
A New Kinect V2-Based Method for Visual Recognition and Grasping of a Yarn-Bobbin-Handling Robot


 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Method and Materials
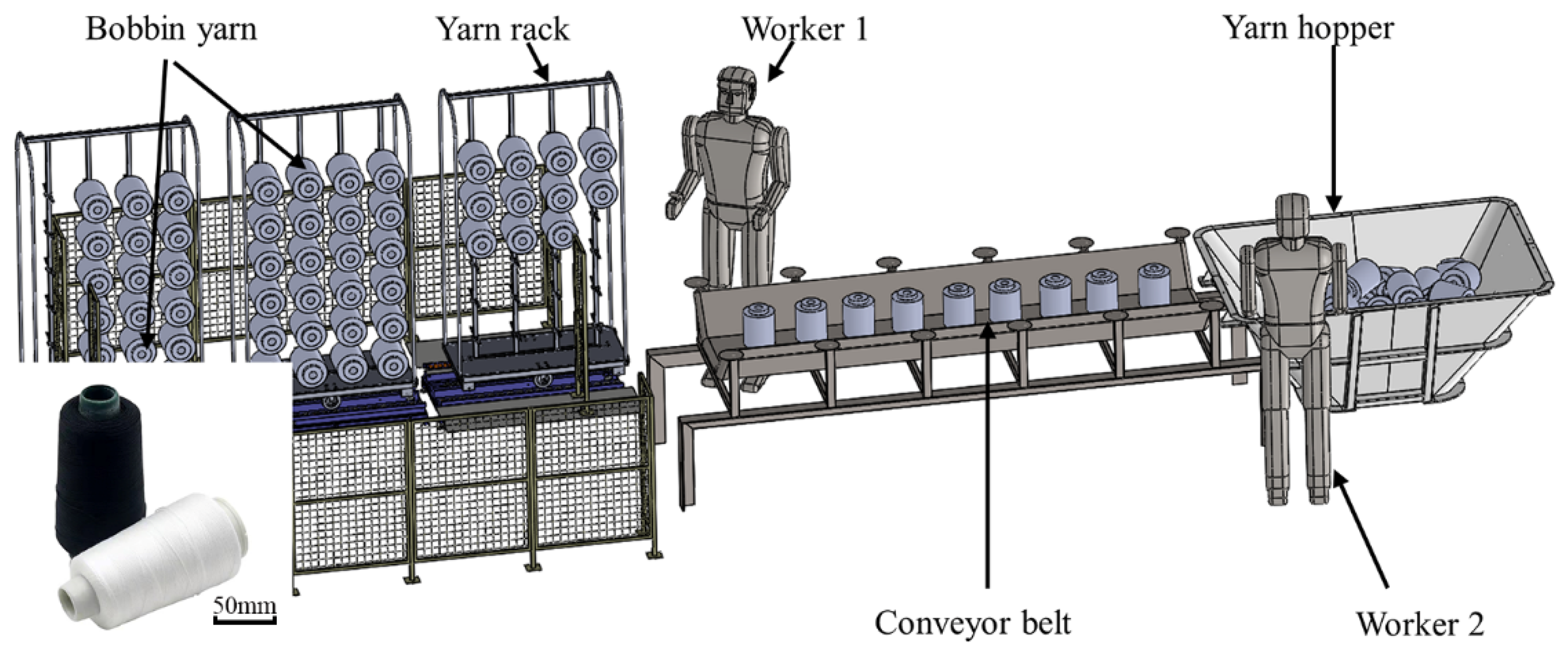
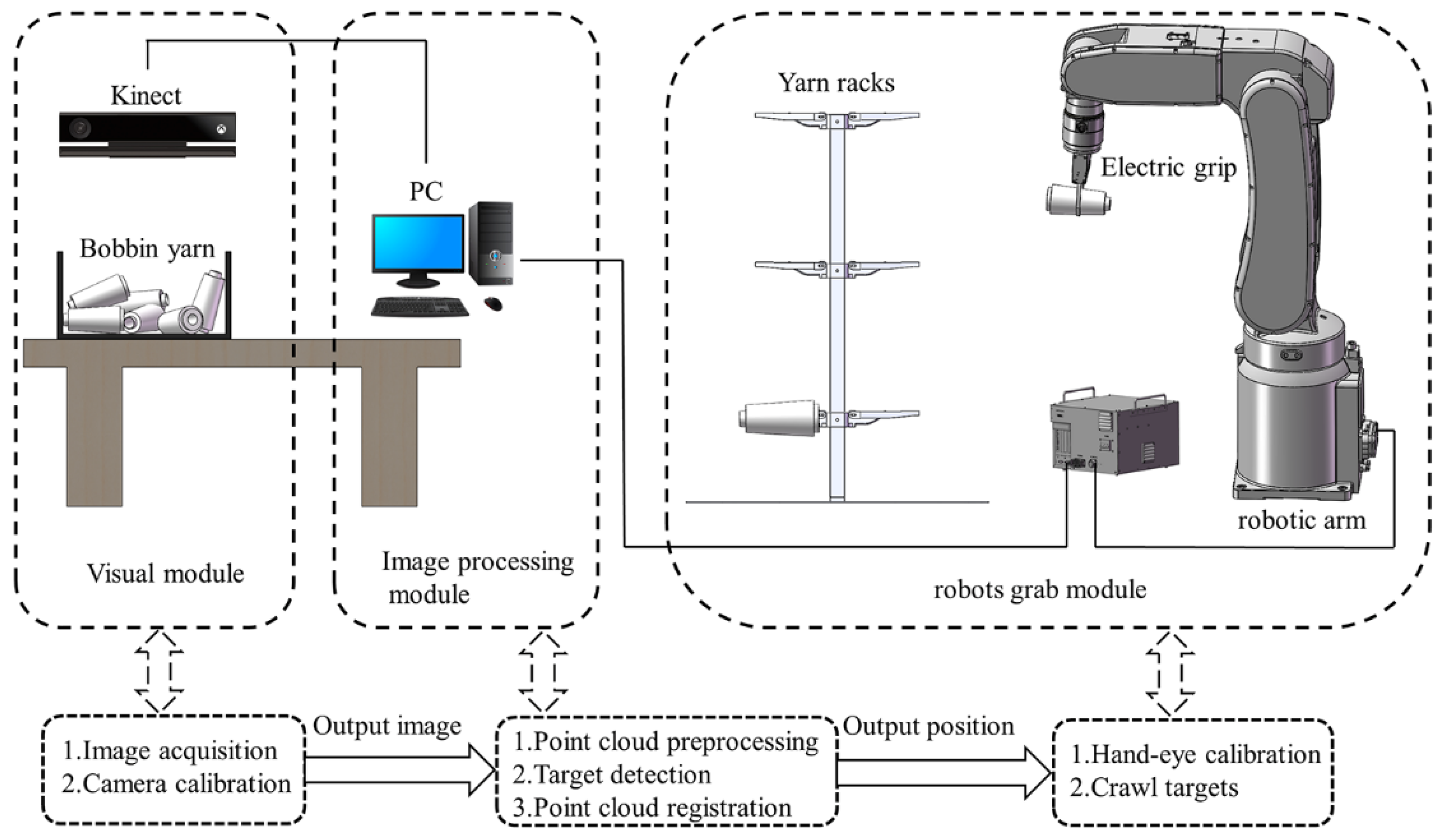
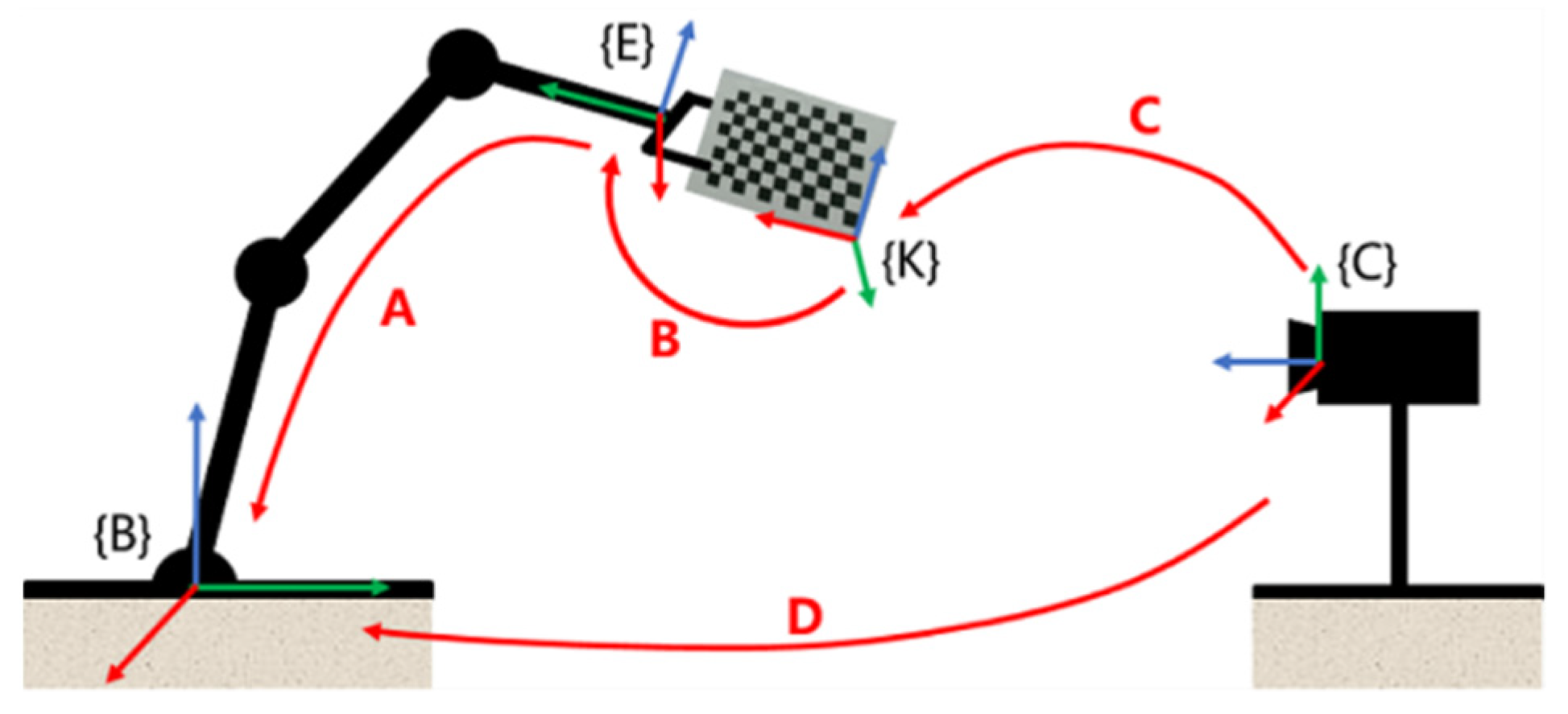
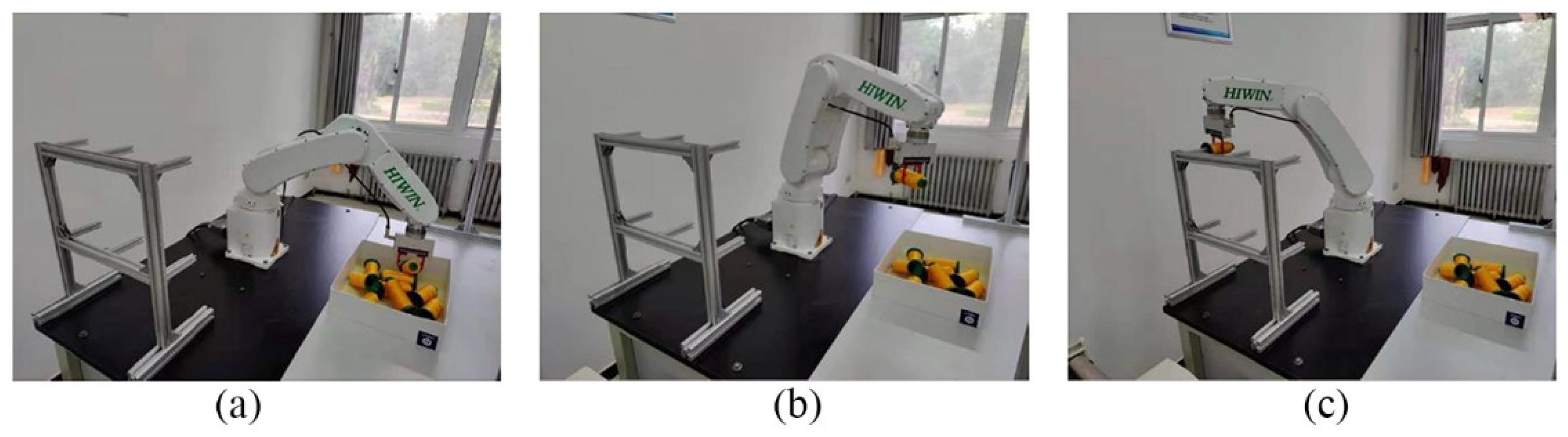
2.1. Establishment of Experimental Platform
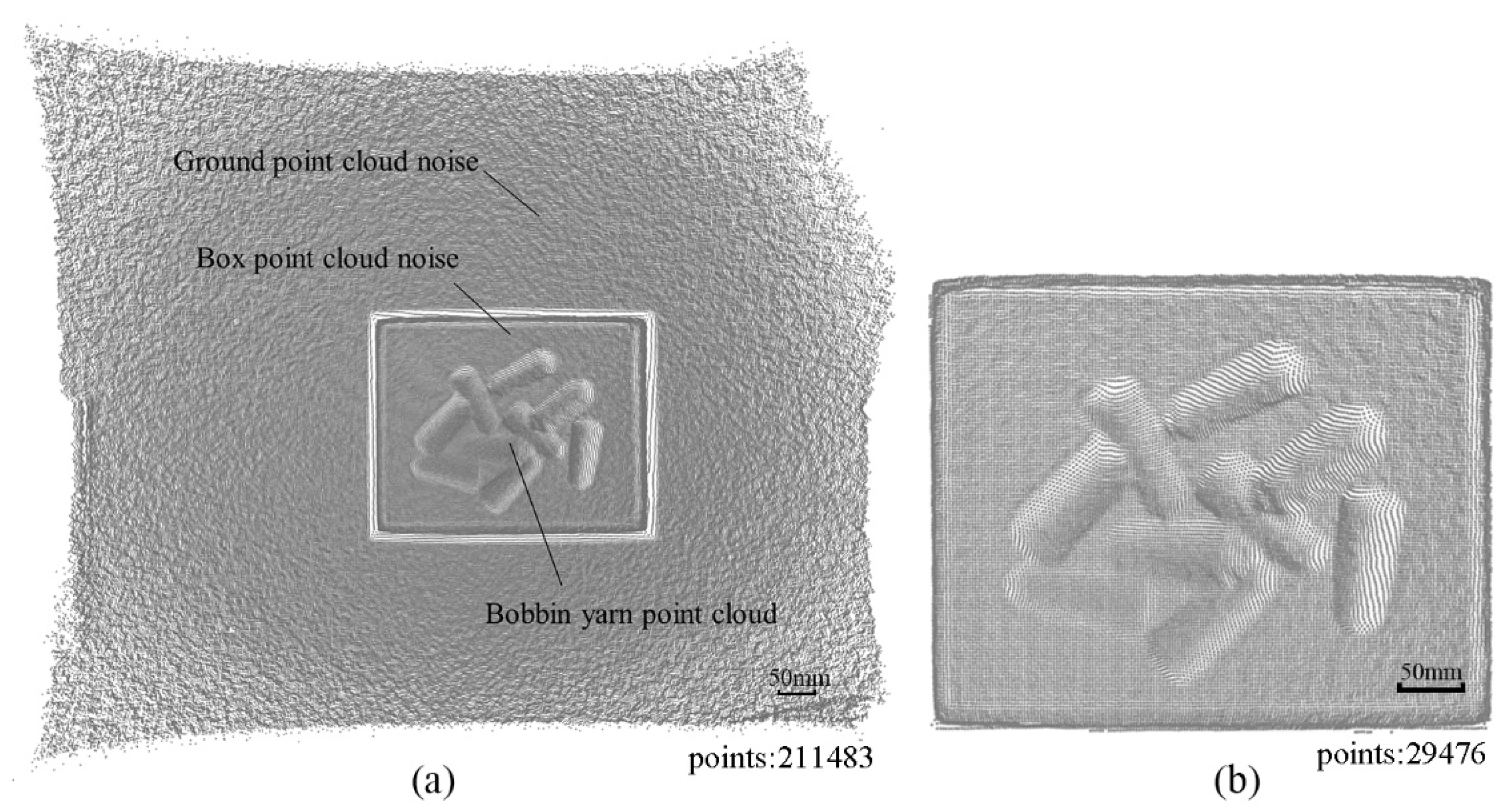
2.2. Vision Image Processing
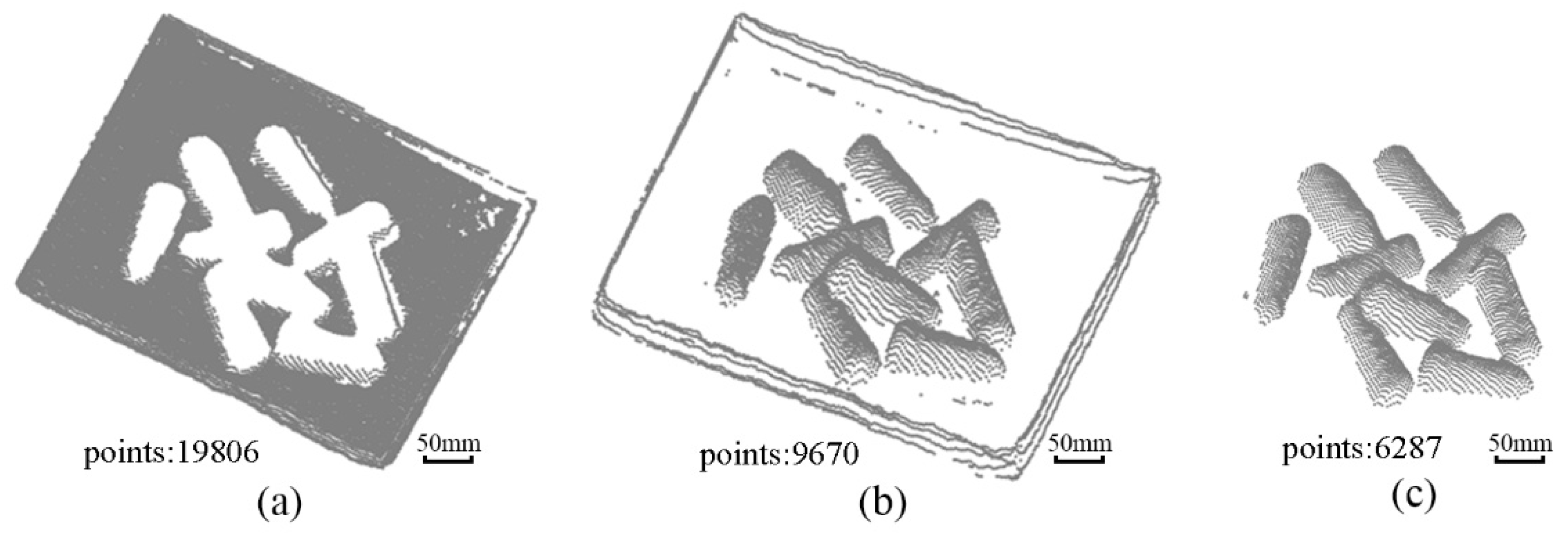
2.3. Identification of Yarn Bobbin Targets
3. Numerical and Experimental Analyses
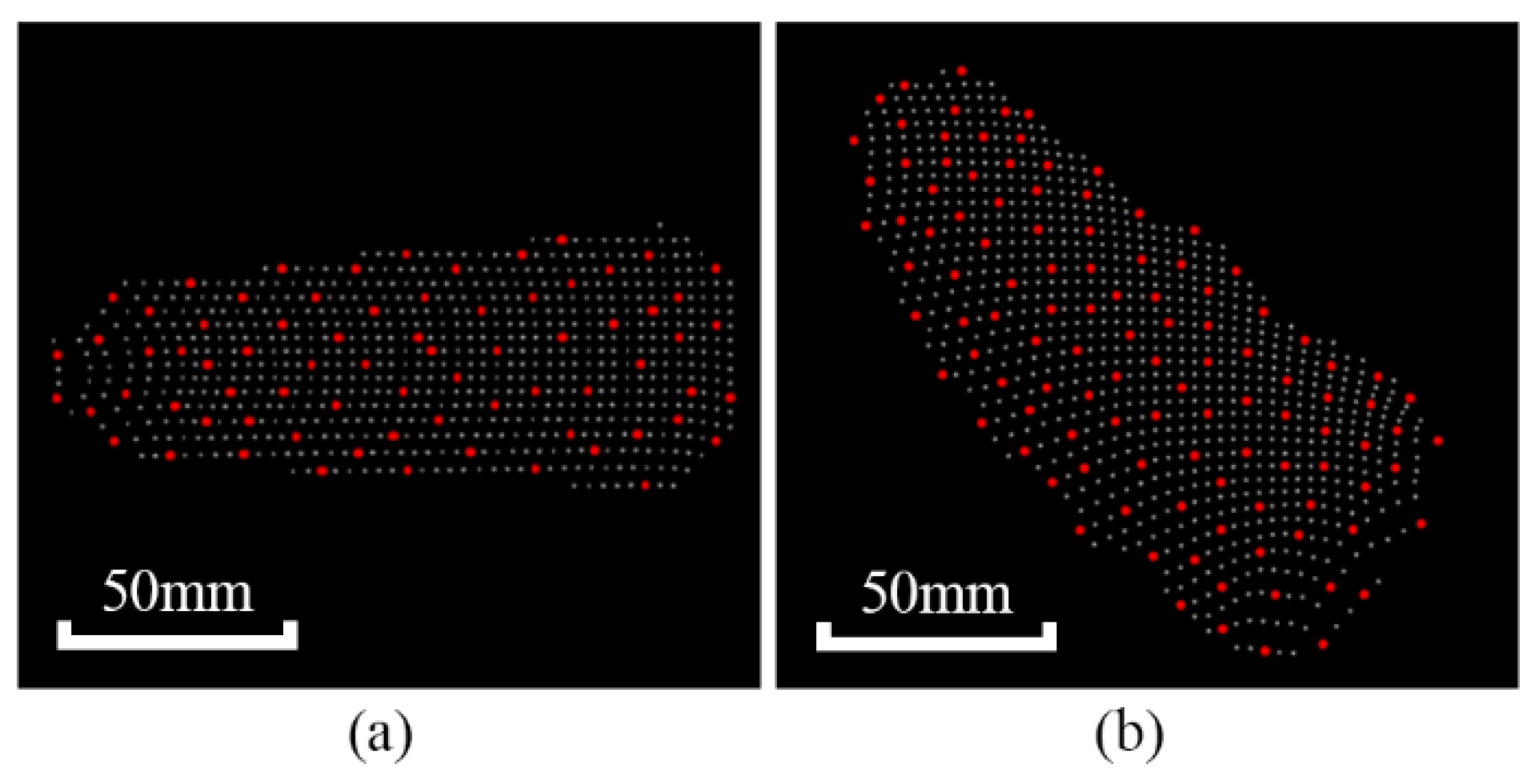
3.1. Calibration Experiments
3.2. Grasping Experiments
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; He, L.; Cheng, L. Is China’s Textile Industry Still a Labour-Intensive Industry? Fibres Text. East. Eur. 2021, 29, 13–16. [Google Scholar] [CrossRef]
- Babu, B.S.; Kumar, P.S.; Kumar, M.S. Effect of yarn type on moisture transfer characteristics of double-face knitted fabrics for active sportswear. J. Ind. Text. 2018, 49, 1078–1099. [Google Scholar] [CrossRef]
- Noor, A.; Saeed, M.A.; Ullah, T.; Uddin, Z.; Khan, R.M.W.U. A review of artificial intelligence applications in apparel industry. J. Text. Inst. 2021, 113, 505–514. [Google Scholar] [CrossRef]
- Xue, B.; Chang, B.; Peng, G.; Gao, Y.; Tian, Z.; Du, D.; Wang, G. A Vision Based Detection Method for Narrow Butt Joints and a Robotic Seam Tracking System. Sensors 2019, 19, 1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramon-Soria, P.; Arrue, B.C.; Ollero, A. Grasp planning and visual servoing for an outdoors aerial dual manipulator. Engineering 2020, 6, 77–88. [Google Scholar] [CrossRef]
- D’Avella, S.; Tripicchio, P.; Avizzano, C.A. A study on picking objects in cluttered environments: Exploiting depth features for a custom low-cost universal jamming gripper. Robot. Comput. Manuf. 2019, 63, 101888. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Sun, Y.; Hu, J.; Yun, J.; Liu, Y. Manipulator grabbing position detection with information fusion of color image and depth image using deep learning. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10809–10822. [Google Scholar] [CrossRef]
- Du, Y.C.; Taryudi, T.; Tsai, C.T.; Wang, M.S. Eye-to-hand robotic tracking and grabbing based on binocular vision. Microsyst. Technol. 2021, 27, 1699–1710. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Ma, Z.; Chen, M.; Zhong, Y.; Deng, F.; Li, M. Computer vision-based high-quality tea automatic plucking robot using Delta parallel manipulator. Comput. Electron. Agric. 2021, 181, 105946. [Google Scholar] [CrossRef]
- Matsuo, I.; Shimizu, T.; Nakai, Y.; Kakimoto, M.; Sawasaki, Y.; Mori, Y.; Sugano, T.; Ikemoto, S.; Miyamoto, T. Q-bot: Heavy object carriage robot for in-house logistics based on universal vacuum gripper. Adv. Robot. 2020, 34, 173–188. [Google Scholar] [CrossRef]
- Xiao, W.; Yang, J.; Fang, H.; Zhuang, J.; Ku, Y.; Zhang, X. Development of an automatic sorting robot for construction and demolition waste. Clean Technol. Environ. Policy 2020, 22, 1829–1841. [Google Scholar] [CrossRef]
- Lin, S.; Wang, N. Cloud robotic grasping of Gaussian mixture model based on point cloud projection under occlusion. Assem. Autom. 2021, 41, 312–323. [Google Scholar] [CrossRef]
- Gao, M.; Li, X.; He, Z.; Yang, Y. An Automatic Assembling System for Sealing Rings Based on Machine Vision. J. Sens. 2017, 2017, 4207432. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Cui, X.; Song, Z.; Gu, F. Precise grabbing of overlapping objects system based on end-to-end deep neural network. Comput. Commun. 2021, 176, 138–145. [Google Scholar] [CrossRef]
- Song, Y.; Luo, Y.; Yu, C. Tactile–Visual Fusion Based Robotic Grasp Detection Method with a Reproducible Sensor. Int. J. Comput. Intell. Syst. 2021, 14, 1753–1762. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, Z.; Liang, S.; Geng, W.; Yu, J. A Novel Vision-Based Grasping Method Under Occlusion for Manipulating Robotic System. IEEE Sens. J. 2020, 20, 10996–11006. [Google Scholar] [CrossRef]
- Bergamini, L.; Sposato, M.; Pellicciari, M.; Peruzzini, M.; Calderara, S.; Schmidt, J. Deep learning-based method for vision-guided robotic grasping of unknown objects. Adv. Eng. Inform. 2020, 44, 101052. [Google Scholar] [CrossRef]
- Hu, J.; Liu, S.; Liu, J.; Wang, Z.; Huang, H. Pipe pose estimation based on machine vision. Measurement 2021, 182, 109585. [Google Scholar] [CrossRef]
- Han, Y.; Zhao, K.; Chu, Z.; Zhou, Y. Grasping Control Method of Manipulator Based on Binocular Vision Combining Target Detection and Trajectory Planning. IEEE Access 2019, 7, 167973–167981. [Google Scholar] [CrossRef]
- Lu, Z.; Zhao, M.; Luo, J.; Wang, G.; Wang, D. Design of a winter-jujube grading robot based on machine vision. Comput. Electron. Agric. 2021, 186, 106170. [Google Scholar] [CrossRef]
- Lou, J. Crawling robot manipulator tracking based on gaussian mixture model of machine vision. Neural Comput. Appl. 2021, 34, 6683–6693. [Google Scholar] [CrossRef]
- Han, X.-F.; Jin, J.S.; Wang, M.-J.; Jiang, W.; Gao, L.; Xiao, L. A review of algorithms for filtering the 3D point cloud. Signal Process. Image Commun. 2017, 57, 103–112. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Czarnuch, S. Automatic Super-Surface Removal in Complex 3D Indoor Environments Using Iterative Region-Based RANSAC. Sensors 2021, 21, 3724. [Google Scholar] [CrossRef]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3d object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar]
- Tian, H.; Dang, X.; Wang, J.; Wu, D. Registration method for three-dimensional point cloud in rough and fine registrations based on principal component analysis and iterative closest point algorithm. Traitement du Signal 2017, 34, 57–75. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Wang, R.; Wang, Y.; Tao, W. Evaluation of the ICP Algorithm in 3D Point Cloud Registration. IEEE Access 2020, 8, 68030–68048. [Google Scholar] [CrossRef]
- Cui, H.; Sun, R.; Fang, Z.; Lou, H.; Tian, W.; Liao, W. A novel flexible two-step method for eye-to-hand calibration for robot assembly system. Meas. Control 2020, 53, 2020–2029. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Parameter | Data |
|---|---|
| Focal length | |
| Point coordinates | |
| Radial distortion | |
| Error |
| Types | Diameter/mm | Height (mm) | Weight (kg) | |
|---|---|---|---|---|
| Tower-shaped | Small 41 | Big 52 | 112 | 0.11 |
| Cylindrical | 47 | 125 | 0.12 | |
| Experimental Scenarios | Experimental Subjects | Average Time Taken | Number of Experiments | Number of Successes | Success Rate |
|---|---|---|---|---|---|
| No contact | Tower-shaped | 8.35 s | 150 | 138 | 92.0% |
| Cylindrical | 8.07 s | 150 | 139 | 92.7% | |
| Unordered stacking | Tower-shaped | 9.68 s | 150 | 127 | 84.7% |
| Cylindrical | 9.82 s | 150 | 129 | 86.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Liu, B.; Jia, Y.; Jin, S.; Sulowicz, M.; Glowacz, A.; Królczyk, G.; Li, Z. A New Kinect V2-Based Method for Visual Recognition and Grasping of a Yarn-Bobbin-Handling Robot. Micromachines 2022, 13, 886. https://doi.org/10.3390/mi13060886
Han J, Liu B, Jia Y, Jin S, Sulowicz M, Glowacz A, Królczyk G, Li Z. A New Kinect V2-Based Method for Visual Recognition and Grasping of a Yarn-Bobbin-Handling Robot. Micromachines. 2022; 13(6):886. https://doi.org/10.3390/mi13060886
Chicago/Turabian StyleHan, Jinghai, Bo Liu, Yongle Jia, Shoufeng Jin, Maciej Sulowicz, Adam Glowacz, Grzegorz Królczyk, and Zhixiong Li. 2022. "A New Kinect V2-Based Method for Visual Recognition and Grasping of a Yarn-Bobbin-Handling Robot" Micromachines 13, no. 6: 886. https://doi.org/10.3390/mi13060886
APA StyleHan, J., Liu, B., Jia, Y., Jin, S., Sulowicz, M., Glowacz, A., Królczyk, G., & Li, Z. (2022). A New Kinect V2-Based Method for Visual Recognition and Grasping of a Yarn-Bobbin-Handling Robot. Micromachines, 13(6), 886. https://doi.org/10.3390/mi13060886