Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining †


Abstract
:
1. Introduction
- We design a novel HEM-CNN framework for airport detection. It integrates shared features extraction, proposal detection and object localization to achieve a speed-accuracy trade-off. In addition, a more robust high-level feature is utilized to extract high-quality proposals in our framework.
- We introduce a new designed hard example mining layer into CNN, which is efficient to improve the network training by automatically select positives and negatives. In addition, HEM layer contributes to release the ratio constraint on airport-background examples.
- We develop a weight-balanced loss function to compute the average loss respectively on airport and background examples. It makes our network training focus on the hard examples and achieves a precision-recall trade-off.
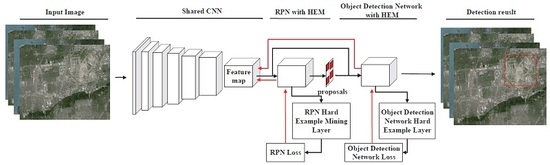
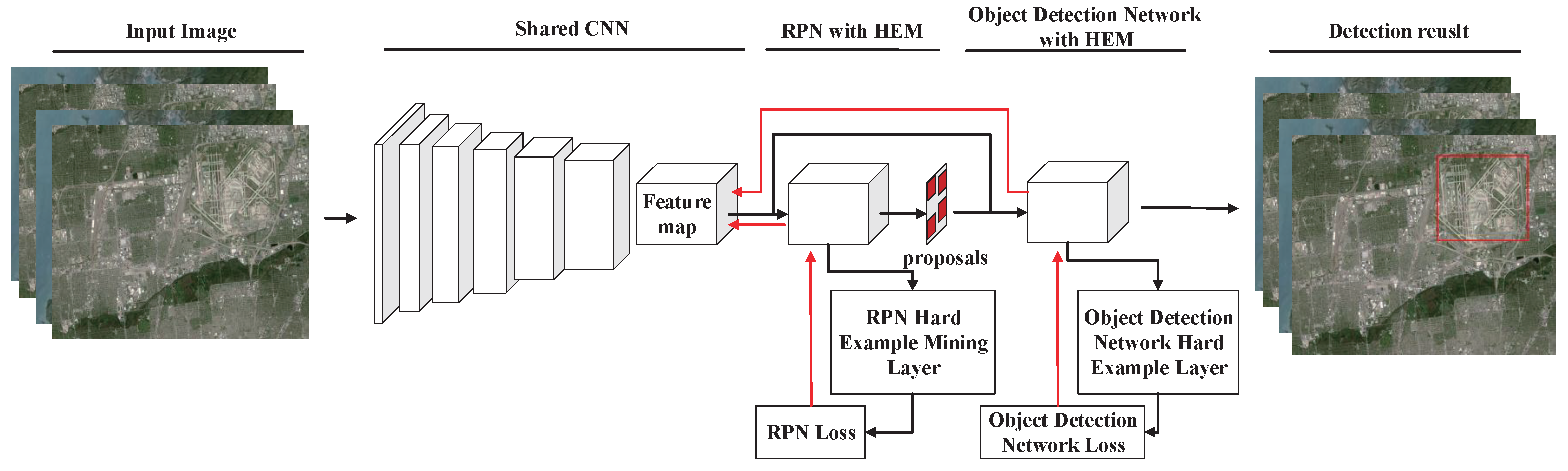
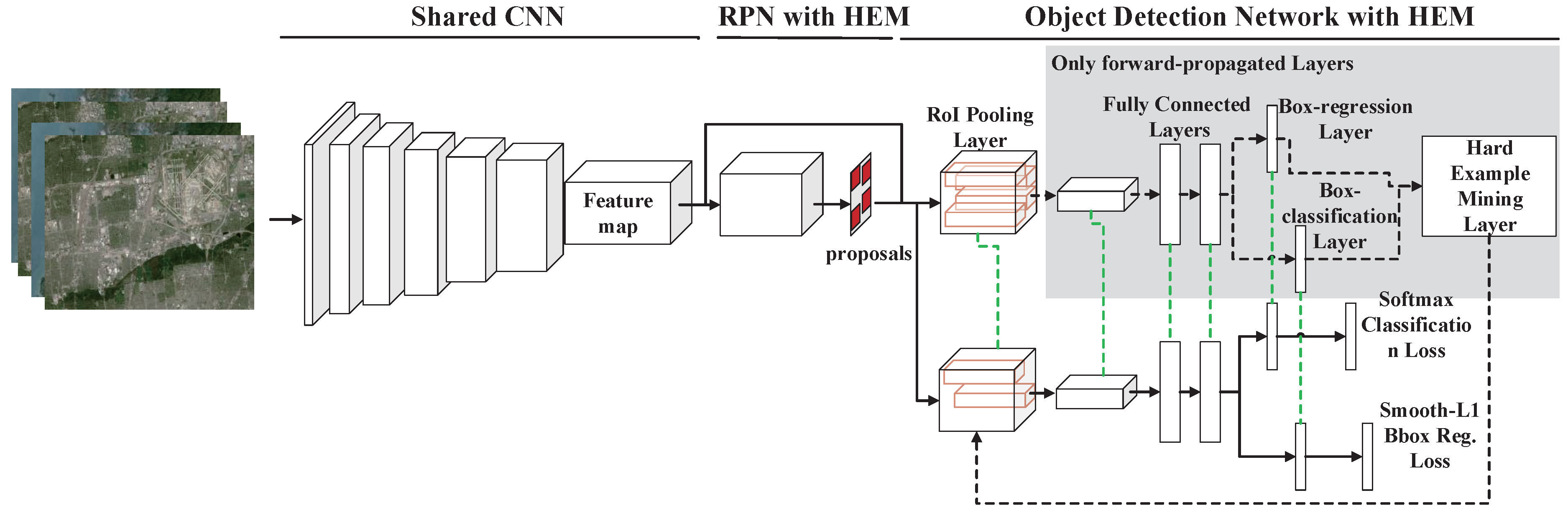
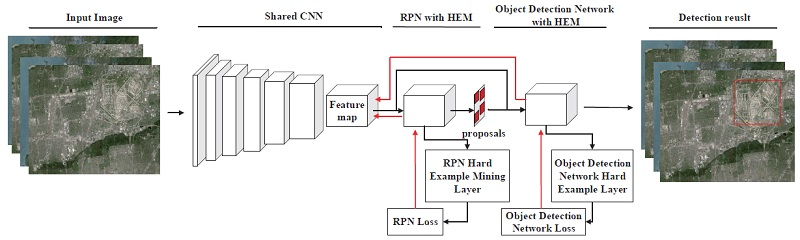
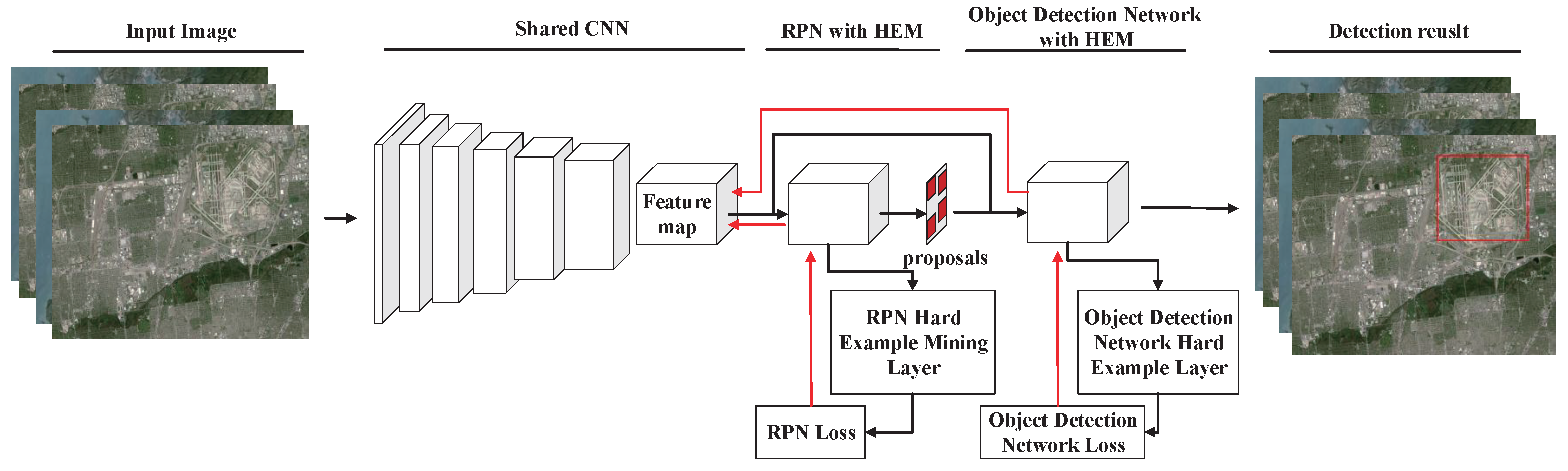
2. Methodology
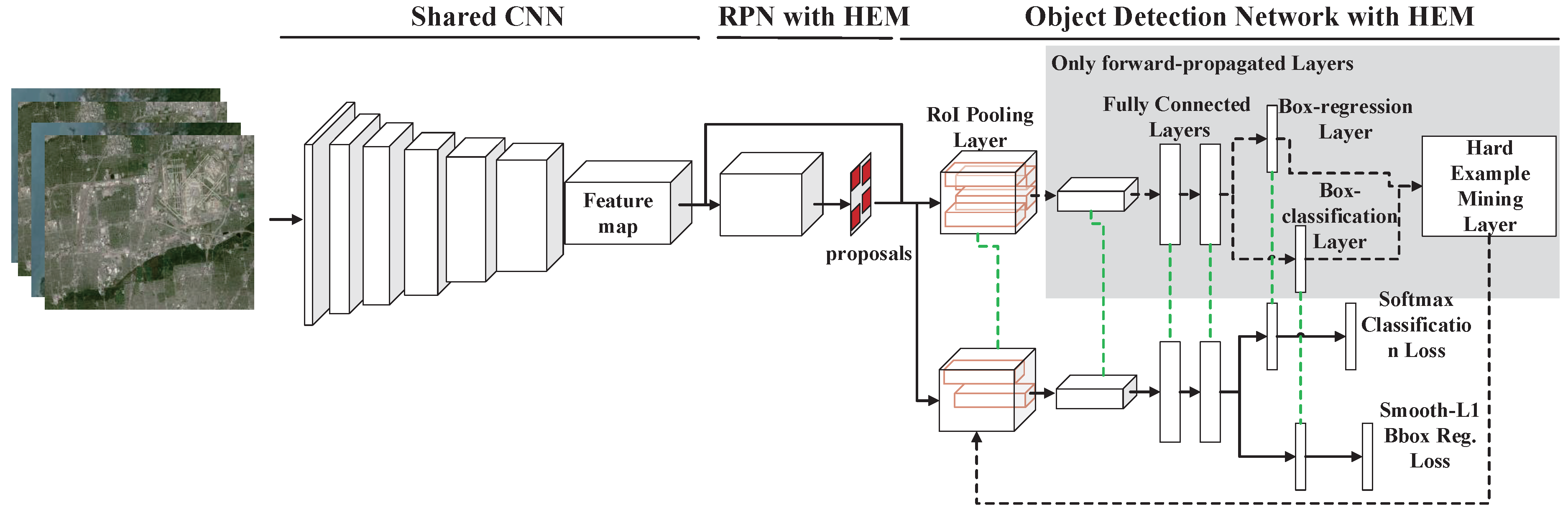
2.1. Shared Convolutional Neural Network
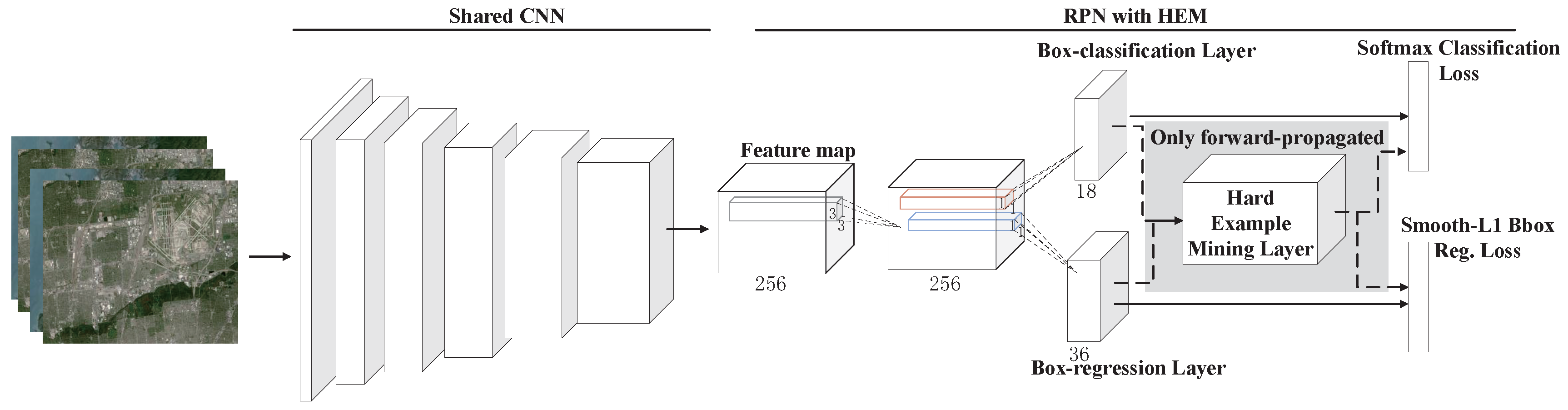
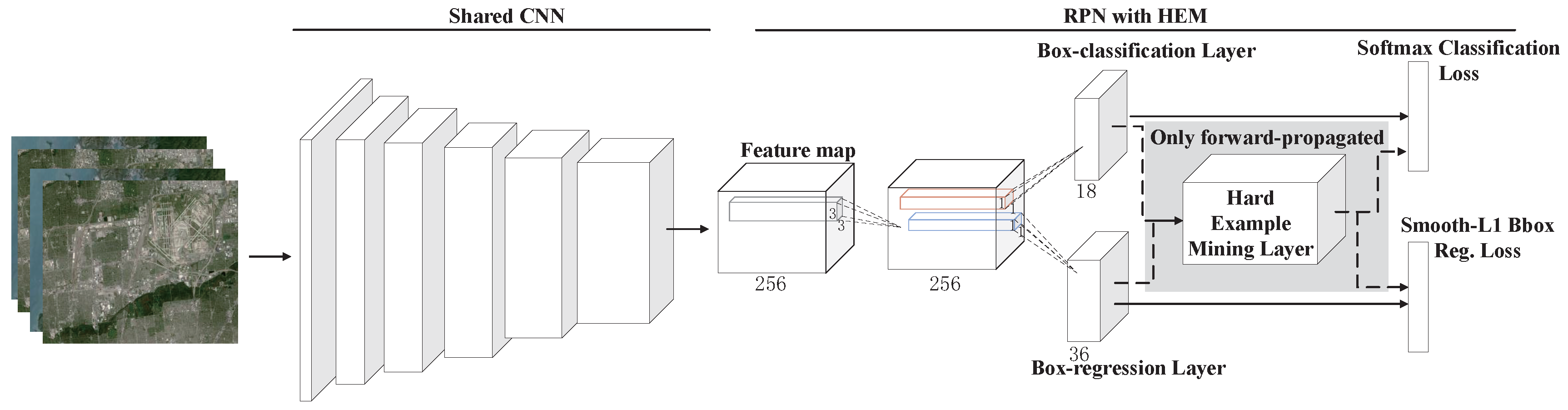
2.2. Region Proposal Network with HEM
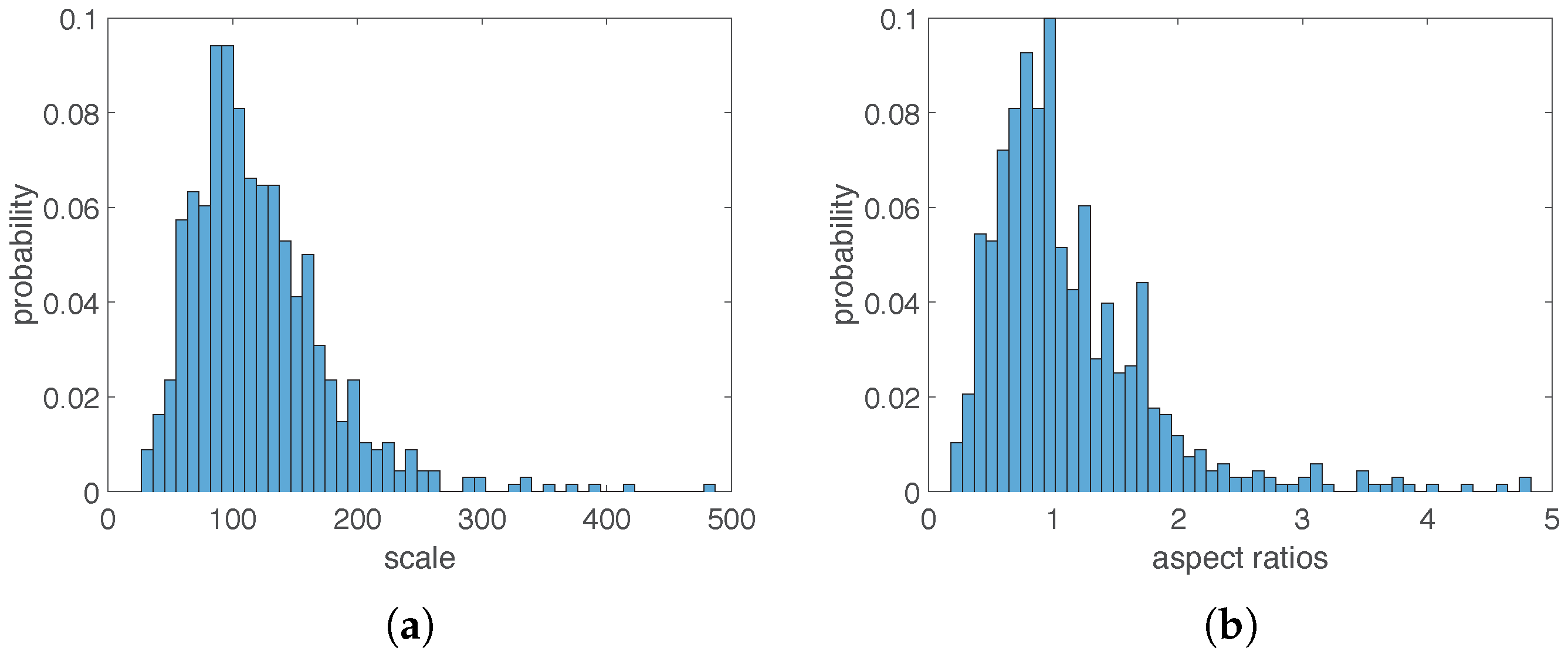
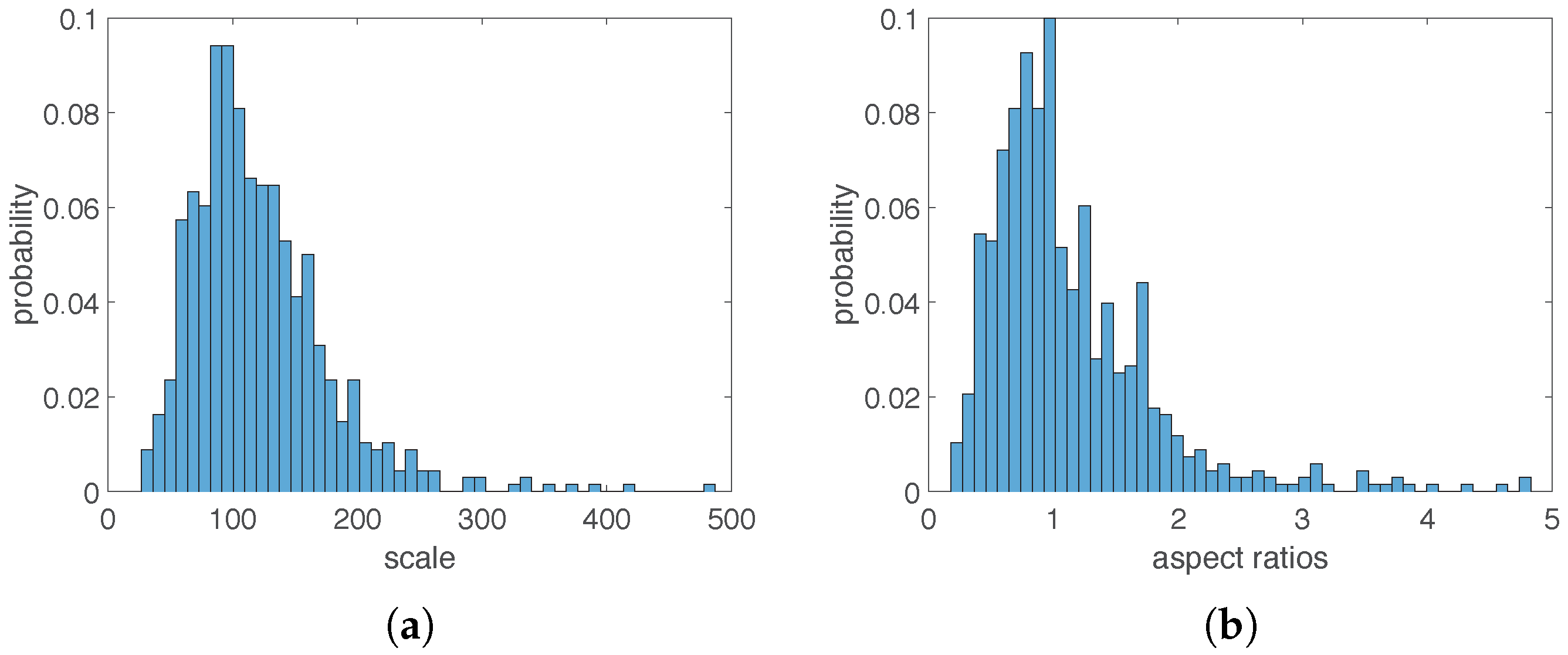
2.2.1. Anchors
2.2.2. Hard Example Mining Layer
2.3. Object Detection Network with HEM
2.4. Approximate Joint Training
3. Results and Discussion
3.1. Dataset and Parameter Setting
3.2. Evaluation Metrics
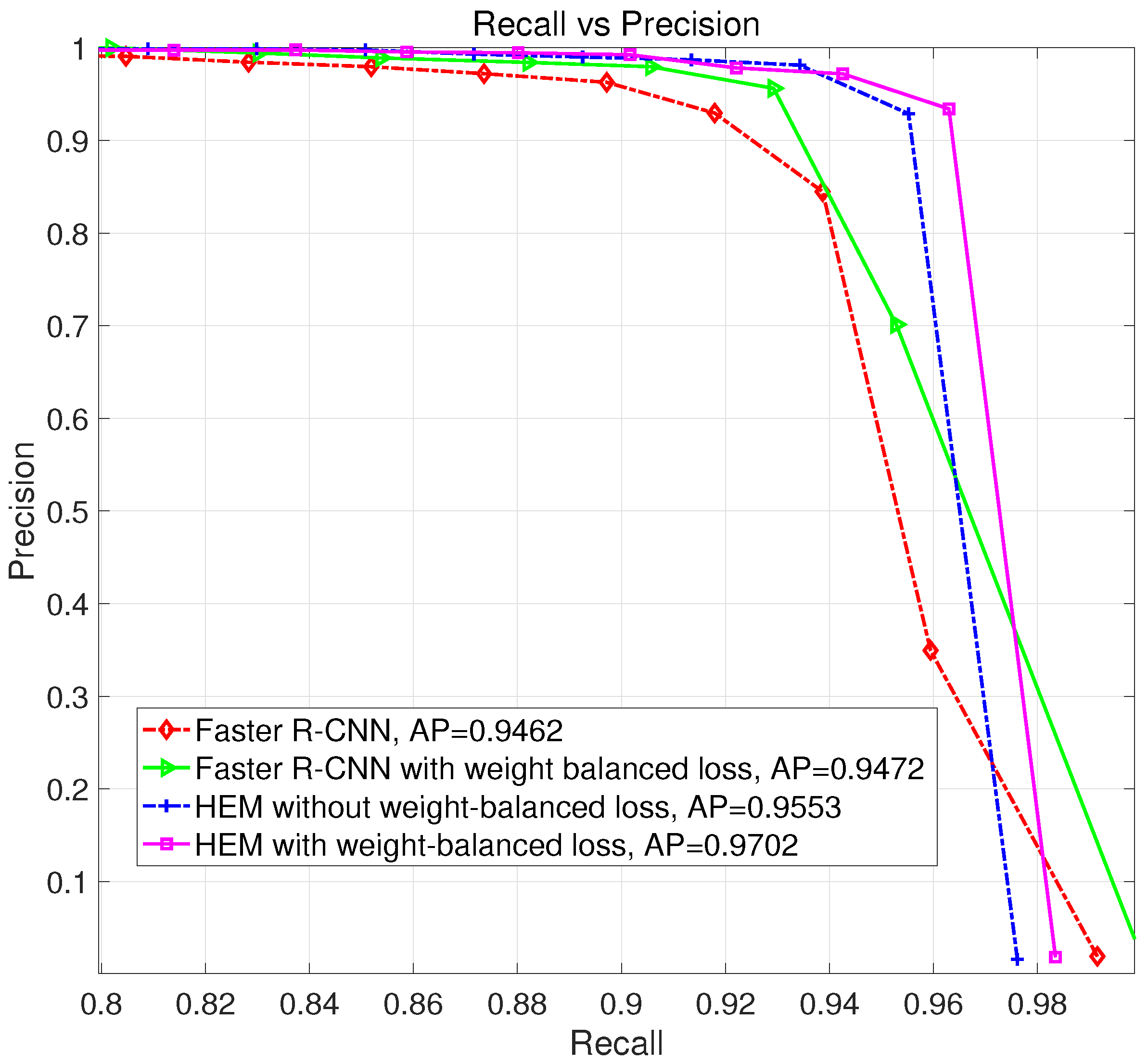
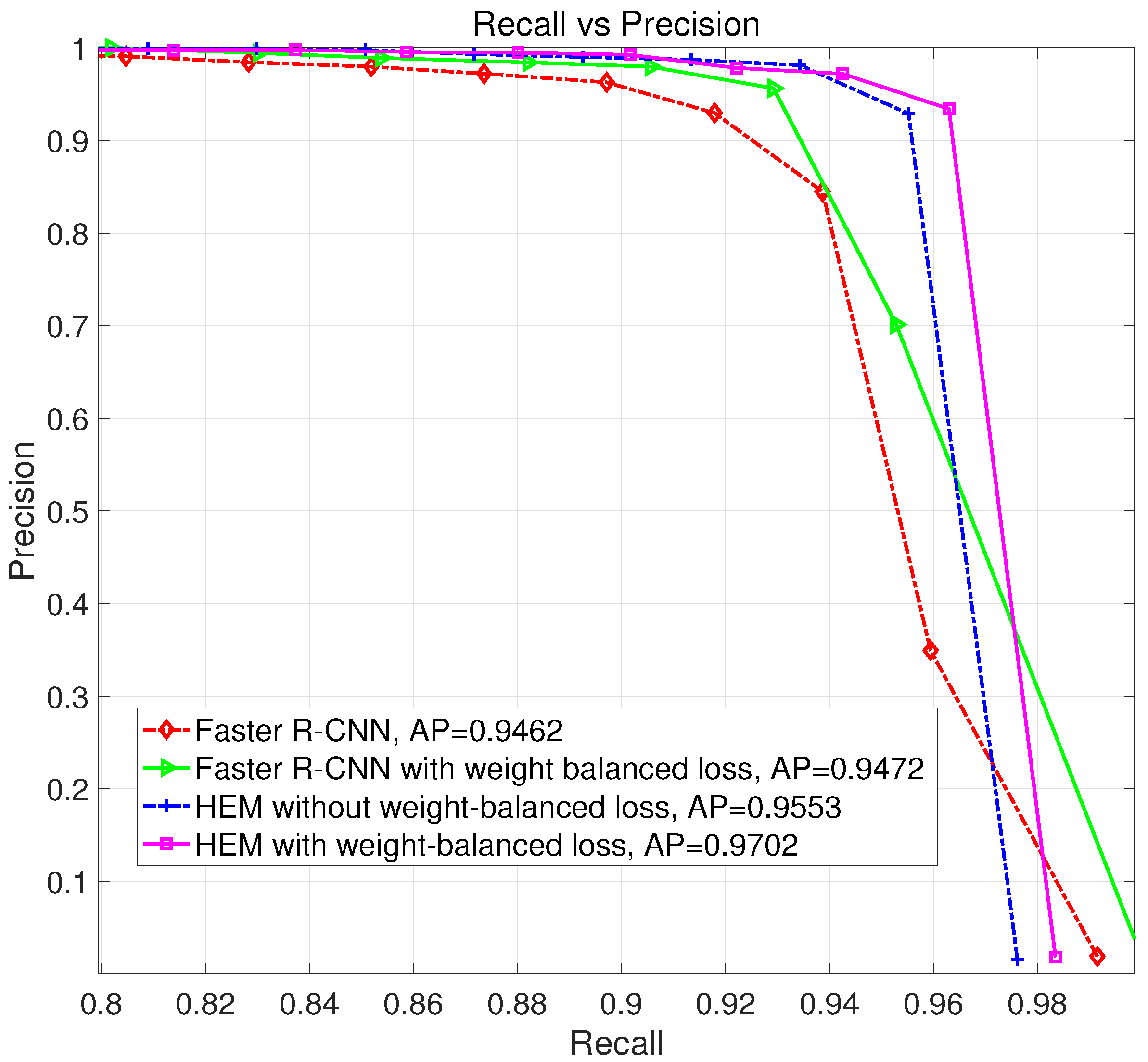
3.3. Verification of HEM and Weight-Balanced Loss Function
- In contrast with hard examples, there are much more easy examples in RSIs.
- Easy examples mainly concentrate on the background areas in RSIs, that is to say, negatives have more easy examples than positives. So it is feasible to employ hard example mining to handle the airport-background class imbalance.
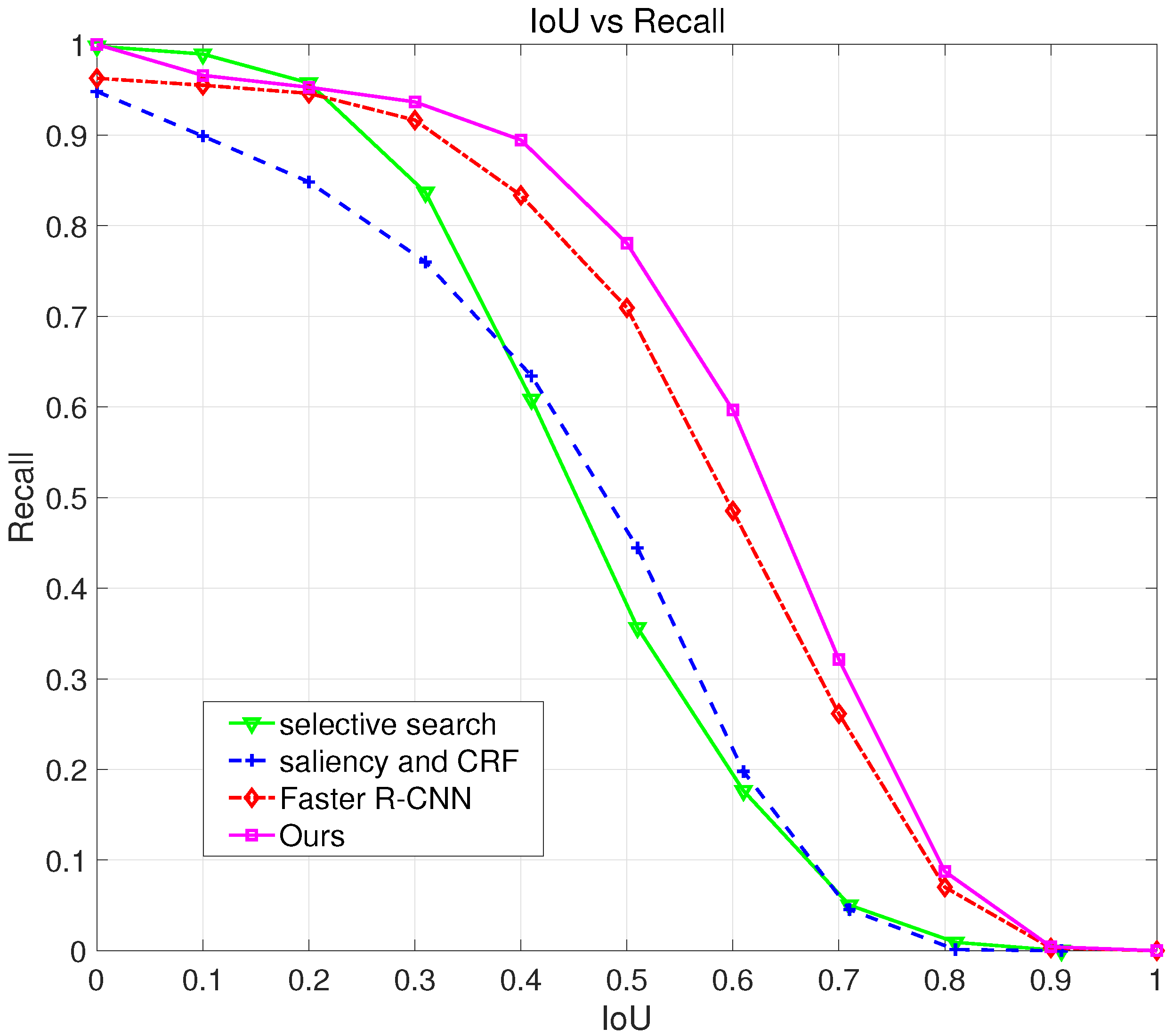
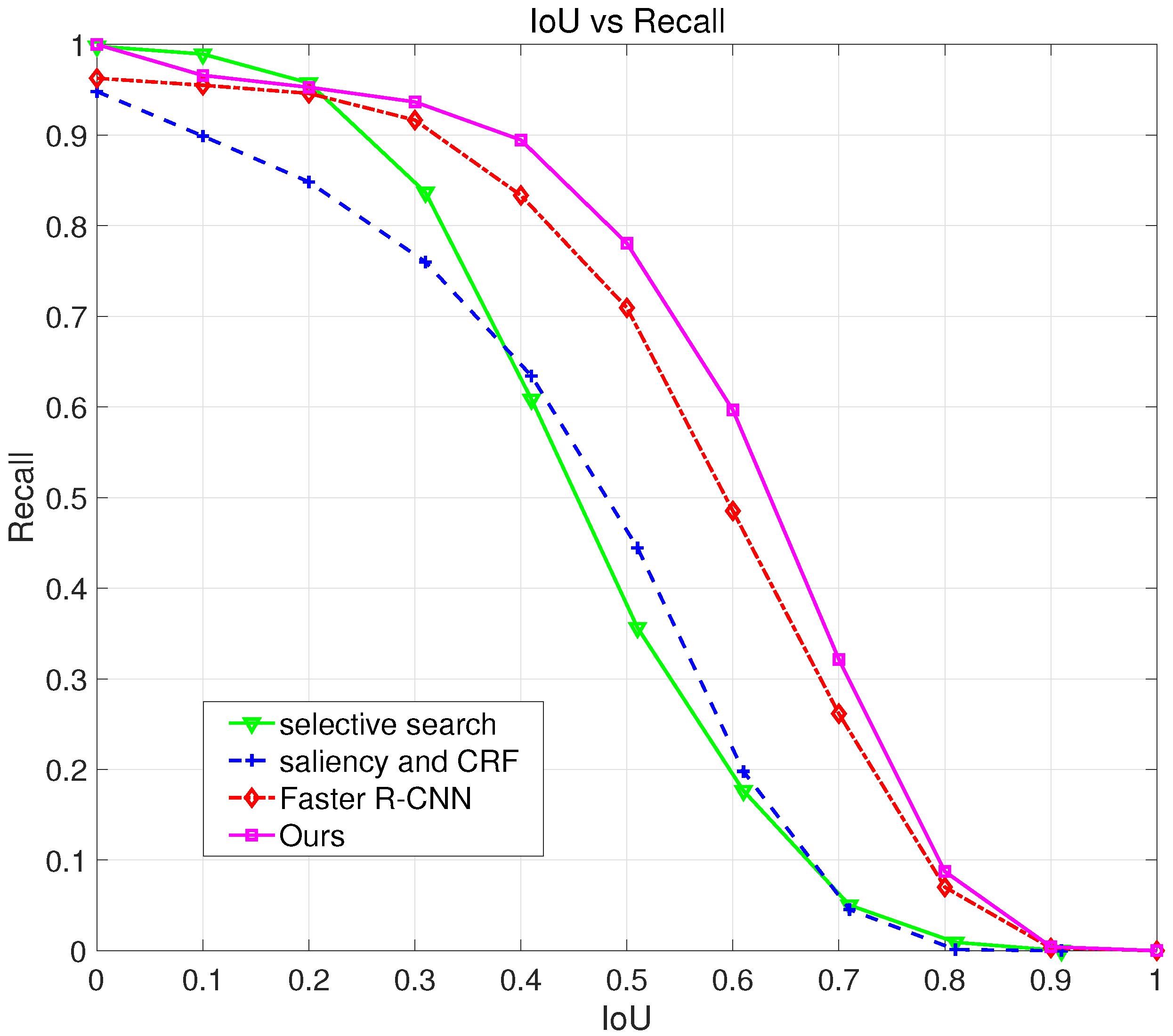
3.4. Performance on Region Proposal Method
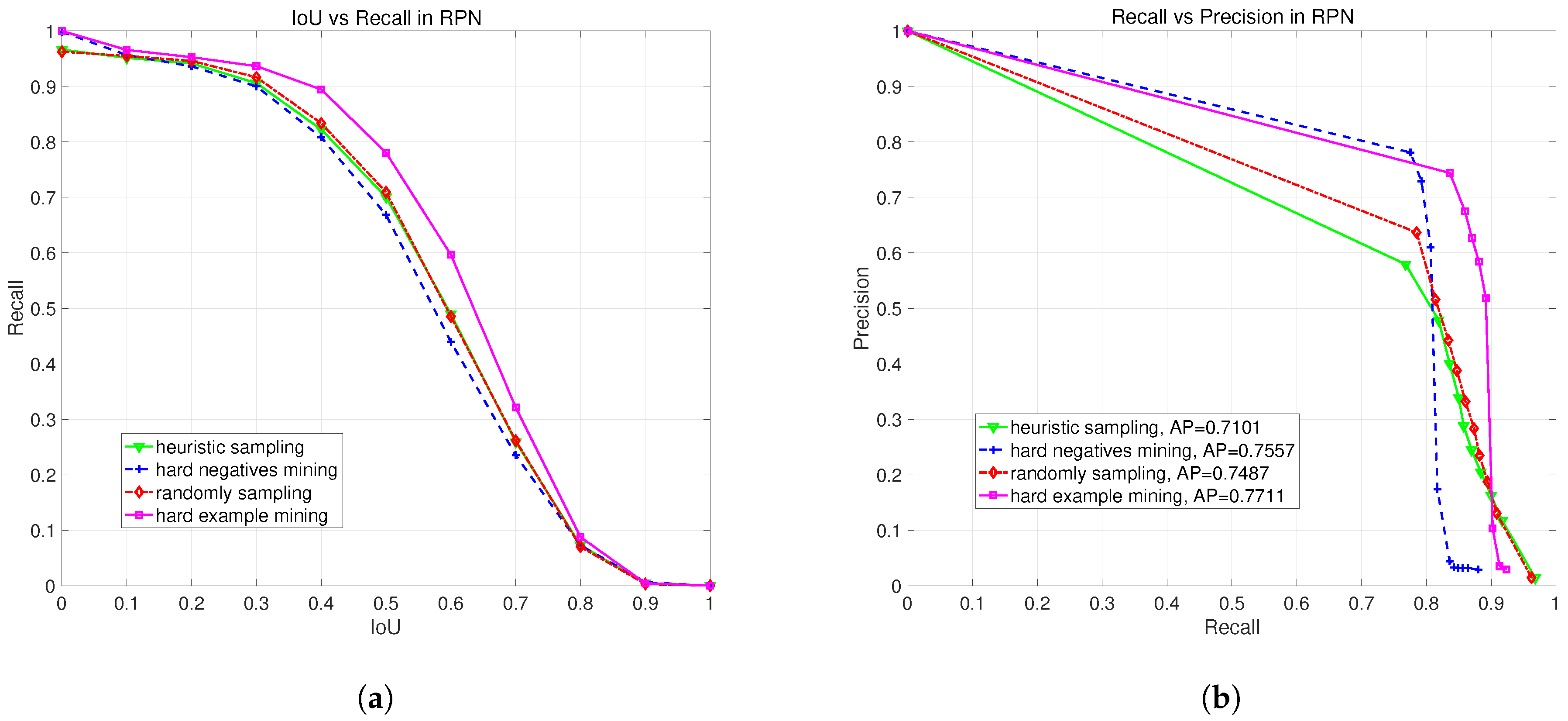
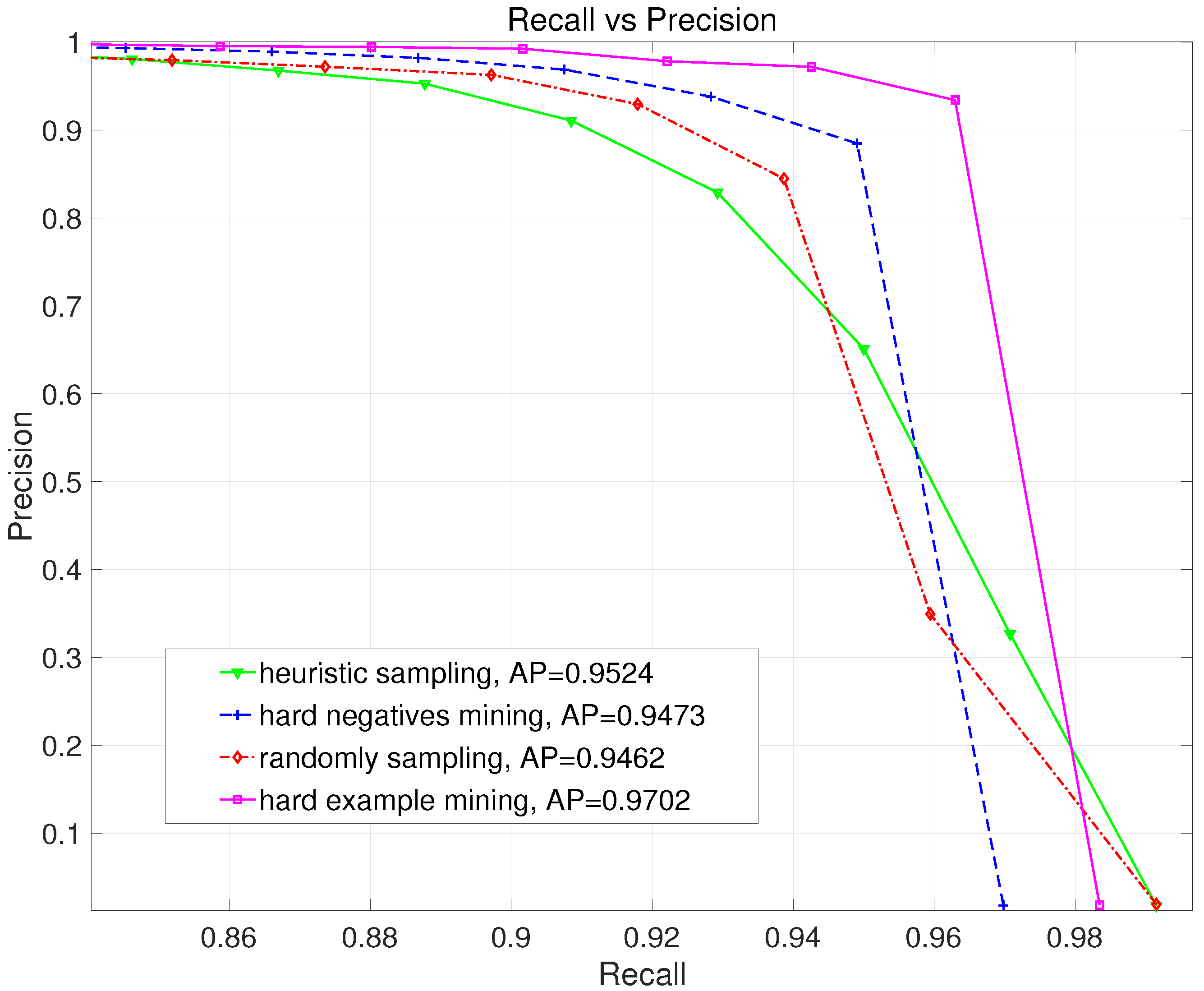
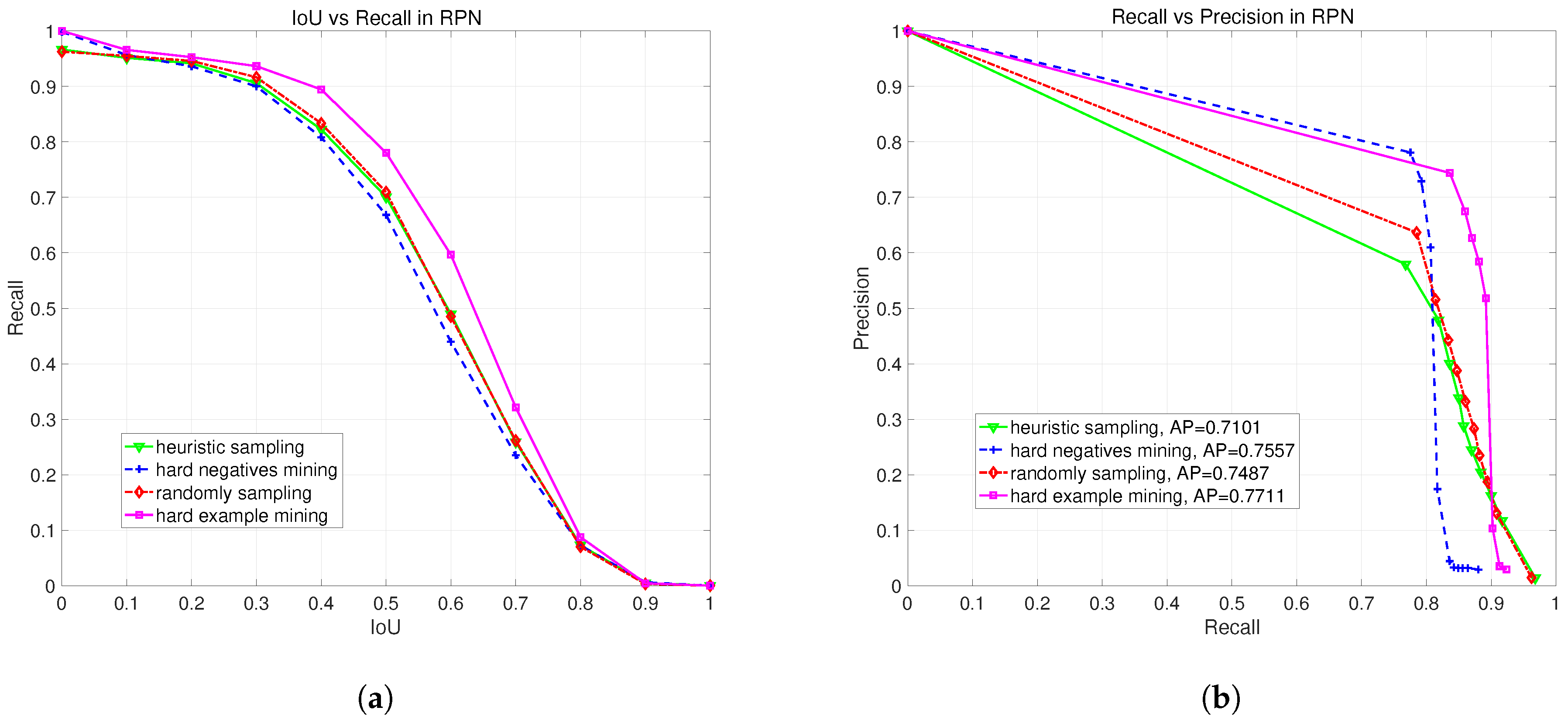
3.5. Comparison on Different Sampling Methods
3.5.1. Overview Sampling Methods
3.5.2. Evaluating Sampling Method on Region Proposal
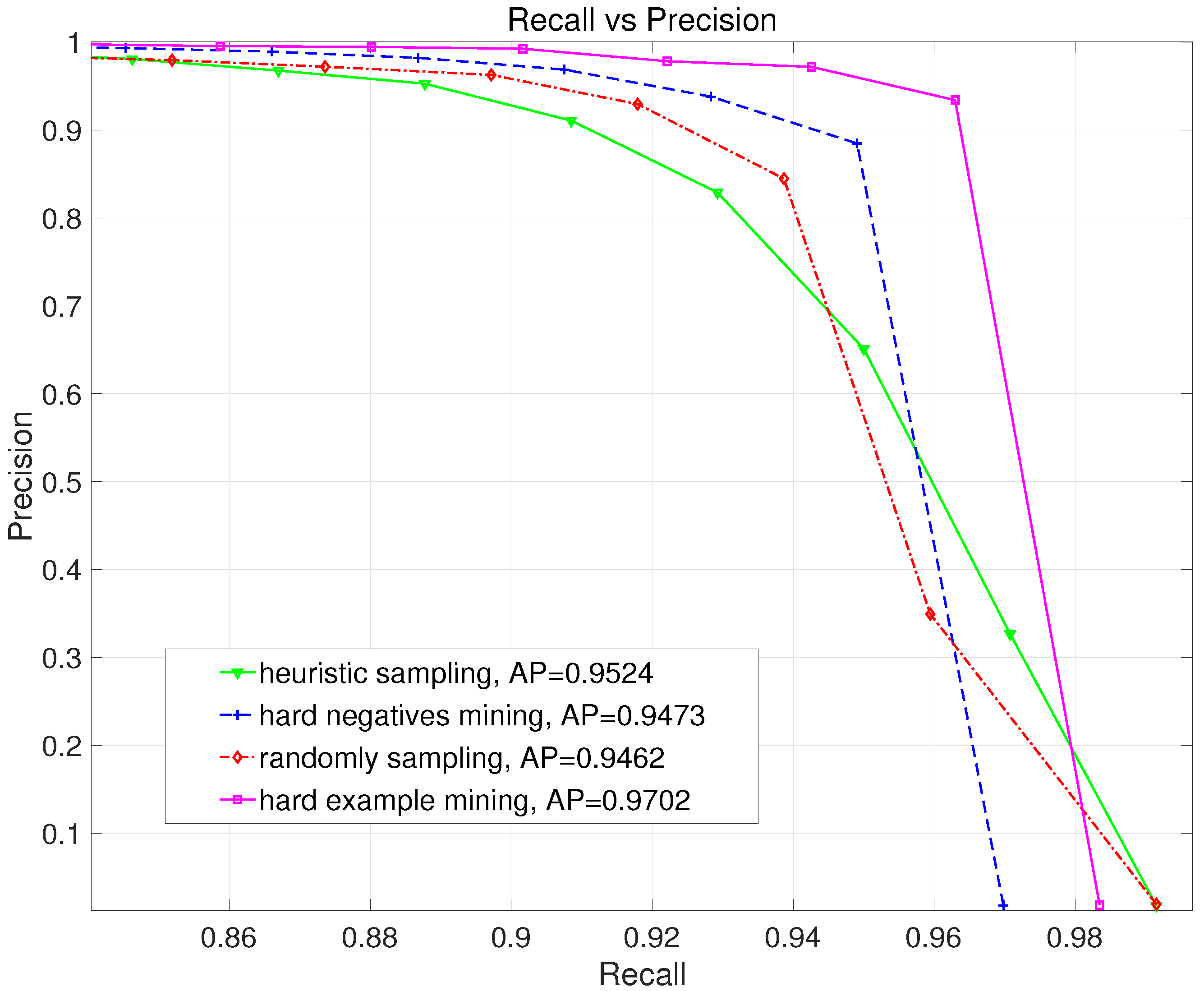
3.5.3. Evaluating Sampling Method on Final Detection
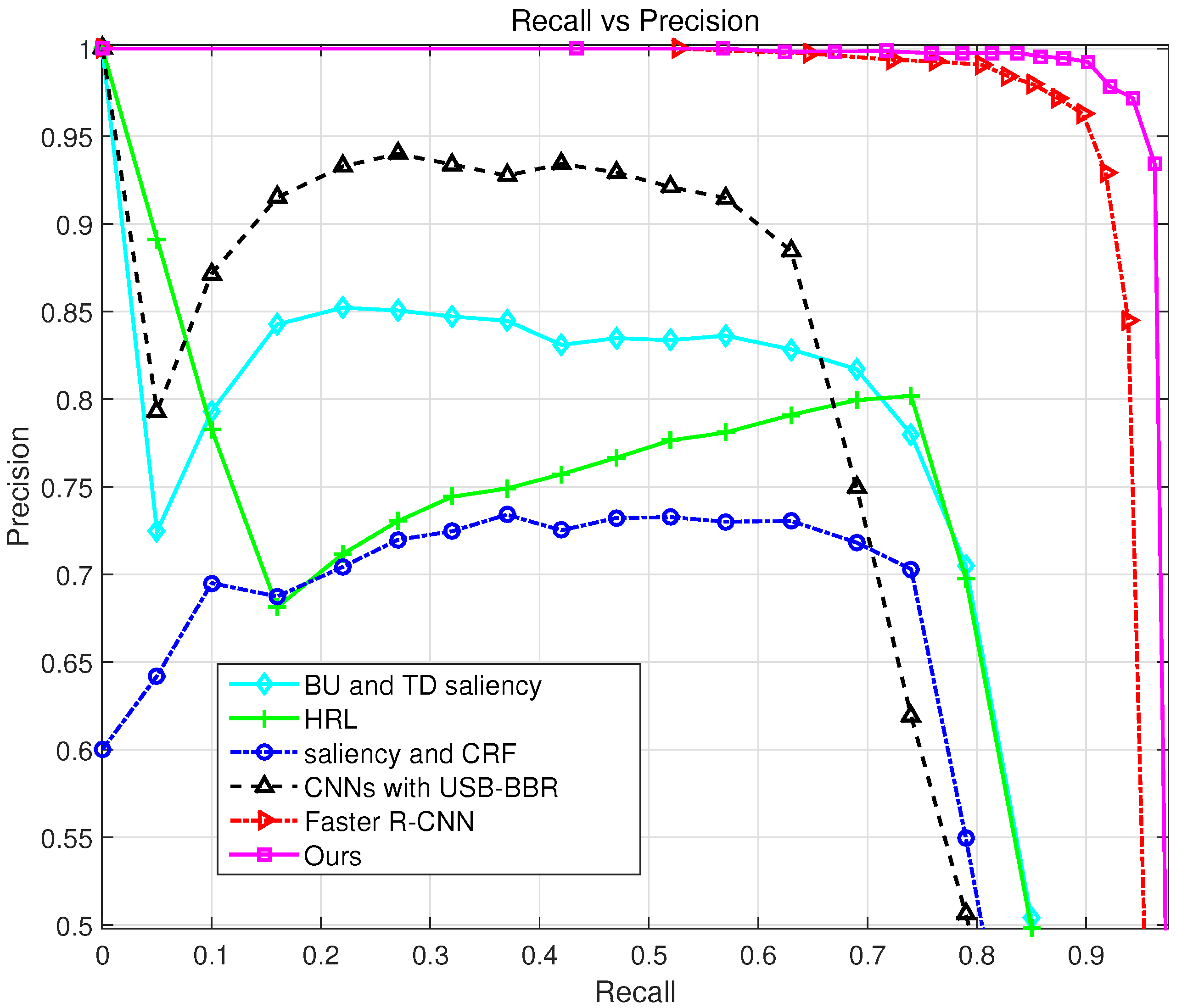
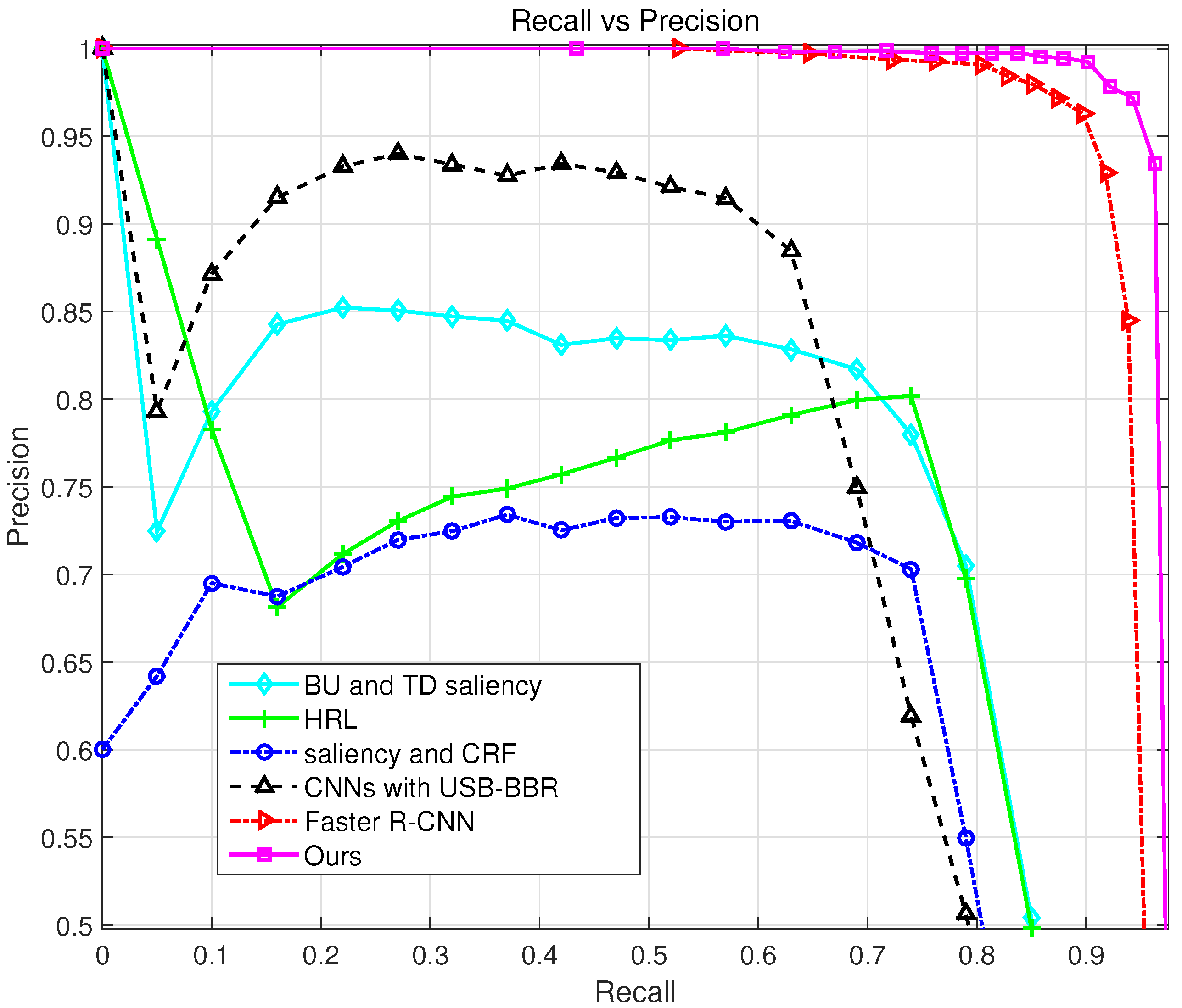
3.6. Comparison on State-of-the-Art Airport Detection Methods
3.7. Performance Analysis on Illumination and Resolution
3.7.1. Illumination
3.7.2. Resolution
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhao, D.; Ma, Y.; Jiang, Z.; Shi, Z. Multiresolution Airport Detection via Hierarchical Reinforcement Learning Saliency Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2855–2866. [Google Scholar] [CrossRef]
- Budak, Ü.; Halıcı, U.; Şengür, A.; Karabatak, M.; Xiao, Y. Efficient Airport Detection Using Line Segment Detector and Fisher Vector Representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1079–1083. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Cao, L.; Zhang, L. Pre-Trained AlexNet Architecture with Pyramid Pooling and Supervision for High Spatial Resolution Remote Sensing Image Scene Classification. Remote Sens. 2017, 9, 848. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. R-VCANet: A New Deep-Learning-Based Hyperspectral Image Classification Method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1975–1986. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; An, Z.; Jiang, Z.; Ma, Y. A Novel Spectral-Unmixing-Based Green Algae Area Estimation Method for GOCI Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 437–449. [Google Scholar] [CrossRef]
- Kou, Z.; Shi, Z.; Liu, L. Airport detection based on line segment detector. In Proceedings of the IEEE 2012 International Conference on Computer Vision in Remote Sensing (CVRS), Xiamen, China, 16–19 December 2012; pp. 72–77. [Google Scholar]
- Aggarwal, N.; Karl, W.C. Line detection in images through regularized Hough transform. IEEE Trans. Image Process. 2006, 15, 582–591. [Google Scholar] [CrossRef] [PubMed]
- Xiong, W.; Zhong, J.; Zhou, Y. Automatic recognition of airfield runways based on Radon transform and hypothesis testing in SAR images. In Proceedings of the IEEE 2012 5th Global Symposium on Millimeter Waves (GSMM), Harbin, China, 27–30 May 2012; pp. 462–465. [Google Scholar]
- Zhang, L.; Zhang, Y. Airport Detection and Aircraft Recognition Based on Two-Layer Saliency Model in High Spatial Resolution Remote-Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016. [Google Scholar] [CrossRef]
- Zhu, D.; Wang, B.; Zhang, L. Airport Target Detection in Remote Sensing Images: A New Method Based on Two-Way Saliency. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1096–1100. [Google Scholar]
- Yao, X.; Han, J.; Guo, L.; Bu, S.; Liu, Z. A coarse-to-fine model for airport detection from remote sensing images using target-oriented visual saliency and CRF. Neurocomputing 2015, 164, 162–172. [Google Scholar] [CrossRef]
- Tao, C.; Tan, Y.; Cai, H.; Tian, J. Airport detection from large IKONOS images using clustered SIFT keypoints and region information. IEEE Geosci. Remote Sens. Lett. 2011, 8, 128–132. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Victoria, BC, Canada, 1–3 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Computer Vision, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Bejiga, M.B.; Zeggada, A.; Nouffidj, A.; Melgani, F. A Convolutional Neural Network Approach for Assisting Avalanche Search and Rescue Operations with UAV Imagery. Remote Sens. 2017, 9, 100. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, P.; Niu, X.; Dou, Y.; Xia, F. Airport detection from remote sensing images using transferable convolutional neural networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2590–2595. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Yao, Y.; Jiang, Z.; Zhang, H.; Zhao, D.; Cai, B. Ship detection in optical remote sensing images based on deep convolutional neural networks. J. Appl. Remote Sens. 2017, 11. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Qian, X.; Zhou, P.; Yao, X.; Hu, X. Object detection in remote sensing imagery using a discriminatively trained mixture model. ISPRS J. Photogramm. Remote Sens. 2013, 85, 32–43. [Google Scholar] [CrossRef]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 761–769. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised Learning of Visual Representations Using Videos. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 2794–2802. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Tang, G.; Xiao, Z.; Liu, Q.; Liu, H. A Novel Airport Detection Method via Line Segment Classification and Texture Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2408–2412. [Google Scholar] [CrossRef]
- Graham, R.L.; Knuth, D.E.; Patashnik, O. Concrete Mathematics: A Foundation for Computer Science, 2nd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1994. [Google Scholar]
- Hosang, J.; Benenson, R.; Dollár, P.; Schiele, B. What makes for effective detection proposals? IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 814–830. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Shi, J.; Wang, J.; Jiang, Z. Saliency-constrained semantic learning for airport target recognition of aerial images. J. Appl. Remote Sens. 2015, 9, 096058. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.1 | 0.1 | 0.1 | 0.25 | 0.25 | 0.25 | 0.4 | 0.4 | 0.4 | |
|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 1 | 1.5 | 0.5 | 1 | 1.5 | 0.5 | 1 | 1.5 | |
| Precision | 0.979 | 0.9949 | 0.9803 | 0.98 | 0.9797 | 0.975 | 0.9753 | 0.9481 | 0.9209 |
| Recall | 0.8947 | 0.9378 | 0.9433 | 0.9378 | 0.9554 | 0.933 | 0.9339 | 0.9481 | 0.934 |
| F1-Measure | 0.935 | 0.9655 | 0.9614 | 0.9584 | 0.9674 | 0.9535 | 0.9542 | 0.9481 | 0.9274 |
| AP | 0.951 | 0.9602 | 0.9552 | 0.9577 | 0.9714 | 0.9627 | 0.9548 | 0.9693 | 0.9689 |
| Positives | Negatives | |
|---|---|---|
| Examples number | 25,712 | 409,374 |
| Hard examples number | 9030 | 19,573 |
| Average Loss | 5.791 | −0.897 |
| Method | Precision | Recall | F1-Measure | AP |
|---|---|---|---|---|
| Faster R-CNN [19] | 0.8881 | 0.9386 | 0.9127 | 0.9462 |
| Faster R-CNN with weight-balanced loss | 0.9299 | 0.9387 | 0.9343 | 0.9472 |
| HEM without weight-balanced loss | 0.9863 | 0.9283 | 0.9564 | 0.9553 |
| HEM with weight-balanced loss | 0.9671 | 0.9465 | 0.9567 | 0.9702 |
| Sampling Method | Random Sampling | Heuristic Sampling [17] | Hard Negatives Mining [23,28] | Hard Example Mining |
|---|---|---|---|---|
| Precision | 0.8881 | 0.7478 | 0.9773 | 0.9671 |
| Recall | 0.9386 | 0.9443 | 0.8971 | 0.9465 |
| F1-Measure | 0.9127 | 0.8347 | 0.9355 | 0.9567 |
| AP | 0.9462 | 0.9524 | 0.9473 | 0.9702 |
| Detection Method | BU and TD Saliency [12] | HRL [1] | Saliency and CRF [13] | CNN with USB-BBR [26] | Faster R-CNN [19] | Ours |
|---|---|---|---|---|---|---|
| Precision | 0.8096 | 0.8077 | 0.7145 | 0.8411 | 0.8881 | 0.9671 |
| Recall | 0.7188 | 0.7283 | 0.716 | 0.6575 | 0.9386 | 0.9465 |
| F1-Measure | 0.7615 | 0.7659 | 0.7152 | 0.7381 | 0.9127 | 0.9567 |
| AP | 0.6046 | 0.5845 | 0.5549 | 0.6427 | 0.9462 | 0.9702 |
| Average time (s) | 2.12 | 3.52 | 1.97 | 4.90 | 0.13 | 0.12 |
| Illumination | Sufficiency | Deficiency |
|---|---|---|
| Precision | 0.9701 | 0.9613 |
| Recall | 0.9498 | 0.9405 |
| Resolution | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|
| Precision | 1 | 0.9881 | 0.9619 | 0.8913 |
| Recall | 0.9284 | 0.9513 | 0.9538 | 0.9441 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, B.; Jiang, Z.; Zhang, H.; Zhao, D.; Yao, Y. Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sens. 2017, 9, 1198. https://doi.org/10.3390/rs9111198
Cai B, Jiang Z, Zhang H, Zhao D, Yao Y. Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sensing. 2017; 9(11):1198. https://doi.org/10.3390/rs9111198
Chicago/Turabian StyleCai, Bowen, Zhiguo Jiang, Haopeng Zhang, Danpei Zhao, and Yuan Yao. 2017. "Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining" Remote Sensing 9, no. 11: 1198. https://doi.org/10.3390/rs9111198
APA StyleCai, B., Jiang, Z., Zhang, H., Zhao, D., & Yao, Y. (2017). Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sensing, 9(11), 1198. https://doi.org/10.3390/rs9111198