
A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds




Abstract
:1. Introduction
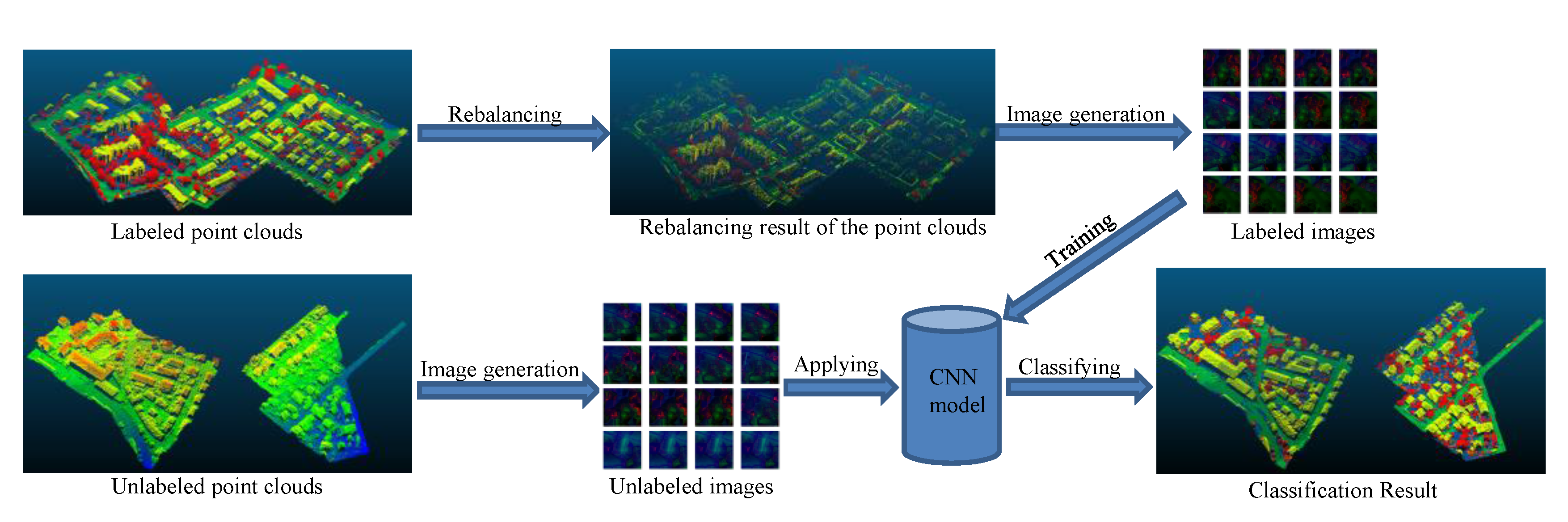
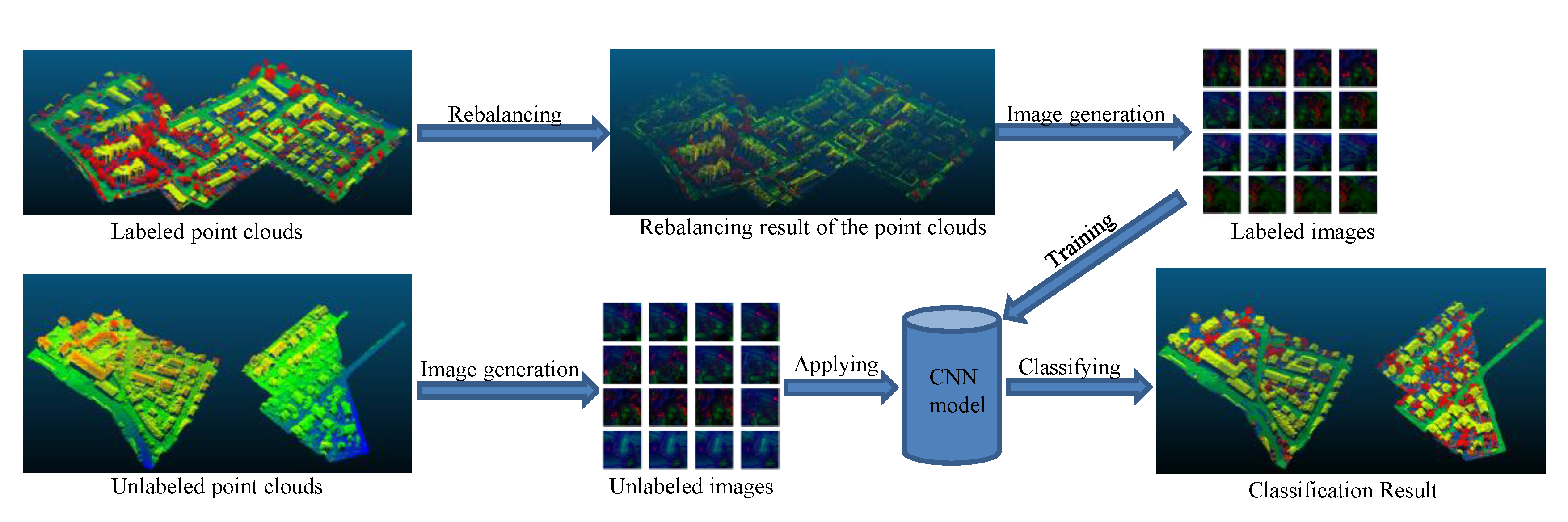
2. Methodology
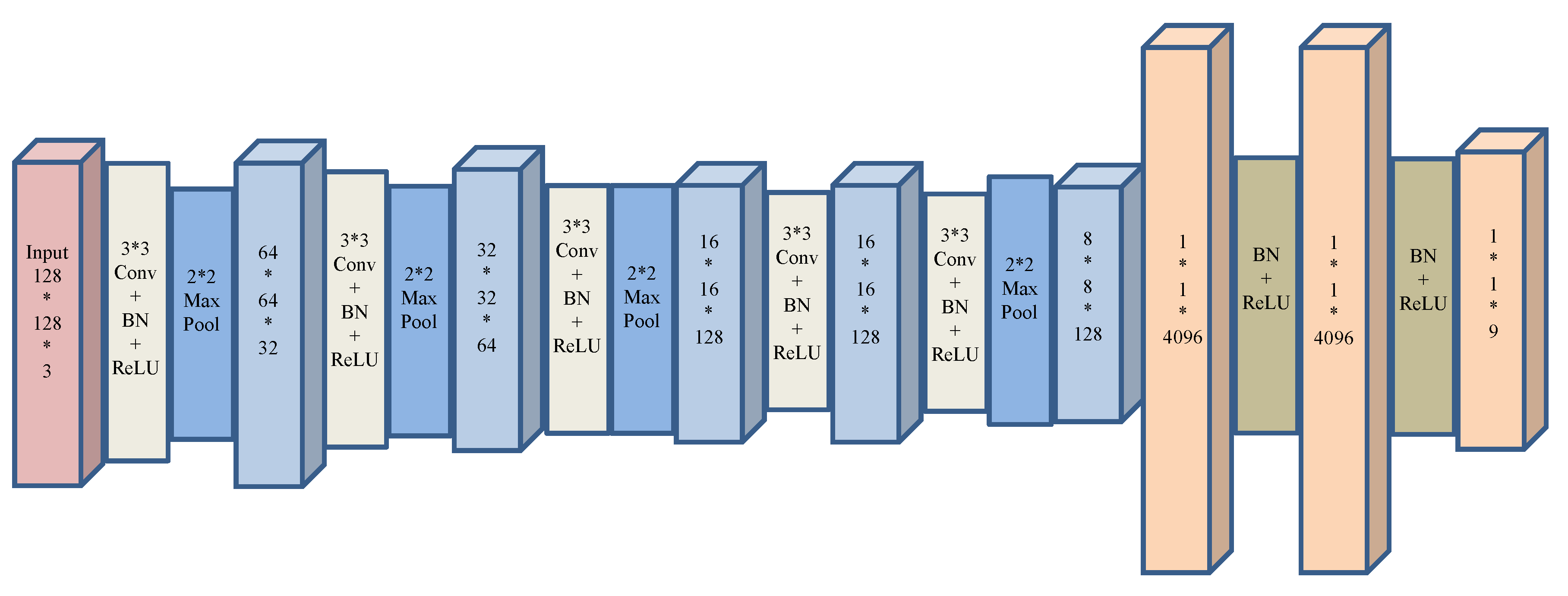
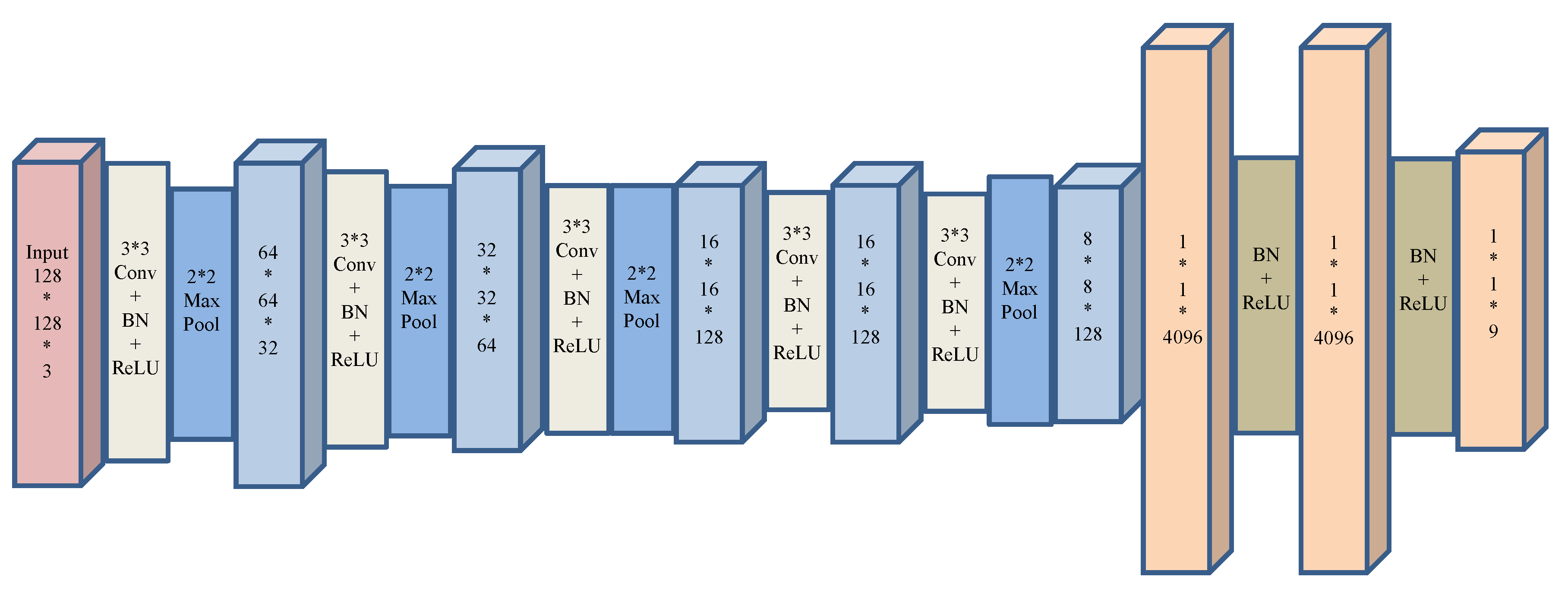
2.1. Convolutional Neural Network
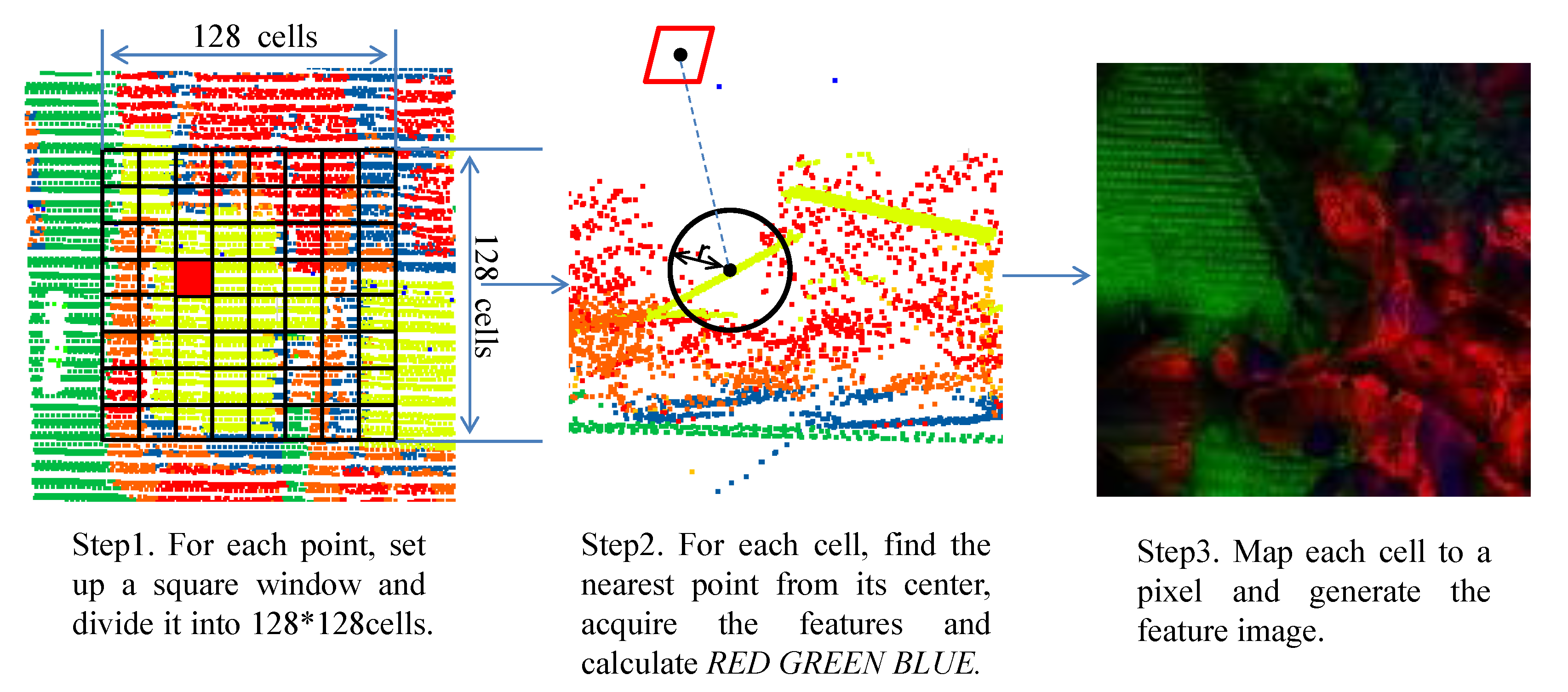
2.2. Feature Image Generation
- (1)
- We calculate the local geometric features. All the features are extracted in a sphere of radius r. For a point , based on its n neighboring points, we obtain a center of gravity . We then calculate the vector . The variance–covariance matrix is written as
- (2)
- (1)
- We extract the global geometric features. We generate the DTM for the feature height above DTM based on robust filtering [30], which is implemented in the commercial software package SCOP++. The height above DTM represents the global distribution for a point and helps to classify the data. Based on the analysis by Niemeyer [15], this feature is by far the most important since it is the strongest and most discernible feature for all the classes and relations. For instance, this feature has the capability to distinguish between a relation of points on a roof or on a road level.
- (2)
2.3. Accuracy Evaluation
3. Experimental Result
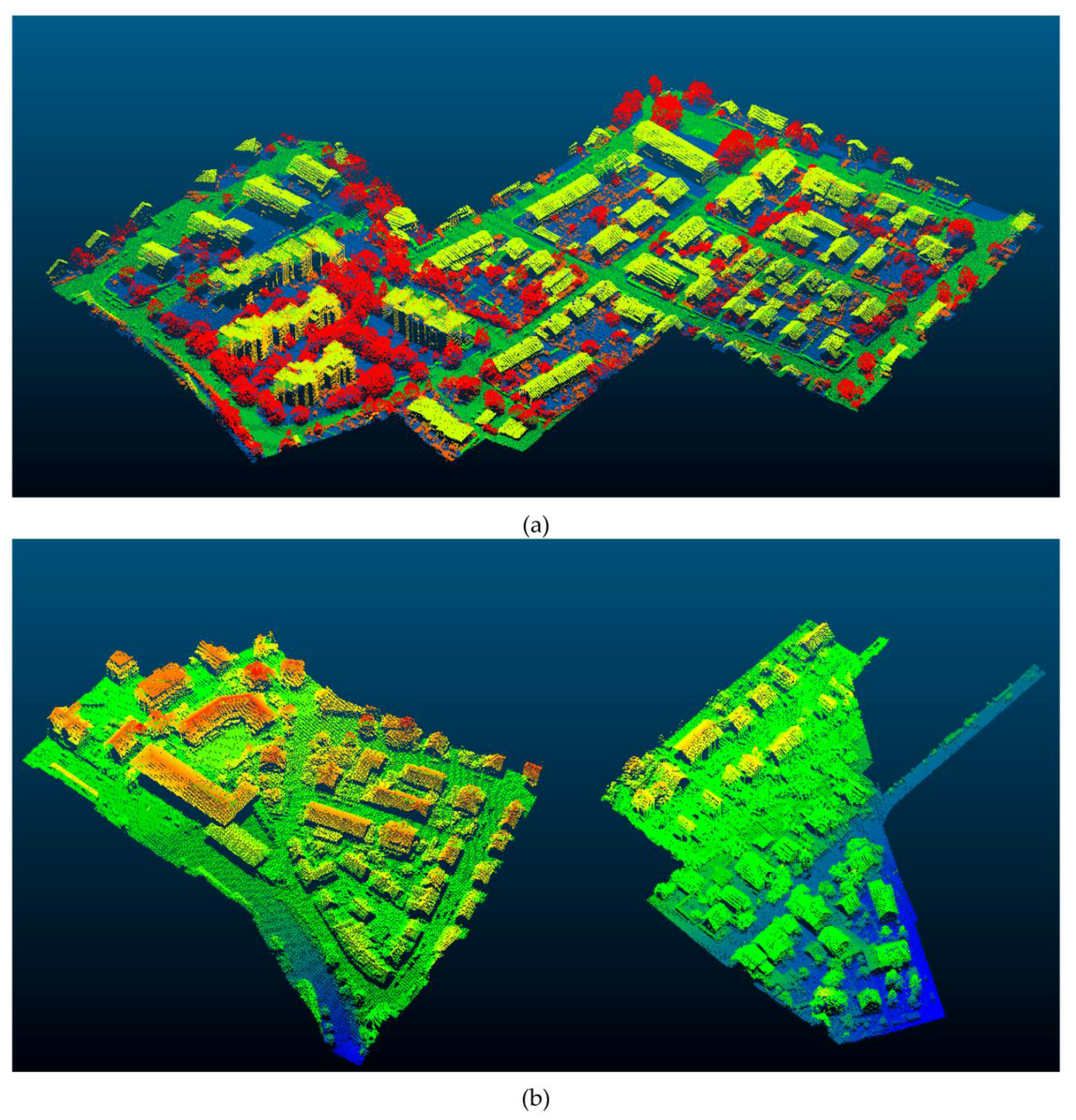
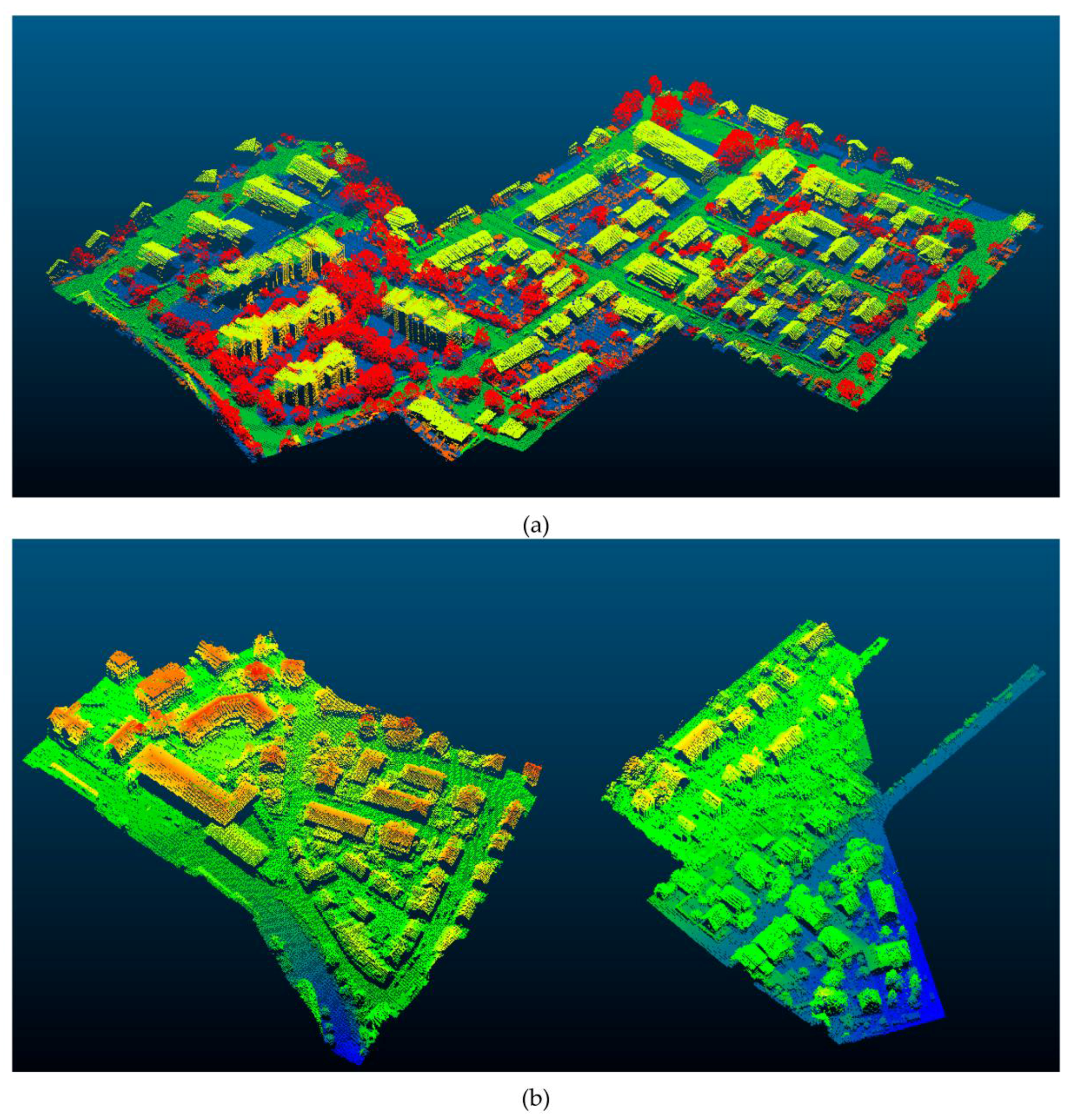
3.1. Dataset
3.2. Experiments
- R0.5 indicates a radius of 0.5 m;
- R0.75 indicates a radius of 0.75 m;
- R1.0 indicates a radius of 1.0 m;
- R2.0 indicates a radius of 2.0 m;
- W0.025 indicates a cell width of 0.025 m;
- W0.05 indicates a cell width of 0.05 m;
- W0.075 indicates a cell width of 0.075 m;
- W0.1 indicates a cell width of 0.1 m;
- W0.2 indicates a cell width of 0.2 m.
- In the CNN_DEIV, we use all five features that were discussed in Section 2.2, D represents using the feature height above DTM , E represents using the two eigenvalue-based features and , I represents using the feature , and V represents using the feature variance of normal vector angle from vertical direction .
- In the CNN_GEIV, all the features we use are the same as the CNN_DEIV except for the feature height above DTM . G indicates that we add some Gaussian noise to the DTM.
- In the CNN_LEIV, all the features we use are the same as the CNN_DEIV except for the feature height above DTM . L indicates that we use the low accuracy DTM to replace the DTM in the CNN_DEIV.
- In the CNN_DEI, all the features we use are the same as the CNN_DEIV except for the feature variance of normal vector angle from vertical direction , which is removed from the Equation (10).
- In the CNN_EI, all the features we use are the same as the CNN_DEI except for the feature height above DTM , which is removed from the Equation (10) and replaced with the relative height difference. This feature is calculated from the difference between the height of a point and the average height value in its neighborhood.
- In the CNN_E, all the features we use are the same as the CNN_EI except for the feature , which is removed from the Equation (10) and replaced with the integer 255.
- Sall uses all the samples to train the CNN model;
- Sreb uses re-balanced samples shown in Table 1;
- Srep repeats the sparser classes in Sreb that makes all the classes have 15,000 samples.
3.3. ISPRS Benchmark Testing Results
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006; p. 049901. [Google Scholar]
- Chan, C.W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2003, 27, 294–300. [Google Scholar] [CrossRef]
- Chehata, N.; Li, G.; Mallet, C. Airborne LiDAR feature selection for urban classification using random forests. Geomat. Inf. Sci. Wuhan Univ. 2009, 38, 207–212. [Google Scholar]
- Mallet, C. Analysis of Full-Waveform LiDAR Data for Urban Area Mapping. Ph.D Thesis, Télécom ParisTech, Paris, France, 2010. [Google Scholar]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform LiDAR data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, S71–S84. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Hebert, M. Discriminative random fields. Int. J. Comput. Vis. 2006, 68, 179–201. [Google Scholar] [CrossRef]
- Anguelov, D.; Taskarf, B.; Chatalbashev, V.; Koller, D.; Gupta, D.; Heitz, G.; Ng, A. In discriminative learning of Markov random fields for segmentation of 3D scan data. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Shapovalov, R.; Velizhev, A.; Barinova, O. Non-associative Markov networks for 3D point cloud classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, XXXVIII, 103–108. [Google Scholar]
- Rusu, R.B.; Holzbach, A.; Blodow, N.; Beetz, M. Fast geometric point labeling using conditional random fields. In Proceedings of the Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of LiDAR data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: https://arxiv.org/abs/1409.1556 (accessed on 8 September 2017).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Boulch, A.; Saux, B.L.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. In Eurographics Workshop on 3D Object Retrieval; The Eurographics Association: Geneva, Switzerland, 2017. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–187. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, Y. Deep-learning-based classification for DTM extraction from ALS point cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 6–11 July 2015. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality based scale selection in 3D LiDAR point clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 38, W12. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Z. Epipolar geometry in stereo, motion and object recognition. Comput. Imaging Vis. 1996, 6. [Google Scholar] [CrossRef]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1998, 53, 193–203. [Google Scholar] [CrossRef]
- Wagner, W.; Ullrich, A.; Ducic, V.; Melzer, T.; Studnicka, N. Gaussian decomposition and calibration of a novel small-footprint full-waveform digitising airborne laser scanner. ISPRS J. Photogramm. Remote Sens. 2006, 60, 100–112. [Google Scholar] [CrossRef]
- International Society for Photogrammetry and Remote Sensing. 3D Semantic Labeling Contest. Available online: http://www2.isprs.org/commissions/comm3/wg4/3d-semantic-labeling.html (accessed on 8 September 2017).
- Cramer, M. The DGPF-test on digital airborne camera evaluation—Overview and test design. Photogramm. Fernerkund. Geoinf. 2010, 2010, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Breiman, L. Using Random Forest to Learn Imbalanced Data; 666; University of California, Berkeley: Berkeley, CA, USA, 2004. [Google Scholar]
- Ramiya, A.M.; Nidamanuri, R.R.; Ramakrishnan, K. A supervoxel-based spectro-spatial approach for 3d urban point cloud labelling. Int. J. Remote Sens. 2016, 37, 4172–4200. [Google Scholar] [CrossRef]
- Steinsiek, M.; Polewski, P.; Yao, W.; Krzystek, P. Semantische analyse von ALS- und MLS-daten in urbanen gebieten mittels conditional random fields. In Proceedings of the 37. Wissenschaftlich-Technische Jahrestagung der DGPF, Würzburg, Germany, 8–10 March 2017. [Google Scholar]
- Horvat, D.; Žalik, B.; Mongus, D. Context-dependent detection of non-linearly distributed points for vegetation classification in airborne lidar. ISPRS J. Photogramm. Remote Sens. 2016, 116, 1–14. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B3, 655–662. [Google Scholar] [CrossRef]
- Guinard, S.; Landrieu, L. Weakly supervised segmentation-aided classification of urban scenes from 3D lidar point clouds. In Proceedings of the ISPRS Workshop 2017, Hannover, Germany, 6–9 June 2017. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training Set | Training Set Used | Test Set |
|---|---|---|---|
| Powerline | 546 | 546 | N/A |
| Low Vegetation | 180,850 | 18,005 | N/A |
| Impervious Surfaces | 193,723 | 19,516 | N/A |
| Car | 4614 | 4614 | N/A |
| Fence/Hedge | 12,070 | 12,070 | N/A |
| Roof | 152,045 | 15,235 | N/A |
| Façade | 27,250 | 13,731 | N/A |
| Shrub | 47,605 | 11,850 | N/A |
| Tree | 135,173 | 13,492 | N/A |
| ∑ | 753,876 | 109,059 | 411,722 |
| Class | R0.5 | R0.75 | R1.0 | R2.0 |
|---|---|---|---|---|
| Power | 31.3 | 26.1 | 24.7 | 20.3 |
| Low Vegetation | 80.2 | 80.9 | 81.8 | 81.2 |
| Impervious Surfaces | 87.8 | 90.2 | 91.9 | 89.2 |
| Car | 59.3 | 71.2 | 69.3 | 64.2 |
| Fence/Hedge | 11.2 | 12.7 | 14.7 | 13.6 |
| Roof | 93.1 | 94.4 | 95.4 | 94.9 |
| Façade | 34.1 | 38.1 | 40.9 | 41.7 |
| Shrub | 36.4 | 37.7 | 38.2 | 38.3 |
| Tree | 77.5 | 77.9 | 78.5 | 78.1 |
| Overall Accuracy | 79.7 | 81.2 | 82.3 | 81.3 |
| Average F1 | 60.5 | 61.3 | 61.6 | 60.7 |
| Class | W0.025 | W0.05 | W0.075 | W0.1 | W0.2 |
|---|---|---|---|---|---|
| Power | 28.4 | 24.7 | 22.1 | 19.3 | 15.1 |
| Low Vegetation | 78.6 | 81.8 | 81.9 | 81.7 | 80.4 |
| Impervious Surfaces | 90.2 | 91.9 | 90.4 | 88.6 | 83.6 |
| Car | 66.7 | 69.3 | 62.1 | 59.3 | 53.2 |
| Fence/Hedge | 18.3 | 14.7 | 14.3 | 10.9 | 9.5 |
| Roof | 93.1 | 95.4 | 95.5 | 95.8 | 96.3 |
| Façade | 40.2 | 40.9 | 35.9 | 36.3 | 39.3 |
| Shrub | 39.1 | 38.2 | 35.7 | 30.4 | 20.1 |
| Tree | 76.6 | 78.5 | 78.9 | 69.3 | 66.8 |
| Overall Accuracy | 80.4 | 82.3 | 81.7 | 79.6 | 77.2 |
| Average F1 | 62.4 | 61.6 | 61.2 | 60.1 | 57.3 |
| Class | CNN_DEIV | CNN_GEIV | CNN_LEIV | CNN_DEI | CNN_EI | CNN_E |
|---|---|---|---|---|---|---|
| Power | 24.7 | 24.3 | 22.7 | 20.5 | 17.2 | 23.0 |
| Low Vegetation | 81.8 | 81.9 | 78.3 | 82.0 | 75.4 | 63.1 |
| Impervious Surfaces | 91.9 | 91.7 | 79.2 | 88.7 | 80.0 | 49.6 |
| Car | 69.3 | 69.1 | 58.7 | 47.5 | 46.8 | 32.1 |
| Fence/Hedge | 14.7 | 15.3 | 17.8 | 15.9 | 20.3 | 19.4 |
| Roof | 95.4 | 95.0 | 84.0 | 92.3 | 83.6 | 84.5 |
| Façade | 40.9 | 40.8 | 45.3 | 46.4 | 44.9 | 47.6 |
| Shrub | 38.2 | 37.9 | 36.3 | 43.9 | 38.4 | 36.0 |
| Tree | 78.5 | 78.7 | 80.1 | 79.7 | 85.9 | 84.9 |
| Overall Accuracy | 82.3 | 82.2 | 75.5 | 81.0 | 75.7 | 65.1 |
| Average F1 | 61.6 | 61.3 | 56.3 | 58.9 | 55.8 | 50.1 |
| Samples | Sall | Sreb | Srep |
|---|---|---|---|
| Training time (h) | 43.1 | 6.5 | 7.2 |
| Testing time (s) | 70.2 | 70.4 | 69.7 |
| Overall Accuracy (%) | 80.2 | 82.3 | 82.2 |
| Average F1 (%) | 60.7 | 61.6 | 62.1 |
| Class | Value | ISS_7 | HM_1 | UM | LUH | WHUY3 |
|---|---|---|---|---|---|---|
| Impervious Surfaces | Precision | 76.0 | 89.1 | 88.0 | 91.8 | 88.4 |
| Recall | 96.5 | 94.2 | 90.3 | 90.4 | 91.9 | |
| F1 | 85.0 | 91.5 | 89.1 | 91.1 | 90.1 | |
| Roof | Precision | 86.1 | 91.6 | 93.6 | 97.3 | 91.4 |
| Recall | 96.2 | 91.5 | 90.5 | 91.3 | 95.4 | |
| F1 | 90.9 | 91.6 | 92.0 | 94.2 | 93.4 | |
| Low Vegetation | Precision | 94.1 | 83.8 | 78.6 | 83.0 | 80.9 |
| Recall | 49.9 | 65.9 | 79.5 | 72.7 | 81.8 | |
| F1 | 65.2 | 73.8 | 79.0 | 77.5 | 81.4 | |
| Tree | Precision | 84.0 | 77.9 | 71.8 | 87.4 | 77.5 |
| Recall | 68.8 | 82.6 | 85.2 | 79.1 | 78.5 | |
| F1 | 75.6 | 80.2 | 77.9 | 83.1 | 78.0 | |
| Car | Precision | 76.3 | 51.4 | 89.6 | 86.4 | 58.4 |
| Recall | 46.7 | 67.1 | 32.5 | 63.3 | 69.3 | |
| F1 | 57.9 | 58.2 | 47.7 | 73.1 | 63.4 | |
| All five classes | Average Precision | 83.3 | 78.8 | 84.3 | 89.1 | 79.3 |
| Average Recall | 71.6 | 80.3 | 75.6 | 79.4 | 83.4 | |
| Average F1 | 74.9 | 79.1 | 77.1 | 83.8 | 81.3 | |
| All nine classes | Overall Accuracy | 76.2 | 80.5 | 80.8 | 81.6 | 82.3 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Jiang, W.; Xu, B.; Zhu, Q.; Jiang, S.; Huang, W. A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds. Remote Sens. 2017, 9, 936. https://doi.org/10.3390/rs9090936
Yang Z, Jiang W, Xu B, Zhu Q, Jiang S, Huang W. A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds. Remote Sensing. 2017; 9(9):936. https://doi.org/10.3390/rs9090936
Chicago/Turabian StyleYang, Zhishuang, Wanshou Jiang, Bo Xu, Quansheng Zhu, San Jiang, and Wei Huang. 2017. "A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds" Remote Sensing 9, no. 9: 936. https://doi.org/10.3390/rs9090936
APA StyleYang, Z., Jiang, W., Xu, B., Zhu, Q., Jiang, S., & Huang, W. (2017). A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds. Remote Sensing, 9(9), 936. https://doi.org/10.3390/rs9090936