Abstract
The Attribute-Based Access Control (ABAC) model provides access control decisions based on subject, object (resource), and contextual attributes. However, the use of sensitive attributes in access control decisions poses many security and privacy challenges, particularly in cloud environment where third parties are involved. To address this shortcoming, we present a novel privacy-preserving Dummy-ABAC model that obfuscates real attributes with dummy attributes before transmission to the cloud server. In the proposed model, only dummy attributes are stored in the cloud database, whereas real attributes and mapping tokens are stored in a local machine database. Only dummy attributes are used for the access request evaluation in the cloud, and real data are retrieved in the post-decision mechanism using secure tokens. The security of the proposed model was assessed using a simulated threat scenario, including attribute inference, policy injection, and reverse mapping attacks. Experimental evaluation using machine learning classifiers (“DecisionTree” DT, “RandomForest” RF), demonstrated that inference accuracy dropped from ~0.65 on real attributes to ~0.25 on dummy attributes confirming improved resistance to inference attacks. Furthermore, the model rejects malformed and unauthorized policies. Performance analysis of dummy generation, token generation, encoding, and nearest-neighbor search, demonstrated minimal latency in both local and cloud environments. Overall, the proposed model ensures an efficient, secure, and privacy-preserving access control in cloud environments.
1. Introduction
Cloud-based systems offer a wide range of benefits to both enterprises and individuals. Microsoft Azure is one of the most widely adopted cloud platforms that provides scalable infrastructure and limited free services to users [1]. These systems enable on-demand services, minimal management, and metered services, which encourage organizations to migrate their data to the cloud [2,3]. Despite these advantages, cloud systems still pose concerns, owing to the involvement of third parties, which may increase security and privacy issues [4]. Cyber attacks are increasing with the development of new techniques. Consequently, users are reluctant to migrate their complete data to the cloud [5].
Information flow and data access must be effectively managed to address the security challenges of cloud systems. Therefore, it is necessary to know who accesses data. Access control mechanisms are crucial for information security. Several access control mechanisms have been proposed.
- Discretionary Access Control (DAC) was one of the earliest access control models. In DAC-based mechanisms, the data owner is responsible for providing access to the data. DAC systems are less secure because information flow is not controlled in these systems [6].
- Mandatory Access Control (MAC): In the MAC model, strict rules are set by the administrator, and the data are classified into levels. Although it is a secure model, it lacks flexibility [7].
- Role-Based access control (RBAC) model: The RBAC model provides access to data using user roles such as “doctor,” “salesperson,” “manager,” and “patient.” It is suitable for organizations, but is role-centric, lacks flexibility, and does not provide fine-grained access [8,9].
- Attribute-Based Access Control (ABAC) model: It is the most popular access control method. It provides access to decisions using subjects, objects (resources), and environmental attributes [10]. It is dynamic and more flexible than other access control models. Despite its numerous benefits, the ABAC system poses many security and privacy challenges, such as sensitive attribute exposure [11]. ABAC can also be vulnerable to policy injection attacks and single-point failure.
To address these issues in traditional ABAC model, we present the first privacy-preserving model called the Dummy-ABAC model. The proposed model uses a hybrid storage mechanism in which real attributes are stored in the local database and dummy attributes are stored in the cloud database (Microsoft Azure SQL database). In addition, secure tokens are generated using Pythons’ (version 3.10) hashlib to remap dummy attributes with their corresponding real attributes. These tokens are stored and utilized in local environment only during post-access control decision. This approach ensured that cloud never knows about the real attributes of user thereby addressing the privacy and security challenges of traditional ABAC systems, provides resistance to security attacks, and preserves privacy.
Moreover, the security of the model was validated by simulating a threat model on a dataset of 1000 users. In the threat model, three types of threats (attribute inference, policy injection, and mapping attacks) were experimentally evaluated using a machine learning ML technique. A model was trained using “Decision Tree (DT) and Random Forest (RF) Classifiers” and “Stratified K-Fold” cross-validation. The effectiveness of the attack was measured using metrics such as accuracy, precision, recall, and F1 scores in a Dummy-ABAC model. Dummy-ABAC is the first model that uses synthetic dummy attributes for access control operations unlike the traditional synthetic data methods only used to train the ML models to analyze the data.
Research Objectives
The main objectives of this research are:
- To design a lightweight, secure privacy-preserving model using ABAC for cloud computing.
- To validate the proposed model against security threats commonly faced by traditional ABAC model such as attribute inference attack, policy injection attack, and reverse-mapping attack.
- To evaluate the computational efficiency of the proposed model including dummy generation, token generation, encoding, and nearest-neighbor search, for both local and cloud environments.
The remainder of this paper is organized as follows. Section 2 discusses the background and Section 3 discusses the related work. Section 4 outlines the methodology and implementation of the proposed Dummy-ABAC model. Section 5 presents an assessment of the experimental configuration and the results. Finally, the conclusions and future work are discussed in Section 6.
2. Background
In this section, the privacy-preserving techniques that are conceptually related to Dummy-ABAC model are discussed. Furthermore, these techniques are compared with the proposed Dummy-ABAC model to highlight the novelty of the proposed model.
2.1. Dummy-ABAC Model vs. Pseudonymization and Anonymization
Pseudonymization and anonymization are inherently used privacy techniques to hide data. However, both techniques have some limitations compared to the Dummy-ABAC model.
In the pseudonymization technique, real data are replaced with consistent pseudonyms, which is reversible only if a pseudonymization key/mapping table is available [12,13]. For example, if a user’s real attributes are name = Sara, role = doctor, and department = Cardiology. These attributes will be converted into pseudonyms such as name = D123, role = D12, and department = C1, and stored in the mapping table. If someone has access to the mapping table these are reversible and can be exploited, and they are performed on the same platform.
Anonymization is also a privacy-preserving technique in which real user attributes are masked with unidentifiable attributes [14]. For example, role = doctor will be masked as role = d*****r in anonymization. It does not involve mapping tables or keys. In contrast, the Dummy-ABAC model is a novel model in which real attributes are replaced with synthetically generated dummy attributes using tools such as the Faker library, and randomization techniques. Dummy attributes look like real attributes. In cloud platform, dummy attributes are non-reversible, whereas dummy attributes are remapped to real attributes (in local environment only) using secure token if access is granted. For example, if a user’s real attributes are name = Sarah, role = Doctor, and department = Cardiology. These real attributes are stored in a local database and dummy attributes will be generated such as name = John, role = Staff, and department = Neurology. These dummy attributes will be sent to the cloud and stored there. The cloud will never know about the real attributes of the user owing to the hybrid storage mechanism.
2.2. Dummy-ABAC vs. Synthetic Data
Synthetic data are also used as a privacy-preserving method, especially in healthcare systems where synthetic data are created to mimic real data to minimize the identification risk [15,16]. Synthetic data are tied to entire dataset and only used to train machine learning models and reduce the risk of data re-identification; additionally, they are not used in access control mechanisms. In contrast, the Dummy-ABAC model is the first to use synthetic dummy attributes for access control operations. The proposed model does not aim to replace complete dataset with synthetic data, but synthetic dummy attributes are generating those that are solely responsible for authentication and authorization in the cloud environment.
Unlike conventional synthetic data mechanisms, Dummy-ABAC introduces secure token-based mapping to remap dummy attributes with real attributes in a local environment only once access is granted. This architectural difference ensured that the Dummy-ABAC model achieved a high level of security.
Thus, Table 1 shows that the Dummy-ABAC model is a novel privacy-preserving technique used to enhance the privacy of access control mechanisms specifically for applications where third parties are involved.

Table 1.
The difference between Dummy-ABAC model and above discussed privacy-preserving techniques.
2.3. Dummy-ABAC Model Architecture
The proposed model obfuscates the actual attributes of users with dummy attributes and sends only dummy (pseudonymous) attributes to the cloud. Real attributes are securely stored in a local database, whereas only dummy attributes are processed and stored in cloud architecture. When a user requests to view the data stored in the cloud, the system re-associates the dummy attributes with the corresponding real data attributes using a secure mapping token and then returns the output. The Dummy-ABAC model comprises the following components:
Registration: New users registered in the system (Flask-based web application is used for the proposed model) using their real attributes (name, age, department, role, gender, etc.). Dummy attributes are generated (using the Faker library of Python with random technique) against each real attribute, and a token (using UUID, hashlib of Python) is generated to remap dummy attributes and real attributes.
Storage: A hybrid approach is used; real attributes and mapping tokens are stored in local database (SQL) and dummy attributes are stored in a cloud database (Microsoft Azure SQL database). Thus, cloud service providers never know about the real sensitive attributes of the user.
Token generation and mapping: An unpredictable secure token is generated and it is only stored in a local database to remap the dummy attributes to real attributes. The tokens were rotated in every session to avoid predictability.
Policy machine: A cloud-based policy machine is used to evaluate policies of user requests. In the proposed model the Microsoft Azure App service is used as a policy machine.
Authentication: A user logs into the system with real attributes. The user’s real attributes are verified at a local machine, and a token (hashed) from local storage is retrieved from the local storage. For cloud side authentication, corresponding dummy attributes will be used, if access-permitted authorized dummy attributes are remapped to real attributes using a secure token and granting the user to access the system.
Using the above architecture Dummy-ABAC model provides privacy-preserving access control mechanism for cloud computing. Conventional systems may use dual-layer encryption (symmetric and asymmetric encryption) to secure data. Our system achieves explicit privacy protection by concealing real attributes with dummy attributes. This ensures that real attributes and mapping tokens are never exposed to cloud without the need for cryptographic storage.
3. Related Work
To enhance the privacy and accountability of the ABAC structure in the blockchain mechanism [17], they proposed an ABAC cloud service blockchain implementation called BC-ABAC. Their approach focuses on accountability and privacy maintenance by utilizing a permission blockchain to record and enforce user attributes and access policies. This shared and immutable ledger prevents the creation of fabricated attributes and unauthorized modifications to policies, thereby ensuring auditability. The authors pointed out privacy concerns regarding conventional ABAC schemes that leave clouds or centralized points of control in charge of all information about a user that requires privacy protection. BC-ABAC introduces a certain amount of computation and communication overhead owing to transaction verification and consensus processes, even when blockchain is incorporated to enhance trust and accountability within access control. The proposed Dummy-Attribute-Based Access Control system addresses these privacy issues differently, because it uses randomized dummy characteristics instead of addressing the actual user.
Ref. [18] addressed several methods, including access control frameworks, anonymization tactics, and cryptography techniques to secure data access and increase collaboration. Some of the most renowned cryptographic algorithms, such as searchable and homomorphic encryption, provide strong guarantees of data privacy during computation and retrieval. The scalability of these methods in practice is limited by the fact that they often have high computational costs and complexity. According to these authors, Attribute-Based Access Control (ABAC) is a more flexible and granular alternative than traditional Role-Based Access Control. However, this presents new implications for privacy because user attributes are directly disclosed to cloud service providers for policy reviews. These issues are also evidenced in a larger volume of the literature, which stresses the importance of attribute-level privacy in ABAC systems. To address these limitations, the Dummy-ABAC model introduces an additional form of attribute obfuscation through pseudonymization.
Ref. [19] designed a privacy-conscious extension of ABAC, ABAC-PA2, which extends functionality with the support of anonymous access, thereby ensuring the flexibility of attribute-based enforcement. Identity-masking techniques are integrated into their strategies, as individuals can use them to prove their value, and their attributes will not be revealed. ABAC-PA2 is an initiative that brings anonymous credential-based authentication to ABAC systems, leading to enhanced privacy at the cost of continuing to invoke secure identity providers and cryptographic protocols to arbitrate access decisions. This is often a source of latency and processing overhead, particularly when deployed at a large scale. The Dummy-ABAC model provides privacy using a novel method of data obfuscation with dummy attributes. Unlike the ABAC-PA2 method, the Dummy-ABAC model does not cause latency or processing overheads.
Ref. [20] dimensioned this problem using their MC-ABAC model, which is an attribute-based access control system built specifically for multi-cloud applications, as well as a mode of collaboration that allows several tenants and services to collaborate by observing similar restrictions on their common policy. There is no clear solution to the privacy issues of revealing sensitive attributes in access decisions, even though the MC-ABAC model focuses on the cooperation between access control and policy coherence across clouds. The MC-ABAC model addresses several shortcomings of conventional ABAC architecture by introducing a centralized attribute authority that coordinates policies across multiple cloud providers. This single control plane enables fine-grained access control and standardizes the policies across numerous cloud platforms. On the other hand, Dummy-ABAC minimizes the threat of attribute inference or leakage in shared or untrusted cloud systems by replacing user attributes with dummy attributes that have the randomization property of their actual counterparts before transmission and policy evaluation.
The conventional deployment of ABAC often exposes these secretive particulars to policy decision points and third-party cloud infrastructures. ABAC allows flexible microlevel user-, resource-, and environment-based access decisions. Ref. [21] proposed a cryptographic solution to this issue and developed a privacy-preserving ABAC protocol based on homomorphic encryption. Owing to the nature of the characteristics and policies being encrypted in their approach, final access choices can be made for encrypted data without decryption. In policy evaluation, this model ensures that no individual, including the access control engine, can view the raw values of the attributes. The proposed solution was tested on actual cloud systems, which proved its viability, and it was implemented using partially homomorphic encryption algorithms. Ensuring scalability and instant reactions may require significant processing power and key handling attention on cloud servers of encrypted policies. Therefore, this may be problematic in situations with restricted resources or on a large scale. The Dummy-ABAC model proposed in the present study is built on the same strategy, but uses randomized dummy characteristics and lightweight pseudonymization techniques, which do not imply complicated cryptographic procedures.
Ref. [22] proposed a formal verification approach to ABAC that extends the Alloy modeling language to verify access control models in both non-collaborative and collaborative settings in the healthcare industry. Their work demonstrated that logic-based mistakes or contradictions in policies may cause both illegal access and legitimate requests, and that the correctness of the ABAC policy configuration is particularly valuable and secure. The authors aimed to improve the reliability of ABAC deployments in highly regulated sectors, such as the healthcare sector, using formal approaches. The privacy issues involved in attribute disclosure in access reviews are not addressed specifically in the Alloy-based paradigm, although they are much more successful in ensuring logical conformity and continuity of policies.
Ref. [23] released an ABAC system that respects privacy and was modeled to provide access control (safe) in a cloud environment. Their approach incorporated anonymous authentication using cryptographic structures based on bilinear pairing. The model ensures that access decisions can be made without releasing the actual identities or attributes associated with users to the points of policy enforcement using hidden credentials and zero-knowledge proofs. The architecture multiplicatively enhances the expressive security of ABAC policies, while also increasing user privacy. The proposed technique has powerful privacy guarantees but is quite complex and incurs cryptographic overhead. Pairing-based cryptography requires greater processing power and care in key management, which may be an issue in scalability and real-time access control scenarios.
The HVAC model, which is based on the hybrid architecture proposed in [24], integrates the basic principles of the explicit protection of privacy and traditional ABAC. The system also attempts to guarantee user protection of data by providing privacy-related rule layers that enforce fine-grained access control. The authors argue that despite its robust and flexible access control capabilities, ABAC fails to defend the confidentiality of sensitive attribute data, particularly in cloud collaboration environments, on a routine basis. They addressed this by ensuring context-specific policy triggers, anonymization tolerances, and role-based policy filters through their approach. Studying these fragments is dynamic and dependent on the privilege level of the user and the sensitivity of the request context. Despite its comprehensive and gradual nature, this approach requires a complex rearrangement of the ABAC policy engine, and reliance on dynamic evaluations may lead to increased overhead in the policy management scheme.
A complicated encryption mechanism that involves time and spatial restrictions in attribute-based encryption (ABE) was provided in [25]. Using this model, data owners can develop precise access controls depending on dynamic aspects, including time masses and geographic locations, in addition to common aspects such as roles or departments. The dual-layer encryption structure used by the authors to guard privacy ensures that the policy and attribute values remain confidential during the access control evaluations. This architecture is computationally intensive because technology involves the use of complicated encryption methods; however, it provides a high level of protection and flexibility, especially in location-aware cloud models. The complexity of spatio–temporal keys, re-encryption operations, and fine-grained key distribution introduces significant overhead, and in large-scale applications also means that real-time processing and scalability are problems. None of the above models provide privacy using dummy attributes at cloud environment to obfuscate real attributes of users.
4. Methodology
This section addresses the architecture and approach used to develop, apply, and evaluate the proposed Dummy-ABAC model using experimentation. The design involves a hybrid storage method in which real attributes are stored in the local database, dummy attributes are stored in the cloud database, and policy decisions are evaluated at Microsoft Azure.
4.1. System Overview
The Dummy-ABAC model is designed as a hybrid, splitting user data into two domains:
- Local environment: This uses a local SQL database and SQLAlchemy to host the real attributes and mapping table of the secure token (access token). A secure token is generated during user registration and stored only in the local database.
- Cloud environment: Store dummy attributes in Microsoft Azure’s SQL database. The policy machine is designed in Microsoft Azure using Azure App Services, which acts as a policy decision point PDP and is used to evaluate policies. A systematic overview of the proposed model is presented in Figure 1.
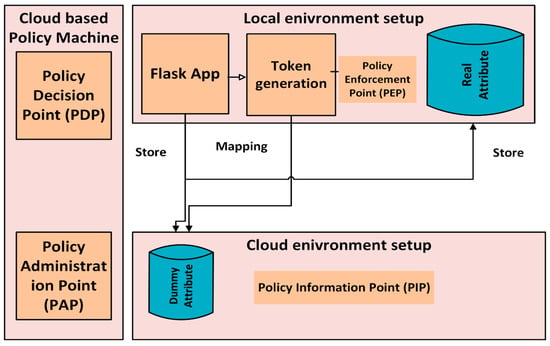 Figure 1. Systematic front-end overview of the proposed model.
Figure 1. Systematic front-end overview of the proposed model.
Hybrid Storage Architecture and Privacy Compliance
The Dummy-ABAC model supports privacy compliance using a hybrid storage structure as shown in Figure 2. The owner of the data manages the local SQL database, local database being the byword of the actual user attributes as well as mapping tokens only. The Microsoft Azure SQL database serves as a source of policy decision point input, but it contains just dummy attributes. Transparent data encryption (TDE) secures dummy data even when data is stored in the cloud. TLS is used to provide security to traffic between cloud and premise environments. Since tokens are never sent to cloud, the cloud does not have the ability to infer any actual user attributes. Role-based access control restricts access to the policy machine in the Azure and all data regarding queries are recorded to allow audit. This design safeguards the privacy policies and shields against the frequent hostile attacks.
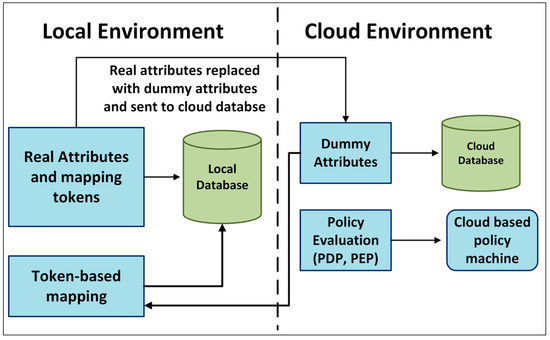
Figure 2.
Hybrid storage architecture of Dummy-ABAC model.
The workflow of the model proceeds as follows:
A Flask-based web application was developed to act as an intermediate between the local and cloud environments. Users register using their real attributes, such as name, age, role, and department. The Faker library in Python was used to generate randomized dummy attributes for each real attribute. A secure token was generated against each registration using Python’s UUID, random, and hashlib libraries. This token acts as a unique mapping key between dummy and real attributes. Real attributes and tokens were stored in the local database only, and dummy attributes were stored in Microsoft Azure’s SQL database. Various policies are designed using a healthcare use case to verify the working of the model, and the policies are stored and evaluated in Azure App Services (which acts as a policy machine). During login time, the registered users’ real attributes are verified through the local database, which retrieves the dummy attributes (using a token) and sends them to the cloud, which means that the cloud does not know the real attributes of users. The policy machine evaluates access requests against policies defined using dummy attributes. The requested dummy data are fetched from Azure SQL and locally mapped back to the real data using the stored token. The detailed workflow of the proposed model is illustrated in Figure 3.
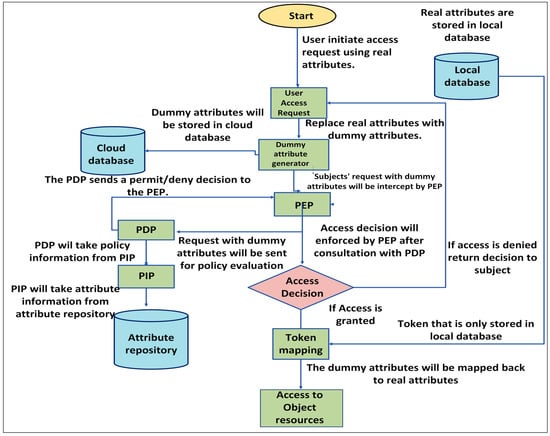
Figure 3.
Detailed implementation workflow of the Dummy-ABAC model.
4.2. Implementation Details
The Dummy-ABAC model is implemented through the following components:
- Backend Framework: Python Flask was used for user interaction, registration, login, and sending requests to the policy machine, the cloud, and local databases.
- Database interface: SQLAlchemy ORM was used to interface with both local SQL and Azure SQL databases.
- Dummy attribute generation: Python’s Faker library was used to generate dummy attributes for each real attribute.
- Mapping: Secure tokens were generated using Python’s UUID, hashlib, and random salt libraries to map dummy and real attributes. The tokens were stored only in a local database.
- Policy machine: A dedicated policy machine was designed to evaluate the policies and act as a PDP. Microsoft Azure’s App Service was developed as a policy machine. It receives access requests in the JSON format and evaluates policies defined using dummy attributes.
- Cloud storage: Dummy attributes are stored in the Azure SQL database (US Central). All database access uses parametrized queries via SQLAlchemy ORM to prevent injections.
4.3. Experimental Setup
In the proposed Dummy-ABAC model, the synthetic healthcare dataset of 1000 users with attributes department, age, gender, specialization, and clearance (target: role). Real and the dummy CSV files that were used for experimentation are provided as Supplementary Material. The data generator was seeded (Faker seed (42), random. seed (42) and np. random. seed (42)) so the generated CSVs are deterministic. All classification experiments used sklearn Pipeline placing categorical encoding inside cross-validation to avoid data leakage (ColumnTransfer + OneHotEncoder (handle_unknown = ‘ignore’) followed by DecisionTreeClassifier DT (criterion = “gini”, random_state = ‘42’) and RandomForestClassifier (random_state = ‘42’) RF. The performance was evaluated using Stratified K-fold cross validation (n_splits = 5, shuffle = True, random_state = 42) and reported ± mean deviation across folds. The 1000 user dataset was used for testing to ensure privacy compliance and security resistance of a model as a proof of concept; no real healthcare data were used, complying with privacy standards.
In this study, local experiments were conducted using local machine equipped with an Intel(R) Core (TM) i5-8250U CPU 1.60 GHz (8 CPUs), ~1.8 GHz and 12 GB RAM, running Windows 11 operating system with Python 3.10 and scikit learn 1.2.0. On the cloud side, a serverless setup was used in Microsoft Azure cloud in which Microsoft Azure SQL Server is used in which ABAC_Machine database was created to store dummy attributes and Microsoft Azure App service is configured to serve as a policy machine to evaluate policies. This is a hybrid storage architecture in which local and cloud environments are used to preserve privacy and provide scalable policy evaluation.
The above-mentioned experimental workflow allowed obtaining the data provided in Table 2, Table 3 and Table 4. In particular:
Table 2.
Hyperparameters used in ML models.
Table 3.
Classifier performance (mean ± std) for DT and RF on real/dummy attributes.
Table 4.
Policy-injection simulation results.
Attribute-inference attacks (Table 2) illustrated an attack executed through sklearn Pipeline. Evaluation of the attacks was done based on stratified 5-fold cross-validation. Random Forest and decision tree classifier were both used on real and dummy data. The mentioned results are the average and standard deviation between folds.
Policy Injection Attack Policy payloads (1000) were sent programmatically to an Azure-based policy machine. The attacks had valid, flawed, invalid-API-key, and escalation-attempt attacks. Logging: The operation was automatic and the results were sorted based upon the escalation check, schema validation, and API-key checks. Table 4 (Reverse Mapping Attack) was created in following three different ways:
- Frequency analysis using collections;
- Nearest-Neighbor matching (sklearn. neighbors. NearestNeighbors (metric = “Euclidean”, n_neighbors = 1));
- Monitored approach, supervised classifiers trained on dummy attributes.
This mapping of datasets, pipelines, and evaluation scripts to the corresponding result tables (using the added CSV files and Python code) ensures that the experiments are fully reproducible. The hyperparameters used in machine learning models are summarized in Table 2.
4.4. Threat Model
Adversary: We assume the primary adversary has access to cloud resources only (dummy data that are stored in Microsoft Azure SQL and policies that are stored in policy machine in cloud). The adversary does not have access to mapping tokens stored in local database. The aim of adversary to recover real attributes of users to perform unauthorized privileges or perform policy injection. The adversaries include a network eavesdropper trying to intercept cloud–local network traffic but cannot access local tokens that are exclusively stored in local database. A local machine compromise does not fit within the scope of this study, but it is discussed in Section 6. An adversary with access to cloud-stored dummy attributes may only attempt the following steps:
- To begin with, gather dummy attribute frequencies information;
- These statistics are then correlated with outside background knowledge to distinguish patterns;
- Then infer potential real attributes of the dummy distributions by means of supervised learning;
- Trying to elevate privileges by feeding rather malicious or untrustworthy policy payloads (policy injection) is useless.
These attempts are blocked due to the following reasons in the Dummy-ABAC model:
- Attributes are obfuscated with dummy attributes;
- Mapping tokens are only local;
- Policies rejected by schema and API-key checks;
- Query rate-limited and recorded.
We consider the following possible security attacks in our model. Our objective was to verify the resistance of the proposed model to these attacks.
4.4.1. Attribute Inference Attack
The primary objective of the attribute inference attack was to determine whether dummy attributes could be inferred, and real attributes could be identified. Machine learning techniques were used to verify the attribute of inference attack. We trained two classifiers from the scikit-learn library of Python; the first classifier was DecisionTreeClassifier DT, and the second classifier was RandomForest RF (detailed hyperparameters of both models are discussed in Table 2) to measure accuracy in both real and dummy attributes. These were employed in a stratified 5-fold cross-validation (n_splits = 5, shuffle = True, and random_state = 42) to maintain class balance in the folds for evaluation. A 1000-user dataset was used and evenly distributed across the attribute categories. The following metrics were used: accuracy_score, precision_score, recall, and F1_score from sklearn. Metrics in Python: The metrics were computed on a per-fold basis. Classifiers were trained on dummy attributes to predict real roles from dummy attributes. The mean and standard deviation of the accuracy_score, precision_score, and F1_score were reported. A synthetic healthcare dataset of 1000 users is used in this study. We applied stratified 5-fold cross-validation to compute the metrics in order to achieve balance in the classes of every fold. The calculations of all folds were as follows:
Precision (P) = True Positive (TP)/TP + False Positive (FP)
Recall (R) = TP/TP + False Negative (FN)
F1 score = 2 × (P × R)/(P + R)
Macro averaging was applied for multiclass evaluation across all classes in each fold. The final values reported in Table 3, Table 4 and Table 5 that represent mean ± standard deviation across all folds.
Table 5.
Reverse-mapping attack results.
The primary objective of the attribute inference attack was to determine the cross-appearance of an adversary with the ability to infer the real attributes using the dummy attributes it maintained in the cloud. This was not achieved. Table 3 depicts that classifiers using real attributes achieved a much higher accuracy (~0.650) than classifiers using dummy attributes, which nevertheless achieved only the accuracy of the random (~0.25). The findings are evidence to the effect that Dummy-ABAC design minimizes the threat of attribute inference.
4.4.2. Policy Injection Attack
The policy injection attack was the second threat model, designed to verify how the model acts if an adversary attempts to insert unauthorized policies. A total of 1000 policy payloads were used, of which a few were valid, a few were malformed, a few had wrong API keys, and a few privilege escalation attempts were verified. Schema validations were performed with “jsonschema. validate”. The API keys were verified via string comparison. The objective of 1000 payload tests were to check the response of the model against policy injection attacks.
4.4.3. Reverse Mapping Attacks
The reverse model was aimed at evaluating the remapping of dummy attributes with real attributes, in which an adversary can use a statistical technique to match dummy attributes with real attributes. To simulate this attack, we preferred to use frequency analysis (Python’s “collections.Counter”), Nearest-Neighbor matching (using NearestNeighbors from sklearn. neighbors, metric = “Euclidean”, n_neighbors = 1), and supervised matching (DecisionTreeClassifier and RandomForestClassifier). Nearest-neighbor matching was used to check whether the dummy record matched that of the real user. In supervised matching, a model was trained to predict real attributes. Frequency analysis was performed on dummy attributes (role, department pairs) to check whether common values could be matched to the real distribution.
To illustrate the mechanism of reverse-mapping attacks, we describe the following steps an adversary may use the following:
- Monitor the dummy attributes in the cloud;
- Use frequency analysis to identify frequently used prefixes of pairs of dummy attributes;
- Use nearest-neighbor matching to align dummy profiles with realistic users;
- Finalize supervised classifiers to predict realistic attributes using dummy ones.
It was assumed that an attacker has access only to dummy attributes but not token mappings. All features were preprocessed using OneHotEncoder (handle_unknown = ‘ignore’) for an earlier similarity search. The preprocessing phase is used to script categories into binary vectors. It facilitates the frequency-based as well as machine learning-based analysis guaranteeing the coherent statistic comparisons and exclusion of unwanted ordinal correlations.
The frequency analysis was done at both the joint distribution level (role/department grouping) and the marginal level (role/department and at the individual department level). The data at these two levels were required to have simple statistics of variables and cross-variable relationships in the dummy being directly compared with the real distributions.
4.5. Performance Evaluation Metrics of the Dummy-ABAC Model
The metrics involved in measuring the performance efficiency of the proposed model were token generation time per user, timed with the time.perf_counter () function, dummy attribute generation time per user, encoding time in total, in which total time is recorded, and search per query time. All the timings were simulated in milliseconds.
Real user attributes were converted into dummy attributes, policies were evaluated on the cloud using these dummy attributes, and real information was retrieved through safe token-based mapping. The steps in the sequential process of the proposed privacy-preserving access control system are shown in Algorithm 1.
| Algorithm 1: Privacy-preserving Dummy-ABAC model |
| “Input: 𝓡ᵤ ← real attribute vector for user u |
| r ← requested resource |
| Output: δ ← access decision ∈ {PERMIT, DENY} |
| 1 Dᵤ ← F(𝓡ᵤ)//Generate dummy attributes using obfuscation function F (e.g., Faker) |
| 2 τ ← GenerateToken ()//Generate a fresh local mapping token |
| 3 StoreCloud (Dᵤ)//Store dummy attributes in cloud (Azure SQL) |
| 4 StoreLocal (𝓡ᵤ, Dᵤ, τ)//Store mapping (real↔dummy) and τ in local protected storage |
| 5 u_auth ← Authenticate (u, credentials) |
| 6 if not u_auth then |
| 7 return DENY |
| 8 end if |
| 9 τ ← LookupToken(u)//Retrieve local token for authenticated user |
| 10 Dᵤ_mapped ← RetrieveDummyMapping (𝓡ᵤ, τ)//Map real input attributes to corresponding dummy attributes using local mapping |
| 11 Preq ← (subject = Dᵤ_mapped, object = r, action = a)//build policy request in terms of dummy attributes |
| 12 δ ← PolicyEvaluate (Preq)//Evaluate policies on cloud using dummy attributes |
| 13 if δ = PERMIT then |
| 14 Dd ← QueryCloudData (Dᵤ_mapped, r)//Retrieve dummy-protected data from cloud |
| 15 𝓡d ← MapBack (Dd, τ)//Convert dummy data back to real data locally using token τ/local mapping table |
| 16 Display(𝓡d)//Present real data to the user |
| 17 else |
| 18 DenyAccess () |
| 19 end if |
| 20 return δ” |
In the above algorithm, F(𝓡ᵤ) is the obfuscation function that generates dummy attributes from real attributes using Python’s Faker library with seeded randomness to ensure reproducibility. The GenerateToken () function creates unique local mapping tokens τ using UUID combined with Python’s hashlib. The StoreCloud (Dᵤ) function stores only dummy attributes in cloud database (Microsoft Azure SQL database), while StoreLocal (𝓡ᵤ, Dᵤ, τ) function stores real, dummy attributes and mapping tokens (used to remap dummy with real attributes) in local database. The Authenticate (u, credentials) function validates the user’s credentials locally, as only authenticated users will proceed further; otherwise, access is denied. RetrieveDummyMapping (𝓡ᵤ, τ) uses τ to map input real characteristics to their corresponding dummy attributes for consistency throughout policy evaluation, while LookupToken(u) retrieves the token τ from the local database after authentication. The PolicyEvaluate(Preq) rule is executed by the Azure App Service cloud-based policy machine which coordinates access requests by comparing them with pre-defined ABAC policies only using dummy attributes. QueryCloudData (Dᵤ_mapped, r) obtains the dummy-protected resource from the cloud if access is allowed. After that, the MapBack(Dd, τ) function remaps the dummy data to their initial real values in the local environment using the token τ. Lastly, Display(𝓡d) shows the authenticated user the reconstructed true data.
4.6. Formal Model
The proposed Dummy-ABAC model comprises the following entities and functions:
𝓤: The set of users;
𝓡: Set of resources;
𝓐real: The set of real user attributes;
𝓐dummy: The set of obfuscated user attributes;
𝓟: The set of access policies;
𝓕: 𝓐real→𝓐dummy: A non-reversible attribute obfuscation function (it is non-reversible for cloud);
𝓣: 𝓤→T: The token mapping function that securely maps dummy attributes with real;
𝓜_𝓣: 𝓐real→𝓐dummy: Local mapping (𝓜_𝓣 was not shared to cloud intentionally, because its sharing would enable trivial inversion).
For each user “u ∈ U”, the real attributes are obfuscated as dummy attributes using the obfuscation function:
Function 𝓕 obfuscates the real attributes with dummy attributes that are non-reversible for a cloud environment, ensuring that the cloud cannot infer real attributes.
Every policy “p ∈ P”
An access request from user “u ∈ U” for a resource “r ∈ R” is allowed if
Here, the symbol denotes the membership relation, meaning that policy is an element of overall policy set P. When evaluated user’s dummy attributes and requested resource , the policy decision function P returns permit.
In cloud policy evaluation, only dummy attributes are used; therefore, the cloud does not observe real attributes.
If access is granted (δ = Permit), the system retrieves the data and maps the dummy data to corresponding real attributes before sending the output to the user.
Here, the function denotes the secure mapping function that links dummy attributes with their corresponding real attributes. The mapping token is stored in the local database and never shared with the cloud system. Mapping token is a unique identifier that is generated using UUID combined with hashlib in Python. is generated during the registration and stored only in the local database. During login or policy evaluation, the system uses _ to re-associate dummy attributes retrieved from the cloud with the corresponding real attributes before presenting results to the user. This ensures that the mapping process remains deterministic, secure, and local, thereby preventing leakage of real attribute information to the cloud.
5. Experimental Results
This section presents the experimental evaluation results of the attack vectors and the performance analysis of the Dummy-ABAC model.
5.1. Attack Vector Results
5.1.1. Attribute Inference Attack (Classifier’s Performance)
By employing dummy attributes, there was a severe reduction in the success of the adversary in the attribute inference tests. The tests were conducted in three ways: first, the test was performed on real attributes only (classifiers were trained and tested for real attributes only); second, the test was performed on dummy attributes only (classifiers were trained and tested on dummy attributes); and finally, the classifiers were trained on dummy attributes but tested on real attributes (roles). Table 3 and Figure 4, Figure 5 and Figure 6 reports the mean ± std for the DT classifier and RF classifiers for accuracy, precision (macro), recall (macro), and f1 (macro).
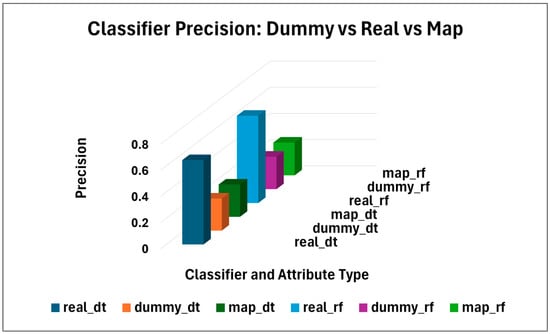
Figure 4.
Classifiers DT and RF precision results.

Figure 5.
Classifiers DT and RF Recall results.
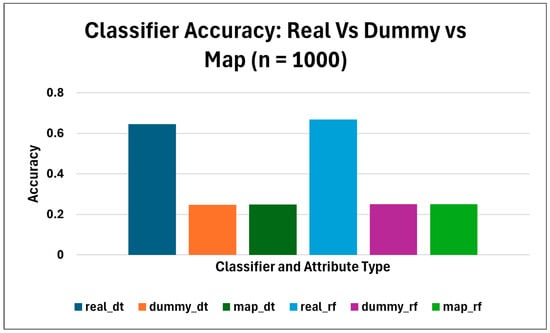
Figure 6.
Classifiers DT and RF’s accuracy results.
For real attributes, classifiers achieved higher inference accuracy with DT at ~0.646 ± 0.013, and RF at ~0.668 ± 0.014; in contrast, for dummy attributes, the inference accuracy rate drops to DT at ~0.248 and RF at ~0.25. The overall accuracy drop for DT was 0.398, and RF was 0.418, indicating that the dummy attributes successfully reduced the ability of the machine learning models to infer roles. Precision, recall, and f1 scores remained stable at ~0.25 for all, while those for real attributes were high, ~0.65. In the mapping test, the accuracy, precision, recall, and f1 for dummy were ~ 0.25, indicating that dummy attributes never expose real attributes as shown in Figure 4, Figure 5 and Figure 6.
5.1.2. Policy Injection Attack Results and Discussion
A total of 1000 payloads were simulated, out of which 559 remained valid, 200 were rejected by schema validations, 185 were rejected due to invalid APIs, and 56 were flagged for escalation. As shown in Figure 7 and Table 4, the model rejected malformed and unauthorized policies.
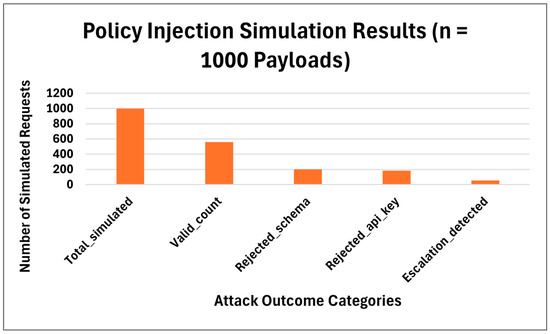
Figure 7.
Policy-injection simulation results for 1000 payloads.
5.1.3. Reverse Mapping Attack
In reverse mapping simulation, Nearest Neighbor scored 0.1% matches from a 1000 dataset, frequency mapping achieved 56 of 1000 correct matches, 5.6%, and in supervised mapping, DT accuracy was ~ 0.25, and RF accuracy was ~0.251, as presented in Figure 8 and Table 5. All reverse mapping techniques failed. The Nearest-Neighbor is almost negligible. The results validate the claim that the Dummy-ABAC model offers strong protection against attacks, based on NN, frequency-based statistics, and supervised mapping using classifiers.
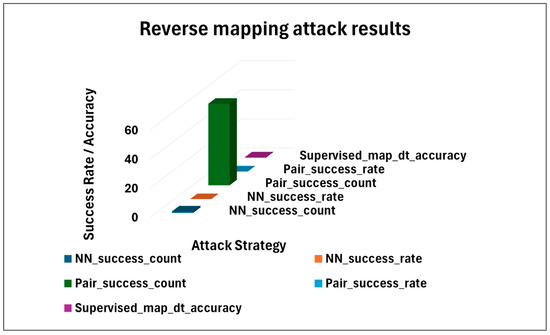
Figure 8.
Reverse mapping attack results.
5.2. Performance Analysis of the Dummy-ABAC Model
The performance of the proposed Dummy-ABAC model was evaluated using the dummy attribute generation time (local machine), token generation time (local machine), encoding time (cloud-based), and nearest-neighbor search time (cloud-based). Time taken to generate tokens for each user was 0.006 ms (~6 µs) per user, and time taken to generate dummy attributes was 0.005 ms (~5 µs) per user, which is negligible. Encoding time is the time taken to convert model attributes (role, department) into binary forms so that machine-learning techniques can be understood. For encoding, a “one-hot encoding” process was used to create a new binary column for every attribute, such as if the department attribute has values “Cardiology, Neurology, and Oncology”, each value department_Cardiology, department_Neurology, and department_Oncology. Each column with a value of 1 indicates presence and a value of 0 indicates absence. The time taken to encode the attributes, role, and department of 1000 users was ~ 7.87 ms. It is lightweight compared to cryptographic solutions. The Nearest-Neighbor NN technique was used to find the most similar data points from a 1000-user dataset. The NN took approximately 5740 ms → 5.74 ms per query. The NN added small delays in real-time systems, which could be a trade-off. The results show that the Dummy-ABAC model is efficient and preserves strong privacy. This method is suitable for cloud-scale deployments. Complete performance evaluation results are presented in Table 6 and Figure 9.
Table 6.
Timing measurements for token generation, dummy generation, encoding, and nn-search (ms).
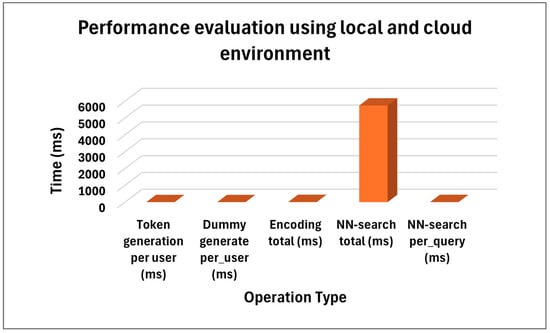
Figure 9.
Performance evaluation of Dummy-ABAC model (ms).
5.3. Effectiveness and Resilience Evaluation of Dummy-ABAC Model
The resistance of Dummy-ABAC system to adversarial risks and validity of policy enforcement were assessed. We modified 1000 policy requests, containing legitimate, flawed, invalid, and privilege-escalation requests. As shown in Table 4, all 559 valid requests were authorized, whereas illegal or unsuccessful attempts were rejected by either escalation detection, schema validation, or API-key checking. These results demonstrate that the proposed system enforces access control regulations.
Resilience of proposed model was demonstrated through three categories of attack simulation. First, attribute inference attack failed to achieve meaningful success. Table 3 shows the results that the classifiers trained on dummy attributes performed only at random level accuracy of (~0.25 accuracy); on the other hand, classifiers trained on real attributes performed high accuracy of (~0.665-67 accuracy). Second, policy injection attempts were successfully rejected in all cases as shown in Table 4. Third, reverse mapping attacks produced negligible recoveries as shown in Table 5; only 0.1% of cases succeeded in matching nearest-neighbor. Only 5.6% of real matches are identified in frequency analysis.
Hence, these results demonstrated that the Dummy-ABAC model is effective and enforces access control policies and is resilient to adversarial risks.
5.4. Comparative Discussion
There are no standard benchmark datasets or metrics, so privacy-preserving ABAC methods are hard to compare numerically. An indirect comparison was made by using real attribute targets versus attribute inference attacks of Dummy-ABAC with a more traditional ABAC baseline, with real attributes. As indicated by the results (Table 3), Dummy-ABAC with dummy attributes dropped the accuracy to just below random (~0.25) whereas the regular ABAC with real attributes facilitated high accuracy (~0.65–0.67). Therefore, Dummy-ABAC is significantly more efficient against inference attacks than the traditional one. In addition, we qualitatively compared Dummy-ABAC model with other known approaches in Section 2 Background (Table 1).
6. Conclusions and Future Work
This study proposes and develops a special privacy-protection access control model called Dummy-ABAC. This approach enhances the user’s privacy in the cloud by providing an obfuscation method to mask the user’s real features using random dummy features. Real attributes remain in the local database, and dummy attributes are transmitted and evaluated in the cloud. Once the policy checks in the cloud are complete, authentic features are recursively recovered by the user using secure, token-based mapping technology. Python, SQLAlchemy for ORM, Azure SQL for cloud-side storage, and RESTful APIs for communication between local and cloud components were used in the implementation of the model. The Azure App Service was used to host the policies, and the Faker library in Python was used to create randomized dummy characteristics.
The experimental evaluation demonstrated that the proposed system is effective in enforcing access control policies and is resilient to various security risks, including attribute inference attacks, reverse mapping attacks, and policy injection attacks. The performance-to-privacy-preservation ratio of the model confirms its suitability for application in actual cloud-based settings, where user privacy is a top priority.
In this study, we used classical ML models (Decision Tree and Random Forest) to evaluate security threats. These models were selected because these are interpretable, perform optimally, and deal with moderately sized datasets (~1000 records). Neural networks (particularly deep learning models) may reveal more complicated relationships between dummy and real attributes on very large datasets and provide more accuracy. Although they also possess certain weaknesses, as they require more data to prevent overfitting, they are computationally more complex to train and infer, and they are not as explainable as classical models. For these reasons, neural networks were not used in this study. However, it would be interesting to consider their potential in the future to simulate an attack and instruct policy makers.
We assume that the local machine environment is secure and safe. However, if the local machine database is compromised, real attributes and mapping tokens would be revealed. To cope with this issue, mapping tokens can be secured with encryption technique. However, in this study, we did not use any encryption technique on local machine, which can be considered as a limitation or a future enhancement of Dummy-ABAC model. On the other hand, database-level-encryption techniques (e.g., AES at rest) can be applied to local database or multifactor authentication techniques for administrators can also be applied to further strengthen the security of Dummy-ABAC model in local environment.
In the future, the Dummy-ABAC model can be improved to allow real-time policy adaptation based on threat intelligence and contextual variables. The ability of the system to absorb and eliminate novel attack vectors can also be enhanced by including novel attack anomaly detection techniques based on machine learning.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/computers14100420/s1. The following supplementary materials are provided to support reproducibility of the experiments: real_1000_synthetic.csv—synthetic dataset of 1000 real user attributes (roles, departments, ages, genders, specializations, and clearance levels). dummy_from_app_1000.csv—corresponding dummy attributes generated through the Dummy-ABAC model for the same 1000 users. inference.py—script to reproduce attribute inference attack experiments using Decision Tree and Random Forest classifiers. reverse_mapping.py—script to simulate reverse-mapping/linkage attacks, including frequency analysis, nearest-neighbor linkage, and supervised classifiers. policy_injection.py—script to simulate policy-injection attacks with schema validation and privilege escalation checks. classifier_summaries_clean.csv—summary of classifier results (accuracy, precision, recall, F1) for real attributes, dummy attributes, and mapping tests. reverse_mapping_results.json—summary results of reverse-mapping experiments. policy_injection_results.json—summary results of policy injection experiments.
Author Contributions
Conceptualization, B.M.; methodology, F.A.A.; software, I.M.; validation, U.R.; formal analysis, F.A.A.; investigation, B.M. and M.N.; resources, M.N.; writing—original draft preparation, B.M.; writing—review and editing, I.M. and F.A.A.; visualization, M.N.; supervision, I.M. and F.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are not publicly available due to privacy restrictions but can be provided by the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ABAC | Attribute-Based Access Control |
| DAC | Discretionary Access Control |
| RBAC | Role-Based Access Control |
| MAC | Mandatory Access Control |
| MC-ABAC | Multi Cloud Attribute-Based Access Control |
References
- Microsoft Azure. Azure Cloud Computing Services. Available online: http://azure.microsoft.com (accessed on 15 July 2025).
- Yang, P.; Xiong, N.; Ren, J. Data Security and Privacy Protection for Cloud Storage: A Survey. IEEE Access 2020, 8, 131723–131740. [Google Scholar] [CrossRef]
- Theodoropoulos, T.; Rosa, L.; Benzaid, C.; Gray, P.; Marin, E.; Makris, A.; Cordeiro, L.; Diego, F.; Sorokin, P.; Di Girolamo, M. Security in Cloud-Native Services: A Survey. J. Cybersecur. Priv. 2023, 3, 758–793. [Google Scholar] [CrossRef]
- Golightly, L.; Modesti, P.; Garcia, R.; Chang, V. Securing Distributed Systems: A Survey on Access Control Techniques for Cloud, Blockchain, IoT, and SDN. Cybern. Appl. 2023, 1, 100015. [Google Scholar] [CrossRef]
- Karataş, G.; Akbulut, A. Survey on Access Control Mechanisms in Cloud Computing. J. Cyber Secur. Mobil. 2018, 7, 1–36. [Google Scholar] [CrossRef]
- Farhadighalati, N.; Estrada Jimenez, L.A.; Nikghadam Hojjati, S.; Barata, J. A Systematic Review of Access Control Models: Background, Existing Research, and Challenges. IEEE Access 2025, 11, 17777–17806. [Google Scholar] [CrossRef]
- Shan, L.; Zhou, H.; Hong, D.; Dong, Q.; Wang, Y.; Song, S. Application of Access Control Model for Confidential Data. Procedia Comput. Sci. 2021, 192, 3865–3874. [Google Scholar] [CrossRef]
- Jin, G.; Wang, D.; Yang, D.; Hong, D.; Dong, Q.; Wang, Y. Role and Object Domain-Based Access Control Model for Graduate Education Information System. Procedia Comput. Sci. 2020, 176, 1241–1250. [Google Scholar] [CrossRef]
- Cobrado, U.N.; Sharief, S.; Regahal, N.G.; Zepka, E.; Mamauag, M.; Velasco, L.C. Access Control Solutions in Electronic Health Record Systems: A Systematic Review. Inform. Med. Unlocked 2024, 49, 101552. [Google Scholar] [CrossRef]
- Hu, V.C.; Ferraiolo, D.; Kuhn, R. Guide to Attribute-Based Access Control (ABAC): Definition and Considerations. NIST Spec. Publ. 2019, 800–162, 1–71. [Google Scholar] [CrossRef]
- Bello, S.A.; Oyedele, L.O.; Akinade, O.O.; Bilal, M.; Delgado, J.M.D.; Akanbi, L.A.; Ajayi, A.O.; Owolabi, H.A. Cloud Computing in the Construction Industry: Use Cases, Benefits, and Challenges. Autom. Constr. 2020, 122, 103441. [Google Scholar] [CrossRef]
- Rai, B.K. Patient-Controlled Mechanism Using Pseudonymization Technique for Ensuring the Security and Privacy of Electronic Health Records. Int. J. Reliab. Qual. E-Healthc. 2022, 11, 1–15. [Google Scholar] [CrossRef]
- Varanda, A.; Santos, L.; Costa, R.L.C.; Oliveira, A.; Rabadão, C. Log Pseudonymization: Privacy Maintenance in Practice. J. Inf. Secur. Appl. 2021, 63, 103021. [Google Scholar] [CrossRef]
- Andrew, J.; Eunice, R.J.; Karthikeyan, J. An Anonymization-Based Privacy-Preserving Data Collection Protocol for Digital Health Data. Front. Public Health 2023, 11, 1125011. [Google Scholar] [CrossRef]
- Goncalves, A.; Ray, P.; Soper, B.; Stevens, J.; Coyle, L.; Sales, A.P. Generation and Evaluation of Synthetic Patient Data. BMC Med. Res. Methodol. 2020, 20, 108. [Google Scholar] [CrossRef]
- Jordon, J.; Yoon, J.; van der Schaar, M. PATE-GAN: Generating Synthetic Data with Differential Privacy Guarantees. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ghorbel, A.; Ghorbel, M.; Jmaiel, M. Accountable Privacy Preserving Attribute-Based Access Control for Cloud Services Enforced Using Blockchain. Int. J. Inf. Secur. 2022, 21, 489–508. [Google Scholar] [CrossRef]
- Chandra, A. Privacy-Preserving Data Sharing in Cloud Computing Environments. Eduzone Int. Peer Rev. Multidiscip. J. 2024, 13, 104–111. [Google Scholar]
- Chaturvedi, G.K.; Shirole, M. ABAC-PA2: Attribute-Based Access Control Model with Privacy-Aware Anonymous Access. Procedia Comput. Sci. 2024, 237, 147–154. [Google Scholar] [CrossRef]
- Madani, M.A.; Kerkri, A.; Aissaoui, M. MC-ABAC: An ABAC-Based Model for Collaboration in Multi-Cloud Environment. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 1182–1190. [Google Scholar] [CrossRef]
- Kerl, M.; Bodin, U.; Schelén, O. Privacy-Preserving Attribute-Based Access Control Using Homomorphic Encryption. Cybern. 2025, 8, 5. [Google Scholar] [CrossRef]
- Abdelkrim, B. Secure EHR Access in the Cloud: An Alloy-Based Formalization of ABAC in Collaborative and Non-Collaborative Models. Stud. Eng. Exact Sci. 2024, 5, e11282. [Google Scholar] [CrossRef]
- Xu, Y.; Zeng, Q.; Wang, G.; Zhang, C.; Ren, J.; Zhang, Y. A Privacy-Preserving Attribute-Based Access Control Scheme. In Proceedings of the International Conference on Security, Privacy, and Anonymity in Computation, Communication, and Storage (SpaCCS 2018), Melbourne, Australia, 11–13 December 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; Volume 11342, pp. 361–370. [Google Scholar] [CrossRef]
- Truong, A.T. A Comprehensive Framework Integrating Attribute-Based Access Control and Privacy Protection Models. In Proceedings of the International Conference on Advances in Engineering Research and Application (ICERA 2021), Bhubaneswar, India, 12 January 2022; pp. 42–58. [Google Scholar] [CrossRef]
- Routray, K.; Bera, P. Privacy Preserving Spatio-Temporal Attribute-Based Encryption for Cloud Applications. Clust. Comput. 2025, 28, 34. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).