
A High-Precision Voltage-Quantization-Based Current-Mode Computing-in-Memory SRAM

Abstract
:1. Introduction
2. Challenges of Current-Based CIM-SRAM
2.1. Analysis of Analog Non-Idealities
2.2. Analysis of Dynamic Range and Signal Margin
2.2.1. Standard 6T Unit without Read Isolation Structure
2.2.2. Computing-in-Memory SRAM Cell with Read Isolation Structure
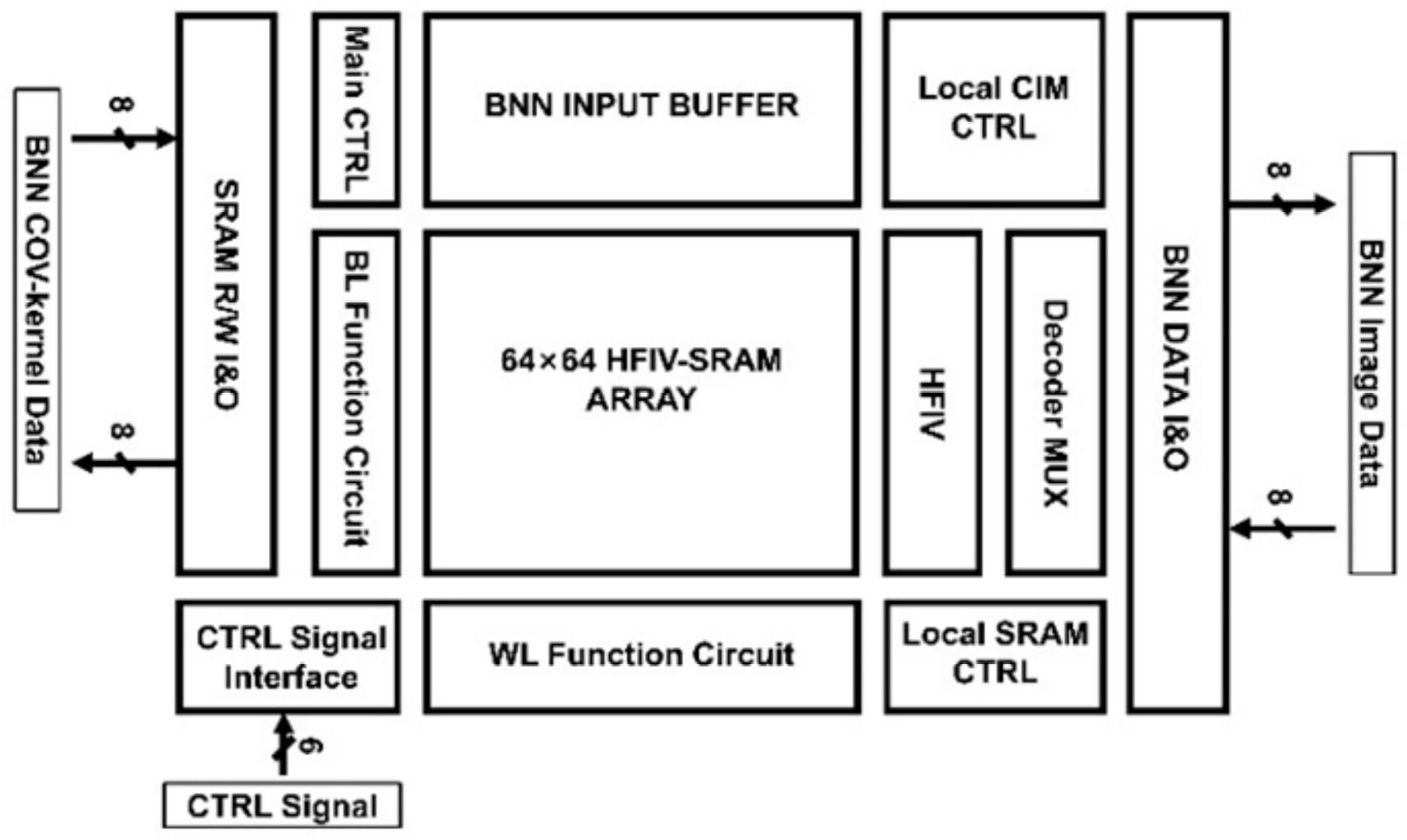
3. Design and Analysis
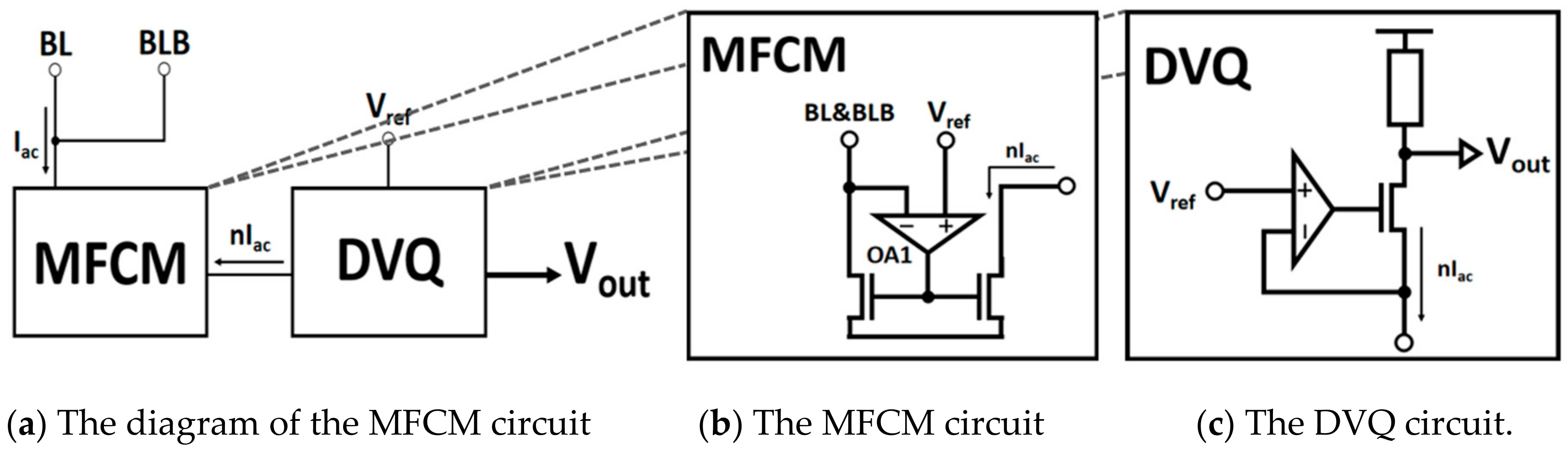
3.1. High-Precision Full Dynamic Range IV (HFIV) Conversion Circuit
3.2. Linearity Analysis
3.2.1. Static Operating Point Analysis of HFIV Circuit
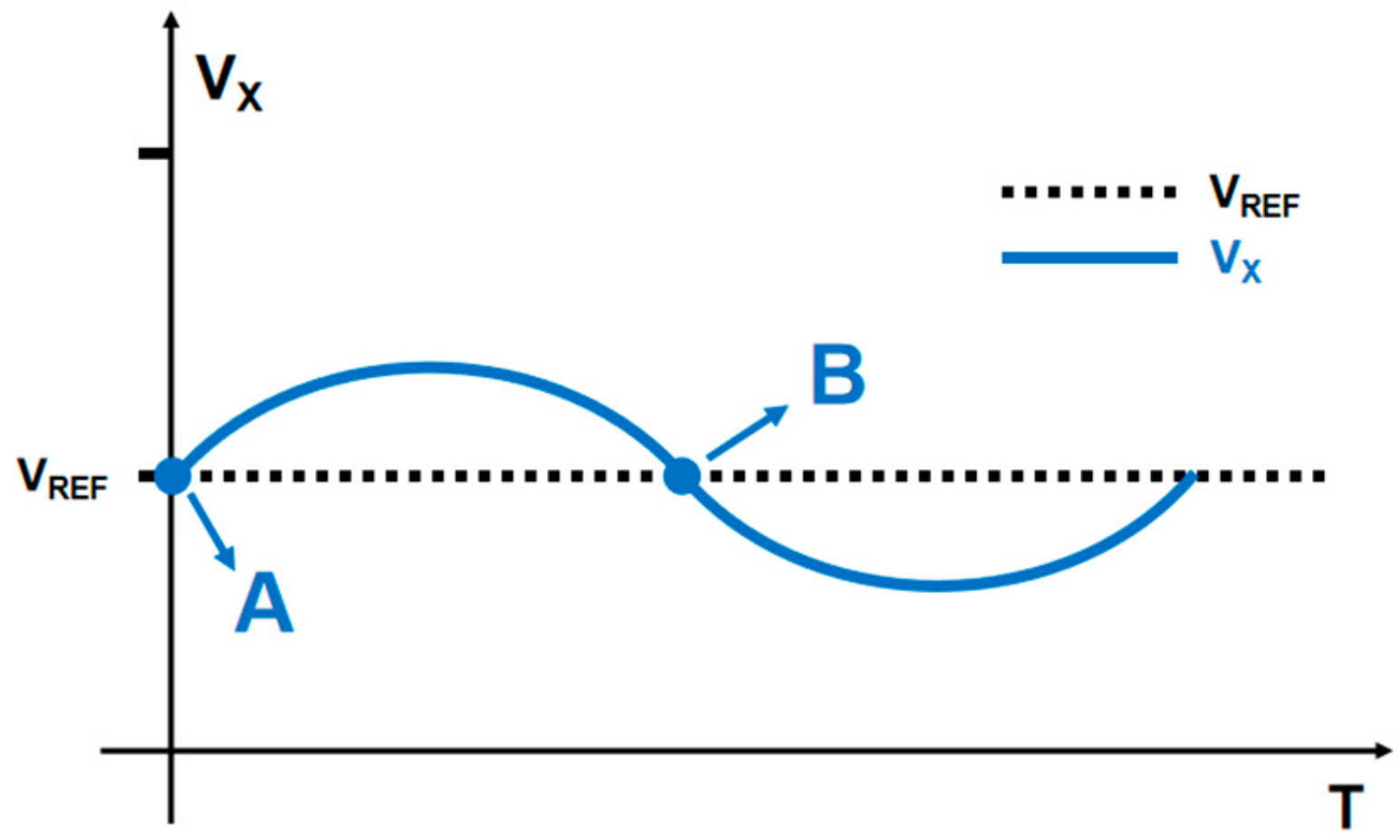
3.2.2. Dynamic Voltage Regulation Analysis of MFCM
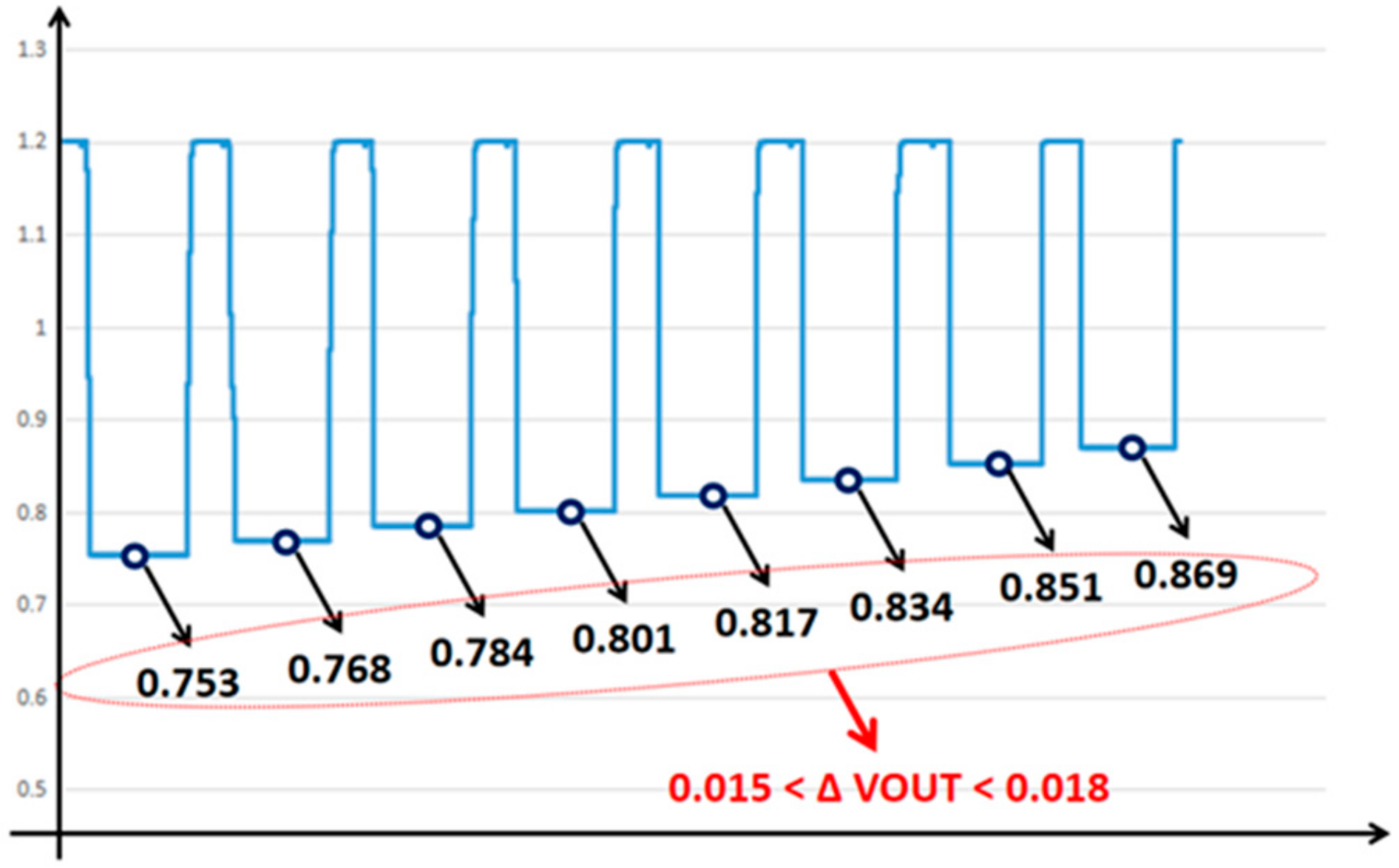
3.3. Behavioral Simulation
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jhang, C.-J.; Xue, C.-X.; Hung, J.-M.; Chang, F.-C.; Chang, M.-F. An Overview of Processing-in-Memory Circuits for Artificial Intelligence and Machine Learning. IEEE J. Emerg. Sel. Top. Circuits Syst. 2022, 12, 338–353. [Google Scholar]
- Jhang, C.-J.; Xue, C.-X.; Hung, J.-M.; Chang, F.-C.; Chang, M.-F. Challenges and Trends of SRAM-Based Computing-In-Memory for AI Edge Devices. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1773–1786. [Google Scholar] [CrossRef]
- Gonugondla, S.K.; Kang, M.; Shanbhag, N. A 42 pJ/decision 3.12 TOPS/W robust in-memory machine learning classifier with onchip training. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 490–492. [Google Scholar]
- Gonugondla, S.K.; Kang, M.; Shanbhag, N.R. A variationtolerant in-memory machine learning classifier via on-chip training. IEEE J. Solid-State Circuits 2018, 53, 3163–3173. [Google Scholar] [CrossRef]
- Lin, Z.; Fang, Y.; Peng, C.; Lu, W.; Li, X.; Wu, X.; Chen, J. Current mirror-based compensation circuit for multirow read in-memory computing. Electron. Lett. 2019, 55, 1176–1178. [Google Scholar] [CrossRef]
- Si, X.; Chen, J.-J.; Tu, Y.-N.; Huang, W.-H.; Wang, J.-H.; Chiu, Y.-C.; Wei, W.-C.; Wu, S.-Y.; Sun, X.; Liu, R.; et al. 24.5 A twin-8T SRAM computation-in-memory macro for multiple-bit CNN-based machine learning. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 396–398. [Google Scholar]
- Lin, Z.; Zhan, H.; Chen, Z.; Peng, C.; Wu, X.; Lu, W.; Zhao, Q.; Li, X.; Chen, J. Cascade Current Mirror to Improve Linearity and Consistency in SRAM In-Memory Computing. IEEE J. Solid-State Circuits 2021, 56, 2550–2562. [Google Scholar] [CrossRef]
- Yu, C.; Yoo, T.; Kim, T.T.-H.; Chuan, K.C.T.; Kim, B. A 16K current-based 8T SRAM compute-in-memory macro with decoupled read/write and 1-5bit column ADC. In Proceedings of the 2020 IEEE Custom Integrated Circuits Conference (CICC), Boston, MA, USA, 22–25 March 2020; pp. 1–4. [Google Scholar]
- Agarwal, S.; Quach, T.-T.; Parekh, O.; Hsia, A.H.; DeBenedictis, E.P.; James, C.D.; Marinella, M.J.; Aimone, J.B. Energy scaling advantages of resistive memory crossbar based computation and its application to sparse coding. Front. Neurosci. 2016, 9, 484. [Google Scholar] [CrossRef] [PubMed]
- Jaiswal, A.; Chakraborty, I.; Agrawal, A.; Roy, K. 8T SRAM cell as a multibit dot-product engine for beyond von Neumann computing. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2556–2567. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of SRAM Bit-Cells | Iac/uA | VOUT/V |
|---|---|---|
| 57 | 165.6 | 0.8688 |
| 58 | 174.3 | 0.8514 |
| 59 | 182.9 | 0.8342 |
| 60 | 191.4 | 0.8172 |
| 61 | 199.73 | 0.80054 |
| 62 | 207.92 | 0.78416 |
| 63 | 215.96 | 0.76808 |
| 64 | 223.58 | 0.75284 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Gong, Z.; Liu, Y.; Chen, J. A High-Precision Voltage-Quantization-Based Current-Mode Computing-in-Memory SRAM. Micromachines 2023, 14, 2180. https://doi.org/10.3390/mi14122180
Zhao R, Gong Z, Liu Y, Chen J. A High-Precision Voltage-Quantization-Based Current-Mode Computing-in-Memory SRAM. Micromachines. 2023; 14(12):2180. https://doi.org/10.3390/mi14122180
Chicago/Turabian StyleZhao, Ruiyong, Zhenghui Gong, Yulan Liu, and Jing Chen. 2023. "A High-Precision Voltage-Quantization-Based Current-Mode Computing-in-Memory SRAM" Micromachines 14, no. 12: 2180. https://doi.org/10.3390/mi14122180
APA StyleZhao, R., Gong, Z., Liu, Y., & Chen, J. (2023). A High-Precision Voltage-Quantization-Based Current-Mode Computing-in-Memory SRAM. Micromachines, 14(12), 2180. https://doi.org/10.3390/mi14122180