
A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification




Abstract
:
1. Introduction
1.1. Motivation and Objective
1.2. Related Works
1.3. Contribution of this Work
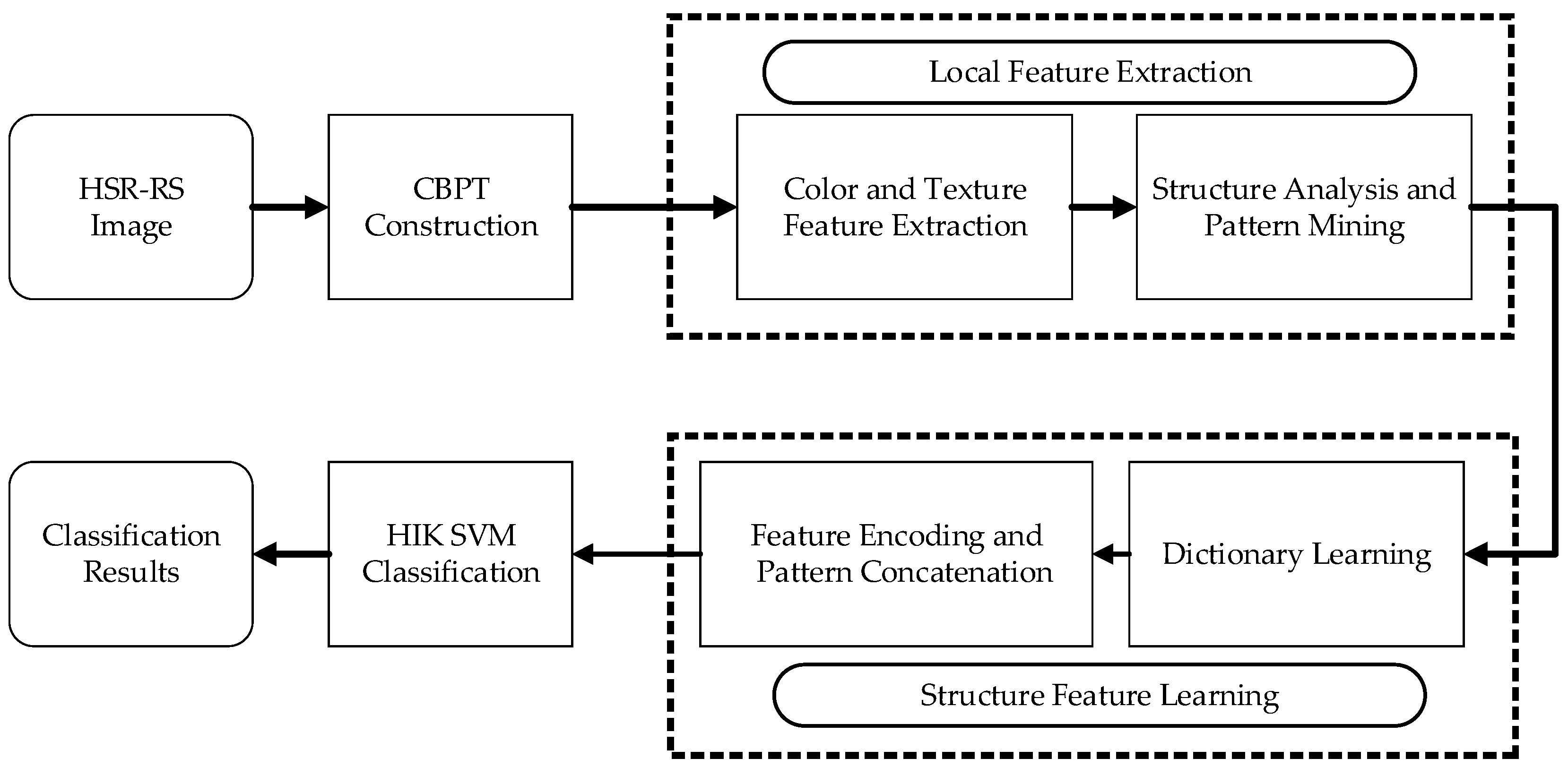
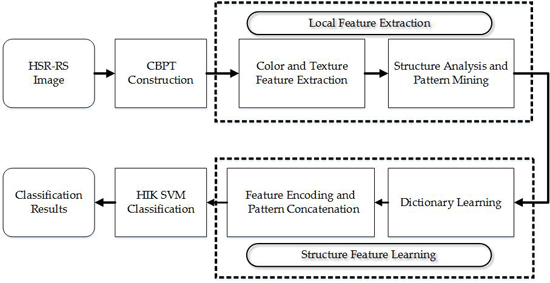
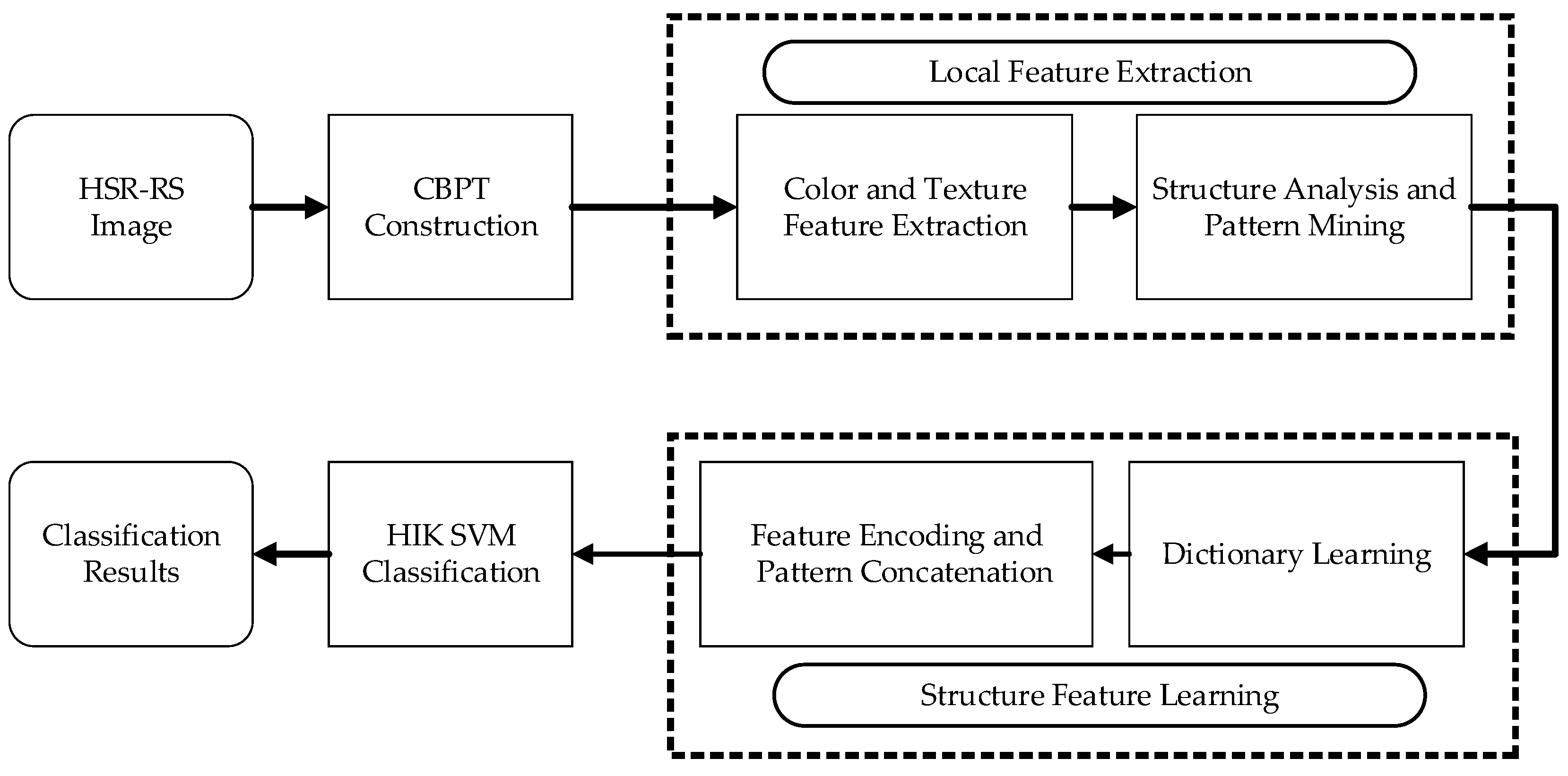
2. CBPT Construction
2.1. Color Description of HRS Image
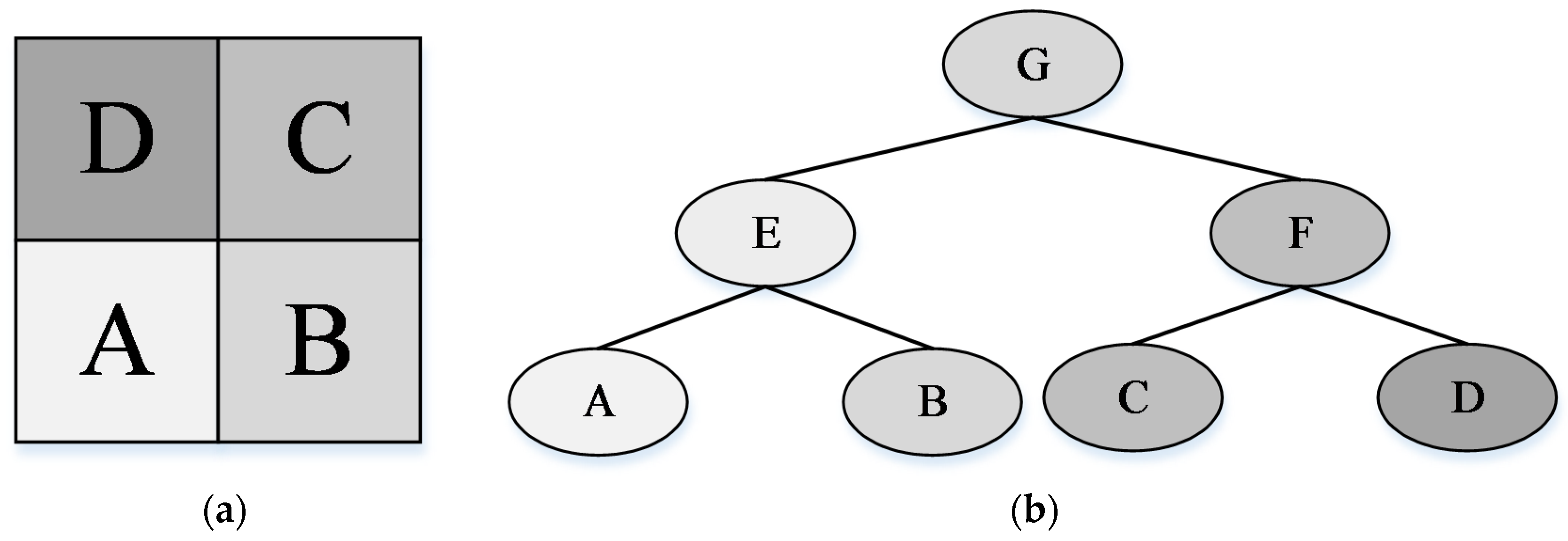
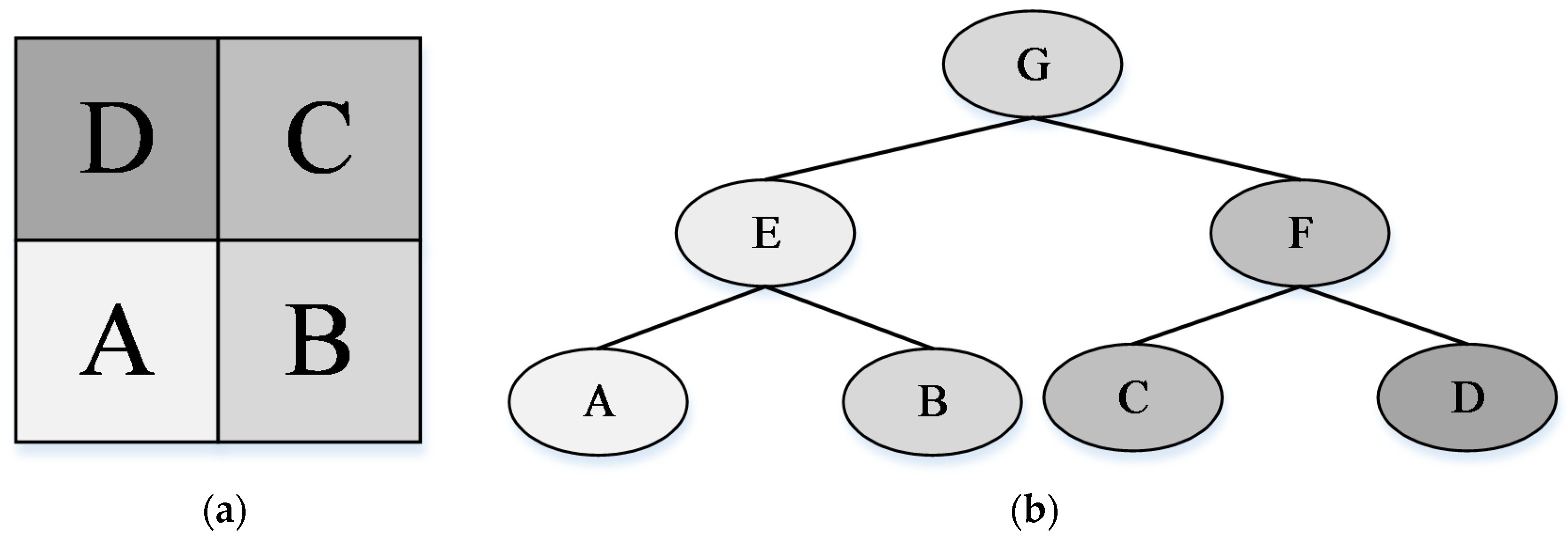
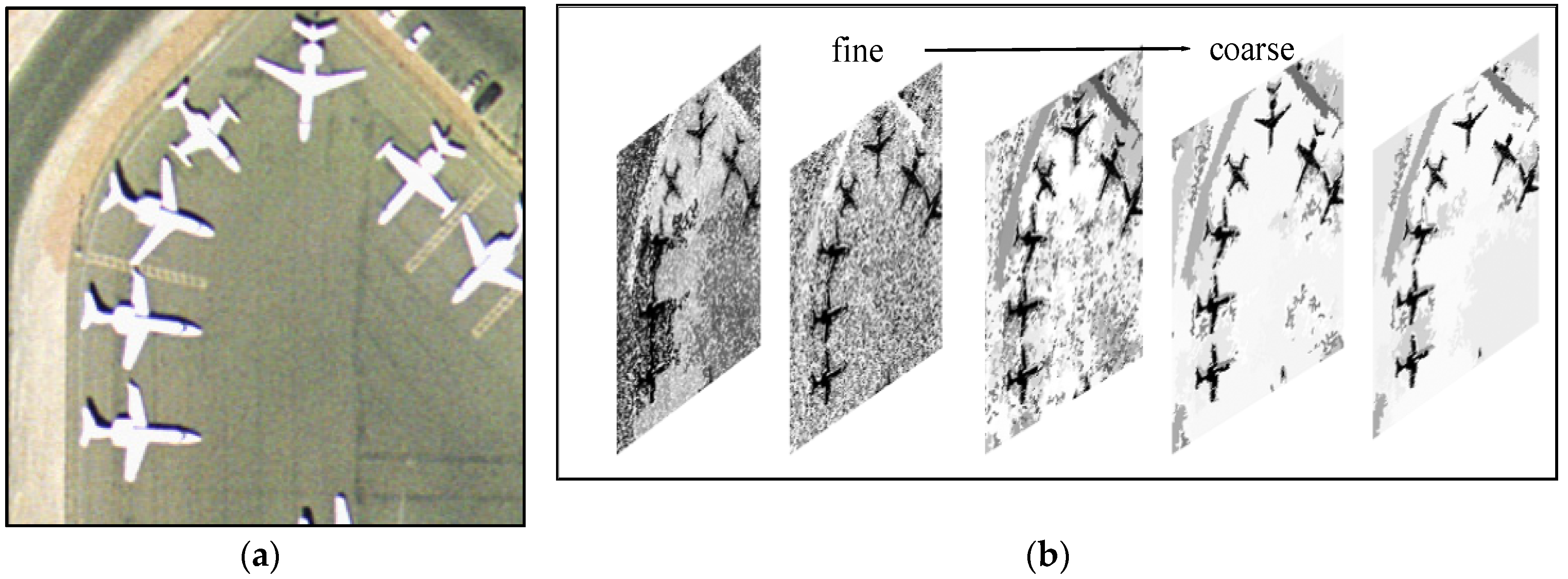
2.2. Color Binary Partition Tree (CBPT) Construction
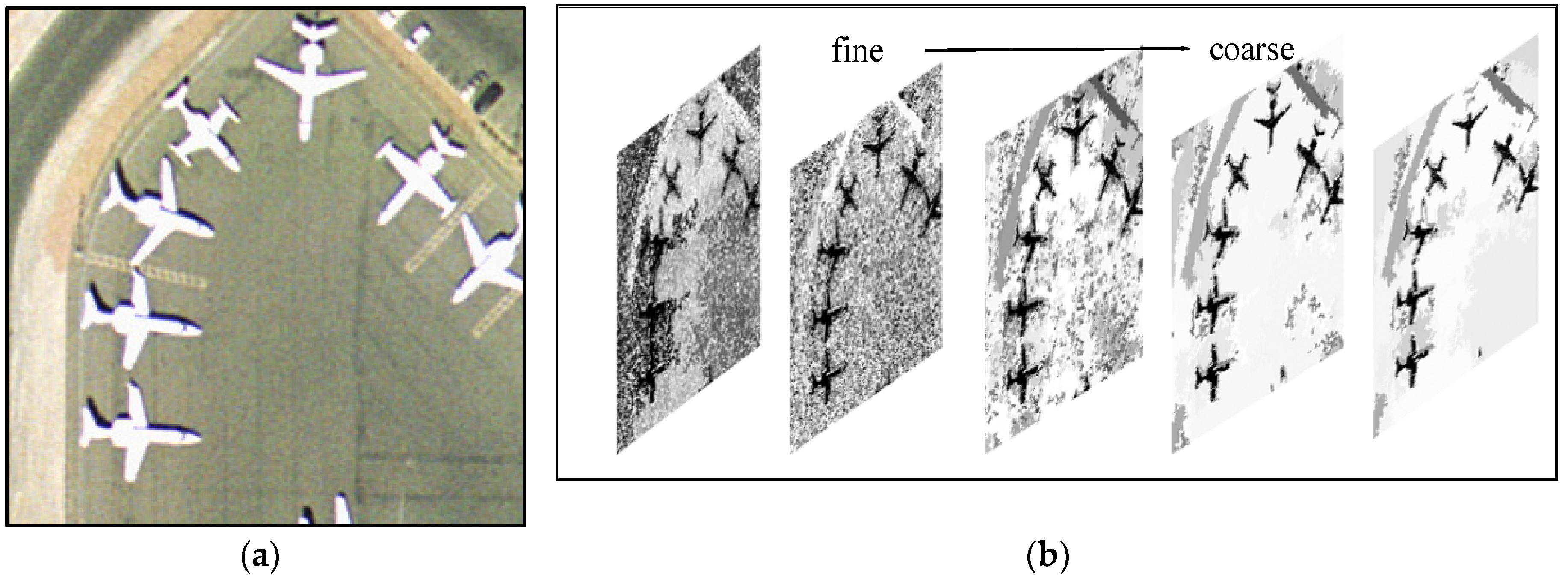
3. Texture and Color Feature Analysis of CBPT Representation
3.1. Shape-Based Invariant Texture Analysis (SITA)
- (1)
- Elongation, which defines the aspect ratio of the region:
- (2)
- Orientation, which defines the angle between the major and minor axes:
- (3)
- Rectangularity, which defines to what extent a region is rectangular:where w and l are the width and height, respectively, of the minimum bounding rectangle.
- (4)
- Circle-compactness, as with the rectangularity:
- (5)
- Eclipse-compactness, as with the rectangularity:
- (6)
- Scale ratio, which defines the relationship between the current region s and its former r ancestors:
- (7)
- Normalized area:
3.2. Color Features
- (1)
- Normalized average:
- (2)
- Variance:
- (3)
- Skewness:
3.3. Pattern Design and Structure Analysis
- Features of P1: ;
- Features of P2: ;
- Features of P3: ;
- Features of P4: .
3.4. Color-Texture-Structure Descriptor Generation
3.4.1. Locality-Constrained Linear Coding
3.4.2. FV Coding
4. Experimental Results
4.1. Experiments on UC Merced Dataset
4.1.1. Coding Method Comparison
4.1.2. Fusion Strategy Comparison
4.1.3. Parameter Effect
4.1.4. Classification Result Comparison
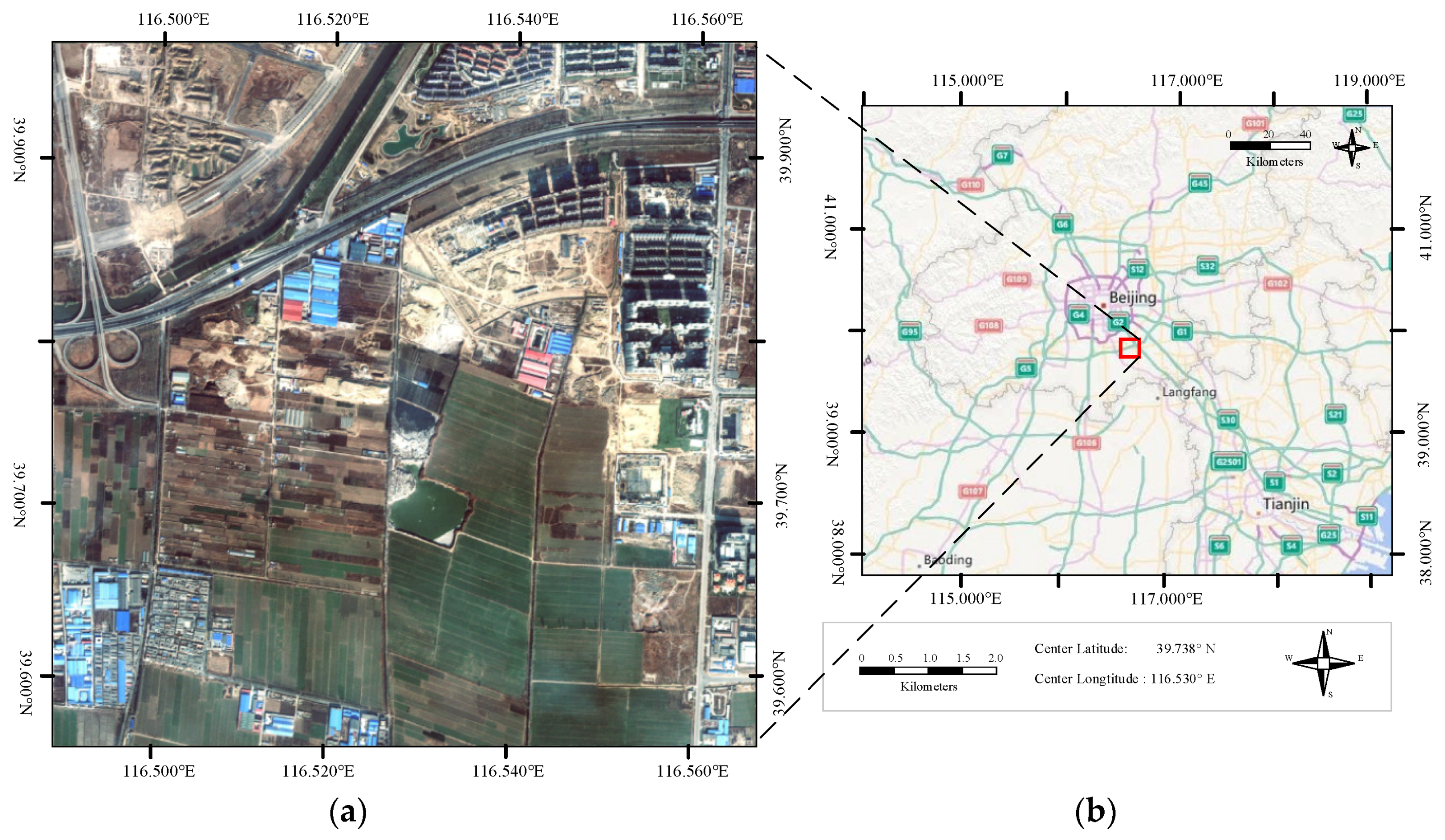
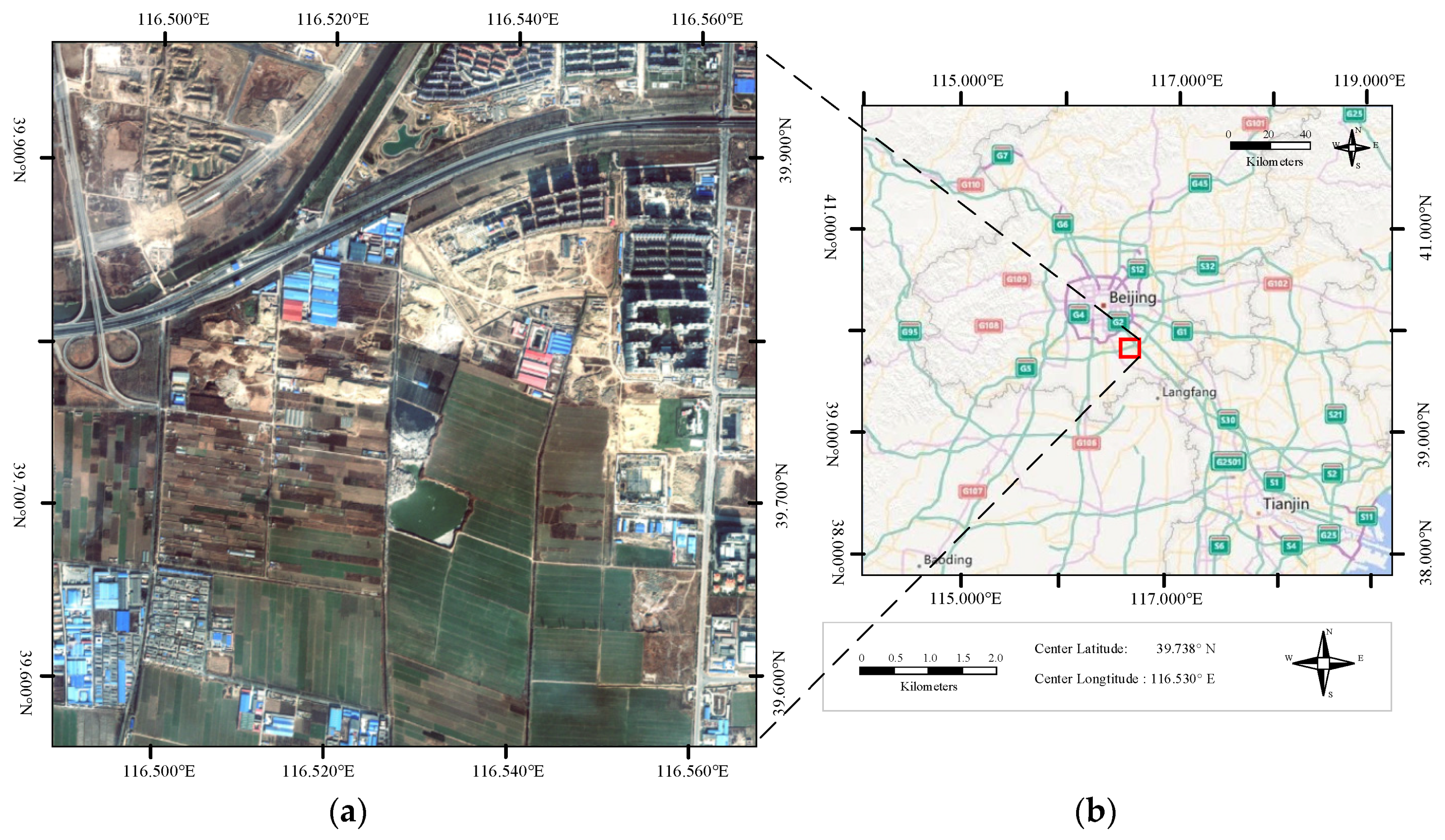
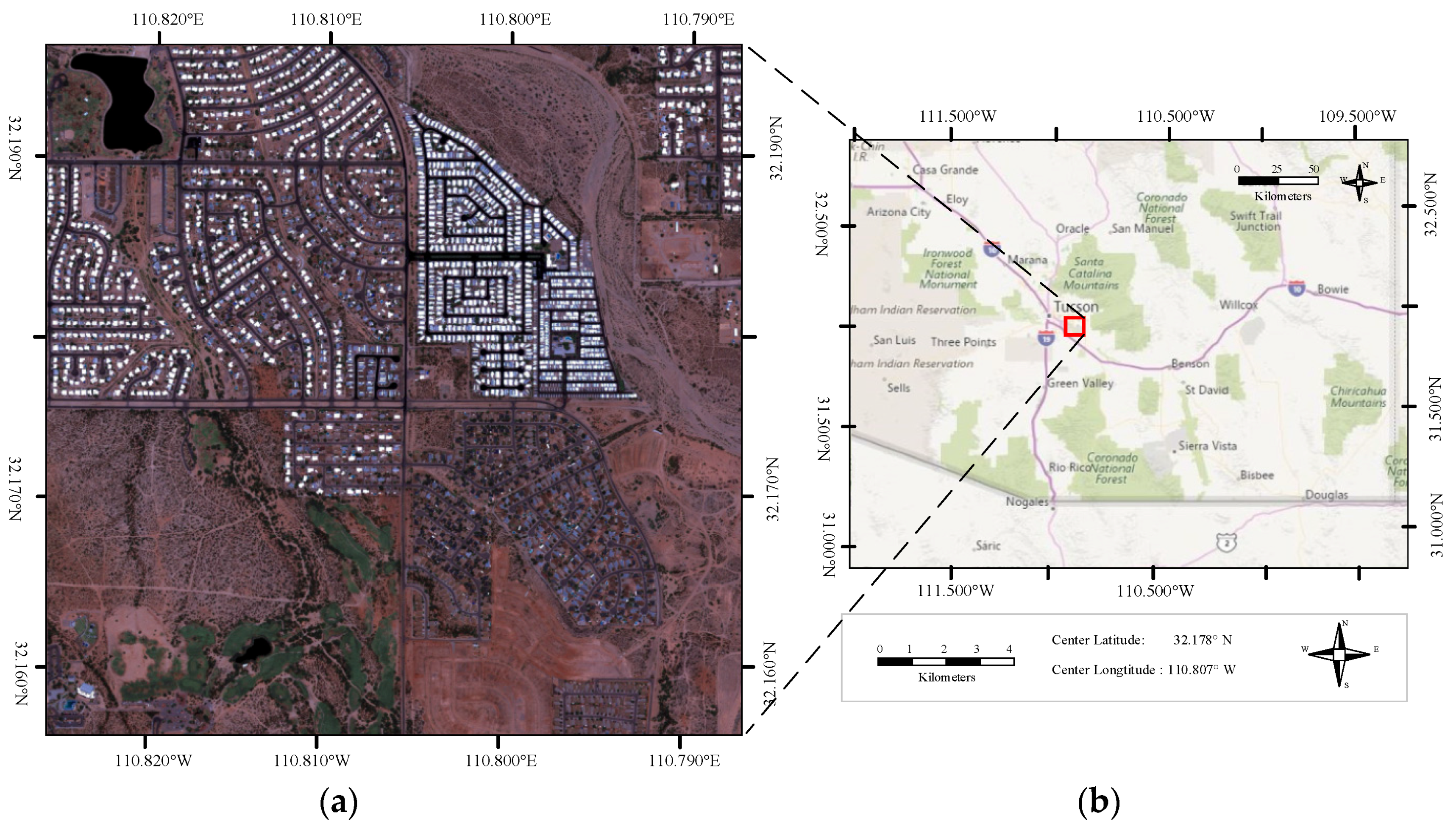
4.2. Experiments on Large Satellite Scenes
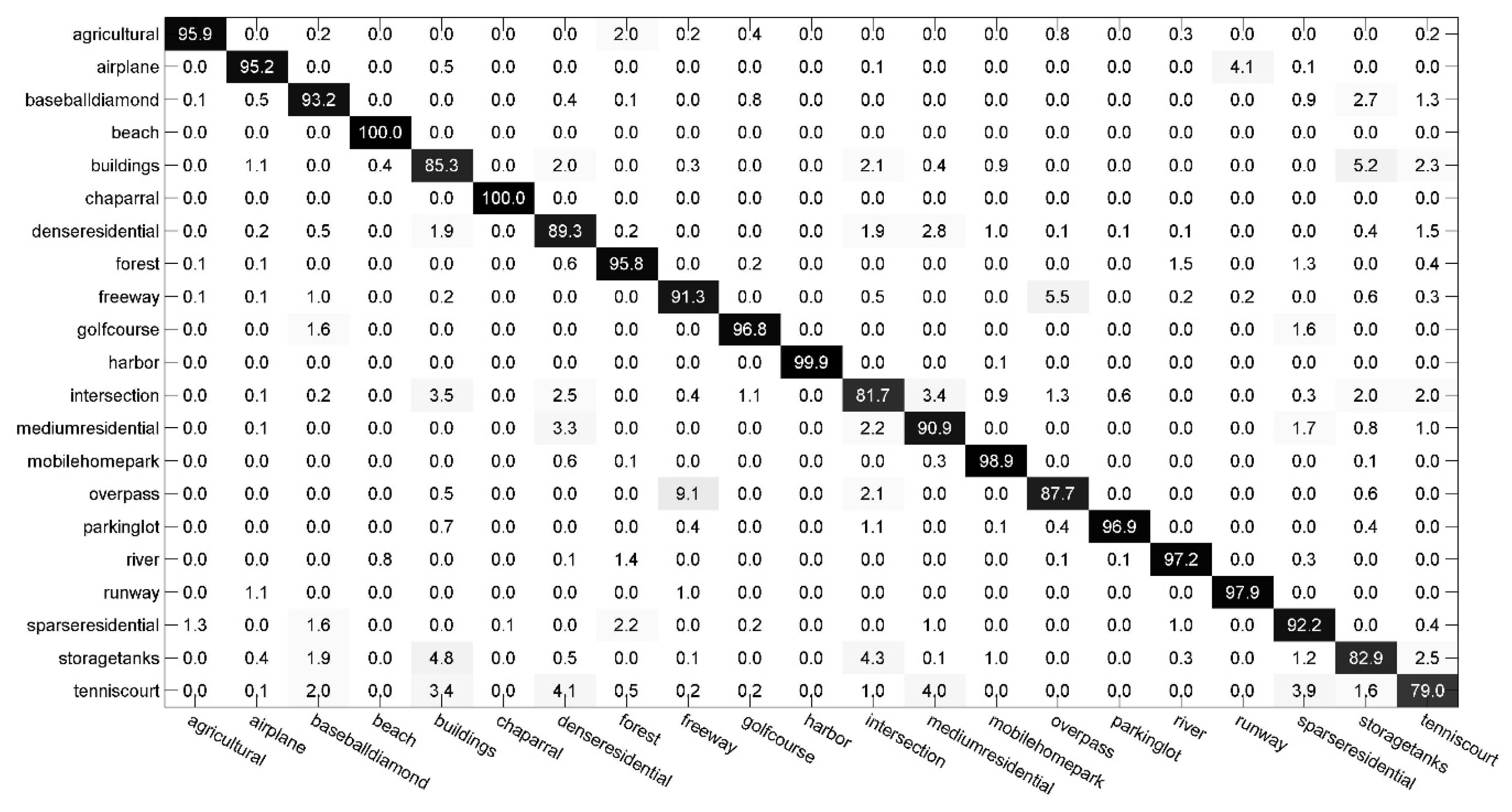
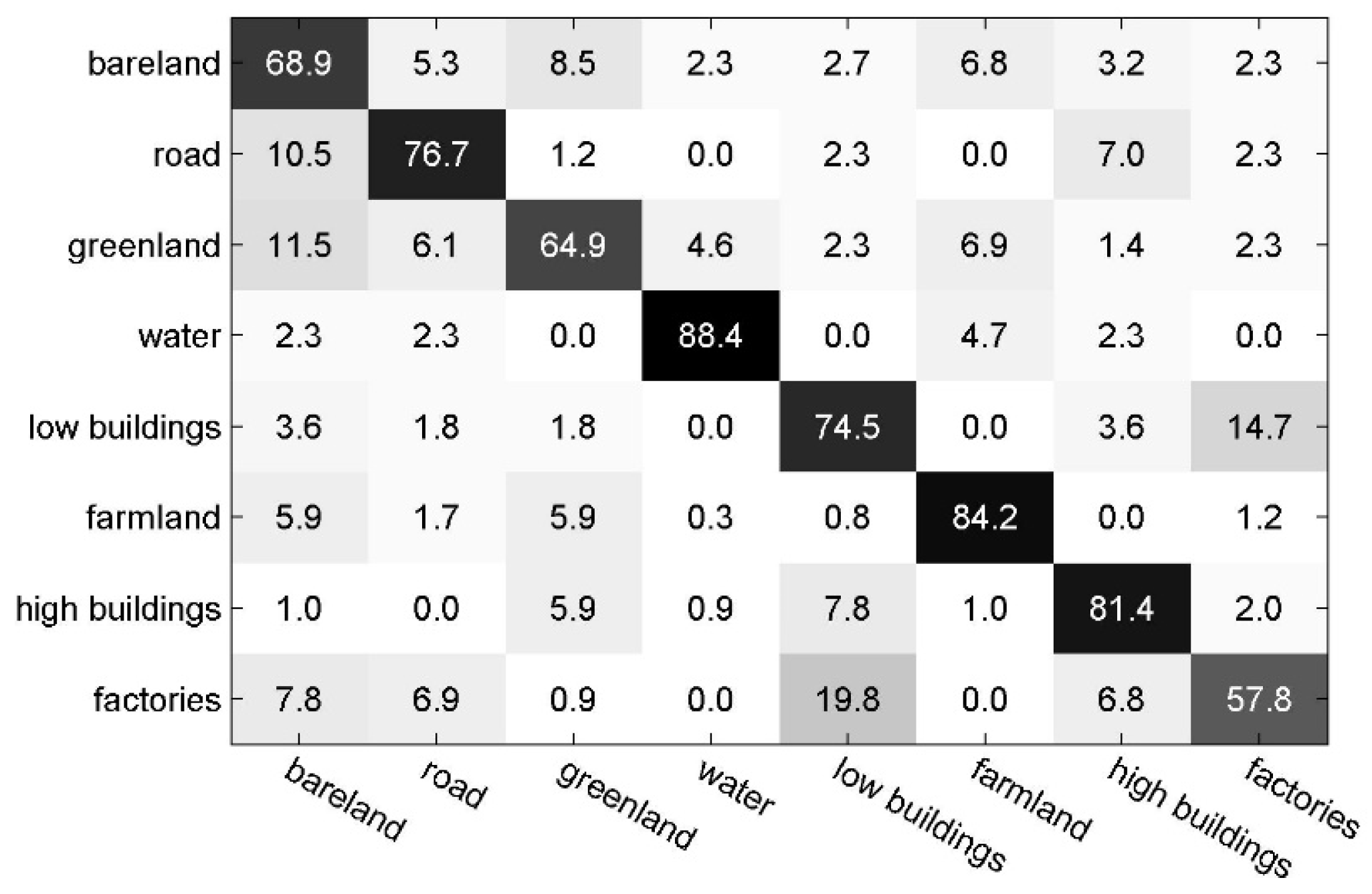
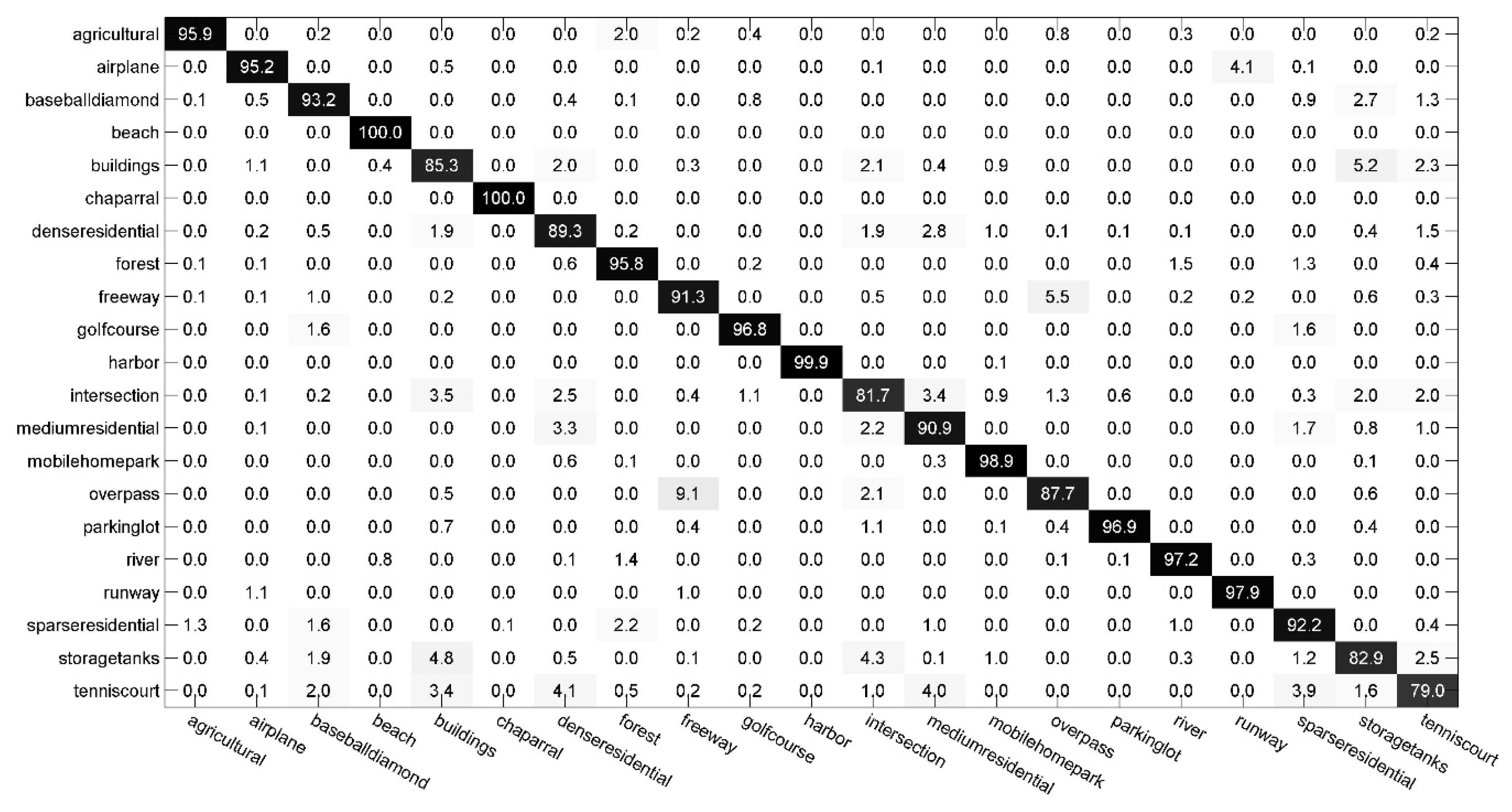
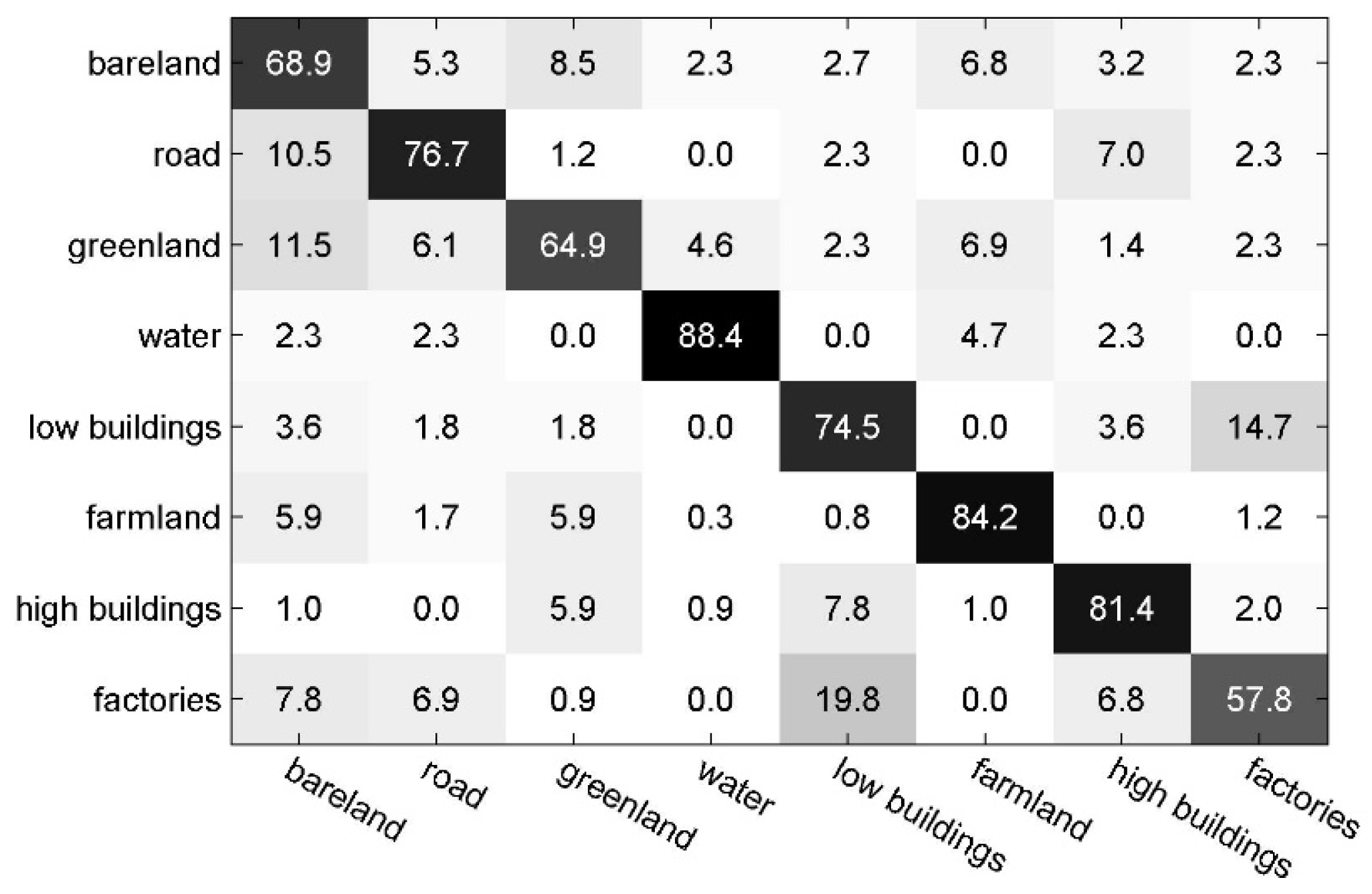
4.2.1. Experiments on Scene-TZ
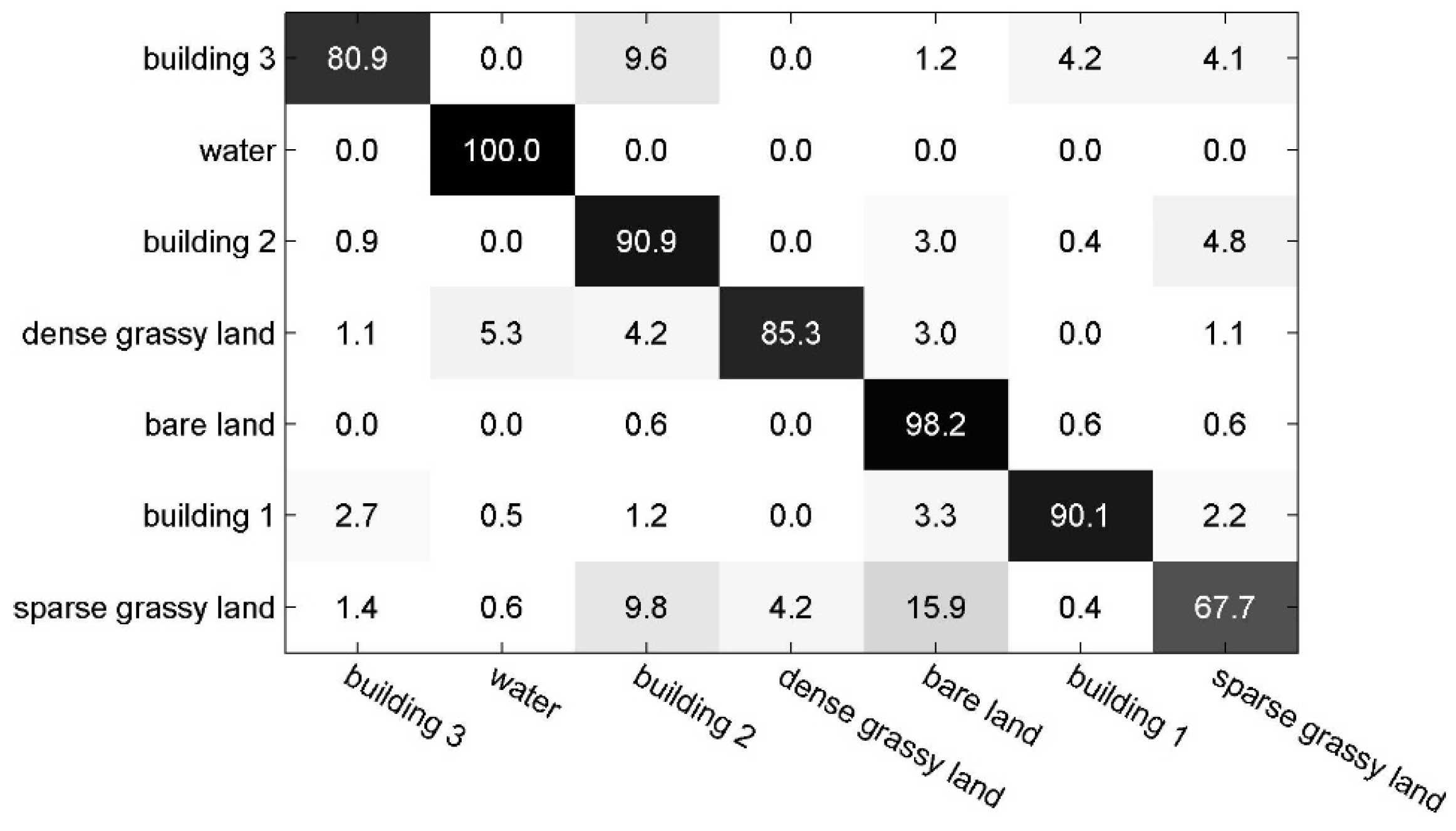
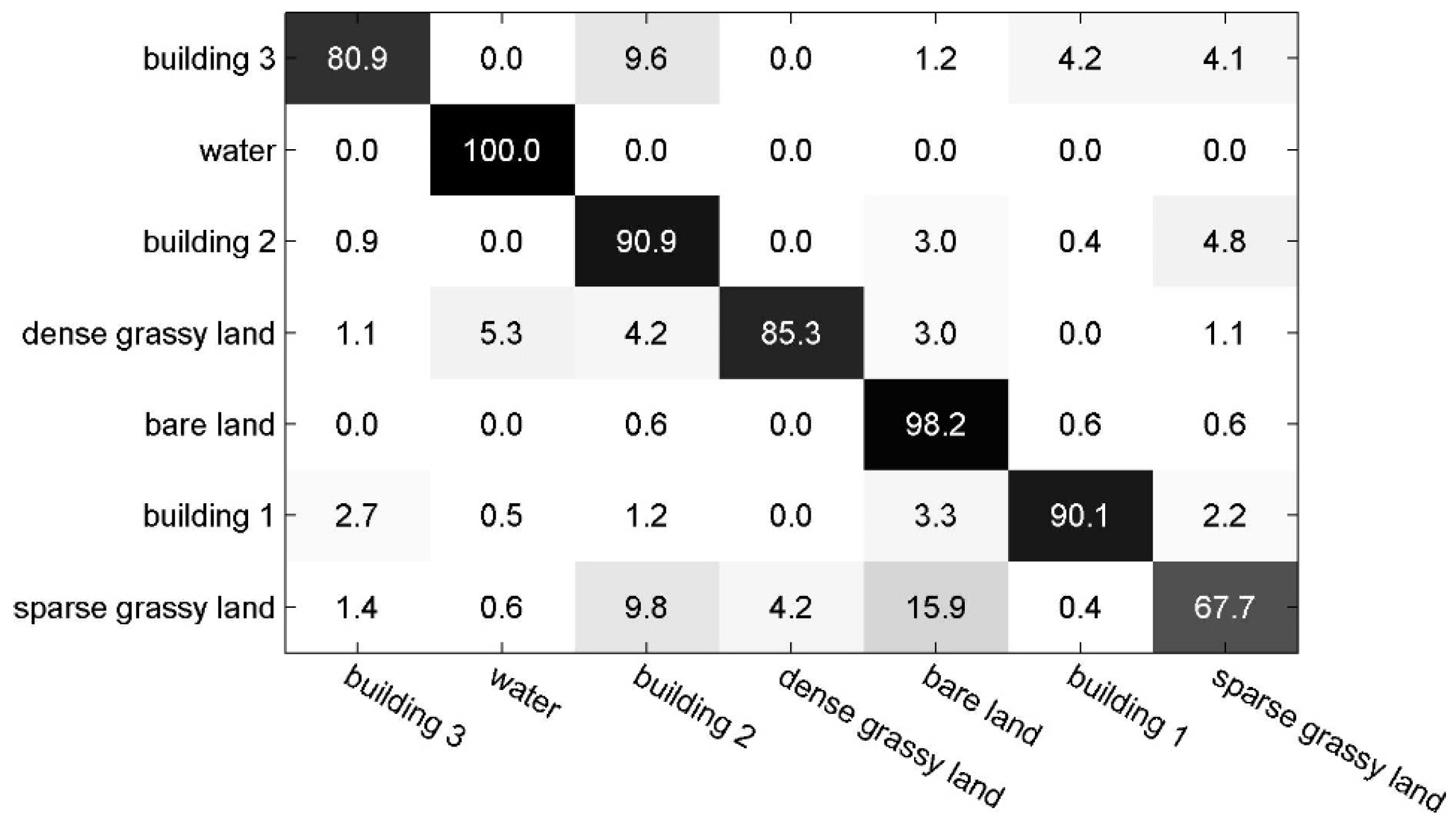
4.2.2. Experiments on Scene-TA
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shao, W.; Yang, W.; Xia, G.-S. Extreme value theory-based calibration for the fusion of multiple features in high-resolution satellite scene classification. Int. J. Remote Sens. 2013, 34, 8588–8602. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Gamba, P.; Bioucas-Dias, J.M.; Zhang, L.; Benediktsson, J.A.; Plaza, A. Multiple feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J. Challenges and opportunities of multimodality and data fusion in remote sensing. In Proceedings of the 22nd European Signal Processing Conference, Lisbon, Portugal, 1–5 September 2014; pp. 106–110.
- Zhong, Y.; Cui, M.; Zhu, Q.; Zhang, L. Scene classification based on multifeature probabilistic latent semantic analysis for high spatial resolution remote sensing images. J. Appl. Remote Sens. 2015, 9. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Binaghi, E.; Gallo, I.; Pepe, M. A cognitive pyramid for contextual classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2906–2922. [Google Scholar] [CrossRef]
- Baraldi, A.; Bruzzone, L. Classification of high spatial resolution images by means of a Gabor wavelet decomposition and a support vector machine. In Proceedings of the International Society for Optics and Photonics, Remote Sensing, Maspalomas, Canary Islands, Spain, 13 September 2004; pp. 19–29.
- Burnett, C.; Blaschke, T. A multi-scale segmentation/object relationship modelling methodology for landscape analysis. Ecol. Model. 2003, 168, 233–249. [Google Scholar] [CrossRef]
- Wengert, C.; Douze, M.; Jégou, H. Bag-of-colors for improved image search. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1437–1440.
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, T.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic object-based image analysis–towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Zhang, L. An adaptive mean-shift analysis approach for object extraction and classification from urban hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2008, 46, 4173–4185. [Google Scholar] [CrossRef]
- Mallinis, G.; Koutsias, N.; Tsakiri-Strati, M.; Karteris, M. Object-based classification using Quickbird imagery for delineating forest vegetation polygons in a Mediterranean test site. ISPRS J. Photogramm. Remote Sens. 2008, 63, 237–250. [Google Scholar] [CrossRef]
- Su, W.; Li, J.; Chen, Y.; Liu, Z.; Zhang, J.; Low, T.M.; Suppiah, I.; Hashim, S.A.M. Textural and local spatial statistics for the object-oriented classification of urban areas using high resolution imagery. Int. J. Remote Sens. 2008, 29, 3105–3117. [Google Scholar] [CrossRef]
- Trias-Sanz, R.; Stamon, G.; Louchet, J. Using colour, texture, and hierarchial segmentation for high-resolution remote sensing. ISPRS J. Photogramm. Remote Sens. 2008, 63, 156–168. [Google Scholar] [CrossRef]
- Van der Werff, H.M.A.; van der Meer, F.D. Shape-based classification of spectrally identical objects. ISPRS J. Photogramm. Remote Sens. 2008, 63, 251–258. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Forestier, G.; Puissant, A.; Wemmert, C. Knowledge-based region labeling for remote sensing image interpretation. Comput. Environ. Urban Syst. 2012, 36, 470–480. [Google Scholar] [CrossRef]
- Hofmann, P.; Lettmayer, P.; Blaschke, T.; Belgiu, M.; Wegenkittl, S.; Graf, R.; Lampoltshammer, T.J.; Andrejchenko, V. Towards a framework for agent-based image analysis of remote-sensing data. Int. J. Image Data Fusion 2015, 6, 115–137. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, G.; Yuan, J. Visual pattern discovery in image and video data: A brief survey. Data Min. Knowl. Disc. 2014, 4, 24–37. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 13th International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1465–1472.
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Weibao, Z.; Wai Yeung, Y.; Shaker, A. Structure-based neural network classification for panchromatic IKONOS image using wavelet-based features. In Proceedings of the 2011 Eighth International Conference on Computer Graphics, Imaging and Visualization (CGIV), Singapore, 17–19 August 2011; pp. 151–155.
- Hay, G.J.; Castilla, G.; Wulder, M.A.; Ruiz, J.R. An automated object-based approach for the multiscale image segmentation of forest scenes. Int. J. Appl. Earth Obs. 2005, 7, 339–359. [Google Scholar] [CrossRef]
- Xia, G.-S.; Delon, J.; Gousseau, Y. Accurate junction detection and characterization in natural images. Int. J. Comput. Vision 2014, 106, 31–56. [Google Scholar] [CrossRef]
- Luo, B.; Aujol, J.-F.; Gousseau, Y. Local scale measure from the topographic map and application to remote sensing images. Multiscale Model. Sim. 2009, 8, 1–29. [Google Scholar] [CrossRef]
- Salembier, P.; Garrido, L. Binary partition tree as an efficient representation for image processing, segmentation, and information retrieval. IEEE Trans. Image Process. 2000, 9, 561–576. [Google Scholar] [CrossRef] [PubMed]
- Vilaplana, V.; Marques, F.; Salembier, P. Binary partition trees for object detection. IEEE Trans. Image Process. 2008, 17, 2201–2216. [Google Scholar] [PubMed]
- Kurtz, C.; Passat, N.; Gançarski, P.; Puissant, A. Extraction of complex patterns from multiresolution remote sensing images: A hierarchical top-down methodology. Pattern Recognit. 2012, 45, 685–706. [Google Scholar] [CrossRef]
- Veganzones, M.A.; Tochon, G.; Dalla-Mura, M.; Plaza, A.J.; Chanussot, J. Hyperspectral image segmentation using a new spectral unmixing-based binary partition tree representation. IEEE Trans. Image Process. 2014, 23, 3574–3589. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Yang, W.; Xia, G.-S. A novel polarimetric-texture-structure descriptor for high-resolution PolSAR image classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1136–1139.
- Stricker, M.A.; Orengo, M. Similarity of color images. In Proceedings of the IS & T/SPIE’s Symposium on Electronic Imaging: Science & Technology, International Society for Optics and Photonics, San Jose, CA, USA, 5 February 1995; pp. 381–392.
- Van De Weijer, J.; Schmid, C. Coloring local feature extraction. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 334–348.
- Van De Weijer, J.; Schmid, C.; Verbeek, J.; Larlus, D. Learning color names for real-world applications. IEEE Trans. Image Process. 2009, 18, 1512–1523. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.S.; Anwer, R.M.; van de Weijer, J.; Bagdanov, A.D.; Vanrell, M.; Lopez, A.M. Color attributes for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3306–3313.
- Xia, G.-S.; Delon, J.; Gousseau, Y. Shape-based invariant texture indexing. Int. J. Comput. Vision 2010, 88, 382–403. [Google Scholar]
- Liu, G.; Xia, G.-S.; Yang, W.; Zhang, L. Texture analysis with shape co-occurrence patterns. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 1627–1632.
- Guo, Y.; Zhao, G.; Pietikäinen, M. Discriminative features for texture description. Pattern Recognit. 2012, 45, 3834–3843. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Aytekin, O.; Koc, M.; Ulusoy, I. Local primitive pattern for the classification of SAR images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2431–2441. [Google Scholar]
- Saikia, H.; Seidel, H.P.; Weinkauf, T. Extended branch decomposition graphs: Structural comparison of scalar data. Comput. Graph. Forum 2014, 33, 41–50. [Google Scholar] [CrossRef]
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene classification via pLSA. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 517–530.
- Van De Sande, K.E.; Gevers, T.; Snoek, C.G. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Bach, F.R. Exploring large feature spaces with hierarchical multiple kernel learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 12–13 December 2008; pp. 105–112.
- Gehler, P.; Nowozin, S. On feature combination for multiclass object classification. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 221–228.
- Fernando, B.; Fromont, E.; Muselet, D.; Sebban, M. Discriminative feature fusion for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3434–3441.
- Van de Weijer, J.; Khan, F.S. Fusing color and shape for bag-of-words based object recognition. In Proceedings of the 2013 Computational Color Imaging Workshop, Chiba, Japan, 3–5 March 2013; pp. 25–34.
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 19–21 June 2007; pp. 1–8.
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2009; pp. 1794–1801.
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367.
- Jaakkola, T.; Haussler, D. Exploiting generative models in discriminative classifiers. In Proceedings of the conference on Neural Information Processing Systems (NIPS), Denver, CO, USA, 29 November–4 December 1999; pp. 487–493.
- Khan, F.S.; van de Weijer, J. Color features in the era of big data. In Proceedings of the 2015 Computational Color Imaging Workshop, Saint Etienne, France, 24–26 March 2015.
- Singh, S.; Gupta, A.; Efros, A. Unsupervised discovery of mid-level discriminative patches. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 73–86.
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vision 2013, 105, 222–245. [Google Scholar] [CrossRef]
- UC Merced Land Use Dataset. Available online: http://vision.ucmerced.edu/datasets/landuse.html (accessed on 16 November 2016).
- Yang, W.; Yin, X.; Xia, G.-S. Learning high-level features for satellite image classification with limited labeled samples. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4472–4482. [Google Scholar] [CrossRef]
- Hu, F.; Yang, W.; Chen, J.; Sun, H. Tile-level annotation of satellite images using multi-level max-margin discriminative random field. Remote Sens. 2013, 5, 2275–2291. [Google Scholar] [CrossRef]
- Yang, J.; Jiang, Y.-G.; Hauptmann, A.G.; Ngo, C.-W. Evaluating bag-of-visual-words representations in scene classification. In Proceedings of the Proceedings of the International Workshop on Multimedia Information Retrieval, Augsburg, Germany, 28–29 September 2007; pp. 197–206.
- Barla, A.; Odone, R.; Verr, A. Histogram intersection kernel for image classification. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 513–516.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the International Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; Springer: Berlin, Germany; Heidelberg, Germany, 2013; pp. 324–333. [Google Scholar]
- Cheng, G.; Han, J.W.; Zhou, P.C.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar]
- Hu, F.; Xia, G.S.; Wang, Z.F.; Huang, X.; Zhang, L.P.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhu, Q.; Zhang, L. Scene classification based on the multifeature fusion probabilistic topic model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6207–6222. [Google Scholar] [CrossRef]
- Sifre, L.; Mallat, S. Combined scattering for rotation invariant texture analysis. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 25–27 April 2012; pp. 127–132.
- Dai, D.; Van Gool, L. Ensemble Projection for Semi-supervised Image Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 30 November–7 December 2013; pp. 2072–2079.
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patterns | Definition | Schematic Map |
|---|---|---|
| Single region (P1) | R |  |
| Region-ancestor (P2) | R − Rr |  |
| Region-ancestor-ancestor (P3) | R − Rr – R2r |  |
| Region-parent-sibling (P4) | R – R1 – R’ |  |
| Coding Method | Dictionary Size | Accuracy (%) |
|---|---|---|
| BOW(VQ) [38] | 1024 | 64.38 ± 2.53 |
| BOW(LLC) [50] | 1024 | 85.11 ± 1.36 |
| FV Coding [54] | 100 | 93.08 ± 1.13 |
| Method | Accuracy (%) |
|---|---|
| Topographic map [36] | 90.61 ± 1.34 |
| Topographic map+ color moments | 92.17 ± 1.16 |
| Gray BPT | 89.77 ± 1.31 |
| Gray-BPT+ color moments | 91.64 ± 1.24 |
| CBPT | 91.71 ± 1.14 |
| CBPT+ color names | 89.48 ± 1.39 |
| CBPT+ color moments | 93.08 ± 1.13 |
| Minimum Region Size | 3 | 6 | 12 | 15 | 20 |
|---|---|---|---|---|---|
| Topographic Map | 92.17 ± 1.16 | 92.36 ± 1.19 | 92.05 ± 1.18 | 91.77 ± 1.26 | 91.72 ± 1.31 |
| BPT | 92.40 ± 1.16 | 92.46 ± 1.20 | 92.55 ± 1.19 | 93.04 ± 1.18 | 92.93 ± 1.14 |
| Dictionary Size | 30 | 50 | 70 | 90 | 100 | 120 |
|---|---|---|---|---|---|---|
| BPT | 91.99 ± 0.20 | 92.45 ± 0.10 | 92.43 ± 0.15 | 92.71 ± 0.12 | 93.08 ± 0.14 | 92.64 ± 0.21 |
| Methods | Classification Results |
|---|---|
| BOVW [20] | 71.86 |
| SPM [38] | 74 |
| SC+ Pooling [61] | 81.67 ± 1.23 |
| Bag of colors [62] | 83.46 ± 1.57 |
| COPD [63] | 91.33 ± 1.11 |
| HMFF [62] | 92.38 ± 0.62 |
| UFL-SC [64] | 90.26 ± 1.51 |
| SAL-LDA [65] | 88.33 ± 1.15 |
| CTS | 93.08 ± 1.13 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Yang, W.; Xia, G.-S.; Liu, G. A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification. Remote Sens. 2016, 8, 259. https://doi.org/10.3390/rs8030259
Yu H, Yang W, Xia G-S, Liu G. A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification. Remote Sensing. 2016; 8(3):259. https://doi.org/10.3390/rs8030259
Chicago/Turabian StyleYu, Huai, Wen Yang, Gui-Song Xia, and Gang Liu. 2016. "A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification" Remote Sensing 8, no. 3: 259. https://doi.org/10.3390/rs8030259
APA StyleYu, H., Yang, W., Xia, G.-S., & Liu, G. (2016). A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification. Remote Sensing, 8(3), 259. https://doi.org/10.3390/rs8030259