1. Introduction
Mycotoxins are common contaminants present in several human food products and animal feed. They are produced during the secondary metabolism of different filamentous fungi (molds), being the most common mycotoxin-producing fungal species
Aspergillus,
Fusarium,
Penicillium,
Claviceps, and
Alternaria [
1]. These genera are responsible for the production of an important variety of mycotoxins, which also include the main mycotoxins reported, such as aflatoxins, trichothecenes, fumonisins, ochratoxins, patulin, and zearalenone [
2]. Some differences can be observed between strains: while
Fusarium species usually infect growing crops in the field,
Aspergillus and
Penicillium species frequently grow on foods and feeds during the storage stage [
3]. As a result, there is a wide range of foodstuffs susceptible to contamination by mycotoxins, including cereals, nuts, pasta, fruits, coffee, and by-products of animal origin [
4]. Thus, mycotoxins can enter the food chain directly from plant-based food components contaminated with mycotoxins or due to the consumption of animal-derived products from animals fed contaminated feedstuffs, due to the carry-over of mycotoxins to animal-derived products such as milk, meat, and eggs [
3]. Even when excellent agronomic, storage, and processing techniques are used, mycotoxin contamination of food and feed is still an unavoidable and unpredictable hazard, creating a challenging risk for food safety. Therefore, mycotoxin occurrence in foodstuffs is an actual problem; indeed, mycotoxins are the main hazard reported in European border rejection notifications by the Rapid Alert System for Food and Feed (RASFF) [
3].
Moreover, it is worth highlighting that the pattern of mycotoxin production by several fungi in different geographical distribution is being affected by climate change, generating increasing concern [
5]. For instance, the rises in temperature and rainfall in some geographical regions may result in more favorable environmental conditions for
Fusarium, as in Europe. On the other hand, longer and more frequent droughts may encourage
Aspergillus flavus to produce aflatoxins under both pre-harvest and post-harvest settings. In addition, recent investigations have demonstrated that the growth of mycotoxin-producing fungi can be stimulated even by a slight elevation in CO
2 levels [
6,
7]. Thus, the changing climatic conditions we are facing nowadays could change mycotoxin production and distribution worldwide.
Consumption of mycotoxin-contaminated food or feed can induce acute or chronic toxicity in humans and animals, with chronic effects being the most prevalent, due to prolonged exposure to lower concentrations. As a result, regulations concerning mycotoxins have been implemented in many countries to safeguard consumers from the harmful effects of these compounds [
3,
8]. Nevertheless, as regulations are primarily based on known toxic effects, maximal allowed limits, or tolerable daily intakes (TDI) were determined only for a few mycotoxins, as there are many mycotoxins for which no experimental data exist [
9].
Therefore, additional risk assessment surveys on non-regulated mycotoxins are urgently required. However, the performance of traditional in vivo assays on thousands of different compounds would be extremely expensive and unethical. In this context, the application of alternative methods, such as in silico strategies could be extraordinarily useful. Indeed, several guidance documents have been drafted to improve standardization, harmonization, and uptake of in silico methods by regulatory authorities including the EFSA (European Food Safety Authority) and the ECHA (European Chemicals Agency) [
10,
11]. In this sense, the Commission Regulation No. 1907/2006 called REACH (Registration, Evaluation and Authorisation of Chemicals) (
http://ecb.jrc.it/reach/reachlegislation/) (accessed on 23 January 2023) foresees the use of in silico methods such as (Quantitative) Structure–Activity Relationship ([Q]SAR) models when the same level of information can be obtained by means other than in vivo testing [
10,
11,
12]. More concretely, information relating to the genotoxic potential of chemicals by using in silico prediction approaches has become an important source, as recommended by the REACH regulation as well as the ICH M7 guideline for the assessment and control of DNA reactive or mutagenic impurities [
12,
13,
14,
15].
Among the toxic effects that can be caused by mycotoxins, the induction of genetic alterations is an important matter of concern [
14,
16,
17,
18], as several mycotoxins and some of their metabolites have been described as genotoxic compounds, including aflatoxins, ochratoxins, citrinin, and HT-2 and T-2 toxins [
19]. However, scarce information has been reported regarding the capability of other mycotoxins to cause these adverse effects.
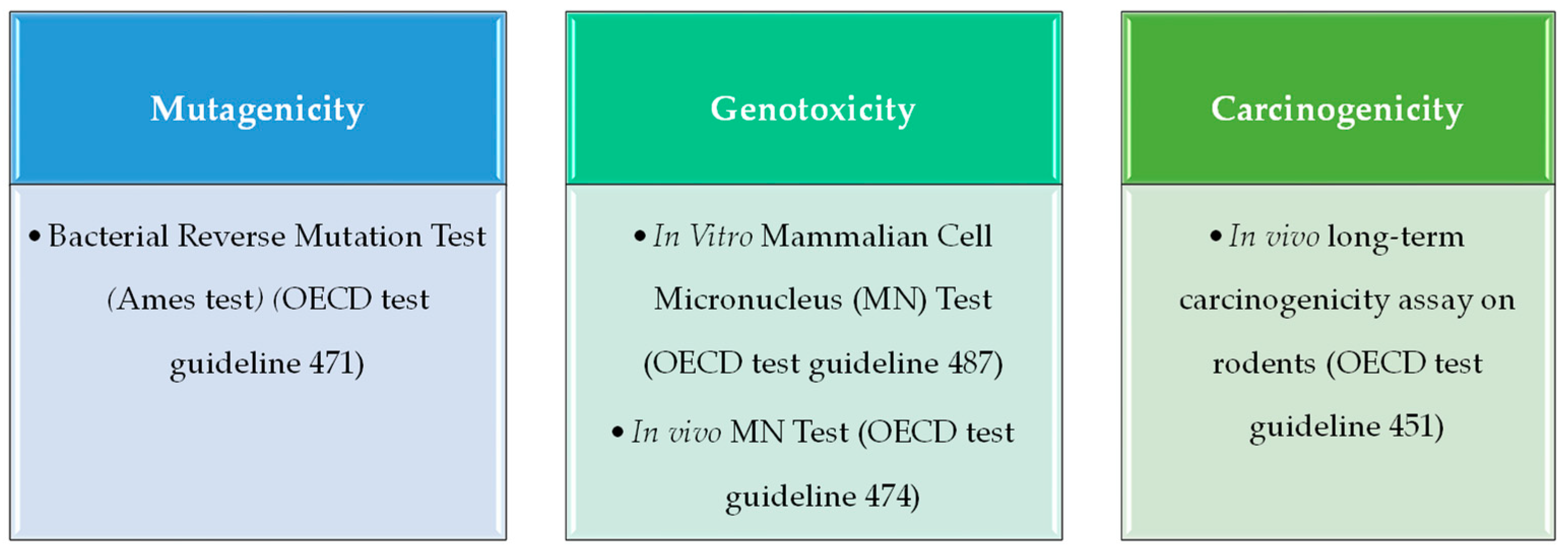
A genotoxic compound can induce mutations (mutagenicity) and/or cause the generation of tumors (carcinogenicity). To characterize these properties, an in silico toxicology (IST) protocol template [
20] as well as a protocol for genetic toxicology (the GIST protocol) [
14] have been designed and developed by an international consortium comprising several industry, academia, and government agencies. Therefore, in the present study, in vitro tests recommended for the mutagenicity and genotoxicity endpoints by the GIST have been taken into account to search experimental data for QSAR model building. To define the mutagenicity, the in vitro bacterial reverse mutation assay (commonly referred to as the Ames test) provides robust and high-quality data, which have been previously used to develop QSAR models with a good performance in predicting mutagenic activity. On the other hand, for genotoxicity assessment, data on in vitro micronucleus (MN) assay have been widely used, while carcinogenicity is evaluated by detecting tumor generation in in vivo models.
The aim of the present study was the development of specific QSAR models to predict genotoxicity, mutagenicity, and carcinogenicity of a wide range of mycotoxins. To this end, we build, for the first time, a comprehensive database including almost 4400 different mycotoxins, clustered in different categories according to their chemical structure. We then overlapped this list with different databases of genotoxicity, mutagenicity, and carcinogenicity to obtain experimental data based on the Ames test for mutagenicity, in vitro and in vivo MN assay for genotoxicity, and data from in vivo models for carcinogenicity. These data were then applied for the building and validation of scientifically valid and robust QSAR models that predicted the endpoints on a test set of mycotoxins with a high accuracy, sensitivity, and selectivity. Finally, the mycotoxins database together with the predicted toxicity values was integrated in a new, open access web server that can be explored interactively.
2. Results
2.1. Mycotoxin Database and Clustering
Our search resulted in a data set of 4360 mycotoxins identified by their name, isomeric SMILES (Simplified Molecular Input Line Entry System) and PubChem CID. In addition, we grouped the mycotoxins according to their chemical structure in 170 different families. To our knowledge, this is the first time that such a comprehensive database of mycotoxins has been published, as previous works only made reference to several hundred mycotoxins [
21,
22,
23,
24,
25]. To provide an easy access to the database, we have created a web application, MicotoXilico, that allows easy exploration of the data (
https://chemopredictionsuite.com/MicotoXilico, accessed on 20 May 2023).
In order to better visualize the structural diversity of the mycotoxins, a clustering based on k-nearest neighbor approach from structural fingerprints was performed (
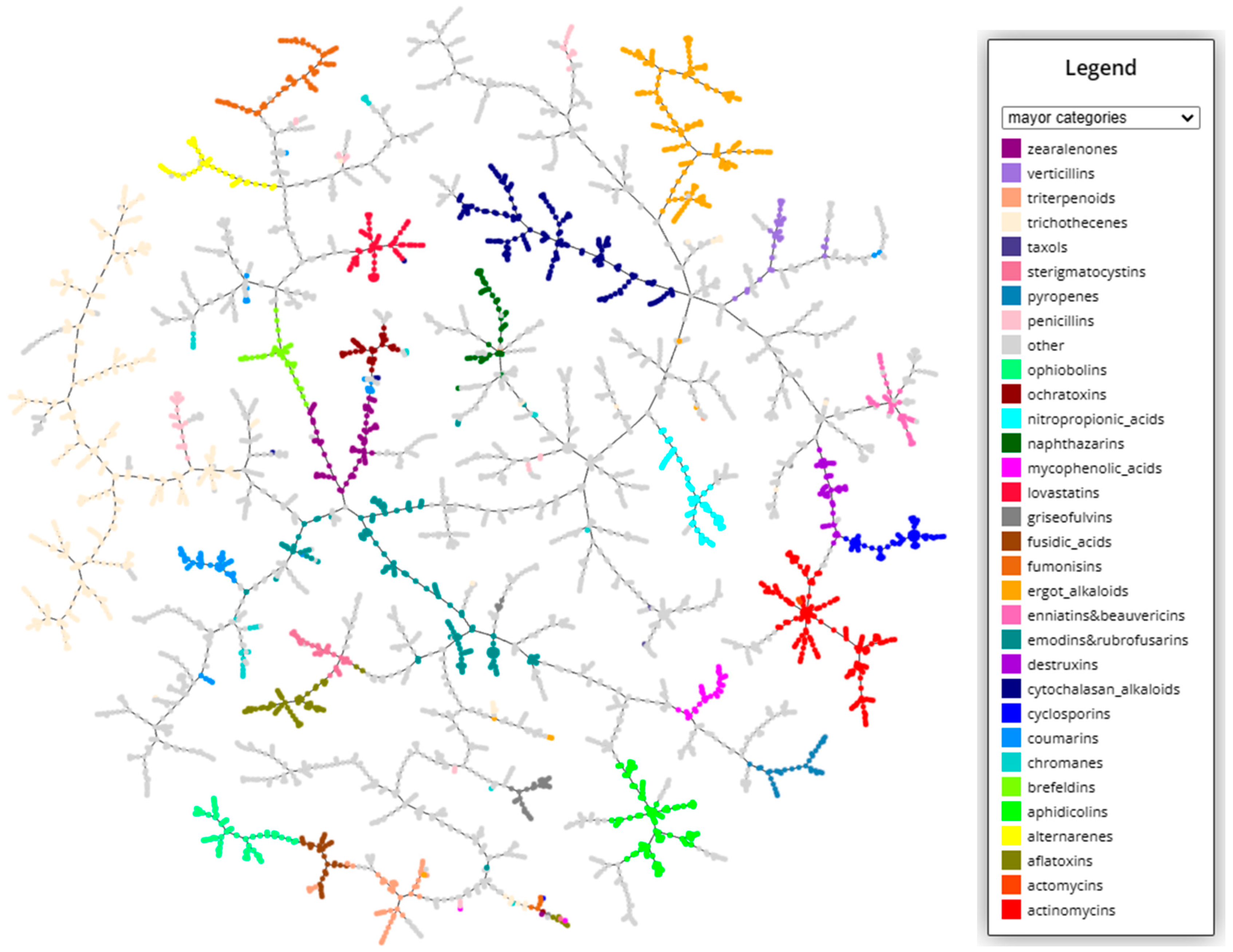
https://tmap.gdb.tools/ accessed on 20 May 2023). The resulting graphs can be explored interactively at the MicotoXilico web. In
Figure 1, a clustering plot indicating the major categories of mycotoxins is depicted. In the graph, the number of linkages between compounds is proportional to their chemical similarity, meaning that similar mycotoxins will be connected through short pathways.
As we see, myctoxins have a very high structural variability, representing almost the full range of natural products. They include alkaloids, terpenoids, peptids, fatty acids, lactones, nucleotids, phenols, and anthraquinones, among others. Until now, even if there were some known categories such as zerealones, ergot alkaloids, or trichothecenes, there exists no general systematic classification of mycotoxins. In our classification, we have maintained the groups based on specific structural motives, including between 5 and 50 different compounds. An overview of the categories and the number of compound in each category can be found in the
Appendix A (
Table A1). In some cases, when there was a very high similarity between structures, we have created unified groups, such enniatins and beauvericins, emodins and rubrofusarins, asperlins and asperlactones, fusarins and fusariens, or usnic acids and ustins. In other cases, the structural similarity was not big enough to unify categories, but it was still remarkable, for instance, between sphingofungins and fumonisins, alternariolides and enniatins, roquefortines and ergot alkaloids, or brefeldins and zearealones. These similarities can be appreciated in the graphical clustering visualization.
Some of the larger, more traditional categories have a higher structural variability because they include several subgroups of compounds. For instance, cytochalasan alcaloids can be subclassified into chaetoglobosins, daldinins, and chalasins. In particular, trichothecenes, the most abundant category, with more than 350 compounds, has a high number of subcategories, as can be explored in the web server (
https://chemopredictionsuite.com/MicotoXilico, accessed on 20 May 2023).
Some compounds could not be associated with a specific structural category, and they have therefore been classified into more general groups comprising alkaloids, terpenoids, amino acid derivatives, peptides, clyclic peptides, nucleotides, anthraquinones, benzoquinones, naphthalenes, phenols, phtalates, furans, lactones, thiazolidines, and fatty acid-like compounds. Furthermore, 79 compounds could not been associated with any category and were labelled as “not classified”.
2.2. QSAR Models Building
Once we had generated a comprehensive database of mycotoxins, we wanted to optimize several machine learning models to predict the genotoxicity, mutagenicity, and carcinogenicity of these compounds. The tests chosen for the characterization of each type of toxicity follow the recommended endpoint protocols of the OECD [
26]. For data searching, we overlapped our ensemble of mycotoxins with different databases of mutagenicity, genotoxicity, and carcinogenicity to obtain experimental data based on the Ames test for mutagenicity, in vitro and in vivo MN assay for genotoxicity, and data from in vivo models for carcinogenicity. As expected, experimental data could only be found for a relatively low number of compounds (350–100 compounds, depending on the endpoint).
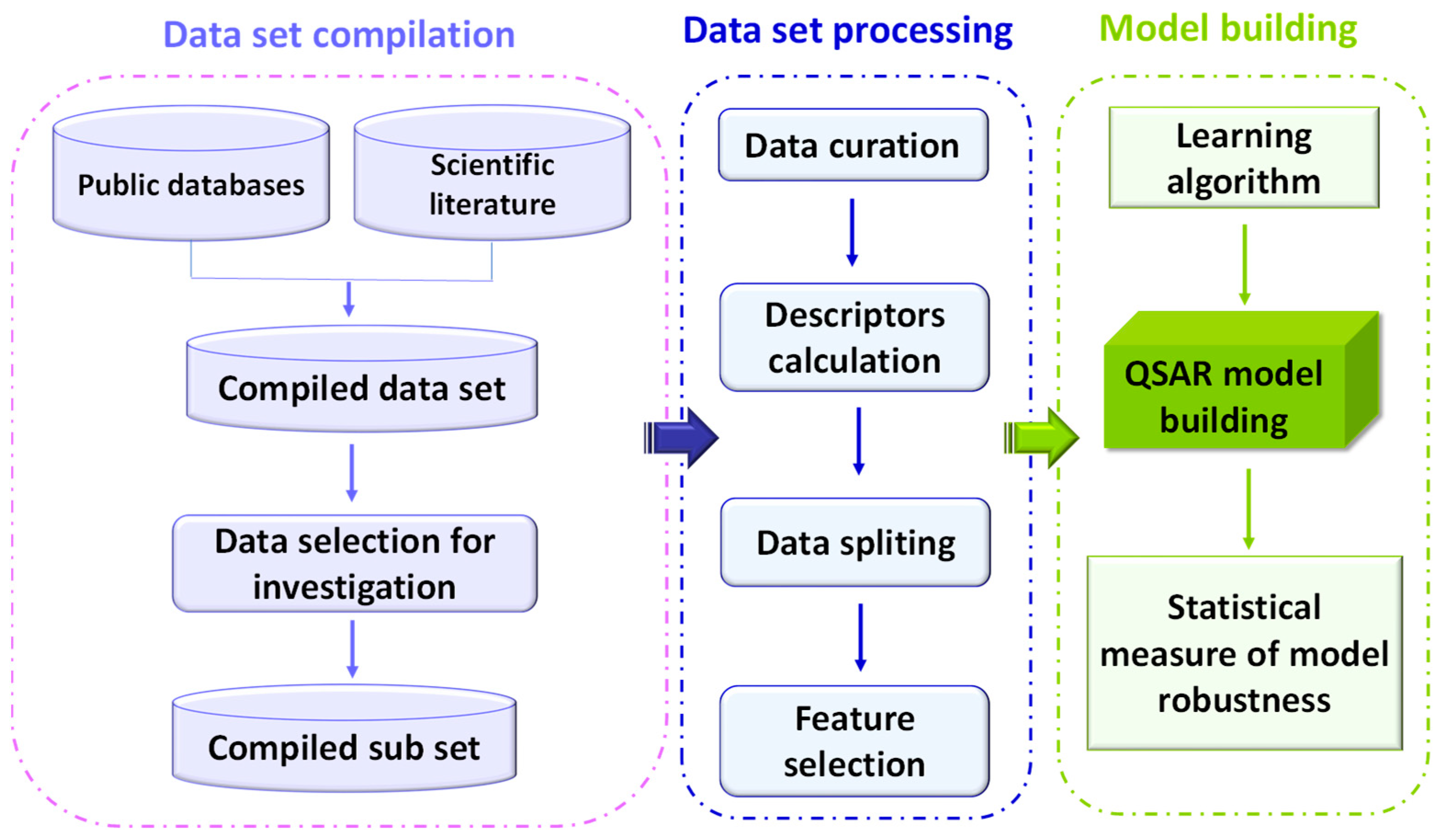
These data were then used for the building and validation of robust QSAR models to predict the four endpoints. For model building, we followed the protocols described in the materials and methods section that meet the requirement of the five principles of the OECD for QSAR model building in a regulatory context [
27].
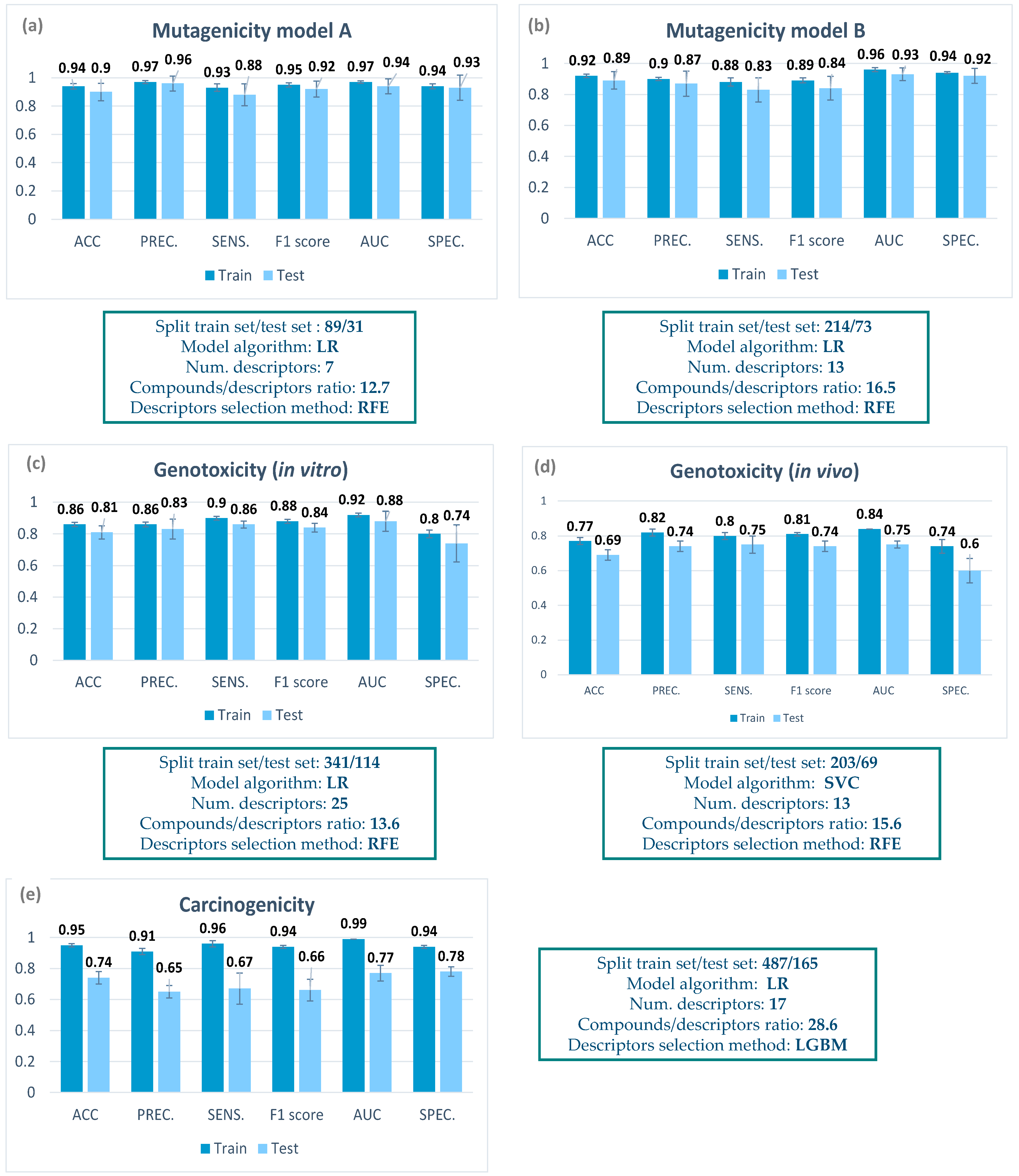
A summary of the characteristics of the final classification models can be found in
Figure 2, including the number of compounds in the training and test set, the descriptor selection method, the number of descriptors, the compound/descriptor ratio, and the model algorithm. In the
Appendix A, a list with the molecular descriptors selected for each model can be found (
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6). It is worth mentioning that the descriptors were selected from a panel of more than 4000, including 2D and 3D descriptors, in order to obtain the best chemical description of the complex mycotoxin structure.
For mutagenicity, models based only on mycotoxin data could be build, as data for up to 365 compounds could be retrieved, with a balanced proportion between mutagenic and non-mutagenic compounds. Two mutagenicity QSAR models (model A and model B) were generated applying two different data selection criteria (for details, see
Section 5.3). In both cases, all the parameters included in the metrics were higher than 0.8, thus showing a good performance. Both models were able to correctly predict the mutagenicity of almost 90% of compounds in the internal cross validation.
For genotoxicity, data retrieval was much more complicated, as very few data from non-genotoxic mycotoxins could be detected. Therefore, we decided to build mixed models including mycotoxins and other organic compounds (for details, see
Section 5.4). Regarding the in vitro genotoxicity QSAR model, information on the in vitro MN assay from 455 compounds was considered (
Figure 2). For a more comprehensive analysis of genotoxicity, we decided to also include an in vivo genotoxicity model. In this case, the ProtoPRED model (
https://protopred.protoqsar.com/, accessed on 20 May 2023) based on the in vivo MN assay was applied, built from a training set that included mycotoxins. Regarding the performance of these models, most parameters were higher than 0.8 (
Figure 3d). Only the specificity was moderate, as some non-genotoxic compounds were predicted as genotoxic in the internal validation. This result could relate to the fact that only a few data from non-genotoxic mycotoxins could be found.
For carcinogenicity, again we applied the in vivo carcinogenicity QSAR model from ProtoPRED (
https://protopred.protoqsar.com/, accessed on 20 May 2023), containing mycotoxins in the training set, as not enough carcinogenicity data were retrieved to build a specific model. The metrics obtained for the carcinogenicity QSAR model showed a good performance on the training set, with all parameters being higher than 0.9. Parameters on the test set showed lower values, especially for precision and sensitivity, but are still close to 0.7, the value recommended for QSAR models by ECHA [
28].
When we compare the metrics of the training and test sets in
Figure 2, we can see that there are almost no differences for the mutagenicity models, small differences in the in vitro genotoxicity model, and a higher difference in the carcinogenicity and the in vivo genotoxicity. This result is coherent with the fact that the mutagenicity models were built only with mycotoxins, while in the other models, only part of the training set were mycotoxins, meaning that we have more structural differences between the training and test set.
2.3. QSAR Model Application to an External Validation Set
After model building and internal validation, we decided to further confirm the performance of the models by performing an external validation with an independent set of mycotoxins with known experimental data. This allows us to evaluate if the model is truly predictive or if the model has been overfit to the data used for model building.
Since only the mutagenicity model A is considered valid from a regulatory point of view, we decided to subject only this model to external validation. The list containing the different mycotoxins used for the external validation for each model can be found in
Table A7,
Table A8,
Table A9 and
Table A10 of the
Appendix A.
Figure 3 shows the resulting confusion matrix for all model validations, proving that the experimental data were in general well predicted.
For mutagenicity (
Figure 3a), the confusion matrix showed that the model was capable of correctly classifying more than 0.8 of the compounds (0.83 accuracy). The in vitro genotoxicity QSAR model showed the highest accuracy (0.93) within all developed models. All genotoxic compounds were predicted as positive (1.00 of sensitivity), while only one compound out of 7 non-genotoxic mycotoxins was predicted as genotoxic (0.86 of specificity) (
Figure 3b), thus improving the specificity of the internal validation of the in vitro model. For the in vivo genotoxicity model, however, although obtaining good values for accuracy (0.81) and sensitivity (0.88), the specificity was again low (0.46), proving that this model was not accurate for the prediction of non-genotoxic compounds.
The carcinogenicity model was applied to a validation set of 75 mycotoxins, showing an accuracy of 0.81. The 89% of non-carcinogenic mycotoxins were predicted as inactive compounds, while 77% of carcinogenic mycotoxins were predicted as active compounds (
Figure 3d).
Thus, even if the models were built with a small data set of experimental data from mycotoxins, they seem to have a good predictive power on the external validation set of mycotoxins.
In order to see how well our models were adapted to mycotoxins, in comparison with other, more general toxicological QSAR models, we also performed a prediction with the validation data set applying three other reference QSAR tools: VEGA [
29], Leadscope, and Case Ultra (the last two being integrated into QSARToolbox) [
30]. We predicted the same four endpoints, obtained from the same or a very similar protocol. The metrics of these predictions can be found on
Table A11.
We can observe that, in general, our models provide a better prediction for the selected test mycotoxins. Only for mutagenicity do we obtain a better prediction with Case Ultra; however, six compounds could not be predicted by this model because they were outside the applicability domain. Also, for the other models, the prediction of several mycotoxins could not be performed because they were not in the applicability domain. We have also found that, in some cases, VEGA could not correctly read and normalize structures with aromatic rings, probably due to the aromaticity model that the software uses. These results show that our models are better adapted to complex structures with several aromatic rings, which are typical mycotoxin structures.
2.4. Mutagenicity, Genotoxicity, and Carcinogenicity Prediction of the General Mycotoxin Database
After model building, we wanted to perform a prediction of the genotoxicity, mutagenicity, and carcinogenicity of the whole mycotoxin database described in
Section 2.1. A general overview of the results is presented in
Figure 4, and detailed predictions can be explored in the MicotoXilico web application (
https://chemopredictionsuite.com/MicotoXilico, accessed on 20 May 2023).
From the figure, we can appreciate that a very high percentage of mycotoxins are predicted to be genotoxic, mutagenic, and/or carcinogenic. This result is not surprising, as the definition of mycotoxin already assumes that we are dealing with toxic compounds. In particular, genotoxicity seems to be a property of most mycotoxins, as 80–90% of these compounds are predicted as genotoxic. However, further studies are required to confirm these results, as the models were built with only a few data from non-genotoxic mycotoxins, and the genotoxicity models only have a moderate specificity.
We also used the Benigni and Bossa rules for mutagenicity [
31], implemented in ProtoICH software (
https://protopred.protoqsar.com/, accessed on 20 May 2023) to identify the presence of structural mutagenicity alerts in our database. The number of molecules detected as positive based on structural alerts were significantly less in comparison with the molecules detected as positive based on QSAR models (
https://chemopredictionsuite.com/MicotoXilico, accessed on 20 May 2023). On the contrary, when we performed the same comparison with a set of over 6000 general organic compounds, most of the compounds predicted as mutagenic had a mutagenicity alert (data not shown).
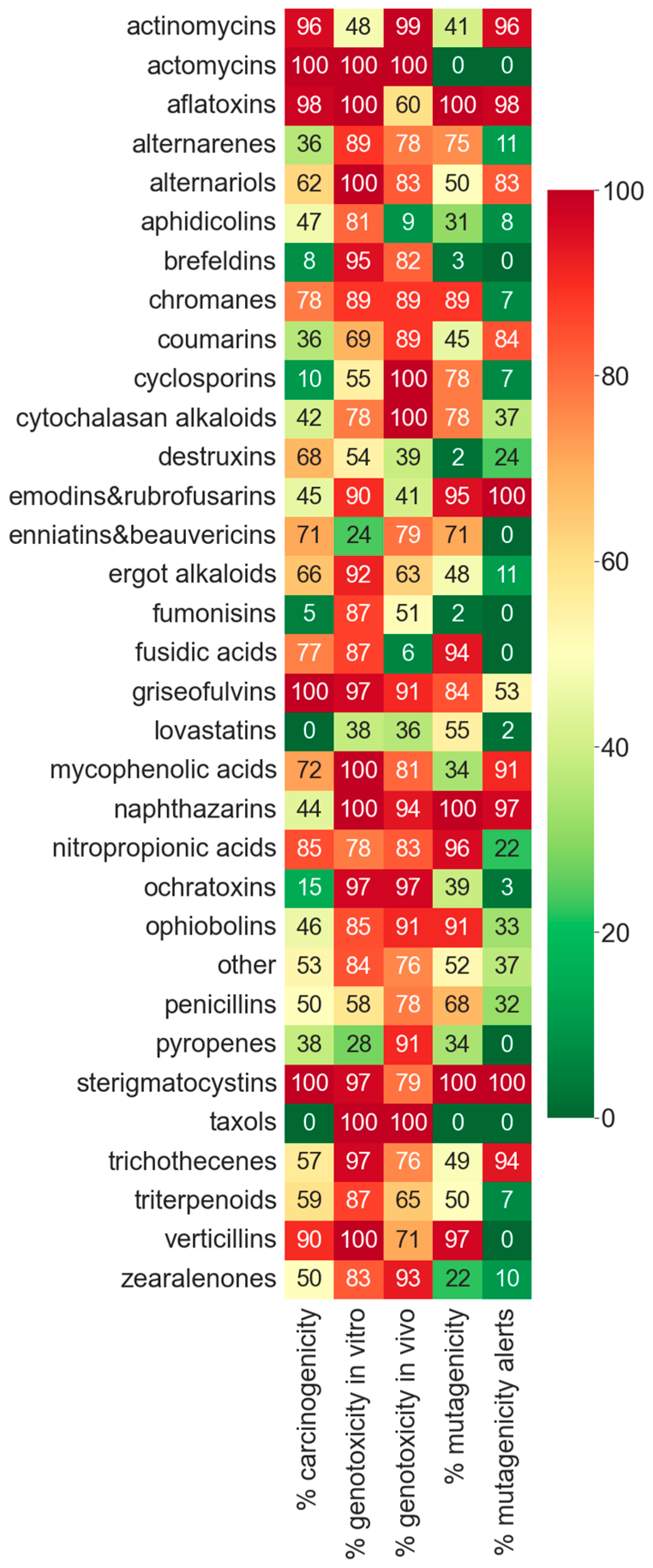
In order to compare the toxicity between mycotoxin categories, we represented the percentage of genotoxic, mutagenic, and carcinogenic compounds for the 30 major mycotoxin categories in a heatmap (
Figure 5).
As we can see, there are several categories that are specially concerning, as they have a very high toxicity prediction in mutagenicity, genotoxicity, and carcinogenicity (
Figure 5), such as aflatoxins, chromanes, fusidic acids, griseofulvins, nitropropionic acids, sterigmatocystins, and verticillins. Some categories have non-positive predictions in some of the toxicity endpoints (taxols and lovastatins), but there is no type of compound that is negative in all three toxicities.
In many categories, the mutagenicity alerts correspond to a very high mutagenicity prediction (<80%), such as in aflatoxins, emodins, napththazarins, and sterigmatocystins. However, it is worth highlighting that several categories without alerts showed a high predicted mutagenicity index, such as alternarenes, chromanes, enniatins and beauvericins, fusidic acids, nitropropionic acids, and verticillins.
3. Discussion
In this work, we explored the application of in silico QSAR models to obtain toxicity data of mycotoxin, which are urgently needed for public health regulations. In order to obtain a general overview of the type and number of mycotoxins that exist, we performed a comprehensive search, generating for the first time a database containing almost 4400 compounds. Our research revealed that the number and diversity of the identified mycotoxins is much higher than generally assumed: most publications only indicate the existence of several hundreds of mycotoxins, while we found more than 4000 known mycotoxins. It is worth mentioning the high structural diversity of these compounds, which generally have relatively high molecular weights and many structures including sugar, aromatic, or peptide rings.
The constructed database allowed us to perform a search of mutagenicity (Ames test), genotoxicity (in vivo and in vitro MN assay), and carcinogenicity (in vivo models) data by overlapping with different experimental databases. The search confirmed a low availability of experimental data, covering only a small percentage of the total existing mycotoxins. Nevertheless, we could obtain and validate robust QSAR models that predicted the four endpoints on an external validation set of mycotoxins with a relatively high accuracy, sensitivity, and specificity. These good results could be achieved by taking into account the specific characteristics of mycotoxins during the model building process, creating an appropriate applicability domain by the inclusion of mycotoxin and mycotoxin-like structure in the training set, and using a broad panel of 2D and 3D chemical descriptors. This was further confirmed by a comparison of the prediction of the mycotoxin’s validation set with three other, more general, QSAR reference tools (
Table A11), which provided a worse prediction and only included part of the molecules in their applicability domain. In the case of the genotoxicity, the specificity of the predictions was moderate to low, probably due the fact that only a few data from non-genotoxic mycotoxins were retrieved and incorporated in the models. Thus, further experiments are required to confirm the existence of non-genotoxic categories of mycotoxins. However, following the caution principle, a model with lower specificity (predicting false positives) is preferred over a model with lower sensitivity (predicting false negatives).
When applying the prediction models to the database constructed containing almost 4400 mycotoxins, we obtained a very high proportion of mutagenic, carcinogenic, and especially genotoxic compounds. This result is not unexpected, as mycotoxins are defined
per se as toxic compounds, and compounds of many categories proved to induce acute toxicity. However, differences between categories can be observed, mainly due to differences in the chemical structure. Concerning genotoxicity, all major categories included compounds with a positive genotoxicity prediction. Among them, some categories are well known to be genotoxic, such as aflatoxins, ochratoxins, or sterigmatocystins. Indeed, 97% of mycotoxins from the ochratoxin family have been predicted as genotoxic compounds. This result agrees with the scientific opinion published by the EFSA in 2020 [
32] indicating the genotoxicity of ochratoxin A and thus eliminating the previously established TDI and establishing instead an MOE (Margin Of Exposure), as no threshold can be allowed for genotoxic compounds. In the case of sterigmatocystin, a mycotoxin structurally related to aflatoxin B1, it has been demonstrated to induce tumors in diverse animal species, and thus, it is a known carcinogen mycotoxin [
33], which agrees with the prediction performed with our QSAR models.
However, some categories showing a high percentage of genotoxic potential, are not well studied. For instance, griseofulvins were predicted as genotoxic by both in vitro and in vivo QSAR models. In the literature, animal studies have shown evidence that they are able to cause a variety of acute and chronic toxic effects, including liver and thyroid cancer in rodents, abnormal germ cell maturation, teratogenicity, and embryotoxicity in various species [
34].
Regarding enniatins and beauvericins, commonly named as emerging
Fusarium mycotoxins, the EFSA concluded in 2014 that a risk assessment was not possible given the lack of relevant toxicity data [
35]. On one hand, in vitro genotoxicity data available suggested a potential genotoxic effect for beauvericin, while in vitro genotoxicity data for enniatins were negative. These results agree with those predicted by the in vitro QSAR model developed in our study (
Figure 6). On the other hand, there are no in vivo genotoxicity data for either beauvericin or enniatins and no studies on carcinogenicity of beauvericin and enniatins have been identified, and thus, the use of in silico predictions for these endpoints can provide valuable information. Thus, according to predictions on enniatins and beauvericin, 79% and 71% of compounds from this category were predicted as genotoxic (in vivo model) and carcinogenic, respectively. In addition, 71% of enniatins and beauvericin were also predicted as mutagenic, thus suggesting a careful assessment of the emerging
Fusarium mycotoxins toxicity.
Compounds from several categories have been classified as carcinogenic by the IARC [
36], such as aflatoxins, trichothecenes, or fumonisins. Other classes, such as actinomycins, cyclosporings, and lovastatins, have still not been classified, but they are labelled as potentially carcinogenic by the ECHA. Furthermore, in several categories, carcinogenicity predictions proved to have an impact on the DNA of cells. For instance, aphidicolin is an inhibitor of eucaryotic nuclear DNA. Brevianamide produced a slightly teratogenic effect in chick embryos [
37]. Emodin is suspected to create DNA strand breaks and/or non-covalently binding to DNA and inhibiting the catalytic activity of topoisomerase II (Toxin and Toxin Target Database (T3DB)); nevertheless, a genotoxic effect could be confirmed [
38]. Mycophenolic acid inhibits the de novo pathway of guanosine nucleotide synthesis without incorporation into DNA (Toxin and Toxin Target Database (T3DB)).
Alternariols and alternarenes are
Alternaria mycotoxins that can be found in cereals around the world, but little relevance is still given to this fact. Currently, the toxicity of several altenariols is being investigated, including alternariol, alternariol monomethyl ether, altertoxins, altenuene, tenuazonic acid, and tentoxin. Among them, tenuazonic acid, alternariol, alternariol monomethyl ether, altenuene, and altertoxin I are the most important mycotoxins that can be found as contaminants in fruits and vegetables [
39]. In 2011, the EFSA carried out a risk assessment on
Alternaria toxins, as they were reported to induce genotoxicity, cytotoxicity, and reproductive and developmental toxicity, among other adverse effects [
40]. Regarding their genotoxic effects, it was reported that alternariol, alternariol monomethyl ether, and altertoxins could induce gene locus mutation, DNA damage or synthesis disorder, chromosome aberration, and other effects in in vitro studies. In fact, according to the in vitro genotoxicity model developed, 100% of mycotoxins from the alternariols category was predicted as genotoxic compounds. In addition, alternariols have been related to the high incidence of esophageal cancer in Linxian, China [
39], which can be related to our findings, as 62% of compounds belonging to this family were predicted as carcinogenic mycotoxins. Thus, special attention should be paid to this mycotoxin category. In this sense, maximum levels have been recently recommended by the EU in the Commission Recommendation 2022/553 [
41] for alternariol, alternariol monomethyl ether, and tenuazonic acid.
A high percentage of trichothecenes have been predicted as genotoxic by the in vitro model (97%) and the in vivo model (76%). The main trichothecene reported to occur in food commodities is deoxynivalenol. Although deoxynivalenol is not genotoxic by itself, it has recently been shown that this toxin exacerbates the genotoxicity induced by model or bacterial genotoxins. In addition, other trichothecenes, namely, T-2 toxin, diacetoxyscirpenol, nivalenol, fusarenon-X, and the newly discovered NX toxin, were also reported as compounds able to exacerbate the DNA damage inflicted by various genotoxins [
42]. In addition, in the study reported by Yang et al. [
43], deoxynivalenol was able to cause damage to the membrane, the chromosomes, and the DNA at all times of culture in human peripheral blood lymphocytes, thus concluding that deoxynivalenol potentially triggers genotoxicity in human lymphocytes. In other study performed on Sprague Dawley rats, deoxynivalenol increased the percentage of chromosomal aberration, DNA fragmentation, and comet score [
44].
Citrinin, a mycotoxin classified in the chromanes category, has been reported to be genotoxic at high concentrations in cultured human lymphocytes, as it caused a significant concentration-dependent increase in MN frequency in human lymphocytes [
45], a result according to our genotoxicity predictions for the chromanes category, where almost 90% of compounds were predicted as genotoxic by both the in vitro and the in vivo models.
The same occurs with zearalenones, which have been predicted as genotoxic by both genotoxicity models, according to some data reported showing that zearalenone and some of its metabolites increased the percentage of chromosome aberrations in mouse bone-marrow cells and in HeLa cells [
46] and can increase the frequencies of polychromatic erythrocytes micronucleated and chromosomal aberrations in bone marrow cells from Balb/c female mice [
47].
Regarding fumonisins, 87% of mycotoxins belonging to this family were predicted as genotoxic by the in vitro model. The most predominant, fumonisins, fumonisin B1, fumonisin B2, and fumonisin B3, are carcinogenic and genotoxic secondary metabolites found in corn-based foods worldwide and are produced by
Fusarium verticillioides and
F. proliferatum [
48]. Fumonisin B1 is defined by IARC as a possible human carcinogen in Group 2B, and it shows genotoxic activity via oxidative stress, DNA damage, cell cycle arrest, apoptosis, inhibition of mitochondrial respiration, and deregulation of calcium homeostasis [
49]. Some studies revealed that exposure to fumonisin B1 caused a significant increase in micronucleus frequency in a concentration- and time-dependent manner in rabbit kidney cells [
50], and in HepG2 cells, fumonisin B1 has shown clastogenic effects [
51].
Studies on the genotoxic activity of ergot alkaloids, also predicted as genotoxic by our models, are very limited. In the scientific report delivered by EFSA in 2012 [
52], it was stated that genotoxicity studies on ergot alkaloids were insufficient, and more concretely, some studies evaluating the genotoxic and mutagenic effects of ergotamine revealed different results. In the literature, it has been reported that ergotamine is able to induce chromosomal abnormalities in human lymphocytes and leukocytes [
53] but does not show mutagenic effects in mouse lymphoma cells [
54]. Other authors have demonstrated that ergotamine and ergometry can induce sister chromatid exchange in ovarian cells [
55]. Due to the scarce and different data obtained, further studies are necessary to evaluate the genotoxic and mutagenic potential of ergot alkaloids.
Furthermore, our results reveal that several mycotoxin categories are predicted as mutagenic but have no mutagenicity alert following ICH-M7 criteria. This did not happen when we performed the same comparison with a general database of organic compounds, where almost all molecules predicted as mutagenic had an alert. For some of these categories, no mutagenicity has been detected previously (alternarenes, enniatins and beauvericins, fusidic acids, and verticillins), while for others, some experimental evidence exists already (chromanes, nitropropionic acids, among others) [
56,
57]. This suggests that the structure of the mycotoxins could have been underestimated in the expert analysis of the mutagenicity, and that ICH-M7 criteria do not take into account specific mutagenic structural motives present in mycotoxins. Regulatory agencies should take this into account and request a revised version of these criteria to obtain a better coverage of mycotoxins, which are a danger for public health, and thus prioritize mycotoxins based on their mutagenic, genotoxic, and carcinogenic potential, as already suggested in other studies [
58,
59,
60].

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






