
Tumor Bud Classification in Colorectal Cancer Using Attention-Based Deep Multiple Instance Learning and Domain-Specific Foundation Models


Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Method
2.2.1. TB and Non-Tumor Bag Creation
2.2.2. Generating Feature Embeddings with Histopathology Foundation Models
CTransPath
Phikon-v2
CHIEF
UNI
2.2.3. Attention-Based Multiple Instance Learning (ABMIL)
2.2.4. Experimental Design
2.2.5. Rationale Behind the Data Splitting Strategy
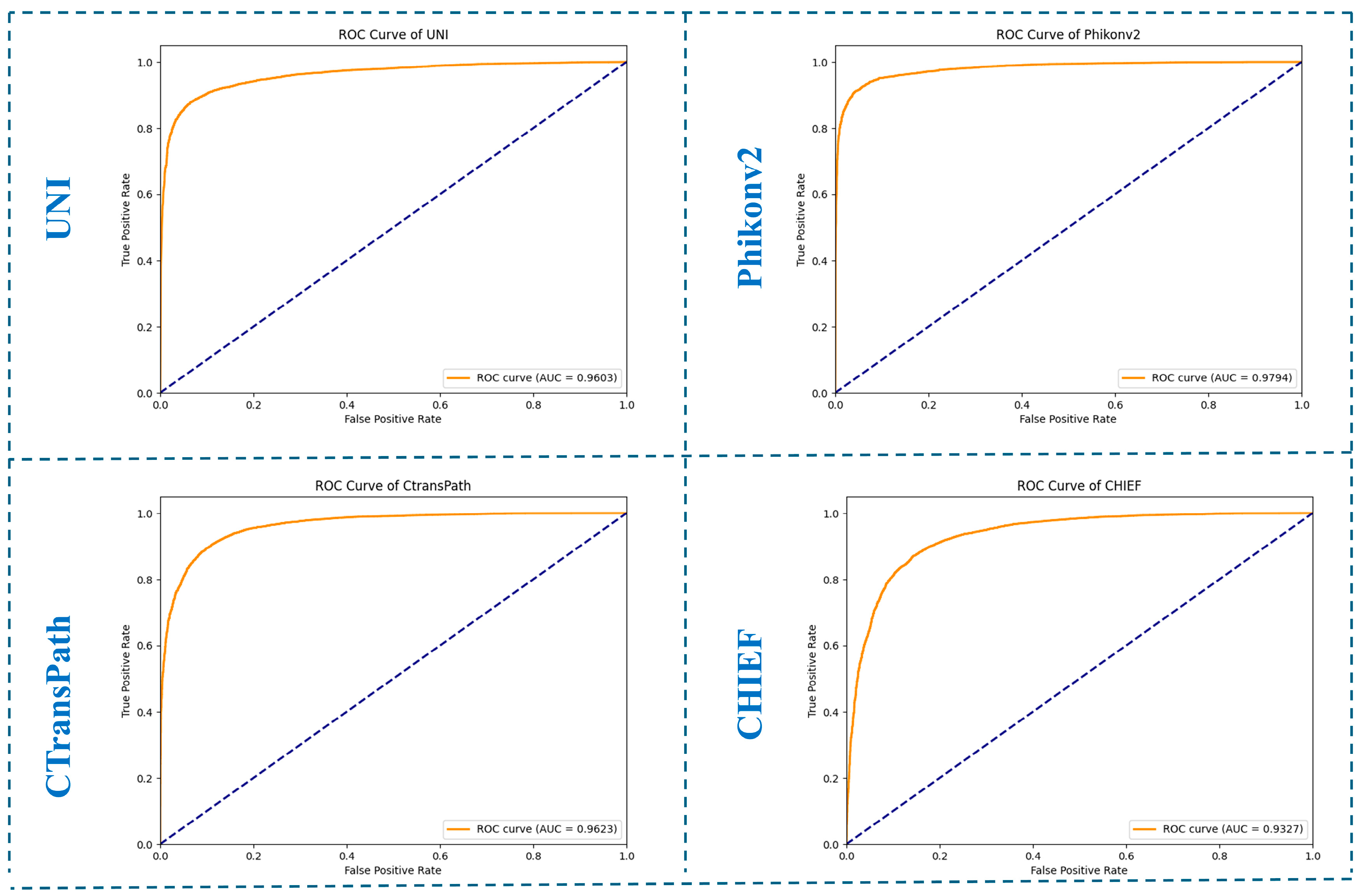
3. Results
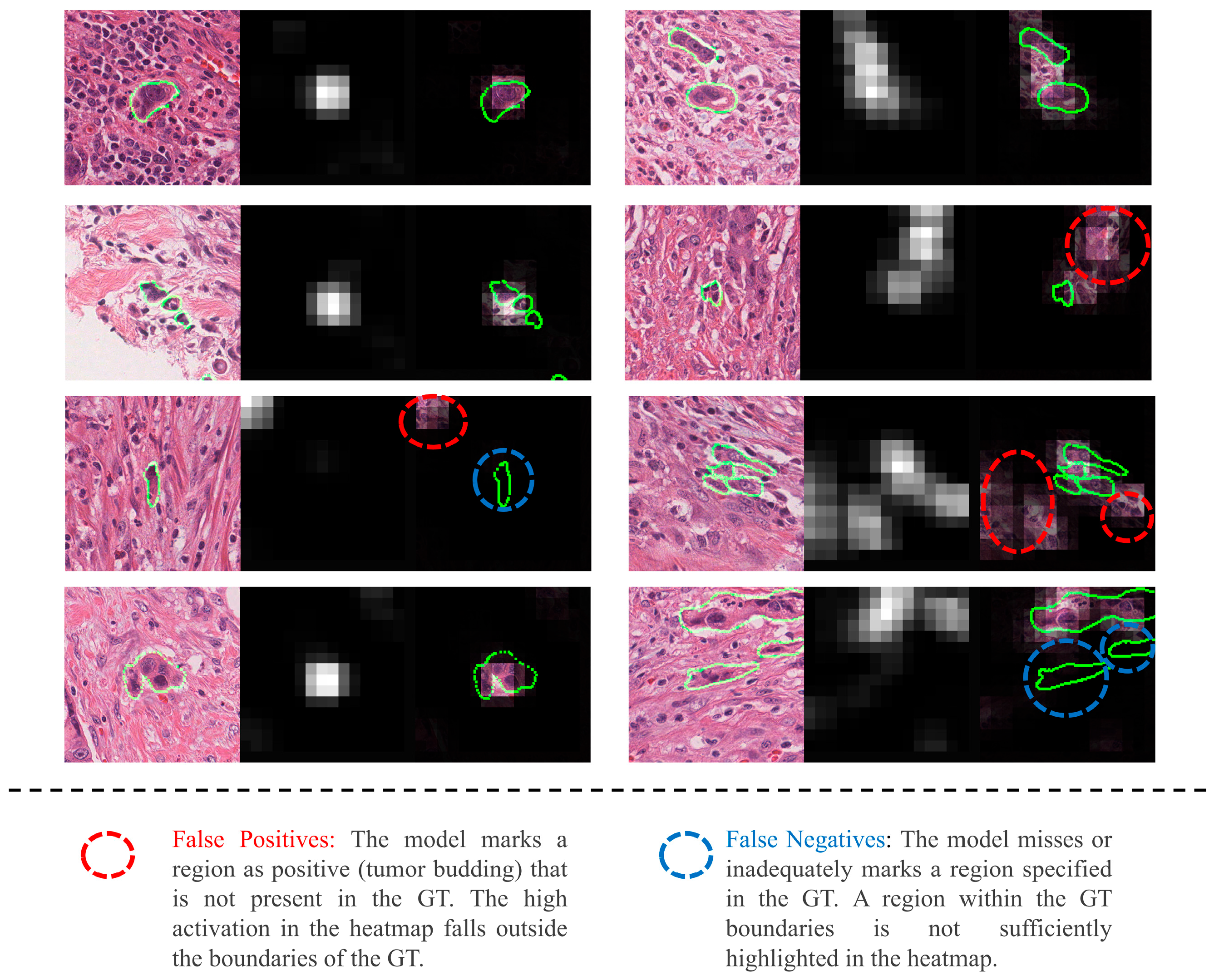
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TB | tumor budding |
| CRC | colorectal cancer |
| ABMIL | attention-based multiple instance learning |
| CAP | College of American Pathologists |
| ITBCC | International Tumor Budding Consensus Conference |
| AI | artificial intelligence |
| SAM | Segment Anything Model |
| CNN | convolutional neural network |
| ROI | region of interest |
| WSI | whole slide image |
| SSL | self-supervised learning |
| SRCL | semantically relevant contrastive learning |
| CPath | computational pathology |
| SA | self-attention |
| BMIL | Bayesian Multiple Instance Learning |
References
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2022. CA Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef] [PubMed]
- Kai, K.; Aishima, S.; Aoki, S.; Takase, Y.; Uchihashi, K.; Masuda, M.; Nishijima-Matsunobu, A.; Yamamoto, M.; Ide, K.; Nakayama, A.; et al. Cytokeratin Immunohistochemistry Improves Interobserver Variability between Unskilled Pathologists in the Evaluation of Tumor Budding in T1 Colorectal Cancer. Pathol. Int. 2016, 66, 75–82. [Google Scholar] [CrossRef] [PubMed]
- Koelzer, V.H.; Zlobec, I.; Berger, M.D.; Cathomas, G.; Dawson, H.; Dirschmid, K.; Hädrich, M.; Inderbitzin, D.; Offner, F.; Puppa, G.; et al. Tumor Budding in Colorectal Cancer Revisited: Results of a Multicenter Interobserver Study. Virchows Arch. 2015, 466, 485–493. [Google Scholar] [CrossRef]
- Chen, K.; Collins, G.; Wang, H.; Toh, J.W.T. Pathological Features and Prognostication in Colorectal Cancer. Curr. Oncol. 2021, 28, 5356–5383. [Google Scholar] [CrossRef]
- Martínez de Juan, F.; Navarro, S.; Machado, I. Refining Risk Criteria May Substantially Reduce Unnecessary Additional Surgeries after Local Resection of T1 Colorectal Cancer. Cancers 2024, 16, 2321. [Google Scholar] [CrossRef]
- Zlobec, I.; Berger, M.D.; Lugli, A. Tumour Budding and Its Clinical Implications in Gastrointestinal Cancers. Br. J. Cancer 2020, 123, 700–708. [Google Scholar] [CrossRef]
- Rogers, A.C.; Winter, D.C.; Heeney, A.; Gibbons, D.; Lugli, A.; Puppa, G.; Sheahan, K. Systematic Review and Meta-Analysis of the Impact of Tumour Budding in Colorectal Cancer. Br. J. Cancer 2016, 115, 831–840. [Google Scholar] [CrossRef]
- Prall, F. Tumour Budding in Colorectal Carcinoma. Histopathology 2007, 50, 151–162. [Google Scholar] [CrossRef]
- De Smedt, L.; Palmans, S.; Andel, D.; Govaere, O.; Boeckx, B.; Smeets, D.; Galle, E.; Wouters, J.; Barras, D.; Suffiotti, M.; et al. Expression Profiling of Budding Cells in Colorectal Cancer Reveals an EMT-like Phenotype and Molecular Subtype Switching. Br. J. Cancer 2017, 116, 58–65. [Google Scholar] [CrossRef]
- Ueno, H.; Hase, K.; Hashiguchi, Y.; Shimazaki, H.; Tanaka, M.; Miyake, O.; Masaki, T.; Shimada, Y.; Kinugasa, Y.; Mori, Y.; et al. Site-Specific Tumor Grading System in Colorectal Cancer. Am. J. Surg. Pathol. 2014, 38, 197–204. [Google Scholar] [CrossRef]
- Lugli, A.; Kirsch, R.; Ajioka, Y.; Bosman, F.; Cathomas, G.; Dawson, H.; El Zimaity, H.; Fléjou, J.-F.; Hansen, T.P.; Hartmann, A.; et al. Recommendations for Reporting Tumor Budding in Colorectal Cancer Based on the International Tumor Budding Consensus Conference (ITBCC) 2016. Mod. Pathol. 2017, 30, 1299–1311. [Google Scholar] [CrossRef] [PubMed]
- Bokhorst, J.-M.; Nagtegaal, I.D.; Zlobec, I.; Dawson, H.; Sheahan, K.; Simmer, F.; Kirsch, R.; Vieth, M.; Lugli, A.; van der Laak, J.; et al. Semi-Supervised Learning to Automate Tumor Bud Detection in Cytokeratin-Stained Whole-Slide Images of Colorectal Cancer. Cancers 2023, 15, 2079. [Google Scholar] [CrossRef] [PubMed]
- Vigdorovits, A.; Köteles, M.M.; Olteanu, G.-E.; Pop, O. Breaking Barriers: AI’s Influence on Pathology and Oncology in Resource-Scarce Medical Systems. Cancers 2023, 15, 5692. [Google Scholar] [CrossRef]
- Gude, S.S.; Veeravalli, R.S.; Vejandla, B.; Gude, S.S.; Venigalla, T.; Chintagumpala, V. Colorectal Cancer Diagnostic Methods: The Present and Future. Cureus 2023, 15, e37622. [Google Scholar] [CrossRef]
- Tavolara, T.E.; Dutta, A.; Burks, M.V.; Chen, W.; Frankel, W.; Gurcan, M.N.; Niazi, M.K.K. Automatic Generation of the Ground Truth for Tumor Budding Using H&E Stained Slides. In Medical Imaging 2022: Digital and Computational Pathology; Levenson, R.M., Tomaszewski, J.E., Ward, A.D., Eds.; SPIE: San Diego, CA, USA, 2022; p. 11. [Google Scholar]
- Lujan, G.; Li, Z.; Parwani, A.V. Challenges in Implementing a Digital Pathology Workflow in Surgical Pathology. Hum. Pathol. Reports 2022, 29, 300673. [Google Scholar] [CrossRef]
- Zalach, J.; Gazy, I.; Avinoam, A.; Sinai, R.; Shmuel, E.; Gilboa, I.; Swisher, C.; Matasci, N.; Basho, R.; Agus, D.B. CanvOI, an Oncology Intelligence Foundation Model: Scaling FLOPS Differently. arXiv 2024, arXiv:2409.02885. [Google Scholar]
- Vorontsov, E.; Bozkurt, A.; Casson, A.; Shaikovski, G.; Zelechowski, M.; Severson, K.; Zimmermann, E.; Hall, J.; Tenenholtz, N.; Fusi, N.; et al. A Foundation Model for Clinical-Grade Computational Pathology and Rare Cancers Detection. Nat. Med. 2024, 30, 2924–2935. [Google Scholar] [CrossRef]
- Xu, H.; Usuyama, N.; Bagga, J.; Zhang, S.; Rao, R.; Naumann, T.; Wong, C.; Gero, Z.; González, J.; Gu, Y.; et al. A Whole-Slide Foundation Model for Digital Pathology from Real-World Data. Nature 2024, 630, 181–188. [Google Scholar] [CrossRef]
- Su, Z.; Chen, W.; Annem, S.; Sajjad, U.; Rezapour, M.; Frankel, W.L.; Gurcan, M.N.; Niazi, M.K.K. Adapting SAM to Histopathology Images for Tumor Bud Segmentation in Colorectal Cancer. Proc. SPIE Int. Soc. Opt. Eng. 2024, 12933, 129330C. [Google Scholar] [CrossRef]
- Sajjad, U.; Chen, W.; Rezapour, M.; Su, Z.; Tavolara, T.; Frankel, W.L.; Gurcan, M.N.; Niazi, M.K.K. Enhancing Colorectal Cancer Tumor Bud Detection Using Deep Learning from Routine H&E-Stained Slides. In Medical Imaging 2024: Digital and Computational Pathology; SPIE: San Diego, CA, USA, 2024; Volume 12933. [Google Scholar] [CrossRef]
- Tavolara, T.E.; Niazi, M.K.K.; Arole, V.; Chen, W.; Frankel, W.; Gurcan, M.N. A Modular CGAN Classification Framework: Application to Colorectal Tumor Detection. Sci. Rep. 2019, 9, 18969. [Google Scholar] [CrossRef]
- Su, Z.; Chen, W.; Leigh, P.J.; Sajjad, U.; Niu, S.; Rezapour, M.; Frankel, W.L.; Gurcan, M.N.; Khalid Khan Niazi, M. Few-Shot Tumor Bud Segmentation Using Generative Model in Colorectal Carcinoma. In Medical Imaging 2024: Digital and Computational Pathology; Tomaszewski, J.E., Ward, A.D., Eds.; SPIE: San Diego, CA, USA, 2024; p. 9. [Google Scholar]
- Tavolara, T.E.; Chen, W.; Frankel, W.L.; Gurcan, M.N.; Niazi, M.K.K. Minimizing the Intra-Pathologist Disagreement for Tumor Bud Detection on H and E Images Using Weakly Supervised Learning. In Medical Imaging 2023: Digital and Computational Pathology; Tomaszewski, J.E., Ward, A.D., Eds.; SPIE: San Diego, CA, USA, 2023; p. 42. [Google Scholar]
- Ciobotaru, A.; Bota, M.A.; Goța, D.I.; Miclea, L.C. Multi-Instance Classification of Breast Tumor Ultrasound Images Using Convolutional Neural Networks and Transfer Learning. Bioengineering 2023, 10, 1419. [Google Scholar] [CrossRef] [PubMed]
- Lobanova, O.A.; Kolesnikova, A.O.; Ponomareva, V.A.; Vekhova, K.A.; Shaginyan, A.L.; Semenova, A.B.; Nekhoroshkov, D.P.; Kochetkova, S.E.; Kretova, N.V.; Zanozin, A.S.; et al. Artificial Intelligence (AI) for Tumor Microenvironment (TME) and Tumor Budding (TB) Identification in Colorectal Cancer (CRC) Patients: A Systematic Review. J. Pathol. Inform. 2024, 15, 100353. [Google Scholar] [CrossRef] [PubMed]
- Banaeeyan, R.; Fauzi, M.F.A.; Chen, W.; Knight, D.; Hampel, H.; Frankel, W.L.; Gurcan, M.N. Tumor Budding Detection in H&E-Stained Images Using Deep Semantic Learning. In Proceedings of the 2020 IEEE REGION 10 CONFERENCE (TENCON), Osaka, Japan, 16—19 November 2020; pp. 52–56. [Google Scholar]
- Bergler, M.; Benz, M.; Rauber, D.; Hartmann, D.; Kötter, M.; Eckstein, M.; Schneider-Stock, R.; Hartmann, A.; Merkel, S.; Bruns, V.; et al. Automatic Detection of Tumor Buds in Pan-Cytokeratin Stained Colorectal Cancer Sections by a Hybrid Image Analysis Approach. In Digital Pathology; Reyes-Aldasoro, C.C., Janowczyk, A., Veta, M., Bankhead, P., Sirinukunwattana, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 83–90. [Google Scholar]
- Bokhorst, J.-M.; Rijstenberg, L.; Goudkade, D.; Nagtegaal, I.; van der Laak, J.; Ciompi, F. Automatic Detection of Tumor Budding in Colorectal Carcinoma with Deep Learning. In Computational Pathology and Ophthalmic Medical Image Analysis; Stoyanov, D., Taylor, Z., Ciompi, F., Xu, Y., Martel, A., Maier-Hein, L., Rajpoot, N., van der Laak, J., Veta, M., McKenna, S., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 130–138. [Google Scholar]
- Lu, J.; Liu, R.; Zhang, Y.; Zhang, X.; Zheng, L.; Zhang, C.; Zhang, K.; Li, S.; Lu, Y. Development and Application of a Detection Platform for Colorectal Cancer Tumor Sprouting Pathological Characteristics Based on Artificial Intelligence. Intell. Med. 2022, 2, 82–87. [Google Scholar] [CrossRef]
- Weis, C.-A.; Kather, J.N.; Melchers, S.; Al-ahmdi, H.; Pollheimer, M.J.; Langner, C.; Gaiser, T. Automatic Evaluation of Tumor Budding in Immunohistochemically Stained Colorectal Carcinomas and Correlation to Clinical Outcome. Diagn. Pathol. 2018, 13, 64. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Transformer-Based Unsupervised Contrastive Learning for Histopathological Image Classification. Med. Image Anal. 2022, 81, 102559. [Google Scholar] [CrossRef]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Zhou, J.; Wei, C.; Wang, H.; Shen, W.; Xie, C.; Yuille, A.; Kong, T. IBOT: Image BERT Pre-Training with Online Tokenizer. arXiv 2021, arXiv:2111.07832. [Google Scholar]
- Filiot, A.; Jacob, P.; Mac Kain, A.; Saillard, C. Phikon-v2, A Large and Public Feature Extractor for Biomarker Prediction. arXiv 2024, arXiv:2409.09173. [Google Scholar]
- Filiot, A.; Ghermi, R.; Olivier, A.; Jacob, P.; Fidon, L.; Kain, A.M.; Saillard, C.; Schiratti, J.-B. Scaling Self-Supervised Learning for Histopathology with Masked Image Modeling. medRxiv 2023. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, J.; Marostica, E.; Yuan, W.; Jin, J.; Zhang, J.; Li, R.; Tang, H.; Wang, K.; Li, Y.; et al. A Pathology Foundation Model for Cancer Diagnosis and Prognosis Prediction. Nature 2024, 634, 970–978. [Google Scholar] [CrossRef]
- Chen, R.J.; Ding, T.; Lu, M.Y.; Williamson, D.F.K.; Jaume, G.; Song, A.H.; Chen, B.; Zhang, A.; Shao, D.; Shaban, M.; et al. Towards a General-Purpose Foundation Model for Computational Pathology. Nat. Med. 2024, 30, 850–862. [Google Scholar] [CrossRef]
- Wang, W.; Shi, W.; Nie, C.; Xing, W.; Yang, H.; Li, F.; Liu, J.; Tian, G.; Wang, B.; Yang, J. Prediction of Colorectal Cancer Microsatellite Instability and Tumor Mutational Burden from Histopathological Images Using Multiple Instance Learning. Biomed. Signal Process. Control 2025, 104, 107608. [Google Scholar] [CrossRef]
- Xu, H.; Wang, M.; Shi, D.; Qin, H.; Zhang, Y.; Liu, Z.; Madabhushi, A.; Gao, P.; Cong, F.; Lu, C. When Multiple Instance Learning Meets Foundation Models: Advancing Histological Whole Slide Image Analysis. Med. Image Anal. 2025, 101, 103456. [Google Scholar] [CrossRef] [PubMed]
- Juyal, D.; Shingi, S.; Javed, S.A.; Padigela, H.; Shah, C.; Sampat, A.; Khosla, A.; Abel, J.; Taylor-Weiner, A. SC-MIL: Supervised Contrastive Multiple Instance Learning for Imbalanced Classification in Pathology. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 7931–7940. [Google Scholar] [CrossRef]
- Qiu, L.; Zhao, L.; Hou, R.; Zhao, W.; Zhang, S.; Lin, Z.; Teng, H.; Zhao, J. Hierarchical Multimodal Fusion Framework Based on Noisy Label Learning and Attention Mechanism for Cancer Classification with Pathology and Genomic Features. Comput. Med. Imaging Graph. 2023, 104, 102176. [Google Scholar] [CrossRef] [PubMed]
- Ilse, M.; Tomczak, J.M.; Welling, M. Attention-Based Deep Multiple Instance Learning. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 5, pp. 3376–3391. [Google Scholar]
- Pai, R.K.; Hartman, D.; Schaeffer, D.F.; Rosty, C.; Shivji, S.; Kirsch, R.; Pai, R.K. Development and Initial Validation of a Deep Learning Algorithm to Quantify Histological Features in Colorectal Carcinoma Including Tumour Budding/Poorly Differentiated Clusters. Histopathology 2021, 79, 391–405. [Google Scholar] [CrossRef]
- Ghaffari Laleh, N.; Muti, H.S.; Loeffler, C.M.L.; Echle, A.; Saldanha, O.L.; Mahmood, F.; Lu, M.Y.; Trautwein, C.; Langer, R.; Dislich, B.; et al. Benchmarking Weakly-Supervised Deep Learning Pipelines for Whole Slide Classification in Computational Pathology. Med. Image Anal. 2022, 79, 102474. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Operation Type | Backbone Architecture | Parameters | Training Type | Training Data Origin | Tissue Types | Magnification | WSIs (Patches) |
|---|---|---|---|---|---|---|---|---|
| CTransPath | CNN-SA | SwinT | 27.5 M | MoCO-v3 | TCGA, PAIP | Cancer Normal | 20× | 32,200 (15 M) |
| Phikon-v2 | SA | Vit-L | 307 M | DINOv2 | TCGA, CPTAC, GTeX, Multiple Public | Cancer Normal | 20× | 58,359 (456 M) |
| CHIEF | CNN-SA (vision encoder) SA (text encoder) | SwinT (vision encoder) Transformer (CLIP text encoder) | 27.5 M (vision encoder) ~63 M (text encoder) | Multiple | TCGA, CPTAC | 19 anatomical sites | 10× | 60,530 (15 M) |
| UNI | SA | ViT-L | 307 M | DINOv2 | Internal-GTeX | Cancer Normal | 20× | 100,426 (100 M) |
| Datasets | Histopathology Foundation Models | AUC | Precision | Recall |
|---|---|---|---|---|
| Average test metrics over six splits | UNI | 0.978 ± 0.003 | 0.845 ± 0.029 | 0.950 ± 0.010 |
| CtransPath | 0.970 ± 0.005 | 0.828 ± 0.005 | 0.919 ± 0.017 | |
| Phikon-v2 | 0.984 ± 0.003 | 0.876 ± 0.004 | 0.947 ± 0.009 | |
| CHIEF | 0.943 ± 0.010 | 0.784 ± 0.052 | 0.882 ± 0.030 | |
| External hold-out test set metrics | UNI | 0.960 | 0.968 | 0.879 |
| CtransPath | 0.962 | 0.947 | 0.911 | |
| Phikonv2 | 0.979 | 0.980 | 0.910 | |
| CHIEF | 0.932 | 0.908 | 0.922 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Şeker, M.; Niazi, M.K.K.; Chen, W.; Frankel, W.L.; Gurcan, M.N. Tumor Bud Classification in Colorectal Cancer Using Attention-Based Deep Multiple Instance Learning and Domain-Specific Foundation Models. Cancers 2025, 17, 1245. https://doi.org/10.3390/cancers17071245
Şeker M, Niazi MKK, Chen W, Frankel WL, Gurcan MN. Tumor Bud Classification in Colorectal Cancer Using Attention-Based Deep Multiple Instance Learning and Domain-Specific Foundation Models. Cancers. 2025; 17(7):1245. https://doi.org/10.3390/cancers17071245
Chicago/Turabian StyleŞeker, Mesut, M. Khalid Khan Niazi, Wei Chen, Wendy L. Frankel, and Metin N. Gurcan. 2025. "Tumor Bud Classification in Colorectal Cancer Using Attention-Based Deep Multiple Instance Learning and Domain-Specific Foundation Models" Cancers 17, no. 7: 1245. https://doi.org/10.3390/cancers17071245
APA StyleŞeker, M., Niazi, M. K. K., Chen, W., Frankel, W. L., & Gurcan, M. N. (2025). Tumor Bud Classification in Colorectal Cancer Using Attention-Based Deep Multiple Instance Learning and Domain-Specific Foundation Models. Cancers, 17(7), 1245. https://doi.org/10.3390/cancers17071245