1. Introduction
Radiotherapy data are used in various clinical research questions aiming to improve patients’ treatment and assess patterns of care such as dosimetry analyses, outcome modelling, toxicity, and automated contouring [
1,
2,
3,
4,
5]. Radiotherapy data are large and require extensive amounts of time to clean and process. According to Dasu and Johnson, 80% of the time in data analytical research is taken up by data cleaning, curation, and the preparation of medical records [
6].
In breast cancer radiotherapy, individualised treatment plans are developed to optimise each patient’s radiation dose delivery. The patient’s restricted-dose organs-at-risk (OAR) and high-dose tumour target volumes (TV) are defined, together with additional regions-of-interest (ROIs) belonging to other categories such as machine specific ROIs, optimisation structures, and control structures. OARs include the heart, left lung, right lung, combined lung, and the contralateral breast. TVs include the breast clinical target volume (CTV) and planning target volume (PTV), chest wall CTV and PTV, and nodal CTVs and PTVs. Control structures include planning risk volumes (PRV) (e.g., heart PRV, lung PRV). Other contours include various number of ROIs (e.g., 2_Elekta_Shell_0, external, RING).
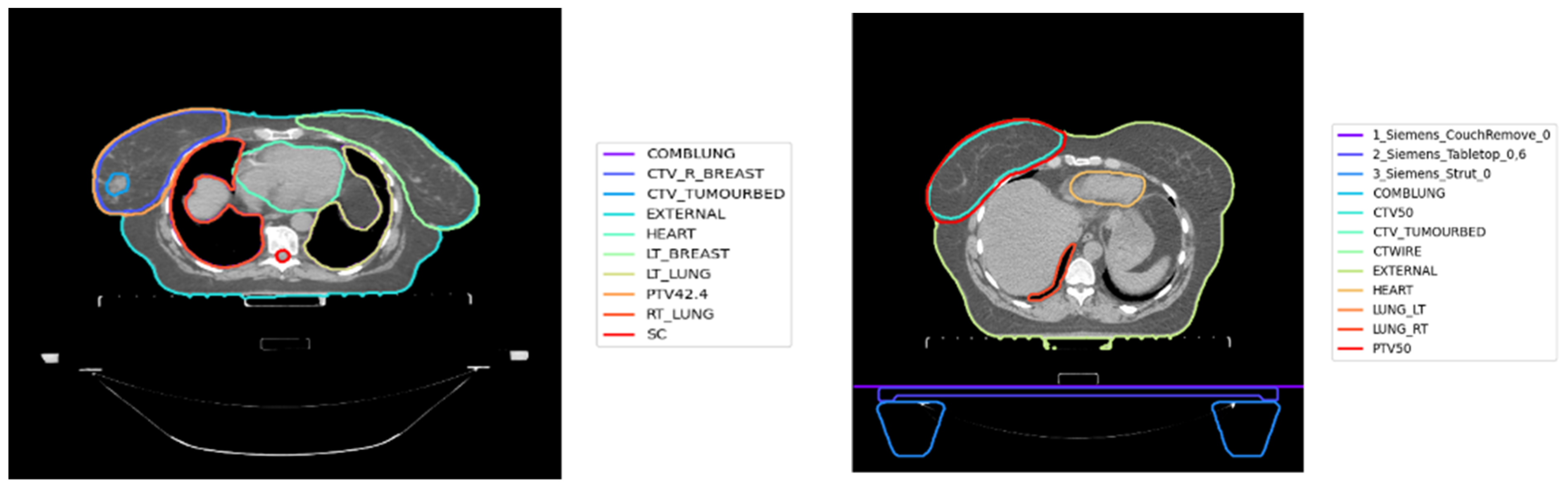
As shown in
Figure 1, inconsistency has been observed in the OAR and TV nomenclature in retrospective datasets. Standardised approaches are required to classify TV and OARs in any cancer site, to utilise big data for radiotherapy applications, and to enable data pooling and analyses. In many radiotherapy planning systems and retrospective datasets, OAR and TV nomenclature has not been standardised. This inconsistency might be due to several reasons, such as the lack of specific templates or protocols for structure naming, variability in naming conventions between institutions, clinicians’ lack of adherence to naming protocols and spelling errors. Furthermore, nomenclature may change with time as new radiotherapy techniques are implemented. Despite strict protocols, inconsistency in structure names have been also recognised as an issue in clinical trials [
7].
To address this issue, health institutions released protocols for standardising treatment structures at certain timeframes [
8,
9]. To handle inconsistency in naming structures, the American Association of Physicists in Medicine (AAPM) developed a protocol for standardising structure names to enable data pooling in multiple areas such as outcomes research, registries, and clinical trials, known as TG-263 [
10]. However, patients treated before the release of these protocols still require standardisation of OARs and TVs for inclusion in retrospective studies. Furthermore, some limitations in treatment planning software character limits the way structure names are displayed during the treatment planning process and has resulted in these protocols being incompletely implemented. There are also challenges for centres not using English for structure naming.
One possible method to handle inconsistency in naming structures is to manually check each patient plan and relabel the structures into standardised names. This is considered expensive and unachievable, in platforms that utilise large datasets from multiple institutions, such as The Australian Computer Aided Theragnostics network (AusCAT), which is a framework that was established across national and international radiation oncology departments, to enable data mining and learning from clinical practice datasets [
11].
Another possible solution is to develop rule-based systems following discussion with clinicians. To handle variations in each environment, clinical staff and researchers are usually involved. The process includes discussion between the clinical staff and the researchers responsible for preparing the datasets to write scripts to interpret the variations. This entails time/effort from each of the involved parties. The variations are then grouped under a standardised name for each structure. With new patients’ records added, the current rules are revisited and updated to match variations in the updated records. Hereafter, these rules gain complexity with time. Manual intervention is still required to validate the results, as no rules can cover the whole set of conditions. This process is also considered expensive and time consuming, especially with datasets from multiple institutions. Considering the time and effort required for standardising nomenclature, we observed the need for new systems to automate the process of standardising OARs and TVs naming.
In recent years, machine learning (ML) algorithms have been incorporated to standardise OARs and TVs nomenclature over multiple types of cancer patients’ datasets. This included lung, prostate, and head and neck cancer datasets [
9,
12,
13], but to our knowledge, no model has yet been developed to standardise nomenclature in breast cancer radiotherapy data. These methods utilised various types of ML algorithms such as convolutional neural networks (CNNs), gradient-boost machine (GBM), and multi-layered perceptron (MLP). In these studies, 2D images, 3D volumes, extracted features from volumes and images, or extracted features for text were used as input to the models trained to standardise naming conventions. The developed studies did not consider all the TVs and OAR used in treatment plan, which is needed for real world applications. Hereafter, we propose a new approach for standardising nomenclature that can be utilised throughout the whole list of breast radiotherapy plan volumes, as well as portions of it by using artificial neural networks (ANNs).
Section 2 reviews related work;
Section 3 describes materials and methods;
Section 4 reports experiments and results; and
Section 5 derives a conclusion.
2. Related Work
Rozario et al. conducted a feasibility study, which was among the first studies that incorporated ML algorithms to automate standardising nomenclature, using a CNN to standardise organ labelling in prostate and head and neck cancer datasets [
12]. Five OARs were used in the prostate dataset and nine OARs in the head and neck cancer dataset. 2D images were extracted and used as input to the CNN. A 100% classification accuracy was reported with the proposed approach, but no TV have been considered. Hence, TV and other structures should be handled before running the developed model.
Another framework was proposed to standardise OARs [
14,
15], which utilised an ensemble of CNNs in head and neck cancer patients (3DNNV). The framework consisted of multiple ResNets, which is a CNN originally trained on the ImageNet dataset, with non-local blocks that were combined using majority voting [
16]. The authors proposed adaptive sampling and adaptive cropping (ASAC) to scale and crop the images as input to the networks. Three cohorts were utilised in the study, one for training and the rest for testing. Twenty-eight head and neck OARs were selected for modelling in this study. 3D volumes were used as input to the ensemble components. Several baseline models were introduced for comparison and analyses purposes. These models were compared to the proposed framework, which reported better performance in terms of three evaluation metrics: true positive rates (TPR), area under the curve (AUC) of the receiver operating characteristic (ROC) curve, and f1-score. The proposed framework was also compared to two alternative approaches, the first uses a fuzzy string-matching algorithm while the other uses a five layered CNN. The authors trained the five layered CNN using their dataset. However, the fuzzy model was used for testing only. Better performance was obtained with the proposed framework compared to the two alternative approaches. However, these studies lack the use of TV such as the Gross-Tumour Volume (GTV), PTV, and CTV.
Text features have also been used in standardising nomenclatures. Syed et al. utilised ML algorithms to standardise OARs in lung and prostate cancer datasets into TG-263 standardised names [
17]. A dataset that consisted of 794 prostate and 754 lung cancer patients from 40 different centres managed by the Veterans health administration (VA) was used for developing the model. Another dataset was collected from the radiation oncology department at Virginia Commonwealth University (VCU) and used as the hold-out sample. Ten prostate and nine lung OARs were identified in the study. The other structures were named as non_OAR. The structure names were processed and manipulated to numerical representations, then an algorithm named fastTEXT was used for training the collected records. The authors reported an f1-score of 0.93 for prostate structures and 0.95 on lung structures over the hold-out samples. Similarly, the study did not consider TV, which usually adds the highest levels of complexity in the standardisation process.
Sleeman et al. proposed an approach to standardise structures based on volumetric bitmap representations and five different ML algorithms [
9]. Prostate and lung cancer datasets were included in the study. Apache spark was used to train the multi-centred datasets across 40 different institutions. A dataset that consisted of 1200 patients was used for training and validation, while a dataset that consisted of 100 patients was used for testing (50 lung, 50 prostate). Five structures were annotated for the lung patients and seven for the prostate patients. Two datasets were created: a curated dataset, which only contains the selected structures, and a non-curated data, which contains everything expected in a study. Bitmap images were created and converted to feature vectors. Two types of images were created with each dataset (curated/non-curated): one contained the patient’s bone anatomy, and the other did not. The generated feature vectors consisted of hundreds of thousands of features, which required the inclusion of dimensionality reduction through truncated singular value decomposition (SVD). The records were reduced to 100 input features. Five different classifiers were used in this study: naïve bayes (NB), random forest (RF), gradient-boost machine (GBM), multi-layered perceptron (MLP), and support vector machine (SVM). The datasets were manipulated to obtain balanced samples for each of the included organs. The f1-score was used to measure the performance of each classifier. The MLP outperformed the other algorithms in majority of the tests over the curated datasets. The results showed improved results with the inclusion of bone anatomy in the datasets. Only one target volume (PTV) was utilised in this study. The highest accuracy achieved by a model was less than 92% when using the non-curated datasets.
3. Materials and Methods
3.1. Data Collection and Labelling
A dataset consisting of 1613 left/right breast cancer patients treated between 2014 and 2018 was collected from Liverpool & Macarthur Cancer Therapy Centres, New South Wales, Australia. This study was approved by the NSW Population & Health Services Research Ethics Committee (2019/ETH01550; 11/09/2016). Each patient’s radiotherapy treatment plan consisted of a set of volumes with inconsistent names over the whole cohort. Several discussions with the clinicians at the centres were required to label the cohort. The labels were clustered into five different groups shown in
Table 1.
3.2. Input Features Generation
Discussions with clinicians about how they determined what a non-conventionally labelled structure was led to several observations. Initially, the clinicians tend to look at the text to categorise each structure. The structure image might be checked and visualised for further interpretation. Furthermore, the position of the structure may be analysed. Finally, the dosimetry values might be checked for analysing the structure name. We aimed to utilise various types of features to mimic the approach followed by the clinicians with the use of neural networks that are originally inspired by the human biological brain. Four types of characteristics were generated for each structure/volume in each patient radiotherapy plan:
Textual features: A treatment plan consists of volumes with associated names. These volumes/structures are defined using alphanumerical characters that represent various patient structures. A set of features was created by highlighting the existence of specific text blocks in each structure, e.g., a feature ‘breast’ was introduced where a value of 1 was associated with all the structures that contained the text ‘breast’, otherwise a value of 0 was allocated. Fifteen features were introduced to represent the occurrence of substrings in structure names (breast, lung, chest wall or cw, axilla or ax, etc.). Five additional features were created that summarises number of letters in a structure name, number of digits in a structure name, number of spaces in a structure name, number of other characters in a structure name (commas, underscores, etc.), and the total number of characters in a structure name. In total, 20 textual features were extracted from each structure/volume text.
Imaging features: 2D central slices were created to include details about the structure shape, size, and imaging biomarkers in modelling. The central slice was defined as the CT slice with the highest number of tumour pixels on the z-axis. Each structure binary mask was overlaid on the CT image to select the pixel values of the central slice. The Hounsfield Units (HU) representing pixel values inside the structure were selected, while pixel values surrounding the structure were replaced by zeros.
Geometry features: Positional features were extracted to include details of the position of each volume. The coordinates of the centroid of the 3D volume were calculated and included as features. For each structure, the magnitude of the vectors connecting the centroid of the structure to the point (0, 0, 0) in the three-dimensional space were calculated. The directions over each axis (cosine angles) of the magnitude vector were also calculated. The index of the central slice over the z-axis was also included. Finally, the number of voxels representing the structure was included. In total, nine positional and volumetric features were used: x, y, and z coordinates of the centroid; cosine angles on each dimension of the magnitude vector connecting (0, 0, 0) to the centroid; magnitude; number of voxels; index.
Dosimetry features: A total of 10 dosimetry features were calculated for each structure: minimum dose, median dose, mean dose, maximum dose, V%20.0, V%10.0, V%5.0, V%95.0, V%105.0, V%110.0, and D50.0, where Vx is the dose received by x% of the volume and Dy is the volume receiving at least y% of the prescription dose.
3.3. Datasets Generation and Pre-Processing
Five datasets were created from the original cohort; the first four represented different subsets of volumes and the last one represented the whole list of volumes. The categories of the classes used in each study are summarised in
Table 2 (further details in
Supplementary Materials S1). The first dataset represents a case study where OARs were targeted for standardisation. In other words, if methods have already been prepared to standardise all/some of the other categories (TV, nodes TV), there is no need to utilise a full model. With Dataset5, it was assumed that no subsets have been standardised and there is a need to identify any possible volume in the patient radiotherapy plan.
To build ML models, the datasets were partitioned into training, validation, and test samples. The training dataset was used to train the algorithm. The validation dataset was used to track the model performance and to avoid overfitting. The test dataset was used to evaluate the performance of the developed model on unseen samples.
The original dataset consisted of 1613 patients; 173 patients were selected as the test dataset, while 1440 patients were used for training and validating the ML algorithms. The number of classes varied per patient. We targeted the selection of a stratified cohort, where at least 10% of each class will be obtained in the test cohort in each study, e.g., the total number of patients with internal mammary lymph node (imc) PTV volumes was five, one sample was guaranteed for testing. In addition, for all the datasets, the same 173 patients were used for evaluation.
ANNs are known to perform better with smaller ranges. Three types of features were tabular, and one was image data (central slices). Text, dose, and geometrical features were normalised into smaller ranges (between 0 and 1). As mentioned earlier, the pixel values in the imaging data were described in HU. For image data, lower (−255) and upper (+255) HU bounds were applied over each pixel value in the central slices. The central slices were then resized into 64 × 64 before being mapped into values between 0 and 1. Values surrounding the structure were reserved as 0 without being altered in the normalisation process.
While labelling the patients datasets, it was noticed that a class might occur one or more times in each plan, e.g., a patient might have a structure named ctv42.4 and another structure named ctv_l_breast. The two structures will be interpreted as left_breast_ctv, however, one will be selected as final. In real case scenarios, this kind of situation is expected. For this reason, we removed the duplicates/alternatives from the training dataset (to explicitly train the model to detect similar patterns in new datasets), but for evaluation purposes we introduced two datasets:
Original test dataset: consists of the final selected structures by the clinicians.
Extended test dataset: consisted of all the structures in the dataset, with the final being flagged.
3.4. Artificial Neural Networks (ANNs)
An ANN is a ML algorithm inspired by the human biological brain. It processes information through multiple processing units, known as neurons, distributed over multiple layers to explore patterns and trends in data. To learn from data, the ANN is trained for a number of rounds, known as epochs, where the data samples are shown repeatedly to the ANN architecture in an attempt to minimise the error between the actual and predicted output. Neural networks are trained by updating weights and bias connecting the information processing units (neurons) across layers. Deep learning is a branch in ML where information is processed in a neural network through multiple layers (four or more) of neural processing units.
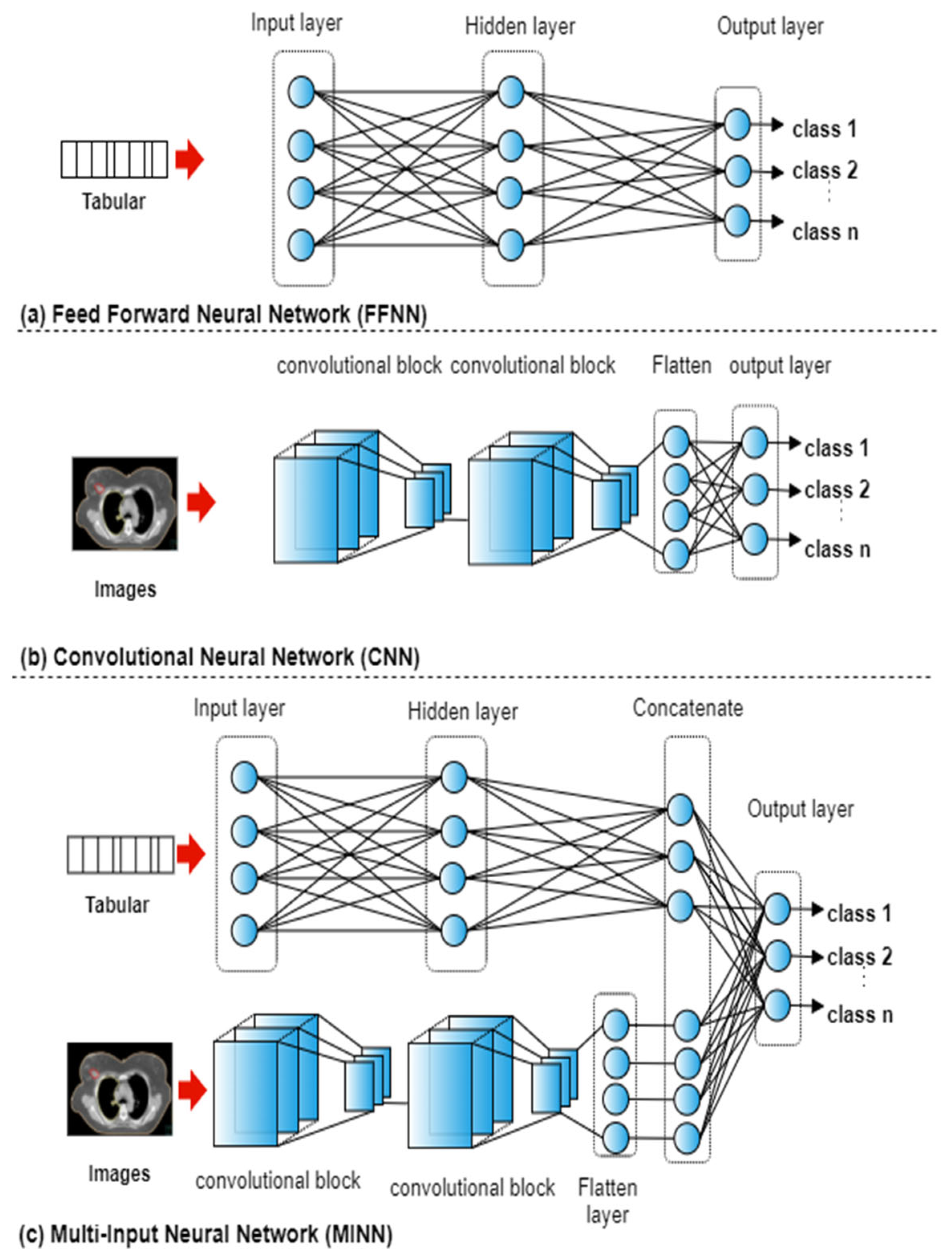
The ANN can be adapted to accept any type of input data such as tabular, images, and multi-modal records. In neural networks where the input data consists of numerical features, fully connected layers are typically utilised to form a Feed Forward Neural Networks (FFNN). In neural networks where the input data consists of images, blocks of convolutional and pooling layers are utilised to form a CNN. With multi-modal input, both fully connected layers and convolutional blocks are used to form a Multi-input neural network (MINN).
For each of the five datasets, a total of 15 experiments were conducted representing the combinations of the four types of input features. FFNNs were utilised with seven case studies that used tabular data (
Figure 2a): text, dose, geometry, text + dose, text + geometry, dose + geometry, text + dose + geometry. A CNN was used with the case study that utilised images only (
Figure 2b). To integrate the textual, geometrical, dosimetric, and imaging data, multi-input deep ANNs were utilised (
Figure 2c). MINNs were utilised with seven case studies that used tabular and imaging data: text + image, dose + image, geometry + image, text + dose + images, text + geometry + images, dose + geometry + images, text + dose + geometry +images.
The network architectures were the same across each of the case studies. The FFNN consisted of three layers with 18 neurons in the hidden layer and sigmoid as the activation function. The CNN consisted of two convolutional blocks (convolutional, pooling, and dropout layers [
18]) followed by a flatten layer and an output layer, as shown in
Figure 2c. The MINN combined the FFNN and CNN architectures by removing the last layer, adding a concatenation layer followed by an output layer. The ‘softmax’ activation function as used in the output layer with the three architectures. In neural networks with mixed input data, a model f is trained by utilising input features that belong to different categories. The output p of the network is defined as:
where
in an input modality,
and
n is the number of input modalities the deep network can receive. The training parameters for each network are shown in
Table 3.
4. Experiments and Results
4.1. Experimental Setup
Four types of volumes characteristics were generated for each structure in each dataset (text, dose, geometry, and images). A total of 15 combinations of input features were generated, each representing an experiment in each dataset. Further details are shown in
Supplementary Materials S2. A windows server with 10 virtual CPUs and 40 GB of RAM was utilised to prepare the datasets and to train the ANNs. Keras and Tensorflow were used for developing the neural networks [
19,
20].
4.2. Results and Analyses
Classification accuracy over the original and extended test datasets of each developed model in each dataset for each combination of features are shown in
Table 4 and
Table 5. Similar to other literature, standardising OAR only (Dataset 1) can be achieved using only imaging data. Any model with images as input showed a 100% accuracy when modelling OARs only. Adding the TV (Dataset 2 and 3) highlighted the need to include more than one type of features for standardising TV nomenclatures. With dose and positional features, the feature characteristics for structures (PTVs and CTVs) are quite similar and would require additional features for identification. It was noticed that using text and images is mandatory to achieve reliable models. As expected, combining multiple features revealed higher classification accuracy compared to using single features. Reliable performance was observed with all the datasets when using the text feature as input to the model, which aligns with the traditional approach, where clinicians tend to look at text initially to standardise nomenclatures.
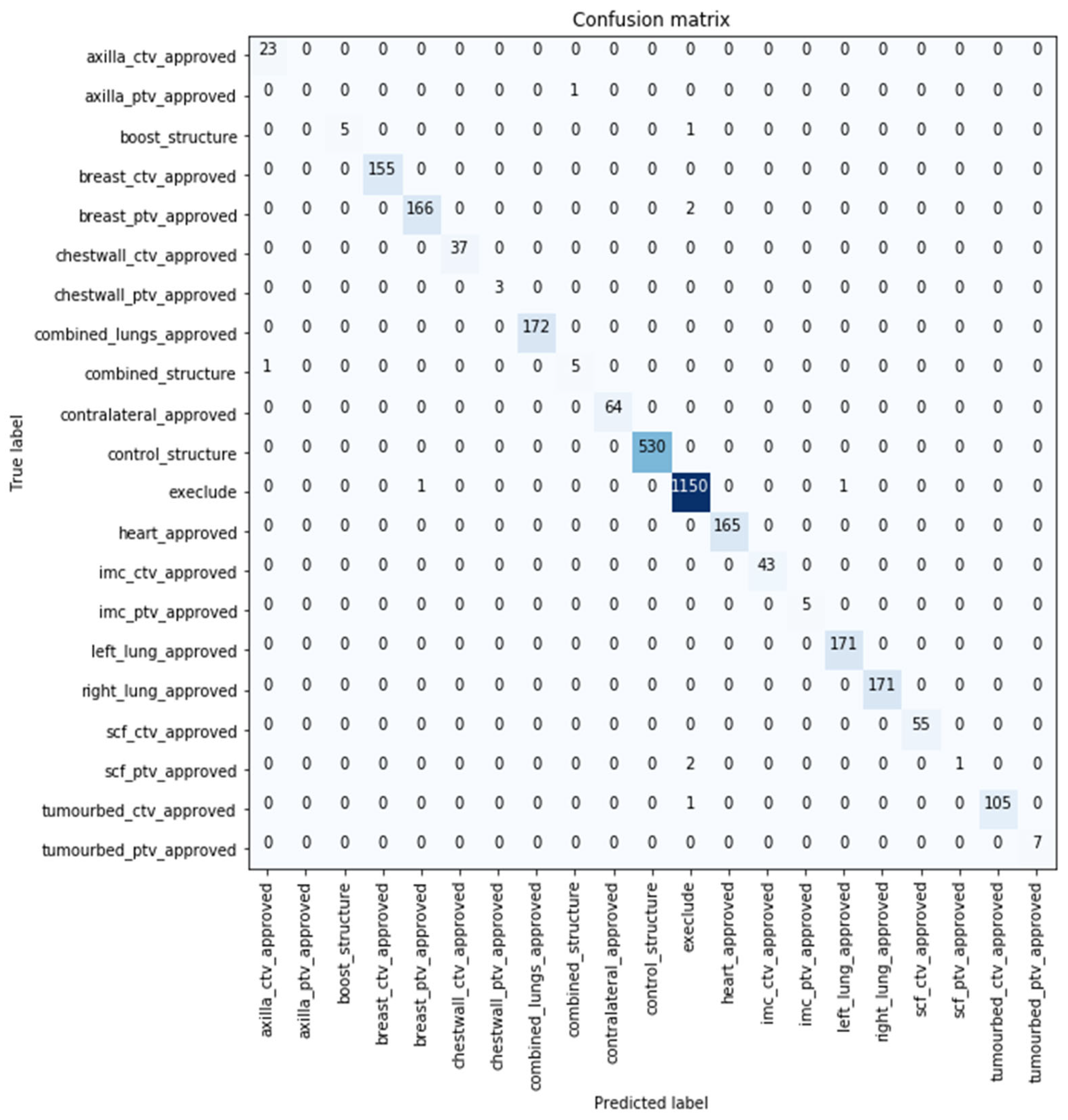
The confusion matrix represents the comparison between the predicted (
x-axis) and true classes (
y-axis). The confusion matrix for the best performing model with 99.671% classification accuracy over the original test sample is shown in
Figure 3, where 0.329% (10 samples) of the volumes were misclassified by the developed model. Six out of the 10 images were predicted not to use (i.e., exclude) by the model. Further details are included
Supplementary Materials S2.
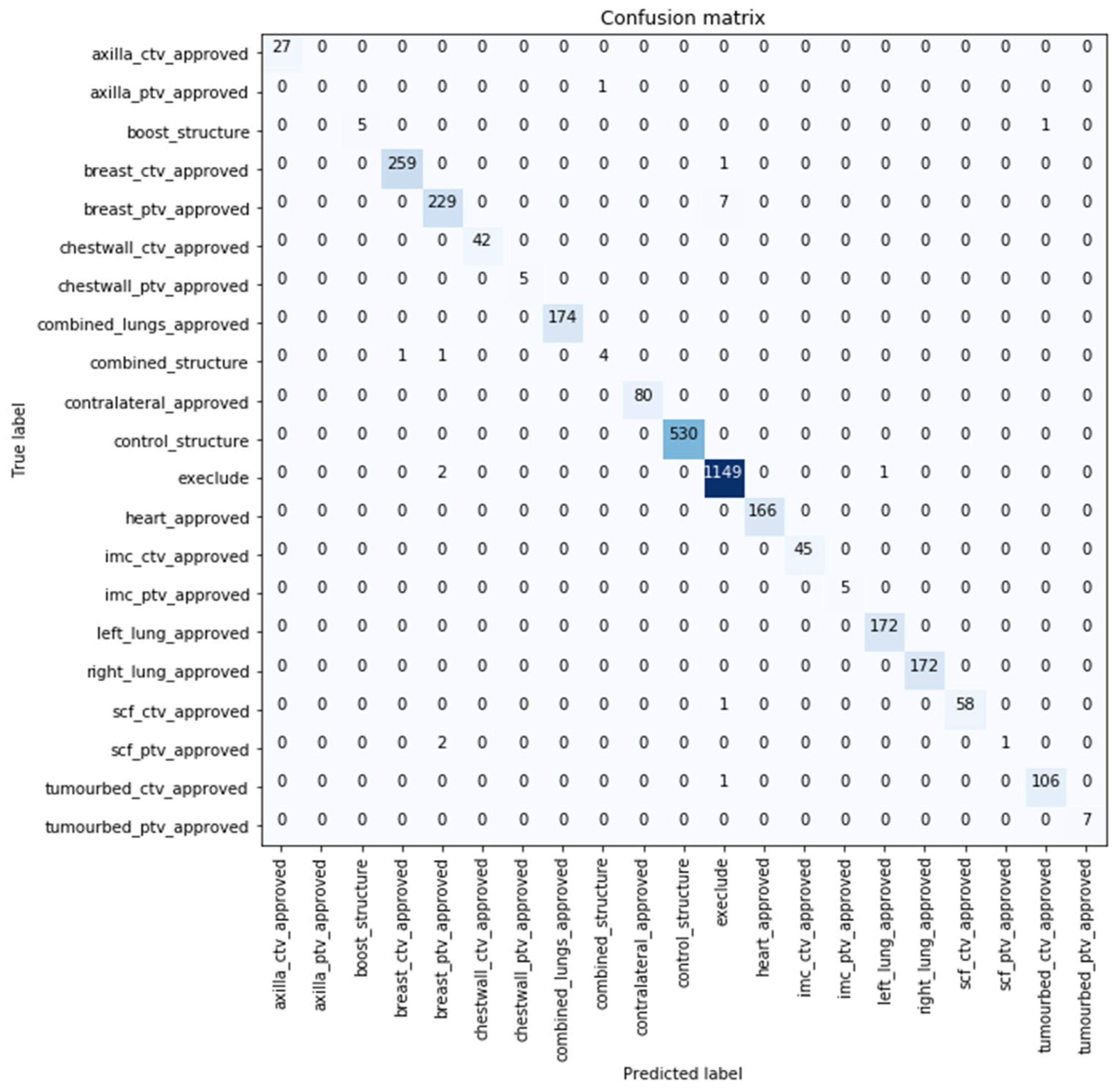
Similar performance was obtained with the models evaluated over the extended test datasets with the best performance being reported by model developed using (text + dose + images) with 99.416% classification accuracy. The confusion matrix for the best performing model over the extended dataset with 99.416% classification accuracy is shown in
Figure 4. Nineteen samples were misclassified by this model, with more than half of them predicted as not to use by the model (i.e., exclude). Further details about the images are shown in
Supplementary Materials S2.
The extended dataset might contain multiple structures in the same plan interpreted as the same TV/OAR. However, one structure will be used as the final structure for data mining analyses. While training, we selected only the structures that were reported as final by the clinicians. The other label referring to the same structure was assumed as a duplicate, registrar contour, etc. For the ‘breast PTV’, 40 patients in the extended test dataset had two or more volumes being referred as ‘breast PTV’ with one of them selected by the clinicians as final. We selected the structure with the highest probability generated for each of the structures and referred to that as final. For 39 patients out of the 40, the structure selected as the final by the clinicians had the highest probability in the patient plan. We assume that this approach worked because we trained the datasets using the final structures only.
4.3. Discussions, Limitations, and Future Work
Compared to other works, this study utilised the whole list of structures in a RT plan. In [
15], the developed model targeted standardising the OARs only, which means that additional time is required to handle the other TVs.
Using multiple modalities enabled the differentiation between TVs. Although CTVs and PTVs hold similar representations (typically the CTV is enclosed within the PTV), the model was capable of differentiating the volumes as shown in
Figure 3 and
Figure 4. While in studies such as [
21], a model misclassified the TV (PTV), although it was the only TV label used in training.
Different models were developed for each of the datasets. These models can be used where some features are not possible to generate (e.g., dosimetric features). With the high accuracy being reported with only two types of features, such models will be available for use in such cases.
In addition, there could be some volumes that have already been standardised such as the control structures. With the successful implementation of the models across the five types of datasets, such models can be used where there will be no need to standardise the already standardised volumes.
The time taken to train the two models that revealed the best performance over the two test datasets in Dataset 5 was less than 1.5 h. Further details about the time taken to train each neural network for each study is shown in
Supplementary Materials S2. The training time was affected by the number of classes, convergence, early stopping, type of input features incorporated, and available hardware. The prediction time was in seconds.
It was noticed that the models converged quickly, that indicates that the extracted features of the volumes contain discriminative features. Within this study, we verified that supervised learning can be utilised in standardising breast cancer radiotherapy data on a single data centre dataset. This showed potential of conducting the experiments using unsupervised learning. In addition, the samples were used as with no undersampling.
Despite its significance, the following paragraph discusses the limitations of this work that also constitutes future work. One limitation of this study is that the classes were generated based on internally accepted labels by the AusCAT network clinicians, which might not be generalisable to national districts. Hereafter, we consider using the TG-263 naming conventions in our future work. Structures volumes were not used in training the machine learning algorithms, which is also targeted in future work. In addition, structures with lower numbers of occurrences were misclassified, which highlights the need for more samples to be able to identify such structures. Furthermore, this work is limited to conventions written in English, taking into consideration that the generated textual features are language dependent. To enable using such models in other languages, new methods and network architectures are needed. Finally, within this work, our scope was to investigate machine learning methods applicability in RT data standardisation using data collected from a single centre. There is a need to further examine such models over multi-centred datasets to enable using such models across multiple locations, which will be done as a part of our future work.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}