
A Multi-Modal Deep Learning Approach for Predicting Eligibility for Adaptive Radiation Therapy in Nasopharyngeal Carcinoma Patients
 ,
,  , and
, and
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Data Preprocessing
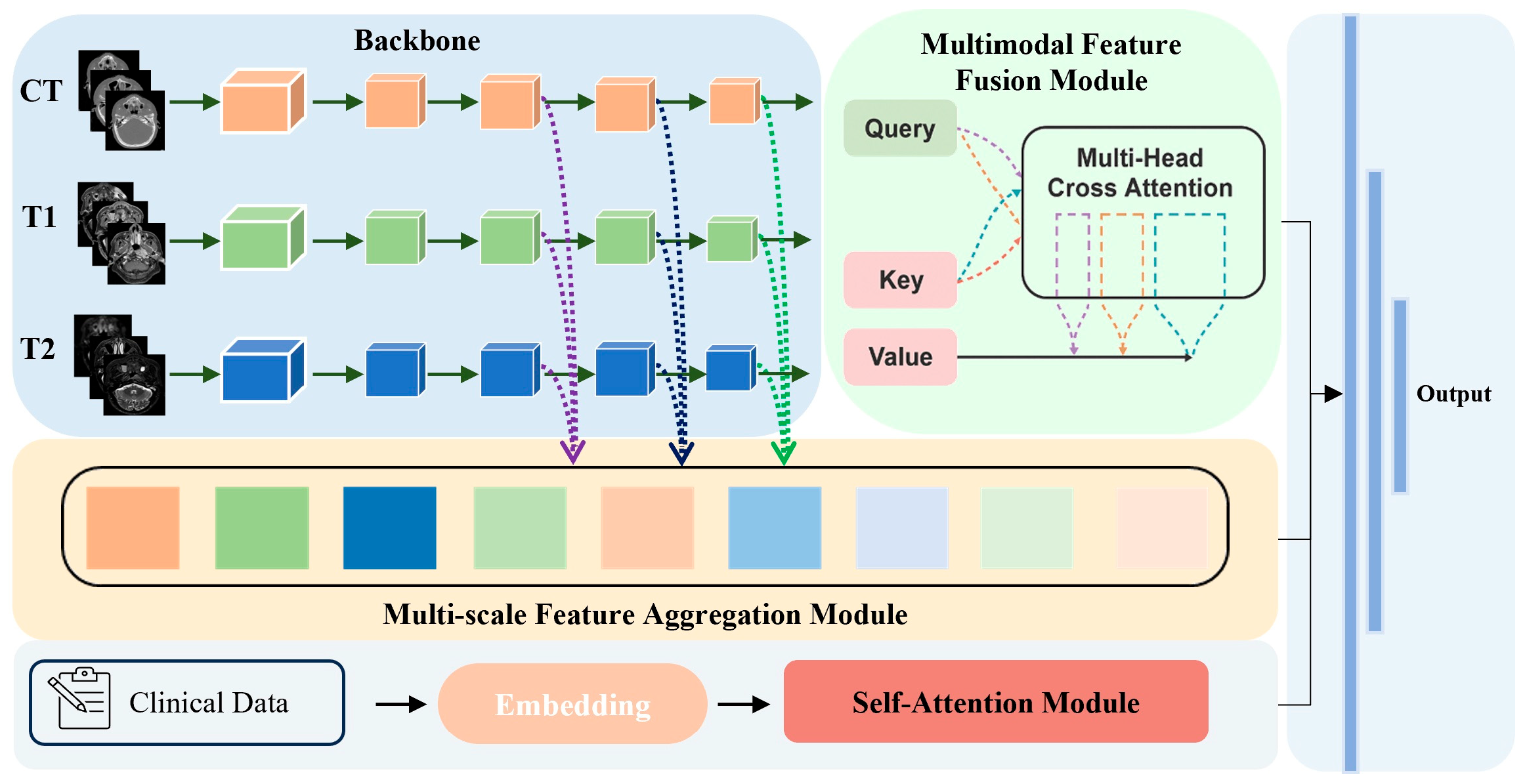
2.3. Model Architecture
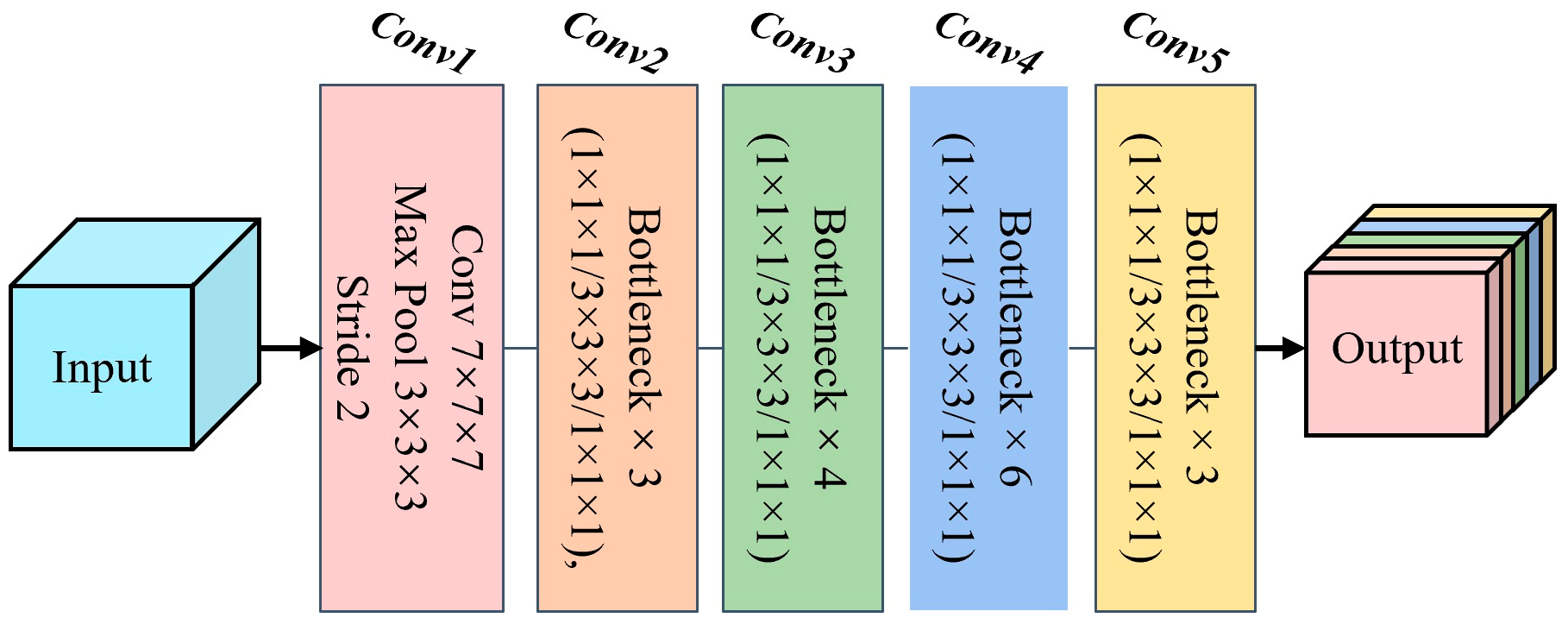
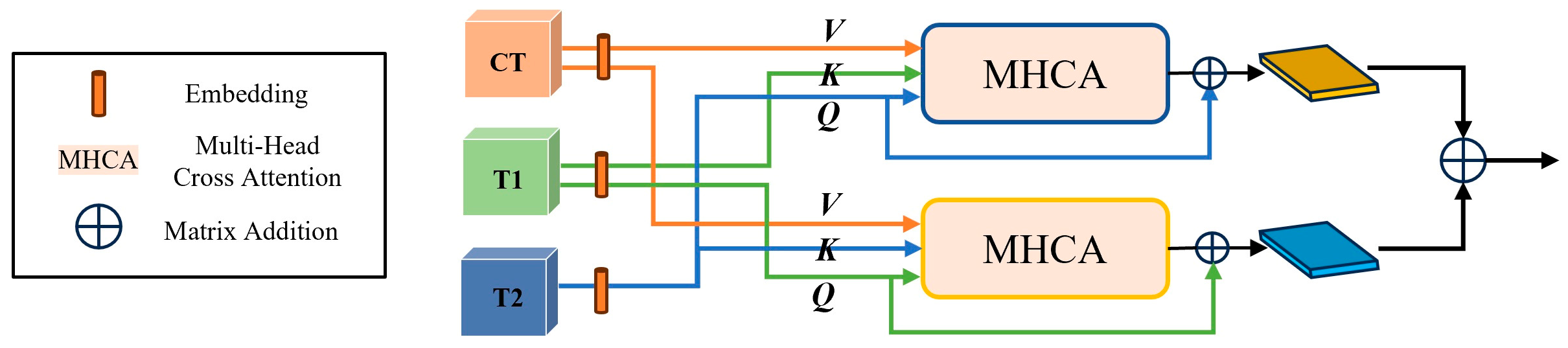
2.3.1. Backbone and Multi-Modal Feature Fusion Module
2.3.2. Multi-Scale Feature Aggregation and Self-Attention Modules
2.4. Implementation Details and Evaluation Metrics
3. Results
3.1. Comparison with Other Deep Learning Networks
3.2. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Cantù, G. Nasopharyngeal carcinoma. A “different” head and neck tumour. Part B: Treatment, prognostic factors, and outcomes. Acta Otorhinolaryngol. Ital. 2023, 43, 155. [Google Scholar] [CrossRef] [PubMed]
- Cellai, E.; Chiavacci, A.; Olmi, P.; Carcangiu, M. Carcinoma of the Nasopharynx Results of Radiation Therapy. Acta Radiol. Oncol. 1982, 21, 87–95. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.-S.; Li, X.-Y.; Chen, Q.-Y.; Tang, L.-Q.; Mai, H.-Q. Future of radiotherapy in nasopharyngeal carcinoma. Br. J. Radiol. 2019, 92, 20190209. [Google Scholar] [CrossRef]
- Barker, J.L., Jr.; Garden, A.S.; Ang, K.K.; O’Daniel, J.C.; Wang, H.; Court, L.E.; Morrison, W.H.; Rosenthal, D.I.; Chao, K.C.; Tucker, S.L.; et al. Quantification of volumetric and geometric changes occurring during fractionated radiotherapy for head-and-neck cancer using an integrated CT/linear accelerator system. Int. J. Radiat. Oncol.* Biol.* Phys. 2004, 59, 960–970. [Google Scholar] [CrossRef]
- Noble, D.J.; Yeap, P.-L.; Seah, S.Y.; Harrison, K.; Shelley, L.E.; Romanchikova, M.; Bates, A.M.; Zheng, Y.; Barnett, G.C.; Benson, R.J.; et al. Anatomical change during radiotherapy for head and neck cancer, and its effect on delivered dose to the spinal cord. Radiother. Oncol. 2019, 130, 32–38. [Google Scholar] [CrossRef]
- Wang, W.; Yang, H.; Hu, W.; Shan, G.; Ding, W.; Yu, C.; Wang, B.; Wang, X.; Xu, Q. Clinical study of the necessity of replanning before the 25th fraction during the course of intensity-modulated radiotherapy for patients with nasopharyngeal carcinoma. Int. J. Radiat. Oncol.* Biol.* Phys. 2010, 77, 617–621. [Google Scholar] [CrossRef]
- Yang, H.; Hu, W.; Ding, W.; Shan, G.; Wang, W.; Yu, C.; Wang, B.; Shao, M.; Wang, J.; Yang, W. Changes of the transverse diameter and volume and dosimetry before the 25th fraction during the course of intensity-modulated radiation therapy (IMRT) for patients with nasopharyngeal carcinoma. Med. Dosim. 2012, 37, 225–229. [Google Scholar] [CrossRef]
- Yang, H.; Hu, W.; Wang, W.; Chen, P.; Ding, W.; Luo, W. Replanning during intensity modulated radiation therapy improved quality of life in patients with nasopharyngeal carcinoma. Int. J. Radiat. Oncol.* Biol.* Phys. 2013, 85, e47–e54. [Google Scholar] [CrossRef]
- Hu, Y.-C.; Tsai, K.-W.; Lee, C.-C.; Peng, N.-J.; Chien, J.-C.; Tseng, H.-H.; Chen, P.-C.; Lin, J.-C.; Liu, W.-S. Which nasopharyngeal cancer patients need adaptive radiotherapy? BMC Cancer 2018, 18, 1234. [Google Scholar] [CrossRef]
- Surucu, M.; Shah, K.K.; Mescioglu, I.; Roeske, J.C.; Small, W., Jr.; Choi, M.; Emami, B. Decision trees predicting tumor shrinkage for head and neck cancer: Implications for adaptive radiotherapy. Technol. Cancer Res. Treat. 2016, 15, 139–145. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.-T.; Lam, S.-K.; To, L.-H.; Tse, K.-Y.; Cheng, N.-Y.; Fan, Y.-N.; Lo, C.-L.; Or, K.-W.; Chan, M.-L.; Hui, K.-C.; et al. Pretreatment prediction of adaptive radiation therapy eligibility using MRI-based radiomics for advanced nasopharyngeal carcinoma patients. Front. Oncol. 2019, 9, 1050. [Google Scholar] [CrossRef] [PubMed]
- Lam, S.-K.; Zhang, J.; Zhang, Y.-P.; Li, B.; Ni, R.-Y.; Zhou, T.; Peng, T.; Cheung, A.L.-Y.; Chau, T.-C.; Lee, F.K.-H.; et al. A multi-center study of CT-based neck nodal radiomics for predicting an adaptive radiotherapy trigger of ill-fitted thermoplastic masks in patients with nasopharyngeal carcinoma. Life 2022, 12, 241. [Google Scholar] [CrossRef]
- Lam, S.-K.; Zhang, Y.; Zhang, J.; Li, B.; Sun, J.-C.; Liu, C.Y.-T.; Chou, P.-H.; Teng, X.; Ma, Z.-R.; Ni, R.-Y.; et al. Multi-organ omics-based prediction for adaptive radiation therapy eligibility in nasopharyngeal carcinoma patients undergoing concurrent chemoradiotherapy. Front. Oncol. 2022, 11, 792024. [Google Scholar] [CrossRef]
- Sheng, J.; Lam, S.-K.; Li, Z.; Zhang, J.; Teng, X.; Zhang, Y.; Cai, J. Multi-view contrastive learning with additive margin for adaptive nasopharyngeal carcinoma radiotherapy prediction. In Proceedings of the 2023 ACM International Conference on Multimedia Retrieval, Thessaloniki, Greece, 12–15 June 2023; pp. 555–559. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Tanaka, S.; Kadoya, N.; Sugai, Y.; Umeda, M.; Ishizawa, M.; Katsuta, Y.; Ito, K.; Takeda, K.; Jingu, K. A deep learning-based radiomics approach to predict head and neck tumor regression for adaptive radiotherapy. Sci. Rep. 2022, 12, 8899. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 2 February 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Matsoukas, C.; Haslum, J.F.; Söderberg, M.; Smith, K. Is it time to replace cnns with transformers for medical images? arXiv 2021, arXiv:2108.09038. [Google Scholar]
- Wu, P.; Wang, Z.; Zheng, B.; Li, H.; Alsaadi, F.E.; Zeng, N. AGGN: Attention-based glioma grading network with multi-scale feature extraction and multi-modal information fusion. Comput. Biol. Med. 2023, 152, 106457. [Google Scholar] [CrossRef]
- Guo, Z.; Li, X.; Huang, H.; Guo, N.; Li, Q. Medical image segmentation based on multi-modal convolutional neural network: Study on image fusion schemes. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 903–907. [Google Scholar]
- Fang, Z.; Zou, Y.; Lan, S.; Du, S.; Tan, Y.; Wang, S. Scalable multi-modal representation learning networks. Artif. Intell. Rev 2025, 58, 209. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhang, G.; Zhang, H.; Yao, Y.; Shen, Q. Attention-guided feature extraction and multiscale feature fusion 3D ResNet for automated pulmonary nodule detection. IEEE Access 2022, 10, 61530–61543. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, X.; Li, M.; Yan, P.; Li, G.; Jiang, Y.; Luo, H.; Yin, S. Deep learning attention mechanism in medical image analysis: Basics and beyonds. Int. J. Netw. Dyn. Intell. 2023, 2, 93–116. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Tsai, Y.-H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.-P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. Proc. Conf. Assoc. Comput. Linguist. Meet. 2019, 2019, 6558–6559. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Chen, S.; Ma, K.; Zheng, Y. Med3d: Transfer learning for 3d medical image analysis. arXiv 2019, arXiv:1904.00625. [Google Scholar]
- Zhang, Z.; Xiao, J.; Wu, S.; Lv, F.; Gong, J.; Jiang, L.; Yu, R.; Luo, T. Deep convolutional radiomic features on diffusion tensor images for classification of glioma grades. J. Digit. Imaging 2020, 33, 826–837. [Google Scholar] [CrossRef]
- Bi, Y.; Abrol, A.; Fu, Z.; Calhoun, V.D. A multimodal vision transformer for interpretable fusion of functional and structural neuroimaging data. Hum. Brain Mapp. 2024, 45, e26783. [Google Scholar] [CrossRef]
- Lin, J.; Lin, J.; Lu, C.; Chen, H.; Lin, H.; Zhao, B.; Shi, Z.; Qiu, B.; Pan, X.; Xu, Z.; et al. CKD-TransBTS: Clinical knowledge-driven hybrid transformer with modality-correlated cross-attention for brain tumor segmentation. IEEE Trans. Med. Imaging 2023, 42, 2451–2461. [Google Scholar] [CrossRef]
- Liu, W.; Liu, T.; Han, T.; Wan, L. Multi-modal deep-fusion network for meningioma presurgical grading with integrative imaging and clinical data. Vis. Comput. 2023, 39, 3561–3571. [Google Scholar] [CrossRef]
- Bhide, S.A.; Davies, M.; Burke, K.; McNair, H.A.; Hansen, V.; Barbachano, Y.; El-Hariry, I.; Newbold, K.; Harrington, K.J.; Nutting, C.M. Weekly volume and dosimetric changes during chemoradiotherapy with intensity-modulated radiation therapy for head and neck cancer: A prospective observational study. Int. J. Radiat. Oncol.* Biol.* Phys. 2010, 76, 1360–1368. [Google Scholar] [CrossRef] [PubMed]
- Yao, W.-R.; Xu, S.-P.; Liu, B.; Cao, X.-T.; Ren, G.; Du, L.; Zhou, F.-G.; Feng, L.-C.; Qu, B.-L.; Xie, C.-B. Replanning criteria and timing definition for parotid protection-based adaptive radiation therapy in nasopharyngeal carcinoma. BioMed Res. Int. 2015, 2015, 476383. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Li, H.; Chen, M.; Wang, J.; Altaye, M.; Dillman, J.R.; Parikh, N.A. Deep multimodal learning from MRI and clinical data for early prediction of neurodevelopmental deficits in very preterm infants. Front. Neurosci. 2021, 15, 753033. [Google Scholar] [CrossRef]
- Yang, J.; Ju, J.; Guo, L.; Ji, B.; Shi, S.; Yang, Z.; Gao, S.; Yuan, X.; Tian, G.; Liang, Y.; et al. Prediction of HER2-positive breast cancer recurrence and metastasis risk from histopathological images and clinical information via multimodal deep learning. Comput. Struct. Biotechnol. J. 2022, 20, 333–342. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Data Acquisition |
|---|---|---|
| Gender | 0 = Female | Demographic |
| 1 = Male | ||
| Age | Patient age (Years) | Demographic |
| BMI | Patient body mass index | Demographic |
| T stage | 1 = Tumor confined to nasopharynx or oropharynx/nasal cavity | Classified in the hospital |
| 2 = Parapharyngeal extension | ||
| 3 = Invasion of bony structures or paranasal sinuses | ||
| 4 = Intracranial extension and/or involvement of cranial nerves, hypopharynx, orbit, or infratemporal fossa | ||
| N stage | 1 = Unilateral lymph node(s), ≤6 cm, above the supraclavicular fossa | Classified in the hospital |
| 2 = Bilateral or contralateral lymph nodes, ≤6 cm | ||
| 3 = Lymph node(s) >6 cm and/or involvement of supraclavicular fossa | ||
| Histological subtype | 1 = Keratinizing squamous cell carcinoma | Classified in the hospital |
| 2 = Differentiated keratinizing differentiated carcinoma | ||
| 3 = undifferentiated carcinoma | ||
| Tumor volume | Estimated value | Estimated from the longest and shortest diameter of the tumor. |
| Hyperparameter | Value |
|---|---|
| Batch size | 2 |
| Maximum epochs | 150 |
| Initial learning rate | 1 × 10−3 |
| Optimizer | Adam |
| Learning rate scheduler | StepLR |
| Step size | 5 |
| Learning rate decay rate | 0.9 |
| Loss function | Cross-entropy |
| Models | Sensitivity | Specificity | Accuracy | AUC |
|---|---|---|---|---|
| DenseNet121 | 0.6377 | 0.8545 | 0.8009 | 0.7521 (0.7381–0.7661) |
| ResNet50 | 0.6806 | 0.8435 | 0.8056 | 0.8215 (0.8172–0.8258) |
| SE-ResNet50 | 0.6778 | 0.8831 | 0.8241 | 0.8266 (0.8055–0.8477) |
| BoTNet18 | 0.6611 | 0.8767 | 0.8148 | 0.8304 (0.8219–0.8389) |
| ViT | 0.7095 | 0.8962 | 0.8426 | 0.8359 (0.8191–0.8527) |
| Our Image Branch | 0.7579 | 0.9157 | 0.8704 | 0.8908 (0.8873–0.8943) |
| Model | Modules | Sensitivity | Specificity | Accuracy | AUC | ||
|---|---|---|---|---|---|---|---|
| Block1 | Block2 | Block3 | |||||
| 1 | × | × | × | 0.6806 | 0.8435 | 0.8056 | 0.8215 (0.8172–0.8258) |
| 2 | ✓ | × | × | 0.7168 | 0.8651 | 0.8287 | 0.8498 (0.8445–0.8548) |
| 3 | × | ✓ | × | 0.6570 | 0.8826 | 0.8148 | 0.8342 (0.8313–0.8371) |
| 4 | × | × | ✓ | 0.6967 | 0.8620 | 0.8132 | 0.8287 (0.8262–0.8312) |
| 5 | × | ✓ | ✓ | 0.7271 | 0.8758 | 0.8380 | 0.8425 (0.8366–0.8484) |
| 6 | ✓ | × | ✓ | 0.7093 | 0.8705 | 0.8194 | 0.8531 (0.8485–0.8577) |
| 7 | ✓ | ✓ | × | 0.7579 | 0.9157 | 0.8704 | 0.8908 (0.8873–0.8943) |
| 8 | ✓ | ✓ | ✓ | 0.8132 | 0.9237 | 0.8935 | 0.9070 (0.9047–0.9093) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, Z.; Lam, S.K.; Wang, X.; Wang, P.; Song, L.; Lee, F.K.-H.; Yip, C.W.-Y.; Cai, J.; Li, T. A Multi-Modal Deep Learning Approach for Predicting Eligibility for Adaptive Radiation Therapy in Nasopharyngeal Carcinoma Patients. Cancers 2025, 17, 2350. https://doi.org/10.3390/cancers17142350
Li Z, Li Z, Lam SK, Wang X, Wang P, Song L, Lee FK-H, Yip CW-Y, Cai J, Li T. A Multi-Modal Deep Learning Approach for Predicting Eligibility for Adaptive Radiation Therapy in Nasopharyngeal Carcinoma Patients. Cancers. 2025; 17(14):2350. https://doi.org/10.3390/cancers17142350
Chicago/Turabian StyleLi, Zhichun, Zihan Li, Sai Kit Lam, Xiang Wang, Peilin Wang, Liming Song, Francis Kar-Ho Lee, Celia Wai-Yi Yip, Jing Cai, and Tian Li. 2025. "A Multi-Modal Deep Learning Approach for Predicting Eligibility for Adaptive Radiation Therapy in Nasopharyngeal Carcinoma Patients" Cancers 17, no. 14: 2350. https://doi.org/10.3390/cancers17142350
APA StyleLi, Z., Li, Z., Lam, S. K., Wang, X., Wang, P., Song, L., Lee, F. K.-H., Yip, C. W.-Y., Cai, J., & Li, T. (2025). A Multi-Modal Deep Learning Approach for Predicting Eligibility for Adaptive Radiation Therapy in Nasopharyngeal Carcinoma Patients. Cancers, 17(14), 2350. https://doi.org/10.3390/cancers17142350