Ensemble Machine Learning of Gradient Boosting (XGBoost, LightGBM, CatBoost) and Attention-Based CNN-LSTM for Harmful Algal Blooms Forecasting




Abstract
:
1. Introduction
2. Results and Discussion
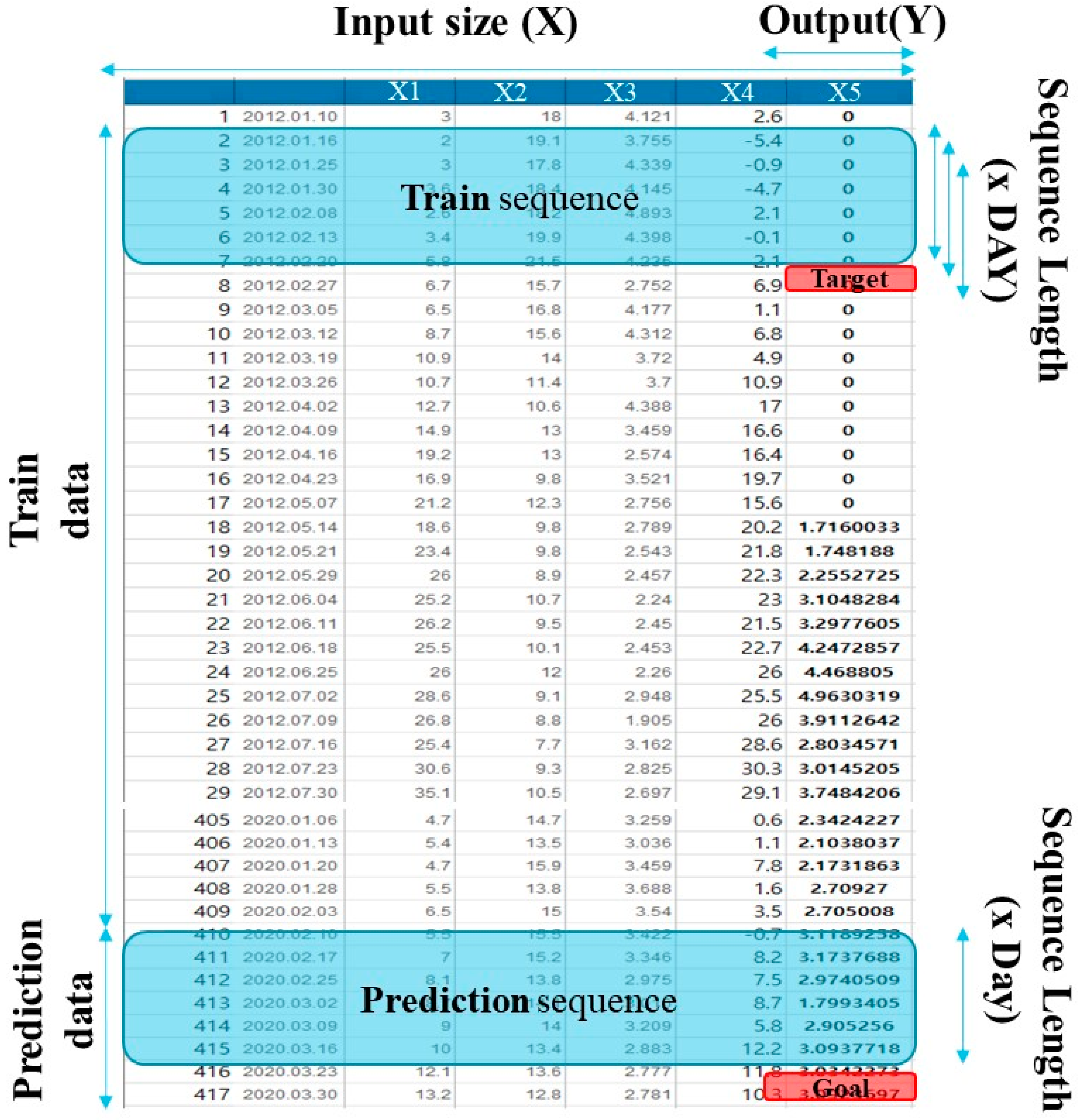
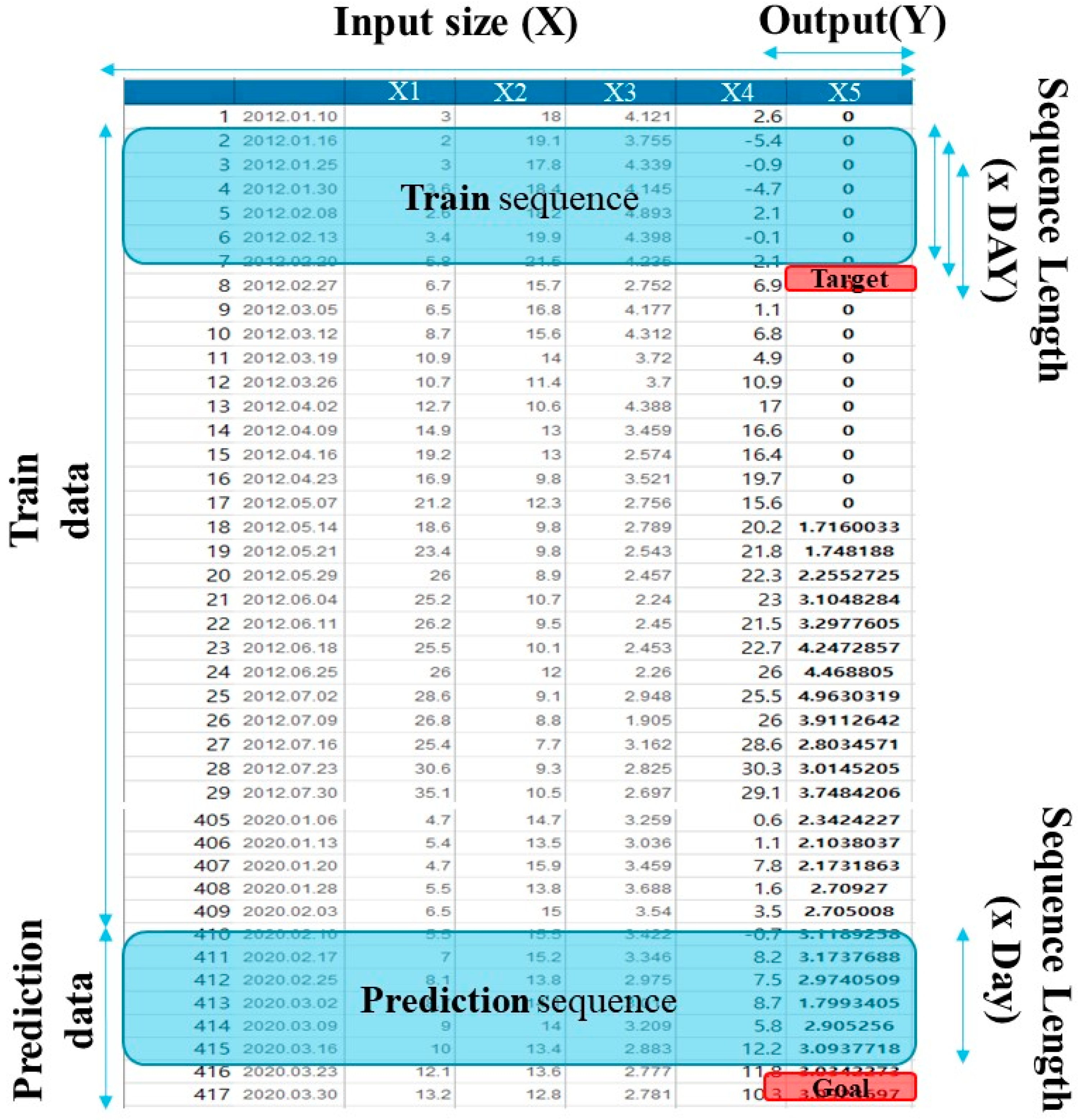
2.1. Data Selection and Preparation
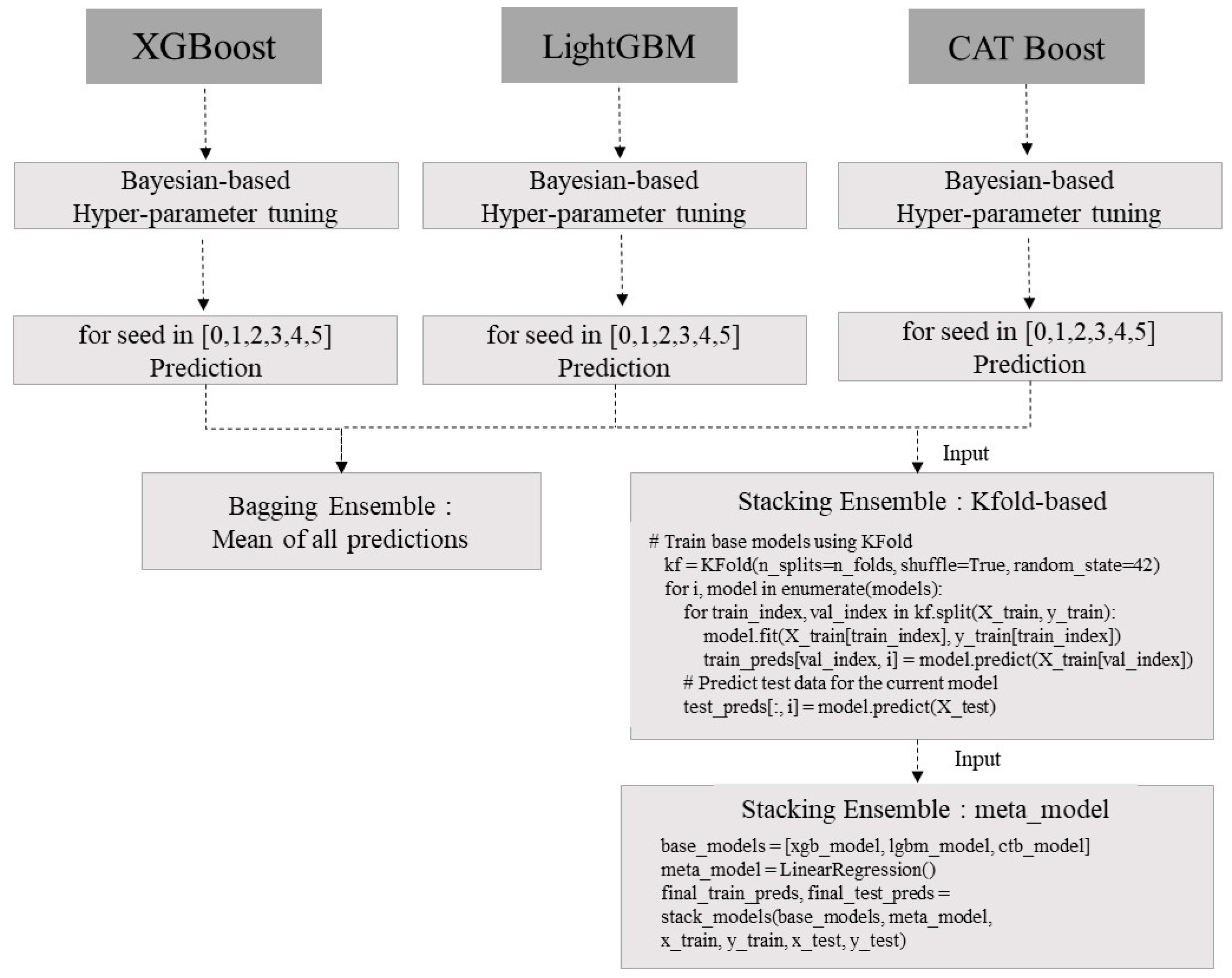
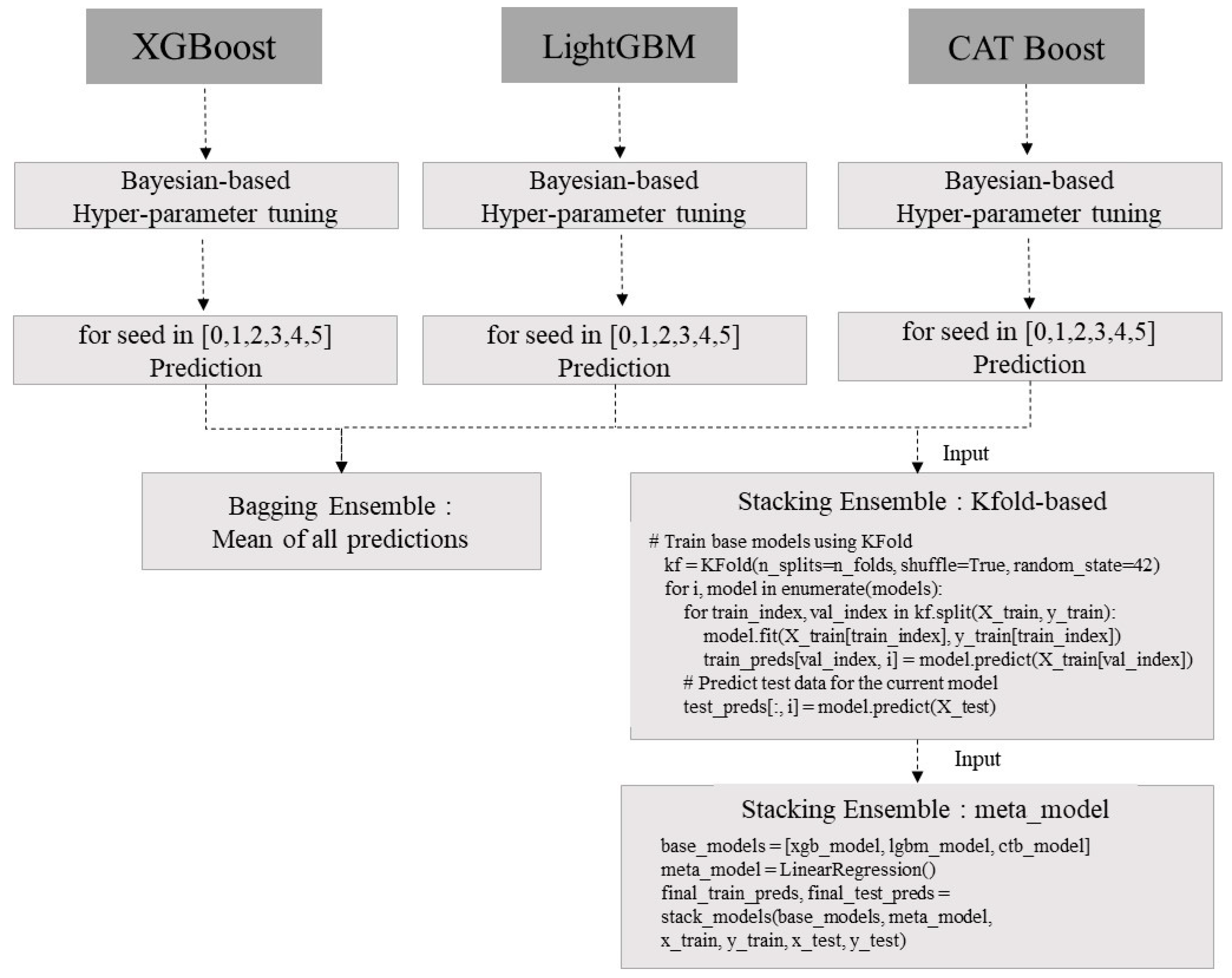
2.2. Ensemble Model Development and Prediction
- (1)
- Randomly sample hyperparameters and observe performance results.
- (2)
- Based on the observed values, the surrogate model estimates the optimal function and confidence interval (=result error deviation = means the uncertainty of the estimation function).
- (3)
- Based on the estimated optimal function, the acquisition function calculates the next hyperparameter to be observed and passes it to the surrogate model.
- (4)
- Optimization is performed in the order of updating the surrogate model again based on the observed values by performing the hyperparameters passed from the acquisition function.
- (1)
- Water quality and algae data are weekly data, so daily data such as temperature are converted to weekly data to ensure that all the data have the same resolution. Here, data preprocessing techniques such as normalization were used to enhance the predictive power of the model. The same preprocessing techniques were applied to XGBoost, LightGBM, and CatBoost.
- (2)
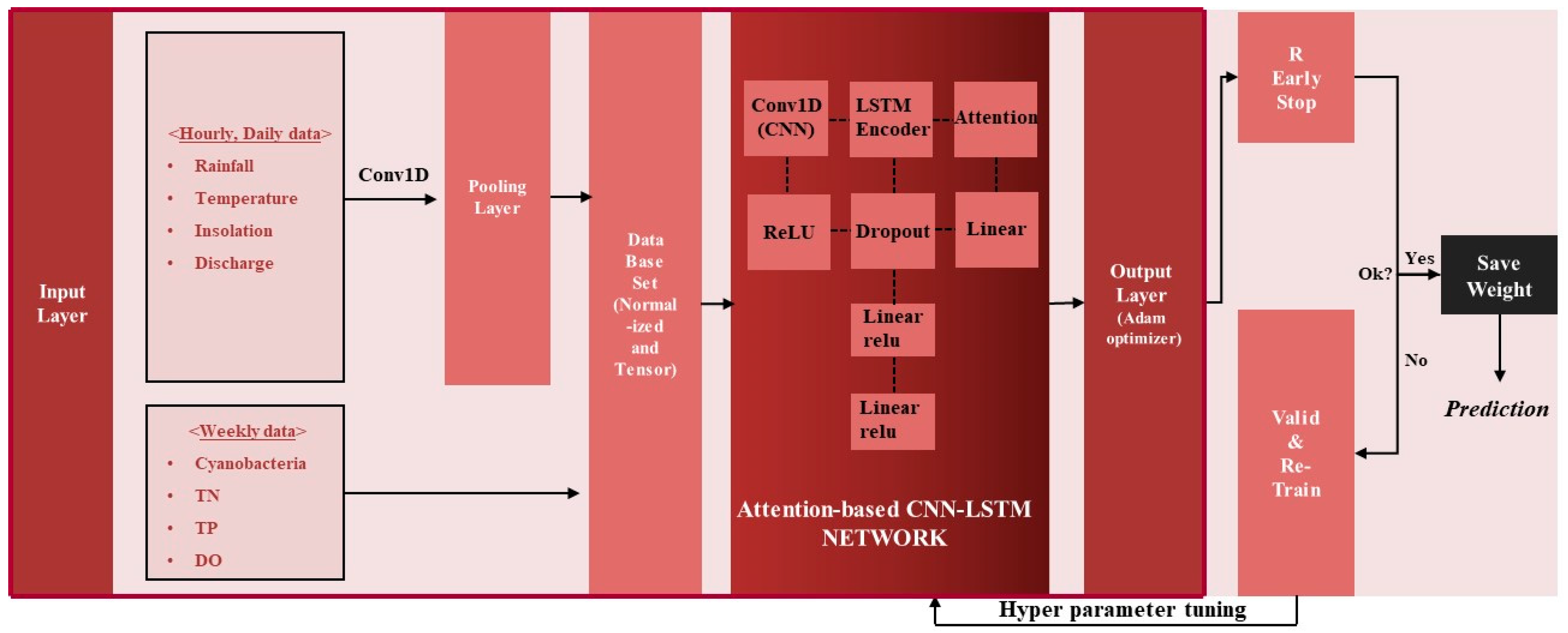
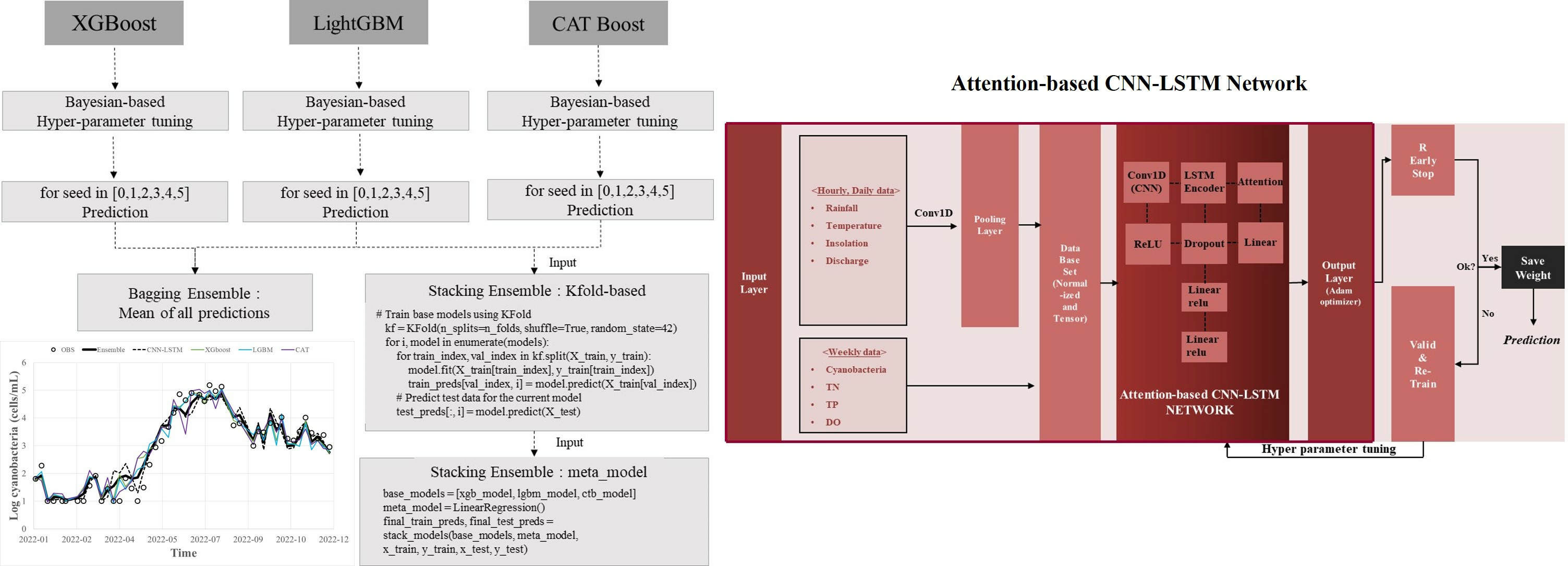
- As shown in Figure 4, when the preprocessed data are first input into a 1D CNN of (2, 1) kernel size, the dimension of the sequence is reduced according to the kernel size, and the sequence of the reduced dimension is learned as an input value to LSTM for prediction. The constructed sequence input data at the present (t) are passed through the CNN layer and then input into the Bahdanau attention-based LSTM layer. The number of cyanobacteria cells one week from the present (t + 1) is set as the target for learning.
- (3)
- The hyperparameters of the attention-based CNN-LSTM deep learning model, such as hidden size, num layers, dropout rate, and learning rate, were tuned using the data from 2014 to 2021, and the tuned result was applied to learn the bird prediction model using the data from 2022.
- (4)
- The process of step (3) was repeated until the verification result was good, and the hyperparameters and weights when the verification result was good were saved. Here, the algae prediction model with stored weights was used to predict future blue-green algae. The model was trained and verified using the same method as described above.
3. Conclusions
- (1)
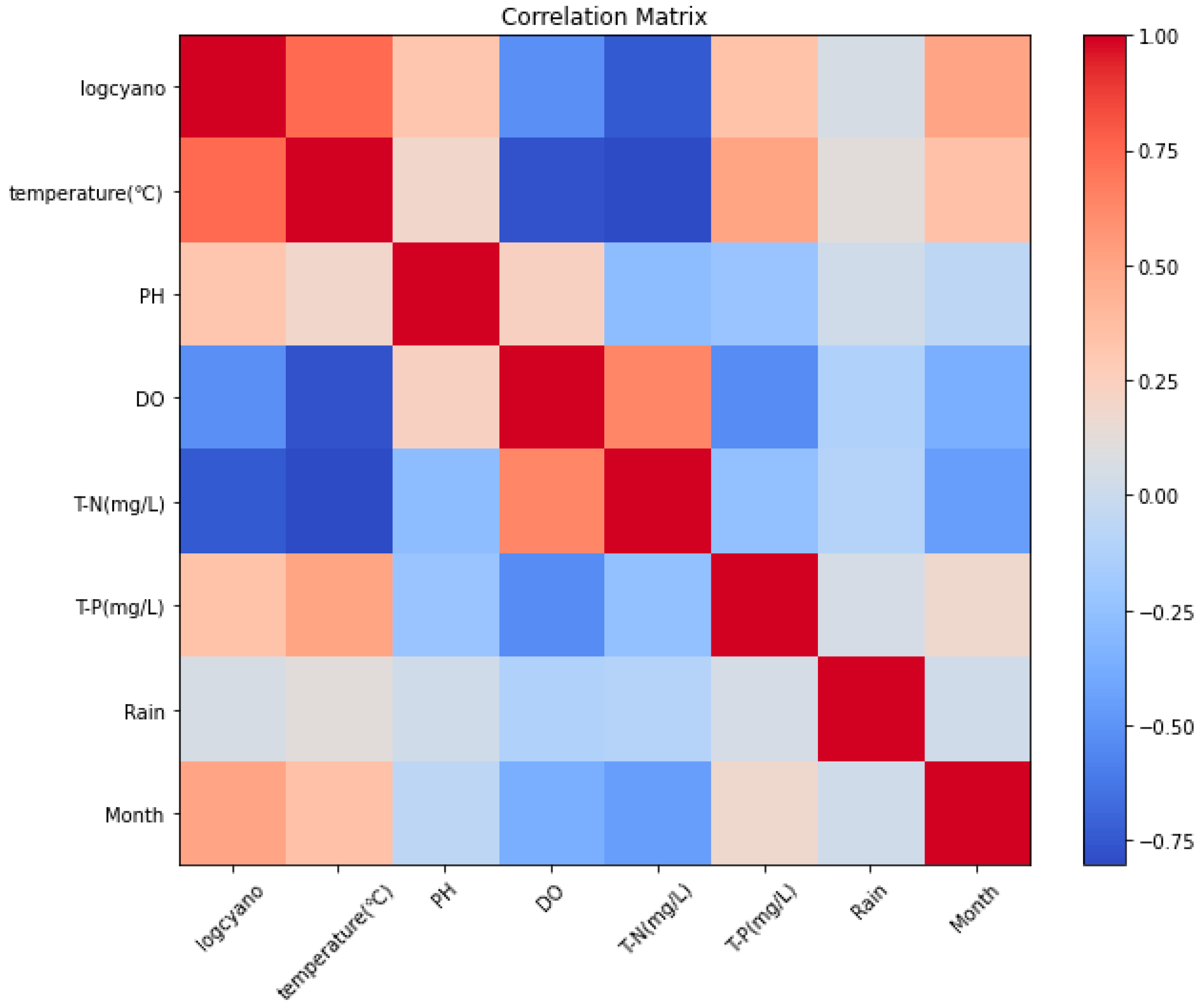
- Water temperature was found to have the greatest correlation with HABs, and positive correlations were shown in month, pH, and T-P, according to the correlation analysis between the learning data. Since the deviation of the data values for HABs was large, log values were substituted, and data preprocessing was applied with MinMaxScaler normalization.
- (2)
- XGBoost, LightGBM, CatBoost models, and attention-based CNN-LSTM models were developed, and optimal hyperparameter results were presented by tuning hyperparameters with Bayesian optimization techniques using observation data from 2014 to 2021.
- (3)
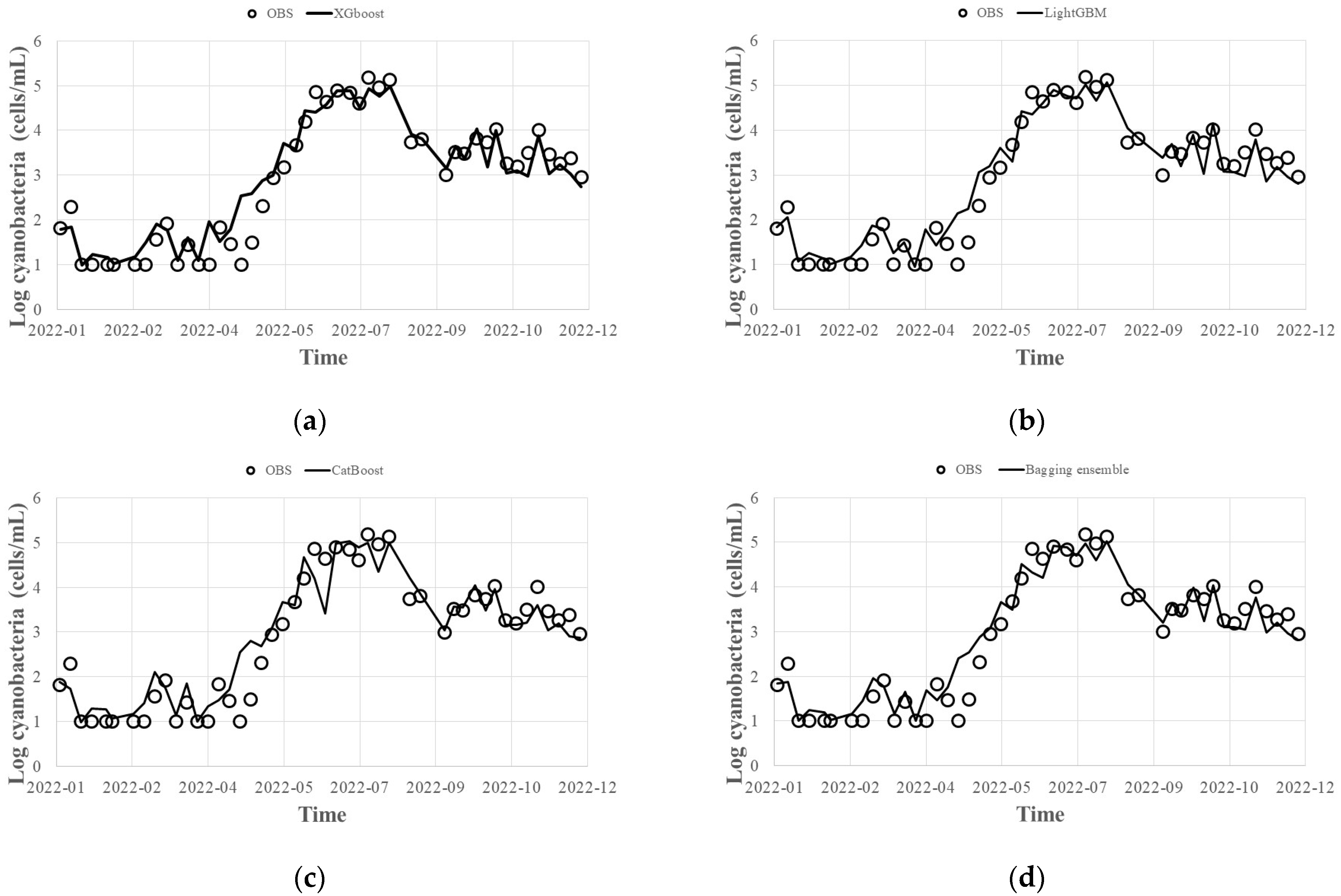
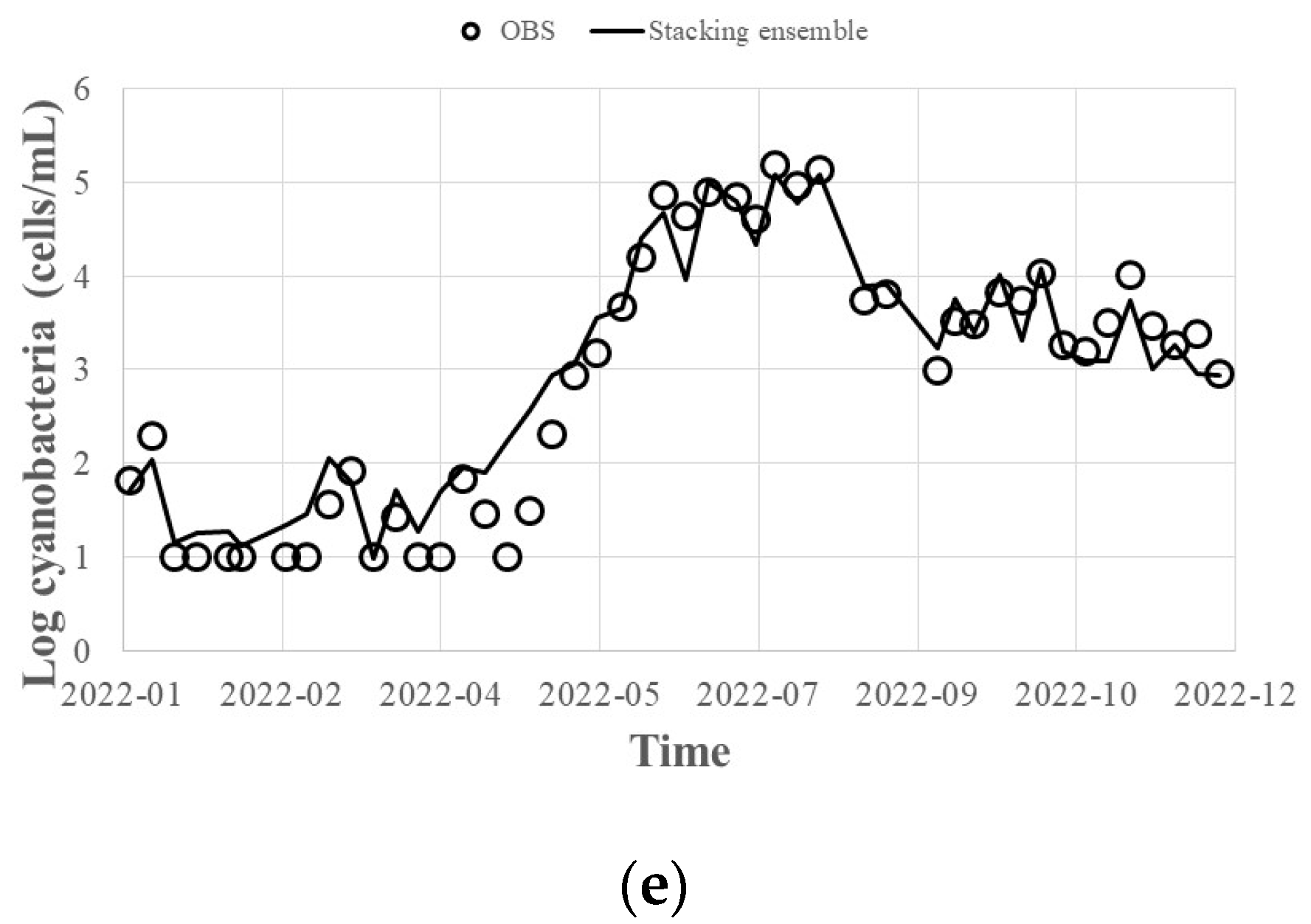
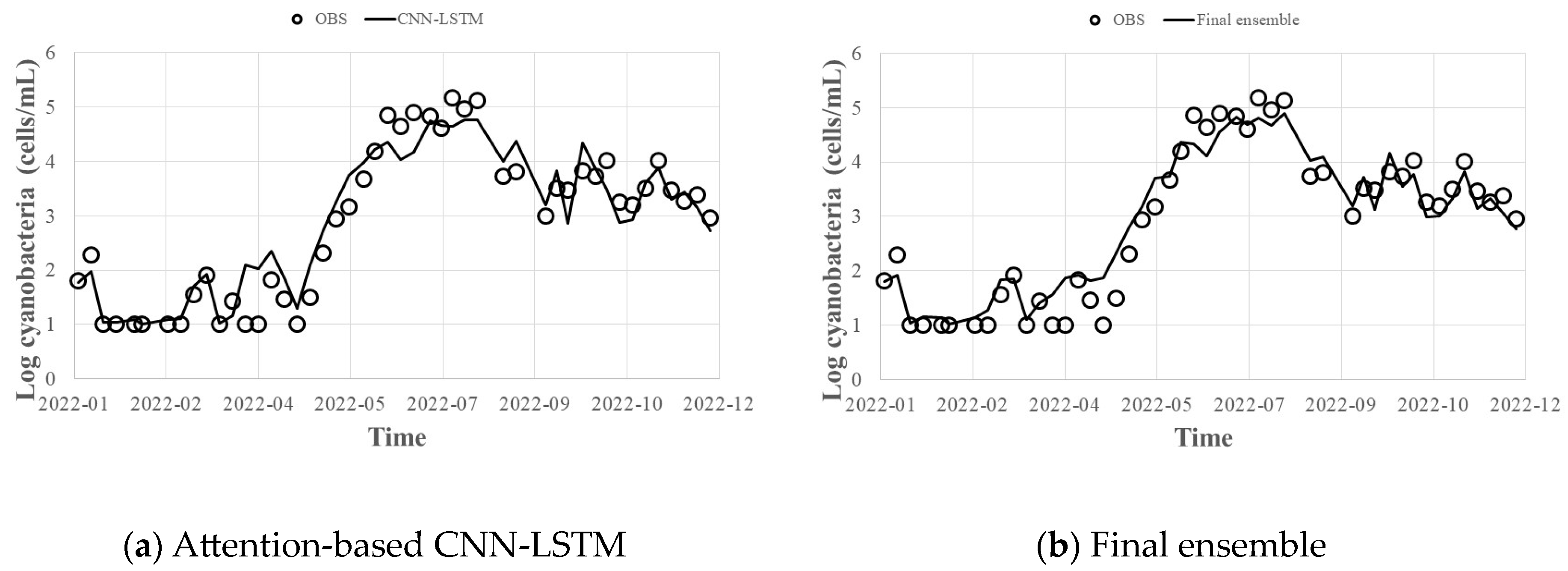
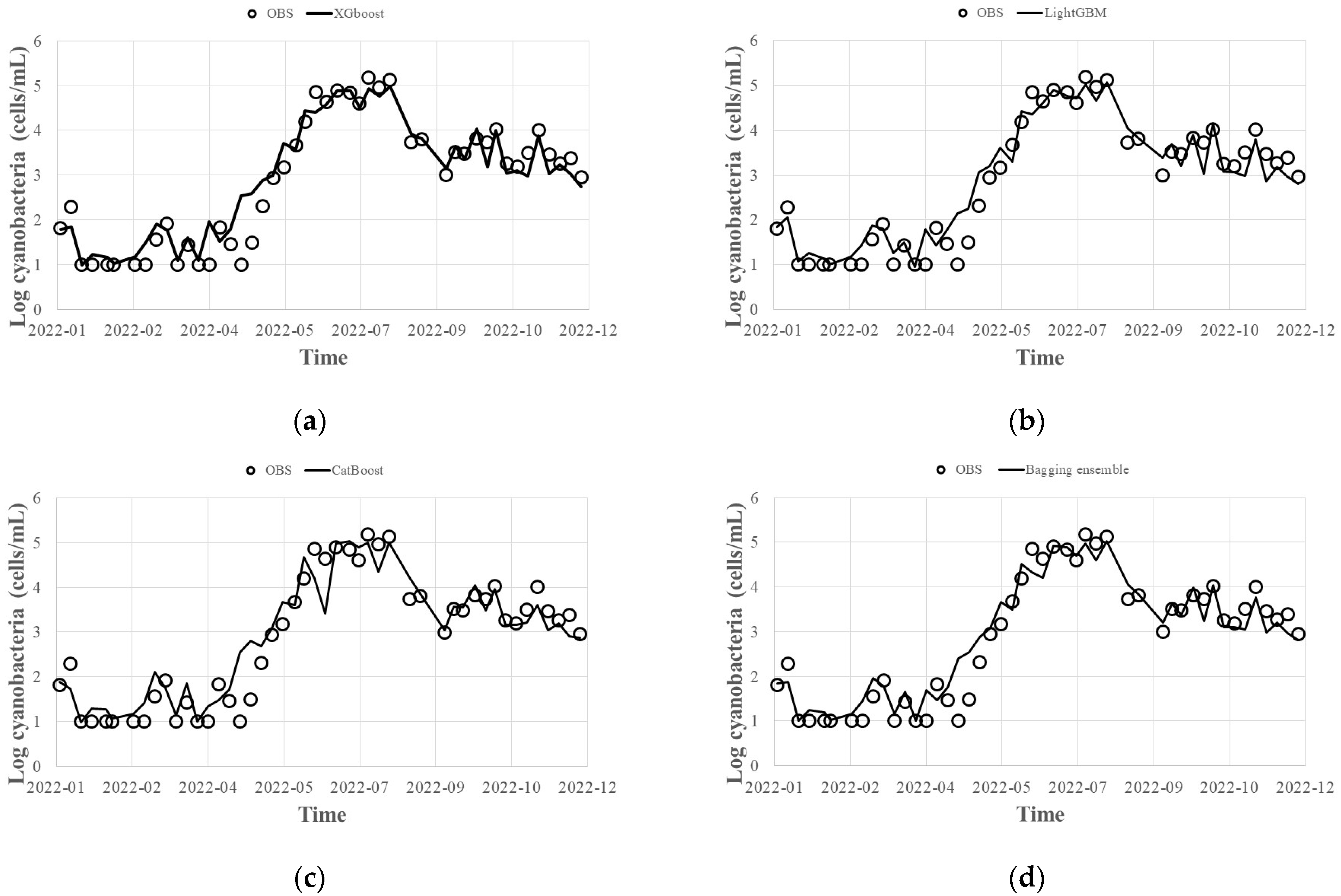
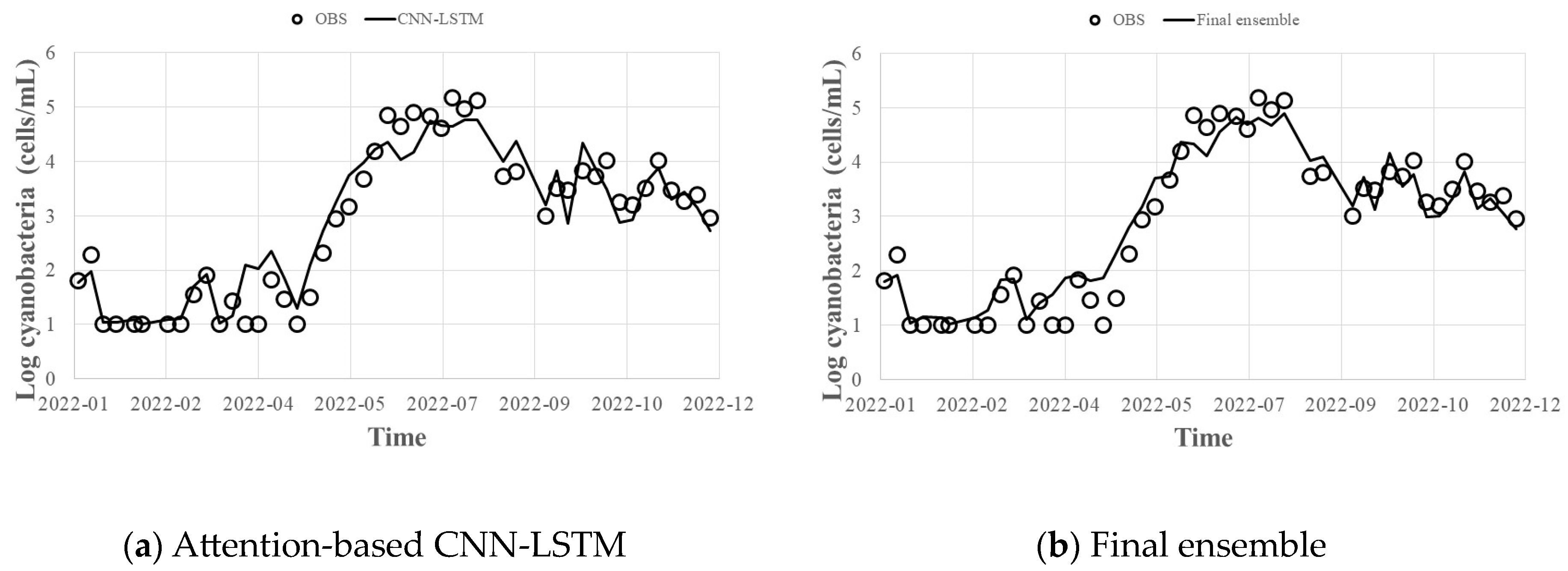
- By applying the hyperparameters derived from the Bayesian optimization technique to predict HABs in 2022, the error of the bagged ensemble prediction result of the Gradient Boosting (XGBoost, LightGBM, CatBoost) model was 0.92 for R2, 0.2 for MAE, and 0.4 for RMSE, and the error of the stacking ensemble prediction result was 0.93 for R2, 0.1 for MAE, and 0.3 for RMSE. Even when predicting with individual methods, the worst results were 0.89 for R2, 0.2 for MAE, and 0.5 for RMSE. Therefore, it is judged that the overall prediction performance can be improved by offsetting errors such as those.
- (4)
- Not much data have been accumulated for HABs observation even though it has been performed on a weekly basis since 2014. Therefore, it was initially expected that the accuracy of prediction would be low if data-based forecasting techniques were used. However, this study shows that a fairly high prediction accuracy can be achieved by applying the ensemble technique. If future data are accumulated and advanced algorithms are developed, the basis for predicting HABs in advance and utilizing them for policy purposes will be laid.
4. Materials and Methods
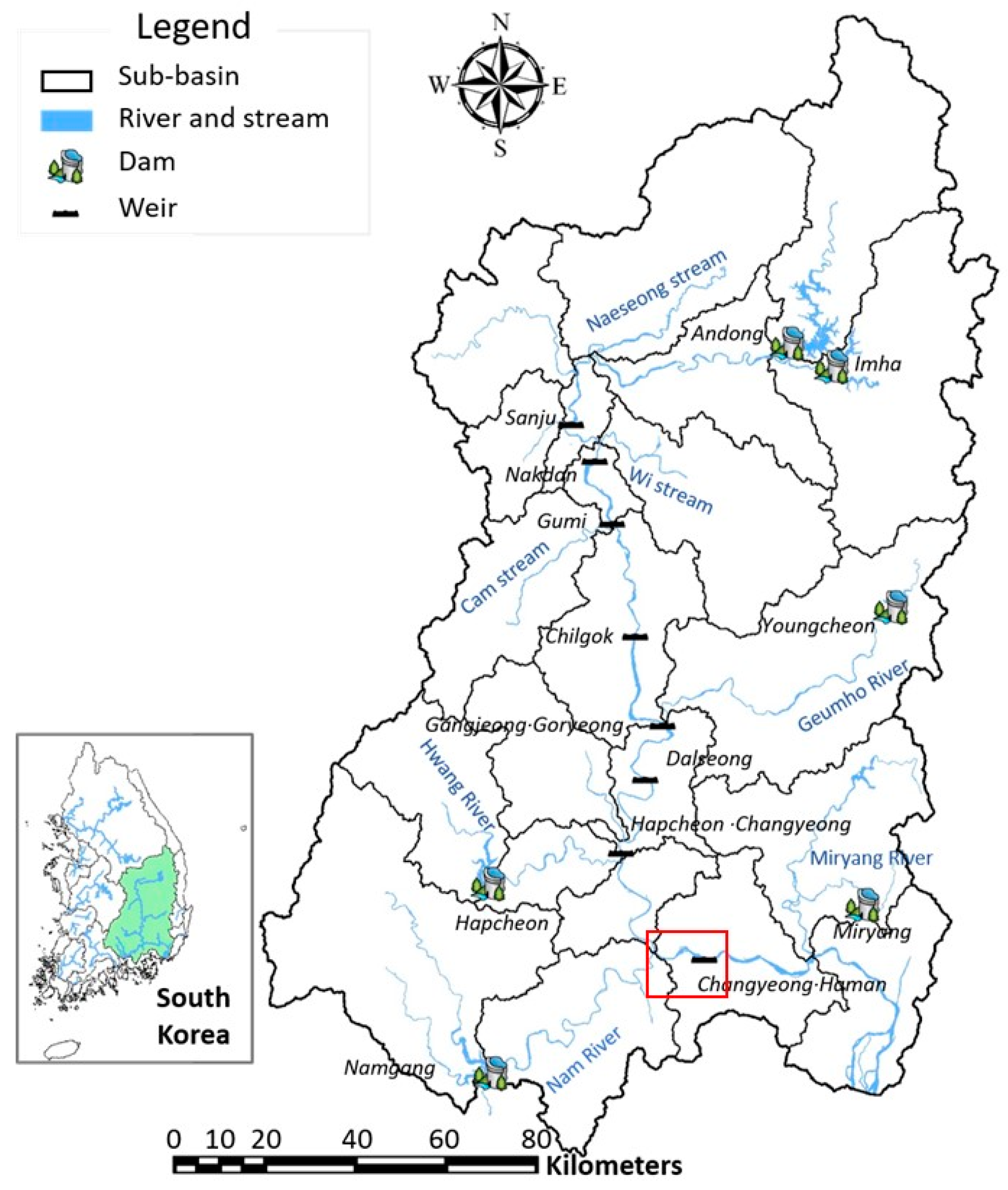
4.1. Study Area
4.2. Gradient Boosting (XGBoost, LightGBM, CatBoost) Method
4.3. Deep Learning (Attention-Based CNN-LSTM) Method
4.4. Ensemble Prediction Method
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Data Preprocessing, Training, and Predicting Procedure
References
- Aksoy, N.; Genc, I. Predictive models development using gradient boosting based methods for solar power plants. J. Comput. Sci. 2023, 67, 101958. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Light GBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. Available online: https://proceedings.neurips.cc/paper/2017/hash/6449f44a102fde848669bdd9eb6b76fa-Abstract.html (accessed on 4 April 2023).
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6638–6648. Available online: https://proceedings.neurips.cc/paper/2018/hash/83b2d666b98a3b304ce08d05729f3c4b-Abstract.html (accessed on 4 April 2023).
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1986, 78, 1550–1560. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Oord, A.V.D.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. arXiv 2016, arXiv:1601.06759. [Google Scholar]
- Lim, B.; Son, W.; Kim, H.G.; Kim, S.W. Temporal fusion transformer for interpretable multi-horizon time series forecasting. arXiv 2019, arXiv:1912.09363. [Google Scholar] [CrossRef]
- Kim, J.H.; Shin, J.; Lee, H.; Lee, D.H.; Kang, J.; Cho, K.H.; Lee, Y.; Chon, K.; Baek, S.; Park, Y. Improving the performance of machine learning models for early warning of harmful algal blooms using an adaptive synthetic sampling method. Water Res. 2021, 207, 117821. [Google Scholar] [CrossRef]
- García Nieto, P.J.; García-Gonzalo, E.; Sánchez Lasheras, F.; Alonso Fernández, J.R.; Díaz Muñiz, C.; de Cos Juez, F.J. Cyanotoxin level prediction in a reservoir using gradient boosted regression trees: A case study. Environ. Sci. Pollut. Res. Int. 2018, 25, 22658–22671. [Google Scholar] [CrossRef]
- Hill, P.R.; Kumar, A.; Temimi, M.; Bull, D.R. HABNet: Machine Learning, Remote Sensing-Based Detection of Harmful Algal Blooms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3229–3239. [Google Scholar] [CrossRef]
- Liang, Z.; Zou, R.; Chen, X.; Ren, T.; Su, H.; Liu, Y. Simulate the forecast capacity of a complicated water quality model using the long short-term memory approach. J. Hydrol. 2020, 581, 124432. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, H.; Liu, C.; Zhang, S.; Ding, A.; Xie, E.; Li, J.; Wang, S. Prediction of harmful algal blooms in large water bodies using the combined EFDC and LSTM models. J. Environ. Manag. 2021, 295, 113060. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Qin, C.; He, W.; Sun, F.; Du, P. Improved predictive performance of cyano bacterial blooms using a hybrid statistical and deep-learning method. Environ. Res. Lett. 2021, 16, 124045. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Nayak, J.; Naik, B.; Dash, P.B.; Vimal, S.; Kadry, S. Hybrid Bayesian optimization hypertuned catboost approach for malicious access and anomaly detection in IoT nomaly framework. Sustain. Comput. Inform. Syst. 2022, 36, 100805. [Google Scholar] [CrossRef]
- Su, J.; Wang, Y.; Niu, X.; Sha, S.; Yu, J. Prediction of ground surface settlement by shield tunneling using XGBoost and Bayesian Optimization. Eng. Appl. Artif. Intell. 2022, 114, 105020. [Google Scholar] [CrossRef]
- Dong, J.; Zeng, W.; Wu, L.; Huang, J.; Gaiser, T.; Srivastava, A.K. Enhancing short-term forecasting of daily precipitation using numerical weather prediction bias correcting with XGBoost in different regions of China. Eng. Appl. Artif. Intell. 2023, 117, 105579. [Google Scholar] [CrossRef]
- Farzinpour, A.; Dehcheshmeh, E.M.; Broujerdian, V.; Esfahani, S.N.; Gandomi, A.H. Efficient boosting-based algorithms for shear strength prediction of squat RC walls. Case Stud. Constr. Mater. 2023, 18, e01928. [Google Scholar] [CrossRef]
- Garcia-Moreno, F.M.; Bermudez-Edo, M.; Rodríguez-Fórtiz, M.J.; Garrido, J.L. A CNN-LSTM Deep Learning Classifier for Motor Imagery EEG Detection Using a Low-invasive and Low-Cost BCI Headband. In Proceedings of the 2020 16th International Conference on Intelligent Environments (IE), Madrid, Spain, 20–23 July 2020; pp. 84–91. [Google Scholar] [CrossRef]
- Xu, G.; Ren, T.; Chen, Y.; Che, W. A One-Dimensional CNN-LSTM Model for Epileptic Seizure Recognition Using EEG Signal Analysis. Front. Neurosci. 2020, 14, 578126. [Google Scholar] [CrossRef] [PubMed]
- Altunay, H.C.; Albayrak, Z. A hybrid CNN + LSTM-based intrusion detection system for industrial IoT networks. Eng. Sci. Technol. 2023, 38, 101322. [Google Scholar] [CrossRef]
- Liang, Y.; Lin, Y.; Lu, Q. Forecasting gold price using a novel hybrid model with ICEEMDAN and LSTM-CNN-CBAM. Expert Syst. Appl. 2022, 206, 117847. [Google Scholar] [CrossRef]
- Ahmed, M.R.; Islam, S.; Islam, A.K.M.M.; Shatabda, S. An ensemble 1D-CNN-LSTM-GRU model with data augmentation for speech emotion recognition. Expert Syst. Appl. 2023, 218, 119633. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, H.; Bao, X.; Cui, H. Outlet water temperature prediction of energy pile based on spatial-temporal feature extraction through CNN–LSTM hybrid model. Energy 2023, 264, 126190. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, Q. A hybrid CNN-LSTM machine learning model for rock mechanical parameters evaluation. Geoenergy Sci. Eng. 2023, 225, 211720. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 2, 199–228. [Google Scholar]
- Trizoglou, P.; Liu, X.; Lin, Z. Fault detection by an ensemble framework of Extreme Gradient Boosting (XGBoost) in the operation of offshore wind turbines. Renew. Energy 2021, 179, 945–962. [Google Scholar] [CrossRef]
- Zhang, J.; Fu, P.; Meng, F.; Yang, X.; Xu, J.; Cui, Y. Estimation algorithm for chlorophyll-a concentrations in water from hyperspectral images based on feature derivation and ensemble learning. Ecol. Inform. 2022, 71, 101783. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| reg_alpha | 1 × 10−5, 1 × 10−4, 1 × 10−3, 1 × 10−2, 0.1, 1, 5, 10, 100 | - | |
| reg_lambda | - | ||
| colsample_bytree | 0.5~1.0 (0.1) | - | |
| min_child_weight | 250~350 (10) | - | |
| eta | 0.1~0.3 (0.1) | - | |
| l2_leaf_reg | - | 3~8 (1) | |
| border_count | - | 32~255 (10) | |
| colsample_bylevel | - | 0.3~0.8 (0.1) | |
| bagging_temperature | - | 0~10 | |
| min_data_in_leaf | - | 1, 5, 10, 20, 30 | |
| max_depth | 10~25 (1) | 3~9 (1) | |
| subsample | 0.7~0.9 (0.1) | 0.5~1.0 | |
| learning_rate | 0.01~0.05 (0.005) | ||
| n_estimators | 1000~10,000 (10) | ||
| eval_metric | Root Mean Square Error | ||
| Hyperparameters | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| reg_alpha | 0 | 4 | - |
| reg_lambda | 7 | 8 | - |
| colsample_bytree | 0.9 | 1.0 | - |
| min_child_weight | 5 | 1 | - |
| eta | 0.1 | 0.1 | - |
| l2_leaf_reg | - | - | 5.0 |
| border_count | - | - | 80 |
| colsample_bylevel | - | - | 0.7 |
| bagging_temperature | - | - | 5.8858097 |
| min_data_in_leaf | - | - | 2 |
| max_depth | 4 | 12 | 3 |
| subsample | 0.7 | 0.8 | 0.720713 |
| learning_rate | 0.05 | 0.045 | 0.025 |
| n_estimators | 428 | 574 | 7600 |
| Hyperparameters | Search Range | Best Parameters |
|---|---|---|
| hidden_size | 1~128 (1) | 4 |
| num_layers | 1~3 (1) | 2 |
| dropout_rate | 0.0, 0.1, 0.2, 0.3, 0.4, 0.5 | 0.1 |
| learning_rate | 0.00001~0.1 | 0.00568939 |
| Model | R2 | MAE | RMSE |
|---|---|---|---|
| XGBoost | 0.92 | 0.2 | 0.4 |
| LightGBM | 0.93 | 0.1 | 0.4 |
| CatBoost | 0.89 | 0.2 | 0.5 |
| Bagging ensemble | 0.92 | 0.2 | 0.4 |
| Stacking ensemble | 0.93 | 0.1 | 0.4 |
| Attention-based CNN-LSTM | 0.92 | 0.2 | 0.4 |
| Final Ensemble | 0.93 | 0.1 | 0.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, J.M.; Kim, J.; Kim, K. Ensemble Machine Learning of Gradient Boosting (XGBoost, LightGBM, CatBoost) and Attention-Based CNN-LSTM for Harmful Algal Blooms Forecasting. Toxins 2023, 15, 608. https://doi.org/10.3390/toxins15100608
Ahn JM, Kim J, Kim K. Ensemble Machine Learning of Gradient Boosting (XGBoost, LightGBM, CatBoost) and Attention-Based CNN-LSTM for Harmful Algal Blooms Forecasting. Toxins. 2023; 15(10):608. https://doi.org/10.3390/toxins15100608
Chicago/Turabian StyleAhn, Jung Min, Jungwook Kim, and Kyunghyun Kim. 2023. "Ensemble Machine Learning of Gradient Boosting (XGBoost, LightGBM, CatBoost) and Attention-Based CNN-LSTM for Harmful Algal Blooms Forecasting" Toxins 15, no. 10: 608. https://doi.org/10.3390/toxins15100608
APA StyleAhn, J. M., Kim, J., & Kim, K. (2023). Ensemble Machine Learning of Gradient Boosting (XGBoost, LightGBM, CatBoost) and Attention-Based CNN-LSTM for Harmful Algal Blooms Forecasting. Toxins, 15(10), 608. https://doi.org/10.3390/toxins15100608