Shadows, which are cast by elevated objects, such as buildings, trees, and clouds, are ever-present phenomena in remote sensing and computer vision. Shadow is a double-edged sword for image interpretation, depending on whether the shadows are modeled or ignored. Additional semantic and geometric cues provided by shadows help us to localize objects. However, shadows can also degrade the accuracy of several tasks (e.g., image classification [
1], change detection [
2], object recognition [
3], image segmentation [
4],
etc.) due to spurious boundaries and confusion between shading and reflectivity. For these reasons, shadow detection has become a crucial preprocessing stage of scene interpretation.
Many shadow detection techniques have been proposed in the last decade. One type is based on interaction, called semiautomatic methods [
5]. Interaction-based methods can achieve good performance results where user-supplied information should be provided. For example, in Wu and Tang [
6], a quadmap that defines the candidate shadow and non-shadow regions is required in their Bayesian framework. Wu
et al. [
7] formulated shadow detection as a matting problem, and users were asked to give several strokes to specify shadows and non-shadows. Despite these methods being accurate, their requirements will dramatically reduce efficiency. Furthermore, incorporating them into a fully automatic workflow is difficult.
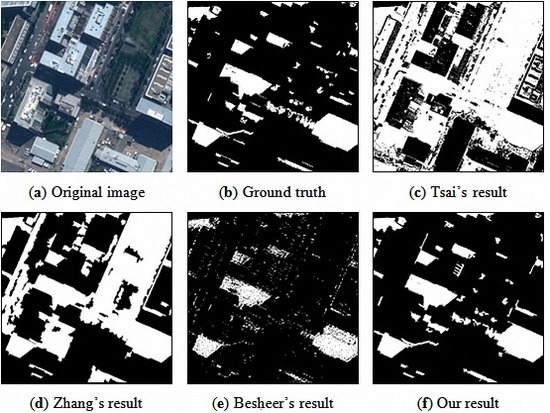
Compared with semi-automatic methods, fully-automatic methods have drawn much more attention in recent years. These methods can be divided into two types: single-image approaches and multi-image approaches [
5]. Tsai [
8] observed that shadow regions have the property of lower luminance, but higher hue values, and a ratio map can be constructed for the detection problem. Zhang
et al. [
9] proposed an object-based method. The authors used a thresholding technique to extract suspected shadow objects and rule out dark objects based on spectral properties and shape information. Besheer and Abdelhafiz [
10] improved the original C1C2C3 invariant color model using near-infrared (NIR) channel information. The authors used bimodal histogram splitting to provide the threshold of binary segmentation. Their method is only suitable for images with a NIR channel. In [
11], an algorithm that uses both spatial and spectral features was proposed. Similar to the method by Zhang
et al., this method is also based on the thresholding technique and object segmentation. Risson presented a shadow detection method in his thesis using a photometric analysis approach to recover lighting conditions of color images [
12]. Panagopoulos
et al. [
13] presented a method based on bright channel cues. The authors used the bright channel to provide an adequate approximation to the illumination component. Then, they adapted a Markov random field (MRF) to refine the bright channel. Boundary information is also a powerful cue to distinguish shadows from non-shadows, such as in [
14,
15,
16]. These methods use only pixel or edge information, which may become limitations in more complicated scenes. To improve robustness, several model-based methods have been studied. Finlayson
et al. [
17] obtained illumination-invariant images by projecting an image’s log chromaticities based on the Planckian illumination model. Panagopoulos
et al. [
18] presented a higher-order Markov random field (MRF) model to recover the illumination map. An impressive performance can be achieved with high-quality images and calibrated sensors, but a poor performance is achieved for typical web-quality photographs [
19]. Tian
et al. [
20,
21] proposed a trichromatic attenuation model (TAM) and combined it with pixel intensity to classify shadow pixels. Data-driven approaches, which is another popular technique, learn a shadow detection model from a training set. Guo
et al. [
22] used a region-based approach. In their work, a relational graph of paired regions is adopted for the problem. Zhu
et al. [
23] learned statistical information.
i.e., intensity, gradient and texture, to classify regions in monochromatic images. More recently, Khan
et al. [
24,
25] proposed an extremely impressive shadow detection framework based on multiple convolutional deep neural networks. This model learns features at the superpixel level and along dominant boundaries; then, smooth shadow masks are detected via a conditional random field model.
To transform the ill-posed problem of recovering an intrinsic image from a single photograph to a well-posed one, other studies have been performed in which multiple images (or additional information) are considered. For example, Weiss [
26] recovered an intrinsic reflectance image based on an image sequence of the same scene with varying illumination conditions. Tolt
et al. [
27] analyzed the line-of-sight on a DSM and estimated the position of the sun to assist illumination component extraction. Drew
et al. [
28] proposed a method to estimate the illumination map by combining flash/no-flash image pairs. These methods can easily obtain an accurate shadow map. However, their application is extremely restricted because most of the scenes do not satisfy their requirements, e.g., the flash/non-flash method may fail in an outdoor environment.
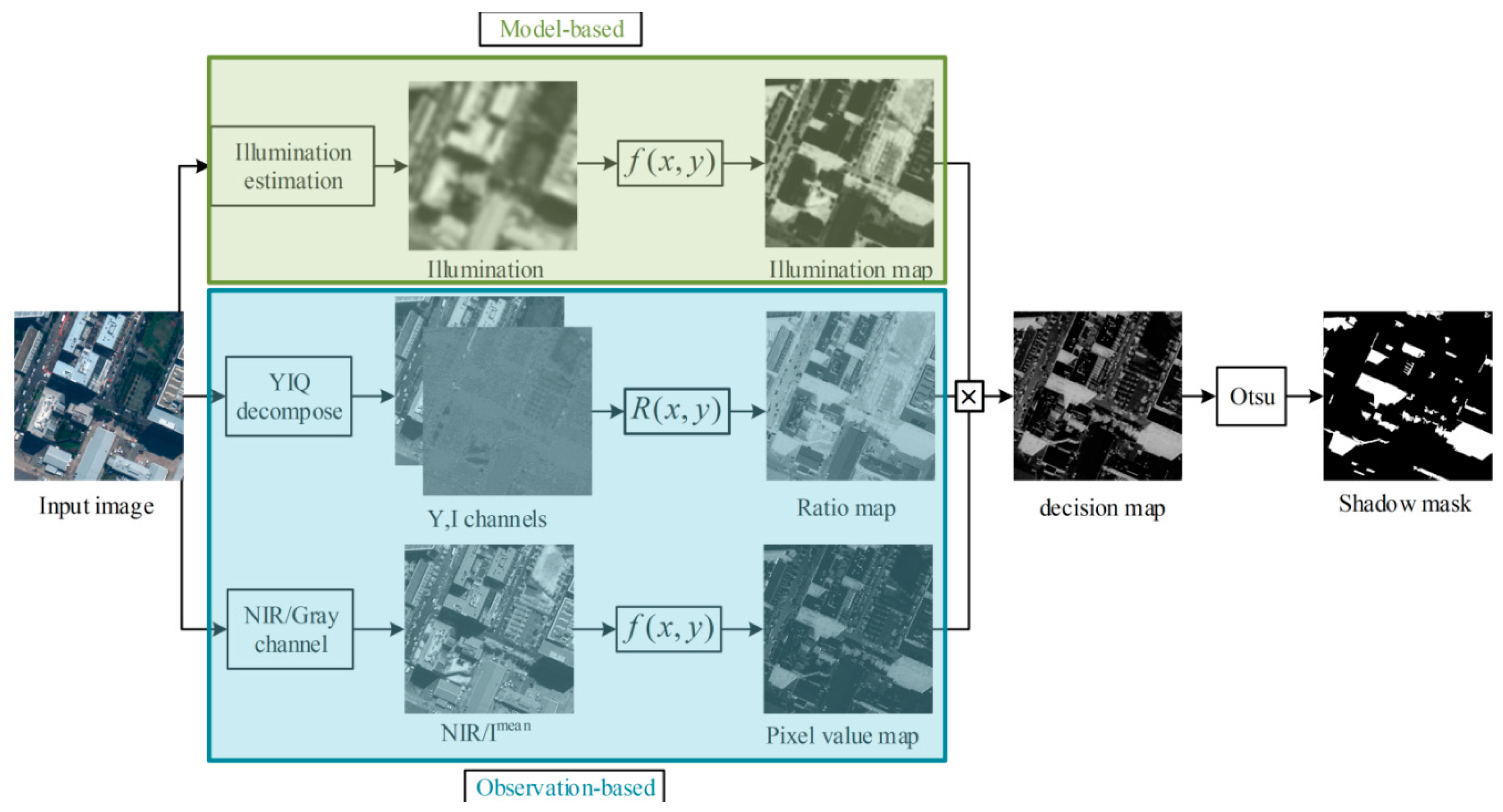
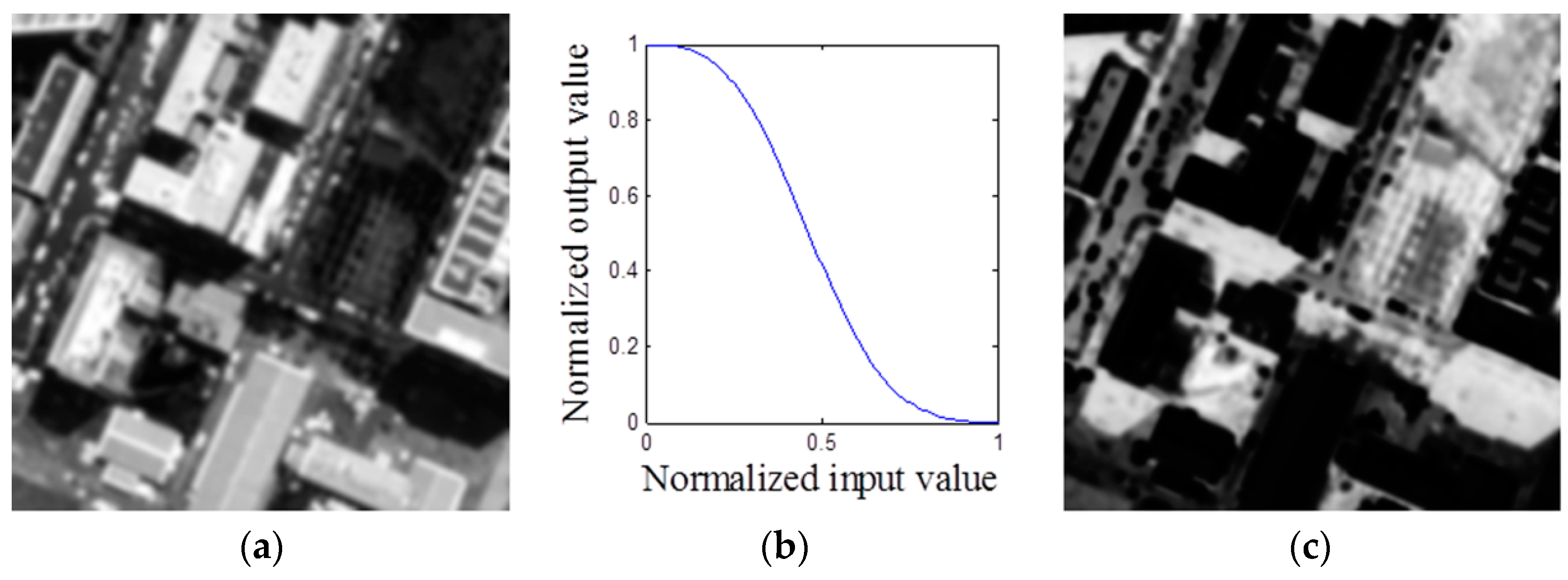
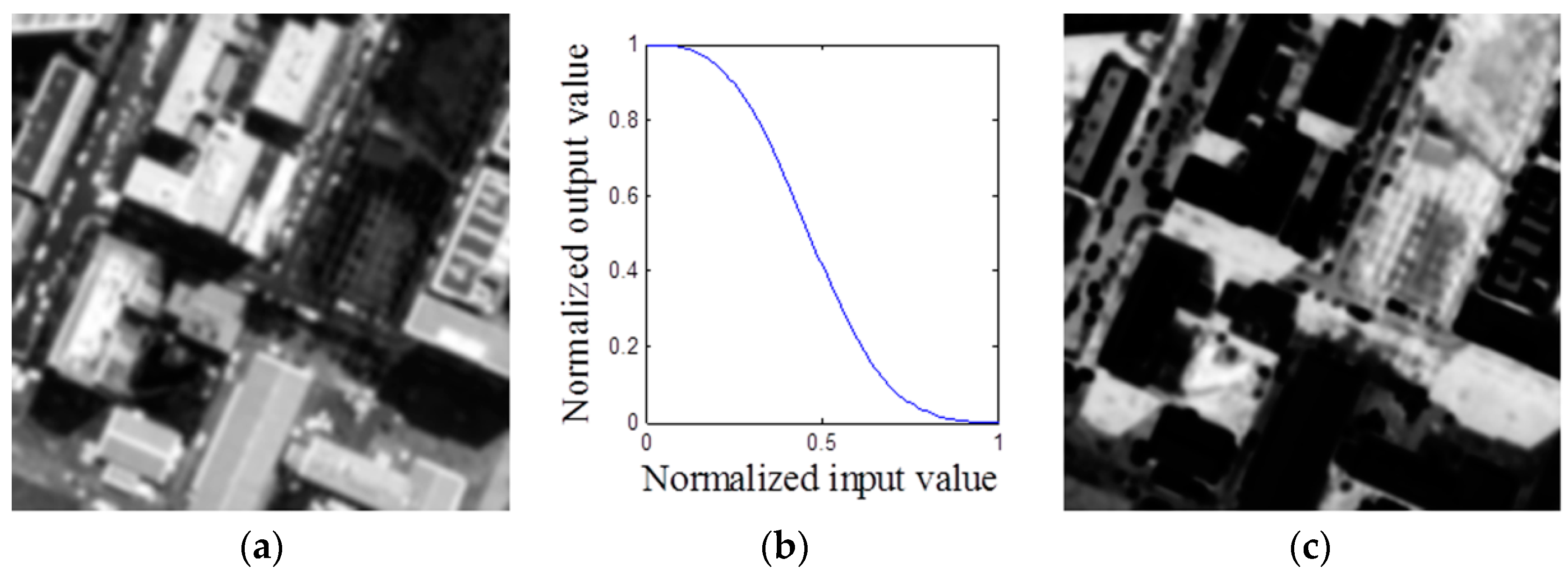
In this paper, we address the shadow detection problem for more complex scenes based only on a single image. Different from the method of Panagopoulos
et al. [
13], whose bright channel cue gives an approximation of the illumination component, our method gives a bright channel prior for the radiance component. We join the model and observation cues to improve the detection accuracy. Firstly, an approximate occlusion map is estimated using a simple prior, called the bright channel prior (BCP). Then, a ratio map and a pixel value map are produced based on the properties of the shadows. Afterwards, the final decision map is generated by fusing these three feature maps to segment out shadows. We evaluate our method from both qualitative and quantitative aspects on two datasets. The results demonstrate that our method is effective for the shadow detection task.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}