
Compute-in-Memory for Numerical Computations


Abstract
:1. Introduction
2. ReRAM
2.1. The Appearance of ReRAM
2.2. The Development of ReRAM as NVM
2.3. ReRAM in CIM
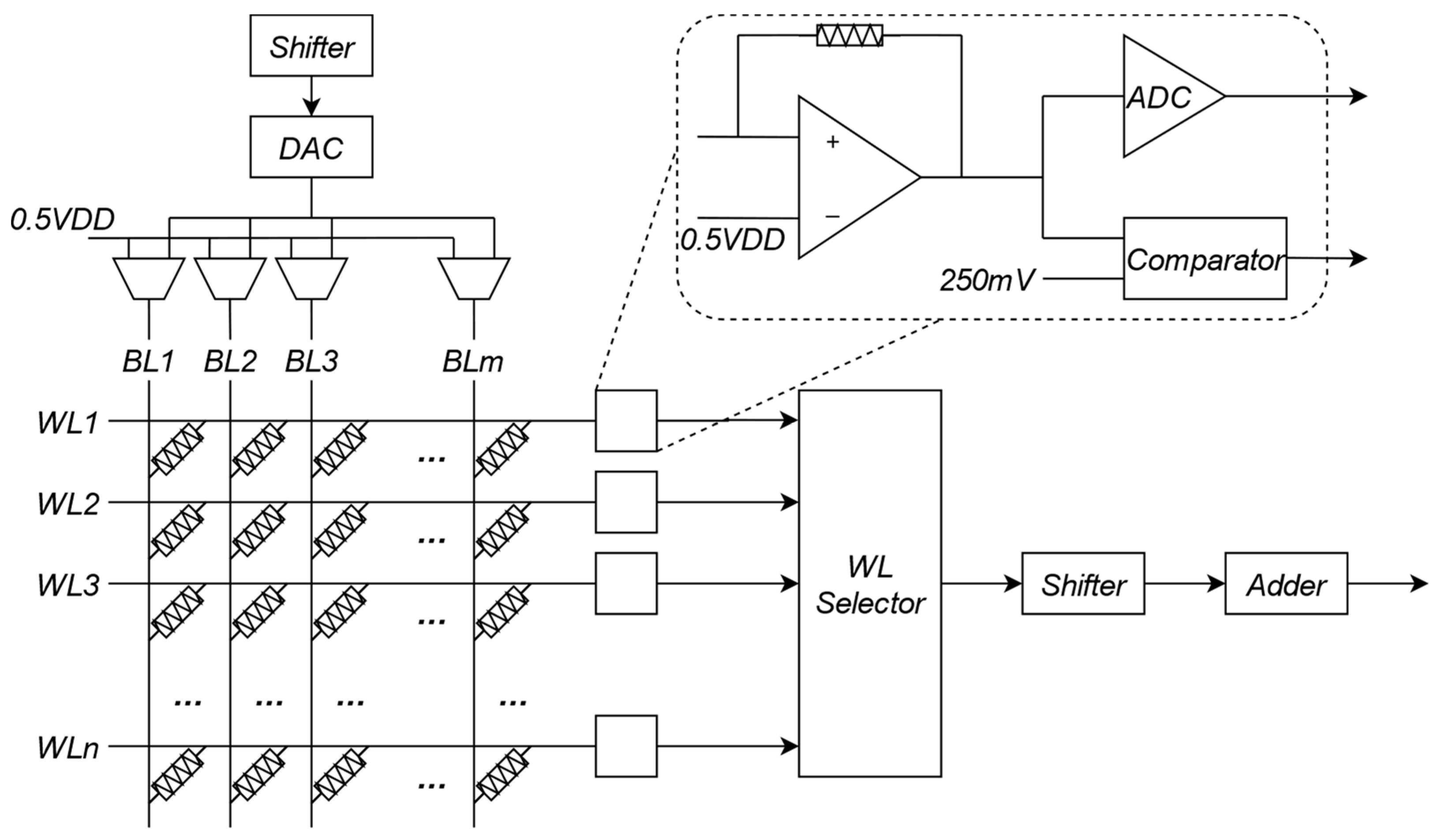
2.4. ReRAM Crossbar
3. Partial Differential Equation
3.1. Numerical Methods
3.1.1. Finite-Difference Method
- (1)
- Regional discretization. According to the appropriate step size, the domain that needs to be calculated is divided into finite grids and using the function values on discrete grid points to approximate the continuous function values.
- (2)
- Transformation of partial differential equations. Using the difference coefficient to approximate the exact derivatives.
- (3)
- Solution of partial differential equations. Bringing the boundary conditions into the equation and repeating calculations to solve a large number of equations.
3.1.2. Runge-Kutta Method
3.2. Matrix Iterative Methods
3.2.1. Jacobi Method
3.2.2. Guass Seidel Method
3.2.3. SOR Method
3.2.4. Krylov Subspace Method
3.3. Rearrangement and Split
4. CIM-Based Partial Differential Equation Solver
4.1. ReRAM-Based Partial Differential Equation Solver
4.2. SRAM-Based Partial Differential Equation Solver
4.3. Flash Memory-Based Partial Differential Equation Solver
4.4. PCM-Based Partial Differential Equation Solver
4.5. Discussion of Partial Differential Equation Solver
5. Summary and Outlook
- Regardless of which array of CIM, the accuracy is still the biggest challenge;
- More research of CIM-based numerical computations should focus on the computational methods of sparse matrixes;
- As for matrix iterative methods, the principal concern is which method has fewer zero elements, so the Jacobi method is still the best choice for CIM-based PDEs solvers at present. In addition, the Krylov subspace method is better when solving very large-scale matrixes;
- The future of CIM for high-precision computing tasks really needs a software/hardware codesign to collaborate the algorithm and the CIM array.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hickmott, T.W. Low-frequency negative resistance in thin anodic oxide films. J. Appl. Phys. 1962, 33, 2669–2682. [Google Scholar] [CrossRef]
- Gibbons, J.; Beadle, W. Switching properties of thin Nio films. Solid-State Electr. 1964, 7, 785–790. [Google Scholar] [CrossRef]
- Nielsen, P.; Bashara, N. The reversible voltage-induced initial resistance in the negative resistance sandwich structure. IEEE Trans. Electron. Devices 1964, 11, 243–244. [Google Scholar] [CrossRef]
- Hiatt, W.R.; Hickmott, T.W. Bistable switching in niobium oxide diodes. Appl. Phys. Lett. 1965, 6, 106–108. [Google Scholar] [CrossRef]
- Chen, Y. ReRAM: History, Status, and Future. IEEE Trans. Electron. Devices 2020, 67, 1420–1433. [Google Scholar] [CrossRef]
- Atalla, M.M.; Kahng, D. 1960—Metal Oxide Semiconductor (MOS) Transistor Demonstrated Silicon Engine; Tech. Rep.; Computer History Museum: Mountain View, CA, USA, 1960. [Google Scholar]
- Kahng, D. Electric Field Controlled Semiconductor Device. U.S. Patent 3 102 230 A, 27 August 1963. [Google Scholar]
- Xue, X.; Jian, W.; Yang, J.; Xiao, F.; Chen, G.; Xu, S.; Xie, Y.; Lin, Y.; Huang, R.; Zou, Q.; et al. A 0.13 µm 8 Mb Logic-Based CuxOy ReRAM With Self-Adaptive Operation for Yield Enhancement and Power Reduction. IEEE J. Solid-State Circuits 2013, 48, 1315–1322. [Google Scholar] [CrossRef]
- Ishii, T.; Johguchi, K.; Takeuchi, K. Vertical and horizontal location design of program voltage generator for 3D-integrated ReRAM/NAND flash hybrid SSD. In Proceedings of the 2014 International Conference on Electronics Packaging (ICEP), Toyama, Japan, 23–25 April 2014. [Google Scholar]
- Joshi, V.; le Gallo, M.; Haefeli, S.; Boybat, I.; Nandakumar, S.R.; Piveteau, C.; Dazzi, M.; Rajendran, B.; Sebastian, A.; Eleftheriou, E. Accurate deep neural network inference using computational phase-change memory. Nat. Commun. 2020, 11, 2473. [Google Scholar] [CrossRef] [PubMed]
- Jain, S.; Ranjan, A.; Roy, K.; Raghunathan, A. Computing in memory with spin-transfer torque magnetic RAM. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 470–483. [Google Scholar] [CrossRef]
- Takashima, D. Overview of FeRAMs: Trends and perspectives. In Proceedings of the 2011 11th Annual Non-Volatile Memory Technology Symposium Proceeding, Shanghai, China, 7–9 November 2011; pp. 1–6. [Google Scholar]
- Wong, H.-S.P.; Lee, H.; Yu, S.; Chen, Y.-S.; Wu, Y.; Chen, P.-S.; Lee, B.; Chen, F.T.; Tsai, M.J. Metal-oxide RRAM. Proc. IEEE 2012, 100, 1951–1970. [Google Scholar] [CrossRef]
- Jameson, J.R.; Blanchard, P.; Cheng, C.; Dinh, J.; Gallo, A.; Gopalakrishnan, V.; Gopalan, C.; Guichet, B.; Hsu, S.; Kamalanathan, D.; et al. Conductive-bridge memory (CBRAM) with excellent high-temperature retention. In Proceedings of the 2013 IEEE International Electron Devices Meeting, Washington, DC, USA, 9–11 December 2013; pp. 738–741. [Google Scholar]
- Yu, S.; Wong, H.-P. Compact Modeling of Conducting-Bridge Random-Access Memory (CBRAM). IEEE Trans. Electron. Devices 2011, 58, 1352–1360. [Google Scholar]
- Baek, I.G.; Lee, M.S.; Seo, S.; Lee, M.J.; Seo, D.H.; Suh, D.-S.; Park, J.C.; Park, S.O.; Kim, H.S.; Yoo, I.K.; et al. Highly scalable non-volatile resistive memory using simple binary oxide driven by asymmetric unipolar voltage pulses. In Proceedings of the IEEE International Electron Devices Meeting, San Francisco, CA, USA, 13–15 December 2004; pp. 587–590. [Google Scholar]
- Lee, H.Y.; Chen, P.S.; Wu, T.Y.; Chen, Y.S.; Wang, C.C.; Tzeng, P.J.; Lin, C.H.; Chen, F.; Lien, C.H.; Tsai, M.-J. Low power and high speed bipolar switching with a thin reactive Ti buffer layer in robust HfO2 based RRAM. In Proceedings of the 2008 IEEE International Electron Devices Meeting, San Francisco, CA, USA, 15–17 December 2008; pp. 297–300. [Google Scholar]
- Yoon, H.S.; Baek, I.-G.; Zhao, J.; Sim, H.; Park, M.Y.; Lee, H.; Oh, G.-H.; Shin, J.C.; Yeo, I.-S.; Chung, U.-I. Vertical cross-point resistance change memory for ultra-high density non-volatile memory applications. In Proceedings of the 2009 Symposium on VLSI Technology, Kyoto, Japan, 15–17 June 2009; pp. 26–27. [Google Scholar]
- Govoreanu, B.; Kar, G.; Chen, Y.-Y.; Paraschiv, V.; Kubicek, S.; Fantini, A.; Radu, I.; Goux, L.; Clima, S.; Degraeve, R.; et al. 10×10 nm2 Hf/HfOx crossbar resistive RAM with excellent performance, reliability and low-energy operation. In Proceedings of the 2011 International Electron Devices Meeting, Washington, DC, USA, 5–7 December 2011; pp. 729–732. [Google Scholar]
- Sills, S.; Yasuda, S.; Strand, J.; Calderoni, A.; Aratani, K.; Johnson, A.; Ramaswamy, N. A copper ReRAM cell for storage class memory applications. In Proceedings of the 2014 Symposium on VLSI Technology (VLSI-Technology), Honolulu, HI, USA, 9–12 June 2014; pp. 80–81. [Google Scholar]
- Hayakawa, Y.; Himeno, A.; Yasuhara, R.; Boullart, W.; Vecchio, E.; Vandeweyer, T.; Witters, T.; Crotti, D.; Jurczak, M.; Fujii, S.; et al. Highly reliable TaOx ReRAM with centralized filament for 28-nm embedded application. In Proceedings of the 2015 Symposium on VLSI Technology (VLSI Technology), Kyoto, Japan, 17–19 June 2015; pp. 14–15. [Google Scholar]
- Yu, S. Compute-in-Memory for AI: From Inference to Training. In Proceedings of the 2020 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 10–13 August 2020. [Google Scholar]
- Ensan, S.S.; Ghosh, S. ReLOPE: Resistive RAM-Based Linear First-Order Partial Differential Equation Solver. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 237–241. [Google Scholar] [CrossRef]
- Ames, W.F. Numerical Methods for Partial Differential Equations; Academic: New York, NY, USA, 2014. [Google Scholar]
- Eymard, R.; Gallouët, T.; Herbin, R. Handbook of Numerical Analysis; Ciarlet, G.P., Lions, L.J., Eds.; Elsevier: Amsterdam, The Netherlands, 2000; pp. 713–1018. [Google Scholar]
- Zidan, M.A.; Jeong, Y.; Lee, J.; Chen, B.; Huang, S.; Kushner, M.J.; Lu, W.D. A general memristor-based partial differential equation solver. Nat. Electron. 2018, 1, 411–420. [Google Scholar] [CrossRef]
- Kabir, H.; Booth, J.D.; Raghavan, P. A multilevel compressed sparse row format for efficient sparse computations on multicore processors. In Proceedings of the 2014 21st International Conference on High Performance Computing (HiPC), Goa, India, 17–20 December 2014; pp. 1–10. [Google Scholar]
- Li, S.; Chen, W.; Luo, Y.; Hu, J.; Gao, P.; Ye, J.; Kang, K.; Chen, H.; Li, E.; Yin, W.-Y. Fully Coupled Multiphysics Simulation of Crosstalk Effect in Bipolar Resistive Random Access Memory. IEEE Trans. Electron. Devices 2017, 64, 3647–3653. [Google Scholar] [CrossRef]
- Yu, S. Resistive Random Access Memory (RRAM): From Devices to Array Architectures; Iniewski, K., Ed.; Morgan & Claypool: Saanichton, BC, Canada, 2016. [Google Scholar]
- Chen, T.; Botimer, J.; Chou, T.; Zhang, Z. An Sram-Based Accelerator for Solving Partial Differential Equations. In Proceedings of the 2019 IEEE Custom Integrated Circuits Conference (CICC), Austin, TX, USA, 14–17 April 2019; pp. 1–4. [Google Scholar]
- Chen, T.; Botimer, J.; Chou, T.; Zhang, Z. A 1.87-mm2 56.9-GOPS Accelerator for Solving Partial Differential Equations. IEEE J. Solid-State Circuits 2020, 55, 1709–1718. [Google Scholar] [CrossRef]
- Feng, Y.; Zhan, X.; Chen, J. Flash Memory based Computing-In-Memory to Solve Time-dependent Partial Differential Equations. In Proceedings of the 2020 IEEE Silicon Nanoelectronics Workshop (SNW), Honolulu, HI, USA, 13–14 June 2020; pp. 27–28. [Google Scholar]
- Le Gallo, M.; Sebastian, A.; Mathis, R.; Manica, M.; Giefers, H.; Tuma, T.; Bekas, C.; Curioni, A.; Eleftheriou, E. Mixed-precision in-memory computing. Nat. Electron. 2018, 1, 246–253. [Google Scholar] [CrossRef]
- Jiang, H.; Huang, S.; Peng, X.; Yu, S. MINT: Mixed-Precision RRAM-Based IN-Memory Training Architecture. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ReRAM | MRAM | FeRAM | PCM | Flash Memory |
|---|---|---|---|---|
| OxRAM | STT-MRAM SOT-MRAM VCMA | FTJ | NAND Flash Nor Flash AG-AND Flash | |
| CBRAM |
| Type of CIM | Reference | Technology Node | Energy Efficiency | Accuracy | Latency |
|---|---|---|---|---|---|
| ReRAM | Sina Sayyah Ensan 2021 VLSI | 65 nm | 31.4× | 11-bit (97%) | 25 ns |
| Mohammed A. Zdan 2018 NE | NA | NA | 64-bit | 1 us | |
| SRAM | Thomas Chen 2020 JSSC | 180 nm | 0.875 TOPS/W | 32-bit | 90 ns |
| Ning Guo 2016 JSSC | 65 nm | 16× | 18-bit (95%) 8-bit (99.5%) | NA | |
| NOR Flash Memory | Yang Feng 2020 SNW | 65 nm | NA | 64-bit | NA |
| PCM | Manuel Le Gallo 2018 NE | 90 nm | 24× | mixed-precision | <100 ns |
| GPU | NVidia Titan RTX | 12 nm FFN | 0.06 TOPS/W | 64-bit | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Wang, Y.; Shao, J.; Chen, Y.; Guo, Z.; Pan, C.; Dong, G.; Zhou, M.; Wu, F.; Wang, W.; et al. Compute-in-Memory for Numerical Computations. Micromachines 2022, 13, 731. https://doi.org/10.3390/mi13050731
Zhao D, Wang Y, Shao J, Chen Y, Guo Z, Pan C, Dong G, Zhou M, Wu F, Wang W, et al. Compute-in-Memory for Numerical Computations. Micromachines. 2022; 13(5):731. https://doi.org/10.3390/mi13050731
Chicago/Turabian StyleZhao, Dongyan, Yubo Wang, Jin Shao, Yanning Chen, Zhiwang Guo, Cheng Pan, Guangzhi Dong, Min Zhou, Fengxia Wu, Wenhe Wang, and et al. 2022. "Compute-in-Memory for Numerical Computations" Micromachines 13, no. 5: 731. https://doi.org/10.3390/mi13050731
APA StyleZhao, D., Wang, Y., Shao, J., Chen, Y., Guo, Z., Pan, C., Dong, G., Zhou, M., Wu, F., Wang, W., Zhou, K., & Xue, X. (2022). Compute-in-Memory for Numerical Computations. Micromachines, 13(5), 731. https://doi.org/10.3390/mi13050731