
Algebraic Zero Error Training Method for Neural Networks Achieving Least Upper Bounds on Neurons and Layers


Abstract
:1. Introduction
2. Related Work
2.1. Approximation Theorems for Single Hidden Layer Networks
2.2. Representation Theorems, Bounds and Construction Methods for Single Hidden Layer Networks
2.3. Approximation and Representation Theorems and Bounds for Networks with More Hidden Layers
2.4. Generalization Theorems and Bounds
3. Construction Method and the Least Upper Bound on Single Hidden Layer Networks
3.1. Constructional Proof-Preliminaries
3.2. Separating Affine Hyperplanes
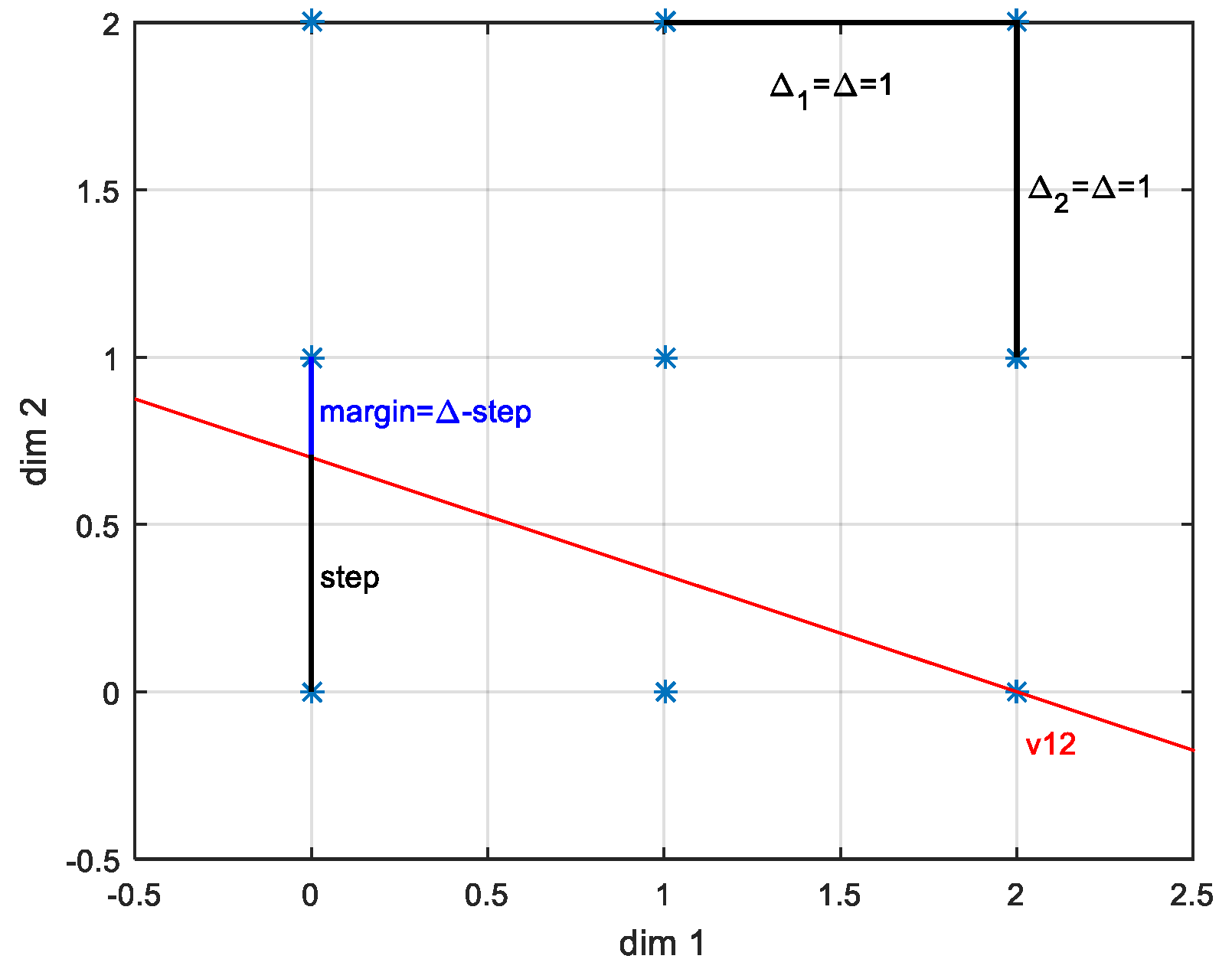
3.2.1. 3D Case
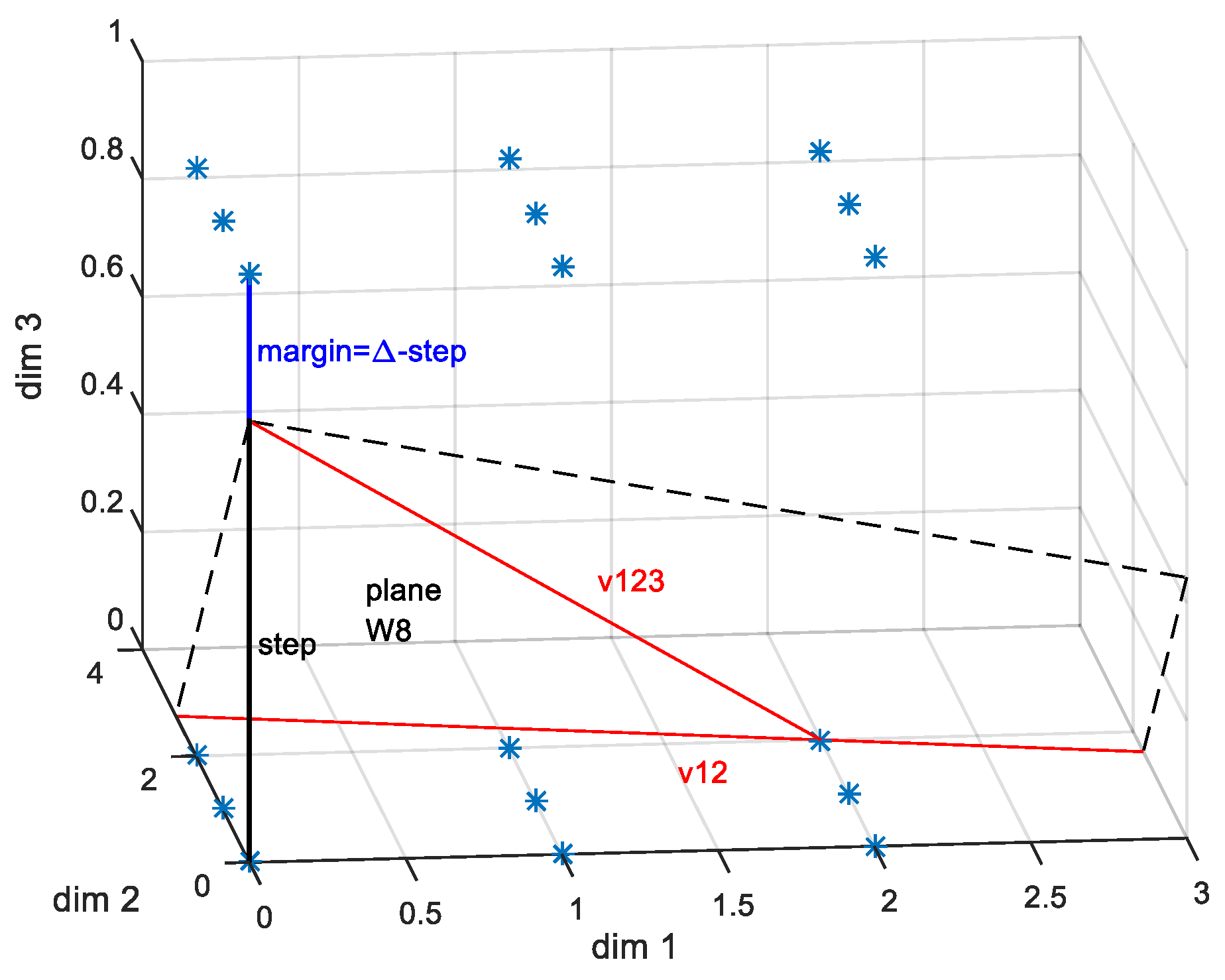
3.2.2. D-Dimensional Case
3.3. Dot-Product Matrix
3.4. Hidden Output Matrix
3.5. Output Neuron Weights and Biases
3.6. Comments and Extensions
4. Results
4.1. Performance of the Proposed Method
4.2. Comparison to Similar Approaches
4.3. Comparison to Back Propagation-Based Approach
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
Appendix C
Appendix D
References
- Regona, M.; Yigitcanlar, T.; Xia, B.; Li, R.Y.M. Opportunities and Adoption Challenges of AI in the Construction Industry: A PRISMA Review. J. Open Innov. Technol. Mark. Complex. 2022, 8, 45. [Google Scholar] [CrossRef]
- Lötsch, J.; Kringel, D.; Ultsch, A. Explainable Artificial Intelligence (XAI) in Biomedicine: Making AI Decisions Trustworthy for Physicians and Patients. BioMedInformatics 2022, 2, 1–17. [Google Scholar] [CrossRef]
- Di Sotto, S.; Viviani, M. Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach. Int. J. Environ. Res. Public Health 2022, 19, 2173. [Google Scholar] [CrossRef] [PubMed]
- Kastrati, M.; Biba, M. A State-Of-The-Art Survey on Deep Learning Methods and Applications. Int. J. Comput. Sci. Inf. Secur. 2021, 19, 53–63. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Neurocomputing; Addison—Wesley: Boston, MA, USA, 1990; ISBN 0201093553. [Google Scholar]
- Haykin, S. Neural Network—A Comprehensive Foundation; Mamillan College Publishing Company: New York, NY, USA, 1994. [Google Scholar]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning From Noisy Labels With Deep Neural Networks: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Magnitskii, N.A. Some New Approaches to the Construction and Learning of Artificial Neural Networks. Comput. Math. Model. 2001, 12, 293–304. [Google Scholar] [CrossRef]
- Guliyev, N.J.; Ismailov, V.E. A single Hidden layer Feedforward Network with only One Neuron in the Hidden Layer can Approximate any Univariate function. Neural Comput. 2016, 28, 1289–1304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, S.-C.; Huang, Y.-F. Bounds on the number of hidden neurons in multilayer perceptrons. IEEE Trans. Neural Netw. 1991, 2, 47–55. [Google Scholar] [CrossRef]
- Huang, G.B.; Babri, H.A. Upper bounds on the number of hidden neurons in feedforward networks with arbitrary bounded nonlinear activation functions. IEEE Trans. Neural Netw. 1998, 9, 224–229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, G.; Yuan, Y. On Theoretical Analysis of Single Hidden Layer Feedforward Neural Networks with Relu Activations. In Proceedings of the 34th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Jinzhou, China, 6–8 June 2019; pp. 706–709. [Google Scholar] [CrossRef]
- Ferrari, S.; Stengel, R.F. Smooth function approximation using neural networks. IEEE Trans. Neural Netw. 2005, 16, 24–38. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-B. Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans. Neural Netw. 2003, 14, 274–281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Ronen, E.; Shamir, O. The Power of Depth for Feedforward Neural Networks. In Proceedings of the 29th Conference on Learning Theory, COLT 2016, New York, NY, USA, 23–26 June 2016; pp. 907–940. [Google Scholar]
- Bölcskei, H.; Grohs, P.; Kutyniok, G.; Petersen, P. Optimal Approximation with Sparsely Connected Deep Neural Networks. SIAM J. Math. Data Sci. 2019, 1, 8–45. [Google Scholar] [CrossRef] [Green Version]
- Kenta, I. Expressive Numbers of Two or More Hidden Layer ReLU Neural Networks. Int. J. Netw. Comput. 2020, 10, 293–307. [Google Scholar]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. 1999, 10, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harvey, N.; Liaw, C.; Mehrabian, A. Nearly-tight VC-dimension bounds for piecewise linear neural networks. In Proceedings of the 2017 Conference on Learning Theory in Proceedings of Machine Learning Research, Amsterdam, The Netherlands, 7–10 July 2017; pp. 1064–1068. [Google Scholar]
- Golowich, N.; Rakhlin, A.; Shamir, O. Size-Independent Sample Complexity of Neural Networks. In Proceedings of the 31st Conference on Learning Theory. In Proceedings of Machine Learning Research, Stockholm, Sweden, 6–9 July 2018; pp. 297–299. [Google Scholar]
- Marin, I.; Kuzmanic Skelin, A.; Grujic, T. Empirical Evaluation of the Effect of Optimization and Regularization Techniques on the Generalization Performance of Deep Convolutional Neural Network. Appl. Sci. 2020, 10, 7817. [Google Scholar] [CrossRef]
- Meyer, C.D. Matrix Analysis and Applied Linear Algebra; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar] [CrossRef]
- Python 3.6 Documentation. Available online: https://docs.python.org/3.6/ (accessed on 9 September 2021).
- Kahan, W. Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic. Available online: https://people.eecs.berkeley.edu/~wkahan/ieee754status/IEEE754.PDF (accessed on 1 September 2021).


{kind=link}
{kind=link}
| Dimension | Input Sample Bounding Space Size | Number of Grid Points | Activation Function | Number of Trainable Parameters | Ratio of Found Nets (0 Classification Error) [%] | MSE |
|---|---|---|---|---|---|---|
| 2 | 1 × 2 | ≈2 × 1012 | Heaviside | 6000 | 100 | 0.0 |
| 50 | 1 × 2 × 1 × … × 1 | ≈2 × 10300 | Heaviside | 6048 | 100 | 0.0 |
| 60 | 1 × 2 × 1 × … × 1 | ≈2 × 10360 | Heaviside | 6058 | 0 | - |
| 2 | 1 × 2 | ≈2 × 1012 | Relu | 6000 | 100 | 2.37 × 10−18 |
| 50 | 1 × 2 × 1 × … × 1 | ≈2 × 10300 | Relu | 6048 | 100 | 1.59 × 10−17 |
| 60 | 1 × 2 × 1 × … × 1 | ≈2 × 10360 | Relu | 6058 | 0 | - |
| 2 | 1 × 2 | ≈2 × 1012 | tanh, α = 1 | 6000 | 100 | 4.27 × 10−28 |
| 50 | 1 × 2 × 1 × … × 1 | ≈2 × 10300 | tanh, α = 1 | 6048 | 100 | 0.0 |
| 60 | 1 × 2 × 1 × … × 1 | ≈2 × 10360 | tanh, α = 1 | 6058 | 0 | - |
| Methods | Dimension | Number of Samples | Number of Hidden Neurons | Number of Trainable Parameters | Ratio of Found Nets (Approx. Error ≤10−9) (%) | Average Training Time (ms) | MSE |
|---|---|---|---|---|---|---|---|
| proposed | 30 | 100 | 99 | 228 | 100 | 1 | 3.2 × 10−31 |
| [11] | 30 | 100 | 99 | 3169 | 100 | 6 | 1.2 × 10−28 |
| [12] | 30 | 100 | 100 | 3070 | 100 | 2.5 | 1.3 × 10−29 |
| [16] | 30 | 100 | 100 | 100 3200 * | 100 | 5 | 1.25 × 10−21 |
| [13] revised | 30 | 100 | 100 | 200 | 93 | 1 | 1.67 × 10−21 |
| proposed | 2 | 3000 | 2999 | 6000 | 100 | 210 | 1.2 × 10−28 |
| [11] | 2 | 3000 | 2999 | 11,997 | 0 | - | - |
| [12] | 2 | 3000 | 3000 | 11,998 | 100 | 400 | 3.8 × 10−27 |
| [16] | 2 | 3000 | 3000 | 3000 9000 * | 0 | - | - |
| [13] revised | 2 | 3000 | 3000 | 6000 | 0 | - | - |
| Neurons in Hidden Layers | Dimension | Samples | Free Parameters | Found Nets (Zero Classification Error) (%) | Average Training Time (Zero Classification Error) (ms) | Found Nets (Approx. Error ≤10−3) (%) | Average Training Time (Approx. Error ≤10−3) (ms) |
|---|---|---|---|---|---|---|---|
| [100] | 30 | 100 | 3201 | 75 | 587 | 0 | - * |
| [1000] | 30 | 100 | 32,001 | 85 | 408 | 0 | - |
| [3000] | 30 | 100 | 96,001 | 95 | 446 | 0 | - |
| [5000] | 30 | 100 | 160,001 | 90 | 497 | 0 | - |
| [100, 10] | 30 | 100 | 4121 | 75 | 603 | 0 | - |
| [500, 10] | 30 | 100 | 20,501 | 85 | 496 | 0 | - |
| [1000, 10] | 30 | 100 | 41,021 | 80 | 467 | 0 | - |
| [3000] | 2 | 3000 | 12,001 | 0 | - | 0 | - |
| [6000] | 2 | 3000 | 24,001 | 0 | - | 0 | - |
| [10,000] | 2 | 3000 | 40,001 | 0 | - | 0 | - |
| [3000, 100] | 2 | 3000 | ≈3 × 105 | 0 | - | 0 | - |
| [6000, 100] | 2 | 3000 | ≈54 × 105 | 0 | - | 0 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kacur, J. Algebraic Zero Error Training Method for Neural Networks Achieving Least Upper Bounds on Neurons and Layers. Computers 2022, 11, 74. https://doi.org/10.3390/computers11050074
Kacur J. Algebraic Zero Error Training Method for Neural Networks Achieving Least Upper Bounds on Neurons and Layers. Computers. 2022; 11(5):74. https://doi.org/10.3390/computers11050074
Chicago/Turabian StyleKacur, Juraj. 2022. "Algebraic Zero Error Training Method for Neural Networks Achieving Least Upper Bounds on Neurons and Layers" Computers 11, no. 5: 74. https://doi.org/10.3390/computers11050074
APA StyleKacur, J. (2022). Algebraic Zero Error Training Method for Neural Networks Achieving Least Upper Bounds on Neurons and Layers. Computers, 11(5), 74. https://doi.org/10.3390/computers11050074