
An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification

 , , ,
, , ,
Abstract
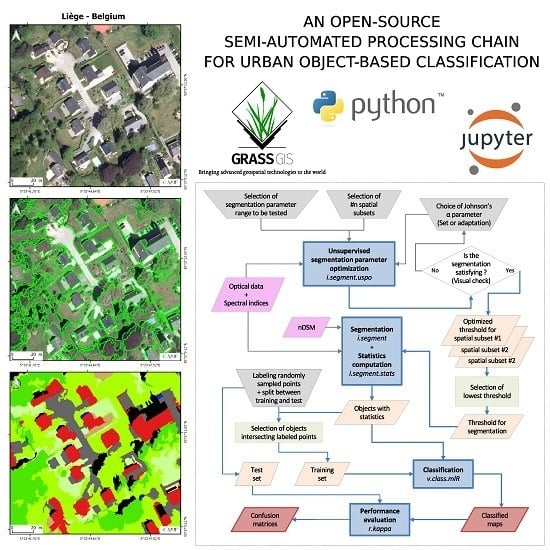
:
1. Introduction
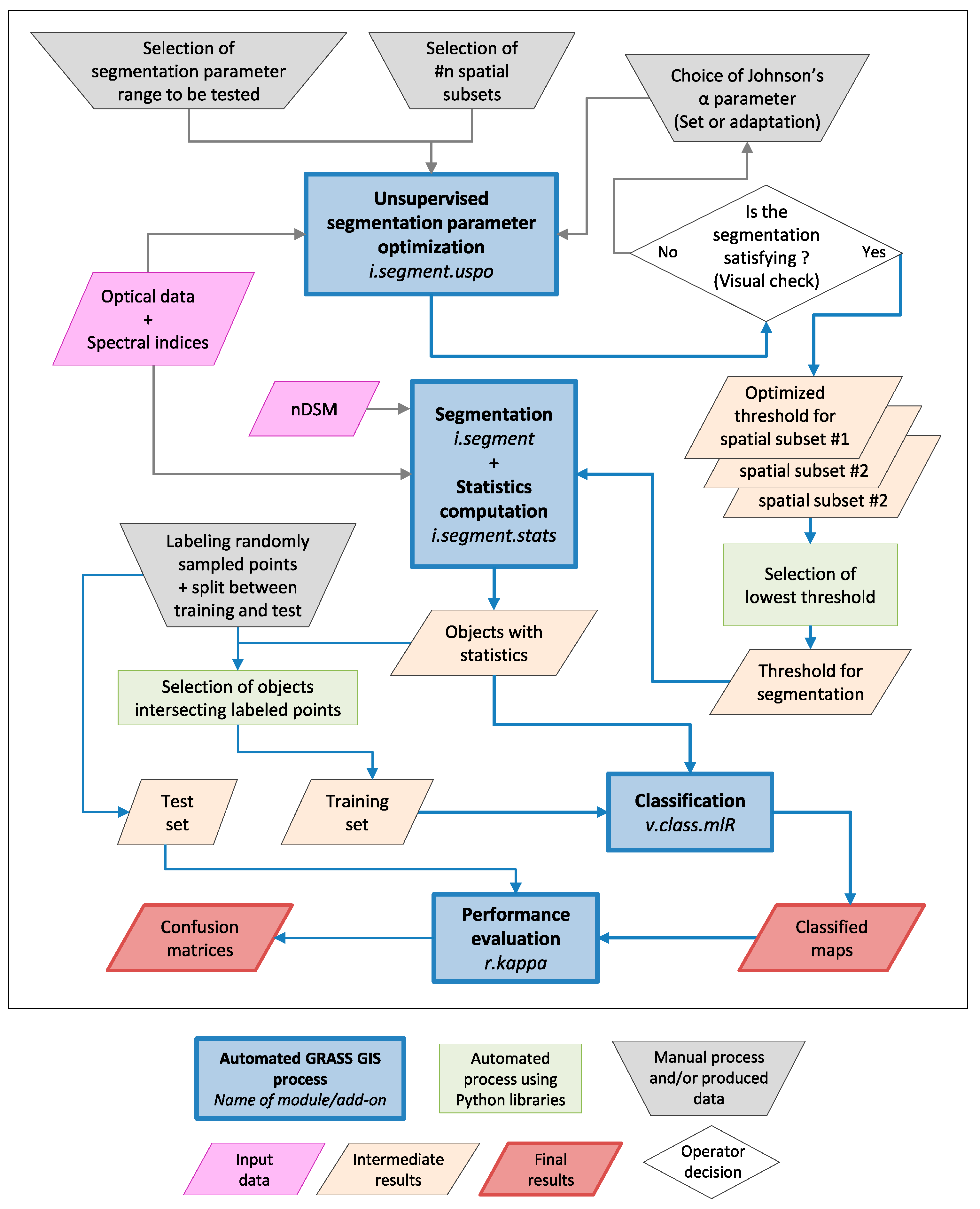
2. Methods and Tools
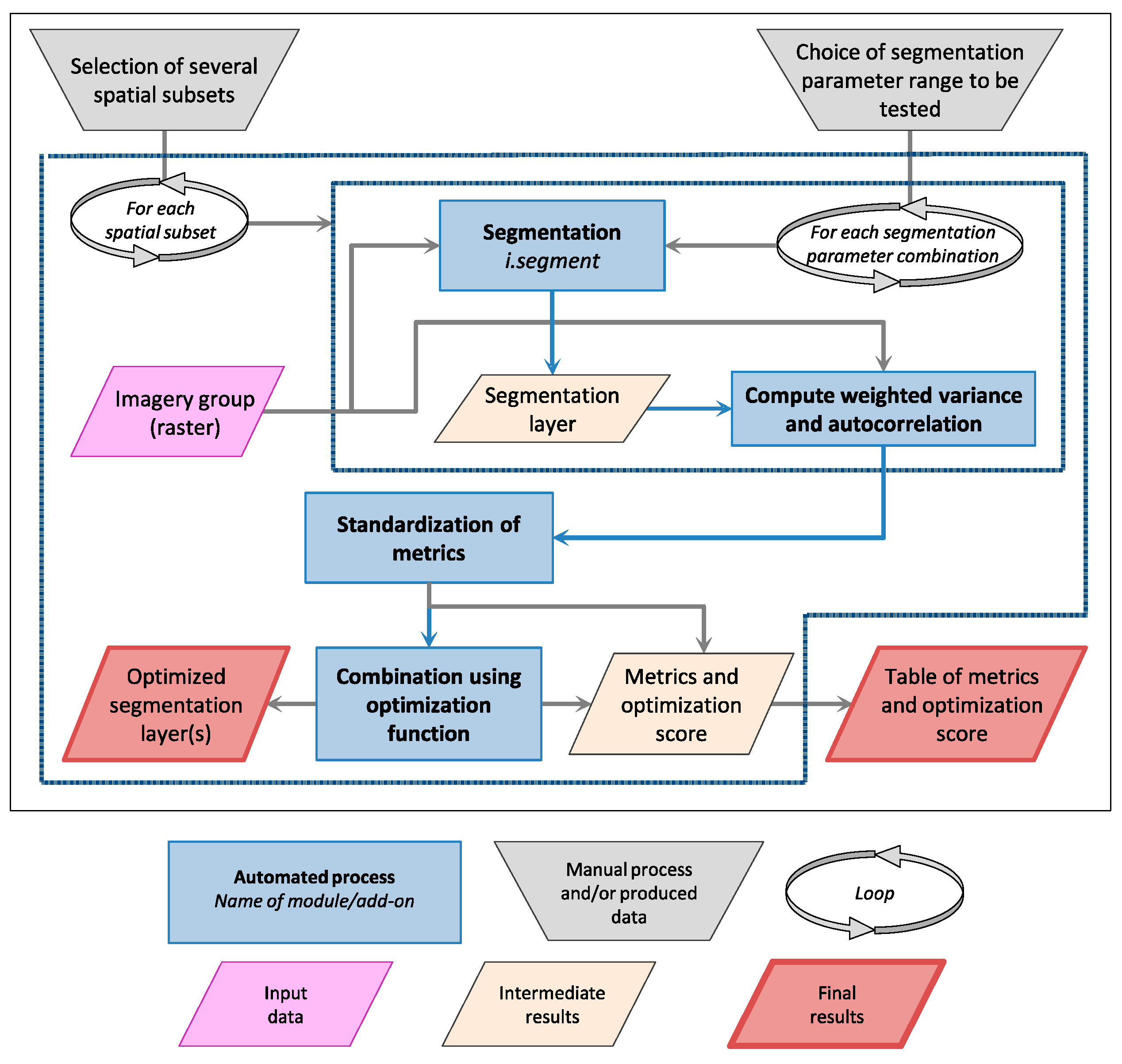
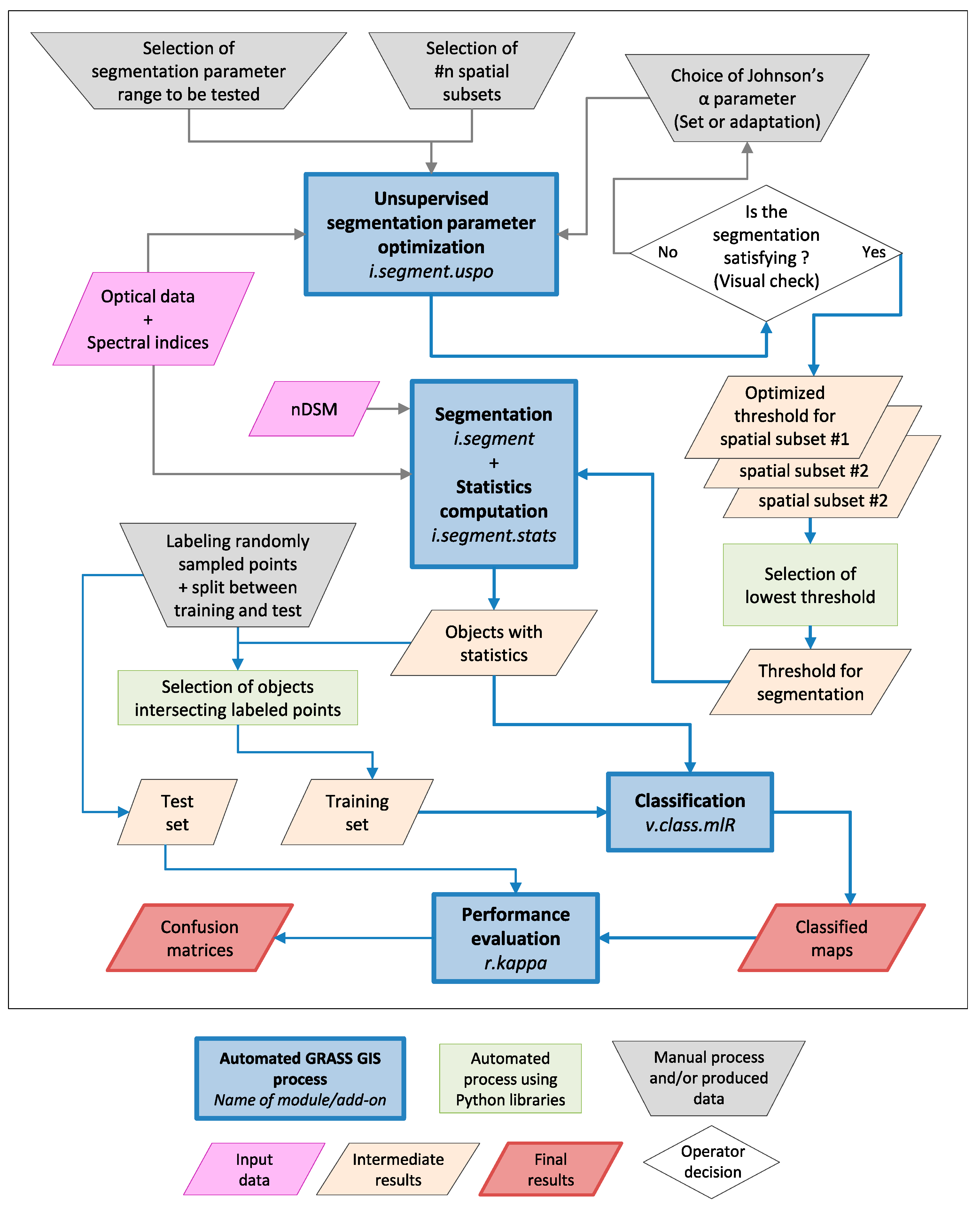
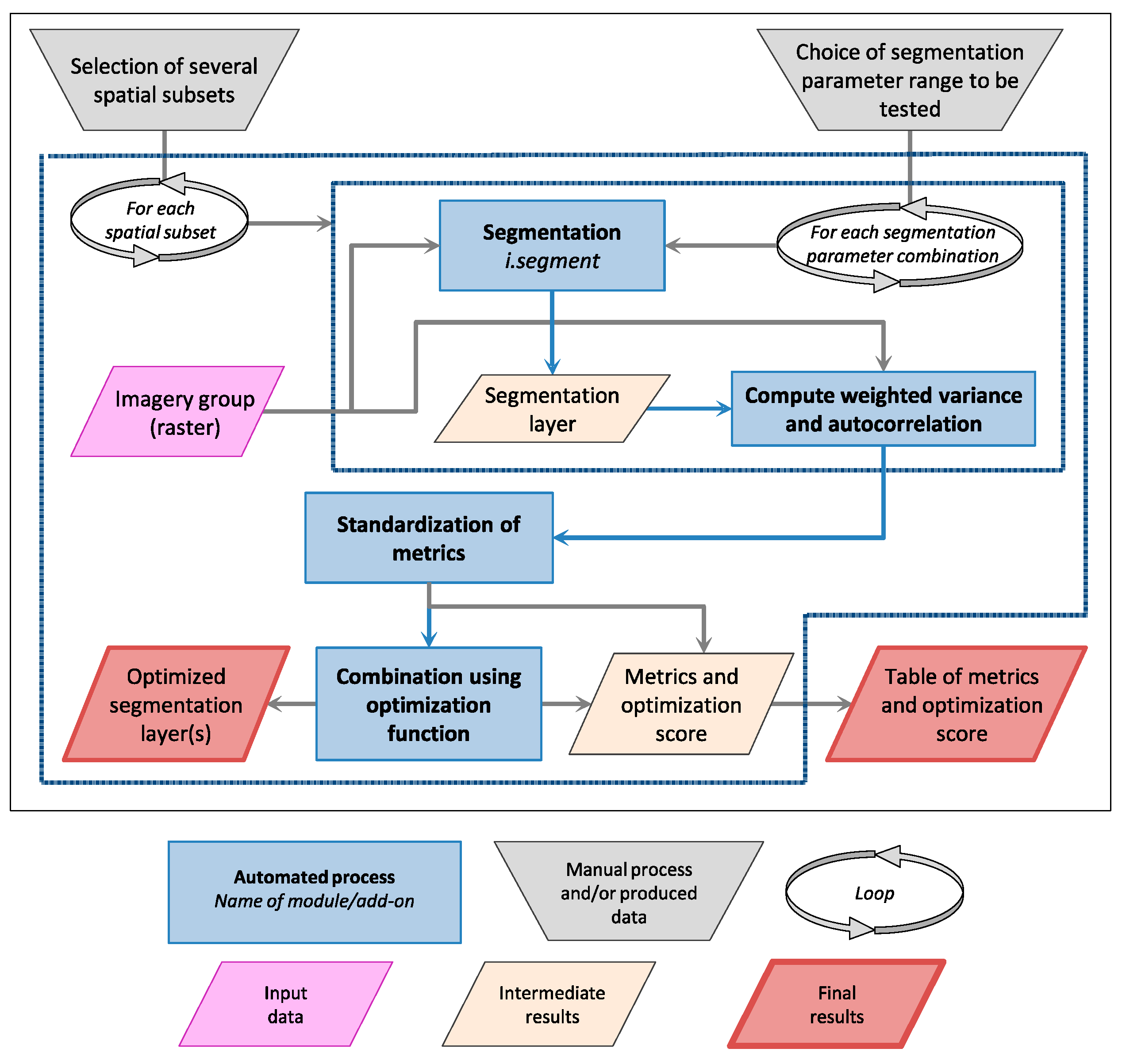
2.1. Segmentation and Unsupervised Segmentation Parameter Optimization (USPO) Tools
2.2. Object Statistics Computation
2.3. Classification by the Combination of Multiple Machine Learning Classifiers
3. Case Studies
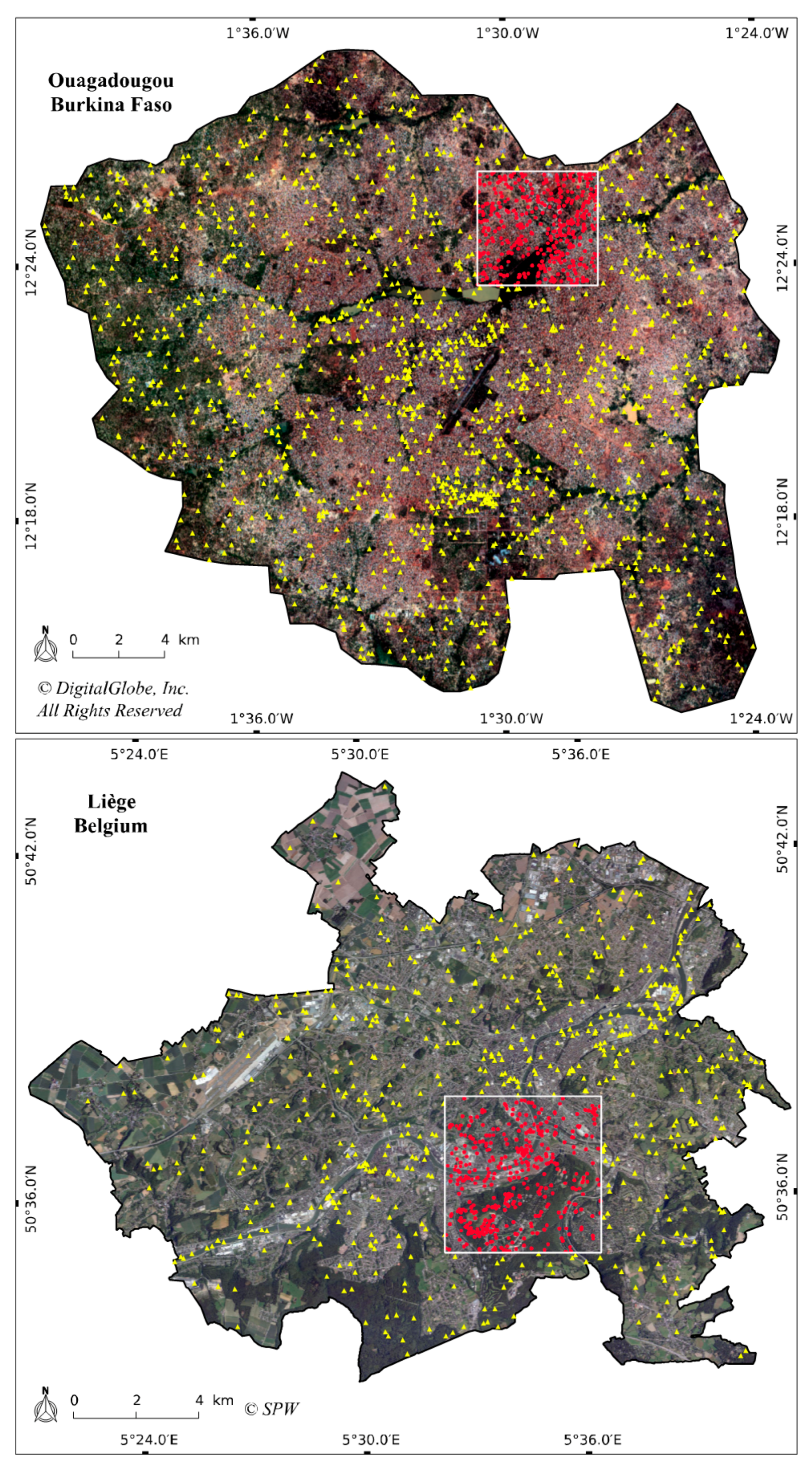
3.1. Study Areas and Data
3.2. Legend/Classification Scheme
3.3. Sampling Scheme
3.4. Segmentation
3.5. Classification Feature
4. Results
5. Discussion and Perspectives
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Individual Classifiers | Votes | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Level 2 Classes | Accuracy | kNN | Rpart | SVMradial | RF | SMV | SWV | BWWV | QBWWV |
| BU | PA: | 79.1% | 79.1% | 100.0% | 95.3% | 97.7% | 97.7% | 95.3% | 95.3% |
| UA: | 51.5% | 77.3% | 64.2% | 91.1% | 76.4% | 89.4% | 89.1% | 89.1% | |
| SW | PA: | 83.9% | 87.1% | 93.5% | 96.8% | 96.8% | 96.8% | 96.8% | 96.8% |
| UA: | 100.0% | 96.4% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | |
| AS | PA: | 56.7% | 83.3% | 56.7% | 90.0% | 86.7% | 90.0% | 90.0% | 90.0% |
| UA: | 44.7% | 48.1% | 53.1% | 77.1% | 74.3% | 77.1% | 77.1% | 77.1% | |
| RBS | PA: | 57.1% | 83.3% | 64.3% | 85.7% | 85.7% | 85.7% | 85.7% | 85.7% |
| UA: | 47.1% | 68.6% | 65.9% | 72.0% | 69.2% | 70.6% | 70.6% | 70.6% | |
| GBS | PA: | 26.7% | 56.7% | 56.7% | 56.7% | 50.0% | 53.3% | 53.3% | 53.3% |
| UA: | 25.0% | 89.5% | 94.4% | 100.0% | 93.8% | 100.0% | 100.0% | 100.0% | |
| TR | PA: | 50.0% | 96.9% | 81.3% | 90.6% | 90.6% | 90.6% | 90.6% | 90.6% |
| UA: | 69.6% | 72.1% | 83.9% | 80.6% | 74.4% | 78.4% | 80.6% | 80.6% | |
| MBV | PA: | 28.1% | 62.5% | 46.9% | 46.9% | 50.0% | 50.0% | 50.0% | 50.0% |
| UA: | 30.0% | 60.6% | 78.9% | 68.2% | 66.7% | 69.6% | 69.6% | 69.6% | |
| DV | PA: | 6.3% | 46.9% | 71.9% | 62.5% | 65.6% | 65.6% | 65.6% | 65.6% |
| UA: | 12.5% | 50.0% | 59.0% | 58.8% | 61.8% | 60.0% | 58.3% | 58.3% | |
| OV | PA: | 63.9% | 61.1% | 72.2% | 80.6% | 69.4% | 77.8% | 80.6% | 80.6% |
| UA: | 48.9% | 84.6% | 74.3% | 74.4% | 80.6% | 77.8% | 80.6% | 80.6% | |
| WB | PA: | 12.9% | 64.5% | 80.6% | 83.9% | 64.5% | 80.6% | 80.6% | 80.6% |
| UA: | 36.4% | 87.0% | 89.3% | 89.7% | 90.9% | 89.3% | 89.3% | 89.3% | |
| SH | PA: | 73.3% | 60.0% | 93.3% | 96.7% | 96.7% | 96.7% | 96.7% | 96.7% |
| UA: | 75.9% | 90.0% | 93.3% | 90.6% | 93.5% | 93.5% | 90.6% | 90.6% | |
| OA | 50,1% | 71.5% | 74.8% | 81.0% | 78.3% | 81.0% | 81.0% | 81.0% | |
| Kappa | 0.45 | 0.69 | 0.72 | 0.79 | 0.76 | 0.79 | 0.79 | 0.79 | |
| Individual Classifiers | Votes | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Level 2 Classes | Accuracy | kNN | Rpart | SVMradial | RF | SMV | SWV | BWWV | QBWWV |
| BU | PA: | 48.6% | 89.2% | 81.1% | 86.5% | 91.9% | 89.2% | 86.5% | 86.5% |
| UA: | 52.9% | 94.3% | 85.7% | 97.0% | 94.4% | 97.1% | 97.0% | 97.0% | |
| AS | PA: | 78.3% | 70.0% | 76.7% | 78.3% | 81.7% | 80.0% | 80.0% | 80.0% |
| UA: | 54.7% | 72.4% | 76.7% | 85.5% | 75.4% | 84.2% | 84.2% | 84.2% | |
| LV | PA: | 32.6% | 69.6% | 65.2% | 78.3% | 78.3% | 71.7% | 71.7% | 71.7% |
| UA: | 42.9% | 86.5% | 76.9% | 81.8% | 81.8% | 82.5% | 82.5% | 82.5% | |
| MV | PA: | 33.3% | 68.8% | 58.3% | 64.6% | 62.5% | 64.6% | 64.6% | 64.6% |
| UA: | 34.8% | 66.0% | 66.7% | 73.8% | 73.2% | 68.9% | 68.9% | 68.9% | |
| HVD | PA: | 33.3% | 72.2% | 75.0% | 75.0% | 75.0% | 75.0% | 75.0% | 75.0% |
| UA: | 25.0% | 53.1% | 49.1% | 54.0% | 50.0% | 52.9% | 52.9% | 52.9% | |
| HVC | PA: | 34.9% | 74.4% | 62.8% | 72.1% | 65.1% | 72.1% | 72.1% | 72.1% |
| UA: | 37.5% | 69.6% | 71.1% | 73.8% | 71.8% | 73.8% | 73.8% | 73.8% | |
| BS | PA: | 40.5% | 61.9% | 69.0% | 76.2% | 57.1% | 73.8% | 73.8% | 73.8% |
| UA: | 60.7% | 65.0% | 72.5% | 72.7% | 77.4% | 75.6% | 73.8% | 73.8% | |
| WB | PA: | 73.0% | 97.3% | 91.9% | 94.6% | 94.6% | 94.6% | 94.6% | 94.6% |
| UA: | 90.0% | 81.8% | 91.9% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | |
| SH | PA: | 71.8% | 69.2% | 92.3% | 94.9% | 94.9% | 94.9% | 94.9% | 94.9% |
| UA: | 68.3% | 93.1% | 85.7% | 86.0% | 86.0% | 86.0% | 86.0% | 86.0% | |
| OA | 50.3% | 74.0% | 74.0% | 79.4% | 77.3% | 78.9% | 78.6% | 78.6% | |
| Kappa | 0.44 | 0.71 | 0.71 | 0.77 | 0.74 | 0.76 | 0.76 | 0.76 | |
References
- Zhang, H.; Fritts, J.E.; Goldman, S.A. Image segmentation evaluation: A survey of unsupervised methods. Comput. Vis. Image Underst. 2008, 110, 260–280. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Salehi, B.; Zhang, Y.; Zhong, M.; Dey, V. Object-Based Classification of Urban Areas Using VHR Imagery and Height Points Ancillary Data. Remote Sens. 2012, 4, 2256–2276. [Google Scholar] [CrossRef]
- O’Neil-Dunne, J.P.M.; MacFaden, S.W.; Royar, A.R.; Pelletier, K.C. An object-based system for LiDAR data fusion and feature extraction. Geocarto Int. 2013, 28, 227–242. [Google Scholar] [CrossRef]
- Kohli, D.; Warwadekar, P.; Kerle, N.; Sliuzas, R.; Stein, A. Transferability of Object-Oriented Image Analysis Methods for Slum Identification. Remote Sens. 2013, 5, 4209–4228. [Google Scholar] [CrossRef]
- Belgiu, M.; Drǎguţ, L.; Strobl, J. Quantitative evaluation of variations in rule-based classifications of land cover in urban neighbourhoods using WorldView-2 imagery. ISPRS J. Photogramm. Remote Sens. 2014, 87, 205–215. [Google Scholar] [CrossRef] [PubMed]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Moreno-Seco, F.; Inesta, J.M.; De León, P.J.P.; Micó, L. Comparison of classifier fusion methods for classification in pattern recognition tasks. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2006; pp. 705–713. [Google Scholar]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef] [PubMed]
- Skaggs, T.H.; Young, M.H.; Vrugt, J.A. Reproducible Research in Vadose Zone Sciences. Vadose Zone J. 2015, 14. [Google Scholar] [CrossRef]
- Walsham, G.; Sahay, S. Research on information systems in developing countries: Current landscape and future prospects. Inf. Technol. Dev. 2006, 12, 7–24. [Google Scholar] [CrossRef]
- Haack, B.; Ryerson, R. Improving remote sensing research and education in developing countries: Approaches and recommendations. Int. J. Appl. Earth Obs. Geoinf. 2016, 45, 77–83. [Google Scholar] [CrossRef]
- Grippa, T.; Lennert, M.; Beaumont, B.; Vanhuysse, S.; Stephenne, N.; Wolff, E. An open-source semi-automated processing chain for urban obia classification. In Proceedings of the GEOBIA 2016: Solutions and Synergies, Enschede, The Netherlands, 14–16 September 2016. [Google Scholar]
- GRASS Development Team. Geographic Resources Analysis Support System (GRASS). Open Source Geospatial Foundation: Chicago, IL, USA, 2015. Available online: https://grass.osgeo.org/ (accessed on 13 June 2016).
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2008. [Google Scholar]
- Walker, J.S.; Blaschke, T. Object-based land-cover classification for the Phoenix metropolitan area: Optimization vs. transportability. Int. J. Remote Sens. 2008, 29, 2021–2040. [Google Scholar] [CrossRef]
- Neteler, M.; Bowman, M.H.; Landa, M.; Metz, M. GRASS GIS: A multi-purpose open source GIS. Environ. Model. Softw. 2012, 31, 124–130. [Google Scholar] [CrossRef]
- Neteler, M.; Beaudette, D.E.; Cavallini, P.; Lami, L.; Cepicky, J. Grass gis. In Open Source Approaches in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2008; pp. 171–199. [Google Scholar]
- Hofierka, J.; Kaňuk, J. Assessment of photovoltaic potential in urban areas using open-source solar radiation tools. Renew. Energy 2009, 34, 2206–2214. [Google Scholar] [CrossRef]
- Frigeri, A.; Hare, T.; Neteler, M.; Coradini, A.; Federico, C.; Orosei, R. A working environment for digital planetary data processing and mapping using ISIS and GRASS GIS. Planet. Space Sci. 2011, 59, 1265–1272. [Google Scholar] [CrossRef]
- Sofina, N.; Ehlers, M. Object-based change detection using highresolution remotely sensed data and gis. In Proceedings of the International Archives Photogrammetry, Remote Sensing and Spatial Information Sciences-XXII ISPRS Congress, Melbourne, Australia, 25 August–1 September 2012; Volume 39, p. B7. [Google Scholar]
- Rocchini, D.; Delucchi, L.; Bacaro, G.; Cavallini, P.; Feilhauer, H.; Foody, G.M.; He, K.S.; Nagendra, H.; Porta, C.; Ricotta, C.; et al. Calculating landscape diversity with information-theory based indices: A GRASS GIS solution. Ecol. Inform. 2013, 17, 82–93. [Google Scholar] [CrossRef]
- Do, T.H.; Raghavan, V.; Vinayaraj, P.; Truong, X.L.; Yonezawa, G. Pixel Based and Object Based Fuzzy LULC Classification using GRASS GIS and RapidEye Imagery of Lao Cai Area, Vietnam. Geoinformatics 2016, 27, 104–105. [Google Scholar]
- Petrasova, A.; Mitasova, H.; Petras, V.; Jeziorska, J. Fusion of high-resolution DEMs for water flow modeling. Open Geospatial Data Softw. Stand. 2017, 2, 6. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Lennert, M. A Complete Toolchain for Object-Based Image Analysis with GRASS GIS 2016. Available online: http://video.foss4g.org/foss4g2016/videos/index.html (accessed on 25 November 2016).
- Momsen, E.; Metz, M.; GRASS Development Team Module i.segment. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2015. Available online: https://grass.osgeo.org/grass73/manuals/i.segment.html (accessed on 25 November 2016).
- Räsänen, A.; Rusanen, A.; Kuitunen, M.; Lensu, A. What makes segmentation good? A case study in boreal forest habitat mapping. Int. J. Remote Sens. 2013, 34, 8603–8627. [Google Scholar] [CrossRef]
- Zhang, Y.J. A survey on evaluation methods for image segmentation. Pattern Recognit. 1996, 29, 1335–1346. [Google Scholar] [CrossRef]
- Johnson, B.A.; Bragais, M.; Endo, I.; Magcale-Macandog, D.B.; Macandog, P.B.M. Image Segmentation Parameter Optimization Considering Within- and Between-Segment Heterogeneity at Multiple Scale Levels: Test Case for Mapping Residential Areas Using Landsat Imagery. ISPRS Int. J. Geo-Inf. 2015, 4, 2292–2305. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgut, L. Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 67–75. [Google Scholar] [CrossRef] [PubMed]
- Haralick, R.M.; Shapiro, L.G. Image segmentation techniques. Comput. Vis. Graph. Image Process. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Lennert, M.; GRASS Development Team Addon i.segment.uspo. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2016. Available online: https://grass.osgeo.org/grass70/manuals/addons/i.segment.uspo.html (accessed on 25 November 2016).
- Espindola, G.M.; Camara, G.; Reis, I.A.; Bins, L.S.; Monteiro, A.M. Parameter selection for region-growing image segmentation algorithms using spatial autocorrelation. Int. J. Remote Sens. 2006, 27, 3035–3040. [Google Scholar] [CrossRef]
- Moran, P.A.P. Notes on Continuous Stochastic Phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Geary, R.C. The Contiguity Ratio and Statistical Mapping. Inc. Stat. 1954, 5, 115–145. [Google Scholar] [CrossRef]
- Grybas, H.; Melendy, L.; Congalton, R.G. A comparison of unsupervised segmentation parameter optimization approaches using moderate- and high-resolution imagery. GISci. Remote Sens. 2017, 0, 1–19. [Google Scholar] [CrossRef]
- Carleer, A.P.; Debeir, O.; Wolff, E. Assessment of very high spatial resolution satellite image segmentations. Photogramm. Eng. Remote Sens. 2005, 71, 1285–1294. [Google Scholar] [CrossRef]
- Johnson, B.; Xie, Z. Unsupervised image segmentation evaluation and refinement using a multi-scale approach. ISPRS J. Photogramm. Remote Sens. 2011, 66, 473–483. [Google Scholar] [CrossRef]
- Schiewe, J. Segmentation of high-resolution remotely sensed data-concepts, applications and problems. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 380–385. [Google Scholar]
- Csillik, O. Fast Segmentation and Classification of Very High Resolution Remote Sensing Data Using SLIC Superpixels. Remote Sens. 2017, 9, 243. [Google Scholar] [CrossRef]
- Cánovas-García, F.; Alonso-Sarría, F. A local approach to optimize the scale parameter in multiresolution segmentation for multispectral imagery. Geocarto Int. 2015, 30, 937–961. [Google Scholar] [CrossRef]
- Lennert, M.; GRASS Development Team Addon i.segment.stats. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2016. Available online: https://grass.osgeo.org/grass70/manuals/addons/i.segment.stats.html (accessed on 25 November 2016).
- Metz, M.; Lennert, M.; GRASS Development Team Addon r.object.geometry. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2016. Available online: https://grass.osgeo.org/grass72/manuals/addons/r.object.geometry.html (accessed on 25 November 2016).
- Lennert, M.; GRASS Development Team Addon v.class.mlR. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2016. Available online: https://grass.osgeo.org/grass70/manuals/addons/v.class.mlR.html (accessed on 25 November 2016).
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 115571. [Google Scholar] [CrossRef]
- Du, P.; Xia, J.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S. Multiple Classifier System for Remote Sensing Image Classification: A Review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef] [PubMed]
- Neteler, M.; Mitasova, H. Open Source GIS—A GRASS GIS Approach. Available online: http://link.springer.com.ezproxy.ulb.ac.be/book/10.1007%2F978-0-387-68574-8 (accessed 2 November 2014).
- Folleco, A.; Khoshgoftaar, T.M.; Hulse, J.V.; Bullard, L. Identifying Learners Robust to Low Quality Data. In Proceedings of the 2008 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 13–15 July 2008; pp. 190–195. [Google Scholar]
- Foody, G.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.; Bastin, L. The Sensitivity of Mapping Methods to Reference Data Quality: Training Supervised Image Classifications with Imperfect Reference Data. ISPRS Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, J.; Van Genderen, J.L. Comparison and Analysis of Remote Sensing Data Fusion Techniques at Feature and Decision Levels. In Proceedings of the ISPRS Commission VII Mid-term Symposium Remote Sensing: From Pixels to Processes, Enschede, The Netherlands, 8–11 May 2006. [Google Scholar]
- Congedo, L. Semi-Automatic Classification Plugin User Manual, Release 5.3.6.1; RoMEO: Paterson, NJ, USA, 2017. [Google Scholar]
- Huth, J.; Kuenzer, C.; Wehrmann, T.; Gebhardt, S.; Tuan, V.Q.; Dech, S. Land Cover and Land Use Classification with TWOPAC: Towards Automated Processing for Pixel- and Object-Based Image Classification. Remote Sens. 2012, 4, 2530–2553. [Google Scholar] [CrossRef]
- Clewley, D.; Bunting, P.; Shepherd, J.; Gillingham, S.; Flood, N.; Dymond, J.; Lucas, R.; Armston, J.; Moghaddam, M. A Python-Based Open Source System for Geographic Object-Based Image Analysis (GEOBIA) Utilizing Raster Attribute Tables. Remote Sens. 2014, 6, 6111–6135. [Google Scholar] [CrossRef]
- Guzinski, R.; Kass, S.; Huber, S.; Bauer-Gottwein, P.; Jensen, I.; Naeimi, V.; Doubkova, M.; Walli, A.; Tottrup, C. Enabling the Use of Earth Observation Data for Integrated Water Resource Management in Africa with the Water Observation and Information System. Remote Sens. 2014, 6, 7819–7839. [Google Scholar] [CrossRef]
- Huth, J.; Kuenzer, C. TWOPAC Handbook: Twinned Object and Pixel-Based Automated Classification Chain; RoMEO: Paterson, NJ, USA, 2013. [Google Scholar]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A Survey of Active Learning Algorithms for Supervised Remote Sensing Image Classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Kanavath, R.; Metz, M.; GRASS Development Team Addon i.superpixels.slic. Geographic Resources Analysis Support System (GRASS) Software, Version 7.3; Open Source Geospatial Foundation: Chicago, IL, USA, 2017. Available online: https://grass.osgeo.org/grass72/manuals/addons/i.superpixels.slic.html (accessed on 20 February 2017).
- Mannel, S.; Price, M.; Hua, D. Impact of reference datasets and autocorrelation on classification accuracy. Int. J. Remote Sens. 2011, 32, 5321–5330. [Google Scholar] [CrossRef]
- Brenning, A. Spatial Cross-Validation and Bootstrap for the Assessment of Prediction Rules in Remote Sensing: The R Package Sperrorest. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 5372–5375. [Google Scholar]
- Brenning, A.; Long, S.; Fieguth, P. Detecting rock glacier flow structures using Gabor filters and IKONOS imagery. Remote Sens. Environ. 2012, 125, 227–237. [Google Scholar] [CrossRef]
- Lisini, G.; Dell’Acqua, F.; Trianni, G.; Gamba, P. Comparison and Combination of Multiband Classifiers for Landsat Urban Land Cover Mapping. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 25–29 July 2005; Volume 4, pp. 2823–2826. [Google Scholar]



| Level 1 Classes Land Cover (LC) | Level 2 Classes Land Use/Land Cover (LULC) | Abbreviation | Training Set Size | Test Set Size |
|---|---|---|---|---|
| Ouagadougou–Burkina Faso | ||||
| Artificial surfaces | Buildings | BU | 216 | 43 |
| Swimming pools | SW | 90 | 31 | |
| Asphalt surfaces | AS | 119 | 30 | |
| Natural material surfaces | Brown/red bare soil | RBS | 130 | 42 |
| White/grey bare soil | GBS | 91 | 30 | |
| Vegetation | Trees | TR | 91 | 32 |
| Mixed bare soil/vegetation | MBV | 99 | 32 | |
| Dry vegetation | DV | 93 | 32 | |
| Other vegetation | OV | 218 | 36 | |
| Water | Water bodies | WB | 115 | 31 |
| Shadow | Shadow | SH | 90 | 30 |
| Liège–Belgium | ||||
| Artificial surfaces | Buildings | BU | 62 | 37 |
| Asphalt surfaces | AS | 86 | 60 | |
| Natural material surfaces | Bare soil | BS | 51 | 42 |
| Vegetation | Low vegetation (<1 m) | LV | 55 | 46 |
| Medium vegetation (1–7 m) | MV | 49 | 48 | |
| High vegetation deciduous (>7 m) | HVD | 63 | 36 | |
| High vegetation coniferous (>7 m) | HVC | 49 | 43 | |
| Water | Water bodies | WB | 72 | 37 |
| Shadow | Shadow | SH | 62 | 39 |
| Individual Classifiers | Votes | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| kNN | Rpart | SVMradial | RF | SMV | BWWV | QBWWV | SWV | |||
| Ouagadougou | L1 | Kappa | 0.69 | 0.80 | 0.84 | 0.90 | 0.87 | 0.90 | 0.90 | 0.90 |
| OA | 77% | 85% | 88% | 93% | 91% | 92% | 92% | 93% | ||
| L2 | Kappa | 0.45 | 0.69 | 0.72 | 0.79 | 0.76 | 0.79 | 0.79 | 0.79 | |
| OA | 50% | 72% | 75% | 81% | 78% | 81% | 81% | 81% | ||
| Liège | L1 | Kappa | 0.75 | 0.83 | 0.87 | 0.89 | 0.88 | 0.89 | 0.89 | 0.89 |
| OA | 82% | 88% | 90% | 92% | 91% | 92% | 92% | 93% | ||
| L2 | Kappa | 0.44 | 0.71 | 0.71 | 0.77 | 0.74 | 0.76 | 0.76 | 0.76 | |
| OA | 50% | 74% | 74% | 79% | 77% | 79% | 79% | 79% | ||
| Individual Classifiers | Votes | |||||||
|---|---|---|---|---|---|---|---|---|
| Level 2 Classes | kNN | Rpart | SVMradial | RF | SMV | SWV | BWWV | QBWWV |
| Ouagadougou–Burkina Faso | ||||||||
| Buildings | 0.62 | 0.78 | 0.78 | 0.93 | 0.86 | 0.93 | 0.92 | 0.92 |
| Swimming pools | 0.91 | 0.92 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| Asphalt surfaces | 0.50 | 0.61 | 0.55 | 0.83 | 0.80 | 0.83 | 0.83 | 0.83 |
| Brown/red bare soil | 0.52 | 0.75 | 0.65 | 0.78 | 0.77 | 0.77 | 0.77 | 0.77 |
| White/grey bare soil | 0.26 | 0.69 | 0.71 | 0.72 | 0.65 | 0.70 | 0.70 | 0.70 |
| Trees | 0.58 | 0.83 | 0.83 | 0.85 | 0.82 | 0.84 | 0.85 | 0.85 |
| Mixed bare soil/vegetation | 0.29 | 0.62 | 0.59 | 0.56 | 0.57 | 0.58 | 0.58 | 0.58 |
| Dry vegetation | 0.08 | 0.48 | 0.65 | 0.61 | 0.64 | 0.63 | 0.62 | 0.62 |
| Other vegetation | 0.55 | 0.71 | 0.73 | 0.77 | 0.75 | 0.78 | 0.81 | 0.81 |
| Inland waters | 0.19 | 0.74 | 0.85 | 0.87 | 0.75 | 0.85 | 0.85 | 0.85 |
| Shadow | 0.75 | 0.72 | 0.93 | 0.94 | 0.95 | 0.95 | 0.94 | 0.94 |
| Liège–Belgium | ||||||||
| Buildings | 0.51 | 0.92 | 0.83 | 0.91 | 0.93 | 0.93 | 0.91 | 0.91 |
| Asphalt surfaces | 0.64 | 0.71 | 0.77 | 0.82 | 0.78 | 0.82 | 0.82 | 0.82 |
| Low vegetation (<1 m) | 0.37 | 0.77 | 0.71 | 0.80 | 0.80 | 0.77 | 0.77 | 0.77 |
| Medium vegetation (1–7 m) | 0.34 | 0.67 | 0.62 | 0.69 | 0.67 | 0.67 | 0.67 | 0.67 |
| High vegetation deciduous (>7 m) | 0.29 | 0.61 | 0.59 | 0.63 | 0.60 | 0.62 | 0.62 | 0.62 |
| High vegetation coniferous (>7 m) | 0.36 | 0.72 | 0.67 | 0.73 | 0.68 | 0.73 | 0.73 | 0.73 |
| Bare soil | 0.49 | 0.63 | 0.71 | 0.74 | 0.66 | 0.75 | 0.74 | 0.74 |
| Inland waters | 0.81 | 0.89 | 0.92 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| Shadow | 0.70 | 0.79 | 0.89 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| Reference | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L2 Classes | BU | SW | AS | RBS | GBS | TR | MBV | DV | OV | WB | SH | |
| Simple Weighted Vote (SWV) | BU | 97.7 | 0 | 0 | 0 | 6.67 | 0 | 0 | 0 | 0 | 9.68 | 0 |
| SW | 0 | 96.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| AS | 0 | 0 | 90 | 11.9 | 0 | 0 | 0 | 9.38 | 0 | 0 | 0 | |
| RBS | 0 | 0 | 3.33 | 85.7 | 36.7 | 0 | 6.25 | 0 | 0 | 3.23 | 0 | |
| GBS | 0 | 0 | 0 | 0 | 53.3 | 0 | 0 | 0 | 0 | 0 | 0 | |
| TR | 0 | 0 | 0 | 0 | 0 | 90.6 | 0 | 3.13 | 19.4 | 0 | 0 | |
| MBV | 2.33 | 0 | 0 | 2.38 | 3.33 | 0 | 50 | 12.5 | 0 | 0 | 0 | |
| DV | 0 | 0 | 0 | 0 | 0 | 0 | 40.6 | 65.6 | 2.78 | 0 | 0 | |
| OV | 0 | 0 | 0 | 0 | 0 | 9.38 | 3.13 | 6.25 | 77.8 | 3.23 | 3.33 | |
| WB | 0 | 0 | 6.67 | 0 | 0 | 0 | 0 | 3.13 | 0 | 80.6 | 0 | |
| SH | 0 | 3.23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.23 | 96.7 | |
| Reference | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L2 Classes | BU | AS | LV | MV | HVD | HVC | BS | WB | SH | |
| Simple Weighted Vote (SWV) | BU | 89.2 | 1.67 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AS | 5.41 | 80 | 0 | 0 | 0 | 0 | 16.7 | 0 | 0 | |
| LV | 0 | 0 | 71.7 | 8.33 | 0 | 0 | 7.14 | 0 | 0 | |
| MV | 0 | 0 | 28.3 | 64.6 | 0 | 0 | 2.38 | 0 | 0 | |
| HVD | 0 | 0 | 0 | 25 | 75 | 27.9 | 0 | 0 | 0 | |
| HVC | 0 | 0 | 0 | 2.08 | 22.2 | 72.1 | 0 | 0 | 5.13 | |
| BS | 2.7 | 15 | 0 | 0 | 0 | 0 | 73.8 | 0 | 0 | |
| WB | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 94.6 | 0 | |
| SH | 2.7 | 3.33 | 0 | 0 | 2.78 | 0 | 0 | 5.41 | 94.9 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grippa, T.; Lennert, M.; Beaumont, B.; Vanhuysse, S.; Stephenne, N.; Wolff, E. An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification. Remote Sens. 2017, 9, 358. https://doi.org/10.3390/rs9040358
Grippa T, Lennert M, Beaumont B, Vanhuysse S, Stephenne N, Wolff E. An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification. Remote Sensing. 2017; 9(4):358. https://doi.org/10.3390/rs9040358
Chicago/Turabian StyleGrippa, Taïs, Moritz Lennert, Benjamin Beaumont, Sabine Vanhuysse, Nathalie Stephenne, and Eléonore Wolff. 2017. "An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification" Remote Sensing 9, no. 4: 358. https://doi.org/10.3390/rs9040358