
Motor Imagery EEG Classification Based on Transfer Learning and Multi-Scale Convolution Network


Abstract
:1. Introduction
2. Methods
2.1. Pre Processing
2.2. Signal Classification
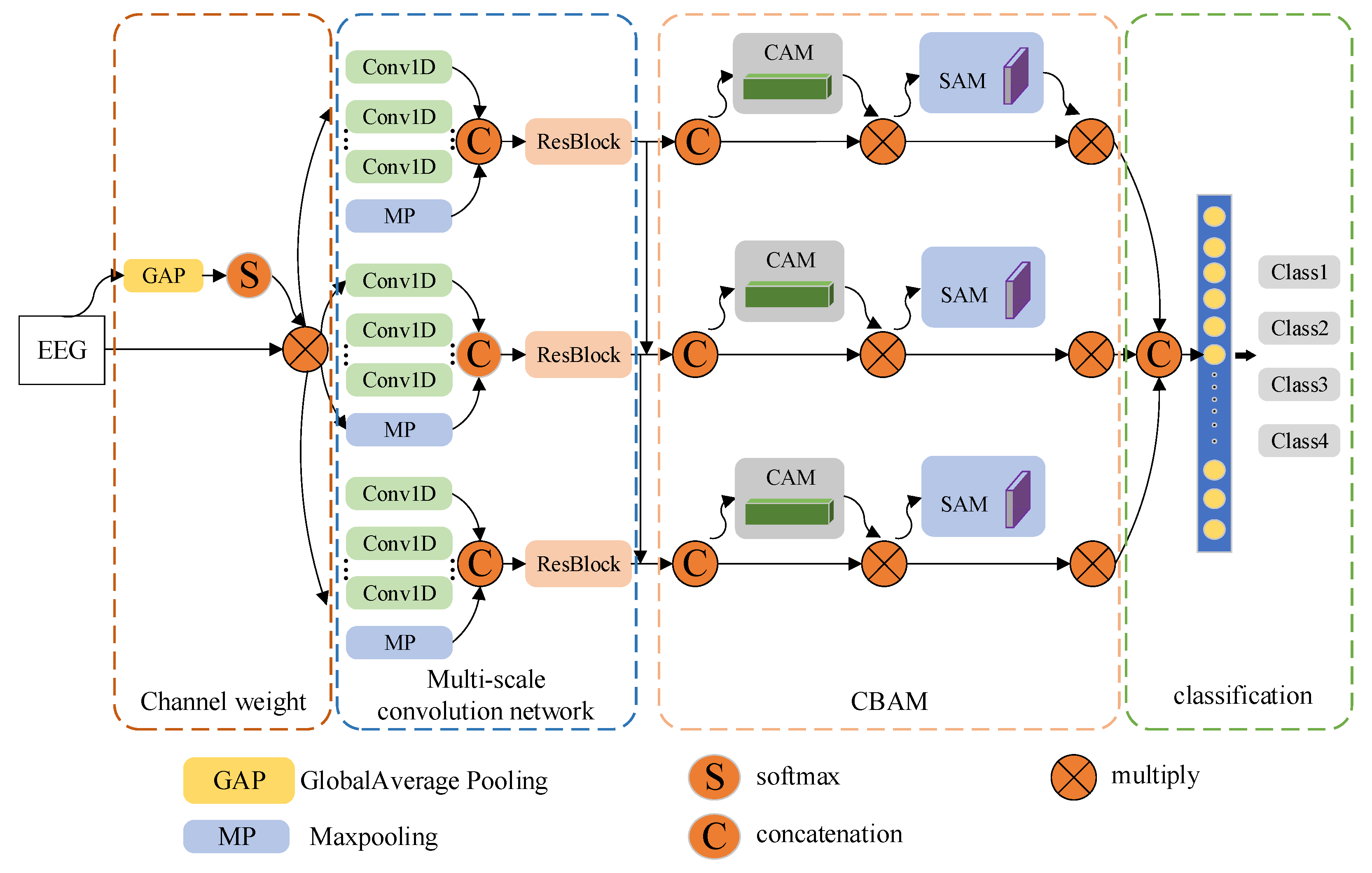
2.2.1. Multi-Scale Convolution Network
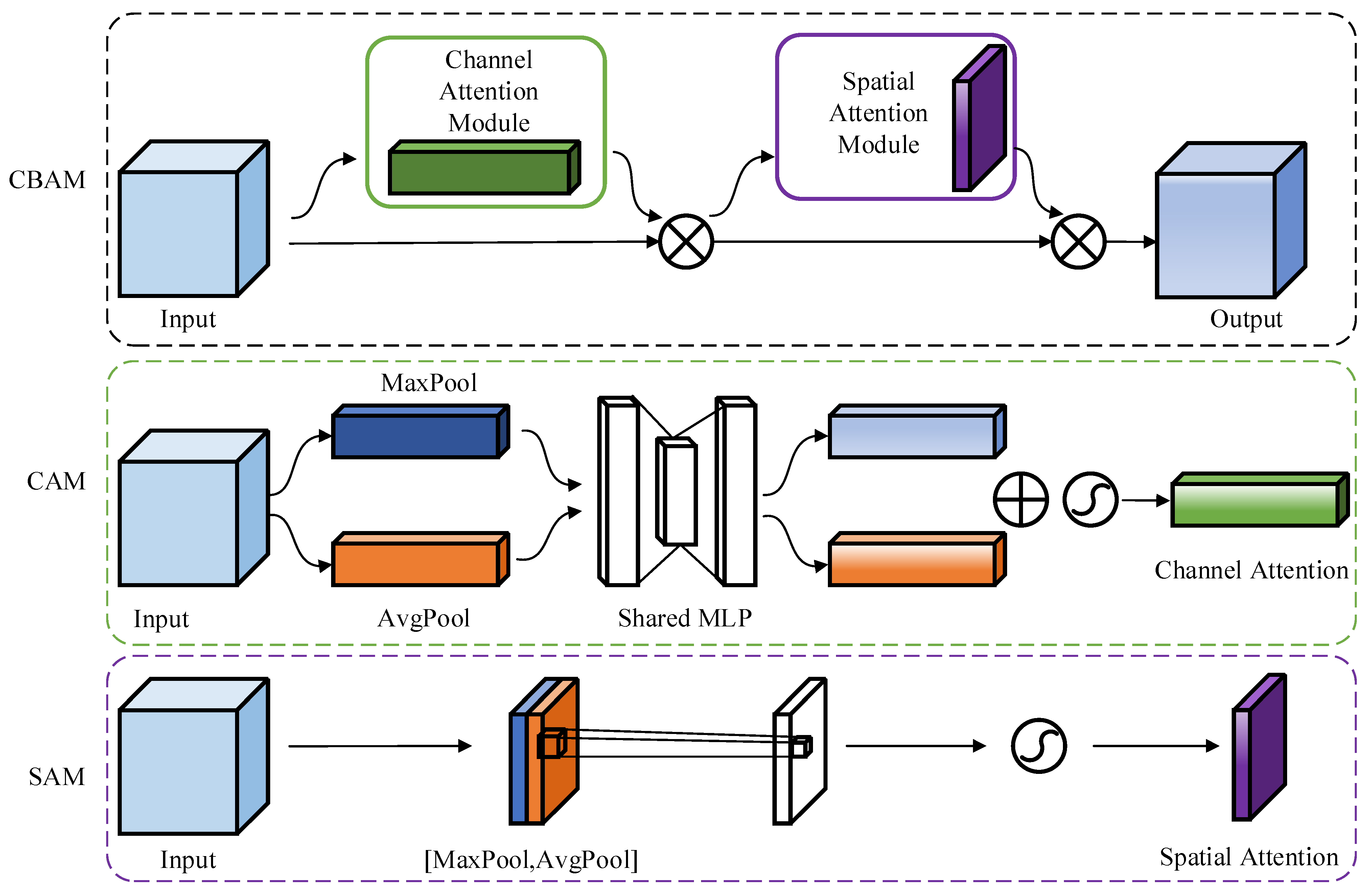
2.2.2. Attention Mechanism
3. Results and Analysis
3.1. Introduction of Experimental Data Set
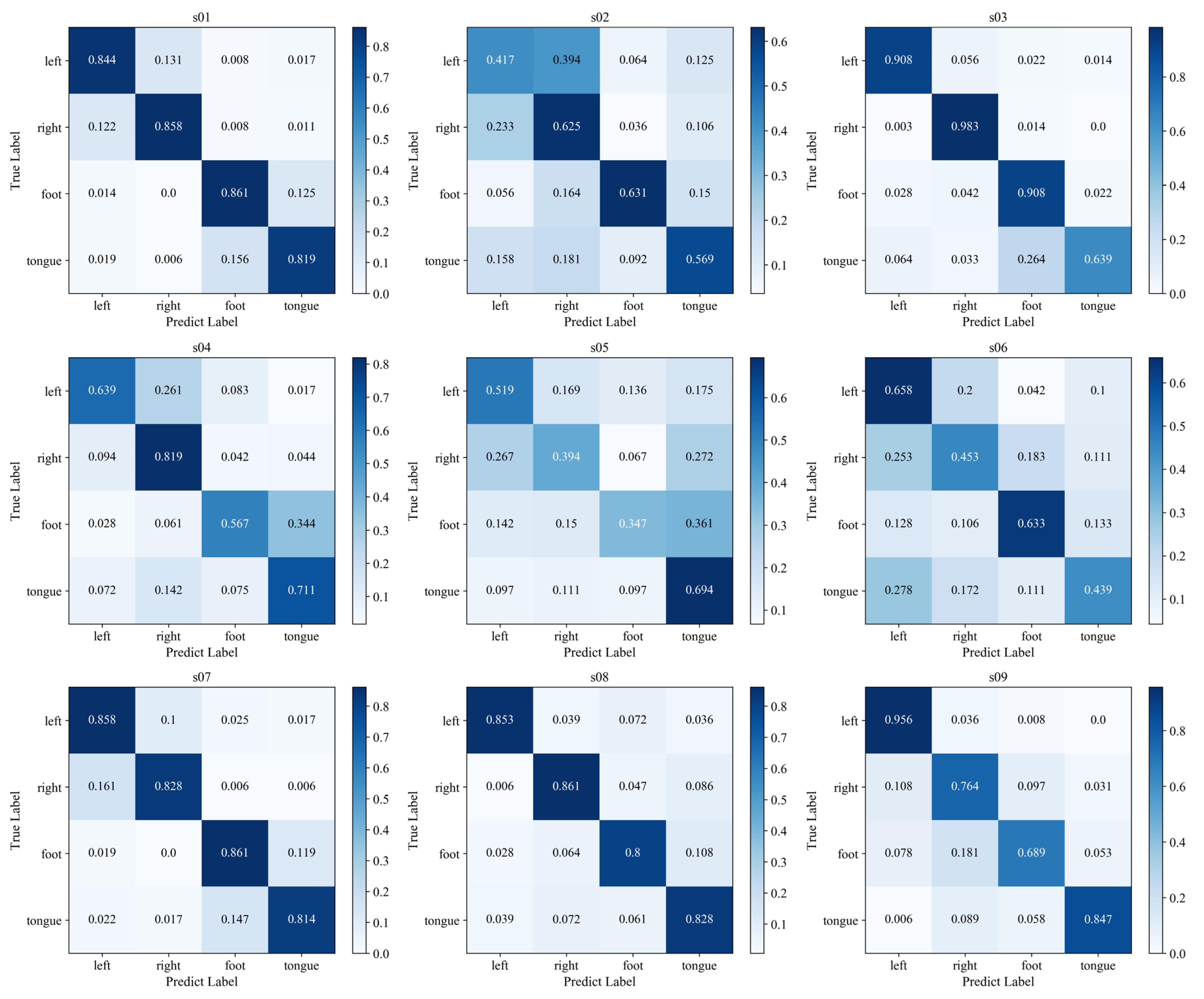
3.2. Experiments and Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sebastián-Romagosa, M.; Cho, W.; Ortner, R.; Murovec, N.; Von Oertzen, T.; Kamada, K.; Allison, B.Z.; Guger, C. Brain Computer Interface Treatment for Motor Rehabilitation of Upper Extremity of Stroke Patients—A Feasibility Study. Front. Neurosci. 2020, 14, 1056. [Google Scholar] [CrossRef] [PubMed]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain Computer Interfaces, a Review. Sensors 2012, 12, 1211–1279. [Google Scholar] [CrossRef] [PubMed]
- Bonnet, L.; Lotte, F.; Lecuyer, A. Two Brains, One Game: Design and Evaluation of a Multiuser BCI Video Game Based on Motor Imagery. IEEE Trans. Comput. Intell. AI Games 2013, 5, 185–198. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, H.; Cao, L.; Shu, X.; Zhang, D. A Shared Control Strategy for Reach and Grasp of Multiple Objects Using Robot Vision and Noninvasive Brain–Computer Interface. IEEE Trans. Autom. Sci. Eng. 2022, 19, 360–372. [Google Scholar] [CrossRef]
- Bozhkov, L.; Georgieva, P. Deep learning models for brain machine interfaces. Ann. Math Artif. Intel. 2020, 88, 1175–1190. [Google Scholar] [CrossRef]
- Al-Saegh, A.; Dawwd, S.A.; Abdul-Jabbar, J.M. Deep learning for motor imagery EEG-based classification: A review. Biomed. Signal Processing Control 2021, 63, 102172. [Google Scholar] [CrossRef]
- Dai, M.; Zheng, D.; Na, R.; Wang, S.; Zhang, S. EEG Classification of Motor Imagery Using a Novel Deep Learning Framework. Sensors 2019, 19, 551. [Google Scholar] [CrossRef] [PubMed]
- Thomas, J.; Maszczyk, T.; Sinha, N.; Kluge, T.; Dauwels, J. Deep learning-based classification for brain-computer interfaces. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 234–239. [Google Scholar]
- An, X.; Kuang, D.; Guo, X.; Zhao, Y.; He, L. A Deep Learning Method for Classification of EEG Data Based on Motor Imagery; Springer International Publishing: Cham, Switzerland; pp. 203–210.
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain—Computer interfaces. J. Neural Eng. 2018, 15, 56013. [Google Scholar] [CrossRef] [PubMed]
- Lu, P.; Gao, N.; Lu, Z.; Yang, J.; Bai, O.; Li, Q. Combined CNN and LSTM for Motor Imagery Classification. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–6. [Google Scholar]
- Riyad, M.; Khalil, M.; Adib, A. MI-EEGNET: A novel convolutional neural network for motor imagery classification. J. Neurosci. Meth 2021, 353, 109037. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. Arxiv Prepr. 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Dai, G.; Zhou, J.; Huang, J.; Wang, N. HS-CNN: A CNN with hybrid convolution scale for EEG motor imagery classification. J. Neural Eng. 2020, 17, 16025. [Google Scholar] [CrossRef] [PubMed]
- Riyad, M.; Khalil, M.; Adib, A. A novel multi-scale convolutional neural network for motor imagery classification. Biomed. Signal Processing Control 2021, 68, 102747. [Google Scholar] [CrossRef]
- Li, D.; Xu, J.; Wang, J.; Fang, X.; Ji, Y. A multi-scale fusion convolutional neural network based on attention mechanism for the visualization analysis of EEG signals decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2615–2626. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Xu, G.; Chen, L.; Tian, P.; Han, C.; Zhang, S.; Duan, N. Instance Transfer subject-dependent strategy for motor imagery signal classification using deep convolutional neural networks. Comput. Math. Methods Med. 2020, 2020, 1683013. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Robinson, N.; Lee, S.; Guan, C. Adaptive transfer learning for EEG motor imagery classification with deep Convolutional Neural Network. Neural Netw. 2021, 136, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Zheng, M.; Yang, B.; Xie, Y. EEG classification across sessions and across subjects through transfer learning in motor imagery-based brain-machine interface system. Med. Biol. Eng. Comput. 2020, 58, 1515–1528. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Xu, M.; Jung, T.; Ming, D. Review of brain encoding and decoding mechanisms for EEG-based brain—Computer interface. Cogn. Neurodyn. 2021, 15, 569–584. [Google Scholar] [CrossRef] [PubMed]
- Jayaram, V.; Alamgir, M.; Altun, Y.; Scholkopf, B.; Grosse-Wentrup, M. Transfer learning in brain-computer interfaces. IEEE Comput. Intell. Mag. 2016, 11, 20–31. [Google Scholar] [CrossRef]
- Zanini, P.; Congedo, M.; Jutten, C.; Said, S.; Berthoumieu, Y. Transfer learning: A Riemannian geometry framework with applications to brain—Computer interfaces. IEEE Trans. Biomed. Eng. 2018, 65, 1107–1116. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Wu, D. Transfer learning for brain-computer interfaces: A Euclidean space data alignment approach. IEEE Trans. Biomed. Eng. 2020, 67, 399–410. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluating Indicator (Evaluation) | Subject | Original | TL | TL + FT | EA + TL | EA + TL + FT |
|---|---|---|---|---|---|---|
| Acc Std (%) | S01 | 84.98 1.17 | 77.85 0.58 | 87.41 1.78 | 82.39 0.92 | 90.63 1.13 |
| S02 | 69.86 2.79 | 74.17 0.79 | 70.38 0.87 | 72.45 0.58 | 79.23 0.79 | |
| S03 | 90.22 1.11 | 81.64 1.36 | 91.16 0.98 | 87.48 0.55 | 91.12 0.88 | |
| S04 | 78.97 1.42 | 73.85 0.92 | 80.34 0.71 | 74.24 1.17 | 84.16 0.69 | |
| S05 | 73.44 1.62 | 74.35 0.61 | 73.90 0.71 | 73.69 1.10 | 77.29 1.00 | |
| S06 | 74.86 1.06 | 72.73 2.85 | 78.55 0.96 | 75.16 0.77 | 79.03 1.31 | |
| S07 | 82.81 0.97 | 75.14 1.31 | 86.53 1.20 | 77.30 1.12 | 92.77 0.86 | |
| S08 | 84.91 1.22 | 80.96 1.66 | 87.35 0.88 | 85.40 2.31 | 90.87 1.44 | |
| S09 | 86.80 1.32 | 78.94 1.59 | 88.13 0.97 | 85.77 1.95 | 89.14 1.09 | |
| Avg | 80.76 0.89 | 76.62 0.75 | 82.64 0.46 | 79.32 0.60 | 86.03 0.55 | |
| Micro-F1 Std | S01 | 0.69 0.026 | 0.61 0.060 | 0.75 0.034 | 0.65 0.023 | 0.81 0.025 |
| S02 | 0.34 0.027 | 0.30 0.035 | 0.35 0.014 | 0.36 0.012 | 0.56 0.023 | |
| S03 | 0.80 0.027 | 0.70 0.048 | 0.82 0.022 | 0.75 0.009 | 0.82 0.018 | |
| S04 | 0.55 0.033 | 0.38 0.041 | 0.58 0.019 | 0.44 0.033 | 0.67 0.019 | |
| S05 | 0.33 0.023 | 0.27 0.017 | 0.36 0.025 | 0.41 0.023 | 0.49 0.028 | |
| S06 | 0.43 0.028 | 0.34 0.049 | 0.51 0.033 | 0.45 0.019 | 0.54 0.028 | |
| S07 | 0.64 0.029 | 0.43 0.038 | 0.71 0.031 | 0.52 0.027 | 0.85 0.017 | |
| S08 | 0.69 0.027 | 0.64 0.057 | 0.73 0.034 | 0.70 0.054 | 0.81 0.031 | |
| S09 | 0.73 0.031 | 0.53 0.042 | 0.76 0.021 | 0.71 0.044 | 0.78 0.024 | |
| Avg | 0.58 0.013 | 0.47 0.023 | 0.62 0.011 | 0.55 0.016 | 0.70 0.012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Z.; Zhang, C.; Li, C. Motor Imagery EEG Classification Based on Transfer Learning and Multi-Scale Convolution Network. Micromachines 2022, 13, 927. https://doi.org/10.3390/mi13060927
Chang Z, Zhang C, Li C. Motor Imagery EEG Classification Based on Transfer Learning and Multi-Scale Convolution Network. Micromachines. 2022; 13(6):927. https://doi.org/10.3390/mi13060927
Chicago/Turabian StyleChang, Zhanyuan, Congcong Zhang, and Chuanjiang Li. 2022. "Motor Imagery EEG Classification Based on Transfer Learning and Multi-Scale Convolution Network" Micromachines 13, no. 6: 927. https://doi.org/10.3390/mi13060927
APA StyleChang, Z., Zhang, C., & Li, C. (2022). Motor Imagery EEG Classification Based on Transfer Learning and Multi-Scale Convolution Network. Micromachines, 13(6), 927. https://doi.org/10.3390/mi13060927