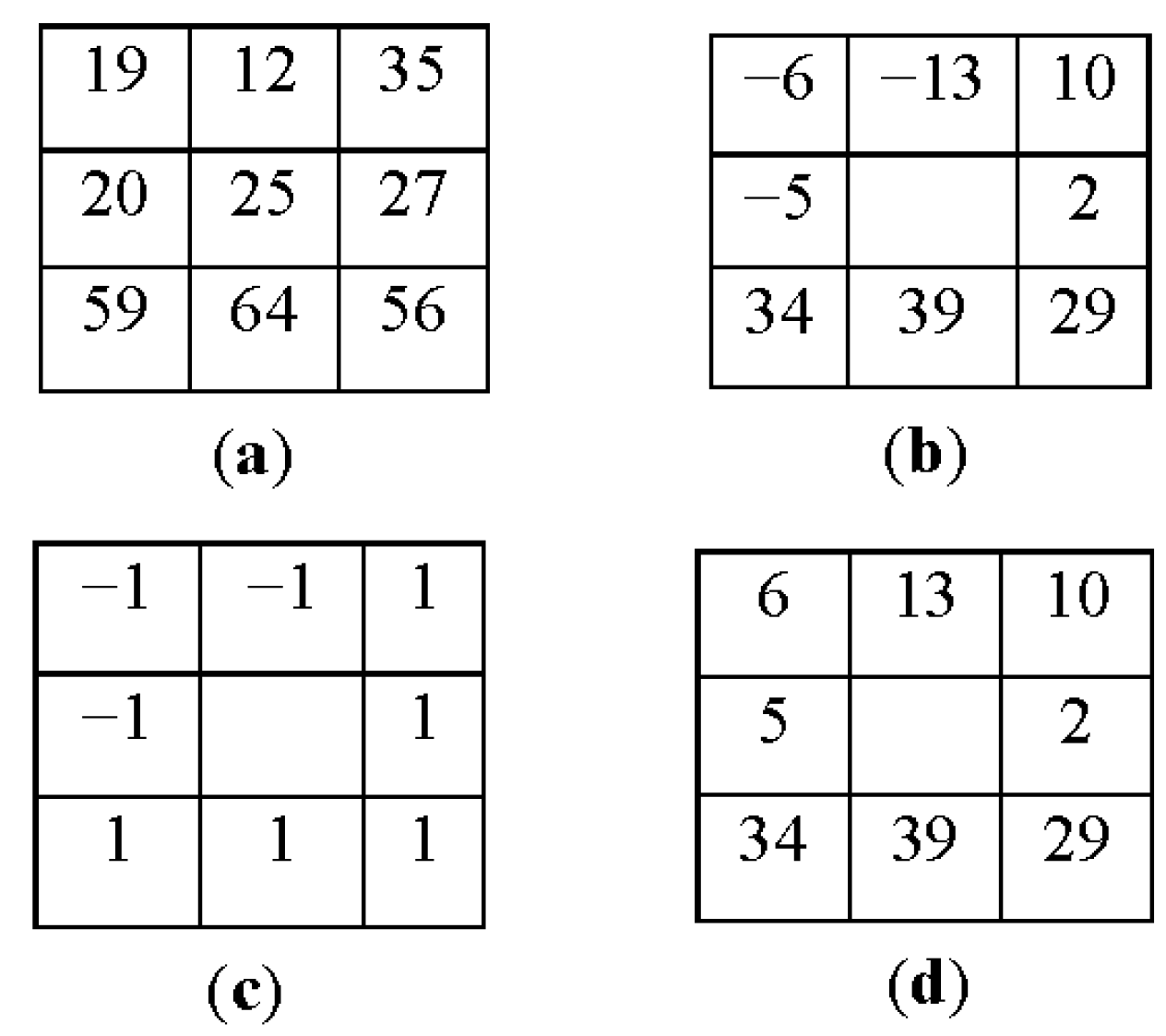
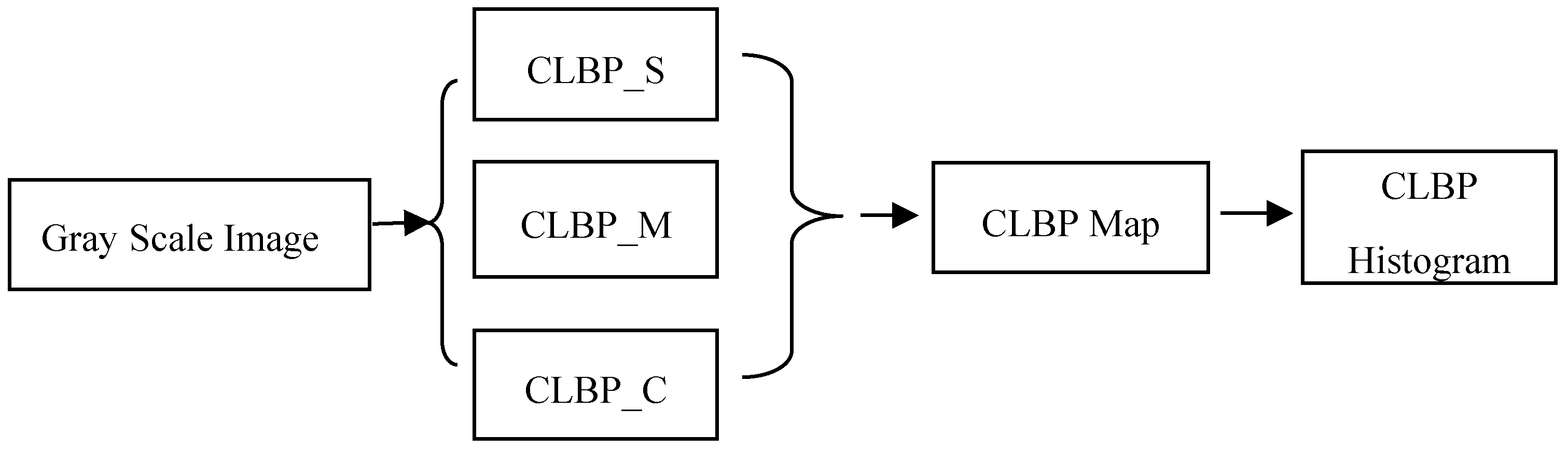
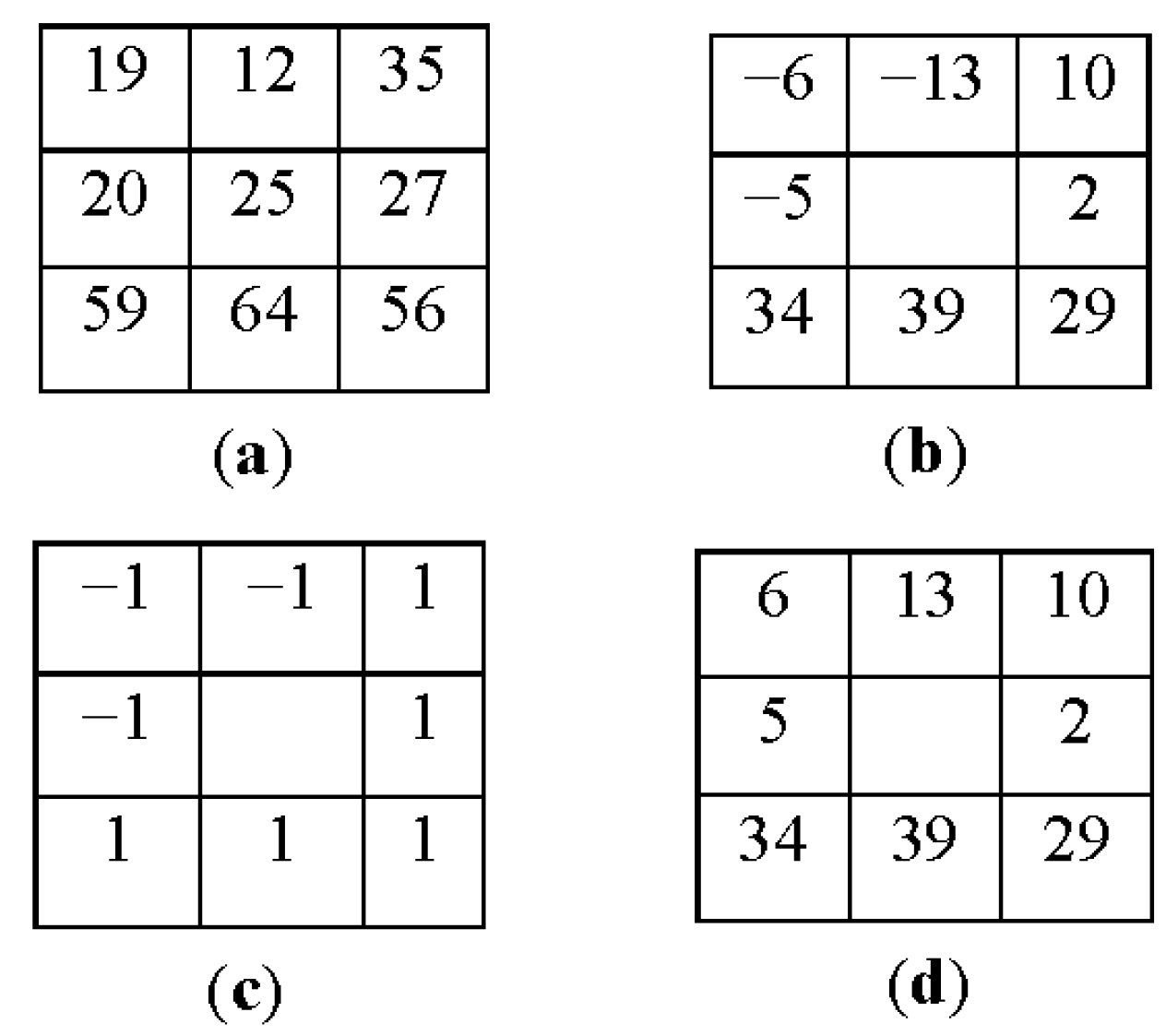
2.3.1. CLBP (Completed Local Binary Pattern)
2.3.2. CENTRIST

2.3.3. Local Ternary Pattern (LTP)
3. Proposed Method

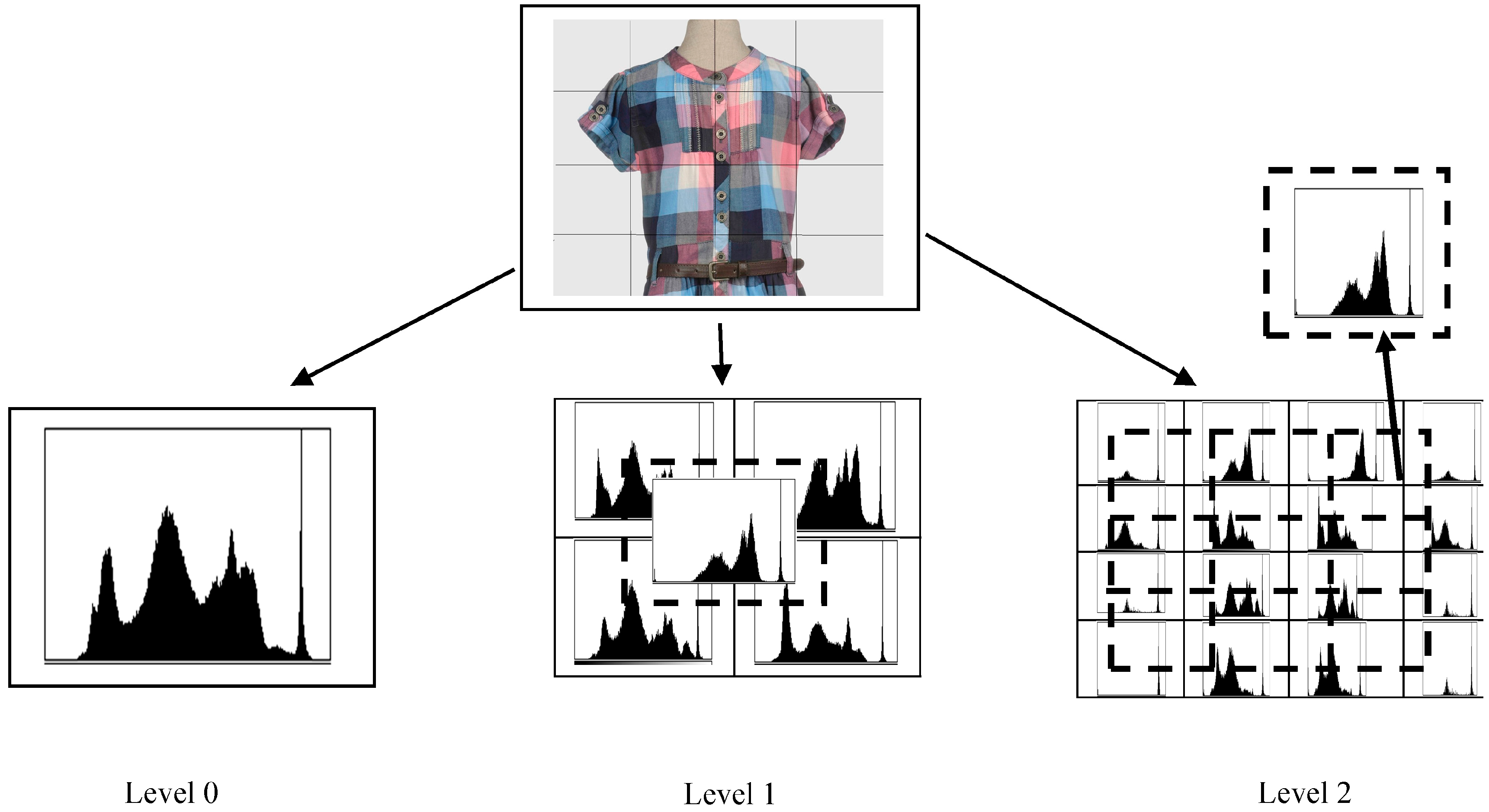
3.1. Completed CENTRIST (cCENTRIST)
| Algorithm1: |
Input:Gray scale image I Output:Feature vector of I 1. For each image I, calculate level 2 Spatial Pyramid (SP) 2. For each block of SP a. Calculate CLBP_SP,R, CLBP_MP,R and CLBP_CP,R b. Construct a 3D histogram (using CLBP_SP,R, CLBP_MP,R and CLBP_CP,R) End For 3. Concatenate all histograms and apply PCA to extract M feature points from each block 4. Combine N blocks for constructing a feature vector of length M × N for the input image. |
3.2. Ternary CENTRIST (tCENTRIST)
| Algorithm 2: |
Input:Gray scale imageI Output: Feature vectors of I 1. For each image I, calculate level 2 Spatial Pyramid (SP) 2. For each block of SP a. calculate LTP b. Construct histogram of LTP End For 3. Concatenate all histograms and apply PCA to extract M feature vector from each block 4. Combine N blocks to construct M × N feature for each image. |
4. Experiments
4.1. Dataset


4.2. Training and Testing Protocol
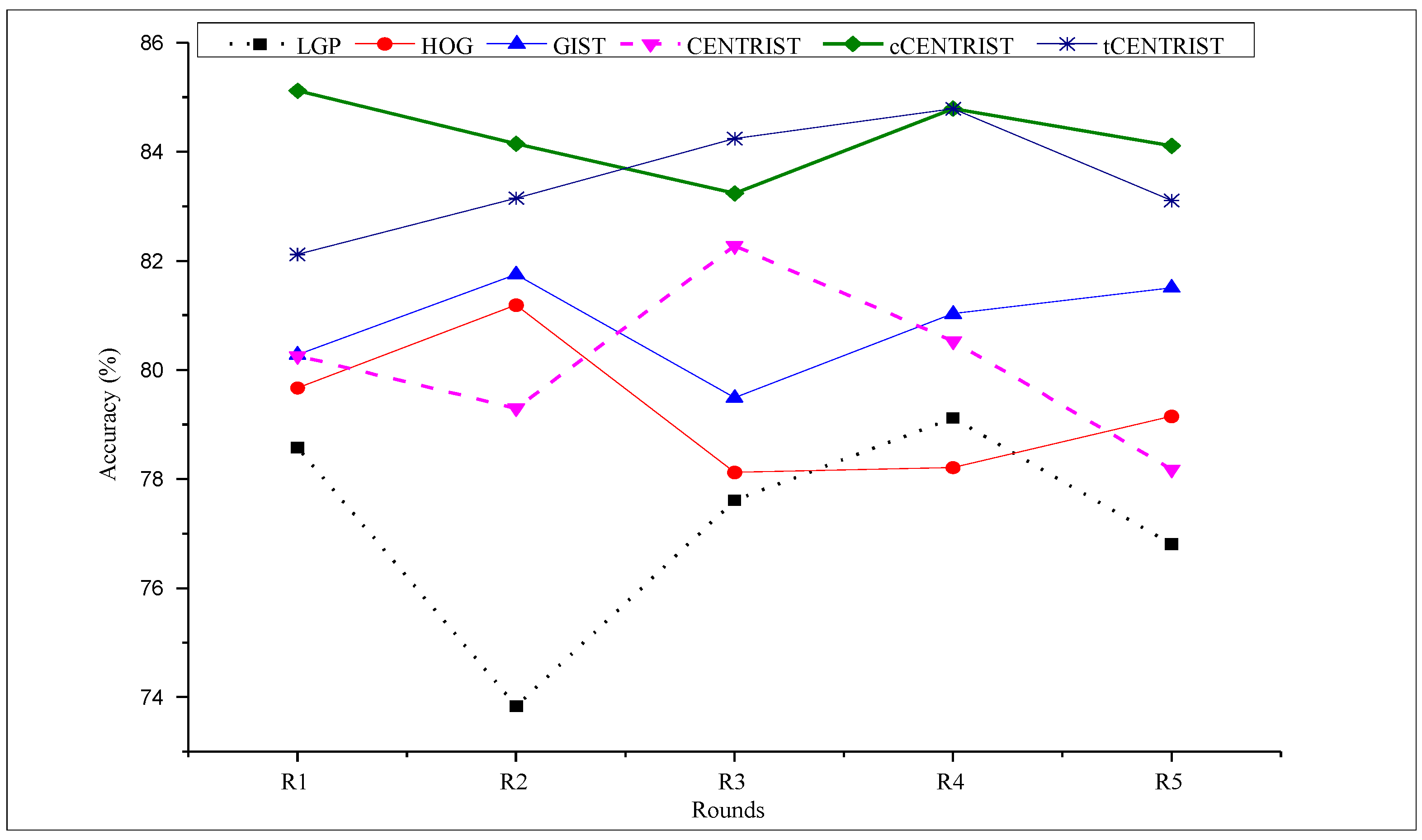
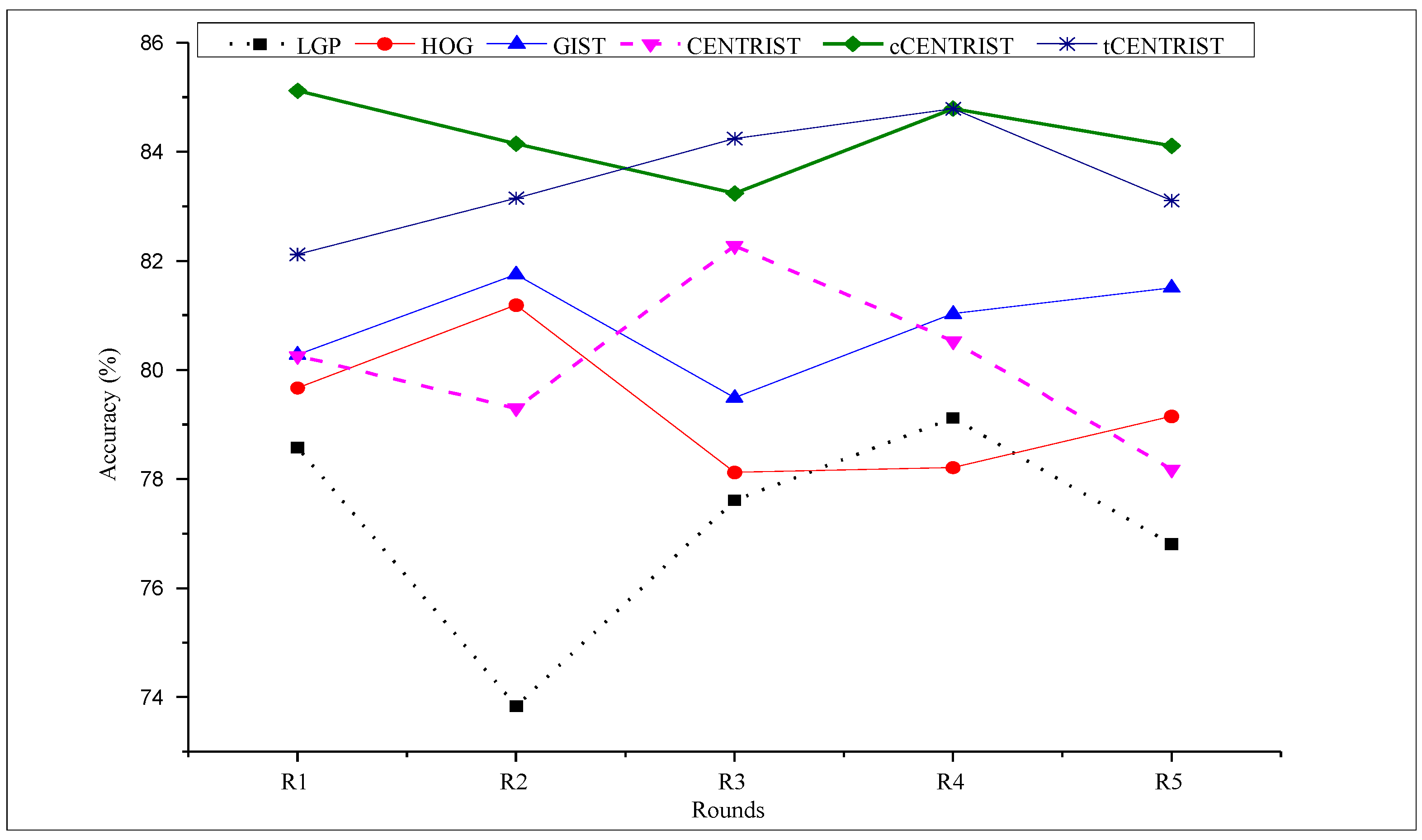
4.3. Experimental Result and Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
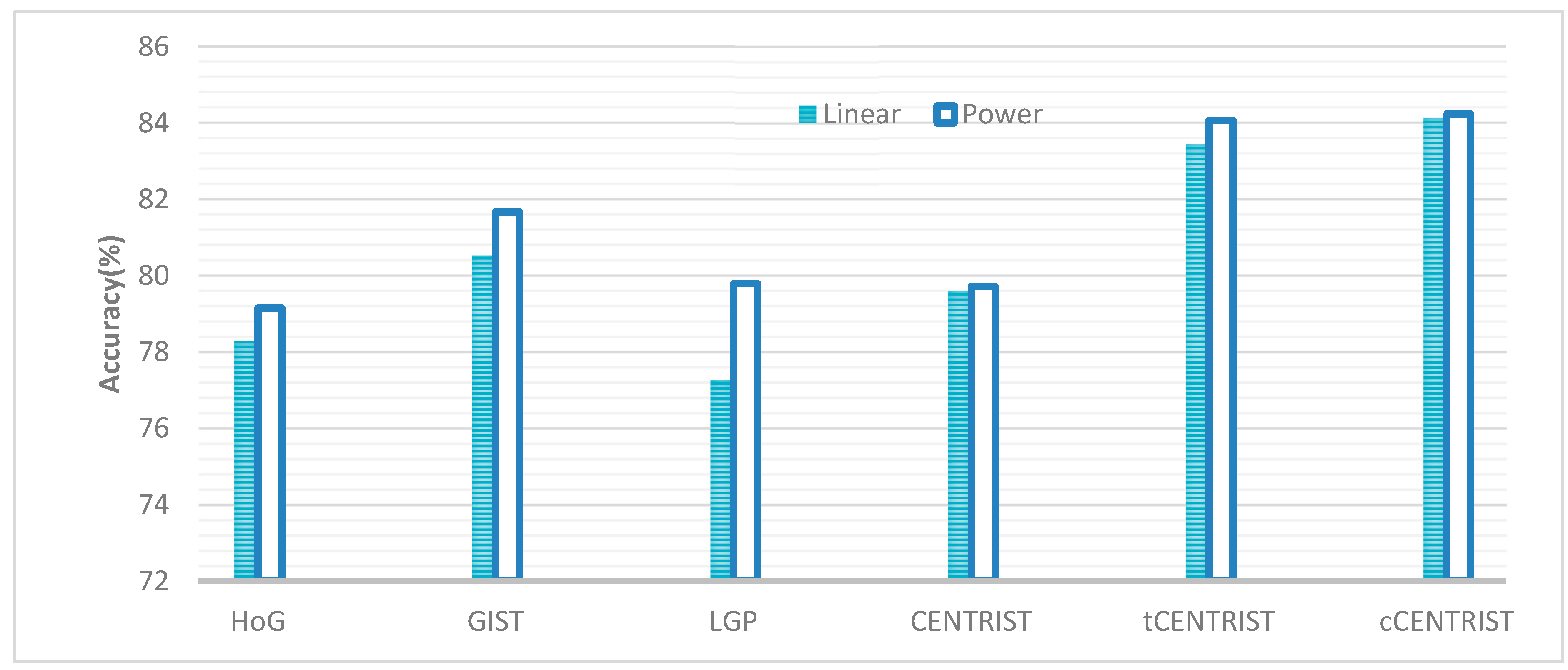
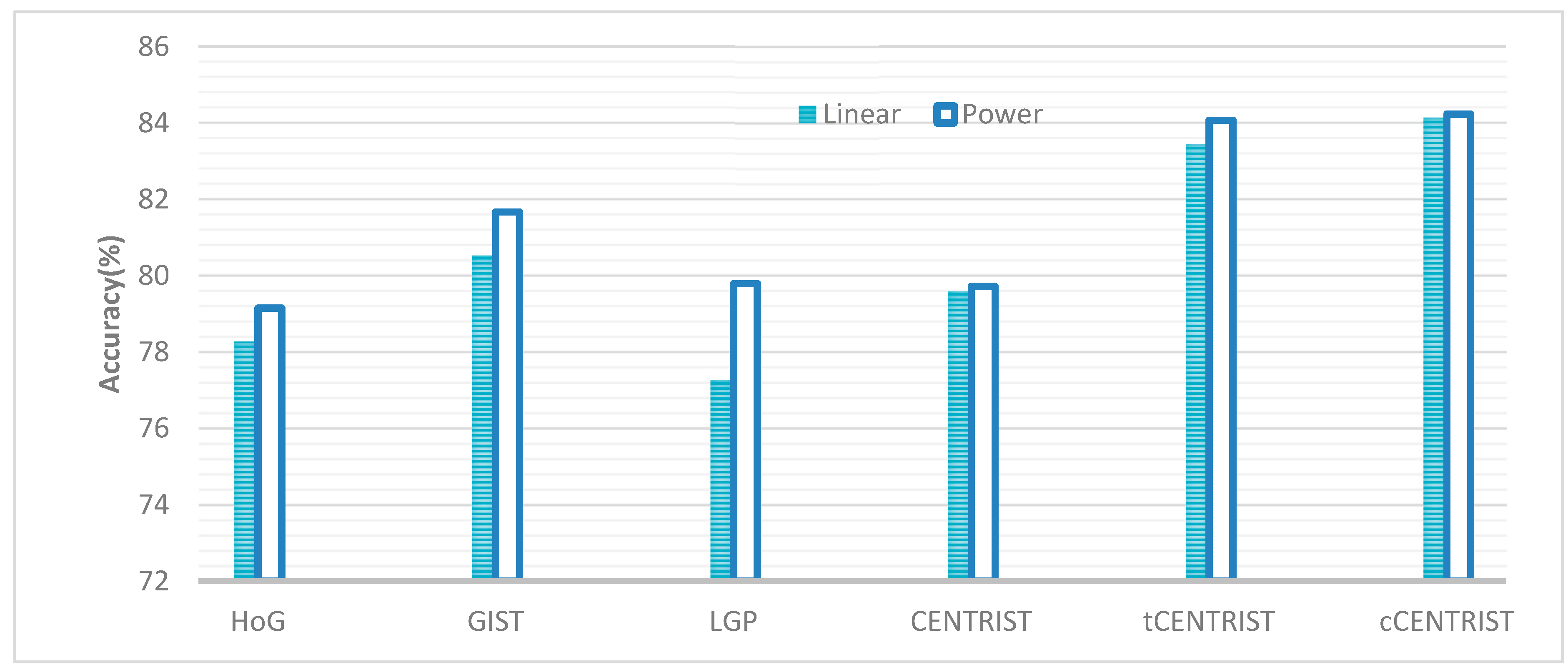
| Print (%) | Single Color (%) | Stripe (%) | Average(%) | ||
|---|---|---|---|---|---|
| HoG | Linear | 82.32 | 84.44 | 68.09 | 78.28 |
| Power+Linear | 82.98 | 85.48 | 69.01 | 79.15 | |
| GIST | Linear | 81.47 | 92.77 | 67.35 | 80.53 |
| Power+Linear | 82.20 | 94.34 | 68.48 | 81.67 | |
| LGP | Linear | 82.51 | 83.45 | 65.85 | 77.27 |
| Power+Linear | 77.58 | 85.58 | 76.22 | 79.79 | |
| CENTRIST | Linear | 81.51 | 83.50 | 73.72 | 79.58 |
| Power+Linear | 81.52 | 81.73 | 75.12 | 79.72 | |
| tCENTRIST | Linear | 85.95 | 88.44 | 75.90 | 83.43 |
| Power+Linear | 88.22 | 87.80 | 76.20 | 84.07 | |
| cCENTRIST | Linear | 86.82 | 89.62 | 75.96 | 84.13 |
| Power+Linear | 86.70 | 89.76 | 75.24 | 84.23 | |
| Using Power Kernel | Using Linear Kernel | ||||||
|---|---|---|---|---|---|---|---|
| Predicted Class | Predicted Class | ||||||
| Single | Stripe | Single | Stripe | ||||
| Actual Class | 882 | 106 | 53 | 805 | 159 | 77 | |
| Single | 220 | 2035 | 85 | 197 | 1979 | 164 | |
| Stripe | 62 | 34 | 440 | 62 | 54 | 420 | |
| Using Power Kernel | Using Linear Kernel | ||||||
|---|---|---|---|---|---|---|---|
| Predicted Class | Predicted Class | ||||||
| Single | Stripe | Single | Stripe | ||||
| Actual Class | 893 | 72 | 76 | 883 | 103 | 55 | |
| Single | 252 | 1950 | 138 | 218 | 2072 | 50 | |
| Stripe | 40 | 51 | 445 | 51 | 75 | 410 | |
| Using Power Kernel | Using Linear Kernel | ||||||
|---|---|---|---|---|---|---|---|
| Predicted Class | Predicted Class | ||||||
| Single | Stripe | Single | Stripe | ||||
| Actual Class | 876 | 105 | 60 | 779 | 178 | 84 | |
| Single | 329 | 1915 | 96 | 197 | 1989 | 154 | |
| Stripe | 75 | 81 | 380 | 72 | 65 | 399 | |
| cCENTRIST | tCENTRIST | CENTRIST | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Single | Stripe | Single | Stripe | Single | Stripe | ||||
| Recall | 0.85 | 0.87 | 0.75 | 0.86 | 0.84 | 0.80 | 0.84 | 0.81 | 0.70 |
| Precision | 0.75 | 0.93 | 0.76 | 0.75 | 0.94 | 0.67 | 0.68 | 0.91 | 0.71 |
| F_Measure | 0.80 | 0.90 | 0.78 | 0.80 | 0.88 | 0.73 | 0.75 | 0.86 | 0.70 |
| cCENTRIST | tCENTRIST | CENTRIST | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Single | Stripe | Single | Stripe | Single | Stripe | ||||
| Recall | 0.78 | 0.85 | 0.79 | 0.84 | 0.88 | 0.70 | 0.74 | 0.84 | 0.71 |
| Precision | 0.76 | 0.91 | 0.64 | 0.76 | 0.91 | 0.77 | 0.73 | 0.89 | 0.60 |
| F_Measure | 0.77 | 0.88 | 0.71 | 0.80 | 0.89 | 0.73 | 0.74 | 0.86 | 0.65 |
| Methods | Accuracy (%) |
|---|---|
| HOG | 63.76 ±1.20 |
| GIST | 72.31 ±1.59 |
| LGP | 65.55 ± 0.87 |
| CENTRIST | 71.97 ±1.34 |
| tCENTRIST | 74.48 ±2.08 |
| cCENTRIST | 74.97 ± 1.67 |
5. Conclusions
Contributions
Conflicts of Interest
References
- Gallagher, A.C.; Chen, T. Clothing cosegmentation for recognizing people. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008.
- Yamaguchi, K.; Kiapour, M.H.; Ortiz, L.E.; Berg, T.L. Parsing clothing in fashion photographs. In Proceedings of the2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3570–3577.
- Kalantidis, Y.; Kennedy, L.; Li, L.-J. Getting the look: Clothing recognition and segmentation for automatic product suggestions in everyday photos. In Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, Dallas, TX, USA, 16–20 April 2013.
- Vittayakorn, S.; Yamaguchi, K.; Berg, A.C.; Berg, T.L. Runway to realway: Visual analysis of fashion. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2015; pp. 951–958.
- Edgar, S.-S.; Fidler, S.; Moreno-Noguer, F.; Urtasun, R. A High Performance CRF Model for Clothes Parsing. In Proceedings of the12th Asian Conference on Computer Vision—ACCV 2014, Singapore, Singapore, 1–5 November 2014.
- Wu, J.; Rehg, J.M. CENTRIST: A visual descriptor for scene categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1489–1501. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Arivazhagan, S.; Ganesan, L.; Priyal, P.S. Texture classification using Gabor wavelets based rotation invariant features. Pattern Recognit. Lett. 2006, 27, 1976–1982. [Google Scholar] [CrossRef]
- Ludwig, O.; Delgado, D.; Goncalves, V.; Nunes, U. Trainable Classifier-Fusion Schemes: An Application to Pedestrian Detection. In Proceedings of the 12th International IEEE Conference On Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009; Volume 1, pp. 432–437. [CrossRef]
- Aude, O.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar]
- Tan, X.; Bill, T. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Guo, Z.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Rother, C.; Kolmogorov, V.; Blake, A. Grabcut: Interactive foreground extraction using iterated graph cuts. TOG 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Manfredi, M.; Grana, C.; Calderara, S.; Cucchiara, R. A complete system for garment segmentation and color classification. Mach. Vis. Appl. 2014, 25, 955–969. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 25 June 2005; pp. 886–893.
- Bourdev, L.; Maji, S.; Malik, J. Describing people: A poselet-based approach to attribute classification. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011.
- Yi, Y.; Ramanan, D. Articulated pose estimation with flexible mixtures-of-parts. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1385–1392.
- Arivazhagan, S.; Ganesan, L. Texture classification using wavelet transform. Pattern Recognit. Lett. 2003, 24, 1513–1521. [Google Scholar] [CrossRef]
- Arivazhagan, S.; Ganesan, L.; Padam, P.S. Texture classification using Gabor wavelets based rotation invariant features. Pattern Recognit. Lett. 2006, 27, 1976–1982. [Google Scholar] [CrossRef]
- Warren, C.; Hamarneh, G. SIFT—Scale Invariant Feature Transform. IEEE Trans. Image Process. 2009, 18, 2012–2021. [Google Scholar]
- Guo, Z.; Zhang, L.; Zhang, D. Rotation invariant texture classification using LBP variance (LBPV) with global matching. Pattern Recognit. 2010, 43, 706–719. [Google Scholar] [CrossRef]
- Hadid, A.; Pietikainen, M.; Ahonen, T. A discriminative feature space for detecting and recognizing faces. In Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; pp. 797–804.
- Jin, H.; Liu, Q.; Lu, H.; Tong, X. Face detection using improved LBP under Bayesian framework. In Proceedings of the Third International Conference on Image and Graphics (ICIG), Hong Kong, China, 18–20 December 2004; pp. 306–309.
- Zhang, L.; Chu, R.; Xiang, S.; Li, S.Z. Face detection based on Multi-Block LBP representation. In Proceedings of the International Conference on Advances in Biometrics (ICB), Seoul, Korea, 27–29 August 2007; pp. 11–18.
- Zhang, H.; Zhao, D. Spatial histogram features for face detection in color images. In Proceedings of the Advances in Multimedia Information Processing: Pacific Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004; pp. 377–384.
- Li, S.Z.; Zhao, C.; Ao, M.; Lei, Z. Learning to fuse 3D+2D based face recognition at both feature and decision levels. In Proceedings of the Second International Workshop on Analysis and Modeling of Faces and Gestures (AMFG), Beijing, China, 16 October 2005; pp. 44–54.
- Zhao, J.; Wang, H.; Ren, H.; Kee, S.-C. LBP discriminant analysis for face verification. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 25 June 2005; p. 167.
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Feng, X.; Hadid, A.; Pietikainen, M. A coarse-to-fine classification scheme for facial expression recognition. In Proceedings of the International Conference on Image Analysis and Recognition (ICIAR), Porto, Portugal, 29 September–1 October 2004; pp. 668–675.
- Liao, S.; Fan, W.; Chung, A.C.S.; Yeung, D.Y. Facial expression recognition using advanced local binary patterns, Tsallis entropies and global appearance features. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Atlanta, GA, USA, 8–11 October 2006; pp. 665–668.
- Zhao, G.; Pietikainen, M. Experiments with facial expression recognition using spatiotemporal local binary patterns. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo (ICME), Beijing, China, 2–5July 2007; pp. 1091–1094.
- Shoyaib, M.; Youl, J.M.; Alam, M.M.; Chae, O. Facial expression recognition based on a weighted local binary pattern. In Proceedings of the 2010 13th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 23–25 December 2010; pp. 321–324.
- Ibrahim, M.; Alam Efat, M.I.; Khaled, S.M.; Shoyaib, M. Face verification with fully dynamic size blocks based on landmark detection. In Proceedings of the 2014 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–5.
- Ibrahim, M.; Alam Efat, M.I.; Kayesh, S.H.; Khaled, S.M.; Shoyaib, M.; Abdullah-Al-Wadud, M. Dynamic Local Ternary Pattern for Face Recognition and Verification. In Proceedings of the International Conference on Computer Engineering and Applications, Tenerife, Spain, 10–12 January 2014.
- Sun, N.; Zheng, W.; Sun, C.; Zou, C.; Zhao, L. Gender classification based on boosting local binary pattern. In Proceedings of the Third International Symposium on Neural Networks (ISNN), Chengdu, China, 28 May–1 June 2006; pp. 194–201.
- Yang, Z.; Ai, H. Demographic classification with local binary patterns. In Proceedings of the international Conference on Advances in Biometrics (ICB), Seoul, Korea, 27–29 August 2007; pp. 464–473.
- Rahman, M.M.; Rahman, S.; Dey, E.K.; Shoyaib, M. A Gender Recognition Approach with an Embedded Preprocessing. Int. J. Inf. Technol. Comput. Sci. 2015, 7, 19–27. [Google Scholar]
- Dey, E.K.; Khan, M.; Ali, M.H. Computer Vision-Based Gender Detection from Facial Image. Int. J. Adv. Comput. Sci. 2013, 3, 428–433. [Google Scholar]
- Heikkila, M.; Pietikainen, M.; Heikkila, J. A Texture-Based Method for Detecting Moving Objects. In Proceedings of the British Machine Vision Conference, London, UK, 7–9 September 2004.
- Huang, X.; Li, S.Z.; Wang, Y. Shape localization based on statistical method using extended local binary pattern. In Proceedings of the Third International Conference on Image and Graphics (ICIG), Hong Kong, China, 18–20 December 2004; pp. 184–187.
- Liao, S.; Law, M.W.K.; Chung, A.C.S. Dominant local binary patterns for texture classification. IEEE Trans. Image Process. 2009, 18, 1107–1118. [Google Scholar] [CrossRef] [PubMed]
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef]
- Shoyaib, M.; Abdullah-Al-Wadud, M.; Chae, O. A Noise-Aware Coding Scheme for Texture Classification. Sensors 2011, 11, 8028–8044. [Google Scholar] [CrossRef] [PubMed]
- Zahid Ishraque, S.M.; Shoyaib, M.; Abdullah-Al-Wadud, M.; Monirul Hoque, Md.; Chae, O. A local adaptive image descriptor. New Rev. Hypermedia Multimed. 2013, 19, 286–298. [Google Scholar] [CrossRef]
- Jun, B.; Choi, I.; Kim, D. Local transform features and hybridization for accurate face and human detection. IEEE Trans Pattern Anal. Mach. Intell. 2013, 35, 1423–1436. [Google Scholar] [CrossRef] [PubMed]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Chang, C.-C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans Audio Speech Lang. Process. 2012, 20, 30–42. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Nair, V.; Hinton, G.E. 3D object recognition with deep belief nets. In Proceedings of the Advances in Neural Information Processing Systems 22, Vancouver, BC, Canada, 7–10 December 2009; pp. 1339–1347.
- Shoyaib, M.; Abdullah-Al-Wadud, M.; Chae, O. A skin detection approach based on the Dempster–Shafer theory of evidence. Int. J. Approx. Reason. 2012, 53, 636–659. [Google Scholar] [CrossRef]
- Chilimbi, T.; Suzue, Y.; Apacible, J.; Kalyanaraman, K. Project adam: Building an efficient and scalable deep learning training system. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 571–582.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587.
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the Third European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; Volume 2, pp. 151–158.
- Chen, H.; Gallagher, A.; Girod, B. Describing Clothing by Semantic Attributes. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012.
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dey, E.K.; Tawhid, M.N.A.; Shoyaib, M. An Automated System for Garment Texture Design Class Identification. Computers 2015, 4, 265-282. https://doi.org/10.3390/computers4030265
Dey EK, Tawhid MNA, Shoyaib M. An Automated System for Garment Texture Design Class Identification. Computers. 2015; 4(3):265-282. https://doi.org/10.3390/computers4030265
Chicago/Turabian StyleDey, Emon Kumar, Md. Nurul Ahad Tawhid, and Mohammad Shoyaib. 2015. "An Automated System for Garment Texture Design Class Identification" Computers 4, no. 3: 265-282. https://doi.org/10.3390/computers4030265
APA StyleDey, E. K., Tawhid, M. N. A., & Shoyaib, M. (2015). An Automated System for Garment Texture Design Class Identification. Computers, 4(3), 265-282. https://doi.org/10.3390/computers4030265