4.1. Dataset Assembly
The field of network intrusion detection has always suffered from a lack of suitable datasets for evaluation. Privacy concerns and the difficulty of posterior attack traffic identification are the reason that no dataset exists that contains realistic U2R/R2L (user-to-root, remote-to-local) traffic and benign traffic from a real-world environment [
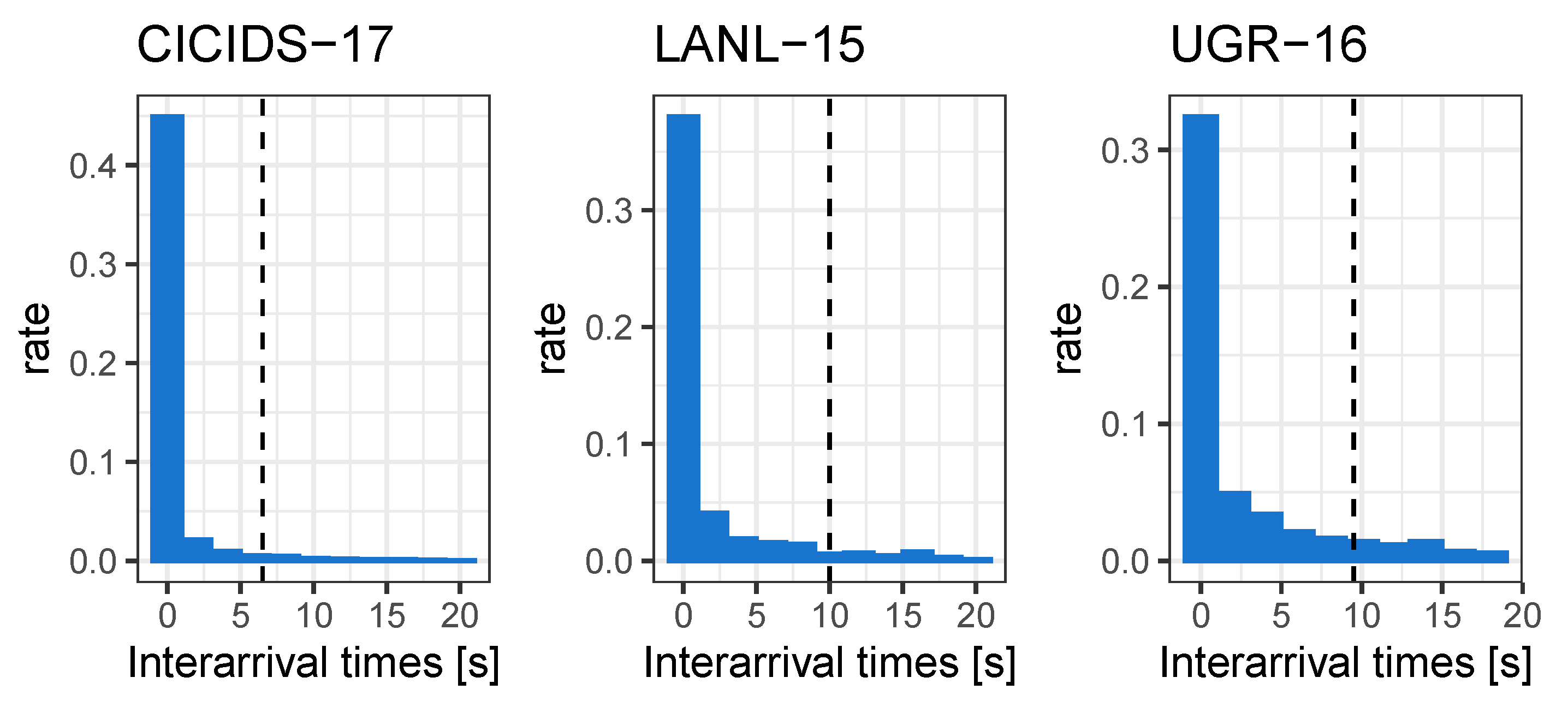
13]. To evaluate CBAM, we need both representative access attack traffic to test detection rates, and background traffic from a realistic environment to test false positive rates. To ensure that both criteria are met, we selected three modern publicly available datasets that complement each other: CICIDS-17 [
14]; LANL-15 [
15]; and UGR-16 [
16]. The CICIDS-17 dataset contains traffic from a variety of modern attacks, while the UGR-16 dataset’s length is suitable for long-term evaluation. The LANL-15 dataset contains enterprise network traffic along with several real-world access attacks.
We trained models with the same hyperparameters on each dataset to demonstrate the capability of CBAM to detect various attacks and perform well in a realistic environment.
CICIDS-17: This dataset [
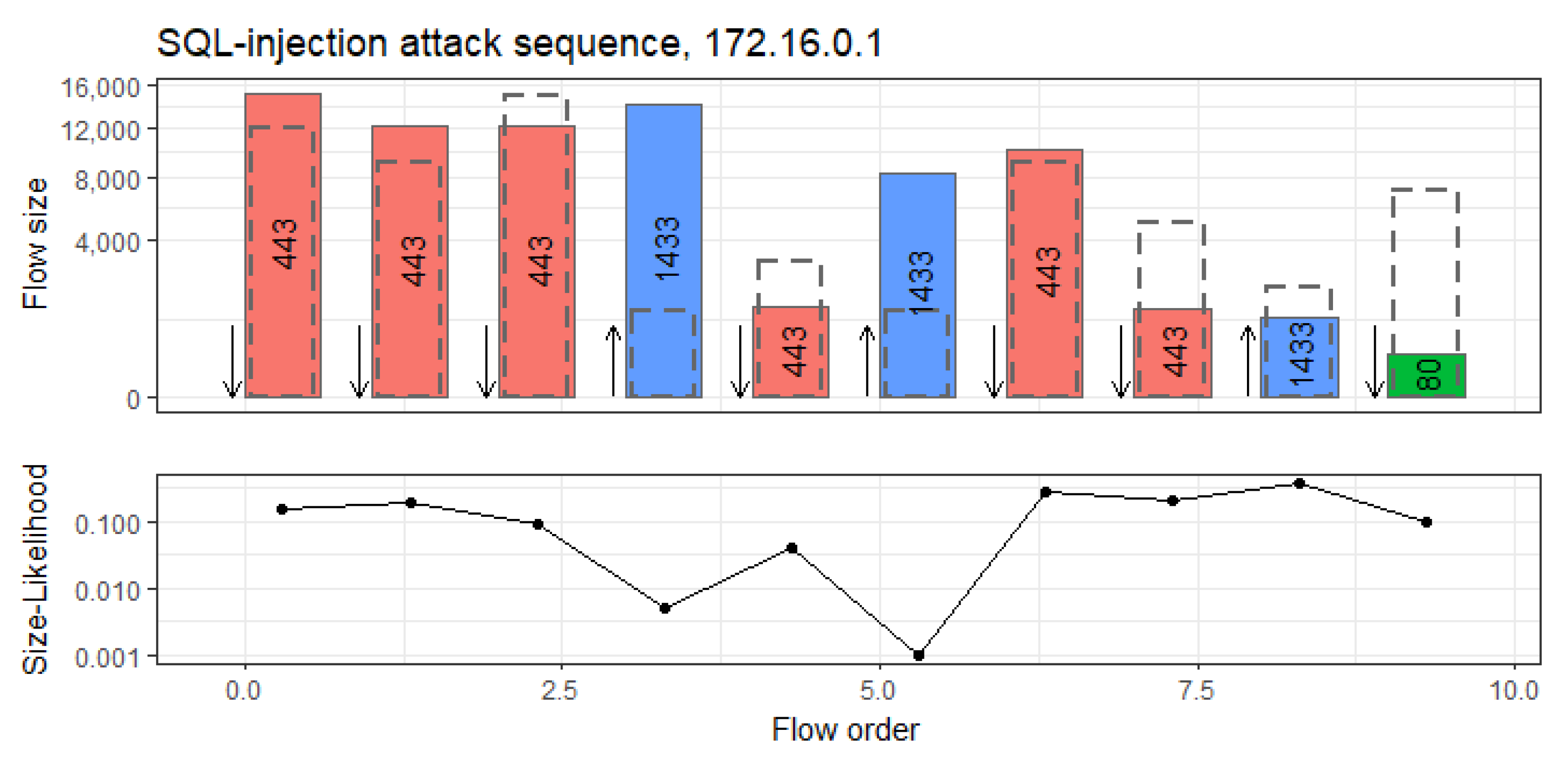
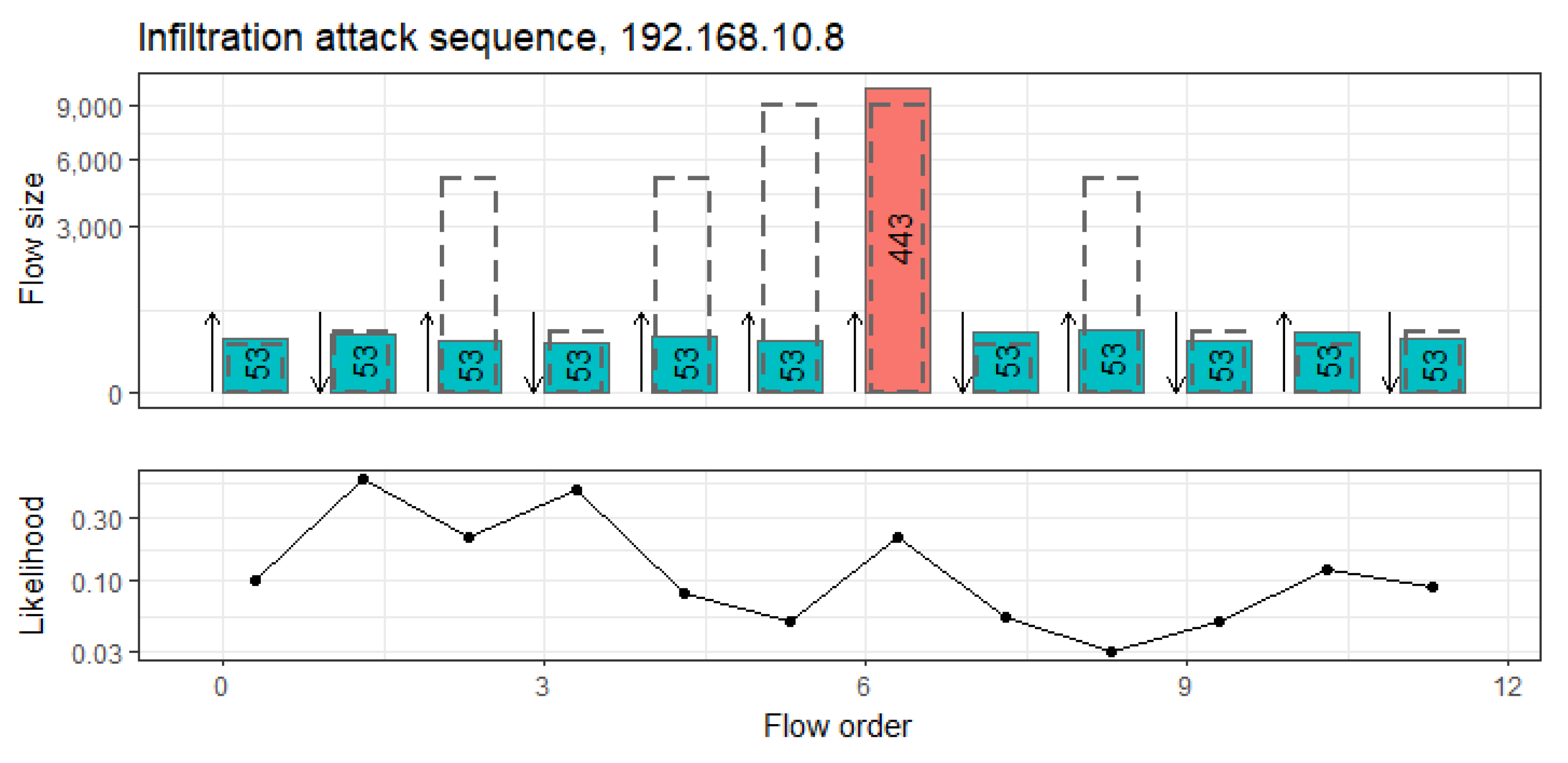
14], released by the Canadian Institute for Cybersecurity (CIC), contains 5 days of network traffic collected from 12 computers with attacks that were conducted in a laboratory setting. The computers all have different operating systems to enable a wider range of attack scenarios. The attack data of this dataset are among the most diverse among NID datasets and contain SQL injections, heartbleed attacks, brute-forcing, various download infiltrations, and cross-site scripting (XSS) attacks, on which we evaluated our detection rates.
The traffic data consist of labelled benign and attack flow events with 85 summary features which can be computed by common routers. The availability of these features makes it suitable to evaluate machine-learning techniques that were only tested on the KDD-99 data.
The benign traffic is generated on hosts using previously gathered and implemented traffic profiles to make the traffic more heterogeneous during a comparably short time span, and consequently closer to reality. For our evaluation, we selected four hosts that are subject to U2R and R2L attacks, two web servers and two personal computers.
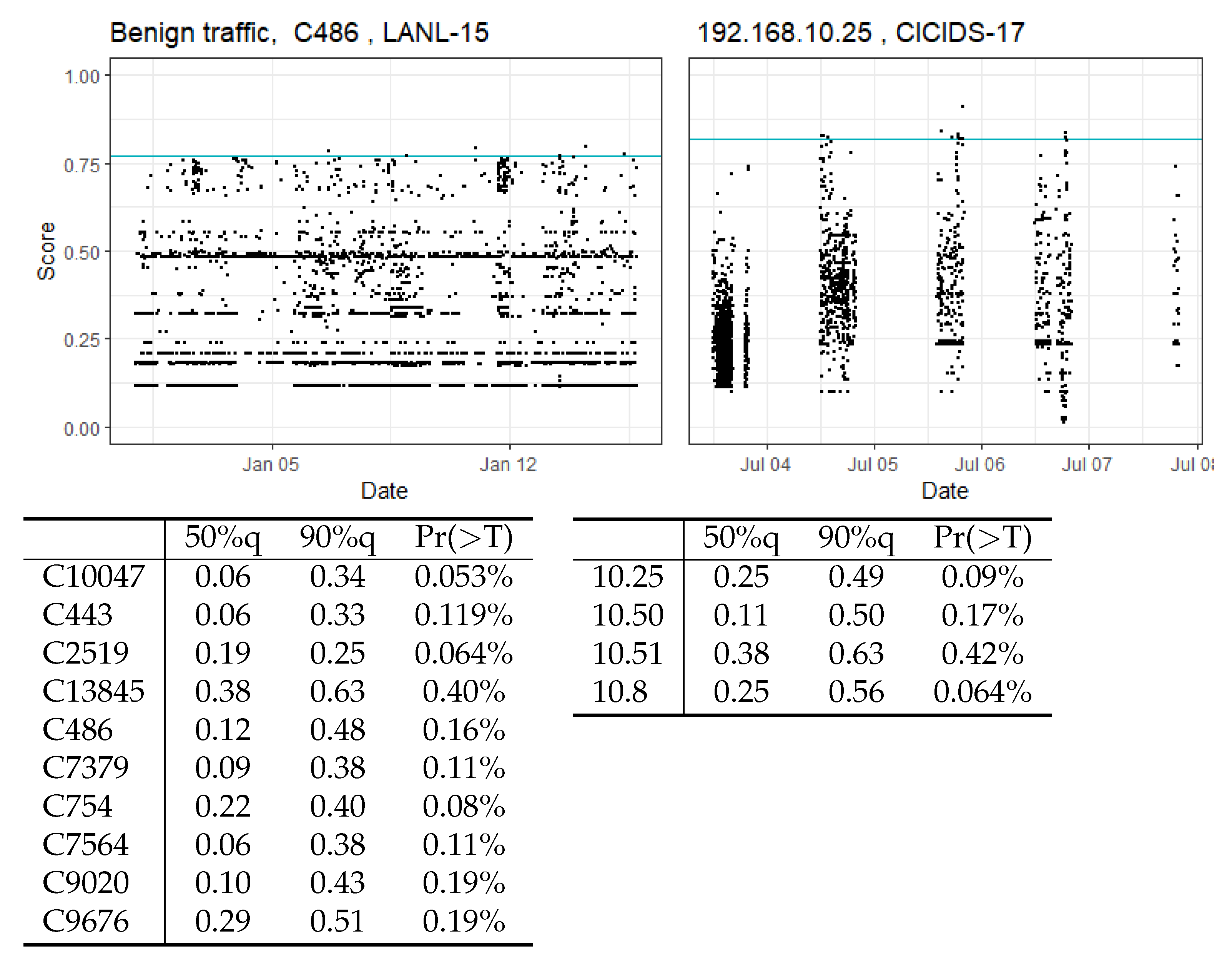
This dataset is generated in a laboratory environment, with a higher proportion of attack traffic than is normally encountered in a realistic setting. Consequently, we need to test it on traffic from real-world environments to prove that CBAM retains its detection capabilities and low false alert rates.
LANL-15 dataset: In 2015, the Los Alamos National Laboratory (LANL) released a large dataset containing internal network flows (among other data) from their corporate computer network. The netflow data were gathered over a period of 27 days with approximately 600 million events per day [
15].
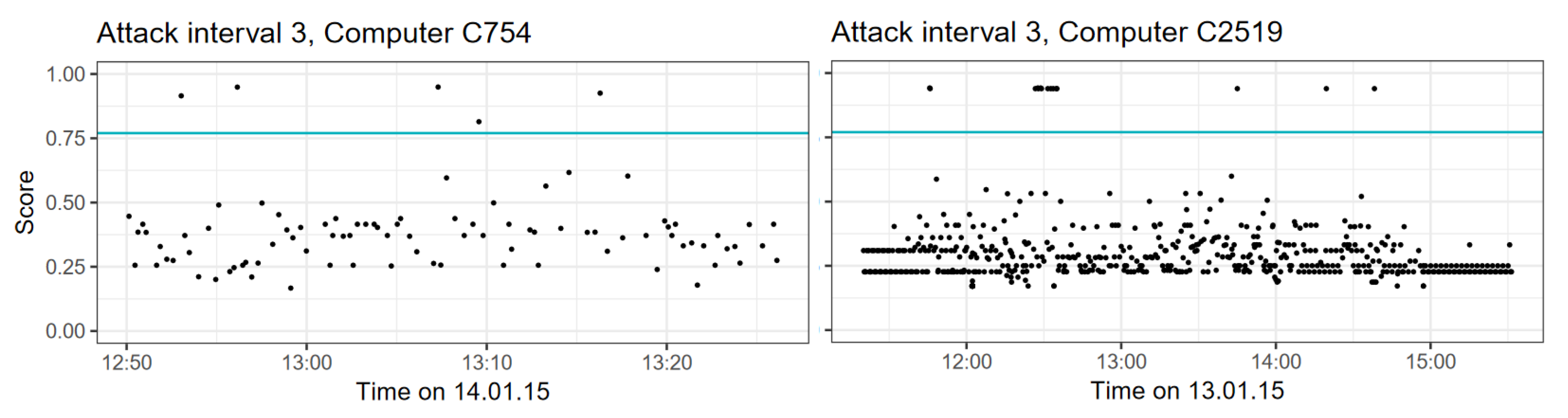
In addition to large amounts of real-world benign traffic, the dataset contains a set of attack events that were conducted by an authorised red team and are supposed to resemble remote access attacks, mainly using the pass-the-hash exploit. We selected this dataset to demonstrate that CBAM is able to detect attacks in a realistic environment with low false alert rates. We isolated traffic from ten hosts, with two being subject to attack events. Two of these hosts resemble server behaviour, while the other eight show the typical behaviour of personal computers.
The provided red team events are not part of the network flow data and only contain information about the time of the attack and the attacked computer. Furthermore, not all of the attack events are conducted on the network level, so it is impossible to tell exactly which flows correspond to malicious activity and which do not. Therefore, we labelled all flows in a narrow time interval around each of the attack timestamps as possibly malicious. As these intervals are narrow, identified anomalies likely correspond to the conducted attack.
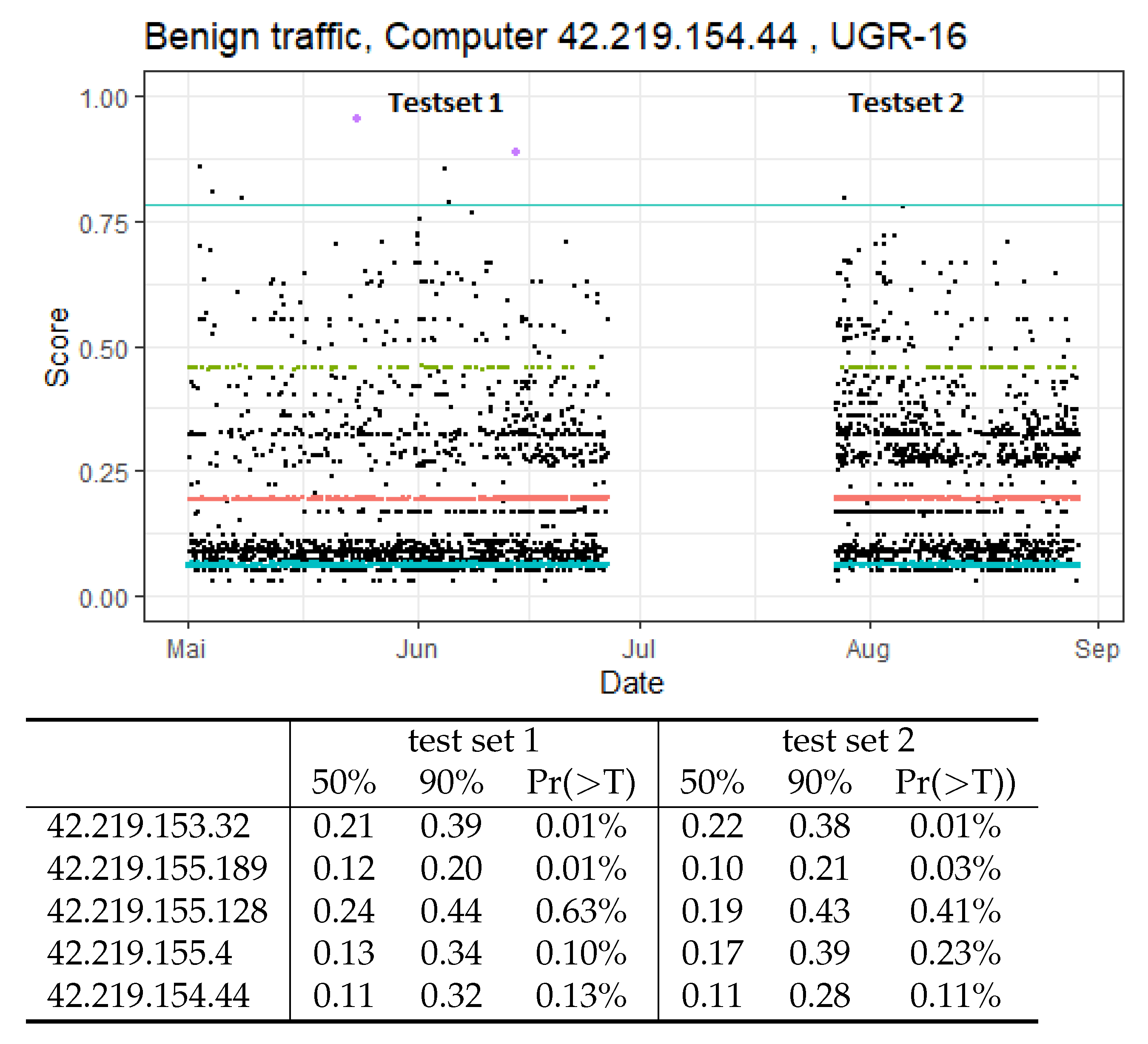
UGR-16 dataset: The UGR-16 dataset [
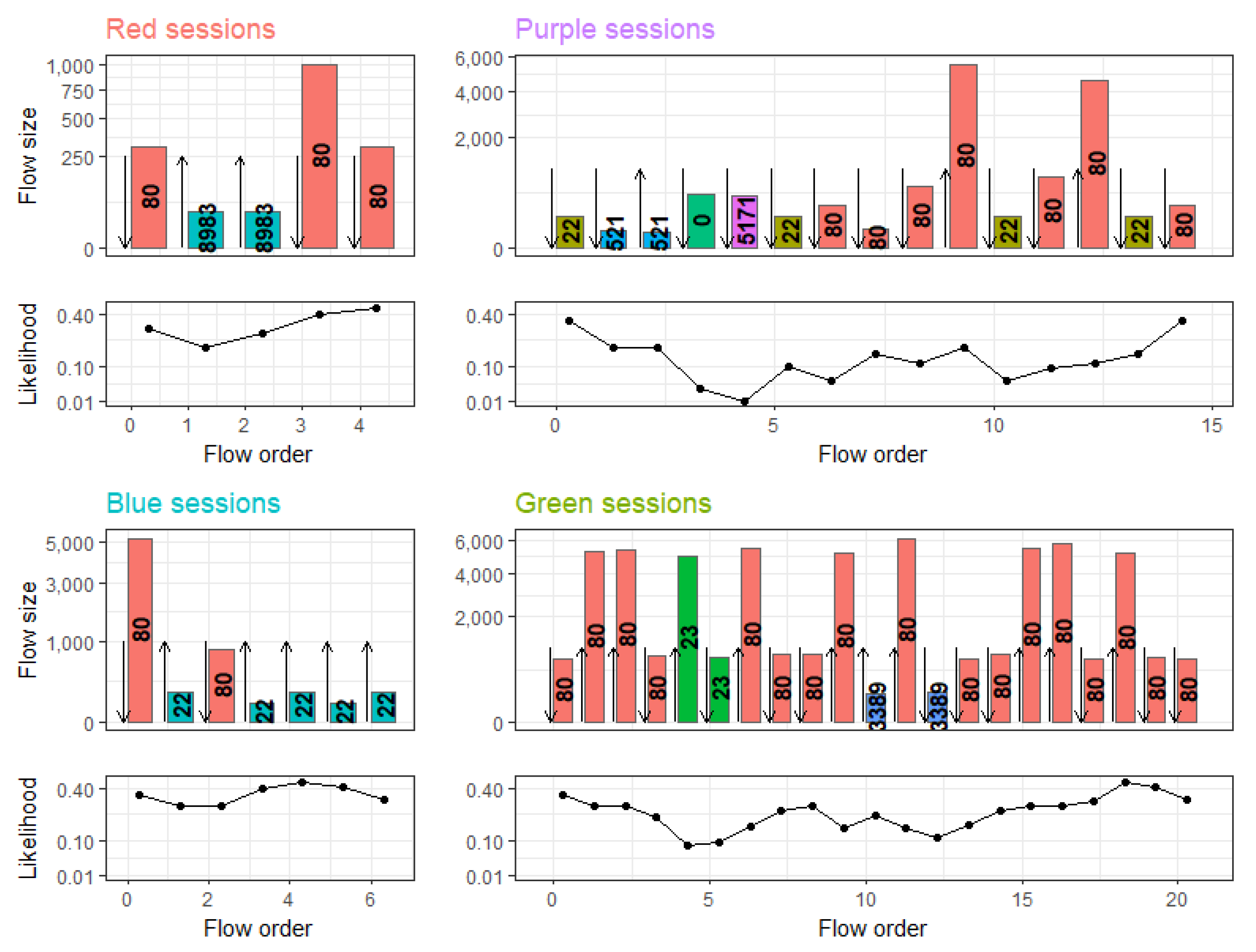
16] was released by the University of Grenada in 2016 and contains network flows from a Spanish ISP. It contains both clients’ access to the Internet and traffic from servers hosting a number of services. The data thus contain a wide variety of real-world traffic patterns, unlike other available datasets. Additionally, a main focus in the creation of the data was the consideration of long-term traffic evolution, which allows us to make statements about the robustness of CBAM to concept drift over the 163 day span of the dataset. For our evaluation, we isolated traffic from five web-servers that provide a variety of services.
Other Datasets
Two datasets and their derivatives, DARPA-98 [
17] and KDD-99 [
18], are often used to benchmark detection models, with all anomaly-based techniques discussed in a recent survey [
3] with reported detection rates on U2R and R2L attacks relying on either of them. Both datasets have been pointed out as flawed and can give overoptimistic results due to inconsistencies, a lack of realistic benign traffic, and an imbalance of benign and attack traffic [
19,
20,
21]. Both datasets are 20 years old and outdated. The KDD-99 dataset was collected using a Solaris operating system in a laboratory environment to collect a wide range traffic and OS features, which makes it the most popular dataset to evaluate machine-learning-based techniques. The collection of many of these features is, however, currently infeasible in real-world deployment. All these factors mean that reported detection rates collected on these datasets have to be taken with care.
CTU 2013: The Stratosphere Laboratory [
22] in Prague released this dataset in 2013 to study botnet detection. It consists of more than 10 million labelled network flows captured on lab machines for 13 different botnet attack scenarios. A criticism of this dataset is the unrealistically high amount of malicious traffic contained in the dataset, which makes it easier to spot it while reducing false positives. Furthermore, the way normal or background traffic is generated is described only poorly and leaves the question of how representative it is of actual network traffic.
UNSW-NB 2015: The dataset released by the
University of New South Wales in 2015 [
23] contains real background traffic and synthetic attack traffic collected at the “Cyber Range Lab of the Australian Centre for Cyber Security”. The data were collected from a small number of computers which generate background traffic, which is overlayed with attack traffic using the
IXIA PerfectStorm tool. The time span of the collection is in total 31 h. An advantage of the data is the variety of the attack data, which contain a number of DoS, reconnaissance and access attacks. However, due to the synthetic injection of these attacks, it is unclear how close they are to real-world attack scenarios, and again, the generation process of benign traffic is poorly described and leaves the question how close to the actual network traffic it is.
ADFA 2013/2014 [
24]: The ADFA dataset, released by the
University of New South Wales, focuses on attack scenarios on Linux and Windows systems as well as stealth attacks. To create host targets, the authors installed web servers and database servers, which were then subject to a number of attacks. The dataset is more directed towards attack scenario analysis and is criticised as being unsuitable for intrusion detection due to its lack of traffic diversity. Furthermore, the attack traffic is not well separated from the normal one.
CICIDS 2018 [
14]: This dataset, released by the
Canadian Institute for Cybersecurity (CIC), is generated in a similar fashion to the CICIDS 2017 data that we used in this work. The main differences are that the CICIDS 2018 data spans over three weeks and include in total 450 hosts but lacks the amount of web-attacks that we require and which are present in the CICIDS-2017 dataset.
The LITNET-2020 [
25] dataset from the Kaunas University of Technology Lithuania from 2020 was collected from an academic network over a timespan of 10 months and contains annotated real-life benign and attack traffic. The corresponding network provides a large network topology with more than a million IP-addresses, and the data were collected in the form of network flows with more than 80 features. However, the dataset only contains traffic from high volume attacks such as DoS-, scanning, or worm attacks, which are not suitable to evaluate CBAM.
The Boğaziçi University distributed denial of service dataset [
26] contains both benign traffic from more than 400 users from an academic network as well as artificially created DoS-attack traffic. The dataset spans only 8 min and contains no access attacks.
4.2. Dataset Split
We split our data into a test set and a training set. To resemble a realistic scenario, the sessions in the training data are from a previous time interval than sessions in the test data.
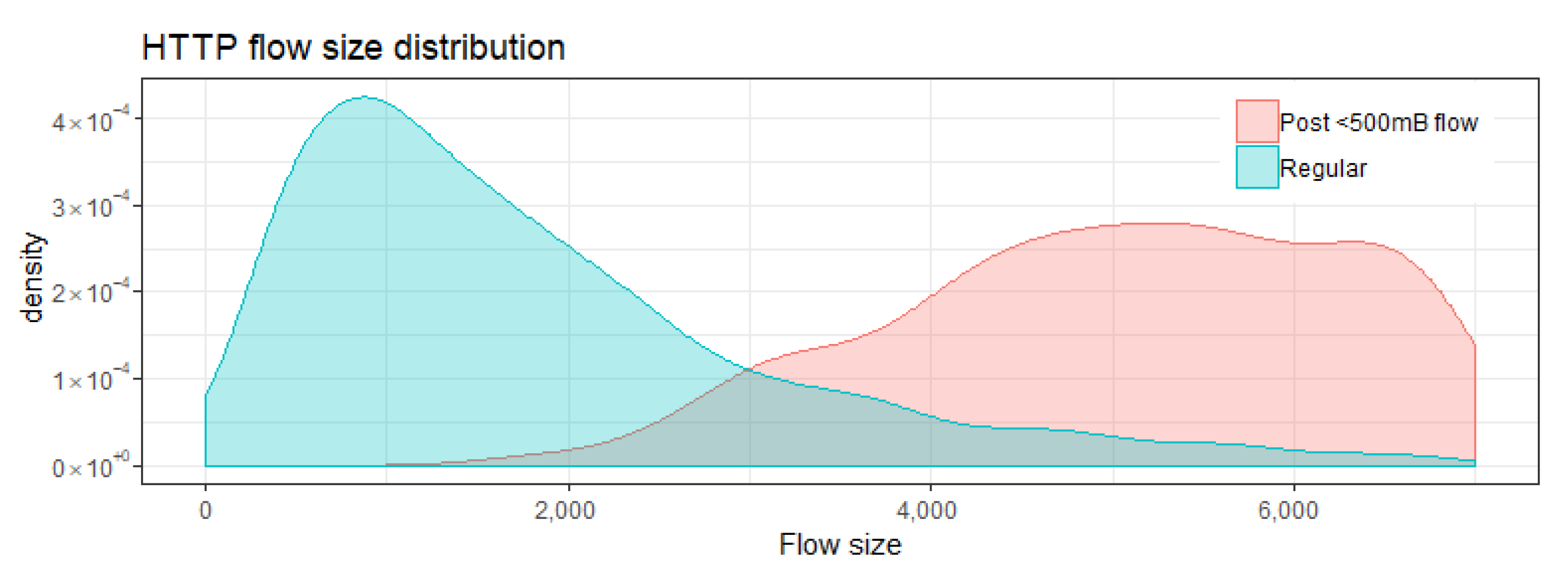
To evaluate detection rates on the CICIDS-17 data, we selected the four hosts in the data that are subject to remote access attacks, two web servers and two personal computers. We chose our test set to contain the known attack data while the training data should only contain the benign data. Due to the short timespan of the dataset, we had to train on traffic from all five days, with the test data intervals being placed around the attack. In total, the test set contains 14 h of traffic for each host while the training set contains 31 h of traffic. While the test set for the CICIDS-17 data covers a shorter timespan, it contains more traffic due to voluminous brute-force attacks.
For the LANL data, the test set stretches approximately over the first 13 days with the training data spanning over the last 14 days. The unusual choice of placing the test set before the training set was made because the attacks occur early in the dataset. However, as the training and test are contained in two non-overlapping intervals, a robustness evaluation is still possible.
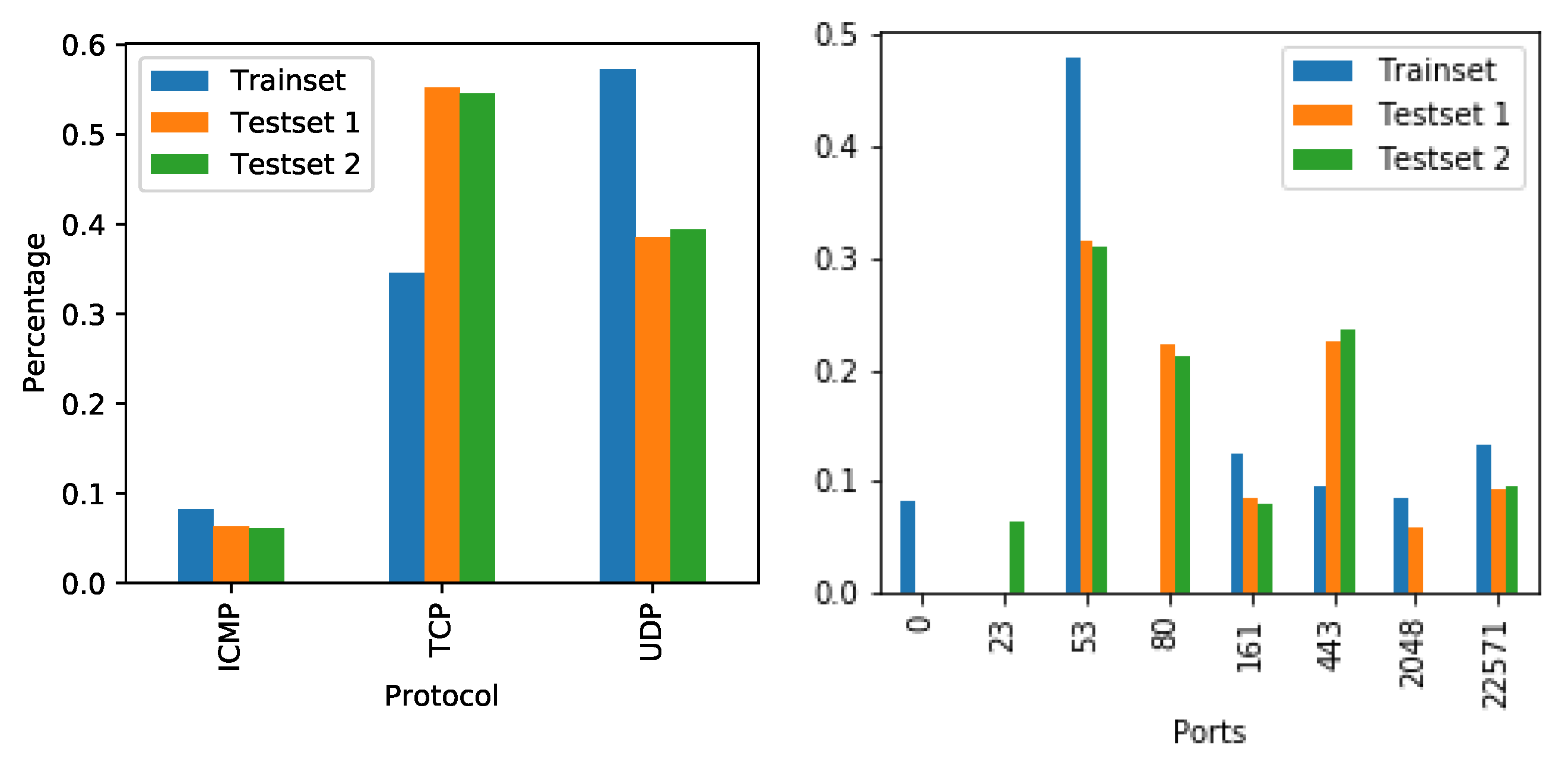
To test the long-term stability and robustness of CBAM against concept drift, we split the UGR-16 data into one training set interval and two test set intervals, for which we can compare model performance. The training set interval stretches over the first month, with the first test set interval containing the sessions from the following two months, and the second test set interval containing the last two months. We then isolated traffic from five web-servers that provide a variety of services that show behavioural evolution.
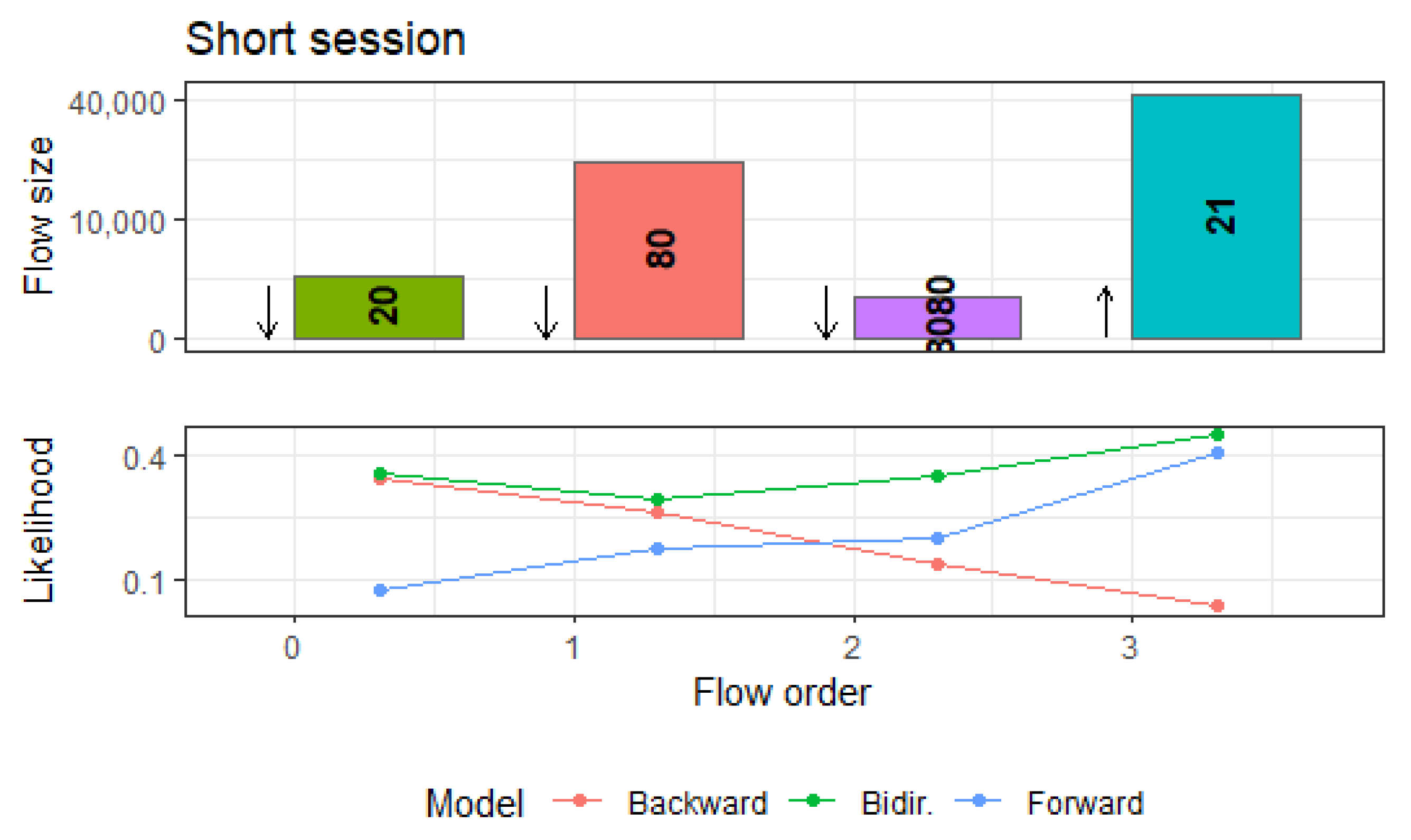
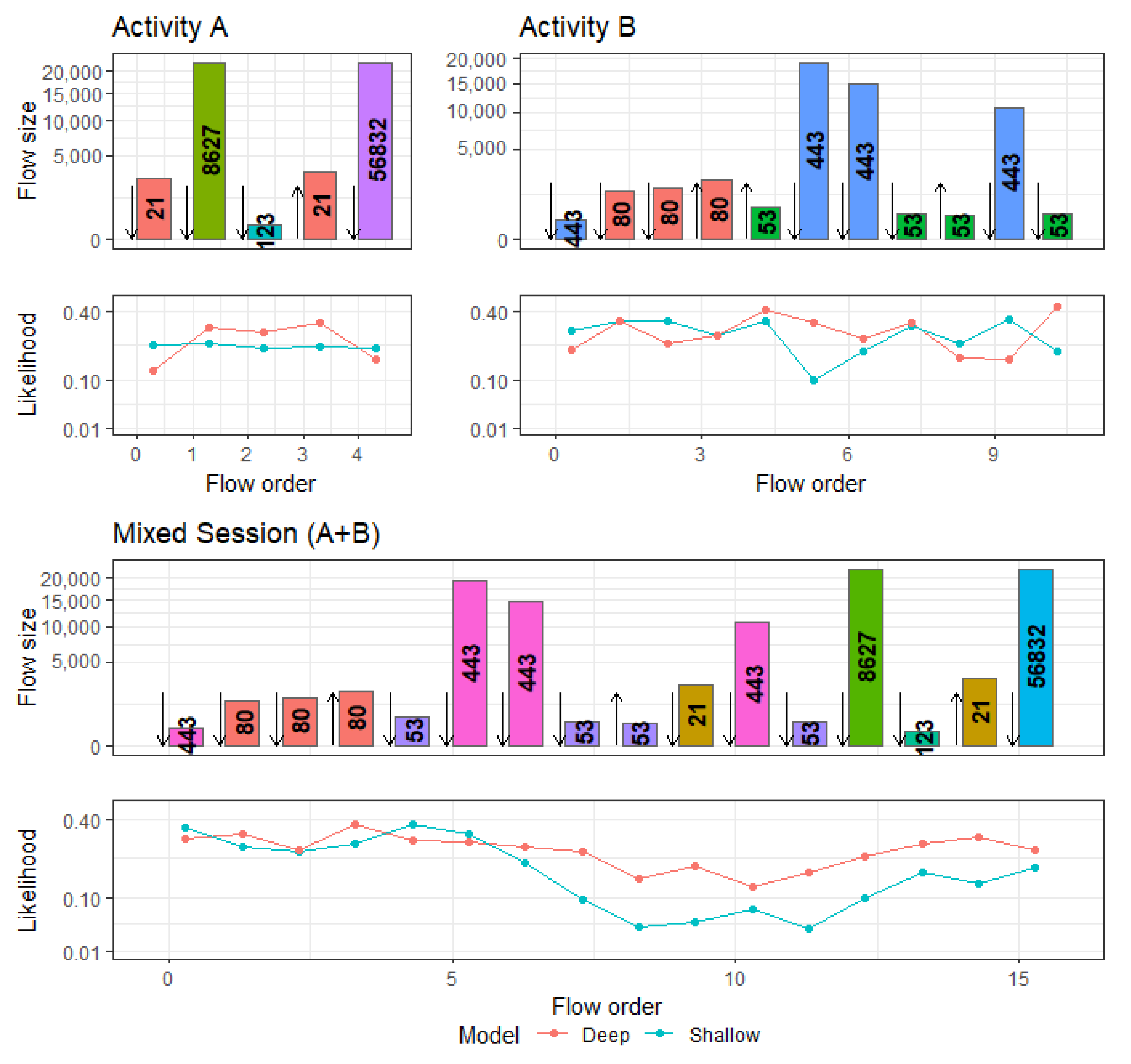
Figure 6 depicts the changes of these servers in terms of protocol and port usage over the different intervals.
We chose our training data to contain approximately 10,000 sessions per host if possible. A summary of the amount of data in the training and test data for each dataset can be found in
Table 2.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}