
Automatic Detection of Traffic Accidents from Video Using Deep Learning Techniques


Abstract
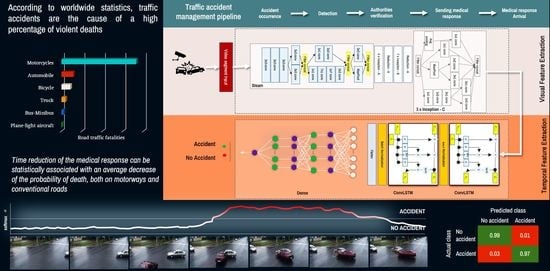
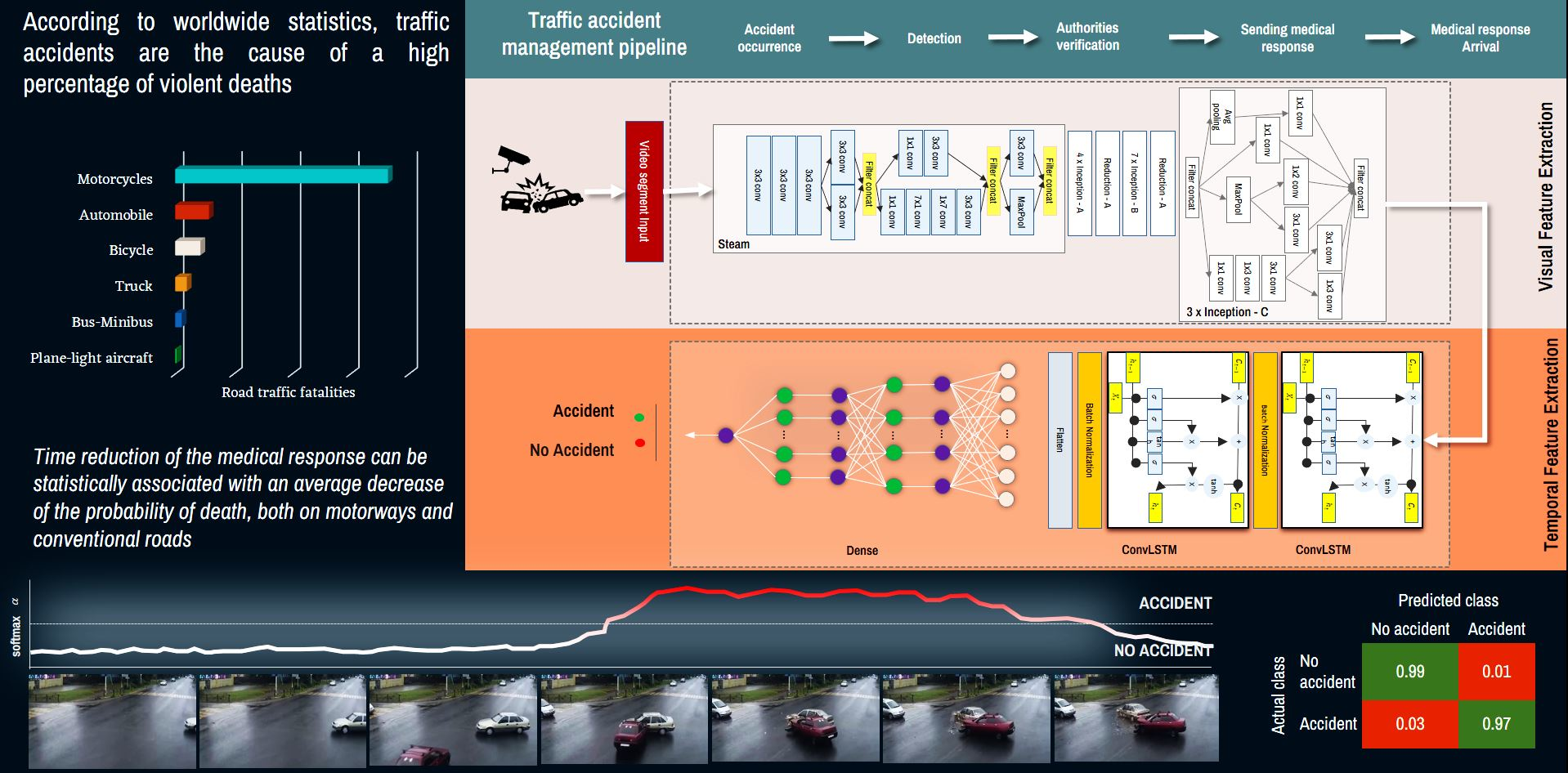
:
1. Introduction
2. Background
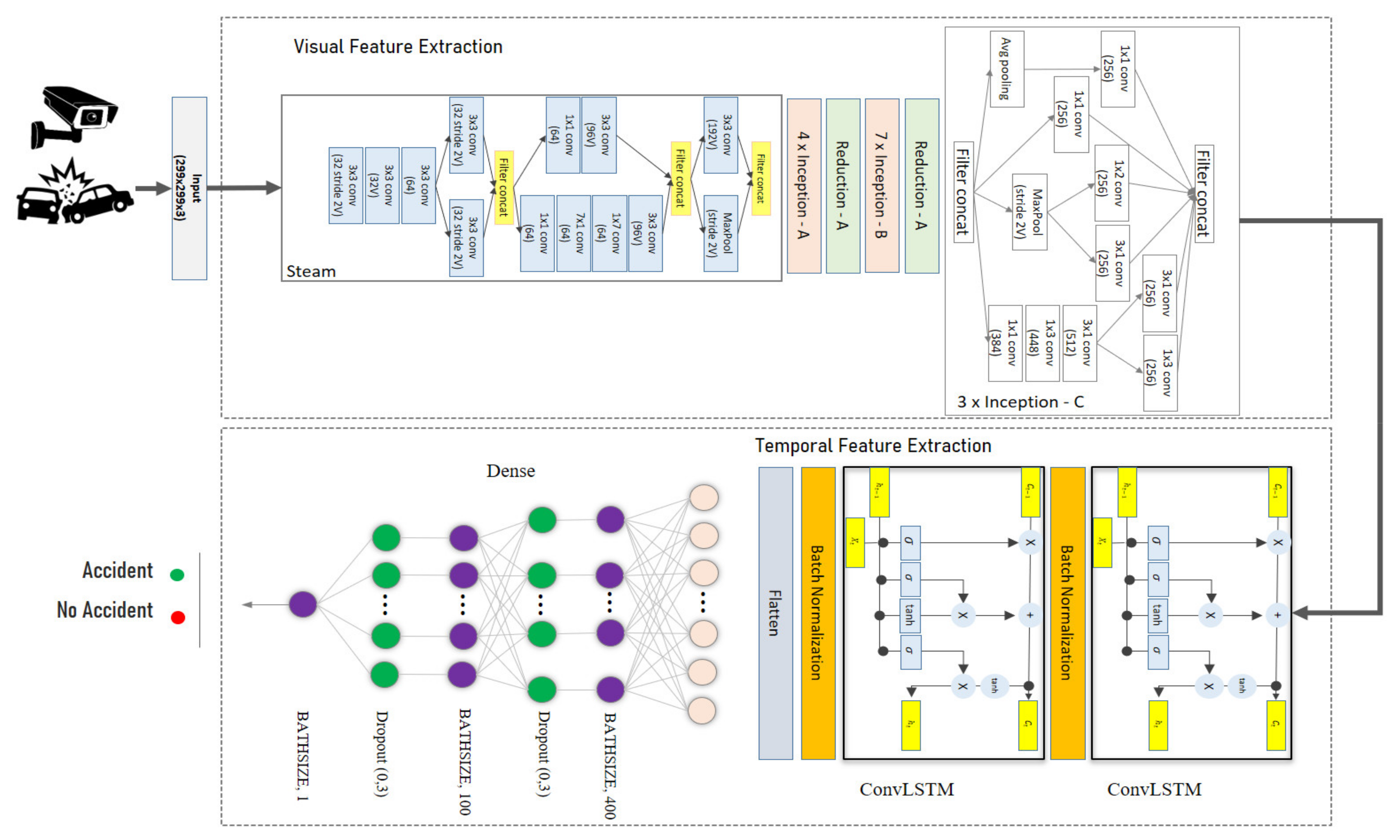
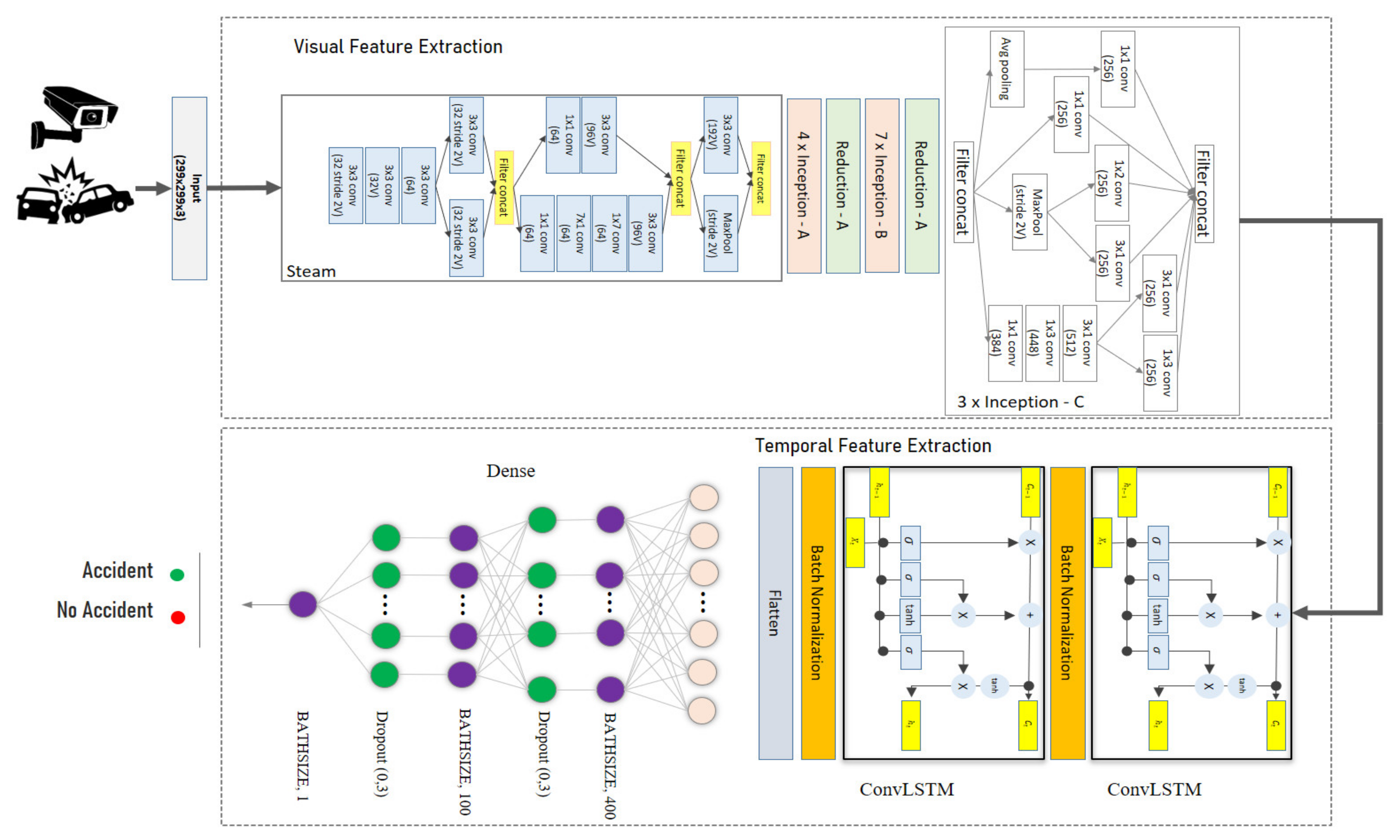
3. Method for Automatic Detection of Traffic Accidents
3.1. Temporal Video Segmentation
3.2. Automatic Detection of Traffic Accidents
4. Results
4.1. Dataset
4.2. Temporal Video Segmentation
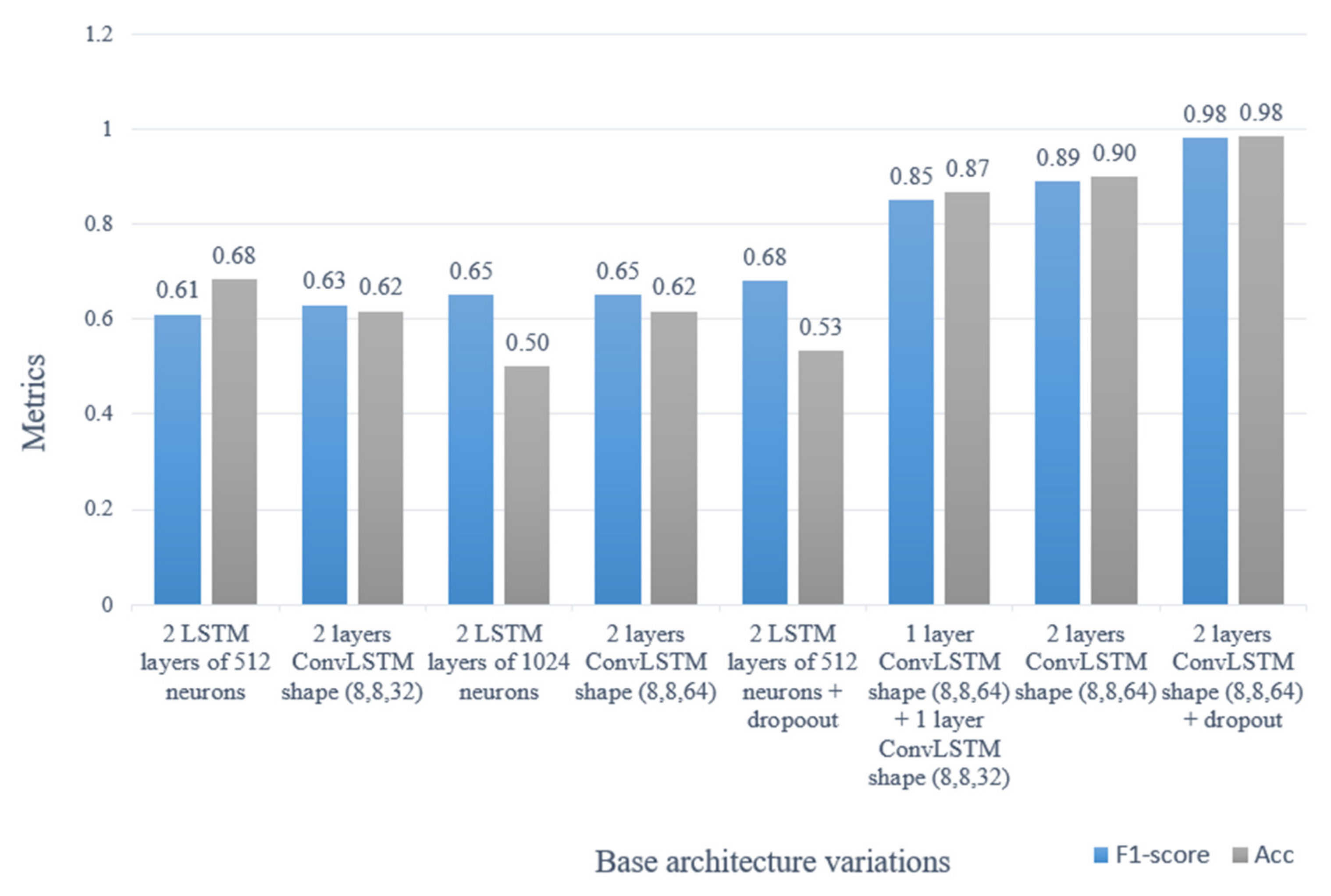
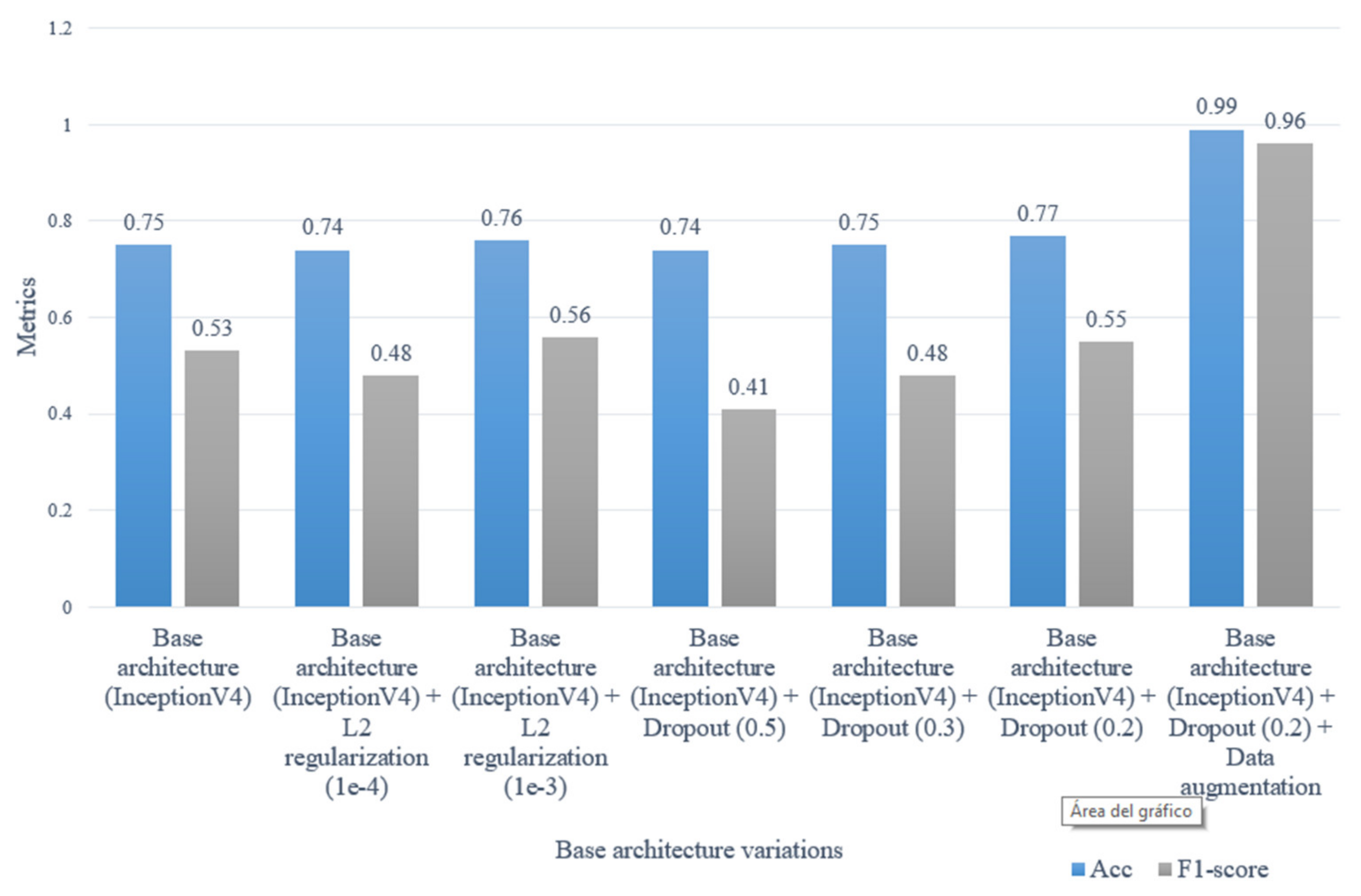
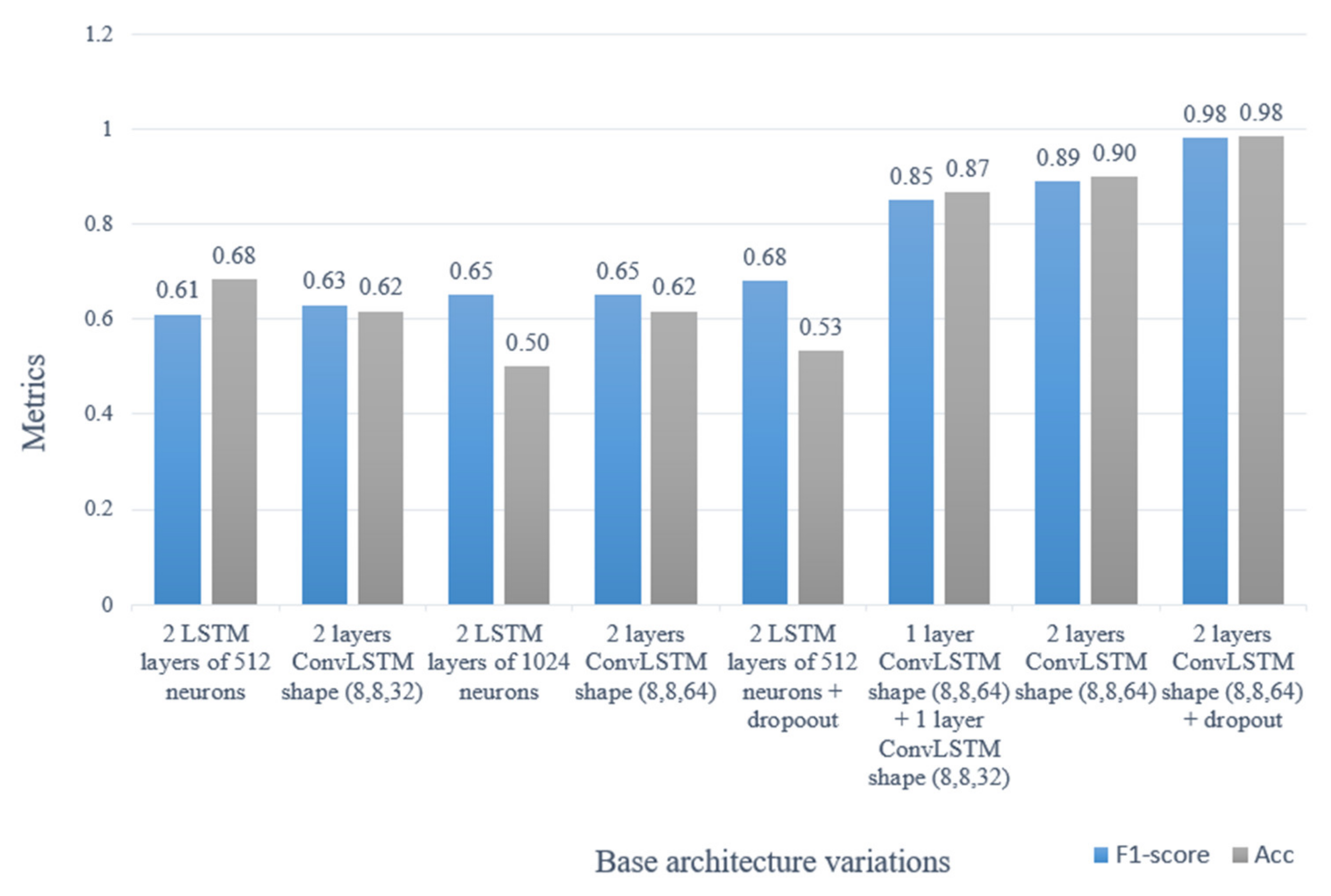
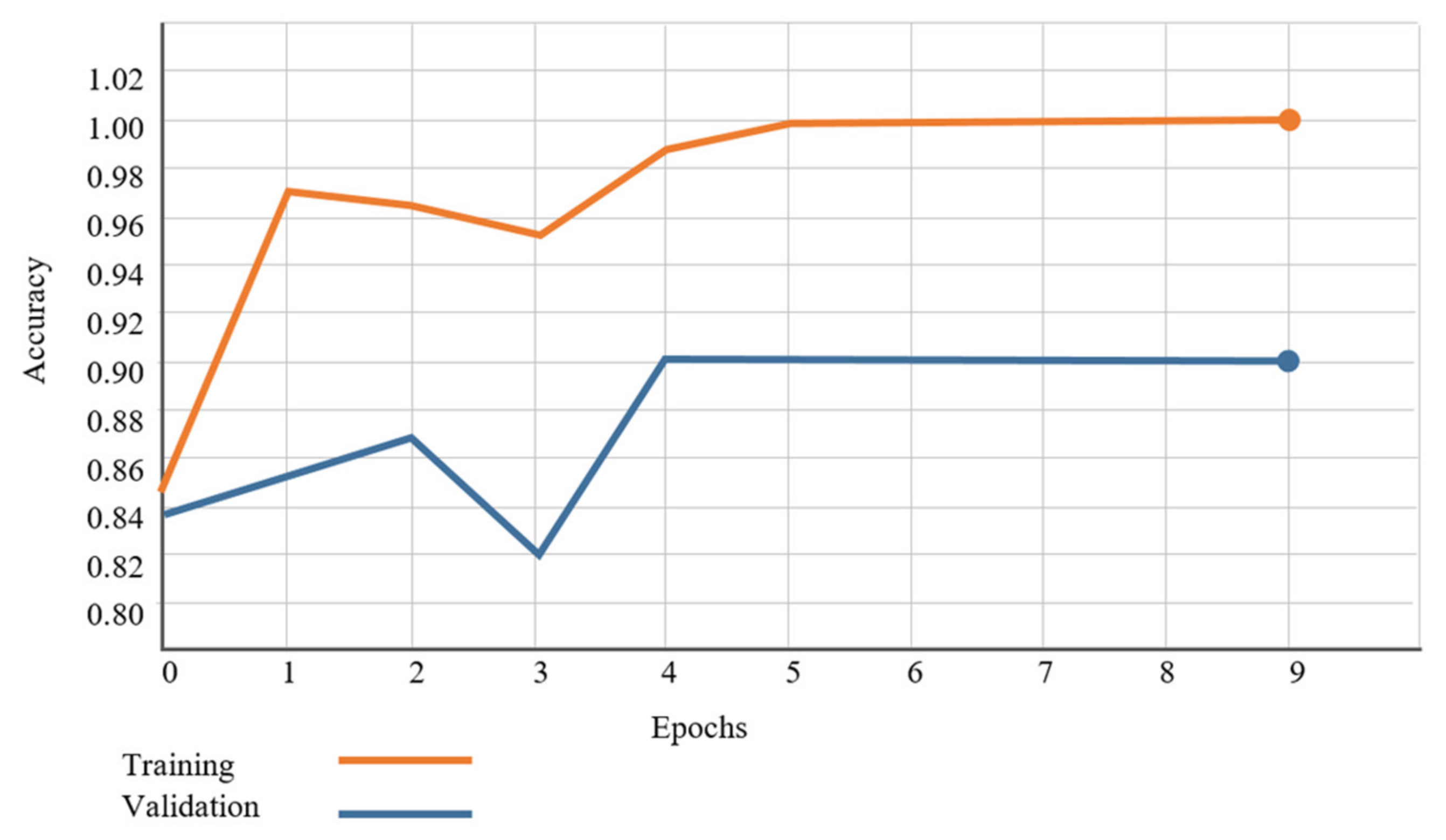
4.3. Automatic Detection of Traffic Accidents
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, M.Z. The Road Traffic Analysis Based on an Urban Traffic Model of the Circular Working Field. Acta Math. Appl. Sin. 2004, 20, 77–84. [Google Scholar] [CrossRef]
- Chu, W.; Wu, C.; Atombo, C.; Zhang, H.; Özkan, T. Traffic Climate, Driver Behaviour, and Accidents Involvement in China. Accid. Anal. Prev. 2019, 122, 119–126. [Google Scholar] [CrossRef]
- Guimarães, A.G.; da Silva, A.R. Impact of Regulations to Control Alcohol Consumption by Drivers: An Assessment of Reduction in Fatal Traffic Accident Numbers in the Federal District, Brazil. Accid. Anal. Prev. 2019, 127, 110–117. [Google Scholar] [CrossRef] [PubMed]
- Nishitani, Y. Alcohol and Traffic Accidents in Japan. IATSS Res. 2019, 43, 79–83. [Google Scholar] [CrossRef]
- Mahata, D.; Narzary, P.K.; Govil, D. Spatio-Temporal Analysis of Road Traffic Accidents in Indian Large Cities. Clin. Epidemiol. Glob. Health 2019, 7, 586–591. [Google Scholar] [CrossRef] [Green Version]
- Sheng, H.; Zhao, H.; Huang, J.; Li, N. A Spatio-Velocity Model Based Semantic Event Detection Algorithm for Traffic Surveillance Video. Sci. China Technol. Sci. 2010, 53, 120–125. [Google Scholar] [CrossRef]
- Parsa, A.B.; Chauhan, R.S.; Taghipour, H.; Derrible, S.; Mohammadian, A. Applying Deep Learning to Detect Traffic Accidents in Real Time Using Spatiotemporal Sequential Data. arXiv 2019, arXiv:1912.06991. [Google Scholar]
- Joshua, S.C.; Garber, N.J. Estimating Truck Accident Rate and Involvements Using Linear and Poisson Regression Models. Transp. Plan. Technol. 1990, 15, 41–58. [Google Scholar] [CrossRef]
- Arvin, R.; Kamrani, M.; Khattak, A.J. How Instantaneous Driving Behavior Contributes to Crashes at Intersections: Extracting Useful Information from Connected Vehicle Message Data. Accid. Anal. Prev. 2019, 127, 118–133. [Google Scholar] [CrossRef] [PubMed]
- Jovanis, P.P.; Chang, H.L. Modeling the Relationship of Accidents To Miles Traveled. Transp. Res. Rec. 1986, 42–51. [Google Scholar]
- Xu, S.; Li, S.; Wen, R. Sensing and Detecting Traffic Events Using Geosocial Media Data: A Review. Comput. Environ. Urban Syst. 2018, 72, 146–160. [Google Scholar] [CrossRef]
- Gu, Y.; Qian, Z.; Chen, F. From Twitter to Detector: Real-Time Traffic Incident Detection Using Social Media Data. Transp. Res. Part C Emerg. Technol. 2016, 67, 321–342. [Google Scholar] [CrossRef]
- Fernandes, B.; Alam, M.; Gomes, V.; Ferreira, J.; Oliveira, A. Automatic Accident Detection with Multi-Modal Alert System Implementation for ITS. Veh. Commun. 2016, 3, 1–11. [Google Scholar] [CrossRef]
- Maha, V.C.; Rajalakshmi, M.; Nedunchezhian, R. Intelligent Traffic Video Surveillance and Accident Detection System with Dynamic Traffic Signal Control. Clust. Comput. 2018, 21, 135–147. [Google Scholar] [CrossRef]
- Ozbayoglu, M.; Kucukayan, G.; Dogdu, E. A real-time autonomous highway accident detection model based on big data processing and computational intelligence. In Proceedings of the 2016 IEEE International Conference on Big Data, Big Data, Washington, DC, USA, 5–8 December 2016; pp. 1807–1813. [Google Scholar] [CrossRef] [Green Version]
- Dong, N.; Huang, H.; Zheng, L. Support Vector Machine in Crash Prediction at the Level of Traffic Analysis Zones: Assessing the Spatial Proximity Effects. Accid. Anal. Prev. 2015, 82, 192–198. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; He, Q.; Gao, J.; Ni, M. A Deep Learning Approach for Detecting Traffic Accidents from Social Media Data. Transp. Res. Part C Emerg. Technol. 2018, 86, 580–596. [Google Scholar] [CrossRef] [Green Version]
- Yu, R.; Wang, G.X.; Zheng, J.Y.; Wang, H.Y. Urban Road Traffic Condition Pattern Recognition Based on Support Vector Machine. Jiaotong Yunshu Xitong Gongcheng Yu Xinxi/J. Transp. Syst. Eng. Inf. Technol. 2013, 13, 130–136. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.M.; Alzawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Yu, Y.; Huang, C.; Yu, K. Deep Multiple Instance Learning for Image Classification and Auto-Annotation. J. Reconstr. Microsurg. 1985, 1, 287–289. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. MIT Press J. 2018, 2733, 2709–2733. [Google Scholar] [CrossRef]
- Howard, A.G. Some improvements on deep convolutional neural network based image classification. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Brinker, T.J.; Hekler, A.; Enk, A.H.; Klode, J.; Hauschild, A.; Berking, C.; Schilling, B.; Haferkamp, S.; Schadendorf, D.; Fröhling, S.; et al. A Convolutional Neural Network Trained with Dermoscopic Images Performed on Par with 145 Dermatologists in a Clinical Melanoma Image Classification Task. Eur. J. Cancer 2019, 111, 148–154. [Google Scholar] [CrossRef] [Green Version]
- Panda, C.; Narasimhan, V. Forecasting Exchange Rate Better with Artificial Neural Network. J. Policy Modeling 2007, 29, 227–236. [Google Scholar] [CrossRef]
- Song, H.J.; Kim, A.Y.; Park, S.B. Translation of natural language query into keyword query using a Rnn encoder-decoder. In Proceedings of the SIGIR 2017—40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 965–968. [Google Scholar] [CrossRef]
- Kahuttanaseth, W.; Dressler, A.; Netramai, C. Commanding mobile robot movement based on natural language processing with RNN encoder-decoder. In Proceedings of the 2018 5th International Conference on Business and Industrial Research: Smart Technology for Next Generation of Information, Engineering, Business and Social Science, ICBIR 2018, Bangkok, Thailand, 17–18 May 2018; pp. 161–166. [Google Scholar] [CrossRef]
- Duan, Y.; Lv, Y.; Wang, F.Y. Travel time prediction with LSTM neural network. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC 2016, Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1053–1058. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Ney, H.; Schluter, R. From Feedforward to Recurrent LSTM Neural Networks for Language Modeling. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2015), Denver, CO, USA, 31 May–5 June 2015; pp. 1494–1504. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action Recognition in Video Sequences Using Deep Bi-Directional LSTM with CNN Features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the ICMI 2016—18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar] [CrossRef]
- Nishani, E.; Cico, B. Computer vision approaches based on deep learning and neural networks: Deep neural networks for video analysis of human pose estimation. In Proceedings of the 2017 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 11–14. [Google Scholar]
- Liu, W.; Yan, C.C.; Liu, J.; Ma, H. Deep Learning Based Basketball Video Analysis for Intelligent Arena Application. Multimed. Tools Appl. 2017, 76, 24983–25001. [Google Scholar] [CrossRef]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble deep learning for skeleton-based action recognition using temporal sliding LSTM networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar] [CrossRef]
- Chen, A.; Khorashadi, B.; Chuah, C.N.; Ghosal, D.; Zhang, M. Smoothing vehicular traffic flow using vehicular-based ad hoc networking & Computing grid (VGrid). In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC 2006, Toronto, ON, Canada, 17–20 September 2006; pp. 349–354. [Google Scholar] [CrossRef]
- Miaou, S.P.; Lum, H. Modeling Vehicle Accidents and Highway Geometric Design Relationships. Accid. Anal. Prev. 1993, 25, 689–709. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A. (Kouros) Toward Safer Highways, Application of XGBoost and SHAP for Real-Time Accident Detection and Feature Analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]
- Hui, Z.; Xie, Y.; Lu, M.; Fu, J. Vision-based real-time traffic accident detection. In Proceedings of the World Congress on Intelligent Control and Automation (WCICA), Shenyang, China, 29 June–4 July 2014; pp. 1035–1038. [Google Scholar] [CrossRef]
- Motamed, M. Developing A Real-Time Freeway Incident Detection Model Using Machine Learning Techniques. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2016. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; He, P.; Rangarajan, A.; Ranka, S. Intelligent Intersection: Two-Stream Convolutional Networks for Real-Time near Accident Detection in Traffic Video. arXiv 2019, arXiv:1901.01138. [Google Scholar] [CrossRef] [Green Version]
- Mokhtarimousavi, S.; Anderson, J.C.; Azizinamini, A.; Hadi, M. Improved Support Vector Machine Models for Work Zone Crash Injury Severity Prediction and Analysis. Transp. Res. Rec. 2019, 2673, 680–692. [Google Scholar] [CrossRef]
- Parsa, A.B.; Taghipour, H.; Derrible, S.; Mohammadian, A. (Kouros). Real-Time Accident Detection: Coping with Imbalanced Data. Accid. Anal. Prev. 2019, 129, 202–210. [Google Scholar] [CrossRef]
- Singh, D.; Mohan, C.K. Deep Spatio-Temporal Representation for Detection of Road Accidents Using Stacked Autoencoder. IEEE Trans. Intell. Transp. Syst. 2019, 20, 879–887. [Google Scholar] [CrossRef]
- Rahimi, A.; Azimi, G.; Asgari, H.; Jin, X. Clustering Approach toward Large Truck Crash Analysis. Transp. Res. Rec. 2019, 2673, 73–85. [Google Scholar] [CrossRef]
- Marimuthu, R.; Suresh, A.; Alamelu, M.; Kanagaraj, S. Driver Fatigue Detection Using Image Processing and Accident. Int. J. Pure Appl. Math. 2017, 116, 91–99. [Google Scholar] [CrossRef]
- Zou, Y.; Shi, G.; Shi, H.; Wang, Y. Image sequences based traffic incident detection for signaled intersections using HMM. In Proceedings of the 2009 9th International Conference on Hybrid Intelligent Systems, HIS 2009, Shenyang, China, 12–14 August 2009; Volume 1, pp. 257–261. [Google Scholar] [CrossRef]
- Gutiérrez, C.; Figueiras, P.; Oliveira, P.; Costa, R.; Jardim-Goncalves, R. An Approach for Detecting Traffic Events Using Social Media. Stud. Comput. Intell. 2016, 647, 61–81. [Google Scholar] [CrossRef]
- Ghandour, A.J.; Hammoud, H.; Dimassi, M.; Krayem, H.; Haydar, J.; Issa, A. Allometric Scaling of Road Accidents Using Social Media Crowd-Sourced Data. Phys. A Stat. Mech. Appl. 2020, 545. [Google Scholar] [CrossRef]
- Weil, R.; Wootton, J.; García-Ortiz, A. Traffic Incident Detection: Sensors and Algorithms. Math. Comput. Model. 1998, 27, 257–291. [Google Scholar] [CrossRef]
- Xiao, J. SVM and KNN Ensemble Learning for Traffic Incident Detection. Phys. A Stat. Mech. Appl. 2019, 517, 29–35. [Google Scholar] [CrossRef]
- Liu, X.M.; Zhang, Z.H.; Li, G.Y.; Lv, T.J. Research on Technology of Traffic Video Incidents Detection under Highway Condition. J. China Univ. Posts Telecommun. 2010, 17, 79–83. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, Y. A novel storing and accessing method of traffic incident video based on spatial-temporal analysis. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Zhangjiajie, China, 18–20 November 2015; Volume 9529, pp. 315–329. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, Y.; Li, T. A vision based traffic accident detection method using extreme learning machine. In Proceedings of the ICARM 2016—2016 International Conference on Advanced Robotics and Mechatronics, Macau, China, 18–20 August 2016; pp. 567–572. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, M.; Wang, Y.; Crandall, D.J.; Atkins, E.M. Unsupervised traffic accident detection in first-person videos. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Chan, F.H.; Chen, Y.T.; Xiang, Y.; Sun, M. Anticipating accidents in dashcam videos. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Volume 10114, pp. 136–153. [Google Scholar] [CrossRef]
- Xia, S.; Xiong, J.; Liu, Y.; Li, G. Vision-based traffic accident detection using matrix approximation. In Proceedings of the 2015 10th Asian Control Conference: Emerging Control Techniques for a Sustainable World, ASCC 2015, Kota Kinabalu, Malaysia, 31 May–3 June 2015. [Google Scholar] [CrossRef]
- Ki, Y.K.; Lee, D.Y. A Traffic Accident Recording and Reporting Model at Intersections. IEEE Trans. Intell. Transp. Syst. 2007, 8, 188–194. [Google Scholar] [CrossRef]
- Maaloul, B.; Taleb-Ahmed, A.; Niar, S.; Harb, N.; Valderrama, C. Adaptive video-based algorithm for accident detection on highways. In Proceedings of the 2017 12th IEEE International Symposium on Industrial Embedded Systems, SIES 2017, Toulouse, France, 14–16 June 2017. [Google Scholar] [CrossRef]
- Shah, A.P.; Lamare, J.B.; Nguyen-Anh, T.; Hauptmann, A. CADP: A novel dataset for CCTV traffic camera based accident analysis. In Proceedings of the AVSS 2018—2018 15th IEEE International Conference on Advanced Video and Signal-Based Surveillance, Auckland, New Zealand, 27–30 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Arinaldi, A.; Pradana, J.A.; Gurusinga, A.A. Detection and Classification of Vehicles for Traffic Video Analytics. Procedia Comput. Sci. 2018, 144, 259–268. [Google Scholar] [CrossRef]
- Pustokhina, I.V.; Pustokhin, D.A.; Vaiyapuri, T.; Gupta, D.; Kumar, S.; Shankar, K. An Automated Deep Learning Based Anomaly Detection in Pedestrian Walkways for Vulnerable Road Users Safety. Saf. Sci. 2021, 142, 105356. [Google Scholar] [CrossRef]
- Jiang, H.; Zhang, G.; Wang, H.; Bao, H. Spatio-Temporal Video Segmentation of Static Scenes and Its Applications. IEEE Trans. Multimed. 2015, 17, 3–15. [Google Scholar] [CrossRef]
- MacKin, A.; Zhang, F.; Bull, D.R. A Study of High Frame Rate Video Formats. IEEE Trans. Multimed. 2019, 21, 1499–1512. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2019, arXiv:1506.02640. [Google Scholar]
- LeCun, Y.; Haffnet, P.; Leon, B.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 1–27. [Google Scholar]
- Lim, W.; Jang, D.; Lee, T. Speech emotion recognition using convolutional recurrent neural networks and spectrograms. In Proceedings of the Canadian Conference on Electrical and Computer Engineering, London, ON, Canada, 30 August–2 September 2020. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Lyu, S.; Chang, M.C.; Du, D.; Li, W.; Wei, Y.; Coco, M.D.; Carcagni, P.; Schumann, A.; Munjal, B.; Dang, D.Q.T.; et al. UA-DETRAC 2018: Report of AVSS2018 IWT4S challenge on advanced traffic monitoring. In Proceedings of the AVSS 2018—2018 15th IEEE International Conference on Advanced Video and Signal-Based Surveillance, Auckland, New Zealand, 27–30 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- González-Díaz, I.; Martínez-Cortés, T.; Gallardo-Antolín, A.; Díaz-De-María, F. Temporal Segmentation and Keyframe Selection Methods for User-Generated Video Search-Based Annotation. Expert Syst. Appl. 2015, 42, 488–502. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Lian, T.; Farrell, J.; Wandell, B.A. Neural Network Generalization: The Impact of Camera Parameters. IEEE Access 2020, 8, 10443–10454. [Google Scholar] [CrossRef]
- Yang, B.; Guo, H.; Cao, E. Chapter Two—Design of cyber-physical-social systems with forensic-awareness based on deep learning. In Advances in Computers; Hurson, A.R., Wu, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2021; Volume 120, pp. 39–79. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| No selection | Low runtime, no data loss | High similarities between adjacent frames |
| Skip frame (n = 1) | Low runtime, with medium/high similarity in adjacent frames | Possible data loss |
| Pixel similarity | Low runtime, with medium/high similarity in adjacent frames | Possible data loss |
| Structural similarity | Low similarity in adjacent frames | High execution time |
| Method | Frames | Execution Time 1 | Similarity |
|---|---|---|---|
| No selection | 45 | 0.918 | 0.824 |
| Skip frame (n = 1) | 45 | 0.971 | 0.761 |
| Pixel similarity | 45 | 1.213 | 0.874 |
| Structural similarity | 45 | 2.456 | 0.822 |
| Predicted Class | |||
|---|---|---|---|
| No Accident | Accident | ||
| Actual class | No accident | 0.99 | 0.01 |
| Accident | 0.03 | 0.97 | |
| Hyper-Parameter | Value |
|---|---|
| Input size | 45 frames |
| Batch size | 4 |
| Loss function | Binary cross-entropy |
| Optimizer | Adam optimization |
| Weight initialization | Xavier initialization |
| Learning rate | 0.0001 |
| Number of epochs | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robles-Serrano, S.; Sanchez-Torres, G.; Branch-Bedoya, J. Automatic Detection of Traffic Accidents from Video Using Deep Learning Techniques. Computers 2021, 10, 148. https://doi.org/10.3390/computers10110148
Robles-Serrano S, Sanchez-Torres G, Branch-Bedoya J. Automatic Detection of Traffic Accidents from Video Using Deep Learning Techniques. Computers. 2021; 10(11):148. https://doi.org/10.3390/computers10110148
Chicago/Turabian StyleRobles-Serrano, Sergio, German Sanchez-Torres, and John Branch-Bedoya. 2021. "Automatic Detection of Traffic Accidents from Video Using Deep Learning Techniques" Computers 10, no. 11: 148. https://doi.org/10.3390/computers10110148
APA StyleRobles-Serrano, S., Sanchez-Torres, G., & Branch-Bedoya, J. (2021). Automatic Detection of Traffic Accidents from Video Using Deep Learning Techniques. Computers, 10(11), 148. https://doi.org/10.3390/computers10110148