
IceMap250—Automatic 250 m Sea Ice Extent Mapping Using MODIS Data



Abstract
:
1. Introduction
2. Materials and Methods
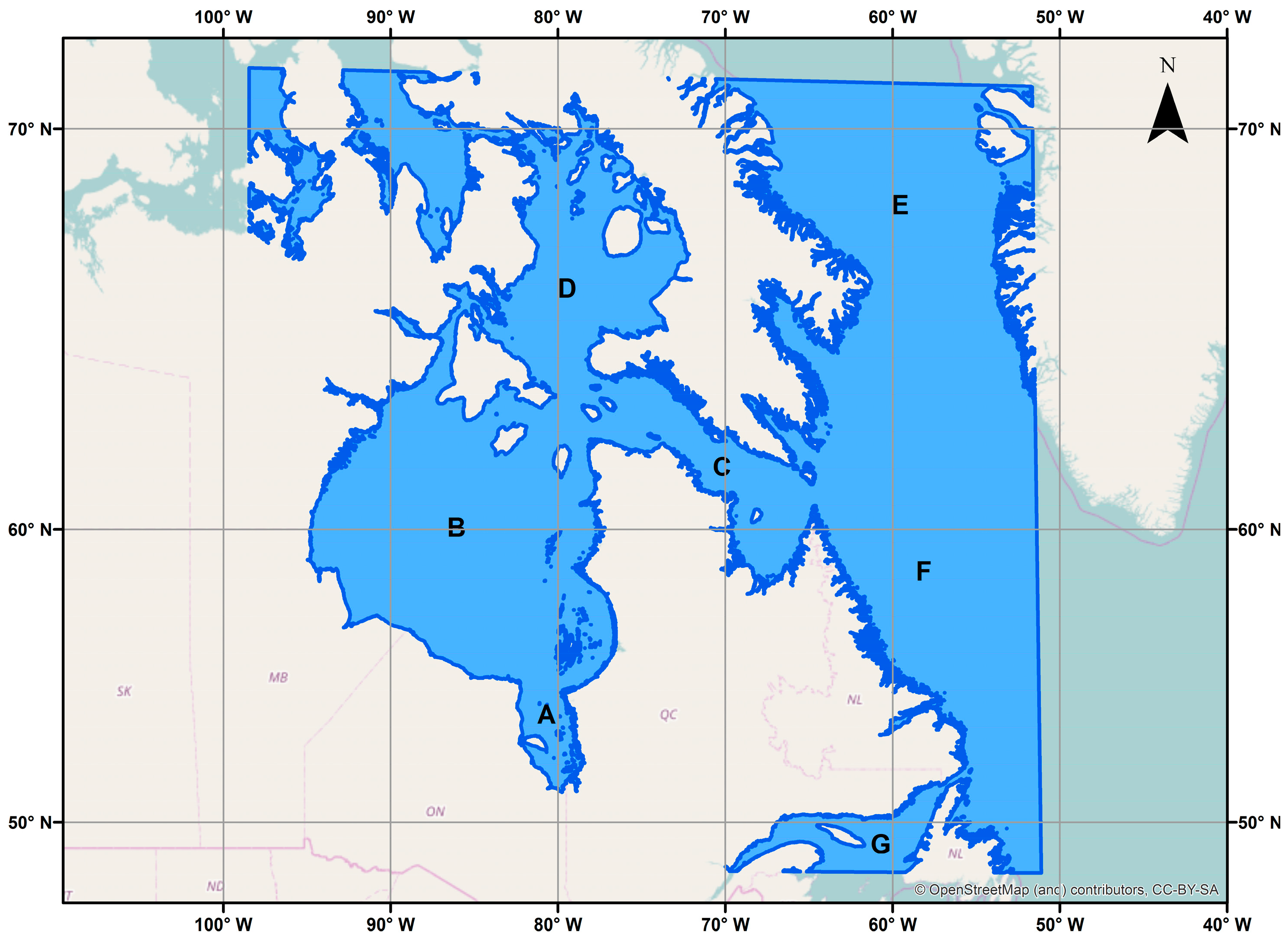
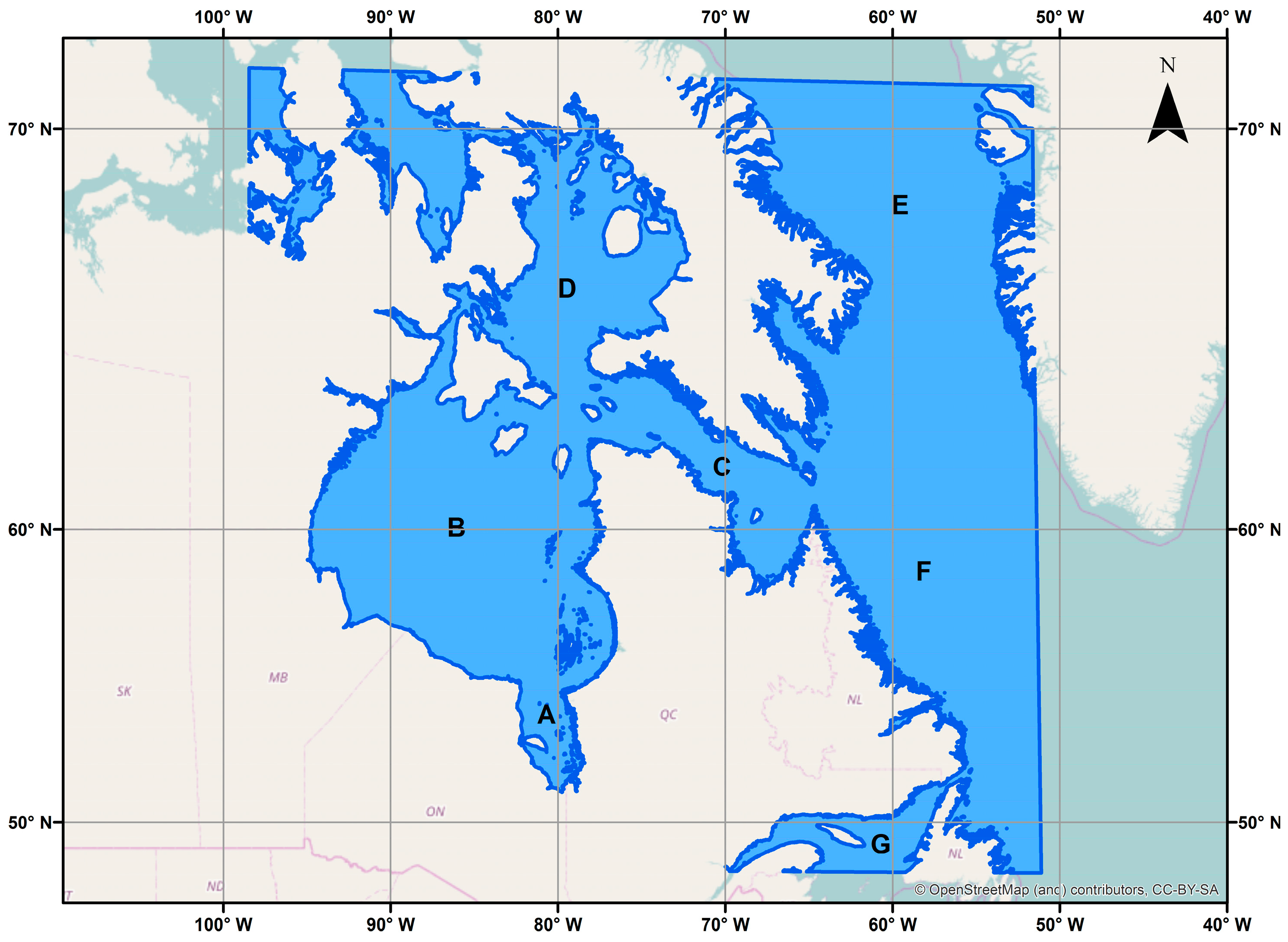
2.1. Study Area
2.2. Data Used in IceMap250
2.2.1. MODIS Sensors and Datasets
- MOD021KM: MODIS-Terra 1 km data;
- MOD02HKM: MODIS-Terra 500 m data;
- MOD02QKM: MODIS-Terra 250 m data;
- MOD03: MODIS-Terra geolocation product;
- MOD35_L2: MODIS-Terra cloud mask product.
- For the stable period from 10 February 2016 to 20 February 2016 (Day of year 41 to 51);
- For the melt period from 13 June 2013 to 23 June 2013 (Day of year 165 to 175);
- For the freeze-up period from 1 December 2015 to 11 December 2015 (Day of year 335 to 345).
2.2.2. Land Mask
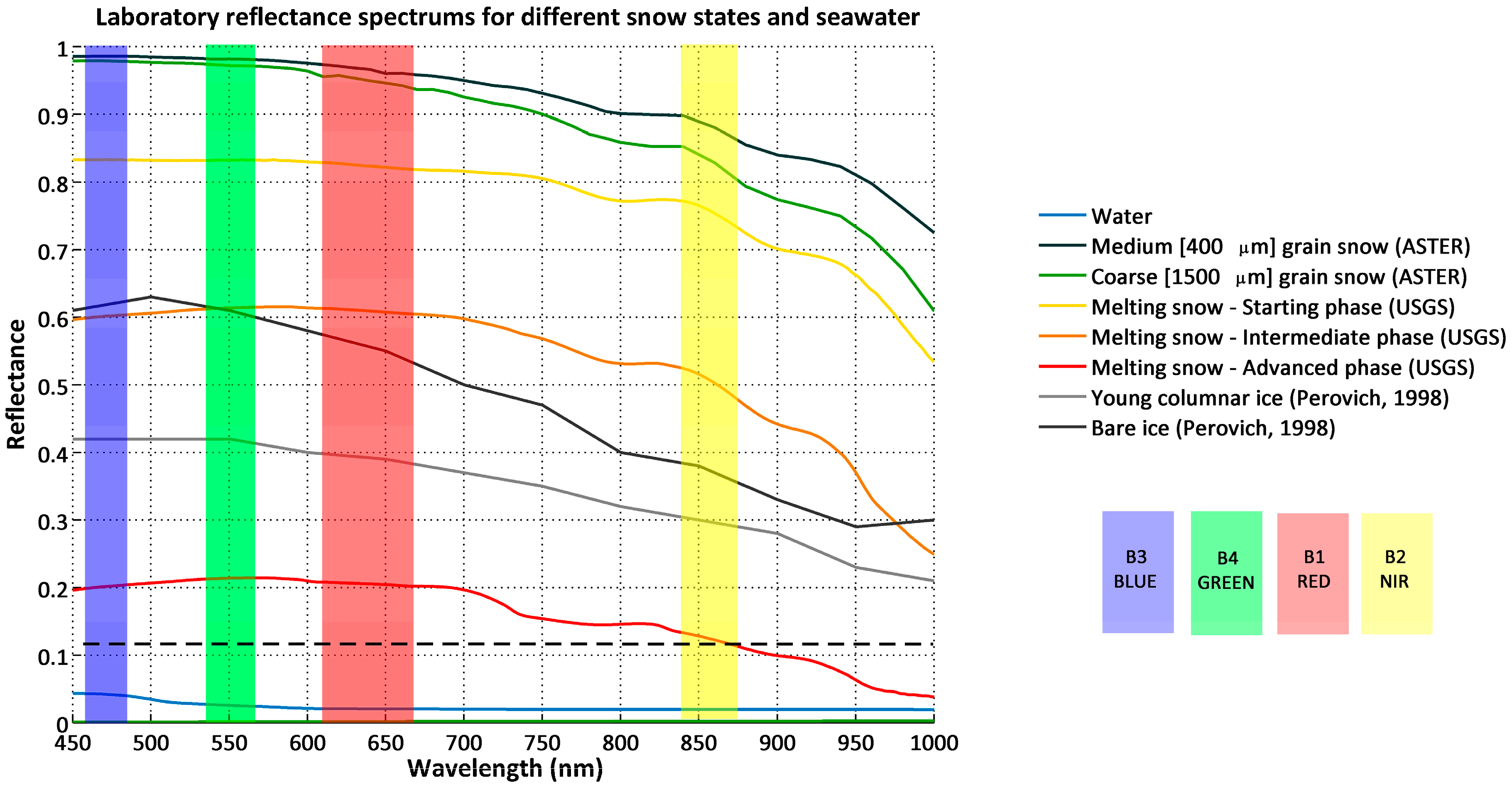
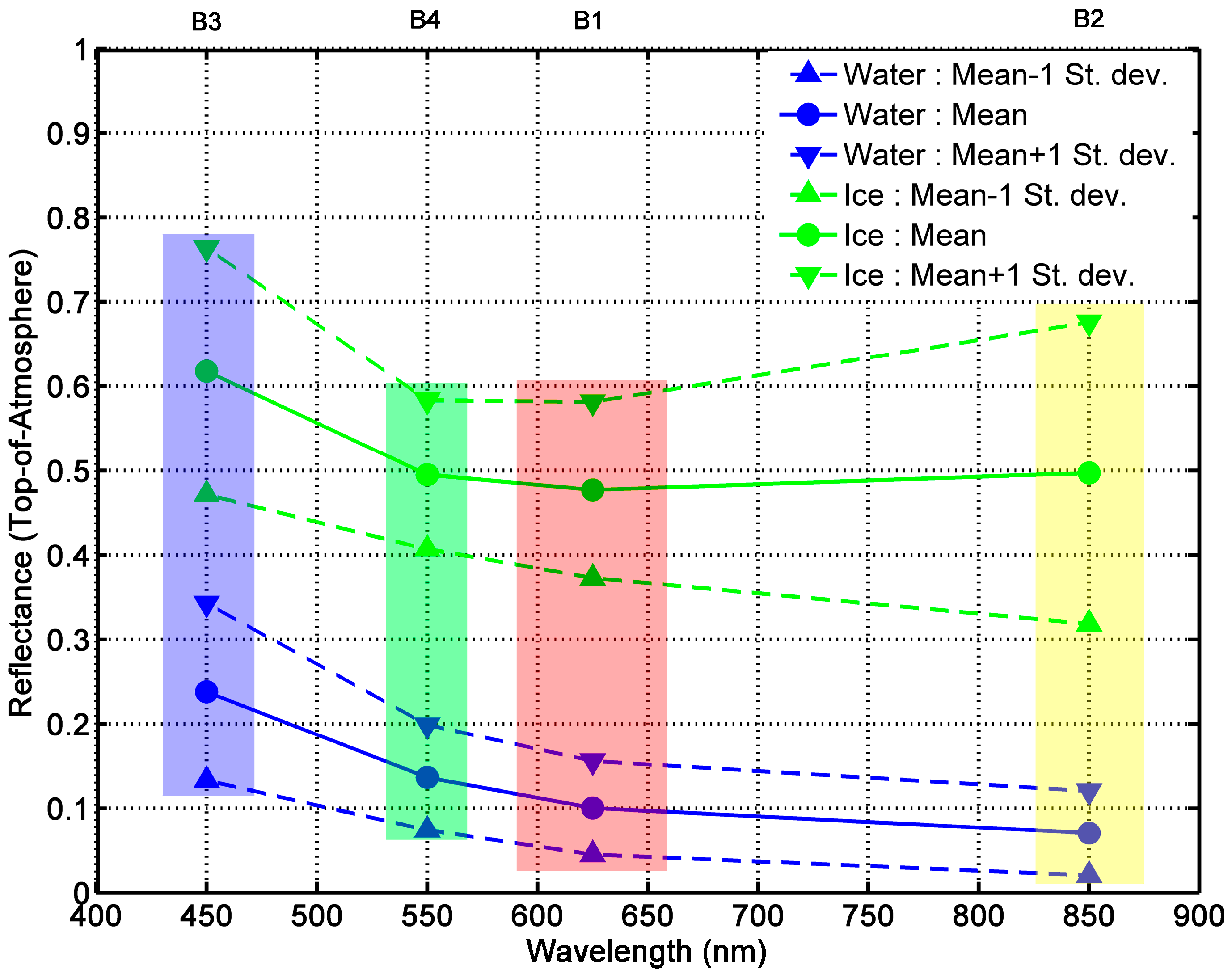
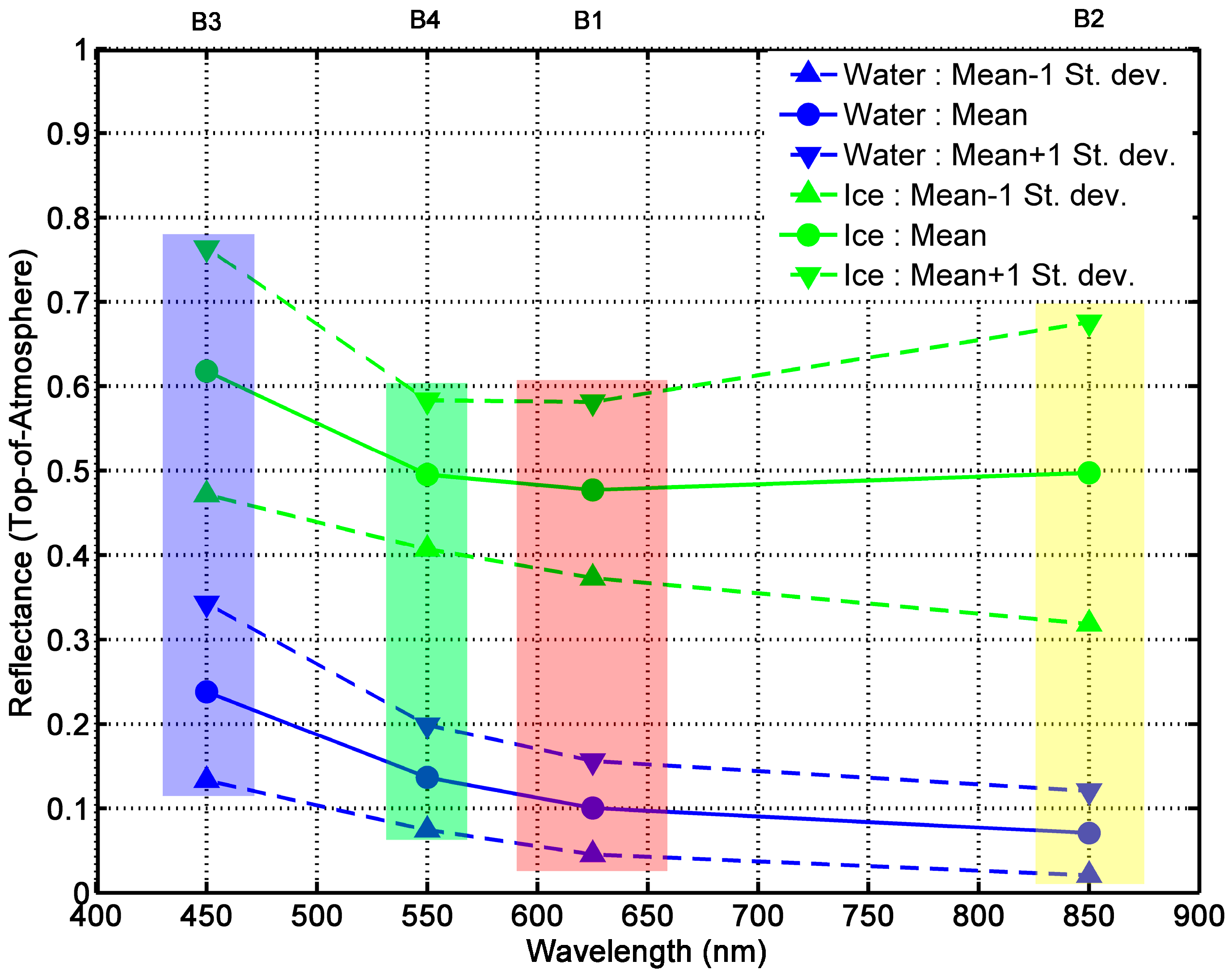
2.3. Spectral Behavior of Sea Ice in the Visible Spectrum
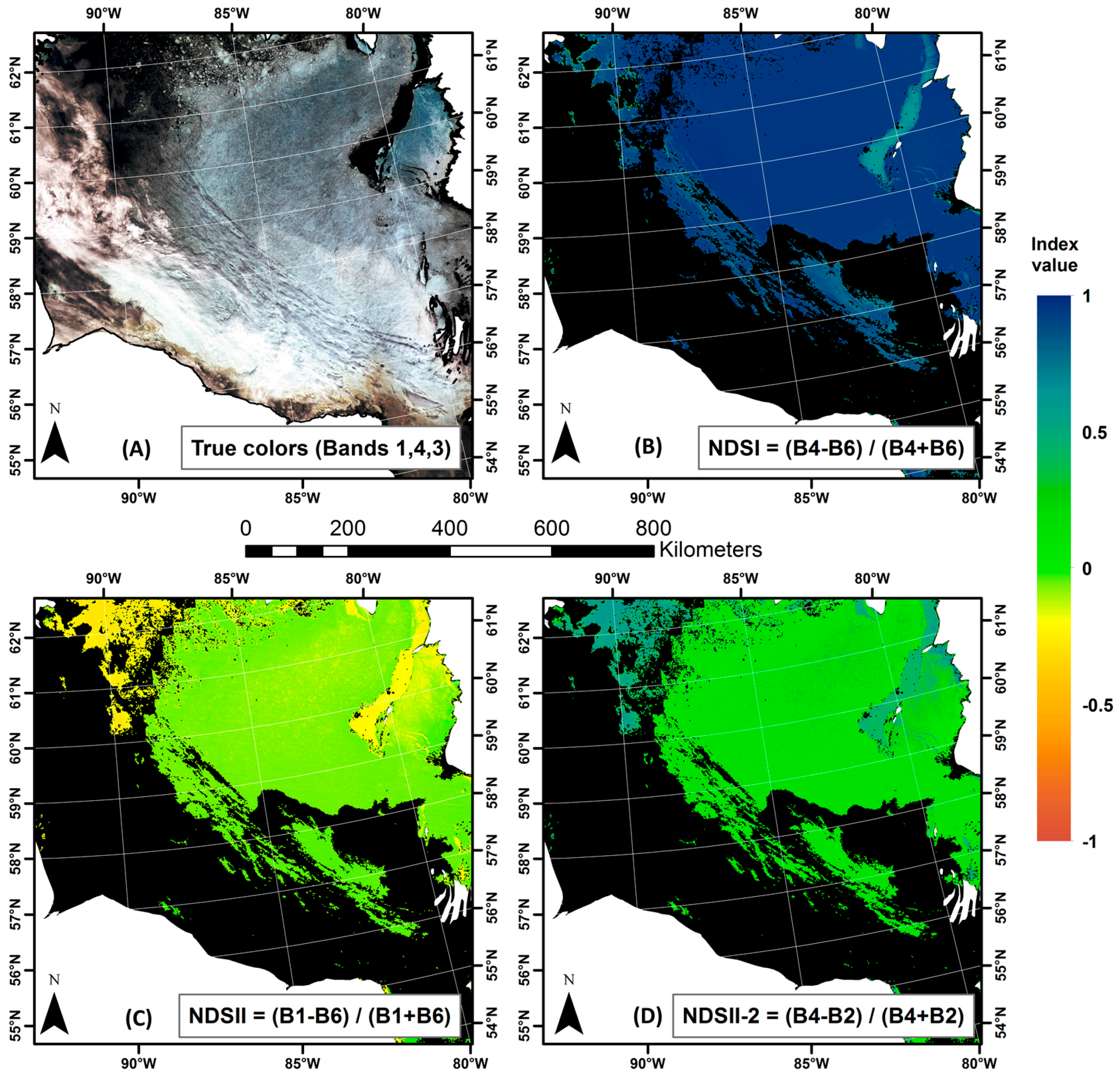
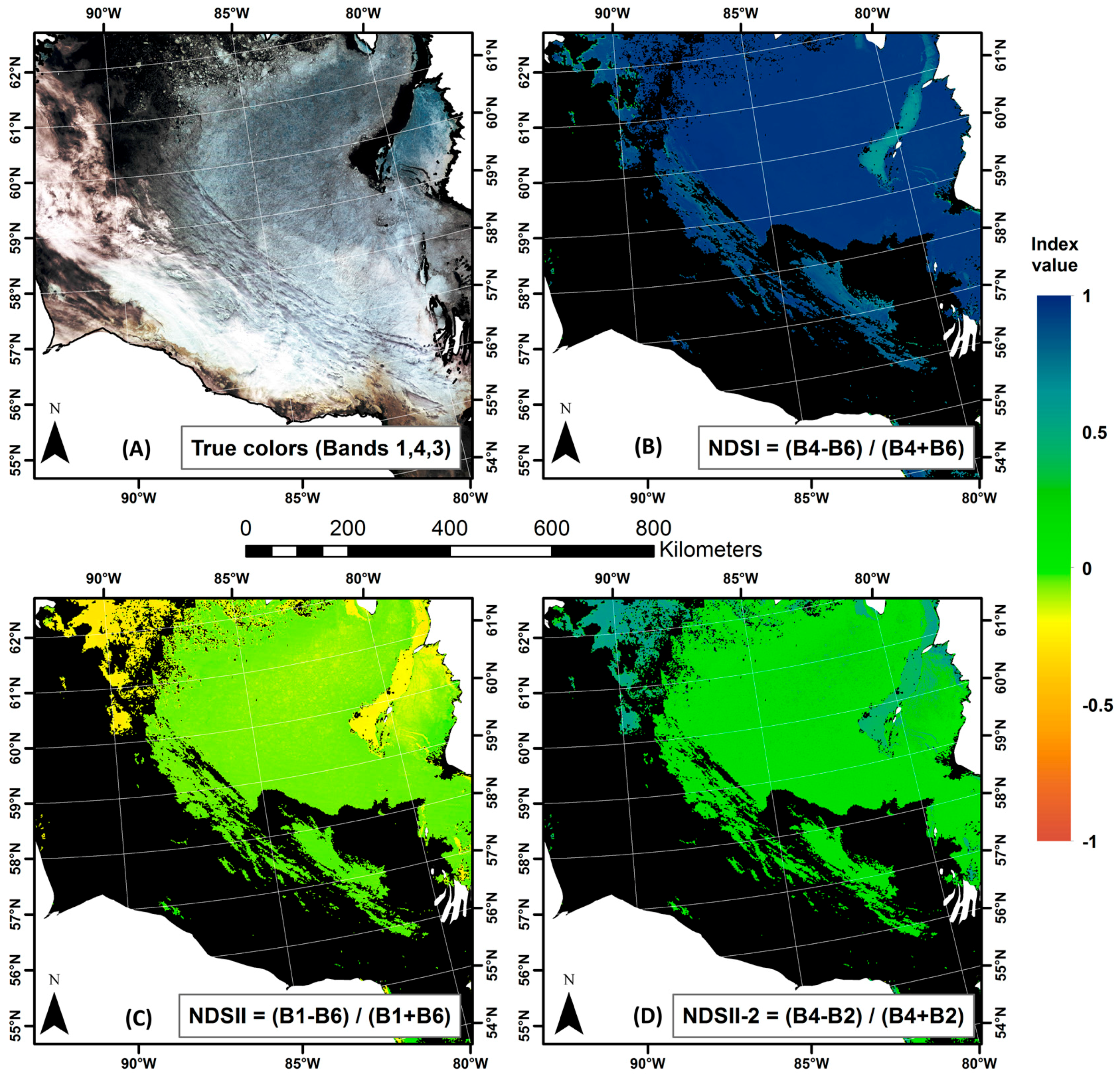
2.4. Normalized Difference Snow Index
2.5. The Original IceMap Algorithm
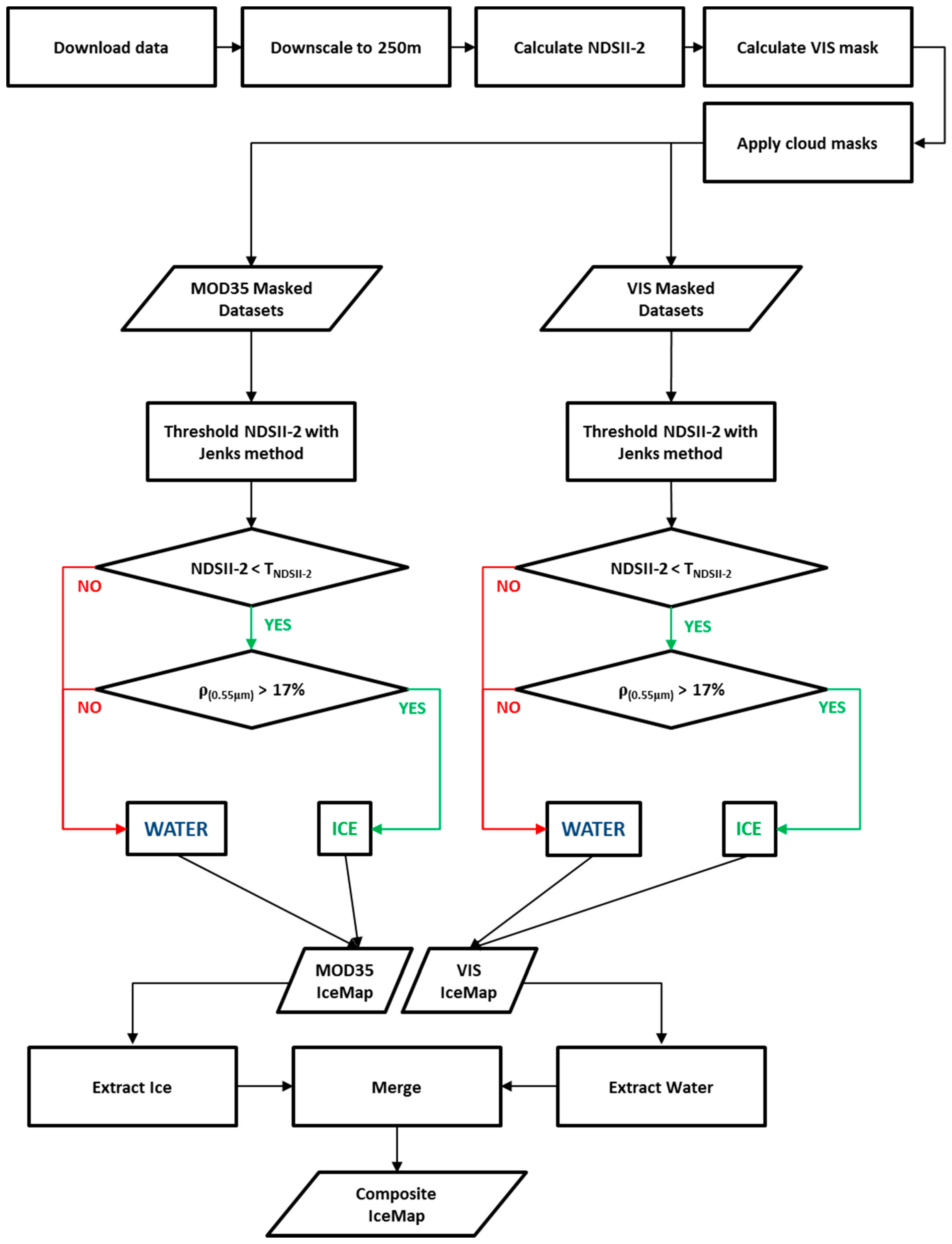
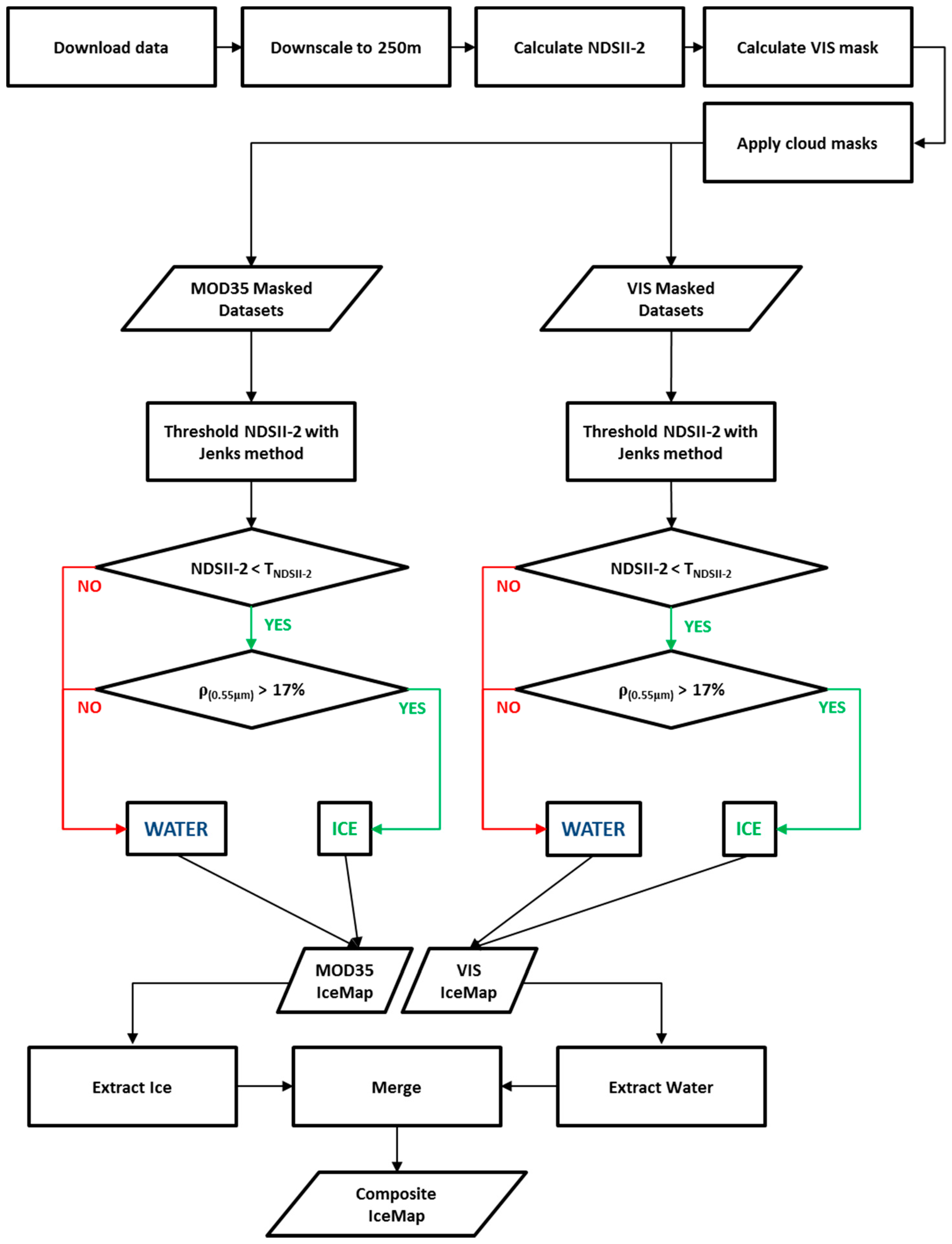
3. The Proposed Algorithm: IceMap250
3.1. Discrimination between Ice and Water: The NDSII-2 Index
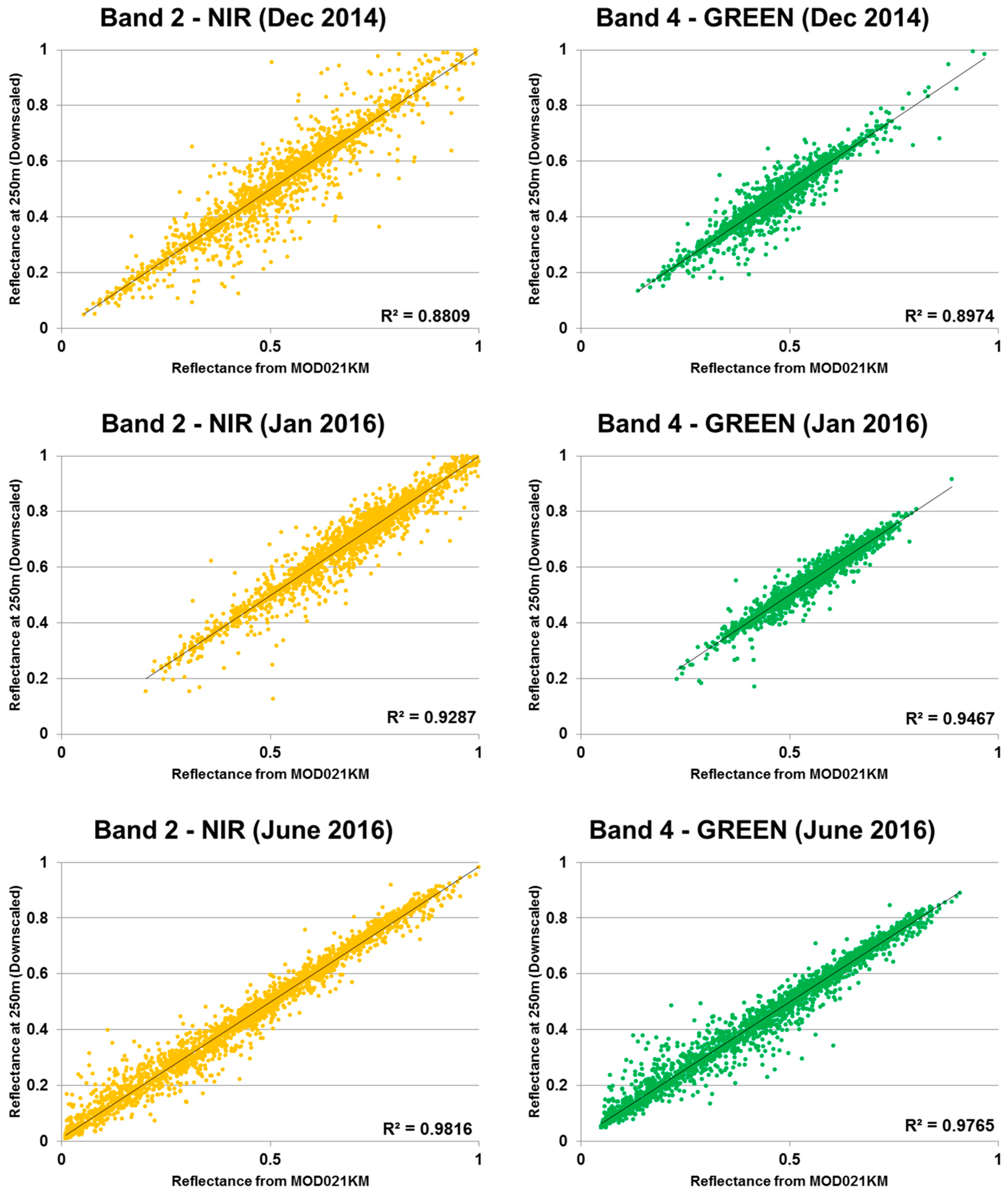
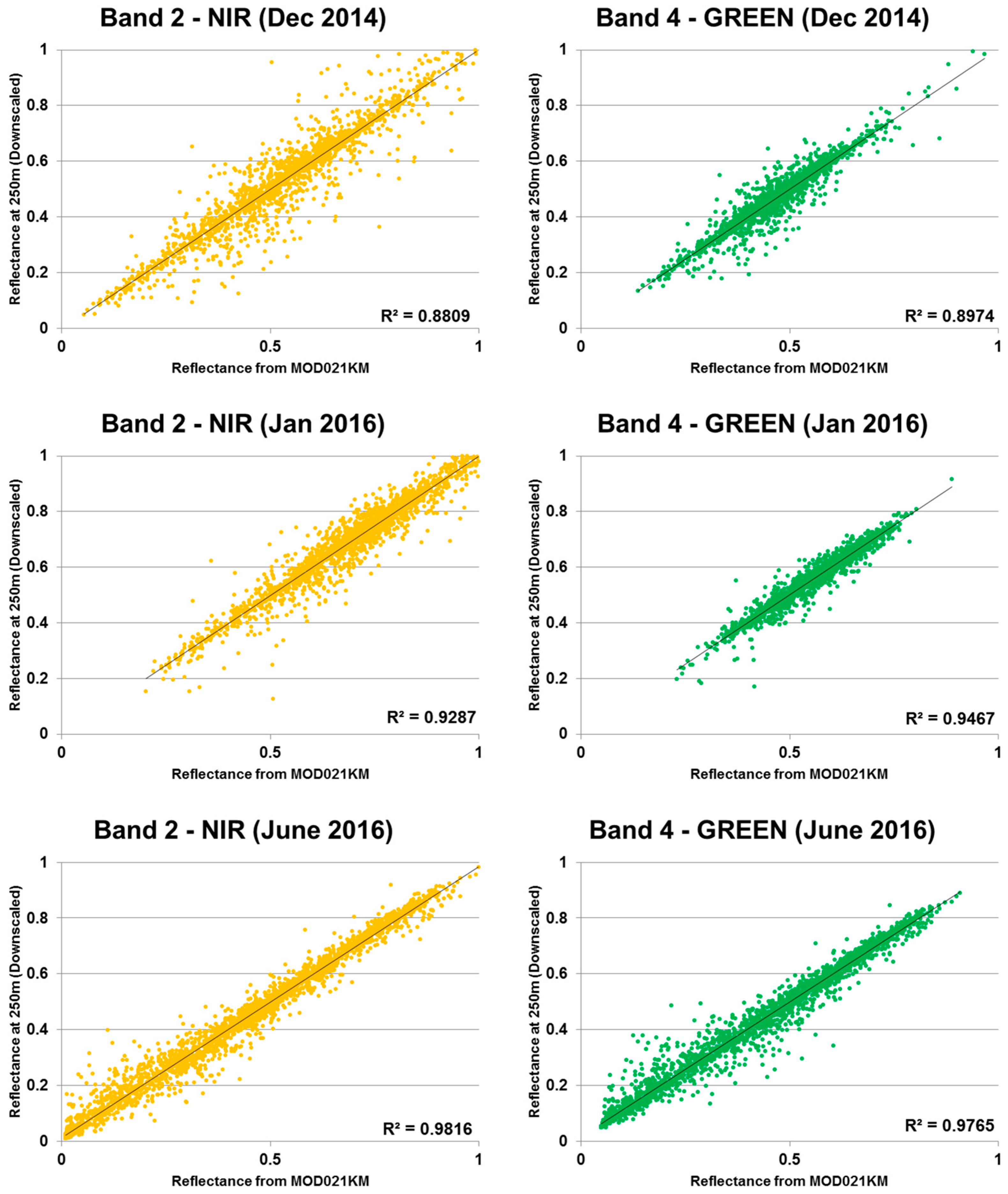
3.2. Downscaling to 250 m: The CCRS MODIS Downscaling Algorithm
3.3. Improving the Mapped Extent: The Visibility Mask
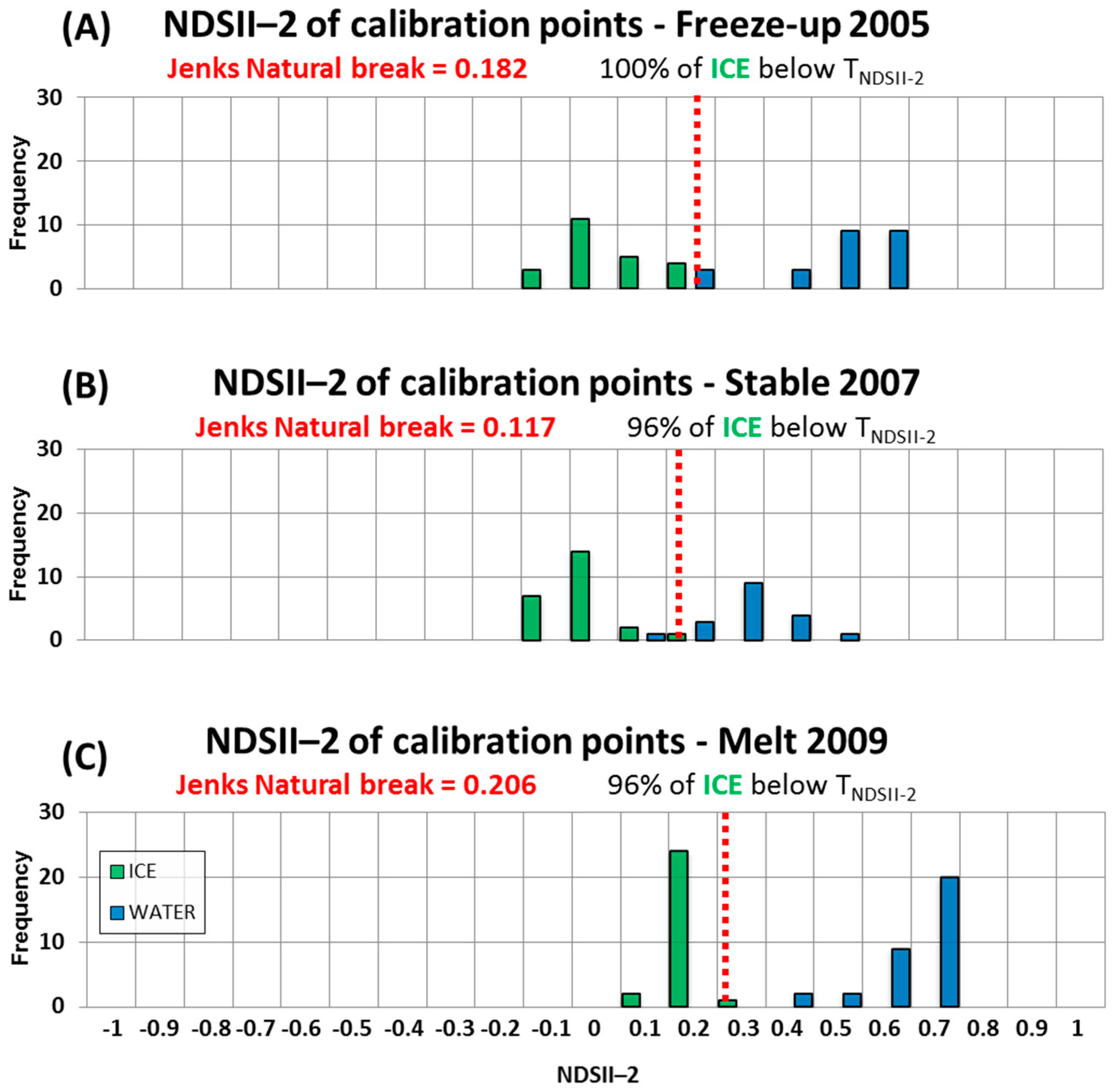
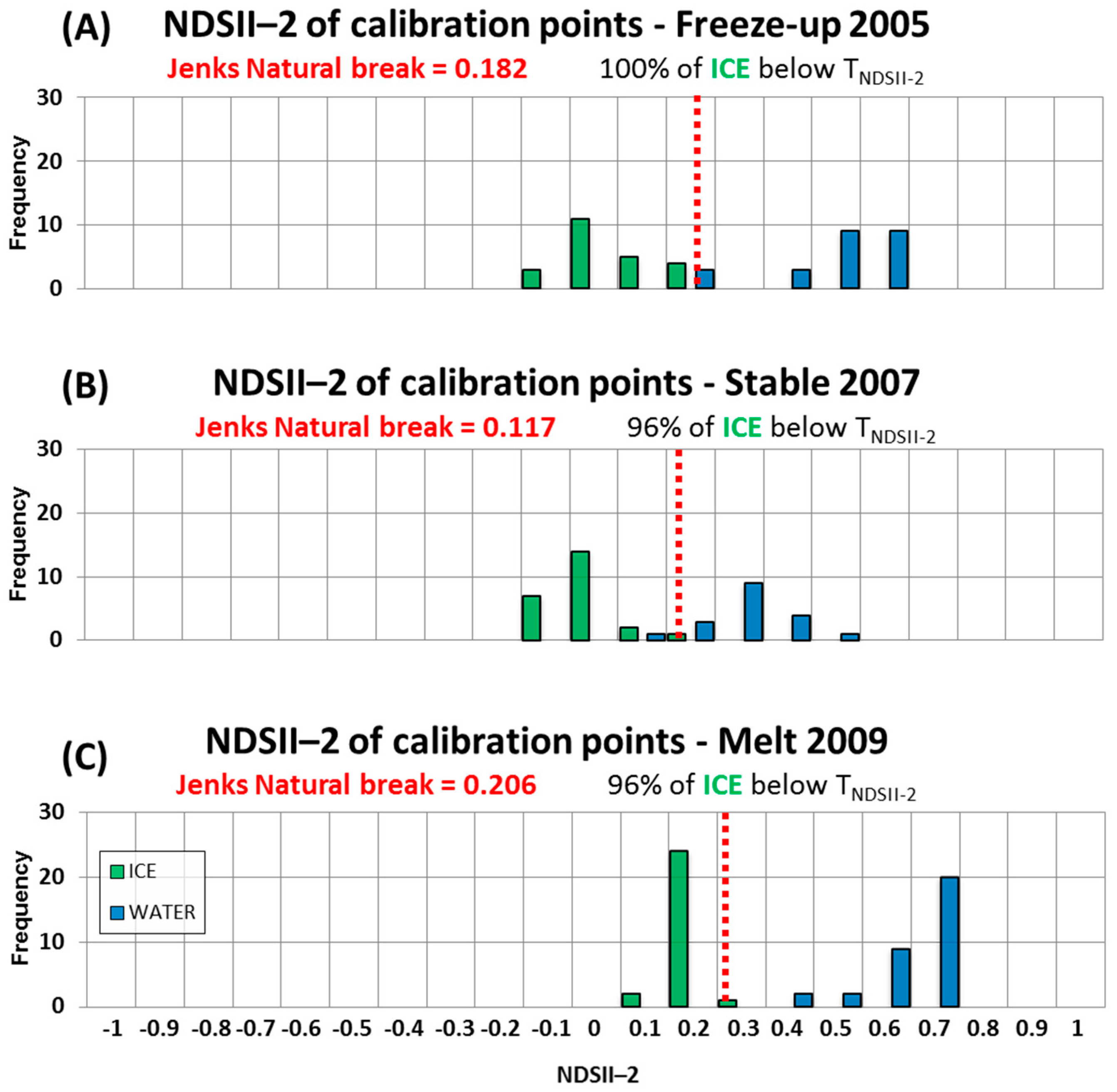
3.4. Calibration: Determination of Algorithm Threshold Values
3.5. Ice Information Outputs of IceMap250
4. Results
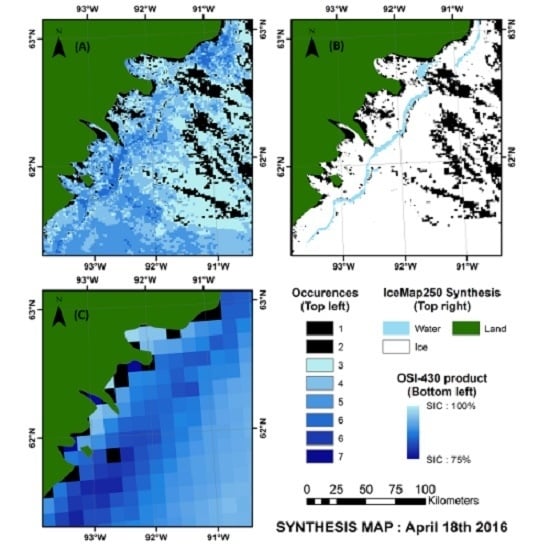
4.1. Validation of the IceMap250 Algorithm
4.2. Validation of the Composite Maps: Assessment of Accuracy Using Contingency Tables
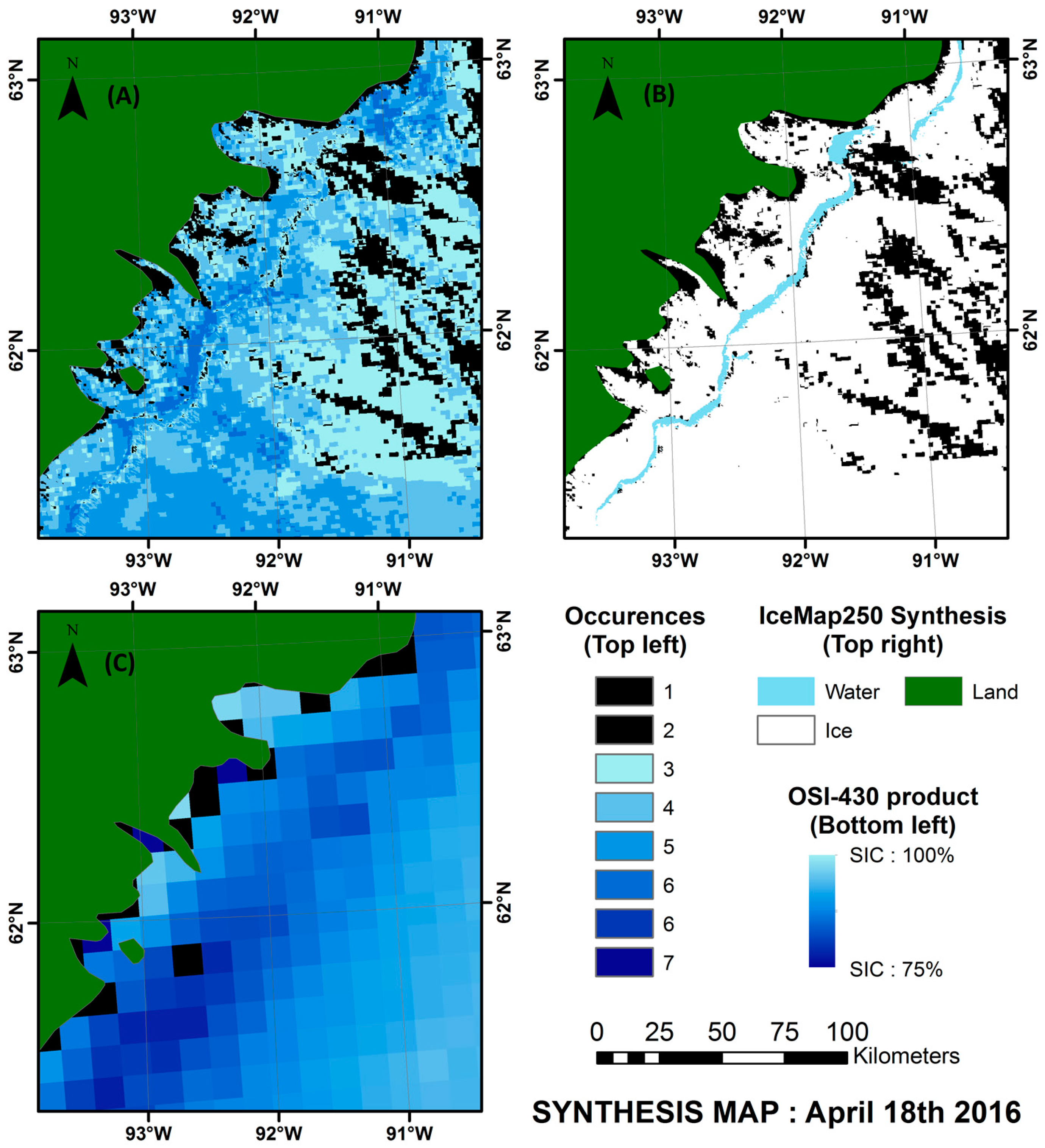
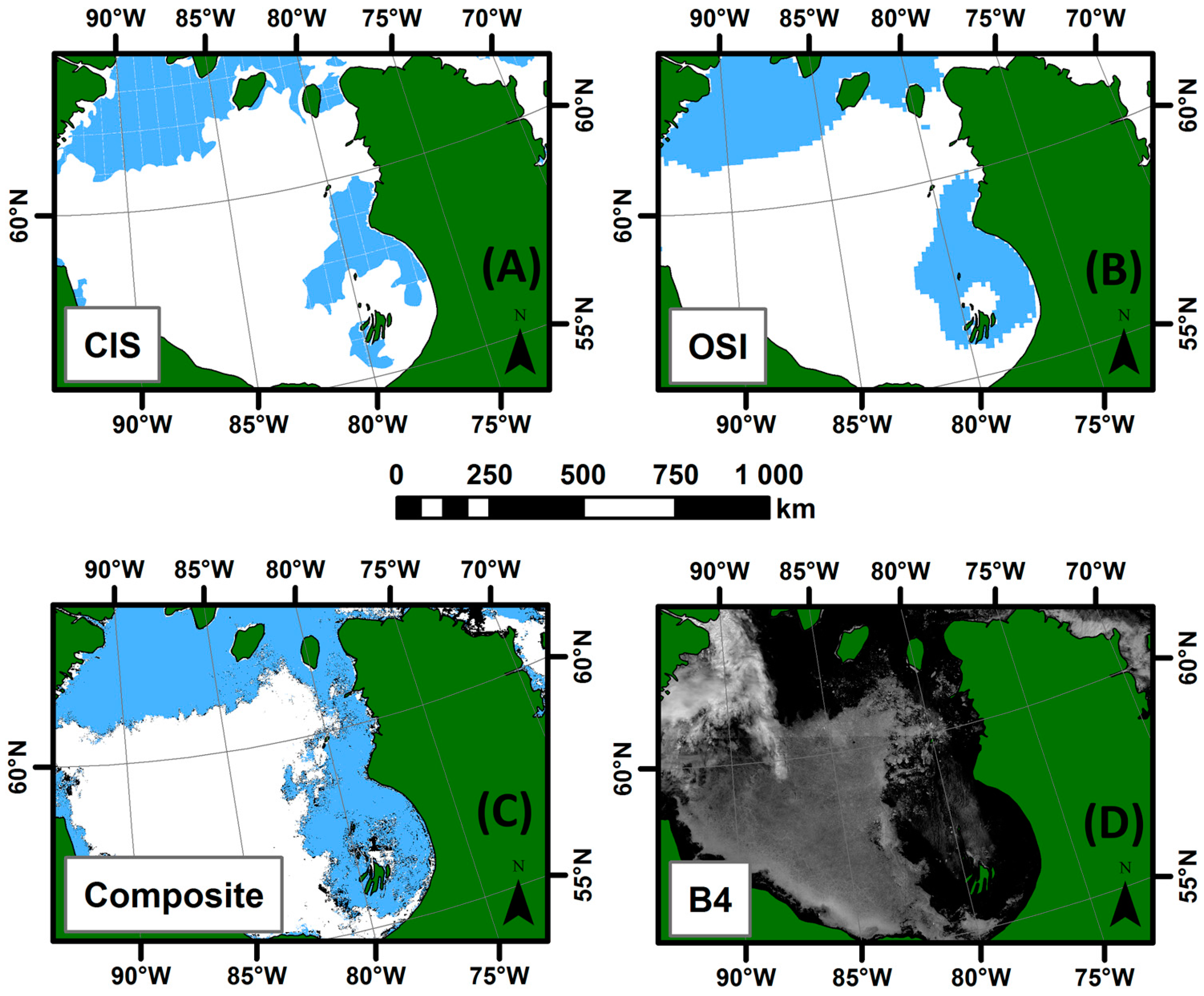
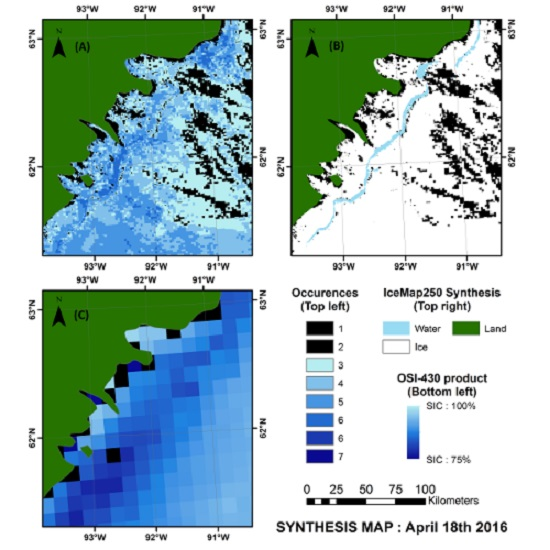
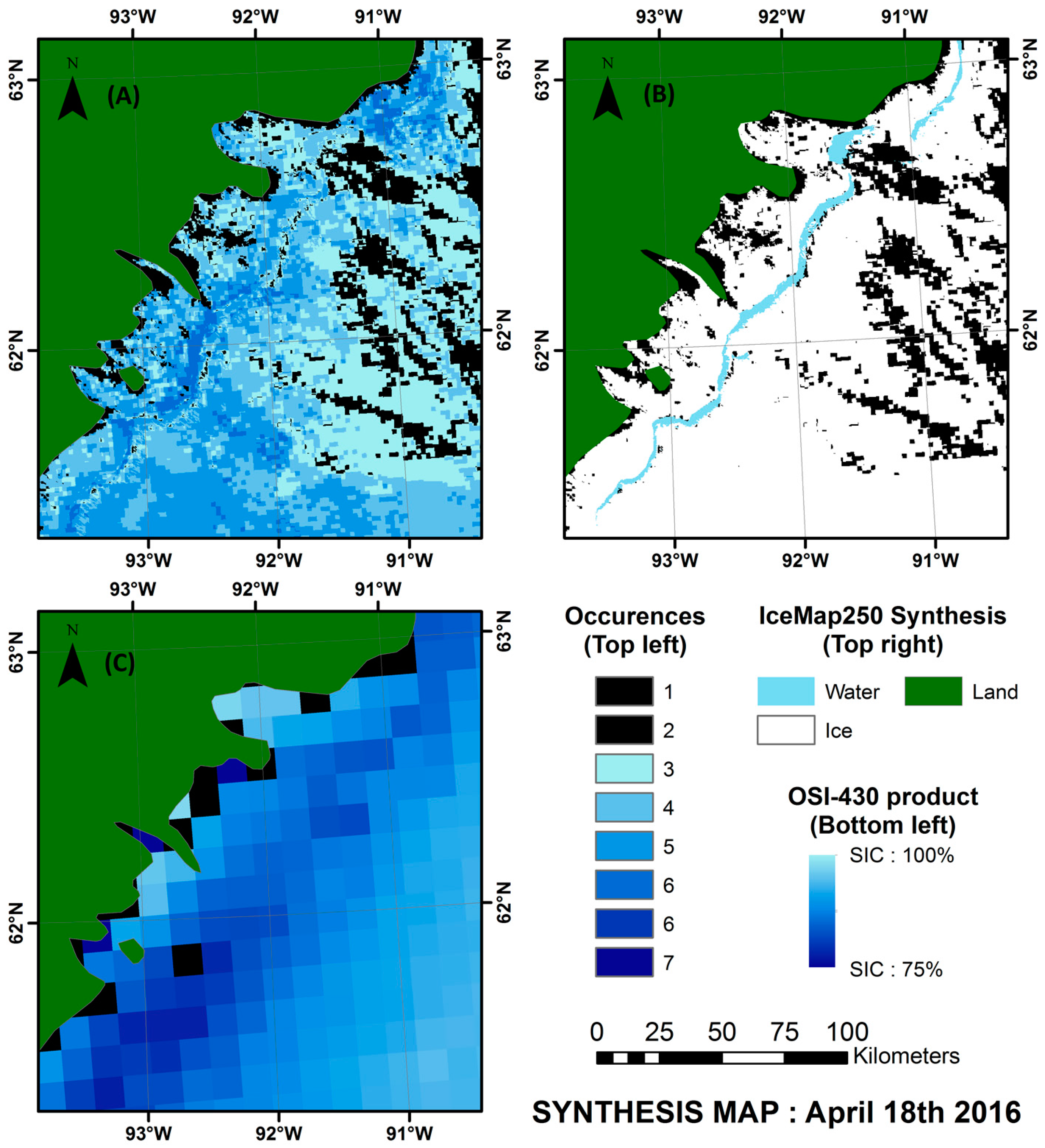
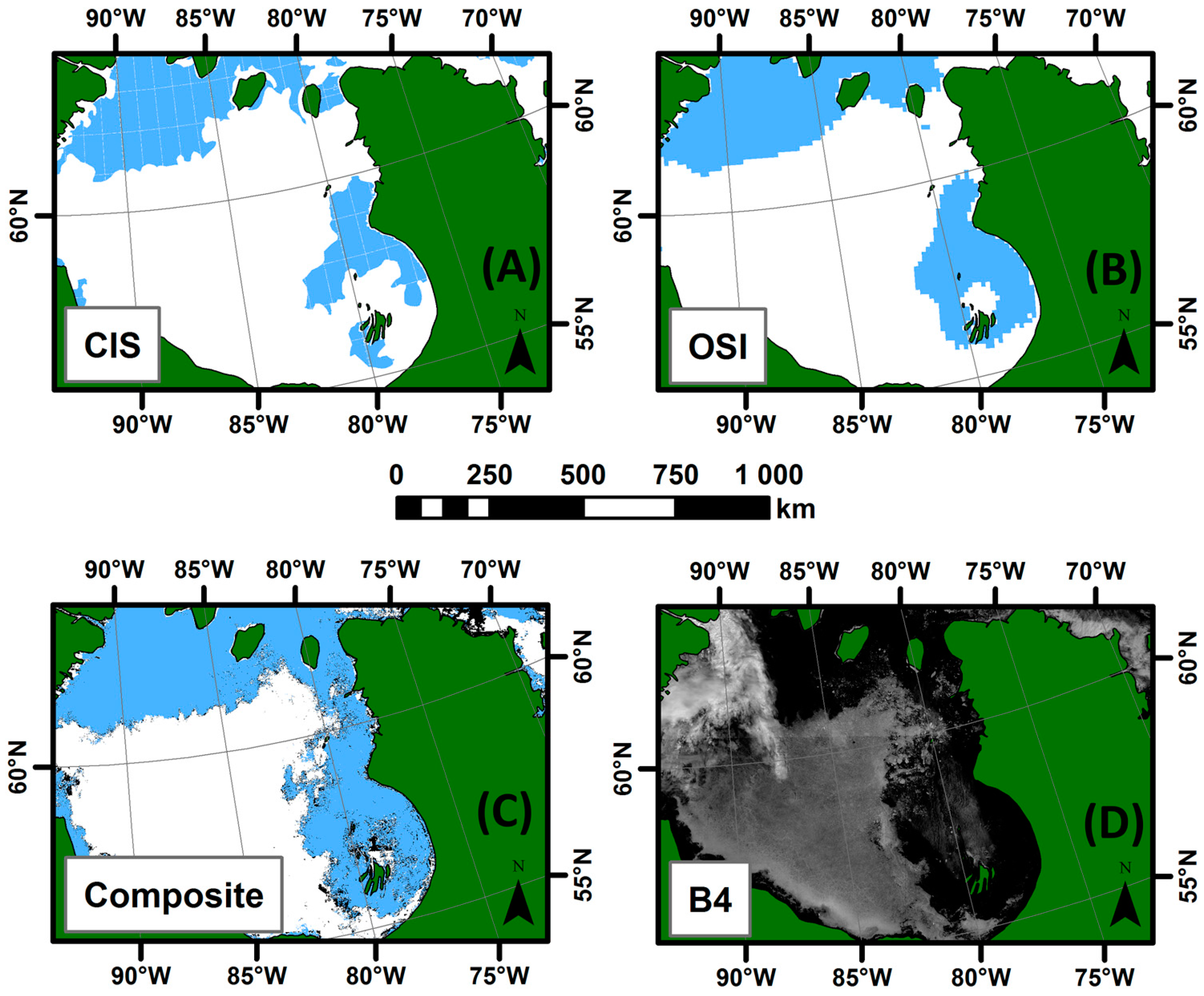
4.3. Validation of the Weekly Synthesis Maps: Comparison with Similar Products
- For all three seasons considered, the general pattern and the sea ice cover agrees between the products compared.
- The IceMap250 product, contrary to the CIS maps of the OSI maps, based respectively on SAR and passive microwave data, does not map the entire area because of its vulnerability to the cloud cover.
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Public Infrastructure Engineering Vulnerability Committee (PIEVC). Adapting to Climate Change—Canada's First National Assessment of Public Infrastructure; Council of Professional Engineers: Ottawa, ON, Canada, 2008. [Google Scholar]
- Ivanova, N.; Pedersen, L.; Tonboe, R.; Kern, S.; Heygster, G.; Lavergne, T.; Sorensen, A.; Saldo, R.; Dybkjar, G.; Brucker, L. Inter-comparison and evaluation of sea ice algorithms: Towards further identification of challenges and optimal approach using passive microwave observations. Cryosphere 2015, 9, 1797–1817. [Google Scholar] [CrossRef] [Green Version]
- Markus, T.; Cavalieri, D.J. An enhancement of the nasa team sea ice algorithm. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1387–1398. [Google Scholar] [CrossRef]
- Shokr, M.; Lambe, A.; Agnew, T. A new algorithm (ECICE) to estimate ice concentration from remote sensing observations: An application to 85-GHZ passive microwave data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4104–4121. [Google Scholar] [CrossRef]
- Spreen, G.; Kaleschke, L.; Heygster, G. Sea ice remote sensing using amsr-e 89-GHz channels. J. Geophys. Res. Oceans 2008. [Google Scholar] [CrossRef]
- Scheuchl, B.; Caves, R.; Cumming, I.; Staples, G. Automated sea ice classification using spaceborne polarimetric sar data. In Proceedings of the 2001 IEEE International Geoscience and Remote Sensing Symposium, Sydney, Ausralia, 9–13 July 2001.
- Soh, L.-K.; Tsatsoulis, C.; Gineris, D.; Bertoia, C. Arktos: An intelligent system for sar sea ice image classification. IEEE Trans. Geosci. Remote Sens. 2004, 42, 229–248. [Google Scholar] [CrossRef]
- Yu, Q.; Clausi, D.A. Sar sea-ice image analysis based on iterative region growing using semantics. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3919–3931. [Google Scholar] [CrossRef]
- Drue, C.; Heinemann, G. High-resolution maps of the sea-ice concentration from modis satellite data. Geophys. Res. Lett. 2004, 31, 08027. [Google Scholar] [CrossRef]
- Hall, D.K.; Key, J.R.; Casey, K.A.; Riggs, G.A.; Cavalieri, D.J. Sea ice surface temperature product from MODIS. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1076–1087. [Google Scholar] [CrossRef]
- Hori, M.; Aoki, T.; Stamnes, K.; Li, W. Adeos-II/GLI snow/ice products—Part III: Retrieved results. Remote Sens. Environ. 2007, 111, 291–336. [Google Scholar] [CrossRef]
- Shokr, M.; Sinha, N. Sea Ice: Physics and Remote Sensing; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Crocker, G.B.; Carrieres, T. The Canandian Ice Service Digital Datedbse: History of Data and Procedures Used in the Preparation of Regional Ice Charts; Ballicater Consulting Ltd.: Ottawa, ON, Canada, 2000. [Google Scholar]
- Kaleschke, L.; Lupkes, C.; Vihma, T.; Haarpaintner, J.; Bochert, A.; Hartmann, J.; Heygster, G. SSM/I sea ice remote sensing for mesoscale ocean-atmosphere interaction analysis. Can. J. Remote Sens. 2001, 27, 526–537. [Google Scholar] [CrossRef]
- Kern, S. A new method for medium-resolution sea ice analysis using weather-influence corrected special sensor microwave/imager 85 GHz data. Int. J. Remote Sens. 2004, 25, 4555–4582. [Google Scholar] [CrossRef]
- Beitsch, A.; Kaleschke, L.; Kern, S. Investigating high-resolution AMSR2 sea ice concentrations during the February 2013 fracture event in the beaufort sea. Remote Sens. 2014, 6, 3841–3856. [Google Scholar] [CrossRef]
- Agnew, T.; Howell, S. The use of operational ice charts for evaluating passive microwave ice concentration data. Atmos. Ocean 2003, 41, 317–331. [Google Scholar] [CrossRef]
- Rees, W.G. Remote Sensing of Snow and Ice; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Meier, W.N.; Fetterer, F.; Stewart, J.S.; Helfrich, S. How do sea-ice concentrations from operational data compare with passive microwave estimates? Implications for improved model evaluations and forecasting. Ann. Glaciol. 2015, 56, 332–340. [Google Scholar] [CrossRef]
- Meier, W.N.; Stroeve, J. Comparison of sea-ice extent and ice-edge location estimates from passive microwave and enhanced-resolution scatterometer data. Ann. Glaciol. 2008, 48, 65–70. [Google Scholar] [CrossRef]
- Heinrichs, J.F.; Cavalieri, D.J.; Markus, T. Assessment of the Amsr-E sea ice-concentration product at the ice edge using radarsat-1 and modis imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3070–3080. [Google Scholar] [CrossRef]
- Meier, W.N. Comparison of passive microwave ice concentration algorithm retrievals with avhrr imagery in Arctic peripheral seas. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1324–1337. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A.; Salomonson, V.V.; Barton, J.; Casey, K.; Chien, J.; DiGirolamo, N.; Klein, A.; Powell, H.; Tait, A. Algorithm Theoretical Basis Document (ATBD) for the MODIS Snow and Sea Ice-Mapping Algorithms; NASA GSFC: Greenbelt, MD, USA, 2001. [Google Scholar]
- Su, H.; Wang, Y.; Xiao, J.; Li, L. Improving modis sea ice detectability using gray level co-occurrence matrix texture analysis method: A case study in the bohai sea. ISPRS J. Photogramm. Remote Sens. 2013, 85, 13–20. [Google Scholar] [CrossRef]
- Su, H.; Wang, Y.; Yang, J. Monitoring the spatiotemporal evolution of sea ice in the bohai sea in the 2009–2010 winter combining MODIS and meteorological data. Estuar. Coasts 2012, 35, 281–291. [Google Scholar] [CrossRef]
- Liu, Y.; Key, J.; Mahoney, R. Sea and freshwater ice concentration from viirs on suomi npp and the future jpss satellites. Remote Sens. 2016, 8, 523. [Google Scholar] [CrossRef]
- Luo, Y.; Trishchenko, A.P.; Khlopenkov, K.V. Developing clear-sky, cloud and cloud shadow mask for producing clear-sky composites at 250-meter spatial resolution for the seven MODIS land bands over canada and North America. Remote Sens. Environ. 2008, 112, 4167–4185. [Google Scholar] [CrossRef]
- Keshri, A.K.; Shukla, A.; Gupta, R.P. Aster ratio indices for supraglacial terrain mapping. Int. J. Remote Sens. 2008, 30, 519–524. [Google Scholar] [CrossRef]
- Canadian-Ice-Service. Sea Ice Climatic Atlas for the Northern Canadian Waters 1981–2010. Available online: https://ec.gc.ca/glaces-ice/default.asp?lang=En&n=4B35305B-1 (accessed on 24 October 2016).
- Riggs, G.A.; Hall, D.K. Snow mapping with the MODIS aqua instrument. In Proceedings of the 61st Eastern Snow Conference, Portland, OR, USA, 9–11 June 2004; pp. 9–11.
- Natural Earth. Coastline. Available online: http://www.naturalearthdata.com/downloads/110m-physical-vectors/110m-coastline/ (accessed on 24 October 2016).
- Wessel, P.; Smith, W.H.F. A global, self-consistent, hierarchical, high-resolution shoreline database. J. Geophys. Res. Solid Earth 1996, 101, 8741–8743. [Google Scholar] [CrossRef]
- Perovich, D.K.; Polashenski, C. Albedo evolution of seasonal Arctic sea ice. Geophys. Res. Lett. 2012. [Google Scholar] [CrossRef]
- Perovich, D.K. Light reflection from sea ice during the onset of melt. J. Geophys. Res. Oceans 1994, 99, 3351–3359. [Google Scholar] [CrossRef]
- Perovich, D.K. The Optical Properties of Sea Ice; DTIC: Fort Belvoir, VA, USA, 1996. [Google Scholar]
- Barber, D.G.; Misurak, K.; Ledrew, E. Spectral albedo of snow-covered first-year and multi-year sea ice during spring melt. Ann. Glaciol. 1995, 21, 337–342. [Google Scholar]
- Fan, C.; Warner, R.A. Characterization of water reflectance spectra variability: Implications for hyperspectral remote sensing in estuarine waters. Mar. Sci. 2014, 4, 1–9. [Google Scholar]
- Clark, R.N.; Swayze, G.A.; Wise, R.; Livo, K.E.; Hoefen, T.M.; Kokaly, R.F.; Sutley, S.J. USGS Digital Spectral Library Splib06a; US Geological Survey: Reston, VA, USA, 2007. [Google Scholar]
- Baldridge, A.; Hook, S.; Grove, C.; Rivera, G. The ASTER spectral library version 2.0. Remote Sens. Environ. 2009, 113, 711–715. [Google Scholar] [CrossRef]
- Perovich, D.K. Observations of the polarization of light reflected from sea ice. J. Geophys. Res. Oceans 1998, 103, 5563–5575. [Google Scholar] [CrossRef]
- Dozier, J. Spectral signature of alpine snow cover from the landsat thematic mapper. Remote Sens. Environ. 1989, 28, 9–22. [Google Scholar] [CrossRef]
- Bishop, M.P.; Bjornsson, H.; Haeberli, W.; Oerlemans, J.; Shroder, J.F.; Tranter, M.; Singh, V.P.; Haritashya, U.K. Encyclopedia of Snow, Ice and Glaciers; Springer: Berlin, Germany, 2011. [Google Scholar]
- Riggs, G.A.; Hall, D.K.; Ackerman, S.A. Sea ice extent and classification mapping with the moderate resolution imaging spectroradiometer airborne simulator. Remote Sens. Environ. 1999, 68, 152–163. [Google Scholar] [CrossRef]
- Trishchenko, A.P.; Luo, Y.; Khlopenkov, K.V. A method for downscaling MODIS land channels to 250-m spatial resolution using adaptive regression and normalization. Proc. SPIE 2006. [Google Scholar] [CrossRef]
- Xiao, X.; Shen, Z.; Qin, X. Assessing the potential of vegetation sensor data for mapping snow and ice cover: A normalized difference snow and ice index. Int. J. Remote Sens. 2001, 22, 2479–2487. [Google Scholar] [CrossRef]
- El-Alem, A.; Chokmani, K.; Laurion, I.; El-Adlouni, S. An adaptive model to monitor chlorophyll-a in inland waters in southern quebec using downscaled MODIS imagery. Remote Sens. 2014, 6, 6446–6471. [Google Scholar] [CrossRef]
- Fontana, F.M.A.; Trishchenko, A.P.; Luo, Y.; Khlopenkov, K.V.; Nussbaumer, S.U.; Wunderle, S. Perennial snow and ice variations (2000–2008) in the Arctic circumpolar land area from satellite observations. J. Geophys. Res. Earth Surf. 2010. [Google Scholar] [CrossRef]
- Gu, Y.; Wylie, B. Downscaling 250-m modis growing season ndvi based on multiple-date landsat images and data mining approaches. Remote Sens. 2015, 7, 3489–3506. [Google Scholar] [CrossRef]
- Trishchenko, A.P.; Khlopenkov, K.V.; Ungureanu, C.; Latifovic, R.; Luo, Y.; Park, W.B. Mapping of surface albedo over mackenzie river basin from satellite observations. In Cold Region Atmospheric and Hydrologic Studies. The Mackenzie Gewex Experience; Springer: Berlin, Germany, 2008; pp. 327–341. [Google Scholar]
- Ackerman, S.A.; Strabala, K.I.; Menzel, W.P.; Frey, R.A.; Moeller, C.C.; Gumley, L.E. Discriminating clear sky from clouds with MODIS. J. Geophys. Res. Atmos. 1998, 103, 32141–32157. [Google Scholar] [CrossRef]
- Kilpatrick, K.A.; Podesta, G.; Walsh, S.; Williams, E.; Halliwell, V.; Szczodrak, M.; Brown, O.B.; Minnett, P.J.; Evans, R. A decade of sea surface temperature from modis. Remote Sens. Environ. 2015, 165, 27–41. [Google Scholar] [CrossRef]
- Chan, M.A.; Comiso, J.C. Arctic cloud characteristics as derived from modis, calipso, and cloudsat. J. Clim. 2013, 26, 3285–3306. [Google Scholar] [CrossRef]
- Jenks, G.F. The data model concept in statistical mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Eastwood, S.; Jenssen, M.; Lavergne, T.; Sorensen, A.; Tonboe, R. Global Sea Ice Concentration Reprocessing—Product User Manual; Ocean and Sea Ice SAF-Eumetsat: Darmstadt, Germany, 2015. [Google Scholar]
- Perovich, D.; Jones, K.; Light, B.; Eicken, H.; Markus, T.; Stroeve, J.; Lindsay, R. Solar partitioning in a changing Arctic sea-ice cover. Ann. Glaciol. 2011, 52, 192–196. [Google Scholar] [CrossRef]
- Eicken, H.; Grenfell, T.C.; Perovich, D.K.; Richter-Menge, J.A.; Frey, K. Hydraulic controls of summer Arctic pack ice albedo. J. Geophys. Res. Oceans 2004. [Google Scholar] [CrossRef]
- Fetterer, F.; Untersteiner, N. Observations of melt ponds on Arctic sea ice. J. Geophys. Res. Oceans 1998, 103, 24821–24835. [Google Scholar] [CrossRef]
- Rosel, A.; Kaleschke, L.; Birnbaum, G. Melt ponds on Arctic sea ice determined from MODIS satellite data using an artificial neural network. Cryosphere 2012, 6, 431–446. [Google Scholar] [CrossRef] [Green Version]
- Tschudi, M.A.; Maslanik, J.A.; Perovich, D.K. Derivation of melt pond coverage on Arctic sea ice using modis observations. Remote Sens. Environ. 2008, 112, 2605–2614. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Number | Grid Resolution (m) | Bandwidth (μm) | Part of Spectrum |
|---|---|---|---|
| 1 | 250 | 0.62–0.67 | VIS (red) |
| 2 | 250 | 0.841–0.876 | NIR |
| 3 | 500 | 0.459–0.479 | VIS (blue) |
| 4 | 500 | 0.545–0.565 | VIS (green) |
| 5 | 500 | 1.230–1.250 | NIR |
| 6 | 500 | 1.628–1.652 | SWIR |
| 7 | 500 | 2.105–2.155 | SWIR |
| Combination: MOD35/VIS | Composite Result |
|---|---|
| Ice/Ice | Ice |
| Ice/Water | Water |
| Water/Water | Water |
| Water/Ice | Rejected |
| No Data/Water | Water |
| No Data/Ice | Rejected |
| Product (Mask) | Algorithm | Resolution | Role |
|---|---|---|---|
| MOD29 | Original IceMap [23] | 1 km | Benchmark |
| (MOD35) | |||
| IceMap1KM | IceMap250 | 1 km | Evaluate impacts of algorithm changes |
| (MOD35) | |||
| IceMap1KM | IceMap250 | 1 km | Evaluate impacts of algorithm and mask changes |
| (VIS) | |||
| IceMap250 | IceMap250 | 250 m | Evaluate impacts of mask, algorithm and resolution changes |
| (MOD35) | |||
| IceMap250 | IceMap250 | 250 m | Evaluate impacts of mask, algorithm and resolution changes |
| (VIS) | |||
| IceMap250 | IceMap250 | 250 m | Evaluate the accuracy and performance of the final map |
| (Composite) |
| Ground Truth | ||||||
|---|---|---|---|---|---|---|
| STABLE | Water | Ice | Total | Commission Error | ||
| MOD29 (M35) | Map | Water | 3 | 6 | 9 | 66.7% |
| Ice | 5 | 486 | 491 | 1.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 62.5% | 1.2% | N/A | Overall accuracy | ||
| Kappa | 34.18% | 97.80% | ||||
| IceMap250 at 1 km (M35) | Map | Water | 3 | 1 | 4 | 25.0% |
| Ice | 5 | 491 | 496 | 1.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 62.5% | 0.2% | N/A | Overall accuracy | ||
| Kappa | 49.46% | 98.80% | ||||
| IceMap250 at 1 km (VIS) | Map | Water | 3 | 1 | 4 | 25.0% |
| Ice | 5 | 491 | 496 | 1.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 62.5% | 0.2% | N/A | Overall accuracy | ||
| Kappa | 49.46% | 98.80% | ||||
| IceMap250 (M35) | Map | Water | 8 | 1 | 9 | 11.1% |
| Ice | 0 | 491 | 491 | 0.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 0.0% | 0.2% | N/A | Overall accuracy | ||
| Kappa | 94.02% | 99.80% | ||||
| IceMap250 (VIS) | Map | Water | 8 | 1 | 9 | 11.1% |
| Ice | 0 | 491 | 491 | 0.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 0.0% | 0.2% | N/A | Overall accuracy | ||
| Kappa | 94.02% | 99.80% | ||||
| IceMap Composite | Map | Water | 8 | 1 | 9 | 11.1% |
| Ice | 0 | 491 | 491 | 0.0% | ||
| Total | 8 | 492 | 500 | N/A | ||
| Omission error | 0.0% | 0.2% | N/A | Overall accuracy | ||
| Kappa | 94.02% | 99.80% | ||||
| Ground Truth | ||||||
|---|---|---|---|---|---|---|
| MELT | Water | Ice | Total | Commission Error | ||
| MOD29 (M35) | Map | Water | 140 | 5 | 145 | 3.4% |
| Ice | 8 | 347 | 355 | 2.3% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 5.4% | 1.4% | N/A | Overall accuracy | ||
| Kappa | 93.72% | 97.40% | ||||
| IceMap250 at 1 km (M35) | Map | Water | 128 | 4 | 132 | 3.0% |
| Ice | 20 | 348 | 368 | 5.4% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 13.5% | 1.1% | N/A | Overall accuracy | ||
| Kappa | 88.11% | 95.20% | ||||
| IceMap250 at 1 km (VIS) | Map | Water | 127 | 3 | 130 | 2.3% |
| Ice | 21 | 349 | 370 | 5.7% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 14.2% | 0.9% | N/A | Overall accuracy | ||
| Kappa | 88.06% | 95.20% | ||||
| IceMap250 (M35) | Map | Water | 140 | 0 | 140 | 0.0% |
| Ice | 8 | 352 | 360 | 2.2% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 5.4% | 0.0% | N/A | Overall accuracy | ||
| Kappa | 96.10% | 98.40% | ||||
| IceMap250 (VIS) | Map | Water | 142 | 0 | 142 | 0.0% |
| Ice | 6 | 352 | 358 | 1.7% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 4.1% | 0.0% | N/A | Overall accuracy | ||
| Kappa | 97.09% | 98.80% | ||||
| IceMap Composite | Map | Water | 142 | 0 | 142 | 0.0% |
| Ice | 6 | 352 | 358 | 1.7% | ||
| Total | 148 | 352 | 500 | N/A | ||
| Omission error | 4.1% | 0.0% | N/A | Overall accuracy | ||
| Kappa | 97.09% | 98.80% | ||||
| Ground Truth | ||||||
|---|---|---|---|---|---|---|
| FREEZE-UP | Water | Ice | Total | Commission Error | ||
| MOD29 (M35) | Map | Water | 78 | 23 | 101 | 22.8% |
| Ice | 3 | 396 | 399 | 0.8% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 3.7% | 5.5% | N/A | Overall accuracy | ||
| Kappa | 82.58% | 94.80% | ||||
| IceMap250 at 1 km (M35) | Map | Water | 73 | 2 | 75 | 2.7% |
| Ice | 8 | 417 | 425 | 1.9% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 9.9% | 0.5% | N/A | Overall accuracy | ||
| Kappa | 92.41% | 98.00% | ||||
| IceMap250 at 1 km (VIS) | Map | Water | 73 | 2 | 75 | 2.7% |
| Ice | 8 | 417 | 425 | 1.9% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 9.9% | 0.5% | N/A | Overall accuracy | ||
| Kappa | 92.41% | 98.00% | ||||
| IceMap250 (M35) | Map | Water | 75 | 2 | 77 | 2.6% |
| Ice | 6 | 417 | 423 | 1.4% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 7.4% | 0.5% | N/A | Overall accuracy | ||
| Kappa | 93.99% | 98.40% | ||||
| IceMap250 (VIS) | Map | Water | 74 | 2 | 76 | 2.6% |
| Ice | 7 | 417 | 424 | 1.7% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 8.6% | 0.5% | N/A | Overall accuracy | ||
| Kappa | 93.20% | 98.20% | ||||
| IceMap Composite | Map | Water | 75 | 2 | 77 | 2.6% |
| Ice | 6 | 417 | 423 | 1.4% | ||
| Total | 81 | 419 | 500 | N/A | ||
| Omission error | 7.4% | 0.5% | N/A | Overall accuracy | ||
| Kappa | 93.99% | 98.40% | ||||
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gignac, C.; Bernier, M.; Chokmani, K.; Poulin, J. IceMap250—Automatic 250 m Sea Ice Extent Mapping Using MODIS Data. Remote Sens. 2017, 9, 70. https://doi.org/10.3390/rs9010070
Gignac C, Bernier M, Chokmani K, Poulin J. IceMap250—Automatic 250 m Sea Ice Extent Mapping Using MODIS Data. Remote Sensing. 2017; 9(1):70. https://doi.org/10.3390/rs9010070
Chicago/Turabian StyleGignac, Charles, Monique Bernier, Karem Chokmani, and Jimmy Poulin. 2017. "IceMap250—Automatic 250 m Sea Ice Extent Mapping Using MODIS Data" Remote Sensing 9, no. 1: 70. https://doi.org/10.3390/rs9010070
APA StyleGignac, C., Bernier, M., Chokmani, K., & Poulin, J. (2017). IceMap250—Automatic 250 m Sea Ice Extent Mapping Using MODIS Data. Remote Sensing, 9(1), 70. https://doi.org/10.3390/rs9010070