
Prediction of Canopy Heights over a Large Region Using Heterogeneous Lidar Datasets: Efficacy and Challenges




Abstract
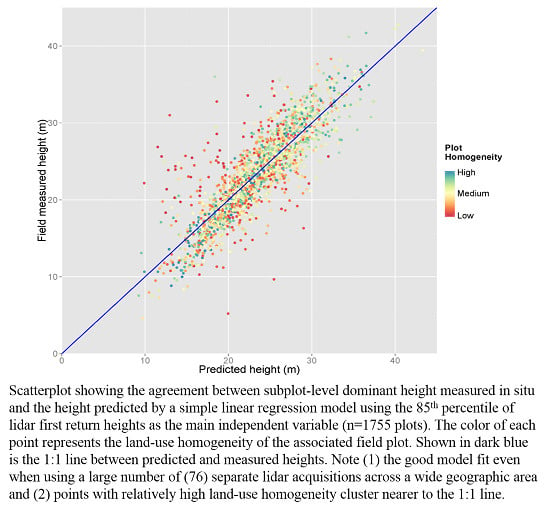
:
1. Introduction
2. Methods
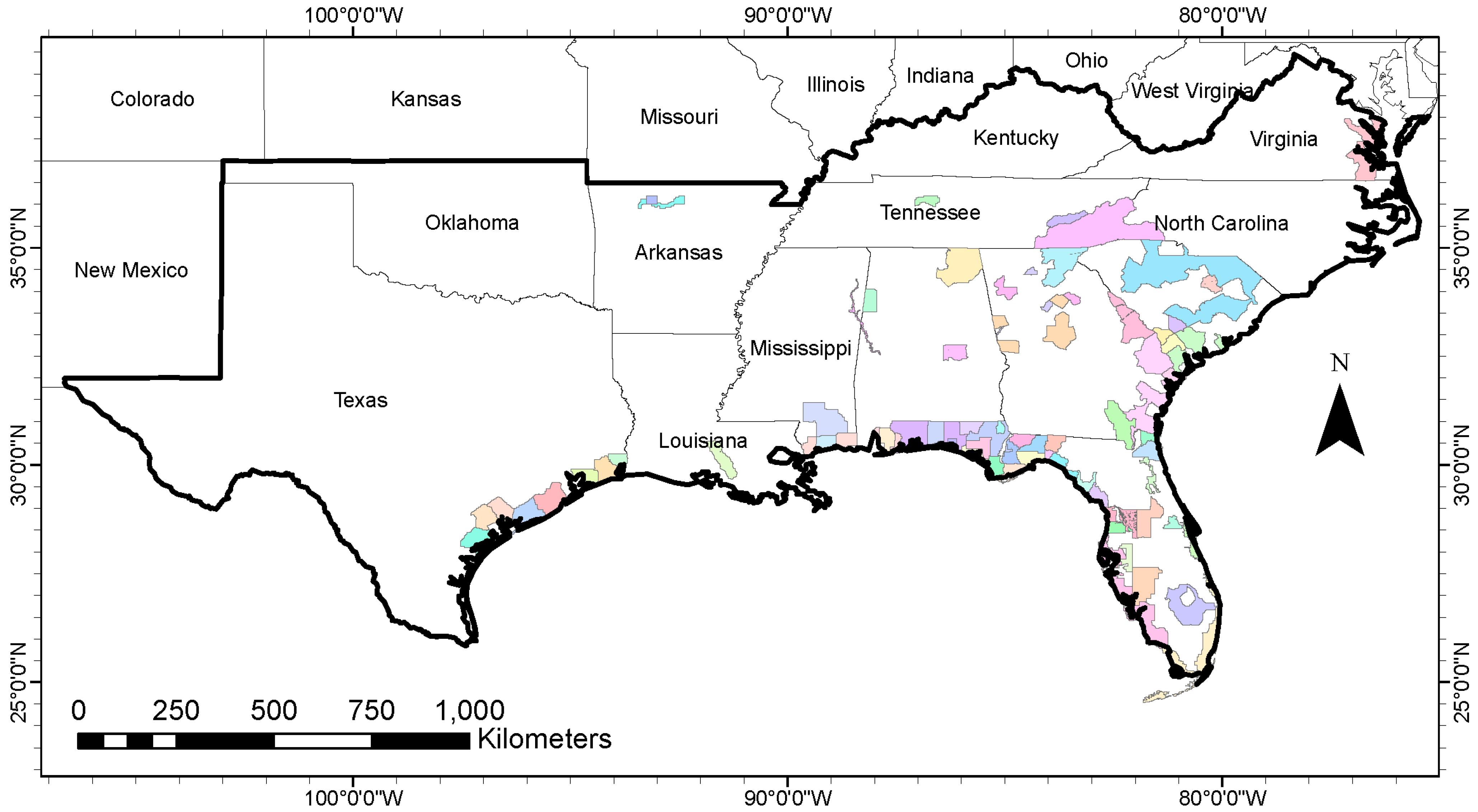
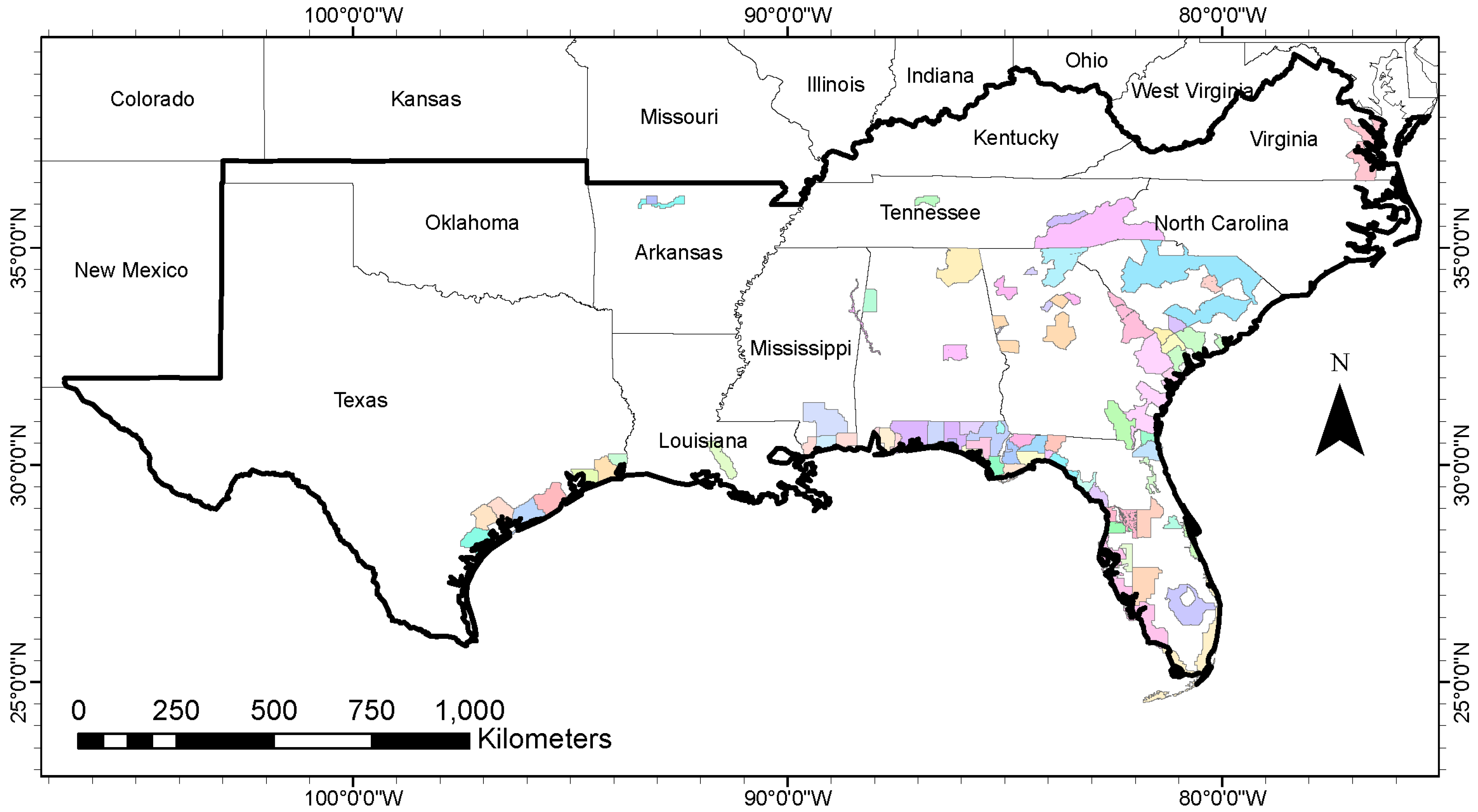
2.1. Study Area and Lidar Data Used
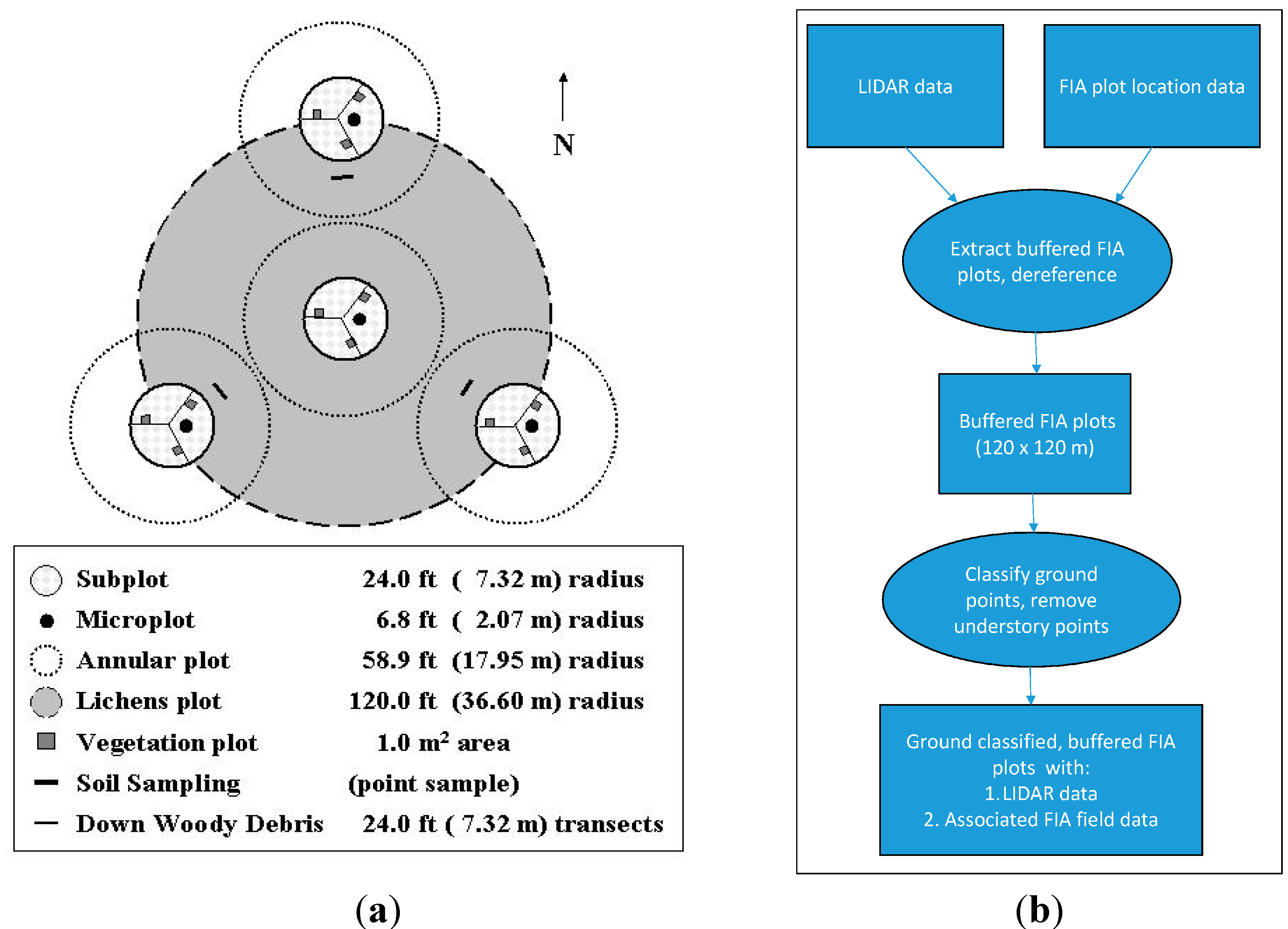
2.2. Forest Inventory Data
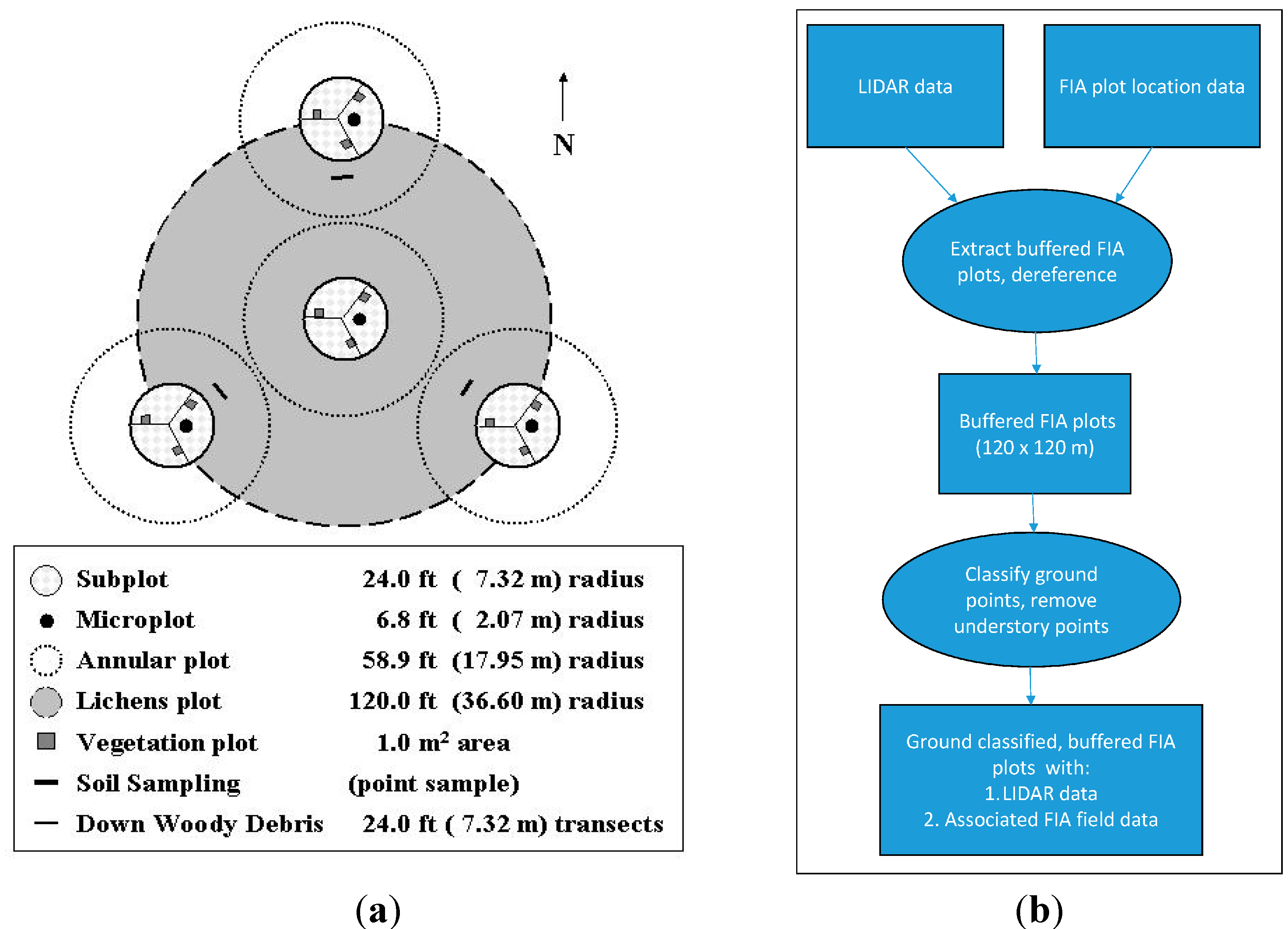
2.3. Lidar Plot Size
- (1)
- The size of the lidar plot should be as close to that needed for the FIA plot (87.8 m).
- (2)
- Given the uncertainty in the spatial location of the FIA plot, the lidar plot should have a good probability of encompassing the entire FIA plot.
2.4. Lidar Data Processing and Metrics Computed
- (1)
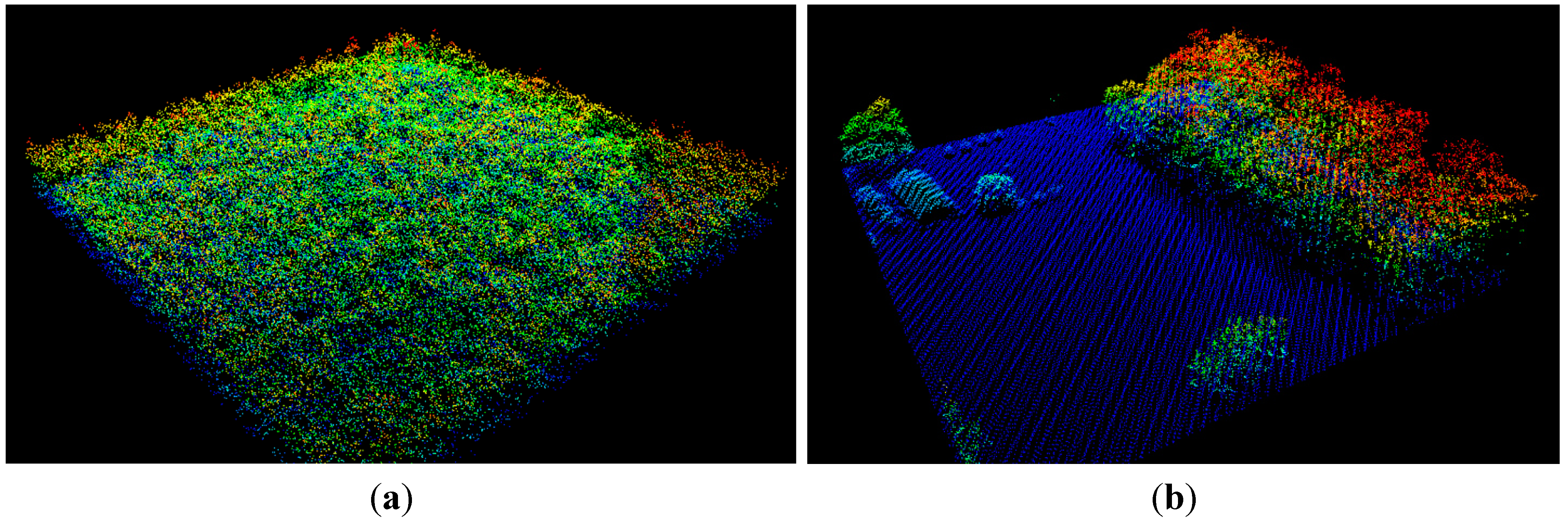
- For each FIA plot location, we checked whether there was a spatially corresponding lidar acquisition within ±2 years of plot measurement. If so, lidar data corresponding to a plot encompassing the FIA plot was extracted. This was a north-south oriented square plot of length 120 m, centered at the given location of the FIA plot center. These square plots will be henceforth called the buffered FIA plots (see Figure 3). A total of 3337 such plots (corresponding to FIA plots) were cut out from the lidar point cloud data.
- (2)
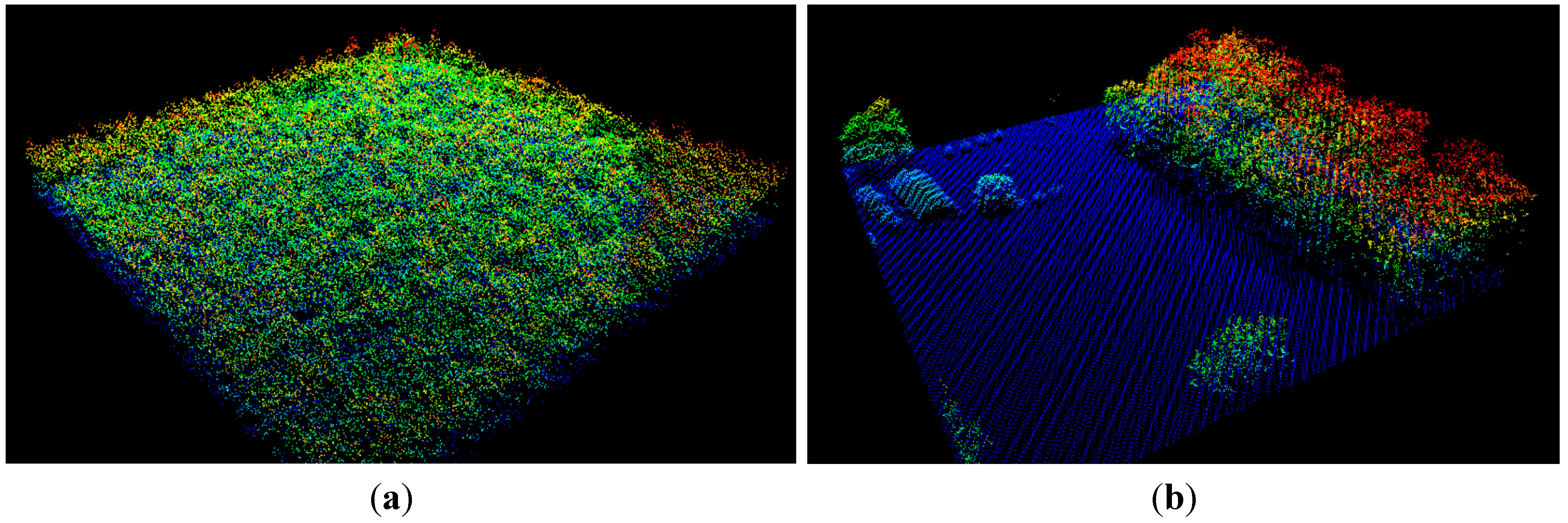
- Ground classification on the buffered FIA plots was done using the method of progressive TIN (triangulated irregular network) densification [26], as implemented in lasground, which is part of the open-source toolset lastools (see http://lastools.org).
- (3)
- Understory removal: Several height thresholds have been used in the literature to remove possible ground and understory points; these range from 0.9 m [27] to 2.0 m [10,28]. We decided on the threshold of 3.0 m for the following two reasons: (a) After manual inspection of several plots for understory height, we decided that a threshold of 3.0 m was better; (b) We looked at the FIA phase 3 plots for the region, where understory heights were also measured. There, we noticed that a good proportion of shrub heights were recorded above 3 m. Hence, all points in the height bin of 0.0–3.0 m (above ground) were considered non-canopy points, and were not considered for calculation of canopy height metrics.
- (1)
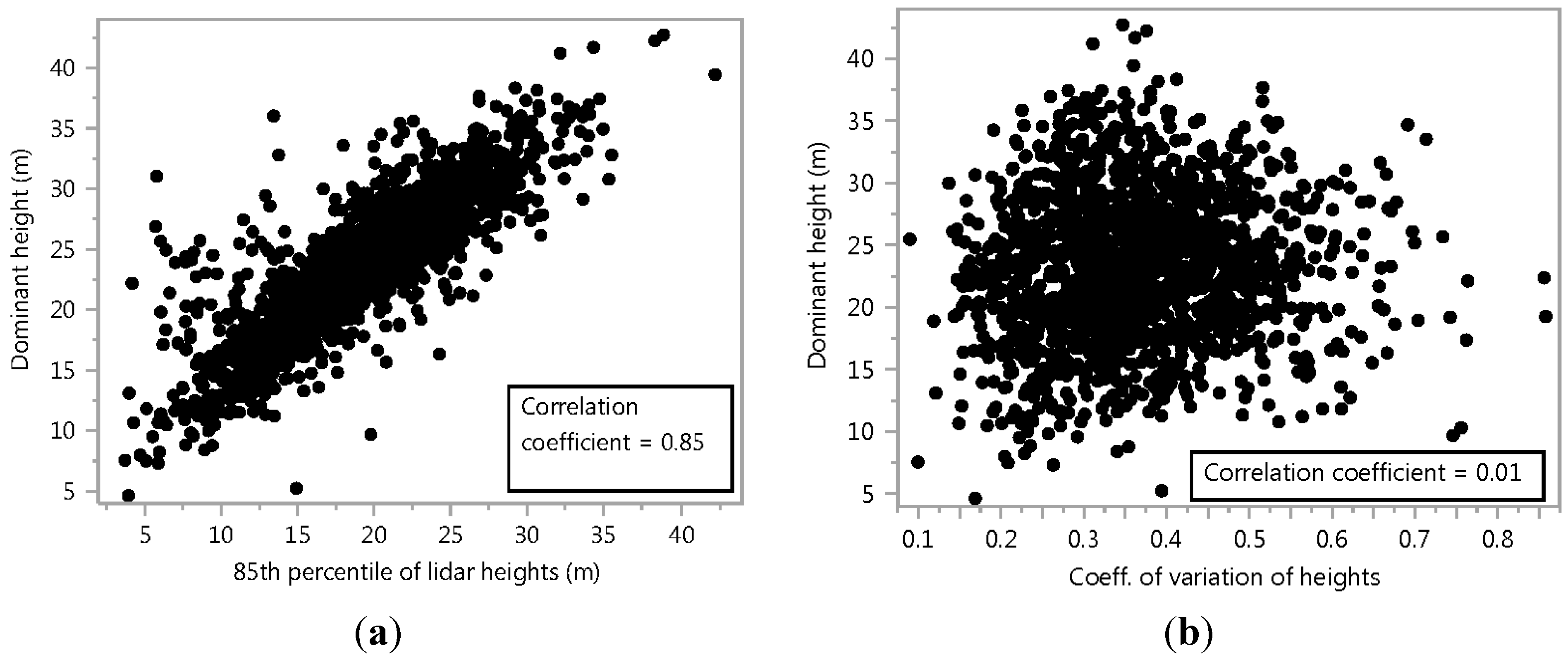
- Lidar distributional metrics for canopy height: Height percentiles have been shown to be significant canopy height predictors in previous related efforts [10,27]. Hence, the major percentiles (5th, 10th, 15th, 20th …) of the heights (above ground) of canopy first returns (i.e., greater than 3.0 m from the ground) over the buffered FIA plots were calculated. These are denoted as h5, h10, h15, etc. We also calculated the coefficient of variation of the heights of canopy first return points, as it has shown to be significant in such models [27]. This metric is denoted as cv_canPts.
- (2)
- Plot homogeneity: This quantifies the homogeneity of distribution of vegetation height in the area around the FIA plots. The importance of this metric will be explained in the next section. For computing it, we divide the buffered FIA plot into 144 square units, each of area 100 m2. This was done by using a regular grid pattern. Then, we calculate the 85th percentile of heights of all returns (including understory) for each of those 144 square units. Finally, we calculate the coefficient of variation of these 144 values (henceforth CV), which is a normalized quantification of the amount of dispersion of vegetation heights over the plot. Hence, given that (h85)i is the 85th percentile height of all lidar returns for the ith square unit, the CV at the plot level is calculated as:
- (1)
- Scan angle: The average scan angle, in degrees, as recorded in the lidar metadata. Additionally, we flagged plots that had lidar data with either no scan angle recorded or had scan angles improperly recorded. Also, we flagged plots where the lidar data were from multiple flight lines (hence, averaged scan angles are not representative). These were marked with a “no good scan angle information” flag.
- (2)
- Slope of the buffered FIA lidar plot: This is the average slope, expressed in degrees, measured in the field by the FIA crew.
- (3)
- The dominant tree height of all the trees measured by FIA on the subplots. The dominant tree height (henceforth “dominant height”) is the average height of the five tallest trees in the four FIA subplots. Note that this definition differs from the more common definition used in forestry. We used this definition to maintain consistency across all plots.
- (4)
- We also estimated the effect of broad species grouping (softwood vs. hardwood) on the models. Softwood trees include evergreen conifers such as pines, spruces and cedars, while hardwoods include deciduous trees such as oaks, maples and birch. The FIA field crew also records species data for all trees measured. We used that information to estimate the percentage (by basal area) of softwoods in the four FIA subplots. That is, we defined and calculated percent_softwood using the following formula:
2.5. Accounting for Plots with Multiple Land Use Conditions
2.6. Main Model Specification
- (1)
- A height percentile from lidar canopy first returns (from the set of h5, h10, h15, h20, etc). The percentile chosen was the one most correlated to the dominant height.
- (2)
- cv_canPts, the coefficient of variation of the heights of canopy first returns.
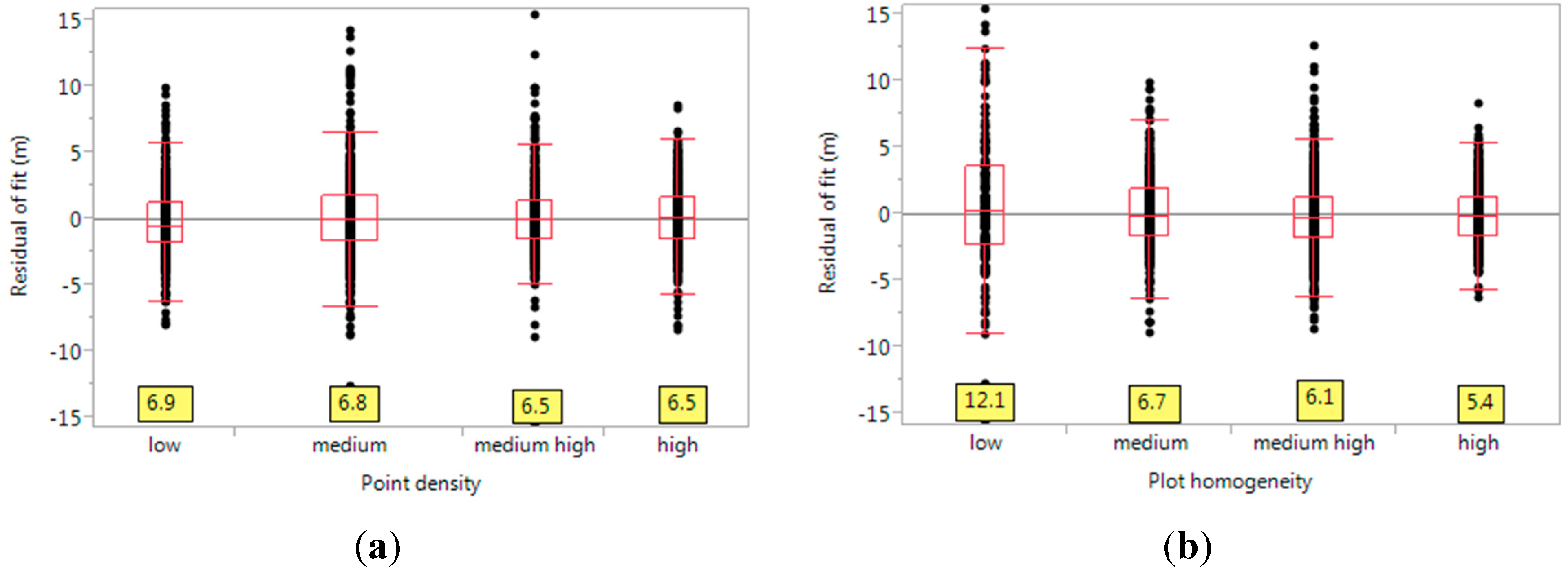
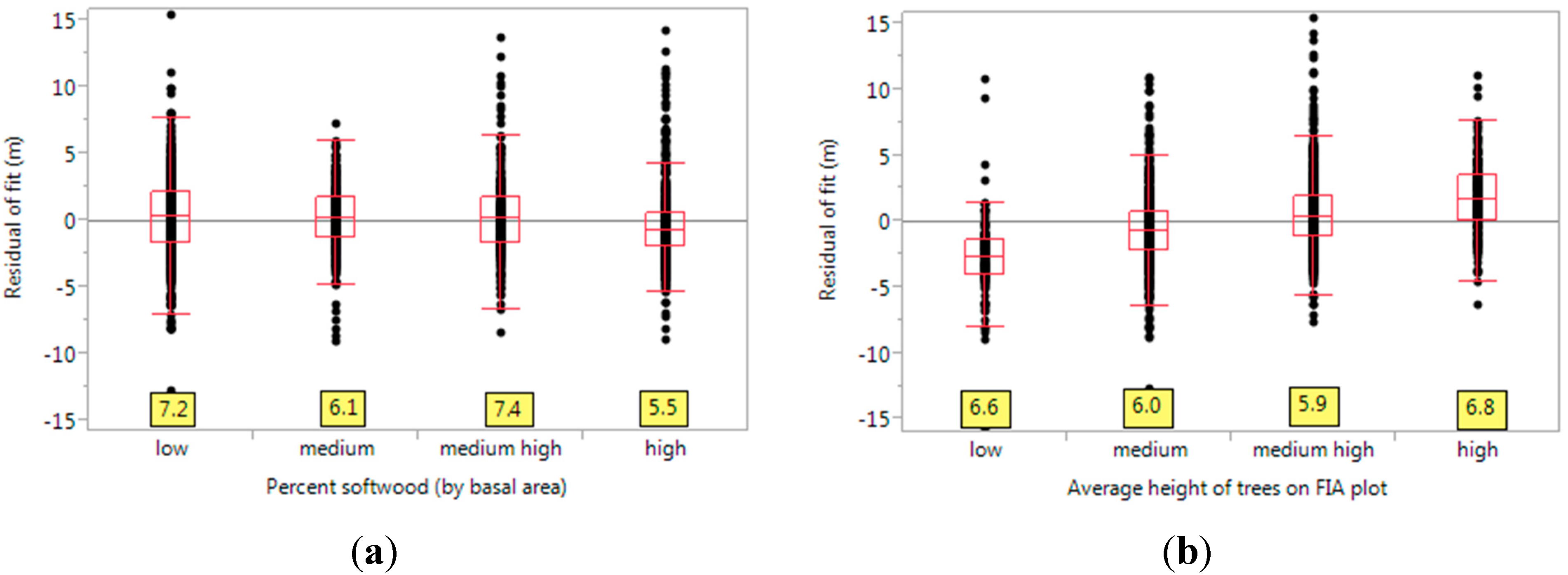
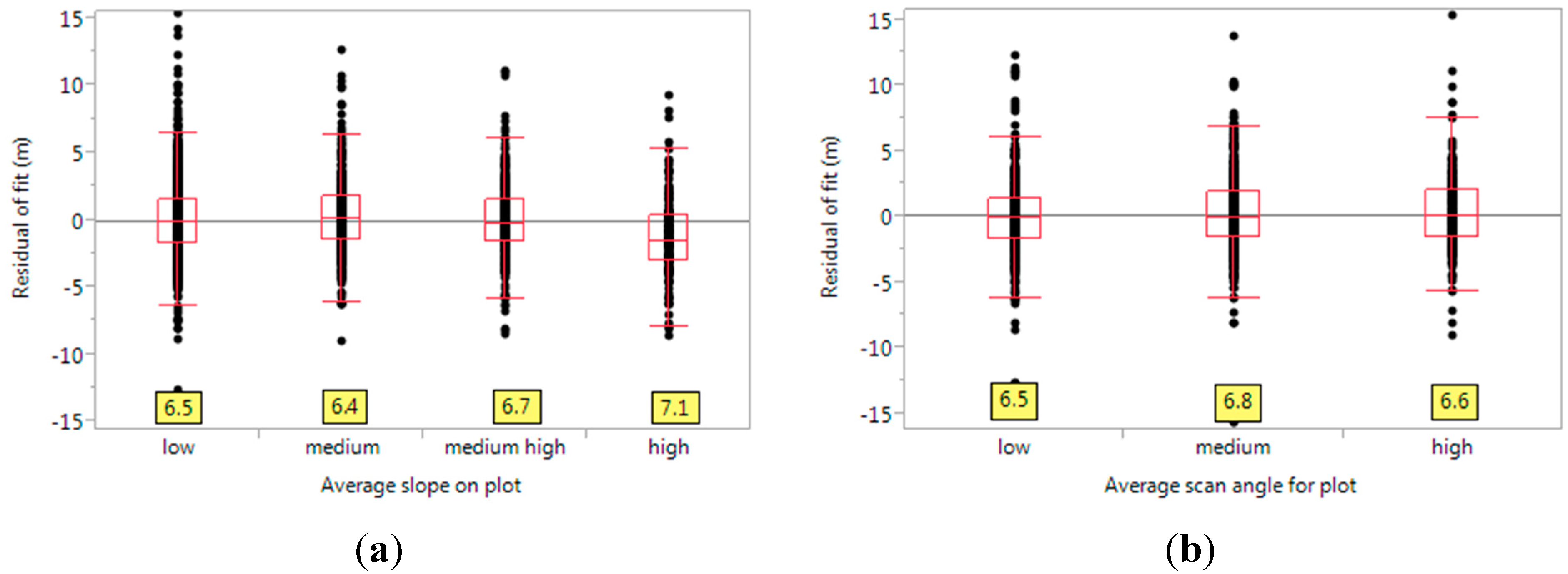
2.7. Factors Affecting Efficacy of Prediction
- (a)
- Point density of lidar returns (all returns), over the buffered FIA plot. This is expressed as (number of returns)/m2.
- (b)
- Plot homogeneity, estimated from lidar returns (quantified by CV).
- (c)
- Percent softwood (estimated from FIA field data).
- (d)
- Average height of trees (estimated from FIA field data).
- (e)
- Slope of the plot terrain (estimated from FIA field data).
- (f)
- Average lidar pulse scan angle (estimated from lidar metadata).
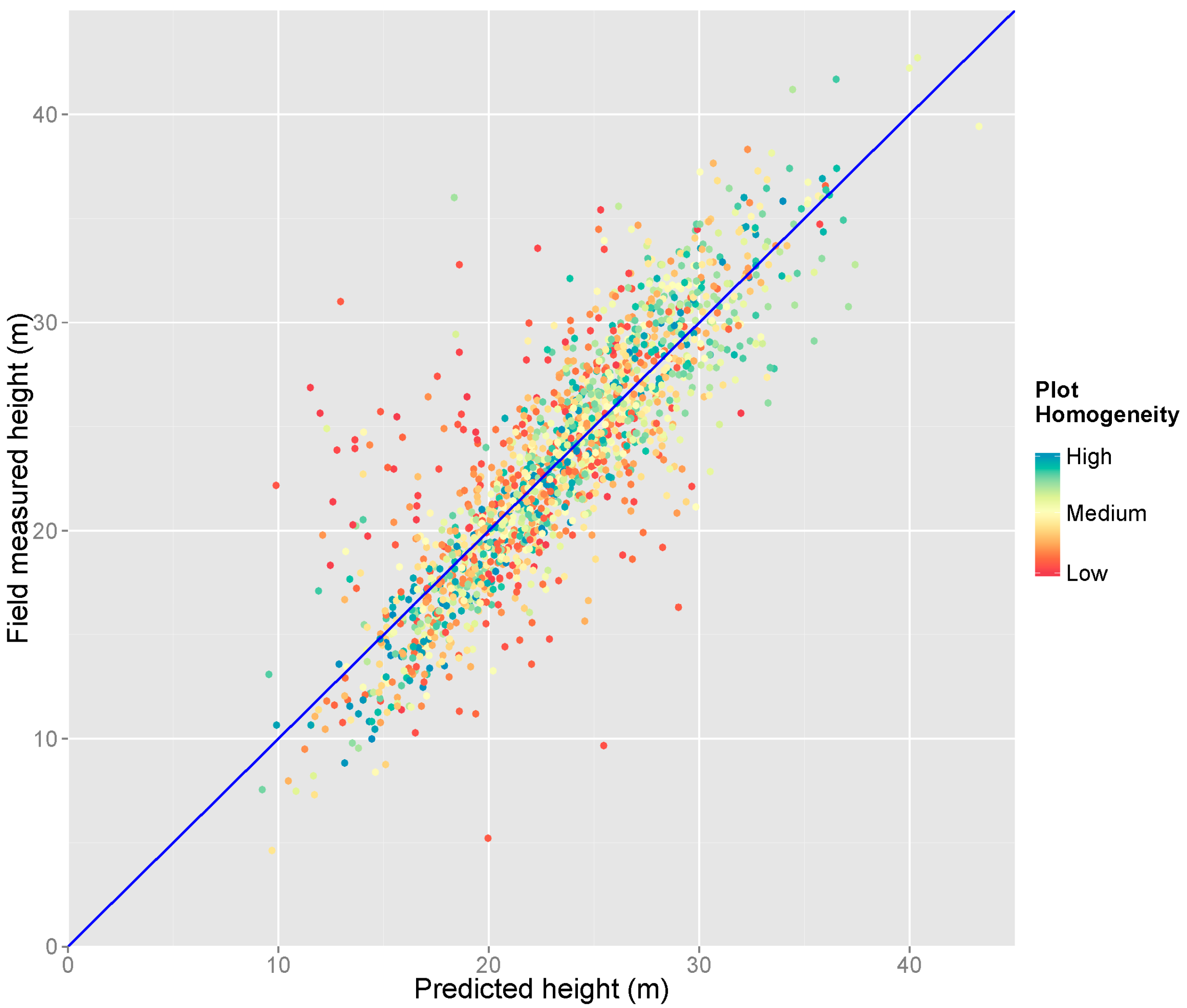
2.8. Generation of Sample Canopy Height Map
3. Results
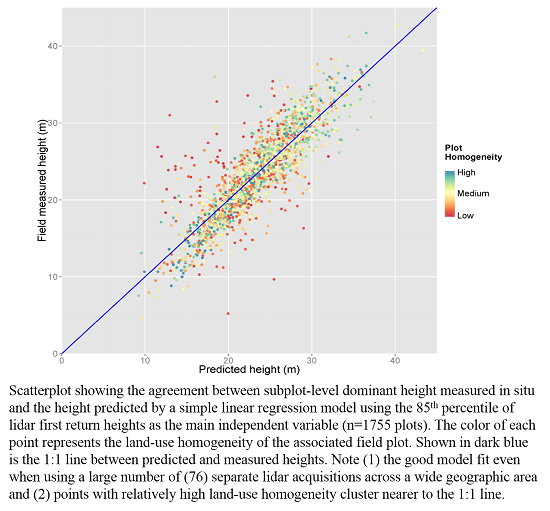
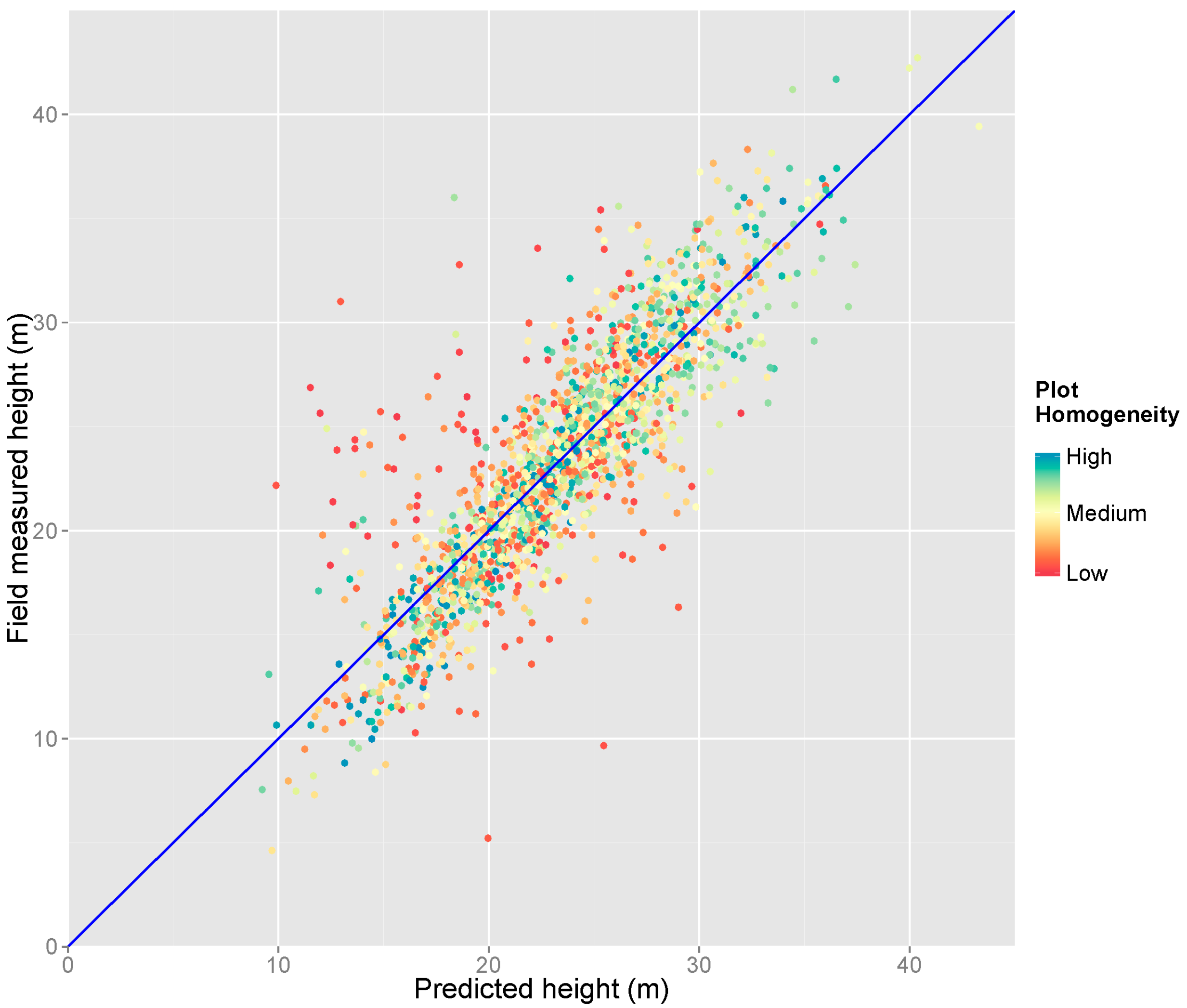
3.1. Main Model
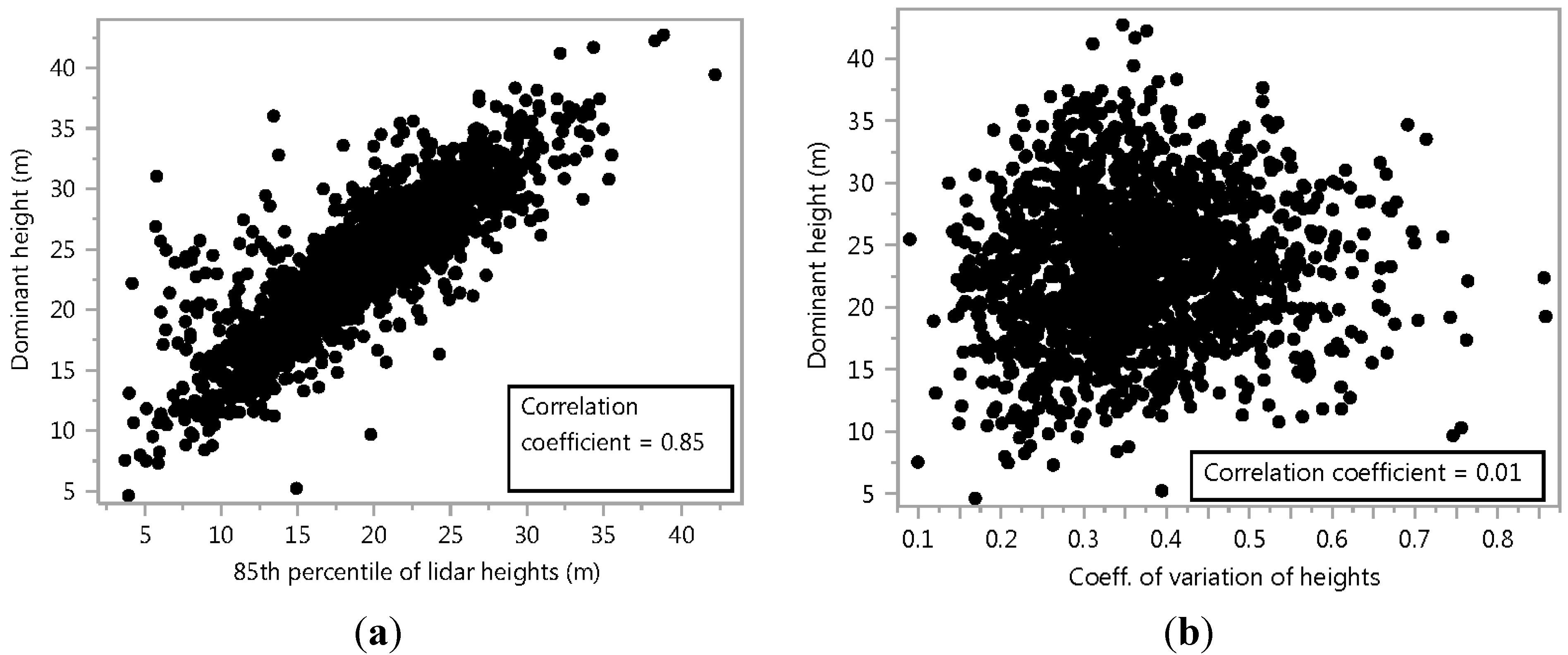
3.2. Variable Importance for Goodness of Fit

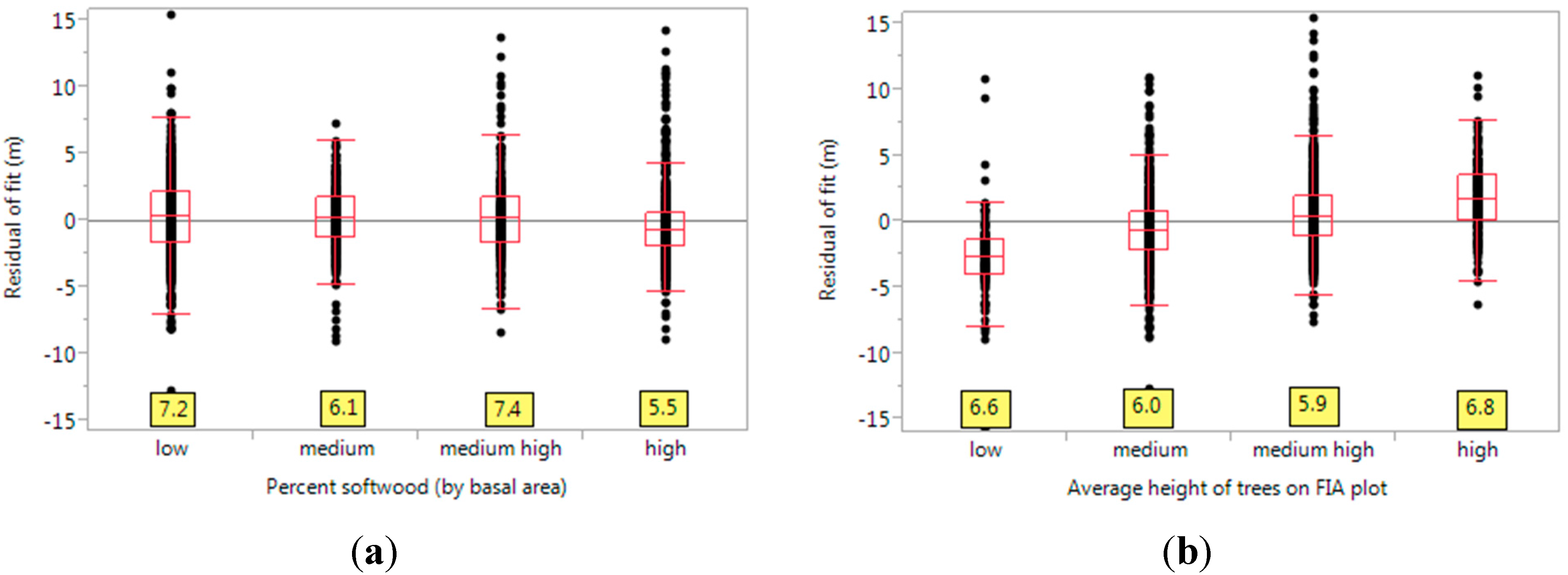

3.3. Variable Importance from the Random Forest Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Increase in Error (%) | Brown-Forsythe Test Statistic |
|---|---|---|
| h85 | 113.2 | NA |
| Percent softwood | 22.3 | 7.28 |
| CV (measure of plot homogeneity) | 15.0 | 55.05 |
| cv_canPts | 14.3 | NA |
| Slope | 9.0 | 0.67 |
| Point density (PD) | 4.2 | 2.17 |
| Scan angle | 3.3 | 0.41 |
3.4. Sample Canopy Height Map

4. Discussion
4.1. The Influence of Co-Registration Issues
- Etotal is the total error, which is the difference between the actual dominant height of the forest patches on that lidar plot, and that predicted by our models.
- Emodel is the error in modelling the dominant height of the trees on the FIA subplots from the lidar data, on the lidar plot. This is captured by the RMSEs of our models, and may be due to several factors, as discussed in Section 2.7.
- Enon-representative-subplots is the error caused by the fact that the dominant height of the trees on the FIA subplots (that we model) is not the same as the dominant height of the trees over the entire lidar plot. The difference can sometimes be large, may be due to the fact that the FIA subplots may be sampling a patch of forest with very different characteristics (see above) or that most of the area of the subplots could be outside the lidar plot (due to very high co-registration errors). But in general, this error term is expected to be lesser in areas where vegetation is more homogeneous. There have been recent reports that LiDAR metrics are less sensitive to co-registration errors in dense, spatially homogeneous stands than sparse, heterogeneous stands [40]. However, further work is needed to quantify this term.
- EFIA-measurements is the error in the FIA measurement, recording and processing of tree heights. We assume this to be relatively so small as to be negligible.
4.2. Lidar-Based Grid Cell Homogeneity
| CV Threshold | Number of Plots | % of Original Num. Plots | R2 | RMSE (m) |
|---|---|---|---|---|
| CV < 0.5 | 1573 | 89.6 | 0.81 | 2.60 |
| CV < 0.2 | 729 | 41.5 | 0.84 | 2.44 |
4.3. The Advantage of Using National-Level Forest Inventory Plots
4.4. Uses of Large-Area Canopy Height Maps
4.5. Possible Improvements to Lidar Data
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gopalakrishnan, R.; Thomas, V.; Coulston, J.; Wynne, R. Efficacy of using heterogeneous Lidar datasets in predicting canopy heights over a large region. In Proceedings of the SilviLaser conference, Beijing, China, 9–11 October 2013.
- Jensen, J.L.; Humes, K.S.; Vierling, L.A.; Hudak, A.T. Discrete return Lidar-based prediction of leaf area index in two conifer forests. Remote Sens. Environ. 2008, 112, 3947–3957. [Google Scholar] [CrossRef]
- Goetz, S.; Steinberg, D.; Dubayah, R.; Blair, B. Laser remote sensing of canopy habitat heterogeneity as a predictor of bird species richness in an eastern temperate forest, USA. Remote Sens. Environ. 2007, 108, 254–263. [Google Scholar] [CrossRef]
- Gorte, R. The Rising Cost of Wildfire Protection; Headwaters Economics: Bozeman, MT, USA, 2013. [Google Scholar]
- Marshall, D.J.; Wimberly, M.; Pete, B.; Stanturf, J. Synthesis of Knowledge of Hazardous Fuels Management in Loblolly Pine Forests; US Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2008. [Google Scholar]
- Wear, D.; Greis, J. The Southern Forest Futures Project: Summary Report. Available online: http://www.srs.fs.usda.gov/pubs/42526 (accessed on 20 March 2015).
- Oswalt, S.N.; Thompson, M.T.; Smith, W.B. US Forest Resource Facts and Historical Trends; US Department of Agriculture, Forest Service: Knoxville, TN, USA, 2009. [Google Scholar]
- Turner, D.P.; Koerper, G.J.; Harmon, M.E.; Lee, J.J. A carbon budget for forests of the conterminous United States. Ecol. Appl. 1995, 5, 421–436. [Google Scholar] [CrossRef]
- White, J.C.; Wulder, M.A.; Varhola, A.; Vastaranta, M.; Coops, N.C.; Cook, B.D.; Pitt, D.; Woods, M. A best practices guide for generating forest inventory attributes from airborne laser scanning data using an area-based approach. For. Chronic 2013, 89, 722–723. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Simard, M.; Pinto, N.; Fisher, J.B.; Baccini, A. Mapping forest canopy height globally with spaceborne lidar. J. Geophys. Res. Biogeosci. 2011, 116. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Harding, D.J.; Keller, M.; Cohen, W.B.; Carabajal, C.C.; Del Bom Espirito-Santo, F.; Hunter, M.O.; de Oliveira, R. Estimates of forest canopy height and aboveground biomass using ICESat. Geophys. Res. Lett. 2005, 32. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Nelson, R.F.; Næsset, E.; Ørka, H.O.; Coops, N.C.; Hilker, T.; Bater, C.W.; Gobakken, T. Lidar sampling for large-area forest characterization: A review. Remote Sens. Environ. 2012, 121, 196–209. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Schumacher, J. Estimation of forest resources from a country wide laser scanning survey and national forest inventory data. Remote Sens. Environ. 2012, 119, 148–157. [Google Scholar] [CrossRef]
- Evans, J.S.; Hudak, A.T.; Faux, R.; Smith, A. Discrete return LiDAR in natural resources: Recommendations for project planning, data processing, and deliverables. Remote Sens. 2009, 1, 776–794. [Google Scholar] [CrossRef]
- Næsset, E. Effects of different sensors, flying altitudes, and pulse repetition frequencies on forest canopy metrics and biophysical stand properties derived from small-footprint airborne laser data. Remote Sens. Environ. 2009, 113, 148–159. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Hyyppä, H.; Maltamo, M. Effects of flight altitude on tree height estimation using airborne laser scanning. Laser-Scanners For. Landsc. Assess. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 36, 96–101. [Google Scholar]
- Næsset, E. Assessing sensor effects and effects of leaf-off and leaf-on canopy conditions on biophysical stand properties derived from small-footprint airborne laser data. Remote Sens. Environ. 2005, 98, 356–370. [Google Scholar] [CrossRef]
- Stoker, J.M.; Cochrane, M.A.; Roy, D.P. Integrating disparate Lidar data at the national scale to assess the relationships between height above ground, land cover and ecoregions. Photogramm. Eng. Remote Sens. 2014, 80, 59–70. [Google Scholar] [CrossRef]
- Davidson, M.A.; Miglarese, A.H. Digital coast and The National Map: A seamless cooperative. Photogramm. Eng. Remote Sens. 2003, 69, 1127–1132. [Google Scholar] [CrossRef]
- NOAA Digital Coast: Frequently Asked Questions. Available online: http://coast.noaa.gov/digitalcoast/sites/default/files/files/1394462725/DigCoast-FAQs.pdf (accessed on 20 March 2015).
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program: National Sampling Design and Estimation Procedures; US Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2005. [Google Scholar]
- Forest Inventory and Analysis: Sampling and Plot Design (FIA fact sheet series). Available online: http://www.fia.fs.fed.us/library/fact-sheets/data-collections/Sampling%20and%20Plot%20Design.pdf (accessed on 20 March 2015).
- McRoberts, R.E. The effects of rectification and Global Positioning System errors on satellite image-based estimates of forest area. Remote Sens. Environ. 2010, 114, 1710–1717. [Google Scholar] [CrossRef]
- Hoppus, M.; Lister, A. The status of accurately locating forest inventory and analysis plots using the Global Positioning System. In Proceedings of the Seventh Annual Forest Inventory and Analysis Symposium, Portland, OR, USA, 3–6 October 2005; Volume 36, p. 179184.
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 111–118. [Google Scholar]
- Erdody, T.L.; Moskal, L.M. Fusion of Lidar and imagery for estimating forest canopy fuels. Remote Sens. Environ. 2010, 114, 725–737. [Google Scholar] [CrossRef]
- Mutlu, M.; Popescu, S.C.; Zhao, K. Sensitivity analysis of fire behavior modeling with lidar-derived surface fuel maps. For. Ecol. Manag. 2008, 256, 289–294. [Google Scholar] [CrossRef]
- Gauch, H.G. Prediction, parsimony and noise. Am. Sci. 1993, 81, 468–478. [Google Scholar]
- Kenyi, L.W.; Dubayah, R.; Hofton, M.; Schardt, M. Comparative analysis of SRTM-NED vegetation canopy height to lidar-derived vegetation canopy metrics. Int. J. Remote Sens. 2009, 30, 2797–2811. [Google Scholar] [CrossRef]
- Andersen, H.E.; Reutebuch, S.E.; McGaughey, R.J. A rigorous assessment of tree height measurements obtained using airborne lidar and conventional field methods. Can. J. Remote Sens. 2006, 32, 355–366. [Google Scholar] [CrossRef]
- Brown, M.B.; Forsythe, A.B. Robust tests for the equality of variances. J. Am. Stat. Assoc. 1974, 69, 364–367. [Google Scholar] [CrossRef]
- Martinuzzi, S.; Vierling, L.A.; Gould, W.A.; Falkowski, M.J.; Evans, J.S.; Hudak, A.T.; Vierling, K.T. Mapping snags and understory shrubs for a lidar-based assessment of wildlife habitat suitability. Remote Sens. Environ. 2009, 113, 2533–2546. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R. News 2002, 2, 18–22. [Google Scholar]
- White, J.C.; Wulder, M.A.; Vastaranta, M.; Coops, N.C.; Pitt, D.; Woods, M. The utility of image-based point clouds for forest inventory: A comparison with airborne laser scanning. Forests 2013, 4, 518–536. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 national land cover database for the conterminous United States—Representing a decade of land cover change information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Wasser, L.; Day, R.; Chasmer, L.; Taylor, A. Influence of vegetation structure on lidar-derived canopy height and fractional cover in forested riparian buffers during leaf-off and leaf-on conditions. PLoS ONE 2013, 8. [Google Scholar] [CrossRef] [PubMed]
- Heurich, M. Automatic recognition and measurement of single trees based on data from airborne laser scanning over the richly structured natural forests of the Bavarian Forest National Park. For. Ecol. Manag. 2008, 255, 2416–2433. [Google Scholar] [CrossRef]
- Takahashi, T.; Yamamoto, K.; Senda, Y.; Tsuzuku, M. Estimating individual tree heights of sugi (Cryptomeria japonica D. Don) plantations in mountainous areas using small-footprint airborne Lidar. J. For. Res. 2005, 10, 135–142. [Google Scholar] [CrossRef]
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Johnson, C.E.; Barton, C.C. Where in the world are my field plots? Using GPS effectively in environmental field studies. Front. Ecol. Environ. 2004, 2, 475–482. [Google Scholar] [CrossRef]
- Bolstad, P.; Jenks, A.; Berkin, J.; Horne, K.; Reading, W.H. A comparison of autonomous, WAAS, real-time, and post-processed global positioning systems (GPS) accuracies in northern forests. North. J. Appl. For. 2005, 22, 5–11. [Google Scholar]
- Wing, M.G.; Karsky, R. Standard and real-time accuracy and reliability of a mapping-grade GPS in a coniferous western Oregon forest. West. J. Appl. For. 2006, 21, 222–227. [Google Scholar]
- Gatziolis, D. Advancements in Lidar-Based Registration of FIA Field Plots. Available online: http://www.nrs.fs.fed.us/pubs/gtr/gtr-nrs-p-105papers/72gatziolis-p-105.pdf (accessed on 20 March 2015).
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 821. [Google Scholar]
- FIA Field Guide Volume 1: Field Data Collection Procedures for Phase2 Plots, Version 6.0. Available online: http://srsfia2.fs.fed.us/data_acquisition/FG_6_SRS_Final_legal_NOV.pdf (accessed on 20 March 2015).
- Rollins, M.G.; Frame, C.K. The LANDFIRE Prototype Project: Nationally Consistent and Locally Relevant Geospatial Data for Wildland Fire Management; Gen. Tech. Rep.; RMRS-GTR-175; U.S. Department of Agriculture (Forest Service): Fort Collins, CO, USA, 2006. [Google Scholar]
- Hawbaker, T.J.; Keuler, N.S.; Lesak, A.A.; Gobakken, T.; Contrucci, K.; Radeloff, V.C. Improved estimates of forest vegetation structure and biomass with a lidar-optimized sampling design. J. Geophys. Res. Biogeosci. 2009, 114. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Bater, C.W.; Coops, N.C.; Hopkinson, C.; Chen, G. Lidar plots—A new large-area data collection option: Context, concepts, and case study. Can. J. Remote Sens. 2012, 38, 600–618. [Google Scholar] [CrossRef]
- Parker, R.C.; Evans, D.L. Stratified light detection and ranging double-sample forest inventory. South. J. Appl. For. 2007, 31, 66–72. [Google Scholar]
- Avery, T.E.; Burkhart, H.E. Forest Measurements, 5th ed.; McGraw Hill: Boston, MA, USA, 2001. [Google Scholar]
- Liu, X. Accuracy assessment of lidar elevation data using survey marks. Surv. Rev. 2011, 43, 80–93. [Google Scholar] [CrossRef]
- Solberg, S.; Næsset, E.; Hanssen, K.H.; Christiansen, E. Mapping defoliation during a severe insect attack on Scots pine using airborne laser scanning. Remote Sens. Environ. 2006, 102, 364–376. [Google Scholar] [CrossRef]
- Vepakomma, U.; St-Onge, B.; Kneeshaw, D. Spatially explicit characterization of boreal forest gap dynamics using multi-temporal lidar data. Remote Sens. Environ. 2008, 112, 2326–2340. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gopalakrishnan, R.; Thomas, V.A.; Coulston, J.W.; Wynne, R.H. Prediction of Canopy Heights over a Large Region Using Heterogeneous Lidar Datasets: Efficacy and Challenges. Remote Sens. 2015, 7, 11036-11060. https://doi.org/10.3390/rs70911036
Gopalakrishnan R, Thomas VA, Coulston JW, Wynne RH. Prediction of Canopy Heights over a Large Region Using Heterogeneous Lidar Datasets: Efficacy and Challenges. Remote Sensing. 2015; 7(9):11036-11060. https://doi.org/10.3390/rs70911036
Chicago/Turabian StyleGopalakrishnan, Ranjith, Valerie A. Thomas, John W. Coulston, and Randolph H. Wynne. 2015. "Prediction of Canopy Heights over a Large Region Using Heterogeneous Lidar Datasets: Efficacy and Challenges" Remote Sensing 7, no. 9: 11036-11060. https://doi.org/10.3390/rs70911036
APA StyleGopalakrishnan, R., Thomas, V. A., Coulston, J. W., & Wynne, R. H. (2015). Prediction of Canopy Heights over a Large Region Using Heterogeneous Lidar Datasets: Efficacy and Challenges. Remote Sensing, 7(9), 11036-11060. https://doi.org/10.3390/rs70911036