
An Assessment of the Cultivated Cropland Class of NLCD 2006 Using a Multi-Source and Multi-Criteria Approach

Abstract
:
1. Introduction
1.1. Review of NLCD 2006 Methodology
1.2. Review of NLCD 2011 Methodology
1.3. Review of National Agricultural Statistics Service (NASS) Cropland Data Layer (CDL)
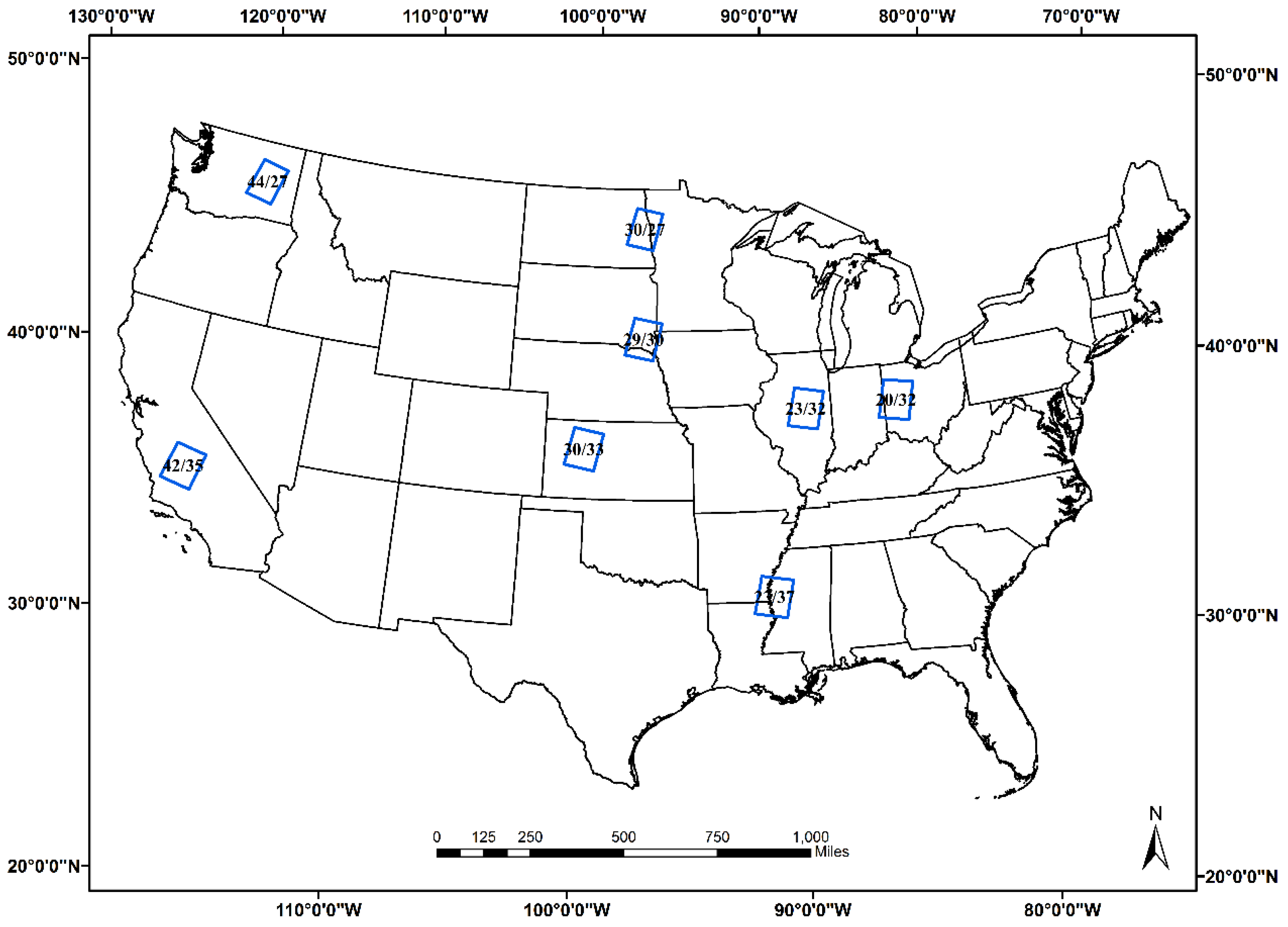
2. Study Area and Data
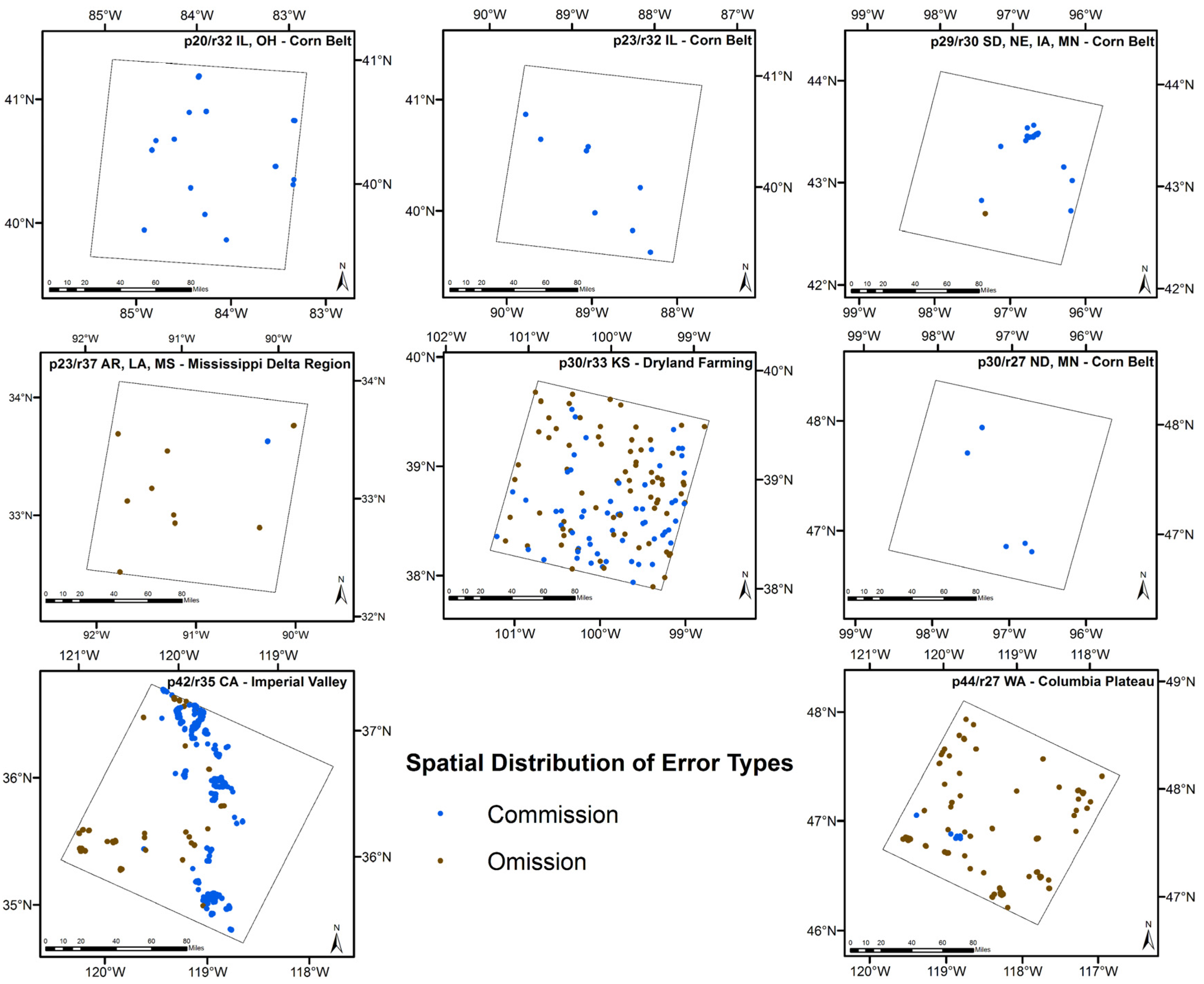
2.1. Study Area
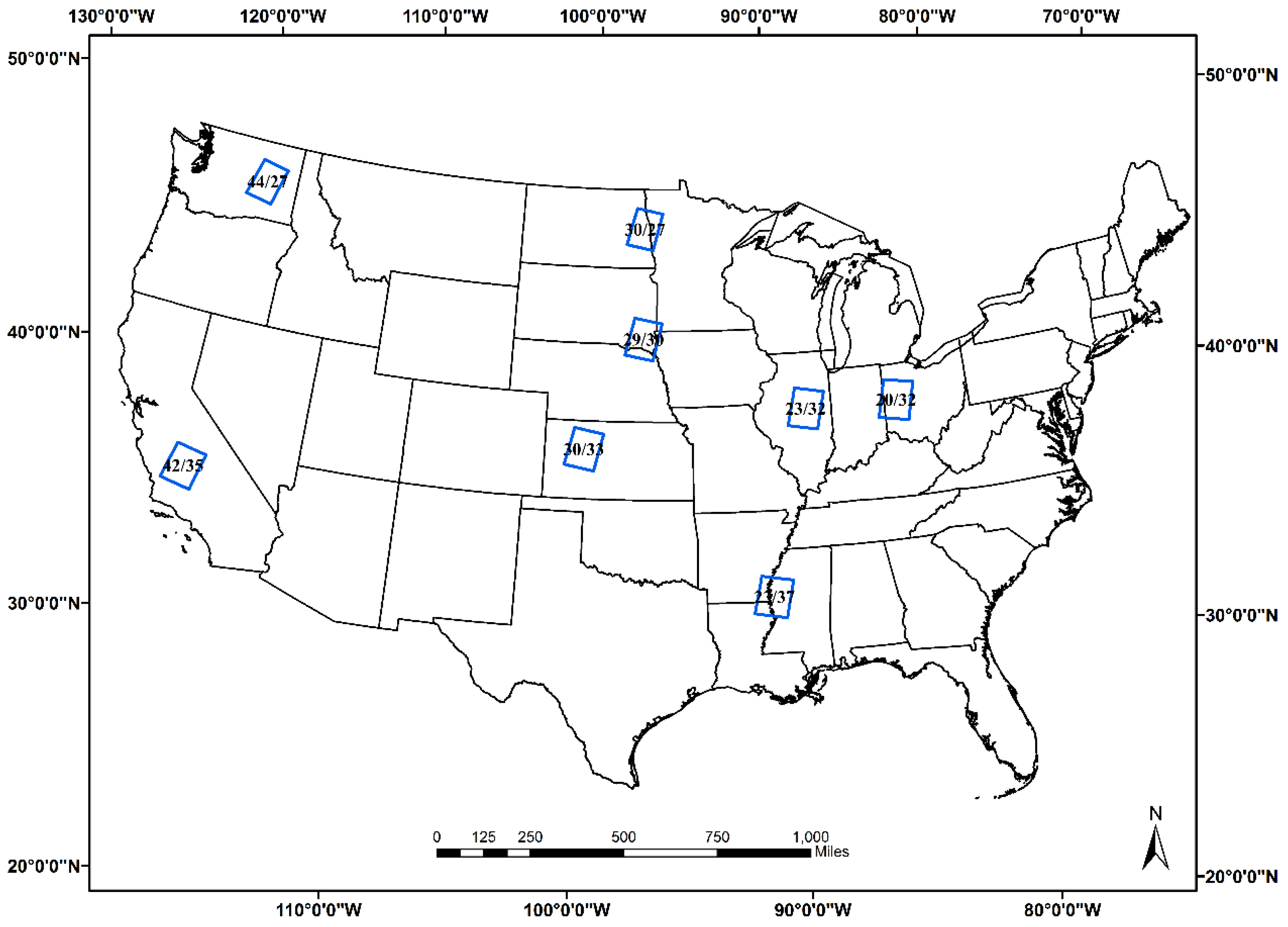

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NLCD Land Cover Classes | 20/32 | 23/32 | 23/37 | 29/30 | 30/27 | 30/33 | 42/35 | 44/27 |
|---|---|---|---|---|---|---|---|---|
| Open Water (11) | 0.75% | 1.00% | 4.42% | 1.43% | 1.68% | 0.46% | 0.42% | 2.21% |
| Perennial Ice/Snow (12) | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| Developed-Open Space (21) | 7.03% | 4.31% | 4.34% | 4.79% | 4.59% | 2.99% | 3.86% | 2.33% |
| Developed-Low Intensity (22) | 3.06% | 4.03% | 0.92% | 0.85% | 0.80% | 0.43% | 1.46% | 0.79% |
| Developed-Medium Intensity (23) | 0.86% | 0.96% | 0.24% | 0.34% | 0.23% | 0.06% | 1.72% | 0.27% |
| High Intensity (24) | 0.35% | 0.29% | 0.08% | 0.11% | 0.08% | 0.01% | 0.33% | 0.04% |
| Barren Land (31) | 0.08% | 0.04% | 0.16% | 0.05% | 0.01% | 0.12% | 3.99% | 0.04% |
| Deciduous Forest (41) | 7.43% | 5.27% | 8.01% | 2.17% | 1.68% | 0.22% | 0.83% | 0.05% |
| Evergreen Forest (42) | 0.08% | 0.01% | 4.88% | 0.08% | 0.09% | 0.00% | 9.03% | 10.07% |
| Mixed Forest (43) | 0.24% | 0.00% | 2.09% | 0.03% | 0.05% | 0.00% | 0.43% | 0.00% |
| Shrub/Scrub (52) | 0.02% | 0.00% | 3.64% | 0.16% | 0.01% | 0.06% | 10.28% | 41.70% |
| Grassland/Herbaceous (71) | 1.15% | 0.23% | 0.55% | 12.88% | 2.48% | 40.92% | 26.64% | 3.05% |
| Pasture/Hay (81) | 5.60% | 3.01% | 3.40% | 13.52% | 5.49% | 0.94% | 4.42% | 1.89% |
| Cultivated Crops (82) | 73.07% | 80.18% | 49.79% | 61.56% | 77.14% | 52.93% | 36.35% | 36.08% |
| Woody Wetlands (90) | 0.09% | 0.63% | 17.00% | 0.33% | 1.54% | 0.85% | 0.12% | 0.25% |
| Herbaceous Wetlands (95) | 0.20% | 0.04% | 0.48% | 1.72% | 4.11% | 0.03% | 0.11% | 1.21% |
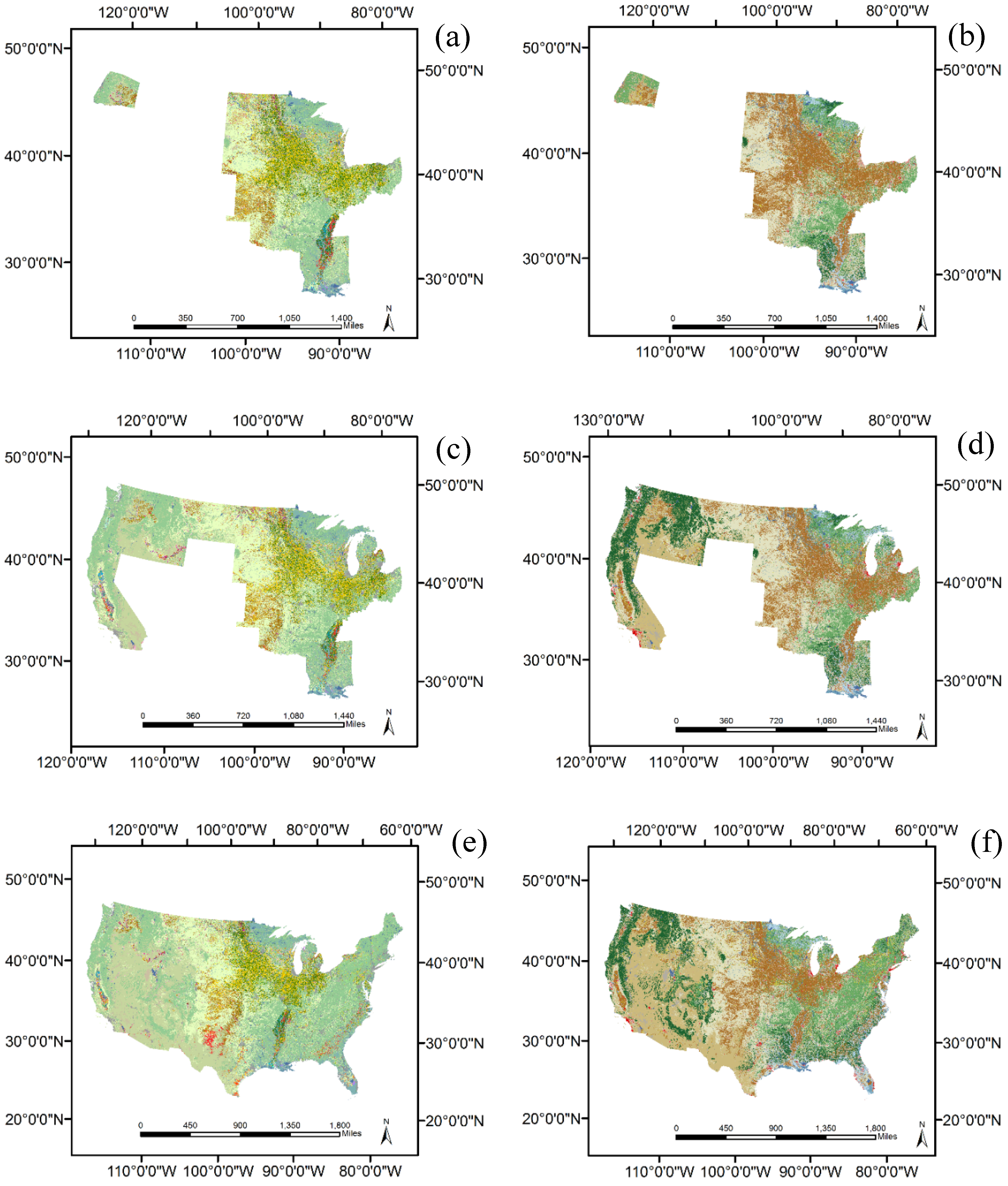
2.2. Data
2.2.1. Landsat Imagery
2.2.2. NASS Cropland Data Layer (CDL) Datasets
3. Methodology
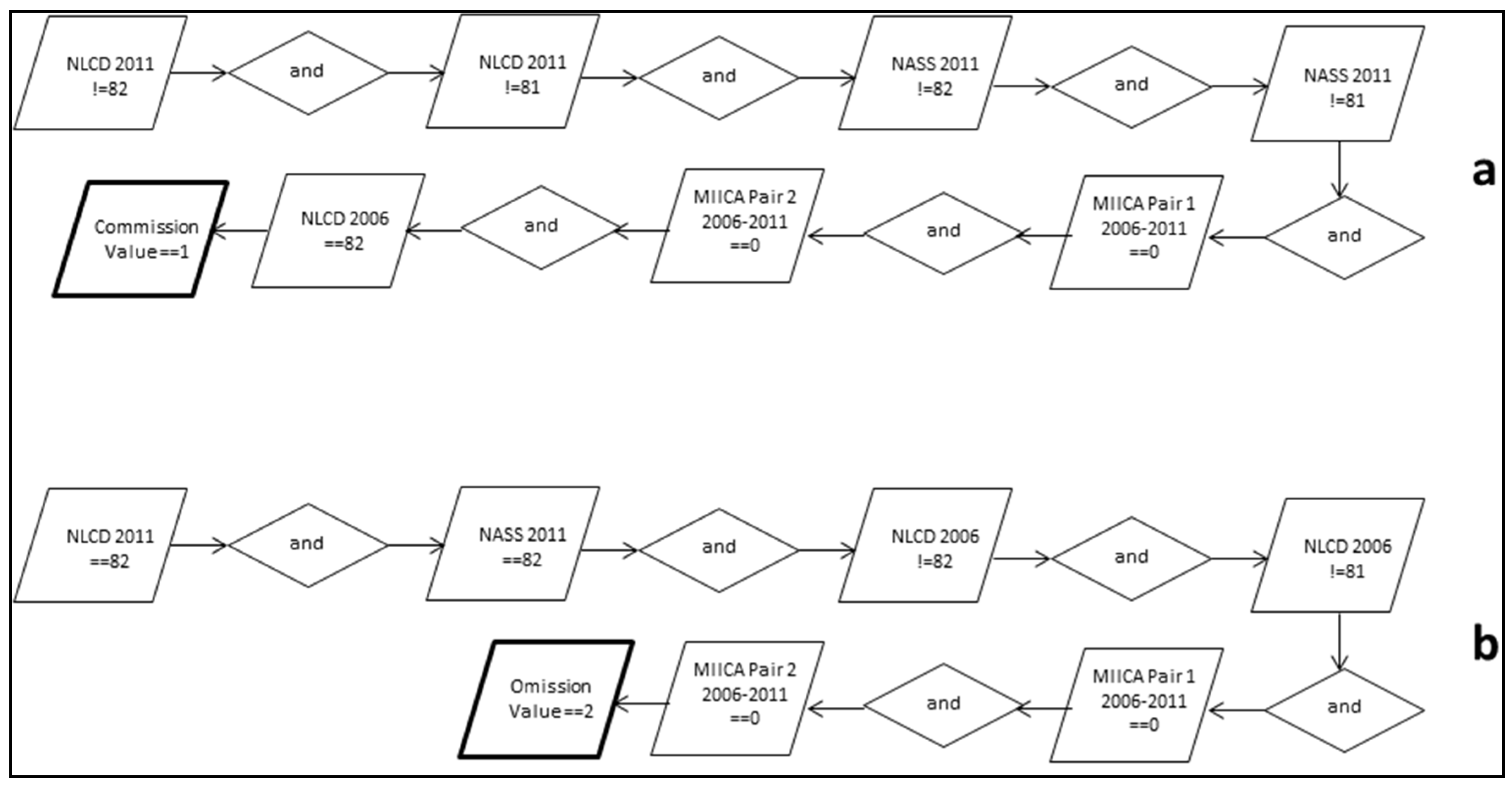
3.1. Models for Identifying Potential Commission or Omission Errors

3.2. Method for Assessing Model Performance
- (a)
- Probability of a commission error, which is the conditional probability that a randomly selected point classified as category i by the map is classified as category k by the reference data (,
- (b)
- Probability of an omission error, which is the conditional probability that a randomly selected point classified as category j by the reference data is classified as category k by the map ()

4. Results
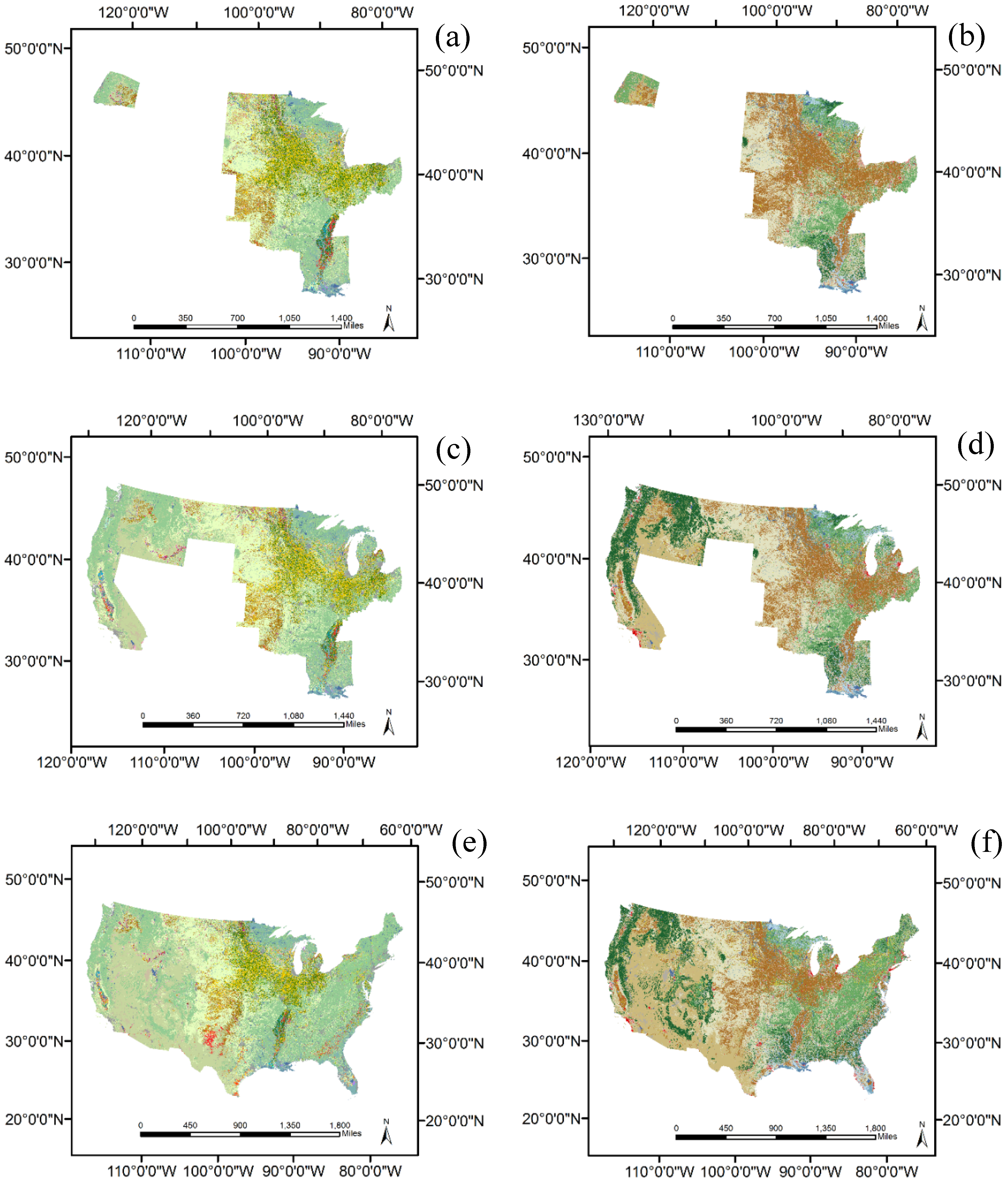
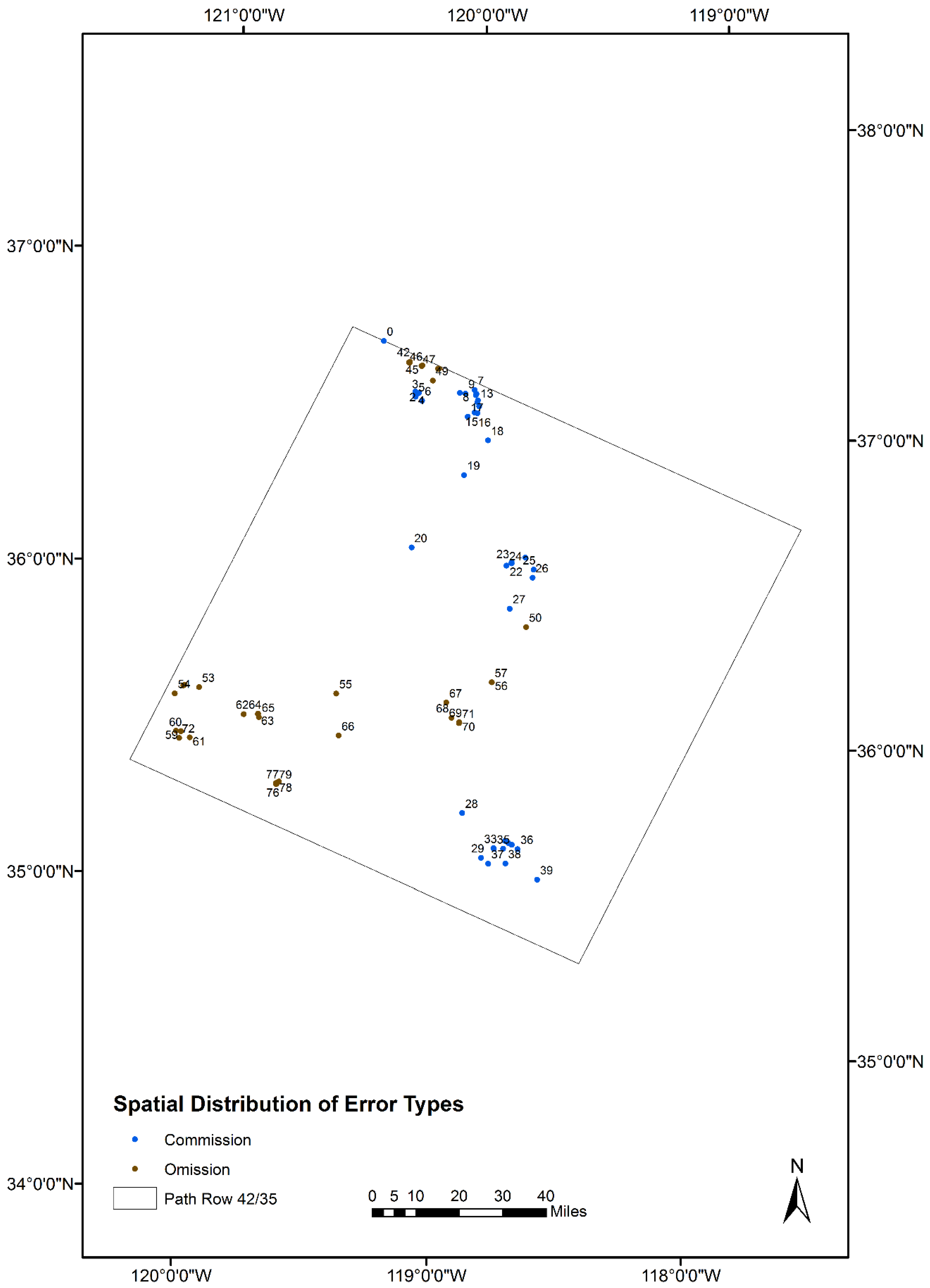
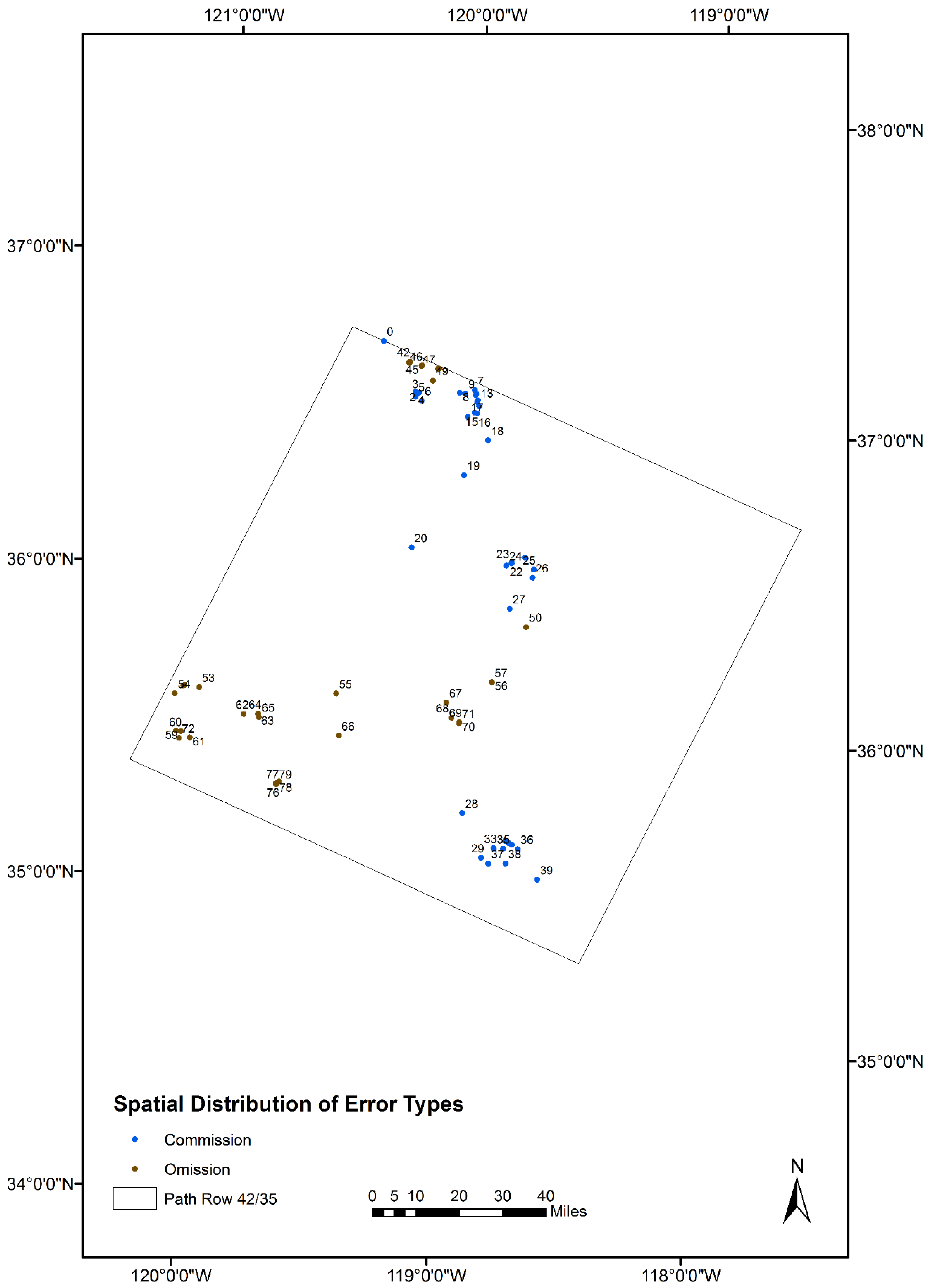
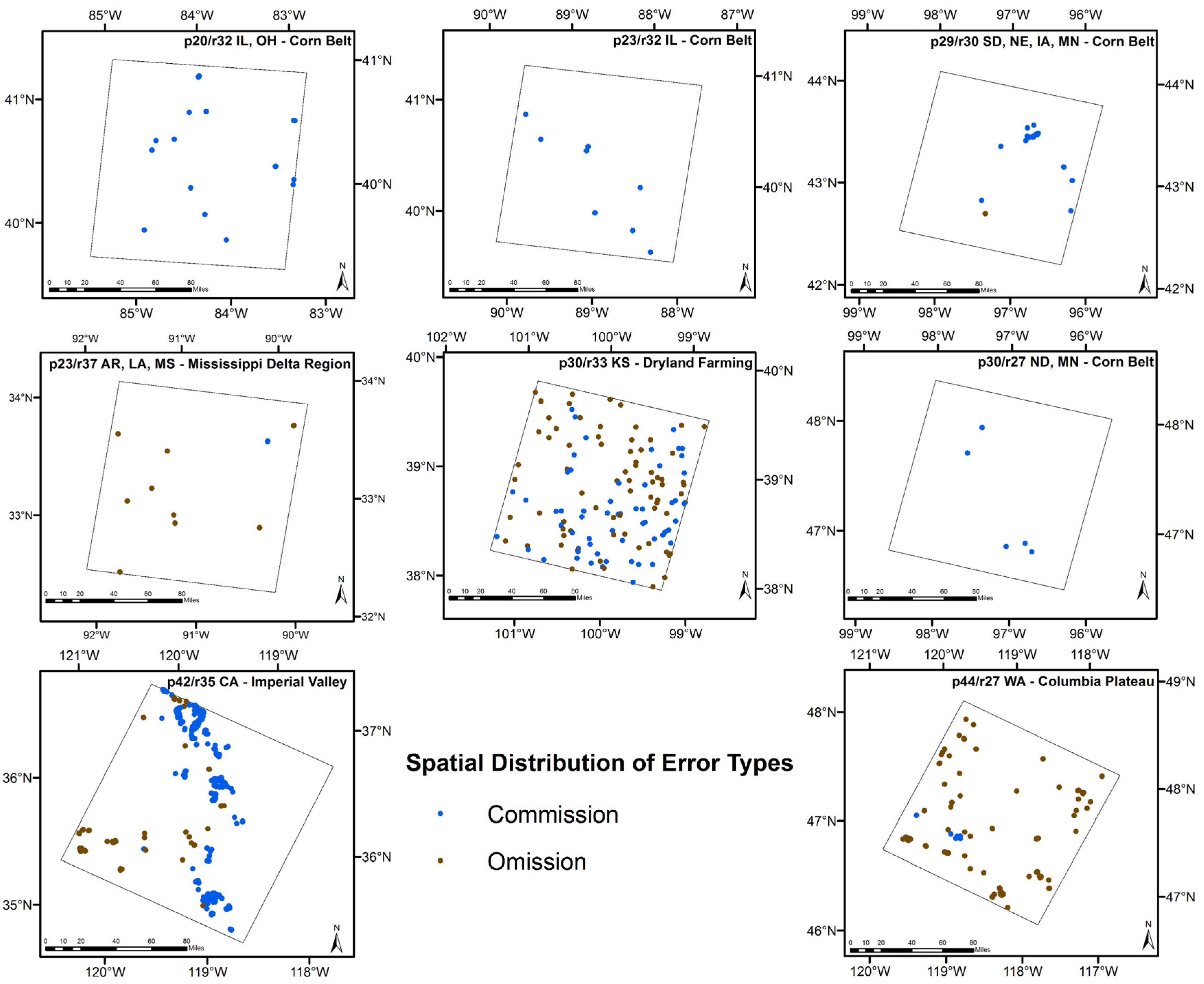
4.1. Spatial Pattern and Statistical Measures
| Descriptive Statistics | 29/30 SD, NE, IA, MN | 23/32 IL | 20/32 IL, OH | 30/27 ND, MN | 23/37 AR, LA, MS | 30/33 KS | 42/35 CA | 44/27 WA |
|---|---|---|---|---|---|---|---|---|
| (a) | 21 | 0 | 0 | 0 | 272 | 309,869 | 2923 | 6655 |
| (b) | 749 | 237 | 482 | 131 | 33 | 200,160 | 13,630 | 178 |
| (c) | 770 | 237 | 482 | 131 | 305 | 510,029 | 16,553 | 6833 |
| (d) | 0.000034% | 0.00% | 0.00% | 0.00% | 0.00045% | 0.48% | 0.0034% | 0.01% |
| (e) | 0.0012% | 0.00033% | 0.00071% | 0.00021% | 0.000054% | 0.31% | 0.016% | 0.00019% |
| (f) | 0.0012% | 0.00033% | 0.00071% | 0.00021% | 0.00050% | 0.79% | 0.02% | 0.01% |
| (g) | 0.000072% | 0.00000% | 0.00000% | 0.00000% | 0.0013% | 1.24% | 0.02% | 0.04% |
| (h) | 0.0026% | 0.00063% | 0.0015% | 0.00038% | 0.00016% | 0.80% | 0.09% | 0.0011% |
| (i) | 0.0027% | 0.00063% | 0.0015% | 0.00038% | 0.0015% | 2.04% | 0.11% | 0.04% |
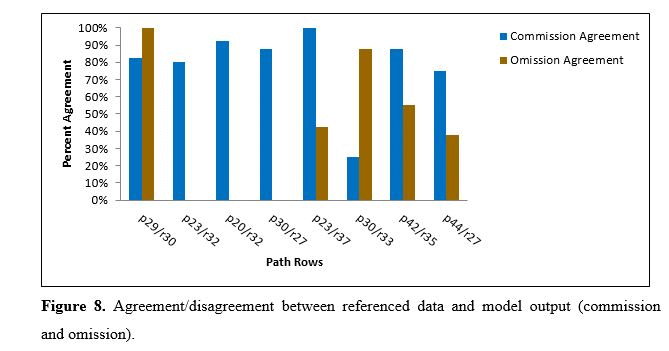
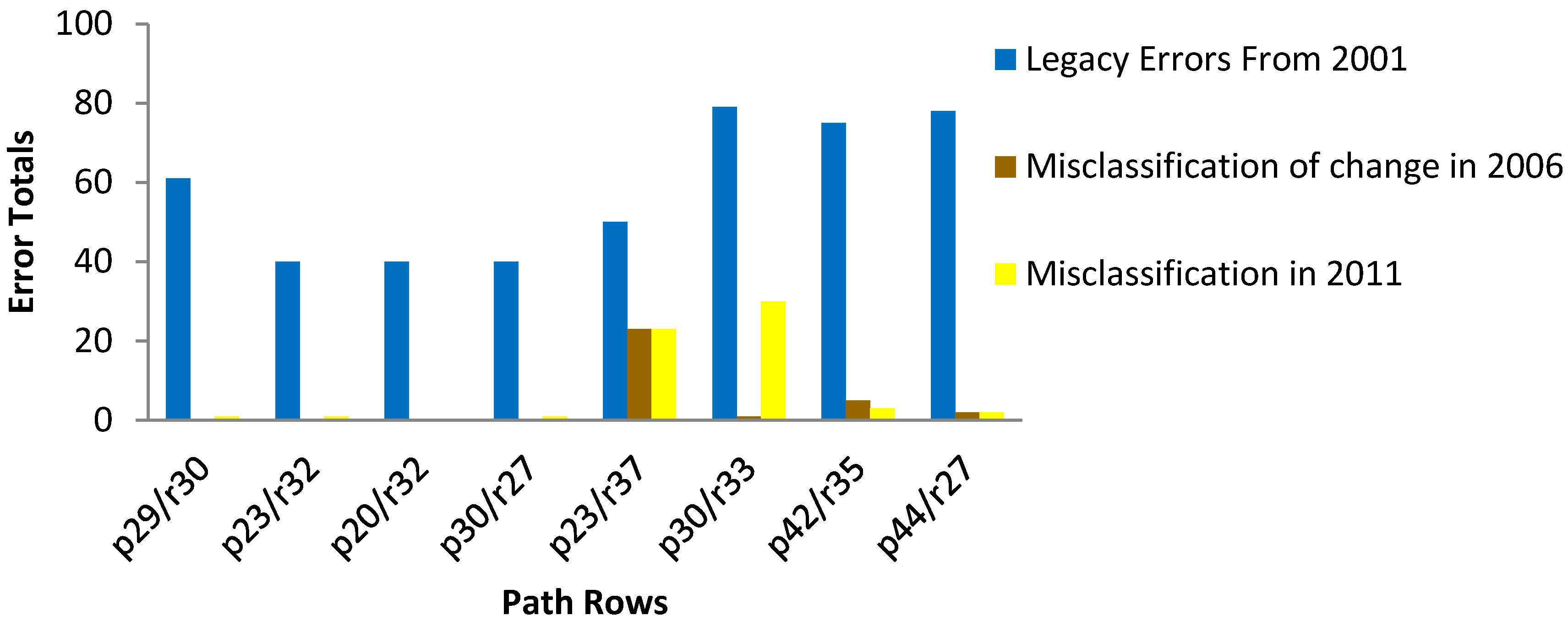
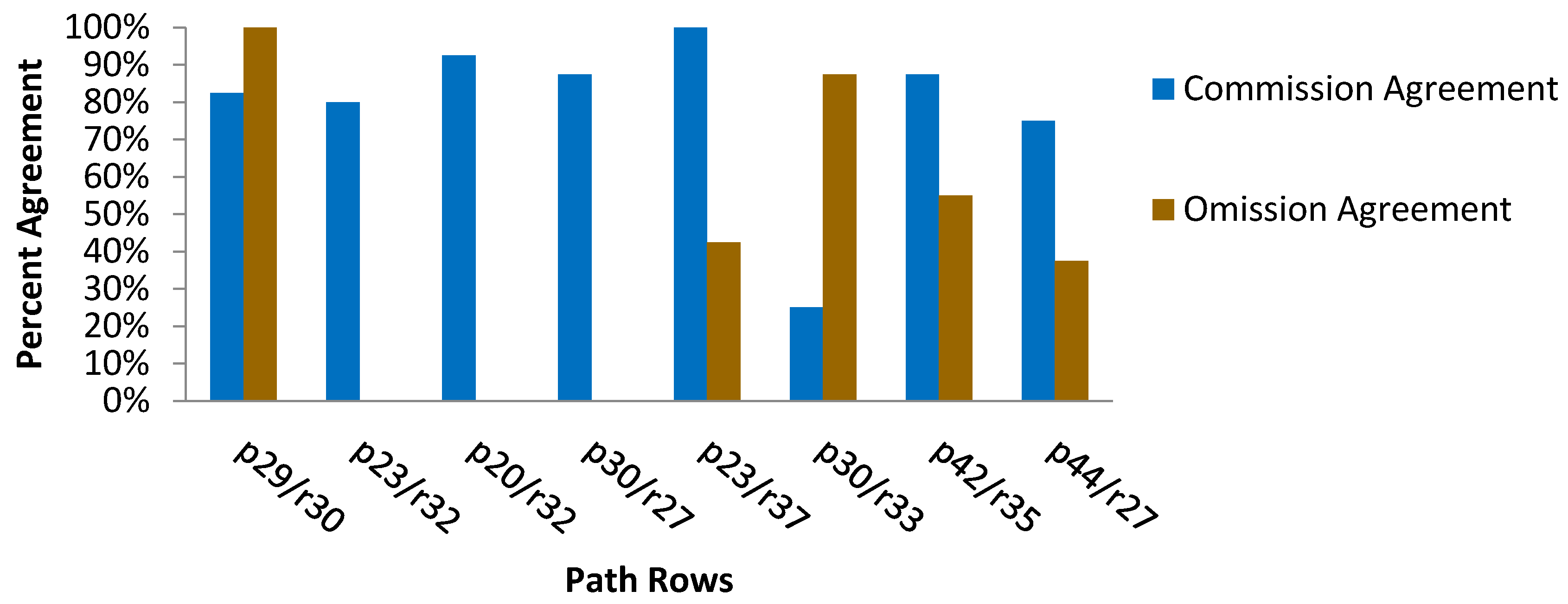
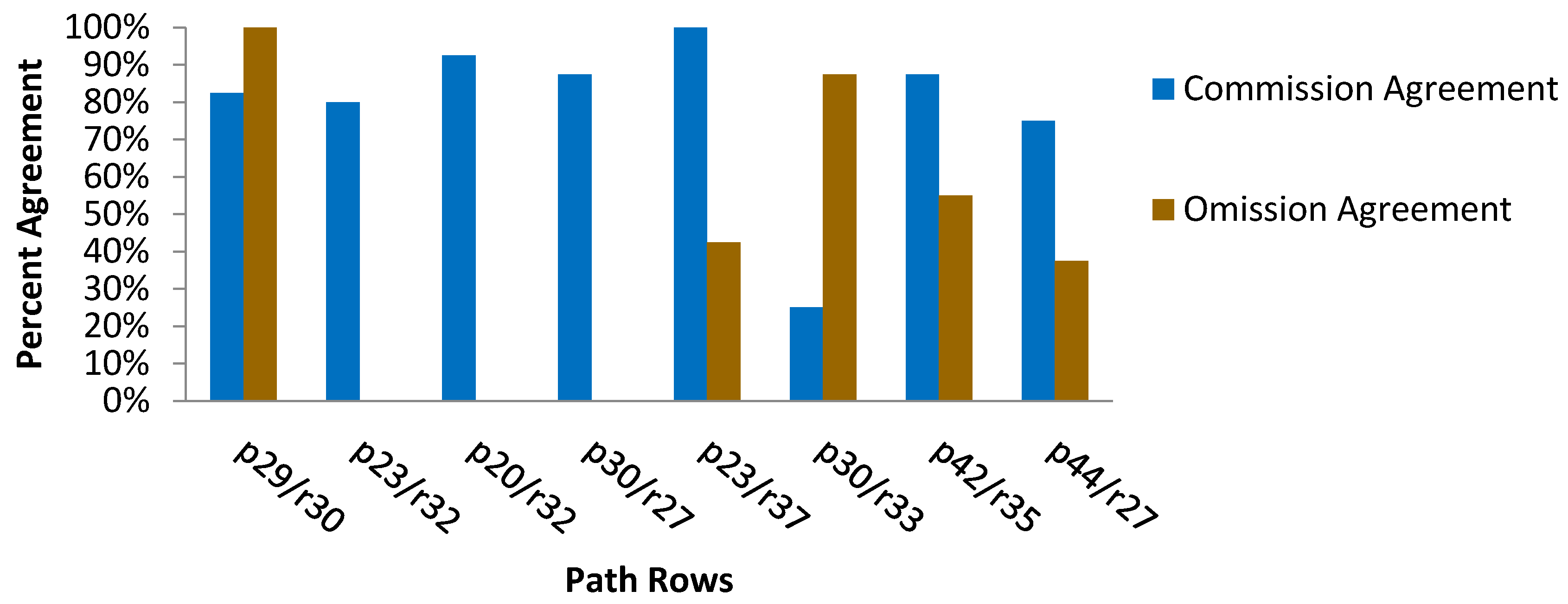
4.2. Sources of Commission and Omission Errors
| From and To Classes | Commission Agreement Total Pixels | Commission Disagreement Total Pixels | Omission Agreement Total Pixels | Omission Disagreement Total Pixels |
|---|---|---|---|---|
| Cropland to Urban | 235 | 38 | ||
| Cropland to Herbaceous | 9 | 30 | ||
| Cropland to Barren | 1 | |||
| Herbaceous to Cropland | 78 | 26 | ||
| Shrub to Cropland | 20 | 34 | ||
| Forest to Cropland | 6 | 6 | ||
| Wetland to Cropland | 4 | 5 | ||
| Water to Cropland | 2 |
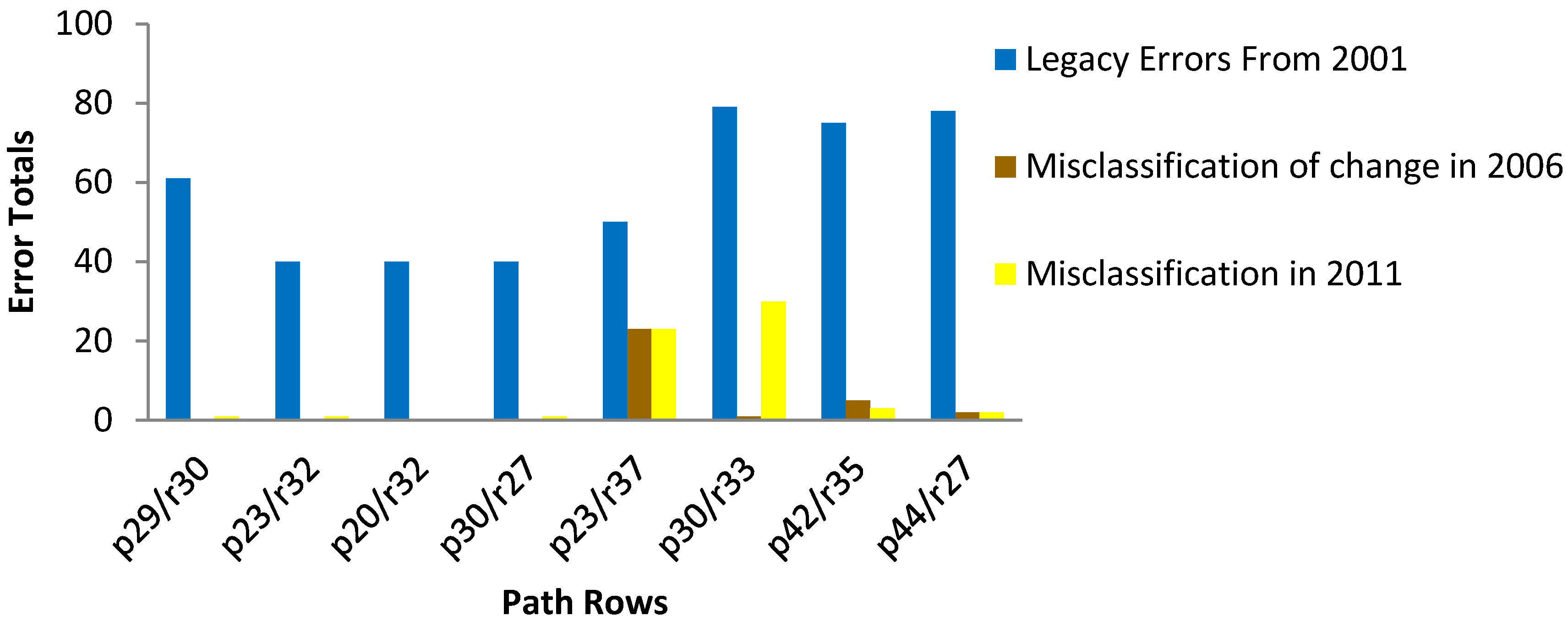
4.3. Evaluation of Model Performance
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Matthews, H.D.; Weaver, A.J.; Meissner, K.J.; Gillett, N.P.; Eby, M. Natural and anthropogenic climate change—Incorporating historical land cover change, vegetation dynamics and the global carbon cycle. Clim. Dyn. 2004, 22, 461–479. [Google Scholar] [CrossRef]
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Turner, B.L., II; Lambin, E.F.; Reenberg, A. The emergence of land change science for global environmental change and sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 20666–20671. [Google Scholar] [CrossRef] [PubMed]
- Homer, C.; Dewitz, J.; Fry, J.; Coan, M.; Hossain, N.; Larson, C.; Herold, N.; McKerrow, A.; VanDriel, J.N.; Wickham, J. Completion of the 2001 National Land Cover Database for the conterminous United States. Photogramm. Eng. Remote Sens. 2007, 73, 337–341. [Google Scholar]
- Fry, J.A.; Xian, G.; Jin, S.; Dewitz, J.A.; Homer, C.G.; Yang, L.; Barnes, C.A.; Herold, N.D.; Wickham, J.D. Completion of the 2006 National Land Cover Database for the conterminous United States. Photogramm. Eng. Remote Sens. 2011, 77, 858–864. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 346–354. [Google Scholar]
- Johnson, D.M.; Mueller, R. The 2009 Cropland Data Layer. Photogramm. Eng. Remote Sens. 2010, 76, 1201–1205. [Google Scholar]
- Wright, C.K.; Wimberly, M.C. Recent land use change in the Western Corn Belt threatens grasslands and wetlands. Proc. Natl. Acad. Sci. USA 2013, 110, 4134–4139. [Google Scholar] [CrossRef] [PubMed]
- Lark, T.J.; Meghan Salmon, J.; Gibbs, H.K. Cropland expansion outpaces agricultural and biofuel policies in the United States. Environ. Res. Lett. 2015, 10. [Google Scholar] [CrossRef]
- Faber, S.; Rundquist, S.; Male, T. Plowed Under—How Crop Subsidies Contribute to Massive Habitat Losses; Environmental Working Group: Washington, DC, USA, 2012; Available online: http://www.ewg.org/node/15941 (accessed on 23 June 2015).
- Cox, C.; Rundquist, S. Going, Going, Gone! Millions of Acres of Wetlands and Fragile Land go Under the Plow; Enviornmental Working Group: Washington, DC, USA, 2013. Available online: http://www.ewg.org/research/going-going-gone (accessed on 23 June 2015).
- Johnston, C.A. Wetland losses due to row crop expansion in the Dakota Prairie Pothole region. Wetlands 2013, 33, 175–182. [Google Scholar] [CrossRef]
- Johnston, C.A. Agricultural expansion—Land use shell game in the U.S. Northern Plains. Landsc. Ecol. 2014, 29, 81–95. [Google Scholar] [CrossRef]
- Stern, A.J.; Doraiswamy, P.C.; Hunt, E.R., Jr. Changes of crop rotation in Iowa determined from the United States Department of Agriculture, National Agricultural Statistics Service cropland data layer product. J. Appl. Remote Sens. 2012, 6. [Google Scholar] [CrossRef]
- Howard, D.M.; Wylie, B.K. Annual crop type classification of the U.S. Great Plains for 2000–2011. Photogramm. Eng. Remote Sens. 2014, 80, 537–549. [Google Scholar] [CrossRef]
- Wickham, J.D.; Stehman, S.V.; Gass, L.; Dewitz, J.; Fry, J.A.; Wade, T.G. Accuracy assessment of NLCD 2006 land cover and impervious surface. Remote Sens. Environ. 2013, 130, 294–304. [Google Scholar] [CrossRef]
- Stehman, S.V.; Wickham, J.D. Pixels, blocks of pixels, and polygons—Choosing a spatial unit for thematic accuracy assessment. Remote Sens. Environ. 2011, 115, 3044–3055. [Google Scholar] [CrossRef]
- Laingen, C. Measuring cropland change: A cautionary tale. Pap. Appl. Geogr. 2015, 1, 65–72. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E.; Strahler, A.H. Maximizing land cover classification accuracies produced by decision trees at continental to global scales. IEEE Trans. Geosci. Remote Sens. 1999, 37, 969–977. [Google Scholar] [CrossRef]
- Wang, Y.; Civco, D.L. Post-Classification of Misclassified Pixels by Evidential Reasoning—A GIS Approach for Improving Classification Accuracy of RS Data. In Proceedings of the XVIIth ISPRS Congress, Technical Commission VII: Interpretation of Photographic and Remote Sensing Data, Washington, DC, USA, 2–14 August 1992; Fritz, L.W., Lucas, J.R., Eds.; International Society for Photogrammetry and Remote Sensing: Bethesda, MD, USA, 1992; pp. 80–86. Available online: http://www.isprs.org/proceedings/XXIX/congress/part7/ (accessed on 20 June 2015). [Google Scholar]
- Xian, G.; Homer, C.; Fry, J. Updating the 2001 National Land Cover Database land cover classification to 2006 by using Landsat imagery change detection methods. Remote Sens. Environ. 2009, 113, 1133–1147. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Danielson, P.; Homer, C.; Fry, J.; Xian, G. A comprehensive change detection method for updating the National Land Cover Database to circa 2011. Remote Sens. Environ. 2013, 132, 159–175. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5 Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993; p. 302. [Google Scholar]
- Multi-Resolution Land Characteristics Concortium (MRLC). National Land Cover Database (NLCD). Available online: http://www.mrlc.gov/ (accessed on 26 November 2012).
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture—The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Johnson, D.M. A 2010 map estimate of annually tilled cropland within the conterminous United States. Agric. Syst. 2013, 114, 95–105. [Google Scholar] [CrossRef]
- Rogers, D.H.; Lamm, F.R. Kansas irrigation trends. In Proceedings of the Annual Central Plains Irrigation Conference, 24th, Colby, KS, USA, 21–22 February 2012; Central Plains Irrigation Association: Colby, KS, USA, 2012; pp. 1–15. Available online: http://www.k-state.edu/irrigate/oow/cpic12.html (accessed on 20 June 2015). [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Danielson, P.; Yang, L.; Jin, S.; Homer, C.; Napton, D. An Assessment of the Cultivated Cropland Class of NLCD 2006 Using a Multi-Source and Multi-Criteria Approach. Remote Sens. 2016, 8, 101. https://doi.org/10.3390/rs8020101
Danielson P, Yang L, Jin S, Homer C, Napton D. An Assessment of the Cultivated Cropland Class of NLCD 2006 Using a Multi-Source and Multi-Criteria Approach. Remote Sensing. 2016; 8(2):101. https://doi.org/10.3390/rs8020101
Chicago/Turabian StyleDanielson, Patrick, Limin Yang, Suming Jin, Collin Homer, and Darrell Napton. 2016. "An Assessment of the Cultivated Cropland Class of NLCD 2006 Using a Multi-Source and Multi-Criteria Approach" Remote Sensing 8, no. 2: 101. https://doi.org/10.3390/rs8020101
APA StyleDanielson, P., Yang, L., Jin, S., Homer, C., & Napton, D. (2016). An Assessment of the Cultivated Cropland Class of NLCD 2006 Using a Multi-Source and Multi-Criteria Approach. Remote Sensing, 8(2), 101. https://doi.org/10.3390/rs8020101