

MEMS Devices-Based Hand Gesture Recognition via Wearable Computing


Abstract
1. Introduction
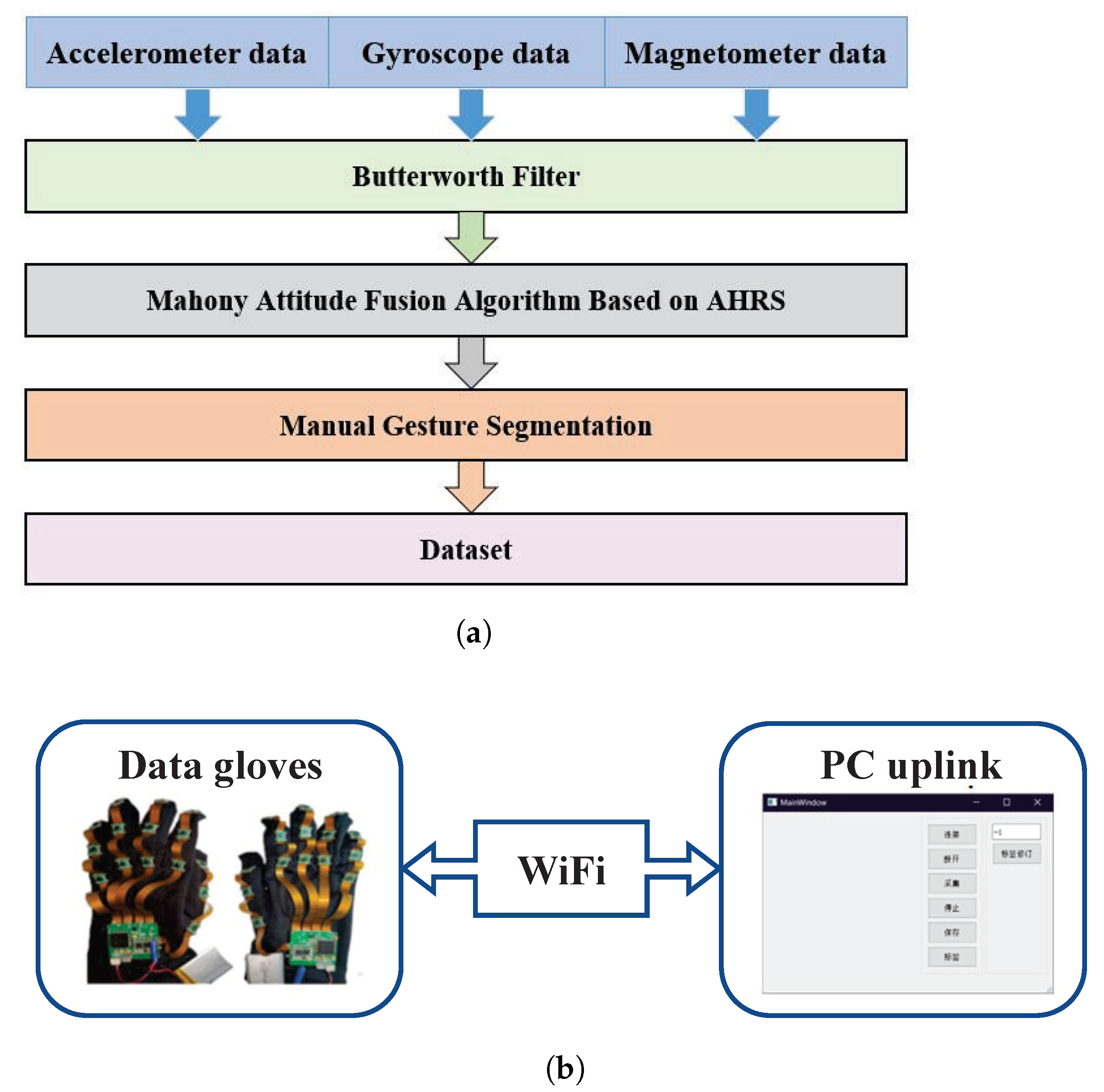
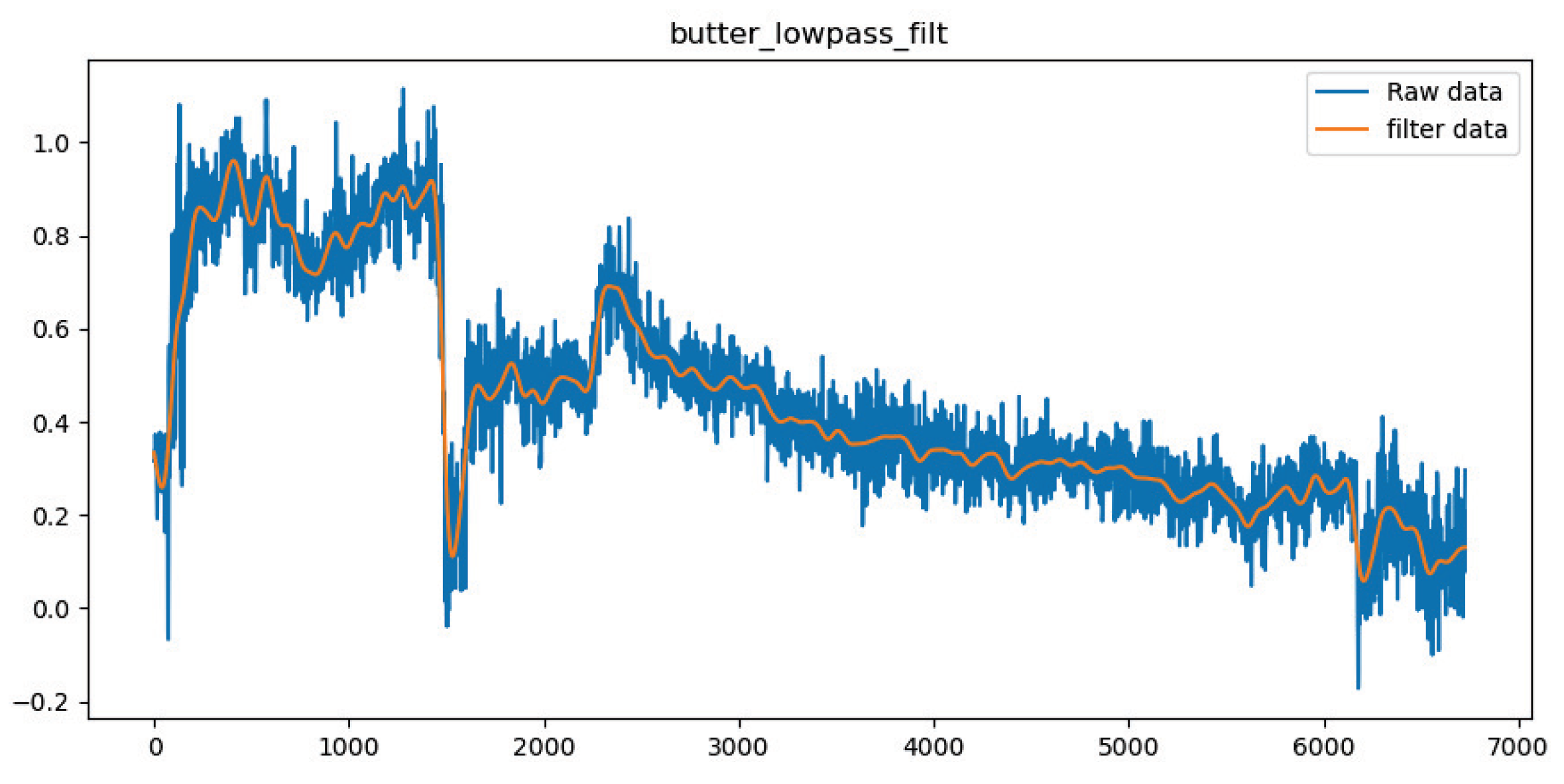
- The raw data were filtered using a Butterworth low-pass filter, the magnetometer data were corrected using an ellipsoidal fitting method, and the dataset was constructed using a gesture-assisted segmentation algorithm.
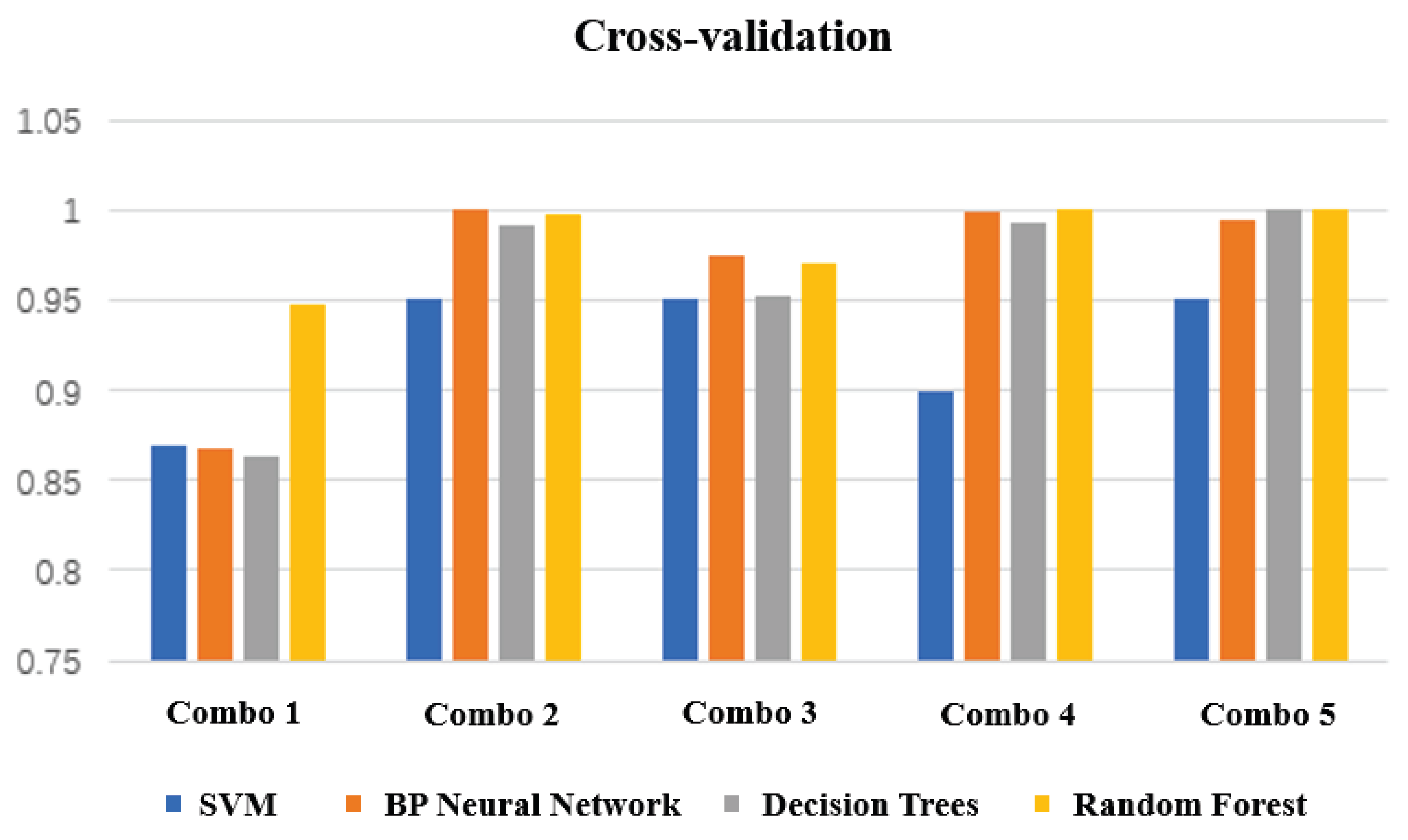
- We used four machine learning algorithms to identify static gesture data and evaluate the prediction effect by cross-validation.
- We constructed a hidden Markov model and an attention-based mechanism neural network model to design recognition methods for dynamic gestures.
2. Systematic Data Collection and Participants
2.1. System Setup
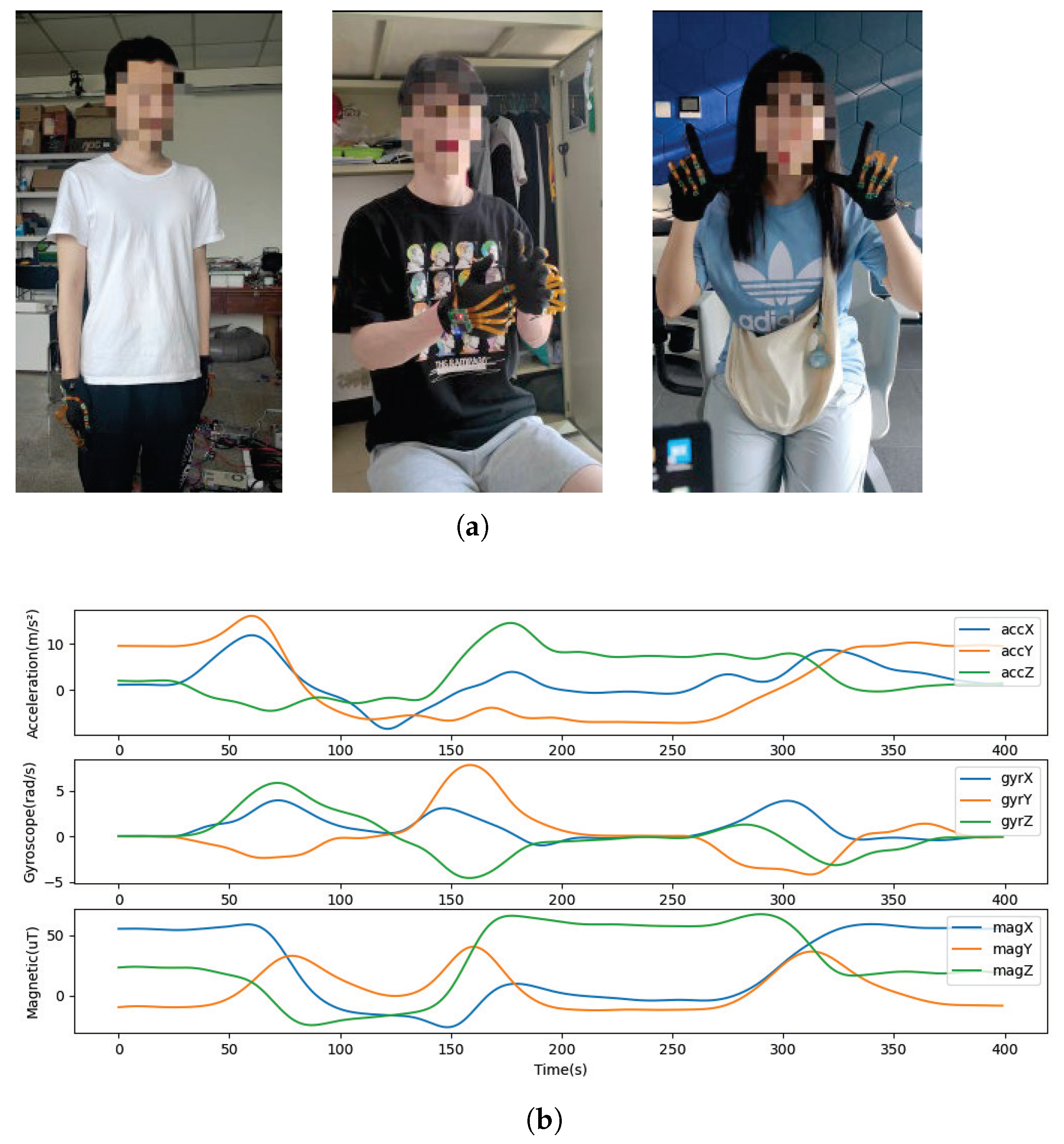
2.2. Participant and Gesture Acquisition Actions
3. Methods
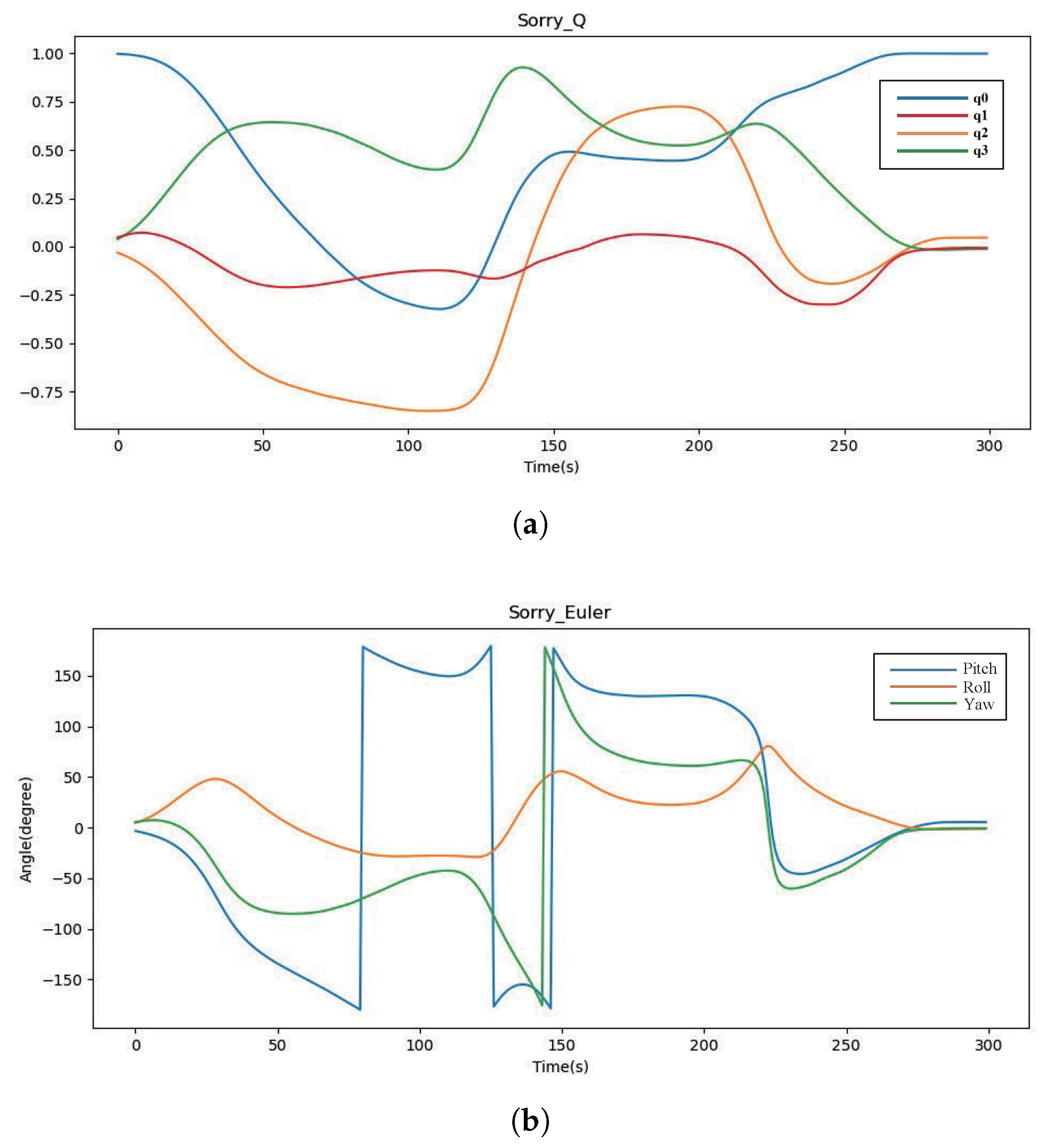
3.1. Definition of Coordinate System and Conversion Relationship
- Sensor coordinate system (SCS): typically, the origin of the sensor coordinate system is the sensor center, and the pointing of the three axes is based on the three-axis gyroscope in the sensor.
- Navigation coordinate system (NCS): the origin is the center of gravity of the hand when standing, and the three axes point to the northeast and the ground direction. It should be noted that north here refers to the north in the geomagnetic sense.
- Body coordinate system(BCS): according to the spatial posture of the palm and each finger segment, the center of mass of the hand is used as the origin of coordinates.
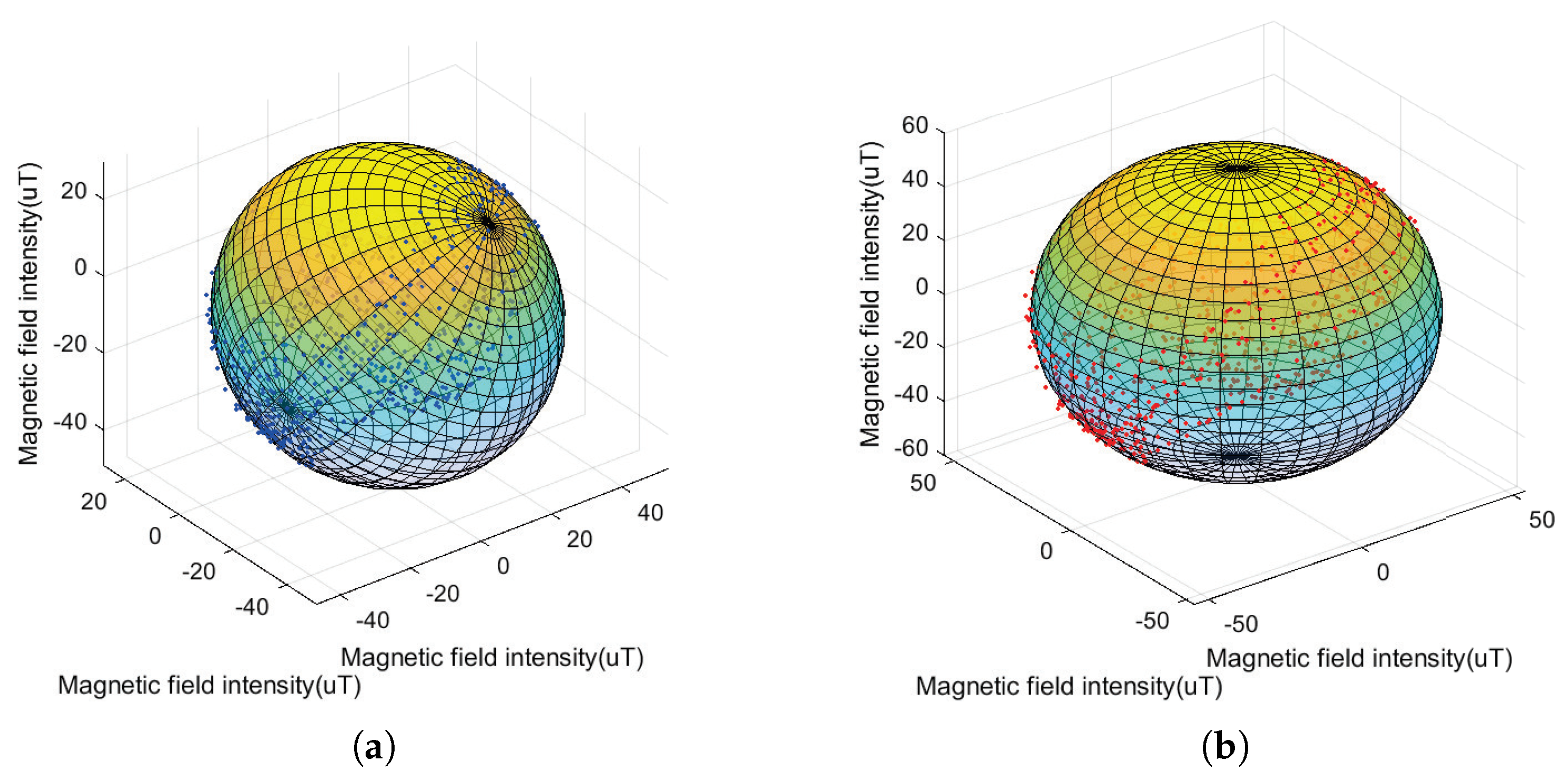
3.2. Calibration of Magnetometer Based on Ellipsoidal Fitting Method
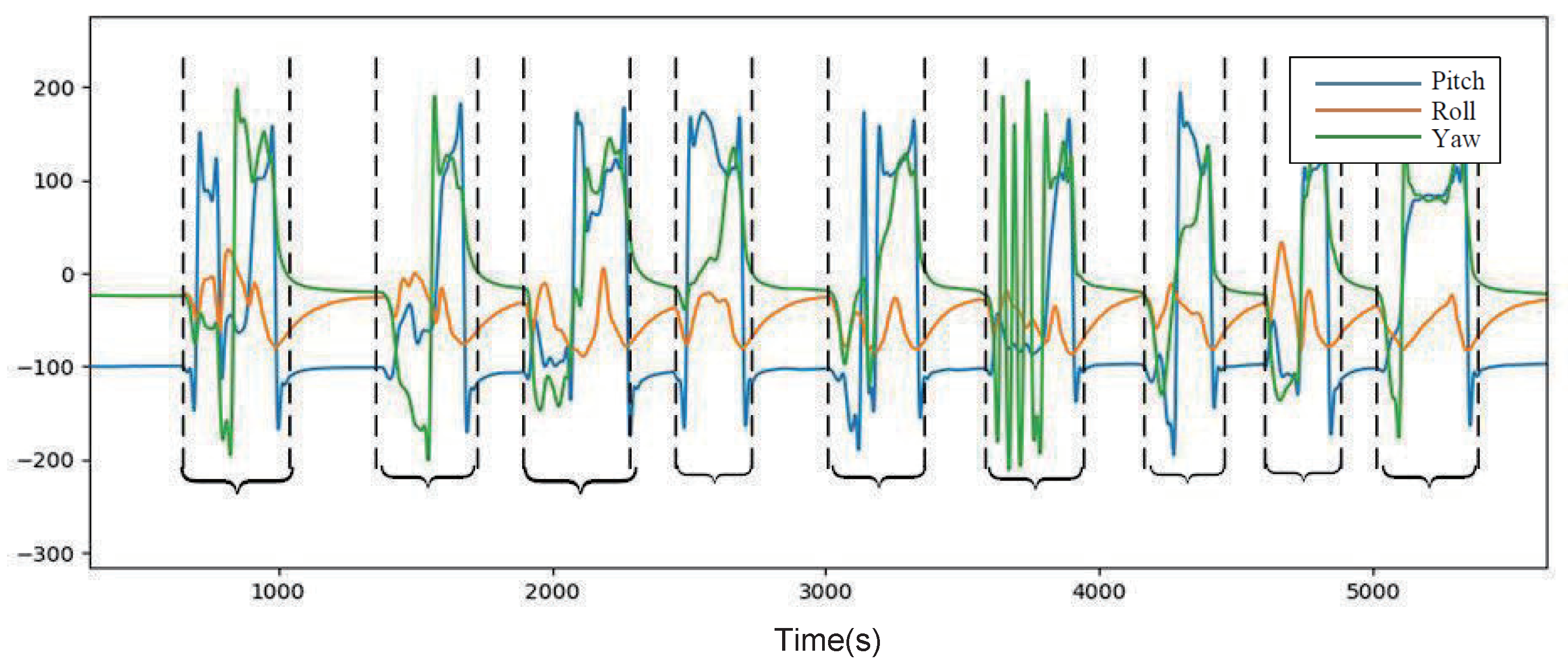
3.3. Gesture Dataset Segmentation
| Algorithm 1: Assisted Segmentation Algorithm |
Input: Continuous gesture data: ; Output: Split start point list S, split end point list O.
|
4. Design of Gesture Recognition Algorithm
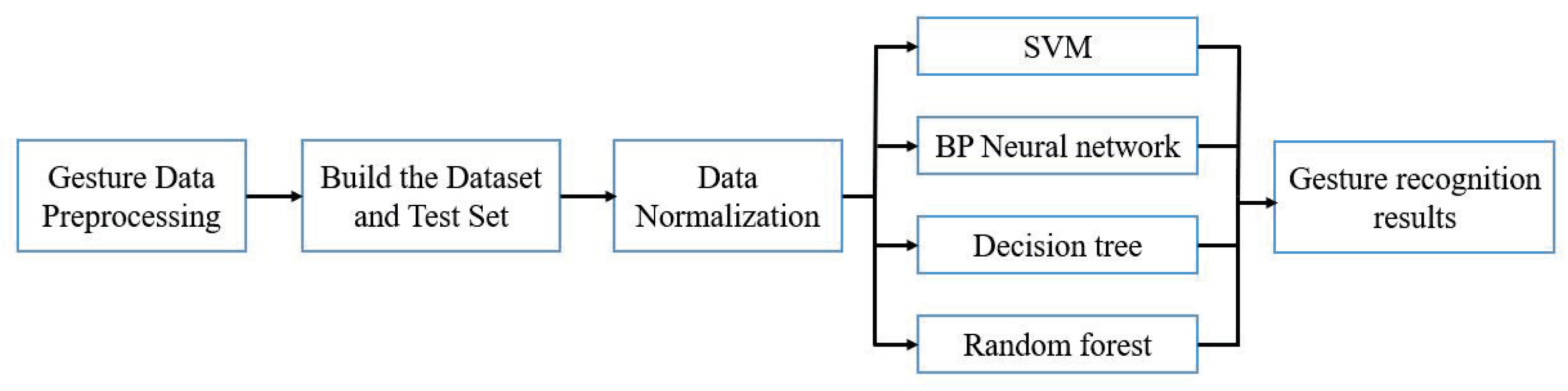
4.1. Static Gesture Recognition Method Based on Machine Learning Algorithm
- Support Vector MachinesSVM [29] is a binary classifier based on supervised learning first proposed by Corinna Cortes and Vapnik et al. in 1995, whose decision boundary is the maximum margin hyperplane solved for the learned samples.The grid search method is an optimization method of parameter selection and cross-validation by specifying a selection list of parameters to be optimized, evaluating the model for all parameter combinations, and finally obtaining the optimal parameters in the list. This method is used in the experimental parameter optimization. The structure of the dataset used is as follows: Training set: . Test set: . The training set part is used for algorithm model training, and the test set data are used to test the algorithm recognition accuracy of the generated model.
- Back-Propagation Neural NetworkNeural network (NN) [30] is a mathematical model or computational model that simulates the structure of biological nerve cells to receive stimulation and generate output signals, and simulates the excitation function, as shown by Michael Houston et al.
- Decision Tree algorithmDecision tree (DT) is a common classification algorithm based on supervised learning in machine learning. Its advantages are its simple structure, logic in line with human intuition, and fast processing speed for large amounts of data. In this paper, we use “information entropy” and “Gini index” to classify the attributes for model training. The CART algorithm and ID3 algorithm have overfitting problems, and the generalization ability of the model can be improved by discarding the over-divided attributes.
- Random forest algorithmRandom forest (RF) is an ensemble algorithm consisting of multiple decision trees. The random forest is composed of several decision trees, and the Gini index is better than the information entropy in dividing conditions with judgmental attributes, so the Gini index is also used to construct the random forest to prevent model overfitting. The maximum depth of the tree is defined as 6 and the number is 20.
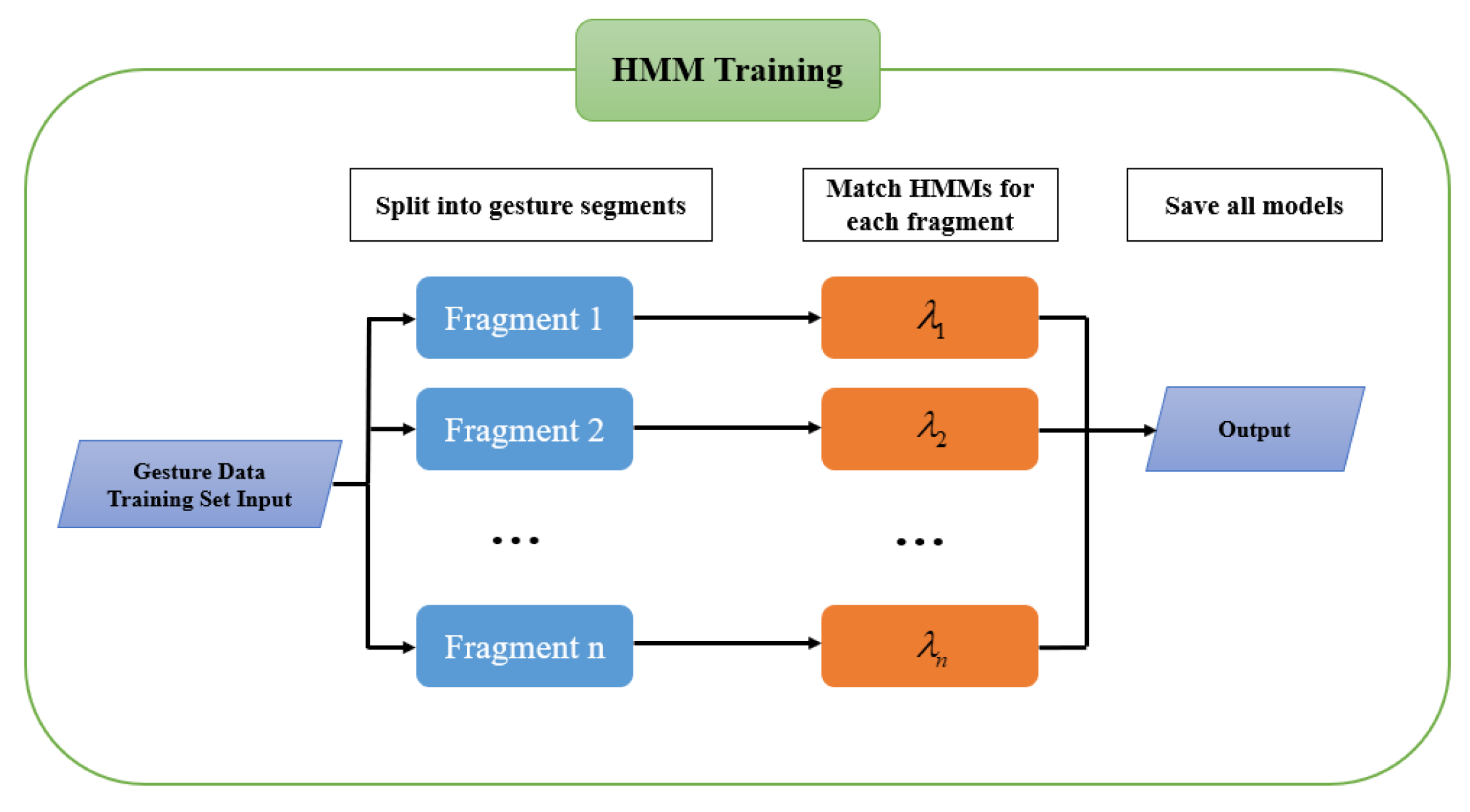
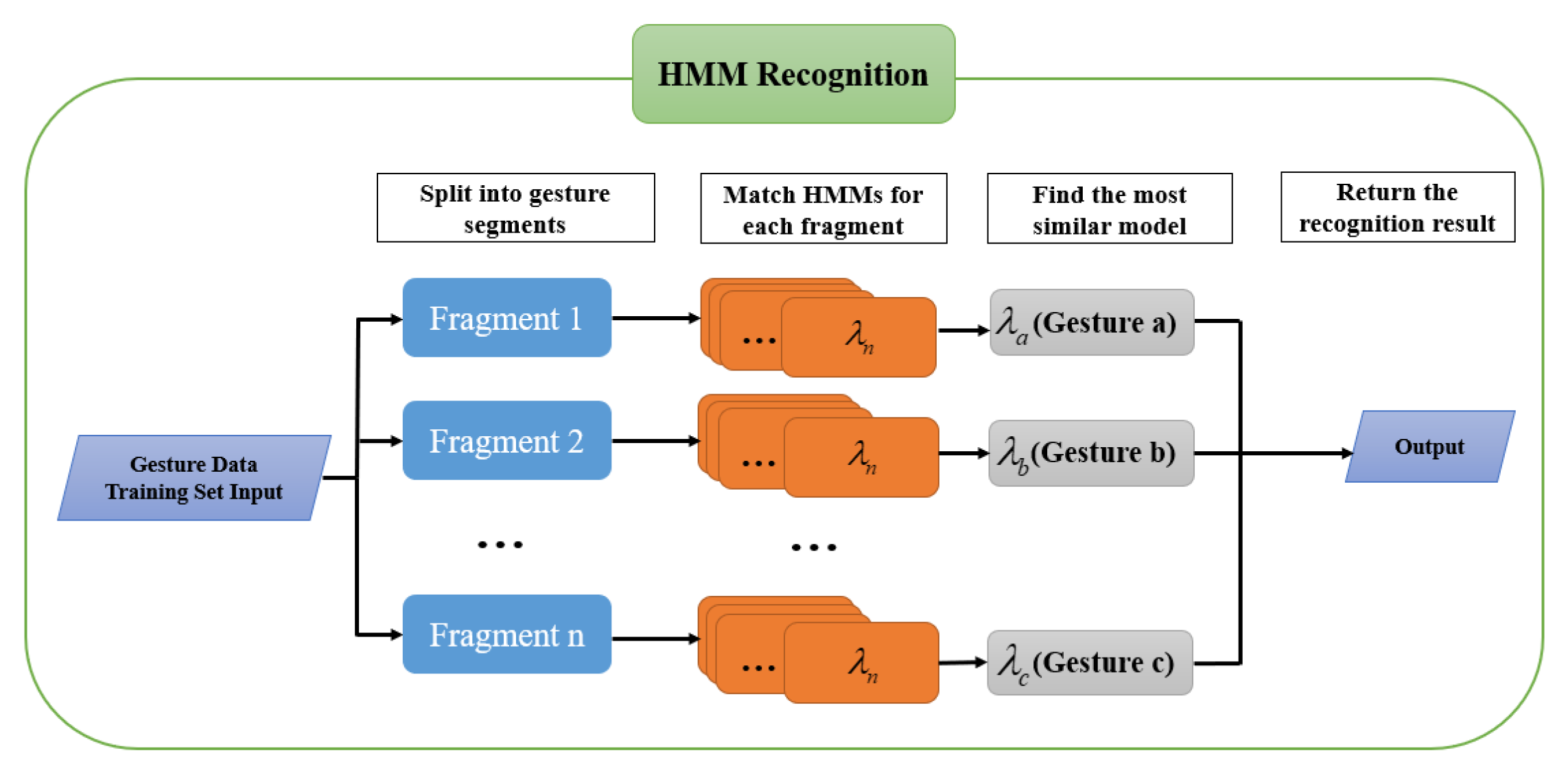
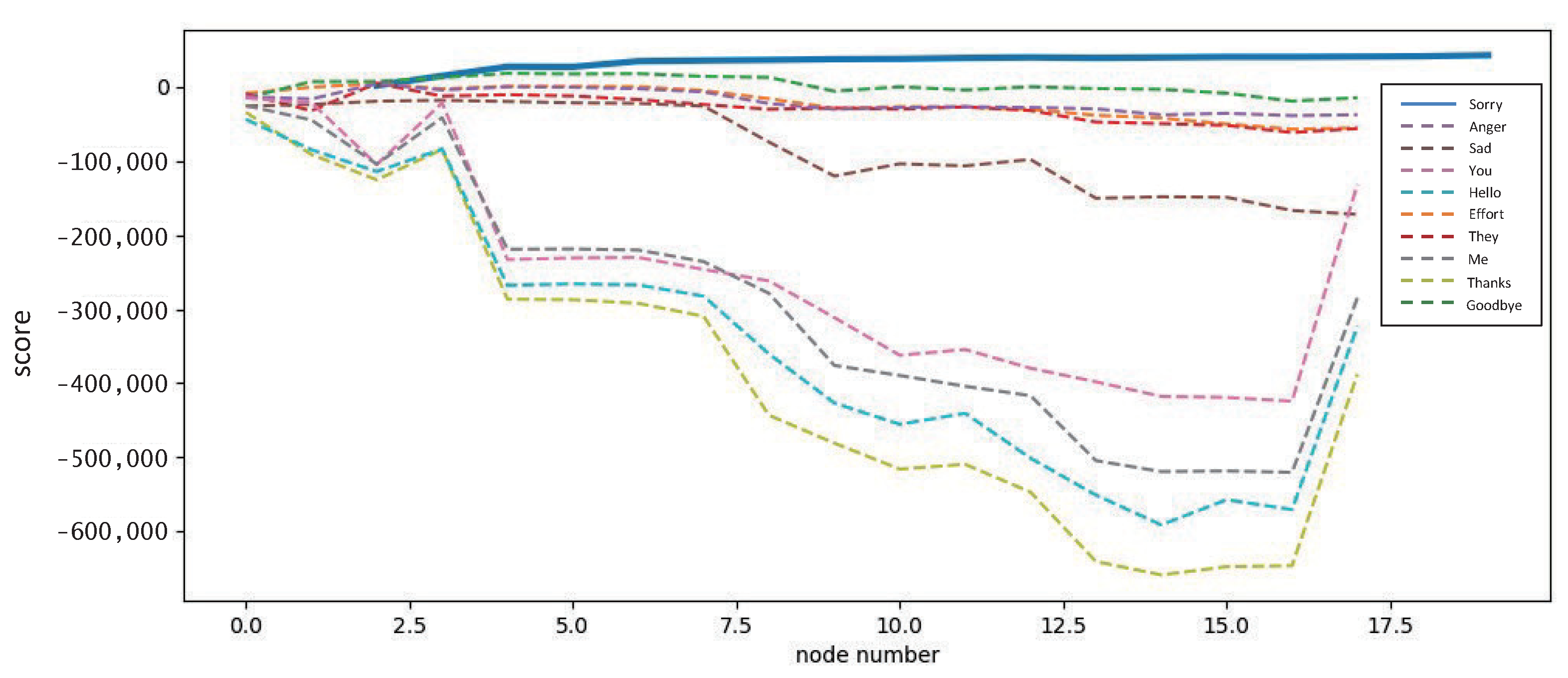
4.2. Dynamic Gesture Recognition Based on Hidden Markov Model
- We generate the first gesture meaning given the initial state probability vector ;
- According to the previous gesture meaning, the next gesture meaning is randomly generated using the state transfer probability matrix A;
- After generating the sequence of gesture meanings, the observation sequence of the corresponding position is generated using the observation probability matrix B according to each gesture meaning.
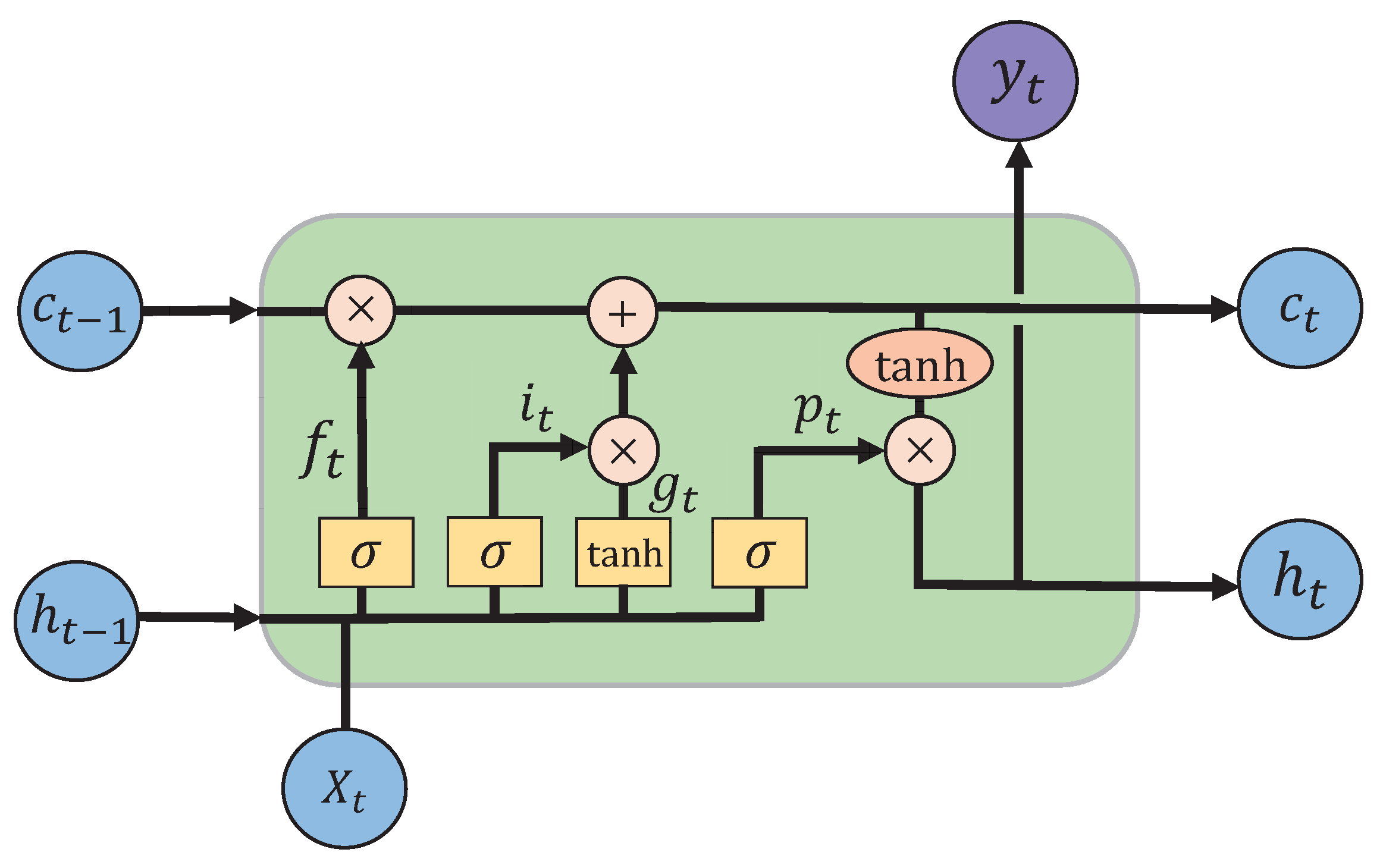
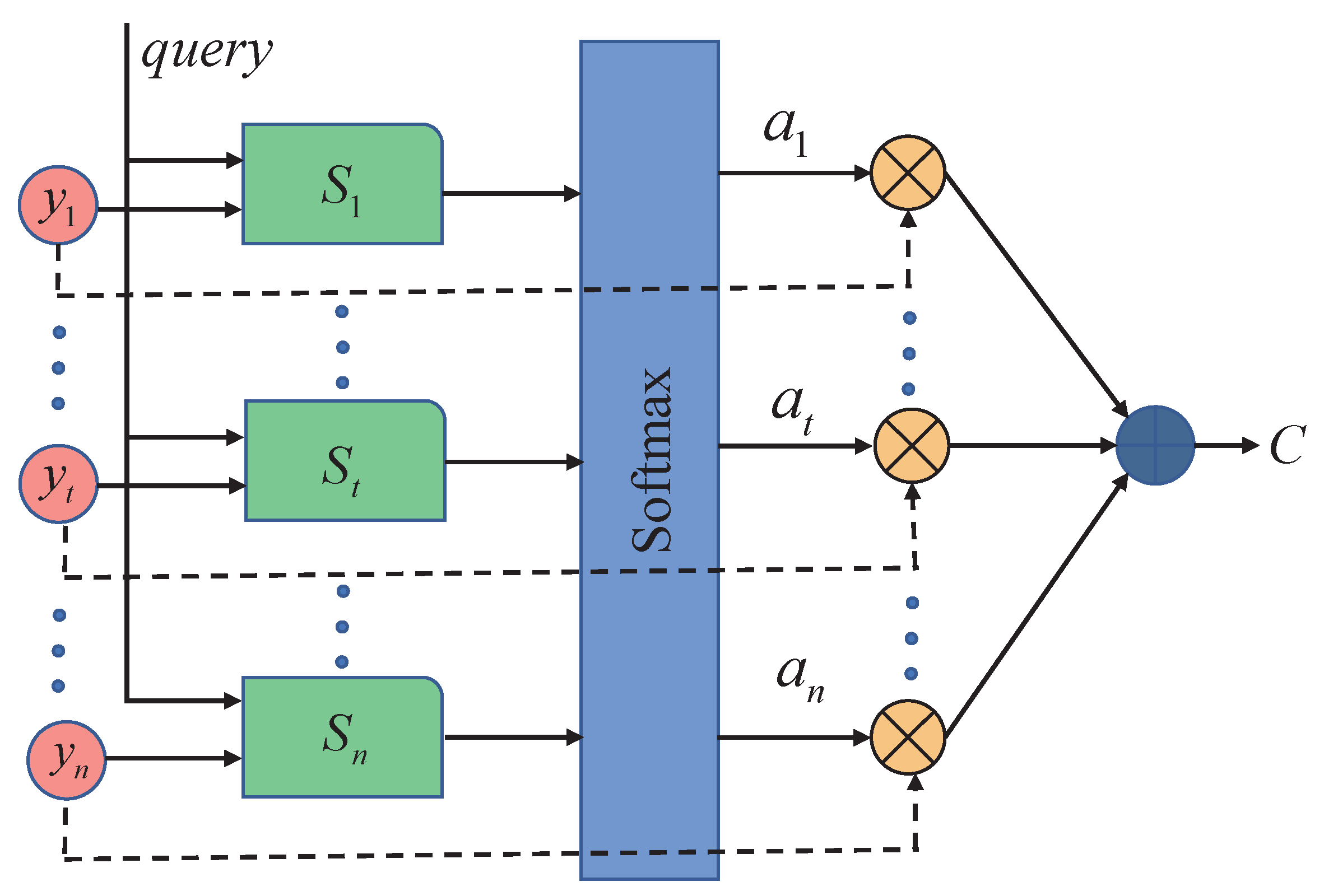
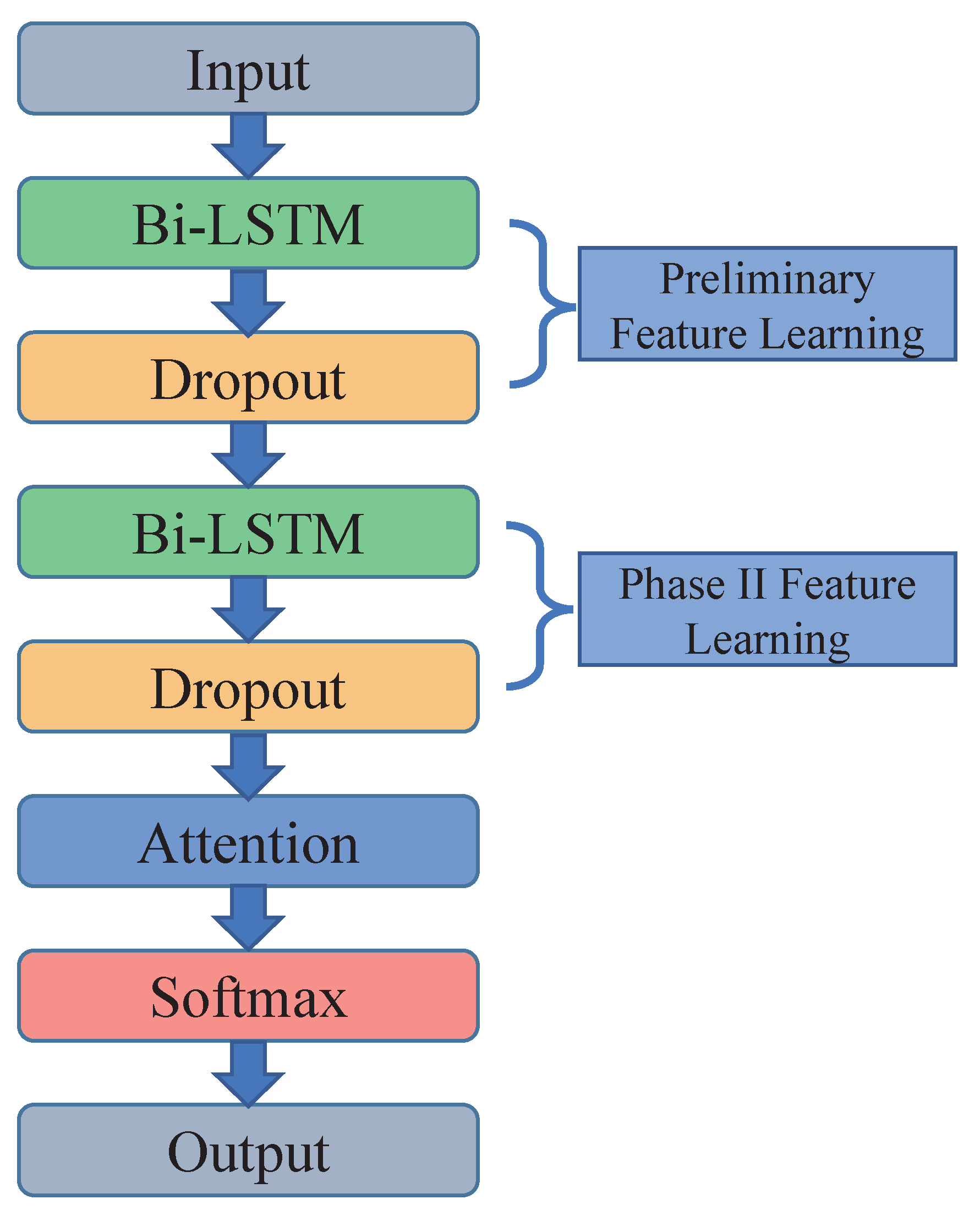
4.3. Design of Gesture-Recognition Algorithm Based on Deep Learning
5. Results
5.1. Static Gesture Recognition Using Machine Learning Algorithms
- 1.
- Support Vector Machines
- When building a support vector machine model, the kernel functions are first selected and the accuracy of all kernel functions is tested. The multiclassification SVM model built using the one vs. rest (OvR) strategy. The kernel function test results are shown in Table 1.
- 2.
- BP Neural Network
- Due to the low complexity of static gesture data and to prevent overfitting, a neural network structure with 2 hidden layers and 20 neurons per layer was built. The prediction accuracy of different activation functions was tested by the grid optimization algorithm, as shown in Table 2.
- 3.
- Decision Tree algorithm
- Generally, the most important part in deciding the superiority of decision tree classification is the judgment algorithm of attribute division. Information entropy and the Gini index are used for model training, and the accuracy is shown in Table 3.
- 4.
- Random Forest algorithm
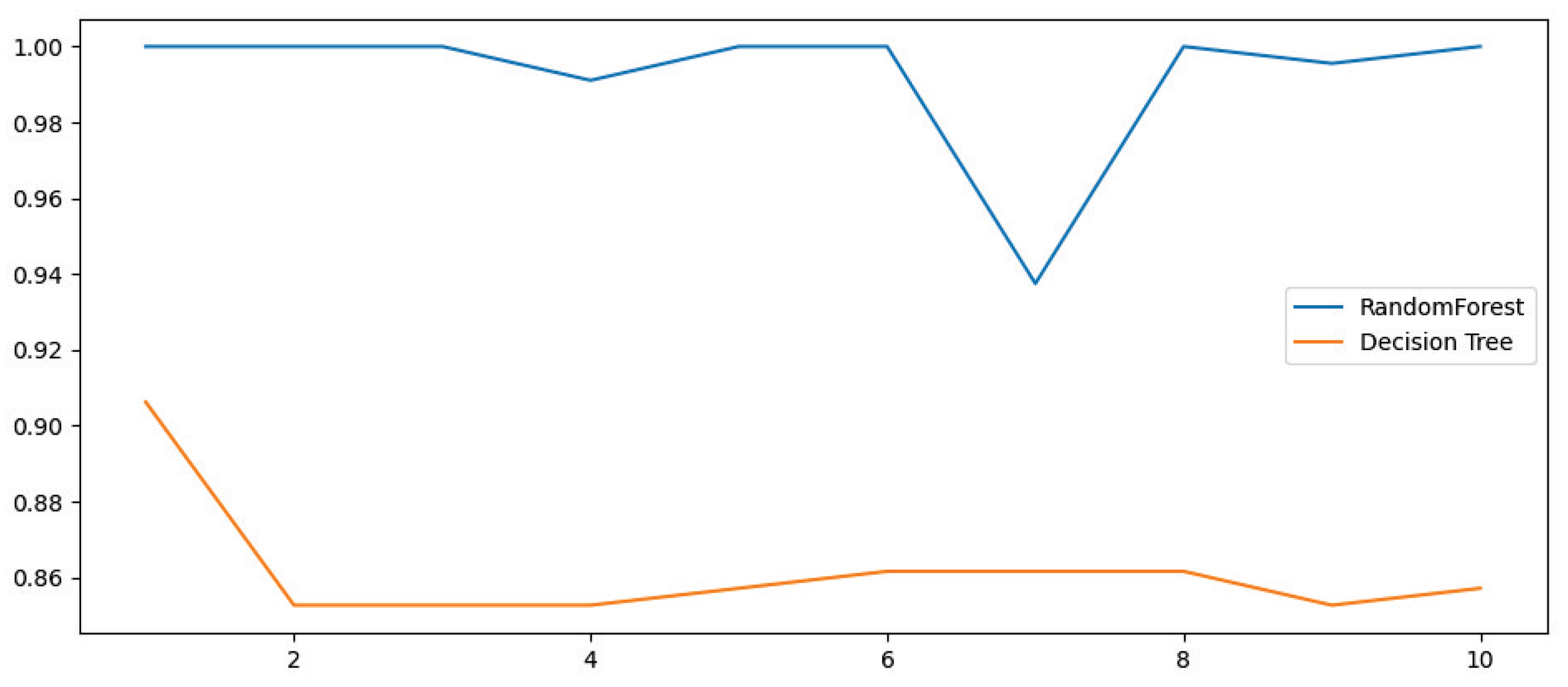
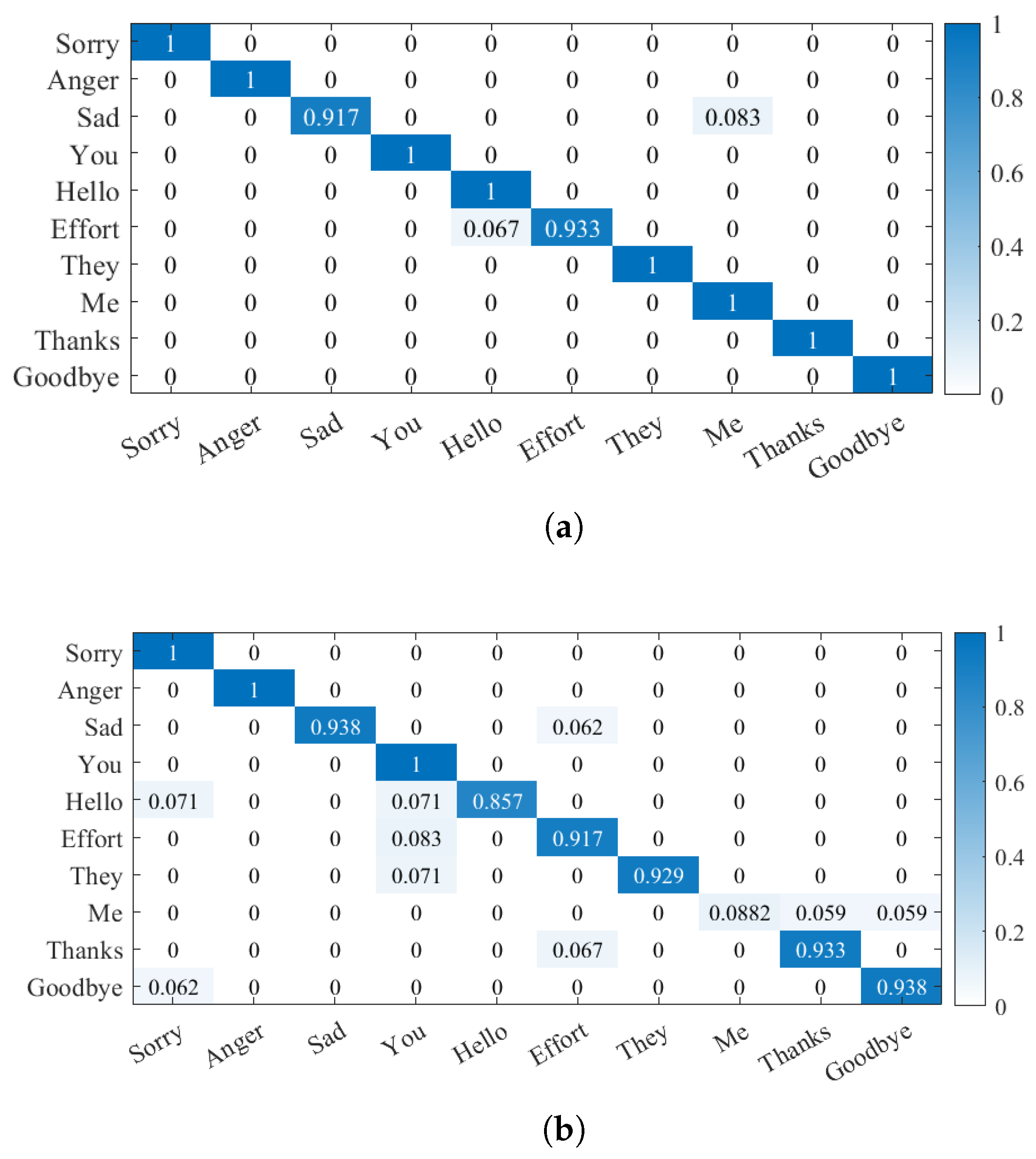
- We define the maximum depth of the tree as 6 and the number as 20. The random forest and decision tree are cross-validated 10 times, and the validation effect is shown in Figure 15.
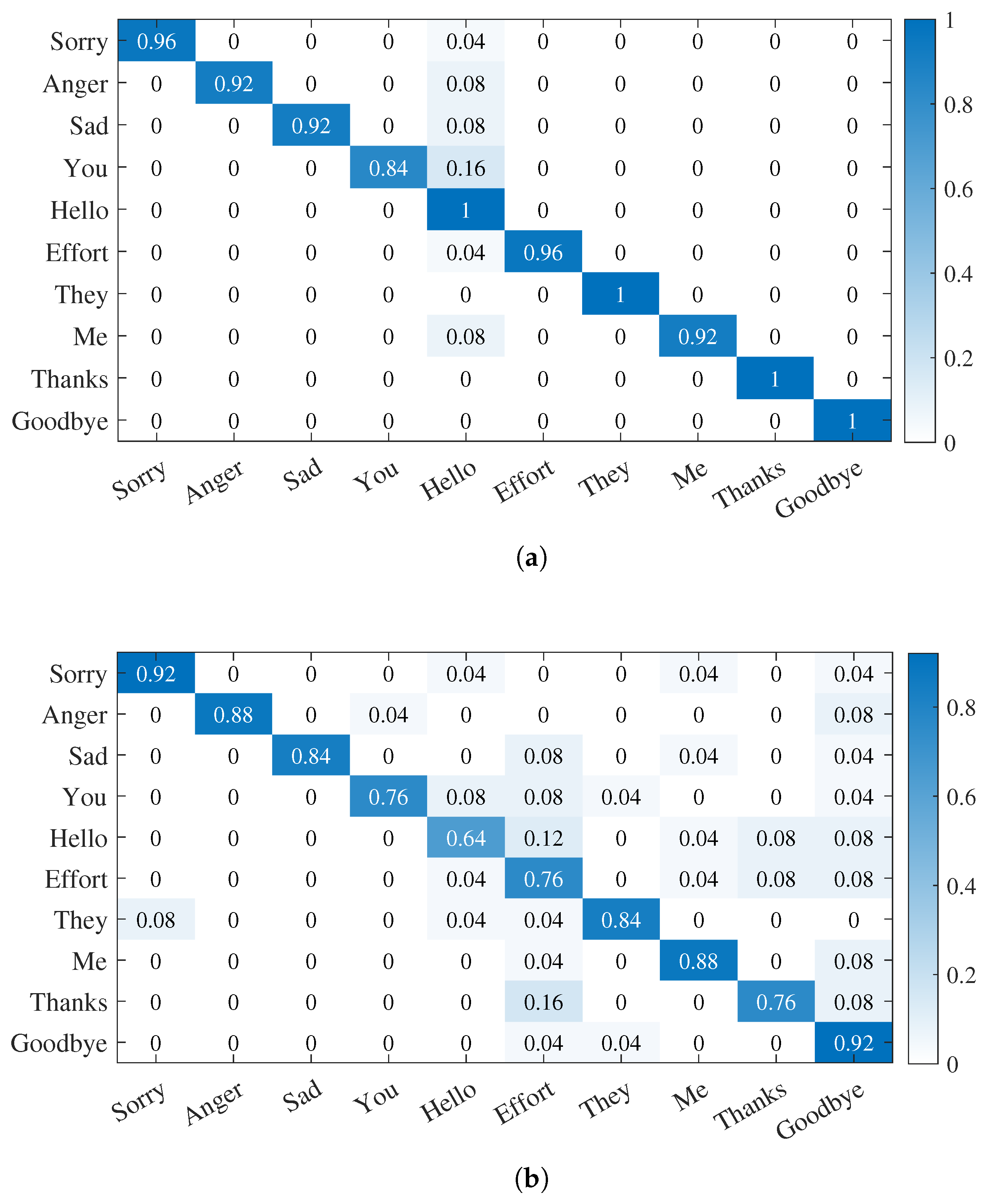
5.2. Dynamic Gesture Recognition Based on Hidden Malcove Model
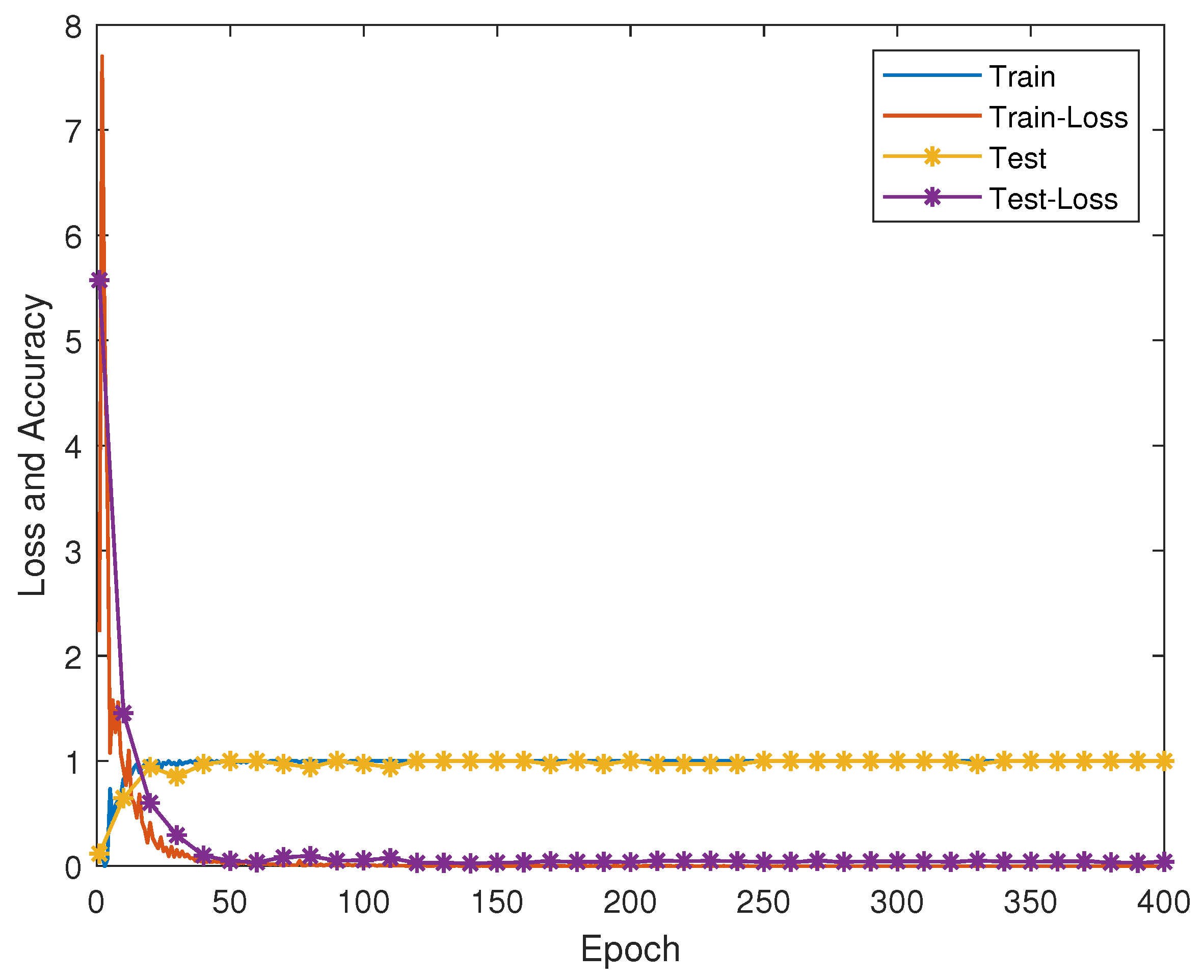
5.3. Dynamic Gesture Recognition Based on Deep Learning Methods
6. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AHRS | Attitude and heading reference system |
| BCS | Body coordinate system |
| BP | Back-propagation neural network |
| Bi-LSTM | Bidirectional long- and short-term memory neural network |
| CNN | Convolutional neural network |
| DT | Decision tree |
| HMM | Hidden Markov model |
| HOG | Hitogram of gradient orientation |
| HD-SEMG | High-density surface electromyography |
| IMU | Inertial measurement unit |
| LSTM | Long- and short-term memory neural network |
| MCU | Microcontroller unit |
| MEMS | Micro-electro-mechanical System |
| MC | Markov chain |
| NCS | Navigation coordinate system |
| NN | Neural networks |
| OvR | One vs. rest |
| PC | Personal computer |
| RF | Random forest |
| RNN | Recurrent neural networks |
| ROI | Region of interest |
| SPI | Serial peripheral interface bus |
| SCS | Sensor coordinate system unit |
| sEMG | Surface electromyography |
| SVM | Support vector machine |
| ViT | Vision transformer |
References
- Chen, Z.; Chen, J. Design and implementation of FPGA-based gesture recognition system. Wirel. Internet Technol. 2020, 17, 3. [Google Scholar]
- Del Rio Guerra, M.S.; Martin-Gutierrez, J. Evaluation of Full-Body Gestures Performed by Individuals with Down Syndrome: Proposal for Designing User Interfaces for All Based on Kinect Sensor. Sensors 2020, 20, 3930. [Google Scholar] [CrossRef] [PubMed]
- Siddiqui, U.A.; Ullah, F.; Iqbal, A.; Khan, A.; Ullah, R.; Paracha, S.; Shahzad, H.; Kwak, K.S. Wearable-Sensors-Based Platform for Gesture Recognition of Autism Spectrum Disorder Children Using Machine Learning Algorithms. Sensors 2021, 21, 3319. [Google Scholar] [CrossRef] [PubMed]
- Ye, S. Research on Hand Gesture Recognition Based on Multi-MEMS Inertial Sensors. Master’s Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2020. [Google Scholar]
- Lin, Q. The Research of Hand Detection and Tracking Using Kinect. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2020. [Google Scholar]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Chang, W.D.; Matsuoka, A.; Kim, K.T.; Shin, J. Recognition of Uni-Stroke Characters with Hand Movements in 3D Space Using Convolutional Neural Networks. Sensors 2022, 22, 6113. [Google Scholar] [CrossRef]
- Ren, H.; Zhu, Y.; Xu, G.; Lin, X.; Zhang, X. Vision-Based Recognition of Hand Gestures:A Survey. Acta Electron. Sin. 2000, 28, 118–121. [Google Scholar]
- Wang, S. Kinect-based Gesture Recognition and Robot Control Technology Research. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2014. [Google Scholar]
- Mazhar, O.; Ramdani, S.; Navarro, B.; Passama, R.; Cherubini, A. Towards Real-Time Physical Human-Robot Interaction Using Skeleton Information and Hand Gestures. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, C.; Shen, J.; Wang, L.; Cai, X. Gesture recognition based on Kinect skeleton data. Comput. Eng. Des. 2019, 40, 1440–1444,1450. [Google Scholar]
- Wang, J. Kinect-Based Gesture Recognition and Human-Machine Interaction. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2018. [Google Scholar]
- Huang, J.; Jing, H. Gesture Control Research Based on Leap Motion. Comput. Syst. Appl. 2015, 24, 259–263. [Google Scholar]
- Li, X.; Wan, K.; Wen, R.; Hu, Y. Development of finger motion reconstruction system based on leap motion controller. In Proceedings of the 2018 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Ottawa, ON, Canada, 12–13 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Alemayoh, T.T.; Shintani, M.; Lee, J.H.; Okamoto, S. Deep-Learning-Based Character Recognition from Handwriting Motion Data Captured Using IMU and Force Sensors. Sensors 2022, 22, 7840. [Google Scholar] [CrossRef]
- Lin, W.; Li, C.; Zhang, Y. Interactive Application of Data Glove Based on Emotion Recognition and Judgment System. Sensors 2022, 22, 6327. [Google Scholar] [CrossRef]
- Qiu, S.; Zhao, H.; Jiang, N.; Wu, D.; Song, G.; Zhao, H.; Wang, Z. Sensor network oriented human motion capture via wearable intelligent system. Int. J. Intell. Syst. 2022, 37, 1646–1673. [Google Scholar] [CrossRef]
- Liu, L. Multi-sensor Gesture Design and Recognition Method Based on Wearable Devices. Master’s Thesis, Xidian University, Xi’an, China, 2019. [Google Scholar]
- Fu, Q.; Fu, J.; Guo, J.; Guo, S.; Li, X. Gesture Recognition based on BP Neural Network and Data Glove. In Proceedings of the 2020 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 13–16 October 2020; pp. 1918–1922. [Google Scholar]
- Gaka, J.; Msior, M.; Zaborski, M.; Barczewska, K. Inertial Motion Sensing Glove for Sign Language Gesture Acquisition and Recognition. IEEE Sens. J. 2016, 16, 6310–6316. [Google Scholar] [CrossRef]
- Qiu, S.; Hao, Z.; Wang, Z.; Liu, L.; Liu, J.; Zhao, H.; Fortino, G. Sensor Combination Selection Strategy for Kayak Cycle Phase Segmentation Based on Body Sensor Networks. IEEE Internet Things J. 2021, 9, 4190–4201. [Google Scholar] [CrossRef]
- Liu, L.; Liu, J.; Qiu, S.; Wang, Z.; Zhao, H.; Masood, H.; Wang, Y. Kinematics analysis of arms in synchronized canoeing with wearable inertial measurement unit. IEEE Sens. J. 2023, 23, 4983–4993. [Google Scholar] [CrossRef]
- Tai, T.M.; Jhang, Y.J.; Liao, Z.W.; Teng, K.C.; Hwang, W.J. Sensor-Based Continuous Hand Gesture Recognition by Long Short-Term Memory. IEEE Sens. Lett. 2018, 2, 6000704. [Google Scholar] [CrossRef]
- Shin, S.; Sung, W. Dynamic hand gesture recognition for wearable devices with low complexity recurrent neural networks. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 2274–2277. [Google Scholar] [CrossRef]
- Yuan, G.; Liu, X.; Yan, Q.; Qiao, S.; Wang, Z.; Yuan, L. Hand Gesture Recognition Using Deep Feature Fusion Network Based on Wearable Sensors. IEEE Sens. J. 2021, 21, 539–547. [Google Scholar] [CrossRef]
- Qiu, S.; Fan, T.; Jiang, J.; Wang, Z.; Wang, Y.; Xu, J.; Sun, T.; Jiang, N. A novel two-level interactive action recognition model based on inertial data fusion. Inf. Sci. 2023, 633, 264–279. [Google Scholar] [CrossRef]
- Geiger, W.; Bartholomeyczik, J.; Breng, U.; Gutmann, W.; Hafen, M.; Handrich, E.; Huber, M.; Jackle, A.; Kempfer, U.; Kopmann, H.; et al. MEMS IMU for ahrs applications. In Proceedings of the 2008 IEEE/ION Position, Location and Navigation Symposium, Monterey, CA, USA, 5–8 May 2008; pp. 225–231. [Google Scholar]
- Namchol, C.; Zhao, H.; Qiu, S.; Yongguk, S. Study of calibration of low-cost MEMS magnetometer. J. Dalian Univ. Technol. 2018, 58, 105–110. [Google Scholar]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2011, 42, 513–529. [Google Scholar] [CrossRef]
- Jiao, L.; Yang, S.; Liu, F.; Wang, S.; Feng, Z. Seventy Years Beyond Neural Networks: Retrospect and Prospect. Chin. J. Comput. 2016, 39, 1697–1717. [Google Scholar]
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing human action in time-sequential images using hidden Markov model. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR, Champaign, IL, USA, 15–18 June 1992; Volume 92, pp. 379–385. [Google Scholar]
- Liu, Y.; Li, J.; Jia, X. Reliability of k-out-of-n: G system in supply chain based on Markov chain. In Proceedings of the 2008 IEEE International Conference on Service Operations and Logistics, and Informatics, Beijing, China, 12–15 October 2008; Volume 1, pp. 1390–1393. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In NeurIPS Proceedings, Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2204–2212. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Experssion | Prediction Accuracy |
|---|---|---|
| Linear Kernel | 98.12% | |
| polynomial kernel | 96.96% | |
| Gaussian kernel | 98.57% | |
| Sigmoid Kernel | 28.93% |
| Activation Function Name | Expression | Prediction Accuracy |
|---|---|---|
| Identity | 98.83% | |
| Logistic | 84.67% | |
| Tanh | 92.58% | |
| Relu | 95.92% |
| Discriminant Algorithm | Prediction Accuracy |
|---|---|
| Entropy | 73.08% |
| Gini index | 88.42% |
| Model Name | Accuracy Rate | Training Time (s) |
|---|---|---|
| SVM | 92.4% | 1.616 |
| BP Neural Network | 96.7% | 0.249 |
| Decision Trees | 95.9% | 0.011 |
| Random Forest | 98.3% | 0.064 |
| Data Characteristics | Prediction Accuracy | Training Time(s) |
|---|---|---|
| Six-axis data | 95.6% | 518 |
| Quaternions | 82.1% | 239 |
| Data Characteristics | Attention-BiLSTM | LSTM |
|---|---|---|
| Six-axis data | 98.3% | 83.8% |
| Quaternions | 94.6% | 87.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Ru, B.; Miao, X.; Gao, Q.; Habib, M.; Liu, L.; Qiu, S. MEMS Devices-Based Hand Gesture Recognition via Wearable Computing. Micromachines 2023, 14, 947. https://doi.org/10.3390/mi14050947
Wang H, Ru B, Miao X, Gao Q, Habib M, Liu L, Qiu S. MEMS Devices-Based Hand Gesture Recognition via Wearable Computing. Micromachines. 2023; 14(5):947. https://doi.org/10.3390/mi14050947
Chicago/Turabian StyleWang, Huihui, Bo Ru, Xin Miao, Qin Gao, Masood Habib, Long Liu, and Sen Qiu. 2023. "MEMS Devices-Based Hand Gesture Recognition via Wearable Computing" Micromachines 14, no. 5: 947. https://doi.org/10.3390/mi14050947
APA StyleWang, H., Ru, B., Miao, X., Gao, Q., Habib, M., Liu, L., & Qiu, S. (2023). MEMS Devices-Based Hand Gesture Recognition via Wearable Computing. Micromachines, 14(5), 947. https://doi.org/10.3390/mi14050947