1. Introduction
Diffuse Intrinsic Pontine Glioma (DIPG) is a rare brain tumour located in the pons, mostly found in children between 5 and 7 years of age. It is considered one of the most aggressive paediatric tumours, with a survival rate of less than 10% beyond 2 years after diagnosis [
1] and a median overall survival below 1 year [
2]. The DIPG is categorised as a diffuse midline glioma, which is mostly characterised by a K27M mutation in genes coding for the histone H3 protein, and/or a loss of H3K27 trimethylation through EZHIP protein overexpression [
3]. The location of the tumour and its corresponding genomic alteration makes the DIPG a completely different type of tumour from other High Grade Glioma (HGG) [
4]. Thanks to a stereotactic biopsy that can be safely performed at diagnosis, molecular stratification correlated with survival [
3] have been uncovered. However, due to the tumour location and its infiltrating characteristics, alternatives are being actively sought to find non-invasive biomarkers to propose innovative therapies and improve treatment monitoring.
The clinical management of DIPG patients includes MR neuroimaging at diagnosis and follow-up based on anatomical T1-weighted (T1w), Gadolinium-enhanced (T1Gd), T2-weighted (T2w) or Fluid Attenuated Inversion Recovery (FLAIR) images [
5]. New imaging modalities, such as perfusion imaging, are thought to show pertinent indicators of the disease progression [
6]. Parallel to this, new classification or prediction approaches based on image features, such as radiomics, allow MRI scans to be used for both disease stratification at diagnosis and progression monitoring [
7]. Yet, learning from images classically requires large cohorts for which tumours are finely delineated. The rarity of DIPG added to the fact that segmentation is not part of the clinical routine procedure, making it difficult to obtain robust statistical classifiers or predictors. Automatic tumour segmentation based on transfer learning could theoretically alleviate this problem, circumventing the small number of manual delineations which prevent directly and efficiently training these segmentation models.
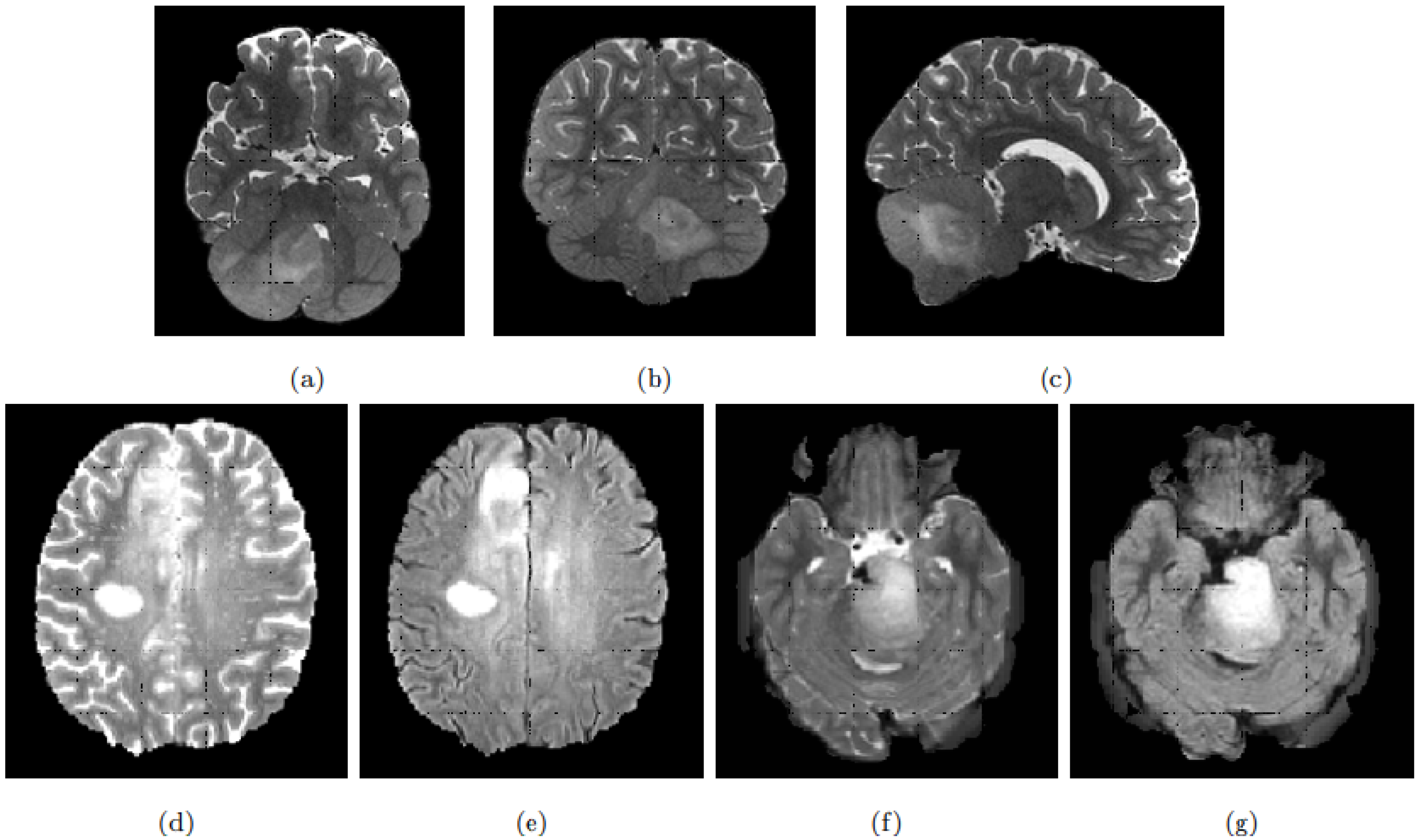
In general, DIPG tumours have a central location involving more than 50% of the pons [
8]. On MRI scans and due to its infiltrating nature, the tumour appears as an intrinsic expansion of the brainstem and not as a distinct foreign mass compressing the pons. However, the tumour is not always restricted to the pons and it can infiltrate other compartments of the central nervous system such as the cerebral peduncles and supratentorial midline or the cerebellum [
9]. The deformation of the pons induced by the tumour and its infiltrating nature makes its detection and delineation non-trivial. On the T2w scans, the tumour presents a hyper-intense signal while it appears hypo-intense with indistinct tumour margins on T1w scans. Enhancement following gadolinium injection (T1Gd) is inconstant and often absent. Finally, the tumour is relatively homogeneous on FLAIR modality [
8].
Figure 1 exhibits a DIPG tumour on different modalities.
DIPG shares some of its visual characteristics with the glioblastoma, especially on T2w and FLAIR modalities. However, glioblastoma presentation differs on T1w and T1Gd, with the absence of a necrosis component in the DIPG, and the gadolinium enhancement which is more intense and always present for the glioblastoma [
10]. Our aim is to exploit the existing macroscopic visual similarities of DIPG with glioblastoma or low-grade gliomas, to train a two-step robust model able to infer DIPG segmentations.
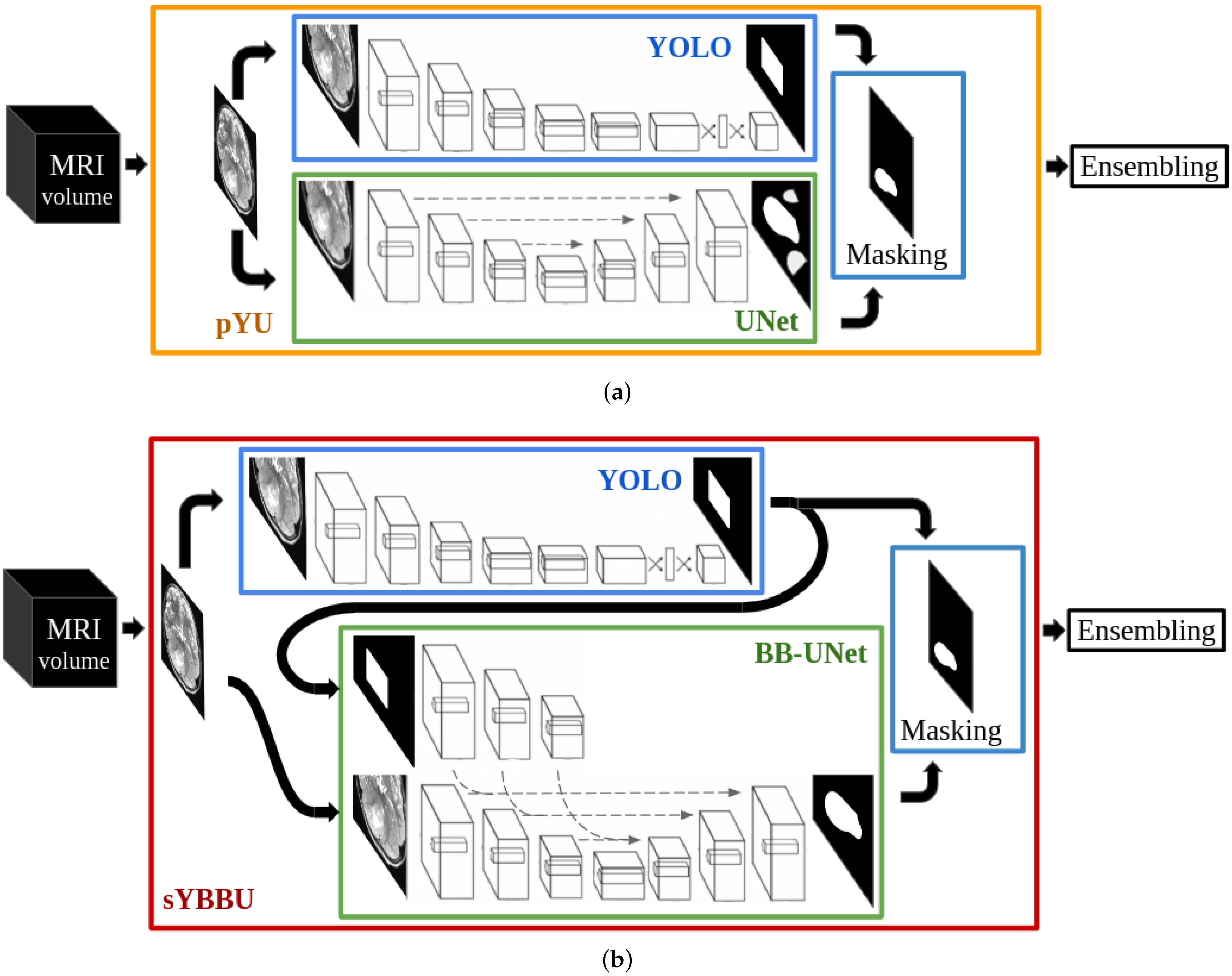
Because rare tumours present some visual similarities with common tumours, in the lesion and around it, one may split the tumour delineation problem into two steps: object detection and segmentation. For each step, trained networks on common lesions could be used on rare ones following a domain adaptation scheme without extra fine-tuning. Our work suggests different architectures to solve the segmentation and detection tasks and two combination strategies of the two tasks. We assessed the performance of our strategies in three different configurations: Using the same tumour as in the training, using a different tumour located in the supratentorial region as in the training and finally using a different rare tumour located in the brainstem, an unseen region during the training.
In the section Related Works, we present current work involving brain tumour segmentation and show their limitation concerning the problem of rare tumours. Then, the section Material and Methods describes our models for each of the two tasks, detection and segmentation, and the proposed combination strategies. Our strategies are trained on a large general database available in neuro-oncology, namely the BRaTS database [
11,
12,
13]. In the section Experiments and Results, we use this publicly available database (subdivided in one train and two test sets) to obtain several global segmentation models and to assess them in the task of providing segmentations on the High Grade Gliomas and Low Grade Gliomas. These data are also used to analyse the relationship between detection and segmentation performance. Finally, results of inference in new DIPG images are presented and discussed.
2. Related Works
Numerous studies have successfully used MRI scans for profiling in many adult tumours. In the case of DIPG, MRI profiling potential has been assessed only in very recent works, as in the work of Leach et al. [
14] where radiological descriptors, among others, have been used to study survival. However, they did not make use of tumour segmentation, but rather visual assessments achieved by a team of neurologists. Accurate tumour volume estimation protocols have been proposed by Singh et al. [
15] for the DIPG. However, they studied only eight patients for whom a neuro-radiologist executed a manual delineation to obtain the volume estimates. This is not scalable to a cohort of more than a hundred patients, and it raises concerns about the stability and bias of the results because of inter-operator variability. To our knowledge, no automatic segmentation strategy has been proposed yet for DIPG.
Segmentation approaches based on the region competition driven by multivariate statistical distribution analysis of the image grey levels [
16] could be applied. Indeed, in the case of DIPG, the location of the tumour is broadly known and the limiting initialising step of the region competition methods should be easy. Yet, it is still to be solved as the DIPG tumour, with its specific infiltrating pattern, has an impact on various brain structures and presents highly variable appearances in the different image modalities. Consequently, these methods, which remain highly dependent on initialising seed, would have to be trained heavily. Moreover, these approaches are very sensitive to the availability of all the imaging modalities present during the learning of the model. They would require a database of expertly labelled images of the size of BraTS (around 250 samples).
Deep learning techniques have shown great success in a wide variety of tasks. Convolution Neural Networks (CNN) [
17], in particular, have proven their efficiency in computer vision tasks such as classification, object detection and segmentation, as they have shown a great capacity to extract highly relevant features for the tasks at hand. These CNN have been successfully used on natural images and medical scans. Numerous works have been proposed for the automatic segmentation of cerebral tumours, notably for glioblastomas. In general, these techniques use either patch-based segmentation or end-to-end segmentation.
Patch-based segmentation relies on multiple patches from the same image for the full segmentation under the assumption that the central region of similar patches will have similar labels. With these techniques, multiple segmentations, extracted from different neighbouring patches, can be proposed for the same set of voxels, and thus increase the stability of these models. Havaei et al. [
18] and Kamnitsas et al. [
19] are among several works related to patch-based techniques. While the first segments the 3D volumes using 2D patches fed into a simple multi-path network, the latter uses 3D patches given into a more complex model. However, these models require more computational resources compared to end-to-end models and introduce a sampling problem, knowing that a brain tumour occupies on average 7% of the brain volume in the studied datasets.
End-to-end segmentation predicts labels from the whole volumes or slices. Contrary to patch-based segmentation, here the model scope is not restricted. Thus, the model has more information to work with, but also it has to determine the tumour location. Most recent studies have found great success using encoder-decoder architectures. Myronenko A. et al. [
20] won the BraTS’18 challenge with a segmentation network that uses 3D MRI scans and employs multitasking to help compensate for the limited dataset size. Meanwhile, Isensee et al. [
21] obtained excellent results, ranking 2nd on BRaTS’18, using the classic UNet architecture with minimal modifications. More recent works in brain tumour segmentation focus on UNet and its iterations [
22,
23,
24] and exhibit the power of this architecture to solve the segmentation problem.
Segmentation models can be improved by providing priors. Since cerebral tumours can come in different shapes [
25] and locations [
26], we cannot use this information as priors, as proposed in numerous works. Bounding-boxes around target objects can be used instead. Lempitsky et al. [
27] incorporated user-provided bounding-boxes as a way to add topology and shape information to their loss function and applied it to the natural images object segmentation problem. Rosana et al. [
28] proposed to feed their UNet architecture with their user-provided bounding-box masks in parallel to their input images. These propositions do not discuss the origin of the bounding-boxes, and while user-provided bounding-boxes can be reliable, automatically detected ones can introduce multiple issues, which we propose to study.
Segmentation approaches can work on 2D or 3D images. Using 2D images limits the scope available to the model and can result in discontinuities. 3D models might seem like a better solution, but these architectures are much more complex and have fewer training examples, making them hard to train. Some works propose hybrid models, which use both 2D and 3D inputs, such as Mlynarski et al. [
29], who propose a neural network that uses 3D images combined with features extracted from different 2D images.
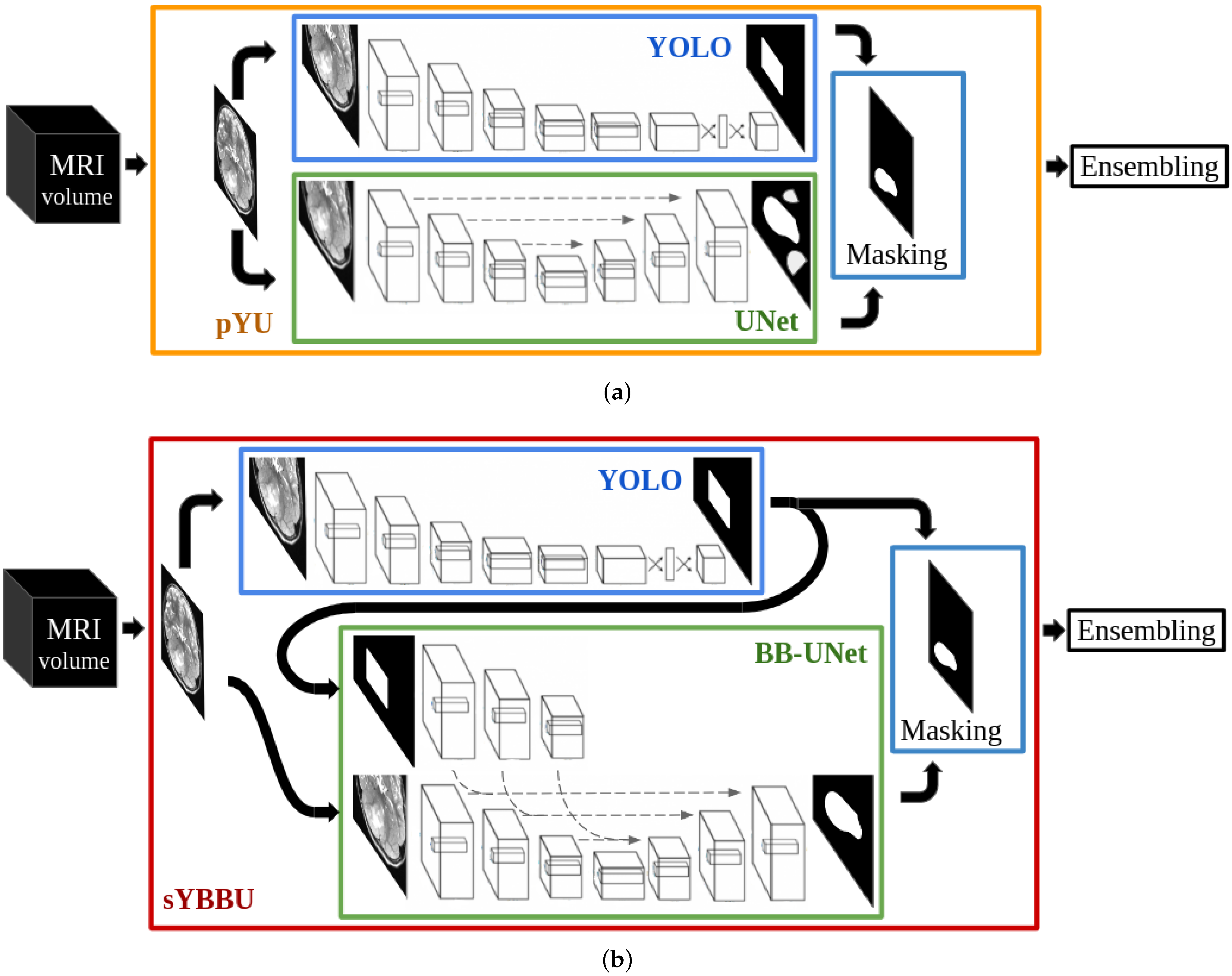
The approach we propose in this work combines object-detection and segmentation models, each trained independently. Thus, our method differs from the Mask R-CNN (Region-based CNN) strategy [
30]. Indeed, Mask R-CNN has linked detection and segmentation architectures, which are trained concurrently, while our proposition relies on multiple different networks that do not share parameters.
In the context of tumour segmentation, our approach is among the methods that use bounding boxes as a priori to help segmentation task. Unlike BB-UNET, our approach suggests a way to obtain the bounding boxes and study their impact on the segmentation results. Solving the segmentation and detection tasks using separate networks allows us to reuse networks in a completely uncoupled way-which differs from the Mask-CNN. Using two architectures independently allows us to extract different features for each task which increases flexibility and robustness of our approach (the ensembling using the separate outcomes may bring a solution).
4. Experiments and Results
4.1. Experimental Designs
To conduct our experiments, we divided the HGG dataset into a 90% training set and 10% validation set. We tested all the models on the TCGA-GBM
dataset, the LGG
dataset and 30 patients (71 sessions) of DIPG
.
Table 1 sums up the dataset sizes.
To assess the performance of our approaches on the different test datasets, we used the provided segmentation labels to compute precision and recall (see Equation (
2)), alongside the Dice index (Equation (
7)), with
M the predicted binary mask, and
the binary ground-truth. These metrics were measured after the 3D reconstruction of the binary masks. We note that the object-detection outputs are also binary masks.
On the TCGA-GBM dataset, we performed a correlation analysis between the ensembled bounding-box performance and the ensembled segmentation performance, in order to establish the impact of the object-detection step on the final segmentation. Furthermore, since BB-UNet models were trained with the ground-truth bounding-boxes while inference was performed using YOLO predicted bounding-boxes, we analysed the impact of the used bounding-boxes on the prediction performance of the networks.
On the DIPG
dataset, we compared the object-detection performance with a generic bounding-box around the pons. This bounding-box was manually extracted from a template [
44] with an enlargement of approximately 50% on each side.
Supplementary Figure S3 summarises the experimental design chosen to evaluate the methods.
4.2. Benchmark Results
4.2.1. Object-Detection Results
Table 2 and
Table 3 give the results of the detection phase on the TCGA-GBM
and LGG
datasets. Overall, both the FLAIR and the T2w obtain a very high recall and a relatively low precision score. The merging of both modalities helps further improve the recall and the stability of the predictions (lowering the standard deviations) while lowering the precision. Low precision scores were expected in this phase since the predictions are piece-wise squares while tumour shapes are complex meshes. Therefore, the precision score depends heavily on the tumour shape and orientation. One must also note that a tumour generally occupies around 7% of the brain, in the studied dataset, which impacts the precision score. To choose the best model, it is important to remember that the main objective of this phase is to generate priors for a segmentation. It is therefore imperative to reliably detect the whole tumour (implying high recall), even if it comes with lower precision.
The detection framework achieved better performance in the TCGA-GBM dataset than in LGG. This was expected since our model was solely trained to detect high-grade-gliomas. Even if the performance was degraded for the LGG dataset, this decrease is moderate, especially when comparing the results of the ensembled model. This shows that the object-detection model is able to detect different types of tumours that occur in the same tissues of the brain.
Morphological opening and closing showed a minimal effect. However, as these effects were always positive on both precision and recall, we kept them in our detection process.
4.2.2. Segmentation Results
YOLO bounding-boxes, obtained in the previous phase, were used during the segmentation. Each segmentation model uses bounding-boxes obtained from the same input image and modality. The bounding-boxes used for the segmentation are all post-processed by the morphological transformations.
Segmentation Results on TCGA-GBM
Table 4 describes the results obtained for the segmentation of TCGA-GBM
. A voxel is considered tumoral if its confidence score
is above 0.5. As expected, precision scores were considerably higher than during the detection phase, however, this came with a decrease in recall.
The UNet models performed poorly on TCGA-GBM compared to the other models. Indeed the mean Dice index ranged from 0.70 to 0.78, which is below the other models’ averages, with values greater than 0.84. This was mainly due to their low precision scores. A deeper look into the results showed that UNet segments healthy bright spots of the brain the same way it segments the bright spots indicating the presence of the tumour, especially edema. On the other side, UNet gave comparable results in the recall metric (i.e., percentage of the tumour detected).
Moreover, we can see a clear improvement after UNet segmentations were masked with the predicted bounding-boxes, i.e., the pYU model. Mean precision scores increased by nearly 15% in all configurations, while the standard deviations were reduced by nearly half. These results suggest that most of the false positives are outside of the bounding-boxes, which is in line with the assumption stated by Equation (
3). These improvements came with a slight decrease in the recall, of around 1%. We consider this decrease is minor compared to the benefits of masking with bounding-boxes in precision.
Furthermore, bounding-boxes also have a positive effect when they are used as inputs in the BB-UNet models. There is an increase in mean precision and a decrease in standard deviations of precision and Dice index. After masking, the results of UNet and BB-UNet are very similar, with BB-UNet coming slightly ahead, with an improvement in precision between 1% and 3%, and a recall that remained similar among all the models.
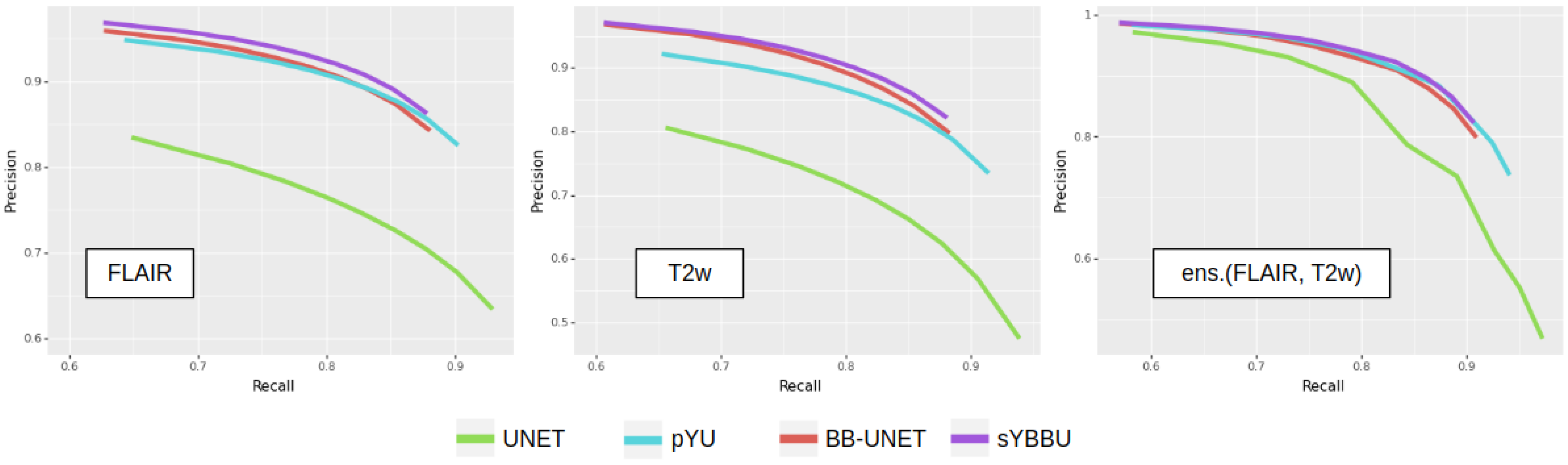
Figure 3 exhibits clearly that models using the bounding-boxes perform better, especially sYBBU models. To compare the sYBBU model as the best approach using bounding-box with UNet that ignores them, we computed the AUC of the mean precision-recall graph. We obtained 0.91, 0.90 and 0.93 on the FLAIR, T2w and ens.(FLAIR, T2w), respectively, on the sYBBU model. Meanwhile, on the UNet model, we obtained 0.80, 0.83 and 0.90 using the FLAIR, T2w and ens.(FLAIR, T2w), respectively.
The precisions and recalls in segmentation using the bounding-boxes are strongly correlated with the respective precisions and recalls of the bounding-boxes detection, by a correlation score between 0.6 and 0.8 (see
Supplementary Table S2 and Table S3). Of note, UNet results are also positively correlated with the object detection results (correlation between the precisions is 0.40 and correlation between the recalls is 0.66), though not as strongly as in the other models. This suggests that part of the performance is related to the images themselves, and some tumours are especially hard or easy to detect or segment for any model due to image quality or tumour visual characteristics. However, the overall performance is strongly dependent on YOLO’s ability to detect the whole tumour. This is shown on the Dice metric, which indicates a strong correlation between bounding-box recall and the Dice of models using the bounding-boxes, ranging from 0.61 to 0.72. This reinforces the strategy consisting in promoting recall over precision during the detection phase in order to obtain overall high performance.
Overall, FLAIR-based models perform better than T2w-based models. It appears that the FLAIR may reflect the diffuse characteristics of the tumour better, while in the T2w images, the intensity distribution of voxels inside the tumour is not as distinguishable from other bright regions of the brain. However, the ensembled models always perform better, across all configurations, and have equal or lower standard deviations. When computing the optimal weights to merge the models, we found for pYU and for sYBBU. However, the gain of an optimized weighted average, as opposed to a basic average, was below 1%. The weighted average improves the log-likelihood, but with little impact on the accuracy after binarization.
Table 5 shows the differences in metrics when ground-truth bounding-boxes were used for the FLAIR in BB-UNet. BB-UNet with ground-truth bounding-boxes was unable to detect, on average, 10% of the tumour. When YOLO bounding-boxes were used, a 6% decrease in recall was observed. This exhibits that two-thirds of the missed voxels are inherently related to BB-UNet and not to errors in YOLO bounding-boxes. Given these results, we can say that YOLO bounding-boxes are not the prevailing source of errors and they are sufficient to be integrated into our detection-segmentation approach.
Concerning Deepmedic architecture, results on the FLAIR modality are slightly below results obtained with the proposed approaches. The Deepmedic model seems to prioritise high precision over recall. However, Deepmedic trained with the T2w failed to give any meaningful result, with an average Dice index of 0.08, which makes the T2w unusable in an ensembled model.
Segmentation Results on LGG
Table 6 shows the segmentation results obtained on the LGG
dataset. Overall, the proposed models exhibit comparable results with those obtained on the TCGA-GBM
dataset but show an average drop in the Dice metric of 0.05. This reduction was expected since the networks were solely trained on High Grade Gliomas and were not readapted for the Low Grade Glioma cases. Unlike the proposed models using bounding-boxes, UNet showed poor performance on the LGG
dataset. However, the pYU model shows an improvement in the overall results by increasing precision by 30% at the cost of a mean decrease of 10% of the recall. We obtained an AUC score of 0.80, 0.87 and 0.89 for the FLAIR, T2w and ens.(FLAIR, T2w), respectively, when using the sYBBU. Comparatively, we obtained an AUC score of 0.71, 0.73, 0.80 for the FLAIR, T2w and ens.(FLAIR, T2w), respectively, when using UNet only. See also
Supplementary Figure S4.
The proposed procedures outperformed the Deepmedic network. On average, the Dice metric was between 6% and 9% lower for Deepmedic compared to our models. This exhibits the robustness of our strategy. Similar to the TCGA-GBM dataset, the Deepmedic model seems to prioritize high precision (the highest on all the models) over the recall.
4.3. Segmentation Results on DIPG
From the 30 DIPG patients, 71 sessions were available obtained at different follow-up visits.
Table 7 shows the inference detection results obtained on 62 out of the 71 DIPG
sessions. The detection step failed to identify the tumour region (tiny bounding-box with recall
) in 9 sessions (13% of the sample).
Supplementary Table S4 shows detection results obtained on all 71 test sessions. Overall, the FLAIR exhibited significantly better results than the T2w, especially for the recall. Bounding-boxes obtained from the FLAIR show robust results. On average, 66% of the tumour is captured, with a mean precision equal to 61%. While the T2w alone failed to give significant results, ensembling T2w bounding-boxes with FLAIR bounding-boxes improves the recall by 7% while lowering its precision by 17% on average. Both FLAIR and ens. (FLAIR, T2w) bounding-boxes performed better than the generic bounding-box around the pons, which gives a 63% recall with a 20% precision. This shows that, even if the location of the tumour is known beforehand, the problem remains non-trivial because of the infiltrating nature of the tumour and its tendency to deform the surrounding tissue or structures (cerebellum, spinal cord, thalamus). Careful inspection of the nine cases with detection step failure indicates that the failure is mostly related to the tumours not being visible on the FLAIR and T2w MRI scans. Due to the low performance of object detection on T2w, we only used FLAIR and ens.(FLAIR, T2w) detection masks in the segmentation phase.
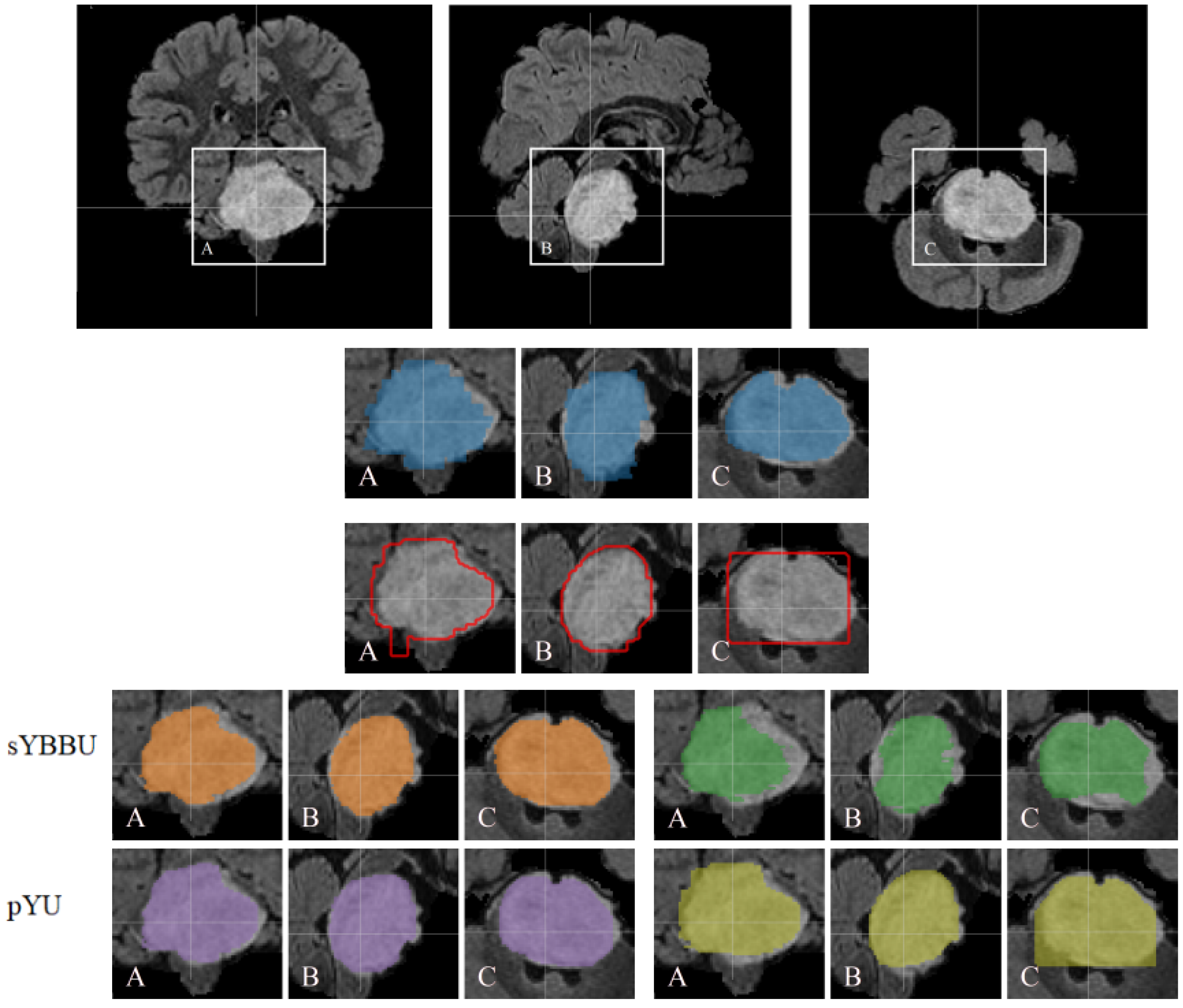
Table 8 shows pYU and sYBBU segmentation results using FLAIR detection masks.
Supplementary Table S5 shows segmentation results with the combined ens.(FLAIR, T2w) detection masks. Overall, across the configuration reported in
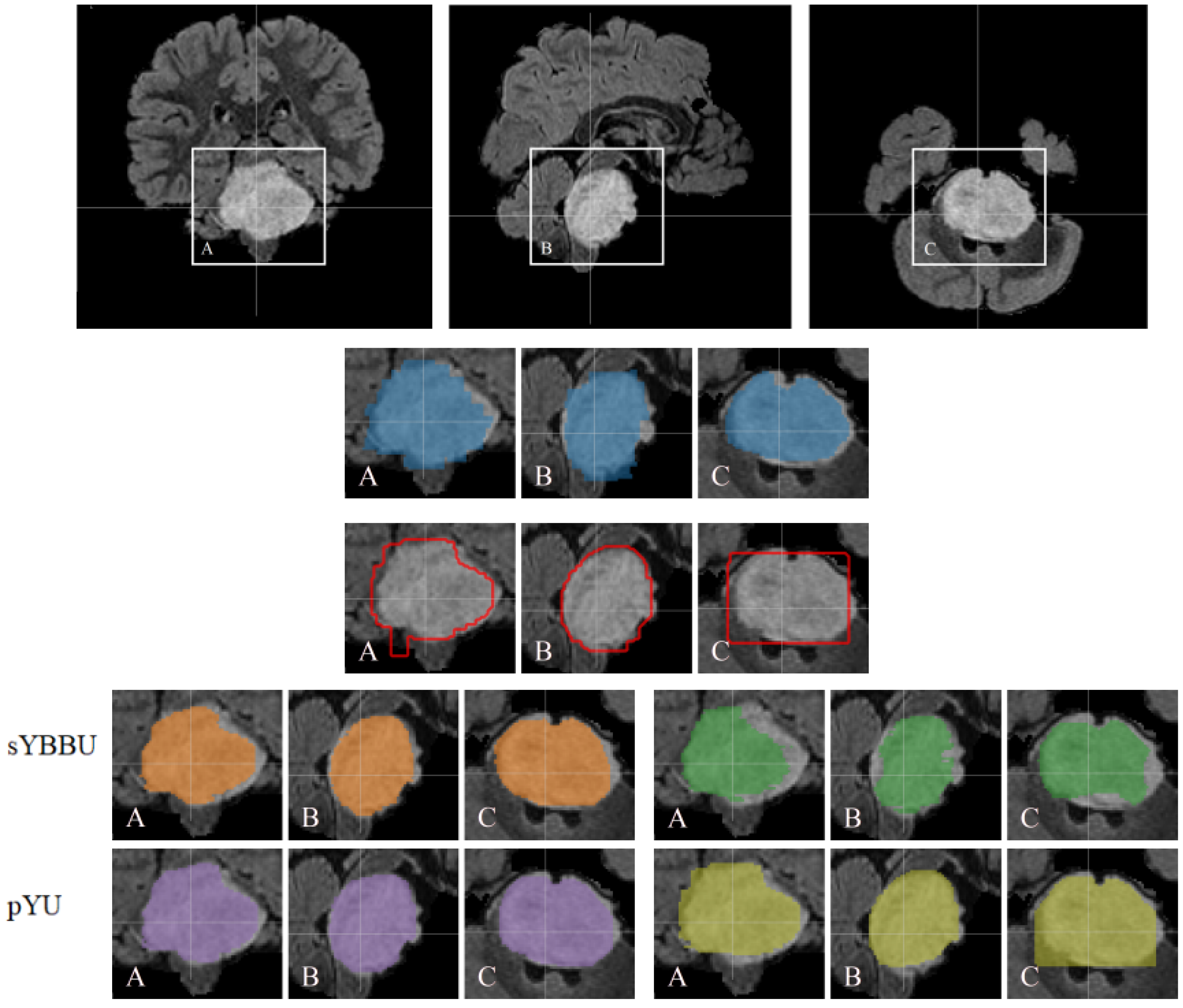
Table 8, the mean Dice index for segmentation results is 61% (with 95% CI 0.56 to 0.66), which is satisfying considering the difficulty of the problem. An example of the segmentations obtained is presented in
Figure 4.
Since the detection and segmentation phases can be done independently, we computed the performance of segmentation on the T2w, using FLAIR and ens.(FLAIR, T2w) detection masks. Despite T2w detection, segmentation using T2w did not fail. However, its results were still below FLAIR ones. On the T2w, pYU performance exhibits a dependence on the detection performance. Indeed, the pYU segmentation model failed to discriminate between tumoral voxels and healthy tissue ones, thus the segmentation results follow the detection performance. This is not the case for sYBBU, using ens.(FLAIR, T2w) detection masks, which have lower precision scores, and did not impact the segmentation model as much as the pYU. Looking at the Dice measurements, FLAIR and ens.(FLAIR, T2w) have similar performance whichever the bounding-boxes and the model used. However, FLAIR tends to have a higher precision while ens.(FLAIR, T2w) has a better recall. The choice between the two approaches should be made in regards to the application.
On the FLAIR, the Deepmedic network was outperformed by the detection model, and therefore obviously outperformed by the segmentation models that use the FLAIR mask. Deepmedic also failed to detect any tumour region on the same 9 cases excluded earlier.
5. Discussion
Our study proposes two detection-segmentation combination strategies that allowed us to obtain better results than the tested state-of-the-art networks (UNet and Deepmedic) on both BraTS’19, an openly available HGG and LGG dataset, and DIPG, a cohort of a rare paediatric tumour. Our strategies were able to segment the DIPG lesion while only training the models on the HGG cohort and without re-adapting the networks to the new tumour type. It was necessary to use this domain adaptation since we did not have access to enough annotated DIPG data nor a complete dataset to fine-tune each of the networks used.
Throughout this work, the FLAIR modality consistently appeared as the most important modality for any segmentation model, aiming at delineating globally the tumour lesion without distinguishing between its multiple compartments. It is therefore not surprising that our detection-segmentation algorithms prefer to rely on the FLAIR sequence. Moreover, the FLAIR modality has also been found as the most relevant for oncologists and features extracted from the FLAIR scans have shown the best results for survival analysis and tumour characterization for a range of tumours [
45]. Specifically in DIPG, Castel et al. [
3] identified differences in FLAIR index according to the type of histone mutated. Our segmentation, which is based on FLAIR imaging and produces a FLAIR-mostly derived delineation, produces regions of interest that appear to be relevant. Overall, having the FLAIR sequence for further imaging investigation on DIPG is a priority. In addition to that it appears that, even if the T2w did not perform as well as expected for the DIPG dataset, its presence always helped the proposed segmentation models.
Our proposals consist of procedures implicating multiple different and distinct models. Having different models, trained separately, has several advantages. The models had very different architectures, and therefore, could have different weaknesses and strengths, which can be complementary. In the DIPG case, even when the T2w detection failed, we were able to use the trained T2w BB-UNet model efficiently using the alternate FLAIR bounding-boxes. This possibility allowed us to circumvent the differences between glioblastoma and DIPG.
Our proposed approaches consist in combining multiple models, each model is relatively small. The inference time for each 3D example is around 5 s on an Nvidia Titan X, including 2.5 s for detection and 2.5 s for segmentation. Meanwhile, the training phase took roughly 4 h each. Comparatively, training Deepmedic took 3 days and had an inference time of 3 min per 3D example, on similar machine and software configurations.
Most recent segmentation efforts have focused on developing deeper and more complex models. While these solutions can be suitable for tumour lesions for which large curated and well-documented datasets, there is no indication that they can be easily adapted to small cohorts of rare tumours, such as DIPG, with missing data and heterogeneous quality. We found that Deepmedic, trained with four modalities (FLAIR, T2w, T1w, T1wgd), performed exceptionally well for HGG, with an average Dice of 0.9, but fails on DIPG with an average Dice of 0.3. In our proposition, the segmentation model is not fully dependent on the object detection performance, given bounding-boxes can be obtained from other input images. This allows us to use the best bounding-boxes assessed during a quality check. Our results are in line with the work of Isensee et al. [
46], which found that recent efficient very complex and deep networks cannot necessarily be easily fine-tuned for rare oncological lesions segmentation problems with few training examples and, promoted the UNet architecture.
Our study presents several limitations. The ground-truth segmentations obtained on the DIPG are done on thick slices of 4 mm3, which negatively bias the results obtained even if it does not question the magnitude of these results. Furthermore, we have only one set of rare tumour data, further studies should investigate the robustness of the method using other rare tumours. Additionally, throughout this study, the used networks are considered black boxes. An ablation study could be made to investigate the limitation of the networks. We also did not investigate what the networks learnt and how they make the inference. Finally, we only focused on binary segmentation using either the FLAIR or T2w, further studies should investigate multi-compartment segmentation possibly using other modalities.
6. Conclusions
This paper addresses the problem of rare tumour types, for which no database can be built to train a deep neural segmentation network. Our work shows that state-of-the-art segmentation methods perform poorly when applied on test cohorts on which they were not trained. We propose to combine different simple models of detection and segmentation to allow us, not only to improve UNet performance but also to obtain satisfying results on a cohort that contained differences compared to the training dataset regarding, among others, patient age, image quality and tumour type.
Although all the sets presented in the paper present cerebral tumours, the differences between an adult brain (in the case of the HGGs and LGGs) and children brains (in the case of DIPG) give rise to challenges during inference. We think that using a set of a wider range of brain tumour types in children might help solve this issue. Additionally, the paper does not explore alternatives to the object detection framework YOLO. Work should be done to compare it to other algorithms, especially the ones dedicated to medical imaging and not only natural images. Lastly, other detection-segmentation strategies, such as the weak supervision paradigm, can be explored and compared to the proposed approaches.
We were able to obtain satisfying segmentation for the DIPG. These segmentations and performance will allow us to perform further clinical work to characterise this rare pathology using radiomics [
47].


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}