
Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing

Abstract
:
1. Introduction
- A detailed assessment between parcel-based smoothing with known parcel boundaries and data-driven CRF smoothing; as far as we know, such an evaluation is missing in the literature.
- The first systematic study that assesses the effects of CRF smoothing, and of different smoothness functions, for high-resolution crop classification.
2. Method
2.1. Smooth Labeling with Conditional Random Fields (CRFs)
2.2. Unary Terms
2.2.1. Support Vector Machines (SVMs)
2.2.2. Random Forests (RFs)
2.2.3. Maximum Likelihood Classification (MLC)
2.2.4. Gaussian Mixture Models (GMMs)
2.3. Pair Wise Terms
2.4. Parcel-Based Smoothing
3. Dataset

4. Experiments
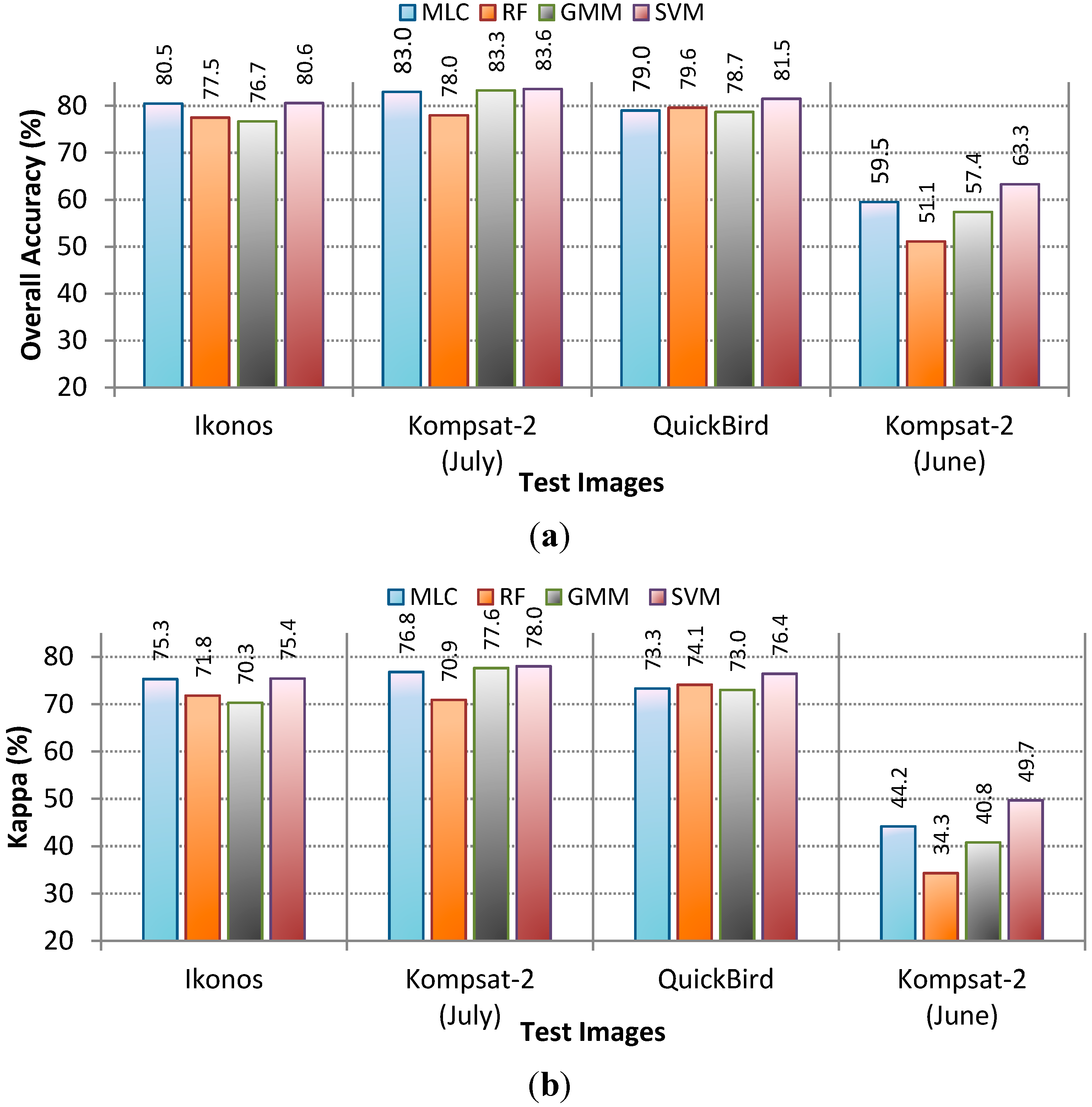
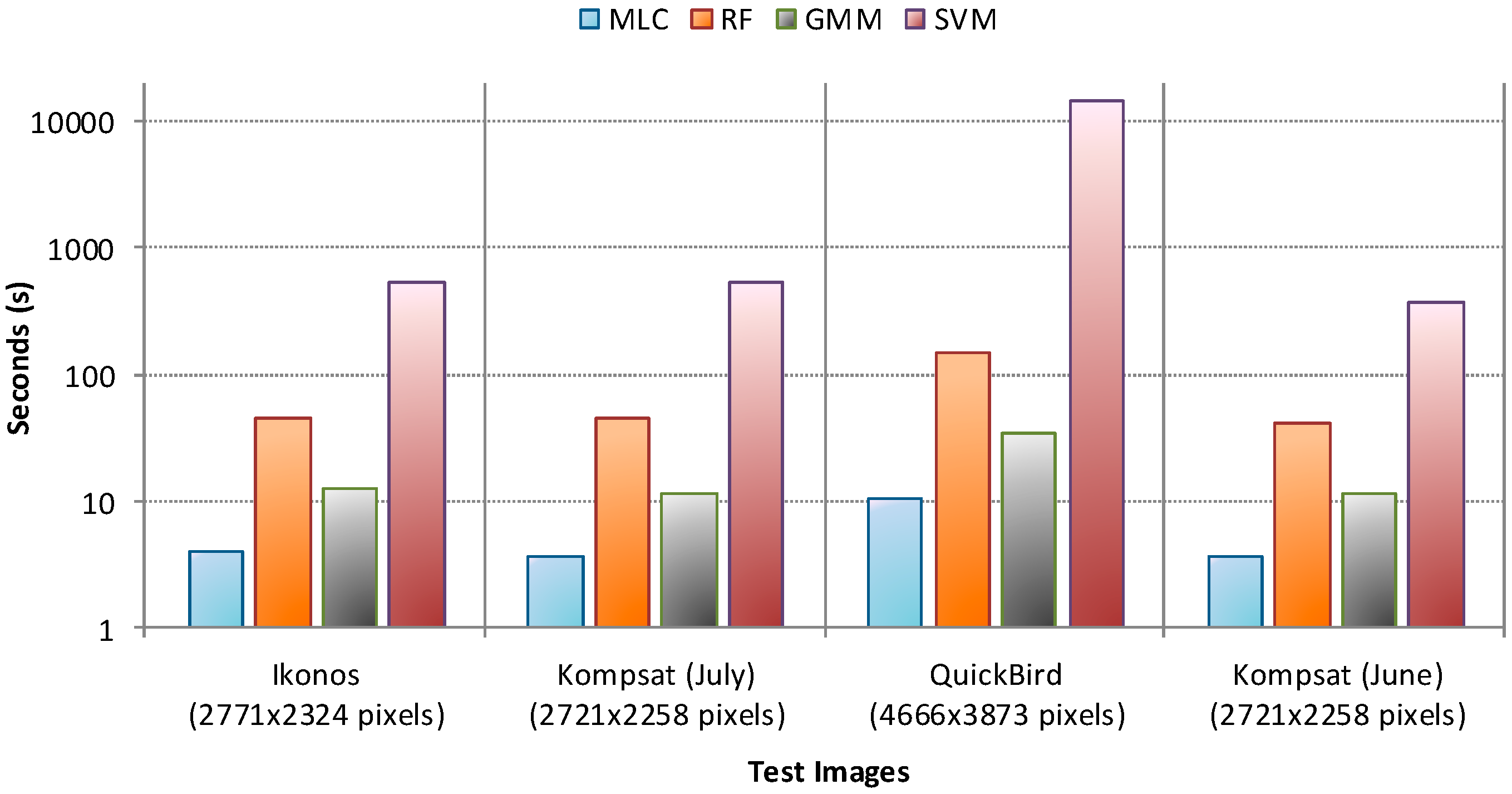
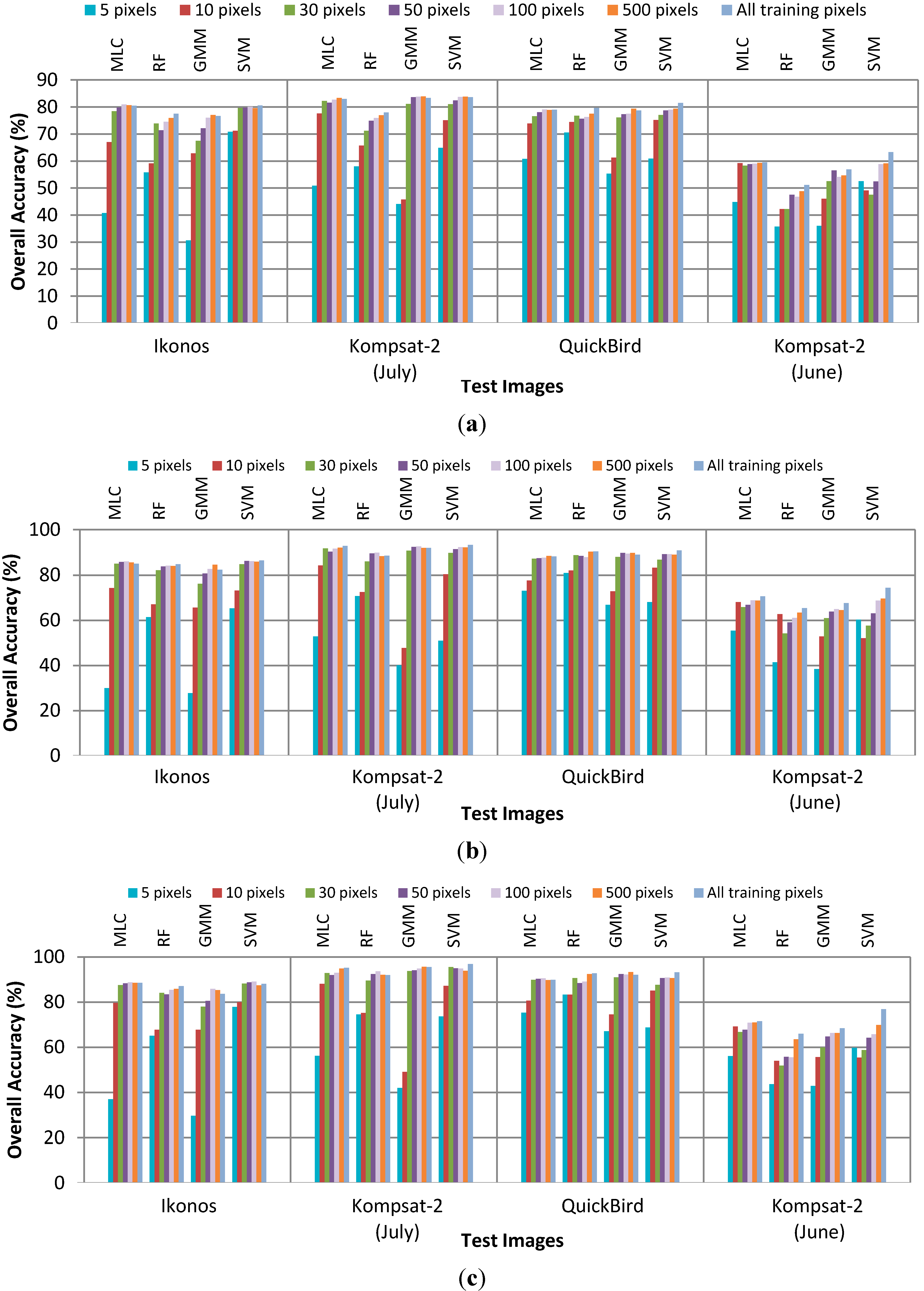
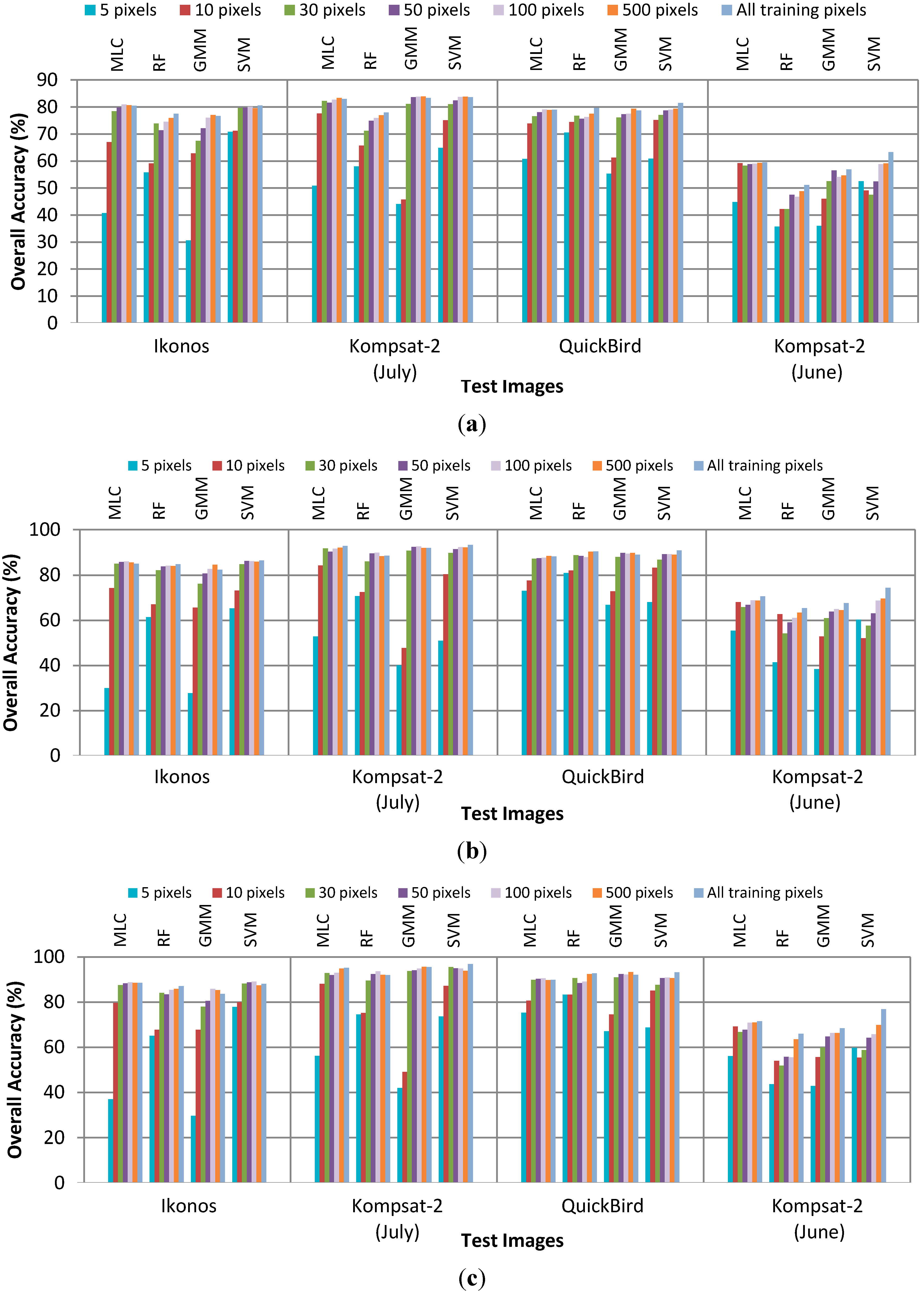
4.1. Performance without Smoothing

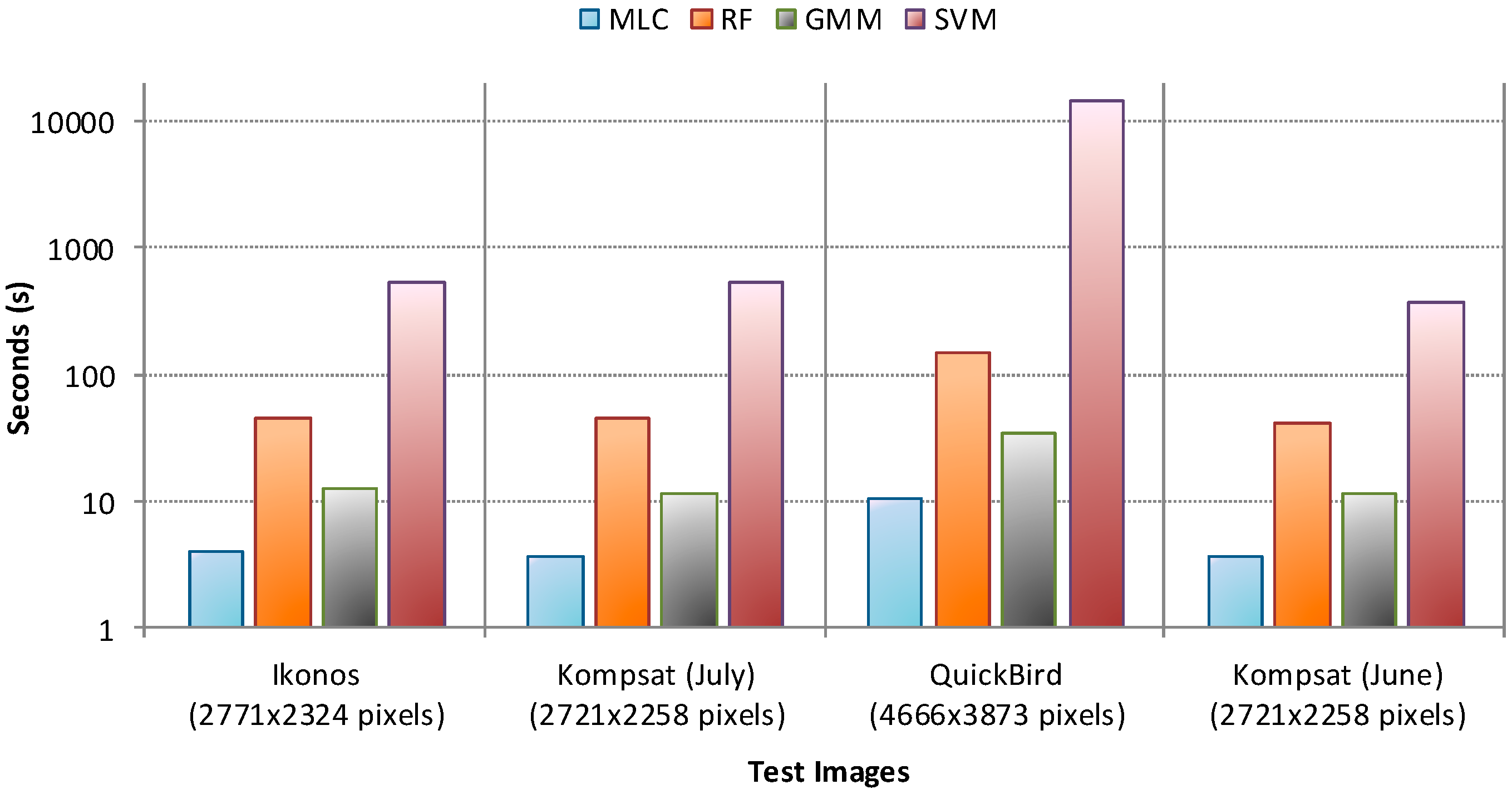
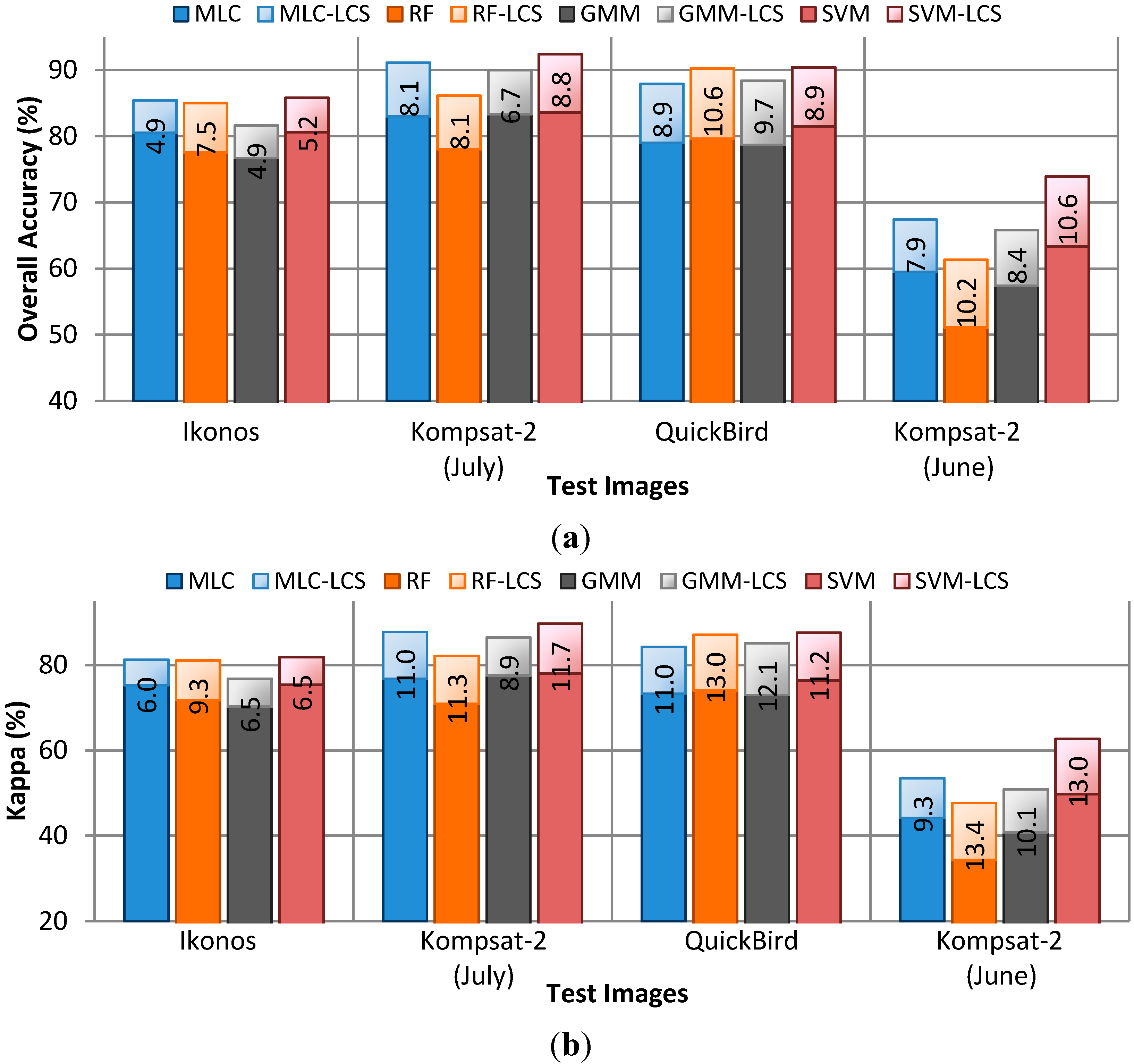
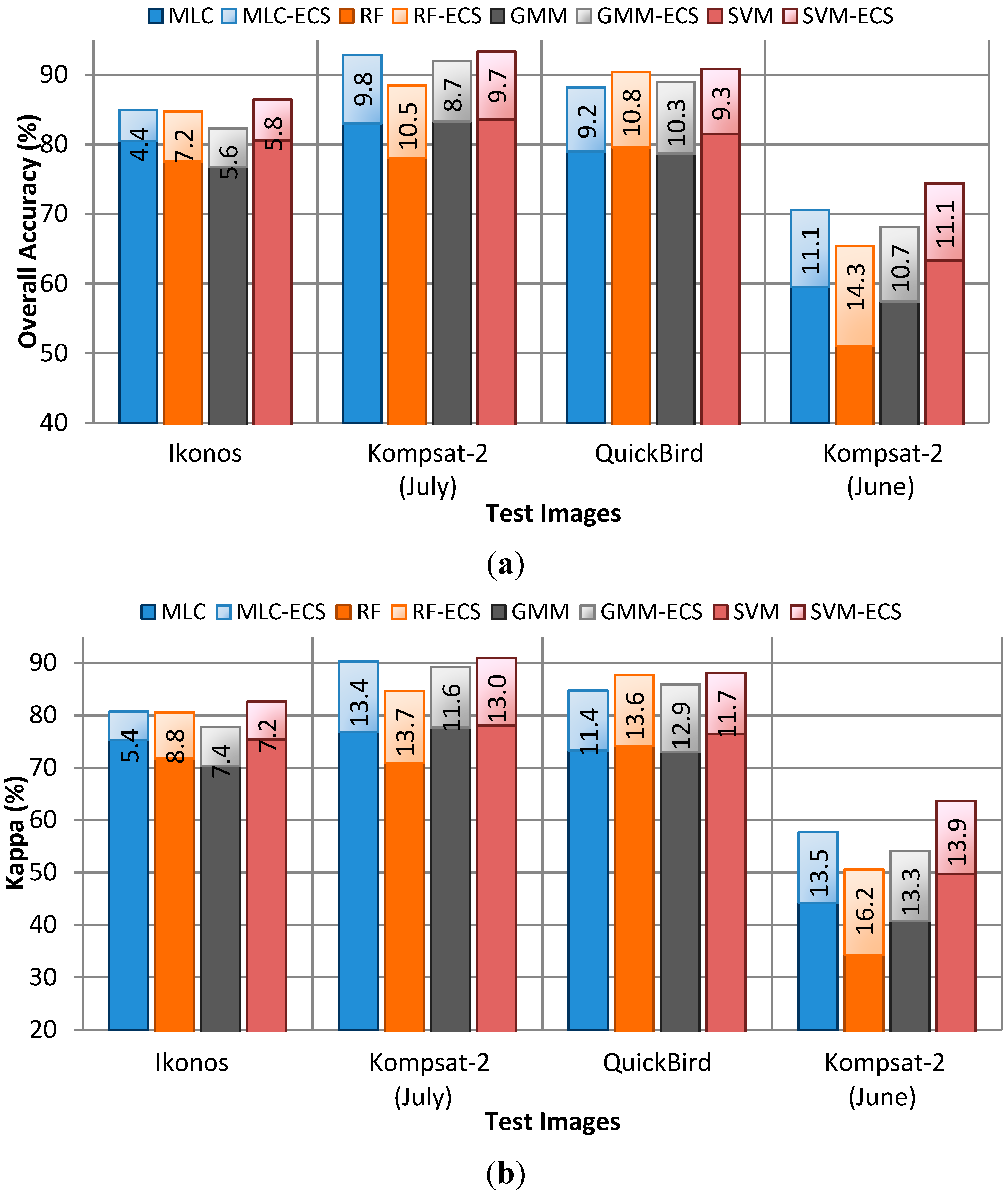
4.2. Performance of CRF Smoothing
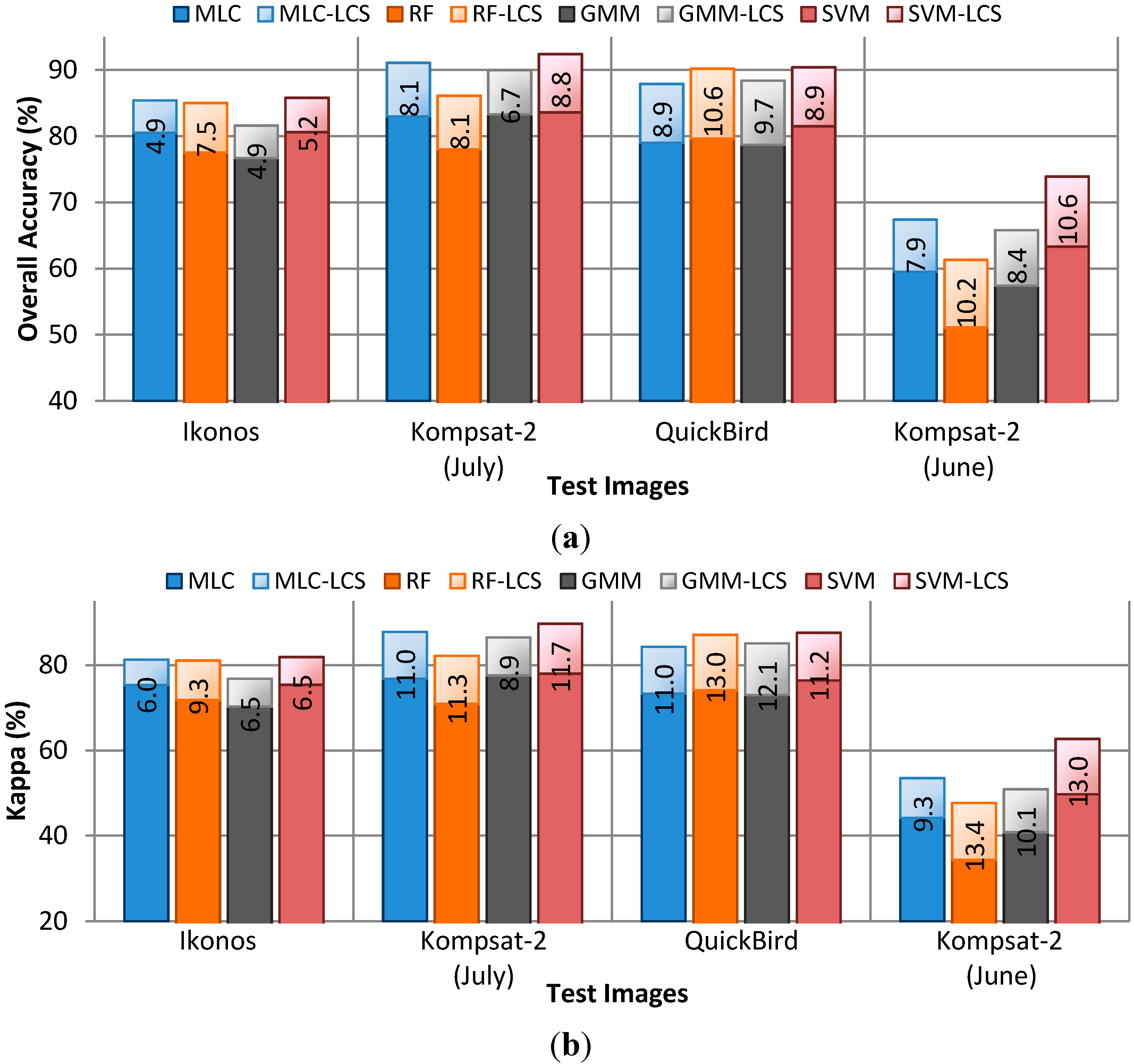

4.3. CRF vs. Parcel-Based Smoothing

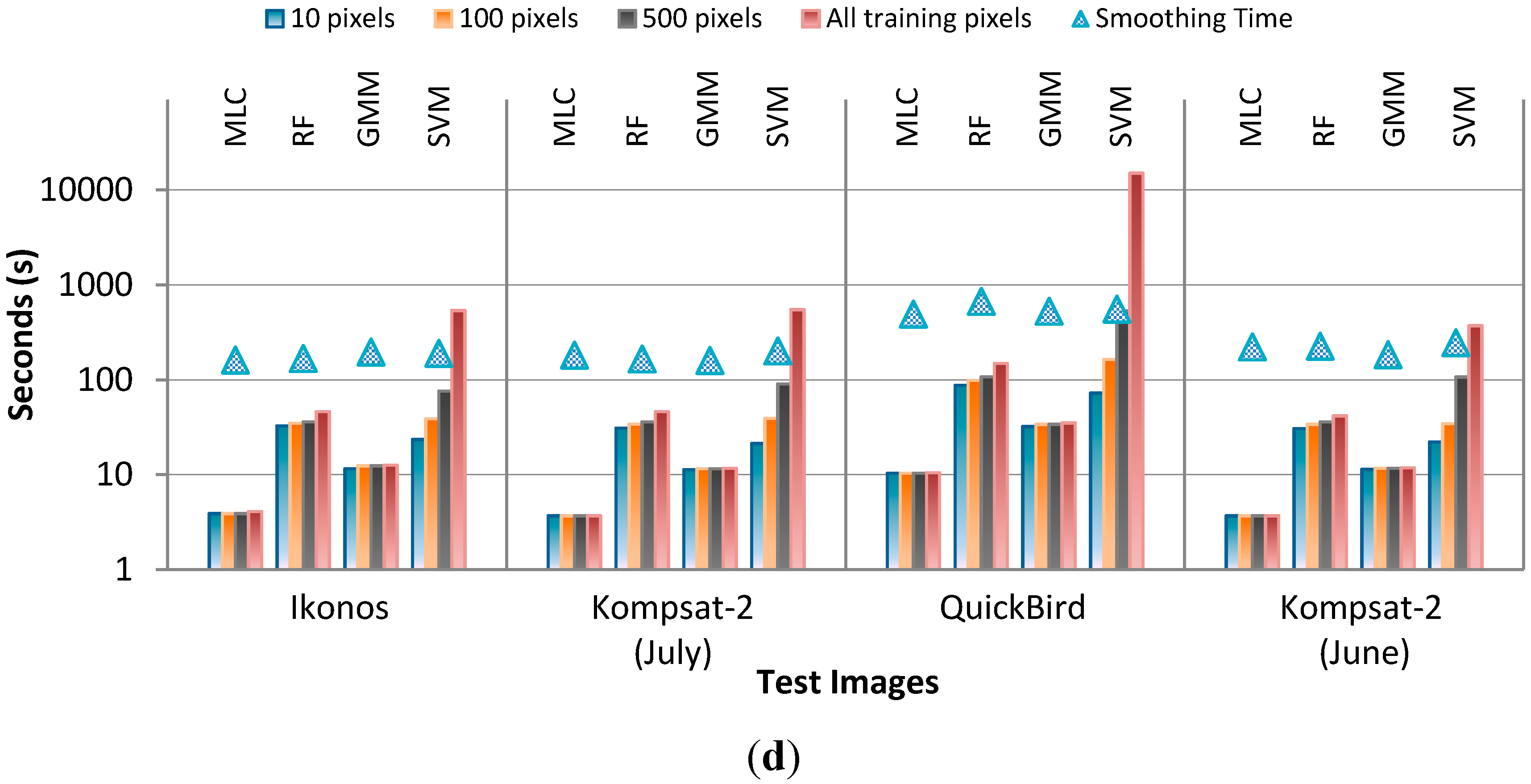
4.4. Discussion of the Classification Results


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corn | Pasture | Rice | Sugar Beet | Wheat | Tomato | Row Total | UA | |
|---|---|---|---|---|---|---|---|---|
| Corn | 467,947 | 3500 | 431 | 453 | 7337 | 2232 | 481,900 | 97.1% |
| Pasture | 85,881 | 153,932 | 34 | 287 | 6247 | 11,322 | 257,703 | 59.7% |
| Rice | 171 | 22 | 143,324 | 40 | 2021 | 181 | 145,759 | 98.3% |
| Sugar Beet | 112 | 0 | 3898 | 61,949 | 192 | 35,838 | 101,989 | 60.7% |
| Wheat | 7250 | 65 | 2469 | 429 | 383,822 | 3838 | 397,873 | 96.5% |
| Tomato | 8855 | 268 | 1082 | 1181 | 65,228 | 378,255 | 454,869 | 83.2% |
| Col. Total | 570,216 | 157,787 | 151,238 | 64,339 | 464,847 | 431,666 | 1,840,093 | |
| PA | 82.1% | 97.6% | 94.8% | 96.3% | 82.6% | 87.6% | ||
| Overall Accuracy: 86.37% Kappa Index: 82.65% | ||||||||

| Corn | Pasture | Rice | Sugar Beet | Wheat | Tomato | Row Total | UA | |
|---|---|---|---|---|---|---|---|---|
| Corn | 18,501 | 105 | 9988 | 597 | 4689 | 189 | 34,069 | 54.3% |
| Pasture | 346 | 204.292 | 261 | 851 | 8587 | 99 | 214,436 | 95.3% |
| Rice | 0 | 24 | 212,352 | 1592 | 284 | 0 | 214,252 | 99,1% |
| Sugar Beet | 266 | 14 | 31 | 77,811 | 182 | 95 | 78,399 | 99.3% |
| Wheat | 22 | 7.068 | 457 | 17 | 318,337 | 0 | 325,901 | 97.7% |
| Tomato | 1685 | 1.446 | 4915 | 11,558 | 4806 | 9640 | 34,050 | 28.3% |
| Col. Total | 20,820 | 212.949 | 228,004 | 92,426 | 336,885 | 10,023 | 901,107 | |
| PA | 88.9% | 95.9% | 93.1% | 84.2% | 94.5% | 96.2% | ||
| Overall Accuracy: 93.32% Kappa Index: 90.95% | ||||||||

| Corn | Pasture | Rice | Sugar Beet | Wheat | Tomato | Row Total | UA | |
|---|---|---|---|---|---|---|---|---|
| Corn | 1,034,386 | 27,363 | 3313 | 829 | 9835 | 7304 | 1,083,030 | 95.5% |
| Pasture | 31,127 | 408,470 | 347 | 683 | 2954 | 56,790 | 500,371 | 81.6% |
| Rice | 84 | 0 | 311,517 | 43 | 17,493 | 4078 | 333,215 | 93.5% |
| Sugar Beet | 222 | 9 | 38,534 | 167,842 | 259 | 24,118 | 230,984 | 72.7% |
| Wheat | 9927 | 1000 | 29,391 | 1111 | 1,205,722 | 74,143 | 1,321,294 | 91.3% |
| Tomato | 5029 | 1352 | 37,945 | 8324 | 49,814 | 1,240,546 | 1,343,010 | 92.4% |
| Col. Total | 1,080,775 | 438,194 | 421,047 | 178,832 | 1,286,077 | 1,406,979 | 4,811,904 | |
| P.A. | 95.7% | 93.2% | 74.0% | 93.9% | 93.8% | 88.2% | ||
| Overall Accuracy: 90.78% Kappa Index: 88.14% | ||||||||

| Corn | Pasture | Rice | Sugar Beet | Wheat | Tomato | Row Total | UA | |
|---|---|---|---|---|---|---|---|---|
| Corn | 3727 | 165 | 945 | 2720 | 5889 | 0 | 13,446 | 27.7% |
| Pasture | 6652 | 153,441 | 121 | 5400 | 152,831 | 2643 | 3,21,088 | 47.8% |
| Rice | 2069 | 106 | 230,478 | 3623 | 32,169 | 1006 | 269,451 | 85.5% |
| Sugar Beet | 6235 | 2139 | 263 | 99,928 | 6038 | 3501 | 118,104 | 84.6% |
| Wheat | 1312 | 60,035 | 2673 | 3603 | 393,385 | 1254 | 462,262 | 85.1% |
| Tomato | 0 | 0 | 0 | 76 | 14 | 2253 | 2343 | 96.2% |
| Col. Total | 19,995 | 215,886 | 234,480 | 115,350 | 590,326 | 10,657 | 1,186,694 | |
| PA | 18.6% | 71.1% | 98.3% | 86.6% | 66.6% | 21.1% | ||
| Overall Accuracy: 74.43% Kappa Index: 63.58% | ||||||||
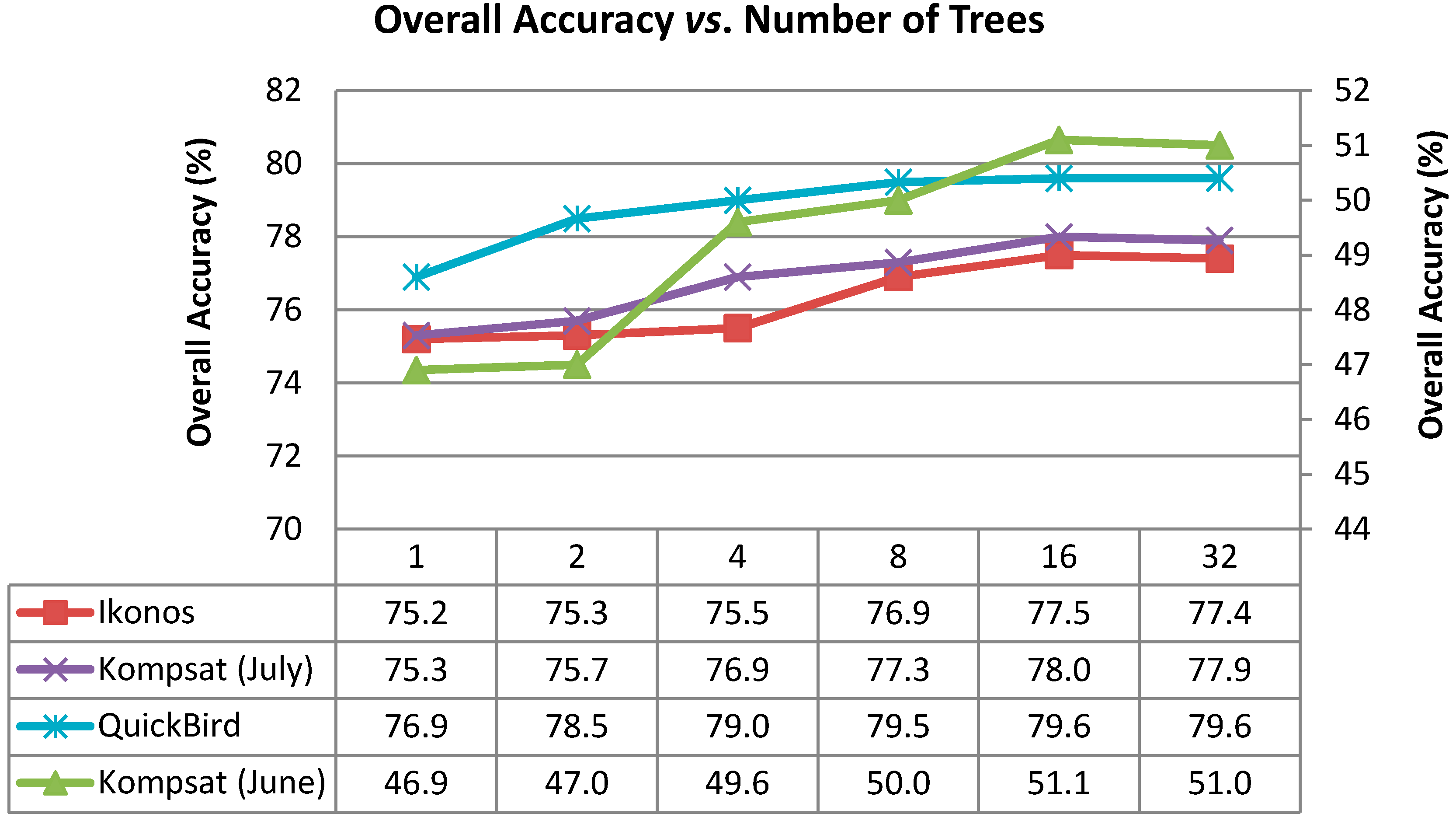
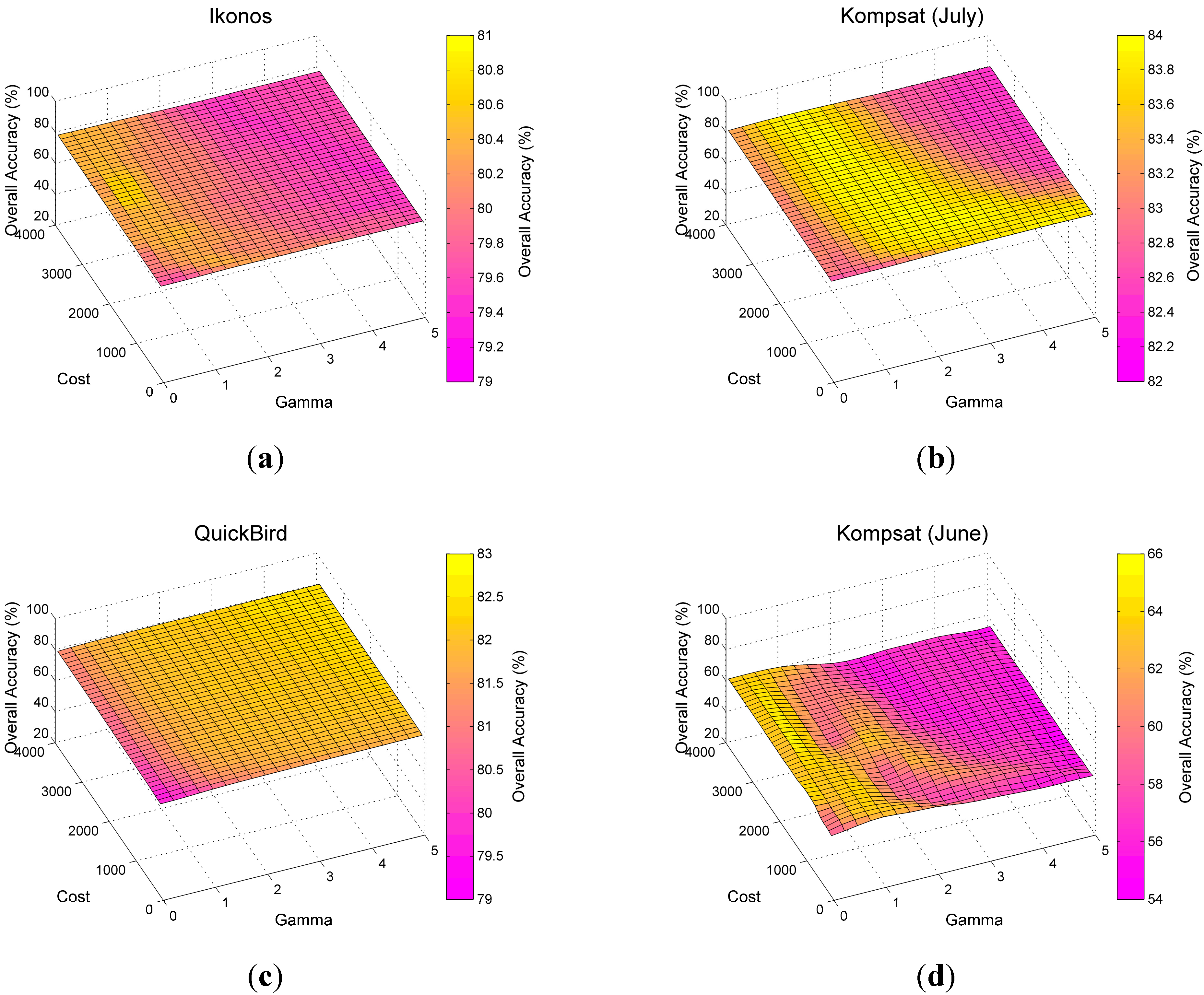
4.5. Sensitivity to Parameters
| Classifier | Parameters | Options | Test |
|---|---|---|---|
| GMM | Num. of components | ≥2 | 2…8 |
| Covariance type | “Full” “Diagonal” | “Full” (Default) | |
| Shared covariance | “Yes” “No” | “No” (Default) | |
| Regularization term | ≥0 | 10−5 | |
| Termination tolerance | ≥0 | 10−6 (Default) | |
| RF | Num. of trees | ≥1 | 1…50 |
| Num. of variables (n) to select for each decision split | (Default) | 2 | |
| Minimum num. of observations per tree leaf | ≥1 | 1 (Default) | |
| SVM | Kernel type | “Linear” “Polynomial” “Radial Function” “Sigmoid” | “Radial Function” |
| Gamma | ≥0 | 0…5 | |
| Cost | ≥0 | 0…4000 | |
| Termination tolerance | ≥0 | 10−3 (Default) |
| Smoothing | Parameters | Options | Set |
|---|---|---|---|
| Linear Contrast Sensitive | Gaussian standard deviation (σ) | >0 | 0,5 (Default) |
| truncated linear potential function constant (ϕ) | 2 ≥ ϕ ≥ 0 | 0…2 | |
| Smoothing constant (γ) | >0 | 1..4 | |
| Neighborhood Connectivity | 4 or 8 | 8 (Default) | |
| Exponential Contrast Sensitive | Smoothing constant (γ) | >0 | 1…12 |
| Neighborhood Connectivity | 4 or 8 | 8 (Default) |



5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lobell, D.B.; Asner, G.P. Climate and management contributions to recent trends in U.S. agricultural yields. Science 2003, 299. [Google Scholar] [CrossRef]
- Penã-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Wilkinson, G.G. Results and implications of a study of fifteen years of satellite image classification experiments. IEEE Trans. Geosci. Remote Sens. 2005, 43, 433–440. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Lillesand, M.; Kiefer, R.W.; Chipman, J.W. Remote Sensing and Image Interpretation, 6th ed.; Wiley: Hoboken, NJ, USA, 2004; p. 638. [Google Scholar]
- Muñoz-Marí, J.; Bovolo, F.; Gómez-Chova, L.; Bruzzone, L.; Camp-Valls, G. Semisupervised one-class support vector machines for classification of remote sensing data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3188–3197. [Google Scholar] [CrossRef]
- Turker, M.; Ozdarici, A. Field-based crop classification using SPOT4, SPOT5, IKONOS, and QuickBird imagery for agricultural areas: A comparison study. Int. J. Remote Sens. 2011, 32, 9735–9768. [Google Scholar] [CrossRef]
- Ozdarici Ok, A.; Akyurek, Z. A segment-based approach to classify agricultural lands by using multitemporal optical and microwave data. Int. J. Remote Sens. 2012, 33, 7184–7204. [Google Scholar]
- Song, M.; Civco, D.L.; Hurd, J.D. A competitive pixel-object approach for land cover classification. Int. J. Remote Sens. 2005, 26, 4981–4997. [Google Scholar] [CrossRef]
- Janssen, L.L.F.; Jaarsma, M.N.; Van Der Linden, E.T.M. Integrating topographic data with remote sensing for land-cover classification. Photogram. Eng. Remote Sens. 1990, 56, 1503–1506. [Google Scholar]
- Aplin, P.; Atkinson, P.M. Sub-pixel land cover mapping for per-field classification. Int. J. Remote Sens. 2001, 22, 2853–2858. [Google Scholar] [CrossRef]
- Smith, G.M.; Fuller, R.M. An integrated approach to land cover classification: An example in the Island of Jersey. Int.l J. Remote Sens. 2001, 22, 3123–3142. [Google Scholar] [CrossRef]
- Lloyd, C.D.; Berberoglu, S.; Curran, P.J.; Atkinson, P.M. A comparison of texture measures for the per-field classification of Mediterranean land cover. Int. J. Remote Sens. 2004, 25, 3943–3965. [Google Scholar] [CrossRef]
- Cheng, H.D.; Jiang, X.H.; Sun, Y.; Wang, J. Color image segmentation: Advances and prospects. Pattern Recognit. 2001, 12, 2259–2281. [Google Scholar] [CrossRef]
- Gong, P.; Marceau, D.; Howarth, P.J. A comparison of spatial feature extraction algorithms for land-use mapping with SPOT HRV data. Remote Sens. Environ. 1992, 40, 137–151. [Google Scholar] [CrossRef]
- Gong, P.; Howarth, P.J. Frequency-based contextual classification and grey-level vector reduction for land-use identification. Photogram. Eng. Remote Sens. 1992, 58, 423–437. [Google Scholar]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Schirokauer, D. Object-based detailed vegetation mapping using high spatial resolution imagery. Photogram. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Rydberg, A.; Borgefors, G. Integrated method for boundary delineation of agricultural fields in multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2514–2520. [Google Scholar] [CrossRef]
- Wang, L.; Sousa, W.P.; Gong, P.; Biging, G.S. Comparison of IKONOS and QuickBird images for mapping mangrove species on the Caribbean coast of Panama. Remote Sens. Environ. 2004, 91, 432–440. [Google Scholar] [CrossRef]
- Lee, J.Y.; Warner, T.A. Segment based image classification. Int. J. Remote Sens. 2006, 27, 3403–3412. [Google Scholar] [CrossRef]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; de la Orden, M.S.; González-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Xiao, P.; Feng, X.; An, R.; Zhao, S. Segmentation of multispectral high-resolution satellite imagery using log gabor filters. Int. J. Remote Sens. 2010, 31, 1427–1439. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogram. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Dronova, I.; Gong, P.; Wang, L. Object-based analysis and change detection of major wetland cover types and their classification uncertainty during the low water period at Poyang Lake, China. Remote Sens. Environ. 2011, 115, 3220–3236. [Google Scholar] [CrossRef]
- Gao, Y.; Mas, J.F.; Kerle, N.; Pacheco, J.A.N. Optimal region growing segmentation and its effect on classification accuracy. Int. J. Remote Sens. 2011, 32, 3737–3763. [Google Scholar] [CrossRef]
- Vieira, M.A.; Formaggio, A.R.; Rennó, C.D.; Atzberger, C.; Aguiar, D.A.; Mello, M.P. Object based image analysis and data mining applied to a remotely sensed Landsat time-series to map sugarcane over large areas. Remote Sens. Environ. 2012, 123, 553–562. [Google Scholar] [CrossRef]
- De Castro, A.I.; López-Granados, F.; Jurado-Expósito, M. Broad-scale cruciferous weed patch classification in winter wheat using QuickBird imagery for in-season site-specific control. Precis. Agric. 2013, 14, 392–413. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Peña, J.M.; Gutiérrez, P.A.; Hervás-Martínez, C.; Six, J.; Plant, R.E.; López-Granados, F. Object-based image classification of summer crops with machine learning methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef]
- Clinton, N.; Holt, A.; Scarborough, J.; Yan, L.I.; Gong, P. Accuracy assessment measures for object-based image segmentation goodness. Photogram. Eng. Remote Sens. 2010, 76, 289–299. [Google Scholar] [CrossRef]
- Schindler, K. An overview and comparison of smooth labeling methods for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4534–4545. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Tyagi, M.; Bovolo, F. A context-sensitive clustering technique based on graph-cut initialization and expectation-maximization algorithm. IEEE Geosci. Remote Sens. Lett. 2008, 5, 21–25. [Google Scholar] [CrossRef]
- Bai, J.; Xiang, S.; Pan, C. A graph-based classification method for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 803–817. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Learning conditional random fields for classification of hyperspectral images. IEEE Trans. Image Process. 2010, 19, 1890–1907. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Zhao, J.; Zhang, L. A hybrid object-oriented conditional random field classification framework for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7023–7037. [Google Scholar] [CrossRef]
- Zhao, J.; Zhong, Y.; Zhang, L. Detail-preserving smoothing classifier based on conditional random fields for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2440–2452. [Google Scholar] [CrossRef]
- Moser, G.; Serpico, S.B. Combining support vector machines and markov random fields in an integrated framework for contextual image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2734–2752. [Google Scholar] [CrossRef]
- Boykov, Y.; Jolly, M.P. Interactive graph cuts for optimal boundary and region segmentation of objects in ND images. In Proceedings of International Conference on Computer Vision, Vancouver, Canada, 7–14 July 2001; pp. 105–112.
- Rother, C.; Kolmogorov, V.; Blake, A. Grabcut: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Szeliski, R.; Zabih, R.; Scharstein, D.; Veksler, O.; Kolmogorov, V.; Agarwala, A.; Tappen, M.; Rother, C. A comparative study of energy minimization methods for markov random fields with smoothness-based priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1068–1080. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Springer-John Wiley: New York, NY, USA, 1998. [Google Scholar]
- Tso, B.; Mather, P.M. Classification Methods for Remotely Sensed Data, 2nd ed.; Taylor & Francis Group, LLC: Danvers, MA, USA, 2009. [Google Scholar]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multi-class support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef] [PubMed]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Pal, M. Support vector machine-based feature selection for land cover classification: A case study with DAIS hyperspectral data. Int. J. Remote Sens. 2006, 27, 2877–2894. [Google Scholar] [CrossRef]
- Archer, K.J. Empirical characterization of random forest variable importance measure. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogram. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Long, J.A.; Lawrence, R.L.; Greenwood, M.C.; Marshall, L.; Miller, P.R. Object-oriented crop classification using multitemporal ETM+ SLC-off imagery and random forest. GIScience Remote Sens. 2013, 50, 418–436. [Google Scholar]
- Sonobe, R.; Tani, H.; Wang, X.; Kobayashi, N.; Shimamura, H. Random forest classification of crop type using multi-temporal TerraSAR-X dual-polarimetric data. Remote Sens. Lett. 2014, 5, 157–164. [Google Scholar] [CrossRef]
- McLachlan, G.; Peel, D. Finite Mixture Models; John Wiley, Sons Inc.: Hoboken, NJ, USA, 2000. [Google Scholar]
- Orchard, M.T.; Bouman, C.A. Color quantization of images. IEEE Trans. Signal Process. 1991, 39, 2677–2690. [Google Scholar] [CrossRef]
- Brisco, B.; Brown, R.J.; Manore, M.J. Early season crop discrimination with combined SAR and TM data. Can. J. Remote Sens. 1989, 15, 44–54. [Google Scholar]
- Aplin, P.; Atkinson, P.M.; Curran, P.J. Fine spatial resolution simulated satellite sensor imagery for land cover mapping in the United Kingdom. Remote Sens. Environ. 1999, 68, 206–216. [Google Scholar] [CrossRef]
- Turker, M.; Arikan, M. Sequential masking classification of multi-temporal Landsat7 ETM+ images for field-based crop mapping in Karacabey, Turkey. Int. J. Remote Sens. 2005, 26, 3813–3830. [Google Scholar] [CrossRef]
- Hutchinson, C.F. Techniques for combining Landsat and ancillary data for digital classification improvement. Photogram. Eng. Remote Sens. 1982, 48, 123–130. [Google Scholar]
- Aplin, P.; Atkinson, P.M.; Curran, P.J. Per-field classification of land use using the forthcoming very fine spatial resolution satellite sensors: Problems and potential solutions. In Advances in Remote Sensing and GIS Analysis; Atkinson, P.M., Tate, N.J., Eds.; John Wiley, Sons: Chichester, UK, 1999; pp. 219–239. [Google Scholar]
- Berberoglu, S.; Lloyd, C.D.; Atkinson, P.M.; Curran, P.J. The integration of spectral and textural information using neural networks for land cover mapping in the Mediterranean. Comput. Geosci. 2000, 26, 385–396. [Google Scholar] [CrossRef]
- Conrad, C.; Fritsch, S.; Idler, J.; Rücker, G.; Dech, S. Per-field irrigated crop classification in arid central Asia using SPOT and ASTER data. Remote Sens. 2010, 2, 1035–1056. [Google Scholar] [CrossRef]
- PCI Geomatica. Geomatica OrthoEngine Course Guide; PCI Geomatics Enterprises Inc.: Richmond Hill, ON, USA, 2009. [Google Scholar]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 1 May 2015). [Google Scholar]
- Figueiredo, M.A.T.; Jain, A.K. Unsupervised learning of finite mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 381–396. [Google Scholar] [CrossRef]
- Yang, X. Parameterizing support vector machines for land cover classification. Photogram. Eng. Remote Sens. 2011, 77, 27–37. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Colkesen, I. Destek vektör makineleri ile uydu görüntülerinin siniflandirilmasinda kernel fonksiyonlarinin etkilerinin incelenmesi. Harita Dergisi 2010, 144, 73–82. [Google Scholar]
- Tokarczyk, P.; Wegner, J.D.; Walk, S.; Schindler, K. Features, color spaces, and boosting: New insights on semantic classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 280–295. [Google Scholar] [CrossRef]
- Komodakis, N.; Tziritas, G. Approximate labeling via graph cuts based on linear programming. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1436–1453. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ozdarici-Ok, A.; Ok, A.O.; Schindler, K. Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing. Remote Sens. 2015, 7, 5611-5638. https://doi.org/10.3390/rs70505611
Ozdarici-Ok A, Ok AO, Schindler K. Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing. Remote Sensing. 2015; 7(5):5611-5638. https://doi.org/10.3390/rs70505611
Chicago/Turabian StyleOzdarici-Ok, Asli, Ali Ozgun Ok, and Konrad Schindler. 2015. "Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing" Remote Sensing 7, no. 5: 5611-5638. https://doi.org/10.3390/rs70505611
APA StyleOzdarici-Ok, A., Ok, A. O., & Schindler, K. (2015). Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing. Remote Sensing, 7(5), 5611-5638. https://doi.org/10.3390/rs70505611