1. Introduction
Soybean is an essential crop serving as a primary source of protein and oil for human consumption and animal feed. It accounts for nearly 60% of global oilseed production [
1]. In 2023, the soybean market was valued at over USD 160 billion, with a projected compound annual growth rate (CAGR) of 4.4% from 2024 to 2030 [
2,
3]. The United States, Brazil, and Argentina collectively contribute more than 80% of the world’s soybean production, highlighting the crop’s importance for food security and international trade [
4]. However, soybean cultivation faces significant challenges due to various diseases affecting both leaves and seeds. These diseases can lead to yield losses of up to 30% annually, resulting in USD billions in economic losses worldwide [
5,
6]. Common diseases include bacterial blight, Cercospora leaf blight, and frogeye leaf spot, along with seed-specific defects such as skin damage and immaturity [
7]. These issues not only reduce yield but also compromise product quality, which impacts market value and food security [
8]. Timely and accurate detection of these diseases is critical for implementing effective disease management strategies and mitigating yield losses [
9]. Traditionally, disease diagnosis relies on manual inspection by agricultural experts. While this approach has been effective in small-scale applications, it is labor-intensive, time-consuming, and prone to human error, particularly in large-scale agricultural operations [
10,
11]. Furthermore, visual inspection often fails to accurately identify early-stage infections or subtle disease symptoms, leading to delayed interventions. These limitations highlight the need for automated, reliable, and scalable solutions [
12].
Deep learning models, such as convolutional neural networks (CNNs), show outstanding performance in the detection of plant diseases [
13]. Transfer learning enhances CNNs in agriculture by fine-tuning pretrained models for specific applications [
14]. However, there are still difficulties due to small, imbalanced datasets that prevent them from generalizing to real-world scenarios. Combining the predictions from multiple models into an ensemble model results in the models often outperforming individual CNNs because of the increase in robustness, accuracy, and generalizability. Bagging, boosting, and stacking reduce overfitting and handle noisy data better [
15]. However, they suffer from high cost for both training and inference and lack interpretability since they consider many models. On the other hand, ViTs provide a unified and scalable architecture that can bypass this and does not require multiple models. The self-attention mechanism of ViTs is able to sufficiently capture the local and global dependencies so that they are able to effectively generalize even when few data are available [
16]. Also, they offer better explainability through attention maps, making them more efficient and interpretable for complex datasets.
While progress has been made in the field of soybean disease classification, there are notable gaps. Most studies focus only on soybean leaf diseases or seed defects, lacking a unified framework for both. This limits the scalability and comprehensiveness of existing approaches. ViTs have shown promise in various tasks, but their potential for soybean diagnostics, particularly for leaf and seed datasets, has not been thoroughly explored. Many existing studies report high classification accuracy on limited datasets but fail to provide rigorous validation and performance analysis. Additionally, current deep learning models often operate as black boxes, offering little transparency. Few studies utilize explainable AI tools to identify key features influencing predictions and practical solutions.
This study aims to fill research gaps by creating a strong, clear, and scalable framework for classifying soybean diseases. The specific objectives are as follows:
Develop a framework to accurately classify diseases affecting soybean leaves and seeds.
Identify the most effective ViT-based architecture that effectively captures both global and local features.
Achieve state-of-the-art performance on multiple datasets for disease identification over existing studies.
Develop a trustworthy web-based application designed to support agricultural professionals.
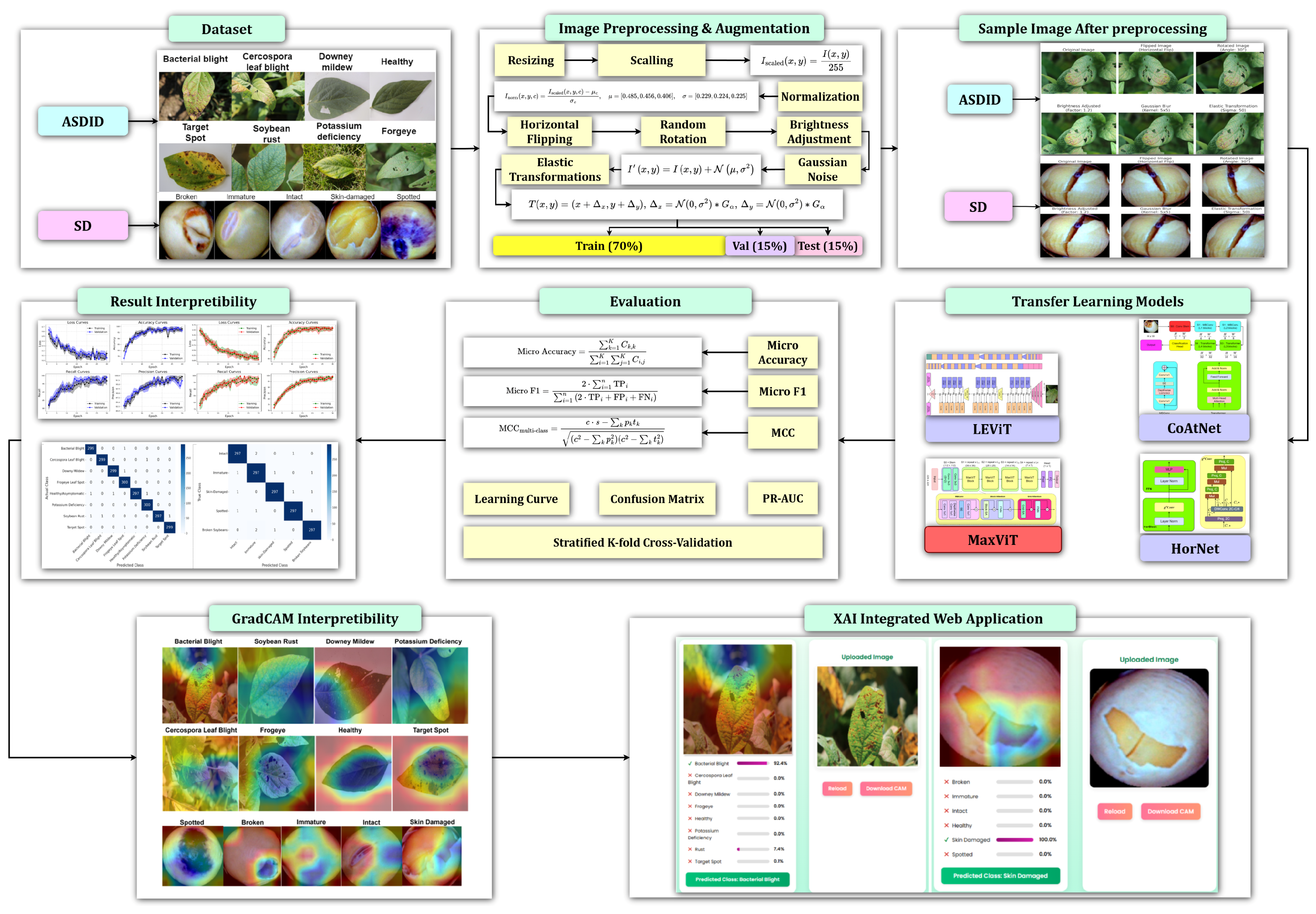
To achieve our objectives, we developed a framework for classifying soybean leaf and seed diseases using MaxViT models on various datasets. Among the various ViT architectures, MaxViT was selected due to its hybrid design, which combines convolutional layers with multiaxis self-attention. This design allows MaxViT to effectively capture both local features (texture, color, and edges) and global spatial patterns present in whole-leaf or seed images. In contrast to standard ViTs, which may overlook fine-grained details or require significant computational resources, MaxViT provides a balanced trade-off between accuracy, efficiency, and interpretability. This makes it particularly suitable for agricultural diagnostics. Although MaxViT is a recognized architecture, this study is the first to apply it in a unified framework for classifying both soybean leaf and seed diseases. Its performance is further enhanced through dataset-specific augmentation, Grad-CAM-based interpretability, and real-time deployment via the SoyScan web platform.
Figure 1 illustrates the complete workflow of the proposed methodology. Our contributions include the following:
We developed an interpretable approach for accurately recognizing diseases in soybean leaves and seeds.
We proposed an efficient MaxVit-XSLD model that considers both local and global features for soybean disease classification.
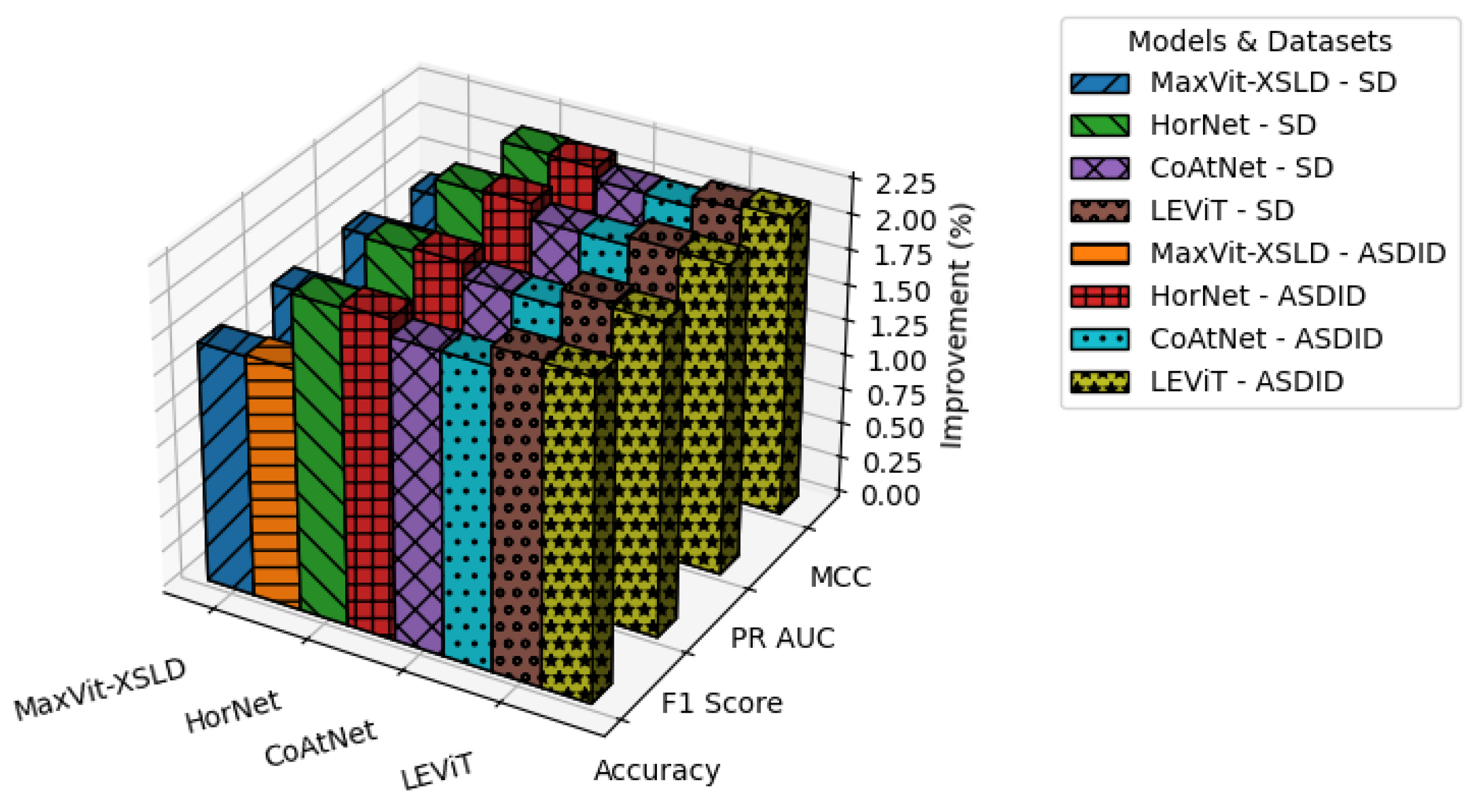
We conducted a comparative performance analysis of various models, providing statistical proof that our method outperforms existing approaches.
We developed a web application for specialists to improve transparency in the global food security and disease management sectors.
The remainder of this paper is organized as follows:
Section 2 reviews related works, with a focus on transfer learning, ensemble methods, and ViTs.
Section 3 describes the datasets, preprocessing techniques, and deep learning architectures utilized in this study.
Section 4 presents the experimental results and their analysis, while
Section 5 discusses the implications and limitations of the findings. Finally,
Section 6 concludes this paper and outlines future research directions.
5. Discussion
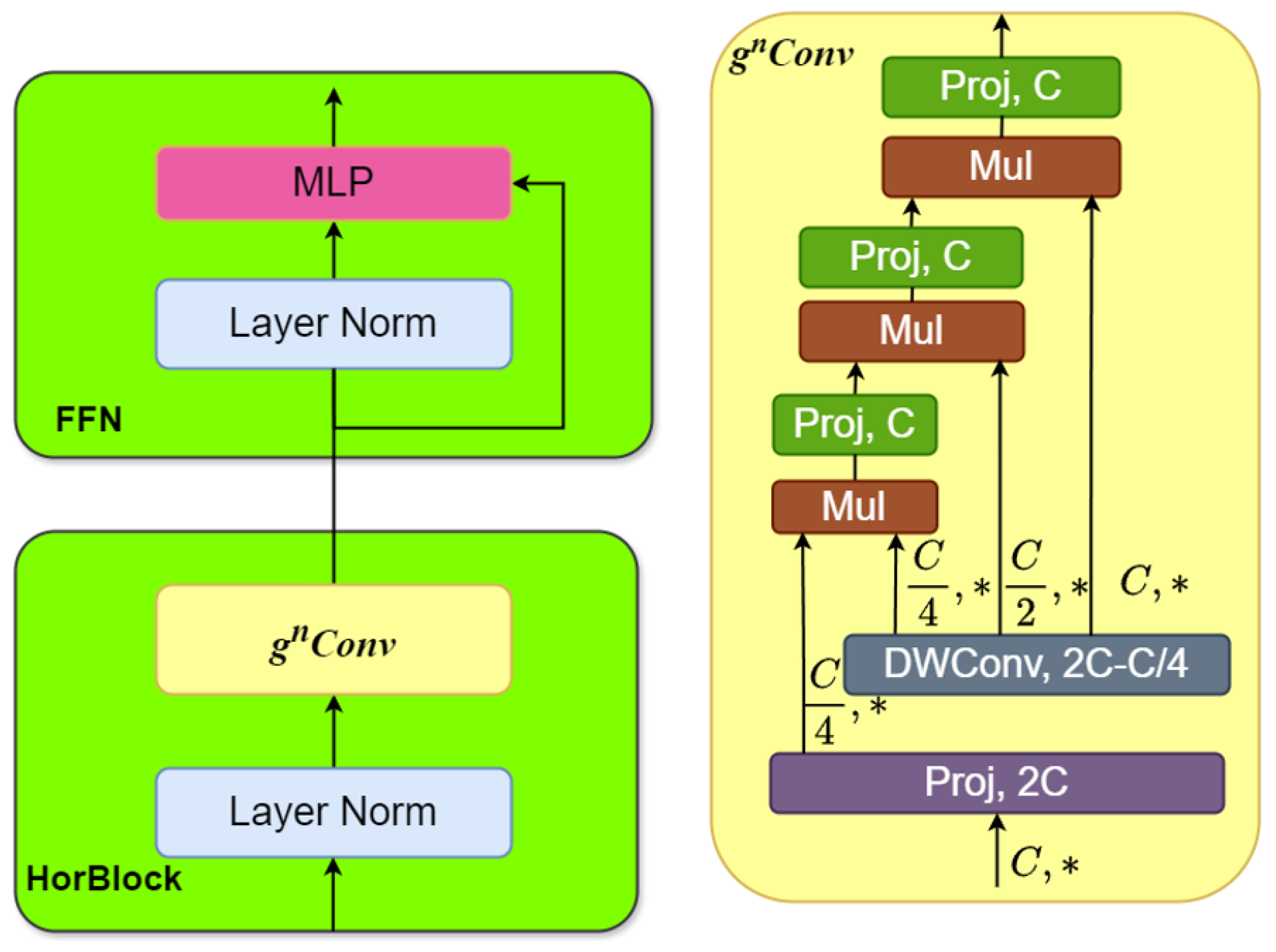
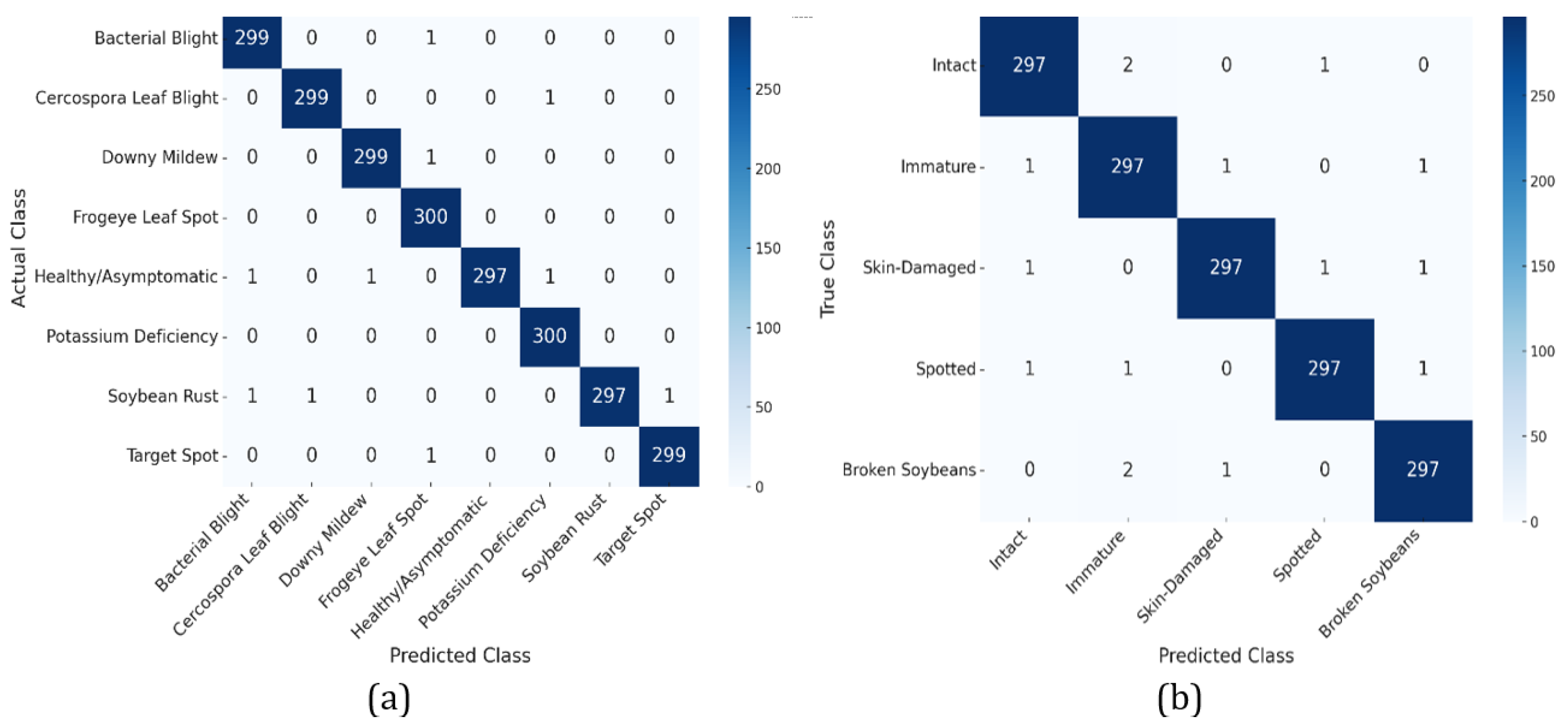
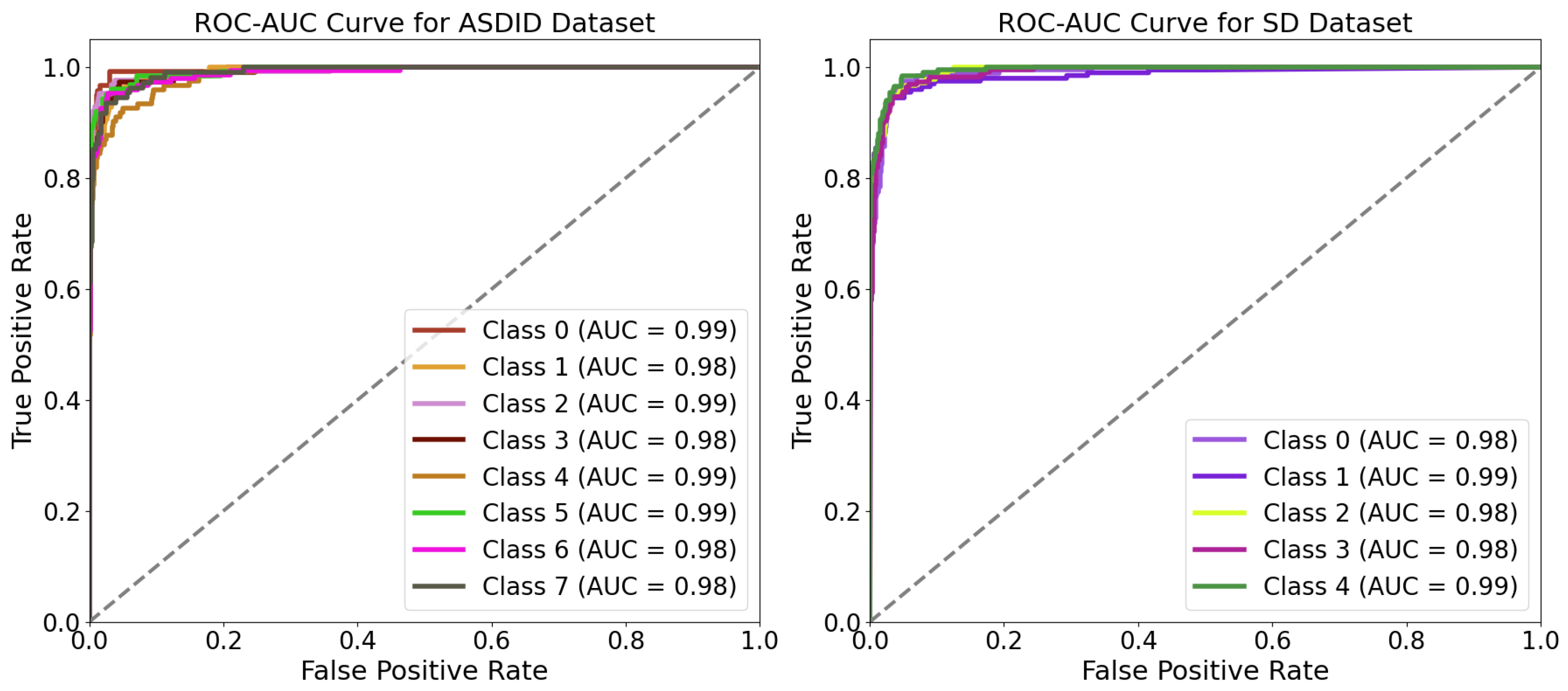
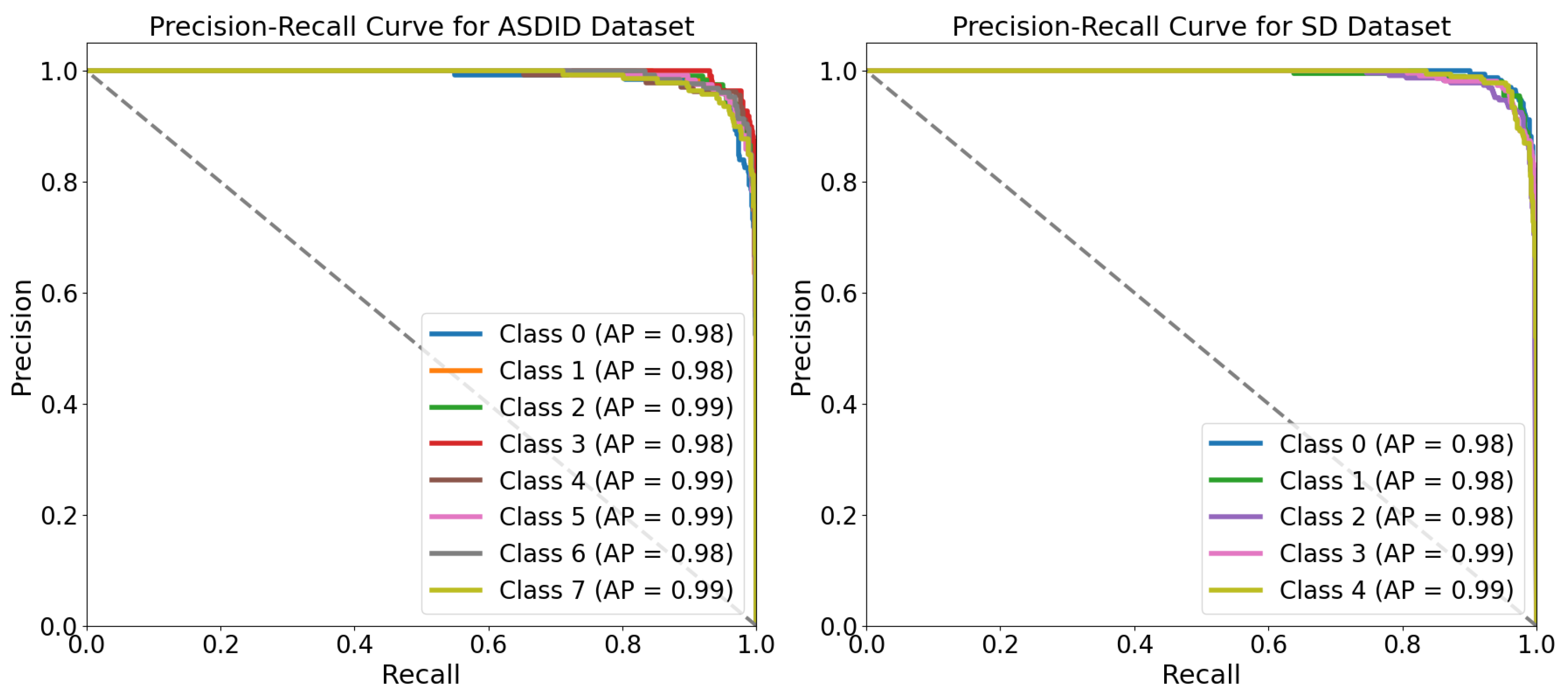
The proposed MaxVit-XSLD method outperforms other models due to its hybrid architecture that merges MBConv layers with multiaxis self-attention mechanisms. The MBConv layers effectively extract local spatial features like lesions and textural anomalies while reducing computational overhead through depthwise separable convolutions and squeeze-and-excitation (SE) blocks. This approach maintains essential spatial relationships with fewer parameters, enhancing efficiency. The multiaxis attention mechanisms capture long-range global dependencies and spatial relationships essential for identifying disease progression patterns, such as pigmentation anomalies. This combination of local and global feature extraction gives MaxVit-XSLD a greater contextual understanding and generalization capability than traditional convolutional networks, which often struggle with long-range dependencies.
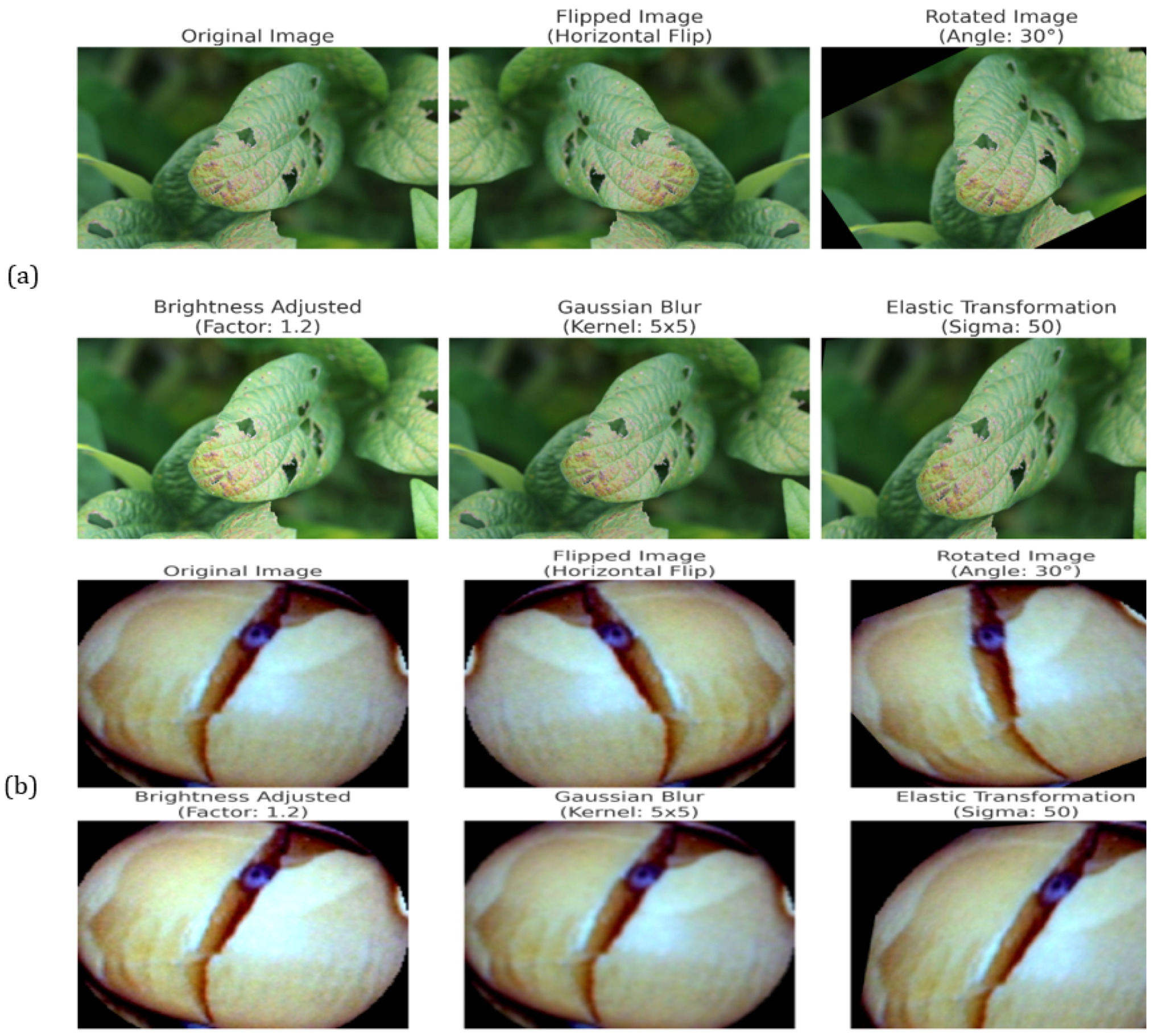
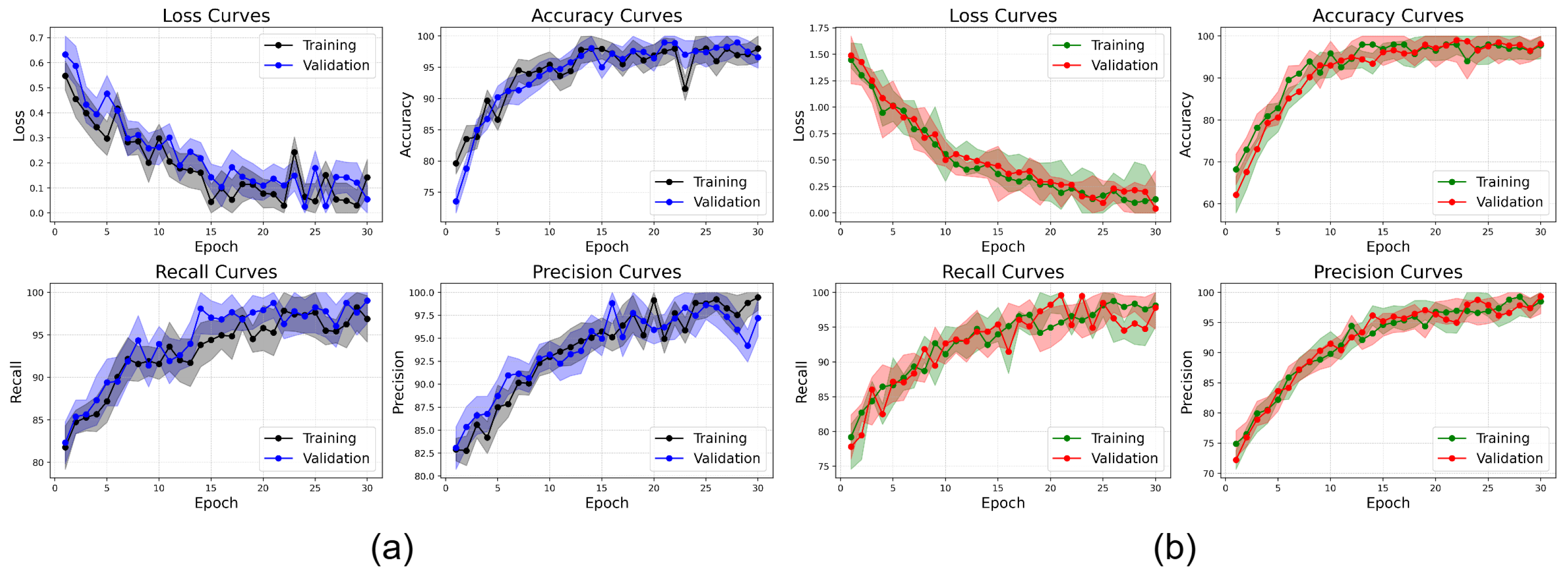
Additionally, the augmentation increases the diversity of the dataset and helps with class imbalances to enhance model performance. To simulate real-world conditions like occlusions and the different conditions of illumination, techniques such as elastic deformations, Gaussian noise injection, and random rotations are used to simulate brightness adjustments. This makes the Seed Disease (SD) dataset more diverse as well as balanced in the class distribution. Therefore, the model has less bias and is more sensitive to the underrepresented classes, and the Average Sensitivity and Diagnostic Inference metrics that it uses are effective in the generalization to unseen data. Standardizing overfits metadata but also guarantees that pretrained weights are compatible with this standard and speeds up convergence during transfer learning. Also, the preprocessing stage mitigates irrelevant variations on the feature space and increases the feature alignment between the images. Augmenting our data and preprocessing are combined to create an input pipeline that robustly allows us to optimally train the model and for it to analyze many complex patterns.
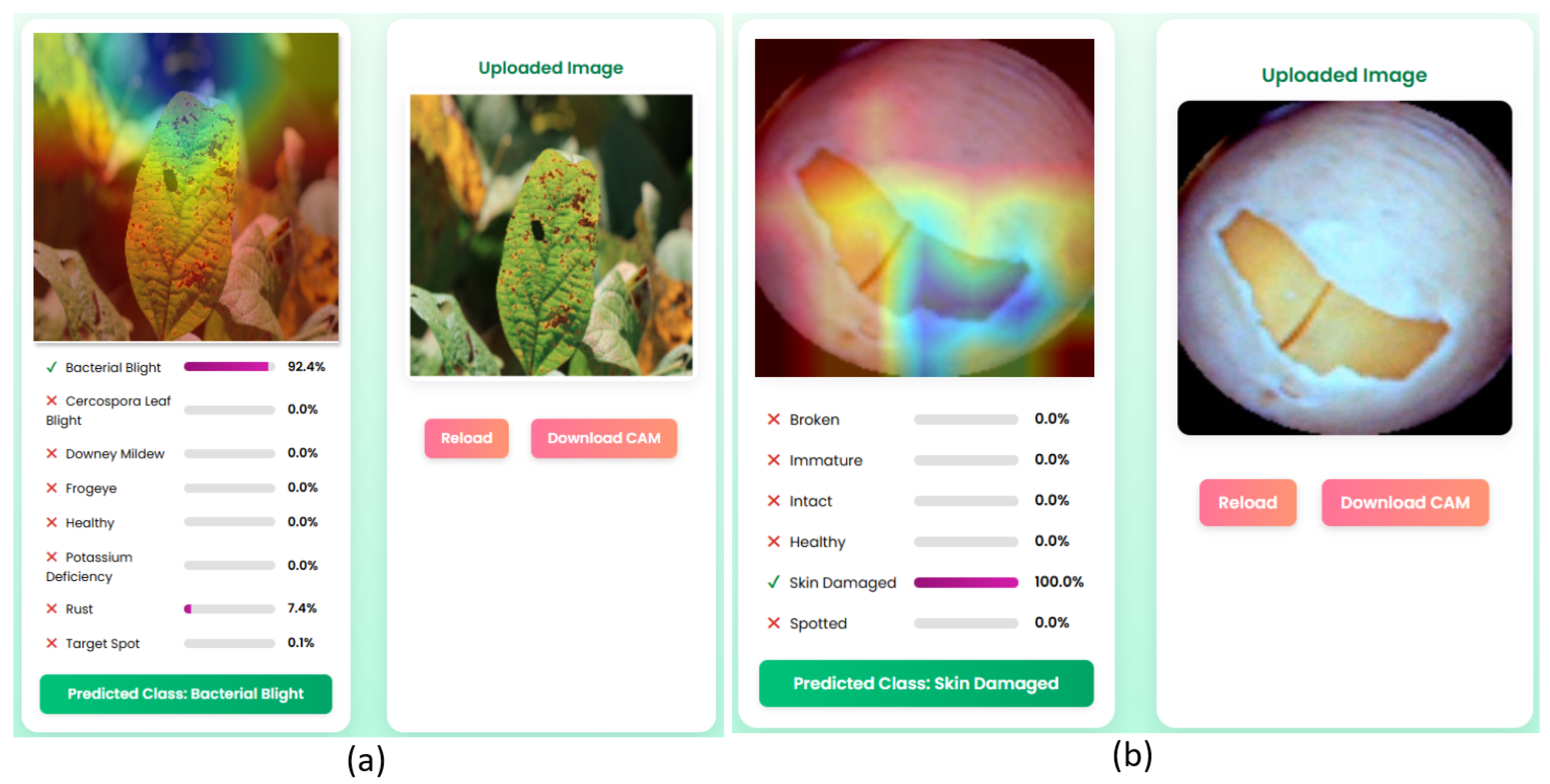
The SoyScan application is designed to improve soybean disease diagnostics by combining high-precision classification using the MaxViT-XSLD architecture with robust interpretability through explainable AI (XAI) methodologies. It utilizes GradCAM to generate class-discriminative localization maps that visually highlight important pathological features, such as necrotic lesions, leaf discoloration, and structural seed anomalies. These visual attributions enhance model interpretability, fostering algorithmic accountability and building user trust among agronomists, researchers, and non-expert stakeholders. SoyScan facilitates rapid detection and decision support, helping to minimize yield loss and economic impact. Its modular micro-service architecture is built for extensibility, allowing for the seamless integration of additional crop models, region-specific disease classifications, and multilingual interfaces, ensuring global adaptability. The system’s design aligns with the principles of trustworthy and human-centric AI, addressing regulatory and user demands for explainability, fairness, and reliability. Moreover, SoyScan is structured for future integration with IoT-enabled sensors and geospatial data streams, paving the way for a scalable and interoperable solution within precision agriculture and smart farming ecosystems.
While GradCAM significantly improves interpretability by visually localizing areas that are critical for class differentiation, it is not without its limitations and challenges. GradCAM relies heavily on the gradient flow from the final convolutional layers, which restricts its resolution and spatial accuracy—especially in Transformer-based architectures like MaxViT-XSLD, where attention mechanisms are more prominent than spatial convolutions. This reliance can produce coarse saliency maps, making it difficult to discern subtle pathological cues such as micro-lesions or fine texture variations in soybean leaf and seed images. In scenarios with high intra-class similarity (e.g., Cercospora leaf blight and frogeye leaf spot), GradCAM may generate overlapping heatmaps, which can reduce class separability and the clarity of interpretation. Furthermore, the technique is sensitive to input variations; minor changes in lighting, occlusions, or image noise can result in unstable gradient attributions, leading to misleading or diffused activation maps. GradCAM also does not include a built-in confidence metric, which means that the saliency visualization may look equally strong for both high-certainty and low-certainty predictions, potentially confusing users. Moreover, in the context of the SD dataset, where morphological differences are subtle (e.g., between immature and intact seeds), the lack of pixel-level detail may limit actionable insights.
Several improvements can be implemented to address these limitations. First, integrating high-resolution attribution methods like Score-CAM, GradCAM++, or Layer-wise Relevance Propagation (LRP) can capture nuanced spatial features that are crucial for distinguishing visually similar classes. Additionally, combining saliency maps from multiple layers—both earlier and deeper—can enhance localization accuracy and contextual relevance. Incorporating uncertainty quantification techniques, such as Monte Carlo Dropout or Deep Ensembles, can help align prediction confidence with the reliability of heatmaps, minimizing the risk of overinterpreting ambiguous outputs. To improve interpretability for non-expert users, the system could feature semantic segmentation overlays alongside GradCAM visualizations, explicitly marking diseased regions. Additionally, creating interactive XAI dashboards with adjustable attention thresholds and class attribution toggles can empower users to explore the reasoning behind decisions dynamically. Finally, training with counterfactual explanations and objectives focused on adversarial robustness can lead to more stable and resilient visual attributions.
SoyScan has several technical and practical limitations in various agricultural environments. The MaxViT-XSLD model relies on combined multiaxis attention with MBConv modules, making it computationally demanding. In this study, it requires 45.2 GFLOPs and over 11 GB of GPU memory, and it consumes approximately 9.8 W of power per inference. These hardware requirements present major challenges for scalability, especially in resource-constrained or embedded edge devices commonly used in rural farming contexts. In contrast, lighter models like LEViT, which require significantly less computational power and offer faster inference times, are more appropriate for mobile or edge deployment scenarios where hardware resources are limited. This trade-off ensures flexibility depending on deployment needs, balancing between predictive power and hardware efficiency. Additionally, MaxViT’s deep and multibranch architecture increases training complexity and sensitivity to hyperparameter settings, which can lead to convergence issues or overfitting when applied to smaller datasets. While MaxViT-XSLD shows strong performance on the ASDID and SD datasets, its adaptability to real-world scenarios may be limited by domain shift. These datasets may not adequately represent the full range of environmental variability, soybean cultivar diversity, or disease phenotypes found in different regions. The model’s Grid and Block Attention mechanisms may struggle to identify irregular or fine-grained features in noisy, occluded, or variably illuminated images, which can reduce the robustness of its inferences. Integrating GradCAM enhances model explainability, but the abstract attention maps in Transformer-based architectures can be hard for non-technical stakeholders like farmers or field technicians to interpret. Finally, the system’s reliance on stable internet for server-based inference restricts its practical deployment in bandwidth-constrained or offline rural environments.
To enhance both user experience and system robustness, the SoyScan web application can undergo several improvements. First, implementing a model compression pipeline—through methods such as pruning, quantization, or knowledge distillation of the MaxViT-XSLD model—can significantly decrease inference latency and reduce computational overhead. This would allow for seamless deployment on resource-constrained edge devices. Additionally, integrating adaptive image preprocessing techniques like histogram equalization, contrast-limited adaptive histogram equalization (CLAHE), and illumination normalization can help mitigate variability caused by environmental noise. This, in turn, will improve feature stability across diverse field conditions. Using hierarchical GradCAM overlays with adjustable saliency thresholds and semantic segmentation for disease localization can provide more precise visual feedback for non-technical stakeholders. Moreover, implementing a multilingual user interface with responsive design and voice-guided navigation via Web Speech APIs can enhance accessibility for users in rural and linguistically diverse areas. The application’s robustness can be further strengthened by introducing an active learning loop that incorporates user-validated labels to periodically retrain the model, encouraging continual learning and adaptation to specific domains. Additionally, adopting a Progressive Web Application (PWA) architecture will enable offline functionality, background synchronization, and caching of inference models using WebAssembly (WASM) or TensorFlow.js, ensuring consistent operation in low-connectivity regions. Finally, incorporating context-aware metadata (geolocation, timestamps, and crop cycle stages) can allow spatiotemporal disease tracking and provide diagnostic recommendations.
Future work should include neural architecture search (NAS) for developing lightweight Transformer variants for edge devices. Additionally, while the augmentation pipeline enhances dataset diversity, it fails to fully capture real-world variability such as occlusion, complex lighting, and overlapping plant structures. To address this, domain adaptation methods like adversarial domain adaptation and semi-supervised learning should be applied. Using GANs for synthetic data generation could further improve robustness to unseen scenarios. The current focus on static RGB images limits the framework’s ability to track disease progression over time. Incorporating multimodal data sources like hyperspectral, thermal, or LiDAR imaging, along with spatio-temporal architectures, would enhance understanding of disease dynamics. GradCAM’s coarse feature attribution may not suffice for complex disease cases; thus, exploring more precise interpretability techniques like Integrated Gradients or SHAP is necessary for better model insights. Finally, developing mobile-friendly implementations with real-time inference capabilities would enhance accessibility, particularly for resource-constrained farming communities.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}