1. Introduction
With the arrival of new servers in the world of database technology, it is necessary to implement search engine optimization to improve the process time and resource consumption. It is essential to understand how AI can reduce costs and consumption. In recent years, cloud computing development has focused on the explosive growth of non-structured data, which leads to cloud storage and control loss risks, including privacy leakage [
1], among others. The growth of mobile devices has promoted the development of apps that rely on external loading services. These limitations often lead to latency issues in service functions, requiring multi-server cooperation through pervasive edge computing, which aids data migration in highly dynamic mobile networks [
2].
Data stored on these devices cannot meet security requirements independently. Blockchain technology has been applied alongside storage and connection technology within an integrated warehouse model [
3]. Some applications involve transferring data, for example, from a mobile device to a vehicle hub or a server, which can merge through a fixed measure—a technique known as
superposing data [
4]. Similarly,
cloud computing, and the
internet of things emerged in the 21st century as communication technology platforms. Their adoption has enabled improved service levels and systematic, continuous innovation [
5]. These factors underscore the need to enhance query speed and reduce the percentage of database usage.
In terms of security, rapid network development has increased the exposure of databases, requiring SQL instructions to be rebuilt and recompiled. However, existing audit products need more precise analysis [
6]. One primary technique violating database security is
SQL injection, which involves using DDL commands (like
DROP TABLE), DML commands (like
DELETE FROM), and DCL commands (like
REVOKE) to delete data or to block everyday activities. Using a tow environment to retrieve the universal resource locator (URL), associated with the SQL injections’ origin, has proved to be effective for the detection of websites subject to vulnerabilities [
7].
Data are critical; their leak or corruption can undermine confidence and lead to the collapse of any enterprise. Concerns about cloud computing’s lack of security are significant because this lack of security can fundamentally affect a business [
8]. Unique aspects, such as content perception, real-time computing, and parallel processing, introduce new challenges to security and privacy, creating paradigms in mobile and fog computing [
9]. For example, vehicle network security (a vehicular ad hoc network) is affected by message identity validation and reliability when data are shared between various units. A security and storage system based on corporate blockchain has been utilized [
10]. Increasing the computing resource speed requires improving the algorithm design for those who manage data queries.
The database query system is currently supported by a standard SQL model that has maintained the same functional design since the emergence of PL/SQL. Research and development centers have focused on computing capabilities, encryption, and security. However, AI tools like Generative AI and ML models, such as artificial neural networks (ANNs), have yet to receive similar investment.
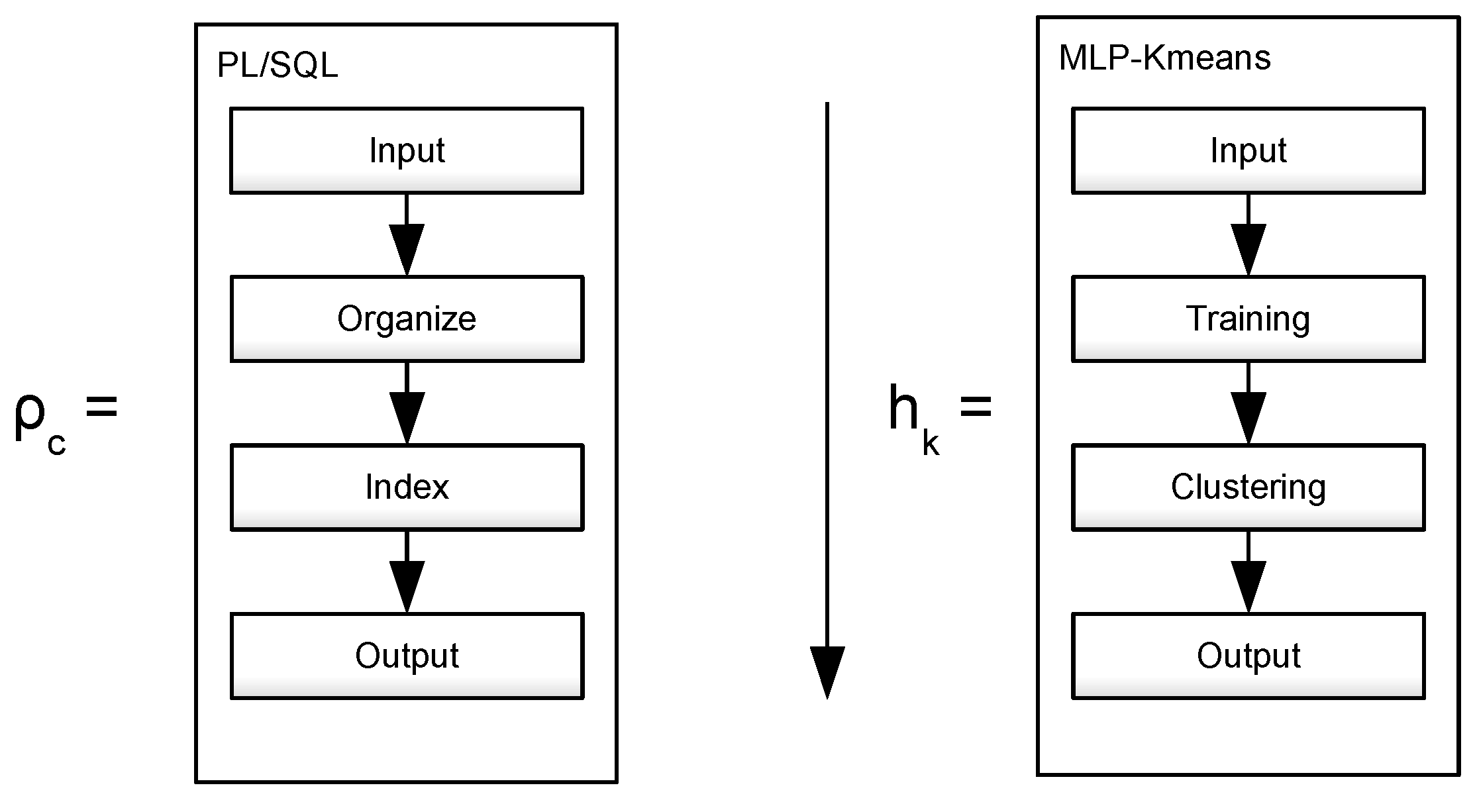
This work aimed to present a methodology integrating an MLP with Kmeans and compare it with traditional PL/SQL tools. This approach aims to improve the database response time, and this work outlines future advantages of using already trained data. The research question posed is the following: What is the effect of an MLP-Kmeans classification model on data servers during search engine execution compared to PL/SQL deterministic models? This methodology will be presented in three parts: 1. Establishing the PL/SQL model for query production; 2. Establishing the MLP-Kmeans model, including parameterization; and 3. Developing a comparative scheme between both models.
3. Materials and Methods
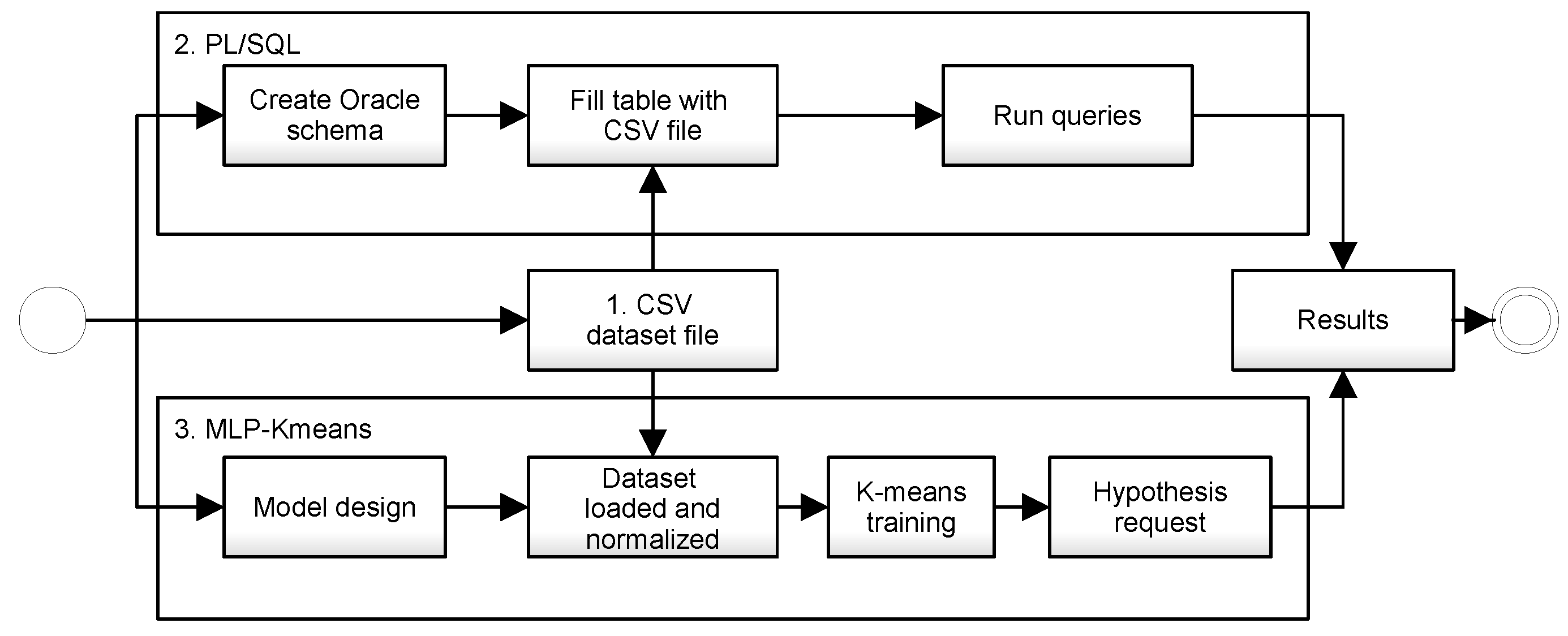
This research was divided into three stages: the first one produces random data and stores it on a comma-separated value (CSV) file; the second one builds a schema on an standard Oracle
® database instance, where PL/SQL queries will be executed; and the third one constructs the MLP-Kmeans model, where training data will be used for a query, as described in
Figure 2. On the PL/SQL side, queries were made through database indexation. On the MLP-Kmeans side, after training the dataset, the query, now termed a hypothesis, performed clustering operations.
3.1. Database and Schema Creation
The dataset simulates retail business operations and was created randomly, resulting in a CSV file with 306,849 records. The dataset includes the following fields:
line: corresponds to the product line and is an Integer type.
idproduct: corresponds to the product ID number and is an Integer type.
amount: corresponds to the quantity sold and is a Double type.
All fields are numeric. Classification and clustering could be applied on fields line and idproduct.
In the sophisticated importation from text to SQL models (
text-to-SQL), a binding a schema is considered easy, with errors mainly attributed to noise [
36]. Systems that interpret human expressions with SQL instructions leverage exact lexical synchronization methods between keywords and schema elements. These methods face challenges in scenarios such as synonym substitution, where differences arise during synchronization [
37]. To address this problem, schema preprocessing for tables and method redesign, consisting of schema expansion and schema pruning, have been incorporated [
38].
3.2. PL/SQL Modeling
According to [
39], database schema structures are sometimes dismissed either because they are too plain or because they are expected to be analyzed during the training or testing stages. For this work, a schema was built within an Oracle
® instance using DDL instructions:
CREATE PROFILE..., CREATE TABLESPACE...and CREATE USER...Data were imported from the CSV file into a table with the same name (ROWDATA) and identical data configuration. A test table was created from the same source by selecting one out of every 100 records, resulting in a table with 3069 records called ROWDATA_TEST.
PL/SQL Query Process
An essential part of software development is understanding how time is spent during program execution. However, more training is needed in using profilers, which often show bugs. These issues can be addressed by establishing a metaphorical relationship, where a bridge is built between statistical coverage and existing mutations [
40]. Data profiling ranges from simple additions to complex statistics, aiding in understanding data. From a scientific perspective, it is crucial to know the data profile for manipulation and to update it according to new data schemas [
41]. For this work, three queries were defined as follows:
Line query. Request for line, product, and amount columns.
Group query. Request for the sum of amount for each product.
Total query. Request for the sum of all data amount.
3.3. MLP Modeling
Clustering modeling algorithms have been used to elaborate on the three kinds of queries, which, according to [
42], are defined by an input and an output.
3.3.1. Input
The input is defined as a set of elements X and a distance function d as follows: , where is the set of non-negative real numbers, and when it is asymmetric, it satisfies for all subsets x that belong to X. In some cases, it requires a parameter k that determines the number of clusters, and according to the three queries established, we can have (line query), (group query), and (total query).
3.3.2. Output
The output is a domain partition of X where , producing the expression and that for every .
All groupings were taken from the sample
X for each
i cycle corresponding to the cluster defined by
k, where the difference between epochs will produce an empty set. There is a link between clustering and optimal transport, equivalent to a restrained formulation where cluster dimensions are prescribed. This makes sense in a structure where each dataset class portion is known, but there is no information available at the individual level, aiming to establish concordant parameters [
43].
In this work, the algorithm defined in [
44] was used. Its mathematical representation is as follows:
where
is the square sum of errors,
C is a cluster,
is the dataset instance that consists of
N points, and
is the cluster centroid in
k, which is updated for each iteration according to
where
is the total number of points in the
kth cluster.
3.3.3. Hypothesis and Contribution
To address the proposed problem, the following
corollary was derived from the
theorem presented in Equation (
1). For any query or hypothesis
h, the search function
is established as follows:
where
is the hypothesis corresponding to the cluster index
k,
H is the set of all possible hypotheses according to the data availability,
is the square sum of errors such that
k is
, and it exist in the dataset
X, which constitutes the scientific proposition of this research.
3.3.4. Pseudocode
According to the last equation, the theorem’s executable application is set through the centroid closeness for each
k measured using its Euclidean distance and established through the pseudocode of Algorithm 1.
| Algorithm 1 Centroid definition for three dimensions (x,y,z) and its euclidean distance |
|
3.3.5. Parameterization
According to the three hypothesis requested, cluster parameterization is defined as follows:
- 1.
Line query: when each element is a cluster or the size of the cluster is equal to the size of elements.
- 2.
Group query: when each k cluster is the sum of all i clusters with the same requested parameter.
- 3.
Total query: when there is only one cluster.
Under this proposal, 306,850 registers were analyzed with three points, A, B, and C, each one with three coordinates: x, y, and z. Although the algorithm was designed for objects in three dimensional calculations (coordinates), in this case, Euclidean and centroid distances were measured only using the x coordinate, corresponding to the point and data: A (line), B (idproduct), and C (amount). The coordinates y and z remained with their initial 0 value.
3.3.6. Training Using Kmeans
Kmeans is used for data classification into categories or clusters, referred to as k, based on the proximities of the Euclidean distances from their centroids. In this study, the training process began by selecting k values randomly from the dataset. Each record was then assigned to the nearest k, based on the Euclidean distance. After the initial assignment, the centroids of each k were iteratively adjusted over n epochs to achieve the optimal Cartesian position.
3.3.7. Parameters for MLP-Kmeans Model
The MLP architecture is defined by the triplet
, where
V represents the number of layers,
E denotes the boundaries that correspond to the weights, and
is the activation function. With the Kmeans component integrated, the entire model is depicted in
Figure 3.
The connection between the two models was established through the group query hypothesis provided by Kmeans, and the interpretability of the MLP model drives to the amount and categorization of the clusters that will be set for analysis in the Kmeans process. The proposed methodology helps as a hash table estimated to improve the computation and resources to minimize the response time in querying a data base. The layers
V are defined as follows:
is the input layer with 2 neurons, corresponding to the
k values provided by Kmeans.
is the hidden layer with 10 neurons, and
is the output layer with 1 neuron, corresponding to the specific prediction or hypothesis. The value of
corresponds to the
sigmoid function. In this work, each neuron requires 3 input values
, corresponding to the
values. The
inner product <
> is calculated, the activation value is defined, and the weight value is transferred to the successive layers, as illustrated in
Figure 4 and the algorithm pseudocode in Algorithm 2.
| Algorithm 2 Layer definition for MLP model linked with Kmeans model |
Require: Ensure: - 1:
function Loop() - 2:
N← - 3:
for to N do - 4:
- 5:
- 6:
- 7:
end for - 8:
if return - 9:
end function
|
4. Results
The training dataset was rewritten from NoSQL by eliminating unnecessary data, removing columns with non-numeric values, and normalizing the remaining data to standardize different categories and visualize query results. For the MLP-Kmeans model, the design incorporated a clustering perspective with corresponding parameters attached to each aleatory category and hypothesis. Finally, a comparative analysis was conducted between both models to discuss the results and establish conclusions.
4.1. PL/SQL Results
At the end of the research activity, the results obtained for each case are the following.
4.1.1. Line Query
Table 1 displays the query line by line without category definitions. This would be the equivalent in Kmeans to
k = 0, or the lack of
k, showing all data and the total amount of the run-time consumption.
4.1.2. Group or Category Query
Table 2 presents the data grouped by categories (lines), and the count of each
idproduct by line. In Kmeans terms, this is equivalent to a hypothesis
k. The third column shows the sum of the
amount value for each
line and the total process time consumption.
4.1.3. Total Query
When the query is applied for one category without using filters, the total calculation k value is 0, and there is no need to deploy data. The result is the total sum of 306,849 lines in 0.013 s. Group queries are the slowest due to the grouping operation.
4.2. MLP Results
The outcome of the MLP-Kmeans model is presented as follows, starting with the Kmeans analysis.
4.2.1. Line Query
For this query, the parameters were set as and . The result was less than 0.009 s.
4.2.2. Group Query
Table 3 represents the classification of randomly selected categories, with parameters set as
and
. The records (
X values) were grouped according to the Euclidean distance concerning each
k.
From the last table, training consisted of adjusting the centroid to the most efficient point from the Euclidean distance concerning each data centroid of its particular category
k, resulting in
Table 4.
The
Elbow Method was used to find the optimal value of
k, where the sum of the square distance between one cluster and the centroid cluster (within-cluster sum of square, WCSS) was calculated. For comparative reasons,
Figure 5 and
Figure 6 are shown for cases where
and
.
To determine the optimal cluster number, the k value must be selected when distortion or inertia begins to decrease linearly. In
Figure 4, this happens from
, and in
Figure 5, it happens when
.
4.2.3. Total Query
The parameters were established as and .
4.2.4. Summary
In summary, the previous queries defined three hypotheses, and their efficiency relationship is shown in
Table 5. It is important to note that all queries were made after data loading and normalization, causing a 0-time consumption in
line query. Also, the execution was not presented in the compiler console.
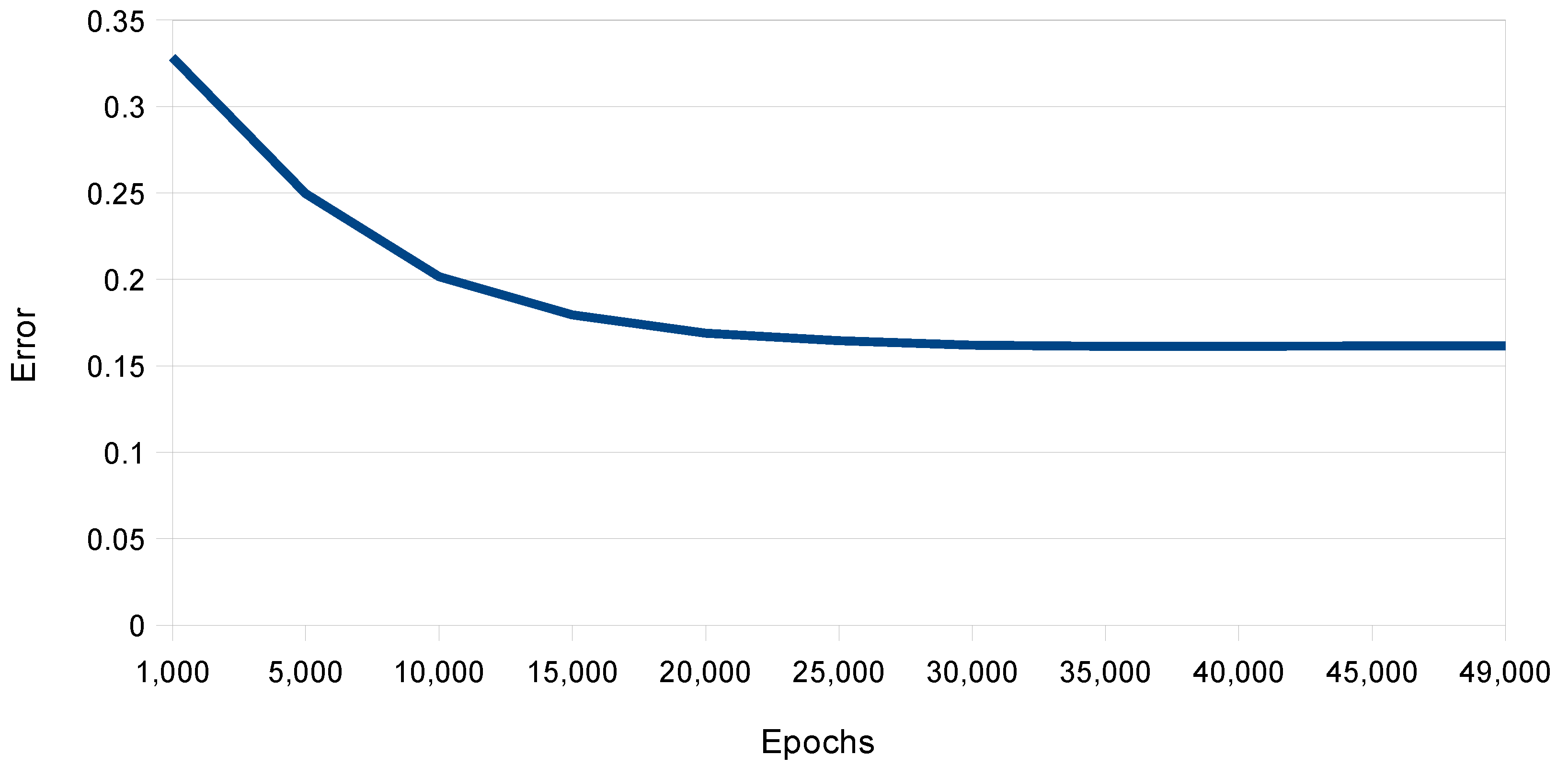
The model was run multiple times with different parameters to enhance the data analysis. The indicators obtained from the model execution after 50,000 epochs were the Mean Absolute Error (MAE) = 0.16, Mean Square Error (MSE) = 0.03, Root Mean Square Error (RMSE) = 0.18,, and Coefficient of Determination (
) = 0.29. The learning curve shown in
Figure 7 indicates a consistent trend from the 20,000 epochs, so extending it further is unnecessary due to the emergence of overfitting.
4.3. Comparative Analysis between PL/SQL and MLP-Kmeans
Once the experimentation was realized, a comparative analysis between the two models was conducted.
Table 6 summarizes the results, indicating the increase in time consumption in the MLP-Kmeans trained model concerning the PL/SQL model.
5. Discussion
In the case of the first hypothesis, the line query where
, it was not necessary to perform training because the number of clusters was the same as the number of data lines, so the data retrieval was immediate. In the case of the group query,
, where
n is the number of clusters selected, the level of training defines the efficiency: time is proportionally direct to the value of
k. In the case of the total query, where
, the data were obtained after grouping some randomly selected centroids. In the end, training consumption is represented by the model’s friction and fatigue: friction for the
k number and fatigue for the
quantity defined in the parameters. Once the model was trained, efficiency depended on the hardware resources.
Table 7 shows some other models used in other research to define the optimal
k value.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}