
Markerless Dog Pose Recognition in the Wild Using ResNet Deep Learning Model


Abstract
:1. Introduction
- We used the technique for markerless pose recognition based on an open-source Deep Lab Cut learning tool set (DLC). The location of the data improves the robustness and provides higher performance in the outside domain where it yields an accurate result due to the training of the data from scratch.
- We add a novel version of networks to the DL package, MobileNetV2s, which pave the way for the most accurate and fast posture detection of the animal.
- We train the DNN to classify 18 image features and excerpt the canine posture by detecting a set of features. This methodology has been experimented with more than 5000 manually marked canine photographs.
- We examine the performance of the proposed methodology for dog posture tracking in various settings and offer an openly available toolbox for the research community.
2. Related Works
3. Methods
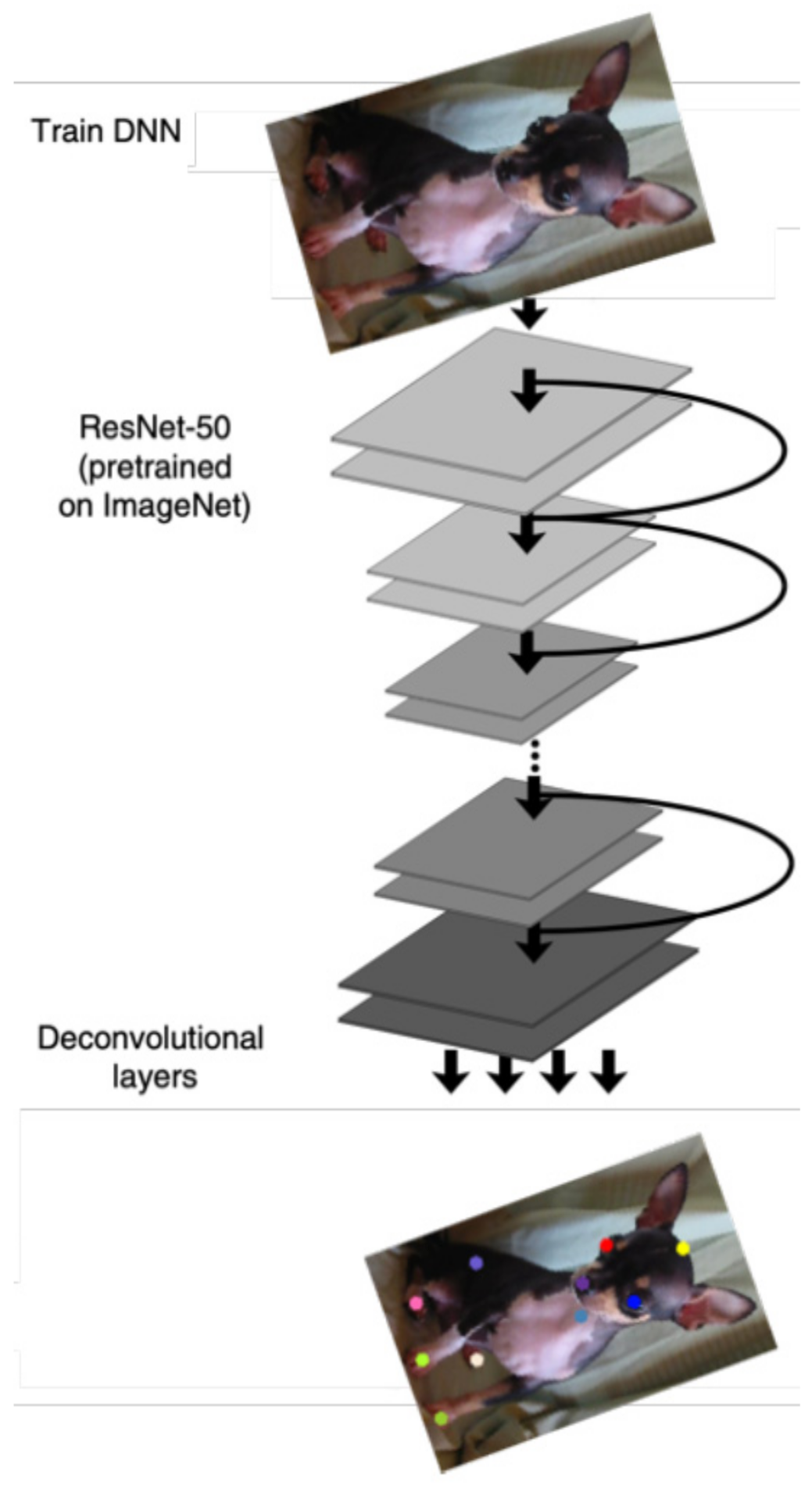
3.1. Pose Recognition Network Model
3.2. Feature Extraction
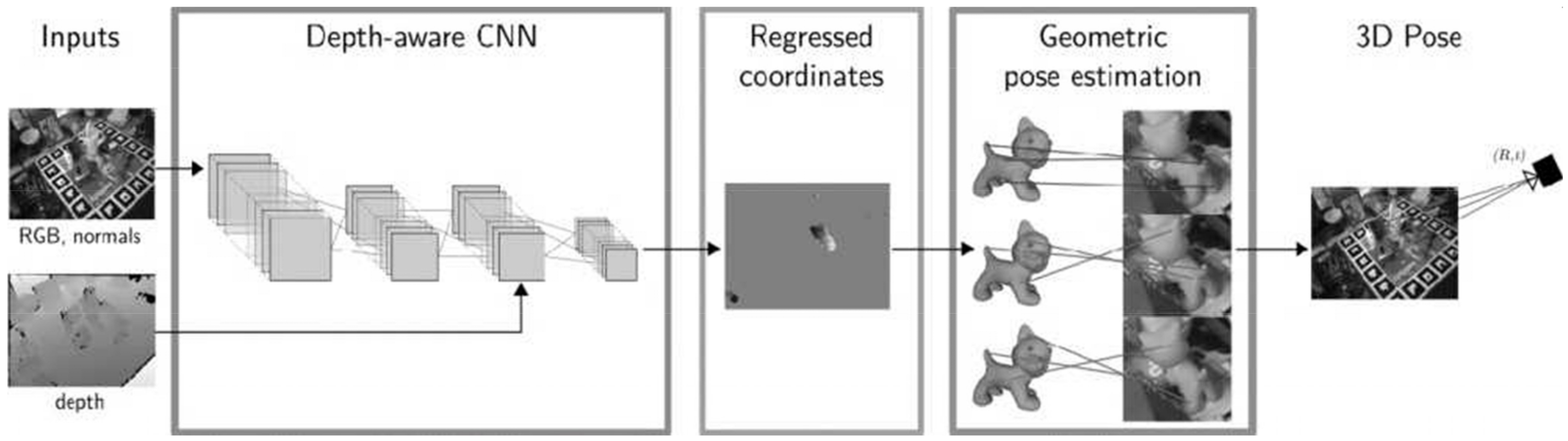
3.3. Framework of Dog Pose Estimation
3.4. Canine Image Recognition
- Batch normalization was performed after each layer. This helped increase mAP to almost 2%. Thus, the dropout layer that was used earlier was no longer required.
- To further increase detection accuracy, the images were resized to a high resolution of (448 × 448). Therefore, increase the mAP to 4%.
- A non-maximum suppression method is implemented on the obtained results to refine the output. For each class, the low-probability predictions are discarded. This is carried out by setting a threshold value. Predictions below the threshold are suppressed, and thus the final output has only features that are detected with a higher confidence value.
4. Experiments and Results
4.1. Data Set and Experimental Setting
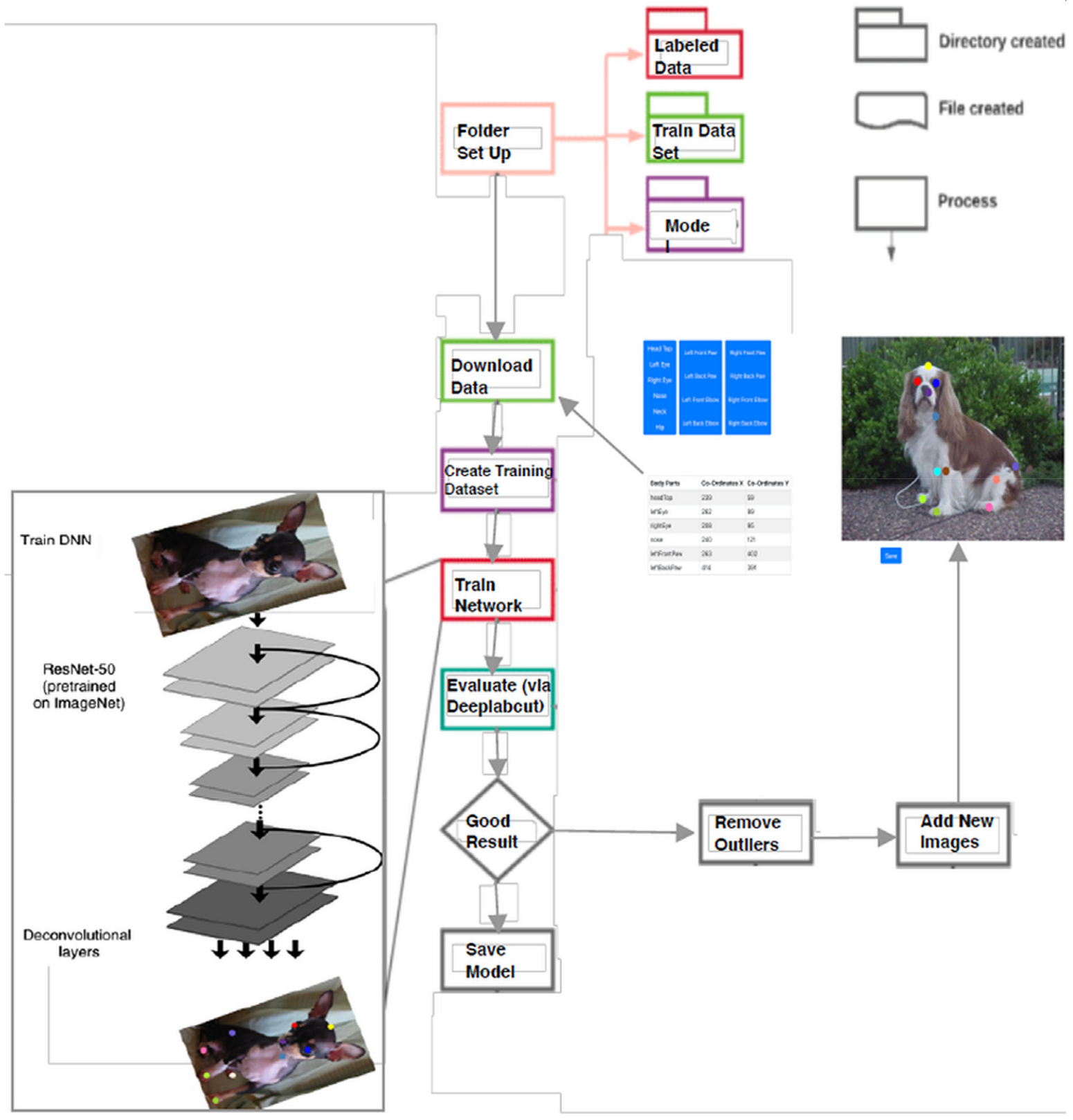
4.2. Procedure for Using the DLC Toolbox
- Training the data set: Collect images with different positions features of the canine animal behavior annotations and select the minimum region-of-interest (ROI), and hence while annotation is compressed the sample dataset is attained.
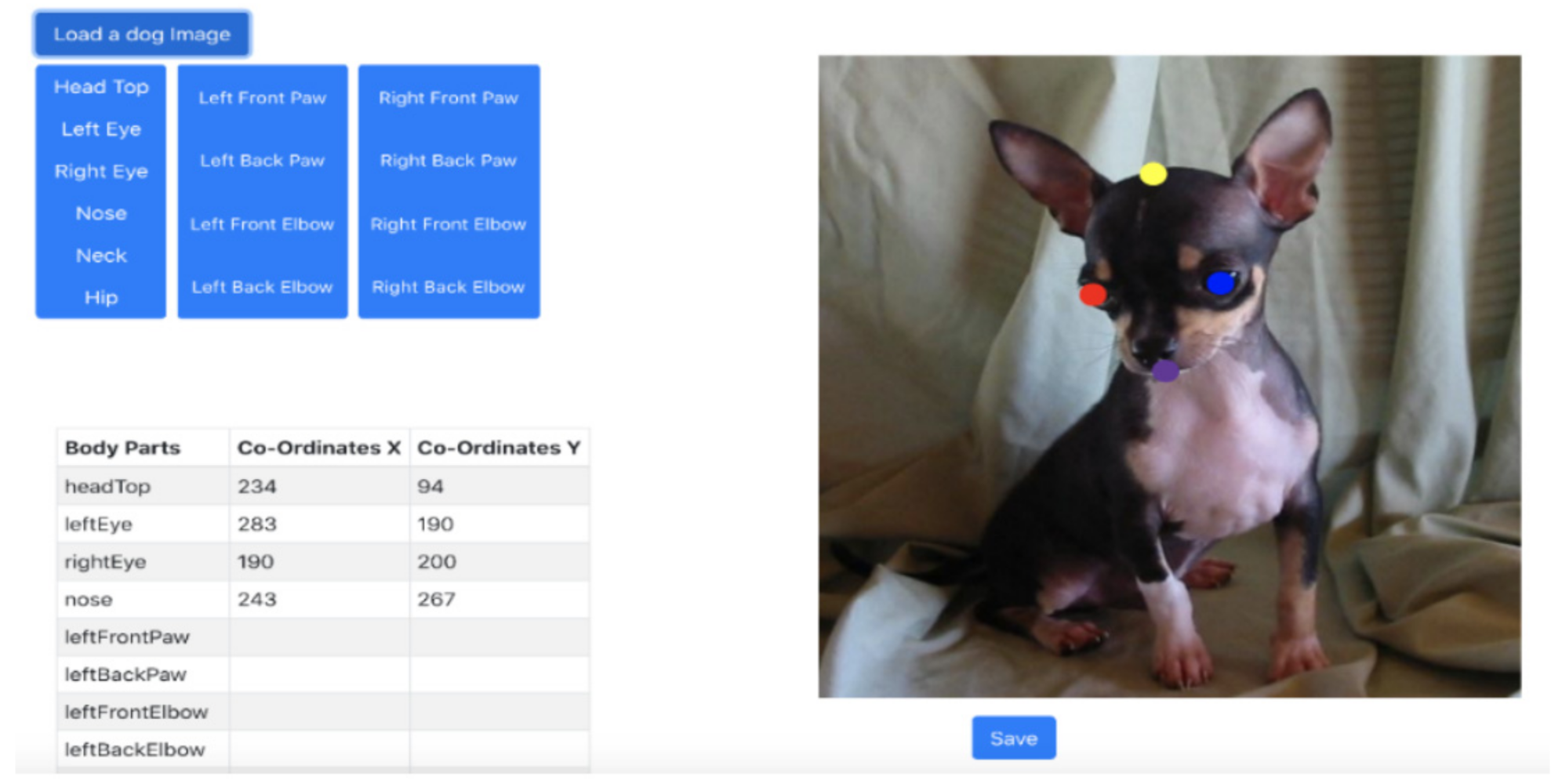
- Manual labelling: Locate the different body characteristics of the dog: The intersection parts of the canine feature are marked manually (for example, the wrist and elbow are marked as features of interest).
- Train a DNN architecture using the DLC toolbox: The manually labeled canine feature is further trained using DNN to predict body part location using the base image loaded in the framework. A different information layer is derived within a part of canine feature to predict the possibility that a canine body feature is in a specific pixel. Training of data adjusts both information and DNN weights and further storage. The trained network (DNN) can be used to derive the positions of canine body parts from images or videos. The images show the most likely locations of canine body parts for 17 labeled canine body parts.
4.3. Markerless Dog Body Annotation
4.4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akihiro, N.; Ishida, Y.; Uezono, N.; Funaya, H.; Nakashima, K.; Suzuki, T.; Shibata, T.; Wakana, S. Low-cost three-dimensional gait analysis system for mice with an infrared depth sensor. Neurosci. Res. 2015, 100, 55–62. [Google Scholar]
- Nakamura, T.; Hori, E.; Matsumoto, J.; Bretas, R.V.; Takamura, Y.; Ono, T.; Nishijo, H. A markerless 3D computerized motion capture system incorporating a skeleton model for monkeys. PLoS ONE 2016, 11, e016615411. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nashaat, M.A.; Oraby, H.; Peña, L.B.; Dominiak, S.; Larkum, M.E.; Sachdev, R.N. Pixying Behavior: A Versatile Real-Time and Post Hoc Automated Optical Tracking Method for Freely Moving and Head Fixed Animals. eNeuro 2017, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pereira, T.D.; Aldarondo, D.E.; Willmore, L.; Kislin, M.; Wang, S.S.; Murthy, M.; Shaevitz, J.W. Fast animal pose estimation using deep neural networks. Nat. Methods 2019, 16, 117–125. [Google Scholar] [CrossRef]
- Mathis, A.; Mamidanna, P.; Abe, T.; Cury, K.M.; Murthy, V.N.; Mathis, M.W.; Bethge, M. Markerless tracking of user-defined features with deep learning. arXiv 2018, arXiv:1804.03142. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Yang, W.; Jiachun, Z. Real-time face detection based on YOLO. In Proceedings of the 1st IEEE International Conference on Knowledge Innovation and Invention, Jeju, Korea, 23–27 July 2018. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Contex. Springer: Cham, Switzerland, 2018. [Google Scholar]
- Pishchulin, L.; Tang, S.; Andres, B.; Insafutdinov, E.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepercut: Joint subset partition and labeling for multi person posture estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 34–50. [Google Scholar]
- Mathis, A.; Biasi, T.; Schneider, S.; Yuksekgonul, M.; Rogers, B.; Bethge, M.; Mathis, M.W. Pretraining boosts out-of-domain robustness for pose estimation. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Seattle, WA, USA, 3–8 January 2021. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliunas, R.; Damaševičius, R. Detection of sitting posture using hierarchical image composition and deep learning. PeerJ Comput. Sci. 2021, 7, e447. [Google Scholar] [CrossRef]
- Žemgulys, J.; Raudonis, V.; Maskeliūnas, R.; Damaševičius, R. Recognition of basketball referee signals from real-time videos. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 979–991. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-time hand gesture recognition based on deep learning YOLOv3 model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Maskeliunas, R.; Raudonis, V.; Damasevicius, R. Recognition of emotional vocalizations of canine. Acta Acust. United Acust. 2018, 104, 304–314. [Google Scholar] [CrossRef]
- Petraitis, T.; Maskeliūnas, R.; Damaševičius, R.; Połap, D.; Woźniak, M.; Gabryel, M. Environment scene classification based on images using bag-of-words. Stud. Comput. Intell. 2019, 829, 281–303. [Google Scholar] [CrossRef]
- Malūkas, U.; Maskeliūnas, R.; Damaševičius, R.; Woźniak, M. Real time path finding for assisted living using deep learning. J. Univers. Comput. Sci. 2018, 24, 475–487. [Google Scholar]
- Cao, J.; Tang, H.; Fang, H.; Shen, X.; Lu, C.; Tai, Y. Cross-domain adaptation for animal pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9497–9506. [Google Scholar] [CrossRef] [Green Version]
- Karashchuk, P.; Rupp, K.L.; Dickinson, E.S.; Walling-Bell, S.; Sanders, E.; Azim, E.; Tuthill, J.C. Anipose: A toolkit for robust markerless 3D pose estimation. Cell Rep. 2021, 36, 109730. [Google Scholar] [CrossRef]
- Kearney, S.; Li, W.; Parsons, M.; Kim, K.I.; Cosker, D. RGBD-dog: Predicting canine pose from RGBD sensors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8333–8342. [Google Scholar] [CrossRef]
- Alameer, A.; Kyriazakis, I.; Bacardit, J. Automated recognition of postures and drinking behaviour for the detection of compromised health in pigs. Sci. Rep. 2020, 10, 13665. [Google Scholar] [CrossRef]
- Ayadi, S.; Ben Said, A.; Jabbar, R.; Aloulou, C.; Chabbouh, A.; Achballah, A.B. Dairy cow rumination detection: A deep learning approach. In International Workshop on Distributed Computing for Emerging Smart Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 123–139. [Google Scholar] [CrossRef]
- Brünger, J.; Gentz, M.; Traulsen, I.; Koch, R. Panoptic segmentation of individual pigs for posture recognition. Sensors 2020, 20, 3710. [Google Scholar] [CrossRef]
- Hahn-Klimroth, M.; Kapetanopoulos, T.; Gübert, J.; Dierkes, P.W. Deep learning-based pose estimation for african ungulates in zoos. Ecol. Evol. 2021, 11, 6015–6032. [Google Scholar] [CrossRef]
- Liu, X.; Yu, S.; Flierman, N.A.; Loyola, S.; Kamermans, M.; Hoogland, T.M.; De Zeeuw, C.I. OptiFlex: Multi-frame animal pose estimation combining deep learning with optical flow. Front. Cell. Neurosci. 2021, 15, 621252. [Google Scholar] [CrossRef]
- Shao, H.; Pu, J.; Mu, J. Pig-posture recognition based on computer vision: Dataset and exploration. Animals 2021, 11, 1295. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, Q.; Chen, S.; Zhu, C. From state estimation for dogs to the internet of dogs. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing ICIVC, Xiamen, China, 5–7 July 2019; pp. 748–753. [Google Scholar] [CrossRef]
- Wang, Y.; Li, J.; Zhang, Y.; Sinnott, R.O. Identifying lameness in horses through deep learning. In Proceedings of the ACM Symposium on Applied Computing, Virtual Event, Korea, 22–26 March 2021; pp. 976–985. [Google Scholar] [CrossRef]
- Wu, A.; Kelly Buchanan, E.; Whiteway, M.R.; Schartner, M.; Meijer, G.; Noel, J.; Paninski, L. Deep graph pose: A semi-supervised deep graphical model for improved animal pose tracking. bioRxiv; 2020. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, L.; Zhao, K.; Wiliem, A.; Hemson, G.; Lovell, B. Omni-supervised joint detection and pose estimation for wild animals. Pattern Recognit. Lett. 2020, 132, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Miami, FL, USA. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Miami, FL, USA, 20–25 June 2009; IEEE: Miami, FL, USA. [Google Scholar] [CrossRef] [Green Version]
- Kulikajevas, A.; Maskeliunas, R.; Damasevicius, R.; Scherer, R. Humannet-a two-tiered deep neural network architecture for self-occluding humanoid pose reconstruction. Sensors 2021, 21, 3945. [Google Scholar] [CrossRef]
- Li, M.; Jiang, Z.; Liu, Y.; Chen, S.; Wozniak, M.; Scherer, R.; Li, Z. Sitsen: Passive sitting posture sensing based on wireless devices. Int. J. Distrib. Sens. Netw. 2021, 17, 17. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dog Feature | Training Image Dataset | Testing Image Dataset |
|---|---|---|
| Eye Left | 2.81 | 4.10 |
| Eye Right | 2.85 | 4.41 |
| Nose | 2.79 | 5.44 |
| Head Top | 3.62 | 9.01 |
| Hip | 3.67 | 11.28 |
| Right Back Paw | 5.77 | 19.87 |
| Right Front Paw | 4.21 | 22.18 |
| Left Back Paw | 3.64 | 21.35 |
| Left Front Paw | 4.16 | 9.35 |
| Left Front Elbow | 6.78 | 21.68 |
| Right Front Elbow | 4.09 | 23.63 |
| Left Back Elbow | 4.16 | 18.33 |
| Right Back Elbow | 2.94 | 24.64 |
| Neck | 1.94 | 21.83 |
| Overall Detection | 2.91 | 20.12 |
| Dog Feature | Training Image Dataset | Testing Image Dataset |
|---|---|---|
| Eye Left | 0.9539 | 0.9434 |
| Eye Right | 0.9536 | 0.9409 |
| Nose | 0.9541 | 0.9325 |
| Head Top | 0.9473 | 0.9034 |
| Hip | 0.9469 | 0.8849 |
| Right Back Paw | 0.9298 | 0.8149 |
| Right Front Paw | 0.9425 | 0.7960 |
| Left Back Paw | 0.9471 | 0.8028 |
| Left Front Paw | 0.9429 | 0.9006 |
| Left Front Elbow | 0.9216 | 0.8001 |
| Right Front Elbow | 0.9435 | 0.7842 |
| Left Back Elbow | 0.9429 | 0.8274 |
| Right Back Elbow | 0.9529 | 0.7760 |
| Neck | 0.9610 | 0.7989 |
| Mean | 0.9462 | 0.8479 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raman, S.; Maskeliūnas, R.; Damaševičius, R. Markerless Dog Pose Recognition in the Wild Using ResNet Deep Learning Model. Computers 2022, 11, 2. https://doi.org/10.3390/computers11010002
Raman S, Maskeliūnas R, Damaševičius R. Markerless Dog Pose Recognition in the Wild Using ResNet Deep Learning Model. Computers. 2022; 11(1):2. https://doi.org/10.3390/computers11010002
Chicago/Turabian StyleRaman, Srinivasan, Rytis Maskeliūnas, and Robertas Damaševičius. 2022. "Markerless Dog Pose Recognition in the Wild Using ResNet Deep Learning Model" Computers 11, no. 1: 2. https://doi.org/10.3390/computers11010002
APA StyleRaman, S., Maskeliūnas, R., & Damaševičius, R. (2022). Markerless Dog Pose Recognition in the Wild Using ResNet Deep Learning Model. Computers, 11(1), 2. https://doi.org/10.3390/computers11010002