
Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes

Abstract
:
1. Introduction
2. Methods
2.1. Overview and General Workflow
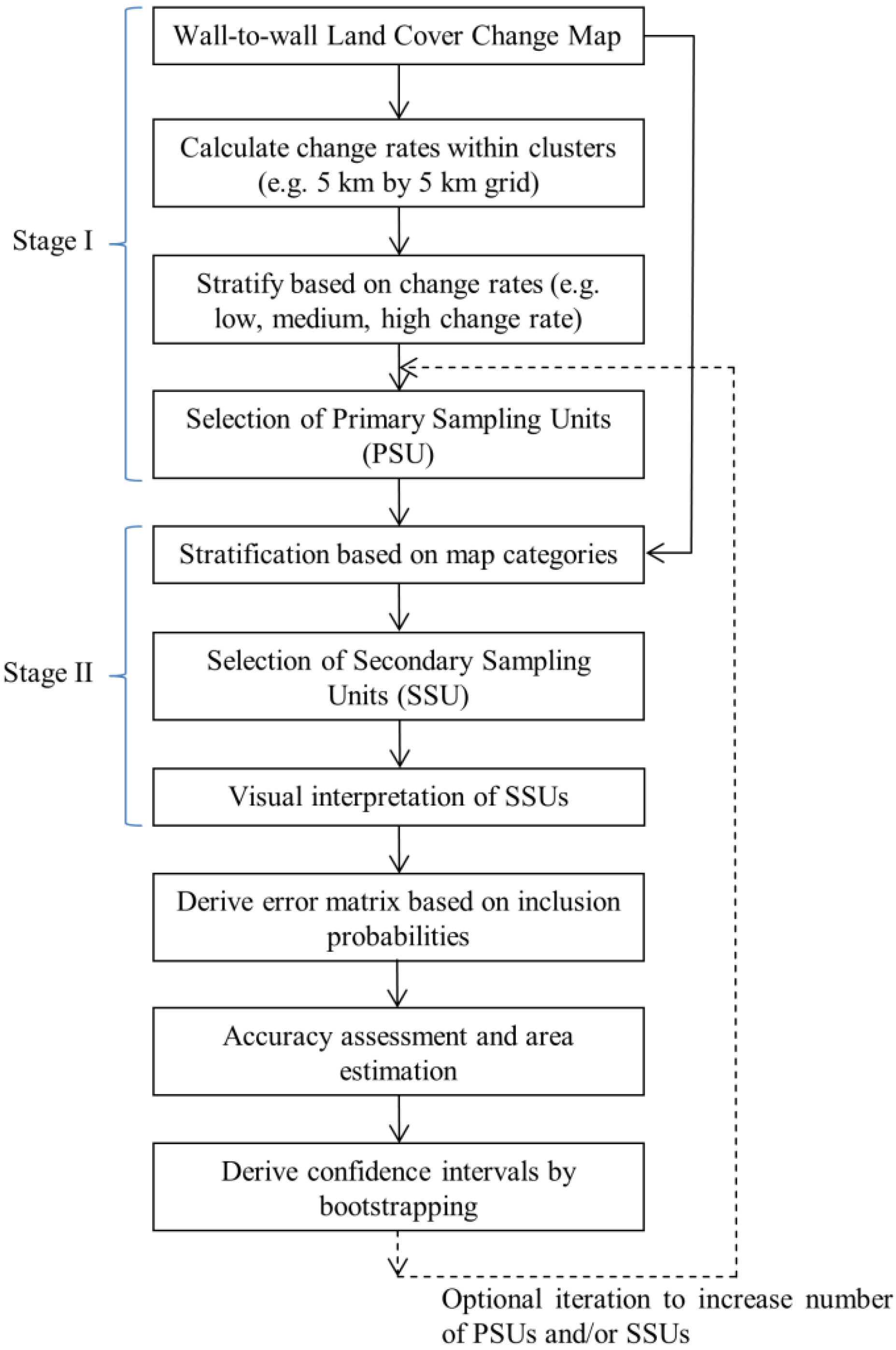
2.2. Sampling Design
- number of SSUs for category c
- estimated error rate for category c
- accepted standard error of the error of commission for category c
- L number of categories
- sample size for category c
- n total sample size
- population size for category c
- estimated error rate for category c
- L number of categories
- Nk population size for category k
- σk estimated error rate for category k
2.3. Accuracy Assessment
2.4. Area Estimation
2.5. Derivation of Confidence Intervals
3. Results of a Case Study for Monitoring Deforestation
3.1. Study Site and Data
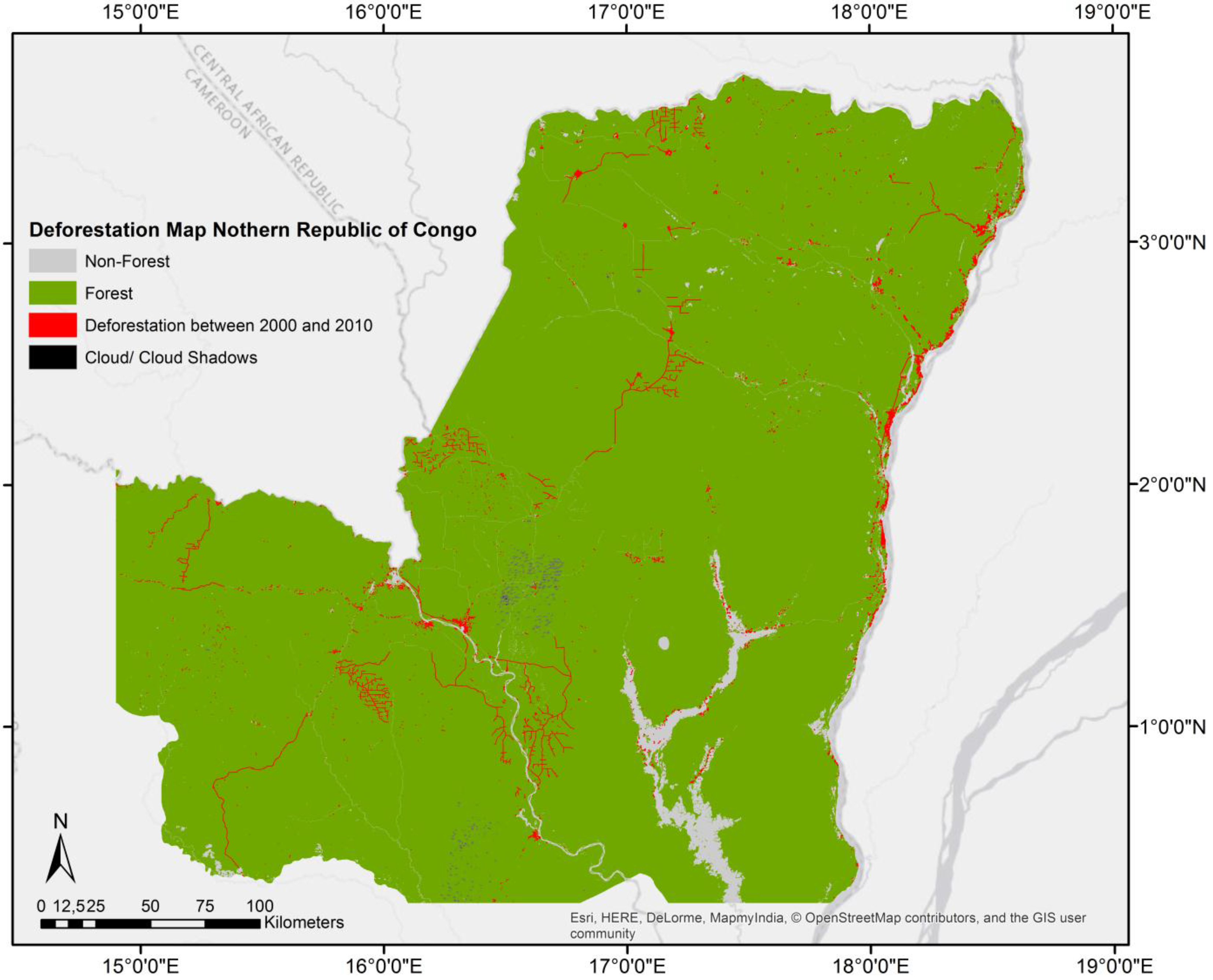

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite Sensor | Spatial Resolution | Acquisition Years | Number of Scenes |
|---|---|---|---|
| GeoEye-1 | 0.5 m (pan), 2 m (ms) | 2009–2011 | 12 |
| Ikonos-2 | 1 m (pan), 4 m (ms) | 2009–2011 | 12 |
| Rapideye MSI | 5 m (ms) | 2009–2011 | 6 |
| Landsat TM and ETM | 15 m (pan), 30 m (ms) | 2000–2013 | 46 |
| Spot 4 HRVIR | 20 m (ms) | 2000, 2001 | 5 |
| Spot 5 HRG | 10 m (ms) | 2009, 2010 | 3 |
| Terra Aster | 15 m (ms) | 2007, 2010 | 2 |
| Pléiades HiRI | 0.5 m (pan), 2 m (ms) | 2013 | 1 |
3.2. Sampling Design
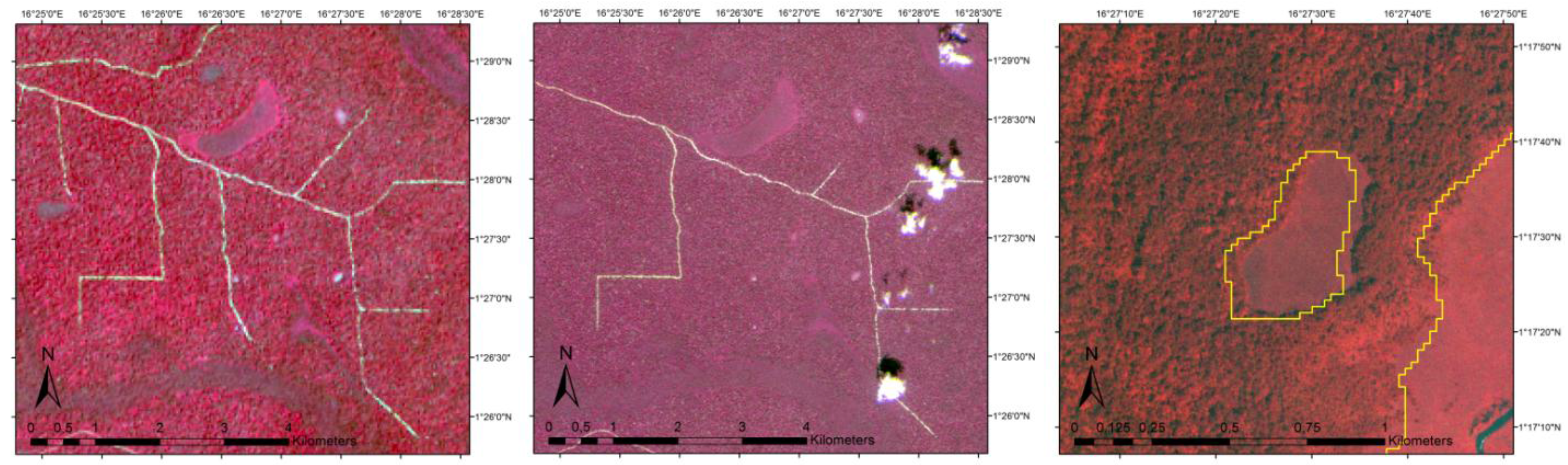
3.3. Accuracy Assessment
| Reference | Stable Non-Forest | Stable Forest | Forest to Cropland | Forest to Grassland | Forest to Wetland | Forest to Settlement | |
|---|---|---|---|---|---|---|---|
| Map | |||||||
| Stable non-forest | 0.0223 | 0.0047 | 0.0004 | 0.0000 | 0.0000 | 0.0000 | |
| Stable forest | 0.0028 | 0.9631 | 0.0029 | 0.0000 | 0.0000 | 0.0009 | |
| Forest to cropland | 0.0000 | 0.0001 | 0.0010 | 0.0000 | 0.0000 | 0.0000 | |
| Forest to grassland | 0.0000 | 0.0003 | 0.0000 | 0.0002 | 0.0000 | 0.0000 | |
| Forest to wetland | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | 0.0000 | |
| Forest to settlement | 0.0000 | 0.0001 | 0.0001 | 0.0000 | 0.0000 | 0.0010 | |
| Total | 0.0251 | 0.9683 | 0.0044 | 0.0002 | 0.0001 | 0.0019 | |
| Stable Non-Forest | Stable Forest | Forest to Cropland | Forest to Grassland | Forest to Wetland | Forest to Settlement | |
|---|---|---|---|---|---|---|
| Error of commission | 18.8 | 0.7 | 8.5 | 60.8 | 39.7 | 18.2 |
| Error of omission | 11.1 | 0.5 | 77.9 | 12.9 | 49.3 | 49.6 |
3.4. Area Estimation
| Category | Mapped Area in km2 | Improved Area Estimates in km2 | Lower Bound (95% Confid.) | Upper Bound (95% Confid.) |
|---|---|---|---|---|
| Non-forest | 2661 | 2442 | 1304 | 2933 |
| Forest | 94396 | 94260 | 93926 | 95595 |
| Forest to cropland | 100 | 426 | 105 | 1094 |
| Forest to grassland | 45 | 20 | 6 | 34 |
| Forest to wetland | 20 | 10 | 0 | 20 |
| Forest to settlement | 117 | 191 | 94 | 360 |
3.5. Derivation of Confidence Intervals
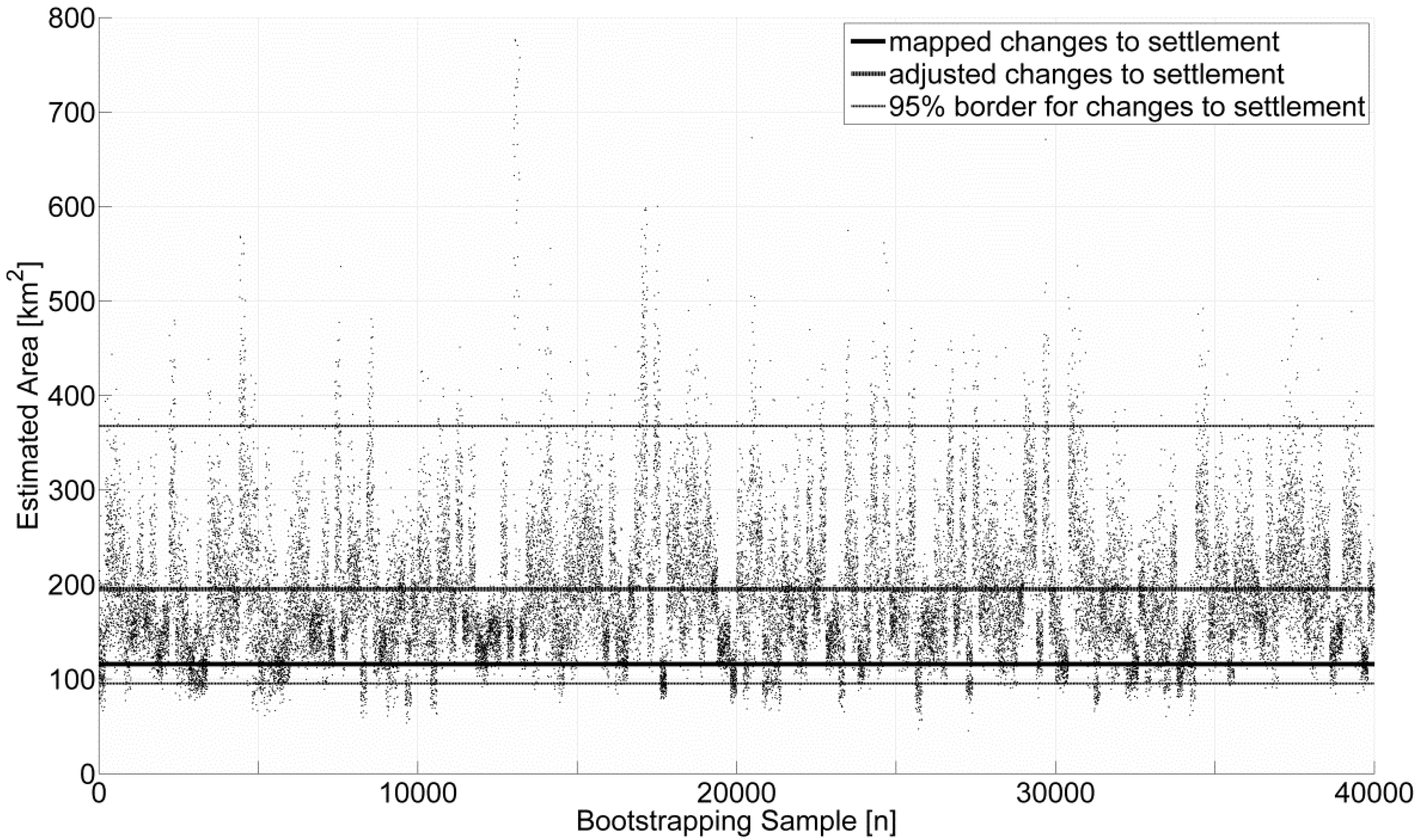
4. Discussion
5. Conclusions
- General applicability for a wide range of operational applications
- Cost-effective implementation for large-area monitoring
- Based on globally available data (e.g., freely available Sentinel 2 imagery, complemented with a limited number of very high resolution scenes)
- Accurate monitoring of typically rare land cover change processes (e.g., change rates below 1%)
- Implementation of a probability sampling design to provide a rigorous foundation for accuracy assessment and area estimation
- Provision of confidence intervals for accuracy measures as well as area estimates as required in international reporting.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- GOFC-GOLD. A Sourcebook of Methods and Procedures for Monitoring and Reporting Anthropogenic Greenhouse Gas Emissions and Removals Associated with Deforestation, Gains and Losses of Carbon Stocks in Forests Remaining Forests, and Forestation, GOFC-GOLD Report version COP20–1; GOFC-GOLD Land Cover Project Office: Wageningen, The Netherlands, 2014. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Card, D.H. Using known map category marginal frequencies to improve estimates of thematic map accuracy. Am. Soc. Photogramm. 1982, 48, 431–439. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Sannier, C.; McRoberts, R.E.; Fichet, L.-V.; Makaga, E.M.K. Using the regression estimator with Landsat data to estimate proportion forest cover and net proportion deforestation in Gabon. Remote Sens. Environ. 2014, 151, 138–148. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Walters, B.F. Statistical inference for remote sensing-based estimates of net deforestation. Remote Sens. Environ. 2012, 124, 394–401. [Google Scholar] [CrossRef]
- McRoberts, R.E. Post-classification approaches to estimating change in forest area using remotely sensed auxiliary data. Remote Sens. Environ. 2014, 151, 149–156. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Stehman, S.V. Statistical rigor and practical utility in thematic map accuracy assessment. Photogramm. Eng. Remote Sens. 2001, 67, 727–734. [Google Scholar]
- Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Arunarwati, B.; Stolle, F.; Pittman, K. Quantifying changes in the rates of forest clearing in Indonesia from 1990 to 2005 using remotely sensed data sets. Environ. Res. Lett. 2009, 4, 034001. [Google Scholar] [CrossRef]
- Stehman, S.V. Impact of sample size allocation when using stratified random sampling to estimate accuracy and area of land-cover change. Remote Sens. Lett. 2012, 3, 111–120. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum 2000; European Environment Agency Copenhagen: Copenhagen, Denmark, 2000. [Google Scholar]
- Selkowitz, D.J.; Stehman, S.V. Thematic accuracy of the National Land Cover Database (NLCD) 2001 land cover for Alaska. Remote Sens. Environ. 2011, 115, 1401–1407. [Google Scholar] [CrossRef]
- Särndal, C.-E.; Swensson, B.; Wretman, J. Model Assisted Survey Sampling; Springer Science & Business Media: Berlin, Germany, 2003. [Google Scholar]
- Foody, G.M. Sample size determination for image classification accuracy assessment and comparison. Int. J. Remote Sens. 2009, 30, 5273–5291. [Google Scholar] [CrossRef]
- Schreuder, H.T.; Ernst, R.L.; Ramirez-Maldonado, H. Statistical Techniques for Sampling and Monitoring Natural Resources; General Technical Report RMRS-GTR-126; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2004.
- Efron, B.; Tibshirani, R. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy. Stat. Sci. 1986, 1, 54–75. [Google Scholar] [CrossRef]
- Penman, J.; Gytarsky, M.; Hiraishi, T.; Krug, T.; Kruger, D.; Pipatti, R.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K. Good Practice Guidance for Land Use, Land-Use Change and Forestry; Institute for Global Environmental Strategies (IGES): Kanagawa Hayama, Japan, 2003. [Google Scholar]
- Stehman, S.V.; Selkowitz, D.J. A spatially stratified, multi-stage cluster sampling design for assessing accuracy of the Alaska (USA) National Land Cover Database (NLCD). Int. J. Remote Sens. 2010, 31, 1877–1896. [Google Scholar] [CrossRef]
- Olofsson, P.; Torchinava, P.; Woodcock, C.E.; Baccini, A.; Houghton, R.A.; Ozdogan, M.; Zhao, F.; Yang, X. Implications of land use change on the national terrestrial carbon budget of Georgia. Carbon Balance Manag. 2010, 5. [Google Scholar] [CrossRef] [PubMed]
- Stehman, S.V. Estimating standard errors of accuracy assessment statistics under cluster sampling. Remote Sens. Environ. 1997, 60, 258–269. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallaun, H.; Steinegger, M.; Wack, R.; Schardt, M.; Kornberger, B.; Schmitt, U. Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes. Remote Sens. 2015, 7, 11992-12008. https://doi.org/10.3390/rs70911992
Gallaun H, Steinegger M, Wack R, Schardt M, Kornberger B, Schmitt U. Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes. Remote Sensing. 2015; 7(9):11992-12008. https://doi.org/10.3390/rs70911992
Chicago/Turabian StyleGallaun, Heinz, Martin Steinegger, Roland Wack, Mathias Schardt, Birgit Kornberger, and Ursula Schmitt. 2015. "Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes" Remote Sensing 7, no. 9: 11992-12008. https://doi.org/10.3390/rs70911992
APA StyleGallaun, H., Steinegger, M., Wack, R., Schardt, M., Kornberger, B., & Schmitt, U. (2015). Remote Sensing Based Two-Stage Sampling for Accuracy Assessment and Area Estimation of Land Cover Changes. Remote Sensing, 7(9), 11992-12008. https://doi.org/10.3390/rs70911992