1. Introduction
Frequently updated land cover data provide useful information for multi-temporal studies and are also required inputs for land cover change models, climate change models or post-catastrophe analysis [
1,
2]. Benefits of high-temporal frequency, remote-sensing imagery include the unique opportunity for acquiring land cover information through the process of imagery interpretation and classification [
3]. To generate updated land cover data at different scales, researchers have proposed a series of remote sensing imagery classification techniques. Using the individual pixel as the basic analytical unit, the techniques can be grouped into one of three categories: unsupervised classification methods (i.e., ISODATA and K-means), supervised classification methods (i.e., decision trees, naive Bayesian, support vector machine, artificial neural network, and maximum likelihood), and hybrid classification methods (i.e., semi-supervised and fusion of supervised and unsupervised learning) [
4,
5]. As the spatial resolution increases quickly, object-based classification methods are proposed to address high-resolution remote-sensing images. In these methods, the pixels with homogeneous properties are grouped into basic units instead of individual pixels and the spatial contextual information is considered [
6,
7,
8].
With the development of remote-sensing data acquisition technology, remote-sensing imagery can be easily obtained through various sensors [
9]. Under these circumstances, remote-sensing classification technology faces new challenges of processing multi-source data and obtaining higher accuracy predictions [
10]. The current classification techniques have respective merits and shortcomings, but different classifiers have complementary information for the correct classification results [
1,
11,
12,
13]. Therefore, one effective solution is to design classifier combinations that are either based on the same base classifiers trained on different data subsets or based on different classifiers trained on the same dataset. Schapire [
14] proved that classifier combinations with a weak learning algorithm could achieve arbitrarily high accuracy. These multiple classifier systems are called classifier ensembles or multiple classifier systems (MCS) [
15,
16,
17]. Bagging and boosting are two classical approaches for creating classifier ensembles at present. Bagging takes bootstrap samples of original objects to generate base classifiers that are used to combine the accurate ensembles. The classification result is obtained by majority voting [
18]. Boosting tries to boost the performance of a “weak” classifier by using it within an ensemble structure [
19]. The classifiers in the ensembles are added one at a time so that each subsequent classifier is trained on data that have been “hard” for the previous ensemble members [
20]. Within this scheme, a pixel in remotely-sensed imagery could be classified using classifier ensembles to improve the accuracy. A comparison of classification performance between random forest classifier ensembles and support vector machines (SVMs) by Pal [
21] indicated that random forest performs equally well to SVMs in terms of classification accuracy and training time and has even more advantages in certain aspects. Foody et al. [
22] used a simple voting procedure to combine various binary classifier outputs to separate a specific class of interest from all others. Maulik and Chakraborty [
23] proposed multiple classifier ensembles combining k-NN, a SVM and an incremental learning algorithm (IL) by majority voting to obtain a more accurate classification result for land cover data compared to any of the single classifiers.
Furthermore, researchers have tried many approaches to improve the performance of the classifier ensemble method. Instead of using the weights of the objects to train the next classifier, García-Pedrajas [
24] used the distribution given by the weighting scheme of boosting to construct a non-linear supervised projection of the original variables. This method has been proved to achieve a better generalization error while being more robust to noise. Zhang and Zhou [
25] proposed a semi-supervised ensemble method, in which the accuracy of basic learners based on labeled data was maximized, whereas the diversity among them on unlabeled data was also maximized. This method has been demonstrated to be highly competitive to other semi-supervised ensemble methods. Kim and Kang [
26] utilized a neural network as a base classifier for a bagging ensemble method to obtain an improved performance over the traditional method. Rodríguez et al. [
27] proposed a new classifier ensemble called rotation forest, in which the original data are projected into a new feature space using Principal Component Analysis (PCA); then, each base classifier (decision tree) is trained using the new training data for linear extracted features. The feature extraction by PCA encourages the diversity of each base classifier. The experimental results, based on hyperspectral remote-sensing imagery, revealed that rotation forest could produce more accurate results than bagging, AdaBoost, or random forest [
28]. These previous studies indicate that the accuracy and diversity of base classifiers are two key features that affect the performance of the classifier ensembles [
27,
28,
29].
Based on this finding, an improved ensemble method, drawing upon the rotation forest framework, is proposed that aims to further improve the diversity and accuracy of base classifiers. To increase the diversity of base classifiers in the ensemble, feature extraction to the subsets of features was applied by PCA, which outperforms non-parametric discriminant analysis (NDA) or random projections [
29], and a full feature set for each classifier was reconstructed. The feature extraction was repeated several times, and each processing instance was able to generate different new training datasets. On each new training dataset, a boosting naïve Bayesian tree was introduced as a base classifier instead of a decision tree in the original classifier ensembles. In this new method, two-layers of voting were applied in the classification phase. We first obtained predictions using the weighted vote boosting naïve Bayesian tree; then, the majority-voting rule was used to integrate the first-layer results to obtain the final result as the prediction of the classifier ensembles. To evaluate performance, this method was applied to 2013 multi-feature remote-sensing imagery classification in Shandong Province, China.
The remainder of this paper is arranged as follows. In
Section 2, we introduce the study area, data source and data filtering processing.
Section 3 describes the improved classifier ensembles.
Section 4 presents the experimental results and the analysis.
Section 5 provides the discussion.
Section 6 offers conclusions and addresses future work.
3. Method
The rotation forest is a successful method for generating classifier ensembles based on feature extraction [
27,
36]. In this method, the feature set of all training samples is randomly split into
K subsets (
K is a parameter of the algorithm), and PCA is applied to rotate the original feature set. All of the principal components are retained to preserve the variability of information in the data. Furthermore,
K-axis rotations occur to form new features for a base classifier. The diversity of each base classifier increases by feature extraction. Furthermore, the accuracy is also promoted by keeping all principal components and using the whole data set to train the base classifier.
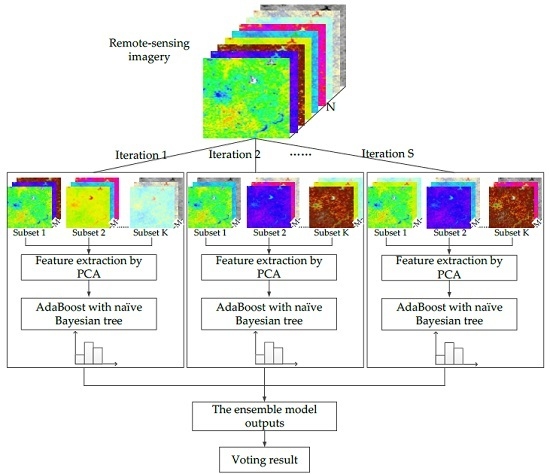
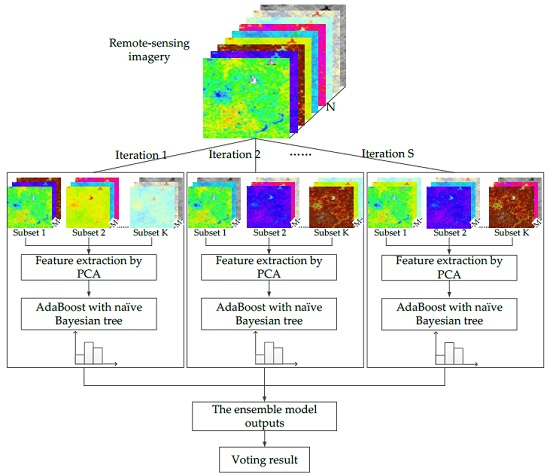
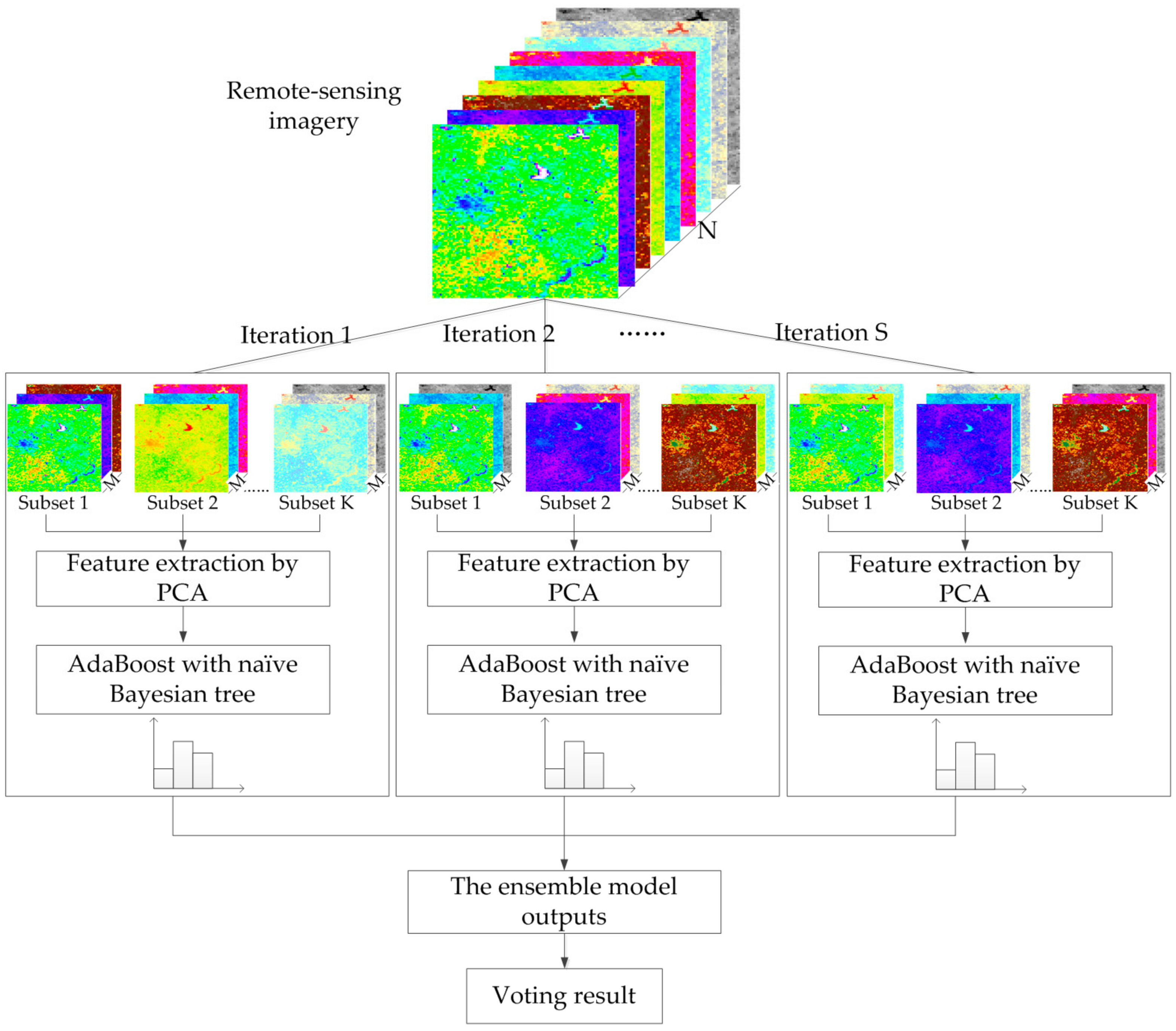
Drawing upon the rotation forest, the modified ensemble method also uses feature extraction to increase the diversity of the base classifier (
Figure 4). However, different from rotation forest that employing a decision tree as a base classifier, we used the boosting naïve Bayesian tree classifier as the base classifier. The classifier ensemble, as a base classifier, could further encourage individual accuracy and achieve lower prediction error. In the classification task, we first obtained several predictions by weighted voting within a boosting naïve Bayesian tree. Then, the several prediction results were voted on to obtain the final classification result. In other words, the modified ensemble method contained two layers of voting to obtain the final result.
To simplify the notations, consider the training set containing N training objects, in which each object (xi, yi) is described by a feature vector xi = [xi1, xi2, xi3, …, xin] and a class label yi that takes a value from the set of class labels Y = {1, 2, 3, …, J}. Let C1, C2, …, CS denote S (number of classifiers) base classifiers in the ensemble, and let F denote the feature set.
To promote individual diversity within the ensemble, the reconstruction of the training set by feature extraction for classifier Cs (s = 1, 2, …, S) is conducted as follows:
F is randomly split into K subsets (K is a number of feature subsets). The disjoint subsets are selected to maximize the diversity. Suppose K is a factor of n; then, each feature subset consists of M = n/K features.
Xsj denotes one subset of the training dataset, which contains M features. A bootstrap sample from Xsj of 75 percent of the data count is drawn. Then, PCA is used to calculate the principal component of the new dataset. The coefficients of the principal components are stored in , an M × 1 matrix.
Dsj is placed on the main diagonal of a zero matrix to obtain a sparse “rotation” matrix
Rs as follows:
Rearrange the columns of Rs in order to correspond to the original features order. Let denote the rearranged matrix; then, the training subset for classifier Cs is .
The feature extraction steps above are repeated S times to construct a corresponding number of classifiers.
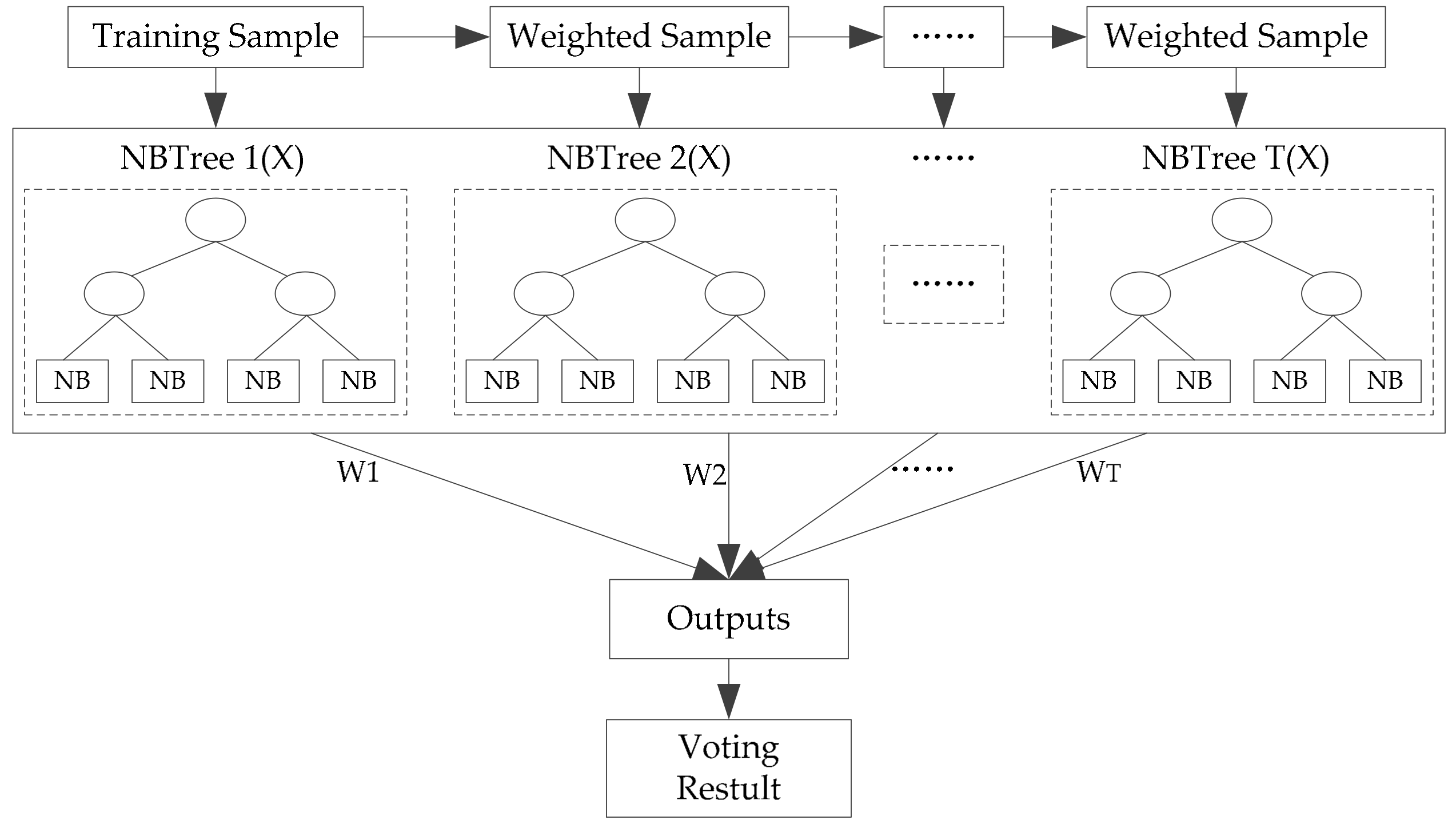
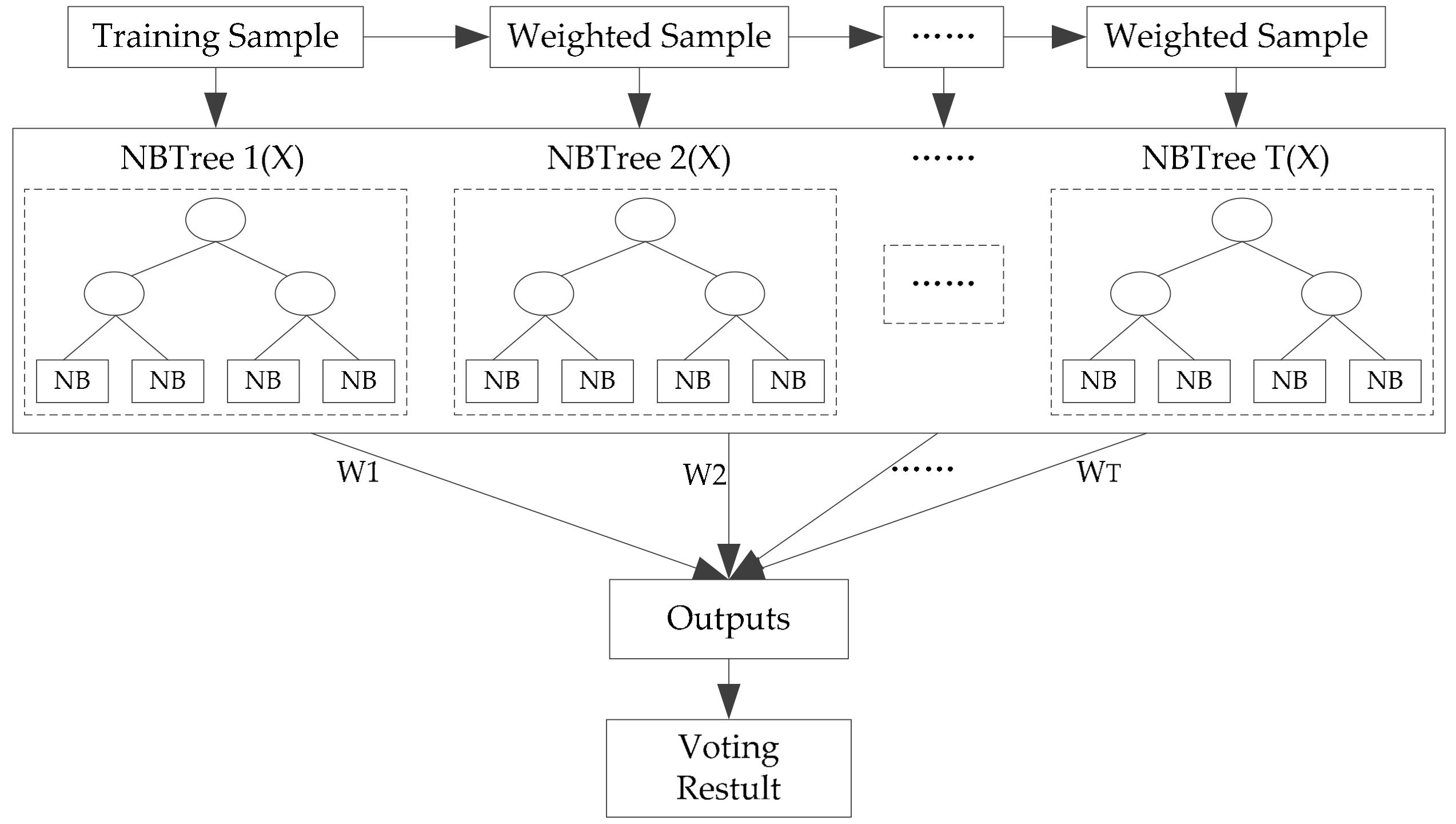
Based on the new training dataset, for which individual diversity has been promoted, a boosting naïve Bayesian tree classifier (
Figure 5) is used as the base classifier. The motivation was to increase the individual accuracy of base classifiers with the first layer voting within the ensemble. First, we briefly review the naïve Bayesian tree.
As indicated by many researchers, the instability of base classifiers is a critical factor limiting classifier ensemble accuracy [
37,
38,
39]. To introduce instability into the boosting method, the NBTree algorithm was selected. NBTree is a hybrid of the naïve Bayesian and the Decision Tree algorithm, which integrates the advantages of the two algorithms [
40,
41,
42]. It has the same tree-growing procedure, but the leaf nodes are a naïve Bayesian classifier. In other words, it first segments the training data by building a Top-Down Decision Tree and then builds a naïve Bayesian classifier in each subset. In this study, similar to C4.5, NBTree also uses the information gain ratio criterion to select the best test at each decision node, and the maximum depth of the tree,
d, is predefined. Furthermore, NBTree does not perform pruning in this study. Because the classification of the dataset at the leaf node is not completed as the maximum depth of the tree has been predefined, the naive Bayesian method is used as the classifier. In the naïve Bayesian approach, the features are assumed to be mutually independent of each other. With this assumption, the probability of a pixel
x belonging to class c can be expressed as in Equation (2):
where
m is the number of features,
aj is the
jth feature value of
x,
P(
c) is the prior probability and
P(
aj|c) is the conditional probability.
where
n is the number of training objects,
nc is the number of classes,
ci is the class label of the
ith training object,
nj is the frequency of values of the
jth feature, and
aij is the
jth feature value of the
ith training object.
Taking NBTree as the base classifier, AdaBoost was used as the boosting method. AdaBoost is a sequential algorithm in which multiple classifiers are induced by adaptively changing the distribution of the training dataset based on the performance of the previously generated classifiers. Denote by Aa the new training set (, Y). Dt = [wt(1), wt(2), …, wt(M)] denotes the weight of M objects at the tth trial, where all of the mth (m = 1, 2, …, M) objects at the tth trail, wt(m), are set to be equal at first. At each trial t = 1, …, T, the boosting procedure is as follows:
If the
mth object is classified correctly by
wt(
m), then
otherwise,
where
Zt is a normalization factor chosen so that
Dt+1 has a probability distribution over
Aa. If
wt+1(
m) < 10
−10,
wt+1(
m) is set to 10
−10 in order to address the numerical underflow problem [
43].
After T trials, the T NBTree models are combined to form a classifier ensemble. The result of each boosting NBTree is summed up by weighted voting of the predicted class in every NBTree. This is the first-layer result. Based on the obtained first-layer results, equal weight voting, which belongs to the second-layer voting, is carried out, and the final result is obtained. These classification algorithms are all run with Matlab software version 2013b.
5. Discussion
In view of the fact that classifier ensembles, such as rotation forest and AdaBoost, that have been successfully applied in some remote-sensing imagery classification researches, it is plausible that a combination of the two methods may achieve lower prediction error than either of them. This paper proposed an improved rotation forest which was constructed by integrating the ideas of rotation forest and AdaBoost. The NBTree was used as the base classifier because it was more accurate than decision tree, yet sufficiently sensitive to rotation of the axes.
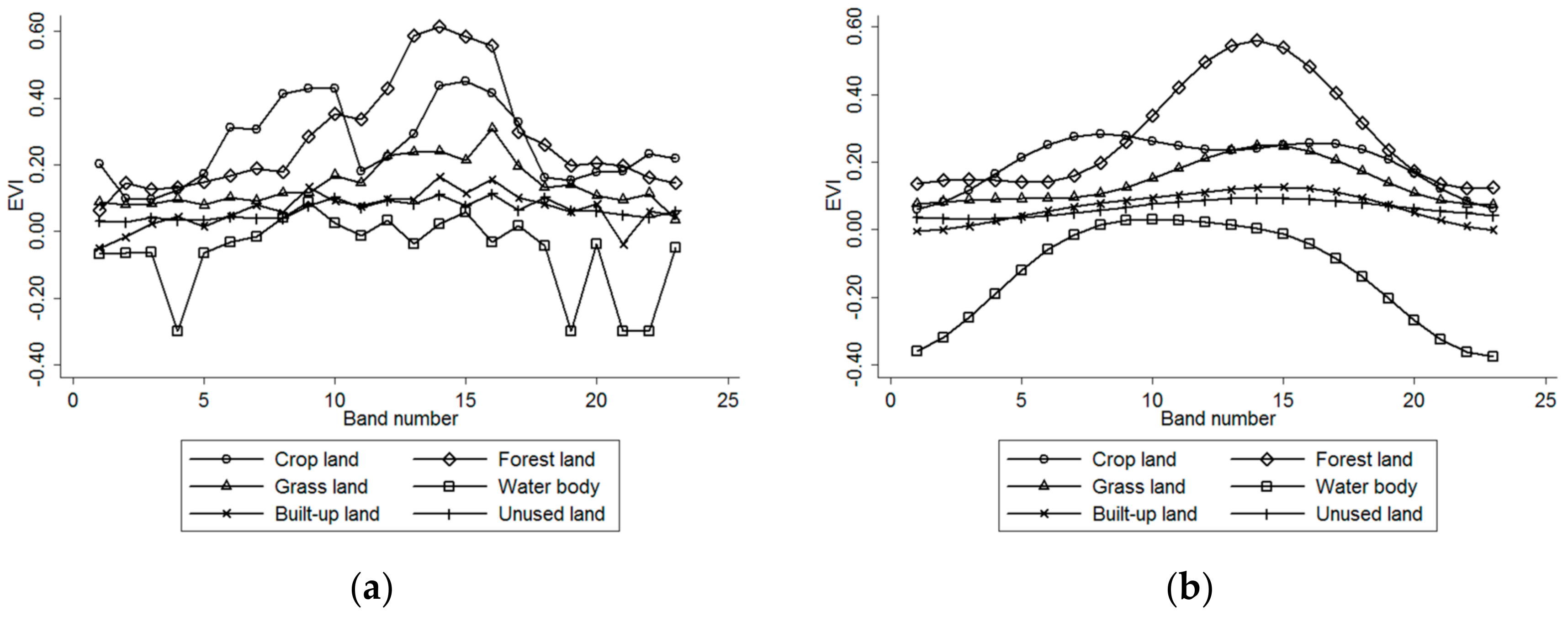
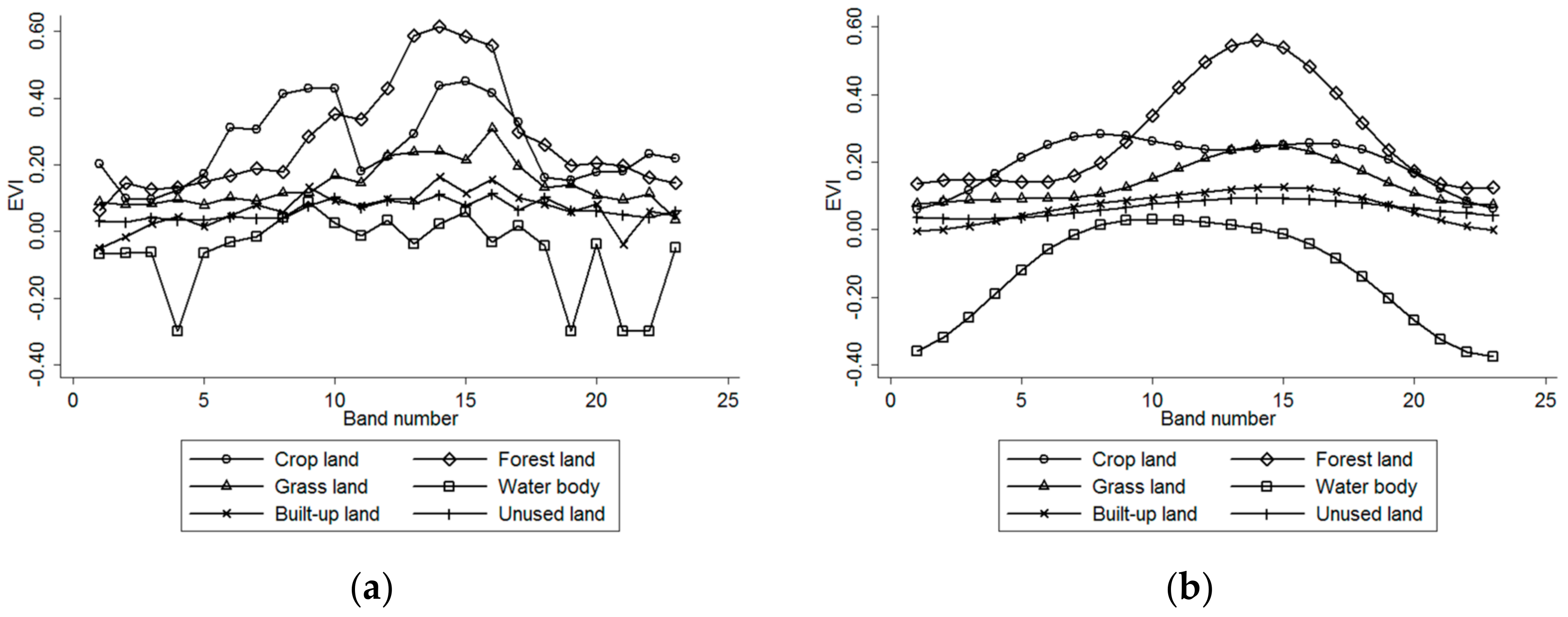
The high temporal resolution MODIS EVI time series, as well as ancillary geospatial and other MODIS data, were selected as the basic data. HANTS filtering was used to preprocess the EVI data. This strategy significantly increased the separability between land classes, especially the vegetation classes, and helped to improve the classification accuracy.
In order to find out which of the parameters and the feature extraction/selection methods are responsible for the good performance of improved rotation forest, multi-group comparison experiments were carried out. The sensitivity of the parameters S and T in the proposed method was investigated and the best parameters combination was selected. However, the best combination of parameters S and T was selected by enumeration. Whether there is a solution to automatically selecting an optimal combination requires further study. Then we compared the performance of feature extraction (in this study PCA) and feature selection (in this study forward and random feature selection). According to the results, no large difference was noticed between random and forward feature selection. It might be explained that in both cases all original features participated in the combined decision. Moreover, the PCA outperformed the two feature selection methods. This was because the PCA succeeded in extracting good features. When the feature extraction approach was used, all original features contribute in the new extracted feature set. The extracted features contained more useful information for discrimination between data classes. Moreover, the feature extraction encouraged individual diversity within the ensemble. On the contrary, the FFS, for instance, selected features sequentially one by one. The union of the first best feature selected with the second best one did not necessarily represent the best discriminative pair of features. By this, the selected feature subset might be not the most advantageous one. The comparison analysis demonstrated that feature extraction with PCA was more advantageous than applying feature selection techniques in the improved rotation forest. It also indicated that the dataset in this study need quite many principal components in order to obtain a classification rule that performs well due to the data distribution. However, if the first principal components succeeded in good discrimination between data classes, the classifier ensemble method on top of PCA may be not the best choice.
In addition, the increasing of the subset size from 4 to 8, and then 16 did not make the classification accuracy change significantly. Kuncheva and Rodríguez [
29] had tested the impact of subset size on the rotation forest and found that there was no consistent relationship between the ensemble accuracy and subset size. In their experiment, the patterns for different data sets vary from decrease of the error with subset size, through almost horizontal lines, to increase of the error with subset size. In our study, the increasing of the subset size also did not make significant accuracy change. This was consistent with their finding. Generally, the performance of almost classifiers depends on the relation between the training sample size and the data dimensionality. The chances are the size of the training set in this study was much larger than feature space dimensionality. There is spacing between parameters of subset size in this experiment. For a thorough comparison, evaluation of the response of the improved rotation forest to the choice of each subset size is needed in the future study.
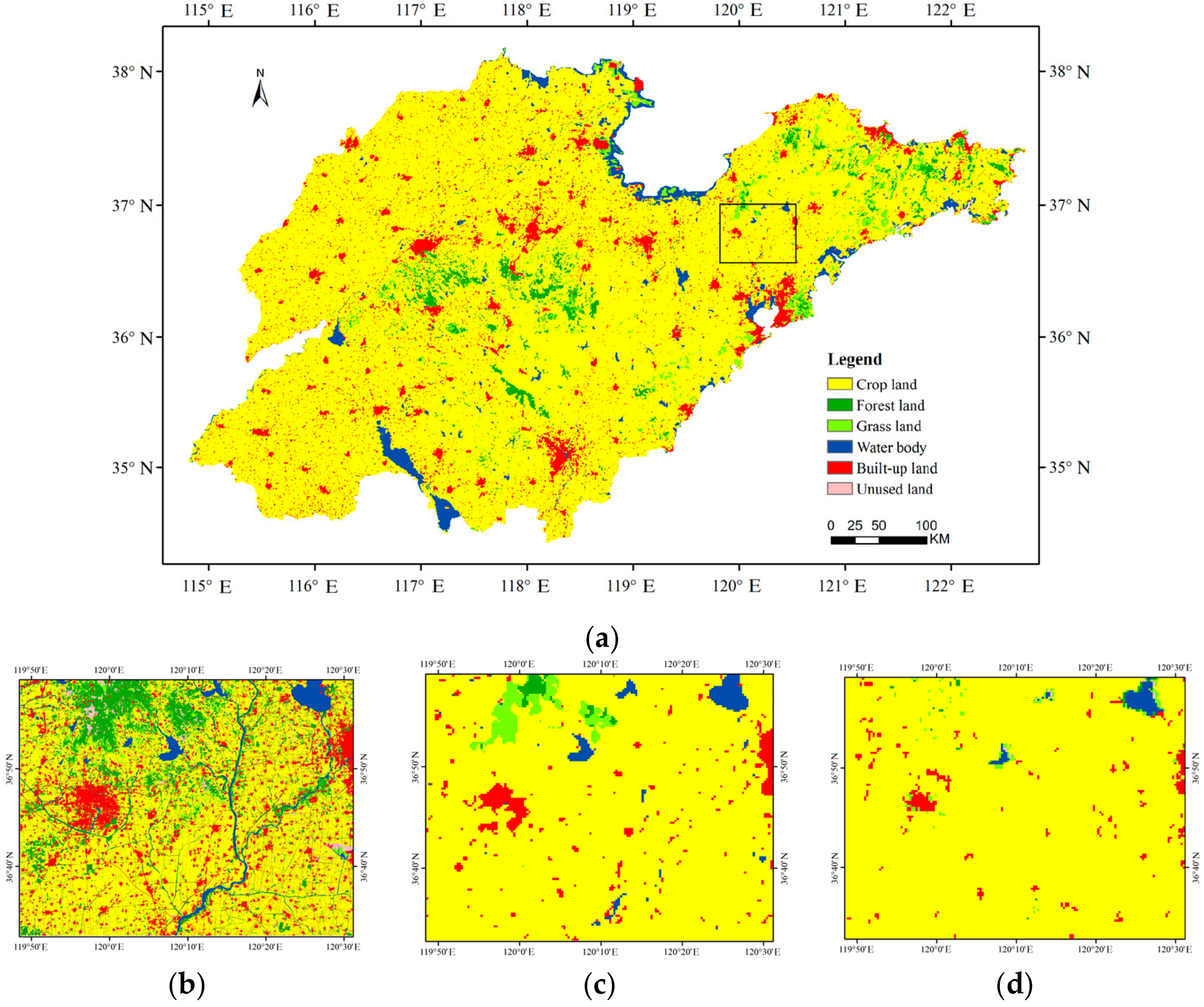
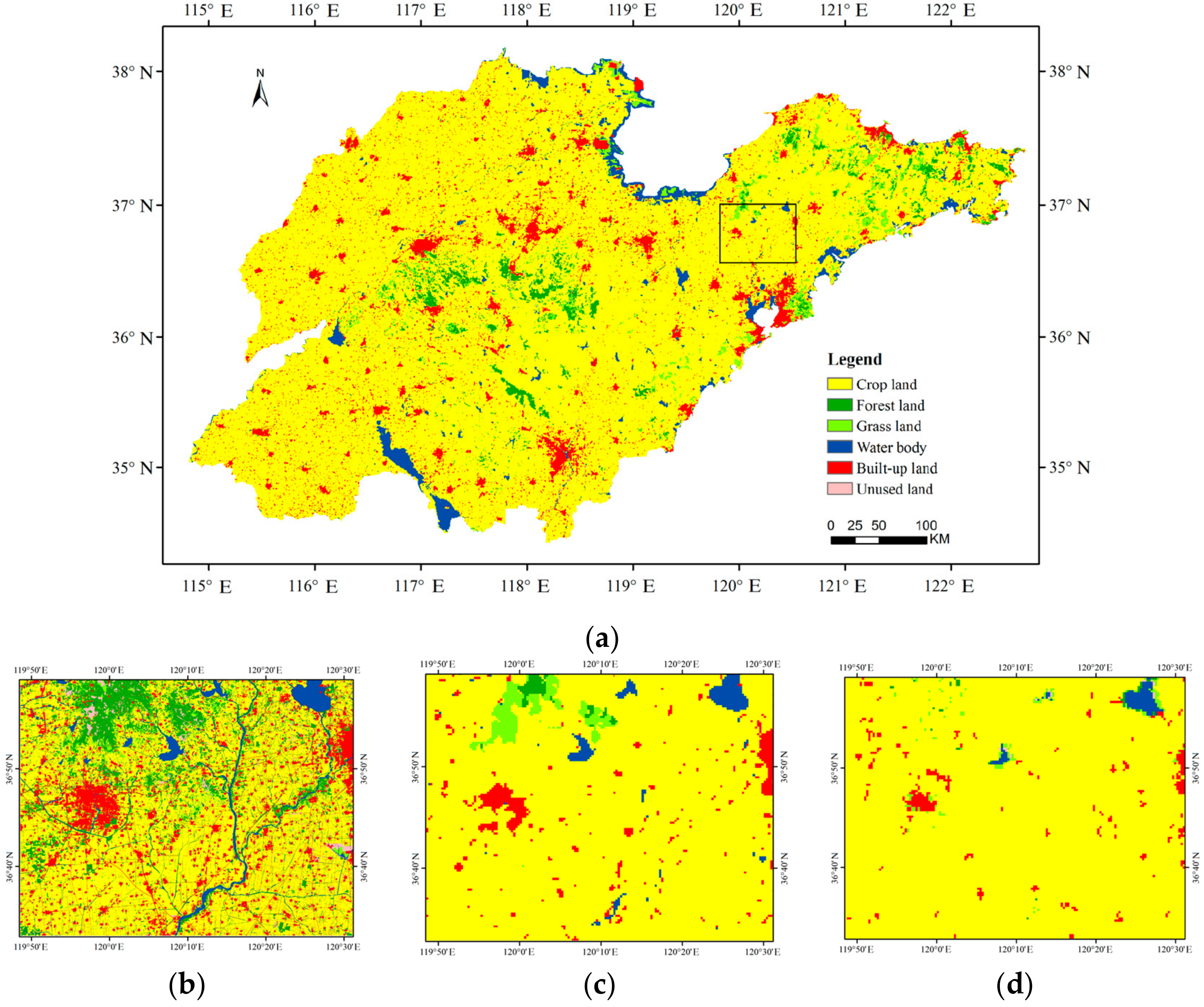
The classification result of the improved rotation forest was compared with other classifier ensembles (that is, NBTree, AdaBoost, random forest, and rotation forest). The result showed that improved rotation forest outperformed all other four methods. In fact, the improved rotation forest has a potential computational advantage over other methods in that it could parallel execute feature extraction, which preserves the variability information for the base classifier; furthermore, it combines the advantages of boosting NBTree, which could obtain an accurate result as a base classifier. An inadequacy of the method is the higher computational costs. The NASA land cover product was also collected, which had an overall accuracy of 65.96% and a Kappa coefficient of 0.33. It was unsatisfactory according to the interpretation of Kappa coefficient. The reason for this lies in two facts: one is the poor ecosystem representation of the 40–60 test sites, and the other is the implementation of algorithms that overcome previously unconsidered challenges involved in classifying high data volumes with complex feature attributes at global scales [
46,
47,
48]. On the whole, the comparison result indicates that our classification data is more useful for land cover applications.
6. Conclusions
Multi-feature, especially multi-temporal, remote-sensing data increase the potential for discriminating different land cover types. However, addressing multiple features remains a challenge in remote-sensing classification. Satisfactory classification results not only depend on basic data with little noise but also on a classification method that performs well.
In this paper, an improved rotation forest was developed to make full use of multiple feature information. HANTS processing was applied for EVI preprocessing to increase the separability between land classes and help to improve classification accuracy. Different feature extraction/selection methods were investigated for the construction of improved rotation forests. It was shown that PCA is more advantageous than feature selection techniques to create training data for a base classifier. Based on the newly generated dataset, AdaBoost with NBTree was adopted as the base classifier to further promote the accuracy. Finally, the classification result was obtained using two-step voting. The classification result of improved rotation forest was compared with other similar classifier ensembles and NASA land cover product. The results showed that improved rotation forest outperformed the other methods. The improvement of prediction accuracy was obtained with negligible increase in computational costs. Generally, the good performance that we identified mainly depended on a high-precision pixel-wise classifier, as well as a better understanding of local land systems, including the phenological rules and the terrain data.
Nevertheless, there are still some shortcomings and problems requiring further investigation. In this study, the pixels were treated as the objects, while neglecting the spatial information effects on the rotation analysis of the remote-sensing images [
49,
50]. Future studies could incorporate spatial information into the improved rotation forest. Furthermore, there are other unstable algorithms, such as a neural network, that could be adopted as the base classifier in AdaBoost. It would be worthwhile to evaluate the effect of other base classifiers in the classifier ensemble on the classification accuracy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}