
Improving the Computational Performance of Ontology-Based Classification Using Graph Databases

Abstract
:
1. Introduction
2. Related Work
2.1. Remote Sensing and Ontologies
2.2. Graph Databases and Applications
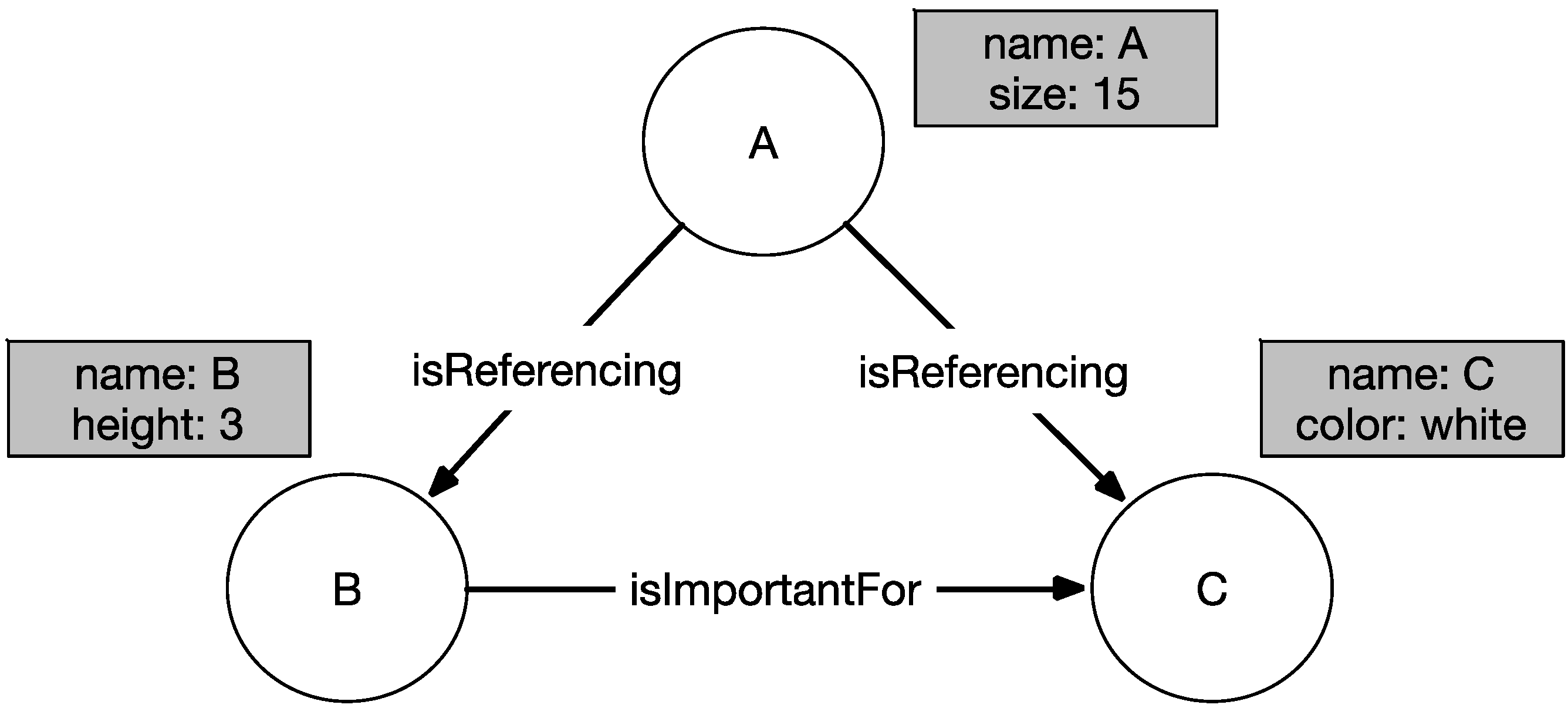
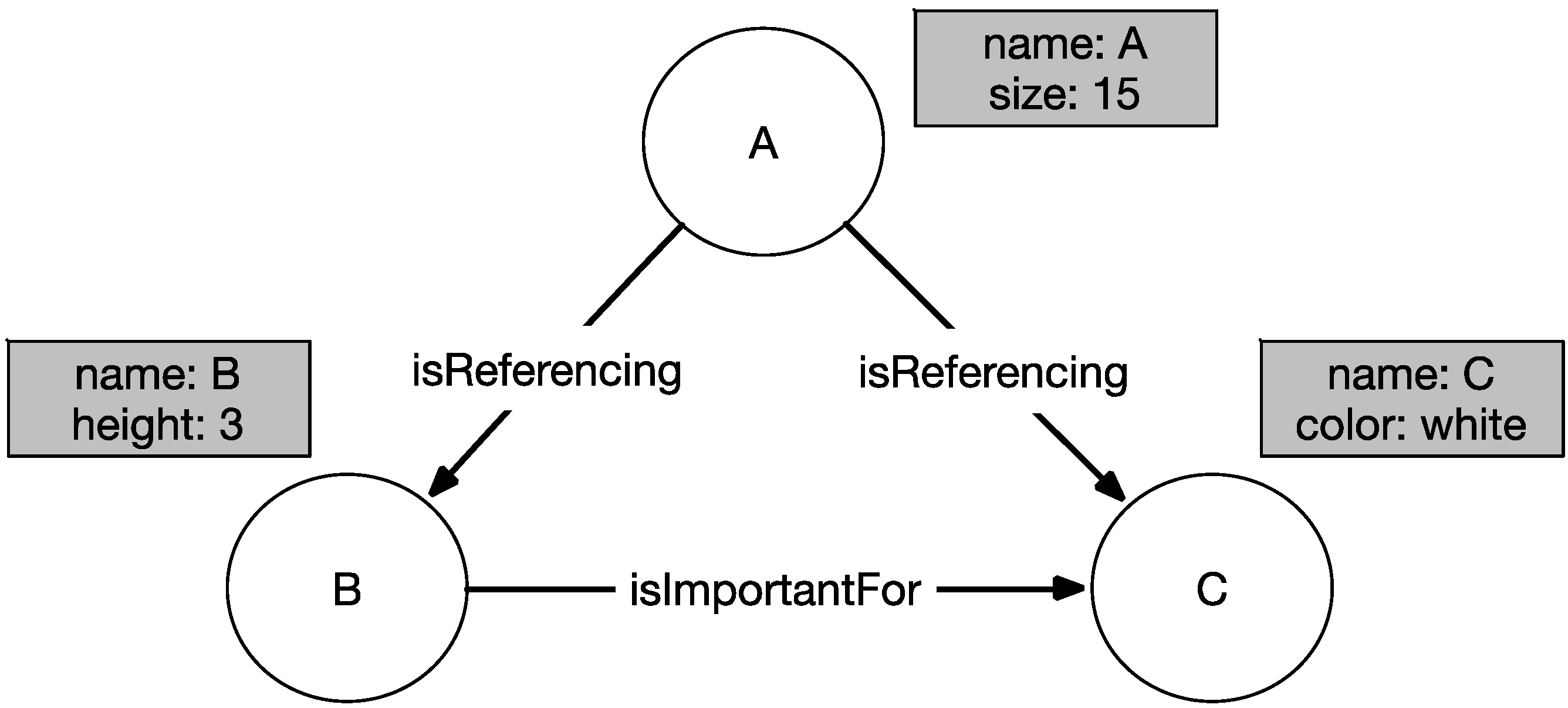
2.3. Advantages of Graph-Based Approaches for Classification Tasks
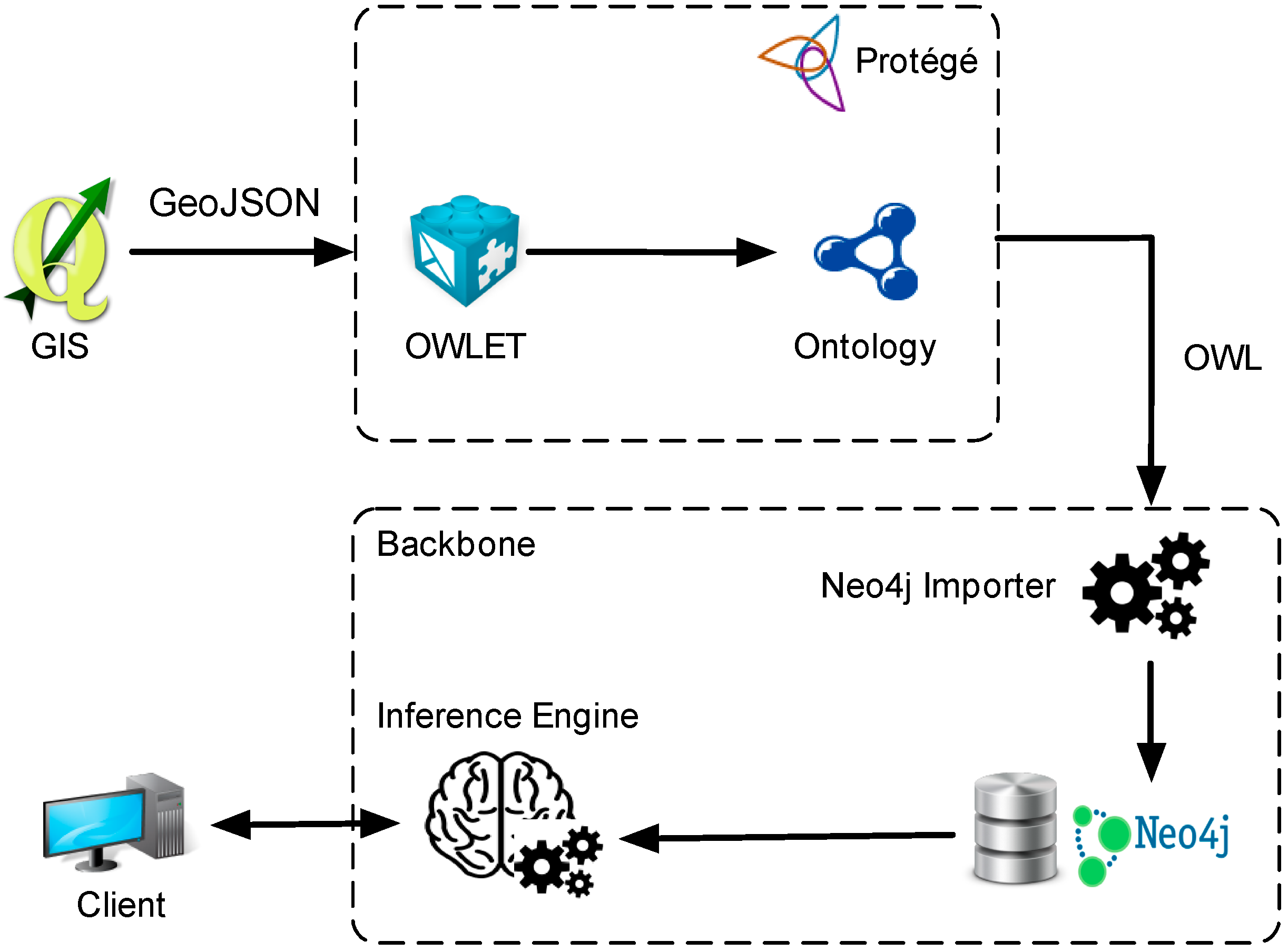
3. Data and Methods
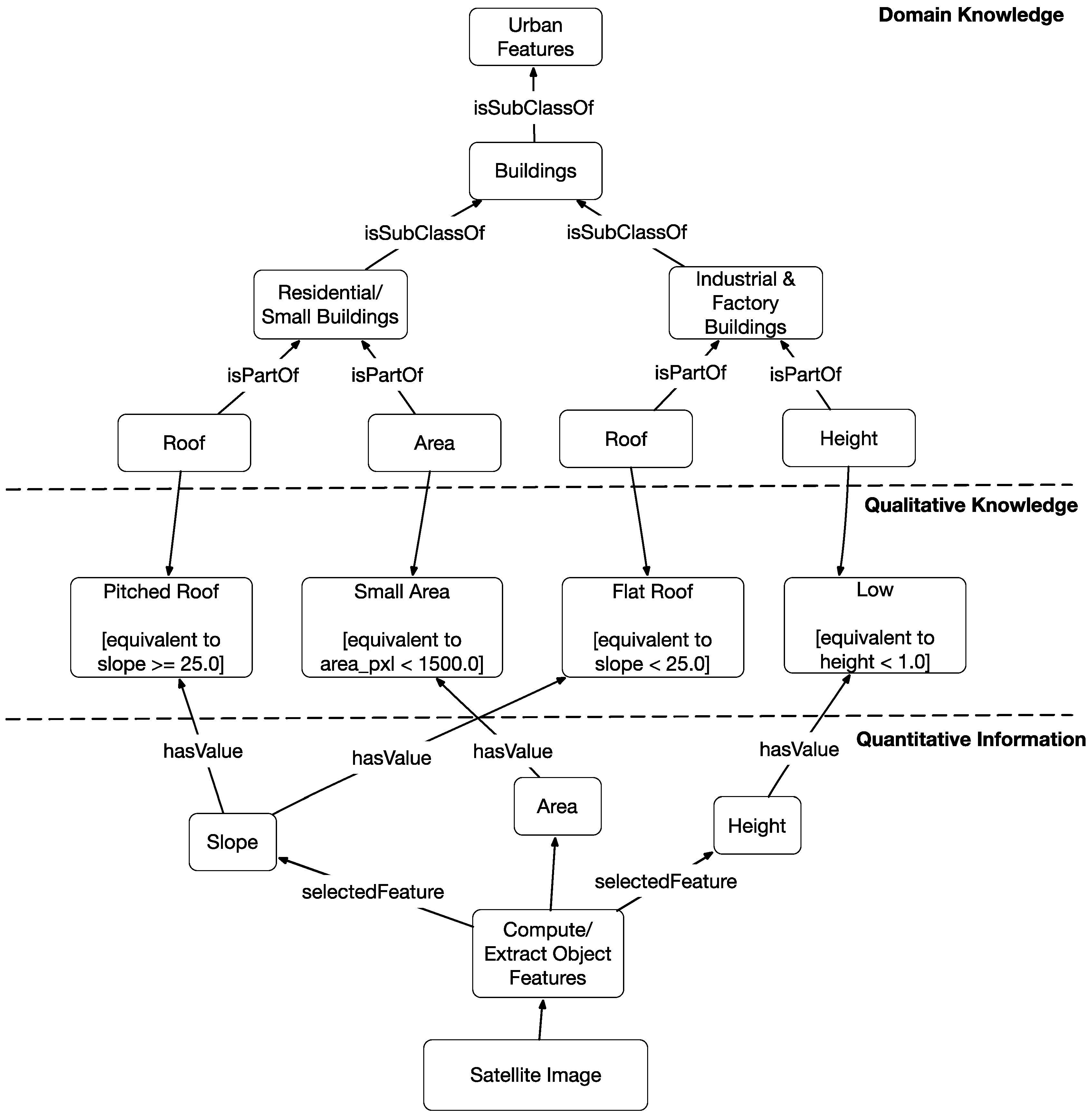
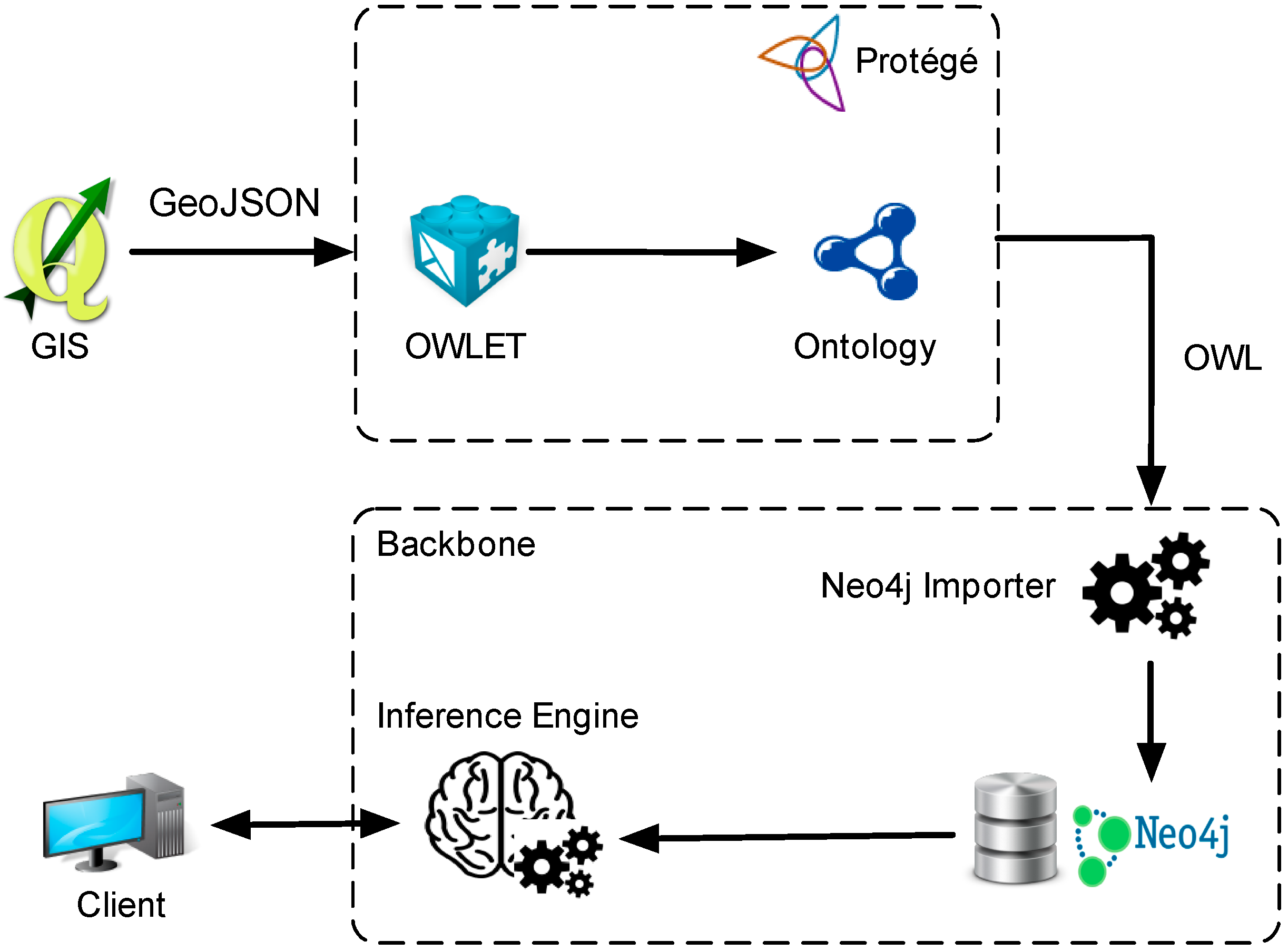
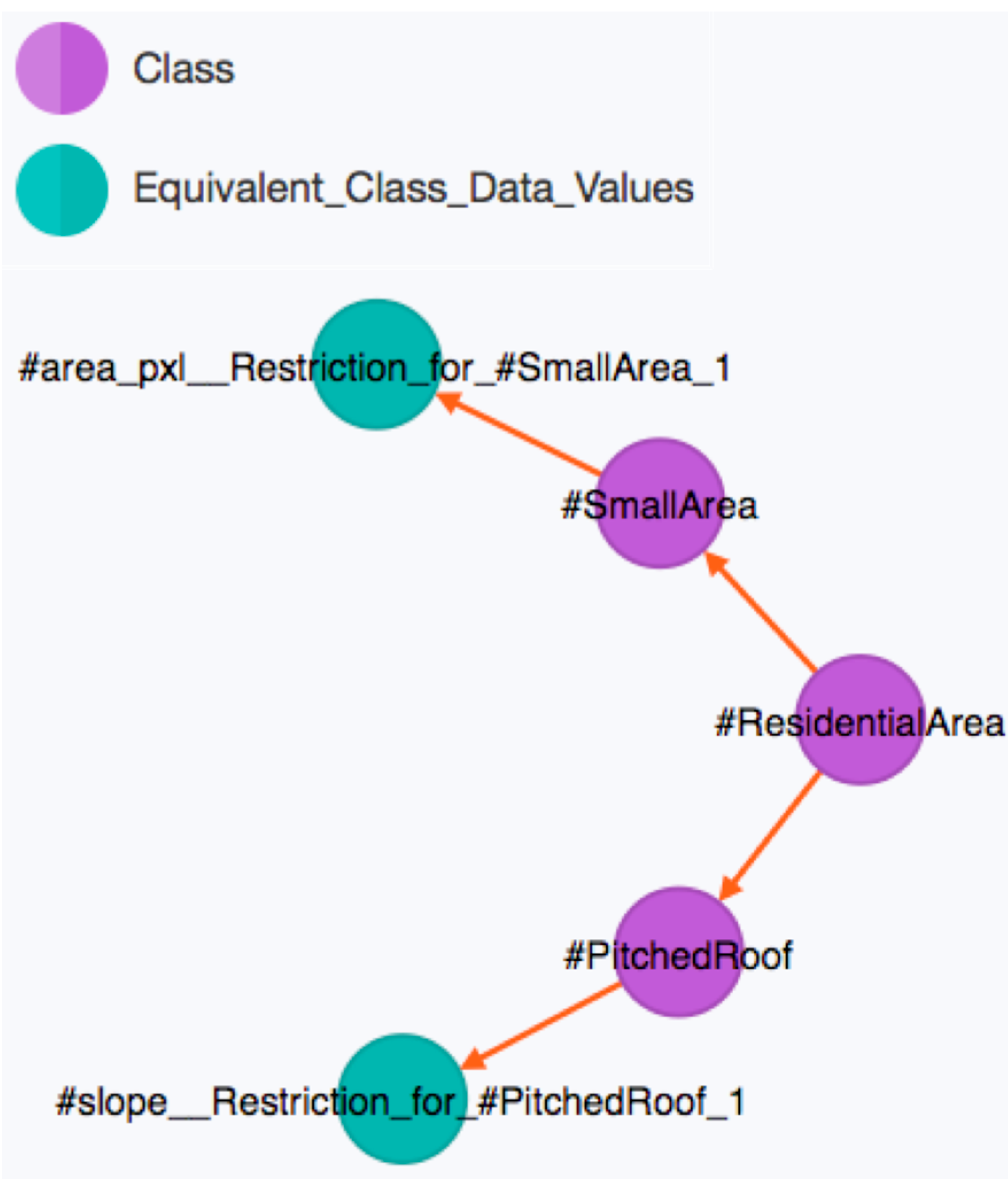
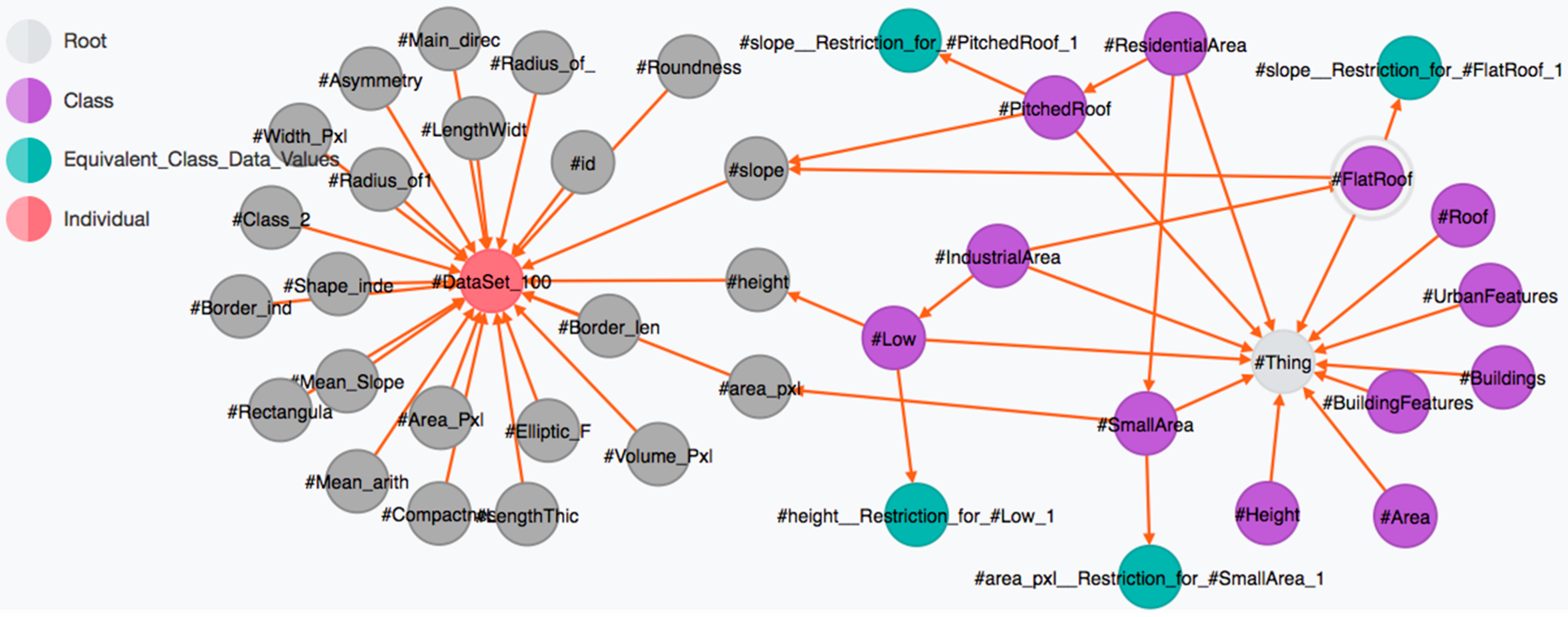
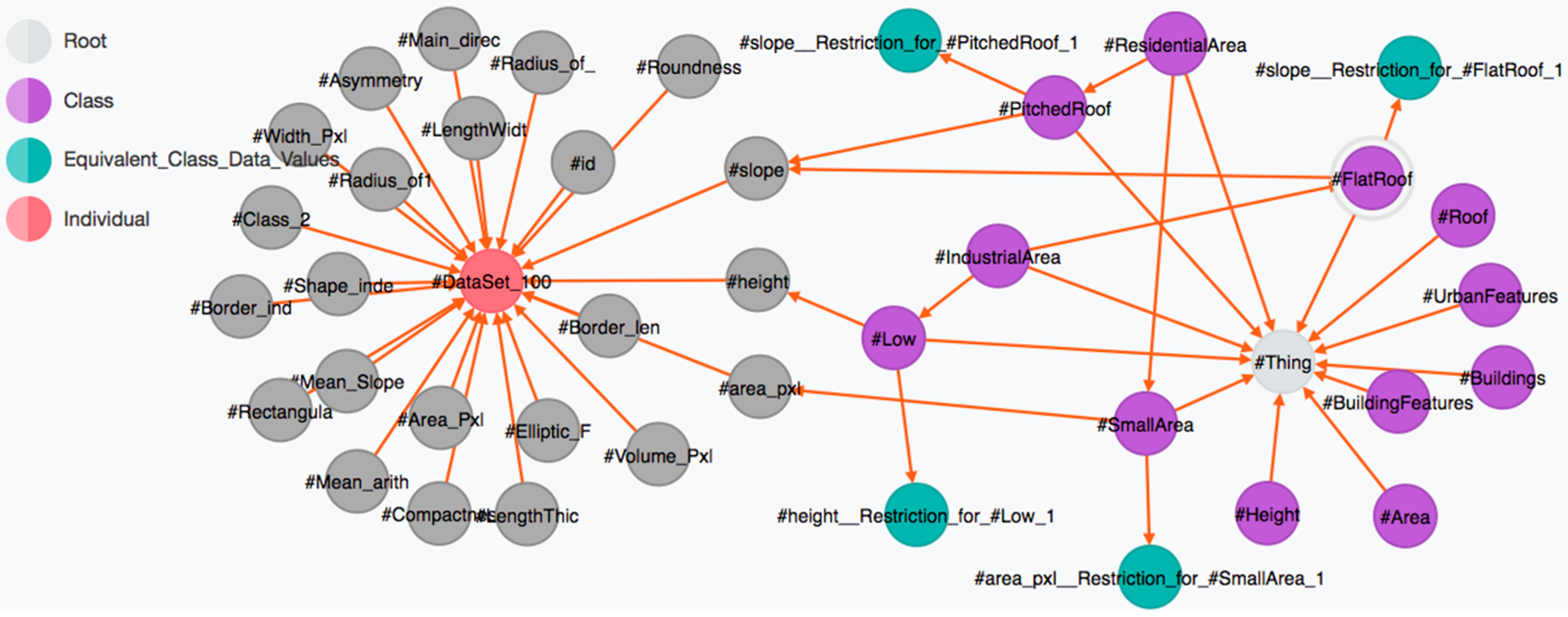
3.1. Remote Sensing Data and the Associated Ontology

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Sizes | Residential Buildings | Industrial Buildings | Other Buildings |
|---|---|---|---|
| 100 | 25 | 25 | 50 |
| 250 | 50 | 50 | 150 |
| 500 | 125 | 125 | 250 |
| 1000 | 250 | 250 | 500 |
| 2500 | 500 | 500 | 1500 |
| 5000 | 1250 | 1250 | 2500 |
| 10,000 | 2500 | 2500 | 5000 |
<EquivalentClasses>
<Class IRI="#PitchedRoof"/>
<DataSomeValuesFrom>
<DataProperty IRI="#slope"/>
<DatatypeRestriction>
<Datatype abbreviatedIRI="xsd:double"/>
<FacetRestriction facet="&xsd;minInclusive">
<Literal datatypeIRI="&xsd;double">25.0</Literal>
</FacetRestriction>
</DatatypeRestriction>
</DataSomeValuesFrom>
</EquivalentClasses>

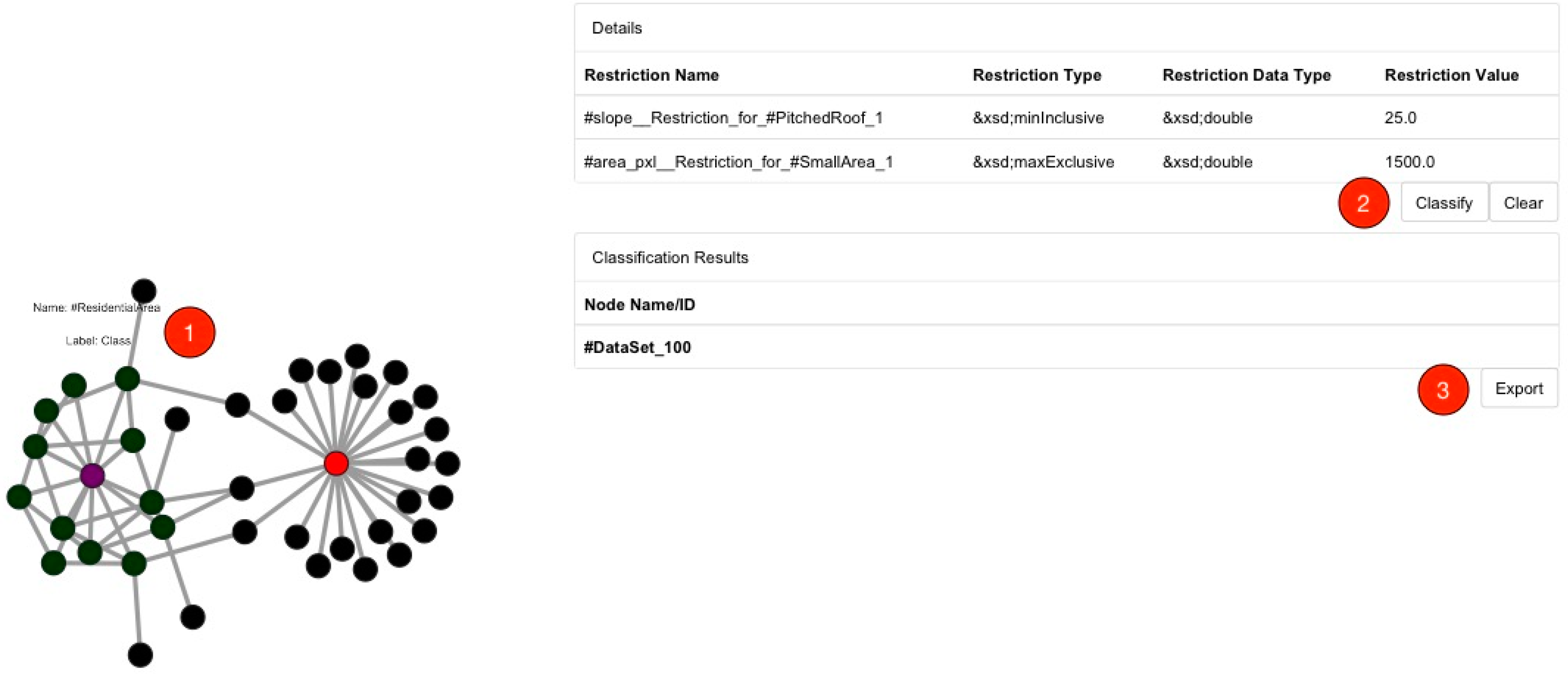
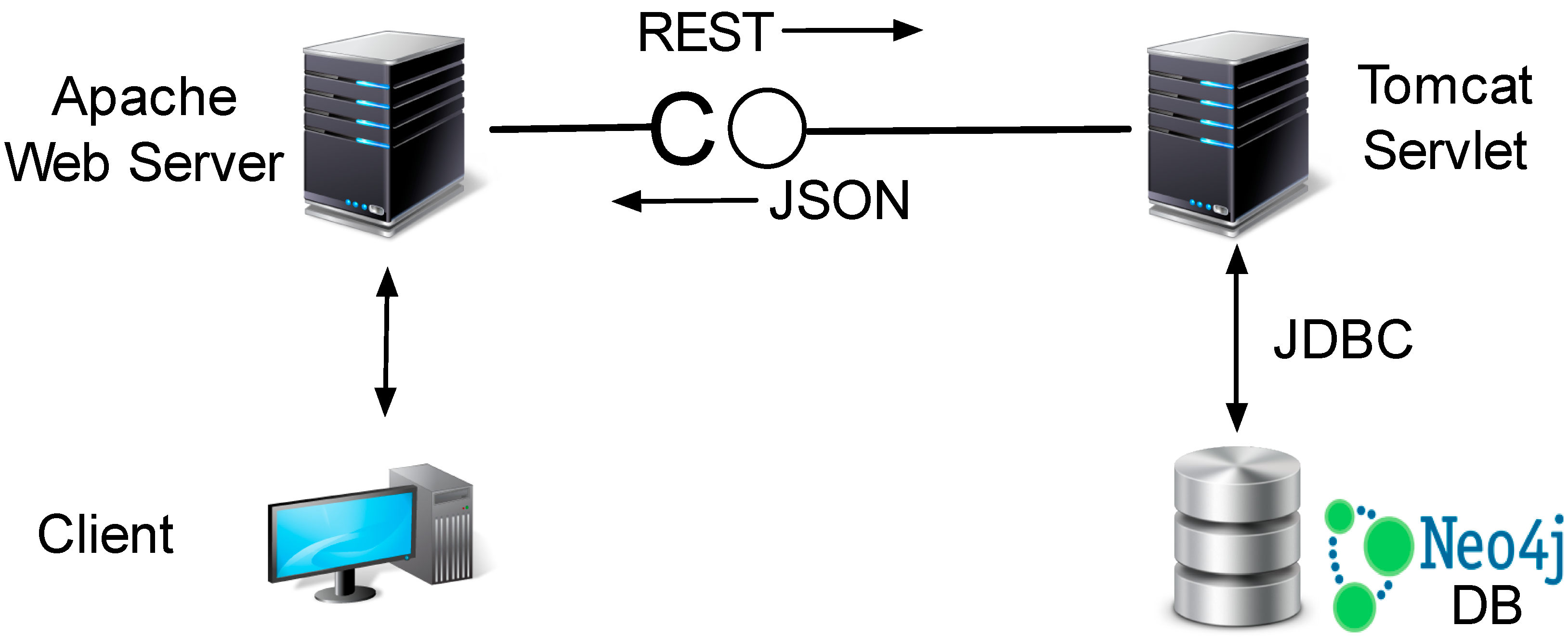
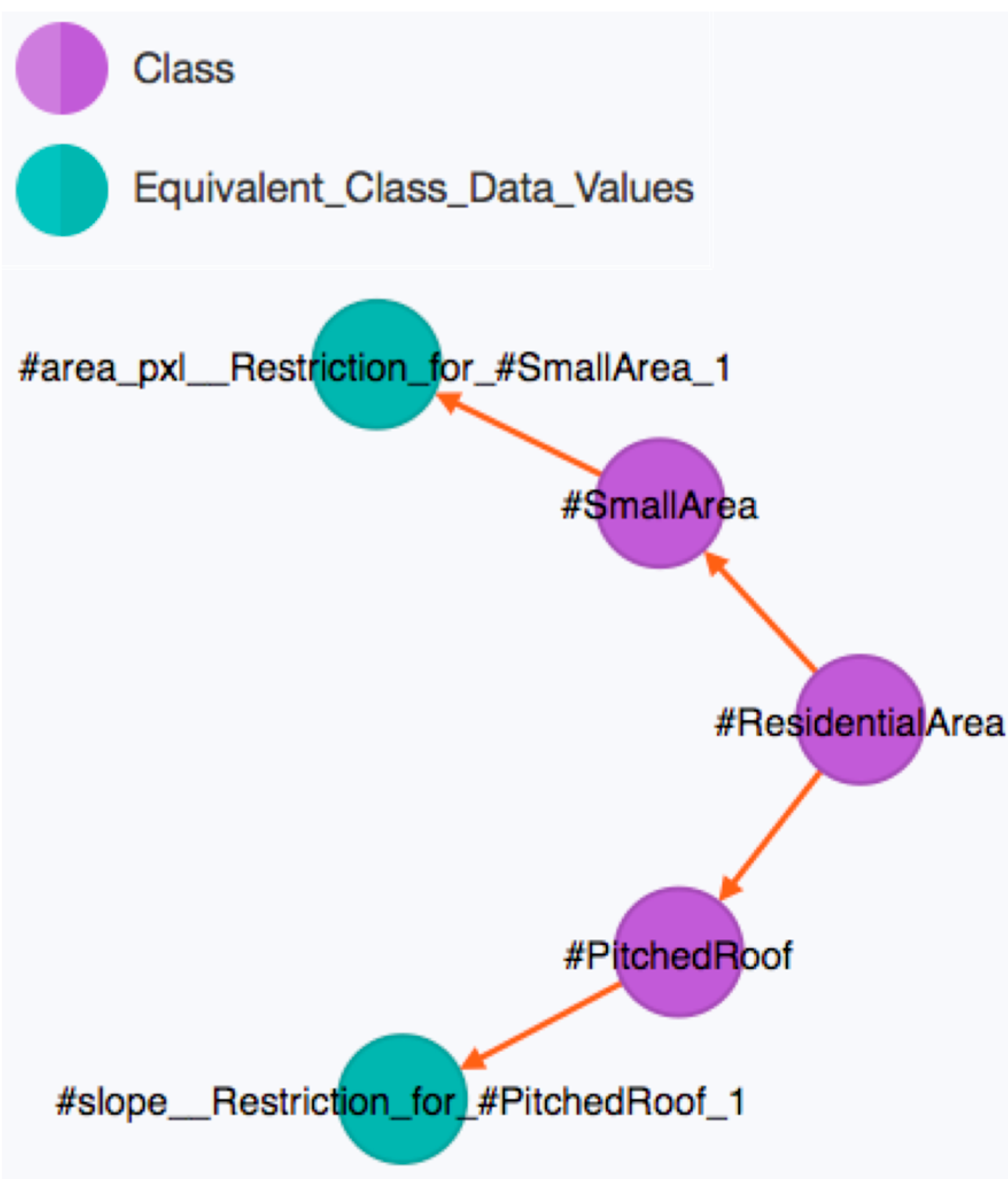
3.2. Neo4j-Based Classification Workflow
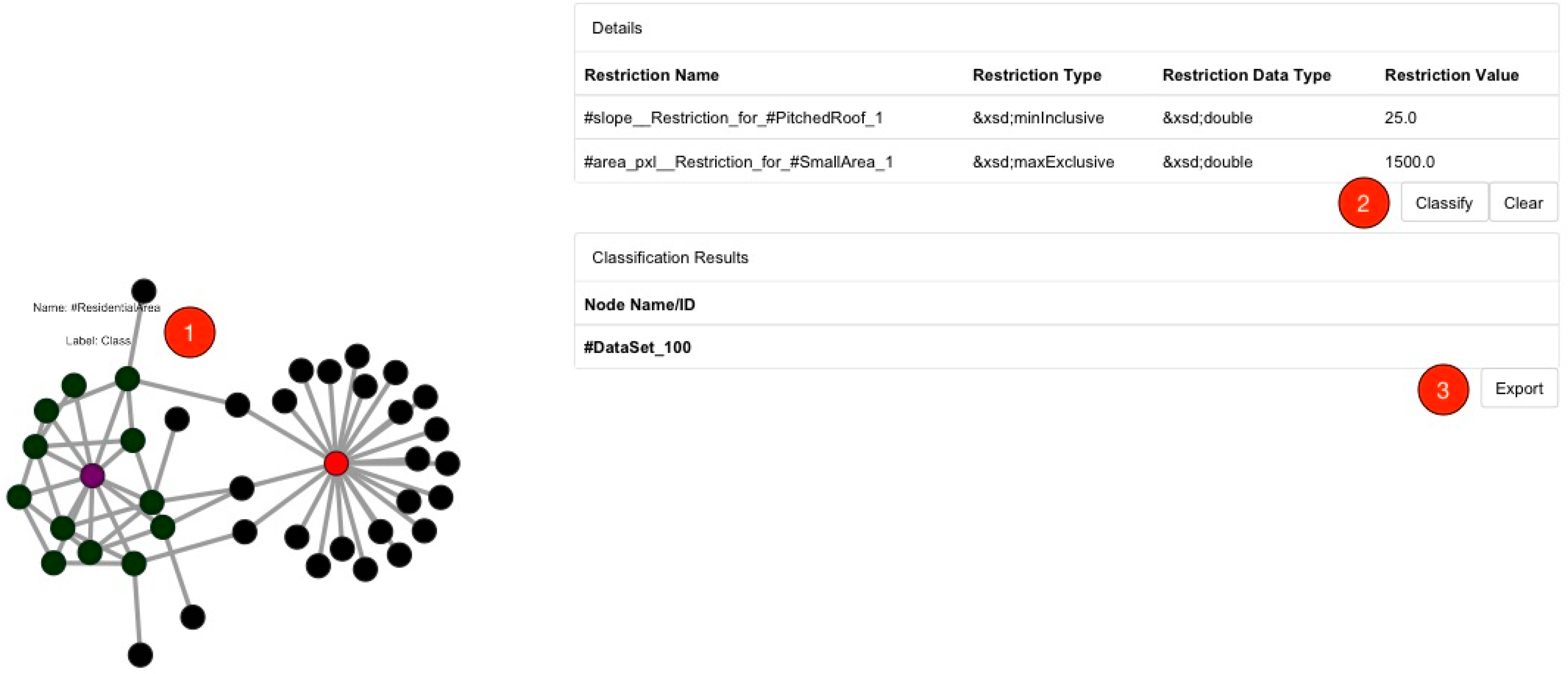
MATCH (startTable { name:'#ResidentialArea'}),(endTable:Equivalent_Class_Data_Values),
paths = (startTable)-[*..15]->(endTable)
return filter(x IN nodes(paths) WHERE x:Equivalent_Class_Data_Values)
MATCH (startTable { name:'#ResidentialArea' }),(endTable:Individual),
paths = (startTable)-[*..15]->(endTable)
return DISTINCT filter(x IN nodes(paths) WHERE x:Individual)
Procedure CLASSIFICATION
Input: Individuals, Restrictions
begin PROPERTY_CHECK
1: while (Individuals)
2: while (Individual_Properties)
3: if (Individual_Property MATCHES Restriction) then SET Classified
4: else SET Not_Classified and break
5: end if
6: end while
7: end while
end PROPERTY_CHECK
Output: Classified Individuals
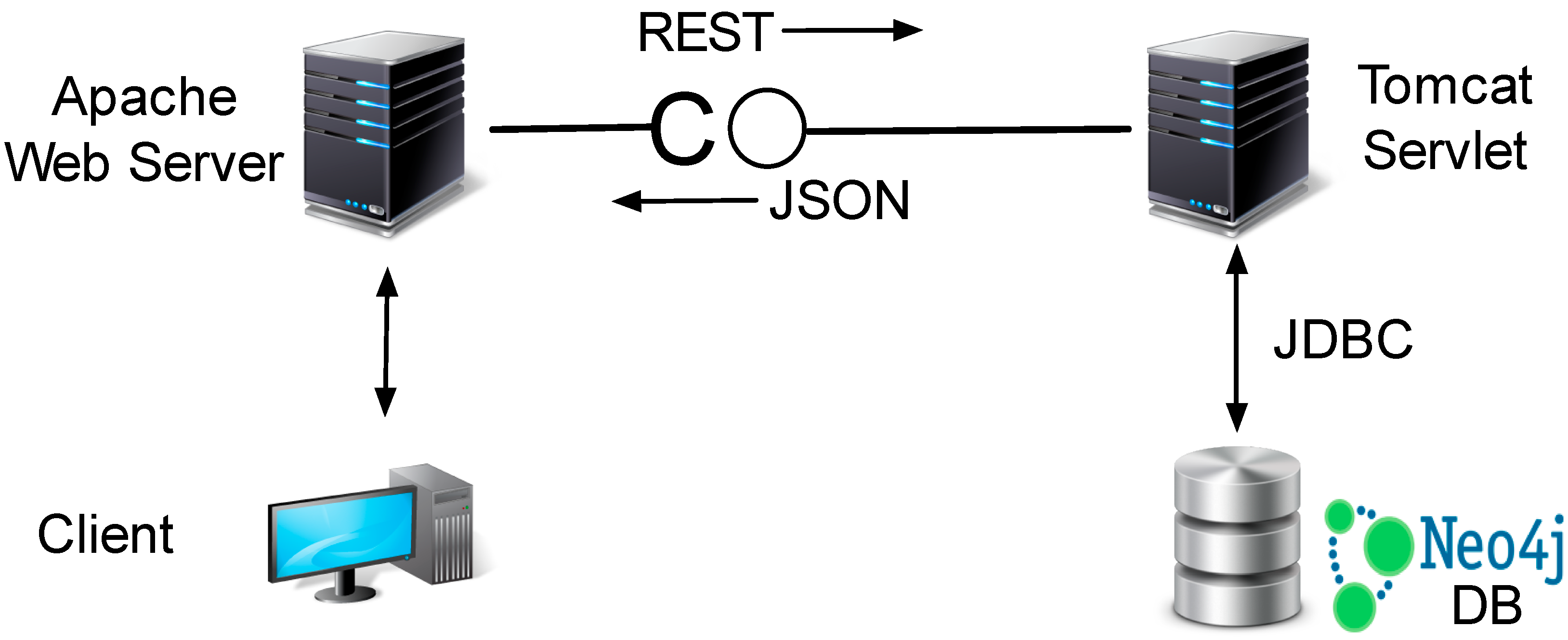
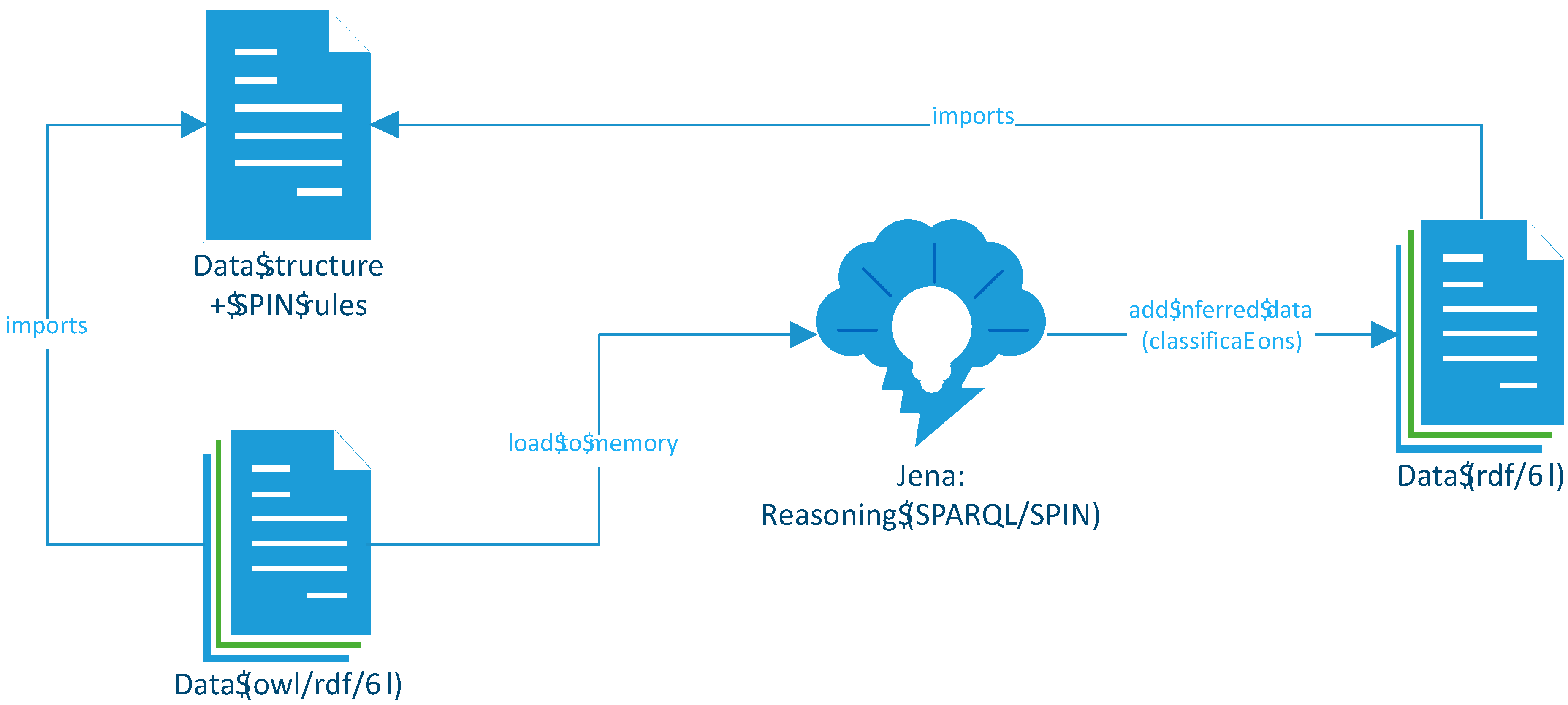
3.3. RDF/SPARQL-Based Approach
4. Benchmarking of Classification Performance
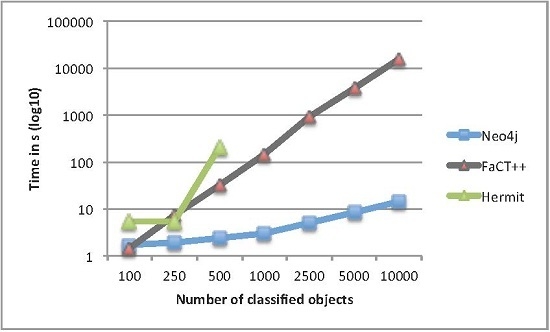
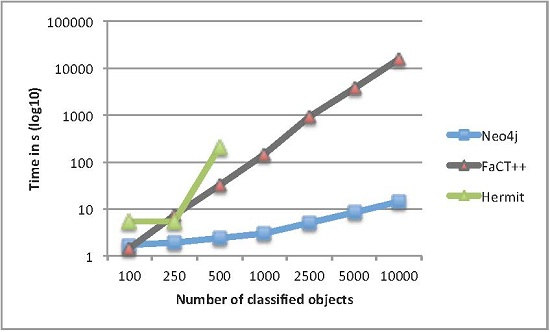
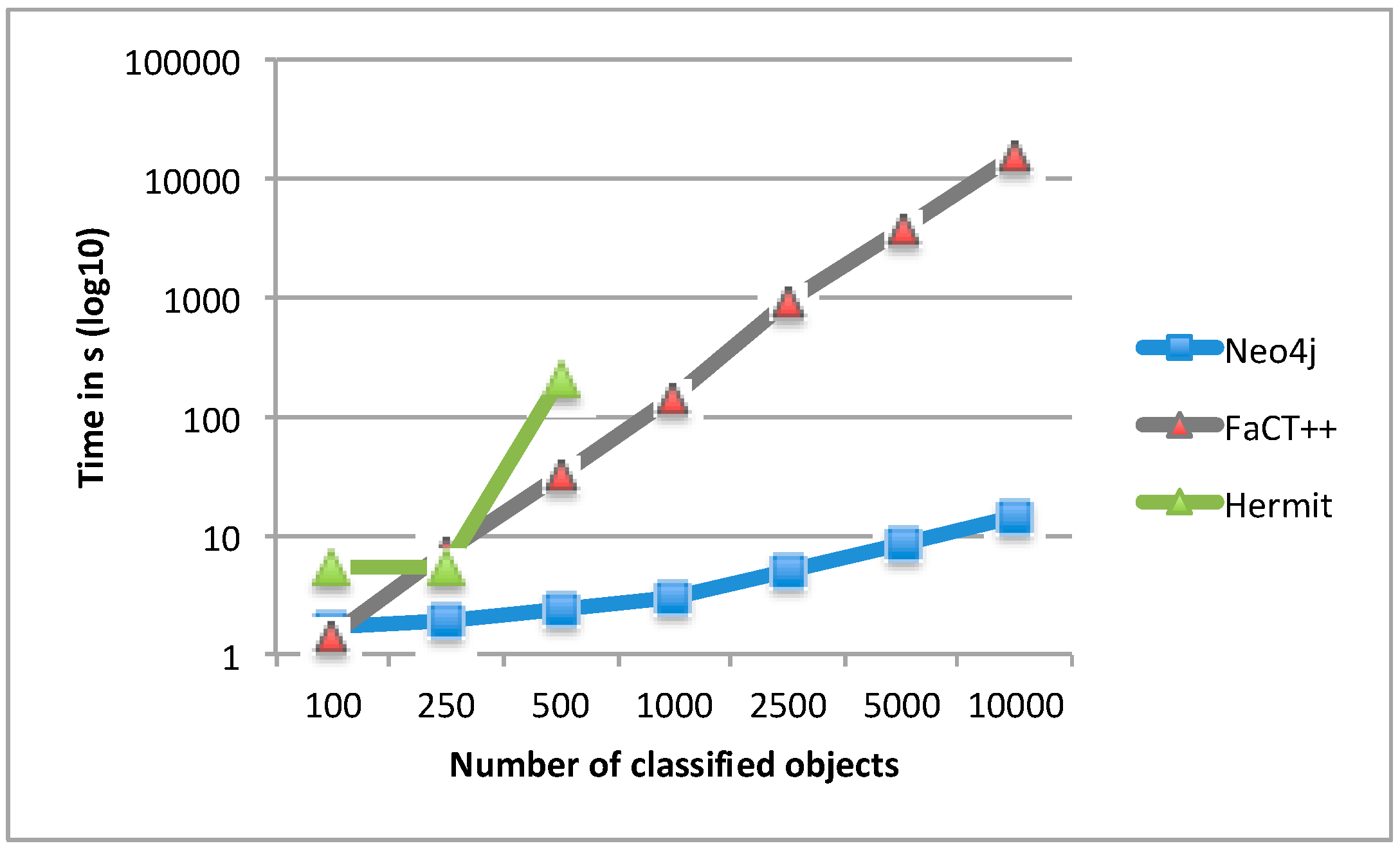
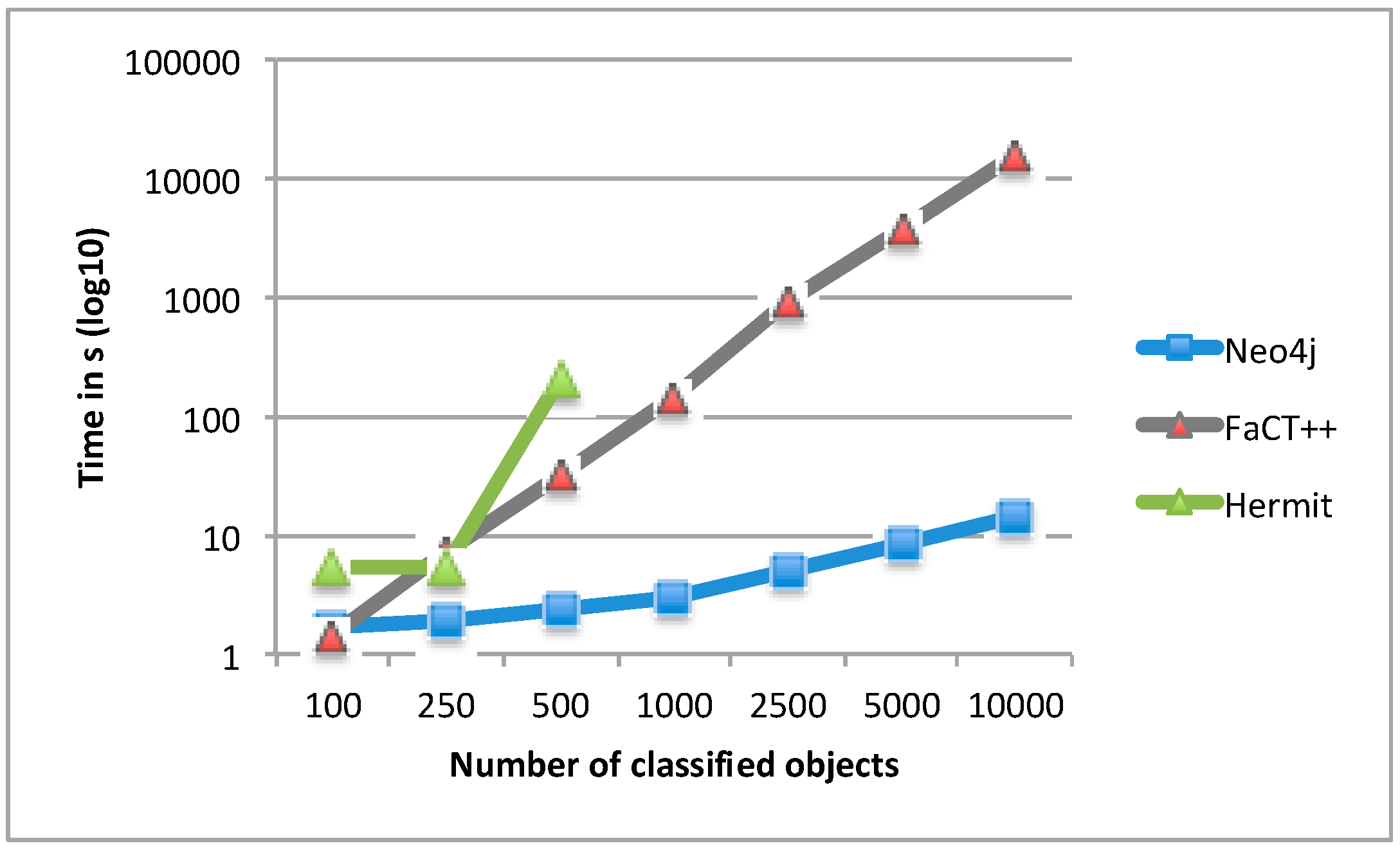
4.1. Classification Results for Protégé-Based Reasoners vs. the Neo4j-Based Approach
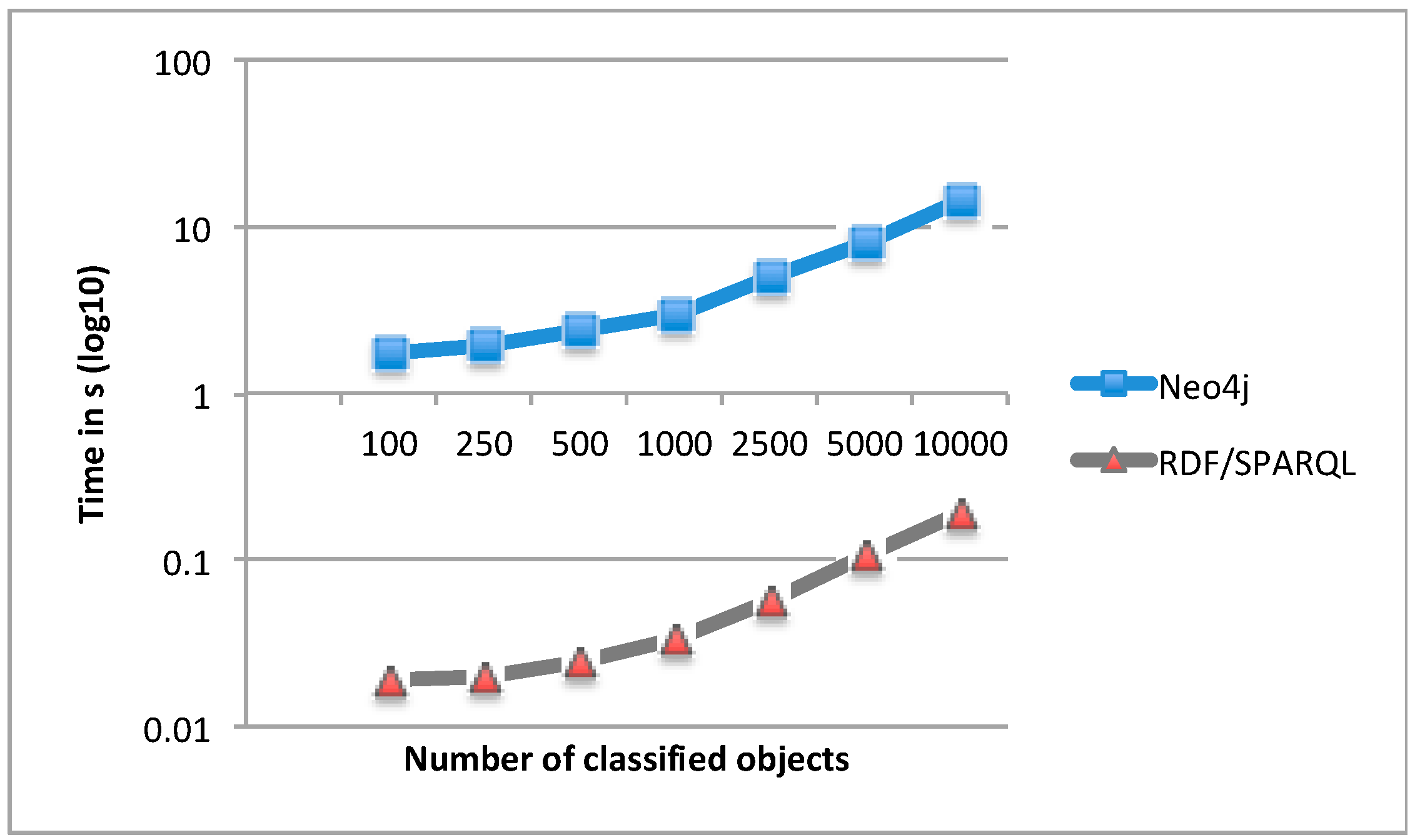
4.2. Classification Results for the Neo4j-Based Approach vs. the RDF/SPARQL-Based Approach
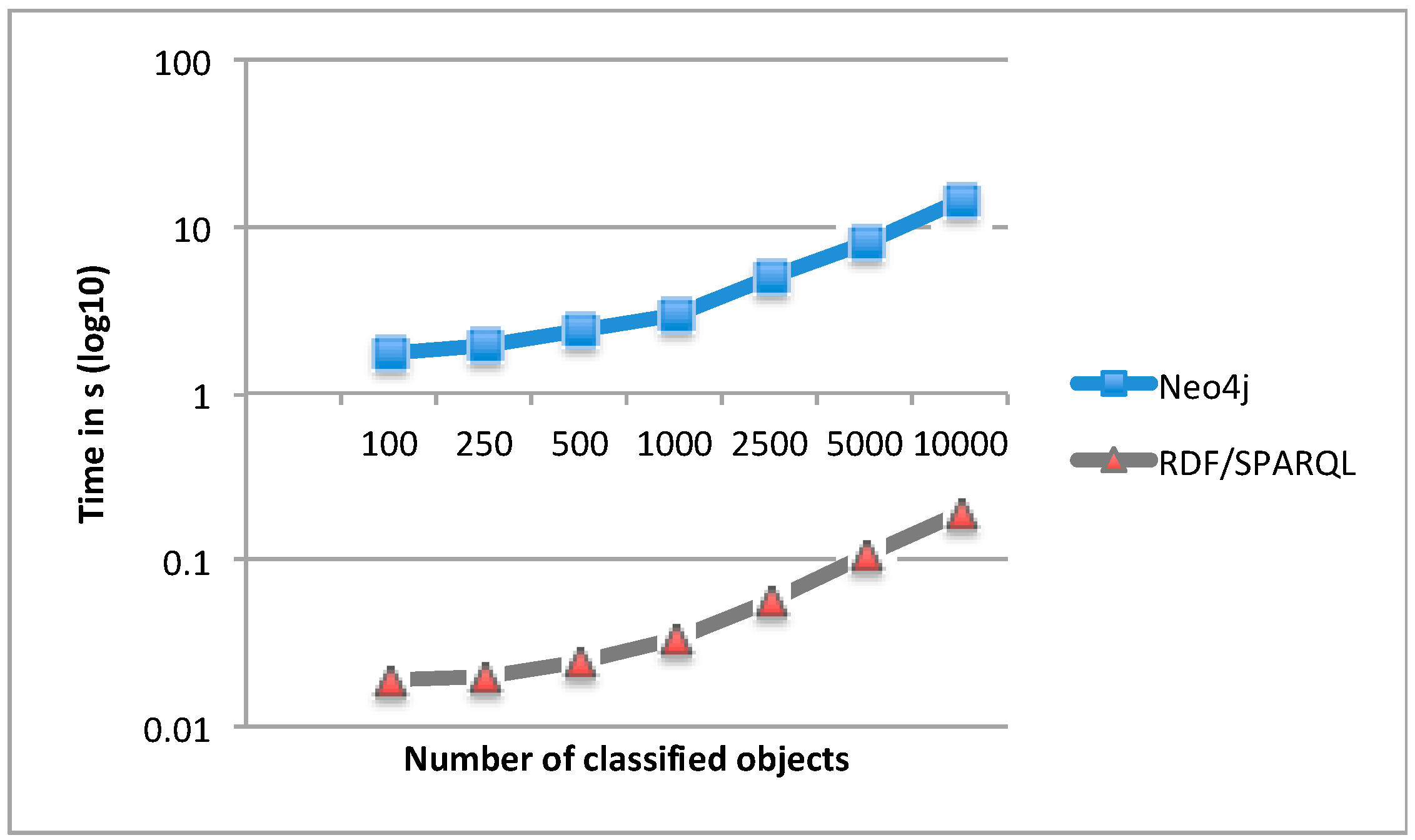
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Baader, F.; Horrocks, I.; Sattler, U. Description logics as ontology languages for the semantic web. In Mechanizing Mathematical Reasoning; Springer: Berlin, Germany, 2005; pp. 228–248. [Google Scholar]
- Bock, J.; Haase, P.; Ji, Q.; Volz, R. Benchmarking OWL Reasoners. Available online: http://ai.ia.agh.edu.pl/wiki/_media/pl:dydaktyka:miw:2010:dltls:prezentacja:testowanie_reasonerow.pdf (accessed on 31 March 2015).
- Li, Y.; Yu, Y.; Heflin, J. Evaluating Reasoners under Realistic Semantic Web Conditions. In Proceedings of the OWL Reasoner Evaluation Workshop (ORE 2012), Manchester, UK, 1 July 2012.
- Lampoltshammer, T.J.; Heistracher, T. Ontology evaluation with Protégé using OWLET. Infocommun. J. 2014, 6, 12–17. [Google Scholar]
- Weithöner, T.; Liebig, T.; Luther, M.; Böhm, S. What’s wrong with OWL benchmarks. In Proceedings of the Second International Workshop on Scalable Semantic Web Knowledge Base Systems (SSWS 2006), Athens, GA, USA, 5–6 November 2006; pp. 101–114.
- Horrocks, I.; Li, L.; Turi, D.; Bechhofer, S. The instance store: DL reasoning with large numbers of individuals. In Proceedings of the 2004 Description Logic Workshop (DL 2004), Whistler, BC, Canada, 6–8 June 2004; pp. 31–40.
- Angles, R.; Gutierrez, C. Survey of graph database models. ACM Comput. Surv. 2008, 40, 1–39. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G.; Wulder, M.A.; Ruiz, J.R. An automated object-based approach for the multiscale image segmentation of forest scenes. Int. J. Appl. Earth Obs. Geoinf. 2005, 7, 339–359. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. J. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Daconta, M.C.; Smith, K.T.; Oerst, L.J. The semantic web: A guide to the future of XML, web services, and knowledge management. Comput. Rev. 2004, 45, 778–779. [Google Scholar]
- Motik, B.; Grau, B.C.; Horrocks, I.; Wu, Z.; Fokoue, A.; Lutz, C. Owl 2 web ontology language: Profiles. W3C Recomm. 2009, 27, 61. [Google Scholar]
- Schmiedel, A. Semantic Indexing Based on Description Logics. Available online: http://ftp.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-1/schmiedel-long.pdf (accessed on 31 March 2015).
- De Giacomo, G.; Lenzerini, M. TBox and ABox Reasoning in Expressive Description Logics. Available online: http://www.aaai.org/Papers/Workshops/1996/WS-96-05/WS96-05-004.pdf (accessed on 31 March 2015).
- Durand, N.; Derivaux, S.; Forestier, G.; Wemmert, C.; Gançarski, P.; Boussaid, O.; Puissant, A. Ontology-based object recognition for remote sensing image interpretation. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; pp. 472–479.
- Belgiu, M.; Lampoltshammer, T.; Hofer, B. An extension of an ontology-based land cover designation approach for fuzzy rules. In GI_Forum 2013. Creating the GISociety; Car, A., Jekel, T., Strobl, J., Eds.; Austrian Academy of Sciences Press: Vienna, Austria, 2013; pp. 59–70. [Google Scholar]
- Belgiu, M.; Tomljenovic, I.; Lampoltshammer, T.J.; Blaschke, T.; Höfle, B. Ontology-based classification of building types detected from airborne laser scanning data. Remote Sens. 2014, 6, 1347–1366. [Google Scholar] [CrossRef]
- Hofmann, P.; Lettmayer, P.; Blaschke, T.; Belgiu, M.; Wegenkittl, S.; Graf, R.; Lampoltshammer, T.J.; Andrejchenko, V. ABIA—A conceptional framework for agent based image analysis. South East. Eur. J. Earth Obs. Geomat. 2014, 3, 125–130. [Google Scholar]
- Hofmann, P.; Lettmayer, P.; Blaschke, T.; Belgiu, M.; Wegenkittl, S.; Graf, R.; Lampoltshammer, T.J.; Andrejchenko, V. Towards a framework for agent-based image analysis of remote-sensing data. Int. J. Image Data Fusion 2015, 6, 115–137. [Google Scholar] [CrossRef]
- Goldberg, A.V.; Harrelson, C. Computing the shortest path: A search meets graph theory. In Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Philadelphia, PA, USA, 23–25 January 2005; pp. 156–165.
- Manola, F.; Miller, E.; McBride, B. RDF Primer. Available online: http://www.w3.org/TR/rdf-primer (accessed on 31 March 2015).
- Prud’Hommeaux, E.; Seaborne, A. SPARQL Query Language for RDF. Available online: http://www.w3.org/TR/rdf-sparql-query/ (accessed on 31 March 2015).
- Pérez, J.; Arenas, M.; Gutierrez, C. Semantics and complexity of SPARQL. In Proceedings of the International Semantic Web Conference, Athens, GA, USA, 5–9 November 2006; pp. 30–43.
- Neo4j the World’s Leading Graph Database. Available online: http://neo4j.com/ (accessed on 31 March 2015).
- Ontotext GraphDB—An Enterprise Triplestore with Meaning. Available online: http://www.ontotext.com/products/ontotext-graphdb/ (accessed on 31 March 2015).
- Sesame Java Framework for Processing and Handling RDF Data. Available online: http://rdf4j.org (accessed on 31 March 2015).
- Orient Technologies 2nd Generation Distributed Graph Database. Available online: http://www.orientechnologies.com/orientdb/ (accessed on 31 March 2015).
- Franz Inc. AlegroGraph. Available online: http://franz.com/agraph/allegrograph/ (accessed on 31 March 2015).
- Deville, Y.; Gilbert, D.; van Helden, J.; Wodak, S.J. An overview of data models for the analysis of biochemical pathways. Brief. Bioinform. 2003, 4, 246–259. [Google Scholar] [CrossRef] [PubMed]
- Olken, F. Tutorial on graph data management for biology. [Tutorial Hand-out]. Available online: https://www.researchgate.net/profile/Frank_Olken2/publication/242497760_Graph_Data_Management_For_Biology/links/02e7e52a21e337ad52000000.pdf (accessed on 21 July 2015).
- Brandes, U.; Erlebach, T. Network Analysis: Methodological Foundations; Springer Science & Business Media: Medford, MA, USA, 2005. [Google Scholar]
- Miller, J.J. Graph database applications and concepts with Neo4j. In Proceedings of the Southern Association for Information Systems Conference, Atlanta, GA, USA, 23–24 March 2013.
- Lampoltshammer, T.J.; Sageder, C.; Heistracher, T. The openlaws platform—An open architecture for big open legal data. In Proceedings of the 18th International Legal Informatics Symposium IRIS 2015, Salzburg, Austria, 26–28 February 2015.
- Karamizadeh, S.; Abdullah, S.M; Zamani, M.; Kherikhah, A. Pattern recognition techniques: studies on appropriate classifications. In Advanced Computer and Communication Engineering Technology; Springer International Publishing: Cham, Switzerland, 2015; Volume 315, pp. 791–799. [Google Scholar]
- QGIS A Free and Open Source Geographic Information System. Available online: http://www2.qgis.org/en/site/ (accessed on 31 March 2015).
- Weidner, U. Contribution to the assessment of segmentation quality for remote sensing applications. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 479–484. [Google Scholar]
- Fielding, R. T. Architectural Styles and the Design of Network-based Software Architectures. Ph.D. Thesis, University of California, Irvine, CA, USA, 2000. [Google Scholar]
- Battle, R.; Benson, E. Bridging the semantic Web and Web 2.0 with representational state transfer (REST). J. Web Semant. Sci. Serv. Agents World Wide Web 2008, 6, 61–69. [Google Scholar] [CrossRef]
- Jordan, G. Practical Neo4j; Apress: New York, NY, USA, 2014. [Google Scholar]
- Xu, X.; Zhang, L.; Wong, T.-T. Structure-based ASCII art. ACM Trans. Graph. 2010, 29. [Google Scholar] [CrossRef]
- Korf, R.E. Depth-first iterative-deepening: An optimal admissible tree search. Artif. Intell. 1985, 27, 97–109. [Google Scholar] [CrossRef]
- Foundation, A. Apache Jena. Available online: http://jena.apache.Org (accessed on 20 March 2014).
- Haarslev, V.; Möller, R. Racer: An OWL Reasoning Agent for the Semantic Web. Available online: http://www1.racer-systems.com/technology/contributions/2003/HaMo03d.pdf (accessed on 31 March 2015).
- Metke-Jimenez, A.; Lawley, M. Snorocket 2.0: Concrete Domains and Concurrent Classification. Available online: http://ceur-ws.org/Vol-1015/paper_3.pdf (accessed on 31 March 2015).
- Kazakov, Y.; Krötzsch, M.; Simančík, F. The incredible ELK. J. Autom. Reason. 2014, 53, 1–61. [Google Scholar] [CrossRef]
- Pan, J.Z.; Ren, Y.; Jekjantuk, N.; Garcia, J. Reasoning the FMA Ontologies with TrOWL. Available online: http://ceur-ws.org/Vol-1015/paper_18.pdf (accessed on 31 March 2015).
- Sirin, E.; Parsia, B.; Grau, B.C.; Kalyanpur, A.; Katz, Y. Pellet: A practical owl-dl reasoner. Web Semant. Sci. Serv. Agents World Wide Web 2007, 5, 51–53. [Google Scholar] [CrossRef]
- Tsarkov, D.; Horrocks, I. FaCT++ description logic reasoner: system description. In Automated Reasoning; Furbach, U., Shankar, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4130, pp. 292–297. [Google Scholar]
- Glimm, B.; Horrocks, I.; Motik, B.; Stoilos, G.; Wang, Z. HermiT: An OWL 2 reasoner. J. Autom. Reason. 2014, 53, 245–269. [Google Scholar] [CrossRef]
- Borgida, A.; Brachman, R.J. Loading data into description reasoners. ACM SIGMOD Rec. 1993, 22, 217–226. [Google Scholar] [CrossRef]
- Jonassen, D.H. Objectivism versus constructivism: Do we need a new philosophical paradigm? Educ. Technol. Res. Dev. 1991, 39, 5–14. [Google Scholar] [CrossRef]
- Kuhn, W. Semantic engineering. In Research Trends in Geographic Information Science; Springer: Berlin, Germany, 2009; pp. 63–76. [Google Scholar]
- Rossmann, J.; Schluse, R.; Waspe, R.; Moshammer, R. Simulation in the woods: From remote sensing based data acquisition and processing to various simulation applications. In Proceedings of the 2011 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 11–14 December 2011; pp. 984–996.
- Hullo, J.F.; Thibault, G.; Boucheny, C. Advances in multi-sensor scanning and visualization of complex plants: The utmost case of a reactor building. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 163–169. [Google Scholar] [CrossRef]
- Maciel, M.; Silva, M.; Escada, M. Mining frequent substructures from deforestation objects. IGARSS 2012. [Google Scholar] [CrossRef]
- Cai, Z.; Zhong, S.; Jiang, W.; Lei, M. A schema of ecological environment sensitivity evaluation based on GIS. In Proceedings of the 2011 International Conference on Multimedia Technology (ICMT), Hangzhou, China, 26–28 July 2011; pp. 6745–6748.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lampoltshammer, T.J.; Wiegand, S. Improving the Computational Performance of Ontology-Based Classification Using Graph Databases. Remote Sens. 2015, 7, 9473-9491. https://doi.org/10.3390/rs70709473
Lampoltshammer TJ, Wiegand S. Improving the Computational Performance of Ontology-Based Classification Using Graph Databases. Remote Sensing. 2015; 7(7):9473-9491. https://doi.org/10.3390/rs70709473
Chicago/Turabian StyleLampoltshammer, Thomas J., and Stefanie Wiegand. 2015. "Improving the Computational Performance of Ontology-Based Classification Using Graph Databases" Remote Sensing 7, no. 7: 9473-9491. https://doi.org/10.3390/rs70709473
APA StyleLampoltshammer, T. J., & Wiegand, S. (2015). Improving the Computational Performance of Ontology-Based Classification Using Graph Databases. Remote Sensing, 7(7), 9473-9491. https://doi.org/10.3390/rs70709473