1. Introduction
Cross parity codes have been used for a long time [
1] as part of channel coding to achieve forward error correction due to their simplicity and fast correction circuits, although the number of parity bits is higher than for other block codes [
2]. Mostly, 2-dimensional parity codes have been used with row and column parities, and they have been extended to correct at least a fraction of 2-bit errors [
3]. We are not aware of a systematic study of higher dimensions; only [
2] mention that they performed experiments, and [
1] mentions that higher than three dimensions are possible.
As the minimum code weight is restricted to , it seems useless to investigates dimensions , yet there are other parameters to be considered as well, such as the number of parity bits.
We therefore first investigate the optimal parity code dimension for a given data size, with respect to the number of parity bits. As the results indicate that higher dimensions can be useful, we investigate higher dimensions with regard to the question of if they can correct a part of the 2-bit errors. To this end, we consider a variant that is only useful in higher dimensions: while the normal
d-dimensional cross parity code computes parities from
-dimensional hyperplanes, we consider parities from
-dimensional hyperplanes. We have not been able to locate literature that investigates this variant. The first dimension where this is useful is
.
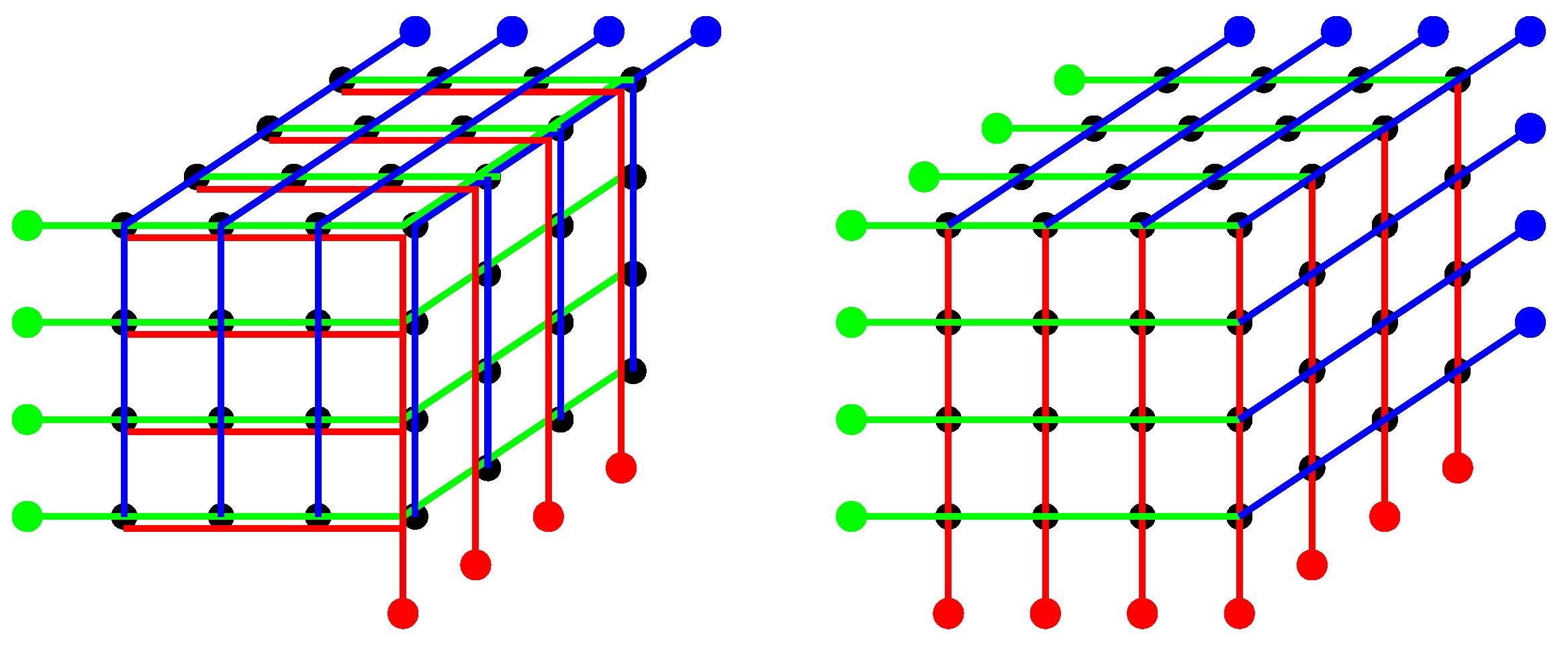
Figure 1 depicts
data bits arranged in a 3-dimensional cube. On the left side, the usual cross parity code with
parity bits from 2-dimensional planes is shown. On the right side, 1-dimensional parities are used, resulting in
parity bits. While the number of parity bits is much higher, the promise is that a larger fraction of 2-bit errors can be corrected.
Our analysis indicates that using higher-dimension parity codes can help to reduce the number of parity bits, and that with the proposed variant, all 2-bit errors can be corrected, in contrast to 2-dimensional parity codes.
The remainder of this article is structured as follows.
Section 2 provides some background on cross parity codes.
Section 3 demonstrates that cross parity codes of higher dimensions can reduce the number of parity bits needed and should therefore be investigated further.
Section 4 investigates a variant that becomes possible with higher dimensions: computing the parities not from
-dimensional hyperplanes as usual, but using
-dimensional hyperplanes.
Section 5 reports on simulation experiments.
Section 6 discusses related work, and
Section 7 provides conclusions and an outlook for future work.
2. Background
In this research, we consider error-correction codes, i.e., codes that add redundancy to information to be transmitted during channel coding to achieve forward error correction. The sender of the information adds the redundant information to form the message to be transmitted. The receiver of the message, i.e., information plus redundant information, can detect if an error in the form of one or several bit flips for binary information (on which we will focus) has occurred during transmission. For a limited number of bit flips, the receiver can even correct these errors, i.e., recover the original information. In particular, we consider systematic codes that leave the information (message) unchanged and merely add redundancy bits.
Let N be the number of information or data bits, to which T redundancy bits are added. Then, each data word is extended by redundancy bits to form a code word or message of length bits to be transmitted. Let be the set of code words. The code distance is the minimum Hamming distance between any two different code words. Then, at least bit flips during transmission are necessary to convert a code word into another code word. If fewer than bit errors occur, this will be detected, as the receiver will not receive a valid code word, i.e., the receiver receives a tuple for which . Also, if fewer than bit flips occur, these errors can be corrected by the receiver by finding the unique code word with a Hamming distance less than to the received tuple . Block codes are often characterized by a tuple message length, information length, and code distance, possibly extended by the size of the alphabet used (2 in our case of binary information), i.e., .
As an example, we consider a -code, i.e., data bit and redundancy bits. The redundancy bits simply replicate the data bit. Then, only two valid code words 000 and 111 exist with Hamming distance . If 1 or 2 bit errors occur, e.g., errors on the first and last bits will convert 000 into 101, then this can be detected as no valid code word is received. However, in our example , and therefore this 2-bit error cannot be corrected, as the unique code word with Hamming distance 1 from 101 will be 111.
As adding redundancy consumes part of the available bandwidth and thus reduces the effective bandwidth for message information, the
code rate of an error-correction code [
4], defined as
, is an important measure (next to the code distance, which defines the number of correctable and detectable errors) to compare codes. If the code rate is close to 1, then the overhead from the redundancy bits is not high.
A final measure to compare codes is the decoding time, i.e., the receiver’s effort to check if an error occurred during transmission and to correct it if possible. For some codes, the decoding can be quite complex and might even necessitate a software algorithm, cf. for instance the Berlekamp–Massey algorithm for Reed–Solomon Codes [
4], while for cross parity codes (see below) it is very short and can be performed in hardware, which allows applications like error correction in memories.
An important class of error-correction block codes are linear codes that can be defined via a binary -matrix M, where for systematic codes the top part is the -identity matrix so that .
Please note that in many cases, one cannot choose the data size
N arbitrarily. Hamming codes are linear codes where
N is of the form
and
redundancy bits are added [
4], resulting in a message of length
and a code rate of
, which is close to 1.
, i.e., one error can be corrected and two errors can be detected. Our (3,1,3)-code above is the simplest form of a Hamming code. For BCH codes with 2-bit error correction (so-called double-error correction or DEC-BCH codes) [
5],
data bits can be used and
redundancy bits are added. Please note that the number
N of data bits is always slightly smaller than a power of 2, which means that the case where
, i.e.,
N is a power of 2, must be treated by using a code for
data bits, where the remaining data bits are assumed to be 0, and there are
redundancy bits.
Let for integers and . Let , and .
Let be binary data of N bits in total, oriented in a d-dimensional cube of side length n. Each data bit is denoted as , where for , in short: .
The usual cross parity code defines
parity bits via all possible
-dimensional planes, of which there is
n in each dimension and
d dimensions to choose from:
where
,
and ∑ means addition modulo 2, i.e., exclusive or. The number of redundancy bits
is thus proportional to
and thus notably higher than for Hamming or BCH codes. The resulting code rate is
and thus depends on the chosen dimension, see the next section.
All 1-bit errors can be corrected, and 2-bit errors can be detected, as the minimum code weight is
[
2]. Yet, for
, no 2-bit errors can be corrected. This, however, can be achieved via an extension with a few additional parity bits [
3].
3. Choosing Dimension
Wong and Shea [
2] give the minimum code weight as
, which seems to suggest that only dimensions
and
are of interest, and there is also no research known to us that systematically investigates parity codes of higher dimensions.
For a given N, the number of parity bits is solely a function of d. If we consider N a constant and as a function on real d with domain , then we can calculate the derivation and see that there is a in the domain with , and the sign of goes from negative to positive, i.e., f will be minimal at . As d really is an integer, the minimum will be reached at either or . Still, not all integral values of d might be possible because must also be integral as well, or at least nearly integral so as not to waste too many bits through using with and ignoring bits.
As an example, we might consider again the
data bits from
Figure 1. If we arrange them in
dimensions, we obtain
and thus
parity bits, i.e., more than for
, where we had 12 parity bits (cf.
Section 1). Yet, an arrangement in
dimensions with side length 3 is also possible. As
, we waste some bits, yet the number of parity bits is still
, and the “superfluous” bits could be ignored by assuming them to be 0 or could be used to add further redundancy. While
seems not to be interesting as
is too small and
cannot be better than
, we finally consider
, leading to a cube of side length 2 with
parity bits. The difference to smaller dimensions is that for
, each parity bit is computed over 32 data bits, while for
, each parity bit is computed over 16 data bits. The code rates for
are
, respectively.
The following examples demonstrate that already for quite moderate values of
N, the minimum number of parity bits is reached in higher dimensions, and the same holds if we use modified cross parity codes that add
parity bits from half planes in each dimension (called quadrants for
[
3]) to be able to correct some of the 2-bit errors.
For
, at least
and
are possible. The minimum is reached at
, and the number of parity bits are 64 for
yet only 20 for
, resulting in code rates of
and
, respectively. For
, at least
are possible, as
would lead to
and
, i.e., almost twice as large as
N. The minimum is reached at
; the function values are given in the upper row of
Table 1 together with the achieved code rates.
If we add
parity bits to obtain the extended cross parity code, function
has the derivation
, which also goes from negative to positive in the domain. For
, the number of parity bits is 68 for
and 52 for
. For
, the minimum is reached at
. The number of parity bits is shown in the lower row of
Table 1 together with the achieved code rates.
This observation indicates that parity codes of higher dimension deserve further investigation, e.g., with respect to their merits for extended cross parity codes.
We also see that these higher-dimensional cross parity codes are not impractical. While the code rates do not reach the level of a 2-bit correcting BCH code (26 redundancy bits for 4096 data bits, achieving code rate 0.994), they are also not far away and lead to simpler decoding functions.
4. Parities from ()-Dimensional Hyperplanes
The usual cross parity codes compute parity from -dimensional hyperplanes, which seems plausible for and . However, as the previous section suggests, higher dimensions might also be of interest. Then, the question arises if parities from lower-dimensional hyperplanes also have some merit, although their number will be higher than in the usual cross parity code.
In this article, we consider parities from
-dimensional hyperplanes. As an example, one may imagine line parities in a cube for
(cf.
Figure 1(right)), which cover the three visible surfaces, i.e., there are
parity bits.
Formally, we define
parity bits via
where
and
.
Please note that in the following, we do not consider bit errors on parity bits, and hence do not specify how these are protected. As protecting the parity bits can be performed in the same manner as for data bits (yet with a smaller size and smaller dimension), we see this as acceptable.
If a single bit error occurs in bit , then this shows in parities: for each , it shows in .
More formally, the receiver computes
for each
and
, and for each
computes
For completeness, i.e., to separate from multi-bit errors, one could additionally multiply with , where either or , or both, for all .
In the case of a single bit error in bit , and all for .
Assume as an example that two-bit errors occur at two bits on a line in one of the dimensions, w.l.o.g. and . The errors show in parities and for each . These errors can be distinguished from 1-bit errors and thus corrected.
Now assume the general case that two-bit errors occur at and , where for and for . Please note that , because otherwise , yet all sets J with are possible. The case has been treated in the example; thus, we assume in the sequel.
For with (if ), all , as for and both errors are counted, and none are counted otherwise.
For with , and , while for and .
For and with (if ), and , while for and (please note that here).
The same holds for and with .
Thus, for each , the following parities have value 1: and for , and and for .
For each pair with , parities are counted twice, so that the total number of parities with value 1 is .
From the number of with value 1, the different sizes of J can be distinguished, and for a particular size of J, the different possibilities for J that correspond to the different error positions can be distinguished. Thus, 2-bit errors are correctable.
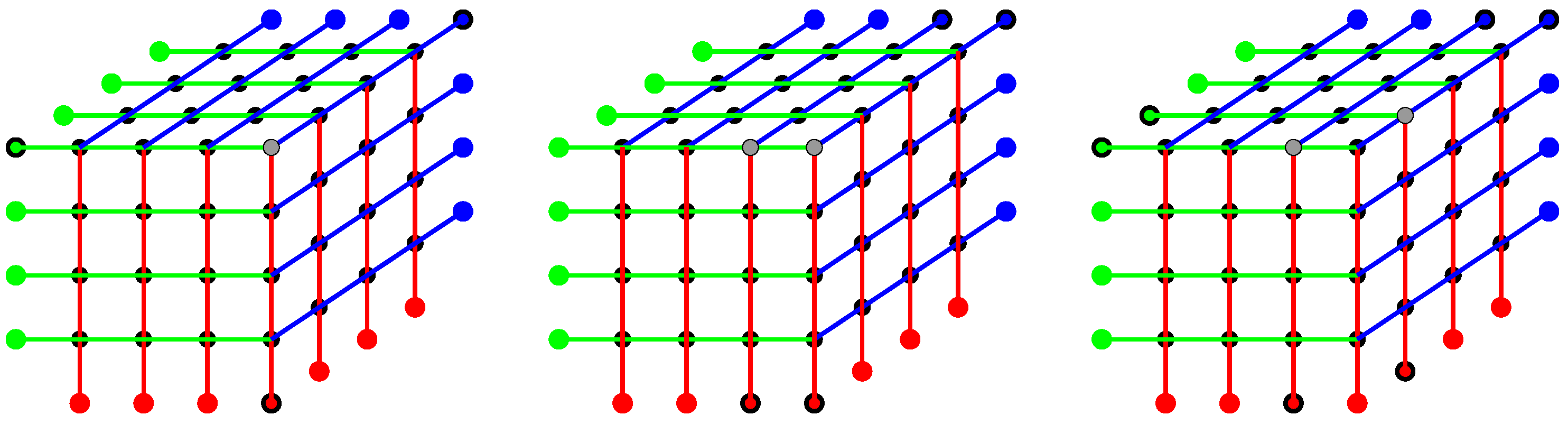
We illustrate this with our example from the right side of
Figure 1. For one error, e.g., on the upper right front corner, three line parity bits (one in each dimension) do not match the re-computed parities, cf. the left side of
Figure 2. If two errors occur in a line, e.g., on the upper right front corner and left to it, four line parity bits do not match the re-computed parities, cf. mid of
Figure 2. If two errors occur yet not in a line, e.g., the two neighbors of the upper right corner, then six parity bits are affected, cf. right side of
Figure 2. If we switch the error bits to the other two data bits in the
-square on the top right, then the affected parities in blue and green would remain the same, yet the red parities would differ.
The code rates for such cross parity codes from
-dimensional hyperplanes for different values of
N and the value
of the dimension that leads to best code rate for the given
N are depicted in
Table 2. The code rates at least for the largest value of
N are competitive with DEC-BCH codes (0.945 vs. 0.994), given that decoding for cross parity codes is quite fast.





{kind=link}
{kind=link}