We developed an API for our service which would be consumed inside the mobile application. We decided on using REST web services as they preferred when working with mobile applications. We needed the application to be available on as many mobile phone operating systems as possible, so we continued by analyzing cross platform mobile development solutions. After comparing Titanium development with other development frameworks we decided on using this platform because it offered a series of advantages such as compiling natively and being able to be extended in order to support more advanced functionality available for iOS or Android.
The specific system that we are developing allows clients (users) to book vehicles directly from their mobile device without having to call through an operator. Having an app for this use case opens the doors for a wide variety of marketing strategies such as offering promotions, coupons, paying by credit card, offering subscriptions. This allows users to have an alternative to the traditional method of booking a vehicle by phone calling, based on the new and powerful trend of mobile cloud applications.
3.3. System Use Cases
There are four types of actors that the system supports, each having specific capabilities. We will analyze each actor together with the associated use cases.
The client actor is the user that has the booking application installed on his mobile phone. He uses the application to order taxis by sending his location to the server that consists of the
Cloud. This is the main functionality of the system, which we will be presenting later on in a more detailed fashion. We note that this use case is composed of two elements: getting the
GPS position of the user, which is used by the system to identify the address of the user, and it also offers the possibility of fix tuning this location to specify it more precisely, as this location will be sent to the operator or the driver. The User use cases are presented in
Table 3.
Table 3.
Client Use Case specifications.
Table 3.
Client Use Case specifications.
| Category | Use case |
|---|
| Book vehicle | Access map view of nearby vehicles |
| Book vehicle | Specify exact location |
| Book vehicle | Get time and cost estimates |
| Book vehicle | Specify advance booking time |
| Book vehicle | See vehicle details |
| Track Vehicle | Track vehicle on map |
| Track Vehicle | Get notifications |
| Pay for the ride | In app payment |
| Rate vehicle | Rate vehicle |
| Share on Social Network | Share on social networks |
The vehicle tracking functionality allows the user to see the taxi approaching on a map. In addition to this time estimation will be displayed together with a distance approximation. In case the response to an order comes from the operator, this functionality will not be available, as the taxi will not have GPS capabilities that allow tracking. The Share on Social networks use case allows the user to share the current ride with his friends on social media. This is an element that enhances the marketing potential for the app and a key component in attracting new users. There are two types of services which users can use with the app: Facebook and Twitter. One of the main benefits of using this app is the possibility of accumulating points, as a rewards program envisioned to spur app usage and attract new users. Each time the user will be making orders using the app, he will accumulate points which can be converted into free apps.
The Driver is responsible for responding to incoming orders. It does this by accepting or declining an order using a simple two buttons interface. The orders are assigned to drivers based on the proximity of the client to the driver. In addition to these functionalities, the Driver can also call the client in case he cannot see him at the specified pick up location or if he needs additional information. The driver cannot see the clients phone number, but only a call button. The rate client functionality allows the driver to rate the client based on his behavior. The rating is based on considerations such as: was the client present at the meeting point, did he leave a tip, was he loudly etc. The rating is based on a 5 star system subjective to the driver. Future orders placed by the client will show the overall rating that this client has.
The operator is responsible for responding to orders that were not answered by drivers directly. This allows companies to use the traditional mechanism for finding a taxi and send a response to the client. Using this mechanism, the client always gets a response to his order, even if no driver is available in his proximity that is active.
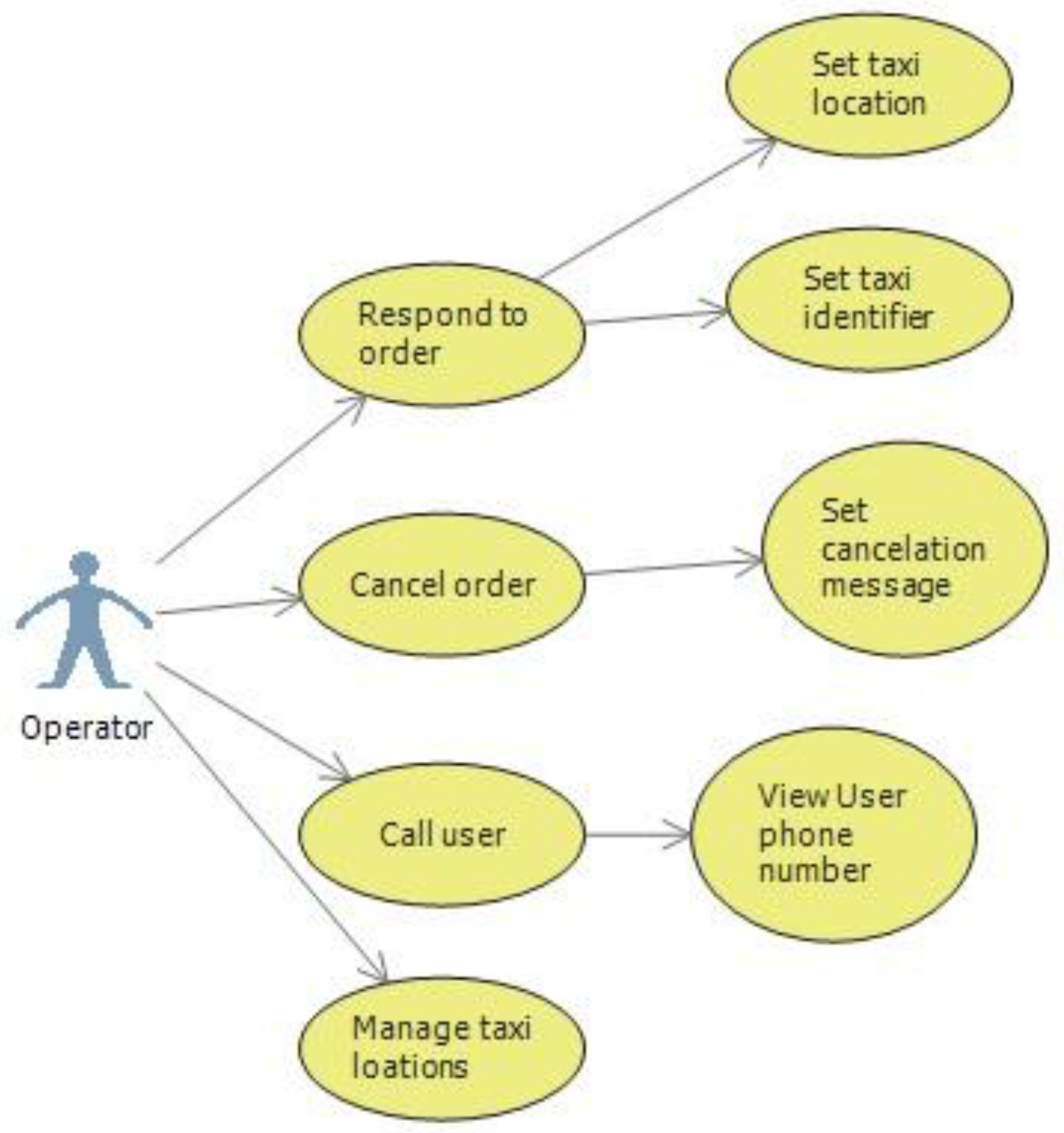
Responding to a client involves two things. First, an identifier for the taxi must be specified. This consists of the car number or some other way for the client to identify the taxi. Also the operator must specify the approximate location where the taxi is at the moment, by selecting it from a map. This creates a more visual context for the client and creates a sense of consistency between orders answered by the driver and the operator. Similar to the driver, the operator can call the client to ask him more details. Distinctly from the driver, the operator can see the users number. As we earlier specified, when a response to an order is set, the operator selects an address from the map which will display the initial taxi position to the client. It is possible for the operator to cancel an order from the client, in which case can write a cancelation message explaining the decision. The operator use cases are illustrated in
Figure 1.
Figure 1.
Operator use case.
Figure 1.
Operator use case.
The Manager actor is responsible with registering taxi companies into the system, setting the areas in which they operate, adding drivers and creating operator accounts. The manager is a role comparable with the administrator of the system. It has the power to change accounts, activate or deactivate them.
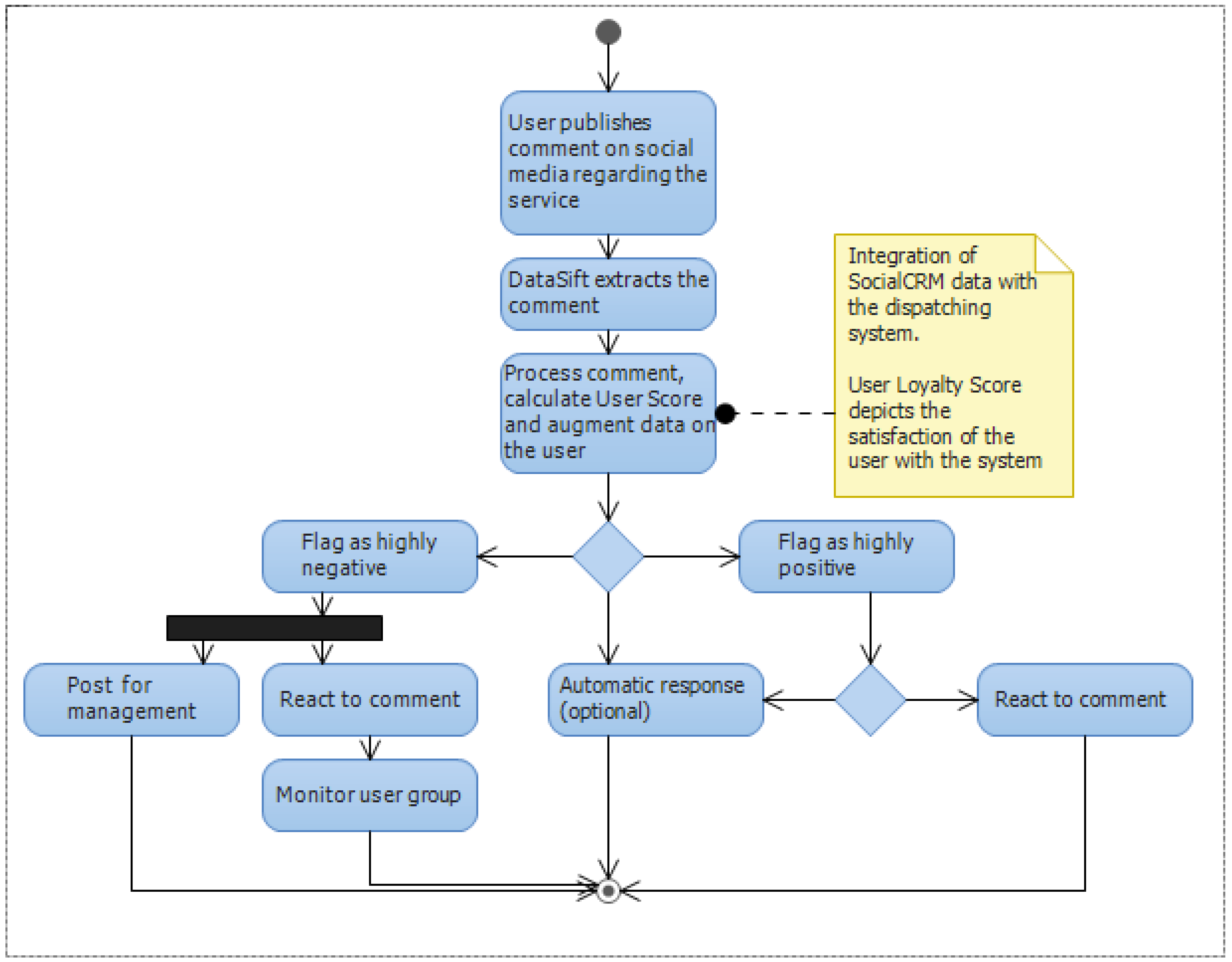
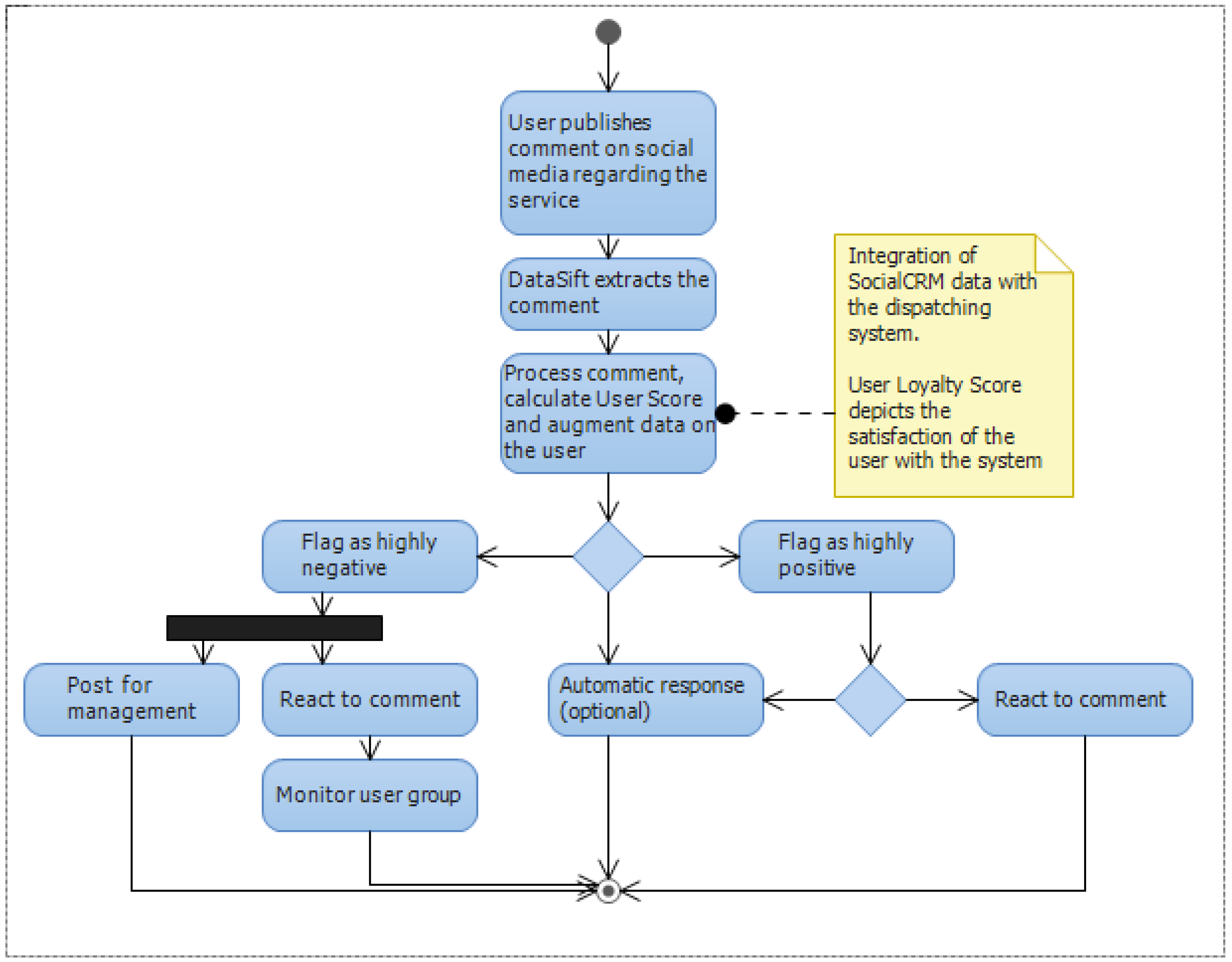
The Social CRM can provide valuable information regarding the user satisfaction level with the service and the potential direct improvement points. The person responsible for the Social CRM management will have access to a dashboard offering metrics such as overall customer satisfaction levels for specific time intervals, highly negative or positive comments in real time and automation and filtering tools. Also the Social CRM component will augment user data with statistics obtained using DataSift. The list of Social CRM use case is presented in
Table 4.
Table 4.
Social Customer Relationship Management (CRM) Use Case specifications.
Table 4.
Social Customer Relationship Management (CRM) Use Case specifications.
| Category | Use Case |
|---|
| User data augmentation | See user satisfaction metric |
| User data augmentation | Segment users by activity levels |
| User data augmentation | Identify promotion targets |
| Data filtering | Identify comments in real time |
| Data filtering | React to comments in real time |
| Customer satisfaction | Create promotion |
| Customer satisfaction | Assign to-do items |
3.4. Conceptual Design
The proposed system is a complex solution which can be decomposed into multiple components. From a high level architectural point of view, the core of the product is represented by the
Cloud Engine, which is stored on Windows Azure. The Cloud Engine uses a
relational SQL database for persistence and interacts with third party services. The mobile applications for clients and drivers access the service through the
custom built API. The
management panel is also a separate component that is built on the Cloud service. The
social media analysis tool cuts across both the cloud service and the operator management panel, providing insights and automating social media data augmentation. A high level representation of the system can be observed in
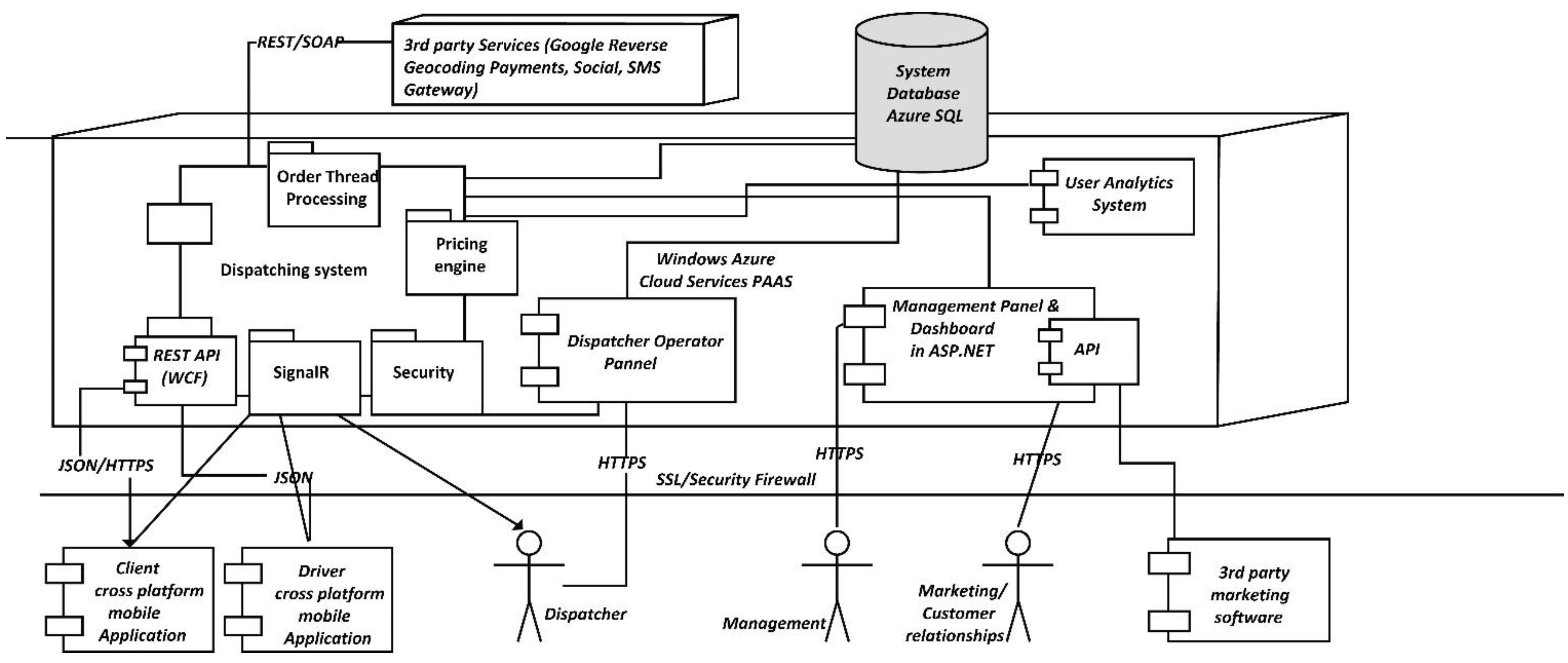
Figure 3.
Figure 3.
The block diagram of the system.
Figure 3.
The block diagram of the system.
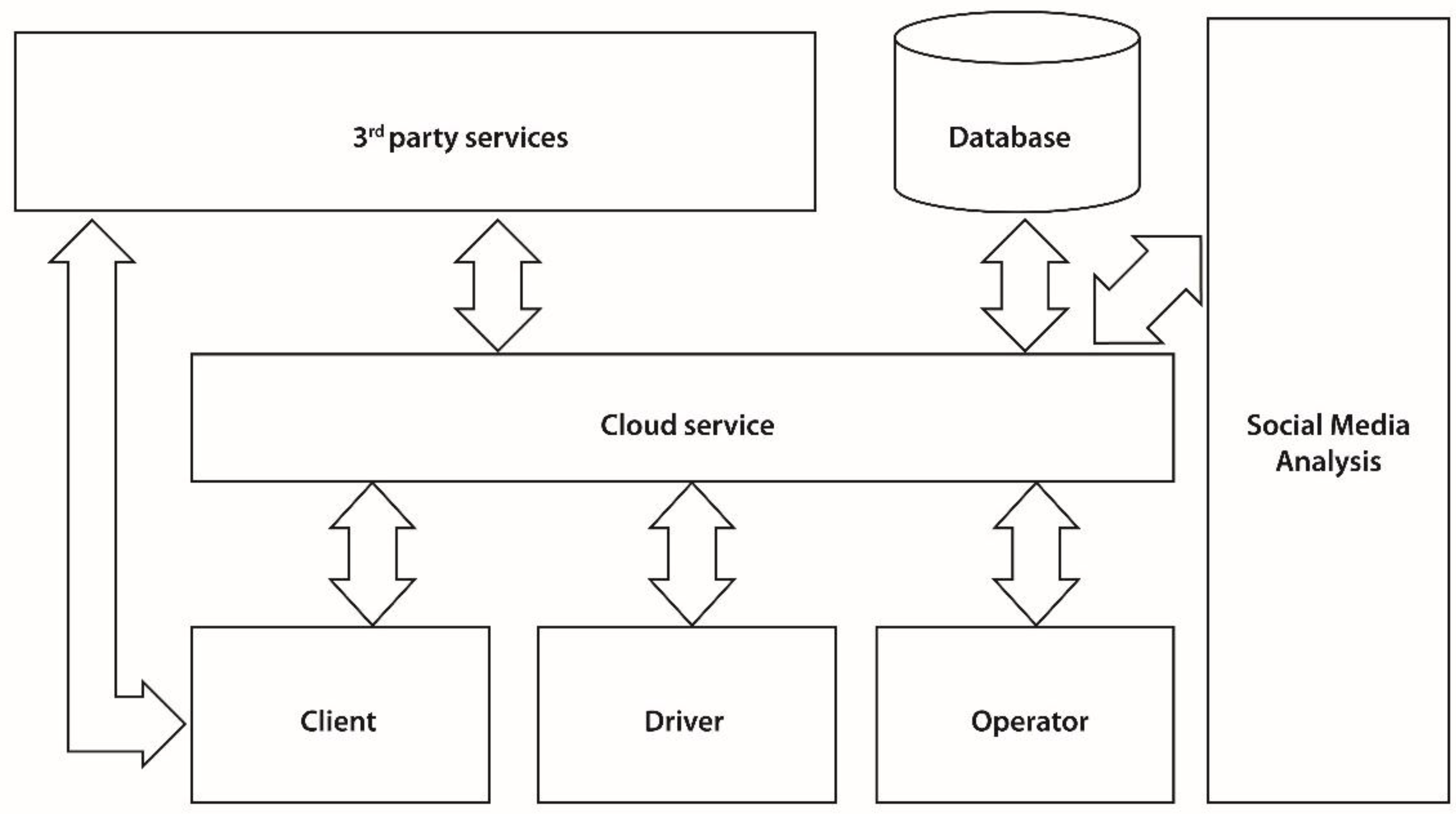
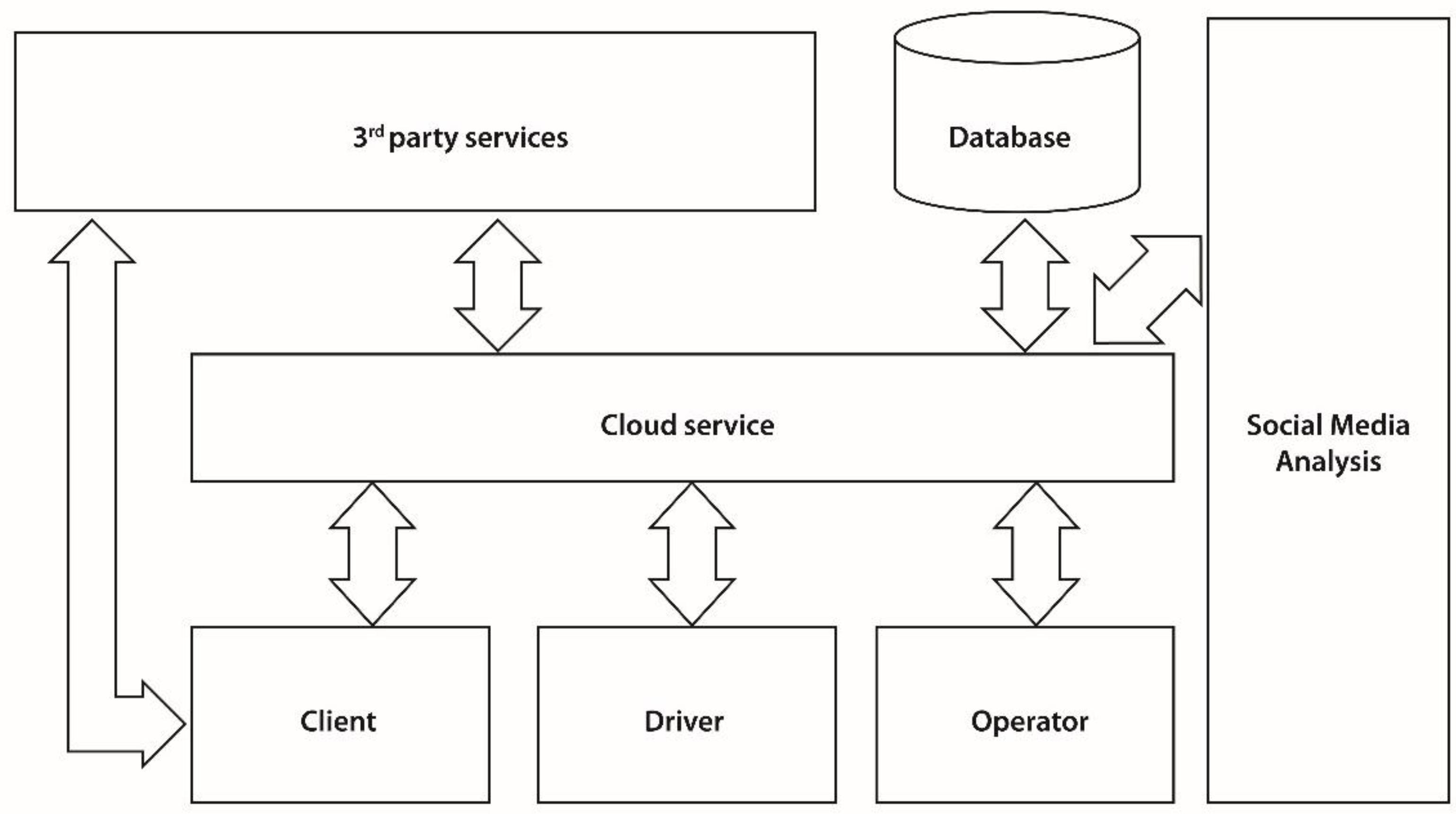
Client and Driver apps and the Operator web interface are the consumers of the API exposed by the Cloud service. The Cloud Service acts as the intermediary between all communication that takes place between these components and handles the data synchronization. The Cloud service relies on its functionality on using a database for persisting information such as orders, responses, users etc. The Cloud service also interacts with external services for performing specific tasks. Examples of this include sending push notifications or reverse geocoding. The client mobile applications can also access external services. For example the Client app accesses Facebook and analytics services.
The Cloud service acts as a hub and intermediating all communication between the clients. While for a client booking a vehicle seems as a P2P operation, it actually constitutes a client-server operation. As illustrated, numerous operators, divers and Clients can connect to the Cloud, new ones can be added, or some can be removed at any time. For example a taxi driver that terminates his work schedule for the day, can disconnect from the Cloud service and will not receive any new orders until he checks in again with the service.
All data is stored into a proprietary SQL database, and specific tasks that have been delegated to external services are managed by the Cloud service. When a client books a vehicle, the Cloud service checks through the fleet of vehicles that are available on that area at that moment and selects one for being dispatched to the client. In case no vehicle is received, the Cloud service sends the order to a specific vehicle company in order to be processed. Not all mobile applications are required to have a server component. However applications that require a higher degree of complexity need to create their own model and an API for exposing the services.
Cloud computing is known to be a promising solution for mobile computing due to reasons including mobility, communication, and portability, reliability, security. In the following, we describe how the Cloud can be used to overcome obstacles in mobile computing, thereby pointing out advantages of
Mobile Cloud Computing (MCC) [
15] MCC refers to an infrastructure where both the data storage and the data processing happen outside of the mobile device. Mobile Cloud applications move the computing power and data storage away from mobile phones and into the Cloud, bringing applications and mobile computing to not just smartphone users but also a much broader range of mobile subscribers.
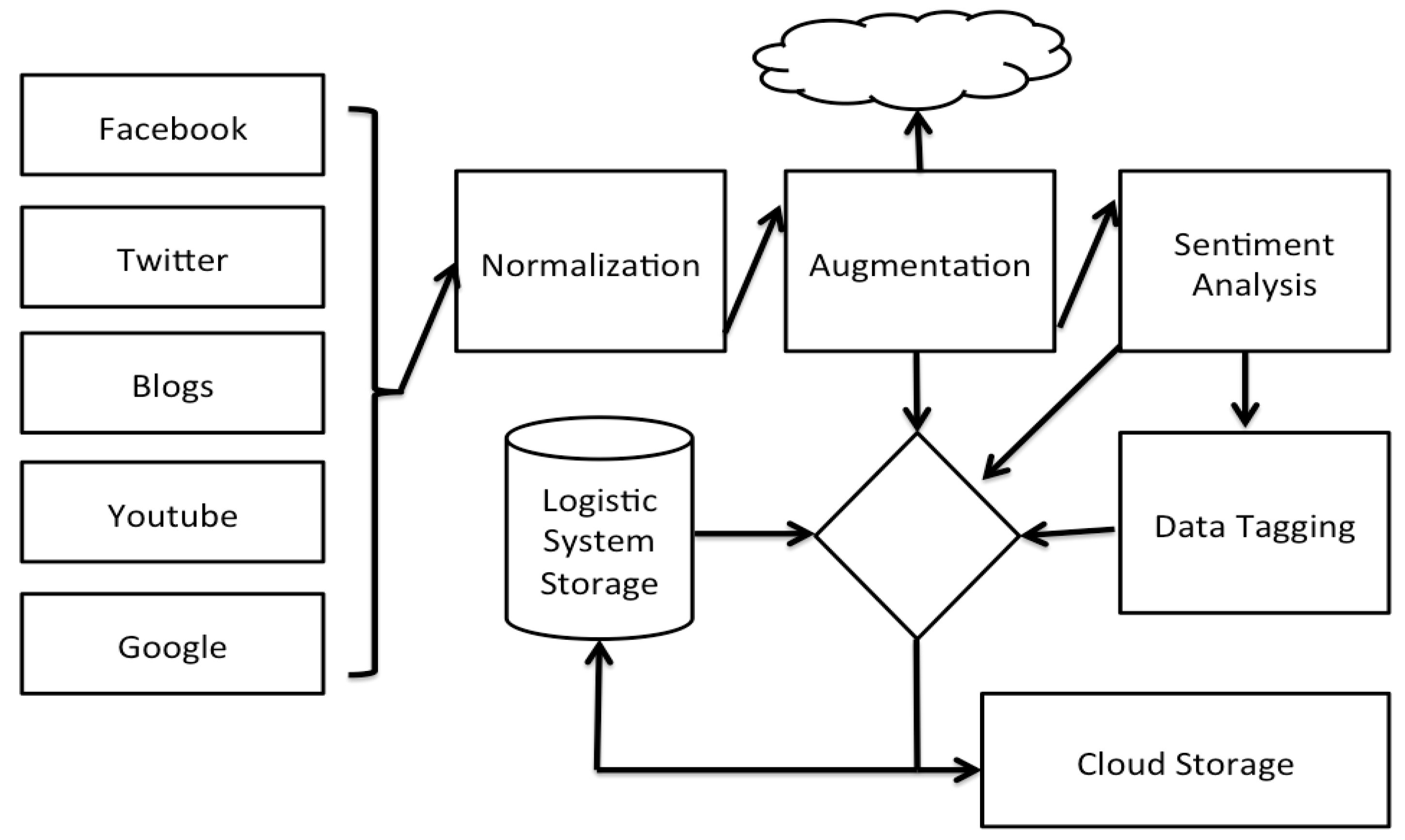
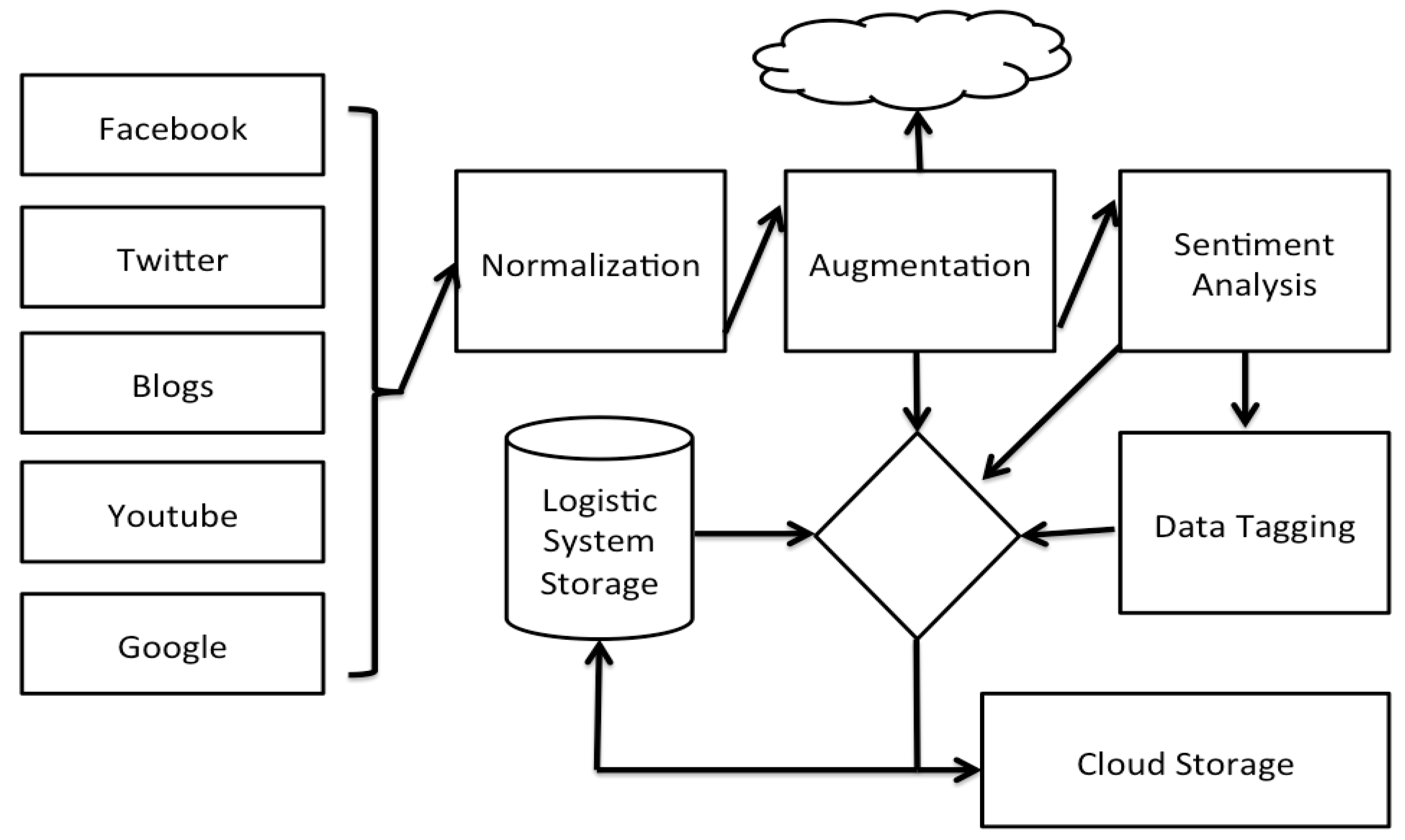
Figure 4 depicts a high level overview of the Social media analysis tool as implemented by DataSift. Facebook, Twitter, Blogs and other online data sources are monitored in real time and processed by the DataSift Engine.
Figure 4.
Social CRM components built on DataSift.
Figure 4.
Social CRM components built on DataSift.
The process of augmentation of the user data in our system and the insights provided to the customer relationship responsible goes through a pipeline of steps. The normalization step converts all interactions into a similar format independent of their source, whether it is Facebook, Twitter or a blog post. Augmentation provides additional data on the interaction such as location context and fetching of the content of a link. The sentiment analysis tool provides a mean of grading the sentiment associated with a given post on a scale from −20 to +20. The sentiment analysis is provided by a Lexalytics algorithm that is offered as a black box solution. Data integration with the dispatching system is handled in the Logistic System Storage, where the data is stored into one common database.
We have analyzed the theoretical approaches and the frameworks required for implementing the proposed application. In the following chapter we are detailing how we implemented the vehicle booking application.
3.5. System Implementation
In this section we will present the system architecture and some implementation deign concerns for all major components. As we have stated in the previous sections, our system consists in a dispatching system which is vertically integrated with a Social CRM system. The Social CRM system is responsible for aggregating information about our users from online data sources and are used for improving the customer relationships or better targeting the users using advertising.
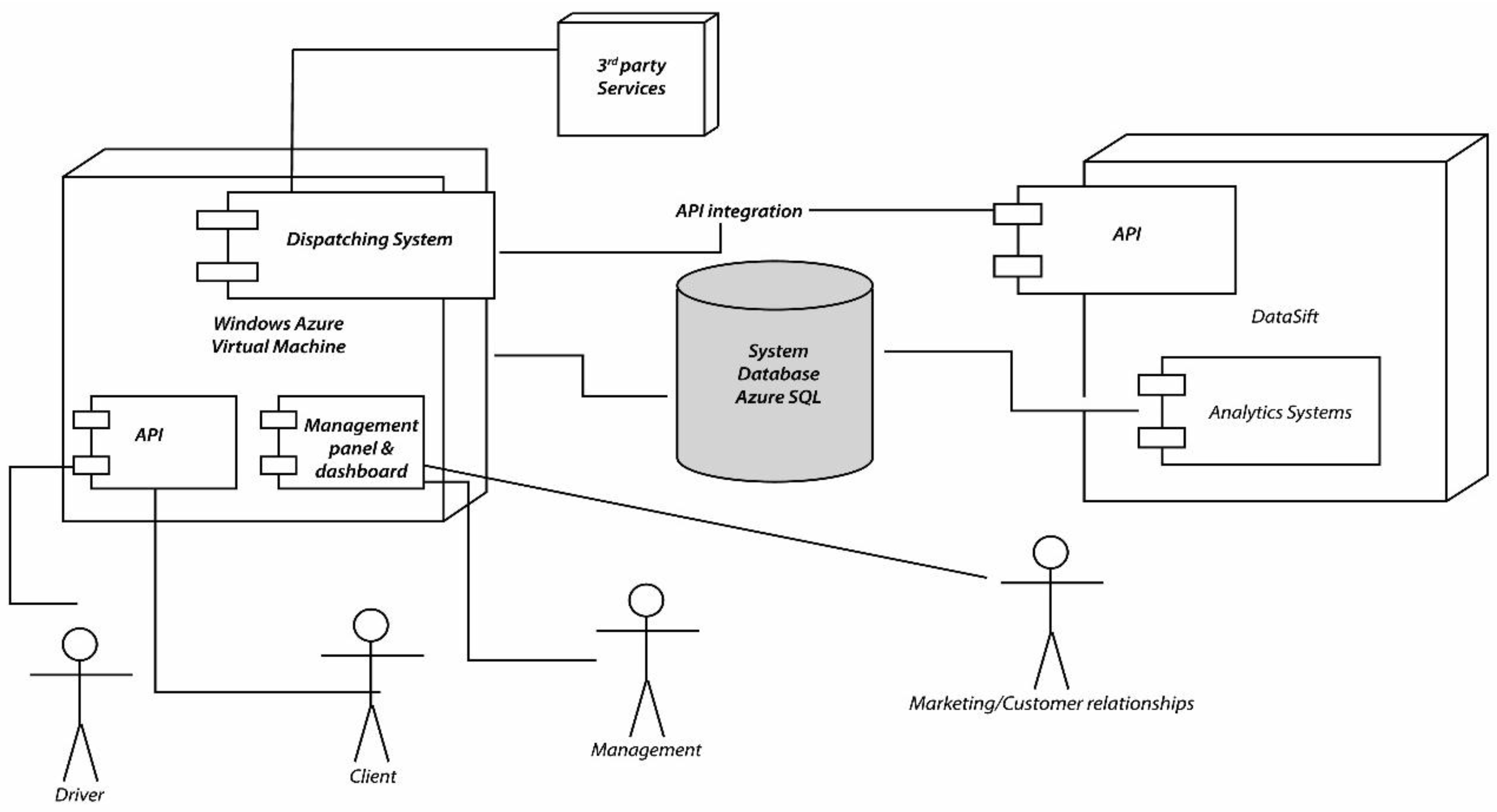
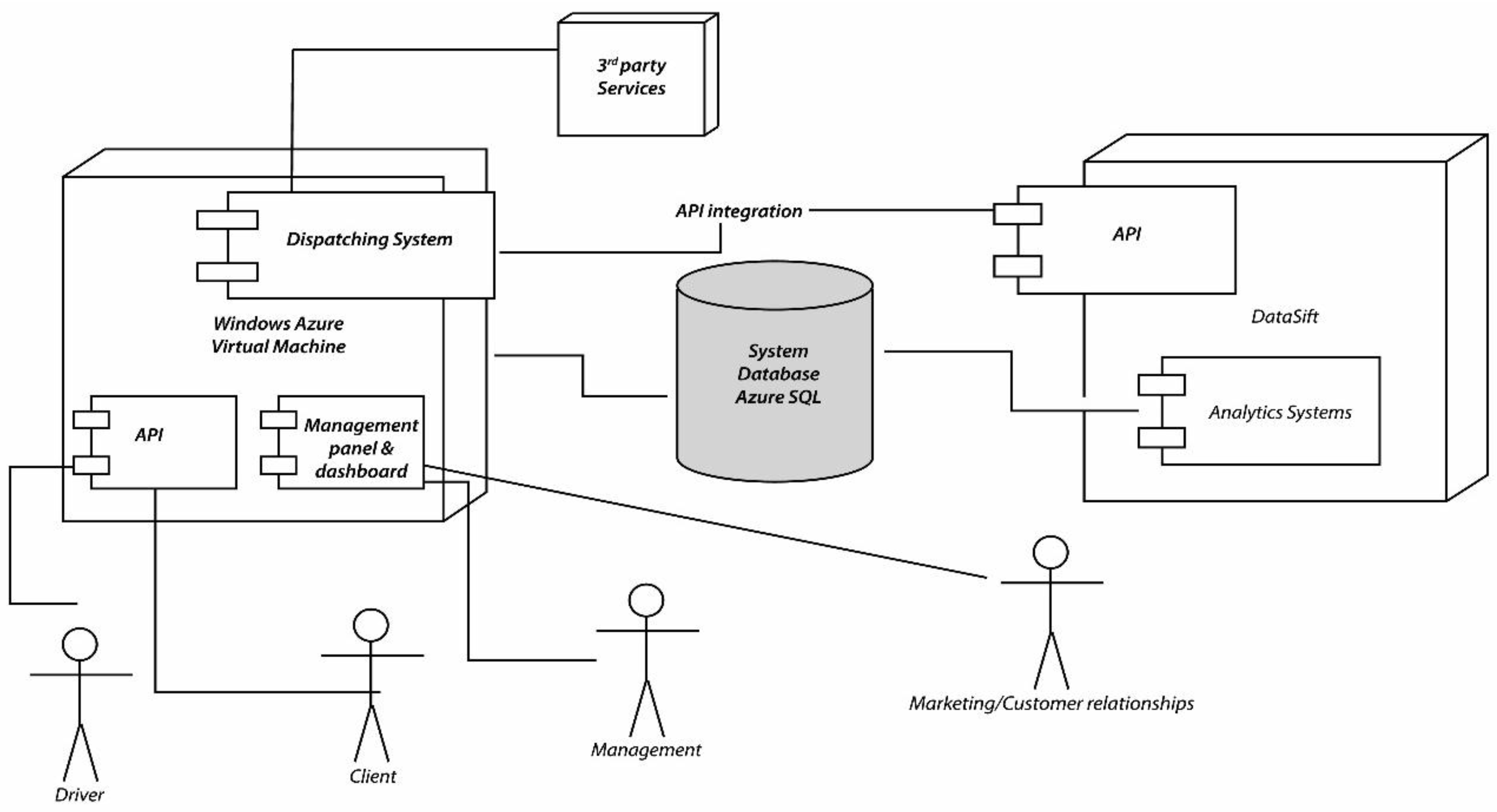
In
Figure 5 we have represented the two systems in more detail. The Social CRM system is built on top of the DataSift platform. The dispatching system is responsible for controlling the DataSift platform using the API it exposes. Through the API we can use filters for sifting only the interactions we need, and then integrating the two systems using a common SQL Azure database.
Figure 5.
System integration.
Figure 5.
System integration.
Next we will analyze both of the two systems and the integration between them. First we will address the dispatching system, and in the second half of this chapter we will analyze the DataSift platform in detail.
3.5.1. General Mobile Dispatching System Architecture and Implementation
The Dispatching System can operate as a standalone application. There can be identified two types of components. The first type includes the proprietary components. This need to be developed by the developers, are based on specific frameworks and include: the components constituting the Cloud service (designating the service built by the developers), the mobile application, the browser client and the management interface. The second type of components are represented by the 3rd party services (distinctly from proprietary services, 3rd party services or external services are built by other organizations and are made available to the public for use) are exposed trough certain API.
In this example we are using five types of external services: The Notification Service—used for sending Push Notifications (a way of alerting a mobile device), social services that offer integration with Facebook and Twitter, Analytics services for tracking usage patterns, SMS gateway service for sending the user an SMS with the activation code (required by the business rules), and a geocoding and reverse geocoding service for converting GPS position into street address. All of these components will be explained together with their implementation technologies and internal working
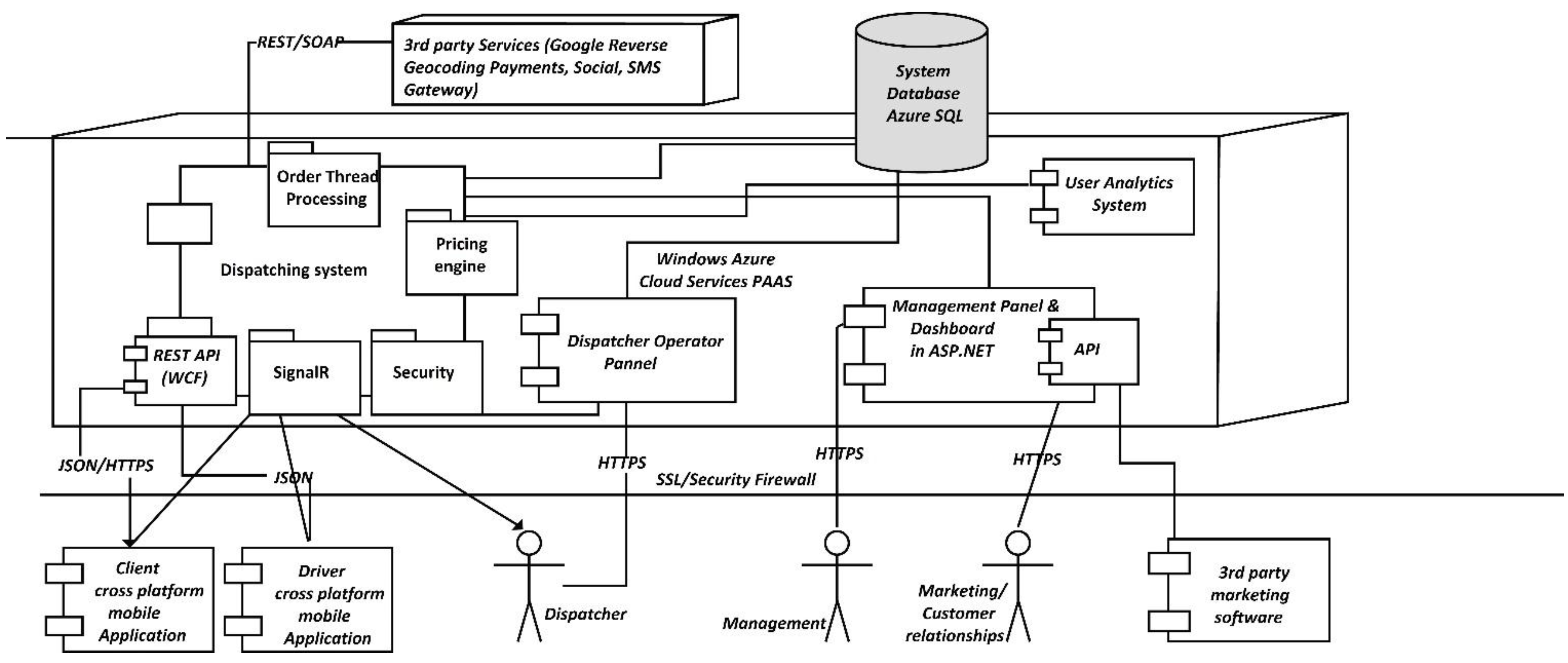
A request is serialized as JSON, signed using the user key and sent to the server through the server API. The server determines the nearest driver to the user, by interrogating the database based on the business logic. Once the nearest driver is determined, the Signaling Framework (used to alert the mobile application) is used to determine the selected driver’s app to download or update the order sent by the client. After the driver confirms the order, the server uses the same approach to inform the user that his order was responded. All requests sent to the proprietary server components need to use SSL for proving security to the system. The dispatching application exposes JSON REST services using WCF Framework. Working with JSON in the context of WCF is easy as the framework automatically serializes JSON request and responses and performs data binding between JavaScript and CLR objects. Once the data is received on the server, the server performs some security check on the request. This usually implies authentication and authorization of the request. As there is no password required for the Taxi Ordering application, signing the data using a key, which is known only by the client and the server, and is unique for each client mobile application, does this.
Figure 6 depicts the integration between the client mobile application and the server. On The client we have the
MVC pattern. The view sends an event to the controller, which calls the send order operation on the
Model. The model component responsible for sending the request (implemented in Titanium using an
HTTP Socket), serializes the data and sends them to the specified service endpoint exposed by the API. Once the request arrives on the server, the reverse process occurs as the JS data objects are translated into
CLR objects by the
WCF framework. The security component is responsible for checking the signature of the user in the case of Order Taxi applications. In other applications a username and password approach can be used for obtaining the same result. It is essential to observe that once the request passes the security verification, it is recorded and the registration key for the order is returned to the client. Further on the client uses this registration key for referring to his order. At this point there is no response available for the client yet.
Figure 6.
General Dispatching System Architecture.
Figure 6.
General Dispatching System Architecture.
The order placed by the user in the system is assigned to the nearest driver. When the driver confirms the order, a response is sent to the client mobile application. This response can come after a variable amount of time which can be anywhere between a few seconds and 3 min. In consequence SignalR is used to inform the client when the response is ready. SignalR is not used to pass the response directly to the user, but rather the user applications download the response once it receives the update signal.
An important characteristic of the service is that it should offer scalability. All the components depicted can be hosted in the Cloud. This allows an elastic hosting environment, which can be used easily. For Order Taxi application, we are using Windows Azure. Using Windows Azure we can easily deploy the server component as it was built completely on the .NET framework.
Location determination. Titanium offers the possibility of interacting with device capabilities such as using the GPS and allows for specific parameter to be set on the GPS such as the precision of positioning, as a balance between time and required accuracy. When the app starts the coordinates are the ones cached on the device, in other words the ones detected at the last time you used the geolocation on your device. Detecting the current position takes time so if you have an app based on geolocation you might want to take this in account to improve the user experience and avoid to get false results. Titanium.Geolocation [
6] provides the necessary methods to manage geolocation.
Implementation of the Model. The business logic of the system is implemented in the model. The service model is composed of a set of classes representing the implementation of the domain model.
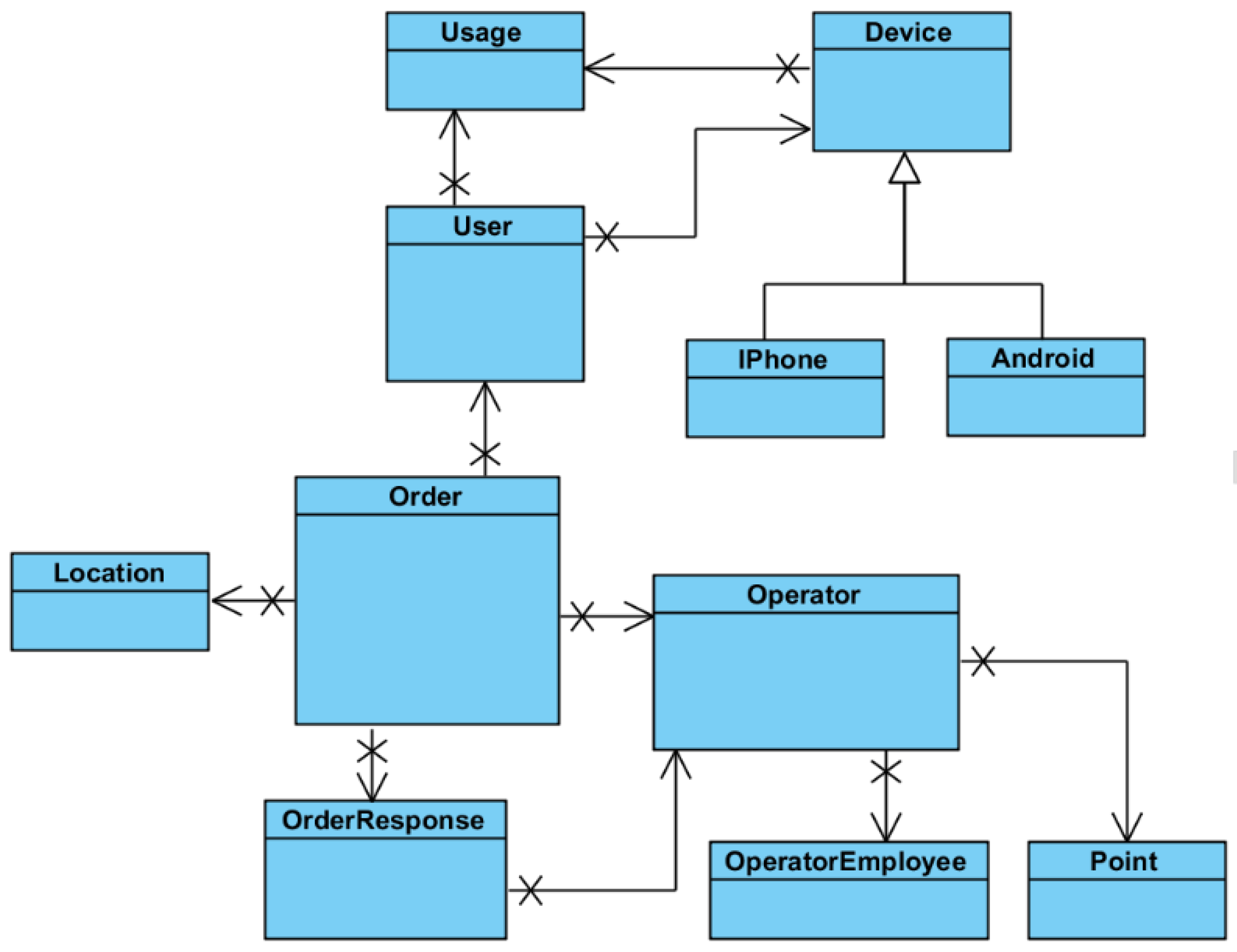
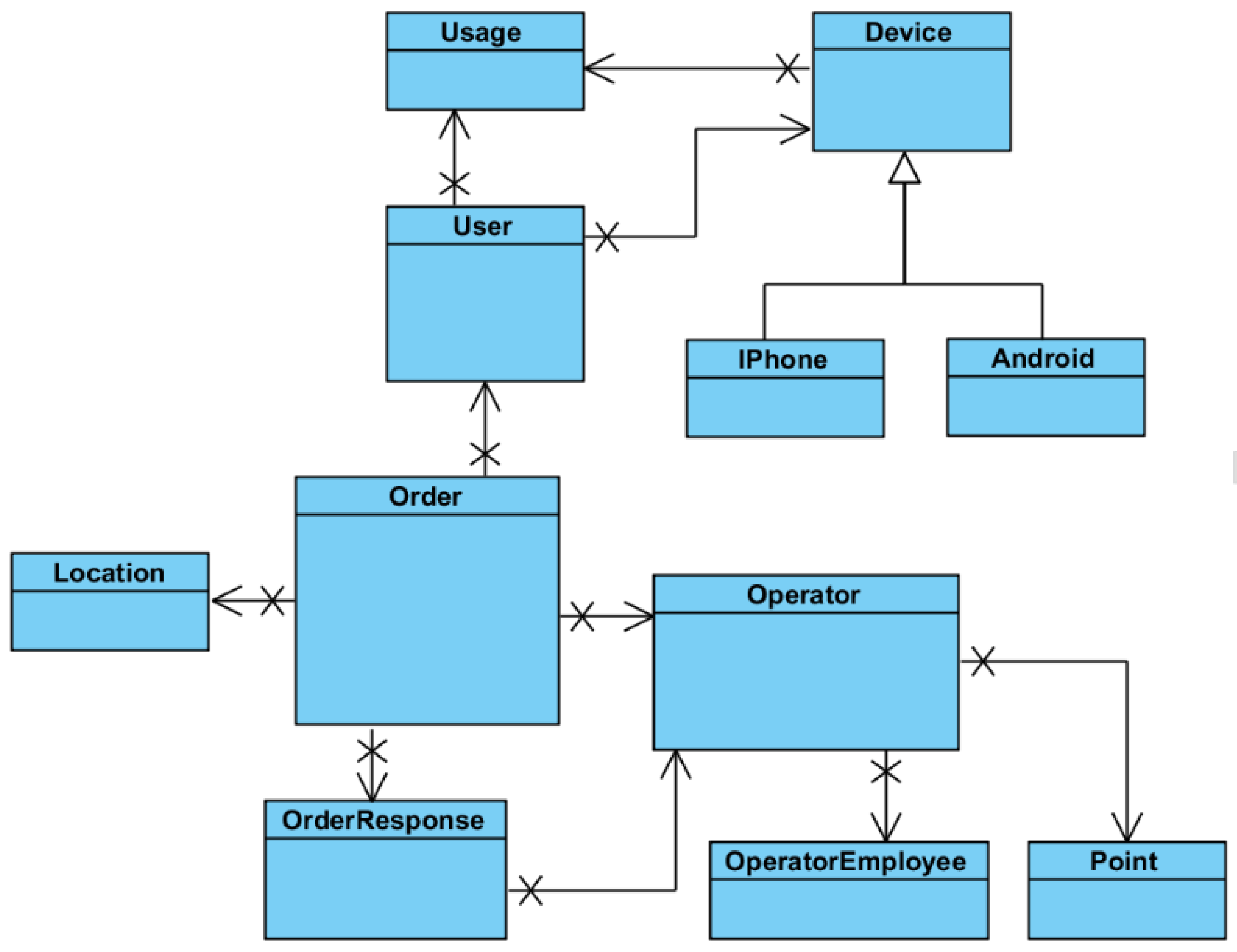
Figure 7 represents the most important objects that constitute the domain model. Because Entity Framework was used for mapping CLR objects to database records, these entities have a corresponding implementation in the SQL server database. We are outlining the most important entities presented in our system:
Figure 7.
The entities of the system model.
Figure 7.
The entities of the system model.
Order: represents an order placed by the client into the system. The Order has a set of attributes representing:
State of the order: IsResolved, IsCanceled, IsPendingResponse. This attributes are used for identifying the current status of the order.
Modification time: Each modification of the state of the order also sets a time stamp on the object, which is used by the system. For example when an order is created, it is displayed to the operator together with a label showing how much time has passed since the order was submitted.
Data associated with an order: Represent information such as the rating of the taxi driver or the feedback of the client following the ride.
Associated data such as the pick-up location or the owner is represented as references to the specific entities.
User: represents the client who is placing orders into the system. The user has the following attributes associated with him:
Name represents the name chosen by the person submitting orders.
Registration date the date when this user registered by submitting his phone number and name
Phone number is used for contacting the person in case he does not show up at the pick-up location
Phone is validated is used to determine whether the specific user was validated by the validation code sent through the SMS.
The user must be marked as active in order to be able to place orders into the system. A user state can be changed to inactive in case abuse has been observed for this particular user.
The confirmation code is the activation code sent to the user through SMS that is used to determine if the phone number is valid.
Location: Represents the position where an order is set. It contains the GPS coordinates for the location together with an optional name for it. There is also a property used for counting how often that location is used. The more frequent locations will be displayed first in the location suggestion list.
Operator: This entity represents an operator, which might me understood as a taxi company or a collection of taxi companies unified as a group. This entity presents the following properties:
Activation date and time, when this operator has been registered
A perimeter that represents where the operator is active, represented by a collection of points.
Stations represent predefined locations on the map where taxis are expected to be present.
OperatorEmployee: This class represents the operator that responds to orders.
The name is the real name of the operator.
IsActive property is set to true for those Operators which are active, meaning having permission to access the system, permission set the manager.
OrderResponse: created by the OperatorEmployee and represents the response the user receives for his order. It contains the necessary information required by the client such as the car number, the name of the driver, and the expected waiting time for the user. It also has an IsRead property which is used for determining whether the response has been read by the user application. If the Response is not read in a certain amount of time, this means that that the client application is closed and as a consequence the response needs to be delivered using push notifications.
Point: This class is used for defining perimeters in which an operator activates. Ay order placed within this perimeter might come to the operator. The number represents the count for the point, so that given a collection of points and their orders, the system can check whether a specific point is inside that perimeter or outside of it.
The entities are mapped by Entity Framework into the CLR classes which are further extended in functionality by means of partial classes, by adding extra functionality.
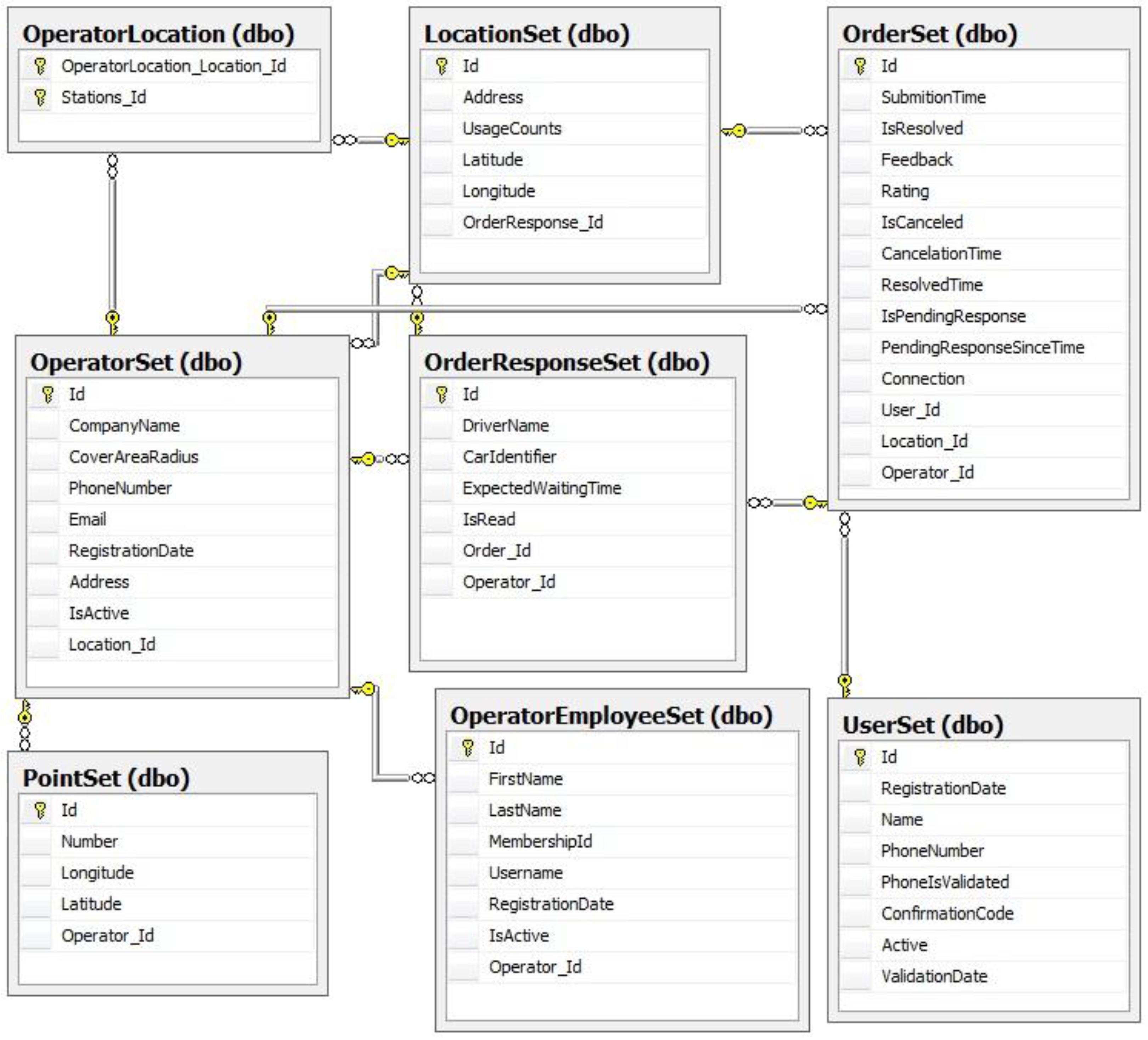
Service Database. The service relies on a SQL rational database. The service database is generated using Entity Framework, and we designed the Entity Framework entities directly mapped to the tables, and providing the same properties as columns in the rational database.
UserSet table represents the client who is placing orders into the system. The most important columns of this table include the name which represents the name chosen by the person submitting orders, the registration date – the date when this user registered by submitting his phone number and name. The phone number is used for contacting the person in case he does not show up at the pick-up location, and is represented as an nVarChar.
We used this representation especially because phone number formats are very different for distinct regions. IsPhoneValidated column is used to determine whether the specific user was validated by the validation code sent through SMS. The user must be marked as active in order to be able to place orders into the system, this column being represented as a non-nullable Boolean type. A user state can be changed to inactive in case abuse has been observed for this particular user. The confirmation code is the activation code sent to the user through SMS that is used to determine if the phone number is valid. This column is also represented as an nVarChar.
The table OrderSet has the foreign key represented by User_id that specifies the User which placed the order inside the system. OrderSet and OrderResponseSet have a one to one relationship between them. We decided to separate these two tables, even though there is a synonymy relationship between them as there can be order, which do not have a response, such as for example an order that was canceled.
We can observe that there was no case for splitting entities in our model. In this mapping scenario, properties from a single entity in the conceptual model are mapped to columns in two or more underlying tables. In this scenario, the tables must share a common primary key. In our mapping scenario each entity in the conceptual model is mapped to a single table in the storage model. This is the default mapping generated by Entity Data Model tools. Each operator can define multiple stations which represent positions on the map which an associated name (records in the
LocationsSet Table) that are by the operator to specify the initial taxi position easily, by clicking the marker on the map associated to that specific location. The mapping of a list of stations (defined as actually being of type location) to the
OperatorSet is done by
EntityFramework by introducing a new table called
OperatorLocation, as can be observed in
Figure 8.
Figure 8.
The MS-SQL database.
Figure 8.
The MS-SQL database.
We are using this database model representing the conceptual model of the system inside SQL Server 2010. We have decided on implementing our database using Entity Framework generate Database from Model approach, as it offered a productive environment where changes in the model could be easily translated into updates of the database. We also notice that there is a balance between the numbers of read and write operations as every record inserted into the database needs to be read usually just one time, processed and then archived. For example an Order is created, added to the system, it is answered by the operator, and the response is sent back to the client and after this there response is no longer used actively and constitutes solely a history used for creating suggestions such as, for example, suggesting pick up locations.
System API specification. The interaction between the client mobile and the server is performed through the means of a REST API and we implemented the REST API trough WCF. For example, IApi is the interface which is implemented by the API class. IApi exposes multiple methods including: UserOrderNew, UserOrderCancel, UserOrderResponse and UserNew.
UserOrderNew—this method is exposed as a resource using the verb POST and is available by invoking the service at the location /Api/user/order/new. The data passed to the method are encoded as JSON and consist of the User name and phone number. Once this data are received on the server the system sends the user an SMS message at the specified phone number. At this moment the user status is set as invalidated. In order to validate the phone number the user needs to send the confirmation code sent to him through SMS by using the next method described, ValidatePhone.
UserOrderCancel—this method is used to validate the users phone number by sending using the POST verb the code sent to him by SMS. This rest resource is available at /Api/user/order/cancel. The data needs to be submitted in the JSON format, as with all API calls to our service. When the code reaches the server, it is checked whether the code matches the one in the system. If the code is correct, the user is allowed to submit the order.
UserOrderResponse—this method allows for creating a new order inside the system. This is performed by sending the information required the order to the address /Api/user/order/response using the POST verb. Once an order is received on the server, it is recorded inside the database; it gets displayed on a specific operator panel. Once the operator responds to the order, an OrderResponse entry is created and an update signal is sent to the client. Among the attributes in a create order request the most important are:
The location where the order was sent for. This consists of the GPS position
The user who submitted the request
The date and time the order was created
The device information
GetOrderResponse—allows the client to read the response to his order. It is accessible using the GET verb at the address /Api/order/response. The request contains the identity of the order. The response is encoded as JSON and contains the information for the client such as:
The car number which was assigned for the order
The information regarding the driver
The estimated arrival time of the driver
UserOrderCancel—allows an order to be canceled by the user. The cancelation is performed by the client, and is accessible at /Api/user/order/cancel. The request verb is POST, as the submitted information contains the identity of the order that should be canceled. We note that we decided on not implementing the DELETE verb combined with the call at /Api/order as some Api best practices recommend as in our case there is no associated delete operation on the server. When an order is canceled what happens is that the IsCanceled property is set for the order, and an update notice is sent to the subscribers, such as the operator.
Security and Membership Framework. The API is secured using ASP.NET Membership Framework that handles the authentication and authorization logic of the application. The benefit of the Membership Framework is that a robust and throughout tested framework offers much better security than self-implemented framework. As a consequence, the Security framework was not extended and was allowed to operate as it is. By not extending or close integrating any services of the Membership framework with our system, we decoupled the two subsystems and allowed for further changes.
Also, all API calls are authenticated. The authentication is done using the user id, password and the session id. Each session is started when a user logs in. This prevents users to run the application on multiple devices in parallel and improves the overall security of the system. For the driver application authentication is done using tokens that are valid for a specific time interval. When a token expires, it needs to be renewed. Using tokens we are able to reduce the resource utilization on the server. If a call fails to authenticate, an error code is retuned. All communication is forced to use SSL, which eliminates or reduces the chance of Man in the middle attacks.
SignalR. It is not feasible to implement data synchronization using a polling interval, as the polling interval is both unknown and will generate large amount of data and CPU usage. In the .NET framework SignalR represents an implementation of long polling. However SignalR does not rely only on the long polling technique. SignalR has a concept of transports, each transport decides how data is sent/received and how it connects and disconnects. SignalR uses two concepts on the server implementation: Hubs and persistent connections. The Client app uses Hubs. Extending the Hub class represents the implementation of a hub on the server. Each method defined inside this class is mapped to a JavaScript implementation at compile time. The JavaScript document is saved on the project root folder and the client must reference it. It is possible to have broadcast events, which alert all the clients or only one in particular. It is also possible to group client and inform a whole group at a time. When the mobile application registers using SignalR, on the server a session ID called client ID is given to it. We are storing this client ID for each order. When a response is available and needs to be sent from the server to the client, we are sending an update request to the mobile app, using the client ID stored earlier.
There are three components of the system that need to be updated from the server. This are the client app, the driver app and the operator panel. The update scenario for the driver app is similar to the one for the client app. We note that the client app and the driver app are components that need to be independently updated, so having groups in this scenario is unnecessarily. However for the operator panel we need multiple operators to be able to respond to an incoming order. In this scenario it is more feasible to group the operators in groups, a group representing one operating company. When a new order is registered into the system the first operator who sees the new order will be able to respond to it.
3.5.2. Management Panel for human aided dispatch
Some orders need to be inserted by the dispatcher, or might come from an external API that integrates with other SCM or ERP systems. Management Panel represents a web interface intended for responding to orders through a human actor acting as a dispatcher. The webpage is developed using ASP.NET and is secured using .NET Membership Framework Forms Authentication. A logged in user will be displayed a panel consisting of the current orders. Color codes are used for different order statuses. Brown is used for canceled orders, Green for orders that were responded successfully. No color is used for orders which have not been responded yet. The webpage uses AJAX techniques for receiving new orders and sending them without requiring complete page reloads. When a new order is inserted into the system, SignalR is used to notify the browser webpage to reload its orders panel. Partial page reloads are designed using the ASP.NET UpdatePanel and the AJAX functionality is built on JQuery. Using the Operator panel website the operator is able to respond to client orders. Whenever a new order that is destined for that operator is inserted into the system, SignalR that the orders grid needs to be updated notifies the webpage. Using an update panel control, as we specified earlier, does the update.
We implemented the operator panel in such a way to allow multiple operators to work on the same set of orders without worrying of responding to the same order. Whenever an operator views the content of an order, the order is marked as pending. When this happens a message is sent to the user notifying him that the operator viewed his order. Also another operator is announced that his colleague is already processing the specific order. If he tries to process the same order he will get an alert.
Feature usage metrics using Analytics. Analytics provide the means of measuring user experience inside the app and becomes a key component of the mobile ecosystem. Analytics provide the means of observing how users are interacting with the app and this provides the information required for further updates. Traditionally two analytics were used: daily active users and user session time. However it has been observed that user engagement falls sharply few days after the app first installation. As a consequence another key metric has become the user retention level after one day, one week and one month. Unless the app uses analytics it cannot understand its users base accordingly.
Analytics provide information regarding usage statistics such as new users, active users (which combines new and returning users into one stat), and sessions (how many times your app is used over a time period). You can grow this stat several ways such as acquiring new users, getting existing users to use more often or retaining users longer), session length (Session Length is a key engagement metric. Although different kinds of apps have different average session lengths, you would like this stat to improve over time with each additional update), frequency of use (this stat reveals the intensity with which your app is used), retention level, and app versions. It is also possible to track custom events such as the user clicking a menu button or completing a game level. We are tracking the address textbox editing feature, the map marker move, the amount the map marker is moved, the amount of time spent editing the address textbox, the amount of time until the order is placed.
Social media integration. Using Social Networks such as Facebook and Twitter we provide a mean of authentication using OAuth v2. For example if the app requires the users email address it can prompt the user to authenticate in the app using his Facebook account. If the user agrees to allow Facebook to share the email address with the app, the app is authorized to retrieve the users email from the Facebook service using the Facebook API. OAuth is an open standard for authorization, it allows users to share their private resources stored on one site with another site without having to hand out their credentials, typically supplying username and password tokens instead.
The other common use of social services integration is for marketing purposes. Many apps allow users to post messages to Facebook or to post on the users behalf. The posted messages should be based on users intention to share them, but they also often serve as a marketing strategy inside the users social network. Order Taxi application uses social services for marketing purposes by sharing the users ride information with the users consent. In order to use social services, as with most third party APIs an API key must be obtained by registering on the providers website. For Facebook this is available in the developers section of their website. Titanium offers modules for integrating Facebook and Twitter services and encapsulating the communication with the REST API. In our Taxi Ordering Application, we are integrating Facebook in order to allow people to post messages on their wall to inform their friend they are using Order Taxi application. They can also invite friends to join the application and earn points.
Management and configuration .There are three types of components that need to be managed: The proprietary server, the mobile client and the third party services. Managing the third party services is usually done by a management panel on the providers’ website. A management panel for changes that have a high occurrence rate manages the proprietary server. For example new drivers are added manually to the system from this management panel. The hardest component to be managed is the mobile client application as there is no direct control over it. If major changes to the system are required for implementing new functionalities and this requires a change in the API it is important that API versioning is used to secure reliability for old clients that do not install the last updates. Backward compatibility of the system must always be respected. If the changes made to the system do not require any change in the API, but rather a change in the address, this can be resolved if the client was designed to adapt to such changes. Otherwise an update of the client app is required.
3.5.3. Social CRM System Using DataSift
DataSift [
3] supports a variety of datasources. However the idea and first implementation addressed just one datasource, which is the most active of them, all that being the Twiter Firehose. Twitter does allow anyone to access its streaming API. However only a subset of all tweets are available through the streaming API, which are less than 1%. Twitter does however have two affiliated companies which get all the tweets through the Twitter Firehose, those being DataSift and Gnip (which is now a subsidiary of Twitter).
In this section we will describe how the DataSift architecture is implemented and build for a massively scalable requirements. DataSift implemented both their software and hardware solution because the large amount of data required to process offered both technical and economic challenges. DataSift runs on Hadoop and has one of the largest Hadoop clusters in the world. By creating their own hardware cluster they were able to take advantage of more low level performance optimizations than if they had used a public cloud provider such as Amazon, Google or Microsoft. Also considering the massive explosion in Big Data over the past few years, their infrastructure is expanding massively which would have been much more costly if they decided to use a public clod solution.
The DataSift architecture can be broken up in three large areas as follows that being data extraction, filtering and delivering.
(1) Data Extraction and Preprocessing
We call data preprocessing the act of extracting or receiving data from the defined datasources. Given the multitude of data sources one important aspect of this step is normalizing the data. The Redis Queue is used as a buffer during high peak usage. This allows the DataSift architecture to remain reliable at all times. Data is extracted out and normalized. Twitter data is highly dimensional, it has 30 plus attributes and you get access to them all. These attributes include geolocation, name, profile data, the tweet itself, timestamp, number of followers, number of retweets, verified user status, client type, etc.
The Interaction Generation thus acts similar to a JOIN operation over multiple streams of proprietary data structures and formats. As one can see the data sources are received using both Push and Pull HTTP requests and the formats are ranging from JSON and XML to Binary Streams. The result of the Interaction Generation block is a normalized object. This object is further augmented with data extracted from third party sources or by analyzing the data using proprietary or licensed algorithms such as Sentiment analysis or Language Detection. Entity extraction and natural language processing is applied to the tweet. Language is determined, for example, and that result is made available in the meta-data. Each link is resolved and the contents fetched so filters can be applied to content and the links themselves. Data is fully elaborated before the filtering process occurs.
Bringing the datasets into their system they needed to form close partnerships. Their sentiment analysis engine was licensed, made fast, made clusterable, and made suitable to handle 500 million hits a day with low latency. Each service must have < 100 ms response time. After 500 ms it is thrown away. In order to respect this they needed to cache the augmentation data sources locally. Also one in 10 tweets is a link, so the system creates a request for fetching the content of the referenced page in order to allow filters against it. So if a brand is mentioned it can be resolved against the actual content to figure out what it all means. This can provide quick insights into new blog posts or product reviews mentioned on social media.
Metadata Generation.
Tagging allow adding custom metadata to interactions. For example, a specific car model can be tagged as luxury or economy. This information can be very useful later on into post processing. Adding tags based on conditional rules gives you the power to code business rules directly into your CSDL code. Normalized data is augmented in order to provide more context into the application. By enrichment the interactions will gather more metadata that can be queried using CSDL. The supported Enrichment engines are Demographics, Sentiment, Gender, Entities, Topics and Trends.
Sentiment scoring allows a computer to consistently rate the positive or negative assertions that are associated with a document or entity. The scoring of sentiment (sometimes referred to as tone) from a document is a problem that was originally raised in the context of marketing and business intelligence, where being able to measure the public’s reaction to a new marketing campaign (or, indeed, a corporate scandal) can have a measurable financial impact on your business.
The Salience Sentiment data source delivers a measure of the positive or negative sentiment in a post. Within DataSift, sentiment is typically scored from −20 to 20 although values outside this range do sometimes occur. A score of zero is neutral, scores below zero indicate negative sentiment, and scores above zero indicate positive sentiment. For example, a score of −1 is mildly negative while a score of 15 is strongly positive.
The Salience Topics data source lists the topics it finds in a post. Salience Topics are derived from an analysis of all the content in Wikipedia. As such, they allow for robust detection of content that is “about” a particular topic. A major advantage of this approach is that the topics analysis engine can easily be extended. The engine independently analyzes the content and the title.
The Salience Entities data source lists the entities it finds in a post. Entities are typically proper nouns (people, companies, products, places) but can also include special patterns like URLs, phone numbers, addresses, currency amounts, and quotes. It can also recognize entities that we have never seen before. Each entity has sentiment associated with it so, if there is a Tweet that says “I really like Brand X, but don’t like Brand Y”, the entity discovery feature will correctly associate the sentiment with the individual entities. Sentiment analysis is also able to understand emoticons and nuances in the language. Only English is available however.
Classifiers take a large sample of interactions from the platform, manually classify the interactions and use machine learning to learn key signals, which dictate which category interactions should belong to. The result is a set of scoring rules that form the classifier. The resulting classifier can be run against live or historic data ongoing. For example a classifier can be used to asses a user’s probability of preaching a specific product or to route specific interactions to specific customer support or marketing teams inside a company.
(2) Filtering the Interactions
The cost of licensing the Twitter Firehose is extremely high and would become an inefficient investment for the majority of companies. Datasift created a declarative language called CSDL is order to filter out the Interaction (such as Tweets, Facebook posts, blog entries etc.) you do not want and keep the Interactions you do want. As we have explained in the previous sections the cost of running a queue includes both a licensing fee and a processing fee. The licensing fee is based on the number of interactions that match the defined query.
CDSL language CDSL allows for defining filtering conditions that specify what information the stream will include and augmenting the objects in the stream with data from third-party sites. A filtering condition has three elements: target, operator and argument. The target specifies the operand such as the content of a Twitter post. The operator defines the comparison Datasift should make. For example, it might search for Tweets from authors who have at least 100 followers. More complex filters can be built by combining simple filters using the logical operators: AND, OR, and NOT. Once a result stream has been defined through a filter, it can be reused as part of the definition of another stream by using the stream keyword to combine it with further filtering conditions. The argument can be any value, as long as the type of the argument matches the type of the target.
All interactions matching a filter form a stream. Each stream is assigned an identifier such as “4e8e6772337d0b993391ee6417171b79. Stream identifiers are included in rules to further qualify which tweets should be in a stream. Rules build on filters and other rules: rule “4e8e6772337d0b993391ee6417171b79” and language.tag = “en” This allows filters to grow on one another. DataSift also pushes for public streams which are more cost effective to process because of resource sharing the computation of a specific rule.
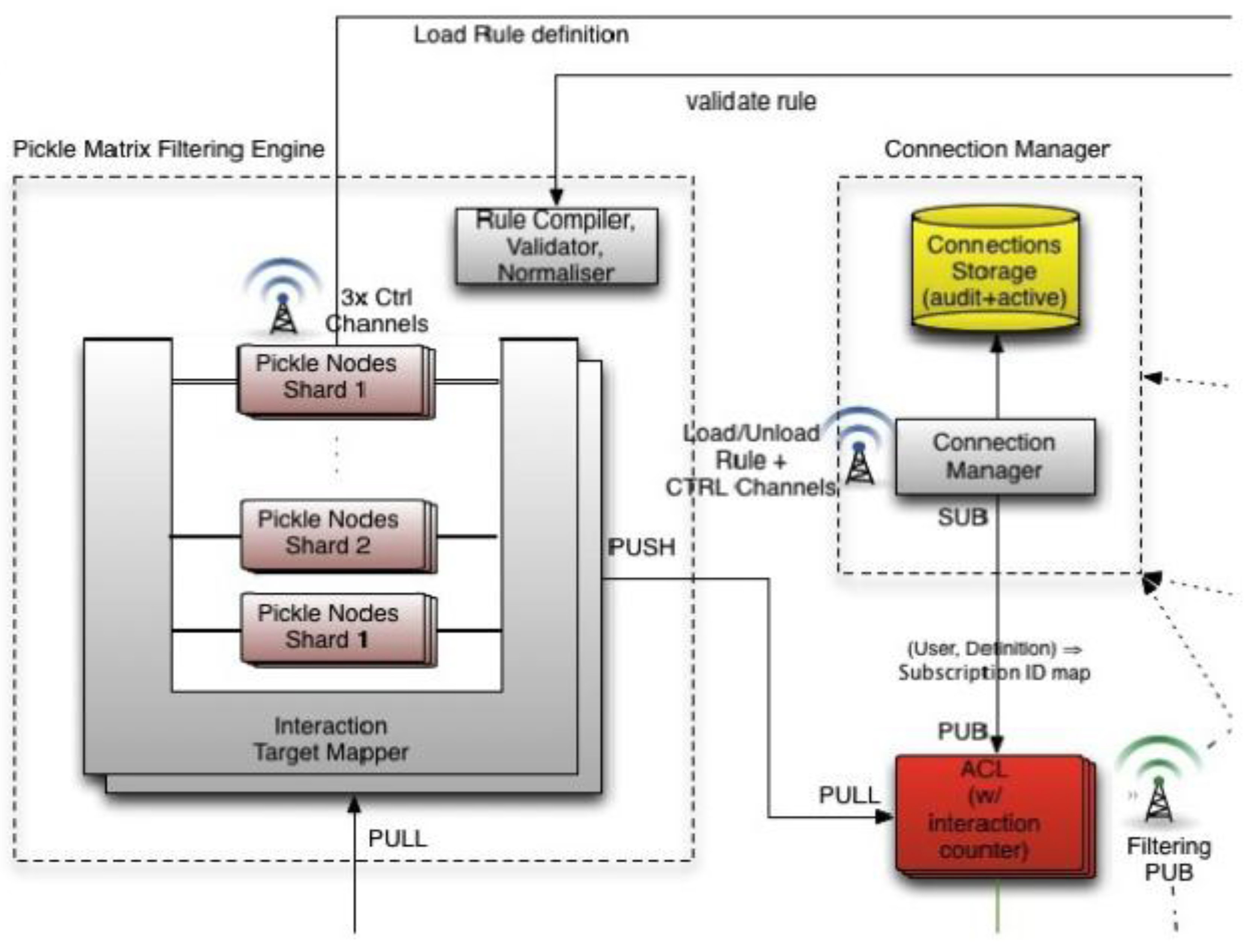
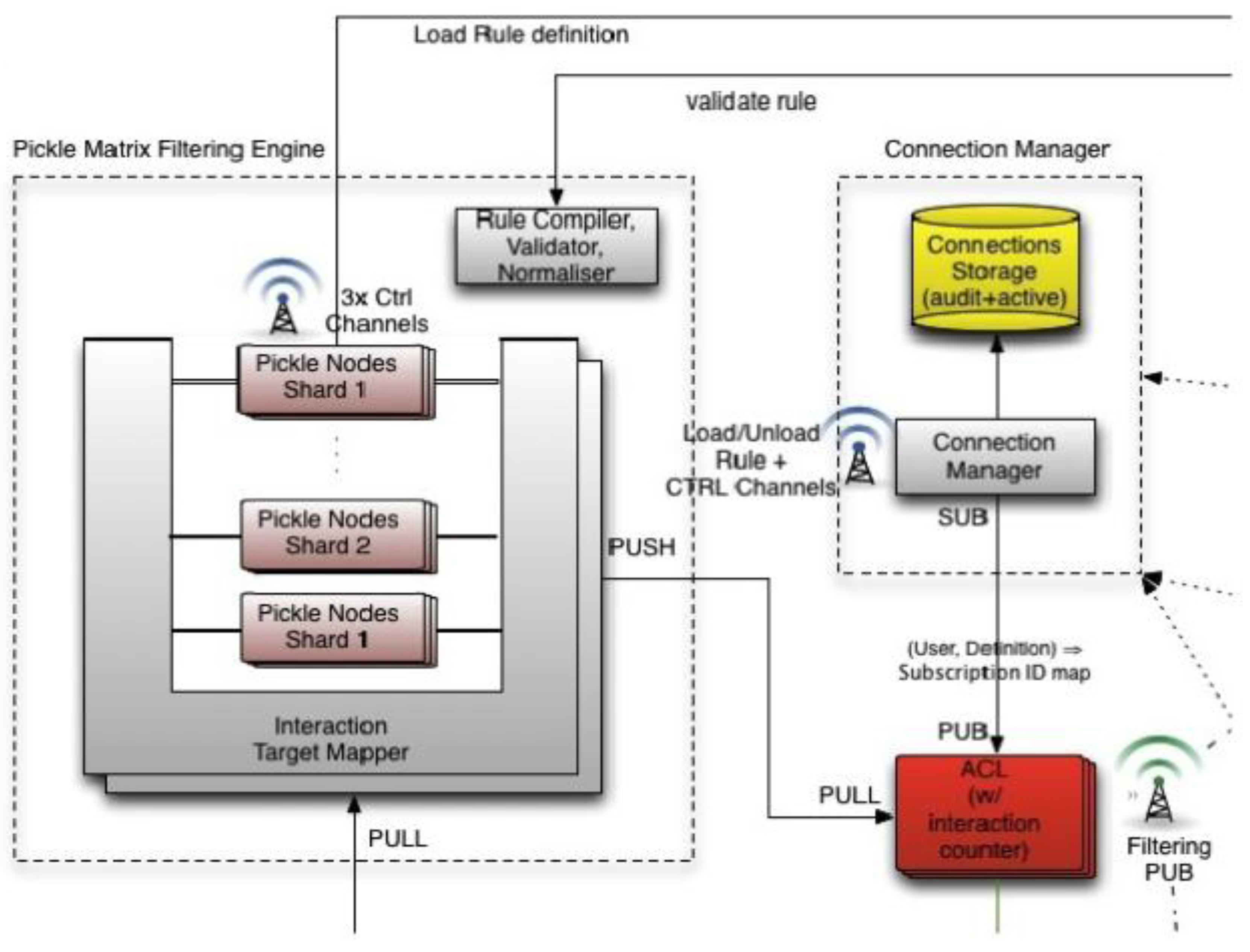
In order to create scalable filters DataSift uses a compiler to schedule filters efficiently across a cluster. Rules are made from a combination of filters and can have 1000 s or millions of terms. Millions of rules can be evaluated simultaneously, scheduled across hundreds of machines. Rules can be reused and hierarchically order. Filters include regular expressions, you can filter out tweets based on text in the profile, for example. There are many different targets and operators. The core filter engine is in C++ and is called the Pickle Matrix and is depicted in the
Figure 9 below. The filtering engine is implemented using a custom built compiler and virtual machine based on Distributed Complex Event Processing with Query Rewriting.
Figure 9.
Real time filtering of normalized posts based on precompiled rules [
3].
Figure 9.
Real time filtering of normalized posts based on precompiled rules [
3].
A compiler takes filters and targets a Hadoop cluster with a Manager and Node servers. The Manager’s job is to determine that if a rule is loaded anywhere else and if can be put somewhere that is highly optimized, like close to someone else that is running a similar stream. Node’s job is filter tweets by rules, get a list of matches, and push the matches down the pipeline.
Custom algorithms are built so rules are shared as much as possible. No filter is run in isolation. The filters form a shared space. If there is a filter that filters only for “computer” references then that filter is run on each tweet once and the result is shared between all rules using the same filter. Instead of continually running duplicate filters they are only run once. Rules can be a hierarchical and the compiler is merges them together so that they share rule evaluations. If a node already has a rule then it will attract filters that use that rule. That rule is run just once for all the filters on the node.
By combining workloads of multiple customers together they can exploit any commonality in the filters. DataSift is paid for every operation even though they only run it once. If a regular expression is shared, for example, it is only run once. It cannot always work this way, perhaps a node is loaded so cannot take another client, so it must run on another machine.
The entire configuration dynamically changeable at runtime. The scheduling algorithm is constantly looking at monitoring data. If latency crosses a threshold then the system will be reconfigured. Filters are processed immediately in memory. Each server, for example, can run 10,000 streams. Nodes have a rule cache so they can be shared.
Compiler supports short circuiting to optimize filters. If a regular expression is bigger than an entire machine, for example, then they will automatically load balance across nodes.
The filtering engine is sharded. Each shard receives the full firehose and every “interaction” (i.e. a “tweet” or “FB status” or “blog post”) is processed by all shards, the results of which are collated before being sent downstream. Each of the N nodes in a single shard (which are replicas of each other) receives 1/N of the hose on a round robin basis. So, supposing there are two shards, with three nodes each, 50% of the filters would be found on each shard. Each node in a shard would receive 1/3 of the hose (and would have 50% of the filters on it). And it would be a replica of the other nodes in that shard. Thus, if a very heavy filter is loaded, that will be balanced by adding more nodes to the shard the heavy rule is loaded into, thus reducing the amount of data that a single node has to process.
A big push is for customers to create reusable public rules to encourage the reusability of data streams. People can use any of the public streams in their own rules. For example, someone could make a word filter that creates a stream. You can build off that stream by using it. Everyone shares that same stream so if a 1000 users are using the dirty word filter the filter is not getting evaluated 1000 times. The filter is getting evaluated once for everyone, which is highly efficient. The platform will thus offer even better performance for a higher number of workloads and become highly scalable with resource usage relative to processing requirement being reduced.
(3) Loading and Delivering the Results
Once the filtering process identifies an interaction that matches the specified query, the interaction is delivered to the specific stream. It is important to mention that DataSift buffers the data it receives for up to one hour. During this time it is possible to request specific interactions from DataSift. The data is stored in Hadoop HBase. However most implementations will require specific custom processing on the results created by DataSift. For example a client might be interested in extracting information such as addresses or mentions of specific users or places and store them later in their own database.
When creating a DataSift Stream running task it is possible to specify a specific output location. Tweets that match the filter are accessible to external applications via a REST API, HTTP Streaming, or Web sockets with a client library exists for: PHP, Ruby, C#, Java, Node.js. The results are JSON objects containing all the data in a normalized, fully augmented format. Augmentations include gender, geolocation, point-of-interest, country, author, the tweet, follower count, Klout score, etc. in the stream. There up to 80 fields for each message. Tweets are not guaranteed to arrive in any order and you are not guaranteed to see all the tweets ever sent. This is because Hadoop MapReduce jobs are used to extract the data out of HBase, which involves sharding and thus change the order. However Hadoop does offer solutions for persisting the order of the analyzed data.
Recording interactions on DataSift
DataSift records the result of the Filtering Task in HBase tables. When data is streamed out of DataSift, Hadoop MapReduce jobs will extract the data in the specific desired format. Most of the time this format will be JSON. DataSift took the decision of storing the normalized data in HBase table instead of pure JSON because it allows further querying if necessarily or exporting it in other formats such as CSV or Excel documents as depicted in the
Figure 10. This storage component is fundamental to DataSift for two reasons. First it is used as an Achiever, where all the Interactions that came through the system are stored in a normalized form and can be later processed using the Historic Task Services. The recorder is used for buffering the data until it is transferred to the client in the specified way (live stream, push to a specific data source, download using HTTP
etc.) The recording table uses entries similar to <interaction ID><recording ID> in order to map the interactions that should be exported to a specific stream.
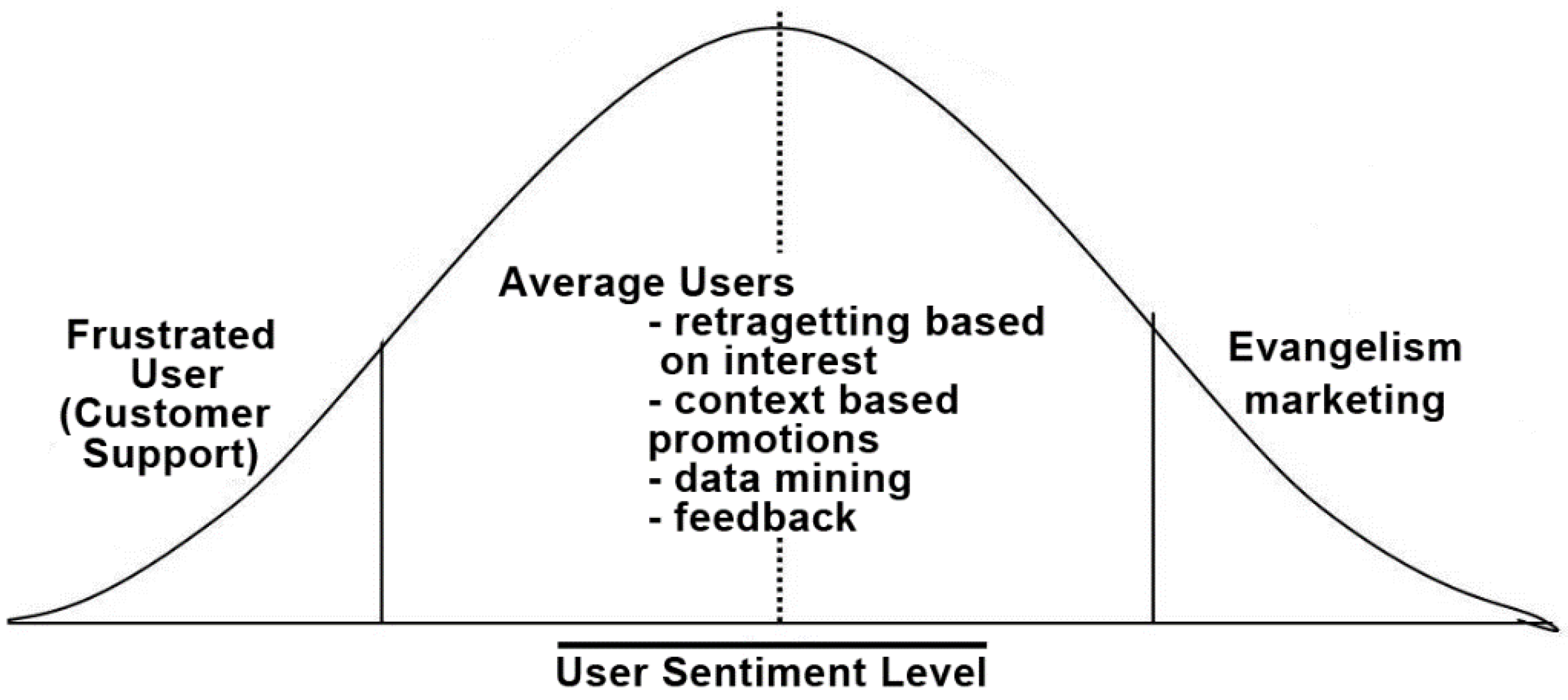
Figure 10.
Bell Curve of our User Base. Social CRM has the purpose of moving the curve to the right and increasing the number of users.
Figure 10.
Bell Curve of our User Base. Social CRM has the purpose of moving the curve to the right and increasing the number of users.
The content of each interaction is only stored once, and will be archive by DataSift. When DataSift introduced Historic Queues, it bought the data from Twitter for the previous two years. This data amounted to 300 TB, which was delivered over the Internet and normalized according to the way all interaction objects are processed, including augmentations.
Social CRM integration with the Dispatching System
The dispatching system is offered as a SAAS product to enterprise clients. The Social CRM system builds upon it and has the purpose of aggregating as much information about the users as possible. The most important data that we extract using DataSift and utilize in our system is presented below.
User sentiment score—describes the sentiment the user has towards the application. This metric is closely monitored as it groups the users into three major categories.
The first category is composed of users that are neither highly enthusiastic about using the system nor highly negative. They are the regular users and compose 80%–90% of the user base. In general no human interaction with these users is performed. They are advertised and retargeted using their profile and interests, as we will describe bellow. The second category is composed of users that are negative on the system. They have probably experienced either a problem with the system or in the interaction with the driver for example. Whatever the cause, the problem should be addressed so that it will not affect other users or have a spillover effect. The most effective way of dealing with highly negative users is an apologetic customer support phone call during which the user is offered free credit for retrying the system and with the promise that his problem will be addressed as soon as possible.
This method has been used effectively by Uber for monitoring their drivers. The last category is composed of users who are extremely positive on using the system, which we will be calling evangelizers. This category should be enticed to promote the system by offering them a more privileged role that allows better service and social recognition. This method of gamification at the high levels of the customer spectrum has been proven by numerous companies including Foursquare, Path, Quora and StackExchange.
Interaction History—this provides anyone interested in a specific user the ability to see the exact posts that constitute the sentiment index, or to identify what the pain points of a highly negative user are. All the interactions provided by DataSift are stored in our database and augment the user profile.
Promotions History—all the promotions and advertising campaigns that have ever been targeted to a specific user are recorded. This is for two reasons. One of them is to see the conversion and activation factors of specific campaigns. The other is to aid us in future campaigns by selecting only those users that have or have not been targeted previously within a specific program.
More information on the users—by aggregating more information about each user such as age, locations, interests, network of friends etc., we are able to understand the user base better and it helps with categorizing them better. The purpose of the entire Social CRM component is to improve the service and increase the success rate of our marketing campaigns by better targeting which will reduce the total cost. We can thus create online marketing campaigns that can be extremely targeted and still benefit from low CPC rates.
In this section we have detailed the implementation of the proposed system and explained the functionality of the complete architecture by breaking it up into the composing parts. We also analyzed how we managed to integrate the two systems in an efficient and scalable manner by using Windows Azure Cloud Computing as the underlying architecture for our system. We decomposed the system into two large subsystems: the dispatching system and the Social CRM system.
We explained how a cross platform approach can be used to developing mobile application and we have proved the native capacities of the system by using the GPS API. We also presented how the mobile application can be integrated with the Cloud and how the Cloud can act as a data synchronization mechanism between the client mobile application, the driver application and the operator panel. Regarding the Social CRM system, we explained how it can be built to extract and augment the data in our database and bring more value and customer engagement.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}