
Enhancing Lung Cancer Classification through Integration of Liquid Biopsy Multi-Omics Data with Machine Learning Techniques

 ,
,  and
and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patients and IRB
2.2. Sample Preparation and cfDNA Extraction
2.3. Library Preparation and NGS Sequencing
2.4. Serum Cancer Protein Marker Tests
2.5. Copy Number Profiling from Cell-Free DNA
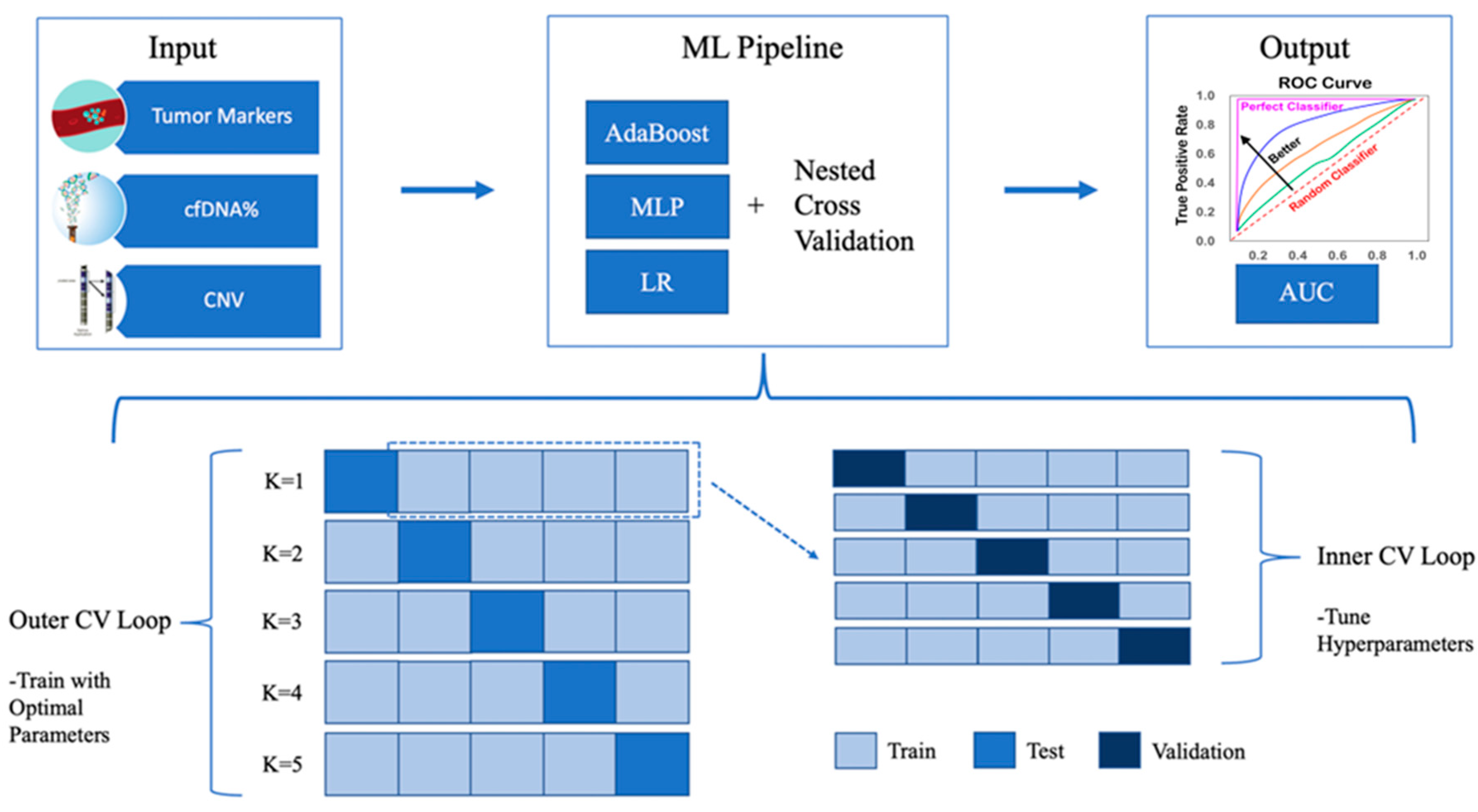
2.6. Nested Cross-Validation
2.7. Machine Learning
3. Results
3.1. Tumor Markers Are Significantly Increased in the Blood of Lung Cancer Patients
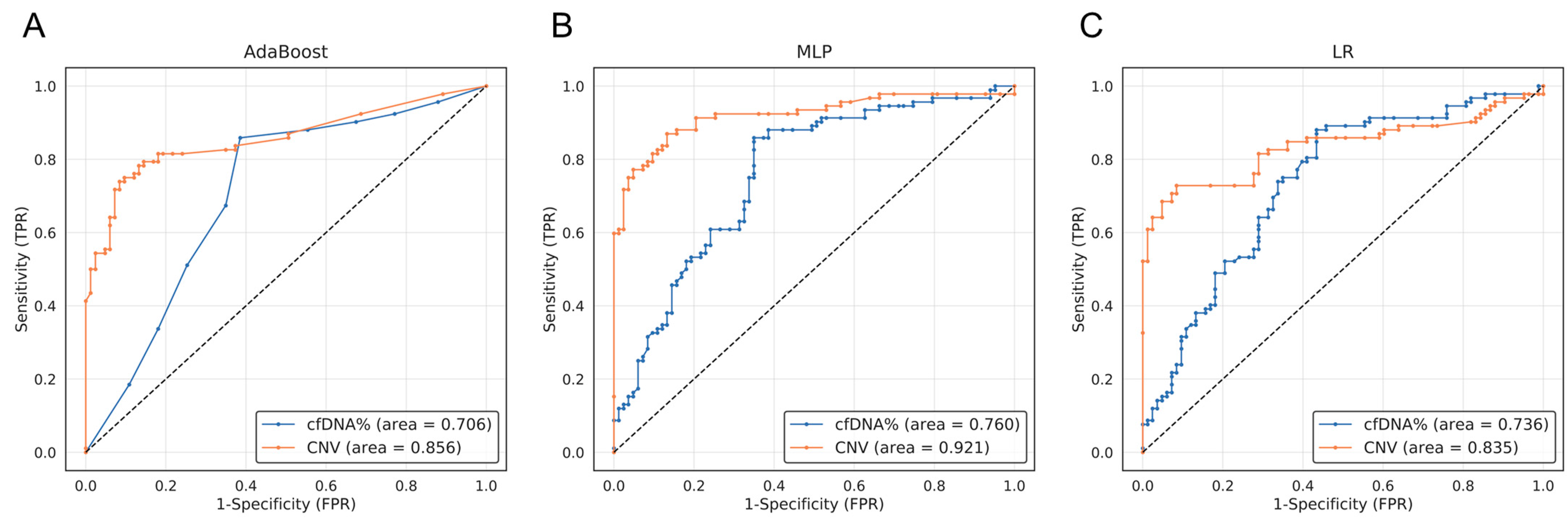
3.2. Low Specificity Observed in Machine Learning (ML) Analysis Using Individual Cancer Marker Expression
3.3. The ML Analysis Utilizing the Concentration of Extracted cfDNA and the CNV Score Demonstrated a Notably High Level of Specificity
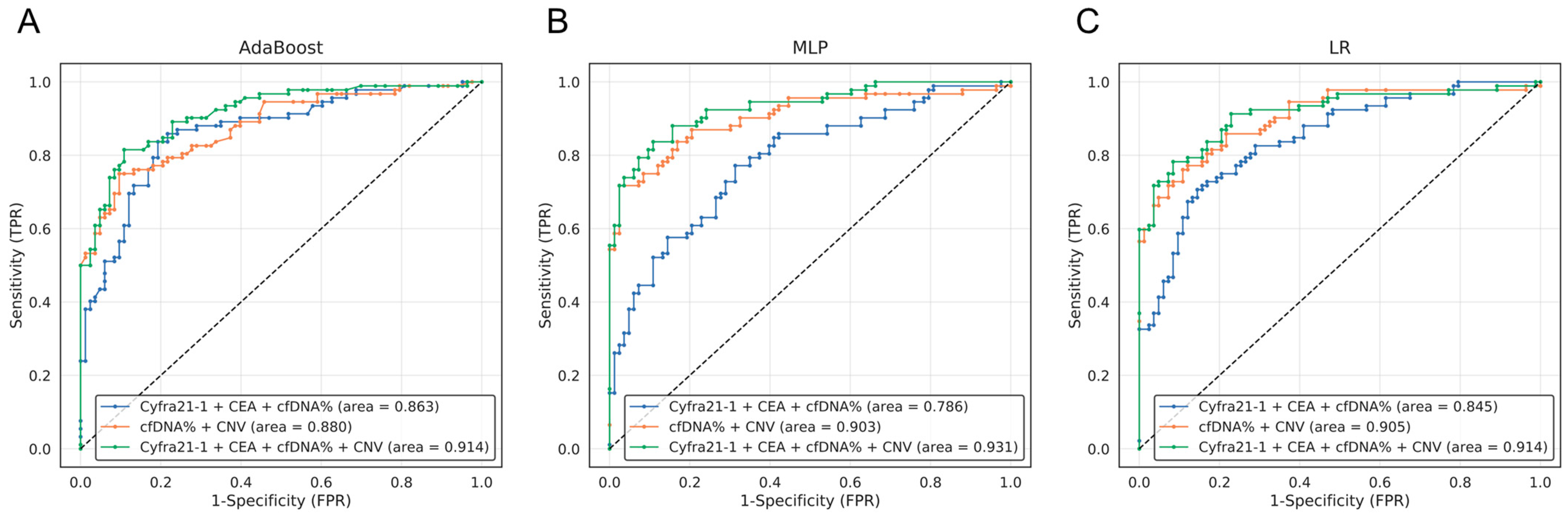
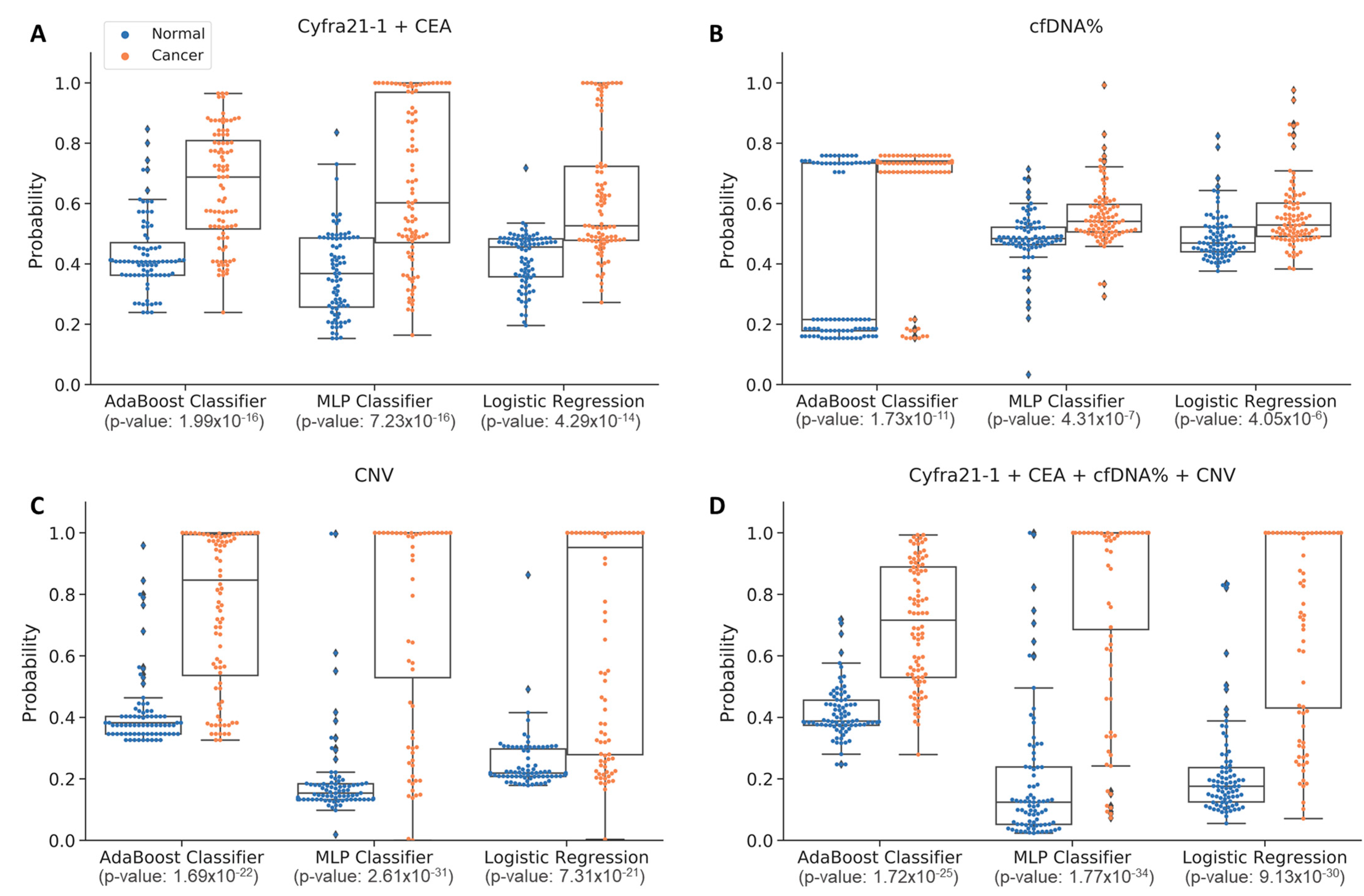
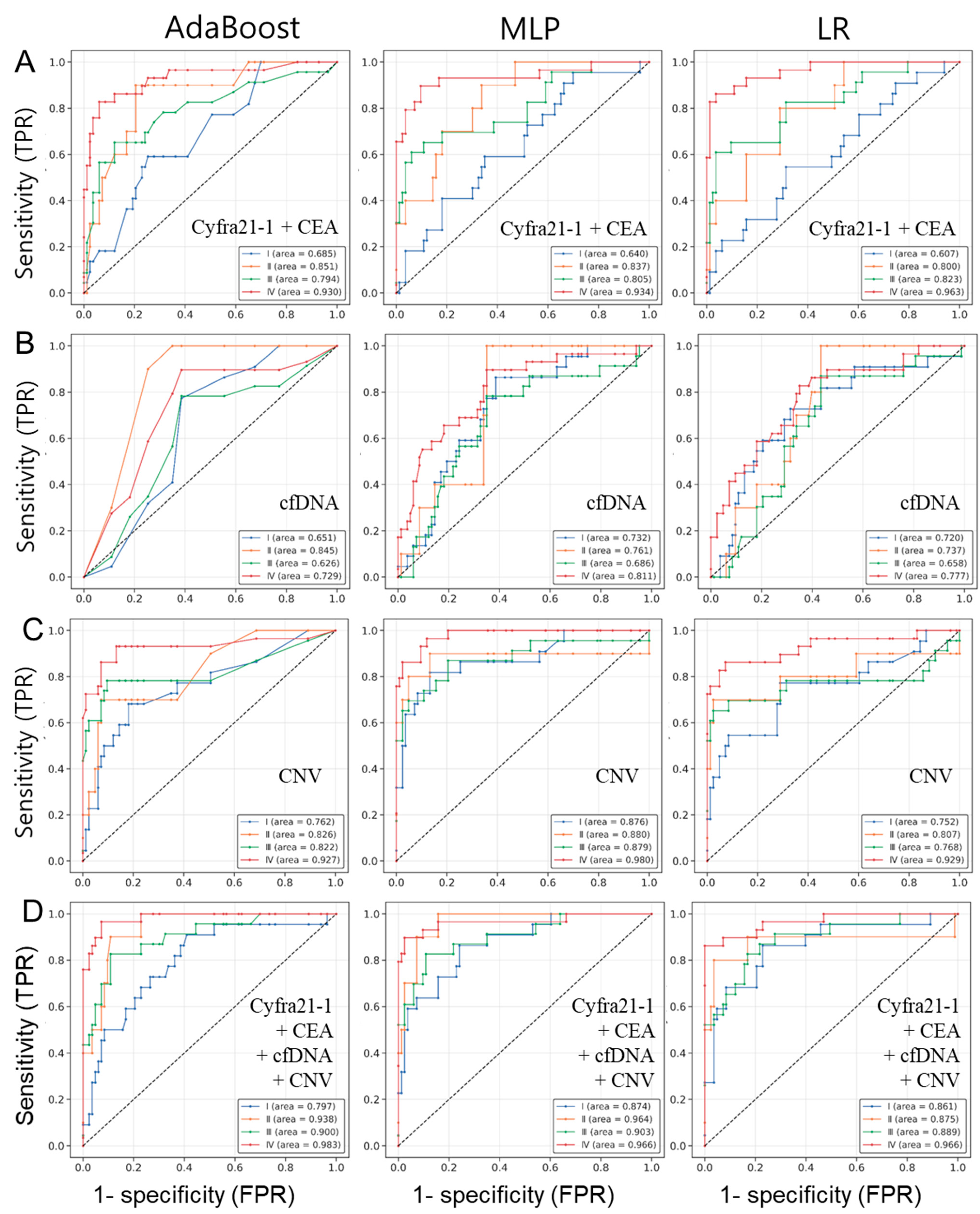
3.4. Selection of the Best Combination of Multi-Omics Data for Lung Cancer Diagnosis
3.5. Comparison of Detection Probabilities for Lung Cancer Patients by Stage Using Multi-Omics Data
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Schwartz, A.G.; Cote, M.L. Epidemiology of Lung Cancer. Adv. Exp. Med. Biol. 2016, 893, 21–41. [Google Scholar] [CrossRef] [PubMed]
- Schabath, M.B.; Cote, M.L. Cancer Progress and Priorities: Lung Cancer. Cancer Epidemiol. Biomark. Prev. 2019, 28, 1563–1579. [Google Scholar] [CrossRef] [PubMed]
- Hirsch, F.R.; Franklin, W.A.; Gazdar, A.F.; Bunn, P.A., Jr. Early detection of lung cancer: Clinical perspectives of recent advances in biology and radiology. Clin. Cancer Res. 2001, 7, 5–22. [Google Scholar] [PubMed]
- Chu, D.; Park, B.H. Liquid biopsy: Unlocking the potentials of cell-free DNA. Virchows Arch. 2017, 471, 147–154. [Google Scholar] [CrossRef] [PubMed]
- Lo, Y.M.D.; Han, D.S.C.; Jiang, P.; Chiu, R.W.K. Epigenetics, fragmentomics, and topology of cell-free DNA in liquid biopsies. Science 2021, 372, eaaw3616. [Google Scholar] [CrossRef] [PubMed]
- Bennett, C.W.; Berchem, G.; Kim, Y.J.; El-Khoury, V. Cell-free DNA and next-generation sequencing in the service of personalized medicine for lung cancer. Oncotarget 2016, 7, 71013–71035. [Google Scholar] [CrossRef] [PubMed]
- Malapelle, U.; Pisapia, P.; Rocco, D.; Smeraglio, R.; di Spirito, M.; Bellevicine, C.; Troncone, G. Next generation sequencing techniques in liquid biopsy: Focus on non-small cell lung cancer patients. Transl. Lung Cancer Res. 2016, 5, 505–510. [Google Scholar] [CrossRef]
- Chabon, J.J.; Hamilton, E.G.; Kurtz, D.M.; Esfahani, M.S.; Moding, E.J.; Stehr, H.; Schroers-Martin, J.; Nabet, B.Y.; Chen, B.; Chaudhuri, A.A.; et al. Integrating genomic features for non-invasive early lung cancer detection. Nature 2020, 580, 245–251. [Google Scholar] [CrossRef]
- Fernandez-Cuesta, L.; Perdomo, S.; Avogbe, P.H.; Leblay, N.; Delhomme, T.M.; Gaborieau, V.; Abedi-Ardekani, B.; Chanudet, E.; Olivier, M.; Zaridze, D.; et al. Identification of Circulating Tumor DNA for the Early Detection of Small-cell Lung Cancer. EBioMedicine 2016, 10, 117–123. [Google Scholar] [CrossRef]
- Peng, H.; Lu, L.; Zhou, Z.; Liu, J.; Zhang, D.; Nan, K.; Zhao, X.; Li, F.; Tian, L.; Dong, H.; et al. CNV Detection from Circulating Tumor DNA in Late Stage Non-Small Cell Lung Cancer Patients. Genes 2019, 10, 926. [Google Scholar] [CrossRef]
- Cainap, C.; Balacescu, O.; Cainap, S.S.; Pop, L.A. Next Generation Sequencing Technology in Lung Cancer Diagnosis. Biology 2021, 10, 864. [Google Scholar] [CrossRef] [PubMed]
- Idris, S.F.; Ahmad, S.S.; Scott, M.A.; Vassiliou, G.S.; Hadfield, J. The role of high-throughput technologies in clinical cancer genomics. Expert Rev. Mol. Diagn. 2013, 13, 167–181. [Google Scholar] [CrossRef] [PubMed]
- Kotelnikova, E.A.; Pyatnitskiy, M.; Paleeva, A.; Kremenetskaya, O.; Vinogradov, D. Practical aspects of NGS-based pathways analysis for personalized cancer science and medicine. Oncotarget 2016, 7, 52493–52516. [Google Scholar] [CrossRef] [PubMed]
- Conrad, D.F.; Pinto, D.; Redon, R.; Feuk, L.; Gokcumen, O.; Zhang, Y.; Aerts, J.; Andrews, T.D.; Barnes, C.; Campbell, P.; et al. Origins and functional impact of copy number variation in the human genome. Nature 2010, 464, 704–712. [Google Scholar] [CrossRef] [PubMed]
- Kallioniemi, O.P.; Kallioniemi, A.; Piper, J.; Isola, J.; Waldman, F.M.; Gray, J.W.; Pinkel, D. Optimizing comparative genomic hybridization for analysis of DNA sequence copy number changes in solid tumors. Genes Chromosomes Cancer 1994, 10, 231–243. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Sheng, Q.; Samuels, D.C.; Lehmann, B.; Bauer, J.A.; Pietenpol, J.; Shyr, Y. Comparative study of exome copy number variation estimation tools using array comparative genomic hybridization as control. BioMed Res. Int. 2013, 2013, 915636. [Google Scholar] [CrossRef]
- Duan, J.; Zhang, J.G.; Deng, H.W.; Wang, Y.P. Comparative studies of copy number variation detection methods for next-generation sequencing technologies. PLoS ONE 2013, 8, e59128. [Google Scholar] [CrossRef]
- Chakraborty, S.; Hosen, M.I.; Ahmed, M.; Shekhar, H.U. Onco-Multi-OMICS Approach: A New Frontier in Cancer Research. BioMed Res. Int. 2018, 2018, 9836256. [Google Scholar] [CrossRef]
- Lu, M.; Zhan, X. The crucial role of multiomic approach in cancer research and clinically relevant outcomes. EPMA J. 2018, 9, 77–102. [Google Scholar] [CrossRef]
- Van Delft, F.A.; Schuurbiers, M.M.F.; Muller, M.; Burgers, S.A.; van Rossum, H.H.; MJ, I.J.; van den Heuvel, M.M.; Koffijberg, H. Comparing modeling strategies combining changes in multiple serum tumor biomarkers for early prediction of immunotherapy non-response in non-small cell lung cancer. Tumor Biol. 2023; pre-press. [Google Scholar] [CrossRef]
- McCarthy, J.F.; Marx, K.A.; Hoffman, P.E.; Gee, A.G.; O’Neil, P.; Ujwal, M.L.; Hotchkiss, J. Applications of machine learning and high-dimensional visualization in cancer detection, diagnosis, and management. Ann. N. Y. Acad. Sci. 2004, 1020, 239–262. [Google Scholar] [CrossRef] [PubMed]
- Foster, K.R.; Koprowski, R.; Skufca, J.D. Machine learning, medical diagnosis, and biomedical engineering research—Commentary. Biomed. Eng. Online 2014, 13, 94. [Google Scholar] [CrossRef] [PubMed]
- Maroco, J.; Silva, D.; Rodrigues, A.; Guerreiro, M.; Santana, I.; de Mendonca, A. Data mining methods in the prediction of Dementia: A real-data comparison of the accuracy, sensitivity and specificity of linear discriminant analysis, logistic regression, neural networks, support vector machines, classification trees and random forests. BMC Res. Notes 2011, 4, 299. [Google Scholar] [CrossRef] [PubMed]
- Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors 2023, 23, 2112. [Google Scholar] [CrossRef] [PubMed]
- Kwon, H.J.; Shin, S.H.; Kim, H.H.; Min, N.Y.; Lim, Y.; Joo, T.W.; Lee, K.J.; Jeong, M.S.; Kim, H.; Yun, S.Y.; et al. Advances in methylation analysis of liquid biopsy in early cancer detection of colorectal and lung cancer. Sci. Rep. 2023, 13, 13502. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Durbin, R. Fast and accurate long-read alignment with Burrows-Wheeler transform. Bioinformatics 2010, 26, 589–595. [Google Scholar] [CrossRef] [PubMed]
- Danecek, P.; Bonfield, J.K.; Liddle, J.; Marshall, J.; Ohan, V.; Pollard, M.O.; Whitwham, A.; Keane, T.; McCarthy, S.A.; Davies, R.M.; et al. Twelve years of SAMtools and BCFtools. Gigascience 2021, 10, giab008. [Google Scholar] [CrossRef]
- Straver, R.; Sistermans, E.A.; Holstege, H.; Visser, A.; Oudejans, C.B.; Reinders, M.J. WISECONDOR: Detection of fetal aberrations from shallow sequencing maternal plasma based on a within-sample comparison scheme. Nucleic Acids Res. 2014, 42, e31. [Google Scholar] [CrossRef]
- Maros, M.E.; Capper, D.; Jones, D.T.W.; Hovestadt, V.; von Deimling, A.; Pfister, S.M.; Benner, A.; Zucknick, M.; Sill, M. Machine learning workflows to estimate class probabilities for precision cancer diagnostics on DNA methylation microarray data. Nat. Protoc. 2020, 15, 479–512. [Google Scholar] [CrossRef]
- Sanner, M.F. Python: A programming language for software integration and development. J. Mol. Graph. Model. 1999, 17, 57–61. [Google Scholar]
- Hatwell, J.; Gaber, M.M.; Atif Azad, R.M. Ada-WHIPS: Explaining AdaBoost classification with applications in the health sciences. BMC Med. Inform. Decis. Mak. 2020, 20, 250. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Si, J. Approximate robust policy iteration using multilayer perceptron neural networks for discounted infinite-horizon Markov decision processes with uncertain correlated transition matrices. IEEE Trans. Neural Netw. 2010, 21, 1270–1280. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Ho, K.M.; Hong, Y. Machine learning for the prediction of volume responsiveness in patients with oliguric acute kidney injury in critical care. Crit. Care 2019, 23, 112. [Google Scholar] [CrossRef] [PubMed]
- Integrative Analysis of Lung Cancer, E.; Risk Consortium for Early Detection of Lung, C.; Guida, F.; Sun, N.; Bantis, L.E.; Muller, D.C.; Li, P.; Taguchi, A.; Dhillon, D.; Kundnani, D.L.; et al. Assessment of Lung Cancer Risk on the Basis of a Biomarker Panel of Circulating Proteins. JAMA Oncol. 2018, 4, e182078. [Google Scholar] [CrossRef] [PubMed]
- Ostrin, E.J.; Bantis, L.E.; Wilson, D.O.; Patel, N.; Wang, R.; Kundnani, D.; Adams-Haduch, J.; Dennison, J.B.; Fahrmann, J.F.; Chiu, H.T.; et al. Contribution of a Blood-Based Protein Biomarker Panel to the Classification of Indeterminate Pulmonary Nodules. J. Thorac. Oncol. 2021, 16, 228–236. [Google Scholar] [CrossRef] [PubMed]
- Negm, R.S.; Verma, M.; Srivastava, S. The promise of biomarkers in cancer screening and detection. Trends Mol. Med. 2002, 8, 288–293. [Google Scholar] [CrossRef] [PubMed]
- Moro, D.; Villemain, D.; Vuillez, J.P.; Delord, C.A.; Brambilla, C. CEA, CYFRA21-1 and SCC in non-small cell lung cancer. Lung Cancer 1995, 13, 169–176. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, D.; Li, L.; Pu, D.; Zhou, P.; Jing, Y.; Yu, H.; Wang, Y.; Zhu, Y.; He, Y.; et al. The important role of circulating CYFRA21-1 in metastasis diagnosis and prognostic value compared with carcinoembryonic antigen and neuron-specific enolase in lung cancer patients. BMC Cancer 2017, 17, 96. [Google Scholar] [CrossRef]
- Anthonisen, N.R.; Connett, J.E.; Enright, P.L.; Manfreda, J.; Lung Health Study Research, G. Hospitalizations and mortality in the Lung Health Study. Am. J. Respir. Crit. Care Med. 2002, 166, 333–339. [Google Scholar] [CrossRef]
- Thandra, K.C.; Barsouk, A.; Saginala, K.; Aluru, J.S.; Barsouk, A. Epidemiology of lung cancer. Contemp. Oncol. 2021, 25, 45–52. [Google Scholar] [CrossRef]
- Goebel, C.; Louden, C.L.; McKenna, R., Jr.; Onugha, O.; Wachtel, A.; Long, T. Diagnosis of Non-small Cell Lung Cancer for Early Stage Asymptomatic Patients. Cancer Genomics Proteomics 2019, 16, 229–244. [Google Scholar] [CrossRef]
- Pinsky, P.F. Assessing the benefits and harms of low-dose computed tomography screening for lung cancer. Lung Cancer Manag. 2014, 3, 491–498. [Google Scholar] [CrossRef] [PubMed]
- Patz, E.F., Jr.; Pinsky, P.; Gatsonis, C.; Sicks, J.D.; Kramer, B.S.; Tammemagi, M.C.; Chiles, C.; Black, W.C.; Aberle, D.R.; Team, N.O.M.W. Overdiagnosis in low-dose computed tomography screening for lung cancer. JAMA Intern. Med. 2014, 174, 269–274. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Poulos, R.C.; Liu, J.; Zhong, Q. Machine learning for multi-omics data integration in cancer. iScience 2022, 25, 103798. [Google Scholar] [CrossRef] [PubMed]
- Pounraja, V.K.; Jayakar, G.; Jensen, M.; Kelkar, N.; Girirajan, S. A machine-learning approach for accurate detection of copy number variants from exome sequencing. Genome Res. 2019, 29, 1134–1143. [Google Scholar] [CrossRef] [PubMed]
- Tandler, N.; Mosch, B.; Pietzsch, J. Protein and non-protein biomarkers in melanoma: A critical update. Amino Acids 2012, 43, 2203–2230. [Google Scholar] [CrossRef] [PubMed]
- Pereira, A.A.L.; Morelli, M.P.; Overman, M.; Kee, B.; Fogelman, D.; Vilar, E.; Shureiqi, I.; Raghav, K.; Eng, C.; Manuel, S.; et al. Clinical utility of circulating cell-free DNA in advanced colorectal cancer. PLoS ONE 2017, 12, e0183949. [Google Scholar] [CrossRef]
- Ding, S.C.; Lo, Y.M.D. Cell-Free DNA Fragmentomics in Liquid Biopsy. Diagnostics 2022, 12, 978. [Google Scholar] [CrossRef]
- Jiang, P.; Sun, K.; Tong, Y.K.; Cheng, S.H.; Cheng, T.H.T.; Heung, M.M.S.; Wong, J.; Wong, V.W.S.; Chan, H.L.Y.; Chan, K.C.A.; et al. Preferred end coordinates and somatic variants as signatures of circulating tumor DNA associated with hepatocellular carcinoma. Proc. Natl. Acad. Sci. USA 2018, 115, E10925–E10933. [Google Scholar] [CrossRef]
- Jiang, P.; Sun, K.; Peng, W.; Cheng, S.H.; Ni, M.; Yeung, P.C.; Heung, M.M.S.; Xie, T.; Shang, H.; Zhou, Z.; et al. Plasma DNA End-Motif Profiling as a Fragmentomic Marker in Cancer, Pregnancy, and Transplantation. Cancer Discov. 2020, 10, 664–673. [Google Scholar] [CrossRef]
- Graw, S.; Chappell, K.; Washam, C.L.; Gies, A.; Bird, J.; Robeson, M.S., 2nd; Byrum, S.D. Multi-omics data integration considerations and study design for biological systems and disease. Mol. Omics 2021, 17, 170–185. [Google Scholar] [CrossRef]
- Eicher, T.; Kinnebrew, G.; Patt, A.; Spencer, K.; Ying, K.; Ma, Q.; Machiraju, R.; Mathe, A.E.A. Metabolomics and Multi-Omics Integration: A Survey of Computational Methods and Resources. Metabolites 2020, 10, 202. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Normal | Lung Cancer | |
|---|---|---|---|
| Enrollment | 80 | 92 | |
| Gender | Male | 43 | 65 |
| Female | 37 | 27 | |
| Age | Median | 32 | 65 |
| Range | 18–72 | 40–80 | |
| Stage | I | - | 30 |
| II | - | 10 | |
| III | - | 23 | |
| IV | - | 29 | |
| Cancer Type | Adenocarcinoma | - | 56 |
| Squamous cell carcinoma | - | 22 | |
| Large-cell neuroendocrine carcinoma | - | 1 | |
| Non-small-cell lung cancer | - | 7 | |
| Small-cell lung cancer | - | 2 | |
| Not specified | - | 2 | |
| Protein Marker | Lung Cancer | Healthy | p-Value | ||
|---|---|---|---|---|---|
| n | Mean ± SEM | n | Mean ± SEM | ||
| Cyfra_21-1 (ng/mL) | 92 | 5.87 ± 1.14 | 80 | 1.4 ± 0.09 | 0.0000 |
| CA_15-3 (U/mL) | 92 | 18.65 ± 3.07 | 80 | 8.68 ± 0.54 | 0.0009 |
| AFP (ng/mL) | 92 | 6.9 ± 4.74 | 80 | 2.27 ± 0.12 | 0.1659 |
| CEA (ng/mL) | 92 | 42.75 ± 14.97 | 80 | 1.84 ± 0.15 | 0.0037 |
| CA_19-9 (U/mL) | 92 | 40.21 ± 13.75 | 80 | 9.06 ± 0.64 | 0.0130 |
| Tumor Makers | AdaBoost | MLP | LR |
|---|---|---|---|
| Cyfra21-1 | 0.734 | 0.756 | 0.781 |
| CA15-3 | 0.555 | 0.603 | 0.612 |
| AFP | 0.482 | 0.510 | 0.484 |
| CEA | 0.713 | 0.797 | 0.791 |
| CA19-9 | 0.570 | 0.558 | 0.556 |
| Cyfra21-1 + CEA | 0.828 a,b | 0.821 a,b | 0.821 a,b |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, H.-J.; Park, U.-H.; Goh, C.J.; Park, D.; Lim, Y.G.; Lee, I.K.; Do, W.-J.; Lee, K.J.; Kim, H.; Yun, S.-Y.; et al. Enhancing Lung Cancer Classification through Integration of Liquid Biopsy Multi-Omics Data with Machine Learning Techniques. Cancers 2023, 15, 4556. https://doi.org/10.3390/cancers15184556
Kwon H-J, Park U-H, Goh CJ, Park D, Lim YG, Lee IK, Do W-J, Lee KJ, Kim H, Yun S-Y, et al. Enhancing Lung Cancer Classification through Integration of Liquid Biopsy Multi-Omics Data with Machine Learning Techniques. Cancers. 2023; 15(18):4556. https://doi.org/10.3390/cancers15184556
Chicago/Turabian StyleKwon, Hyuk-Jung, Ui-Hyun Park, Chul Jun Goh, Dabin Park, Yu Gyeong Lim, Isaac Kise Lee, Woo-Jung Do, Kyoung Joo Lee, Hyojung Kim, Seon-Young Yun, and et al. 2023. "Enhancing Lung Cancer Classification through Integration of Liquid Biopsy Multi-Omics Data with Machine Learning Techniques" Cancers 15, no. 18: 4556. https://doi.org/10.3390/cancers15184556
APA StyleKwon, H.-J., Park, U.-H., Goh, C. J., Park, D., Lim, Y. G., Lee, I. K., Do, W.-J., Lee, K. J., Kim, H., Yun, S.-Y., Joo, J., Min, N. Y., Lee, S., Um, S.-W., & Lee, M.-S. (2023). Enhancing Lung Cancer Classification through Integration of Liquid Biopsy Multi-Omics Data with Machine Learning Techniques. Cancers, 15(18), 4556. https://doi.org/10.3390/cancers15184556