
In-Depth Analysis of Ransom Note Files


Abstract
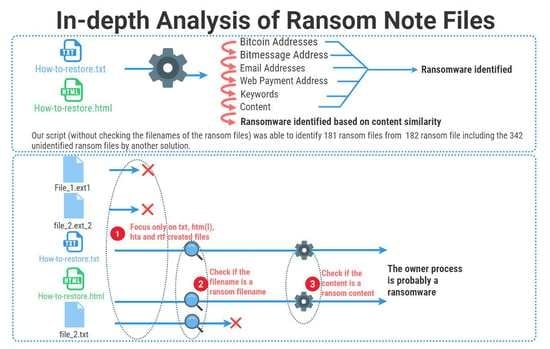
:
1. Introduction
- We make the first and probably unique available collection of ransom files. This collection contains more than 170 ransom files of 62 different ransomware families. This collection is shared in GitHub (https://github.com/lemmou/RansomNoteFiles, accessed on 15 September 2021) for evaluation and study by the research community. It can also be used in the area of criminology and profiling ransomware developers. These ransom files were collected manually from different sources:
- -
- From Malware Traffic Analysis Project (https://www.malware-traffic-analysis.net/, accessed on 15 September 2021);
- -
- From Hybrid-Analysis, looking for the ransom note filenames (https://hybrid-analysis.com/, accessed on 15 September 2021);
- -
- By running some ransomware samples in our virtual machines;
- -
- From The Week in Ransomware of BleepingComputer (https://www.bleepingcomputer.com/, accessed on 15 September 2021);
- -
- From the Pastebins of the owner of ID-Ransomware project (https://pastebin.com/u/Demonslay335, accessed on 15 September 2021).
- We present a depth analysis of the ransom files including some statistics based on their filenames and contents;
- We propose a prototype to identify the ransomware family associated with a given ransom file;
- We apply an approach to classify the ransom files and benign files and another approach to check their similarities using some models of Machine Learning and Latent Semantic Analysis (LSA);
- The results of the previous items allow us to propose a new approach to detecting ransomware using the filenames and the content of the ransom files. This approach can be used with other behaviors to make a ransomware detector or added to the currently available solutions of ransomware detection, identification or prevention. Moreover, several ransomware families can be detected or identified using only this approach before their damage. In particular, the ones that add their ransom files before encryption;
- We compare the effectiveness of our approach on some ransomware detection tools at the end of this paper.
2. Ransom Note Files and Related Works
- Minimize the ransomware damage to few encrypted files if the ransomware encrypts the files of a target directory then puts the ransom files in this directory;
- Detect the ransomware without encrypting any file if the ransomware creates its ransom files before encryption.
3. Identification of Ransom Note Files
3.1. Addresses
3.1.1. Email Addresses
3.1.2. Bitcoin Addresses
3.1.3. Bitmessage Address
3.1.4. Web Payment Address
3.2. Keyword
- The identifier must be aware of the encoded ransomware names. We suggest storing the previously encoded names by the ransomware in the ransom note identifier database;
- Take the most cited ransomware names in the ransom file or the first cited name in the case of equality between many cited ransomware names in the content;
- The identifier can search for the used extensions of the encrypted files in the content. Indeed, some ransomware adds these extensions to the content of their ransom files. For example, Blind ransomware added the extension NAPOLEON and BTCWare ransomware added the extension Gryphon.
- The version of TeslaCrypt that was seen in July 2015. Our script identified this version as a ransom file of CryptoWall ransomware. The reason for this false prediction is that the ransom file of this version is an exact copy of the ransom file of CryptoWall 3.0 ransomware;
- An unknown version of CrypMic. Our script identified this version as a ransom file of Alpha ransomware. This is due to the injected terms alpha in the content.
3.3. Names and Content of the Ransom Note Files
3.4. Ransom Note Files Identifier
- Using only the email addresses: 65 ransom files were correctly identified. ID-Ransomware failed to identify seven ransom files;
- Using only the Bitmessage addresses: eight ransom files were correctly identified. ID-Ransomware identified correctly only five ransom files and the others were identified using the email addresses embedded in the content;
- Using only the URL addresses: 102 ransom files were correctly identified. ID-Ransomware failed to identify 18 ransom files and 33 ransom files were identified using other markers like the Bitcoin addresses and some custom rules;
- Using only the Bitcoin addresses: 25 ransom files were correctly identified. ID-Ransomware identified 14 ransom files, it failed to identify three ransom files and eight ransom files were identified using other markers;
- Using only the ransomware tracker: two ransom files of one family were identified. ID-Ransomware was able to identify more ransom files using the ransomware tracker. We think that our script to identify the ransom files using the ransomware tracker must be improved to identify the ransom files;
- Using only LSA on the content of the ransom files (with 0.99995 as a threshold of similarity between the ransom files), only 13 ransom files (7% of 182 ransom files) were not correctly identified. Table 5 shows these false positives. LSA matched the ransom files of different versions of the same ransomware family. For example, the txt ransom file of the version seen during May 2016 of Cerber has high similarity with the ransom file of the version seen during August 2016. The hta ransom file of the abido version of Dharma has high similarity with all the hta ransom files of the other versions. Moreover, we tested LSA on the content of the ransom files of some new versions have been seen during 2021 of Dharma and GlobImposter. We found high similarity between the content of these ransom files and the content of their old ransom files.
- The ransom note file identifier starts searching, then checking the Bitcoin addresses in the content to associate them with the ransomware that used these addresses using the saved Bitcoin addresses in its database or using any external service. We choose that the ransom note identifier starts searching for Bitcoin addresses in the content because several ransomware families are known by their Bitcoin addresses and they keep them in several versions;
- The identifier checks the Bitmessage addresses if it is not able to associate the Bitcoin address with any known ransomware or the ransom file does not contain Bitcoin addresses. Generally, the ransomware keeps the Bitmessage addresses for a long period of time like the Bitcoin addresses despite that only few ransomware use them;
- The identifier searches for any email address in the content. Moreover, the ransomware identifier can search for any known ransomware name in the extracted email addresses to identify the ransom file;
- In the fourth step, the identifier searches for the URL addresses in the content. If it fails to identify the ransom note from the extracted URLs, it submits them to a ransomware tracker service;
- If the identifier fails to identify the ransom file using the previous items, it can search for the known ransomware names or any known keyword (extensions, patterns, …) in the content. It can use the filename of the ransom file as a secondary indicator to prove its choice between many suggestions;
- If the identifier fails to identify the ransom file, it uses LSA (or other methods) on the content to search any high similarity with the content of any known ransom file.
4. Filenames of the Ransom Files
4.1. Ransom Names Pre-analysis
- Tokenization: extension, ransomware name, victim ID, unknown or random characters used in the filenames were changed to [ext], [ransomwarename], [id], [unknown] or [random]. Some filenames such as _R_E_A_D___T_H_I_S__[random] of Cerber were changed to _READ___THIS__[random]. After these modifications, we used each word in the filename as a unit in our analysis;
- Standardization and Cleaning: the words were converted to lowercase. We do not want Read me, READ ME, and READ Me to be considered as separate terms. The non-alphanumeric characters were stripped, concatenated terms in the filenames were split (readme to read me). Some filenames were corrected, for example Thi$ to This or bl0cked to blocked;
- Stop word removal: this step is used to drop frequently used words that did not add value to our test. Firstly, we used a predefined stop words list from the Python library Nltk, but it removed some interesting words like the interrogative pronouns. For this reason, we made a list containing the words to avoid: to, me, your, this, if, you, all, my, it, for and with;
- Stemming or lemmatization: this step tries to transform the evaluated words to their root form [23]. Table 6 displays an example of stemming using PorterStemmer and lemmatization using WordNetLemmatizer. We applied PorterStemmer, WordNetLe-mmatizer, LancasterStemmer and SnowballStemmer from Nltk on the words. The latter gave us the desired results.
4.2. Unsupervised and Classification Analysis on the Ransom Filenames
- On a corpus of filenames of the ransom files;
- On a corpus of filenames of the ransom files and user files;
- On a corpus of filenames of files collected from an infected machine by ransomware.
4.2.1. LSA on a Corpus of Filenames of the Ransom Files
4.2.2. LSA Applied on Files of an Uninfected Machine
- In the case with splitter, the number of queries tends to be 62 queries that have similarities approximately from ;
- Without splitter, the number of queries tends to be 60 queries that have similarities approximately from .
4.2.3. LSA Applied on Files of an Infected Machine
- All ransom files !-GET_MY_FILES-!.txt and @_RESTORE-FILES_@.txt were detected. However, the txt files of #RECOVERY-PC#.txt were not detected because their filenames contain the word PC, which did not exist in any ransom filename of our dataset and the chosen threshold of similarity (>0.8) was not sufficient to detect this filename without false positives. Generally, we can detect this ransom file by adjusting the used stemmer to include recovery and recover in the some word recov. Therefore, the stemming method on the filenames has some effects on the results: using one word, we can detect other related words.
4.2.4. Machines Learning on Ransom Names
5. LSA on the Content of Ransom Files
5.1. The Content to Identify the Ransom File
5.2. The Content to Detect the Ransomware
- By checking the filenames of the created txt, htm(l), hta and rtf files by LSA, the detector focuses only on the filenames of these files than focusing on the whole content of all the created files;
- The detector applies LSA again on the content of any created file marked by the first item as a ransom filename;
- If the content is marked as a ransom note content, the owner process that created this file is suspicious and it is probably ransomware. In this case, v is added to the malice score of this process. For this behavior, we suggest that the added value v is high such that m reaches the threshold t.
- CryptoMix that adds a ransom note file named _HELP_INSTRUCTION.txt at the beginning of infection (before encryption) in the root directory;
- French101 adds the ransom file HOW TO RECOVER ENCRYPTED FILES.txt in any target directory containing target files before encrypting its content;
- StopDjvu ransomware adds _readme.txt in the Desktop of the current user before encrypting its content.
6. Conclusions
- Assembling all the markers cited in the third section to make a complete and automatic ransomware identifier;
- Proving our approach to detect ransomware using the ransom files with other ransomware suspicious behaviors in a real ransomware detection tool like CryptoDrop, ShieldFS, DaD and other tools. We have started the first tests on DaD by checking the filenames of the ransom files. Firstly, we tested this detection tool on 60 arbitrary samples of several ransomware families, including some known families like Dharma, Spora, StopDjvu, GandGrab and GlobImposter. Dad detected all the 60 ransomware except five ransomware. One of these ransomware adds the ransom file before encryption. Three ransomware add the ransom file after encrypting the content of one target directory. The last ransomware is a multi-threading ransomware that adds the ransom file after encrypting at least one file. By adding our approach to DaD, we were able to detect all these ransomwares with few encrypted files. The result of using DaD and checking the ransom files to detect ransomware will be published in our future work;
- Using LSA on other features such as dumps memory of the running process on a target machine. Indeed, until the date of writing this paper, most ransomwares use the ransom files to notify the victims. However, with our detection technique using LSA on the filenames, the content of the ransom files is useful for fighting future ransomware. This detection technique can show some limits to detecting more ingenious future ransomware such as the ones that use encoded content for their ransom files or new communication channels through URL links. As proven in this paper, LSA has shown its effectiveness to differentiate between benign files and ransom files. For these reasons, we suppose that LSA can differentiate between the dump memory of a ransomware process and other benign processes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Families | Number of Ransom Files | Extensions | |||
|---|---|---|---|---|---|
| TXT | HTM (L) | HTA | RTF | ||
| Alpha | 1 | 1 | - | - | - |
| Alpha Crypt | 2 | 2 | - | - | - |
| Argus | 1 | - | 1 | - | - |
| BadBlock | 1 | - | 1 | - | - |
| Blind | 1 | - | - | 1 | 1 |
| BTCWare | 4 | 2 | - | 2 | - |
| Cerber | 17 | 6 | 3 | 8 | - |
| Chip | 1 | 1 | - | - | - |
| Comonransomware | 1 | 1 | - | - | - |
| CrypMIC | 2 | 1 | 1 | - | - |
| Crypt0l0cker | 1 | - | 1 | - | - |
| Cryptfile2 | 1 | 1 | - | - | - |
| CryptoBit | 1 | 1 | - | - | - |
| Cryptolocker | 1 | 1 | - | - | - |
| CryptoMix | 2 | 2 | - | - | - |
| Crypton | 1 | - | 1 | - | - |
| CryptoShield | 6 | 3 | 3 | - | - |
| CryptoWall | 7 | 4 | 3 | - | - |
| Cryptxxx | 13 | 6 | 7 | - | - |
| Dharma | 16 | 6 | - | 10 | - |
| Diamond | 1 | - | 1 | - | - |
| Dr.Fucker | 1 | - | 1 | - | - |
| Eq | 1 | - | 1 | - | - |
| Everbe | 1 | - | 1 | - | - |
| Evil locker | 1 | 1 | - | - | - |
| GandCrab | 7 | 6 | 1 | - | - |
| Gibon | 1 | 1 | - | - | - |
| GlobeImposter | 4 | - | 3 | 1 | - |
| HC7 | 2 | 2 | - | - | - |
| Hermes | 1 | - | 1 | - | - |
| HydraCrypt | 1 | 1 | - | - | - |
| JAFF | 4 | 2 | 2 | - | - |
| Keyholder | 1 | - | 1 | - | - |
| LockeR | 1 | - | 1 | - | - |
| Locky | 8 | 1 | 7 | - | - |
| Matrix | 4 | - | - | 2 | 1 |
| MMM | 2 | - | 2 | - | - |
| Mole | 1 | 1 | - | - | - |
| Mr.Dec | 1 | - | - | 1 | - |
| NemucodAES | 1 | - | - | 1 | - |
| Omerta | 1 | 1 | - | - | - |
| PrincessLocker | 4 | 2 | 2 | - | - |
| Qwerty | 1 | 1 | - | - | - |
| Rapid | 1 | 1 | - | - | - |
| RaRansomware | 1 | - | 1 | - | - |
| Sad | 3 | 1 | 1 | 1 | - |
| Sage | 2 | - | 1 | 1 | - |
| Satana | 1 | 1 | - | - | - |
| Saturn | 1 | 1 | - | - | - |
| Scarab | 2 | 2 | - | - | - |
| Sigma | 2 | 1 | 1 | - | - |
| Sigrun | 1 | - | 1 | - | - |
| Spora | 2 | - | 2 | - | - |
| Striked | 1 | - | 1 | - | - |
| TeslaCrypt | 18 | 11 | 7 | - | - |
| UIWIX | 1 | 1 | - | - | - |
| Unknown | 5 | 4 | 1 | - | - |
| Velso | 1 | 1 | - | - | - |
| Vendetta | 1 | 1 | - | - | - |
| WhiteRose | 1 | 1 | - | - | - |
| X3m | 1 | - | 1 | - | - |
| Zoro | 1 | 1 | - | - | - |
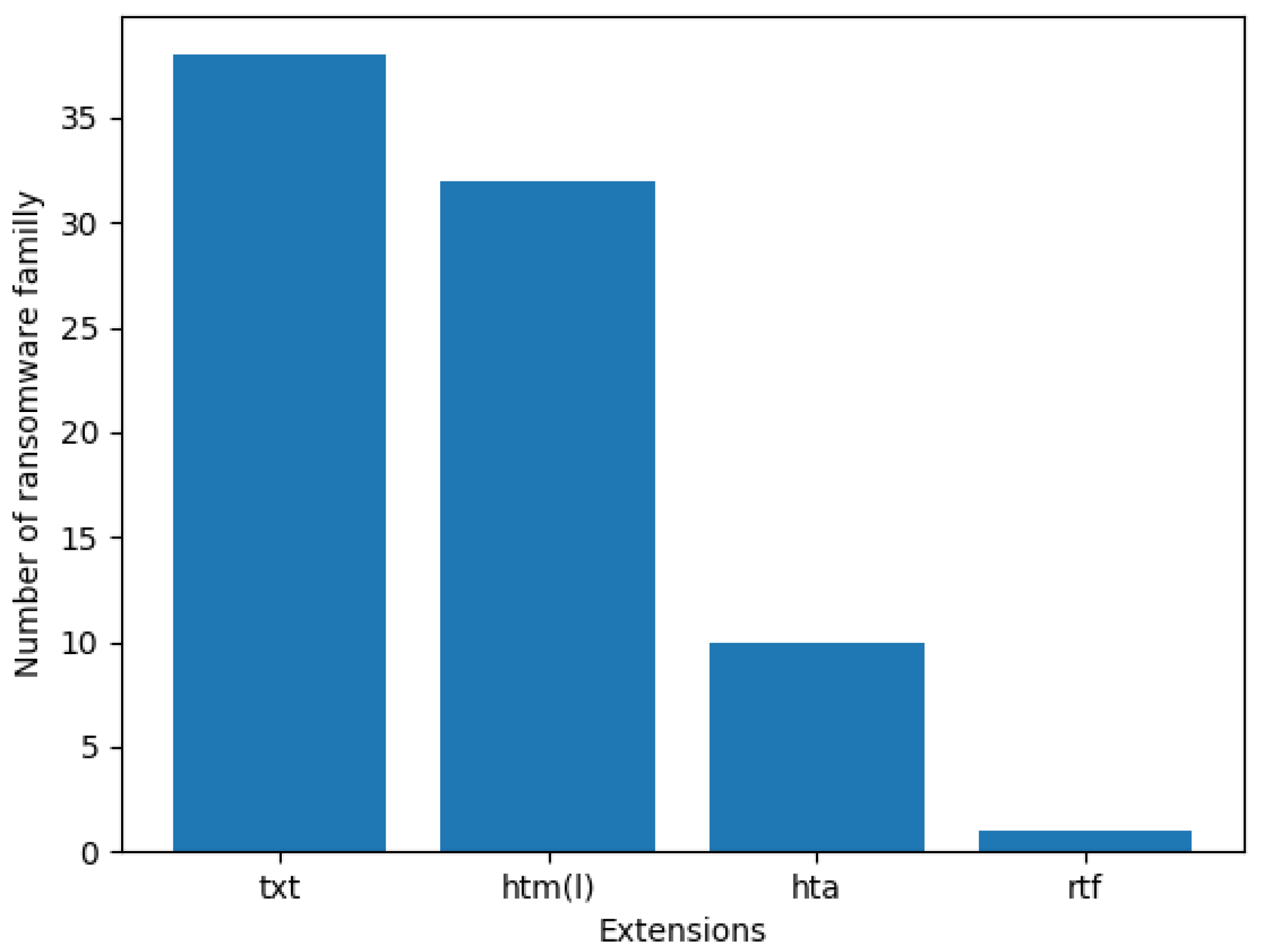
| Total | 176 | 84 | 62 | 28 | 2 |
| Dim. | Terms |
|---|---|
| 0 | decrypt, file, how, restor, to, help, my, readm, your, encrypt |
| 1 | decrypt, help, my, readm, me, inform, argus, de, crypt, sos |
| 2 | readm, save, to, your, crypt, de, back, cke, bl, 23 |
| 3 | info, as, in, get, this, do, text, repair, use, payday |
| 4 | recoveri, how, decrypt, to, my, ra, ware, ransom, do, text |
| 5 | recoveri, instruct, help, recov, your, readm, me, save, decod, sos, |
| 6 | recov, how, instruct, decrypt, to, encrypt, my, for, it, read, |
| 7 | encrypt, file, read, my, this, your, get, me, recoveri, thi, |
| 8 | restor, instruct, my, file, readm, recoveri, encrypt, decrypt, run, sig, |
| 9 | read, me, this, instruct, restor, thi, how, now, if, you, |
| 10 | instruct, encrypt, to, how, my, save, back, get, file, this, |
| 11 | encrypt, me, how, decrypt, help, restor, readm, read, now, inform, |
| 12 | my, me, help, how, readm, encrypt, get, decod, now, sos, |
| 13 | me, save, to, your, restor, encrypt, now, repair, use, my, |
| 14 | your, back, how, me, get, about, if, you, all, want, |
| 15 | back, get, repair, use, to, if, you, want, all, this |
References
- Mager, M. Stop and Step Away from the Data: Rapid Anomaly Detection via Ransom Note File Classification. Endgame. 2018. Available online: https://www.elastic.co/fr/blog/stop-and-step-away-data-rapid-anomaly-detection-ransom-note-file-classification (accessed on 15 September 2021).
- Nieuwenhuizen, D. A Behavioural-Based Approach to Ransomware Detection. MWR Labs Whitepaper. 2017. Available online: https://labs.f-secure.com/assets/resourceFiles/mwri-behavioural-ransomware-detection-2017-04-5.pdf (accessed on 15 September 2021).
- Scaife, N.; Carter, H.; Traynor, P.; Butler, K.R.B. CryptoLock (and Drop It): Stopping Ransomware Attacks on User Data. In Proceedings of the 36th IEEE International Conference on Distributed Computing Systems, ICDCS 2016, Nara, Japan, 27–30 June 2016; pp. 303–312. [Google Scholar]
- Lemmou, Y.; Souidi, E. An Overview on Spora Ransomware. In Security in Computing and Communications; Springer: Singapore, 2017; pp. 259–275. [Google Scholar] [CrossRef]
- Perekalin, A. WannaCry: Are You Safe? Kaspersky. 2017. Available online: https://www.kaspersky.com/blog/wannacry-ransomware/16518/ (accessed on 15 September 2021).
- Lemmou, Y.; Souidi, E.M. PrincessLocker analysis. In Proceedings of the 2017 International Conference on Cyber Security And Protection of Digital Services (Cyber Security), London, UK, 19–20 June 2017; pp. 1–10. [Google Scholar]
- Gazet, A. Comparative analysis of various ransomware virii. J. Comput. Virol. 2010, 6, 77–90. [Google Scholar] [CrossRef]
- Caivano, D.; Canfora, G.; Cocomazzi, A.; Pirozzi, A.; Visaggio, C.A. Ransomware at X-Rays. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 348–353. [Google Scholar]
- Lemmou, Y.; Lanet, J.L.; Souidi, E.M. A behavioural in-depth analysis of ransomware infection. IET Inf. Secur. 2021, 15, 38–58. [Google Scholar] [CrossRef]
- Kharraz, A.; Robertson, W.K.; Balzarotti, D.; Bilge, L.; Kirda, E. Cutting the Gordian Knot: A Look Under the Hood of Ransomware Attacks. In Proceedings of the Detection of Intrusions and Malware, and Vulnerability Assessment—12th International Conference, DIMVA 2015, Milan, Italy, 9–10 July 2015; pp. 3–24. [Google Scholar]
- Continella, A.; Guagnelli, A.; Zingaro, G.; Pasquale, G.D.; Barenghi, A.; Zanero, S.; Maggi, F. ShieldFS: A self-healing, ransomware-aware filesystem. In Proceedings of the 32nd Annual Conference on Computer Security Applications, ACSAC 2016, Los Angeles, CA, USA, 5–9 December 2016; pp. 336–347. [Google Scholar]
- Palisse, A.; Durand, A.; Le Bouder, H.; Le Guernic, C.; Lanet, J.L. Data Aware Defense (DaD): Towards a Generic and Practical Ransomware Countermeasure. In Proceedings of the NordSec2017: 22nd Nordic Conference on Secure IT Systems, LNCS, Tartu, Estonia, 8–10 November 2017; Volume 10674, pp. 192–208. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Lee, J.; Hong, J. How to Make Efficient Decoy Files for Ransomware Detection? In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, RACS’17, Krakow, Poland, 20–23 September 2017; pp. 208–212. [Google Scholar] [CrossRef]
- Palisse, A.; Bouder, H.L.; Lanet, J.; Guernic, C.L.; Legay, A. Ransomware and the Legacy Crypto API. In Proceedings of the Risks and Security of Internet and Systems—11th International Conference, CRiSIS 2016, Roscoff, France, 5–7 September 2016; pp. 11–28. [Google Scholar]
- Kolodenker, E.; Koch, W.; Stringhini, G.; Egele, M. PayBreak: Defense Against Cryptographic Ransomware. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, AsiaCCS 2017, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 599–611. [Google Scholar]
- Bello, I.; Chiroma, H.; Ali, U.; Jauro, F.; Khan, A.; Okesola, J.; Abdulhamid, S. Detecting ransomware attacks using intelligent algorithms: Recent development and next direction from deep learning and big data perspectives. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 8699–8717. [Google Scholar] [CrossRef]
- Poudyal, S.; Dasgupta, D. Analysis of Crypto-Ransomware Using ML-Based Multi-Level Profiling. IEEE Access 2021, 9, 122532–122547. [Google Scholar] [CrossRef]
- Kok, S.; Azween, A.; Jhanjhi, N. Evaluation metric for crypto-ransomware detection using machine learning. J. Inf. Secur. Appl. 2020, 55, 102646. [Google Scholar] [CrossRef]
- Khan, F.; Ncube, C.; Ramasamy, L.K.; Kadry, S.; Nam, Y. A Digital DNA Sequencing Engine for Ransomware Detection Using Machine Learning. IEEE Access 2020, 8, 119710–119719. [Google Scholar] [CrossRef]
- Ketzaki, E.; Toupas, P.; Giannoutakis, K.M.; Drosou, A.; Tzovaras, D. A Behaviour based Ransomware Detection using Neural Network Models. In Proceedings of the 2020 10th International Conference on Advanced Computer Information Technologies (ACIT), Deggendorf, Germany, 16–18 September 2020; pp. 747–750. [Google Scholar] [CrossRef]
- Moussaileb, R.; Bouget, B.; Palisse, A.; Le Bouder, H.; Cuppens, N.; Lanet, J.L. Ransomware’s Early Mitigation Mechanisms. In Proceedings of the 13th International Conference on Availability, Reliability and Security, ARES, Hamburg, Germany, 27–30 August 2018. [Google Scholar] [CrossRef]
- Jawaheri, H.A.; Sabah, M.A.; Boshmaf, Y.; Erbad, A. Deanonymizing Tor hidden service users through Bitcoin transactions analysis. Comput. Secur. 2020, 89, 101684. [Google Scholar] [CrossRef]
- Anandarajan, M.; Hill, C.; Nolan, T. Practical Text Analytics: Maximizing the Value of Text Data, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Cosma, G.; Joy, M. An Approach to Source-Code Plagiarism Detection and Investigation Using Latent Semantic Analysis. IEEE Trans. Comput. 2012, 61, 379–394. [Google Scholar] [CrossRef]
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Open American National Corpus: MASC. Available online: http://www.anc.org/data/masc/downloads/data-download/ (accessed on 15 September 2021).
- Schler, J.; Koppel, M.; Argamon, S.E.; Pennebaker, J.W. Effects of Age and Gender on Blogging. In AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs; American Association for Artificial Intelligence: Menlo Park, CA, USA, 2006. [Google Scholar]




| Family | Version | Email Address |
|---|---|---|
| Argus | - | argusdecrypt@cock.li |
| argusdecrypt@mailfence.com | ||
| BTCWare | Aleta | chines34@protonmail.ch |
| Gryphon | oceannew_vb@protonmail.com | |
| Payday | checkzip@india.com | |
| Dharma | abido | abibo@protonmail.com |
| arrow | jamie_white25@aol.com, dot_faldo@aol.com | |
| Bip | emailpeekabooo@qq.com, peekabooo@qq.com | |
| bkp | bkp@cock.li | |
| brrr | paydecryption@qq.com | |
| cmb | paymentbtc@firemail.cc | |
| manpecman | manpecamet1974@aol.com, raxisubsro1977@aol.com | |
| monro | icrypt@cock.li | |
| skynet | skynet45@cock.li, skynet45@tutanota.com | |
| stopencrypt | stopencrypt@qq.com |
| Family | Bitmessage Address |
|---|---|
| BadBlock | 19zvmsm7qsqgfxcckxbjstdvdbt99zuwbp |
| Comonransomware | 35m1zjhtati4iduufzena75ibyjoq9ibgf |
| Cryptolocker | 1LfX1pFa2uSH6HDfH47zRDZgre4Ms7uZTk |
| Diamond | 1L6PpSehR8V7YsZTc3L3F5RwbWoNma1nno |
| Family | Version | Bitmessage Address |
|---|---|---|
| Amnesia | - | BM-NBdUQmYVn43e3nK4amuoeaSm4ZStr8oZ |
| CryptoBit | - | BM-NAxZ29ouecw2Y7ibaXKus1vxDRDfheW6 |
| Crypton | - | BM-2cwzhonfbjq3x8puliwsykhc6dedq54zq1 |
| Family | Versions | Onion address |
|---|---|---|
| Cerber | 2017-01-05, 2017-01-26 | p27dokhpz2n7nvgr.onion |
| 2017-03-15, 2017-05-12 | ||
| CryptoWall | 2016-01-17, 2016-02-05 | 3wzn5p2yiumh7akj.onion |
| GandCrab | v1 and v2 | gdcbghvjyqy7jclk.onion.top |
| v5.0.1, v5.0.2, v5.0.3, v5.0.4 | gandcrabmfe6mnef.onion |
| Family | Version | Ransom Note | Result by LSA (Label) |
|---|---|---|---|
| Cryptowall | 3.0 | HELP_DECRYPT.txt | TeslaCrypt (2 false ransom notes) |
| CryptoLocker | - | HELP_RESTORE_FILES.txt | TeslaCrypt & Alpha Crypt |
| Alpha Crypt | 2015-04-30 | HELP_TO_SAVE_FILES.txt | CryptoLocker & TeslaCrypt |
| TeslaCrypt | 2015-04-03 | HELP_RESTORE_FILES.txt | Alpha Crypt & CryptoLocker |
| 2015-10-23 | howto_recover_file_[].txt | CryptoWall | |
| V2.1 | HOWTO_RESTORE_FILES.txt | CryptoWall | |
| CryptoMix | 2016-11-28 | - | Cryptfile2 |
| Cryptfile2 | - | - | CryptoMix |
| CrypMIC | - | README.txt | Cryptxxx (2 false ransom notes) |
| Rapid | - | _READ_ME_FOR_DECRYPT.txt | StorageCrypt |
| Cryptxxx | 2016-05-05 | de_crypt_readme.html | CrypMic |
| de_crypt_readme.txt | CrypMic | ||
| StorageCrypt | - | - | Rapid |
| 13 ransom notes files | 18 FP labels | ||
| Before | After | |
|---|---|---|
| Stemming | restoring files | restor file |
| Lemmatization | restoring files | restoring file |
| Ransom Note | Sim. | Ransom Note | Sim. |
|---|---|---|---|
| HELP_YOUR_FILES (Cryptowall 2016-01-17) | 0.500 | _HELP_HELP_HELP_[random]_ (Cerber 2017-01-26) | 0.770 |
| DECRYPT_INSTRUCTION (Cryptowall 2.0) | 0.350 | _HELPME_DECRYPT_ (Sad) | 0.750 |
| INSTRUCTIONS_[ID] (Cryptowall 2016-02-05) | 0.005 | Decoding help (Mr.Dec) | 0.740 |
| Number of Queries | ||||||
|---|---|---|---|---|---|---|
| s = 1 | ||||||
| k = 1000 | S | 240245 (96.92%) | 311 (0.129%) | 1 (0.0004%) | 1 (0.0004%) | 60 (0.025%) |
| NS | 247556 (99.87%) | 214 (0.089%) | 11 (0.004%) | 19 (0.007%) | 60 (0.025%) | |
| k = 1100 | S | 240245 (96.92%) | 311 (0.129%) | 1 (0.0004%) | 2 (0.0008%) | 59 (0.024%) |
| NS | 247561 (99.88%) | 209 (0.086%) | 11 (0.004%) | 23 (0.009%) | 56 (0.023%) | |
| k = 1400 | NS | 247590 (99.89%) | 208 (0.086%) | 1 (0.0004%) | 5 (0.002%) | 56 (0.023%) |
| k = 1700 | NS | 247634 (99.90%) | 166 (0.069%) | 0 (0.0%) | 46 (0.019%) | 14 (0.005%) |
| With Splitter () | Without Splitter () | ||||
|---|---|---|---|---|---|
| Ransom Note | Nbr of Queries | Similar Files | Ransom Note | Nbr of Queries | Similar Files |
| “ReadMe” | 14 for | ExifTool∖README | “ReadMe” | 14 for | same files |
| “_[]_README_” | each | Recent∖readme.lnk | "_[]_READ | each | like with |
| “README” | ransom | hexrays∖readme.txt | ME_" | ransom | splitter |
| “@README” | name | IDAscope∖README.md | “README” | name | |
| ExeinfoPE∖readme.txt | “@README” | ||||
| plugsdk∖readme.txt | |||||
| PeiD∖readme.txt | |||||
| WebAdmin∖Readme.html | |||||
| Doc∖ReadMe.txt | |||||
| PESpin∖ReadMe.txt | |||||
| odbg∖readme.txt | |||||
| upx∖README | |||||
| upx∖README.1ST | |||||
| reghost∖readme.txt | |||||
| “_HELP_HELP_HELP_[]_” | 5 | Mnt∖Help.lnkepydoc∖help.htmlIDA∖idahelp.chmodbg∖help.pdfodbg2∖help.pdf | “_HELP_HELP_HELP_[]_” | 4 | same files like with splitter case but without idahelp.chm |
| “asasin” | 1 | ExifTool∖ASF.pm | |||
| File Name | Uninfected State | Infected State |
|---|---|---|
| ..∖Maintenance∖Help.lnk | FP | FP |
| ..∖epydoc∖help.html | FP | FP |
| ..∖ExifTool∖README | FP | FP |
| ..∖Recent∖readme.lnk | FP | FP |
| ..∖IDAscope∖README.md | FP | FP |
| ..∖WebAdmin∖Readme.html | FP | FP |
| ..∖upx∖README | FP | FP |
| ..∖upx∖README.1ST | FP | FP |
| ..∖Recover My Files.lnk | TN | FP |
| ..∖Recover My Files v5.lnk | TN | FP |
| ..∖ExifTool∖ASF.pm | FP | FP |
| ..∖hexrays_sdk∖readme.txt | FP | TN |
| ..∖ExeinfoPe∖readme.txt | FP | TN |
| ..∖pluginsdk∖readme.txt | FP | TN |
| ..∖PeiD∖readme.txt | FP | TN |
| ..∖Documentation∖ReadMe.txt | FP | TN |
| ..∖PESpin∖ReadMe.txt | FP | TN |
| ..∖odbg∖readme.txt | FP | TN |
| ..∖regshot∖readme.txt | FP | TN |
| ..∖IDA∖idahelp.chm | FP | TN |
| ..∖odbg∖help.pdf | FP | TN |
| ..∖odbg2∖help.pdf | FP | TN |
| Order | Model | Overall F-Measure | Overall Accuracy |
|---|---|---|---|
| 1 | Random Forests | 0.920 | 98.32% |
| 2 | Support Vector Machine | 0.895 | 97.81% |
| 3 | Decision Tree | 0.900 | 97.81% |
| 4 | Naive Bayes | 0.900 | 97.68% |
| 5 | Logistic Regression | 0.890 | 97.55% |
| 6 | k-Nearest Neighbor | 0.425 | 52.89% |
| Actual | |||
|---|---|---|---|
| (47 Ransom Filenames + 730 File Filenames) | |||
| Ransom Filename | Benign Filename | ||
| Predicted | Ransom Name | 38 | 4 |
| Benign Name | 9 | 726 | |
| Precision | Recall | F-measure | |
| Ransom Filename | 0.90 | 0.80 | 0.85 |
| Benign Filename | 0.98 | 0.99 | 0.99 |
| Term | Count | Term | Cont | ||
|---|---|---|---|---|---|
| 1 | file | 1417 | 6 | instruct | 409 |
| 2 | tor | 951 | 7 | key | 371 |
| 3 | browser | 910 | 8 | instal | 359 |
| 4 | decrypt | 617 | 9 | address | 353 |
| 5 | encrypt | 419 | 10 | internet | 346 |
| Threshold | ||||
|---|---|---|---|---|
| FP | TP | FP | TP | |
| 0.9 | 6926 | 1180 | 2586 | 954 |
| 0.99 | 1512 | 826 | 390 | 742 |
| 0.999 | 332 | 582 | 86 | 486 |
| 0.999995 | 14 | 376 | 8 | 372 |
| 0.999999 | 8 | 372 | 8 | 372 |
| 0.9999999 | 8 | 372 | 8 | 372 |
| Ransom Note File | False Positive Ransomware Label |
|---|---|
| HELP_RESTORE_FILES.txt of CryptoLocker | TeslaCrypt & Alpha Crypt |
| HELP_TO_SAVE_FILES.txt of the version seen on 2015-04-30 of Alpha Crypt | TeslaCrypt & CryptoLocker |
| HELP_RESTORE_FILES.txt of the version seen on 2015-04-03 of TeslaCrypt | CryptoLocker & Alpha Crypt |
| _READ_ME_FOR_DECRYPT.txt of Rapid | StorageCrypt |
| _READ_ME_FOR_DECRYPT of StorageCrypt | Rapid |
| Threshold of Similarity | Dimensions | ||
|---|---|---|---|
| 6 | 10 | 11 | |
| 234 | 3 | 1 | |
| 199 | 1 | 1 | |
| 160 | 1 | 1 | |
| 94 | 1 | 1 | |
| 46 | 0 | 0 | |
| 6 | 0 | 0 | |
| 0 | 0 | 0 | |
| Ransom Note Name | Sim. | Similar Files |
|---|---|---|
| _HELP_INSTRUCTION.txt (CryptoMix) | 0.9858 | helloreadmenow23.txt of CryptoBit ransomware |
| 0.9817 | READ THIS IF YOU WANT TO GET ALL YOUR FILES BACK.txt of Omerta ransomware | |
| 0.9872 | How to decrypt files.txt of Vendetta ransomware | |
| 0.9869 | all info.hta files of Dharma ransomware | |
| 0.9902 | !! RETURN FILES !!.txt and Payday.hta of BTCWare ransomware | |
| HOW TO RECOVER ENCRYPTED FILES.txt (French101) | 0.9884 | !#_READ_ME_#!.hta BTCWare ransomware |
| 0.9974 | HOW TO RECOVER ENCRYPTED FILES.txt of Scarab ransomware (2018-10-12) | |
| 0.9930 | IF YOU WANT TO GET ALL YOUR FILES BACK, PLEASE READ THIS.txt of scarab ransomware (2017-11-23) | |
| 0.9923 | DECRYPTING.txt of Comonransomware ransomware | |
| 0.9829 | README_DECRYPT.html of striked ransomware | |
| 0.9592 | RECOVER.txt of hc7 ransomware | |
| 0.9755 | ransom_pay.html (unknown ransomware) | |
| _readme.txt (StopDjvu) | 0.9813 | how_to_back_files.html of GlobImposter |
| 0.9768 | How to restore your files.hta of GlobImposter ransomware | |
| 0.9503 | [unknown].txt of Amnesia | |
| 0.9706 | DECRYPT.[].txt of rapid | |
| 0.9734 | README_BACK_FILES.htm of Eq |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lemmou, Y.; Lanet, J.-L.; Souidi, E.M. In-Depth Analysis of Ransom Note Files. Computers 2021, 10, 145. https://doi.org/10.3390/computers10110145
Lemmou Y, Lanet J-L, Souidi EM. In-Depth Analysis of Ransom Note Files. Computers. 2021; 10(11):145. https://doi.org/10.3390/computers10110145
Chicago/Turabian StyleLemmou, Yassine, Jean-Louis Lanet, and El Mamoun Souidi. 2021. "In-Depth Analysis of Ransom Note Files" Computers 10, no. 11: 145. https://doi.org/10.3390/computers10110145
APA StyleLemmou, Y., Lanet, J.-L., & Souidi, E. M. (2021). In-Depth Analysis of Ransom Note Files. Computers, 10(11), 145. https://doi.org/10.3390/computers10110145