1. Introduction
For several decades, electric energy has been essential for living, and it is a basic utility that governments must provide for their people. Indeed, power utilities or electricity providers must procure and supply electric energy to consumers sufficiently, safely, reliably, and continuously [
1]. In order to achieve all those factors previously mentioned, forecasting electric energy demand is necessary for utilities. Forecasting is the famous well-known method that learns the historical data and then predicts the expected data [
2]. Many works have used various forecasting models [
3], such as the dynamic regression model [
4], ARIMA model [
5], exponential smoothing model [
6], neural network model [
7], and so on, to generate the trend of future forecasted data and select the best model that is evaluated from its performance and accuracy.
Many researchers have proposed machine learning models to increase the accuracy of electric energy demand forecast. Gholamreza Memarzadeh and Farshid Keynia [
8] proposed the new optimal long short-term memory model to predict electric energy demand and price based on Pennsylvania, New Jersey, and Maryland databases. Zongying Liu et al. [
9] proposed the novel adaptive method applied with the kernel ELM model called the error-output recurrent two-layer ELM and used the quantum particle swarm optimization to increase the forecast accuracy of the time-series predicted demand. Mikel Larrea et al. [
10] proposed the particle swarm optimization algorithm to optimize weight parameters in the ensemble ELM model for forecasting the Spanish time-series electric consumption. Yanhua Chen et al. [
11] proposed the empirical mode decomposition to decompose the time-series forecasting data and mixed kernel with radial basis function and UKF to implement on the ELM model. The New South Wales, Victoria, and Queensland electric load databases were used for testing the proposed model. Qifang Chen et al. [
12] proposed the novel deep learning model by using the stacked auto-encoder framework applied to the ELM model to improve the capabilities of forecasting. Moreover, the raw time-series data were analyzed by using the empirical mode decomposition method. Shafiul Hasan Rafi et al. [
13] proposed the hybrid methodology of deep learning by integrating the convolutional neural network and long short-term memory to improve the forecast accuracy for forecasting the Bangladesh power system dataset. Muhammad Sajjad et al. [
14] proposed the hybrid convolutional neural network and gated recurrent units to maximize forecast performance for appliance energy demand and individual household electric power demand. Yusha Hu et al. [
15] proposed the optimization methods consisting of the genetic algorithm and particle swarm optimization applied to the backpropagation model to forecast the electric demand dataset. Mohammad-Rasool Kazemzadeh et al. [
16] proposed the novel hybrid optimization method, which combines the particle swarm optimization with a machine learning model, to forecast the long-term electricity peak demand and electric energy demand. Ghulam Hafeez et al. [
17] proposed the novel hybrid model of modified mutual information, factored condition restricted Boltzmann machine, and genetic wind driven optimization to forecast the hourly load data of FE, Dayton, and EKPC USA power grids.
From the aforementioned works, one of the machine learning models that can learn rapidly and provide acceptable results is the Extreme Learning Machine (ELM) [
18]. The concept of this model is to learn the data without iterative tuning in the hidden layer phase and then calculate the output weight parameter with a pseudo-inverse matrix called the Moore–Penrose inverse matrix [
19] in the output layer phase. However, the disadvantage of the ELM model [
20,
21,
22] is that it uses the standard randomization of the input weight to compute in the input layer phase that can cause overfitting and has a high probability to fall into local optima.
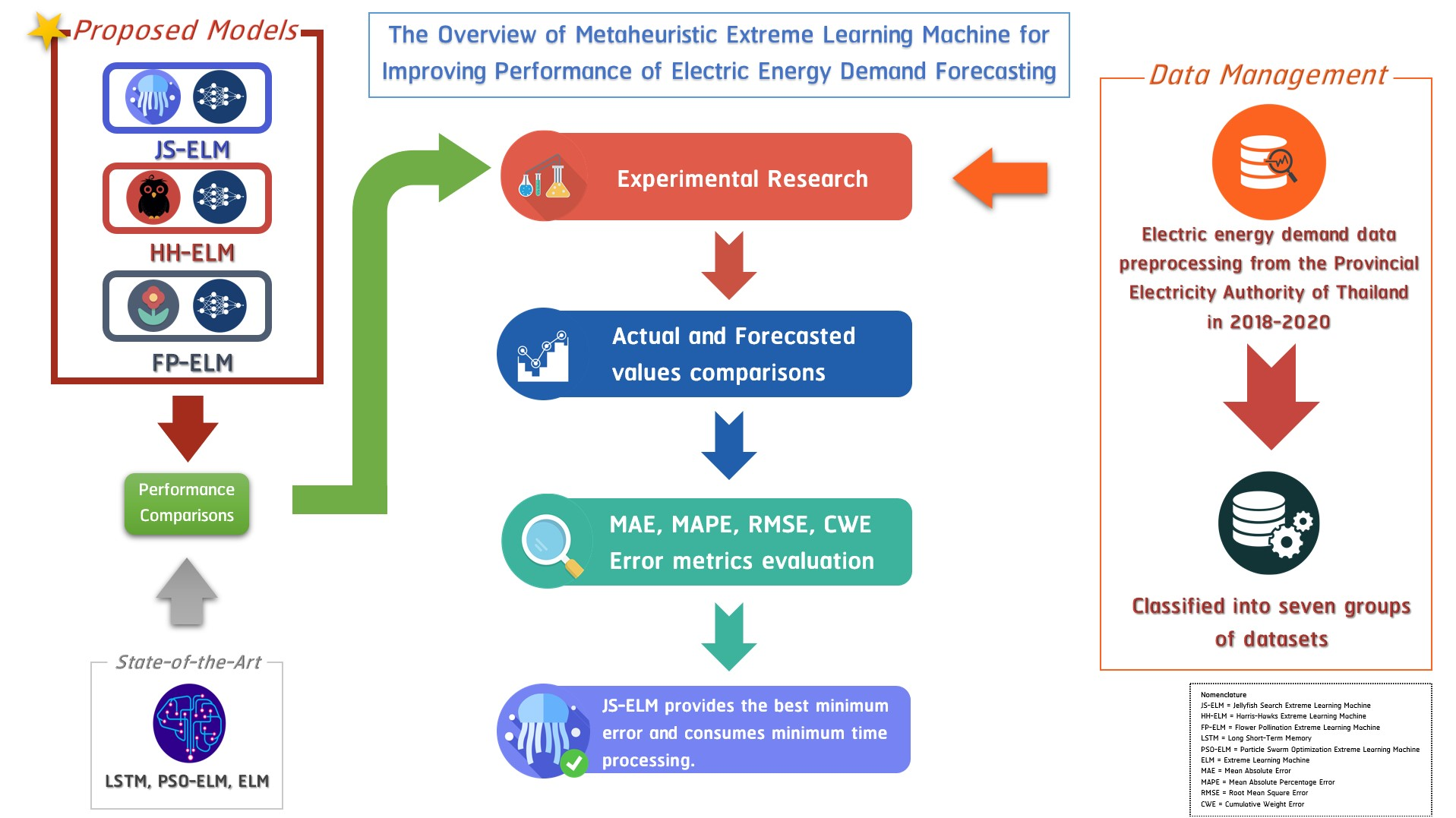
To improve the performance of the electric energy demand forecasting model, this paper proposes a method to develop the ELM model by using metaheuristic optimization algorithms to adjust the appropriate result of the output weight, which can reduce the cause of overfitting. The Jellyfish Search Optimization (JSO) [
23], the Harris Hawk Optimization (HHO) [
24], and the Flower Pollination Algorithm (FPA) [
25] were selected for adjusting the output weight and reducing the cause of overfitting as mentioned before. The performances of these three proposed forecasting models were evaluated via an experiment that used the seven groups of the electric energy demand datasets in Thailand. The main contributions of this work can be summarized as follows:
This paper presents the novel hybrid method combining the ELM and metaheuristic optimization consisting of the JSO, the HHO, and the FPA to forecast the electric energy demand. Furthermore, the proposed model is investigated with the real-life dataset of electric energy demand to challenge the forecasting performance in terms of forecasting accuracy and stability.
To increase the robustness of forecasting in the training and testing processes of the traditional ELM model, the randomization process of the initial weight parameter in the ELM is developed to obtain the optimal weight parameter. The proposed metaheuristic optimization algorithms are not complex to implement, leading to less processing time, low population usage, and fast convergence to the optimal solution. In addition, these three optimization methods can reduce the number of hidden nodes of the ELM model.
Finally, the presented metaheuristic algorithms (the JSO, the HHO, and the FPA) have the characteristic of being self-adaptive to tune the weight parameter of the ELM without trapping in the local optima. This characteristic can increase the forecasting stability of the traditional model. Furthermore, this method can reduce the cause of sensitivity to outliers, which leads the forecasting process to be more stable, and the standard deviation was used to calculate the forecasting stability of the proposed models.
This paper is organized as follows.
Section 2 indicates the basic principles of the algorithms used in this paper.
Section 3 indicates the methodology of the datasets’ preparation and the proposed models.
Section 4 indicates the overall experimental results using the datasets and the proposed models in
Section 3. Lastly, the conclusion and future work of this work are described in
Section 5.
2. Basic Principles
This section describes the basic principles and materials used in this research, which consists of forecasting methodology, ELM, JSO, HHO, FPA, a summary of selected metaheuristic optimization, and related works as shown below.
2.1. Forecasting Methodology
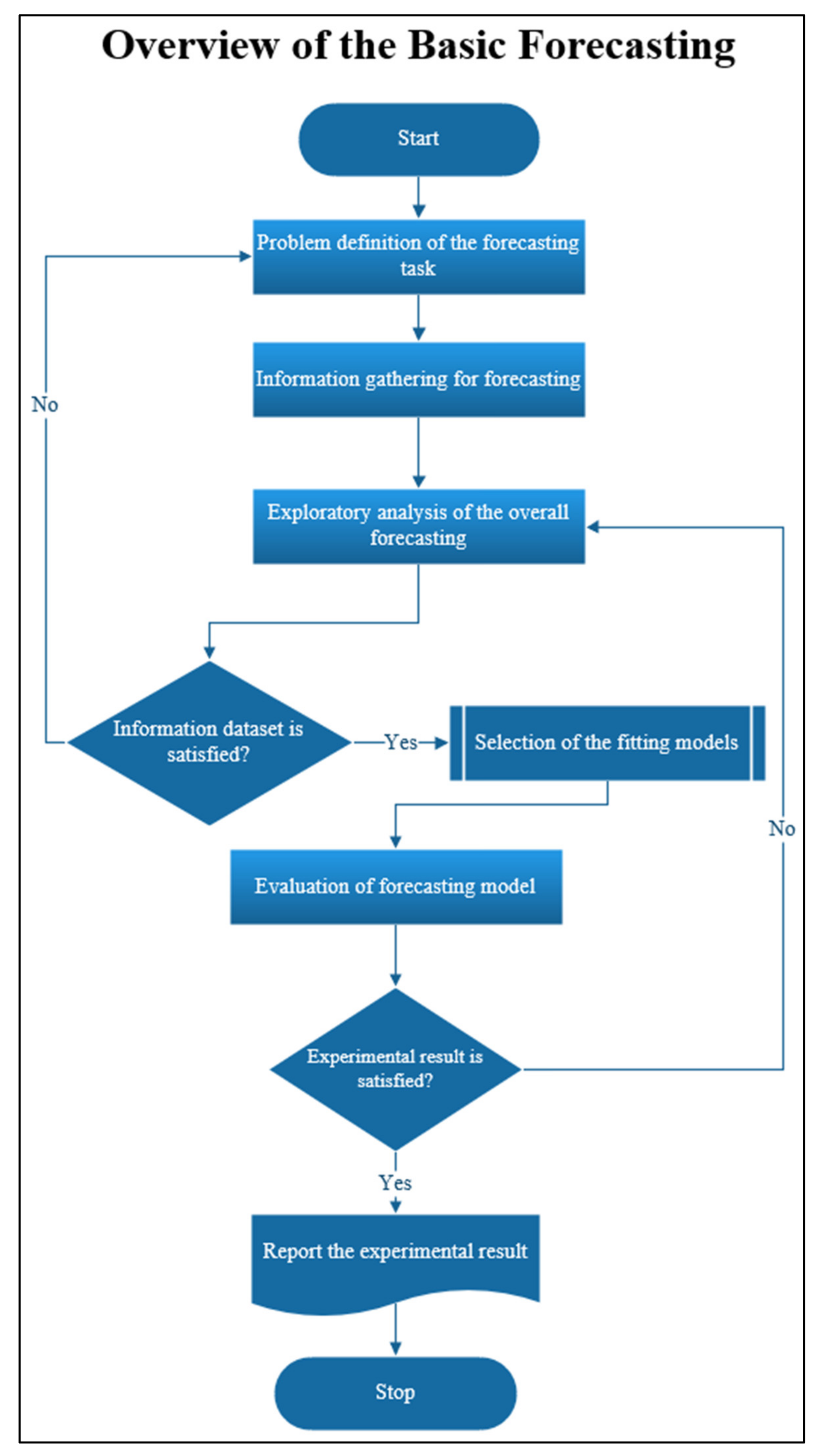
The basic methodology for forecasting (
Figure 1) can be described in five steps [
26] as follows. Firstly, the forecasting task problem is defined; the aim of this step is to study the problem and factors that can affect the outcome of forecasting. Secondly, the information is gathered for forecasting; the aim of this step is to collect and analyze the significant data needed for forecasting and finding the expected result [
27]. Thirdly, the exploratory analysis of the overall forecasting is conducted; the aim of this step is to actively analyze the consistency of data to so that they can be implement without noise or elements missing in the dataset such as the imbalance or inconsistency of data [
28], missing values of data [
29], and so on. Fourthly, the fitting models are selected; this step is the key of this research, which proposes the new model to increase the performance of the forecasting. Fifthly, the evaluation of the forecasting model is conducted, this step aims to consider and evaluate the experimental results obtained from all models and then select the best model for forecasting. The performances of all models [
30] can be compared by considering error metrics such as the Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE), and so on.
2.2. Extreme Learning Machine
The Extreme Learning Machine (ELM) was proposed by Guang-Bin Huang et al. [
18]. Due to the non-iterative tuning model, the training time of the ELM model was faster than other machine learning models in the hidden layer.
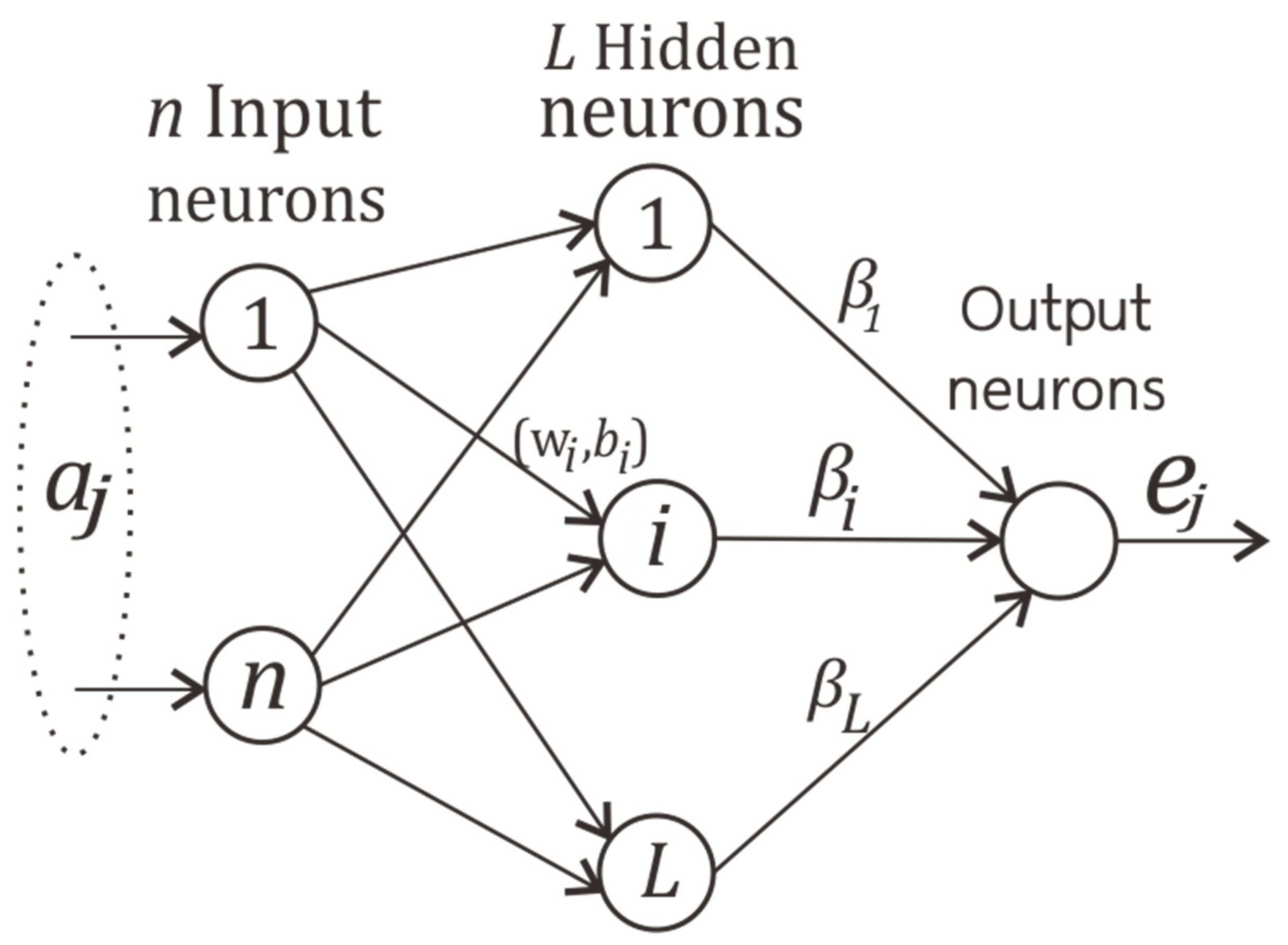
Figure 2 is the architecture of the ELM model. The structure of this model has three layers. The first layer is the input layer, which imports the sample dataset
of input data
and target data
where
is the number of instances of data with
. After the input layer step is completed, the second hidden layer is calculated as shown as in (1).
where
is the initial weight randomization,
is the connecting weight of hidden nodes and output nodes,
is the random number of hidden nodes, and
is the activation function. Equation (1) can be revised to a short equation defined as the matrix, as in (2).
where
and
.
After the hidden layer step is completed, the aim of the third output layer step is to find the β matrix; Equation (2) is inversed to Equation (3) as shown below.
where
is the Moore–Penrose pseudo-inverse [
19] of the
matrix.
Due to the problem of overfitting of the ELM model [
20], this paper proposes a method to find the optimal weight parameter with the metaheuristic optimization that can reduce the cause of the overfitting.
2.3. Jellyfish Search Optimization
Jellyfish Search Optimization (JSO) was proposed by Jui-Sheng Chou and Dinh-Nhat Truong [
23]. The main idea of this optimization was inspired by the nature of jellyfish behavior in the ocean when hunting prey for their food [
32].
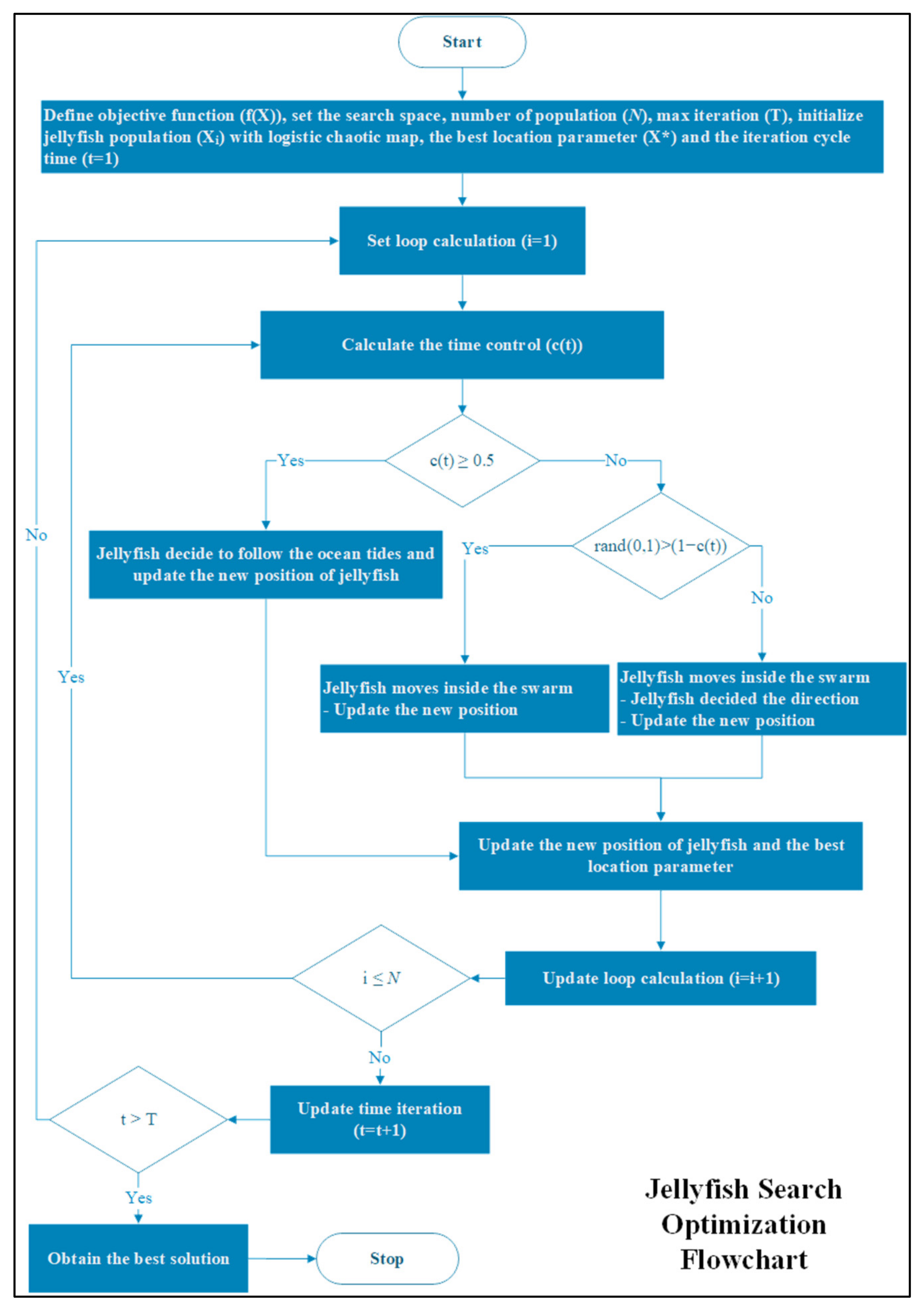
Figure 3 is the JSO algorithm flowchart that can be described as follows:
Define the objective function (
) in terms of
, the best location parameter (
), the number of search space, the number of population (
), the max iteration (
), the iteration cycle time starting from 1 to max iteration (
). Jellyfish population
is initialized with a logistic chaotic map [
33].
Calculate the control time (
) as presented in (4).
where
is the number of randomization from 0 to 1, which changes in every iteration.
If the control time is greater than or equal to 0.5 (
), then the jellyfish decides to follow the ocean tides as shown in (5). Otherwise, the movement of jellyfish to the swarm is calculated by Equation (7).
where
is the direction of the ocean tides,
is a distribution coefficient that is greater than 0 (
and
is the mean location of all jellyfishes.
After that, jellyfish live at the new position that can be calculated as shown as in (6).
If
is greater than
, then jellyfish show the passive motions, which can be calculated by Equation (7). Otherwise, jellyfish show the active motions by deciding the direction as shown by Equation (8).
where
is the motion coefficients, and
and
are upper bound and lower bound, respectively.
where
is the direction of the movement of jellyfish and
can be decided by Equation (9).
- 3.
Update the new position of the jellyfish and the best location parameter.
- 4.
Repeat step 2 until the iteration reaches the max iteration criterion.
The JSO algorithm is used to optimize the weight parameter in the ELM model that is described in
Section 3.3.
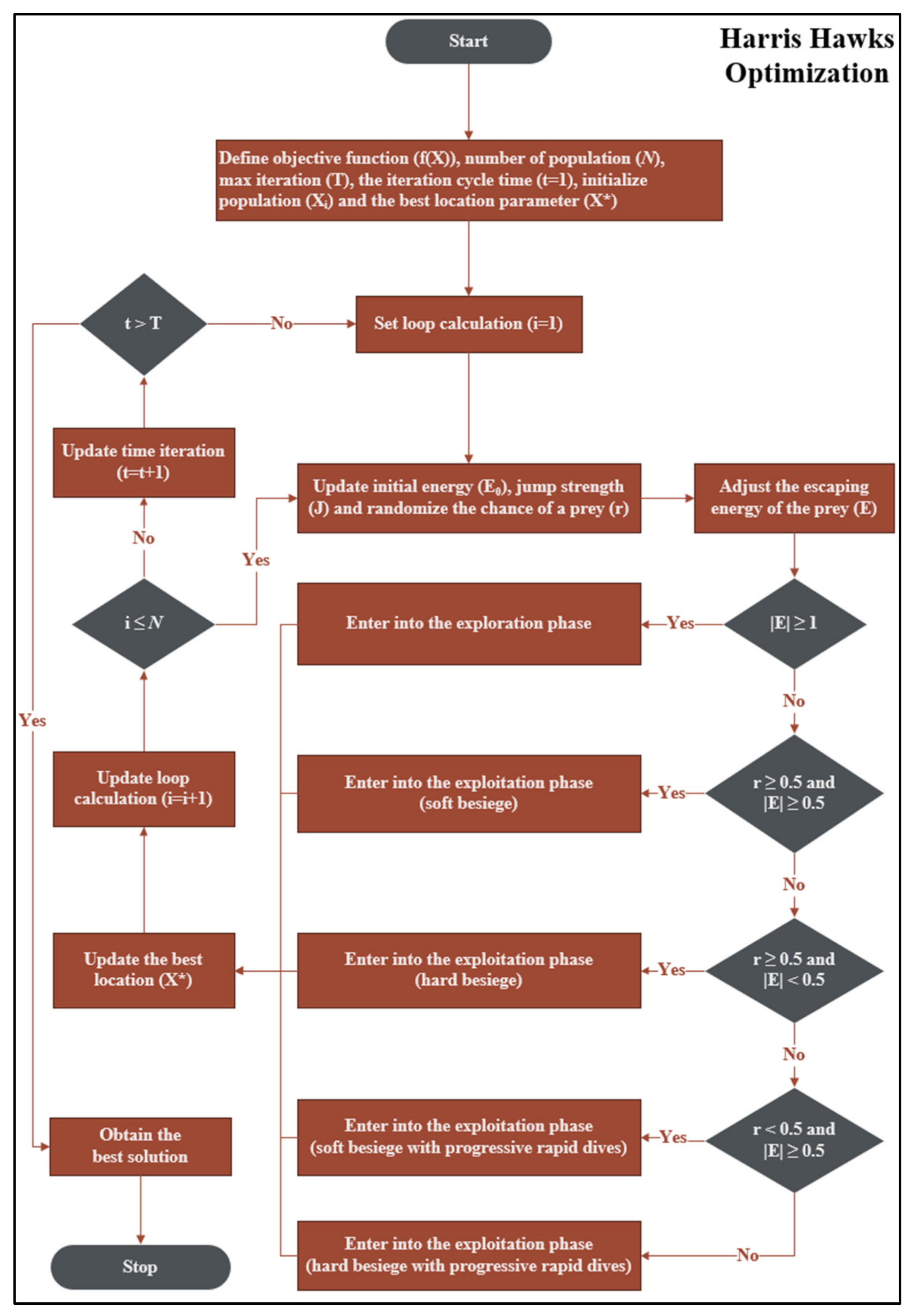
2.4. Harris Hawk Optimization
The Harris Hawk Optimization (HHO) was proposed by Ali Asghar Heidari et al. [
24]. The main idea of this optimization model came from the cooperative behavior and hunting of prey of Harris Hawk [
34].
Figure 4 presents a flowchart of the HHO algorithm that can be described as follows:
Define the objective function () in terms of , the location of rabbit (best location parameter) (), the number of population (), the max iteration (), the iteration cycle time starting from 1 to max iteration (), and initialize hawk population .
Specify the initial energy
as in (10).
Specify the initial jump strength (
) as in (11).
Adjust the escaping energy of the prey (
) as in (12).
If
, then go to the exploration phase as in (13).
where
is the random position of the currently selected hawk,
is the average position of the current population, and
is random numbers between 0 and 1.
If , then consider with four conditions of the exploitation phase as follows:
- 6.1.
If the instantly randomized number
is greater than or equal to 0.5
and
, then go to the soft besiege as in (14).
- 6.2.
If
and
, then go to the hard besiege as in (15).
- 6.3.
If
and
, then go to the soft besiege with progressive rapid dives as in (16).
where
is the next movement of the hawk as in (17).
and
Z is the random movement of the hawk with the levy flight concept as in (18).
where
is the dimension of the problem,
is the
size of random vector and
is the levy flight function [
35] as in (19).
where
is the default constant set to 1.5.
- 6.4.
If
and
, then go to the hard besiege with progressive rapid dives as in (20).
where
is the next movement of the hawk as in (21).
and
Z is the random movement of the hawk with levy flight concept as in (22).
Update the new position of the hawk and the location of the rabbit (best location parameter).
Repeat step 4 until the iteration reaches the max iteration criterion.
The HHO algorithm is used to optimize the weight parameter in the ELM model that is described in
Section 3.3.
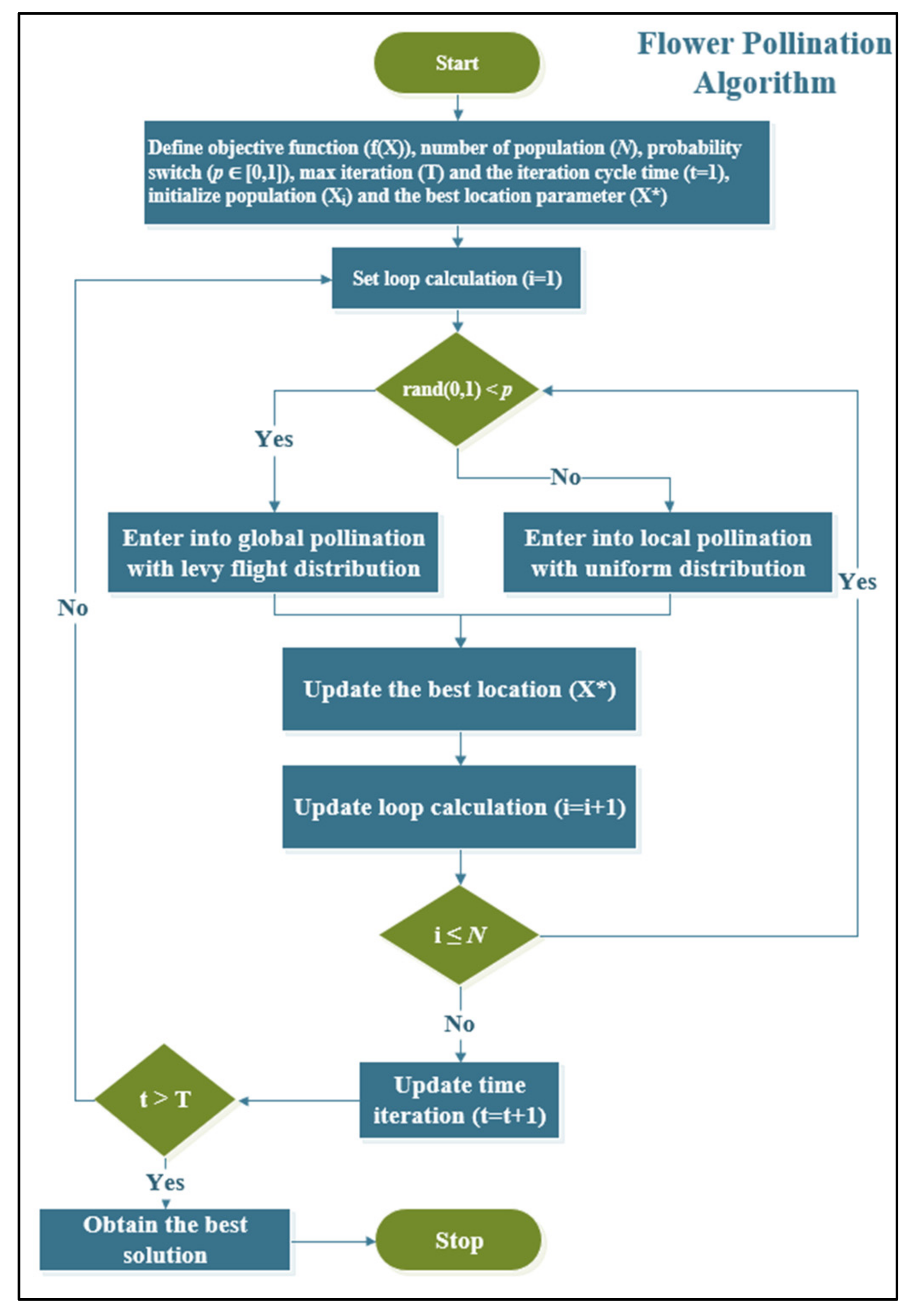
2.5. Flower Pollination Algorithm
The Flower Pollination Algorithm (FPA) was proposed by Xin-She Yang [
25]. The main idea of this optimization model was inspired by the nature of the pollination process of flowers.
Figure 5 presents the FPA algorithm flowchart that can be described as follows:
Define the objective function () in terms of , define the best location parameter (), set the number of population (), set the max iteration (), set the iteration cycle time starting from 1 to max iteration (), and initialize flower population and fixed switch probability set to 0.8 .
Define the random number between 0 and 1 and compare it with switch probability. If
, then go to the global pollination phase as in (23). Otherwise, go to the local pollination phase as in (24).
where
LF is the levy flight function [
35], which is defined as in (19).
where
and
are other populations obtained from a random position in terms of
.
Update the new position of flowers and the best location parameter.
Repeat step 2 until the iteration reaches the max iteration criterion.
The FPA algorithm is used to optimize the weight parameter in the ELM model that is described in
Section 3.3.
2.6. Summary of the JSO, the HHO, and the FPA
As aforementioned, the Jellyfish Search Optimization, the Harris Hawk Optimization, and the Flower Pollination Algorithm are the metaheuristic algorithms inspired by animals’ and plants’ behavior in nature [
36,
37]. According to
Table 1, the benefits and drawbacks of the three metaheuristics are summarized. The benefits of JSO [
23] include its fast speed to converge calculation, stability in the processing of the problem, and being hard to trap in local optima. However, the drawback of JSO is that there are quite a minor of related works because this optimization was a novel metaheuristics model in 2020. The benefit of HHO [
38] is there are many steps of calculation that are hard to trap in local optima; however, the drawback of HHO is that it is slow to converge calculation. Finally, the benefits of FPA [
39] are it is fast to converge calculation because the steps of this optimization are simple and easy to implement; however, the drawback of FPA is that it is easy to trap in local optima.
In conclusion, the three metaheuristic optimizations were merged with the ELM model to optimize the weight parameter, compare the three proposed models with the forecasting dataset, and evaluate the model with the error metrics objective function.
3. Data Preparation and Proposed Models
This section describes the technique of this research work, which consists of an overview of the electric energy demand datasets in Thailand, proposed data, and models used in the experiment to achieve the best result, the experimental setup and hyper-parameter settings for all proposed and state-of-the-art models, and performance evaluation of each model.
3.1. Preparation of Electric Energy Demand Data
Electric energy demand datasets were collected from Provincial Electricity Authority in Thailand (PEA), which can be accessed from references [
40,
41]. The scope of the electric energy demand datasets in this research was set from 2018 to 2020.
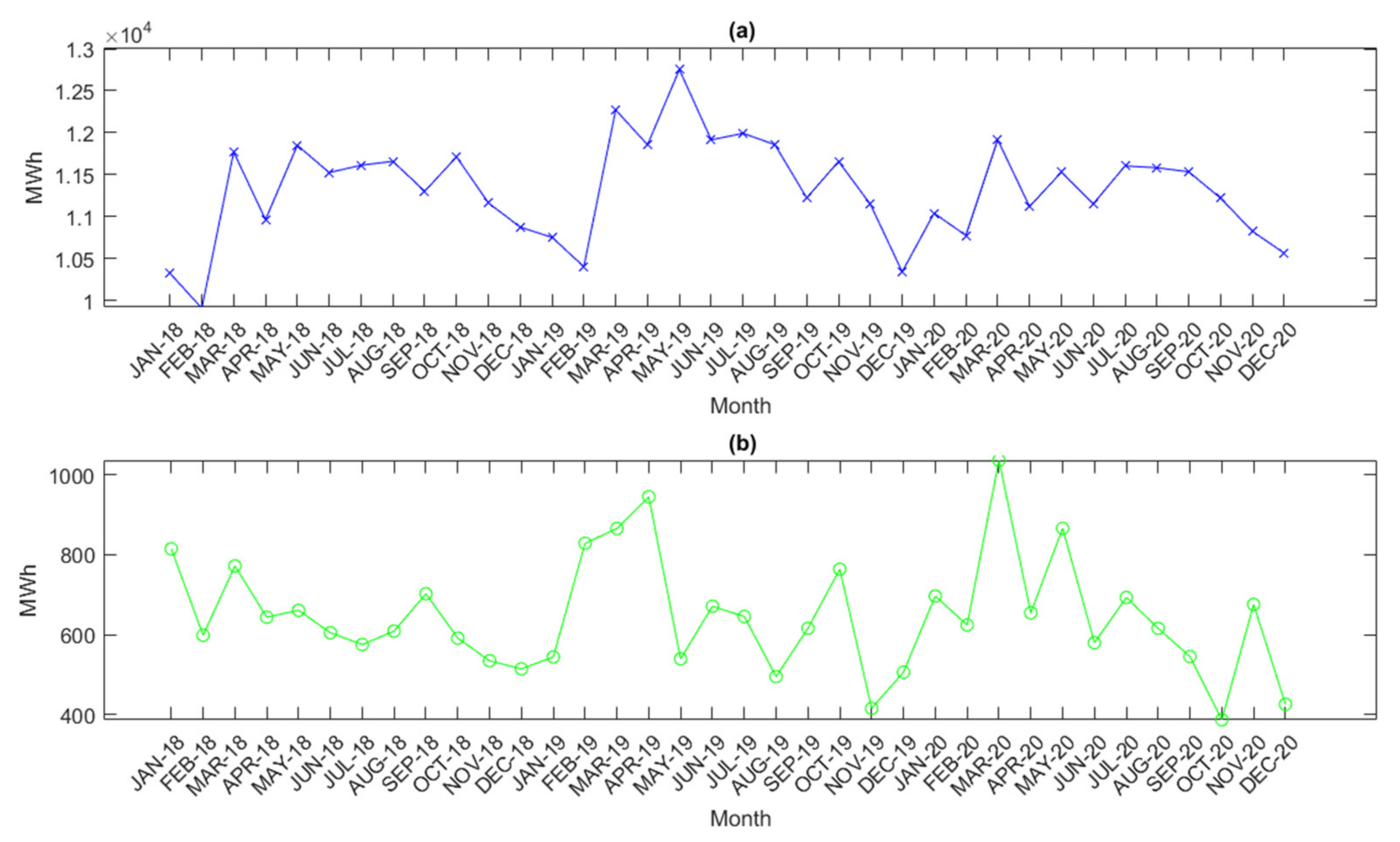
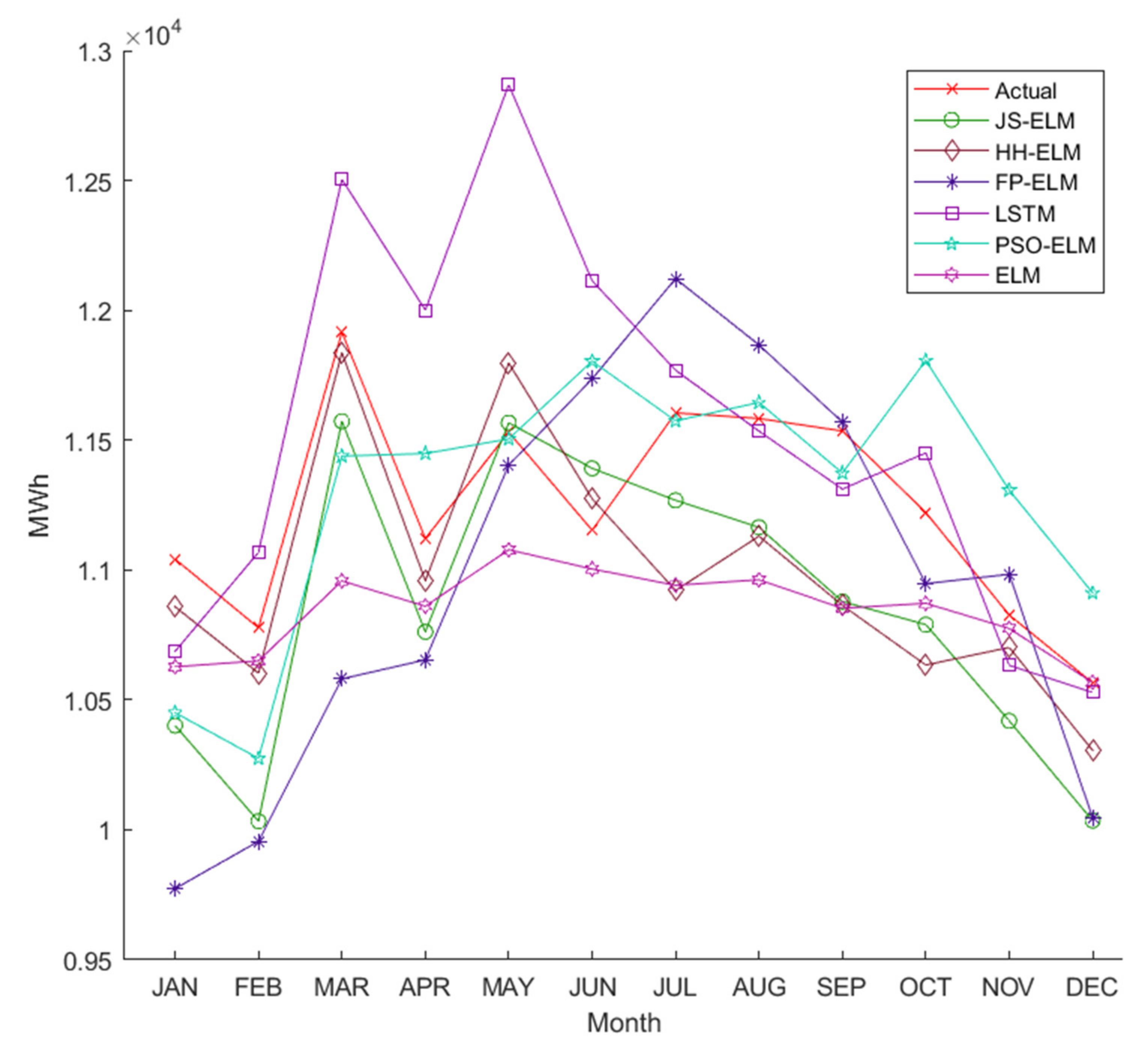
Figure 6a is the pattern of the monthly demand data of electric energy from January 2018 to December 2020 in terms of MegaWatt-Hour (MWh). The minimum electric energy demand is 9909 MWh in February 2018, the maximum electric energy is 12,752 MWh in May 2019, and the average electric energy demands in 2018, 2019, and 2020 are 11,222 MWh, 11,514 MWh, and 11,239 MWh, respectively.
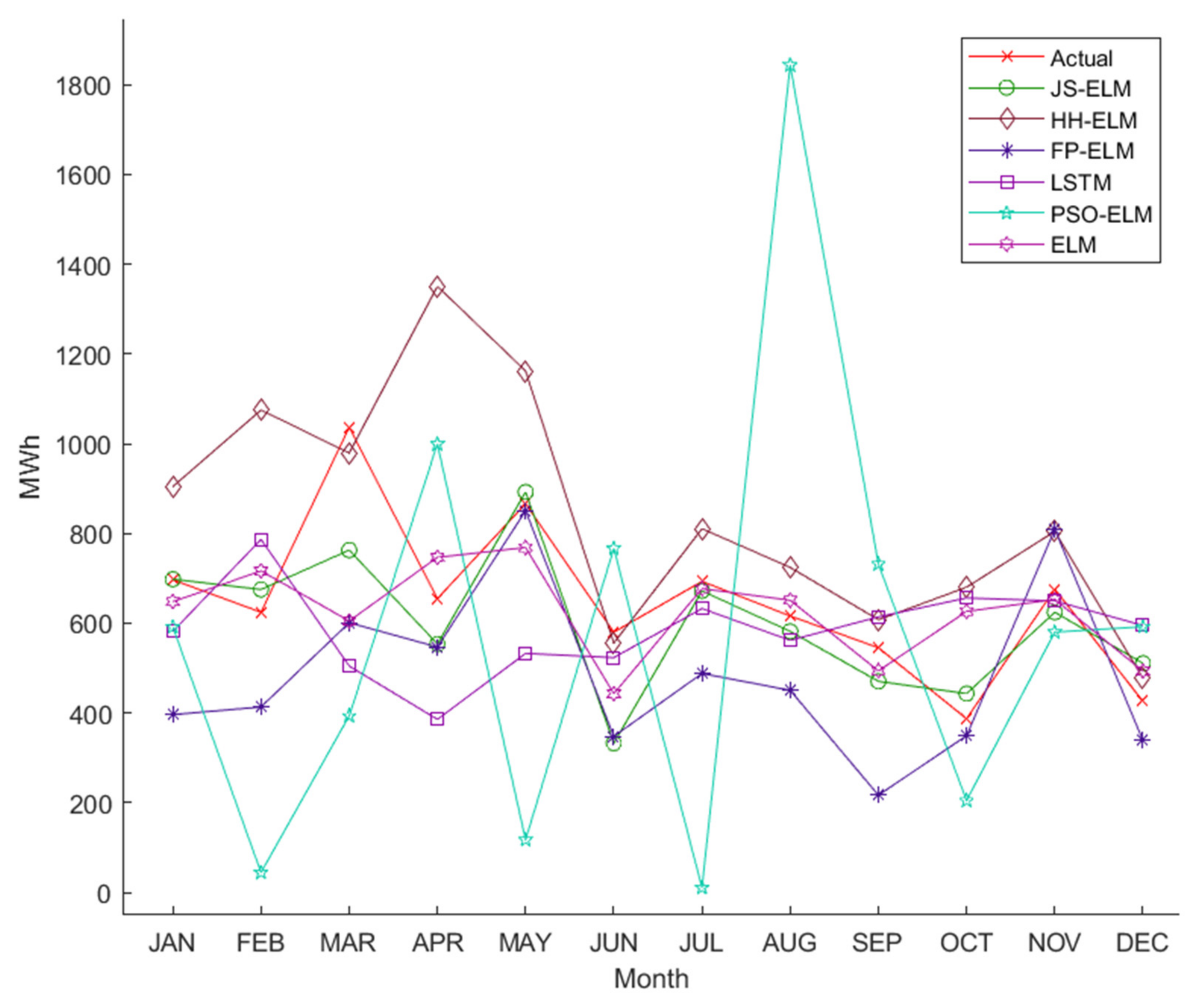
Figure 6b is the pattern of the monthly loss data of electric energy in Thailand from January 2018 to December 2020. The minimum loss is 387 MWh in October 2020, the maximum loss is 1036 MWh in March 2020, and the average losses in 2018, 2019, and 2020 are 635 MWh, 653 MWh, and 650 MWh, respectively.
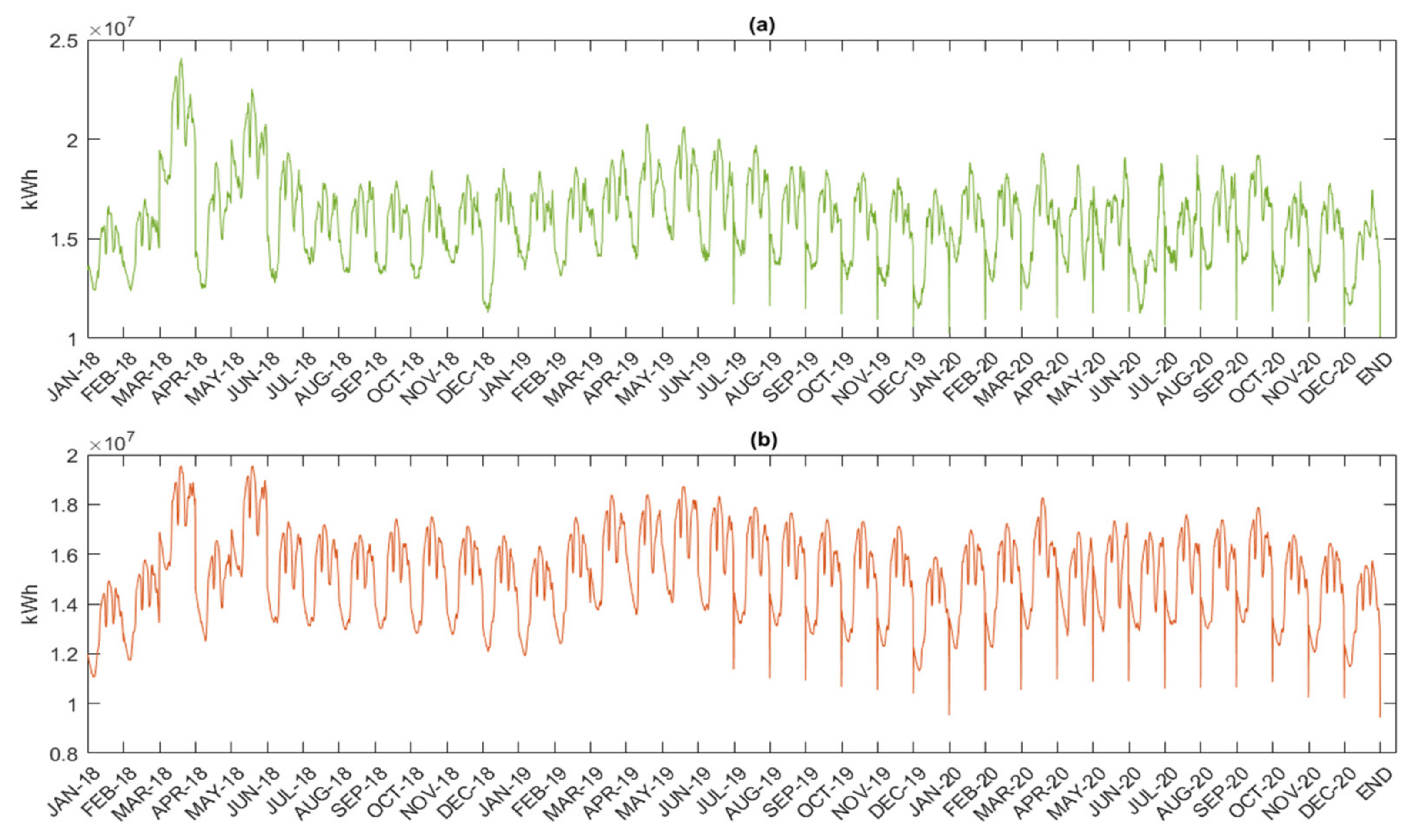
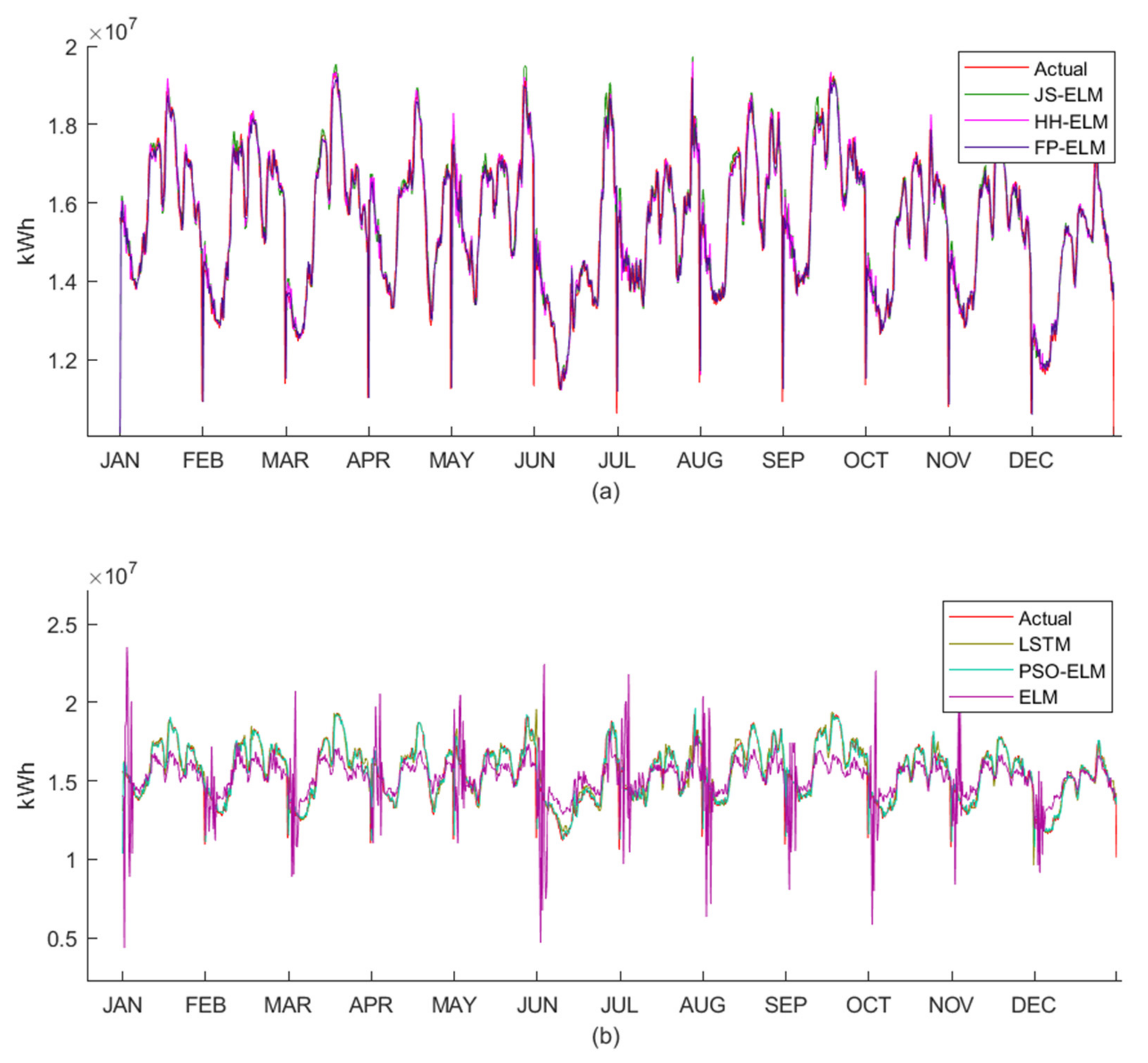
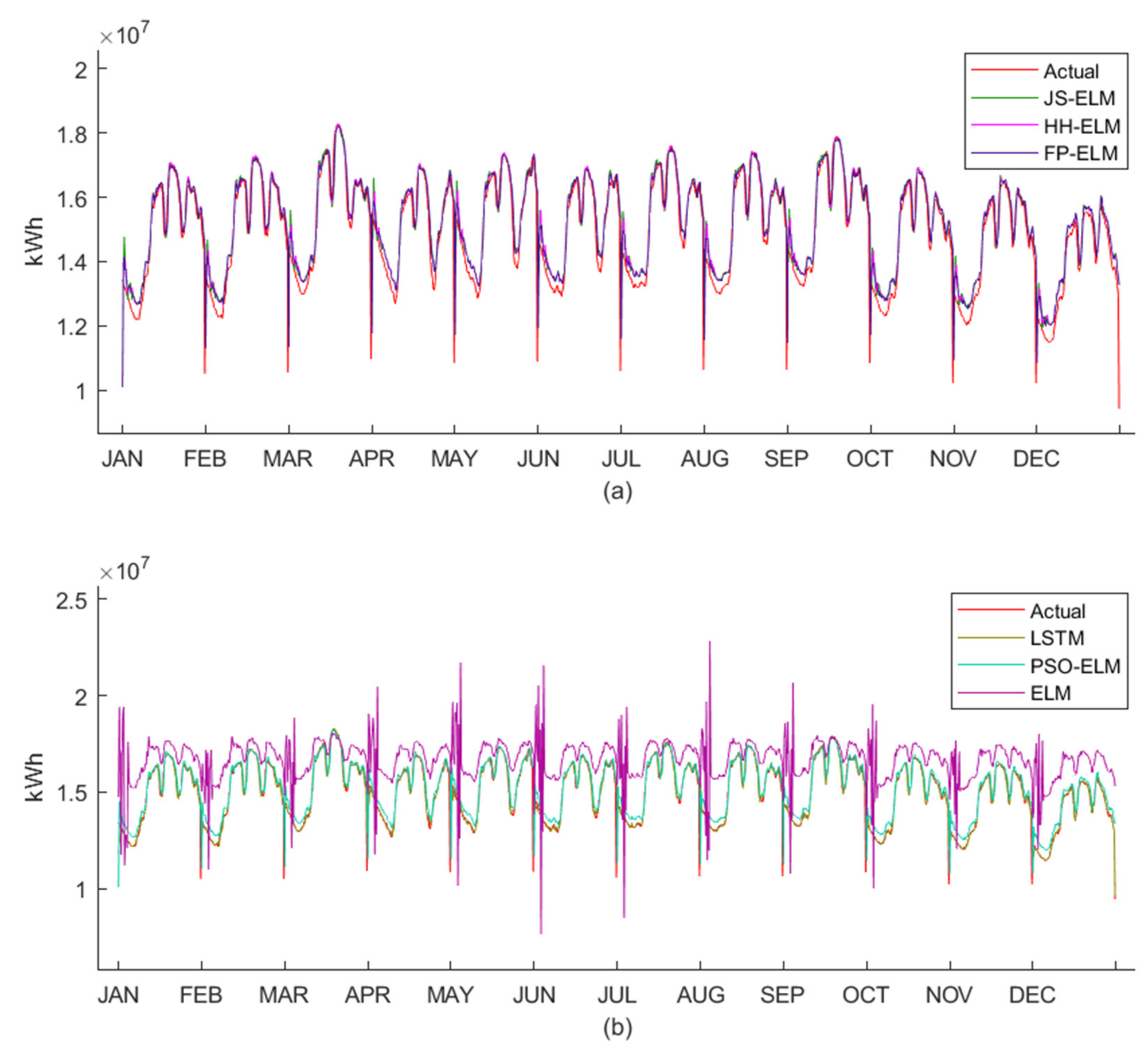
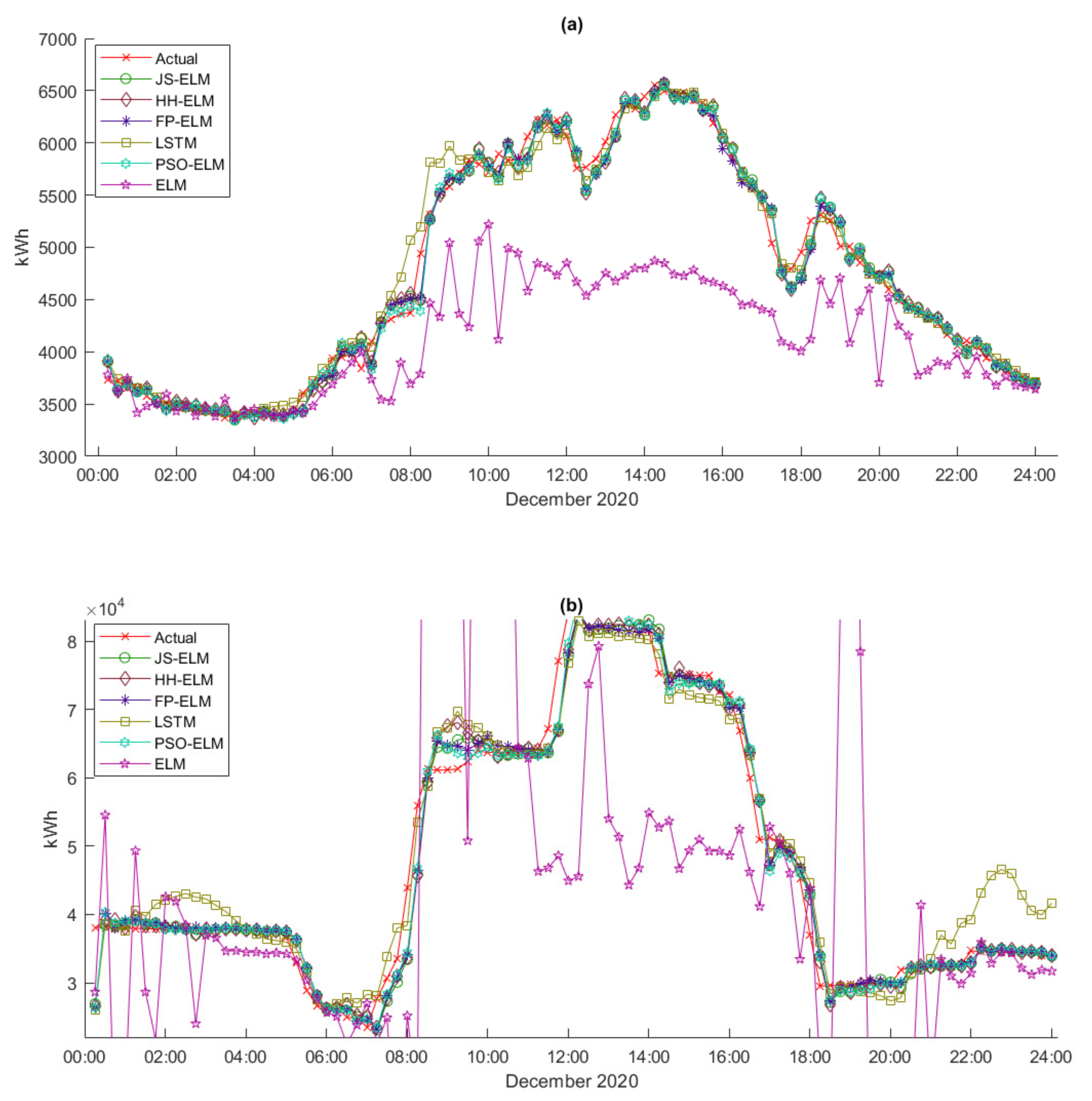
Figure 7a,b are the patterns of the peak demand data of electric energy and the pattern of the workday demand data of electric energy, respectively. Both peak demand data and workday demand data were collected in 15 min intervals from January 2018 to December 2020 in terms of a kiloWatt-Hour (kWh). The peak demand data were collected from the days that use the highest electricity for each month, and the workday demand data were collected from Monday to Friday for each month.
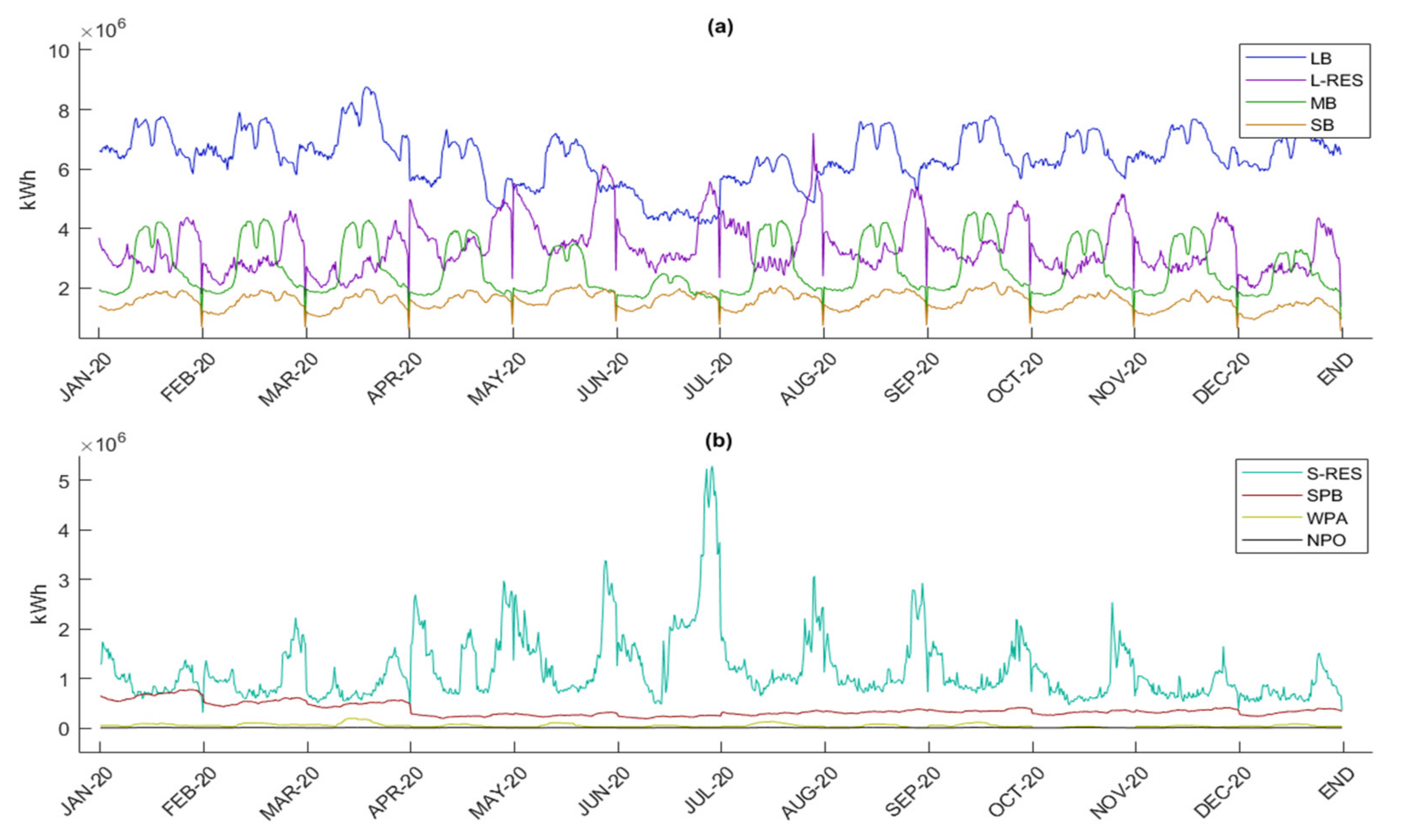
Figure 8 is the group pattern of the peak demand data of electric energy collected in 15 min intervals from January 2018 to December 2020 in terms of kWh. This dataset can be separated into 8 clusters when sorting from the highest total electric energy demand to the lowest total electric energy demand. The 8 clusters consist of Large Business (LB), Large Residential or Residential (L-RES) demand, which consumes energy greater than or equal to 150 kWh per month, Medium Business (MB), Small Business (SB), Small Residential or Residential (S-RES) demand, which consumes energy less than 150 kWh per month, Specific Business (SPB), Water Pumping for Agriculture (WPA), and Nonprofit Organization (NPO).
3.2. Dataset
When the preparation of electric energy demand data was completed, the experimental datasets were built to be tested in proposed models to forecast data with minimum error. In this research, the datasets were classified into seven groups for testing the proposed models.
Table 2 describes the detail of each dataset, which is separated in terms of train and test data.
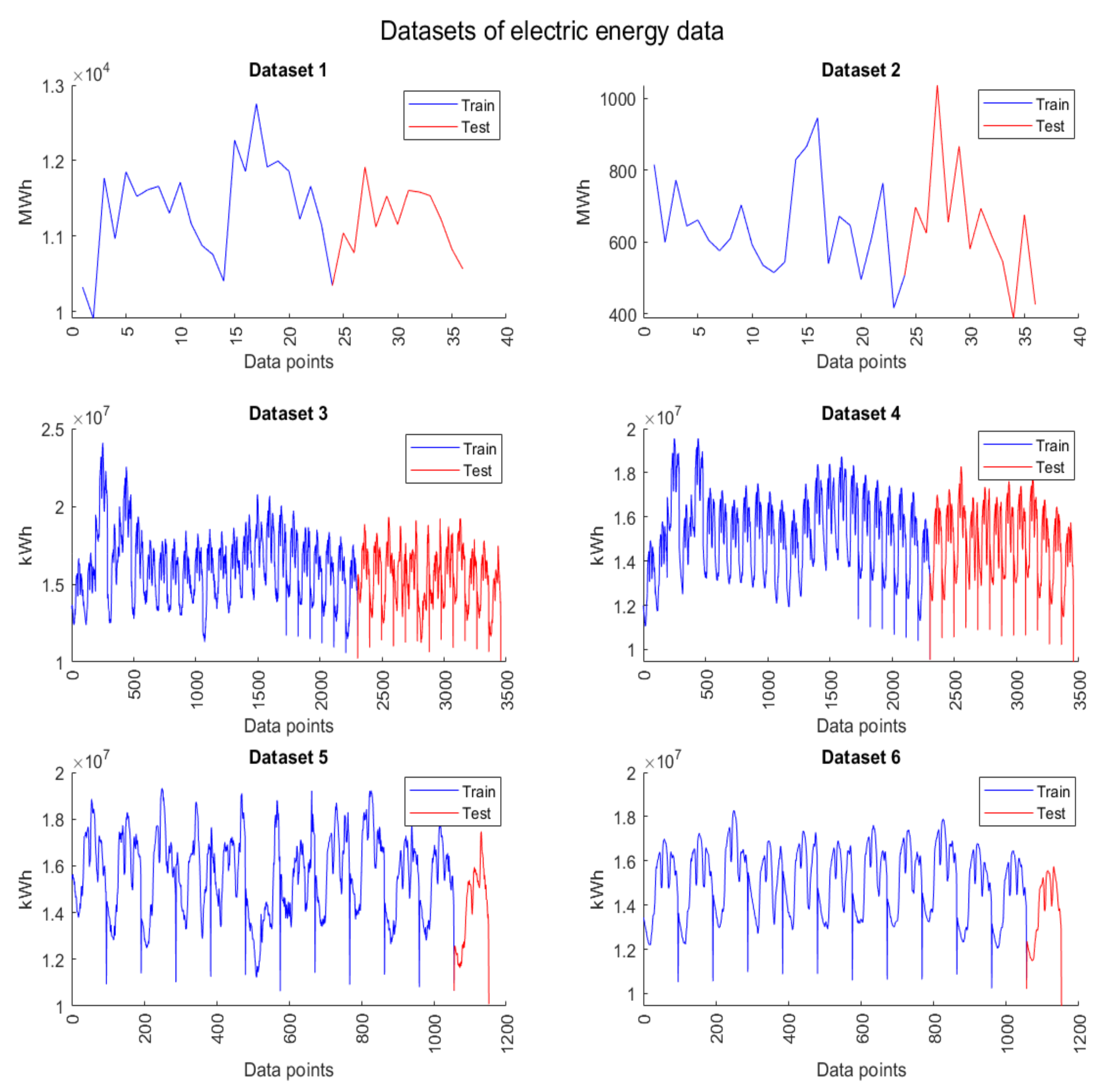
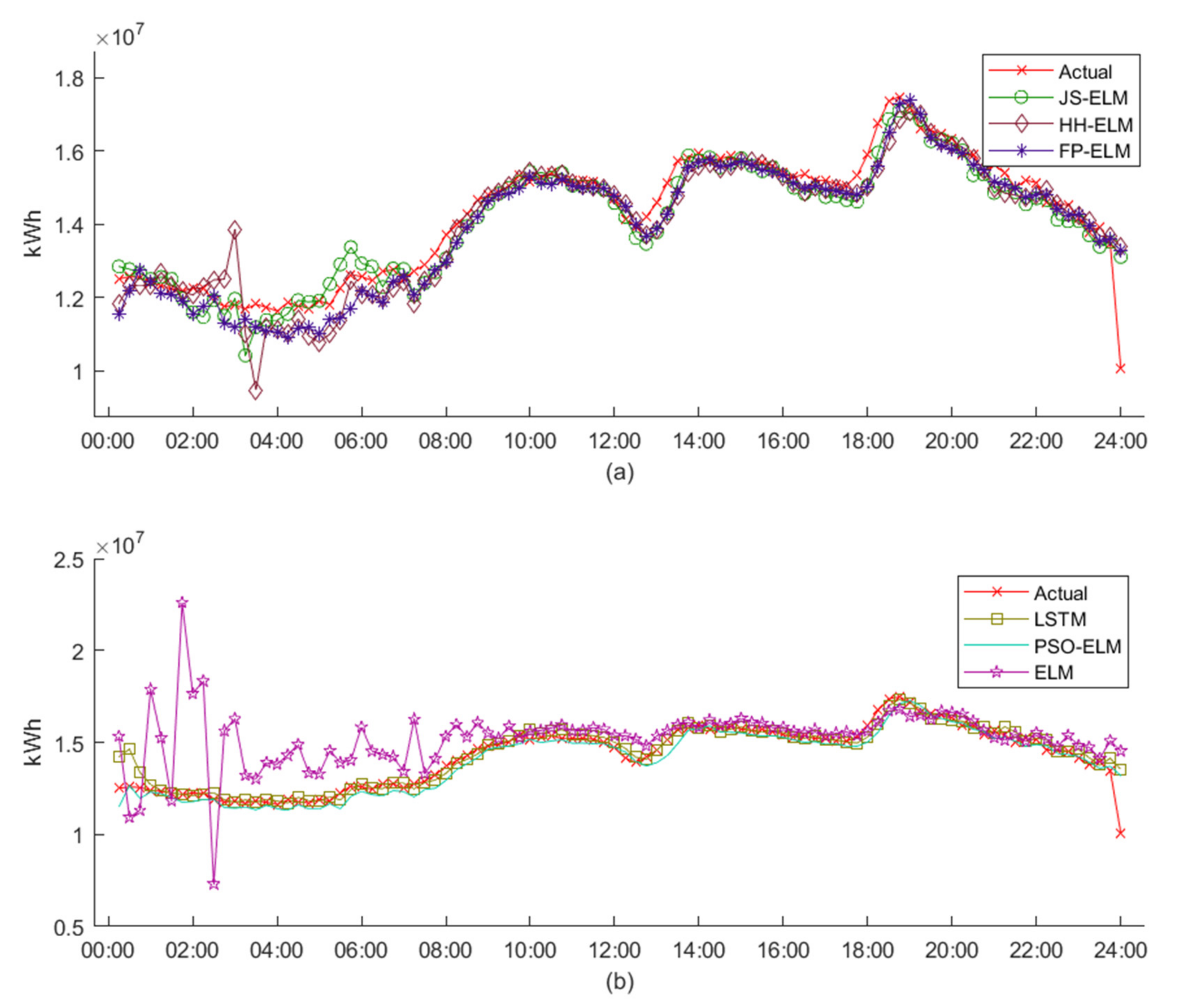
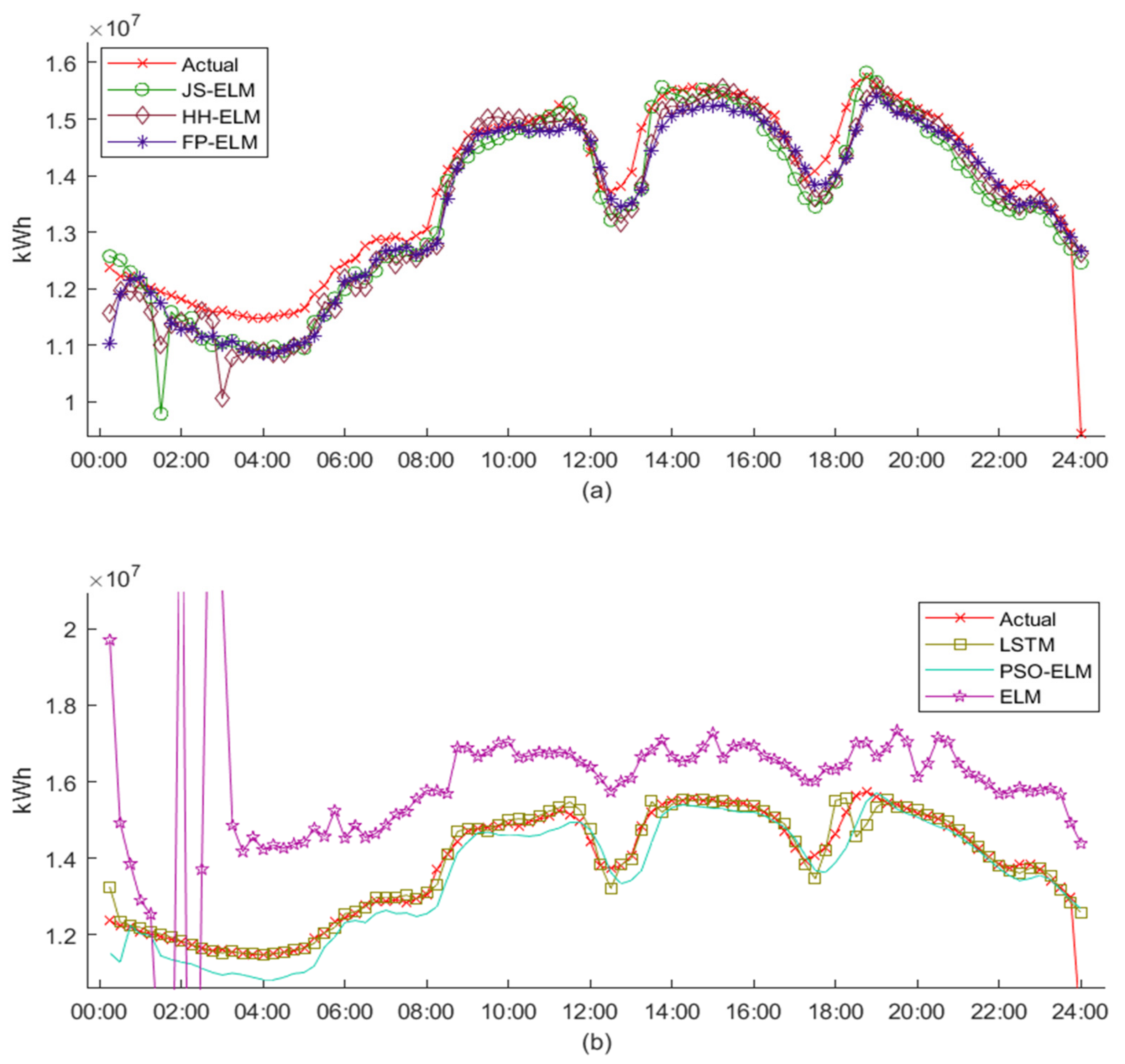
Figure 9 is the electric energy pattern data from dataset 1 to dataset 6, where the blue line is the train data for machine learning, and the red line is the test data for machine learning. Therefore, the detail from dataset 1 to dataset 6 can be described as follows:
Dataset 1 is the monthly electric energy demand data that is separated from January 2018 to December 2019 as train data (24 instances) and from January 2020 to December 2020 as test data (12 instances).
Dataset 2 is the monthly electric energy loss data that is separated from January 2018 to December 2019 as train data (24 instances) and from January 2020 to December 2020 as test data (12 instances).
Dataset 3 is the peak day 15 min interval electric energy demand data that is separated from January 2018 to December 2019 as train data (2304 instances) and from January 2020 to December 2020 as test data (1151 instances).
Dataset 4 is the workday 15 min interval electric energy demand data that is separated from January 2018 to December 2019 as train data (2304 instances) and from January 2020 to December 2020 as test data (1151 instances).
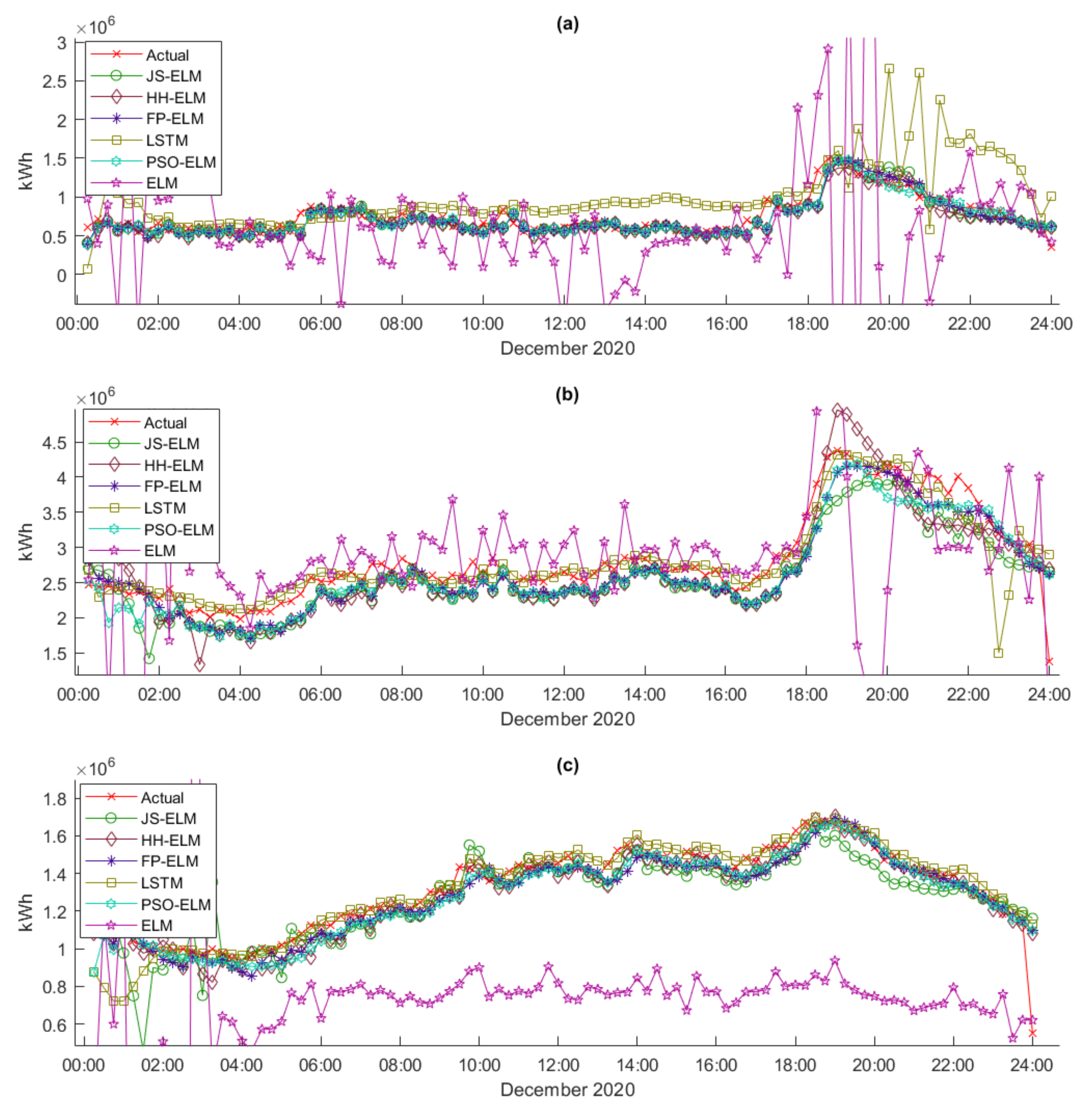
Dataset 5 is the peak day 15 min interval electric energy demand data that is separated from January 2020 to December 2020 as train data (1506 instances) and only December 2020 as test data (96 instances).
Dataset 6 is the workday 15 min interval electric energy demand data that is separated from January 2020 to December 2020 as train data (1506 instances) and only December 2020 as test data (96 instances).
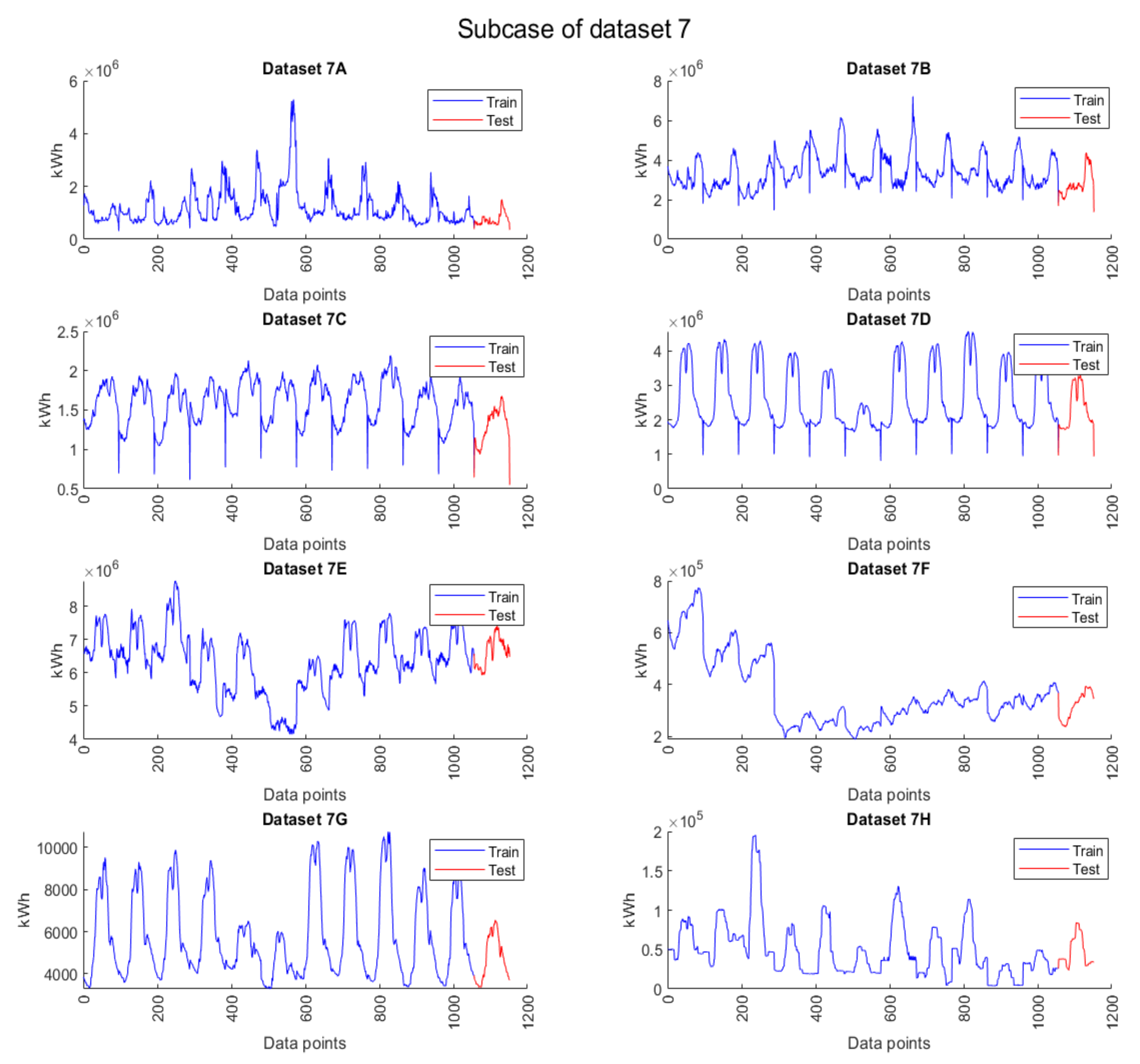
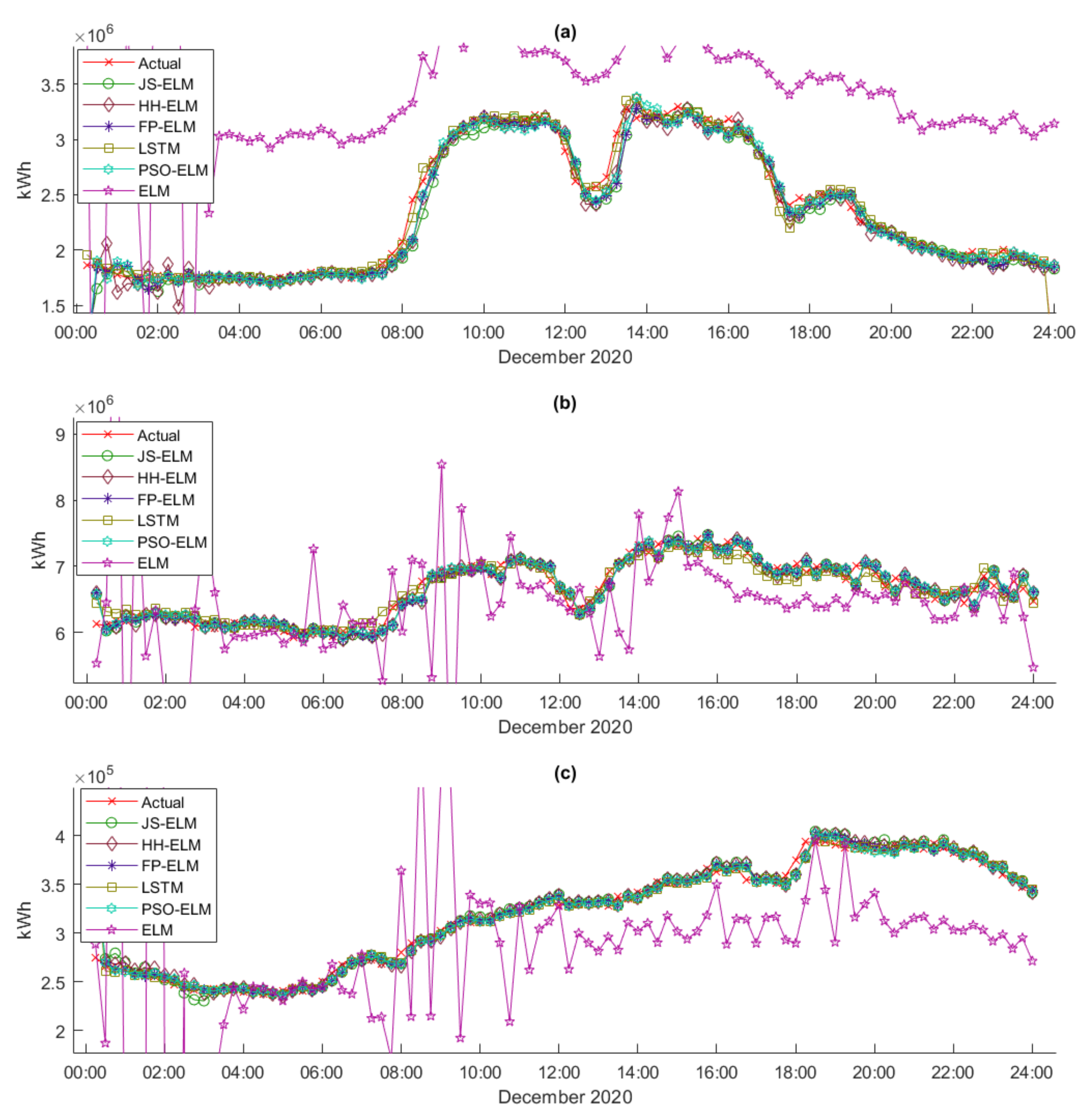
Figure 10 is the electric energy pattern data of dataset 7, where the blue line is the train data for machine learning, and the red line is the test data for machine learning. Therefore, the detail of dataset 7 can be described as follows:
Dataset 7 is the cluster of 15 min interval peak day electric energy demand data that are separated into 8 subcases (7A to 7H). Subcase 7A is the cluster of S-RES electric energy demand data, subcase 7B is the cluster of L-RES electricity demand data, subcase 7C is the cluster of SB electricity demand data, subcase 7D is the cluster of MB electricity demand data, subcase 7E is the cluster of LB electricity demand data, subcase 7F is the cluster of SPB electricity demand data, subcase 7G is the cluster of NPO electricity demand data, and subcase 7H is the cluster of WPA electricity demand data. All subcases are separated from January 2020 to December 2020 as train data (1506 instances) and only December 2020 as test data (96 instances).
3.3. Proposed Models
The concept of the proposed models is using metaheuristic algorithms to optimize the weight parameter to reduce the cause of overfitting. In this research, three metaheuristic algorithms, which consist of JSO, HHO, and FPA, modified the randomization of weight parameter for searching the best weight parameter to improve the performance of the forecasting. The algorithm of the proposed models is described in Algorithm 1.
| Algorithm 1. Pseudo-code of the Proposed Models. |
| 1: | Define objective function f(x), by |
| 2: | Define the initialize n number of population in metaheuristic models (JSO, HHO, or FPA) |
| 3: | Define a switch probability p [0,1] (FPA only) |
| 4: | Define the best solution in the initial population |
| 5: | Define L hidden nodes in ELM |
| 6: | Define Hidden nodes activation function in ELM (sigmoidal function) |
| 7: | Define output weight vector |
| 8: | Define T as the max iteration for metaheuristic models |
| 9: | while (t < T) |
| 10: | for i = 1: n |
| 11: | Adjust as the population with the metaheuristic models (JSO, HHO, or FPA) |
| 12: | Evaluate new solution to ELM |
| 13: | for i = 1:L |
| 14: | for j = 1:N |
| 15: | H(i,j) = |
| 16: | end |
| 17: | end |
| 18: |
|
| 19: | If new solutions are better, update new in the population |
| 20: | end for |
| 21: | Find the current best solution & best output weight |
| 22: | end while |
First of all, based on the ELM model, all setting parameters were defined in the model, which consisted of a number of hidden nodes, input and target data, and initial weight parameter. Secondly, based on metaheuristic models, all setting parameters of each model were defined, which consisted of the number of populations, switch probability for the FPA model, and the best solution of the population. Thirdly, the weight parameter was defined based on metaheuristic models and then evaluated the new weight parameter for calculating in the ELM model. Fourthly, the activation function was calculated in the ELM model to receive the last weight parameter from the hidden layer. All processes were calculated until the iteration reached the max iteration criterion and the best weight parameter was received for calculating in the testing phase.
3.4. Experimental Setup and Hyper-Parameters Setting
The hardware specification of the computer used in this research work was CPU Intel Core i7-7700HQ 2.80 GHz (up to 3.40 GHz), RAM 32 GB, and SSD NVMe. The software was the MATLAB version R2020a. The major hyper-parameters [
42,
43] of proposed models consisted of the number of hidden nodes and the number of populations and the major hyper-parameters [
44] of state-of-the-art models consisting of the number of hidden nodes that were analyzed through the electric energy demand datasets. The objective function to find the best hyper-parameters was the Root Mean Square Error (RMSE).
The hyper-parameter tuning [
45,
46] of the proposed and state-of-the-art models is shown in
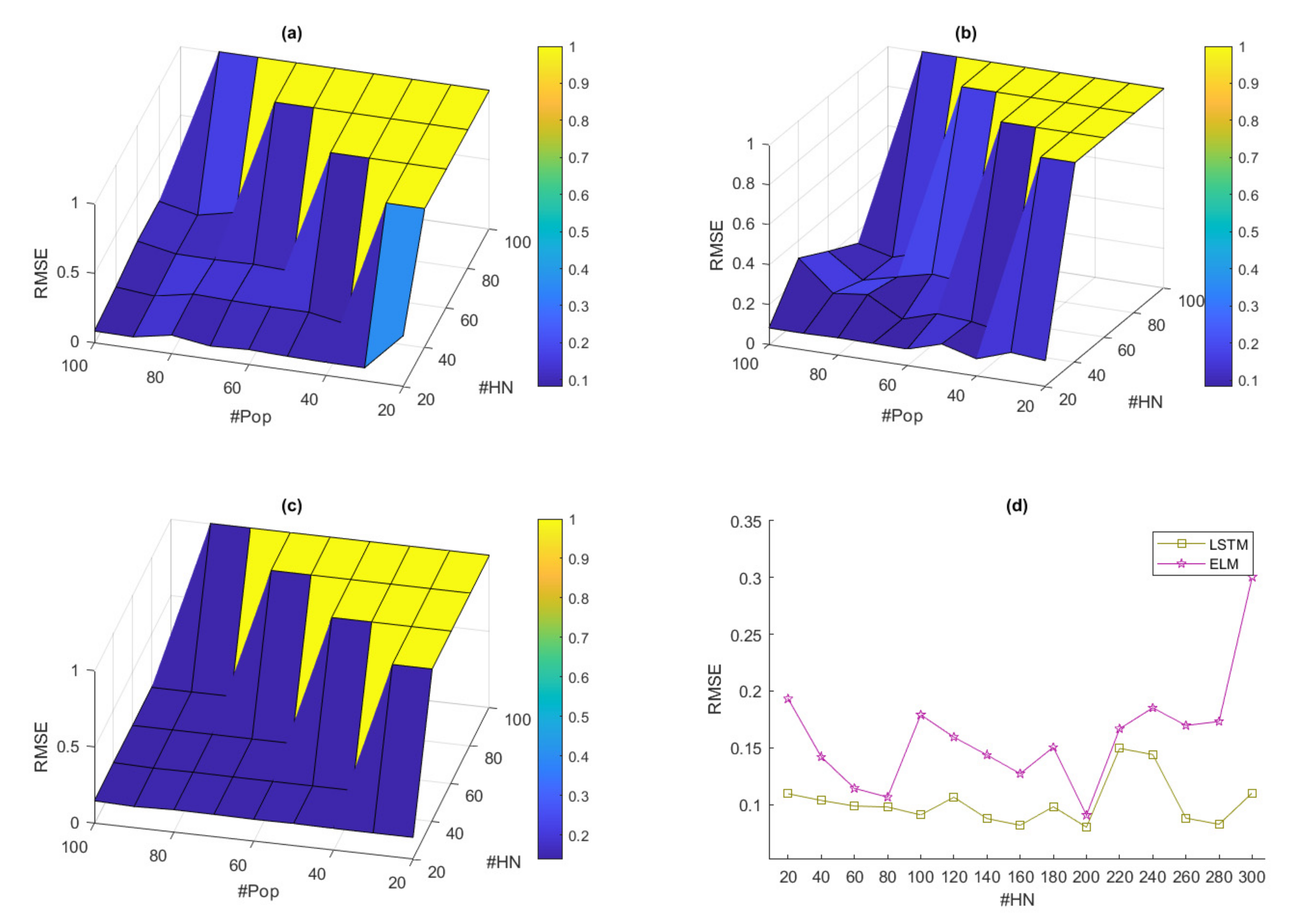
Figure 11. In this experiment, the average of RMSE from all models was obtained by taking all the datasets (7 datasets) used to find the RMSE value, then averaging RMSE value in terms of the number of hidden nodes and population. In the proposed models, the boundary of hidden nodes was set from 20 to 200 (increasing 20 nodes), the boundary of populations was set from 20 to 100 (increasing 10 populations), and the number of iterations for metaheuristics was set to 100 due to the fast computation. In the state-of-the-art models, the boundary of hidden nodes was set from 20 to 300 (increasing 20 nodes). For fast computing in the long short-term memory (LSTM) model, the fixed setting of hyper-parameters in the LSTM model consisted of 2 hidden layers, 1000 epochs, 64 batch size, and optimizer was set to Adam.
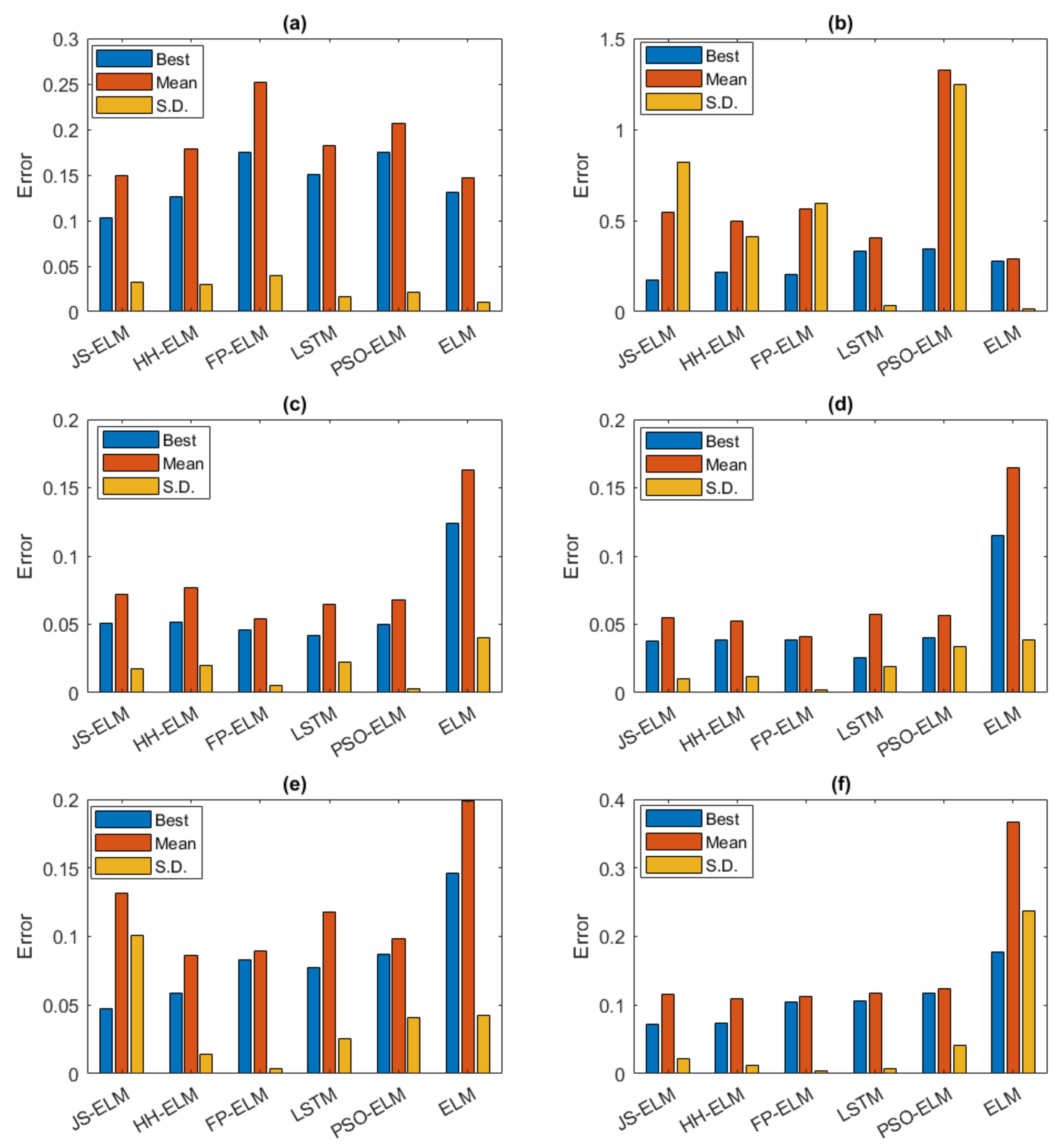
According to
Figure 11, the hyper-parameter experiment results show that the best average RMSE of JS-ELM is 0.0838, and the locations of hidden nodes and populations are 40 and 50, respectively. The best average RMSE of HH-ELM is 0.0927, and the locations of hidden nodes and populations are 40 and 50, respectively. The best average RMSE of FP-ELM is 0.1384, and the locations of hidden nodes and populations are 40 and 50, respectively. The best average RMSE of LSTM is 0.0880, and the location of hidden nodes is 200. The best average RMSE of ELM is 0.0907, and the location of hidden nodes is 200.
For comparing with the metaheuristic-based proposed models, the Particle Swarm Optimization Extreme Learning Machine (PSO-ELM) [
47,
48] model was considered to forecast in electric energy demand datasets. The best hyper-parameters of PSO-ELM model were received from [
48], which consist of 150 hidden nodes, 30 populations (swarm size), acceleration coefficients
and
, and inertia weight was set to 0.9.
To summarize, the best hyper-parameters of JS-ELM, HH-ELM, and FP-ELM are 40 hidden nodes and 50 populations. The best hyper-parameters of LSTM and ELM are 200 hidden nodes. All suitable hyper-parameters were defined as presented in
Table 3.
3.5. Performance Evaluation
In this research, all datasets were processed by min–max normalization [
49] as calculated in (25).
where
is a data point and
is normalized data.
To evaluate the performance of proposed models, three error metrics, Mean Absolute Error (
MAE), Mean Absolute Percentage Error (
MAPE), and Root Mean Square Error (
RMSE), were used in this experiment as presented in (26)–(28), respectively.
where
is the present time variable,
n is the number of input data,
is the expected data at the time
i, and
is the actual data at the time
i.
To receive the best solution from the performance evaluation, which is suggested from [
50,
51], all error metrics were combined to the Cumulative Weighted Error (
CWE) for evaluating the final result of the experiment as presented in (29).
After error metrics were completely calculated, the result of error metrics was used to evaluate the performance of the proposed models as discussed in
Section 4.
5. Conclusions and Future Work
This research proposed the novel ELM model optimized by metaheuristic algorithms, namely JS-ELM, HH-ELM, and FP-ELM, to forecast the electric energy dataset. The characteristic of the metaheuristic optimizations, namely JSO, HHO, and FPA, is that they are self-adaptive to tune the weight parameter of the ELM model without being trapped in the local optimum. Therefore, the models mentioned earlier were applied to the ELM model by tuning the weight parameter of the ELM model instead of using the traditional randomization of the weight parameter. In addition, these three optimization methods can reduce the number of hidden nodes of the ELM model. To demonstrate the performance of the proposed method, all models were applied to forecast seven real-life electric energy datasets. The dataset of electric energy demand consists of monthly electric energy demand data from 2018 to 2020, monthly electric energy loss data from 2018 to 2020, peak day 15 min interval electric energy demand data from 2018 to 2020, workday 15 min interval electric energy demand data from 2018 to 2020, peak day 15 min interval electric energy demand data in 2020, workday 15 min interval electric energy demand data in 2020, and cluster of 15 min interval peak day electric energy demand data. Consequently, the result showed that the proposed models could improve the forecasting accuracy, provide forecasting stability, and reduce the cause of overfitting from the traditional model.
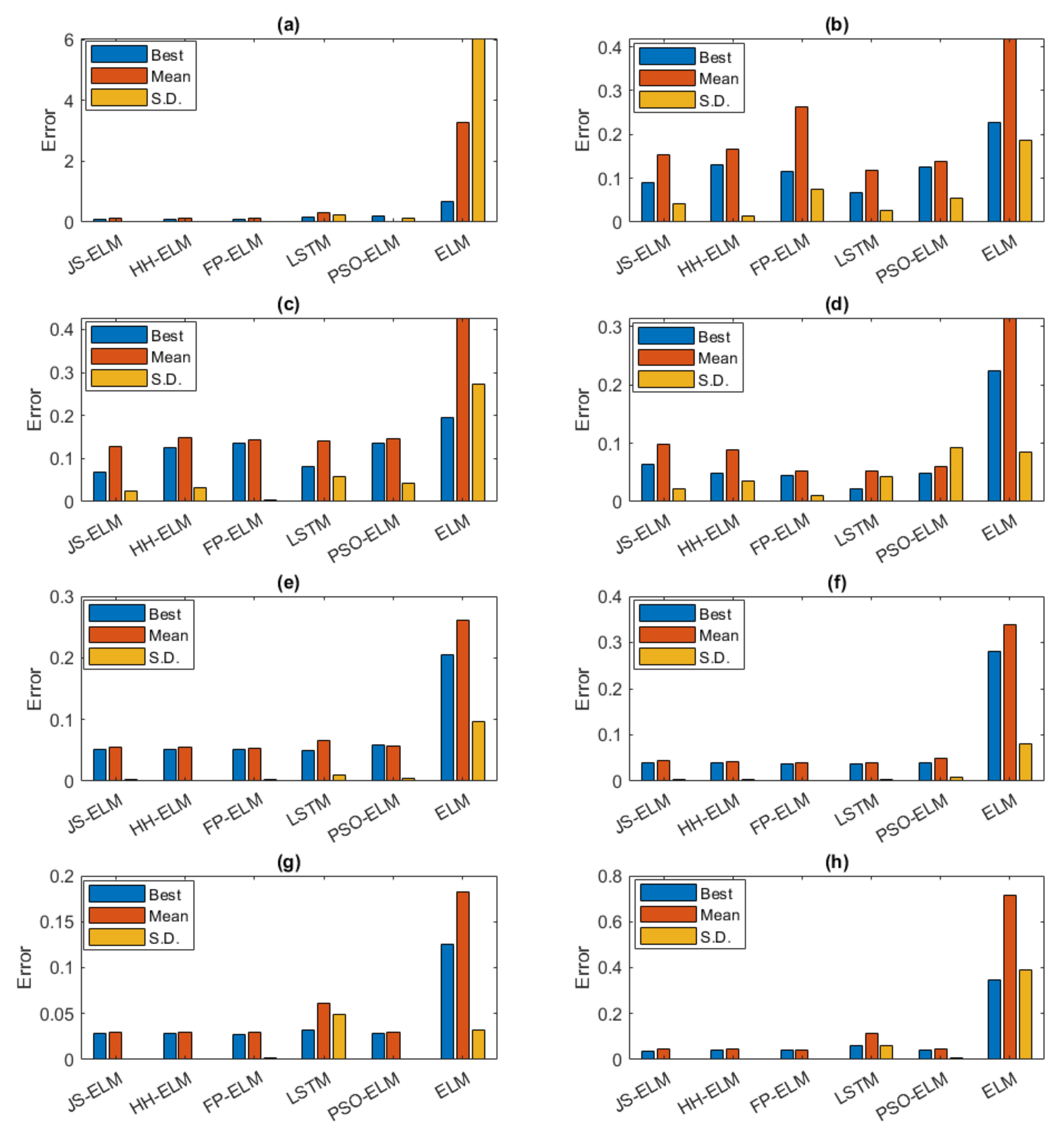
According to
Table 6, the JS-ELM model was the most suitable for the minimum error result. The overall forecasting results of the HH-ELM model were similar to the JS-ELM model results, but the time consumption was higher than the time consumption of other models. The FP-ELM model was the most suitable in terms of the minimum mean error and minimum S.D. The time consumption of the proposed models depended on the number of populations, iterations criterion of metaheuristics algorithms, and the number of hidden nodes of the ELM model. The HH-ELM model used twice the time consumption compared with the time consumptions of the JS-ELM and the FP-ELM models. Furthermore, the time consumptions of the proposed models were lower than the LSTM model, while the overall error results of the proposed models and LSTM were close.
For suggestions for future works, the proposed models can improve the stability of forecasting, for instance, according to
Table 6, JS-ELM was the most suitable when considering the minimum error result, and FP-ELM was the most suitable when considering the S.D. result. Therefore, future work may propose a novel model that applies the hybrids of JSO and FPA to the ELM model. Due to the benefits of JSO and FPA, the expected results of the aforementioned novel model can be achieved with a more stable accuracy of forecasting and provide the best forecasting result. Moreover, the time consumption of forecasting is the major topic to discuss. According to
Table 5, the time consumption of JS-ELM and FP-ELM were close and less than other models except for ELM. The time consumption of the proposed models and the future novel model can be reduced by using the step of tuning the hyper-parameters with a suitable algorithm and the methodology of an ensemble learning algorithm [
52,
53,
54] that splits the appropriate sub-datasets from the primary dataset, forecasts the sub-datasets, and aggregates the forecasted model results. Finally, due to the variety of metaheuristics algorithms [
47] that are continuously being developed, an alternative metaheuristics algorithm can be discussed to implement with the ELM model or other machine learning models to improve the accuracy of the forecasted electric energy demand.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}