Abstract
To address the limitations of existing knowledge graph-based recommendation algorithms, including insufficient utilization of semantic information and inadequate modeling of user behavior motivations, we propose SKGRec, a novel recommendation model that integrates knowledge graph and semantic features. The model constructs a semantic interaction graph (USIG) of user behaviors and employs a self-attention mechanism and a ranked optimization loss function to mine user interactions in fine-grained semantic associations. A relationship-aware aggregation module is designed to dynamically integrate higher-order relational features in the knowledge graph through the attention scoring function. In addition, a multi-hop relational path inference mechanism is introduced to capture long-distance dependencies to improve the depth of user interest modeling. Experiments on the Amazon-Book and Last-FM datasets show that SKGRec significantly outperforms several state-of-the-art recommendation algorithms on the Recall@20 and NDCG@20 metrics. Comparison experiments validate the effectiveness of semantic analysis of user behavior and multi-hop path inference, while cold-start experiments further confirm the robustness of the model in sparse-data scenarios. This study provides a new optimization approach for knowledge graph and semantic-driven recommendation systems, enabling more accurate capture of user preferences and alleviating the problem of noise interference.
1. Introduction
With the rapid development of Internet technology, the amount of data in the network is growing exponentially. Users often find it difficult to quickly access the content they are really interested in when facing the huge amount of information. In order to improve user experience and information access efficiency, recommender systems are widely used in e-commerce [1], music [2], movies [3], and other scenarios. The core of a recommender system lies in the recommendation algorithm, whose goal is to mine the hidden interest associations from the complex user–item interaction data and predict the items that users may be interested in. Traditional recommendation algorithms mainly include collaborative filtering, content-based recommendation, and hybrid recommendation. Among these, recommendation systems based on collaborative filtering are widely used in various scenarios because they can efficiently capture user preferences without the need for complex feature extraction, unlike content-based recommendation systems. However, this system also faces challenges such as data sparsity and cold-start problems. To address these issues, hybrid recommendation systems have emerged, effectively compensating for the shortcomings of single collaborative filtering recommendation systems by integrating interaction-level and content-level similarities. In this process, researchers have explored various types of auxiliary information, such as item attributes, user reviews, and users’ social networks, to further optimize recommendation effectiveness and enhance the system’s overall performance.
A knowledge base is a typical dataset that represents real-world facts and semantic relations in the form of triplets. When the triplets are represented as a graph with edges as relations and nodes as entities, it is considered a knowledge graph [4]. Many large-scale knowledge graphs exist, such as DBPedia [5], Freebase [6], WordNet [7], and YAGO [8], which make it easier to build knowledge graphs for recommendation purposes. As a structured knowledge representation, knowledge graphs enable interpretable modeling of complex relationships by displaying semantic associations.
In recent years, knowledge graph-based recommendation algorithms have become the core research direction in the field of recommender systems by virtue of their ability to deeply integrate structured semantic information. The algorithm breaks through the limitation of traditional collaborative filtering by relying on interaction data by constructing entity-relationship-attribute ternary networks, mining the higher-order associations between users and items (e.g., “user preference—actor—same type of work”), and at the same time utilizing the semantic path of knowledge graph and the node aggregation capability of graph neural networks to realize the synergistic improvement of recommendation precision, diversity, and interpretability, especially in solving the cold-start problem and the cross-domain knowledge problem.
In summary, how to better integrate semantic information in a knowledge graph into a recommender system to achieve optimal recommendation has been an urgent problem that needs to be solved. Existing knowledge graph-based recommendation algorithms usually enhance the recommendation effect by aggregating neighbor node information or multi-hop path mining, but this approach often ignores the variability of the relationship semantics in the path. Meanwhile, symbol-based approaches cause the loss of semantic hierarchical information to a certain extent, and do not fully utilize the interaction information of implicit semantics in relations. To address the above problems, we propose SKGRec, a recommendation model driven by the fusion of knowledge graph and semantic representation. Our main contributions are summarized as follows:
- We construct a semantic interaction graph USIG of user behaviors, use a self-attention mechanism to semantically analyze and model the aggregation of user interactions, and propose a new ranking optimization loss function to learn the similarity between user behaviors.
- We design a relation-aware aggregation module to extract multi-level semantic features from the knowledge graph and optimize the entity representation through the relation-aware attention mechanism.
- We introduce a higher-order relational path inference module to capture remote semantic dependencies for more accurate modeling of potential user preferences.
2. Related Work
In this section, we systematically review recommendation models based on knowledge graphs and summarize related work. These models can be broadly categorized into three main types: embedding-based methods, path-based methods, and unified methods. Subsequently, we conduct an in-depth analysis of several representative models from three key dimensions: semantic modeling, graph structure utilization, and behavioral interpretation, and compare them with our proposed SKGRec model.
2.1. Embedding-Based Methods
Embedding-based methods enhance the representation of users and items by embedding entities and relationships from knowledge graphs into low-dimensional spaces. The core of these methods lies in utilizing knowledge graph embedding (KGE) algorithms to encode information from knowledge graphs into low-rank embeddings, thereby enriching the representation of items or users and improving the accuracy and interpretability of recommendations.
Zhang et al. [3] proposed CKE. This method integrates structured item knowledge, text features, and visual features into a unified framework, calculating user preference scores for items through inner product computations. Experiments demonstrate that CKE significantly outperforms baseline methods in movie and book recommendation tasks, particularly in sparse scenarios. However, CKE relies on predefined embedding methods (e.g., TransR [9]), which may fail to fully capture the dynamic propagation of user interests.
Xin et al. [10] proposed RCF, which introduces item relationship type embeddings and relationship value embeddings to accurately characterize user preferences. It utilizes the DistMult model in knowledge graph embedding (KGE) to capture the relationship structure between items, thereby preserving the semantic associations between items in the embedding space. Building on this, RCF further employs attention mechanisms to model users’ type-level preferences and value-level preferences separately, enabling user preferences to be dynamically adjusted based on different relationship types and relationship values. Through joint training of the recommendation module and the knowledge graph relationship modeling module, RCF optimizes recommendation performance while fully leveraging the structured information in the knowledge graph, thereby achieving high-quality recommendation results.
2.2. Path-Based Methods
Path-based recommendation methods construct heterogeneous user–item interaction graphs and utilize multi-hop connection patterns between entities in the graph for recommendation modeling. Since the introduction of HIN analysis methods into the field of recommendation systems, path-based recommendation methods have gradually developed into an important research direction. The core idea of these methods is to enhance traditional collaborative filtering recommendations by mining multi-type connection paths (such as user–item–attribute–item) between users and items in HIN and calculating path-based semantic similarity.
Yu et al. [11] proposed HeteRec, which enhances the representational capacity of the user–project interaction matrix by systematically utilizing meta-path similarity. Specifically, HeteRec first constructs an HIN containing multi-type entities and relationships, and then models user behavior patterns under different semantic paths using predefined meta-paths. Based on these meta-paths, the model can calculate higher-order similarities between users and items, thereby uncovering deeper underlying interest associations. This meta-path-based similarity measurement method not only enriches the representation of users and items but also significantly alleviates the data sparsity issue present in traditional collaborative filtering.
Wang et al. [12] proposed a Knowledge-aware Path Recurrent Network (KPRN) model for path-based recommendation tasks. The model constructs path sequences between users and items by combining entity embeddings and relationship embeddings, thereby capturing the semantic associations between them. These paths are encoded through LSTM layers, and the preferences of users for items in each path are predicted through fully connected layers. Preference scores for all paths are aggregated via a weighted pooling layer to generate a comprehensive preference estimate for items, which is used to generate recommendation results.
2.3. Unified Methods
Embedding-based methods and path-based methods often focus only on a certain type of information in the graph when utilizing knowledge graph information. To more comprehensively mine the rich information in knowledge graphs and improve recommendation effectiveness, researchers have proposed unified methods. These methods organically integrate the semantic representations of entities and relationships with the connection information in the graph, aiming to fully utilize the multidimensional information in knowledge graphs. Their core idea is based on an embedding propagation mechanism, which iteratively updates the embedding representations of entities to enable them to fuse information from multi-hop neighbors, thereby generating richer and more accurate user and item representations.
The KGCN [13], KGAT [14], and AKGE [15] methods achieve deep modeling of higher-order relationships in knowledge graphs by introducing message passing mechanisms and attention weights. KGCN was the first to apply graph convolutional operations to recommendation systems; KGAT further added attention mechanisms to distinguish the importance of neighboring nodes; and AKCG innovatively introduced an adaptive relationship learning module. The Ripplenet [16] method uses a joint optimization strategy to deeply integrate semantic information from knowledge graphs with user behavior data by constructing a unified embedding space. This method has excellent computational efficiency and a moderate parameter scale, making it suitable for large-scale recommendation scenarios. The AKUPM [17] method introduces cognitive computing concepts into recommendation systems, focusing on the dynamic evolution of user preferences to achieve time-aware knowledge graphs, which enables time-aware knowledge graph representation learning.
2.4. Compared to Our Work
SKGRec introduces a unified framework that explicitly models user behavior semantics and relationship-aware multi-hop reasoning. Our USIG module captures the fine-grained semantic motivations behind user interactions with projects, whereas most previous studies treat these interactions as flat data. Additionally, our relationship-aware aggregation mechanism assigns dynamic importance weights to different relationships, thereby enhancing the semantic expressiveness of entity embeddings. Finally, our multi-hop reasoning module enables the model to capture long-range dependencies along relationship paths, thereby achieving better generalization capabilities in cold-start and sparse-data scenarios.
3. A Semantic-Enhanced Knowledge Graph Fusion Recommendation Algorithm
3.1. Definition of the Problem
Users in recommender systems usually choose different items based on multiple behavioral motives. These motivations may originate from various factors such as personal interests, social influences, cultural backgrounds, and personal needs. The current research on recommendation algorithms based on graph neural networks (GNNs) [18] often does not fully consider the fine-grained relationships between user behaviors at the semantic level. For example, a user’s fondness for a certain movie may be due to the fact that they like the actors of the movie or because they like the genre of the movie. Different user behavioral motives will affect their preferences and decisions, which in turn will have a corresponding impact on the recommendation effect.
Let the ternary representation of the knowledge graph be , where h and t denote head and tail entities, respectively, and r is a relation. , where is a set of real-world entity sets and is a set of relations. Let user be denoted as and item be denoted as . denotes the set of users, and denotes the set of items. denotes the user interaction data, i.e., the information that user u interacts with the item i.
3.2. Model Structure
SKGRec is designed as a multi-module framework. Each component is derived from observations of limitations in existing methods, such as flat modeling of interactions or a lack of contextual reasoning. The introduction of self-attention mechanisms in semantic modeling captures user intent, while attention-weighted aggregation ensures the distinctiveness of relationship encoding. These modules collectively enhance the model’s expressiveness and generalization capabilities, particularly in scenarios with sparse data.
The model is mainly composed of three parts: a user behavior semantic interaction module, a relationship-aware aggregation module, and a higher-order relationship path inference module. The model overview diagram is shown in Figure 1. In the user behavior semantic interaction module, the user’s behavior sequence is represented as a series of nodes, which are connected by edges to represent the associations between user behaviors, with the purpose of aggregating the user’s behavior information and extracting the user’s behavioral features. In the relationship-aware aggregation module, the user’s behavioral features are received and further aggregated with additional knowledge (e.g., the user’s historical behaviors, preferences, etc.), which are processed through a multilayer neural network and activation functions to enhance the model’s understanding of the user’s behavior. Finally, the user behavioral features and the output of the relationship-aware aggregation module are used to perform higher-order relationship path inference.
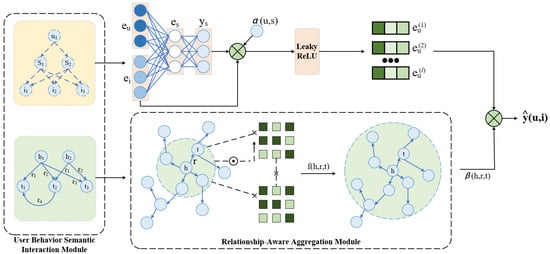
Figure 1.
Overall architecture of the proposed SKGRec model, which consists of three main modules: user behavior semantic interaction module, the relationship-aware aggregation module, and the higher-order relational path inference module.
3.2.1. User Behavior Semantic Interaction Module
When utilizing graph neural networks for recommendation, the algorithms often assume that there is either only or no interaction between the user and the item, and ignore the multiple considerations that may exist under the user’s choice. In this model, we choose to focus on the deep tendency between users and items, and construct a user behavioral semantic interaction graph, USIG, to model and analyze the user’s behavioral semantics. Let S be the set of behavioral semantics shared by all users, partition the unified user–item relationship into behavioral semantics, and update the corresponding user interaction information as a ternary representation . The user–item interaction data are reconstructed into a user behavior semantic interaction graph USIG with user u and item i as nodes. The user behavior semantic interaction graph is shown in Figure 2.
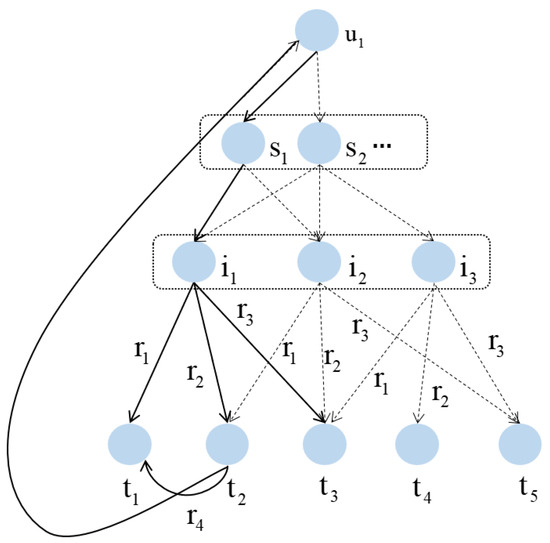
Figure 2.
Construction of the User Semantic Interaction Graph (USIG). Each user–item interaction is enriched with semantic intent labels, forming a triplet (user, semantic, item) structure. This enables the model to identify latent behavioral motivations and perform fine-grained semantic aggregation.
The model creates semantic feature relation embedding representations with higher levels of semantic features through an optimized self-attention mechanism, which is first introduced with the following mathematically defined formula:
where Q denotes the denotation index, K denotes the keyword index, and V denotes the keyword value; the model prevents the risk of a gradient that is too large by scaling the attention score by .
The mechanism is optimized by setting and to be the identifier embedded representations of the behavioral semantics s and relationship r, respectively, and computing the self-attention score to quantify the importance of . For this model, the vectors in the self-attention mechanism are , , and , where and are trainable weights, respectively, and the vectors are normalized by the function to obtain the self-attention weights with the following formula:
The embedded representations of all relations are weighted and summed, and each behavioral semantics is assigned a relation distribution on the knowledge graph, and the updated user behavioral semantics embedding vector is shown below:
The model’s analysis of user behavior semantics not only considers the direct correlation weights between user behavior semantics and relationships, but also captures the complex dependencies between user behaviors and relationships more comprehensively, which enables the model to take advantage of more contextual information when learning the semantic embedded representation of user behaviors. During the process, the model introduces relationship distribution analysis to integrate semantic information from multiple relationships in the behavioral intent, an approach that takes into account multi-hop interactions and long-term dependencies and outperforms simple even correlations. As a result, the model provides a deeper understanding of the underlying motivations of user behavior, which can improve the predictive power of recommendation algorithms.
Traditional word and sentence analysis methods are mainly performed based on word frequency or shallow semantics, where users’ behaviors are independent of each other during word vector computation, thus ignoring contextual semantics and long-text dependencies. Semantic similarity metrics evaluate the intrinsic relevance of user behaviors (e.g., clicking, searching, favoriting, etc.) by analyzing their semantic features. This model analyzes the semantics of user actions to capture the motivation behind them. In this subsection, a new semantic similarity metric mechanism is proposed to learn the semantic similarity between user behaviors. The similarity learning process between user behaviors can systematically extract, organize, and effectively utilize relevant interaction semantic information, and this approach reduces the algorithm’s overemphasis on independence while ensuring the effective preservation of important information. This section compares and analyzes the embedded representations between the semantics of user behaviors to quantify their similarity using a ranked optimization loss function, which is shown below:
where and are the embedding representations of the user behavioral semantics and , respectively, and is a semantic embedding representation that is highly similar to the user’s semantics . The model learns the embeddings of the highly similar behavioral semantics through the multilayer perceptual (MLP) machine. c is a function to measure the similarity, and the model uses the cosine similarity to compute it. is a hyperparameter that controls the interval between positive and negative samples. By minimizing the loss function, the model is guided to learn such that the similarity between similar behavioral semantics score higher, thus capturing semantic similarity.
Considering user u in USIG, using to denote the identifier embedding of user u, an attention weight score is introduced to differentiate the importance of the behavioral semantics s. The computational function is shown below:
An elementwise product operation on the behavioral semantics creates a representation of user u as shown below:
where is the identifier embedding of item i, and ⊙ is the element-by-element product.
In order to enhance the expressive power of the model, a nonlinear activation function is introduced after the element-by-element product, and the result of the element-by-element product is passed through a fully connected layer, which is then operated by the activation function to obtain a new embedding representation, as follows:
where is the weight matrix and is the bias vector.
Interacting with user behavioral semantics, is used to denote the historical information of user behavioral semantics and the set of first-order neighbors of user u. N denotes the set of user behavioral semantics–item triples, and is the representation of user u, as follows:
Finally, after modeling the first-order interaction information, the model further stacks more aggregation layers to collect valid signals from higher-order neighbors. The recursive representation of user u is shown below:
3.2.2. Relationship-Aware Aggregation Module
In knowledge graphs, the same entity may participate in multiple triadic relationships, which makes the entity present different semantic features in different relationship contexts. Based on this characteristic, we consider other entities connected to it as their associated attributes, thus effectively reflecting the potential content similarity among items. In order to extract the core semantic information required by the recommender system from the complex knowledge graph structure and better analyze user preferences, we design a relationship-aware aggregation model for learning multi-level semantic representations in the knowledge graph. The model is shown in Figure 3.
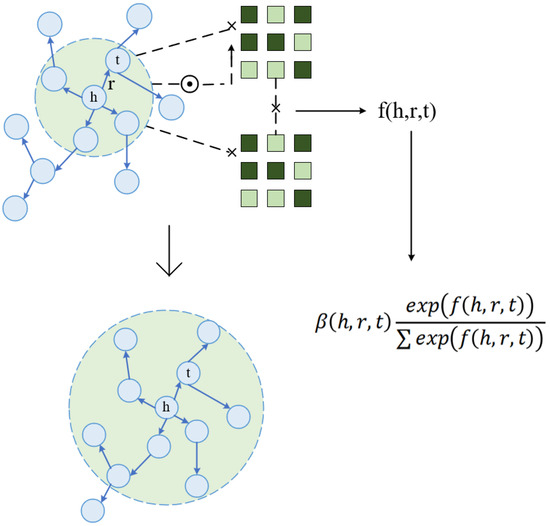
Figure 3.
Relationship-aware aggregation model. By computing attention scores over different types of entity relations, this module generates context-aware embeddings for entities, highlighting the impact of heterogeneous relationships in the knowledge graph.
An entity can often coexist in multiple knowledge graph triples, so entities have specific semantics in different relational contexts. As in the previous subsection, this section uses to represent the attributes and first-order neighbor connections of an entity. Injecting the relational context into the embeddings of neighboring entities, a relationally aware attention scoring function is designed here to weight the embedded representations and normalize the importance of the triad within the neighbor connections of the same head entity as follows:
The weighting function f is shown below:
where is the identifier embedding of entity h and is the identifier embedding of entity t.
Finally, all relationship-aware information from neighboring entities is integrated to generate a representation of entity h as follows:
By assigning different weights to different relationships, the model can better integrate the relationship-aware information of neighboring entities, which helps to improve the model’s ability to understand and express entity characteristics.
3.2.3. Higher-Order Relational Path Reasoning Module
Traditional recommendation algorithms (e.g., KGAT [14], KGCN [13]) simply aggregate single-hop neighborhood relationships (e.g., direct association of “movie-director”) during the aggregation process, but the actual user’s interests are often represented by multi-order semantic paths (e.g., “user-Inception (movie)—Christopher Nolan (director)—Science fiction (genre)”).
The relationship knowledge-aware aggregation in the previous section has been able to store the overall semantics of multi-hop paths while highlighting the dependencies between entity relationships. In this subsection, to reason about the relational paths, the model fuses the interaction information and knowledge graph information into a graph space, while utilizing the knowledge graph information and user–item interaction information in order to discover higher-order relational dependency information, and the relational path reasoning process is shown in Figure 4.
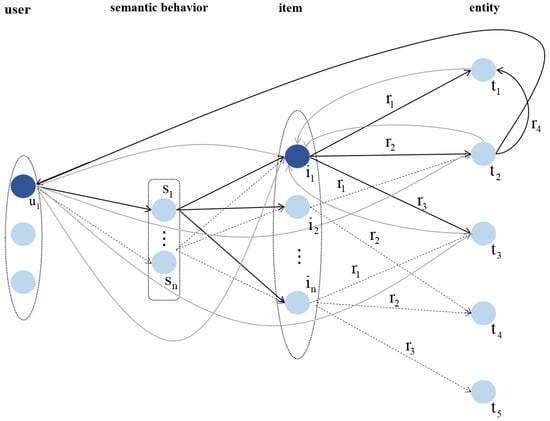
Figure 4.
Relational path reasoning process. The model performs relational path aggregation to capture long-distance semantic dependencies between entities. This mechanism enables the model to infer implicit user–item associations through intermediate entities and relation types.
Let denote an l-hop path with entity i as the root node, and the sequence of its relations is , and the higher-order representation of the entity i is shown below:
where is the initial embedding of the end node, is the set of all l-hop paths of entity i, and is the vector splicing of the knowledge-aware attention scoring function for different relations within k paths. The initial embedding is used here to introduce the original information of the path starting point when aggregating the multi-hop path information, in order to completely capture the information transfer and change process on the path from the starting point to the end point. If the l-1 layer embedding of the end node is used, the initial feature information of the path starting point will be lost, and it is impossible to comprehensively collect the complete semantics carried by the path and store the whole process information of higher-order transfer.
By using the above higher-order relational path inference mechanism, it is possible to effectively integrate the relational semantics of each layer in the path with the feature representation of the starting node, thus realizing a more accurate update of the target node’s representation.
4. Model Prediction
The model captures long-distance relational paths through multilayer aggregation, and finally, the representations in each layer are summed up to obtain the final user and item embeddings for predicting ratings. After propagating through the L-layer attention embedding propagation layer, the representations of user u and item i in different layers are obtained, and since each propagation updates different levels of information and all of them have an impact on the results predicted by the model, the L-layer vectors of users and items need to be spliced separately considering the information updated in each propagation at the same time, as shown below:
By performing the above, the model encodes the semantics of user behavior in USIG and relational path dependencies in KG. The internal product of the user u and item i representations is used to predict the predictive score of the user’s choice of the item as follows:
We choose the pairwise BPR [19] loss function to analyze user history data. Specifically, this loss function should assign higher prediction scores to historical items than unobserved items for a given user. The loss value increases when the algorithm is incorrectly ranked for a given user preference. The loss function is shown below:
where is the training dataset consisting of observed historical interactions and unobserved counterparts , and is the function, which is calculated as shown below:
Finally, the model jointly optimizes the loss function and the BPR loss function with the semantic ranking of user behavior, and obtains the final loss function by regularization as follows:
where and are hyperparameters and is the parameter set of the model and set .
Furthermore, the proposed model is not solely designed for the memorization of training data, but is also equipped with mechanisms to dynamically adjust its attention toward informative signals while suppressing irrelevant or noisy patterns. Specifically, the integration of relation-aware attention and semantic self-attention modules enables the model to assign lower importance to less informative interactions and relations, thereby reducing their influence during the learning process. In addition, dropout techniques and L2 regularization are employed to mitigate overfitting and enhance the model’s generalization capacity. Collectively, these strategies allow SKGRec to effectively alleviate the risk of overfitting, promote adaptive learning of meaningful relational and semantic structures, and improve both the robustness and accuracy of the recommendation results.
5. Experiment and Result Analysis
5.1. Dataset
To comprehensively evaluate the performance of the recommendation algorithm proposed in this section, two representative public datasets, Amazon-Book and Last-FM, are selected for the evaluation of the model. The above two datasets cover data from two different domains, namely books and music, and the two datasets have a certain gap in size and data sparsity, which can effectively verify the applicability of the algorithm in different scenarios.
The Amazon-Book dataset [20] is derived from Amazon-review [21], which covers various entities and relationships such as authors, publishers, categories, etc., related to books, as well as the complete book knowledge graph, and also contains a large amount of information about users’ purchases and evaluations, which can be used to test the performance of recommendation algorithms in e-commerce book recommendation scenarios.
The Last-FM dataset [22] comes from the music social platform, which collects a large number of users’ historical behavior of music listening, as well as information data on music and artists, albums, genres, etc., which can be used to test the performance of recommendation algorithms in music recommendation scenarios.
In this paper, we refer to the Amazon-Book and Last-FM dataset processing methods released by the KGAT model, and use the same 10-core setting to ensure that there are no less than ten pieces of interaction data for each user in the training set, which provides sufficient training samples for the model, and the detailed information of each dataset is shown in Table 1.

Table 1.
Amazon-Book and Last-FM dataset information.
5.2. Parameter Setting
In the experimental implementation phase, we carefully divided each dataset into three independent subsets: the training set for model training, the validation set for checking the model performance, and the test set for ultimately testing the model generalization ability. The experiment involved randomly selecting 80% of the interaction history of each user as the training set in order to keep the remaining 20% of the interaction history for the test set. In addition, 10% of the interaction histories in the training set were randomly selected as the validation set for optimizing the hyperparameter settings.
In the parameter initialization process, we used the Xavier initialization technique and also Adam [23] optimization algorithm in order to optimize the parameters in the model, setting the batch_size to 1024, the learning rate to 0.0001, and the epoch to 200. The detailed environment and parameter settings are shown in Table 2. The parameters in SKGRec are defined based on standard practices in graph-based recommendation models and validated through hyperparameter tuning experiments. Specifically, the embedding dimension was set to 64 to balance expressiveness and computational efficiency. Larger dimensions did not yield significant gains but increased training cost. The learning rate was set to 0.0001, chosen based on the stability of the Adam optimizer and the convergence behavior across datasets. The number of context hops was set to 3, as empirical results showed that three-hop reasoning captures sufficient semantic context without introducing excessive noise from long paths. The node dropout rate was set to 0.5 to help mitigate overfitting, especially in high-sparsity settings, inspired by prior work such as KGAT [14] and KGCN [13]. These parameter settings were informed by previous studies and experimentally validated on two diverse datasets, Amazon-Book and Last-FM.
Table 2.
Experimental configuration and parameters.
5.3. Evaluation Index
In this paper, two commonly used metrics for recommender system evaluation—Recall@K and Normalized Discounted Cumulative Gain (NDCG@K) [2]—are employed. Recall@K was used to evaluate the model’s recall, which indicates the proportion of correctly predicted positive samples to the actual positive samples in the test sample, and NDCG@K was used to evaluate the results of different recommender algorithms to rank the relevance of the recommendation results and to compare the cumulative normalized effects. In this experiment, K is taken as a value of 20 to measure the accuracy and ranking quality of recommendation algorithms in the Top-20 recommendation tasks.
5.4. Results and Analysis
5.4.1. Comparison Experiment
Our proposed modeling approaches were compared and experimented with a variety of mainstream recommendation algorithms, including the knowledge graph-based recommendation approaches CKE and KGAT, as well as the comparative learning-based recommendation approach KGCL, among others; each baseline approach is described below:
CKE [3]: CKE is a representative approach based on knowledge graph embedding, which is a model that simply embeds the knowledge graph into MF (Matrix Factorization) and combines it with collaborative filtering to jointly learn user and item representations.
KGAT [14]: KGAT defines the integration of knowledge graphs and user–item bipartite graphs as collaborative knowledge graphs, and applies fine-grained neighborhood aggregation mechanisms to the overall model to enrich user and item representations, which solves the problem of traditional collaborative filtering-based recommendation methods that are difficult to use for mining the higher-order connectivity of user–items.
KGCN [13]: KGCN is a recommendation method that combines graph convolutional networks and knowledge graphs, extracting the neighbor sets of entities from the knowledge graph as neighbors a. It then aggregates the knowledge of item representations by processing the higher-order neighbor information of the graph neural network, and selects the user’s preference as the weights so as to mine the user’s potential interests.
CKAN [24]: CKAN employs a heterogeneous propagation strategy to naturally encode collaboration signals and knowledge associations, and applies different neighbor aggregation schemes to user–item bipartite graphs and knowledge graphs, respectively, to distinguish the importance of neighbors.
KGCL [25]: KGCL introduces cross-view contrast learning for knowledge graphs to reduce the potential knowledge noise of items and further utilizes the contrast signals of knowledge graphs to guide user preference learning. The model is highly robust and more suitable for dealing with noisy knowledge graphs.
KGRec [26]: KGRec solves the noise and sparsity problems in traditional knowledge-aware recommendation through self-supervised learning and knowledge rationalization mechanisms. The model uses meticulous knowledge rationalization to generate task-relevant rationality scores for knowledge triples, and proposes a rationality-aware masking mechanism to identify and highlight the most important information in the knowledge graph while suppressing potentially noisy or irrelevant knowledge graph information connections.
The results of the comparison between the model of this paper and the six benchmark models mentioned above are shown in Table 3. Experimental results show that our proposed SKGRec recommendation model driven by the fusion of knowledge graph and semantic representation achieves better performance than the baseline algorithm on both datasets. On the Amazon-Book dataset, The recall of this model (Recall@20) is increased by about 26.8%, 14%, 6.9%, 4.87%, and 2.4%, and NDCG@20 improves about 29%, 12.5%, 10.5%, 5.2%, and 2.5%. Similar advantages are presented on the Last-FM dataset, and the data fully demonstrate that the algorithm is able to mine user preferences more efficiently and thus provide more accurate recommendations. It can be seen that the performance of our proposed method on the Amazon-Book and Last-FM datasets, respectively, has basically achieved superior results. The model deeply integrates the structural information in the knowledge graph and the semantic features of users’ behaviors, which not only mines potential user interests through higher-order relational paths, but also utilizes the semantic features to accurately portray the characteristics of the users and the items, and thus is able to make a breakthrough in the recommendation accuracy and sorting reasonableness.
Table 3.
Comparison of experimental results of different models.
5.4.2. Model Efficiency Experiments
In order to validate the performance of the model in different situations, this subsection analyzes the effects of different model depths (semantic counts) and different knowledge graph shares on the recommendation effect through two model benefit experiments, respectively.
To analyze the impact of different user behavior semantic numbers S′ on model performance, the model varies the S′ value in the range of and the experimental results are shown in Table 4.
Table 4.
Experimental results of semantic number (S′) for different user behaviors.
Experimental results show that increasing the number of user behavioral semantics improves performance in most cases. Specifically, when the model only models coarse-grained relationships (i.e., S′ = 1), the algorithm is unable to distinguish the motivation of the user’s behavior, which makes it more difficult to understand user behavior, leading to a generally poorer performance of the model. As the number of user behavioral semantics increases, the model achieves larger correlation coefficients. It can be seen that deep behavioral semantic analysis can help the model to better understand the intent of user behavior, while the semantics carry rich information about different relationship paths, which facilitates in-depth understanding of the user’s potential preferences.
The model can reduce the noise problem existing in the recommendation algorithm to a certain extent. Compared with Last-FM, Amazon-Book contains a richer set of entity relationships. Specifically, the entity relations in Last-FM are converted from attributes such as album, song, and singer, while the entity relations in Amazon-Book are extracted from the Freebase library, which contains noisy relations that are not related to user behavior. However, the model can still handle more noisy data, which is due to the fact that the model enhances the user–item associations by more tightly aggregating user behaviors with entities and relationships in the knowledge graph and performing relational path inference. The performance curves of the model on the Amazon-Book and Last-FM datasets are shown in Figure 5 and Figure 6. The error bars in Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9 are based on standard errors.
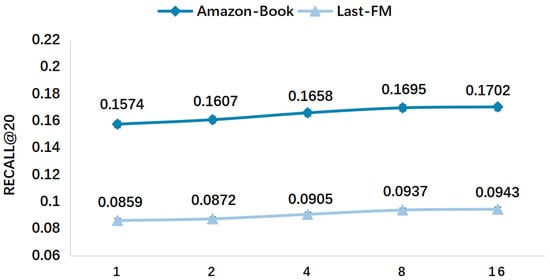
Figure 5.
Recall@20 experimental results for different user behavioral semantic numbers S′.
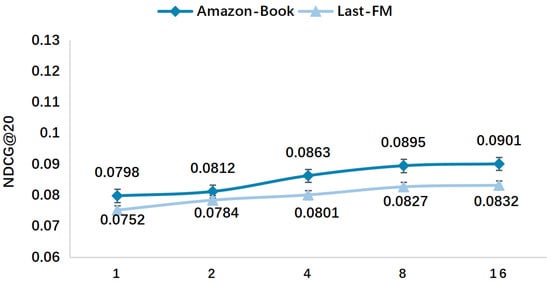
Figure 6.
NDCG@20 experimental results for different user behavioral semantic numbers S′.
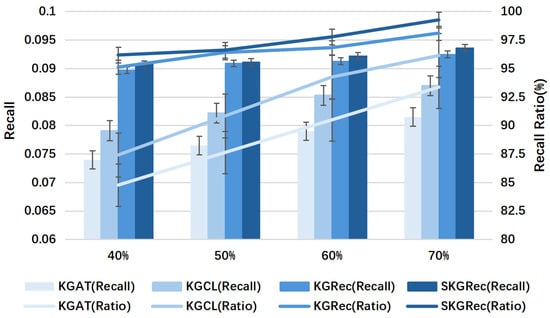
Figure 7.
Test results under Last-FM dataset with different knowledge graph shares.
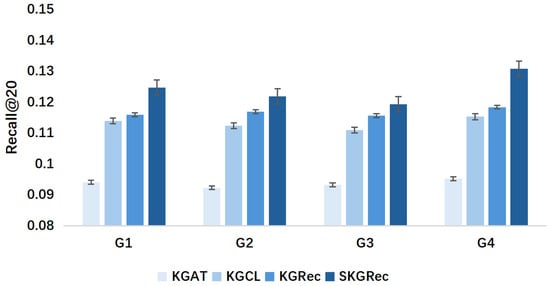
Figure 8.
Experimental results of cold-start effect based on Alibaba-iFashion dataset (Recall@20).
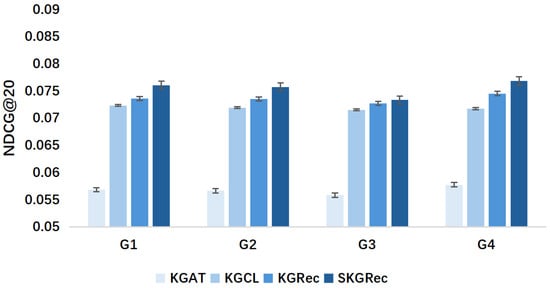
Figure 9.
Experimental results of cold-start effect based on Alibaba-iFashion dataset (NDCG@20).
To analyze the impact of different knowledge graph percentages on the model effect, we tested the recommendation performance of the SKGRec model and baseline model using a partial knowledge graph, with the graph usage rate set between 40% and 70%, and four control groups set at a 10% span, respectively. A certain percentage of knowledge triads are randomly discarded from the recommended knowledge graph, and the remaining part is involved in knowledge-aware aggregation. Recall@20 is analyzed on the Last-FM dataset, and the experimental results are shown in Table 5.
Table 5.
Impact of different knowledge graph percentages on modeling effectiveness.
The experimental results show that by using only a small portion of the knowledge graph, SKGRec can still maintain a considerable performance, with the model’s Recall@20 > 95% on the Last-FM dataset in the case of 40% of the knowledge graph. Compared to the baseline model, SKGRec shows better performance stability in all cases, and it can effectively extract useful knowledge from a given portion of the knowledge graph. The results of specific experimental tests with different knowledge graph shares are shown in Figure 7.
5.4.3. Cold-Start Effect Experiment
In order to test the performance of the model when dealing with sparse data, a cold-start effect experiment was designed to evaluate the effectiveness of the SKGRec model in solving the common cold-start problem in recommender systems. The user behavior data were divided into four groups by the number of interactions G. The lower the number of interactions, the more serious the cold-start problem, with the number of cold-start interactions increasing from G1 to G4, which were set to 10, 20, 50, and 100, respectively. Specifically, group G1 includes users with no more than 10 interactions, group G2 includes users with 11–20 interactions, group G3 includes users with 21–50 interactions, and group G4 includes users with 51–100 interactions. The performance of SKGRec was then tested in each group and compared with several stronger baseline models.
The Last-FM dataset has a more homogeneous and semantically explicit type of data relationships, and the model can more easily determine the relevance of a new user or a new item through relational path inference. In particular, we refer to the methodology of the KGRec model and use the same Alibaba-iFashion [20] dataset to test the cold-start effect of the model. In contrast, due to the relational complexity and noisy relationships in the Alibaba-iFashion dataset, the model may face greater challenges in cold-start scenarios. Therefore, the Alibaba-iFashion dataset is chosen here for the cold-start effect experiment, and the experimental results are shown in Figure 8 and Figure 9.
The results show that the SKGRec model performs particularly well when dealing with sparse data, outperforming the other baseline methods in all cold-start groups, which suggests that the model is effective in solving the cold-start problem for a variety of users. This is attributed to the model’s relationship-aware aggregation mechanism, which dynamically weights neighboring nodes, allowing the model to focus on knowledge connections that are more important contributors to the recommendation task in a timely manner, thus capturing higher-order semantic information about multi-hop paths in the knowledge graph. For a new item i, even if there are no direct historical user interaction data, the model can still infer their relevance to users through the higher-order information in the knowledge graph. For example, a new movie can be linked to a user’s historical preferences through multi-hop semantic information such as director, actor, genre, and so on.
In conclusion, this model can obtain more knowledge supplements from the knowledge graph than the baseline model based on graph neural networks, and maintain path-level semantic consistency during information propagation. Compared with traditional graph neural network baselines, our method achieves stronger cold-start performance by systematically capturing higher-order connections (e.g., user → item → creator → genre relationships). It can effectively alleviate cold-start challenges and maintain explainable recommendation paths. Therefore, SKGRec can effectively mitigate the cold-start problem to a certain extent.
6. Conclusions
In this paper, we propose a semantic-enhanced knowledge graph fusion recommendation algorithm with multi-hop reasoning and user behavior modeling, SKGRec, based on knowledge graph and semantic representation. First, a semantic interaction graph USIG of user behaviors is constructed to semantically analyze and model the aggregation of user interactions, where a new ranking optimization loss function is proposed to learn the similarity between user behaviors; then, the relationship-aware aggregation of relationships in the recommended knowledge graph KG is performed in order to deeply extract higher-order information in the knowledge graph. To ensure that the theoretical scores between neighbors of the same entity are comparable, this paper uses a relation-aware attention scoring function to optimize the design of the relation-aware aggregation mechanism; finally, inference is performed on the relation paths to capture remote relational semantic information from the multi-hop paths, which helps the recommendation algorithms to better understand the user’s preferences and motivations for their behaviors, and thus reduces the algorithm’s noise introduced due to short-term fluctuations or meaningless operations. The experiments show that the model has excellent performance on both the Amazon-Book dataset and the Last-FM dataset, verifying the effectiveness of the model design. Furthermore, the core components of SKGRec, such as multi-hop relational reasoning and semantic behavior modeling, are potentially transferable to other domains. In fields like journalism or social media, SKGRec could be adapted to recommend articles, posts, or content by leveraging knowledge graphs that capture entity relationships, user interests, and content semantics.
Author Contributions
Conceptualization, S.X., Z.Y. and P.F.; Data curation, S.X., Z.Y. and J.X.; Investigation, S.X. and Z.Y.; Project administration, J.X.; Supervision, P.F.; Writing—original draft, S.X. and Z.Y.; Writing—review and editing, J.X. and P.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Science and Technology Development Plan Project of Jilin Provincial Science and Technology Department (Key Technology Research on Risk Prediction and Assessment of Old Chronic Diseases Based on Medical Knowledge Graph (2023JB405L07)), and the University-Enterprise Joint Research Project of Jilin Provincial Department of Science and Technology (Development of a Precision Medication Service System Based on Large Language Models and Knowledge Graphs (2024JBH05LA3)).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
We would like to express our deepest gratitude to all those who have contributed to the completion of this research and the writing of this paper. This article is partially based on part of the second author’s unpublished Master’s thesis (“Recommendation Algorithm Study Based on Knowledge Graph and Semantic Features”).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1531–1540. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 353–362. [Google Scholar]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge graphs: Opportunities and challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef] [PubMed]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. AAAI Conf. Artif. Intell. 2015, 29. [Google Scholar] [CrossRef]
- Xin, X.; He, X.; Zhang, Y.; Zhang, Y.; Jose, J. Relational collaborative filtering: Modeling multiple item relations for recom mendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Ser. SIGIR’19, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019; pp. 125–134. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Sturt, B.; Khandelwal, U.; Gu, Q.; Norick, B.; Han, J. Recommendation in heterogeneous information networks with implicit user feedback. In Proceedings of the 7th ACM conference on Recommender systems, Hong Kong, China, 12–16 October 2013; ACM: New York, NY, USA, 2013; pp. 347–350. [Google Scholar]
- Wang, X.; Wang, D.; Xu, C.; He, X.; Cao, Y.; Chua, T.S. Explainable reasoning over knowledge graphs for recommendation. AAAI Conf. Artif. Intell. 2019, 33, 5329–5336. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Sha, X.; Sun, Z.; Zhang, J. Attentive knowledge graph embedding for personalized recommendation. arXiv 2019, arXiv:1910.08288. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Tang, X.; Wang, T.; Yang, H.; Song, H. Akupm: Attention enhanced knowledge-aware user preference model for recom mendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 1891–1899. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Wang, X.; Huang, T.; Wang, D.; Yuan, Y.; Liu, Z.; He, X.; Chua, T.S. Learning intents behind interactions with knowledge graph for recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 878–887. [Google Scholar]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- Cantador, I.; Brusilovsky, P.; Kuflik, T. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 387–388. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Lin, G.; Tan, H.; Chen, Q.; Liu, X. CKAN: Collaborative knowledge-aware attentive network for recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 219–228. [Google Scholar]
- Yang, Y.; Huang, C.; Xia, L.; Li, C. Knowledge graph contrastive learning for recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1434–1443. [Google Scholar]
- Yang, Y.; Huang, C.; Xia, L.; Huang, C. Knowledge graph self-supervised rationalization for recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 3046–3056. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).